essential data engineering for data scientist
TRANSCRIPT

Essential Data Engineering for Data Scientist

Me, myself, and I: Valentyn Kropov
• Sr. Big Data Solutions Architect.
• 14 years of work experience with Databases.
• 4 years in Big Data.
• Big Data Consulting Lead at SoftServe (20+ Engineers and Architects).
• Founder of Kyiv Big Data Community (600+ people).
webinar

Agenda1. Level of Involvement2. Choosing the Right Tools (Distribution of Hadoop)3. RDBMS vs. NoSQL4. NoSQL Data Modeling5. Deployment6. On-Premises vs. Cloud7. Scalability and Performance8. Storage
webinar

Level of Involvement

Who Should be Leading Data Science Projects?
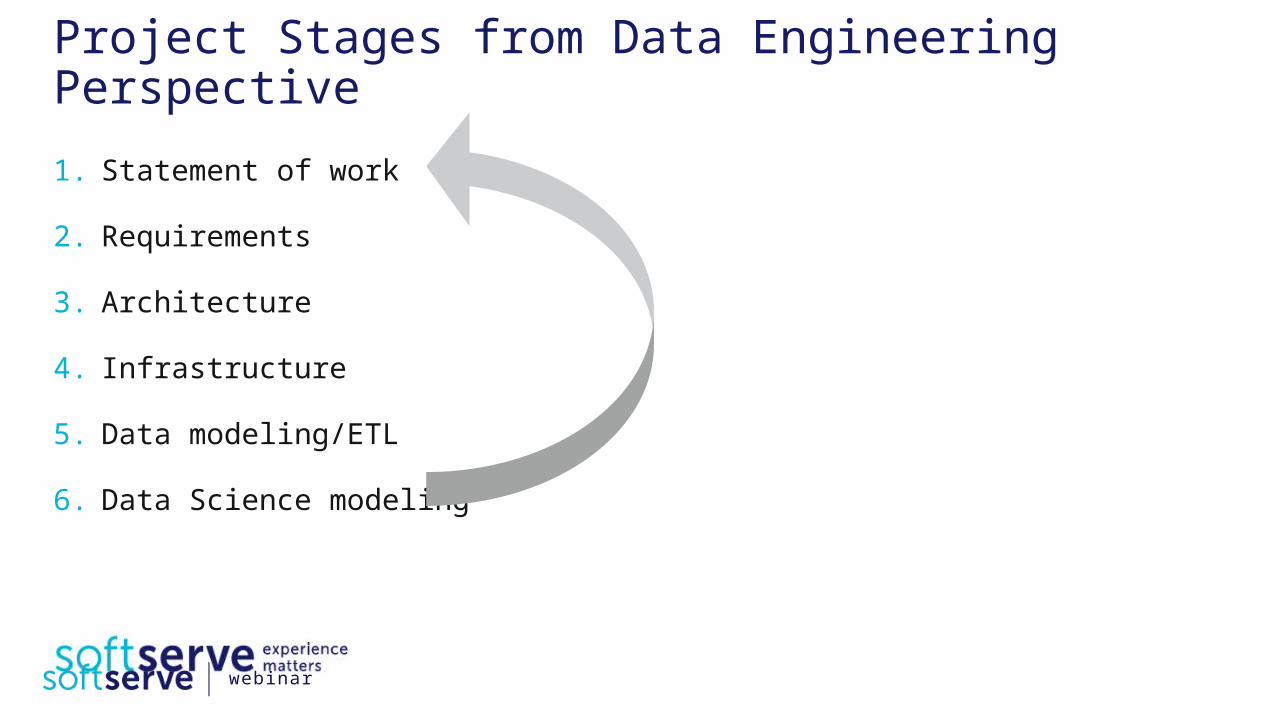
Project Stages from Data Engineering Perspective
1. Statement of work
2. Requirements
3. Architecture
4. Infrastructure
5. Data modeling/ETL
6. Data Science modeling
webinar

Involvement: Checklist
1. You’re the boss!
2. You have a right to demand the infrastructure you need.
3. But, you need to have perfect argumentation.
4. And I’ll show it to you right now.
webinar

Choosing the Right Tools

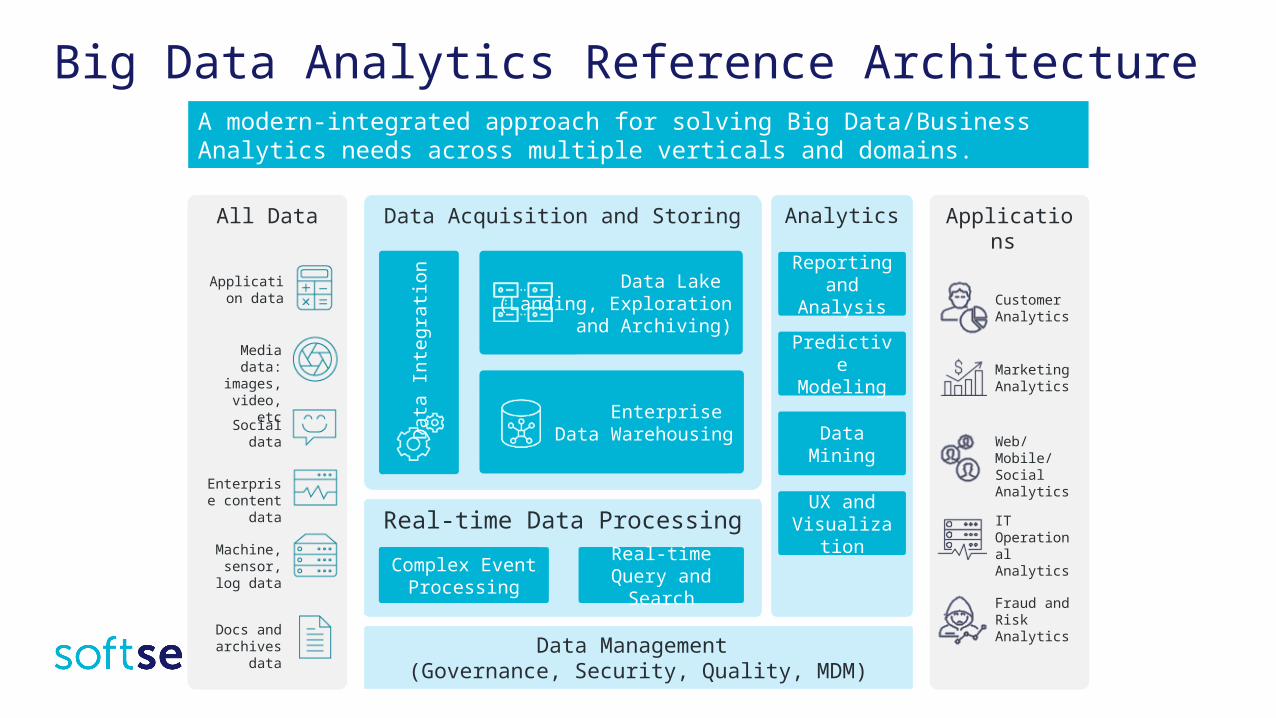
Big Data Analytics Reference ArchitectureA modern-integrated approach for solving Big Data/Business Analytics needs across multiple verticals and domains.
All Data
Real-time Data Processing
Data Acquisition and Storing
Data
Inte
grat
ion
Enterprise Data Warehousing
Data Management (Governance, Security, Quality, MDM)
Analytics
Reporting and
Analysis
Predictive Modeling
Data Mining
Data Lake (Landing, Exploration
and Archiving)
UX and Visualizatio
n
Applications
Application data
Media data:
images, video, etc
Social data
Enterprise content
data
Machine, sensor, log
data
Docs and archives
data
Customer Analytics
MarketingAnalytics
Web/Mobile/Social AnalyticsIT Operational Analytics
Fraud and Risk Analytics
Complex Event Processing
Real-time Query and
Search
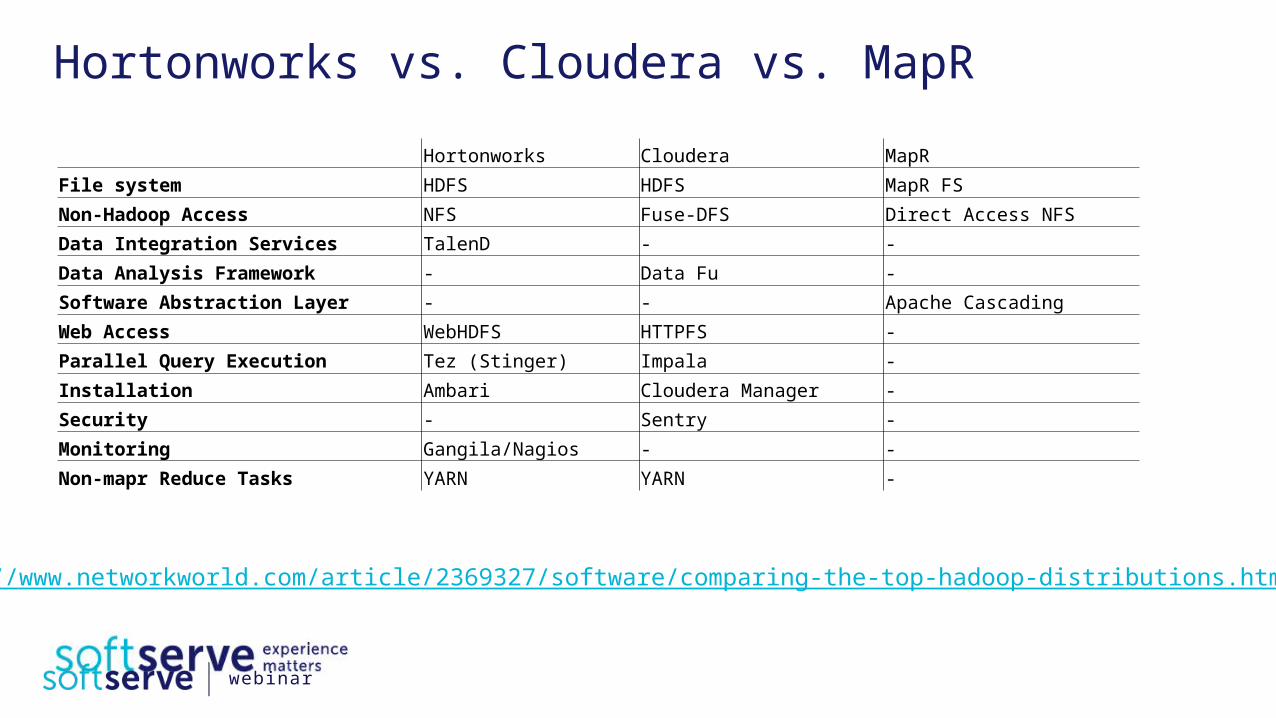
Hortonworks vs. Cloudera vs. MapR Hortonworks Cloudera MapRFile system HDFS HDFS MapR FSNon-Hadoop Access NFS Fuse-DFS Direct Access NFSData Integration Services TalenD - -Data Analysis Framework - Data Fu -Software Abstraction Layer - - Apache CascadingWeb Access WebHDFS HTTPFS -Parallel Query Execution Tez (Stinger) Impala -Installation Ambari Cloudera Manager -Security - Sentry -Monitoring Gangila/Nagios - -Non-mapr Reduce Tasks YARN YARN -
http://www.networkworld.com/article/2369327/software/comparing-the-top-hadoop-distributions.html
webinar

Or Even More: IBM, Oracle, Amazon, …
1. IBM: Big R (set of Data Science algorithms) and Big SQL (SQL-like interface to data).
2. Oracle: Big Data appliance/connectors.
3. Amazon: Elastic MapReduce.

Choosing the Right Tools: Example (Description)Data Volume:• 270-300 Web Servers (Apache HTTPD)• 447 392 events per minute• 644 245 094 events / day• ~100-250 bytes per event• 150GB of data per day
Log Types:• Apache HTTPD access log• Apache HTTPD error log• Service log (CPU, RAM, I/O, Disk)• Application server servlet log
Retention:• Last 30 days: Raw data• Last 24 hours: per minute aggregation• Whole period: per hour aggregation
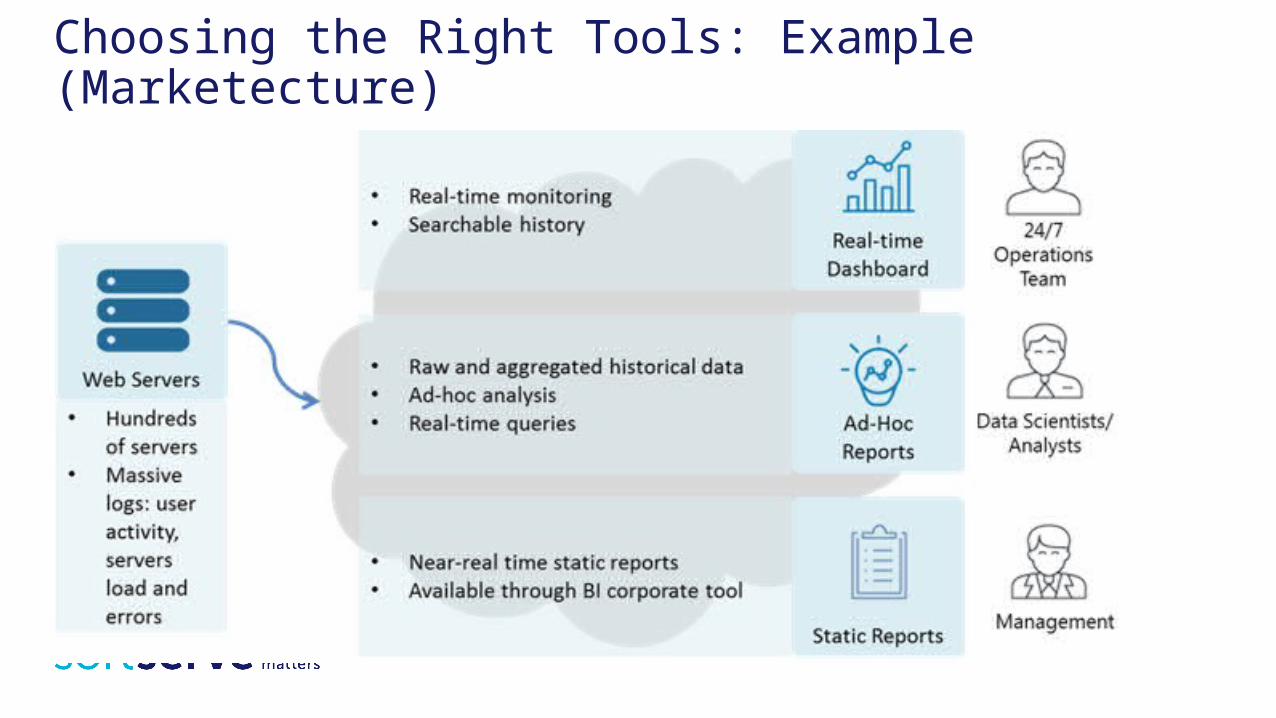
Choosing the Right Tools: Example (Marketecture)

Choosing the Right Tools: Example (Description - data)Access log:127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
Error log:[Sun Mar 7 20:58:27 2004] [info] [client 64.242.88.10] (104)Connection reset by peer: client stopped connection before send body completed[Sun Mar 7 21:16:17 2004] [error] [client 24.70.56.49] File does not exist: /home/httpd/twiki/view/Main/WebHome
Vmstatprocs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 305416 260688 29160 2356920 2 2 4 1 0 0 6 1 92 2 0
iostatLinux 2.6.32-100.28.5.el6.x86_64 (dev-db) 07/09/2011
avg-cpu: %user %nice %system %iowait %steal %idle 5.68 0.00 0.52 2.03 0.00 91.76
webinar

Choosing the Right Tools: Example (Description - data)
webinar
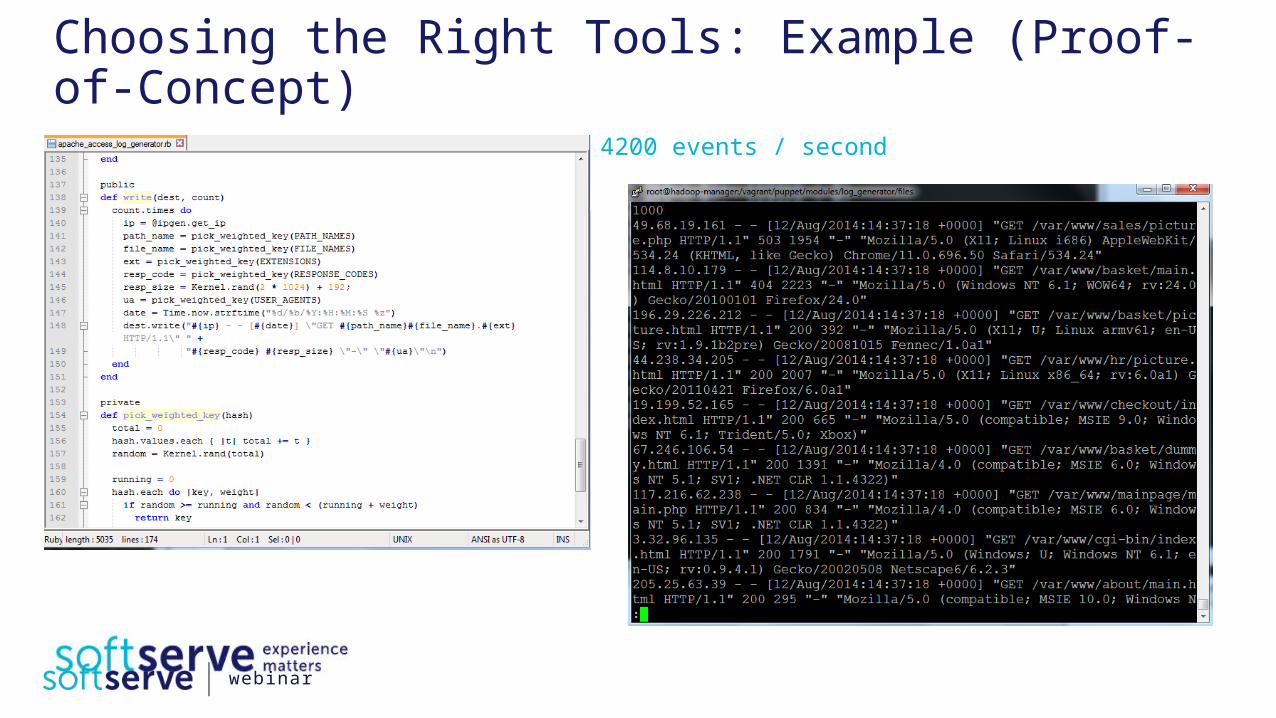
Choosing the Right Tools: Example (Proof-of-Concept)
4200 events / second
webinar
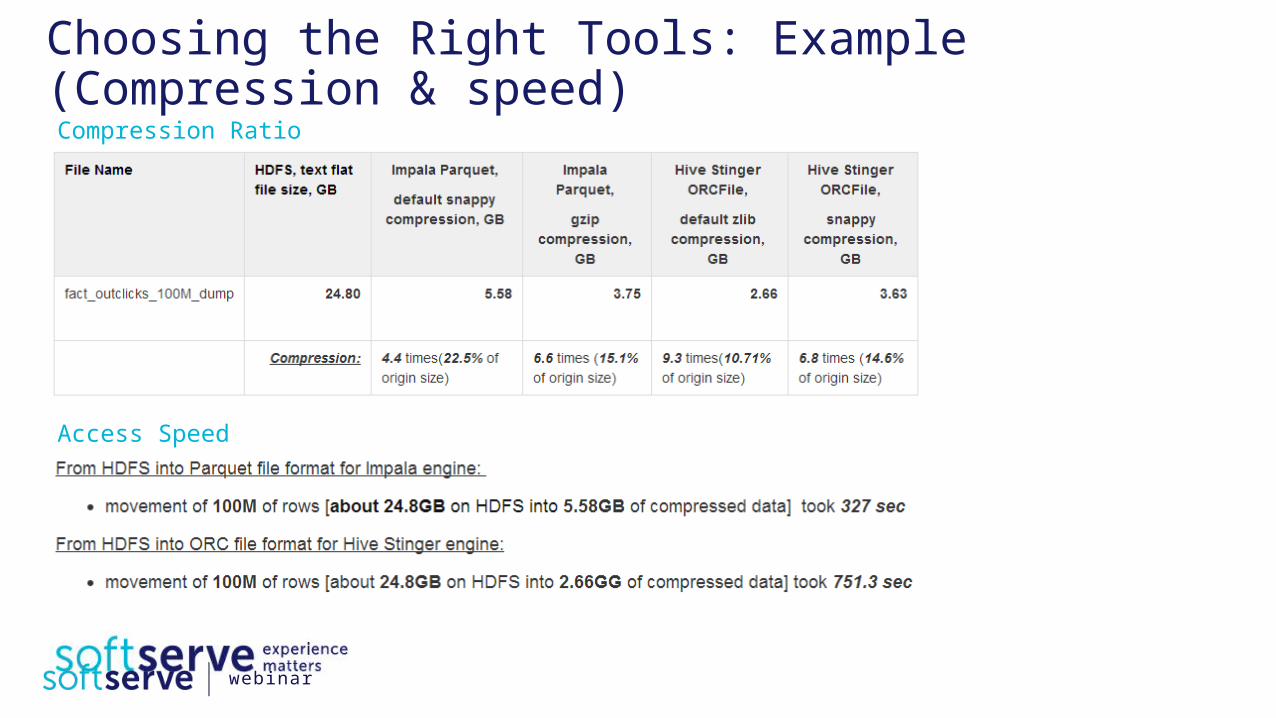
Choosing the Right Tools: Example (Compression & speed)Compression Ratio
Access Speed
webinar
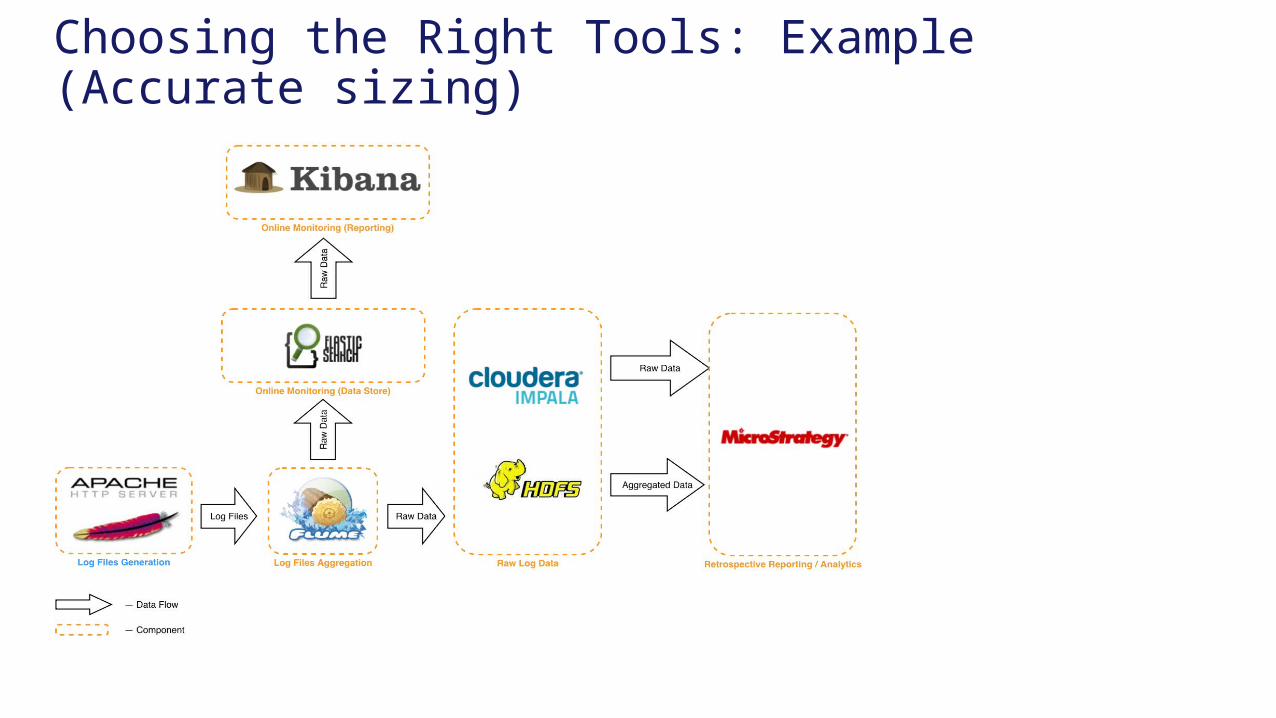
Choosing the Right Tools: Example (Accurate sizing)

Choosing the Right Tools: Checklist
1. Fastest random access to the data: Cloudera (Impala).
2. Universal (and fast!) access to data: MapR (MapR FS).
3. Data Integration: Hortonworks (built-in TalenD).
4. Never trust papers, always double check: Proof-of-Concept.
5. Lastly, ensure you have rightsizing and check every element of the chain!
webinar

RDBMS vs. NoSQL
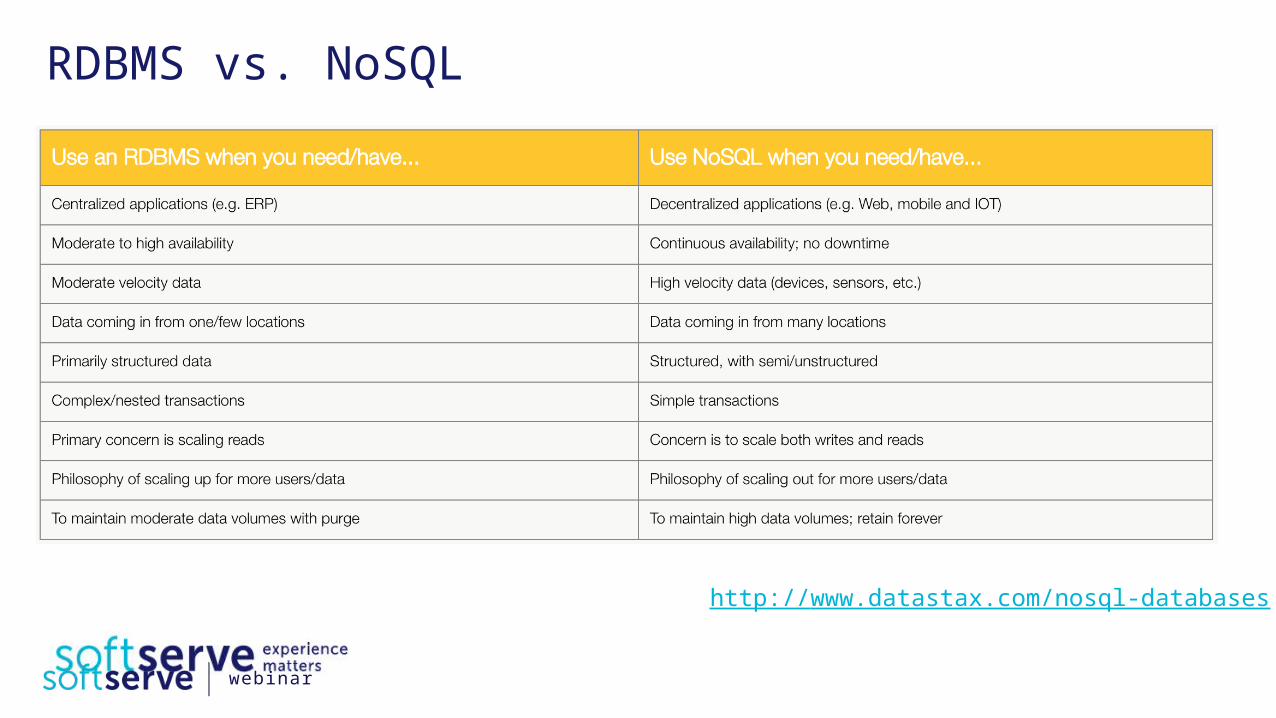
RDBMS vs. NoSQL
http://www.datastax.com/nosql-databases
webinar

It’s Not Necessarily Always Black and White!
• Traditional-relational
• Extended-relational
• Non-relational
• Lambda architecture (Hybrid)
• Data refinery (Hybrid)
webinar

SoftServe Lambda Architecture Accelerator• Lambda architecture – Is a highly scalable and reliable data processing architecture based
on Twitter successful experience in Big Data and Analytics.• Supports majority of use cases: Real-time analytics, data discovery, and business reports.• SoftServe’s pre-built Lambda architecture stack accelerates customer’s Time to Market
(TTM) to 15-20+ man/month.

RDBMS vs NoSQL: Checklist1. RDBMS: Structured data, moderate velocity and volume (up
to TB), with complex transactions.2. NoSQL: Unstructured data, high velocity or volume (up to
PB+), with simple transactions.
3. Hybrid, Lambda, Refinery: Something in-between.

NoSQL Data Modeling

NoSQL: How is it Different than RDBMS?
1. Write operations are cheap.
2. Less transactions and is less consistent.
3. Read operations are blazingly fast!
webinar

NoSQL: Two Main Rules to Remember
1. Spread Data evenly around the cluster.
2. Minimize the number of partitions read.
webinar
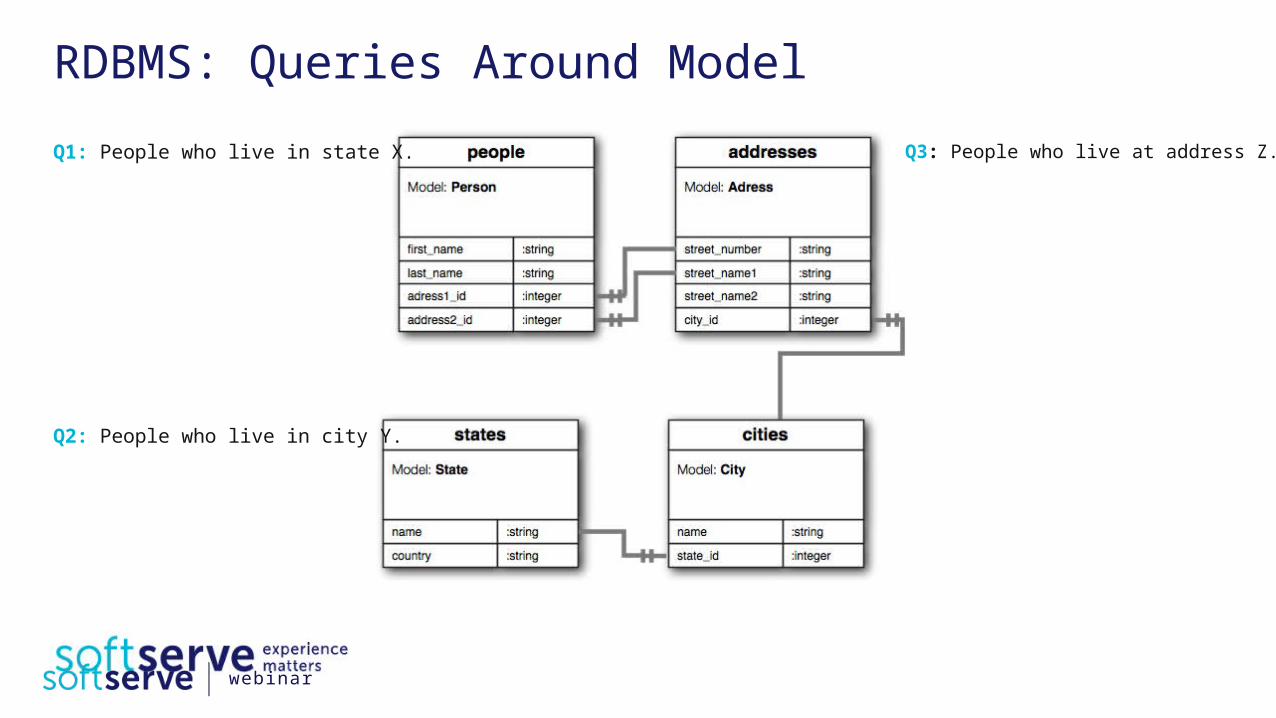
RDBMS: Queries Around ModelQ1: People who live in state X.
Q2: People who live in city Y.
Q3: People who live at address Z.
webinar

NoSQL: Model Around Queries!
Q1: People who live in state X. Q2: People who live in city Y. Q3: People who live at address Z.
People_by_Statesstate - Partition / Primary Keycountryfirst_namelast_namecitystreet_name1street_name2street_number
People_by_Citycity - Partition / Primary Keycountryfirst_namelast_namestatestreet_name1street_name2street_number
People_by_FullAddresscountry, city, state, street_name1 – Partition / Primary Keyfirst_namelast_namestreet_name2street_number
webinar

Data Modeling: Checklist1. In NoSQL, you can have a table for each query, and it is totally OK, don’t save
disk space! (sacrifice cheap writes for the fastest reads).
2. There are (almost) no secondary indexes in NoSQL, only primary.
3. Pick up correct primary (partitioning) key to read only one partition per request.
webinar

Deployment

Deployment DefinedIn short, deployment is the litmus paper for a project that defines the level of maturity. And, the overall project success depends on it.
webinar

Deployment Stages
1. Bootstrapping: Create VM’s and hosts.
2. Provisioning: Install software like Hadoop.
3. Configuration: Initial parameters and data.
4. Validation: Verify installation.
webinar
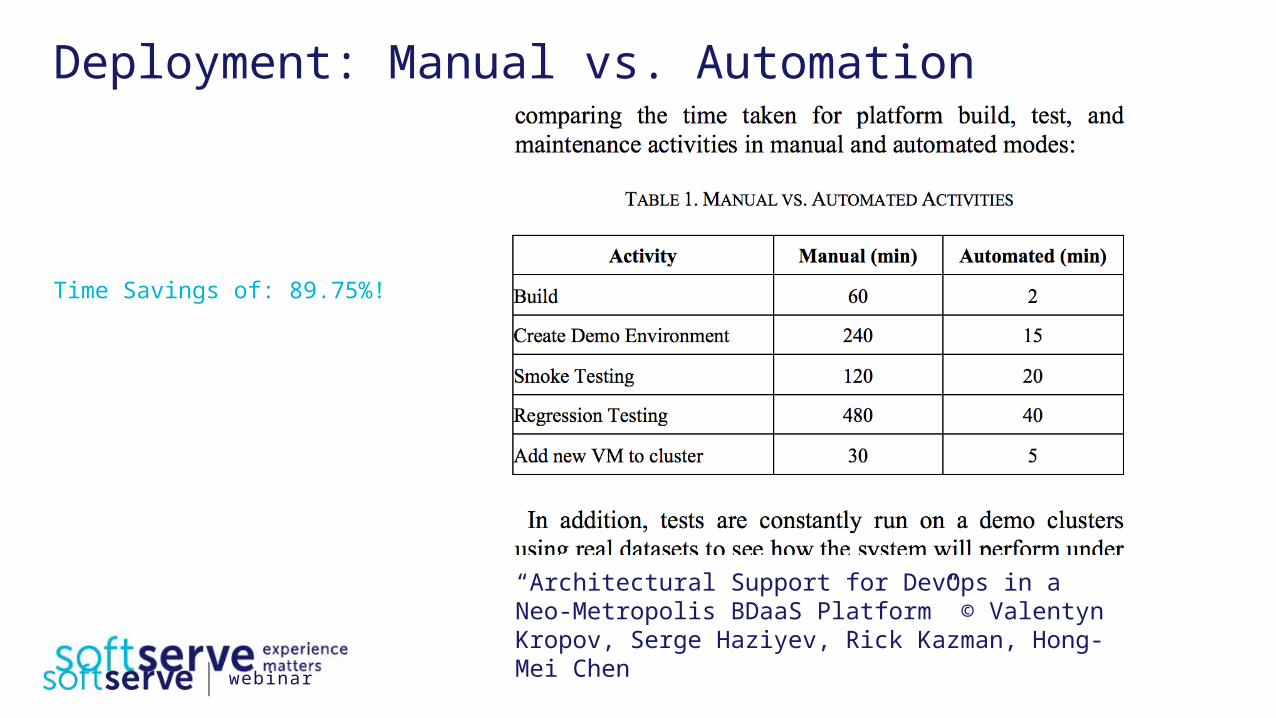
Deployment: Manual vs. Automation
“Architectural Support for DevOps in a Neo-Metropolis BDaaS Platform” © Valentyn Kropov, Serge Haziyev, Rick Kazman, Hong-Mei Chen
Time Savings of: 89.75%!
webinar
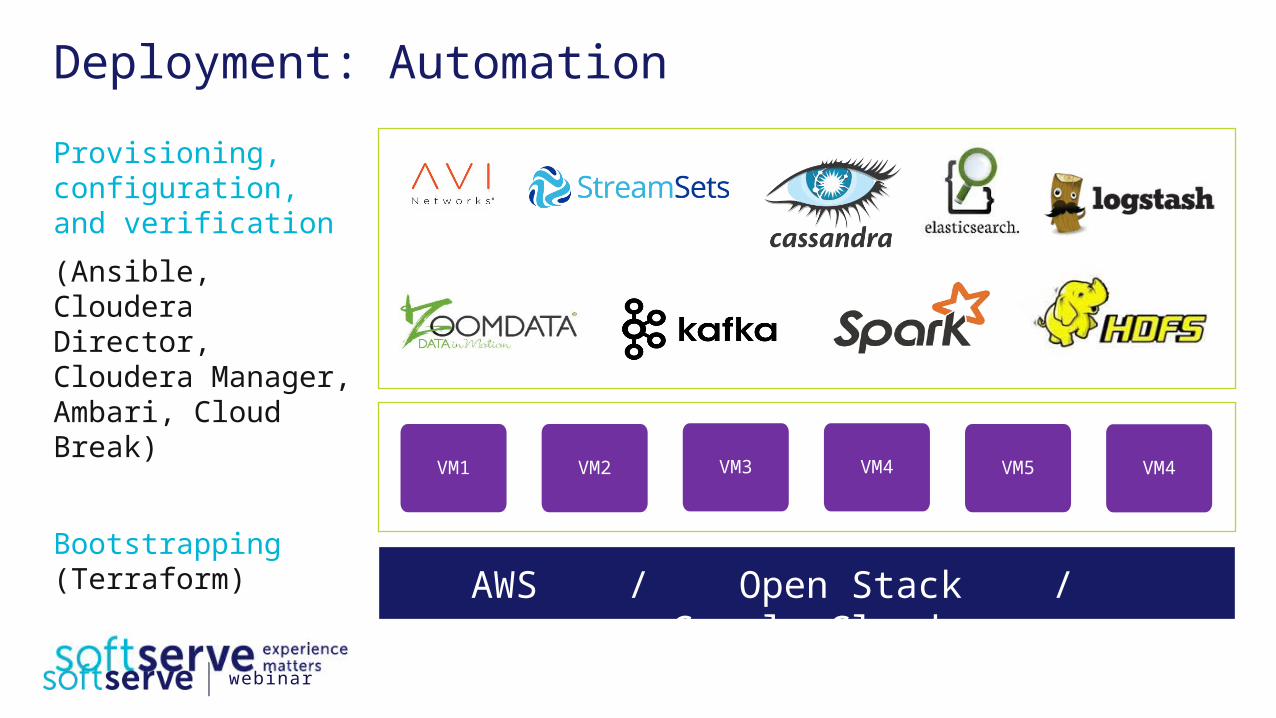
Deployment: AutomationProvisioning, configuration, and verification(Ansible, Cloudera Director, Cloudera Manager, Ambari, Cloud Break)
Bootstrapping (Terraform)
VM1 VM2 VM3 VM4 VM5 VM4
AWS / Open Stack / Google Cloud
webinar

Deployment: Automation (Hadoop Cluster)
1. Bootstrapping: HoshiCorp Terraform.
2. Provisioning & Configuration: Cloudera Director.
3. Validation: Cloudera Manager API.
webinar
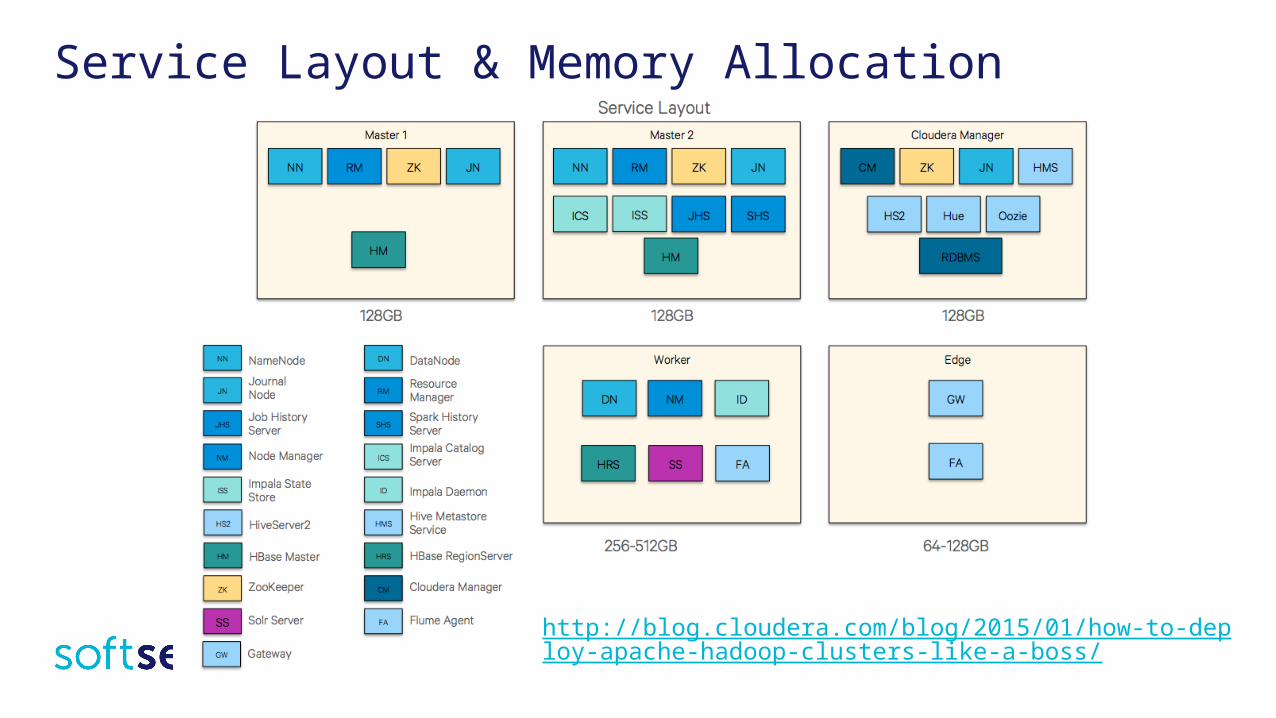
Service Layout & Memory Allocation
http://blog.cloudera.com/blog/2015/01/how-to-deploy-apache-hadoop-clusters-like-a-boss/

Automation: Checklist
1. Deployment should be fully automated (Terraform and Ansible).
2. Ensure service layout is correct (master nodes, worker nodes, and edge nodes).
3. Double check to see if enough memory has been given for nodes (~64-128GB for master/edge nodes, ~256-512GB for data/workers nodes).
webinar

On-Premises vs. Cloud

On-Premises(real hardware somewhere in your building or data center)1. Highest data privacy (Regulations and sensitive data).
2. Quickest access to data (Latency).
3. Best velocity (Transfer rates).
4. Existing Hardware.
5. Control over resource usage.
webinar

Cloud (Amazon, Azure, etc.)
1. Efficient cost-reduction.
2. Universal access.
3. Flexibility.
4. Choice of applications.
5. Built-in maintenance and support.
6. Scalability!
webinar

Hybrid
1. Hybrid: a combination of on-premises and cloud.
2. On-premises: sensitive information and data for high-performance access.
3. Cloud: non-sensitive data.
webinar

On-Premises vs. Cloud
1. Oracle ExaData ~ $1.000.000
2. Biggest instance in Amazon EC2 (40CPU) ~ 50 years!
webinar

On-Premises vs. Cloud: Checklist1. On-premises: If customer has existing unused hardware, has predicted data
volume growth, or has strong data security requirements.2. Cloud: If the customer doesn’t have a large budget, is not sure about data &
load growth, and doesn’t have strong security requirements or a team of engineers to support hardware.
3. Hybrid: Mixture of requirements above.
webinar

Scalability & Performance
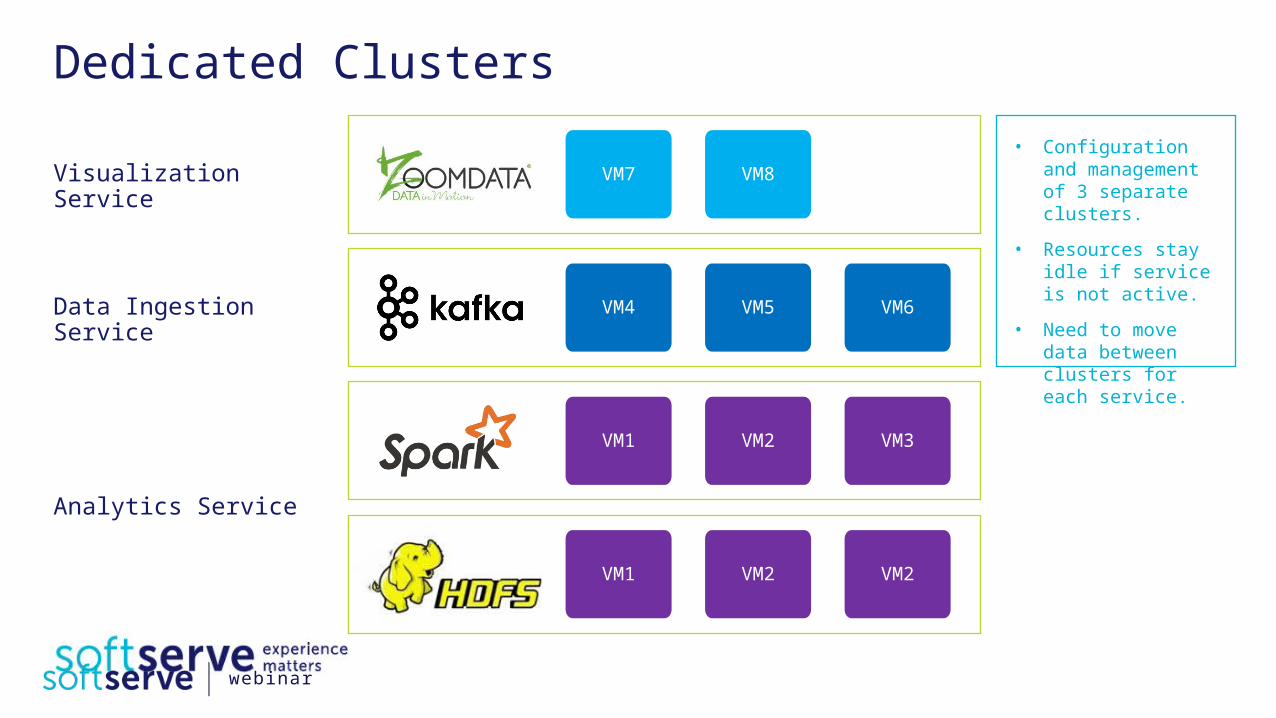
Dedicated Clusters
Visualization Service
Data Ingestion Service
Analytics Service
VM1 VM2 VM3
VM1 VM2 VM2
VM4 VM5 VM6
VM7 VM8• Configuration and
management of 3 separate clusters.
• Resources stay idle if service is not active.
• Need to move data between clusters for each service.
webinar
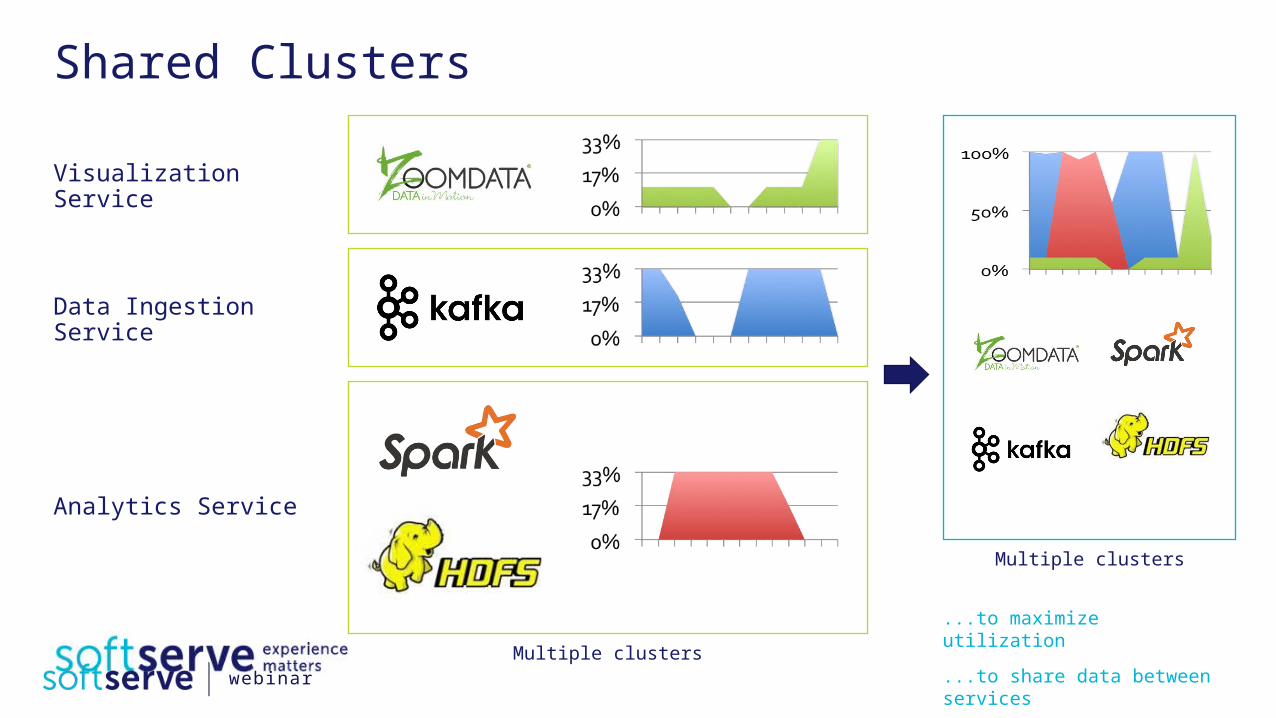
Shared Clusters
Visualization Service
Data Ingestion Service
Analytics Service
Multiple clusters
Multiple clusters
...to maximize utilization
...to share data between serviceswebinar
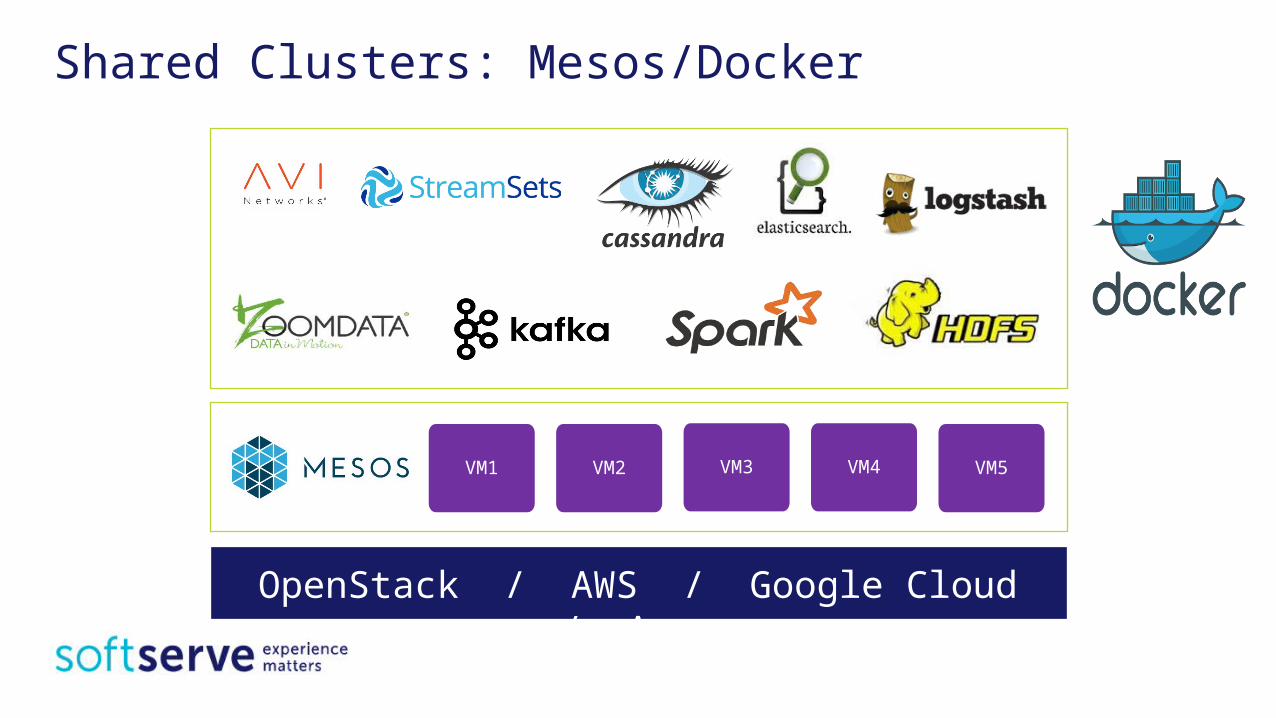
Shared Clusters: Mesos/Docker
OpenStack / AWS / Google Cloud / Azure
VM5VM1 VM2 VM3 VM4

Shared Clusters: Mesos/DockerMaximize utilization & performance:Deliver more services with smaller footprint.
Shared clusters for all services:Easier deployment and management with unified service platform.
Shared data between services:Faster and more competitive services and solutions.
webinar
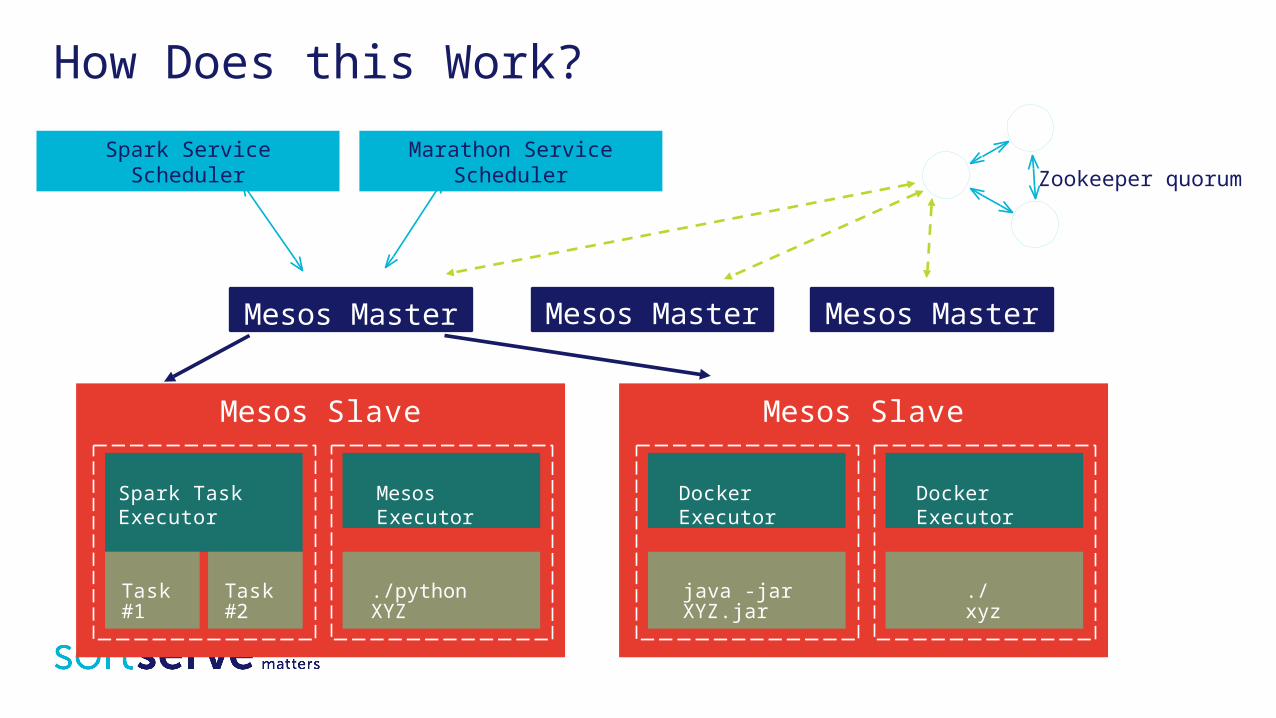
How Does this Work?
Zookeeper quorum
Mesos Master Mesos Master Mesos Master
Spark Service Scheduler Marathon Service Scheduler
Mesos Slave
Spark Task Executor Mesos Executor
Mesos Slave
Docker Executor Docker Executor
Task #1 Task #2 ./python XYZ java -jar XYZ.jar ./xyz
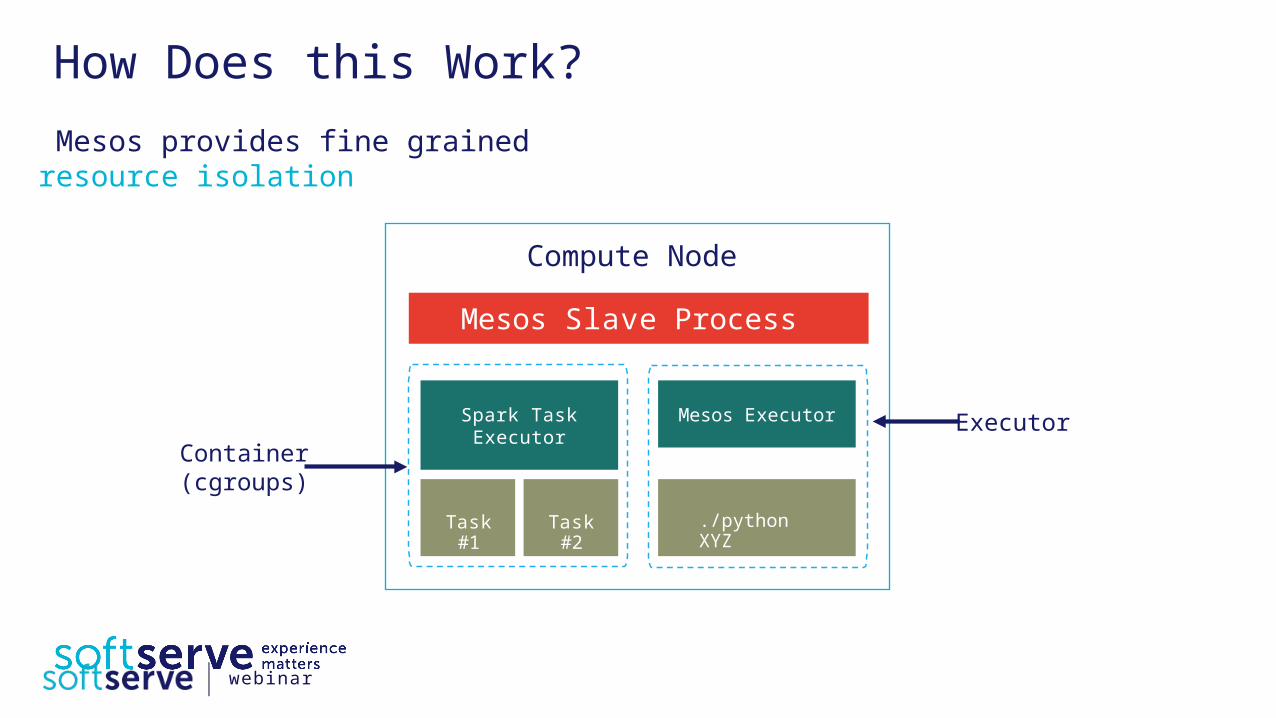
How Does this Work? Mesos provides fine grained resource isolation
Mesos Slave Process
Spark Task Executor
Mesos Executor
Task #2
./python XYZ
Compute Node
ExecutorContainer(cgroups)
Task #1
webinar
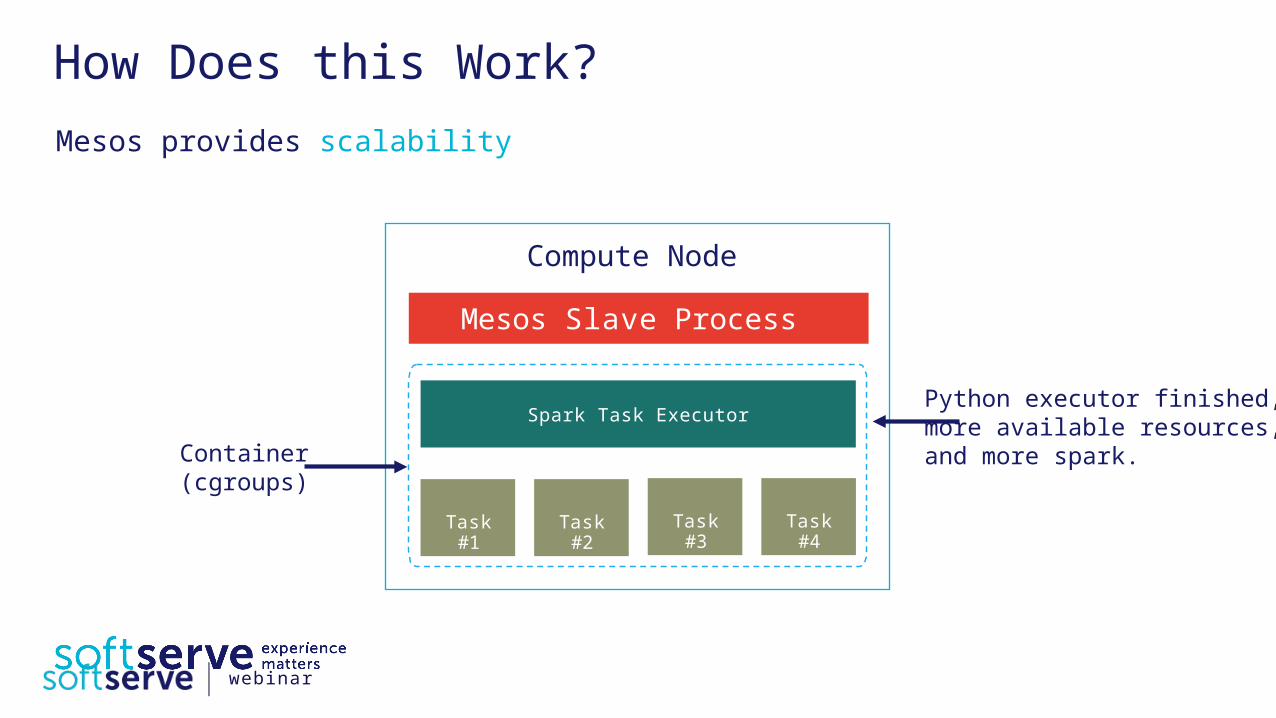
How Does this Work? Mesos provides scalability
Mesos Slave Process
Spark Task Executor
Task #2
Compute Node
Container(cgroups)
Task #1
Python executor finished,more available resources,and more spark.
Task #4
Task #3
webinar
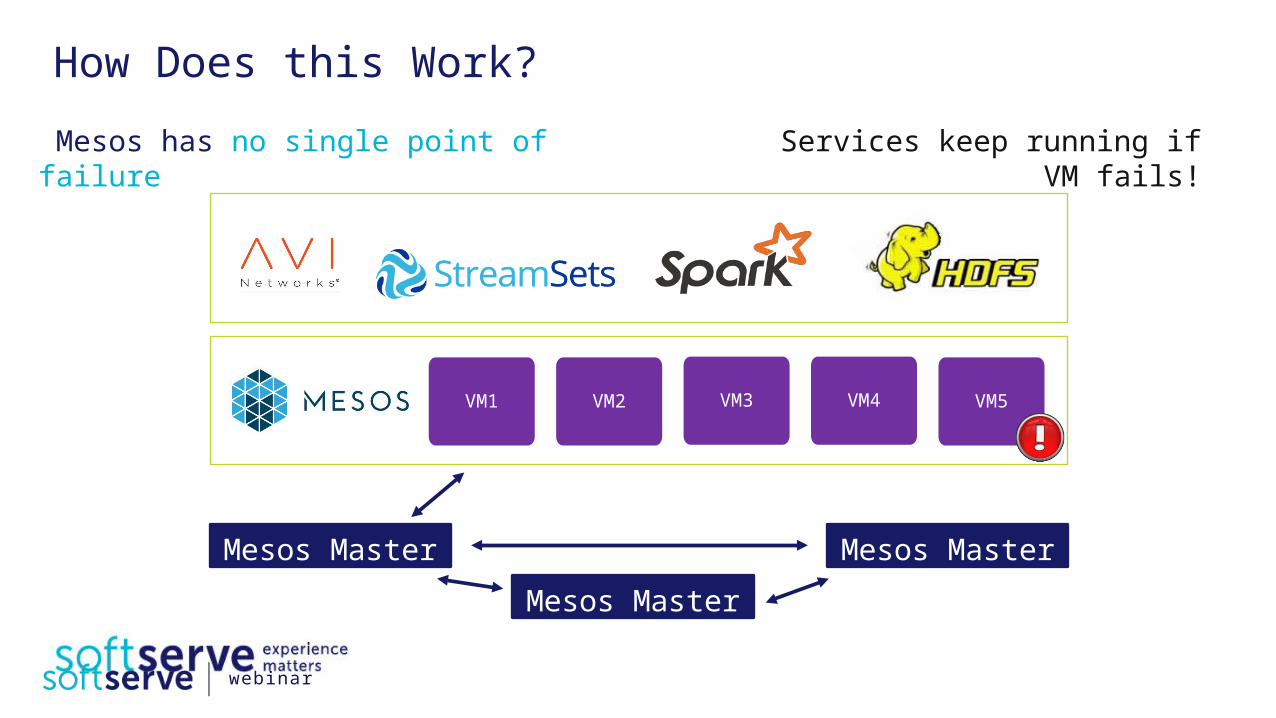
How Does this Work?
VM5VM1 VM2 VM3 VM4
Mesos has no single point of failure Services keep running if VM fails!
Mesos Master
Mesos Master Mesos Master
webinar
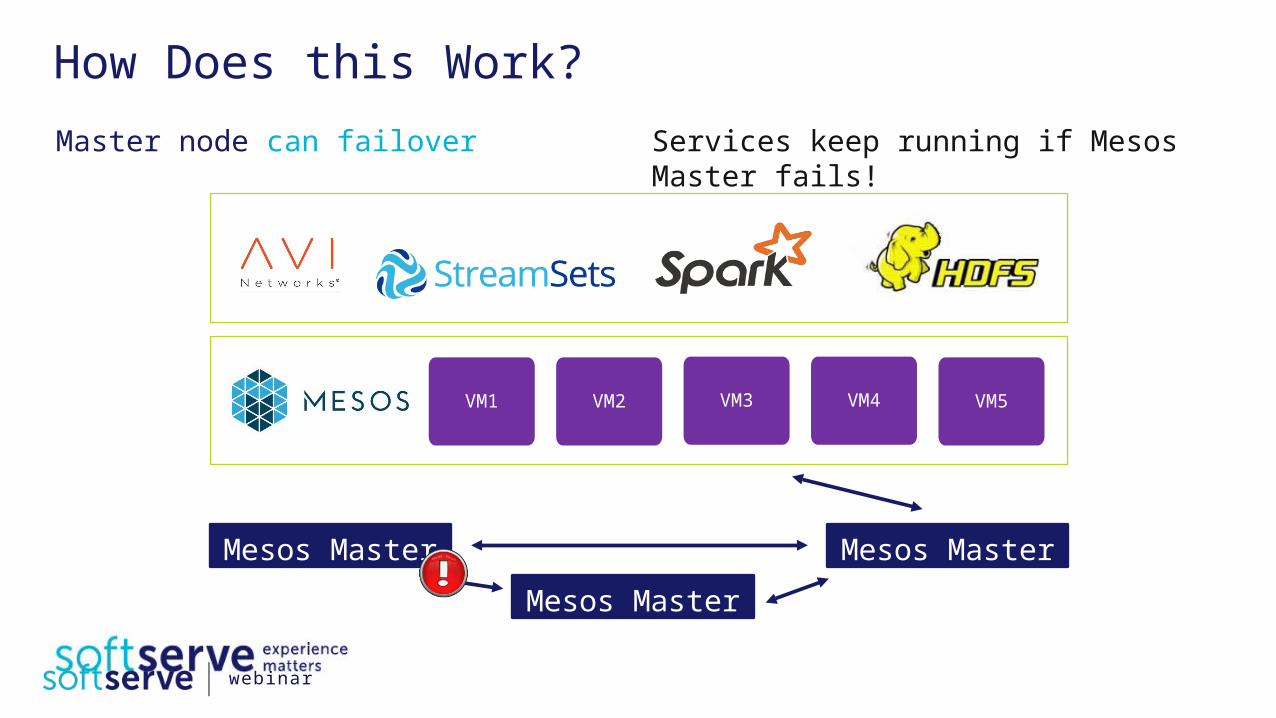
How Does this Work?
VM5VM1 VM2 VM3 VM4
Master node can failover Services keep running if Mesos Master fails!
Mesos Master
Mesos Master Mesos Master
webinar
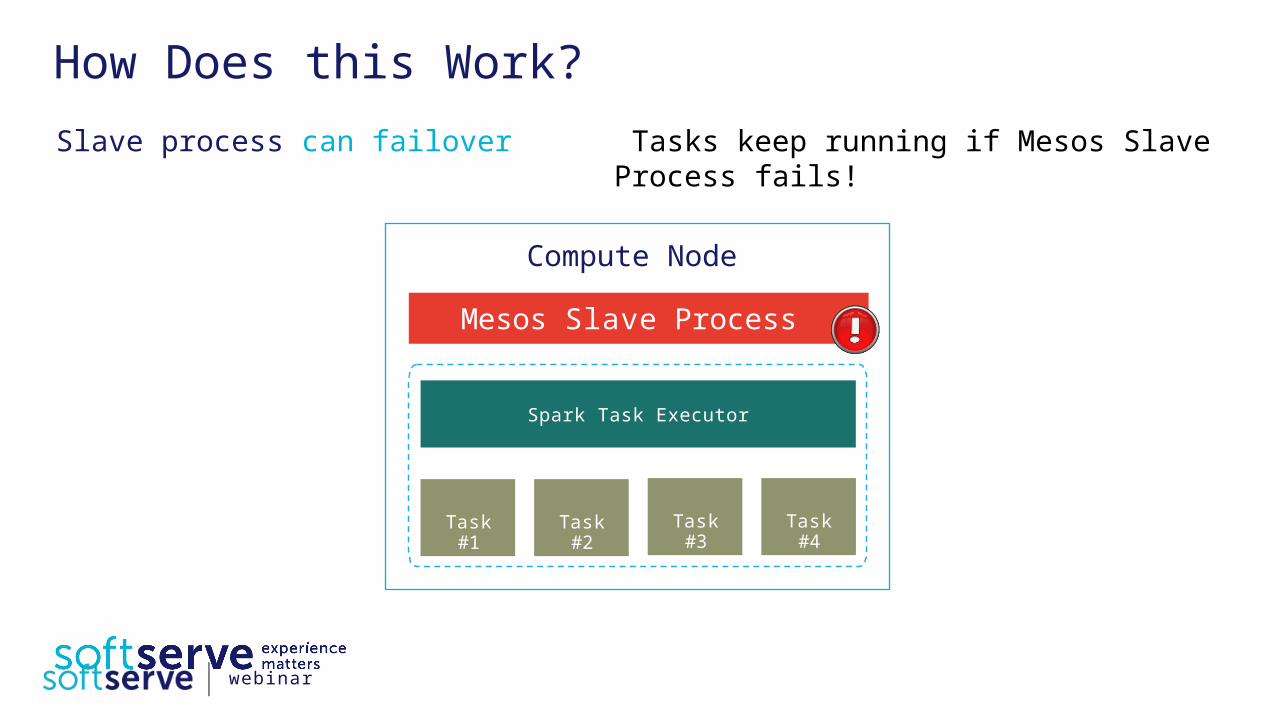
How Does this Work? Slave process can failover Tasks keep running if Mesos Slave
Process fails!
Mesos Slave Process
Spark Task Executor
Task #2
Compute Node
Task #1
Task #4
Task #3
webinar

Scalability & Performance: Checklist
1. If you need real scalability then use shared clusters.
2. Shared clusters love to host in Cloud.
3. Scalability means performance (in most cases). Use it as a synonym.
webinar

Storage

Netflix Storage: Situation
1. ~25PB Data Warehouse on Amazon S3.
2. Read ~10% daily.
3. Write ~10% daily.
4. ~550 billion events daily.
5. ~350 active platform users (> 80% – Data Science engineers).
webinar
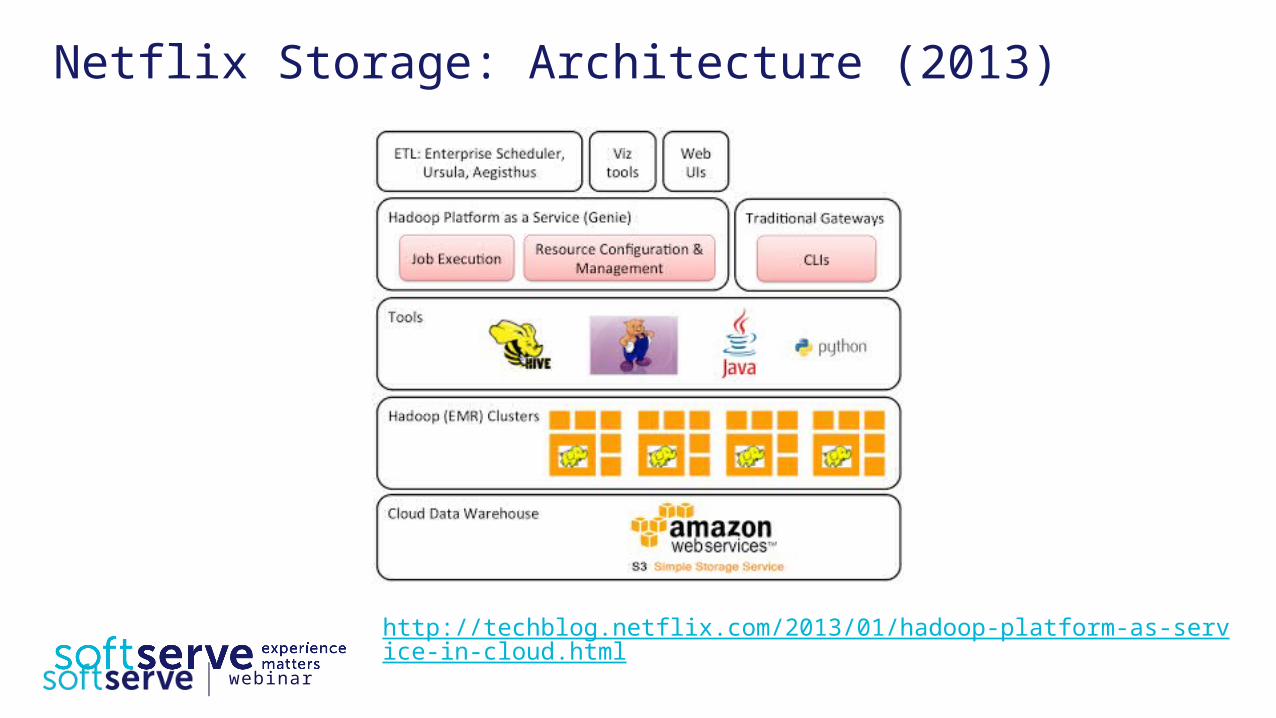
Netflix Storage: Architecture (2013)
http://techblog.netflix.com/2013/01/hadoop-platform-as-service-in-cloud.html
webinar
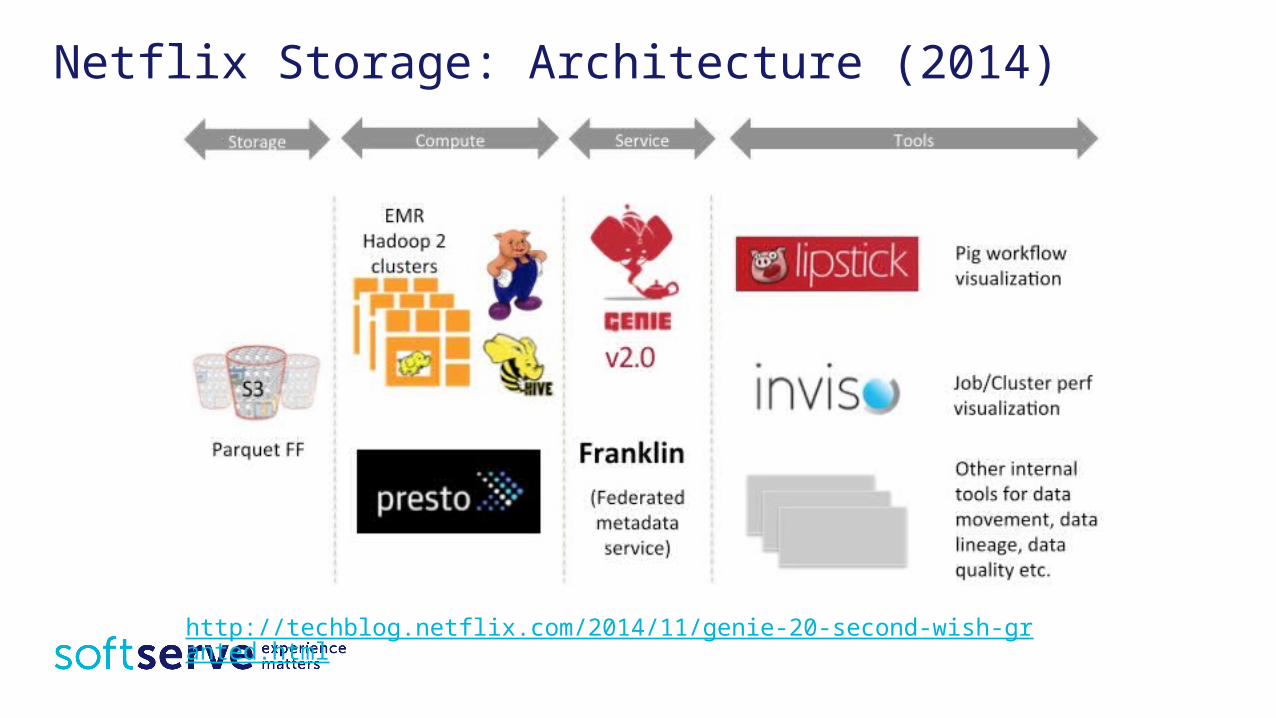
Netflix Storage: Architecture (2014)
http://techblog.netflix.com/2014/11/genie-20-second-wish-granted.html
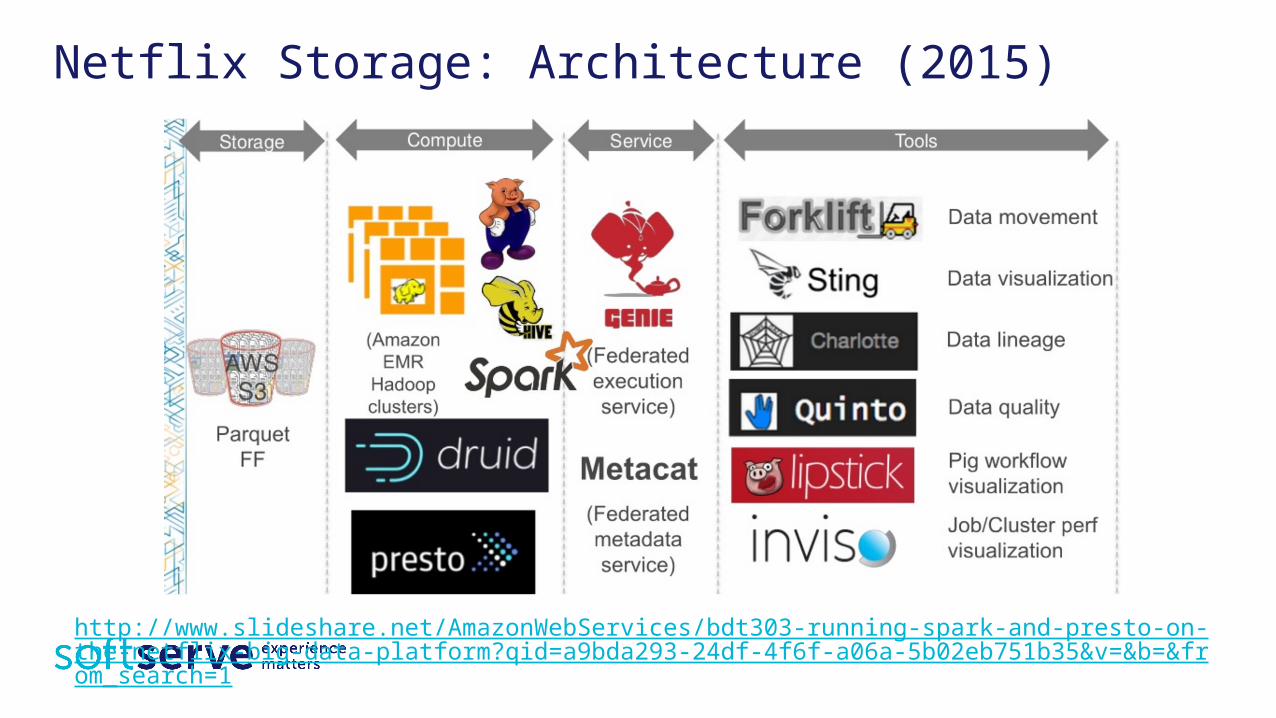
Netflix Storage: Architecture (2015)
http://www.slideshare.net/AmazonWebServices/bdt303-running-spark-and-presto-on-the-netflix-big-data-platform?qid=a9bda293-24df-4f6f-a06a-5b02eb751b35&v=&b=&from_search=1

Storage Comparison1. Amazon S3: universal access, cheap, and data needs to be copied before
processing.2. HDFS: compatible with Hadoop ecosystem, relatively cheap, and data can be
processed where it is being stored.3. Directly Attached Storage/Network Attached Storage: expensive, fastest
access to data, and it also can be processed where data is being stored.
webinar
Storage: Checklist1. If you need unified access to data and use some universal
Cloud FS, then this would be similar to Amazon S3.2. For immediate access to data (OLTP system), you need Directly
Attached Storage (DAS), Network Attached Storage (NAS), Elastic Block Storage (Amazon EBS), and so on.
3. If you choose NoSQL, you’ll need much more space than actual data (each query might require duplicate copy of data).
4. Pick storage carefully and use PoC/Prototyping, otherwise changing storage later on will be hard to almost impossible.
webinar

Final Checklist

Final Checklist
1. You’re the Boss!
2. You have a right to demand the infrastructure you need.
3. However, you need to have perfect argumentation.
4. Now you have it and know where to get details.
5. Good luck and see you in the field!
webinar

Contacts
https://ua.linkedin.com/in/valentin-kropov-032a147
https://www.facebook.com/bigdatakyiv
webinar

USA HQToll Free: 866-687-3588 Tel: +1-512-516-8880
Ukraine HQTel: +380-32-240-9090
Bulgaria
Tel: +359-2-902-3760
GermanyTel: +49-69-2602-5857
NetherlandsTel: +31-20-262-33-23
PolandTel: +48-71-382-2800
UKTel: +44-207-544-8414
WEBSITE:www.softserveinc.com
Thank you!