enhancing fairness of fib lookup in named data networking
TRANSCRIPT

! i!
NATIONAL TAIWAN NORMAL UNIVERSITY
COMPUTER SCIENCE AND INFORMATION ENGINEERING
Enhancing Fairness of FIB Lookup in Named Data
Networking
Author: Supervisor:
Jing-Yung FU Dr. Ling-Jyh CHEN

! ii!
,
IP
I ,
B
F
I ,
I
FIB
DePT (Dispersed eminent Patricia Trie)
I Patricia Trie

! iii!
Abstract
The novel network architecture Named Data Networking (NDN) has been proposed.
The way of information transfer will be pass by name content rather than IP address.
Users could get the content by directly describe the information. However, with the
appearance of Internet of Things (IoT), there will be more information in the network
flow. On the other hand, names do not have the same length and content, the lookup
time of names in router would be very different. The difference of lookup time may
result in that every user will get his data by during very different waiting time.
Therefore, the “unfair” situation happened. In order to solve the fairness issue, we
propose a method “DePT (Dispersed eminent Patricia Trie)” which based on two basic
methods. This proposed method will make each name have about the same lookup
time in FIB. Besides, the lookup efficiency will be better and the memory consumption
will be lower. It will reduce the burden on the hardware.
Key words: Name Data Networking, fairness, FIB

! iv!
TABLE OF CONTENTS
1. Introduction………………………………………………………………………1� � � � � � � � � � � � � � � � � �
2. Backgrounds and Related work………………………………………….............4� � � � � � � � � � � � � � � � � �
2.1 NDN overview………………………………….…….…….…......................4
2.2 Forwarding process in NDN………………………….……………….…......8
2.3 Name lookup in NDN………………………………………………………..9
2.3.1 Pending Interest Table lookup……………...........................................9
2.3.2 Forwarding Information Base lookup…………………………..…….11
3. Problem Definition………………………………………………………….…...14� � � � � � � � � � � � � � � � � �
4. Our Approach……………………………………………………………….…...15� � � � � � � � � � � � � � � � � �
4.1 DePT - Building DePT....................................................................................17
4.1.1 Building DePT - Filtering phase...........................................................17
4.1.2 Building DePT - Incremental update phase..........................................18
4.2 DePT - FIB lookup..........................................................................................19
5. Evaluation………………..………………….…….…….….................................21� � � � � � � � � � � � � � � � � �
5.1 Dataset……………….………………….….….…….…................................21
5.1.1 Real-world dataset................................................................................22
5.1.2 Synthetic dataset...................................................................................22
5.2 Measurement……………….………….……………….…............................23
5.2.1 Data distribution…….………………………………………..............23
5.2.2 FIB lookup time of Real-world dataset….……………………..……24
5.2.3 FIB lookup time under different n……….……………………..........25
5.2.4 FIB lookup time under different p……….……………………..........26

! v!
5.2.5 Coefficient of Variation of FIB lookup time under different p….…..29
5.2.6 Memory consumption of DePT under different p……….….……....30
5.2.7 Incremental update of DePT under different k………………………31
6. Discussion……………………………………………………………..………..32
7. Conclusion � Future Work...………………………………………..………..33
8. References……………………………………………………………….……..34
!

! vi!
!!
LIST OF TABLE
1. Relationship between length (number of characters) and lookup time ………...24!!
LIST OF FIGURES
1. Internet and NDN hourglass architecture .………………………………………..5
2. Packets in NDN architecture …...….……………………………………………..6
3. Entry in PIT and FIB..…………………………………………………………….7
4. Interest / Data forwarding process in NDN router …..………………...................9
5. Trie, Ternary Trie and Patricia Trie for names “by”, “sea”, “sells”, ”shells” and
“shore”……………………………………………………………………….......13
6. Flow chart of building DePT…………………………………………………….16
7. Building DePT – Filtering phase………………………………………………..18
8. Building DePT – Incremental update phase……………………………………..19
9. Distribution of name length in real-world dataset……………………………….23
10. FIB lookup time for four methods comparison under different n
(a) Real-world dataset…………………………………………..……………….25
(b) Synthetic dataset…………………………………….……………………….25
11. FIB lookup time for four methods comparison among 0%, 30%, 60% and 90% of
common prefix
(a) 0%....................................................................................................................26
(b) 30%..................................................................................................................26
(c) 60%..................................................................................................................26
(d) 90%..................................................................................................................26
12. Average FIB lookup time for four methods comparison in different p………….28
13. Coefficient of Variation of FIB lookup time for four methods comparison in
different p………………………………………..……………………………...29
14. Memory consumption for four methods comparison in different p………..…...30
15. Incremental update under different k……………………………………….…...31
!

!1!
1. INTRODUCTION
The increasing demand for highly scalabe and efficient distribution of content
has motivated the development of future Internet architecture. Different from
traditional IP network, it focused on information objects such as videos, documents,
and other pieces of information rather than physical address or location of desired data.
This approach of this architecture is commonly called information centric networking
(ICN) [1]. ICN favors the deployment of in-network caching and multicast
mechansims. Based on ICN conception, a clean-slate network architecture Named
Data Networking [2] has been proposed. It focuses on “What” the information (content)
is rather than “Where” the information is located. Data transferring between nodes in
NDN will reduce the cost of bandwidth required for content providers. And improve
the consumer’s download speed even increase system stability.
However, NDN has been applied to certain places and the detail as follow.
Named Data Networking for Internet of Things (IoT) [3] has been concerned. NDN is
recognized as a content retrieval solution in wired and wireless domains. Due to its
innovative concepts, such as named content, name-based routing and in-network
caching, paticularly suit the requirement of Internet of Things. Besides, directly
management in security, naming, data aggregation are also beneficial for IoT. The
most significant thing is that IP address assignment procedure is to be spared. Device
in IoT communicates with each other by meaningful names. Therefore, application
developers are free to design its own namespace that fits the constraints of their
environment. Vehicular ad-hoc network (VANET) [4] is another application for NDN.
Indeed an increasing number of vehicles are connected to Internet today and they
mainly connected via cellular network only. A new design V-NDN [5] has been

!2!
proposed and demonstrated through real expreimatation. In V-NDN, communication
between cars would be content name and consists of abundant traffic information.
For example applications above, names in NDN play an important role. Every
consumer receives its desired data by going through routers. Regardless of getting data
from Content Store (CS) directly or find its corresponding name prefix in Forwarding
Information Base (FIB), lookup time is the most important thing that every consumer
cares about. However, many methods for name lookup have been proposed and they
mainly based on Hash Table (HT), Bloom Filter (BF) and Trie. In Pending Interest
Table (PIT), exact string matching (ESM) of NDN name would be most efficient by
using a kind of hardware such as Ternary Content Addressable Memories (TCAM) [6].
It minimizes the memory access required to locate an entry by comparing it against all
memory words in one clock cycle. On the other hand, longest prefix matching (LPM)
is frequently used in FIB and Trie is the core method. Therefore, our preliminary
approach has implemented two relative Trie, Ternary Trie and Patricia Trie. The
reason why we try another Trie for name prefix search is that lookup efficiency of Trie
depends on length of name. Another purpose of our approach is to achieving fairness
in searching as possible as it can. Consequently, the remaining problem is that how to
serve every request in NDN router in fairness. Because of uncertain length of name
and number of routers name goes through, time to receive data packet may have great
difference.
In this paper, we propose and implement our method Distributed-eminent
Patricia Trie (DePT), name prefix lookup architecture to obtain high speedup and
achieve fairness in NDN FIB. Name prefix lookup in FIB is not as same as in PIT,
unknown length of name will be matched in FIB. We develop DePT to be a generic
architecture to solve fairness issue. DePT is based on multiple Patricia Trie so as to

!3!
narrow the range of name prefix lookup. Every Patricia Trie has almost the same
number of name prefix, every name serverd in fair search range. Besides, we make the
following contributions.
1. We propose DePT that performs accelerated NDN name lookup in FIB. The core
of DePT is a distributing method that classifies all name prefix in FIB into several
groups according to its specific value. Search scope will therefore become smaller
and efficiency will be better.
2. We use Patricia Trie as basis of our method DePT because it not only achieves
remarkable average speedup for name prefix lookup than general Trie but also has
fairer lookup time.
3. We have a incremental update in our method DePT to face special cases. In order
to prevent the specific situation that much the common prefix appeared in FIB and
resulted in worse lookup efficiency and unfairness in DePT, we have a incremental
update deal with it. The incremental update would be activated immediately when
reaching the standard.
4. We demonstrate a better saving of memory consumption; Trie is viewed as
higher memory consumption method than hash table or bloom filter. However,
DePT using Patricia Trie to saving memory consumption in case name greatly
increase in the future.
The rest of this paper is organized as follows. Section II introduces NDN such as
architecture; packet forwarding and some name prefix lookup methods that have been
proposed. Section III defines the key problems existing in NDN cache components and

!4!
Section IV decribes DePT approach in detail. Section VI is our experimental
evaluation and we conclude our research in Section VII.
2. BACKGROUNDS & RELATED WORK
Before introducing our approach, we have a brief introduciton of NDN that
consists of interior architecture, forwarding process and name prefix lookup method
proposed that relative to our research.
2.1 NDN overview
Named Data Networking (NDN) is a proposal for the information-centric
networking (ICN) conception. A most significant distinction from IP is that every
piece of content in NDN routed and forwarded by its assigned name instead of fixed
length IP addressed. However, NDN names are application-dependent and opaque to
the network.
NDN aims to remove the restriction that packets can only name communication
endpoints. Consequently, names in packet can be anything: an endpoint, a chunk of
movie or book, a command to do something, etc. In Figure1, NDN has an evolution of
the IP architecture that generalize the role of thin waist and it means packets can name
objects other than communication endpoints.

!5!
Figure 1: Internet and NDN hourglass architecture [2]
Besides, security is another noteworthy point. In NDN, security is built into data
itself rather than being a function. Signature is a security key binding with data, not
only coupled with data publisher information but also enables determination of data
provenance. In network traffic, router in NDN can control the traffic load by
controlling the number of interest to achieve flow balance between Interest packet and
Data packet.
However, in-network storage is the core of the practice compared with IP
network. Routers in IP cannot reuse the data after forwarding them. But routers in
NDN can cache data to satisfy future request since they are identified by the data
names. This caching mechanism can accelerate the speed of information obtained and
achieve almost optimal data delivery. Other details about caching will be narrated in
the following section.
Different from traditional Internet Protocol (IP) network, NDN has many
distinctive features. NDN is a consumer-driven and data-driven communication
protocol. In Figure 2, every data consumer and data provider will exchange their
information by using two distinct packets: Interest Packet and Data Packet. Both of

!6!
them carry a content name that uniquely identifies a piece of data. Unlike IP address, a
serial meaningless number in IP network.
Figure 2: Packets in NDN architecture
By using Interest Packet and Data Packet as medium in NDN infrastructure, a
consumer will put the name of a desired piece of data into an Interest Packet and send
it to the network. Routers in NDN use this name to forward the Interest Packet toward
the data producer. Once the Interest reaches a node that has requested data, the node
will return a Data packet that contains both the name and the content, together with a
signature by the producer’s key. The most significant difference between NDN and IP
network is that NDN has cache mechanism. Consists of Content Store (CS), Pending
Interest Table (PIT) and Forwarding Information Base (FIB).
1. The purpose of Content Store (CS) is like a buffer memory in today’s network
and it mainly used to store content that have ever been forwarded. On the other
hand, there is no information left in router after packet forwarding in IP network.
In NDN network, CS left some reusable data through computational algorithms as
possible as it can, like popular news and information. When a lot of users request

!7!
for same contents, it can save bandwidth to download the data, and consumers can
also ensure that the data couldn’t be tampered with by signed info and signature in
data packet. In addition, the replacement algorithm to improve the hit ratio and
configuration size for CS is an important research topic in NDN.
2. Pending Interest Table (PIT), which keeps track of the Interest Packet upstream.
In Figure 3, Each PIT entry contains the name of the Interest and a set of interfaces
from which the Interests for the same name have been received. When its
corresponding data packet arrives, router will forward data to all the interfaces
listed in the PIT entry. Then router removes the corresponding PIT entry, and
caches the data in the Content Store. Furthermore, in order to preclude that PIT
consists of overfull entries, the incoming interface is also removed from PIT when
the lifetime expires.
3. In Figure 3, Forwarding Interest Base (FIB) in NDN differs from IP FIB in two
ways. First, entry in IP FIB only contains a single best next-hop. On the contrary,
FIB entry in NDN contains a list of multiple interfaces. Besides, an IP FIB entry
contains nothing but the information of next-hop, while an NDN FIB entry records
both data planes and routing preference to provide every name a adaptive
forwarding decisions.

!8!
Figure 3: Entry in PIT and FIB
2.2 Forwarding process in NDN
In Figure 4, forwarding process in NDN node follow a specified rule. A
consumer put the name of desired data into an Interest Packet and put it into network.
Routers use this name to forward to data producers. In particular, it follows a specific
rule.
In NDN router, when an Interest Packet arrives, an NDN router first checks
whether the corresponding matching data is in CS or not. If desired data exist, Data
Packet that contains both the name, content and producer’s key will be transferred
back to requesting consumer. Otherwise the router will keep looking up the name in its
PIT. If a matching entry exists in PIT, it records the incoming interface of this Interest
and forwards it to the next station FIB. FIB then forward it to the data producer based
on router’s adaptive forwarding strategy. Among it, if a router receives Interest Packets
that have same name from multiple downstream nodes, it forwards only the first one
upstream toward the data producer. In contrast, if there is no matching entry in PIT,
the name will be added in PIT entry and forwarded to FIB.
After a Data Packet arrives, an NDN router will forward the data to all
downstream nodes whose interfaces listed in that PIT entry. So every Interest Packet
that arrived in the same time slot will receive this Data Packet. Simultaneously, the
PIT entry will be removed and data will be cached in the Content Store. But if Data
Packet arrives over the setting time, the waiting Interest Packet in PIT entry will also
be removed and this Data Packet will be dropped to prevent network congestion.

!9!
Figure 4: Interest/Data forwarding process in NDN router [2]
2.3 Name lookup in NDN
In this paper, our method and estimation mainly aim at name lookup in FIB.
Apart from name lookup for data caching in Content Store, we simply mention some
proposed method of name lookup in PIT and introduce the basis of our method for
name prefix lookup in FIB. Different from fixed IP address comparing process in
router, there are two ways for name lookup metioned before in NDN router, Exact
String Matching and Longest Prefix Matching. However, PIT used Exact String
Matching for entire name searching and Longest Prefix Matching is applied in FIB.
The only one common thing is that existence of name to wait for searching in PIT and
FIB has limited time and the name would be deleted due to nothing responds.
Therefore, the lookup method must be fit the property of them. In the following
subsection, we discuss some proposed method for name lookup in PIT and FIB.
2.3.1 Pending Interest Table (PIT) Lookup

!10!
Exact string matching in PIT is similar to string matching in traditional data
structure. In proposed method, there are mainly based on DFA, Hash Table and Bloom
Filter. The basic and classical method we have ever seen is DFA (Deterministic finite
automata) [7]. The difficulty of DFA is that each name prefix in NDN is associated
with unbounded string and it requires a special encoding scheme.
Another method is hash table (HT), HT-based lookup algorithm is efficient but
the choice of a hash function significantly affects its performance. As a result, many
extension or deformation of hash table has been proposed. In [8], there is various hash
function at efficiency and collision rate comparison, it verify that different hash
function may bring about large difference between them. And [9] shows multi-hash
name lookup table and the main objective is lower false positive rate. In other words,
size of hash table and number of linked list in every location will be another threshold.
However, [10] wants to using hash table based on compact array rather than linked
lists, it also set a certain number of components for lookup start to prevent DoS attack
in NDN router. Similarly, number of default lookup start will be a threshold and affect
the efficiency.
In [11], Bloom Filter (BF) is a method used for IP network and it is based on
multiple hash function. About Bloom Filter in NDN usage, [6] shows distributed
Bloom Filter to reduce the necessary memory space for implementing the PIT; A name
lookup engine with Adaptive Prefix Bloom Filter [12] has been proposed. Each NDN
name is split into B-prefix followed by T-suffix. The B-prefix is matched in Bloom
Filter and T-prefix is matched in Trie. However the length of these two segments
depend on how popular they are. It needs a additional statistic to adjust boundary.
NameFilter [13] is a two-stage Bloom Filter for name lookup. The first stage
determines the length of a name prefix, and the second stage lookup the prefix in a

!11!
narrow group of Bloom Filters. Mapping Bloom Filter [14] that is a modified data
structure of Bloom Filter has been proposed to minimize the on-chip memory
consumption by using SRAM and even decreases the false positive rate. In summary,
there are two drawbacks in Bloom Filter, one of drawback is requiring large memory
bandwidth when operating multiple hash functions. Another one drawback is how to
choose adequate hash functions to lower false positive rate.
2.3.2 Forwarding Information Base (FIB) Lookup
The purpose of name prefix lookup in FIB is to find the longest prefix of the
name and toward the face to obtain the desired data. Different from Exact String
Matching, Longest Prefix Matching only needs to find a shorter or equal length prefix.
In terms of Longest Prefix Matching, the majority of methods are based on Trie.
[15,16] is Trie-based longest prefix matching algorithm for IP network, which cannot
satisfy the need of storing millions of variable and unbounded names. Fu Li et al.[17]
presented a framework of a fast longest prefix name lookup based on name space
reduction scheme. The method use fat tree and extensible hybrid data structures to
accelerate the name lookup process. Yi Wang et al. [18] proposed a Name
Components Encoding approach for longest prefix lookup in NDN. This technique
involves a code allocation mechanism and an evolutionary state transition arrays. Not
only increase the search complexity but also reduce the efficiency of lookup. However
[19] also used tree-based structured upon hardware parallelism to achieve high lookup
speed.
After discussing proposed approach before, we found that most of methods and
approaches mentioned above are used for entire name lookup and fit the property in

!12!
PIT. In contrast, less approach aimed at searching longest prefix in FIB. Besides,
another point worth noting is that insertion and deletion of name prefix in NDN router
will often occur. Therefore we engaged in basic data structure in our approach to do
longest prefix matching, Trie, Ternary Trie and Patricia Trie. Although Trie has
relatively higher memory consumption, content management is more convenient than
hash table or Bloom Filter. Consequently, we implement and discuss about the other
two extensive methods to our DePT basis, Ternary Trie and Patricia Trie and there are
three brief introductions below.
1. Trie [20] is a data structure in which each path from the root to a leaf
corresponds to one key in the represented set. Each node in Trie has an array which
consists of several characters. The path in the Trie corresponds to characters of the
key in the FIB. When input request doing longest prefix matching in Trie, the
value with existing key will be returned. Figure 5 (a) shows that five strings stored
in Trie and each existing string has its corresponding value. Consequently, the
request name “season” will obtain a returned value “7” after doing lookup process.
2. Ternary Trie [21] must have three children in each node. The location of each
node depends on the order of input due to its comparison of letters. When input
request doing longest prefix matching in Ternary Trie, each character of name will
compare not only character in string but also other characters in lookup path. In
Figure 5 (b), a request name “season” will meet two additional existed characters
“h” and “l” before matching longest string “sea”. Besides, another disadvantage of
Ternary Trie is that alphabetical order may result in nodes in Ternary Trie tilt in
certain side and make lookup procedure more difficult. Therefore, Ternary Trie not

!13!
only reduces the speed of name prefix searching but also increases memory
consumption.
3. Patricia Trie [22] is equivalent to compressed Trie, it is a simple variant on a
trie in which any path whose interior vertices all have only one child is compressed
into a single edge. The lookup path is as same as Trie but it has better efficiency
due to its less number of nodes. In Figure 5 (c), a request name “shellshock”
lookup in Patricia Trie only needs to meet three nodes rather than six nodes in Trie.
Figure 5 : Trie, Ternary Trie and Patricia Trie for names “by”, “sea”, “sells”,
“shells” and “shore”
In NDN router in current simulator ndnsim [23], Trie is used to longest prefix
matching. Compare with general method hash table, it has lower computational
complexity and it is favorable for data insertion and deletion. According to the
introduction above, the complexity of lookup in Trie and Patricia Trie at most O (|s|)
which s represents the length of name. However, Ternary Trie has additional
comparing step so its complexity is O (|s| + log n) and n equals to number of string.

!14!
For Patricia Trie, it saves a lot of memory storage and greatly speed up the efficiency
of longest prefix matching. That is why we used Patricia Trie as basis of our method
DePT to store name prefix in FIB.
3. PROBLEM DEFINITION
With respect to longest prefix matching of NDN name in FIB, efficiency is the
most concerned issue. However, fairness issue has not been mentioned before.
Considering throughput and overhead at the same time, our emphasis and another goal
on name prefix lookup is achieving fairness as far as possible. In the following section,
we define three main goals and they are searching delay, memory consumption and
searching fairness and our purpose is to optimize these three key points.
1) Searching delay in FIB represents the time that Interest Packet waits for longest
prefix matching process. It means that each request name from Interest Packet has
a searching delay d and we define D as total searching delay of our name dataset.
(n equals to number of data).
2) Memory consumption in FIB means how much memory consumption a data
structure used to store name prefix. In our method DePT, we need k sub data
structure to store all name prefix and each subsection occupies m memory.
Consequently, total memory consumption M in FIB could show as k∗m

!15!
3) Searching fairness of input requests in FIB shows how fair the searching delay of
longest prefix matching process. About measuring fairness, we use Coefficient of
Variation (CV) to estimate whether the searching delay is fair or not.
According to details of these three key points, we summarize the ideal solution
below. Searching delay is smaller represents that lookup process in FIB has better
efficiency, however, if the data structure used in FIB has lower memory consumption,
it would be a better methodology. The last one point is CV, smaller CV represents that
searching delay of input requests are similar and concentrated, it is under a fair
situation. Therefore, the ideal state is that evaluations of these three methodologies are
smaller in common.
4. OUR APPROACH
We proposed a method named DePT. Based on alphabetical build conception in
Ternary Trie; we also have a novel classified idea for building prompt data structure.
Unlike a disadvantage that input order of string will greatly affects the lookup
efficiency in Ternary Trie. We have a better-classified mehod, therefore, our design
rationale behind DePT is that we evenly classify all name prefix of FIB into many sub-
tries to narrow the lookup scope and enchance the lookup fairness. Besides, we have
an incremental update mechanism to avoid the happening of special situation and it
will be descripted in the following.
The word “dispersed” in DePT is the core conception. We separate entire
structure into several subsections so as to narrow the searching range. Besides, the

!16!
searching scope of every name request is nearly the same, so the lookup time of them
are close to each other and the searching fairness becomes better.
However, more than one method of dispersing and we considered that the
method must have at lesat two basic properties, efficiency and diversity. In our method,
we use hash function to classify all name prefix into group. The hash function make
number of name prefix evenly distributed in every Patricia Trie. About longest prefix
matching, we use Patricia Trie as our data structure due to its efficiency and fairness.
The detail of Patricia Trie has been mentioned in the section two in this paper.
Summarize the above description; DePT also takes advantage of hash function
and Patricia Trie. Figure 6 shows the flow chart of building DePT, and we will detail
each phase of our approach in the following subsection.
Figure 6 : Flow Chart of building DePT

!17!
4.1 DePT – Building DePT
1) Building DePT – Filtering phase
In first part of our approach, the destination is to narrow the scope of searching.
In general FIB, all name prefix are put into a single data structure like Trie.
However in order to enhance the search speed, we use a filtered way to split original
structure into multiple subsection. All name prefix will be classified and restricted
into a range depend on hash table size. At the same time, in order to control the
number of name prefix in every bucket in hash table, we allocate a counter in every
bucket to prevent special circumstance which affects the efficiency and fairness
mentioned later.
In our default, we set a normal number of input components. We capture first
three components of name prefix and put into our default hash function. The reason
why we select “three” as our preliminary number is that almost first three
components represents domain name in URL. Besides, almost every name prefix
has at least three components and has common prefix in NDN status [24].
In terms of hash function, we choose CityHash64 as our hash function and it
serves every name prefix a 64-bits hash value. After this action, our narrow step will
shrink hash value to a specific range to ensure that every name prefix is in the table
of DePT. Figure 7 shows the procedure of entire filtering and our default size of
DePT is one thousand buckets. Therefore, every hash value needs to mod 1000 to
obtain corresponding sub-trie number.

!18!
Figure 7: Building DePT – Filtering phase
2) Building DePT – Incremental Update Phase
By using DePT, a worst case would happen. This situation is excessive
concentration of name prefix. For example, the majority name has “ndn/ntnu/office”
in their first three (n) components in this campus NDN router. In this scenario, a
certain Patricia Trie will be larger and deeper than others in DePT. Thus, the lookup
efficiency and fairness will be affected. In order to avoid this situation, we have to
check counter Ci we set in every bucket. The counter Ci can show how many name
prefix has been put into this number of sub-trie. If the counter of someone sub-trie
(s) exceeds fifty percent of total number of name prefix in FIB, the Incremental
Update mechansim will be activated. Name prefix in sub-trie (s) that has more than
three components will be put into another DePT by hashing first four (n+1)
components. In this additional DePT, name prefix that comes from someone sub-trie

!19!
will be reassigned into sub-trie in the new DePT. The excessive accumulation of
name prefix in sub-trie in the first DePT will be solved.
Figure 8 (a), (b) shows the procedure of incremental update. In Figure 8 (a),
there are relatively more name prefix accumulating in number four sub-trie. After
doing incremental update, name prefix will be evenly distributed in new DePT,
Figure 8 (b).
(a) Original DePT (b) New DePT
Figure 8 : Building DePT - Incremental update phase
Although the default n in every NDN router is three, the n may be adjusted
according to circumstance in router at that time. Consequently, initial n in every
router may be different but the integrity of name will not be changed.
4.2 DePT – FIB lookup
After filtering phase, name prefix in FIB have been classified into sub-trie in
DePT. If the number of sub-trie is n and there are N name prefix in FIB, then the name
prefix lookup range has been shorten to N/n. According to pseudo-code shown below,

!20!
each input request name will obtain the hash value after hashing the first n components.
Then, the hash value will be limited to a specific range in line with DePT default.
Therefore, the NDN name will do longest prefix matching in specific sub-trie. There
are two kinds of content in this sub-trie, the name which has same first n components
and gets same hash value of first n components. However, if number of sub-trie name
gets is equal to new_DePT, name will do longest prefix matching in the additional
DePT according to new sub-trie number first to find the corresponding face. If the
name is not matching, it will do name prefix lookup in original DePT by original
sub-trie number. After that, the request name will get the face list of router which
destination router should go. However, which face should name forwards in face list
depend on the forwarding stratege NDN router use and it is not discussed in this paper.
Algorithm of Name lookup in DePT
Input : request_name
Output : face_number
Procedures:
01: (com1, com2, …, comk) � Decompose(request_name);
02: value � CityHash64(com1~n)
03: Number_of_subtrie � value mod(table size)
04: if (Number_of_subtrie = new_DePT) then
05: value � CityHash64(com1~n+1)
06: Number_of_subtrie � value mod(table size)
07: if LongestPrefixMatching(Number_of_subtrie) then
08: return face_number

!21!
09: if (Number_of_subtrie != new_DePT) then
10: if LongestPrefixMatching(Number_of_subtrie) then
11: return face_number
5. EVALUATION
In our evaluation, we designed our own dataset by several cases and compared
longest prefix search time by using our approach based on it. Among it, our
experiment is focused on comparison of lookup efficiency, storage and fairness. In
terms of lookup efficiency, we have served each input request about 100 repeat times
and obtained a mean value to enhance the experiment accuracy.
5.1 Dataset
Naming scheme in NDN has not been specified. It may have different naming
rule on different purpose. However, we investigate some characteristics of NDN name.
Names in NDN are hierarchically structured and design decision allows each
application to choose the naming scheme that fits its needs. Such as names in V-NDN,
name content has traffic, vehicular and road information. Because the amount of
current NDN name is not enough, we use URLs (Uniform Resource Locator) as our
real-world dataset that its property and structure is similar to NDN name. In URL, ‘/’
is a delimiter which separate every part of name and its domain name most have its
meaning. On the other hand, we have randomly created the same amout of data based

!22!
on NDN basic rule. The details of these two types of dataset will be described in the
following.
1) Real-world data:
In real-world dataset, URLblacklist[25] provides a collection of URL domain
and short URLs for access. We used the dataset after modifying it to NDN name
according to a specific rule. For example, a URL name
1-domination.com/video-bdsm/massage-du-corps-puis-coups will be converted
into /ndn/com/1-domination/video-bdsm/massage-du-corps-puis-coups by adding a
component “ndn” to title of name to represent it is used for ndn router. Another
modification is the reversion of the first component, content will be reversed
according to ‘.’ and split into components. This action could increase the property
of hierarchy and similarity to NDN names currently. In order to compare the
efficiency of name prefix matching, we randomly selected a hundred of thousand
URLs for our experiment.
2) Synthetic data:
In synthetic data, we imitated NDN naming characteristic to build our FIB
dataset. By observation in NDN status, we found almost every name prefix in FIB
in NDN router has at least three components. Every name from request has at least
5 components and has 5-20 random characters in every component. Compared with
real-world data, character strings of synthetic data are not meaningful. It is
completely a random combination of letters and numbers. On the other hand, name
prefix in FIB we set are 4 components.

!23!
Besides, we emulate a situation that it has p percentage common prefix in FIB.
The variable p range from 10 to 100, and it represents that it has p% common
prefix in FIB. The reason why we designed these types of dataset is that we
consider local NDN router may has most of common prefix. For example, a NDN
router in supermarket like costco has common prefix for their same kinds of food,
and this situation may have an influence on our method DePT.
5.2 Measurement
5.2.1. Data distribution
Figure 9 : Distribution of name length in real-world dataset
In Figure 9, we analyze the length of each NDN name in our real-world dataset
by number of characters. In real-world dataset, we try our best to select names which
consists of short length and long length. In particular, the shortest length of name is 19
characters and 5 components, the longest length of name is 766 characters and 26

!24!
components. Besides, the coefficient of variation of length is 0.33 (characters) and
0.18 (components), it represents that the disparity of name length is large enough.
5.2.2. FIB lookup time of Real-world dataset
Q1 (0~25%) Q2 (25~50%) Q3 (50~75%) Q4 (75~100%)
Data_1 31 33 42 43
Data_2 41 41 40 62
Data_3 38 46 65 80
Table 1: Relationship between length (number of characters) and lookup time
In Table1, we used three datasets to test how Trie data structure affects the
lookup efficiency with different length ndn name. They are different number of
real-world datasets, 1000,10000,100000 names in Data_1, Data_2 and Data_3
respectively. For these three datasets, we partition the name prefix lookup time by
interquatile range (IQR) Q1- Q4. Lookup time of each dataset will be partitioned into
four parts. Consequently, Q1 has first 25% shortest time and Q4 stands for last 25%
longest lookup time. However, numbers in average length column represent the
number of characters in name. We can found that if a name has longer length then it
has longer name lookup time. On the contrary, shorter name needs shorter lookup time.
Thus proving, using Trie as data structure in FIB will have an influence on lookup
fairness.
!25!
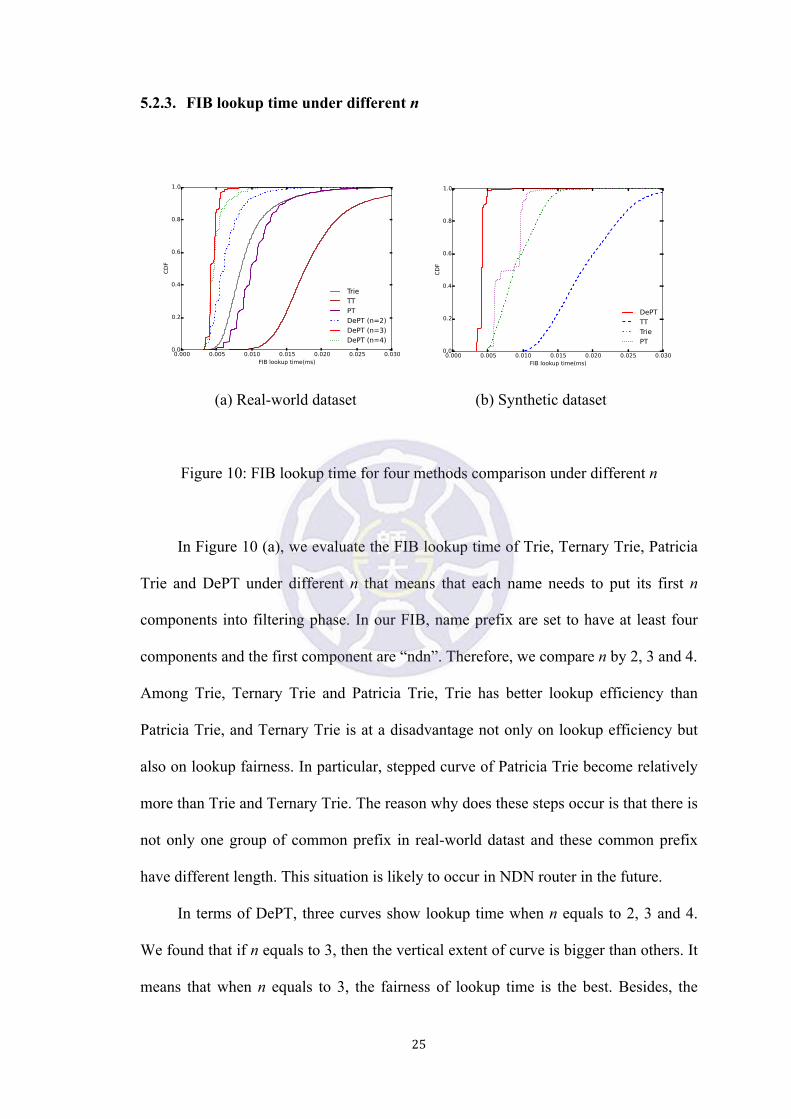
5.2.3. FIB lookup time under different n
(a) Real-world dataset (b) Synthetic dataset
Figure 10: FIB lookup time for four methods comparison under different n
In Figure 10 (a), we evaluate the FIB lookup time of Trie, Ternary Trie, Patricia
Trie and DePT under different n that means that each name needs to put its first n
components into filtering phase. In our FIB, name prefix are set to have at least four
components and the first component are “ndn”. Therefore, we compare n by 2, 3 and 4.
Among Trie, Ternary Trie and Patricia Trie, Trie has better lookup efficiency than
Patricia Trie, and Ternary Trie is at a disadvantage not only on lookup efficiency but
also on lookup fairness. In particular, stepped curve of Patricia Trie become relatively
more than Trie and Ternary Trie. The reason why does these steps occur is that there is
not only one group of common prefix in real-world datast and these common prefix
have different length. This situation is likely to occur in NDN router in the future.
In terms of DePT, three curves show lookup time when n equals to 2, 3 and 4.
We found that if n equals to 3, then the vertical extent of curve is bigger than others. It
means that when n equals to 3, the fairness of lookup time is the best. Besides, the
!26!
curves show that lookup time is the best also. Therefore, DePT has the best lookup
efficiency and fairness when n is initialized to 3.
In Figure 10 (b), the number of common prefix is 50% of total name prefix (p =
50), and the number of components in common prefix we set is 3. It represents that
there are more than half of total name prefix have the same prefix in their first 3
components. After incremental update, n in additional DePT will be set to 4.
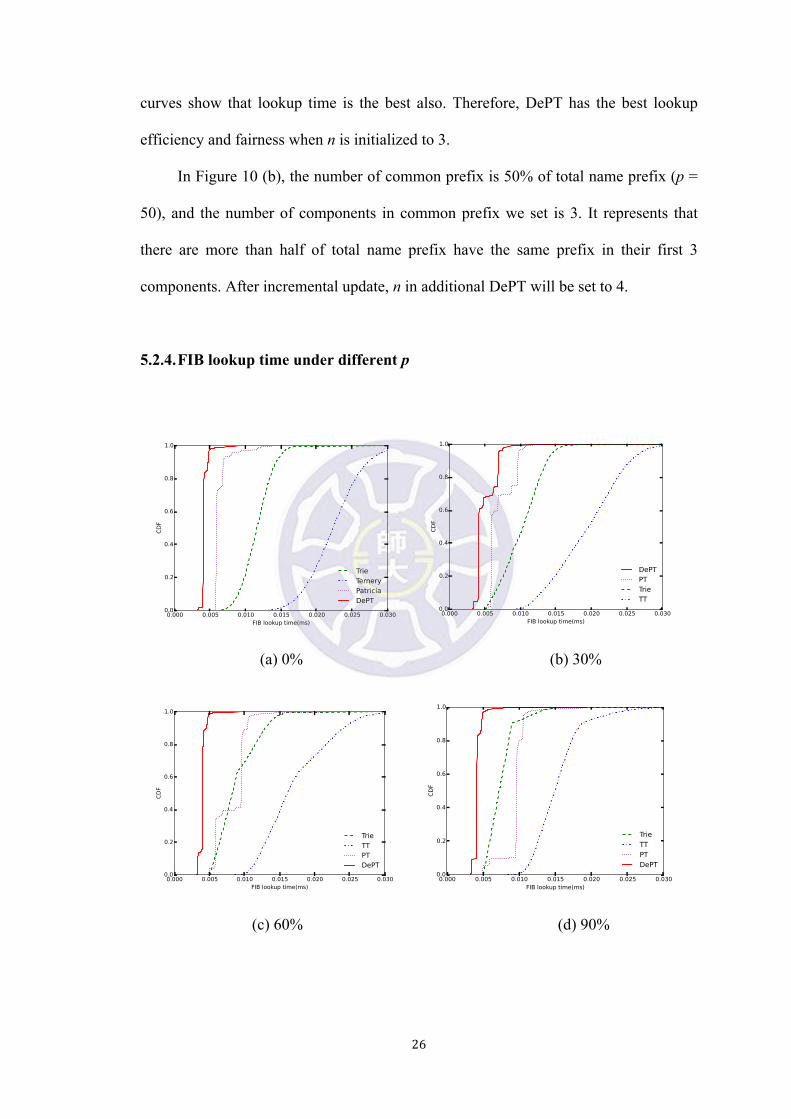
5.2.4. FIB lookup time under different p
(a) 0% (b) 30%
(c) 60% (d) 90%

!27!
Figure 11: FIB lookup time for four methods comparison among 0%, 30%, 60% and
90% of common prefix
In Figure 11, there are Trie, Ternary Trie, Patricia Trie and DePT four methods
comparisons of FIB lookup time under 0%, 30%, 60% and 90% (p = 0, 30, 60, 90)
common prefix. Besides, the standard k we set for incremental update is 50. In (a),
there are totally different name prefix in their first three components. Ternary has a
worst-case for lookup efficiency and lookup fairness, on the contrary, DePT is the
most efficient and fair method. However, DePT method is based on Patricia Trie, the
maximum difference between these two methods and others is that their curves have
vibration. The reason why the vibration exists is that matching process in Patricia Trie
may not has only one character, it will be a long section of name. Therefore, curves are
not as smooth as Trie and Ternary Trie. Besides, zero percentage of common prefix in
FIB is the best case for our method DePT, the situation which excessive name prefix
accumulate in one sub-trie will hardly occur.
In (b) and (c), the curve of Trie and Ternary Trie is more vertical than zero
percentage. The reason is that as number of common prefix increase and variant prefix
decrease, name prefix lookup needs relatively less time. Besides, there is an
increasingly segment of smooth part in curves and it represents that a section of name
prefix has nearly lookup time. In (b), we can find that Trie is faster than Patricia Trie
in the beginning of curve, and the vibration amplitude is much bigger than zero
percentage in (a), and tendency of DePT curve is similar to Patricia Trie curve.
However in (c), curve of Patricia Trie shows that a part of lookup time is worse than
Trie, and the gap in curve is bigger and obvious than zero percentage in (a), and
tendency of DePT curve is not similar to Patricia curve due to incremental update in
!28!
building DePT when p is more than 50 so it will not affected by increasing number of
common prefix.
In (d), p is equal to 90 and it shows that names are almost following a common
prefix in FIB and it may be a local NDN router. In terms of Trie and Ternary Trie, they
both have a relatively vertical part in curve. It represents that almost name lookups are
gather in the same part of Trie. Similarly, curve of Patricia Trie has a relatively larger
gap than (b) and (c). Although vertical extent of Patricia Trie curve is better than Trie,
most of the lookup time obviously is worse than Trie. Best of all, DePT has the best
lookup efficiency and lookup fairness because it has an incremental update when
number of name prefix in one sub-trie achieves the default standard. After incremental
update, the number of name prefix in every sub-trie in DePT keeps in nearly equal so
that it has better fairness of lookup.
!
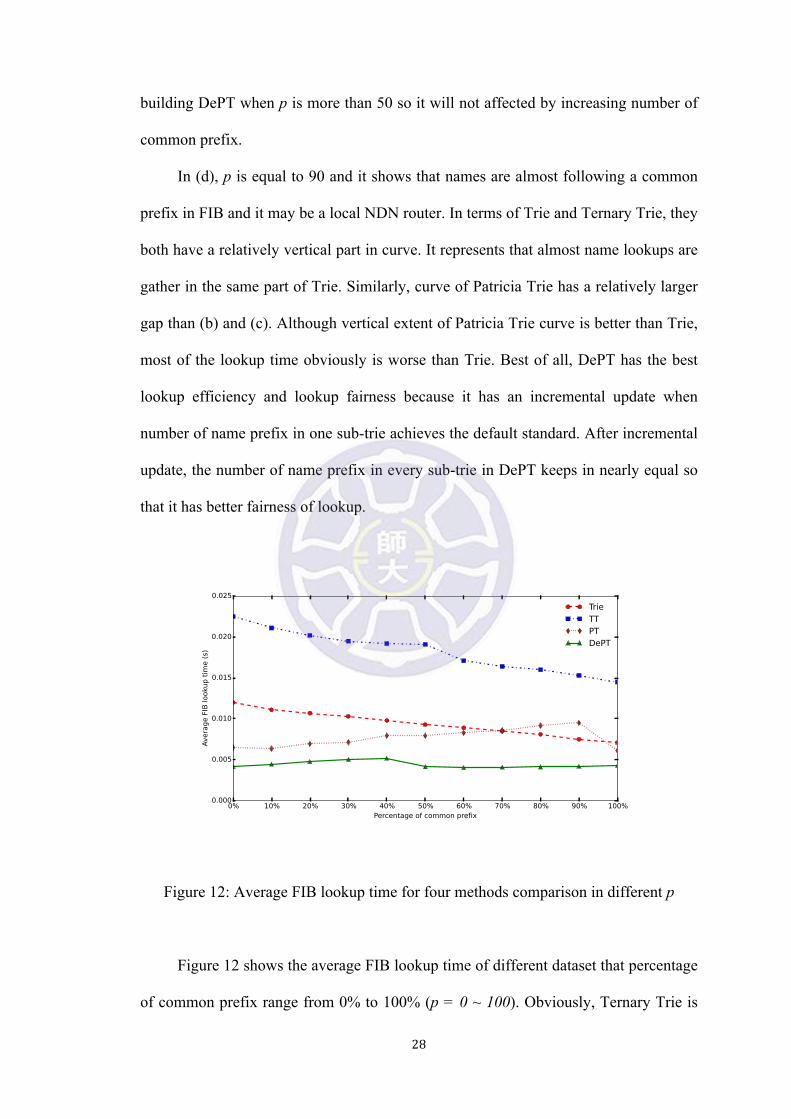
Figure 12: Average FIB lookup time for four methods comparison in different p
Figure 12 shows the average FIB lookup time of different dataset that percentage
of common prefix range from 0% to 100% (p = 0 ~ 100). Obviously, Ternary Trie is

!29!
the worst one of these four methods due to its redundant comparison of alphabetical
order. Unlike methods like Patricia Trie and DePT, average lookup time of Trie and
Ternary Trie decrease as the ratio increaces. It indicates that more common prefix in
FIB, lookup efficiency in Patricia Trie become worse instead. The fact is that if
Patricia Trie has a lot of common prefix, decomposition of string in Patricia Trie is
more than general Trie and Ternary Trie. Therefore, name lookup needs relatively
more time. In particular, DePT line shows that almost every percentage point has about
the same search time. The reason is that incremental update mechanism has been
activated when number of common prefix in someone sub-trie exceeds 50% (p = 50)
of total name prefix in FIB.
5.2.5. Coefficient of Variation of FIB lookup time under different p
Figure 13: Coefficient of Variation of FIB lookup time for four methods comparison in
different p

!30!
Figure 13 shows coefficient of variation of name prefix lookup time. We
analyzed the CV value of every percentage of common prefix in dataset. The CV value
smaller the fairer lookup time it has. In average, DePT is better than other three
methods. However, curves of Patricia, Ternary and Trie are close to each other and an
overlapping point appears in 40% point. Upon 40% point, we found Patricia Trie and
Ternary Trie both achieve the highest CV value and have a large gap between 30% and
50%. On the other hand, Trie has the highest CV value in 60% point. Above all, we
considered that if there has 40% to 60% common prefix in dataset, the lookup time
would be less concentrated and unfairer. That is the reason why the default k for
incremental update in DePT is 50. Accidentally, in DePT curve, the incremental
update k we set is 50, and we found that the 50% point has relatively smaller
coefficient of variation than 40% point. It represents that fairness of name prefix
lookup has been improved.
5.2.6. Memory consumption of DePT under different p
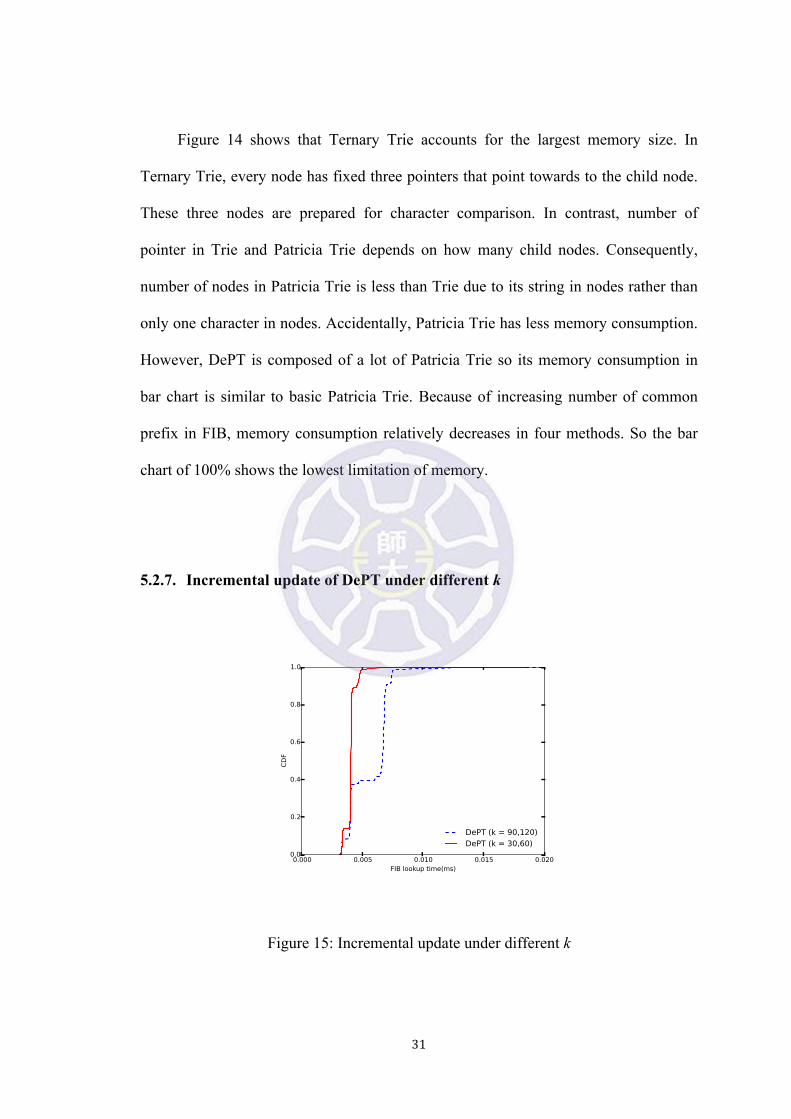
Figure 14: Memory consumption for four methods comparison in different p
!31!
Figure 14 shows that Ternary Trie accounts for the largest memory size. In
Ternary Trie, every node has fixed three pointers that point towards to the child node.
These three nodes are prepared for character comparison. In contrast, number of
pointer in Trie and Patricia Trie depends on how many child nodes. Consequently,
number of nodes in Patricia Trie is less than Trie due to its string in nodes rather than
only one character in nodes. Accidentally, Patricia Trie has less memory consumption.
However, DePT is composed of a lot of Patricia Trie so its memory consumption in
bar chart is similar to basic Patricia Trie. Because of increasing number of common
prefix in FIB, memory consumption relatively decreases in four methods. So the bar
chart of 100% shows the lowest limitation of memory.
5.2.7. Incremental update of DePT under different k
Figure 15: Incremental update under different k

!32!
In Figure 15, we compared the difference k for incremental update in 60%
common prefix synthetic dataset. In our dataset, there are 100000 name requests so it
means that there are more than 60000 name prefix would be classified into someone
sub-trie. Due to excessive name prefix accumulate in the same sub-trie in DePT, the
lookup efficiency and fairness are both affected. In order to avoid that more percentage
of name prefix in one sub-trie, the incremental update needs to be implemented. In
figure 15, when k is set 30 and 60, it means that if number of name prefix in someone
sub-trie is more than 30% or 60% of total name prefix in FIB, the incremental update
will add an additional DePT by adding n to n+1 for filtering phase insertion. In this
experiment, our default n is three, and the n in additional DePT will be four after doing
incremental update. Besides, name prefix will be well distributed in DePT.
In Figure 15, when k is 90 and �, the incremental update will not be activated.
Because of there are totally 60% (p = 60) or more name prefix in someone sub-trie and
it doesn’t exceed default k, according to the curve, the lookup efficiency and fairness
are both worse than curve that has incremental update.
6 DISCUSSION
Our method DePT is focused on enhancing fairness of search process. For
unbounded length NDN name, a lot of information will be consists in request name.
Unlike mothod that based on Hash function or Bloom Filter, process complexcity
depends on how long the name is. If the name has more components, it needs more
processing time. According to our evaluation results, our method DePT has better
lookup fairness. Besides, we have considered the special case happening in the future.

!33!
The incremental update mechanism in DePT not only enhances the scalability but also
make lookup more efficient and fair.
However, our method DePT has not been implemented on simulator or testbed
and under real scenario. Consequently, the real time insertion and deletion of name
prefix in FIB may have some influences on our lookup process. If there are frequent
insertion and deletion that makes number of prefix in someone sub-trie achieves the
standard of activating incremental update, the building of new DePT will be frequent
and it may affect the name lookup process in FIB. In our experiment, we do not
estimate the time to build an additional DePT when acitivating incremental update.
Besides, we deal with each request in the continuous time rather than in the same time.
The hardware problem like access simultaneously is another external factor.
In terms of dataset, because of formal NDN naming rule has not been formulated,
our real world dataset is converted to NDN form according to public steps that
proposed in another paper. It is not sure that our names of evaluation will meet the
actual NDN name in the future.
7 CONCLUSION & FUTURE WORK
We focused on the fairness of the name lookup in FIB in Named Data
Networking, and proposed a method that not only has great lookup efficiency but also
has better lookup fairness. Simultaneously, we reduce the memory requirement of data
structure which used to store name prefix of FIB. In particular, fairness of name prefix
lookup is the most significant issue we mind. We hope every name from Interest
Packet will be served in fair treatment no matter how long its name is and what content
it has. Then we implemented and evaluated our method DePT under real-world dataset

!34!
and synthetic dataset. Experimental results of them both show better fairness and
lookup efficiency.
Compared with HT-based and other methods, DePT must have good fairness and
unncessarily cares about length of name. Consequetly, we do not need to worry about
the abundant information name contains in the future. The future work we want to do
is collect real NDN name and implement our method DePT on the NDN testbed.
REFERENCES
[1] Bengt Ahlgren, Christian Dannewitz, Claudio Imbrenda, Dirk Kutscher and
B ̈orje Ohlman, “A Survey of Information-Centric Networking,” IEEE
Communications Magazine, July 2012, vol. 50, no. 7, pp.26-36.
[2] Lixia Zhang, Deborah Estrin, and Jeffrey Burke, et al, “Name Data Networking
(ndn) Project,” PARC, Palo Alto, CA, Tech. Rep. NDN-0001, October 2010.
[3] M. Amadeo, C. Campolo, et al, “Named Data Networking for IOT: an
Architectural Perspective,” European Conference on Networks and Communications
(EuCNC), June 2014, pp.1-5.
[4] Ghassan Samara, Wafaa A.H. Al-Salihy, R. SuresS, “Security Analysis of
Vehicular Ad Hoc Networks (VANET),” Second International Conference on Network
Applications, Protocols and Services, NETAPPS 2010, pp.55-60.
[5] Giulio Grassi, Davide Pesavento, Giovanni Pau, Rama Vuyyuru, Ryuji
Wakikawa and Lixia Zhang, “VANET via Named Data Networking,” IEEE
Conference on Computer Communications Workshops (INFOCOM WKSHPS), April
2014, pp.410-415.

!35!
[6] Wei You, Bertrand Mathieu, Patrick Truong and Jean-Franc ̧ois Peltier, “DiPIT:
a Distributed Bloom-Filter based PIT table for CCN Nodes,” 21st International
Conference on Computer Communications and Networks (ICCCN), 2012, pp.1-7.
[7] Yujian Fan, Hongli Zhang, Jiahui Liu and Dongliang Xu, “An Efficient Parallel
String Matching Algorithm Based on DFA,” Trustworthy Computing Services,
Communications in Computer and Information Science, 2013, vol. 320, pp.349-356.
[8] Won So, Ashok Narayanan, David Oran and Yaogong Wang, “Toward Fast
NDN Software Forwarding Lookup Engine based on Hash Tables,” ACM/IEEE
Symposium on Architectures for Networking and Communications Systems, October
2012, pp.85-86.
[9] D. Xu, and H. Zhang et al. “A Scalable Multi-Hash Name Lookup Method for
Named Data Networking.”
[10] Won So, Ashok Narayanan and David Oran, “Named Data Networking on a
Router: Fast and DoS-resistant Forwarding with Hash Tables,” ACM/IEEE Symposium
on Architectures for Networking and Communications Systems, October 2013,
pp.215-226
[11] Sarang Dharmapurikar, Praveen Krishnamurthy and David E. Taylor, “Longest
Prefix Matching using Bloom filters,” IEEE/ACM Transactions on Networking, April
2006, vol. 14, no.2, pp.397-409.
[12] Wei Quan, Changqiao Xu, Jianfeng Guan, Hongke Zhang and Luigi Alfredo
Grieco, “Scalable Name Lookup with Adaptive Prefix Bloom Filter for Named Data
Networking,” IEEE Communications Letters, January 2014, vol. 18, pp.102-105.
[13] Yi Wang, Tian Pan, Zhian Mi, Huichen Dai, Xiaoyu Guo, Ting Zhang, Bin Liu
and Qunfeng Dong, “NameFilter: Achieving fast name lookup with low memory

!36!
consumption via applying two-stage Bloom Filters,” IEEE INFOCOM, April 2013,
pp.95-99.
[14] Zhuo Li, Kaihua Liu, Yang Zhao and Yongtao Ma, “MaPIT: An Enhanced
Pending Interest Table for NDN with Mapping Bloom Filter,” IEEE Communications
Letters, November 2014, pp.1915-1918.
[15] Ioannis Sourdis, Georgios Stefanakis, Ruben de Smet, and Georgi N. Gaydadjiev,
“Range Tries for Scalable Address Lookup,” ACM/IEEE Symposium on Architectures
for Networking and Communications Systems, 2009, pp. 143-152.
[16] I. Sourdis, and S. H. Katamaneni, et al. “Longest Prefix Match and Updates in
Range Tries,” IEEE International Conference on Application-Specific Systems,
Architectures and Processors (ASAP), September 2001, pp.51-58.
[17] Fu Li, Fuyu Chen, Jianming Wu and Haiyong Xie , “Fast longest prefix name
lookup for content-centric network forwarding,” ACM/IEEE Symposium on
Architectures for Networking and Communications Systems, 2012, pp.73-74
[18] Yi Wang, Keqiang He, Huichen Dai, Wei Meng, Junchen Jiang, Bin Liu and
Yan Chen, “Scalable Name Lookup in NDN using Effective Name Component
Encoding,” IEEE 32nd International Conference on Distributed Computing Systems
(ICDCS), June 2012, pp.688-697.
[19] Yi Wang, Huichen Dai, Junchen Jiang, Keqiang He, Wei Meng and Bin Liu,
“Parallel Name Lookup for Named Data Networking,” IEEE Global
Telecommunications Conference (GLOBECOM), December 2011, pp.1-5.
[20] Jun-Ichi Aoe, Katsushi Morimoto and Takashi Sato, “An Efficient
Implementation of Trie Structures,” Software: Practice and Experience, September
1992, Vol. 22, Issue 9, pp. 695–721.

!37!
[21] Ghada Hany Badr and B. John Oommen, “Self-Adjusting of Ternary Search
Tries Using Conditional Rotations and Randomized Heuristics,” The Computer
Journal, 2005, vol. 48, pp.200-219.
[22] Sebastian Kniesburges and Christian Scheideler, “Hashed Patricia Trie: Effective
Longest Prefix Matching in Peer-to-Peer Systems,” 5th International Workshop
WALCOM: Algorithms and Computation, 2011, vol. 6552, pp.170-181.
[23] ndnsim. http://ndnsim.net/2.0/
[24] URLBlacklist. http://urlblacklist.com.
[25] NDNstatus. http://www.arl/wustl.edu/~jdd/ndnstatus/ndn_prefix/tbs_ndnx.html.