end of term harvest user interface
TRANSCRIPT

Slides used for CDL staff meeting demo of End of Term
Harvest prototype

End-of-Term Harvest
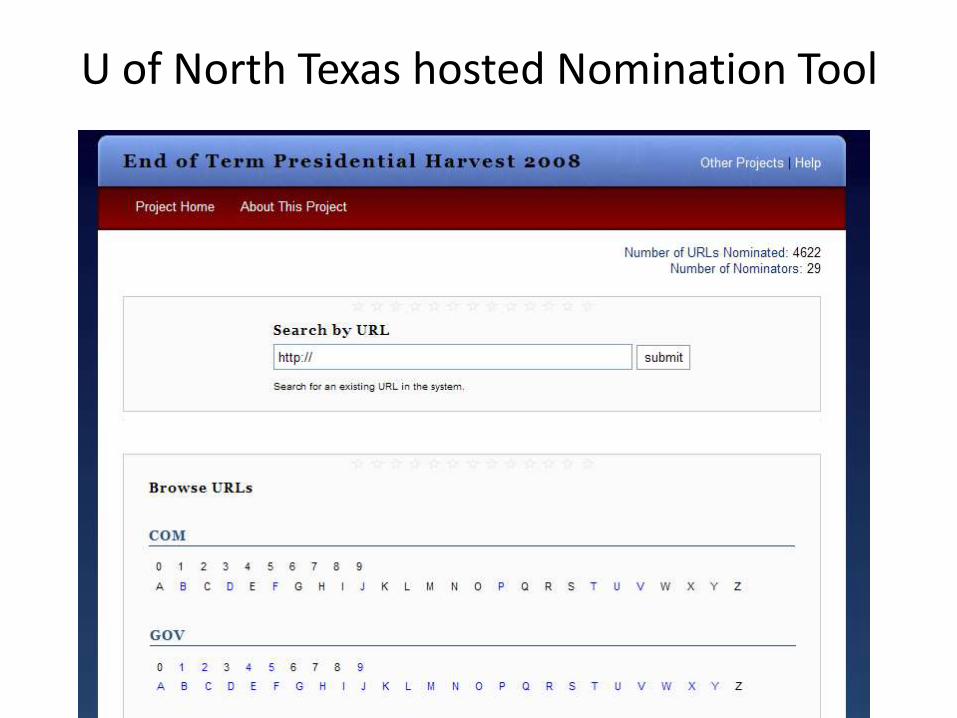
U of North Texas hosted Nomination Tool

The Content
• 25 terabytes of federal government websites
• Captured by Internet Archive, CDL and University of North Texas: August 2008-August 2009.
• All content at Internet Archive: keyword search, URL lookup.

CDL (Tracy) and IA (Kris Carpenter Negulescu) charged with providing public access interface to collection
1st Tuesday of each month, 12:00 pm:
Anything to report on public access?
No, nothing to report on public access.

Also of note
• Internet Archive experiments with generating MODS records for web archived content
• Uses selenium to take snapshot images of archived content for QA
• International Internet Preservation Consortium Access Working Group looking for some means of implementing cross-archive public access

Then:
Martin Haye demonstrates XTF front-end to content in Merritt repository.Tracy thinks “hmmm….”

Demo

Slides used to show CDL publishing group (XTF developers)
• Minor changes to implement in navigation
• Clear distinction between searching full text and searching metadata
• Confirming that API for IA search results can be integrated (yep)
• Some screens are images of functioning interfaces, others are images of wireframes. Fully functional screens are noted.

Abbie G. will work on text / layout of home page

Each organization can send some text to be included here.

Search vs. browse
• Keep ‘search full text’ from ‘search metadata’ as distinct as possible.
– Brief results will look different. Full text search results will have no thumbnail and likely different metadata.
– Document display will behave differently. Full text search results will render an archived page. Displaying a browse result will lead to the date navigation to all versions of the site’s home page.

Search vs browse contd.
• Will not attempt to integrate two kinds of searching on one screen or within one result set.
• Search tab devoted strictly to full text search of IA content
• Browse tab contains a ‘lookup’ that lets you search against site metadata.

Results come back via API for full text search at IA.

Except for top navigation bar, this is currently fully functional

Except for top navigation bar, this is currently fully functional

Browse by URL not yet functioningexpect to add facet by domain (.gov, .edu etc.)

Metadata lookup: except for top navigation bar, this is currently fully functional
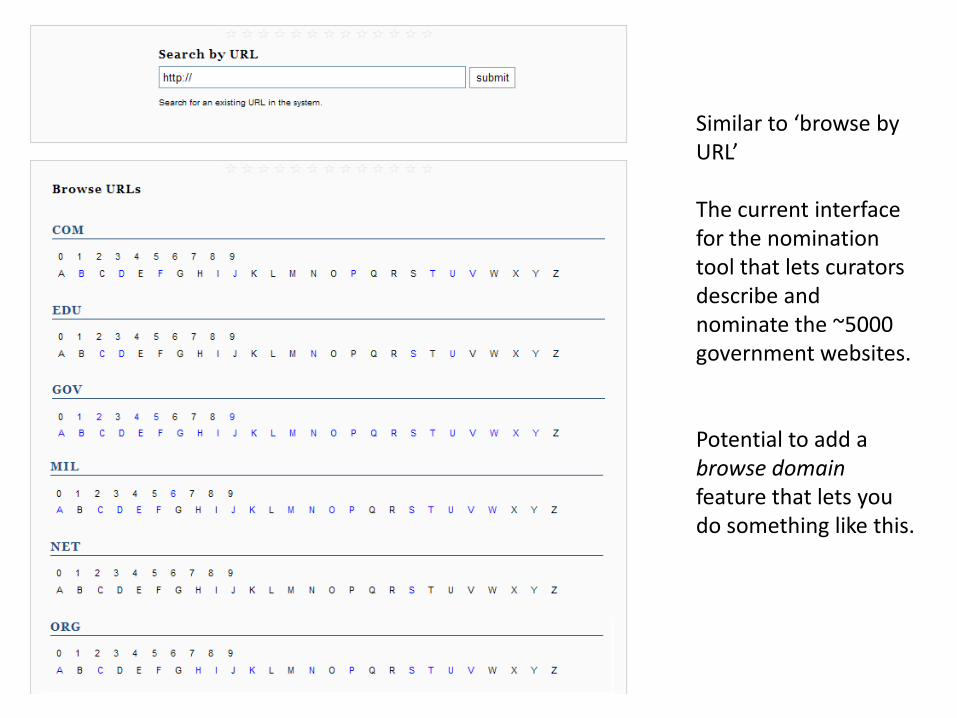
Similar to ‘browse by URL’
The current interface for the nomination tool that lets curators describe and nominate the ~5000 government websites.
Potential to add a browse domain feature that lets you do something like this.

Other expected elements
• creator
– The agency name
– Include as browse page and facet
• Provenance[2]
– Domain (.gov, .mil) etc.
– Derive from URL
– Facet for at least the browse by URL screen

The record needed:<title>Visualization of Remote Sensing Data</title><creator>Agency name information if you have it</creator><identifier>http://crawls-wm.us.archive.org/eot08/*/rsd.gsfc.nasa.gov/</identifer><provenance>http://rsd.gsfc.nasa.gov/</provenance><date>2008-09-16</date><date>2009-08-14</date><description>The Vis/RSD website is a showcase for stunning visualizations of satellite data by NASA's Goddard Laboratory for Atmospheres.</description><subject>remote sensing</subject><subject>data</subject><subject>satellite</subject><subject>radar</subject><subject>telescope</subject><subject>earth</subject><subject>space</subject><subject>land</subject><subject>oceans</subject><subject>science education</subject><subject>land use</subject><subject>NASA</subject><type>web site</type><format>text</format><coverage>Executive</coverage><relation> http://crawls.archive.org/collections/eot08/</relation>
Other elements used, such as source for URL segments, are extracted from this data as they come into XTF. We don’t need a root dc element or namespace reference, but records would still work if IA had a reason to need them there.