electronic design automation
TRANSCRIPT


© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Electronic design automation: Scaling EDA workflows
M F G 3 0 4
Mark Duffield
WW Tech Lead, Semiconductor
Amazon Web Services
Simon Burke
Distinguished Engineer
Xilinx

Abstract
Semiconductor product development is constantly pushing the boundaries of physics to meet power, performance, and area (PPA) requirements for silicon devices. Electronic design automation (EDA) workflows, from RTL to GDSII, require scale-out architectures to meet the constantly changing semiconductor design process. This session will discuss deployment tools, methods, and use cases for running the entire EDA workflow on AWS. Using customer examples, we will show how AWS can improve performance, meet tape-out windows, and effortlessly scale-out to meet unforeseen demand.

Agenda
EDA on AWS
Customer use cases
The Xilinx AWS journey with Simon Burke
Deployment tools and methods

Related breakouts
[MFG206-L] [Leadership session: AWS for the Semiconductor industry]Monday, Dec 2, 4:00 PM - 5:00 PM – Aria, Level 1 West, Bristlecone 9 Red
[MFG404] [Using Amazon SageMaker to improve semiconductor yields]Wednesday, Dec 4, 8:30 AM - 9:30 AM – Aria, Level 3 West, Starvine 1
[MFG403] [Telemetry as the workflow analytics foundation in a hybrid environment]Wednesday, Dec 4, 10:00 AM - 11:00 AM – Aria, Plaza Level East, Orovada 3
[MFG405] [Launch a turnkey scale-out compute environment in minutes on AWS] Thursday, Dec 5, 12:15 PM - 2:30 PM – Aria, Level 1 East, Joshua 7
[MFG304] [Electronic design automation: Scaling EDA workflows]Thursday, Dec 5, 3:15 PM - 4:15 PM – Aria, Level 1 West, Bristlecone 7 Green

© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.

Semiconductor design to product distribution
Design and
verification
Wafer
production
Chip
packaging
PCB and
assembly
Product
integration
Product
distribution
Many opportunities for cloud-accelerated innovation

Digital IC design workflow
Design specificationDesign
verificationSynthesis
Physical layout
Physical verification
Power/Signal analysis
Tape out/manufacturing
Silicon validation
Front-end design
• Design capture• Design modeling
Back-end design Production and test
Simulation• Functional• Formal• Gate-level
DFT insertion
Wo
rklo
ad
s
• Floorplanning• Placement• Routing
• OPC• Yield analysis
• LVS/DRC/ERC• Extraction• Timing
• Chip tests• Wafer tests
• Power• Thermal• Signal integrity
Ph
ase
• High job concurrency
• Single-threaded
• Mixed random/sequential file I/O,
metadata-intensive
• Millions of jobs and small files
• More multi-threading
• Memory intensive
• Long run times
• Large files
• More sequential data access patterns
Ch
ara
cteri
stic
s • Often performed by third parties
• Big data analytics
• AI/ML
Advanced node design and signoff
Cloud is becoming the new signoff platform

Electronic Design Automation infrastructure
Traditional EDA IT stackCorporate data center
Remote desktop
• License managers
• Workload schedulers
• Directory services
Compute nodes
Shared file storage
Remote desktop client

Electronic Design Automation infrastructure on AWS
Virtual Private Cloud on AWS
Remote desktop
• License managers
• Workload schedulers
• Directory services
Cloud-based, auto-scaling HPC clusters
Shared file storage Storage cache
On AWS, secure and well-
optimized EDA clusters can
be automatically created,
operated, and torn down in
just minutes
Encryption everywhere, with your
own keys
Amazon Simple Storage
Service (Amazon S3) and
Amazon Simple Storage
Service Glacier
On-premises
HPC resources
Corporate datacenter
AWS Snowball
AWS Direct Connect
Third-party IP providers
and collaborators
Machine learning
and analytics

Faster design throughput with rapid, massive scaling
Scale up when needed, then scale down
In a traditional EDA datacenter, the only certainty is that you always have the wrong number of servers—too few or too many
Every additional EDA server launched in the cloud can improve speed of innovation—if there are no other constraints to scaling
Overnight or over-weekend workloads reduced to an hour or less
Think bigWhat if you could launch
one million concurrent
verification jobs?
C P U C O R E S O V E R T I M E
Product development cycle

Our own journey: Our own digital transformation
2011 2015
Annapurna startupFormed 2011, Israel
Started with on-prem datacenter
2014
AWS silicon
optimizationsFormed 2014, Austin
Born in the cloud
US expands
deployment in AWS
Israel expands
productivity via AWS
AWS
One Team
acquisition of
Annapurna
Multi-site
development
Hybrid
model
On-prem data center On-prem data center
Multi-site
development
US expands
deployment in AWS
Multiple end-to-end
silicon projects in AWS
2016 2017 Today
Full SoC development
in the cloud
Latest semiconductor
fab 7nm process
Multi-site
On-prem data center only
for emulators

AWS global infrastructure
22 geographic regionsA region is a physical location
in the world where we have
multiple Availability Zones
69 Availability Zones Distinct locations that are
engineered to be insulated
from failures in other
Availability Zones
NetworkAWS offers highly reliable, low latency, and high throughput
network connectivity. This is achieved with a fully redundant
100 Gbps network that circles the globe.

Amazon custom hardware
• The AWS global infrastructure is
built on Amazon’s own
hardware
• By using its own custom
hardware, AWS provides
customers with the highest
levels of reliability, the fastest
pace of innovation, all at the
lowest possible cost
• AWS optimizes this hardware for
only one set of requirements:
Workloads run by AWS
customers
Silicon
Routers
Compute
servers
The internet
Storage servers
Load balancers
...
...
...
AWS Inferentia: Custom silicon for deep learning
aws.amazon.com/machine-learning/inferentia/
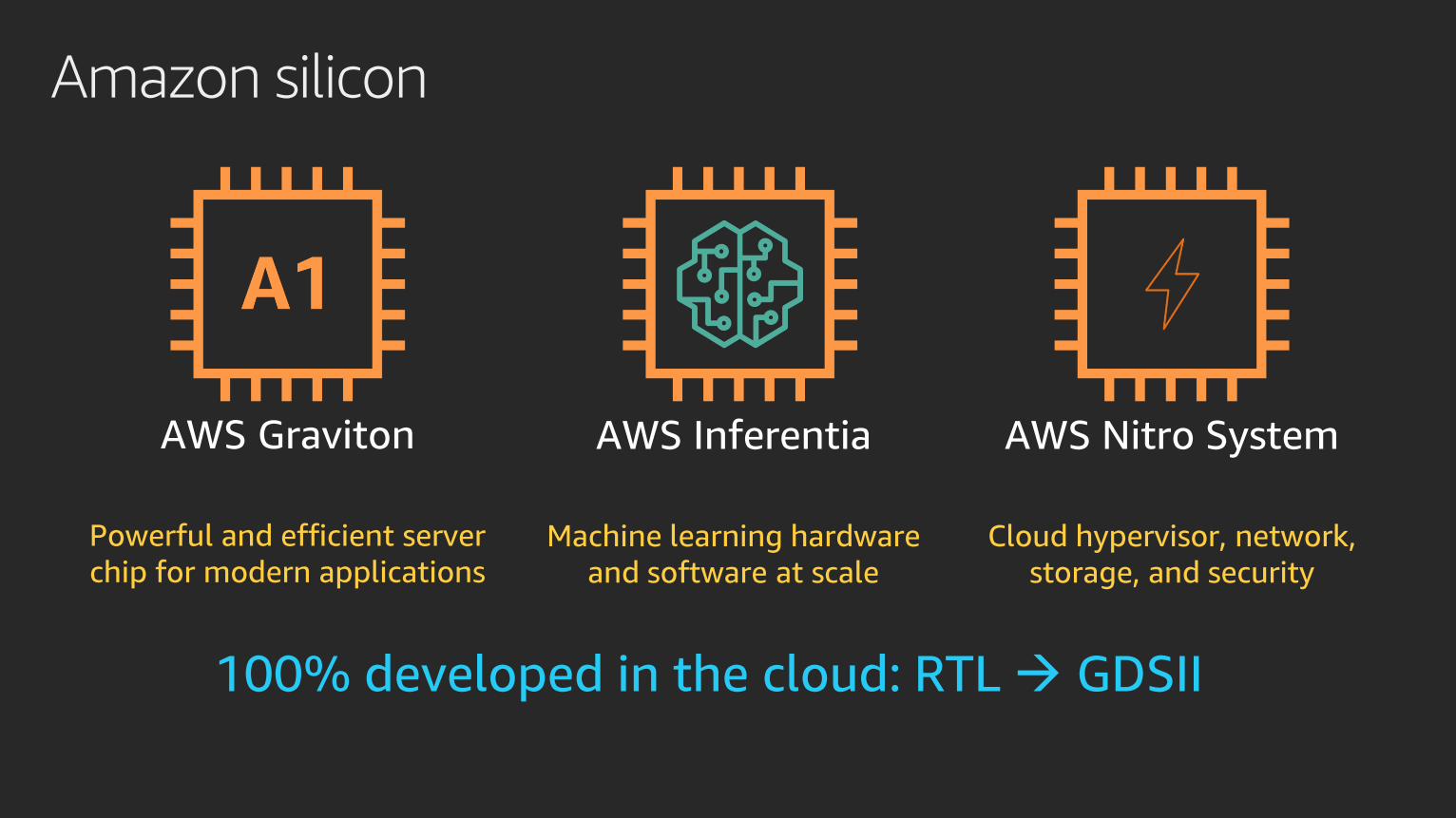
Amazon silicon
AWS Graviton
Powerful and efficient server
chip for modern applications
AWS Inferentia
Machine learning hardware
and software at scale
AWS Nitro System
Cloud hypervisor, network,
storage, and security
100% developed in the cloud: RTL → GDSII

High clock speed compute instances: z1d
EDA stack on AWS
Desktop visualization
Cloud-based, auto-scaling HPC clusters
Shared file storage Storage cache
License managers
Workload schedulers
Directory services
Up to 4 GHz sustained, all-turbo performance• Z1d instances are optimized for memory-intensive,
compute-intensive applications
• Up to physical 24 cores
• Custom Intel Xeon scalable processor
• Up to 4 GHz sustained, all-turbo performance
• Up to 384GiB DDR4 memory
• Enhanced networking, up to 25 Gbps throughput
Featuring

High memory instances: R5
EDA stack on AWS
Desktop visualization
Cloud-based, auto-scaling HPC clusters
Shared file storage Storage cache
License managers
Workload schedulers
Directory services
Up to 3.1 GHz sustained, all-turbo performance• R5 instances are optimized for memory-intensive,
compute-intensive applications
• Up to physical 48 cores
• Custom Intel Xeon scalable processor
• Up to 3.1 GHz sustained, all-turbo performance
• Up to 768 GiB DDR4 memory
• Enhanced networking, up to 25 Gbps throughput
Featuring

High memory instances: X1e
EDA stack on AWS
Desktop visualization
Cloud-based, auto-scaling HPC clusters
Shared file storage Storage cache
License managers
Workload schedulers
Directory services
2.3 GHz performance• X1e instances are optimized for memory-intensive workloads
• Up to physical 64 cores
• High-frequency Intel Xeon E7-8880 v3 (Haswell) processors
with Turbo Boost
• Up to 4 TiB DDR4 memory
• Enhanced networking, up to 25 Gbps throughput
Featuring

FPGA accelerator development: F1
EDA stack on AWS
Desktop visualization
Cloud-based, auto-scaling HPC clusters
Shared file storage Storage cache
License managers
Workload schedulers
Directory services
Up to 8x Xilinx UltraScale+ VU9P, each FPGA has:• Dedicated PCIe x16 interface to the CPU
• Approx. 2.5 million logic elements
• Approx. 6,800 DSP engines
• 64 GiB ECC-protected memory, 288-bit
wide bus
• Virtual JTAG interface for debugging
• Fabricated using a 16 nm process
Instance capability• 2.7 GHz Turbo all cores and 3.0 GHz Turbo one core
• Up to 976 GiB of memory
• Up to 4 TB of NVMe SSD storage
Featuring

Amazon Elastic Compute Cloud (Amazon EC2) bare metal instances
• Provide applications with direct access to hardware
• Built on the Nitro system and ideal for workloads that are not virtualized, require specific
types of hypervisors, or have licensing models that restrict virtualization
EC2
BARE
METAL

Comprehensive storage portfolio
Block storage File storage Object storage
Amazon Elastic Block Store
(Amazon EBS)
Amazon Elastic File System
(Amazon EFS)
gp2io1
st1 sc1
Amazon S3
HDD
SSDAmazon S3
lifecycle management
Amazon S3 Glacier
Amazon FSx for Lustre

Mapping storage to EDA data types
Tools
Project
IP libraries
Workspaces
Scratch
Home
TE
MP
OR
AR
YP
ER
SIS
TE
NT
Amazon FSx for Lustre
Data type Storage solutionsR
EA
D-O
NLY
RE
AD
-WR
ITE
RE
AD
-WR
ITE
DIY/Marketplace
NFS server
DIY/Marketplace
NFS server
Amazon FSx
for Lustre
Amazon S3 archiveDIY/marketplace
NFS serverAmazon EFS
Amazon FSx
for LustreAmazon S3 archive

Commercial schedulers
• IBM Spectrum LSF resource connector
• Univa UGE and NavOps launch
• Altair Accelerator (RTDA NC)
AWS supported by popular workload and resource managers

Remote desktops with NICE DCV
Single or multiple persistent sessions
Optional GPU acceleration
• Native clients on Linux, Mac, Windows
• HTML5 for web clients
• Dynamic hardware compression
• Encrypted communication
• Multi-monitor support
• Support for various peripherals
No added cost on an Amazon EC2 instance
EC2 instance

© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.

Industry: Semiconductor and
Electronics
Headquarters: San Jose CA
Website: www.asteralabs.com
At Astera Labs, we are intensely focused on
delivering high-quality PCIe connectivity
solutions to our customers and reduce time-
to-results. Our High-Performance Compute
(HPC) infrastructure is hosted entirely on AWS
and we heavily leverage the cloud-scalability
enabled by AWS and Synopsys tools to
accelerate our development schedule.
Jitendra Mohan
CEO Astera Labs
“
”
About Astera Labs
We are intensely focused on customers'
needs. We execute to meet our promises
on-time, on-spec, and on-cost. We
innovate exponentially rather than
incrementally in everything we do. We
operate with integrity and the highest
ethical standards—aiming to earn our
partners' trust.
Example: Astera Labs

Example: Arm limited
For details, see session MFG-206 L
• Migrating EDA to AWS for a hybrid cloud platform
• Goal: improve engineering productivity and shift-left silicon verification
• Using intelligent job scheduling with advanced telemetry and automation
• Range of EDA applications
The hybrid platform
Cloud
On prem
Jobs submitted to common user interface, stating preferences for
cost/speed
Intelligent scheduler runs job in most
suitable location (AI/ML to improve performance
over time)
IN OUT
Results available to user
Telemetry/visualisation/modeling deliver information to user & scheduler for workflow improvements

Example: MediaTek
For details, see session MFG-206 L
Proven results for EDA running on AWS
• Static Timing Analysis (STA) for 7nm process SoC
• 1000 AWS instances (32,000 physical cores)
• 12 million core-hours of computing for STA
• 8PB of data, between Taiwan and US West AWS Region
• Successfully eliminated IT compute resource bottleneck
• World’s first 5G So announced at Computex 2019 (May 29)

© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.

© Copyright 2018 Xilinx
Xilinx develops highly flexible and adaptive
processing platforms that enable rapid
innovation across a variety of technologies –
from the endpoint to the edge to the cloud. Xilinx
is the inventor of the FPGA, hardware
programmable SoCs, and the ACAP, designed
to deliver the most dynamic processor
technology in the industry and enable the
adaptable, intelligent, and connected world of
the future. For more information:
Visit www.xilinx.com.
The explosion of AI and pervasive intelligence,
combined with the demand for exponentially
increasing computing power after Moore's Law,
has given rise to domain-specific architectures
(DSAs). Xilinx technology is ideally suited for
DSAs as it can be programmed and tuned to
address today's most complex and demanding
architectures with impressive results across a
wide variety of workloads and applications. The
same piece of silicon can be updated and
reconfigured to tackle multiple tasks.

© Copyright 2018 Xilinx
New packaging and integration
technologies offering numerous scaling
opportunities
FPGA designs have very specific
requirements that demand more than
standard flows and methodologies
Amazon and AWS are our chosen cloud
vendor for deployment of EDA flows
@Xilinx
Tight collaboration between TSMC, Xilinx,
and Synopsys on cloud technologies
enables the fastest path to productization
Broad collaboration key in maximizing potential of latest technologies

© Copyright 2018 Xilinx
Cloud enablement key considerations: Use model
In the industry we see three major types of cloud use model
˃ All-in model
Storage, compute and licenses are cloud based (no infrastructure on premise)
A flow or tool run can be run either on cloud or on premise determined at project setup time
Popular with startups and smaller companies with no existing infrastructure
Third party companies can provide “turnkey” enablement and solutions
EDA vendors provide “EDA locked” solutions on custom cloud
˃ Hybrid model
Similar to all-in model, a single project or flow is cloud enabled, that project or flow has cloud storage, licenses and compute
‒ Other projects may exist on premise only
‒ Other flows may exist on premise only
‒ A flow may be duplicated on cloud and on premise but be partitioned by design or design type
A flow or tool run can be run either on cloud or on premise determined at project setup time
˃ Burst model
A project or flow exists both on cloud and on premise
Data and licenses are shared between cloud and on premise
A flow or tool run can be run either on cloud or on premise determined at flow run time

© Copyright 2018 Xilinx
Cloud enablement key considerations: Use model
In the industry we see three major types of cloud use model
˃ All-in model
Storage, compute and licenses are cloud based (no infrastructure on premise)
A flow or tool run can be run either on cloud or on premise determined at project setup time
Popular with startups and smaller companies with no existing infrastructure
Third party companies can provide “turnkey” enablement and solutions
A vendors provide “ A locked” solutions on custom cloud
˃ Hybrid model
Similar to all-in model, a single project or flow is cloud enabled, that project or flow has cloud storage, licenses and compute
‒ Other projects may exist on premise only
‒ Other flows may exist on premise only
‒ A flow may be duplicated on cloud and on premise but be partitioned by design or design type
A flow or tool run can be run either on cloud or on premise determined at project setup time
˃ Burst model
A project or flow exists both on cloud and on premise
Data and licenses are shared between cloud and on premise
A flow or tool run can be run either on cloud or on premise determined at flow run time
Xilinx has chosen to pursue a burst
model for cloud deployment to
augment our on-premise farm for
existing projects

© Copyright 2018 Xilinx
Cloud enablement key considerations: Storage
Cloud vendors are very good at compute and networking
However POSIX-based storage management is a
challenge especially for hybrid and burst use models
˃ Fundamentally cloud & on-premise infrastructures are different
˃ Cloud typically uses block storage, which is incompatible with
most EDA tools
˃ Complex EDA tool workflows rely on network shared POSIX
filesystems based on an NFS filer to ensure that the same
coherent data is accessible across thousands of nodes
˃ However, NFS filers are not available as a native instance in
the cloud, and cloud NFS equivalents can have performance
issues
Today, companies typically try to attain hybrid workflows by setting
up the cloud environment, copying the data, and then running
jobs using pseudo NFS filesystems
But uploading data and keeping data “in sync” between on
premise and cloud is time consuming to setup and manage
Storage falls into two broad categories
˃ Large semi static read data
Tool binaries, IP views, etc.
Access can be sparse, and typically read only (but constantly changing)
˃ Smaller dynamic workspaces
Sometimes prepopulated with data, sometimes empty at start
Flow appends or creates data in this file system
Access is typically heavy with read and write

© Copyright 2018 Xilinx
Cloud enablement key considerations: Storage
Cloud vendors are very good at compute and networking
However POSIX-based storage management is a
challenge especially for hybrid and burst use models
˃ Fundamentally cloud & on-premise infrastructures are different
˃ Cloud typically uses block storage, which is incompatible with
most EDA tools
˃ Complex EDA tool workflows rely on network shared POSIX
filesystems based on an NFS filer to ensure that the same
coherent data is accessible across thousands of nodes
˃ However, NFS filers are not available as a native instance in
the cloud, and cloud NFS equivalents can have performance
issues
Today, companies typically try to attain hybrid workflows by setting
up the cloud environment, copying the data, and then running
jobs using pseudo NFS filesystems
But uploading data and keeping data “in sync” between on
premise and cloud is time consuming to setup and manage
Storage falls into two broad categories
˃ Large semi static read data
Tool binaries, IP views, etc.
Access can be sparse, and typically read only (but constantly changing)
˃ Smaller dynamic workspaces
Sometimes prepopulated with data, sometimes empty at start
Flow appends or creates data in this file system
Access is typically heavy with read and write
Xilinx has chosen to use a virtual
filesystem model for both the
semi-static and workspace
storage based on the IC Manage
PeerCache product

© Copyright 2018 Xilinx
Cloud enablement key considerations: StorageCloud vendors are very good at compute and networking, however Posix-based storage
management is a challenge especially for hybrid and burst use models
Fundamentally, cloud & on-premise infrastructures are different. The cloud typically uses block storage, where the
data is accessed by only one host at a time, while complex tool workflows rely on POSIC filesystems based on an
NFS filer to ensure that the same coherent data is accessible across thousands of nodes. However, NFS filers are
not available as a native instance in the cloud.
Consequently, companies typically try to attain hybrid workflows today by setting up the cloud environment, copying
the data, and then running jobs using pseudo NFS filesystems.
Even with such solutions, uploading data and keeping data in sync between on premise and cloud is time
consuming to setup and manage.
Storage falls into two broad categories
˃ Large semi-static read data
Tool binaries, IP views, etc.
Access can be sparse, and typically read only (but constantly changing)
˃ Smaller dynamic workspaces
Sometimes prepopulated with data, sometimes empty at start
Flow appends or creates data in this file system
Access is typically head with read and write

© Copyright 2018 Xilinx
Cloud vendors are very good at compute and networking, however Posix-based storage
management is a challenge especially for hybrid and burst use models
Fundamentally, cloud & on-premise infrastructures are different. The cloud typically uses block storage, where the
data is accessed by only one host at a time, while complex tool workflows rely on POSIC filesystems based on an
NFS filer to ensure that the same coherent data is accessible across thousands of nodes. However, NFS filers are
not available as a native instance in the cloud.
Consequently, companies typically try to attain hybrid workflows today by setting up the cloud environment, copying
the data, and then running jobs using pseudo NFS filesystems.
Even with such solutions, uploading data and keeping data in sync between on premise and cloud is time
consuming to setup and manage.
Storage falls into two broad categories
˃ Large semi-static read data
Tool binaries, IP views, etc.
Access can be sparse, and typically read only (but constantly changing)
˃ Smaller dynamic workspaces
Sometimes prepopulated with data, sometimes empty at start
Flow appends or creates data in this file system
Access is typically head with read and write
Cloud enablement key considerations: Storage
Xilinx has chosen to use a virtual
filesystem model for both the semi-static
and workspace storage based on the IC
Manage PeerCache product

© Copyright 2018 Xilinx
Cloud enablement key considerations: Cost managementCloud vendors are very good at providing infinite compute and networking; however it comes
at a per-compute instance, per-hour cost that can accumulate quickly
There are numerous cost management tools available that run after the fact, but few that run ahead of
the job to manage cost to a budget
Consequently, Xilinx has created a cost management process built into the job submission architecture
Job submission
Is job
eligible for
cloud
Y
N
Run on-premise queue
Is the on-
premise
queue full
Y
N
Does
user/group
have budget
Does job
predicted
cost exceed
budget
Y
N
NY
Run on-AWS queue
• All jobs submitted create a unique
signature used to track predicted and
actual run time and server usage
• Signatures are used to predict next run
profile and cost
• Budget database is dynamically
updated initially with predicted costs,
later by actual costs
• Dynamically size AWS instance for job
needs (cost management)

© Copyright 2018 Xilinx
Cloud enablement key considerations: Other considerations
Other considerations include
˃ Security, something to be aware of but not a show-stopper issue today
˃ EDA vendor license agreements usually prohibit off-premise execution, addendums required
˃ IP vendors usually prohibit off-premise storage and use, addendums required
˃ Become best friends with your IT organization and cloud vendors
˃ Although cost is a factor, we’re focusing on agility, scalability, and fast time to tapeout

© Copyright 2018 Xilinx
Cloud enablement key considerations: Overview
Use Model: Burst
Storage: ICM peer cache virtual storage for semi-static and workspace data
Compute: AWS C5D, Z1D, R5, and X1e depending on job type
Queue: LSF, including LSF connector for instance creation and clean up
Custom daemons for additional cleanup to manage runaway instances
Network: Cloud vendor within cloud
Secure AWS Direct Connect between Xilinx and cloud
Licenses: Host on premise, served to cloud

© Copyright 2018 Xilinx
Burst model cloud network, storage, and execute architecture
8TB EBS
Peer cache VTRQ
server
Compute instance
NVME workspace
Compute instance
NVME workspace
Compute instance
NVME workspace
2TB EBS
ICM proxy
LDAP proxy
XLNX Netapp NFS
Peer cache
Holodeck
MongoDB
SQL
Secure network
Xilinx Amazon

© Copyright 2018 Xilinx
Amazon EC2 server selection and instance typesInstance
purchasing
option
Risk Cost Features
On-demand Low High • Pay, by the second, for the instances that you launch
Reserved Low Medium • Dedicated compute, paid for up-front
Spot High Low • Spare compute at steep discounts
• Spot Instances can be interrupted by Amazon EC2 with two minutes of
notification when Amazon EC2 needs the capacity back
AWS instance Core count MaxMemory On-demand cost
per hour
Reserve cost per
hour
Spot cost per
hour
Spot versus
OnD cost
ratio
Xilinx usages
c5d.9xlarge 18 72GB $1.73 $1.02 $0.36 21% “50G” jobs
c5d.18xlarge 72 144GB $3.46 $2.34 $1.16 33% Not Used(Cost)
r5d.24xlarge 48 768GB $6.91 $4.07 $6.89 99% Not used (Cost)
R4x16xlarge 32 488GB $4.26 $2.50 $0.64 15% “512GB” jobs
x1.16xlarge 32 976GB $13.40 $7.67 $2.00 15% “1TB” jobs
x1.32xlarge 64 1952GB $26.68 $15.35 $4.00 15% “2TB” jobs
Costs provided for example only from public data, costs change constantly, refer to cloud vendors for specific details

© Copyright 2018 Xilinx
SI workload general cloud guidelines
˃ Decision of instance types/on-prem based on
requirements:
Low duty cycle + Low job restart cost: Spot instance
High duty cycle + Low job restart cost: Spot instance
Low duty cycle + High Job restart cost: On-demand instances
High duty cycle + High job restart cost: On-premise infrastructure
On-demand
instancesOn-premise
Spot instances Spot instancesJob r
esta
rt c
ost
Duty cycle
Duty cycle: Average amount of time HPC (high performance compute) servers will be in use, computing engineering jobs in a day or a year
50% duty cycle is 12 hours of 24 hours (or) 6 months in a year
35% duty cycle is 8.4 hours of 24 hours (or) 4.2 months in a year
25% duty cycle is 6 hours of 24 hours (or) 3 months in a year
Inflection point/break even point: Point (measured in quarters) at which expense in AWS will surpass the expense if we were to acquire, install and
operate the same number of servers on-premise

© Copyright 2018 Xilinx
Cloud enablement problem statement
Xilinx already uses Amazon AWS environment for internal software regressions and now VCS verification
execution, so we have an existing infrastructure on which to execute a new POC
As part of our internal product development we run a flow called timing capture to create a database to support
our proprietary FPGA place & route tools
˃ This involves capturing net delays for net segments and logical blocks on our devices and providing them to our
place & route tools. Path delays of customer designs are then calculated form this data.
The capture flow uses EDA standard tools in non-standard use models to collect this data set
˃ Use Synopsys Primetime for primary path selection and secondary delay calculation
˃ Use Synopsys HSPICE for primary path delay calculation (validated against Primetime delay)
˃ Accumulate delay data into single XML file for Q/A and delivery
Xilinx made a decision to investigate a deployment of this flow as part of a proof of concept for execution on AWS
Cloud in burst mode
˃ Flow setup completed on premise using Altair flow-tracer environment
˃ Major compute executed on cloud, submit via LSF (from Xilinx to AWS)
˃ Final Q/A and delivery completed on premise using Altair flow tracer environment

© Copyright 2018 Xilinx
Cloud enablement problem statementTiming capture is not a vanilla STA run

© Copyright 2018 Xilinx
AWS proof of concept results: Flow execution
˃ Diagrams show our Altair flow tracer for running on
premise flows. Two flows are shown: A small test
case and a larger production test case.
˃ Each box corresponds to a task or tool execution,
color corresponds to run state
˃ For POC
purposes, high
compute flow
steps redirected to
AWS environment

© Copyright 2018 Xilinx
AWS proof of concept results: Runtime metrics
˃ Fig 1: Total runtime on prem versus on AWS for small test case
˃ Fig 2: Primetime sample path runtime on prem versus on AWS
for small test case
˃ Fig 3: Hspice sample path runtime on prem versus on AWS for
small test case
Design metrics˃ Small test case
AWS c5d.18xlarge instance type 72vCPU, 144G ram, used 16cpu’s, 60G ram
> Input design (pre-filtered to not load unused FSR’s) • 3 FSR• Components : 1mil (IP blocks)• Nets : 1.5B (SOC nets)
˃ Pruned output design, 3fsr• Components : 250k ( 4:1 reduction)• Nets : 300M (5:1 reduction)
˃ Large test caseAWS z1d.12xlarge instance type 48vCPU, 384G ram, used 16cpu’s, 360G ram
˃ Input design (pre-filtered to not load unused FSR’s) • 70 FSR’s• Components : 2.3B (IP blocks)• Nets : 16.5B (SOC nets)
˃ Pruned output design, Group0• Components : 32mil ( 72:1 reduction)• Nets : 1.1B (16:1 reduction)
Total
runtime
On prem On AWS delta (AWS)
PT 61 hrs 33.8 hrs 1.8x
Spice 61 hrs 115 hrs 0.5x
Total 122 hrs 149 hrs 0.82x
Fig .1
Path group pt on
prem(sec)
pt AWS
(sec)
pt delta
(AWS)
90 1110 1140 1x
91 1130 830 1.3x
92 1370 840 1.6x
93 2580 1030 2.5x
Fig .2
Path group Hspice on
prem (sec)
Hspice AWS
(sec)
Hspice delta
(AWS)
90 1040 2680 0.4x
91 2070 3860 0.5x
92 1590 3236 0.5x
93 2590 2732 1x
Fig .3

© Copyright 2018 Xilinx
AWS proof of concept results: Delay correlation
˃ Comparing final delays calculated on AWS environment to Xilinx on-premise
results using same flow
˃ Results correlate 100% (within acceptable data noise margin)

© Copyright 2018 Xilinx
Conclusion
Using our existing infrastructure (deployed to support VCS verification flow execution in burst
mode on AWS), we were able to quickly deploy a new timing capture flow, not previously designed
to run on the cloud, and execute the compute intensive parts on the cloud while the rest of the flow
ran on premise
This was a proof of concept exercise, so this is not a production ready flow as is but productizing it
is within the scope of an incremental development if we choose
The POC demonstrated we can on demand execute part of an internal flow on the cloud versus on
premise with minimal impact to runtime, turn around time or quality of results, taking advantage of
server scale out provided by the cloud vendors that may not be available on premise
Thanks to TSMC, Synopsys, AWS, ICManage and Xilinx for supporting this work and enabling
this to be possible

© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.

Scale-out computing on AWS
• EDA/HPC environment on AWS
• Easy installation in your AWS account
• Amazon EC2 Integration
• Simple job submission
• OS agnostic and AMI support
• Desktop cloud visualization
• Automatic errors handling
• Web UI
• 100% customizable
• Persistent and unlimited storage
• Centralized user-management
• Support for network licenses
• EFA support
• Simple cost/budget management
• Detailed cluster analytics
• Used in production
aws.amazon.com/solutions/scale-out-computing-on-aws
Amazon
S3
Amazon Elastic
File System
Amazon FSx
for Lustre
Users
(access web
UI, DCV, ssh
to
scheduler)
Elastic Load
Balancing (manages
access)
DCV graphical
sessions
web UI
Amazon EC2
(scheduler
instance)
python scripts
(used to run jobs)
Amazon EC2
Auto Scaling
(launch
instances to run
jobs)
Amazon
Elasticsearch
Service
(stores job & host
information)
AWS Secrets Manager
(stores cluster
information)
(storage options
for either
persistent or
ephemeral data)

IBM LSF workshop
Vivado writes job runtime data and results to /ec2-nfs/scratch
8Vivado loads example IP and design from /ec2-nfs/proj
7Jobs load pre-licensed Xilinx
Vivado Design Suite from FPGA
Developer AMI
6Jobs are dispatched to new
execution hosts
5Provisioned Amazon EC2 instances
join the cluster as dynamic
execution hosts
4IBM Spectrum LSF provisions
Amazon EC2 instances to satisfy
workload in the queue
3 User submits simulation jobs from
the login server
2
User logs into the login server from
from within the corporate network1
Amazon EC2 instances are terminated by LSF after jobs finish
9
IBM Spectrum LSF binaries,
configuration, and logs are read
from and written to Amazon EFS
10
Amazon Elastic File System (Amazon
EFS)
AWS Cloud
User
Corporate data
center
Login server
LSF master
Execution hosts
Amazon EC2 NFS server
1
2
3
/tools/ibm/lsf
FPGA developer AMI
/opt/Xilinx
4
/ec2-nfs/proj
/ec2-nfs/scratch
6
7
8 9
5
10
https://github.com/aws-samples/aws-eda-workshops/blob/master/workshops/eda-workshop-lsf

NICE DCV remote desktop with Xilinx Vivado
Optional: Specify additional existing
security groups9
Optional: Configure Amazon S3
bucket access to load design data8
The remote desktop is displayed on
the engineer’s local system7
In the FPGA Developer AMI, launch
the Xilinx Vivado Design Suite, and
by typing “vivado” in a terminal
window
6
Connect to NICE DCV using the NICE
DCV client or over a web browser,
using port 8443
5
Choose a remote desktop instance
type that works for your tools4
Optional: Create an Elastic IP address
(persistent IP)3
Specify required parameters (VPC,
Subnet, AZ, etc.) and launch the AWS
CloudFormation stack
2
Subscribe to the FPGA Developer
AMI, located in AWS Marketplace.
The Xilinx Vivado Design Suite is
included with this AMI.
1
AWS Cloud
Availability Zone
VPC
Remote desktop
AWS
Marketplace
NICE DCV
Remote site
1
Security group
EIP
3
4
67
9
Port 8443
Amazon S3
CloudFormation stack
2
8
5
TM
https://github.com/aws-samples/aws-remote-desktop-for-eda

Serverless Scheduler with Resource Automation
AWS Cloud
Part 1 - CloudFormation Stack
Amazon SQS
Users Amazon
DynamoDB
Amazon EC2
AWS Step Functions
workflow
Part 2 - CloudFormation Stack
Auto Scaling
group
1
2
3
4
AWS Cloud 5
6
https://github.com/aws-samples/aws-decoupled-serverless-scheduler
Users download results5
EC2 Auto Scaling Group scales the
number of workers from 0 to defined
maximum
4
AWS Lambda monitors job queue
and updates Auto Scaling Group with
desired instance count
(customizable)
3
AWS Lambda triggers from S3 event,
creates and submits the new job(s)2
Users upload input files and
executables for job(s)1
User monitors job status through
AWS Console or AWS CLI6
The user uploads the job input
file(s) and executable to the S3
bucket instead of SQS. This
upload triggers job start and EC2
Instance management is now
handled by the Auto Scaling
Group. There is no longer a need
to create a json job definition.

Semiconductor white papers
https://aws.amazon.com/whitepapers

Related content: AWS re:Invent 2018
Leadership Session: AWS semiconductor AWS re:Invent 2018 MFG201-L
• Slides: http://bit.ly/2TQ5A8N
• Recording: http://bit.ly/2S5ZK1E
Amazon on Amazon: How Amazon designs chips on AWSAWS re:Invent 2018 MFG305
• Slides: http://bit.ly/2TR4vhd
• Recording: http://bit.ly/2tpiQG0
How to build performant, highly available license services in the cloudAWS re:Invent 2018 MFG306
• Slides: http://bit.ly/2BO9bNZ
Rightsizing your silicon design environment: Elastic clusters for EDA workloadsAWS re:Invent 2018 MFG401
• Slides: http://bit.ly/2DL7S26

Thank you!
© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.

© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.