ekt 357 digital communications. properties of coding basic coding algorithm data compression ...
TRANSCRIPT

Chapter 2 Source Coding (part 2)
EKT 357 Digital Communications

Chapter 2 (Part 2) Overview
Properties of coding Basic coding algorithm Data compression Lossless Compression Lossy Compression

Digital Communication System

Properties of coding
Code Types Fixed-length codes – all codewords have
the same length (number of bits)▪ A-000, B-001, C-010, D-011, E-100, F-101
Variable-length codes- may give different lengths to codewords▪ A-0, B-00, C-110, D-111, E-1000, F-1011

Uniquely Decodable Codes
Allow to invert the mapping to the original symbol alphabet.
A variable length code assigns a bit string (codeword) of variable length to every message value
e.g. a = 1, b = 01, c = 101, d = 011What if you get the sequence of bits1011 ?
Is it aba, ca, or, ad? A uniquely decodable code is a variable
length code in which bit strings can always be uniquely decomposed into its codewords.

Prefix-Free Property
No codeword be the prefix of any other code word. e.g a = 0, b = 110, c = 111, d = 10
A prefix code is a type of code system (typically a variable-length code) distinguished by its possession of the "prefix property", which requires that there is no code word in the system that is a prefix (initial segment) of any other code word in the system.

Basic coding algorithm Code word lengths are no longer fixed like ASCII. ASCII uses 8-bit patterns or bytes to identify which
letter is being represented.
Not all characters occur with the same frequency. Yet all characters are allocated the same amount of
space 1 char = 1 byte

Data Compression
For a binary file of length 1,000,000 bits contains 100,000 “1”s. This file can be compressed by more than a factor of 2 with the given of p=0.9 . Try to verify this using Source Entropy.

Data Compression

Data Compression
Data compression ratio is defined as the ratio between the uncompressed size and compressed size

Data Compression Methods
Data compression is about storing and sending a smaller number of bits.
There’re two major categories for methods to compress data: lossless and lossy methods

Data compression Encoding information in a relatively
smaller size than their original size▪ Like ZIP files (WinZIP), RAR files (WinRAR),TAR files etc..
Data compression: Lossless: the compressed data are
an exact copy of the original data Lossy: the compressed data may be
different than the original data
Data Compression

Lossless Compression Methods
In lossless methods, original data and the data after compression and decompression are exactly the same.
Redundant data is removed in compression and added during decompression.
Lossless methods are used when we can’t afford to lose any data: legal and medical documents, computer programs.

Lossless compression
In lossless data compression, the integrity of the data is preserved.
The original data and the data after compression and decompression are exactly the same because the compression and decompression algorithms are exactly the inverse of each other.
Example: Run-length coding Lempel-Ziv (L Z) coding (dictionary-based
encoding) Huffman coding

Run-length coding
Simplest method of compression. How: replace consecutive repeating
occurrences of a symbol by 1 occurrence of the symbol itself, then followed by the number of occurrences.

Run-length coding
The method can be more efficient if the data uses only 2 symbols (0s and 1s) in bit patterns and 1 symbol is more frequent than another.
Compression technique Represents data using value and run length Run length defined as number of consecutive
equal values

Introduction - Applications Useful for compressing data that contains
repeated values e.g. output from a filter, many consecutive
same values. Very simple compared with other
compression techniques

Example 1
A scan line of a binary digit is 00000 00000 00000 00000 00010 00000 00000 01000 00000 00000

Example 2
What does code X5 A9 represent using run-length encoding?

Run-length coding
Every code word is made up of a pair (g, l) where g is the gray level, and l is the number of pixels with that gray level (length, or “run”).
E.g.,56 56 56 82 82 82 83 80 56 56 56 56 56 80 80 80
creates the run-length code (56, 3)(82, 3)(83, 1)(80, 4)(56, 5).
The code is calculated row by row. Very efficient coding for binary data. Used in most fax machines and Image Coding

Run-length coding
Row 1
Row 2
Row 3
Row 4
Row 5
Row 6
Row 7
Row 8
8 8
8

Run-length coding
Row Run-Length Code1 (0,8)2 (0,2) (1,2) (2,1) (3,3)3 (0,1) (1,2) (3,3) (4,2)4 (0,1) (1,1) (3,2) (5,2) (4,2)5 (0,1) (2,1) (3,2) (5,3) (4,1)6 (0,2) (2,1) (3,2) (4,1) (8,2)7 (0,3) (2,2) (3,1) (4,2)8 (0,8)

Run-length coding
Compression Achieved
Original image requires 3 bits per pixel (in total - 8x8x4=256 bits).
Compressed image has 29 runs and needs 3+4=7 bits per
run (in total - 203 bits or 3.17 bits per pixel).
Row Run-Length Code
1 (0,8)
2 (0,2) (1,2) (2,1) (3,3)
3 (0,1) (1,2) (3,3) (4,2)
4 (0,1) (1,1) (3,2) (5,2) (4,2)
5 (0,1) (2,1) (3,2) (5,3) (4,1)
6 (0,2) (2,1) (3,2) (4,1) (8,2)
7 (0,3) (2,2) (3,1) (4,2)
8 (0,8)

Lempel-Ziv coding
It is dictionary-based encoding LZ creates its own dictionary (string of
bits), and replaces future occurrences of these strings by a shorter position string:
Basic idea: Create a dictionary(a table) of strings used during
communication.
If both sender and receiver have a copy of the dictionary, then previously-encountered strings can be substituted by their index in the dictionary.

Lempel-Ziv coding
Have 2 phases: Building an indexed dictionary Compressing a string of symbols
• Algorithm: Extract the smallest substring that cannot be
found in the remaining uncompressed string. Store that substring in the dictionary as a new
entry and assign it an index value. Substring is replaced with the index found in the
dictionary. Insert the index and the last character of the
substring into the compressed string.

Lempel-Ziv coding
Consists of scattered repetition bits or characters (strings)
E.g. A B B C B C A B A B C A A B C A A B

Lempel-Ziv coding
Original Code: ABBCBCABABCAABCAAB
The compressed message is: (0,A)(0,B)(0,C)(1,B)(2,C)(5,A)(2,A)(6,A)(8,B)

Lempel-Ziv coding
Example: Uncompressed String: ABBCBCABABCAABCAAB Number of bits = Total number of characters * 8
= 18 * 8 = 144 bits
Suppose the codewords are indexed starting from 1: Compressed string( codewords): (0,A)(0,B)(0,C)(1,B)(2,C)(5,A)(2,A)(6,A)
(8,B) Codeword index 1 2 3 4 5 6 7 8 9
Note: The above is just a representation, the commas and parentheses are not transmitted;
• Each code word consists of an integer and a character:
• The character is represented by 8 bits.

Lempel-Ziv coding
Codeword (0,A) (0,B) (0,C) (1,B) (2,C) (5,A) (2,A) (6,A) (8,B)index 1 2 3 4 5 6 7 8 9 Bits: (1 + 8) + (1 + 8) + (1 + 8) + (1 + 8) + (2 + 8) + (3 + 8) + (2 + 8) + (3+8) + (3+8) = 89 bits
The actual compressed message is: 0A 0B 0C 1B 10C 100A 10A 101A 111B
where each character is replaced by its binary 8-bit ASCII code.

Example: 3
Encode RSRTTUUTTRRTRSRRSSUU using Lempel-Ziv method.

Huffman coding
Huffman coding is a form of statistical coding
Huffman coding is a prefix-free, variable-length code that can be achieve shortest average code length.
Code word lengths vary and will be shorter for the more frequently used characters.

Background of Huffman of coding
Proposed by Dr. David A. Huffman in 1952 “A Method for the Construction of
Minimum Redundancy Codes”
Applicable to many forms of data transmission example: text files

Creating Huffman coding
1. Scan text to be compressed and tally occurrence of all characters.
2. Sort or prioritize characters based on number of occurrences in text.
3. Build Huffman code tree based on prioritized list.
4. Perform a traversal of tree to determine all code words.
5. Scan text again and create new file using the Huffman codes.

Huffman Coding (by example) A digital source generates five symbols
with the following probabilities:
S , P(s)=0.27 T, P(t)=0.25 U, P(u)=0.22 V,P(v)=0.17 W,P(w)=0.09
Use Huffman Coding algorithm to compress this source

Step 1: Arrange the symbols in a descending order according to their probabilities
S0.27
T0.25
U0.22
V0.17
W0.09
Huffman Coding (by example)

Step 2: take the symbols with the lowest probabilities and form a leaf
V0.17
U0.22
LIST
T0.25
S0.27
W0.09
V,W(x1)0.26
Huffman Coding (by example)
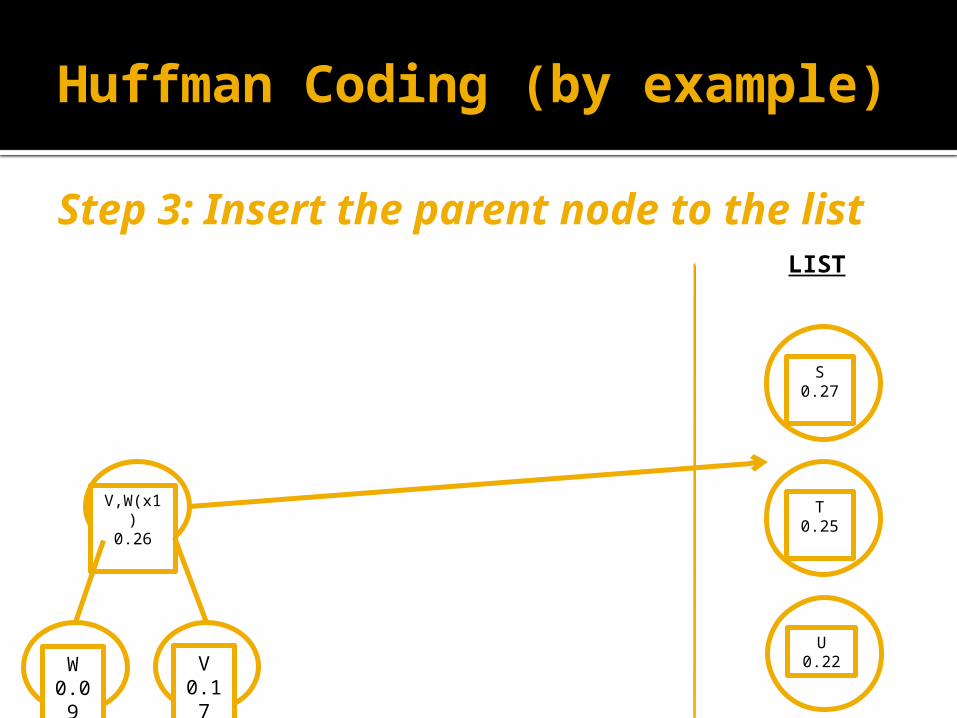
Step 3: Insert the parent node to the list
V0.17
U0.22
LIST
T0.25
S0.27
W0.09
V,W(x1)0.26
Huffman Coding (by example)

Step 3: Insert the parent node to the list
V0.17
U0.22
LIST
T0.25
S0.27
W0.09
V,W(x1)0.26
X10.26
Huffman Coding (by example)

Step 4: Repeat the same procedure on the updated list till we have only one node
U0.22
LIST
T0.25
S0.27
V0.17
W0.09
V,W(x1)0.26
X10.26
T0.25
U0.22
X20.47
Huffman Coding (by example)

LIST
S0.27
V0.17
W0.09
S0.27 X1
0.26
T0.25
U0.22
X20.47
X20.47
X10.26
X30.53
Huffman Coding (by example)

LIST
X30.53
X20.47
V0.17
W0.09
T0.25
S0.27
X10.26
X30.53
U0.22
X20.47
X41
Huffman Coding (by example)
V0.17
W0.09
T0.25
S0.27
X10.26
X30.53
U0.22
X20.47
X41
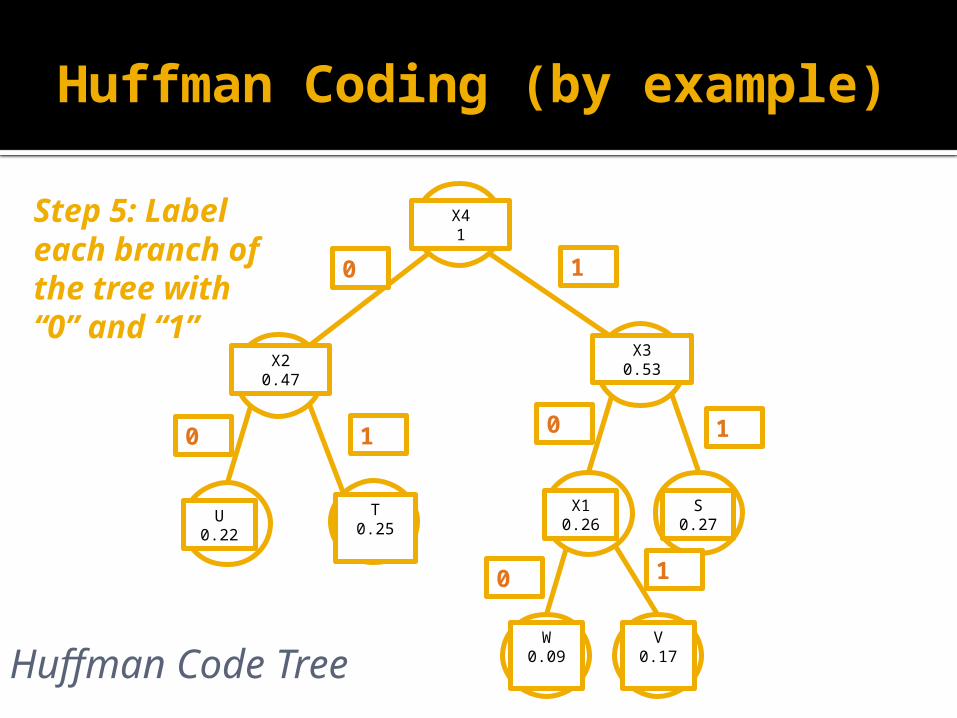
Step 5: Label each branch of the tree with “0” and “1”
Huffman Code Tree
0
0
0
0
1
11
1
Huffman Coding (by example)

V0.17
W0.09
T0.25
S0.27
X10.26
X30.53
U0.22
X20.47
X41
Huffman Code Tree
0
0
0
0
1
11
1
Huffman Coding (by example)
Codeword of w = 100

V0.17
W0.09
T0.25
T0.27
X10.26
X30.53
U0.22
X20.47
X41
Huffman Code Tree
0
0
0
0
1
11
1
Huffman Coding (by example)
Codeword of u=00

As a result:
Symbol Probability Codeword
S 0.27 11
T 0.25 01
U 0.22 00
V 0.17 101
W 0.09 100
Symbols with higher probability of occurrence have a shorter codeword length, while symbols with lower probability of occurrence have longer codeword length.

Average codeword length
The average codeword length achieved can be calculated by:
ni = Sum of the binary code lengths P(Xi) = Probability of that code
For the previous example we have the average codeword length as follows:
m
iii nXPL
1
)(
L (0.27 2) (0.25 2) (0.22 2) (0.17 3) (0.09 3)
L 2.26 bits

The Importance of Huffman Coding Algorithm
As seen by the previous example, the average codeword length calculated was 2.26 bits
Five different symbols “S,T,U,V,W” Without coding, we need three bits to represent all
of the symbols By using Huffman coding, we’ve reduced the
amount of bits to 2.26 bits Imagine transmitting 1000 symbols
▪ Without coding, we need 3000 bits to represent them
▪ With coding, we need only 2260 That is almost 25% reduction “25% compression”

Summary of Huffman Coding Huffman coding is a technique used to
compress files for transmission
Uses statistical coding more frequently used symbols have shorter
code words
Works well for text and fax transmissions
An application that uses several data structures

Example 3:
Building a tree by assuming that the relative frequencies are: A: 40 B: 20 C: 10 D: 10 R: 20

Lossy Compression Methods Used for compressing images and video
files (our eyes cannot distinguish subtle changes, so lossy data is acceptable).
Several methods:
JPEG: compress pictures and graphics MPEG: compress video MP3: compress audio

JPEG Compression: Basics Human vision is insensitive to high spatial
frequencies JPEG Takes advantage of this by compressing
high frequencies more coarsely and storing image as frequency data
JPEG is a “lossy” compression scheme.
Losslessly compressed image, ~150KB JPEG compressed, ~14KB
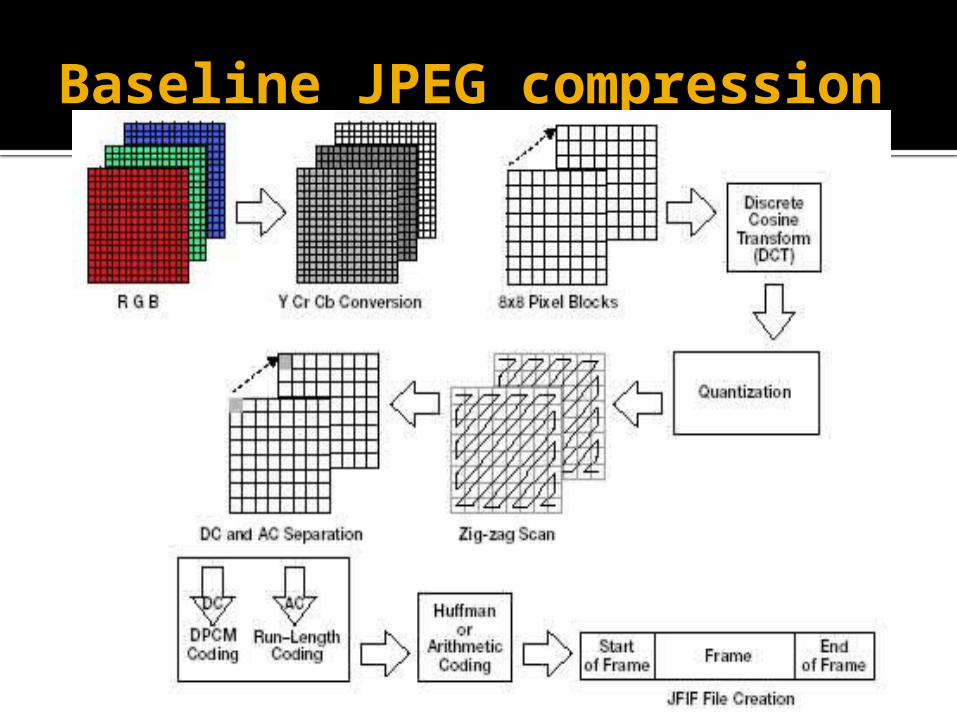
Baseline JPEG compression

Baseline JPEG compression
YCbCb colour space is based on YUV colour space
YUV signals are created from an original RGB (red, green and blue) source. The weighted values of R, G and B are added together to produce a single Y (lumsignal, representing the overall brightness, or luminance and chrominance (Cr, Cb) of that spot.
Y = luminanceCr, Cb = chrominance

Discrete cosine transform
DCT transforms the image from the spatial domain into the frequency domain
Next, each component (Y, Cb, Cr) of the image is "tiled" into sections of eight by eight pixels each, then each tile is converted to frequency space using a two-dimensional forward discrete cosine transform (DCT, type II). The 64 DCT basis functions

QuantizationThis is the main lossy operation in the whole process.
After the DCT has been performed on the 8x8 image block, the results are quantized in order to achieve large gains in compression ratio. Quantization refers to the process of representing the actual coefficient values as one of a set of predetermined allowable values, so that the overall data can be encoded in fewer bits (because the allowable values are a small fraction of all possible values).
Example of a quantizing matrix
The aim is to greatly reduce the amount of information in the high frequency components.

Example of Frequency Quantization with 8x8 blocks
-80
4 -6 6 2 -2 -2 0
24 -8 8 12 0 0 0 2
10 -4 0 -12 -4 4 4 -2
8 0 -2 -6 10 4 -2 0
18 4 -4 6 -8 -4 0 0
-2 8 6 -4 0 -2 0 0
12 0 6 0 0 0 -2 -2
0 8 0 -4 -2 0 0 0
16 11 10 16 24 40 51 61
12 12 14 19 26 58 60 55
14 13 16 24 40 57 69 56
14 17 22 29 51 87 80 62
18 22 37 56 68 109
103
77
24 35 55 64 81 104
113
92
49 64 78 87 103
121
120
101
72 92 95 98 112
100
103
99
-5 0 0 0 0 0 0 0
2 -1 1 1 0 0 0 0
1 0 0 -1 0 0 0 0
1 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
Quantization Matrix to divide by
Quantized frequency values
Color space values (data)

Scanning and Compressing
-5 0 0 0 0 0 0 0
2 -1 1 1 0 0 0 0
1 0 0 -1 0 0 0 0
1 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
Spatial Frequencies scanned in zig-zag pattern (note high frequencies mostly zero)
Run-Length Coding/ Huffman Coding used to losslessly record values in table
-5,0,2,1,-1,0,0,1,0,1,1,0,0,1,0,0,0,-1,0,0,… 0
Can be stored as:
(1,2),(0,1),(0,-1),(2,1),(1,1),(0,1),(2,1),(3,-1),EOB

So now we can all grow beards!
http://www.imaging.org/resources/jpegtutorial/jpgimag1.cfm
Quality factor =20