estimating the impact of ocr quality on research tasks in the digital humanities
TRANSCRIPT

1
Estimating the Impact of OCR Quality on Research Tasks in the Digital HumanitiesMyriam C. Traub, Jacco van Ossenbruggen!Centrum Wiskunde & Informatica
24/03/2015

01
Use of digital archives for…
✤ selection for close reading!
✤ first occurrence of specific words!
✤ word frequency patterns over !✤ time !✤ different sources
It all depends on OCR
quality!
2

We care about average performance
on representative subsets for generic
cases.
I care about actual performance
on my non-representative subset
for my specific query.
3
Two different perspectives of OCR quality
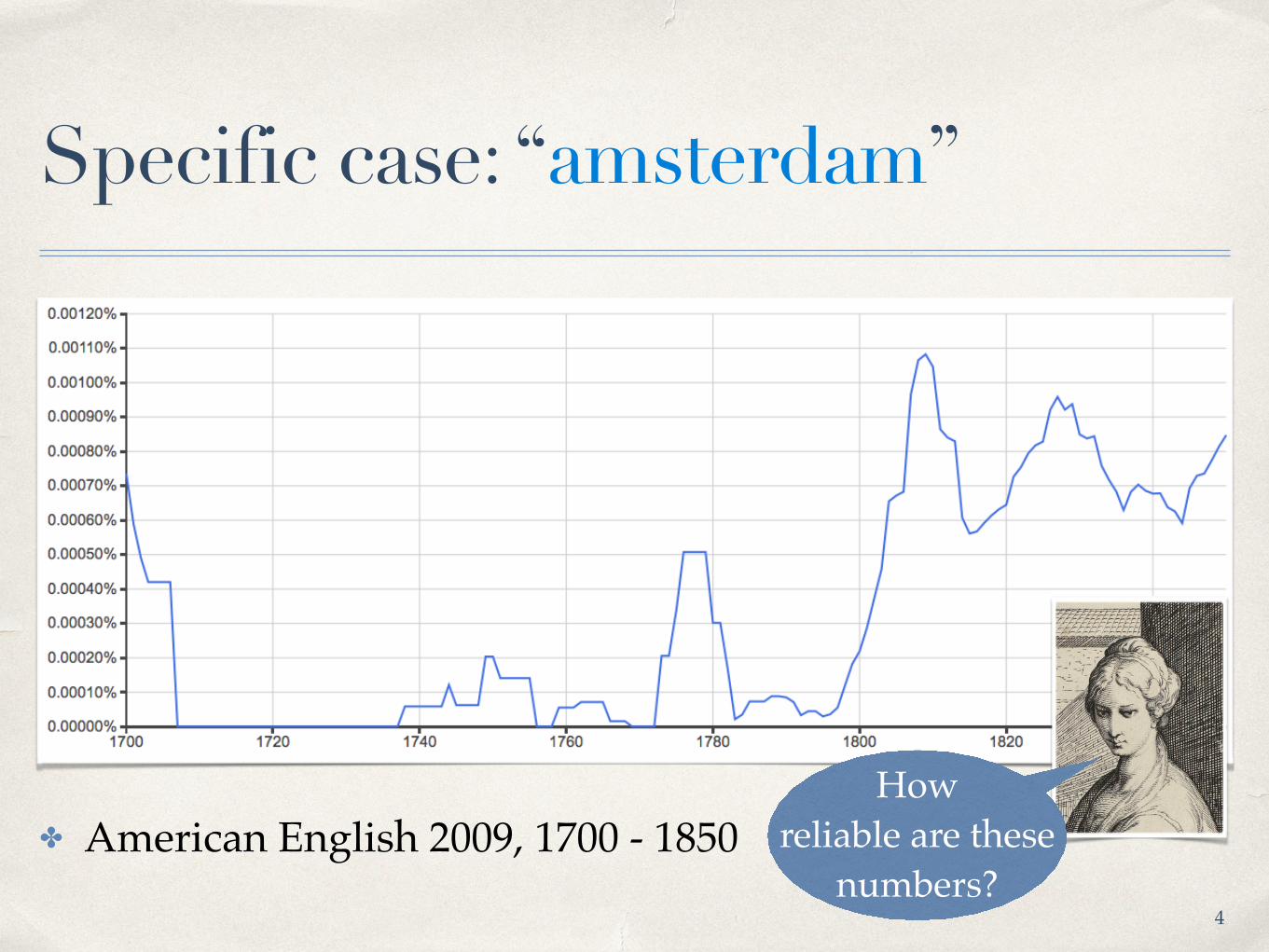
Specific case: “amsterdam”
✤ American English 2009, 1700 - 1850How
reliable are these numbers?
4

Specific case: “amsterdam”
✤ American English 2009, 1700 - 18505
Tool maker:!recall (average) = 90%
Is “amsterdam” in the 10% or in the
90%?

✤ American English 2009, 1700 - 1850
“amsterdam” and “amfterdam”
How do I know?!
What else?6

✤ Current American English, 1700 - 1850
Different versions / pipelinesHow do I know
that they fixed it?!What else?
7

Research questions
✤ How can we give humanities researchers the information they need to understand how the OCR limitations influence their research tasks?!
✤ What is a good way of estimating uncertainty for a specific case?!
✤ How to get (the data for) better estimates?
8

OCR
pre-processing
post-!
processing
ingestion
scanning
9
Understanding potential sources of bias
✤ some details difficult to reconstruct !
✤ essential to understand overall impact

OCR
pre-processing
post-!
processing
ingestion
scanning
10
Potential starting point:
✤ Confidence in the pipeline?

Example for OCR confidence values
11
What does 0.732
mean?

Example for post-processing
12

01
OCR confidence values useful?
✤ available for all items in the collection: page, word, character!
✤ calibration based on limited ground truth?!
✤ only for highest ranked words / characters, other candidates missing
13

01
Future work
✤ How to estimate impact of OCR errors on use cases outside the ground truth?!
✤ Can we crowdsource part of this estimation problem?!
✤ How to convey the estimated impact to researchers?
14
