estructuras de datos y algoritmos -...
TRANSCRIPT

Estructuras de Datos y AlgoritmosFacultad de Informatica
Universidad Politecnica de Valencia
Curso 2009/2010
Tema 2:Representacion de conjuntos
FI– UPV: Curso 2009/2010

EDA-2
TEMA 2. Representacion de conjuntos
Objetivos• Estudiar los tipos de datos conjunto dinamico: diccionario, cola de prioridad, conjuntos
disjuntos.• Estudiar tecnicas de representacion de conjuntos y algoritmos asociados.• Aprender a seleccionar el tipo de datos e implementacion mas adecuados para resolver
un problema dado.
Contenidos1 Introduccion2 Tablas de dispersion (Hash)3 Conjuntos disjuntos (MFset)4 Arboles parcialmente ordenados: Montıculos (Heaps)5 Arboles binarios de busqueda (ABB)
Bibliografıa• Introduction to Algorithms, de Cormen, Leiserson y Rivest (capıtulos 7, 11.1, 11.2, 12,
13 y 22)• Fundamentos de Algoritmia, de Brassard y Bratley (capıtulo 5)• Estructuras de datos y algoritmos, de Aho, Hopcroft y Ullman (capıtulos 4 y 5)
FI– UPV: Curso 2009/2010 Pagina 2.1

EDA-2
2.1 IntroduccionDe nuevo el problema de la moda
Uno de los ejemplos que vimos en el tema de introduccion a C++ consistıa enobtener la moda de un conjunto de valores numericos en un rango determinado.Ahora nos planteamos un “pequeno” cambio de este problema, en lugar de numerosson cadenas de caracteres:
Dada una enumeracion de ciudades donde estas puede aparecer repetidas¿Que ciudad aparece mas veces?
La forma de resolver el problema original consistıa en crear un vector v de enterosde manera que v[i] guardaba el numero de veces que habıa aparecido el numeroi en la secuencia.
Sin embargo, ahora consideramos cadenas de caracteres y por tanto no podemosutilizar un simple vector porque los vectores no se indexan con cadenas decaracteres. Ademas, ahora los elementos de la secuencia no estan en un rangoprefijado determinado, sino que las cadenas de caracteres forman parte de unacoleccion infinita (si bien es cierto que ninguna ciudad tiene nombres de masde 1000000 caracteres, por ejemplo, pero ese conjunto, aunque sea finito, esdemasiado grande).
FI– UPV: Curso 2009/2010 Pagina 2.2

EDA-2
El problema de la moda con cadenas
Ejemplo:
Madrid Valencia Sevilla Barcelona Zaragoza Valencia Albacete AlicanteValencia Sevilla Barcelona Valencia Madrid Valencia Sevilla BarcelonaZaragoza Valencia Albacete Alicante Valencia Sevilla BarcelonaValencia Madrid Valencia Sevilla Barcelona Zaragoza Valencia AlbaceteAlicante Valencia Sevilla Barcelona Valencia Madrid Valencia SevillaBarcelona Zaragoza Valencia Albacete Alicante Valencia SevillaBarcelona Valencia Madrid Valencia Sevilla Barcelona Zaragoza ValenciaAlbacete Alicante Valencia Sevilla Barcelona Valencia Madrid ValenciaSevilla Barcelona Zaragoza Valencia Albacete Alicante Valencia SevillaValencia Madrid Valencia Barcelona Valencia Zaragoza Valencia
Solucion:Albacete aparece 6 vecesAlicante aparece 6 vecesBarcelona aparece 12 vecesMadrid aparece 7 vecesSevilla aparece 12 vecesValencia aparece 27 vecesZaragoza aparece 7 veces
La moda es Valencia
FI– UPV: Curso 2009/2010 Pagina 2.3

EDA-2
El problema de la moda con cadenas yrepresentacion de conjuntos
Este problema se puede resolver considerando las palabras comoelementos de un conjunto. Cada vez que llega una palabra miramosa ver si es nueva, en cuyo caso la insertamos en el conjunto yponemos su contador a 1. Si por el contrario la palabra ya estabaen el conjunto, incrementamos su contador en una unidad.
En este tema veremos que tipo de estructuras de datos y algoritmosse pueden implementar para representar conjuntos arbritarios. Elobjetivo es lograr que ciertas operaciones sobre los conjuntos seanmuy eficientes en coste temporal, manteniendo los requisitos dememoria (coste espacial) reducidos lo maximo posible.
FI– UPV: Curso 2009/2010 Pagina 2.4

EDA-2
El problema de la moda con cadenasutilizando map de la librerıa stl
1 #include <iostream>2 #include <iomanip>3 using namespace std;4 #include <string>5 #include <map>6 typedef map<string,int> diccionario;7 int main() 8 diccionario d;9 diccionario::iterator it;
10 string nombre;11 while (cin >> nombre) // leer los nombres por entrada estandar12 it = d.find(nombre); // buscamos nombre en el diccionario13 if (it == d.end()) 14 d[nombre] = 1; // el nombre aparece por 1a vez15 else 16 it->second++; // el nombre habia aparecido17 18
FI– UPV: Curso 2009/2010 Pagina 2.5

EDA-2
El problema de la moda con cadenasutilizando map de la librerıa stl
19 int max = -1;20 const string *nombremoda;21 for (it = d.begin(); it != d.end(); it++) // recorremos diccionario22 cout << left << setw(10) << it->first << " aparece "23 << right << setw(3) << it->second24 << ((it->second == 1) ? " vez\n" : " veces\n");25 if (it->second > max) 26 max = it->second;27 nombremoda = &(it->first);28 29 30 cout << "La moda es " << *nombremoda << endl;31 return 0;32
En este tema veremos que tipo de representaciones y algoritmos hay en el interiorde la “caja negra” map para representar diccionarios y otros tipos de dato conjuntodinamico.
FI– UPV: Curso 2009/2010 Pagina 2.6

EDA-2
2.1 IntroduccionTipo de datos conjunto dinamico
Coleccion de elementos de un determinado tipo o universo U . Todos loselementos de un conjunto son diferentes. Si pueden repetirse se habla demulticonjunto.
Los elementos de un conjunto pueden tener asociado un valor (que no seconsidera de cara a determinar la pertenencia del elemento al conjunto).Nomenclatura:
• clave: campo de identificacion, el que determina el conjunto.• informacion satelite o valor: asociada a la clave
Algunos conjuntos se caracterizan porque en el conjunto de claves se puedeestablecer una relacion de orden total (ejemplos: enteros, reales, cadenas).
En este caso se puede definir el elemento mınimo (o maximo) de un conjunto,o el sucesor (o predecesor) de un elemento en el conjunto.
FI– UPV: Curso 2009/2010 Pagina 2.7

EDA-2
Operaciones con conjuntos
Consultoras (“queries”): Buscar, Mınimo, Maximo, Predecesor, Sucesor
Modificadoras: Insertar, Borrar
Algunas operaciones requieren la clave k de un elemento x, o una referencia r a una partede la estructura de datos S asociada a x. En la tabla, a se refiere a r o a x. m es un natural.
S.Buscar(k) indica si el elemento esta en el conjunto y devuelve aS.Insertar(x) anade el elemento x en el conjunto SS.Borrar(a) borra el elemento x de S con clave kS.Mınimo() devuelve el elemento de S cuya clave sea mınimaS.Maximo() devuelve el elemento de S cuya clave sea maximaS.BorrarMin() borra el elemento de S cuya clave sea mınimaS.BorrarMax() borra el elemento de S cuya clave sea maximaS.Predecesor(a) devuelve el elemento de clave inmediatamente inferior a k o un
valor especial si k es la mınimaS.Sucesor(a) devuelve el elemento de clave inmediatamente superior a k o un
valor especial si k es la maximaS.Selectop(m) devuelve el m-esimo menor elemento
Coste de las operaciones: suele depender del tamano (cardinal) del conjunto |S| = n.
FI– UPV: Curso 2009/2010 Pagina 2.8

EDA-2
Algunos tipos de conjuntos dinamicos
Diccionarios
• Operaciones: Buscar, Insertar, Borrar• Ejemplo: tabla de sımbolos de un compilador• Tablas de dispersion, arboles binarios de busqueda (ABB)
Colas de prioridad
• Operaciones: Insertar, BorrarMax (BorrarMin)• Ejemplos: cola de procesos, simulacion de eventos discretos.• Heaps, ABB
Conjuntos disjuntos (las posibles particiones de un conjunto C quetiene un numero fijo de elementos)
• Operaciones: crear, union, busqueda de un representante de la clase.• Ejemplo: componentes conexas de un grafo.• MF-Set
FI– UPV: Curso 2009/2010 Pagina 2.9
EDA-2
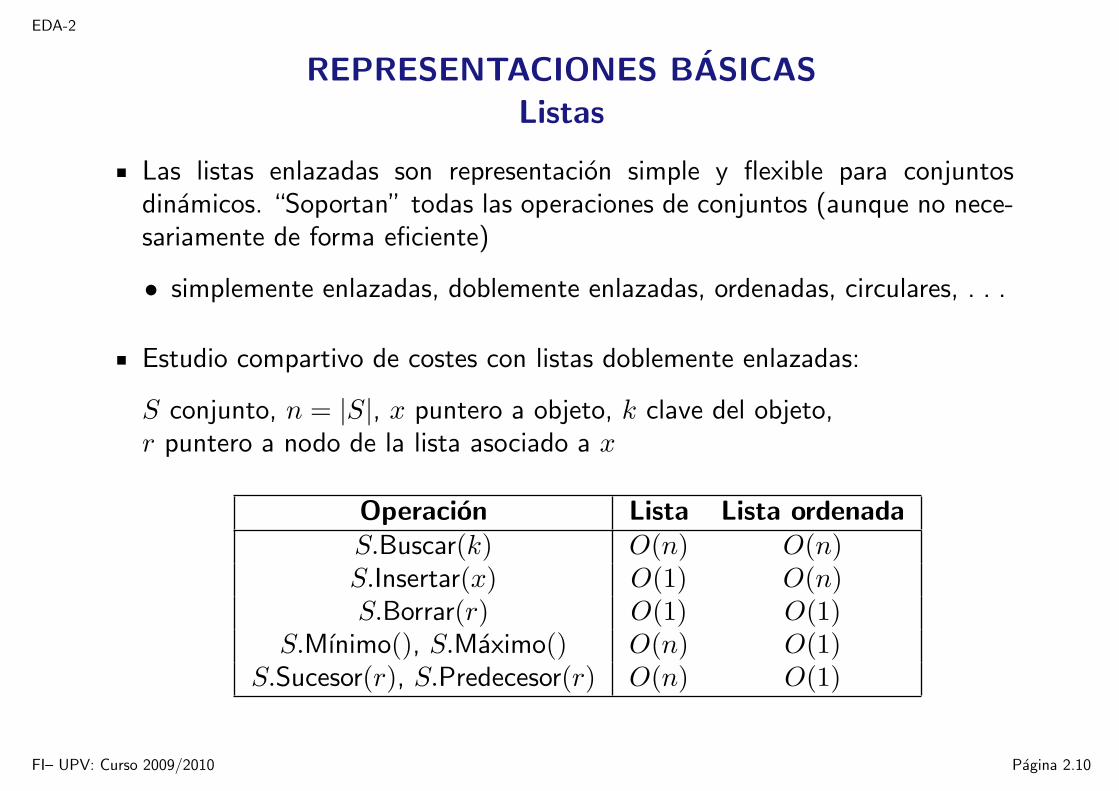
REPRESENTACIONES BASICASListas
Las listas enlazadas son representacion simple y flexible para conjuntosdinamicos. “Soportan” todas las operaciones de conjuntos (aunque no nece-sariamente de forma eficiente)
• simplemente enlazadas, doblemente enlazadas, ordenadas, circulares, . . .
Estudio compartivo de costes con listas doblemente enlazadas:
S conjunto, n = |S|, x puntero a objeto, k clave del objeto,r puntero a nodo de la lista asociado a x
Operacion Lista Lista ordenadaS.Buscar(k) O(n) O(n)S.Insertar(x) O(1) O(n)S.Borrar(r) O(1) O(1)
S.Mınimo(), S.Maximo() O(n) O(1)S.Sucesor(r), S.Predecesor(r) O(n) O(1)
FI– UPV: Curso 2009/2010 Pagina 2.10

EDA-2
REPRESENTACIONES BASICASTablas de acceso directo
Tablas de acceso directo o vectores de bits: Sirve cuando el universoU de los elementos tiene un cardinal finito y no muy grande. Ental caso se utiliza un vector de bits de tamano |U |. Cada bit sirvepara indicar la pertenencia de cada elemento.
Si queremos representar un diccionario, el vector puede ser deelementos de tipo valor o informacion satelite o tambien a punterosde los mismos (si el tipo valor ocupa mucho mas que un puntero).Ejemplo: el caso del programa para calcular la moda de un conjuntode numeros, que vimos en el tema 1.
Con independencia del tamano del universo, este ha de ser de laforma 0, 1, . . . , |U | − 1 o facilmente transformable a estos valorespara poder implementarlo usando vectores en C o en C++.
FI– UPV: Curso 2009/2010 Pagina 2.11

EDA-2
2.2 TABLAS DE DISPERSION (Hash)
Estructura de datos especialmente disenada para la implementacionde DICCIONARIOS (operaciones Buscar, Insertar y Borrar en untiempo “esperado” O(1)).
Es una generalizacion de las tablas de acceso directo.
Contenidos:
• Concepto de dispersion (“hashing”)
• Resolucion de colisiones: Encadenamiento (“Separate Chaining”)
Direccionamiento abierto (“Open addressing”)
• Costes.
• Funciones de dispersion.
• Histograma de ocupacion.
• Tablas de dispersion dinamicas: Redispersion (“Rehashing”)
FI– UPV: Curso 2009/2010 Pagina 2.12

EDA-2
Concepto de dispersionComo ya sabes, las tablas de acceso directo son faciles de implementar pa-ra representar conjuntos del universo 0, 1, . . . , |U | − 1 puesto que nos sirvendirectamente para indexar un vector en C o C++.
¿Que podrıamos hacer para representar conjuntos de un universo U diferente? Porejemplo, ¿que pasa si U es un conjunto de cadenas de caracteres?
¿Que ocurre si |U | es mucho mayor que el tamano del conjunto que queremosrepresentar? Por ejemplo, el conjunto de todas las cadenas de caracteres hasta unalongitud maxima crece de manera exponencial con esa longitud.
Idea: Crear una funcion h : U −→ 0, . . . ,m − 1 donde m es el tamano delconjunto que queremos representar. Esta funcion se llama funcion hash o dedispersion.
Ejemplo: Queremos representar el conjunto de m = 5 nombres de ciudad Valencia,Madrid, Sevilla, Zaragoza, Alicante y asociarles un valor de tipo X.
• Definimos un vector V de tipo X de tamano m.
• Una funcion que asocia a cada ciudad un valor 0, . . . , 4. Por ejemplo, h(Valencia)= 3, h(Madrid) = 1, h(Sevilla) = 0, h(Zaragoza) = 4, h(Alicante) = 2.
• Guardamos el valor de la ciudad c en V [h(c)].FI– UPV: Curso 2009/2010 Pagina 2.13

EDA-2
Ejemplo: Funciones de dispersion para cadenas
1 unsigned int taulaHash::func1(char *cadena) 2 unsigned int h=0; // -- metodo simple (’de la suma’)3 for (char* p=cadena; *p!=’\0’; p++)4 h += (unsigned int)(*p);5 return(h % tamany);6 1 unsigned int taulaHash::func2(char * x) // -- metodo ’de la division’2 const int firstChar = 32; // Codigo del primer caracter (’ ’)3 const int rangChar = 227; // Numero de caracteres (’ ’-’y’)4 const int base = rangChar; unsigned int h=0;5 for (char* p=x; (*p)!=’\0’; p++)6 h = (h*base + (unsigned int)(*p)-firstChar) % tamanyo;7 return(h);8 1 unsigned int taulaHash::func3(char *cadena) // Metodo multiplicativo2 const unsigned int cte_hash = 2654435769U; // 2**32/proporcion_aurea3 unsigned int h = 0; // proporcion_aurea = (sqrt(5)+1)/24 for (char* p=cadena; *p!=’\0’; p++) // calculo implıcito de modulo5 h = (h + (unsigned int)(*p)) * cte_hash; // 2ˆ32 por desbordamiento6 return(h % tamanyo);7
FI– UPV: Curso 2009/2010 Pagina 2.14

EDA-2
Concepto de colision
Queremos que f sea inyectiva ¿Que ocurre si no lo es?
Ejemplo: Si h(Valencia) = h(Zaragoza) puede ocurrir lo siguiente:• Asociamos un valor α a Valencia: V[h(Valencia)] = α• Asociamos un valor β a Zaragoza: V[h(Zaragoza)] = β• Consultamos el valor de Valencia, tendrıa que valer α pero vale β
Cuando dos elementos distintos van a parar mediante lafuncion f a la misma posicion en la tabla, se dice que seha producido una COLISION.
A veces no sabemos de antemano el conjunto que vamos a representarni su tamano. Nos gustarıa que f fuese lo mas independiente posible delconjunto a representar. Por ejemplo, queremos una funcion que asocie unvalor 0, . . . ,m− 1 a cualquier cadena de caracteres. Una funcion ası nopuede ser inyectiva (|U | > m).
Tabla de dispersion = funcion de dispersion +resolucion de colisiones.
FI– UPV: Curso 2009/2010 Pagina 2.15

EDA-2
Resolucion de colisiones
Dos estrategias diferentes para resolver las colisiones:
Encadenamiento (“Separate Chaining”): Una vez obtenido un ındice0, . . . ,m − 1 con la funcion de dispersion, accedemos a un vector de lis-tas donde guardamos en el todos los elementos que caigan en esa posicion.
Direccionamiento abierto (“Open addressing”): Si vamos a insertar unelemento en una posicion y esa posicion estuviese ocupada, se busca unaposicion alternativa utilizando una segunda, tercera,... funcion de dispersion.Es decir, en lugar de tener una funcion de dispersion h, tenemos un conjuntoh1, h2, . . . de funciones o mejor, una funcion de la forma h(x, k) = hk(x).Ejemplo: direccionamiento abierto lineal consiste en tener h(x, k) = h′(x)+k.
Observacion: En cualquiera de los dos casos, ahora hay que comprobar si seproduce o no colision. Es decir, tenemos que guardar tanto la clave como el valor.
FI– UPV: Curso 2009/2010 Pagina 2.16
EDA-2
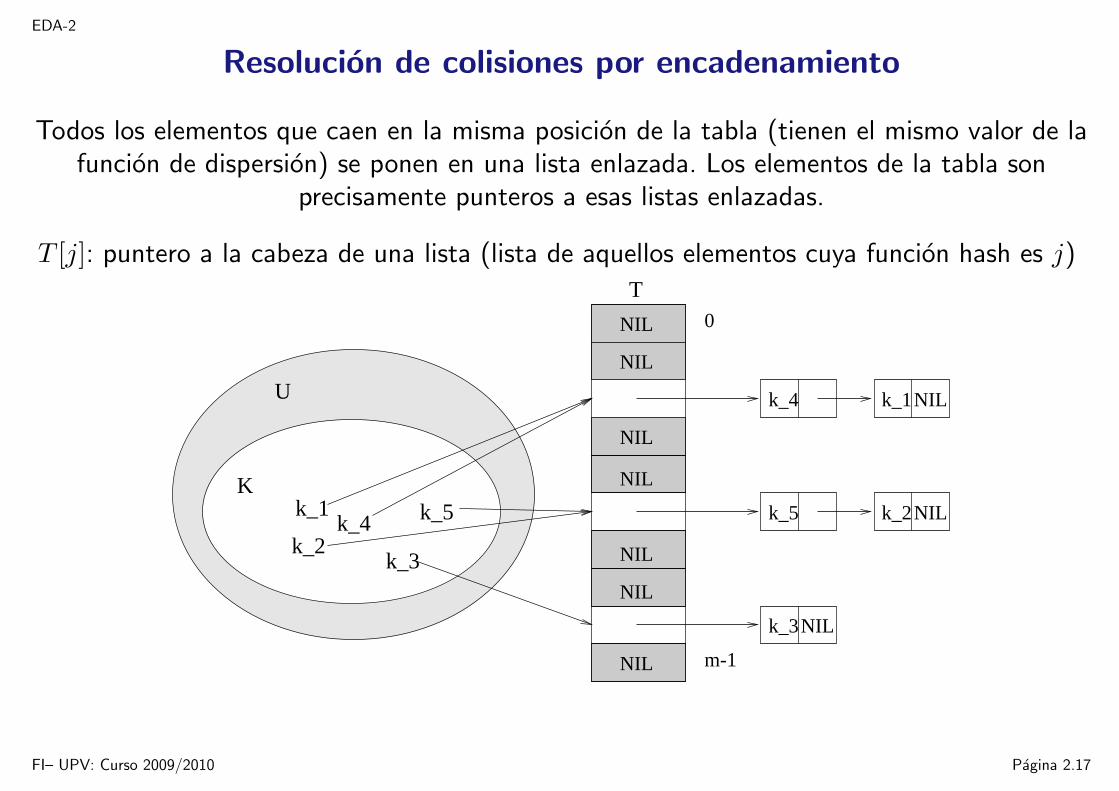
Resolucion de colisiones por encadenamiento
Todos los elementos que caen en la misma posicion de la tabla (tienen el mismo valor de lafuncion de dispersion) se ponen en una lista enlazada. Los elementos de la tabla son
precisamente punteros a esas listas enlazadas.
T [j]: puntero a la cabeza de una lista (lista de aquellos elementos cuya funcion hash es j)
NIL
k_5
0
T
NIL
NIL
NIL
NIL
NIL
U
k_1
k_3
K
m-1
k_5
k_1NILk_4
k_3NIL
k_4
NIL
k_2
k_2NIL
FI– UPV: Curso 2009/2010 Pagina 2.17
EDA-2
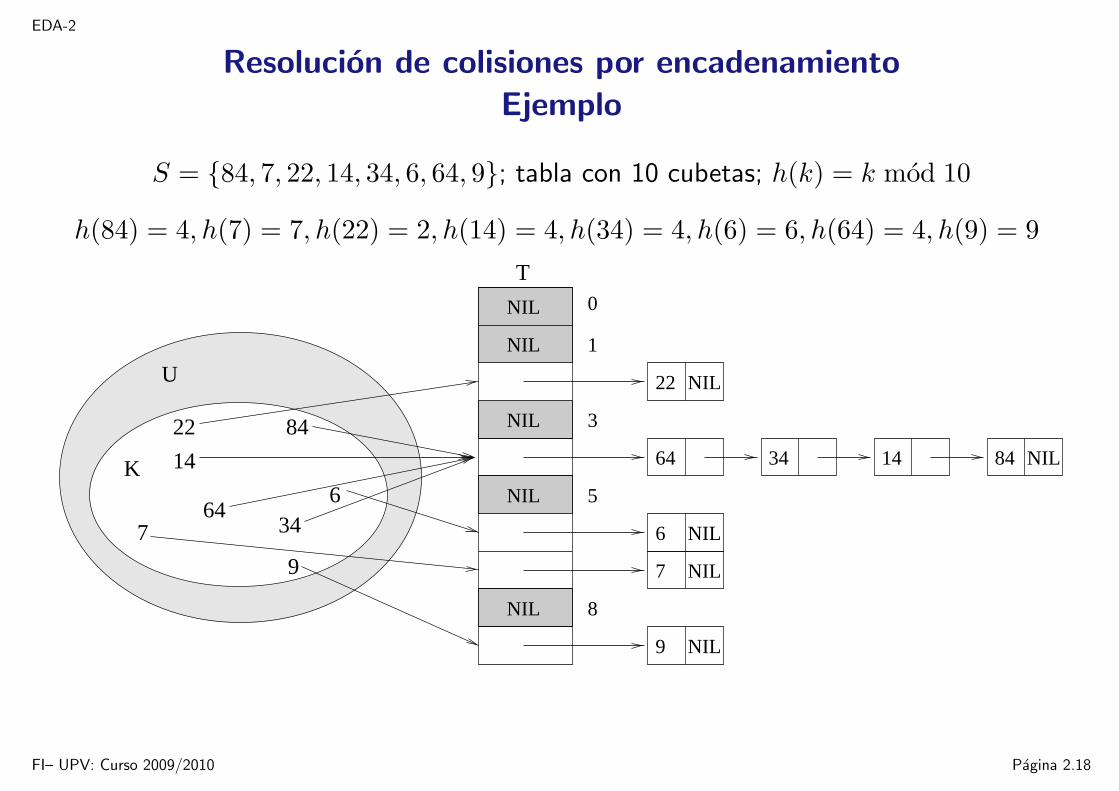
Resolucion de colisiones por encadenamientoEjemplo
S = 84, 7, 22, 14, 34, 6, 64, 9; tabla con 10 cubetas; h(k) = k mod 10
h(84) = 4, h(7) = 7, h(22) = 2, h(14) = 4, h(34) = 4, h(6) = 6, h(64) = 4, h(9) = 9
7 NIL
T
NIL
NIL
U
K
22
NIL
0
1
3
5
8NIL
NIL
14 84 NIL3464
NIL
6 NIL
9 NIL
6
9
22 84
14
7 3464
FI– UPV: Curso 2009/2010 Pagina 2.18

EDA-2
Resolucion de colisiones por encadenamientoAnalisis del coste medio de Buscar
Dada un tabla de m cubetas que almacena n elementos, definimos elfactor de carga de la tabla como α = n/m (numero medio de elementosalmacenados en una lista)
El caso peor de una busqueda es: O(n) (todos los elementos de estan en lamisma cubeta)
Analisis del coste medio:
• Asumimos “hashing uniforme simple”: La probabilidad de que un elementode U se almacene en cualquier posicion de la tabla es la misma.• Asumimos que el coste de calcular h es O(1)• Suponemos que las colisiones se han resuelto por encadenamiento
El coste de buscar es O(1 + α)
Si n es proporcional a m, n ∈ Θ(m), α = n/m = O(m)/m ∈ Θ(1) Y por lo tanto el coste de buscar es O(1) Ası, todas las operaciones del tipo diccionario (buscar, insertar y borrar)
se pueden efectuar con coste constante O(1)
FI– UPV: Curso 2009/2010 Pagina 2.19

EDA-2
La funcion de dispersion h
Metodo de la Division: h(k) = k mod m
Conveniente: m numero primo no cercano a una potencia de 2.
Ejemplo: se desea almacenar n ≈ 2000 elementos. Podemos examinar una media de 3elementos en una busqueda
• Seleccionamos tamano tabla: α = 3 = 2000/m, m = 666,66.. → m = 701 (primocercano a 666.66.. pero no cercano a una potencia de 2)• Funcion h(k) = k mod 701• Ejemplo: h(1600) = 1600 mod 701 = 198
FI– UPV: Curso 2009/2010 Pagina 2.20

EDA-2
La funcion de dispersion h
Metodo de la Multiplicacion: h(k) = bm((kφ) mod 1)c , 0 < φ < 1
Seleccion m no crıtica (m se suele tomar una potencia de 2, facilidad operaciones)Cuando φ = (
√5− 1)/2 ≈ 0,618... se denomina funcion hash de Fibonacci
Nota: (√
5− 1)/2 es la inversa de la proporcion aureaNota: x mod 1 significa x− bxc
Ejemplo: se desea almacenar n ≈ 3000 elementos. Podemos examinar una media de 3elementos en una busqueda
• Seleccionamos tamano tabla: α = 3 = 3000/m, m = 1000→ m = 1024 = 210
• Funcion h(k) = b1024(k · 0,6180339887... mod 1)c• Ejem.: h(1600) = b1024(1600 · 0,6180339887... mod 1)c
= b1024(988,84800... mod 1)c= b1024 · 0,84800c= b868,352c = 868
FI– UPV: Curso 2009/2010 Pagina 2.21

EDA-2
Consideraciones para tablas de dispersion
Definir una funcion de dispersion que• Minimize el numero de colisiones (dispersion efectiva).• Sea eficiente de calcular.Definir la estrategia para tratar las colisiones. Elegir:• Encadenamiento (“Separate Chaining”). Soporta mejor el borrado, mejor comporta-
miento cuando crece el factor de carga. Tener en cuenta el coste total de los punterosy la asignacion de memoria dinamica.• Direccionamiento abierto (“Open addressing”). Borrado problematico. El factor de carga
debe ser inferior a 1 (menos versatilidad, ademas tiene mal comportamiento temporalcuando el factor de carga se aproxima a 1).
Elegir un tamano de la tabla segun necesidades (tamano del conjunto, estrategia deresolucion de colisiones, coste permitido) y compatible con la funcion de dispersionelegida.
A partir de ahora, cuando hablemos de tablas de disper-sion, seran mediante encadenamiento a menos que seindique lo contrario.
FI– UPV: Curso 2009/2010 Pagina 2.22

EDA-2
Ejercicio
¿Que supondrıa en una tabla de dispersion de tallam = 1001 tener una funcion de dispersion parala cual la variable talla de las cubetas tuviera unamedia k = 100 y una varianza 0?
FI– UPV: Curso 2009/2010 Pagina 2.23

EDA-2
Solucion
Como la varianza es 0, todas las cubetas almacenan el mismonumero de elementos, es decir, 100 y, por tanto, el numero deelementos total almacenados en la tabla de dispersion es 100100.
FI– UPV: Curso 2009/2010 Pagina 2.24

EDA-2
Ejercicio
Dos ficheros F1 y F2, ambos con el mismo numero depalabras, se dispersan en sendas tablas de dispersion, ambasde la misma dimension, y usando la misma funcion dedispersion. Se mide la ocupacion de las cubetas en amboscasos, y se obtiene:
F1 F2Media 4.25 4.25Desviacion tıpica 0.84 16.73
¿Para cual de los dos ficheros es mas adecuada la funcionde dispersion usada? Justificad la respuesta.
FI– UPV: Curso 2009/2010 Pagina 2.25

EDA-2
Solucion
F1 F2Media 4.25 4.25Desviacion tıpica 0.84 16.73
La ocupacion media es el valor medio de las longitudes de las listasasociadas a las cubetas.
La desviacion tıpica para F1 es muy pequena (en relacion a la media),lo que implica que el tiempo de acceso en el peor caso ha sido muyproximo al tiempo medio; es decir, el comportamiento ha sido muyuniforme para todas las instancias (palabras) de F1.
FI– UPV: Curso 2009/2010 Pagina 2.26

EDA-2
Solucion (continuacion)
Sin embargo, la desviacion tıpica para F2 es muy grande con respectoa la media, lo que significa que hay (muchas) cubetas con listasvacıas o con muy pocos elementos y otras con listas muy grandes,con muchos elementos.
Si existen cubetas no ocupadas, la longitud media observadasera (muy) inferior a la longitud media de las listas correspondientesa las cubetas ocupadas, que son las unicas que realmente se utilizandurante los accesos a la tabla.
En esta situacion, el tiempo medio de acceso en el caso de F2habra sido probablemente (muy) superior que en el caso de F1.
En cualquier caso, siempre sera preferible un comportamiento unifor-me, es decir, cuanto menor sea la desviacion tıpica, mas representativasera la media de la ocupacion de las cubetas.
FI– UPV: Curso 2009/2010 Pagina 2.27

EDA-2
Histogramas de ocupacion
Una forma concisa de estimar lo bien distribuida que esta una tabla dedispersion con encadenamiento consiste en ver la media y la varianza delas longitudes de las listas asociadas a cada cubeta. La media es el factorde carga. Lo ideal es que todas las listas tengan una longitud similar(valor bajo de la varianza).Otros datos que tambien aportan esta informacion de manera menosconscisa, pero que se puede apreciar graficamente, es el denominadohistograma de ocupacion. Para cada longitud de lista se muestra elnumero de cubetas cuyas listas que tienen esa longitud.Lo ideal es un histograma de ocupacion donde el valor mas alto se de enla longitud “factor de carga” o que se concentre alrededor de ese valor,mientras que el resto de longitudes tengan valores bajos.
FI– UPV: Curso 2009/2010 Pagina 2.28

EDA-2
Tablas de dispersion dinamicasRedispersion (“Rehashing”)
Muchas veces no es facil estimar el tamano del conjunto que vamos arepresentar. Esto imposibilita la hipotesis de elegir un numero de cubetasm del mismo orden que el tamano del conjunto n, con lo que el coste deinsertar, buscar y borrar puede crecer de manera no controlada.La solucion consiste en aumentar el tamano de la tabla de dispersionde manera dinamica. Cuando el factor de carga supere cierto umbral,se realiza una operacion de redispersion (“rehashing”) que consiste encrear otro vector de listas de mayor tamano m′ y mover los nodos de laslistas a los lugares correspondientes en el nuevo vector. El coste de estaoperacion es O(m+m′ + n) (suponiendo que el coste de h es O(1)).¿Cual es el coste amortizado de una operacion de busqueda en una tablade dispersion con redispersion? Para que este coste este controlado, loideal es hacer que la tabla crezca de manera geometrica, por ejemplom′ = 2m ¿Por que? Analiza el coste amortizado en ese caso.
FI– UPV: Curso 2009/2010 Pagina 2.29

EDA-2
Ejemplo C++1 class hash_clave_valor 2 lista* cubeta;3 int tamanyo,n_elementos,umbral_rehashing;4 int mascarahash; // permite "& mascarahash" en lugar de "% tamano"5 int potencia2(int valor);6 double f_carga_rehashing; // factor de carga t.q. conviene rehashing7 void rehashing(); // duplica el tamano de la tabla8 void rehashing(int tam); // cambia el tamano de la tabla9 public:
10 hash_clave_valor(int tam, double fcr); // constructor11 ˜hash_clave_valor(); // destructor12 bool insertar(Tclave clav, Tvalor valor); // "true" si es nuevo13 Tvalor& insertar(Tclave clav, bool &nuevo);14 bool buscar(Tclave clav, Tvalor& valor); // "true" si encontrado15 // buscar devuelve el valor asociado mediante paso por referencia16 bool buscar(Tclave clave); // "true" si se ha encontrado17 const Tvalor& operator [] (Tclave clav) const;18 Tvalor& operator [] (Tclave clav);19 bool borrar(Tclave clav); // "true" si estaba y se ha borrado20 void estadisticas(21 double& media, double& desv_tipica,int longmax, int histogram[]);22 int num_cubetas(); // devuelve el tamano de la tabla hash23 int num_elementos(); // devuelve el numero de elementos almacenados24 void listar(ostream &s);25 ;
FI– UPV: Curso 2009/2010 Pagina 2.30

EDA-2
2.4 CONJUNTOS DISJUNTOS: MFset
Tenemos un conjunto C previamente fijado. Una relacion R definida en C esun subconjunto del producto cartesiano C ×C de manera que aR b denota(a, b) ∈ R. Se dice que una relacion es de equivalencia si se verifican las tressiguientes propiedades:
(Reflexiva) aRa para todo a ∈ C.(Simetrica) aR b si y solo si bR a, para todo a, b ∈ C.(Transitiva) aR b y bR c implica aR c, para todo a, b, c ∈ C.
El problema de la Union-Busqueda (Merge-Find) tiene como espacio elconjunto de las posibles particiones de un conjunto C.El objetivo es el desarrollo de estructuras de datos eficientes para agruparn elementos distintos en una coleccion de k conjuntos disjuntos S =S1, S2, . . . , Sk con dos tipos de operaciones: union de dos conjuntosdisjuntos y busqueda para saber a que conjunto pertenece un elemento.
FI– UPV: Curso 2009/2010 Pagina 2.31
EDA-2
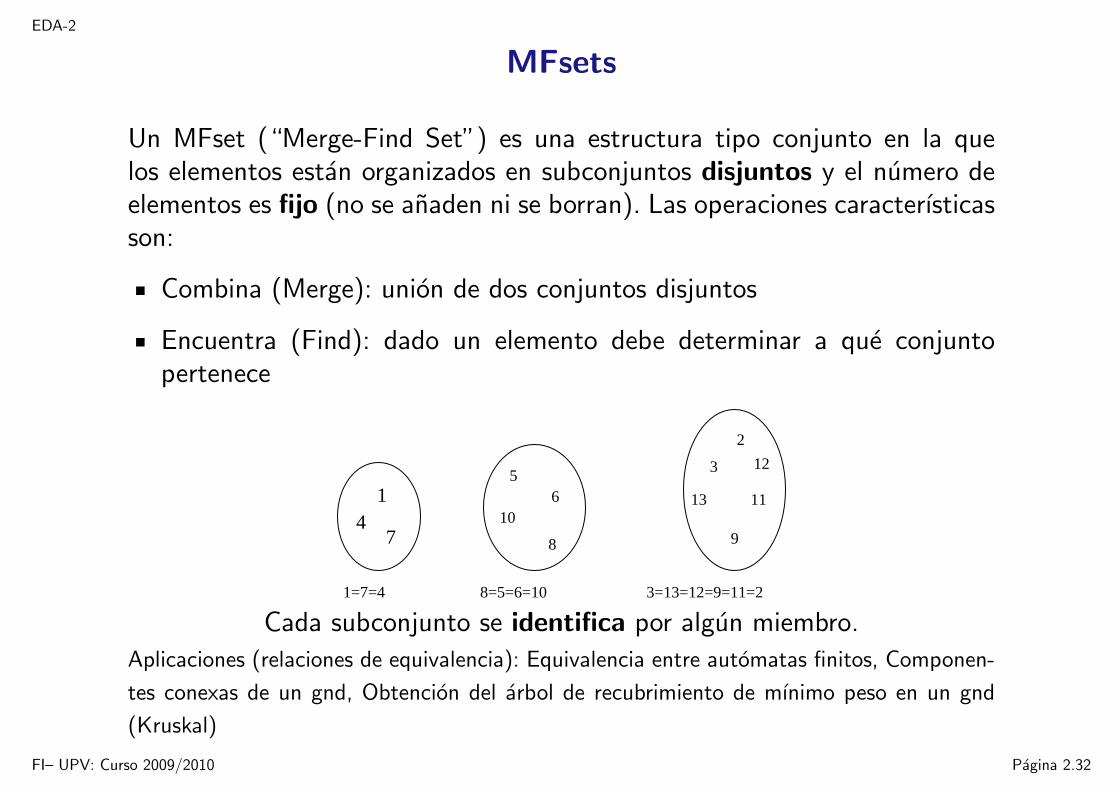
MFsets
Un MFset (“Merge-Find Set”) es una estructura tipo conjunto en la quelos elementos estan organizados en subconjuntos disjuntos y el numero deelementos es fijo (no se anaden ni se borran). Las operaciones caracterısticasson:
Combina (Merge): union de dos conjuntos disjuntos
Encuentra (Find): dado un elemento debe determinar a que conjuntopertenece
47
15
610
8
1=7=4 8=5=6=10 3=13=12=9=11=2
12
13
9
11
2
3
Cada subconjunto se identifica por algun miembro.
Aplicaciones (relaciones de equivalencia): Equivalencia entre automatas finitos, Componen-
tes conexas de un gnd, Obtencion del arbol de recubrimiento de mınimo peso en un gnd
(Kruskal)
FI– UPV: Curso 2009/2010 Pagina 2.32

EDA-2
Operaciones sobre MFsets
1 class MFset 2 // ya veremos los atributos necesarios...3 public:4 MFset(int cardinalC);5 ˜MFset();6 void merge(int x, int y);7 int find(int x);8 ;
Nota
El conjunto C sera de la forma 0, 1, . . . , n− 1 donden es el numero de elementos de C, i.e., |C|.
FI– UPV: Curso 2009/2010 Pagina 2.33

EDA-2
Representacion en vector de MFsets
M es un vector de enteros de tamano n = |C|.M[i] indica directamente el conjunto o clase al que pertenece el elemento i.El coste de find(i) es O(1)El coste de merge(i,j) es O(n)
EJEMPLO
0, 1, 2, 3, 4 0 1 2 3 4
Merge(0,1)
0, 1, 2, 3, 4 0 0 2 3 4
Merge(1,2)
0, 1, 2, 3, 4 0 0 0 3 4
Merge(3,4)
0, 1, 2, 3, 4 0 0 0 3 3
Merge(2,3)
0, 1, 2, 3, 4 0 0 0 0 0
FI– UPV: Curso 2009/2010 Pagina 2.34
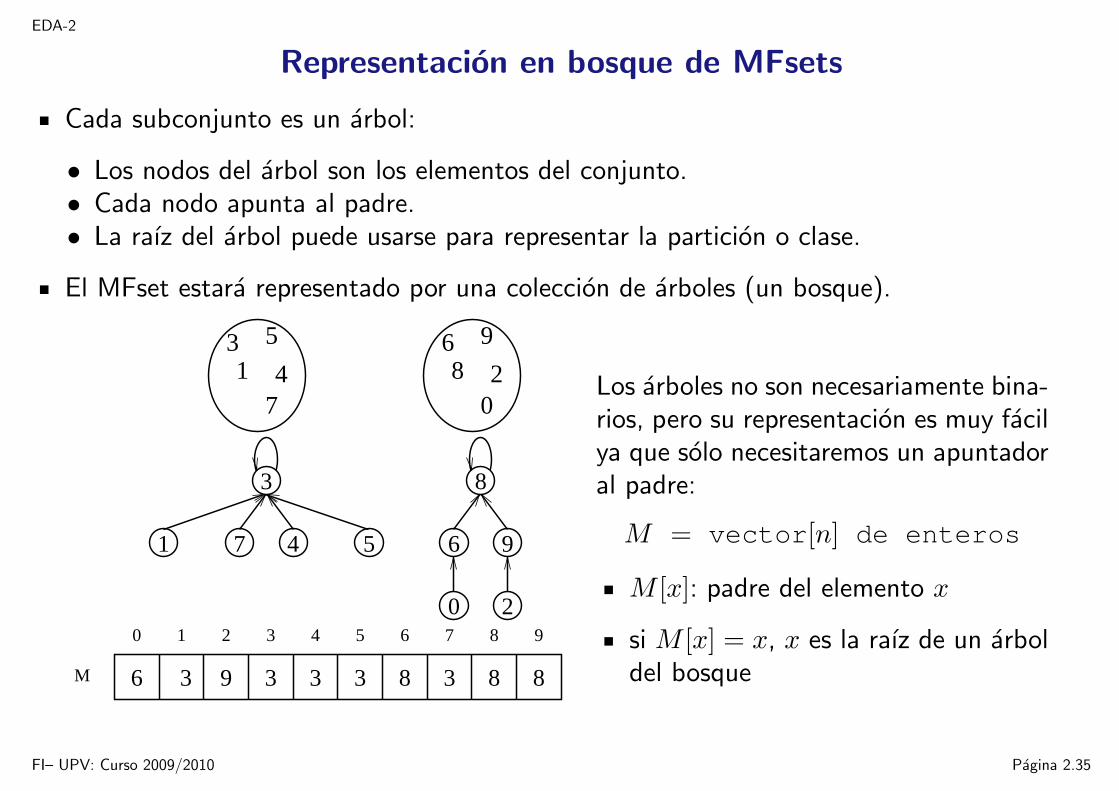
EDA-2
Representacion en bosque de MFsets
Cada subconjunto es un arbol:
• Los nodos del arbol son los elementos del conjunto.• Cada nodo apunta al padre.• La raız del arbol puede usarse para representar la particion o clase.
El MFset estara representado por una coleccion de arboles (un bosque).
1 57 4 6 9
0 2
3 8
3 51
74
6 98
02
0 1 2 3 4 5 6 7 8 9
6 3 83 3 83 3 89M
Los arboles no son necesariamente bina-rios, pero su representacion es muy facilya que solo necesitaremos un apuntadoral padre:
M = vector[n] de enteros
M [x]: padre del elemento x
si M [x] = x, x es la raız de un arboldel bosque
FI– UPV: Curso 2009/2010 Pagina 2.35

EDA-2
Clase MFsets para larepresentacion en bosque
1 class MFset 2 int *mfset;3 int n,num_particiones;4 public:5 MFset(int cardinalC); // constructor6 ˜MFset(); // destructor7 void merge(int x, int y);8 int find(int x);9 ;
FI– UPV: Curso 2009/2010 Pagina 2.36
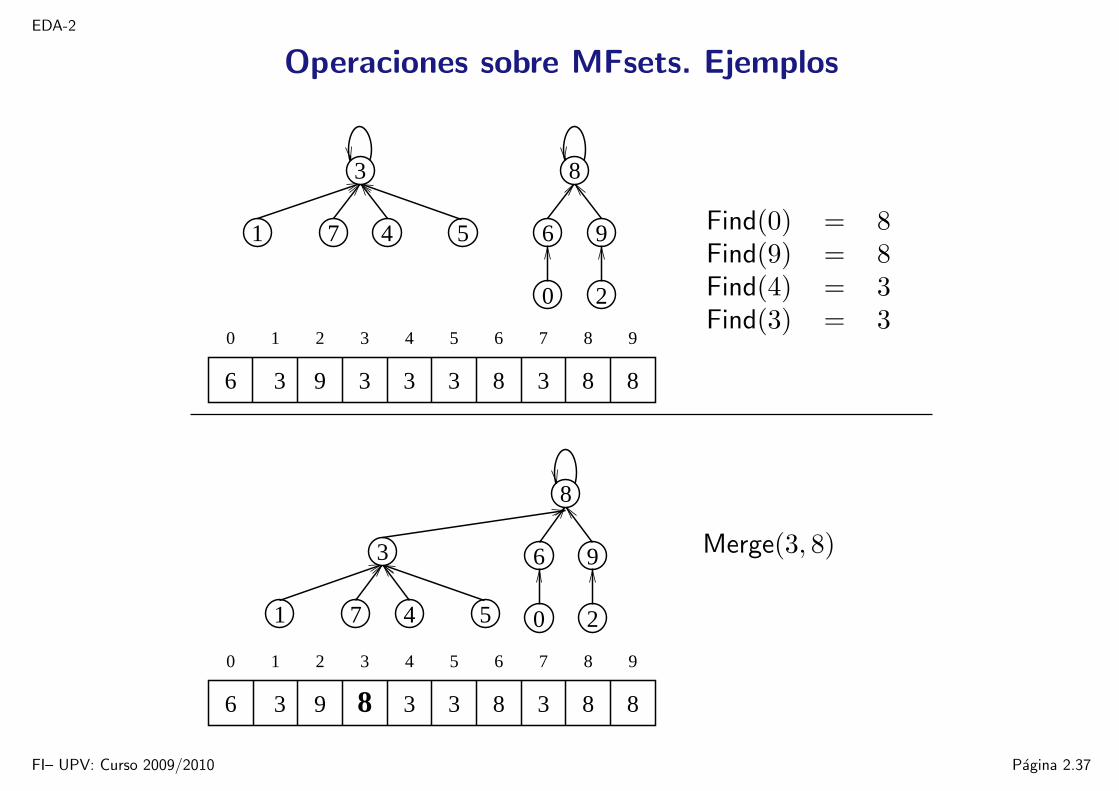
EDA-2
Operaciones sobre MFsets. Ejemplos
1 57 4 6 9
0 2
3 8
0 1 2 3 4 5 6 7 8 9
6 3 83 3 83 3 89
Find(0) = 8Find(9) = 8Find(4) = 3Find(3) = 3
1 57 4
6 9
0 2
3
8
0 1 2 3 4 5 6 7 8 9
6 3 83 83 3 889
Merge(3, 8)
FI– UPV: Curso 2009/2010 Pagina 2.37

EDA-2
Operaciones sobre MFsets. Algoritmos1 MFset::MFset(int cardinalC) // constructor2 num_particiones = n = cardinalC;3 mfset = new int[n];4 for (int i=0; i < n; i++)5 mfset[i] = i;6 7 MFset::˜MFset() // destructor8 delete[] mfset;9
10 int MFset::find(int x) 11 while (mfset[x] != x)12 x = mfset[x];13 return x;14 15 void MFset::merge(int x, int y) 16 int rx,ry;17 rx = find(x);18 ry = find(y);19 if (rx != ry) 20 num_particiones--; // se juntan dos particiones distintas21 mfset[ry] = rx; // colgamos y como hijo de x22 23
FI– UPV: Curso 2009/2010 Pagina 2.38

EDA-2
Operaciones sobre MFsets. Caso peor
Una secuencia de m operaciones Merge y Find tiene un coste O(mn) enel peor caso (se puede crear un arbol degenerado en una lista de n nodos).
Operacion BosqueMFset(5) 0 1 2 3 4Merge(0,1) 0(1) 2 3 4Merge(2,0) 2(0(1)) 3 4Merge(3,2) 3(2(0(1))) 4Merge(4,3) 4(3(2(0(1))))
FI– UPV: Curso 2009/2010 Pagina 2.39

EDA-2
Mejoras del coste. Heurısticos
Una secuencia de m operaciones Merge y Find tiene un coste O(mn) enel peor caso (arbol como lista).
Mejoras del coste a base de reducir la altura del arbol: m operacionesMerge y Find tendran un coste casi lineal con m:
Combinar por Rango (rango basado en la altura o basado en el numerode nodos)
Comprimir Caminos (Path Compression)
FI– UPV: Curso 2009/2010 Pagina 2.40

EDA-2
Combinar por rango basado en la altura
Idea: hacer la operacion Merge de forma que la raız del arbol de menor alturaapunte a la raız del arbol de mayor altura. Para ello, se mantiene la altura decada arbol del bosque. Este valor se puede mantener en el propio vector enel nodo asociado a la raız poniendo un numero negativo. Si las alturas sondistintas, la altura resultante es la mayor. En caso de unir 2 arboles con lamisma altura, aumenta en 1 y da igual quien se situa como hijo.
1 MFsetR::MFsetR(int cardinalC) // constructor2 num_particiones = n = cardinalC;3 mfset = new int[n];4 for (int i=0; i < n; i++)5 mfset[i] = -1; // -(altura+1)6 7 int MFsetR::find(int x) 8 while (mfset[x] >= 0)9 x = mfset[x];
10 return x;11
FI– UPV: Curso 2009/2010 Pagina 2.41

EDA-2
Combinar por rango basado en la altura
1 void MFsetR::merge(int x, int y) 2 int rx,ry;3 rx = find(x);4 ry = find(y);5 if (rx != ry) 6 num_particiones--; // se juntan dos bloques distintos7 if (mfset[rx] == mfset[ry]) // altura(x) == altura(y)8 mfset[ry] = rx; // ponemos y como hijo de x9 mfset[rx]--; // incrementamos la altura de x
10 // uno de los arboles es mas alto11 else if (mfset[rx] < mfset[ry]) // altura(x) > altura(y)12 mfset[ry] = rx; // ponemos y como hijo de x13 else14 mfset[rx] = ry; // ponemos x como hijo de y15 16
Se puede demostrar que si se realiza la union por altura, la altura de un arbolde n elementos nunca sera superior a dlog ne.
FI– UPV: Curso 2009/2010 Pagina 2.42
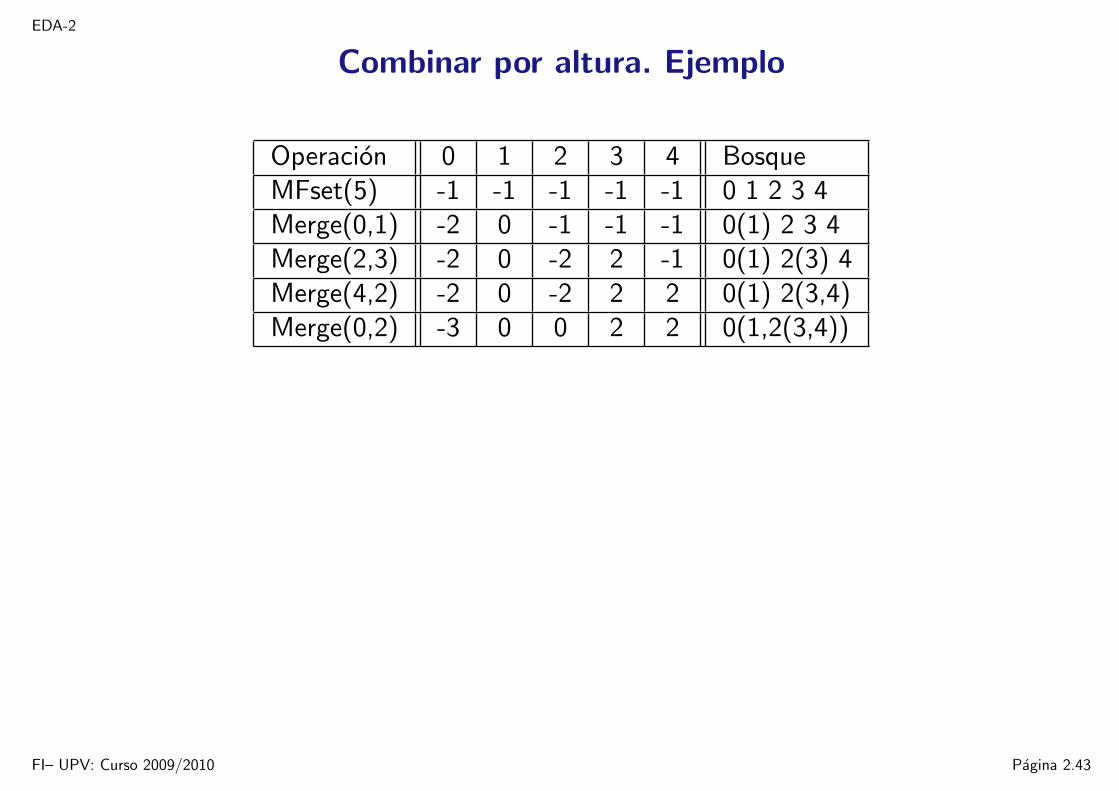
EDA-2
Combinar por altura. Ejemplo
Operacion 0 1 2 3 4 BosqueMFset(5) -1 -1 -1 -1 -1 0 1 2 3 4Merge(0,1) -2 0 -1 -1 -1 0(1) 2 3 4Merge(2,3) -2 0 -2 2 -1 0(1) 2(3) 4Merge(4,2) -2 0 -2 2 2 0(1) 2(3,4)Merge(0,2) -3 0 0 2 2 0(1,2(3,4))
FI– UPV: Curso 2009/2010 Pagina 2.43
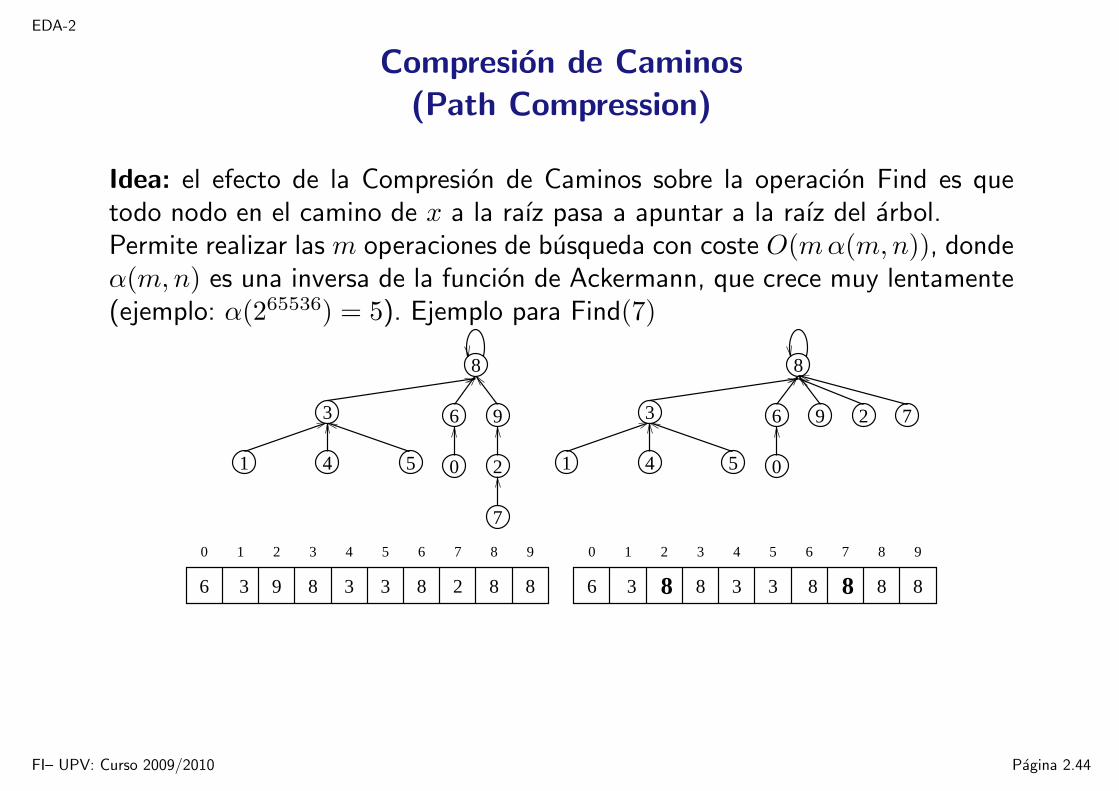
EDA-2
Compresion de Caminos(Path Compression)
Idea: el efecto de la Compresion de Caminos sobre la operacion Find es quetodo nodo en el camino de x a la raız pasa a apuntar a la raız del arbol.Permite realizar las m operaciones de busqueda con coste O(mα(m,n)), dondeα(m,n) es una inversa de la funcion de Ackermann, que crece muy lentamente(ejemplo: α(265536) = 5). Ejemplo para Find(7)
24
6 9
01 5
7
4
6 9
01 5
2 7
8
3
0 1 2 3 4 5 6 7 8 9
6 3 88 2 83 3 89
8
3
0 1 2 3 4 5 6 7 8 9
6 88 83 33 8 88
FI– UPV: Curso 2009/2010 Pagina 2.44

EDA-2
Algoritmo para Compresion de Caminos
1 int MFsetPC::find(int x) // version iterativa2 int rx=x;3 while (mfset[rx] != rx) // buscamos representante4 rx = mfset[rx];5 while (mfset[x] != rx) // volvemos a recorrer el camino6 int tmp = x; x = mfset[x]; mfset[tmp] = rx;7 8 return rx;9
FI– UPV: Curso 2009/2010 Pagina 2.45

EDA-2
Combinacion de estrategias
Las tecnicas de union por rango y compresion de caminos son compatibles entresı. En este caso el algoritmo de Find quedarıa de la manera siguiente:
1 int MFsetRPC::find(int x) 2 int rx=x;3 while (mfset[rx] >= 0) // buscamos representante4 rx = mfset[rx];5 while (mfset[x] != rx) // volvemos a recorrer el camino6 int tmp = x; x = mfset[x]; mfset[tmp] = rx;7 8 return rx;9
Puede ocurrir que la compresion de caminos disminuya la altura del arbol. Ental caso, la altura almacenada en el vector ya no coincide necesariamente conla altura real del arbol, pero ese una cota pesimista de la altura real, con loque se sigue manteniendo una cota de O(log n) que en la practica sera muchomenor por la compresion de caminos. Esta cota sigue siendo un rango.
FI– UPV: Curso 2009/2010 Pagina 2.46

EDA-2
Coste amortizado
Secuencia de operaciones: n− 1 operaciones Merge (por rango)m operaciones Find
Path Compresion Total † Nota AmortizadoSin O(m log n)Con O(mα(m+ n, n)) ' O(m) ' O(1)
† Nota: Lo usual es que α(m+ n, n) ≤ 4 (ejemplo: α(265536) = 5).
FI– UPV: Curso 2009/2010 Pagina 2.47
EDA-2
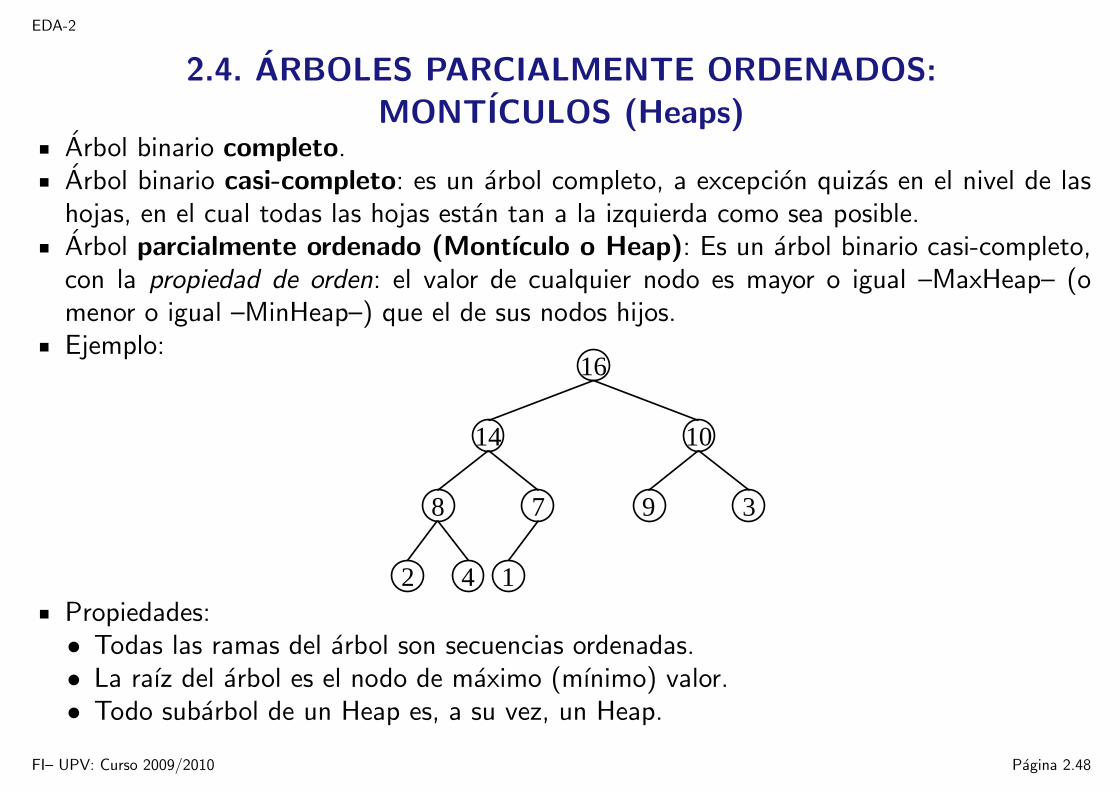
2.4. ARBOLES PARCIALMENTE ORDENADOS:MONTICULOS (Heaps)
Arbol binario completo.Arbol binario casi-completo: es un arbol completo, a excepcion quizas en el nivel de lashojas, en el cual todas las hojas estan tan a la izquierda como sea posible.Arbol parcialmente ordenado (Montıculo o Heap): Es un arbol binario casi-completo,con la propiedad de orden: el valor de cualquier nodo es mayor o igual –MaxHeap– (omenor o igual –MinHeap–) que el de sus nodos hijos.Ejemplo:
16
14 10
3
2 4 1
978
Propiedades:• Todas las ramas del arbol son secuencias ordenadas.• La raız del arbol es el nodo de maximo (mınimo) valor.• Todo subarbol de un Heap es, a su vez, un Heap.
FI– UPV: Curso 2009/2010 Pagina 2.48
EDA-2
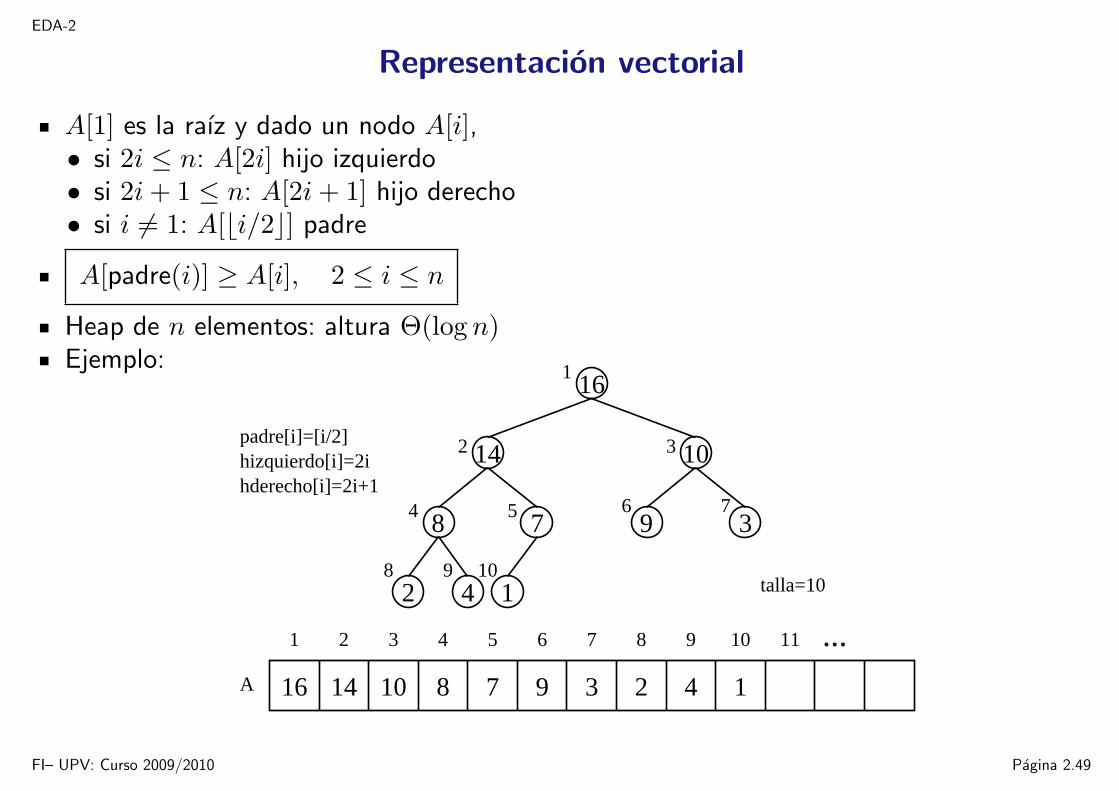
Representacion vectorial
A[1] es la raız y dado un nodo A[i],• si 2i ≤ n: A[2i] hijo izquierdo• si 2i+ 1 ≤ n: A[2i+ 1] hijo derecho• si i 6= 1: A[bi/2c] padre
A[padre(i)] ≥ A[i], 2 ≤ i ≤ n
Heap de n elementos: altura Θ(log n)Ejemplo: 1
5
8 9 10
6 7
32
4
16
14 10
3
2 4 1
978
1 2 3 4 5 6 7 8 9 10 11
16 48 2 17 9 31014
...
padre[i]=[i/2]hizquierdo[i]=2ihderecho[i]=2i+1
talla=10
A
FI– UPV: Curso 2009/2010 Pagina 2.49

EDA-2
EjercicioElementos en Heap
Suponiendo que todos los elementos de un MaxHeap son diferentes,
a) ¿donde estara el maximo?
b) ¿donde estara el mınimo?
c) ¿cualquier elemento que sea una hoja es menor que un elemento deun nodo interno?
d) ¿es un vector ordenado de forma decreciente un MaxHeap?
e) ¿es la secuencia 23, 17, 14, 6, 13, 10, 1, 5, 7, 12 un MaxHeap?
FI– UPV: Curso 2009/2010 Pagina 2.50

EDA-2
Operaciones basicas sobre Heaps
Demostraran la utilidad de esta estructura para:
el diseno de un algoritmo de ordenacion rapido (Heapsort)
la representacion de colas de prioridad
S.Insertar(x) anade el elemento apuntado por x en el conjunto SS.Maximo() devuelve el elemento de S cuya clave sea maximaS.BorrarMax() elimina y devuelve el elemento de S cuya clave sea maxima
Operaciones basicas sobre Heaps
Heapify (“Ajustar”) es la operacion clave para mantener la pro-piedad de Heap. O(log n)
Build-Heap (“Construir heap”) para convertir un vector, en principio des-ordenado, en un Heap. O(n)
Heapsort para ordenar un vector. O(n log n)Heap-Maximum (“Consulta maximo”) devuelve el maximo (return A[1]). O(1)Heap-Extract-Max (“Eliminar Maximo”) para extraer el maximo del conjunto y eli-
minarlo. O(log n)Heap-Insert (“Insertar”) para insertar en el conjunto. O(log n)
FI– UPV: Curso 2009/2010 Pagina 2.51

EDA-2
Implementacion de un Heap1 class max_heap // maxheap binario de valores de tipo T comparables2 T *vector; // vector que empieza con indice 13 int tamanyo,ocupados;4 int padre(int pos) return pos/2; // estas tres5 int hijo_izq(int pos) return 2*pos; // funciones6 int hijo_der(int pos) return 2*pos+1; // son inline7 public:8 max_heap(int tamanyo_maximo); // constructor9 ˜max_heap(); // destructor
10 void vaciar() ocupados = 0; 11 bool vacio() const return ocupados == 0; 12 bool lleno() const return ocupados == tamanyo; 13 int ocupacion() const return ocupados; 14 bool maximo(T& elemento);15 bool minimo(T& elemento);16 void heapify(int pos);17 void heapify_recursiva(int pos);18 bool borrar_maximo(); // "true" si se ha borrado19 bool borrar(int pos); // "true" si se ha borrado20 bool extraer_maximo(T& elemento); // extrae y borra21 bool insertar(T elemento); // "true" si se ha podido insertar22 void buildheap(); // se usa para imponer propiedad de orden23 void heapsort(); // despues de esto, el vector YA NO es un heap24 ;
FI– UPV: Curso 2009/2010 Pagina 2.52

EDA-2
Implementacion de un Heap
1 max_heap::max_heap(int tamanyo_maximo) // constructor2 tamanyo = (tamanyo_maximo > 0) ? tamanyo_maximo : 1;3 ocupados = 0;4 T *rv = new T[tamanyo]; // queremos empezar con indice 15 vector = rv - 1; // vector[1] es rv[0],...6 7 max_heap::˜max_heap() // destructor8 delete[] vector+1;9
10 bool max_heap::maximo(T &elemento) 11 if (ocupados > 0) 12 elemento = vector[1];13 return true;14 15 return false;16
FI– UPV: Curso 2009/2010 Pagina 2.53
EDA-2
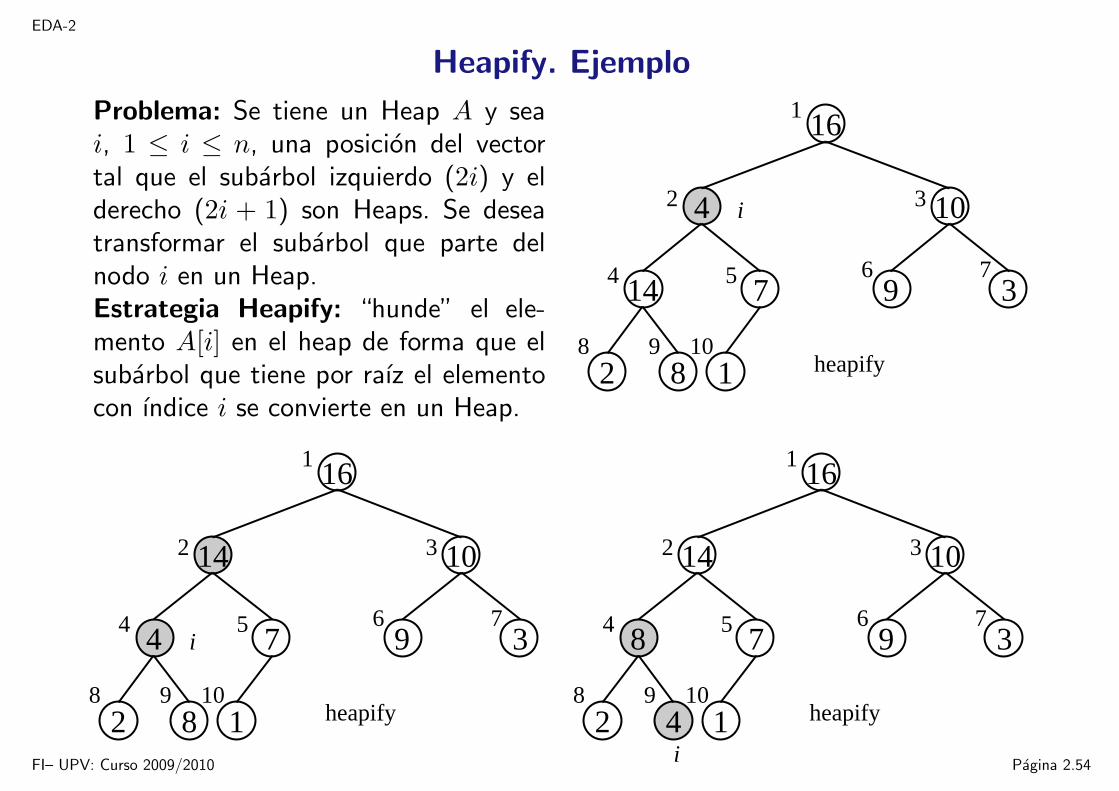
Heapify. Ejemplo
Problema: Se tiene un Heap A y seai, 1 ≤ i ≤ n, una posicion del vectortal que el subarbol izquierdo (2i) y elderecho (2i + 1) son Heaps. Se deseatransformar el subarbol que parte delnodo i en un Heap.Estrategia Heapify: “hunde” el ele-mento A[i] en el heap de forma que elsubarbol que tiene por raız el elementocon ındice i se convierte en un Heap.
1
5
8 9 10
6 7
32
4
16
10
3
2 8 1
9714
4 i
heapify
1
5
8 9 10
6 7
32
4
16
10
3
2 8 1
974
14
i
heapify
1
5
8 9 10
6 7
32
4
16
10
3
2 4 1
978
14
i
heapify
FI– UPV: Curso 2009/2010 Pagina 2.54

EDA-2
Heapify. Algoritmo recursivo
1 void max_heap::heapify(int pos) // version recursiva2 int hijo = hijo_izq(pos);3 if (hijo > ocupados)4 return;5 if (hijo < ocupados && vector[hijo+1] > vector[hijo])6 hijo++; // el hijo derecho7 if (vector[hijo] > vector[pos]) // hijo apunta al mayor de los dos8 T tmp = vector[pos]; // intercambiamos valores9 vector[pos] = vector[hijo];
10 vector[hijo] = tmp;11 heapify(hijo);12 13
FI– UPV: Curso 2009/2010 Pagina 2.55
EDA-2
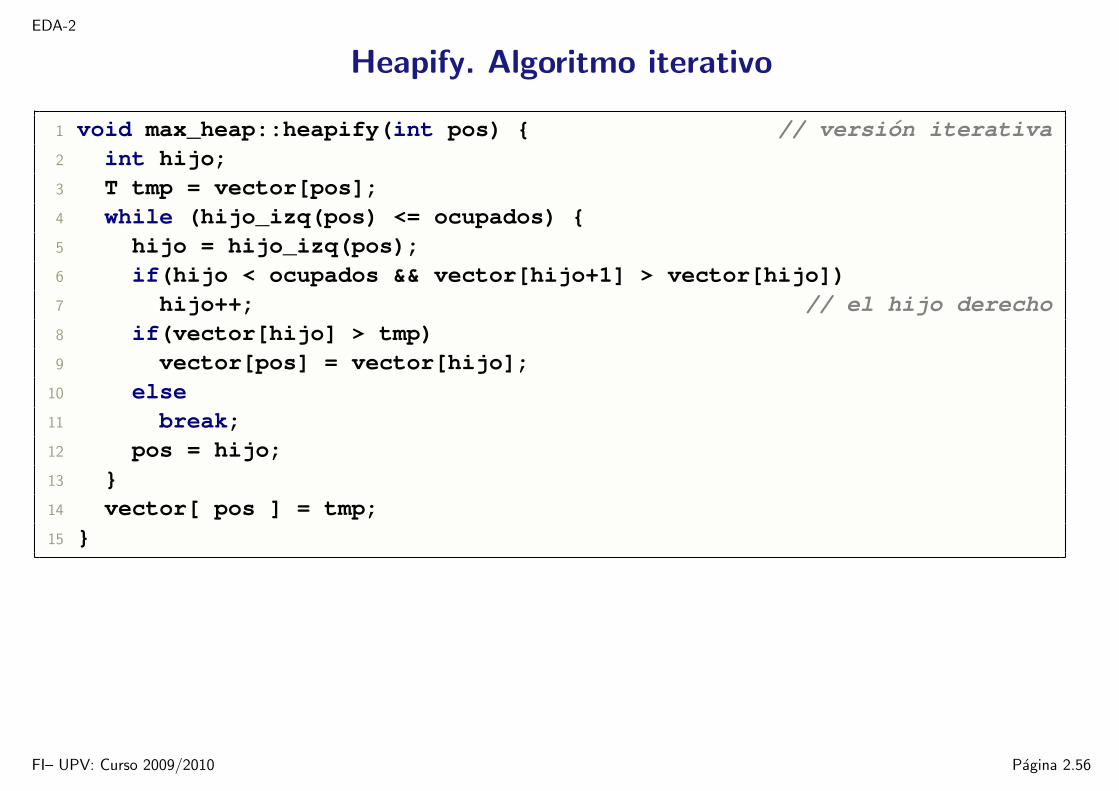
Heapify. Algoritmo iterativo
1 void max_heap::heapify(int pos) // version iterativa2 int hijo;3 T tmp = vector[pos];4 while (hijo_izq(pos) <= ocupados) 5 hijo = hijo_izq(pos);6 if(hijo < ocupados && vector[hijo+1] > vector[hijo])7 hijo++; // el hijo derecho8 if(vector[hijo] > tmp)9 vector[pos] = vector[hijo];
10 else11 break;12 pos = hijo;13 14 vector[ pos ] = tmp;15
FI– UPV: Curso 2009/2010 Pagina 2.56

EDA-2
Heapify. Costes. Ejercicios
Coste: si h es la altura del arbol que tiene por raız el elemento con ındice i,
Mejor caso: Ω(1) si A[i] es un heapPeor caso: O(h) ∈ O(log n), n = heap-size[A]
Ejercicio. Traza. Hacer una traza de Heapify(A, 3) sobre el vector A =27, 17, 3, 16, 13, 10, 1, 5, 7, 12, 4, 8, 9, 0
Ejercicio. Heapify. ¿Cual es el efecto de la accion Heapify(A, i) cuando elelemento A[i] es mayor que sus hijos?
Ejercicio. Heapify. ¿Cual es el efecto de la accion Heapify(A, i) parai > (heap-size(A)/2)?
FI– UPV: Curso 2009/2010 Pagina 2.57
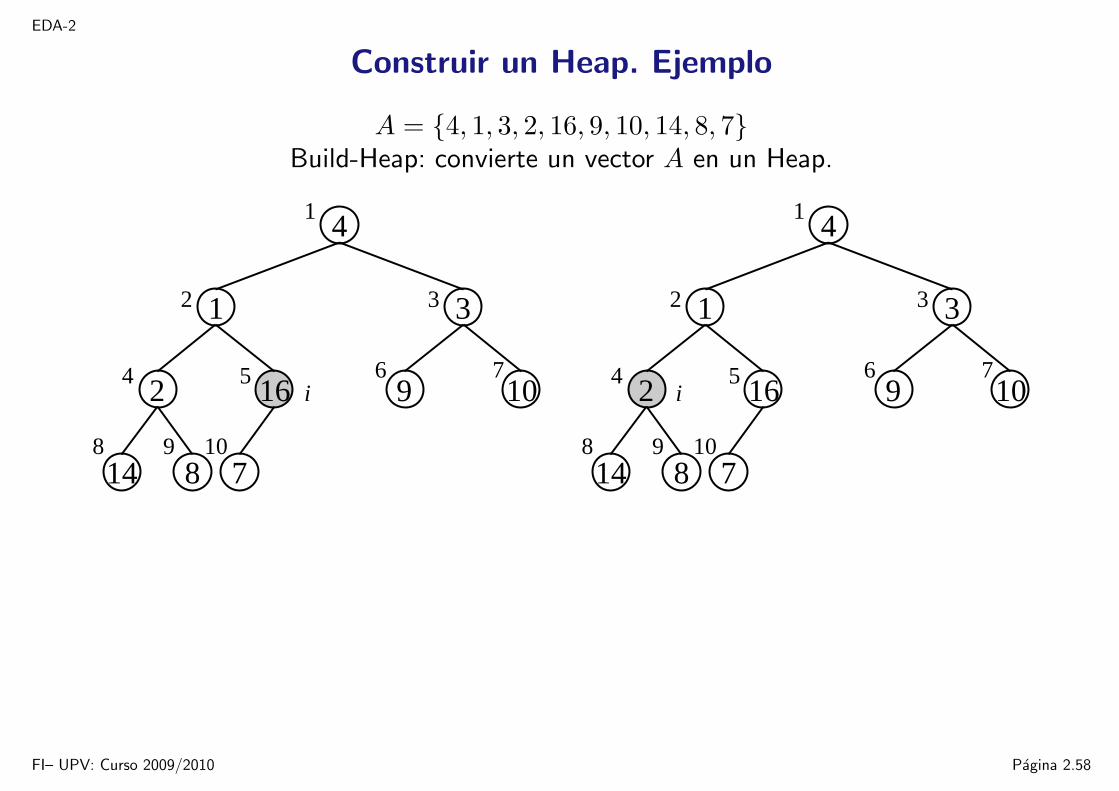
EDA-2
Construir un Heap. Ejemplo
A = 4, 1, 3, 2, 16, 9, 10, 14, 8, 7Build-Heap: convierte un vector A en un Heap.
1
5
8 9 10
6 7
32
4
4
1 3
10
14 8 7
9162 i
1
5
8 9 10
6 7
32
4
4
1 3
10
14 8 7
9162 i
FI– UPV: Curso 2009/2010 Pagina 2.58
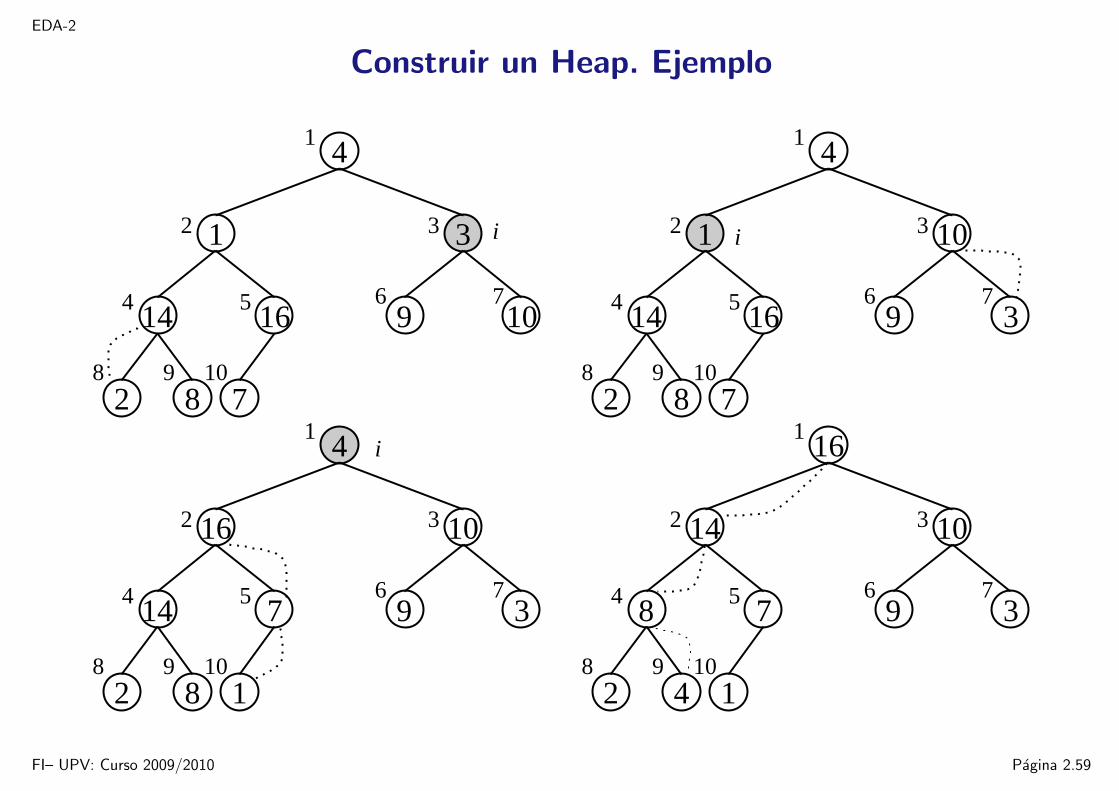
EDA-2
Construir un Heap. Ejemplo
1
5
8 9 10
6 7
32
4
4
1 3
10
2 8 7
91614
i
1
5
8 9 10
6 7
32
4
4
1 10
3
2 8 7
91614
i
1
5
8 9 10
6 7
32
4
4
16 10
3
2 8 1
9714
i1
5
8 9 10
6 7
32
4
16
14 10
3
2 4 1
978
FI– UPV: Curso 2009/2010 Pagina 2.59

EDA-2
Construir un Heap. Algoritmo
1 void max_heap::buildheap() 2 for (int i = ocupados/2; i >= 1; i--)3 heapify(i);4
Ejercicio. Traza Build-Heap. Realiza una traza de Build-Heap con el vectorA = 5, 3, 17, 10, 84, 19, 6, 22, 9.
Complejidad temporal:
Cota NO ajustada: O(n) llamadas a Heapify: O(n log n)
Cota ajustada: O(n)
• Coste Heapify de un nodo es proporcional a su altura O(h)• Propiedad: En un Heap de n elementos hay, como mucho, 2blog nc/2h nodos de alturah.
FI– UPV: Curso 2009/2010 Pagina 2.60
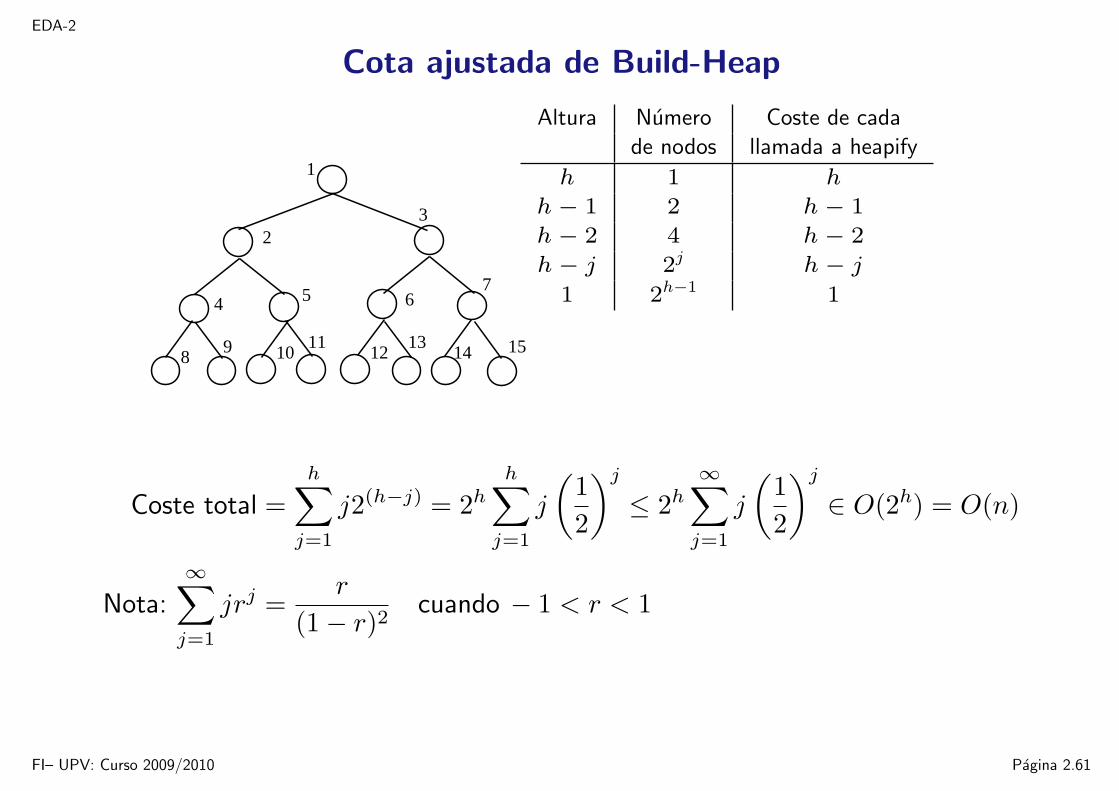
EDA-2
Cota ajustada de Build-Heap
1
11 13109
8 12 14 15
7
3
6
2
4 5
Altura Numero Coste de cada
de nodos llamada a heapify
h 1 h
h− 1 2 h− 1
h− 2 4 h− 2
h− j 2j h− j
1 2h−1 1
Coste total =h∑
j=1
j2(h−j) = 2hh∑
j=1
j
(12
)j
≤ 2h∞∑
j=1
j
(12
)j
∈ O(2h) = O(n)
Nota:∞∑
j=1
jrj =r
(1− r)2cuando − 1 < r < 1
FI– UPV: Curso 2009/2010 Pagina 2.61
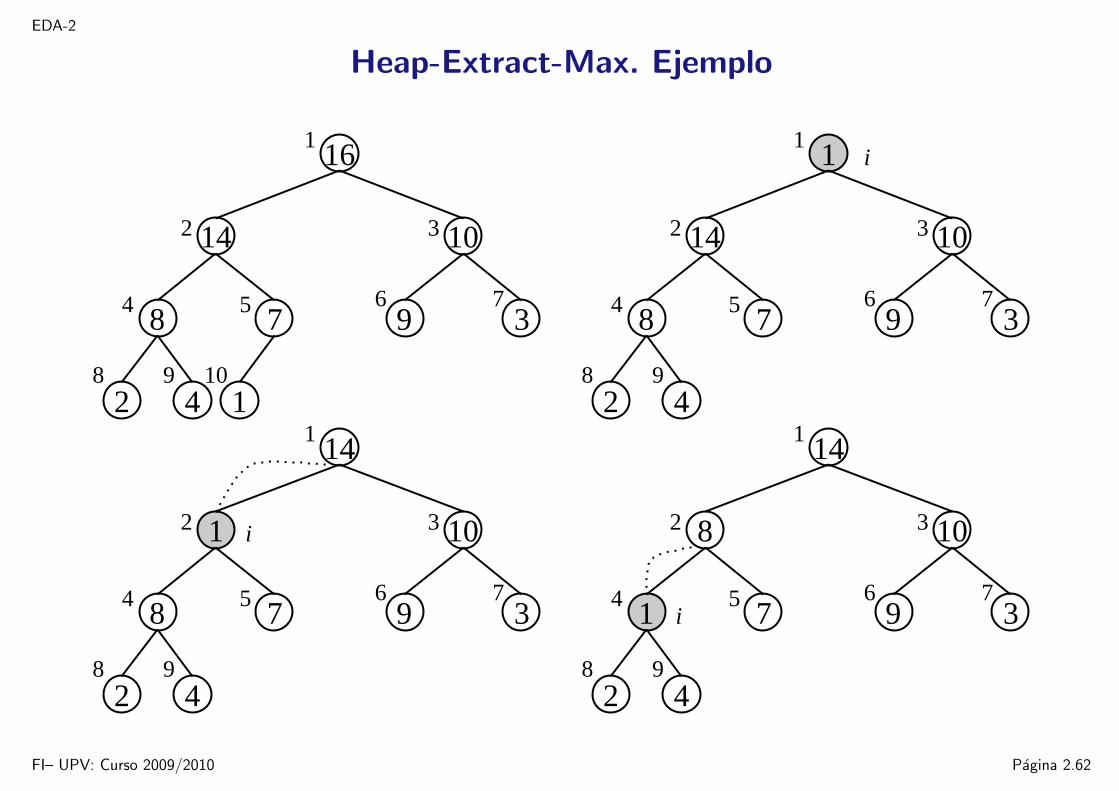
EDA-2
Heap-Extract-Max. Ejemplo
1
5
8 9 10
6 7
32
4
16
14 10
3
2 4 1
978
1
5
8 9
6 7
32
4
1
14 10
3
2 4
978
i
1
5
8 9
6 7
32
4
14
1 10
3
2 4
978
i
1
5
8 9
6 7
32
4
14
8 10
3
2 4
971 i
FI– UPV: Curso 2009/2010 Pagina 2.62
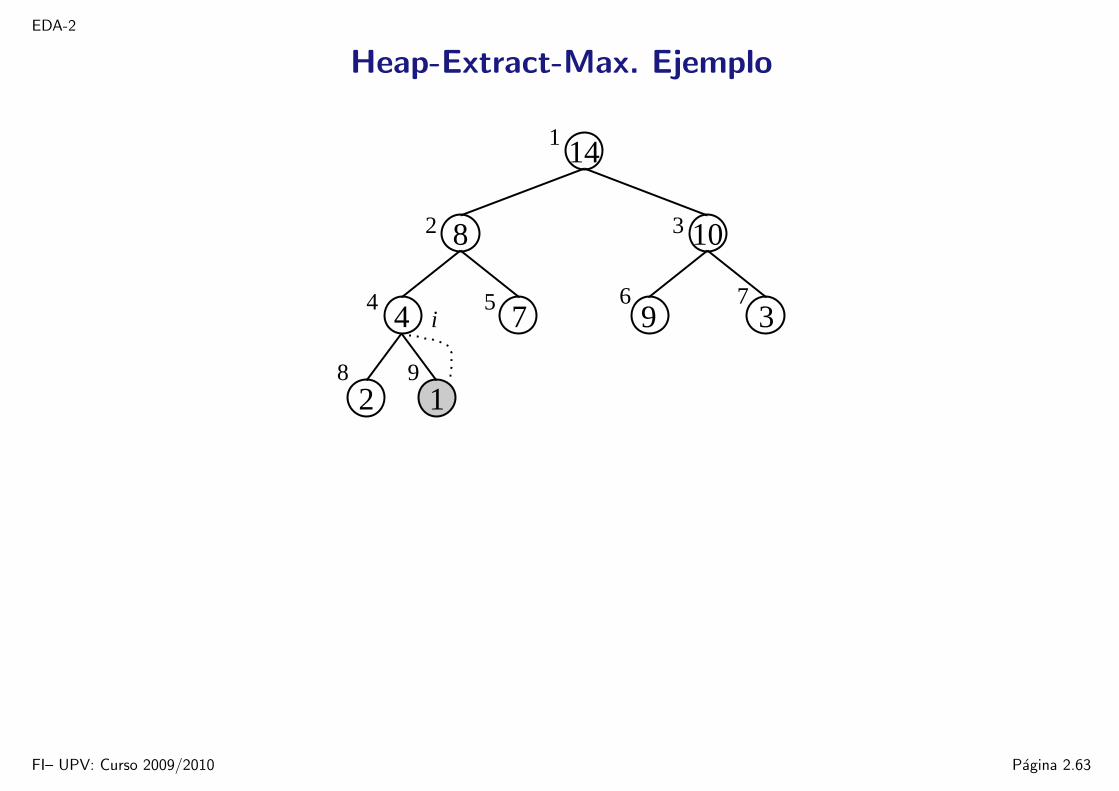
EDA-2
Heap-Extract-Max. Ejemplo
1
5
8 9
6 7
32
4
14
8 10
3
2 1
974 i
FI– UPV: Curso 2009/2010 Pagina 2.63

EDA-2
Heap-Extract-Max. Algoritmo
1 bool max_heap::extraer_maximo(T& elemento) 2 if (ocupados <= 0)3 return false;4 elemento = vector[1];5 vector[1] = vector[ocupados];6 ocupados--;7 heapify(1);8 return true;9
Coste temporal O(log n), ya que realiza solo un trabajo constante antes dellamar a Heapify, que tiene un coste O(log n).
FI– UPV: Curso 2009/2010 Pagina 2.64
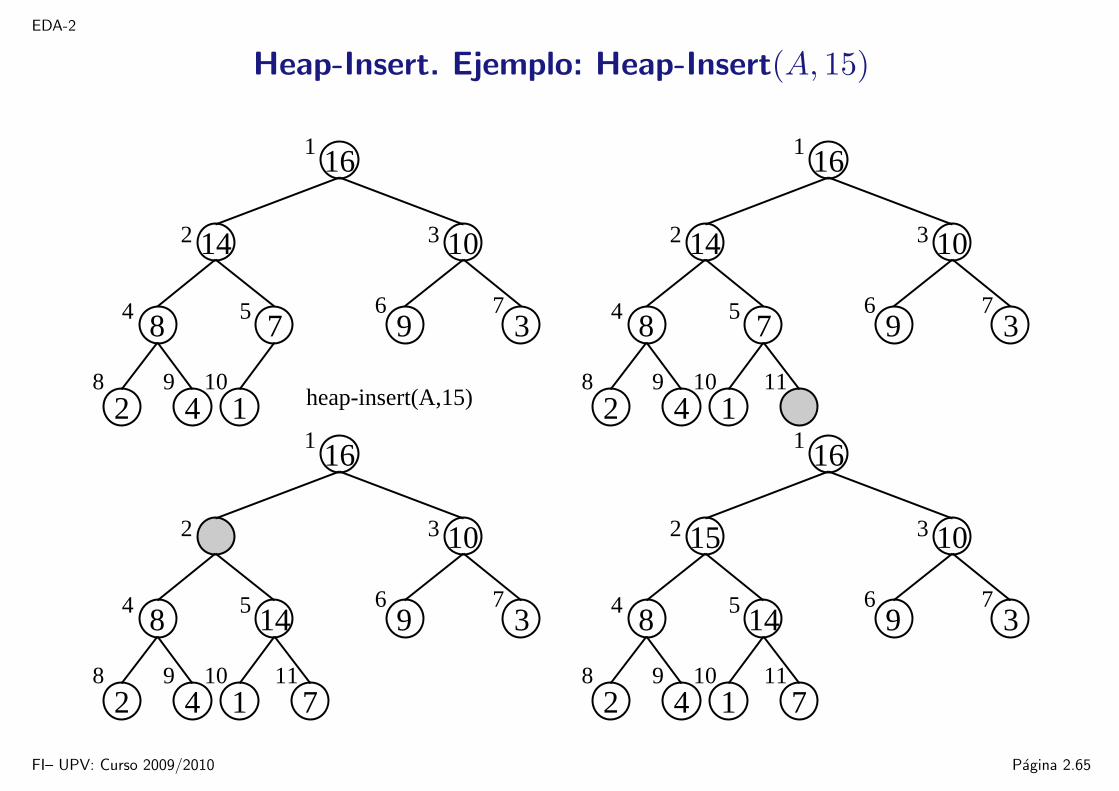
EDA-2
Heap-Insert. Ejemplo: Heap-Insert(A, 15)
1
5
8 9 10
6 7
32
4
16
14 10
3
2 4 1
978
heap-insert(A,15)
1
5
8 9 10
6 7
32
4
16
14 10
3
2 4
978
111
1
5
8 9 10
6 7
32
4
16
10
3
2 4
9148
1 711
1
5
8 9 10
6 7
32
4
16
10
3
2 4
9148
1 7
15
11
FI– UPV: Curso 2009/2010 Pagina 2.65

EDA-2
Heap-Insert. Algoritmo
1 bool max_heap::insertar(T elemento) 2 if (ocupados >= tamanyo)3 return false;4 ocupados++;5 int posicion = ocupados;6 while ((posicion > 1) && (elemento > vector[padre(posicion)])) 7 vector[posicion] = vector[padre(posicion)];8 posicion = padre(posicion);9
10 vector[posicion] = elemento;11 return true;12
Coste temporal O(log n), ya que el camino trazado de la nueva hoja a la raızdel heap tiene talla O(log n).Ejercicio. Traza Insertar. Hacer una traza de Heap-Insert(A, 3) sobre elHeap A = 15, 13, 9, 5, 12, 8, 7, 4, 0, 6, 2, 1.Ejercicio. Traza Heap-Extract-Max. Hacer una traza de Heap-Extract-Maxsobre el mismo Heap.
FI– UPV: Curso 2009/2010 Pagina 2.66

EDA-2
Heapsort. Algoritmo
Ejemplo: A = 4, 1, 3, 2, 16, 9, 10, 14, 8, 7Estrategia Heapsort: Se insertan los elementos en un MaxHeap y se va eliminandosucesivamente el mayor para obtener los elementos en orden inverso.
1 void max_heap::heapsort() 2 int hay = ocupados; // para saber tamano del vector al finalizar3 buildheap(); // coste O(n)4 for (int i = ocupados; i > 1; i--) // intercambiar:5 T tmp = vector[1]; vector[1] = vector[i]; vector[i] = tmp;6 ocupados--; // eliminar ultimo del heap, se queda en vector7 heapify(1); // restaurar propiedad heap bajando 1er elemento8 // al finalizar, el vector YA NO es un heap9 ocupados = hay; // restauramos atributo ocupados
10
Complejidad Temporal: Coste de Build-Heap + Coste del bucle (n−1 llamadas a Heapify)
T (n) ∈ O(n) + (n− 1)O(log n) ∈ O(n log n)
FI– UPV: Curso 2009/2010 Pagina 2.67
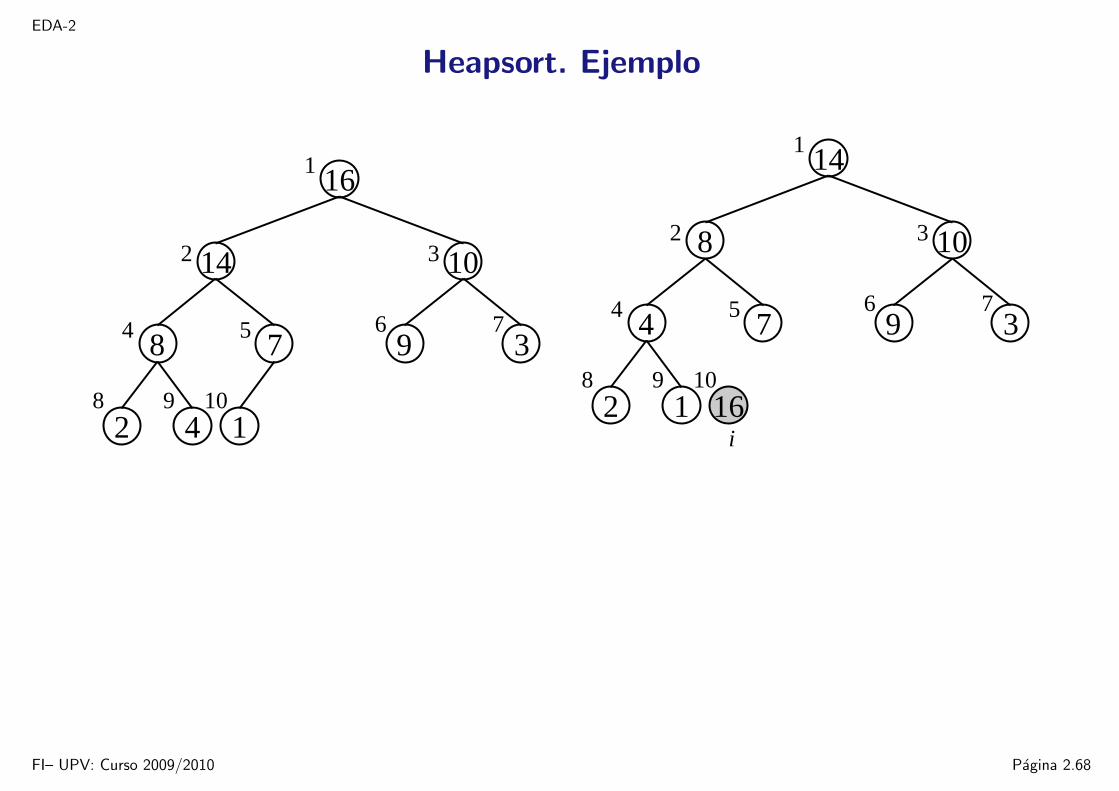
EDA-2
Heapsort. Ejemplo
1
5
8 9 10
6 7
32
4
16
14 10
3
2 4 1
978
1
5
8 9 10
6 7
32
4
14
8
3
2 1 16
974
10
i
FI– UPV: Curso 2009/2010 Pagina 2.68
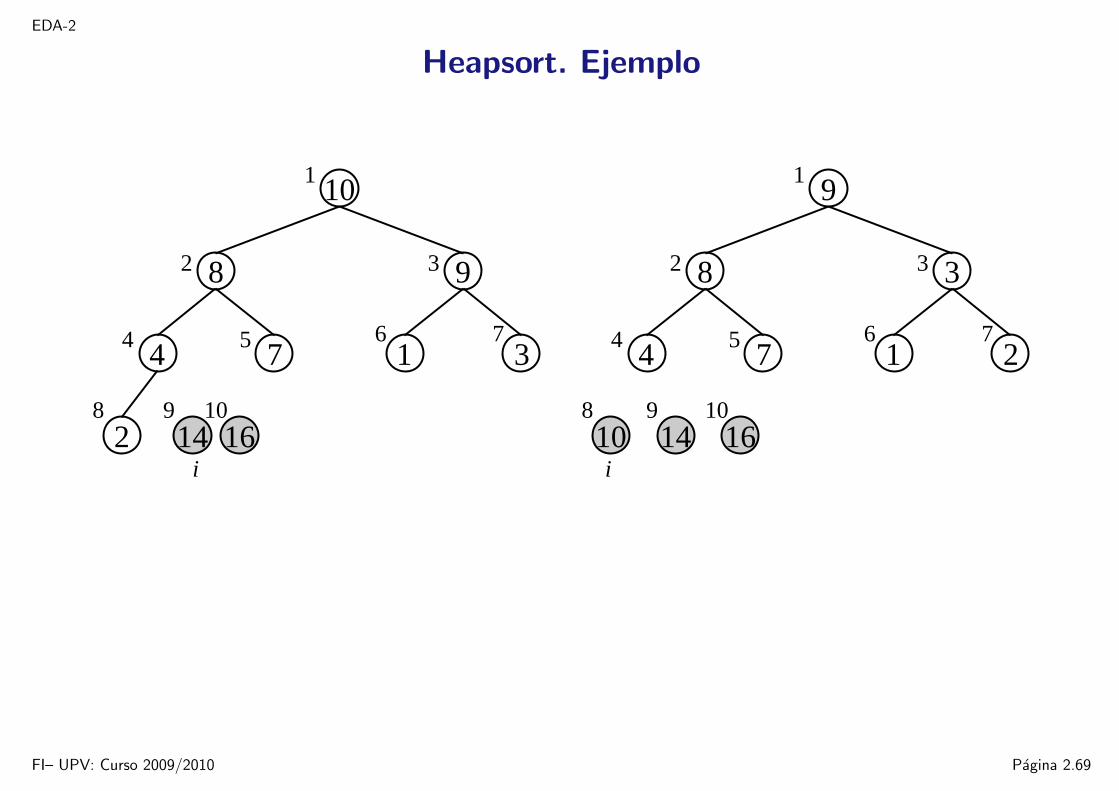
EDA-2
Heapsort. Ejemplo
1
5
8 9 10
6 7
32
4
10
8
3
2 14 16
174
9
i16
10914
1
5
8
6 7
32
4
9
8
2
10
174
3
i
FI– UPV: Curso 2009/2010 Pagina 2.69
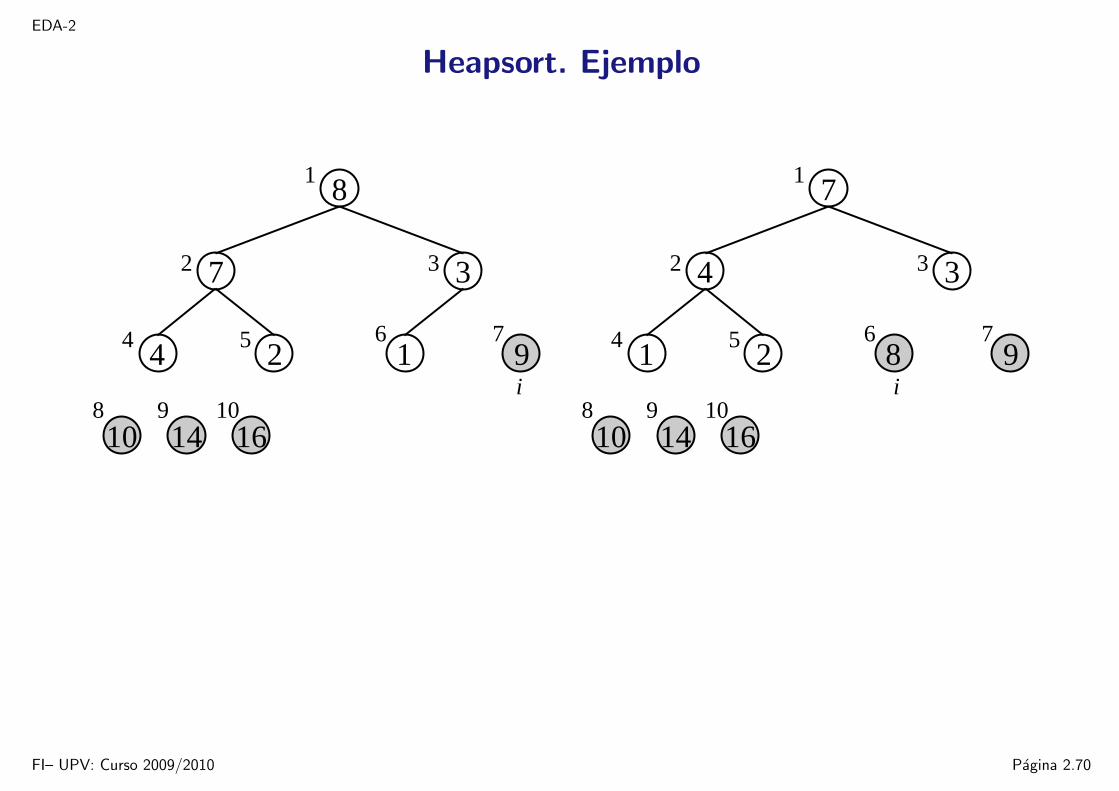
EDA-2
Heapsort. Ejemplo
16109
14
1
5
8
6 7
32
4
8
7
9
10
124
3
i
16109
14
1
5
8
6 7
32
4
7
4
9
10
821
3
i
FI– UPV: Curso 2009/2010 Pagina 2.70
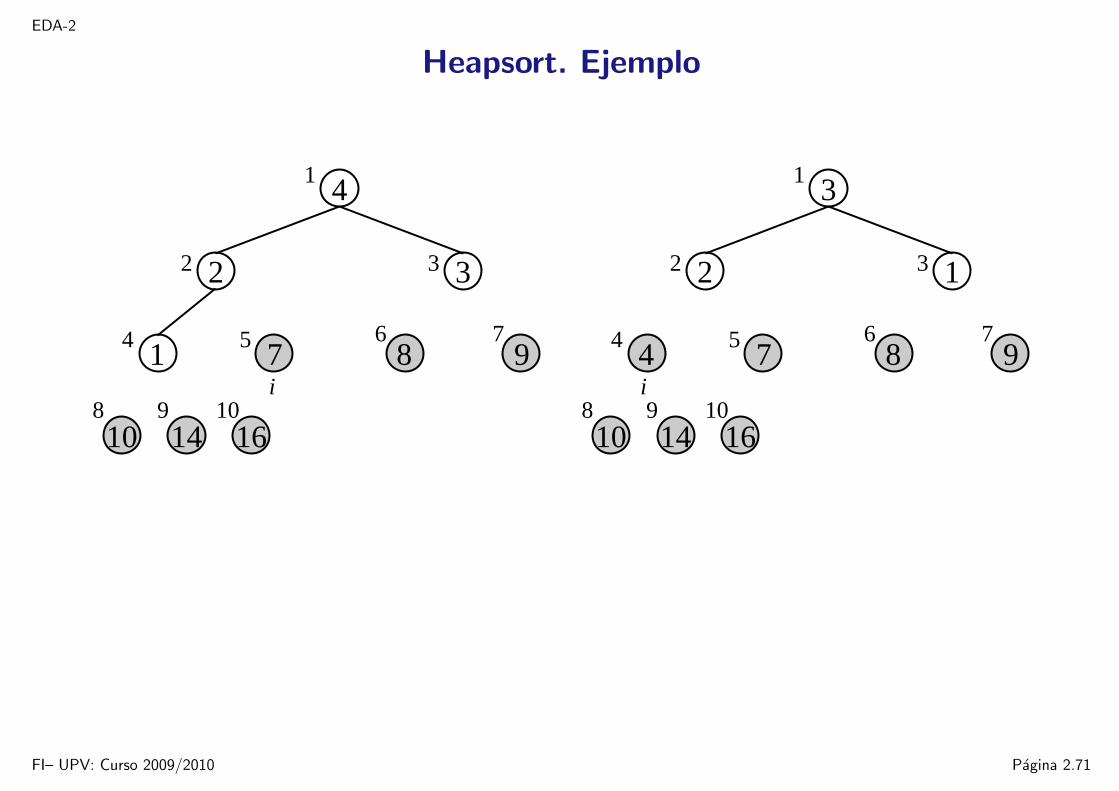
EDA-2
Heapsort. Ejemplo
16109
14
1
5
8
6 7
32
4
4
2
9
10
871
3
i
16109
14
1
5
8
6 7
32
4
3
2
9
10
874
1
i
FI– UPV: Curso 2009/2010 Pagina 2.71
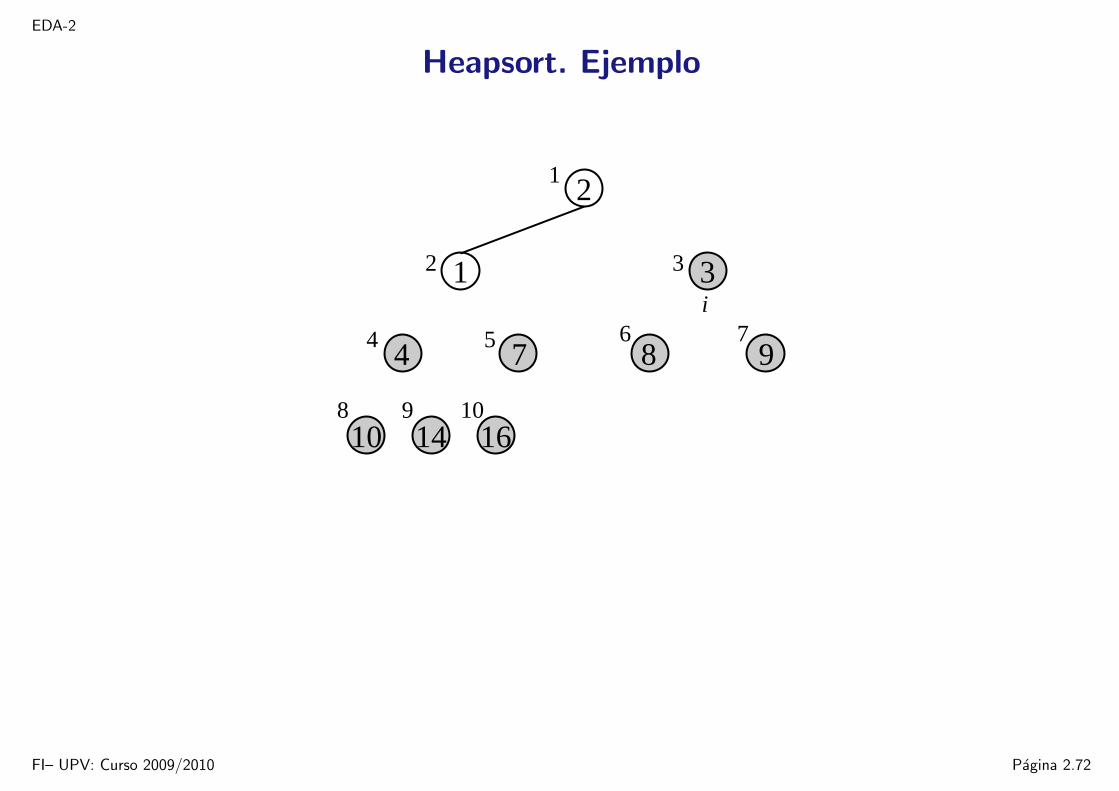
EDA-2
Heapsort. Ejemplo
16109
14
1
5
8
6 7
32
4
2
1
9
10
874
3i
FI– UPV: Curso 2009/2010 Pagina 2.72
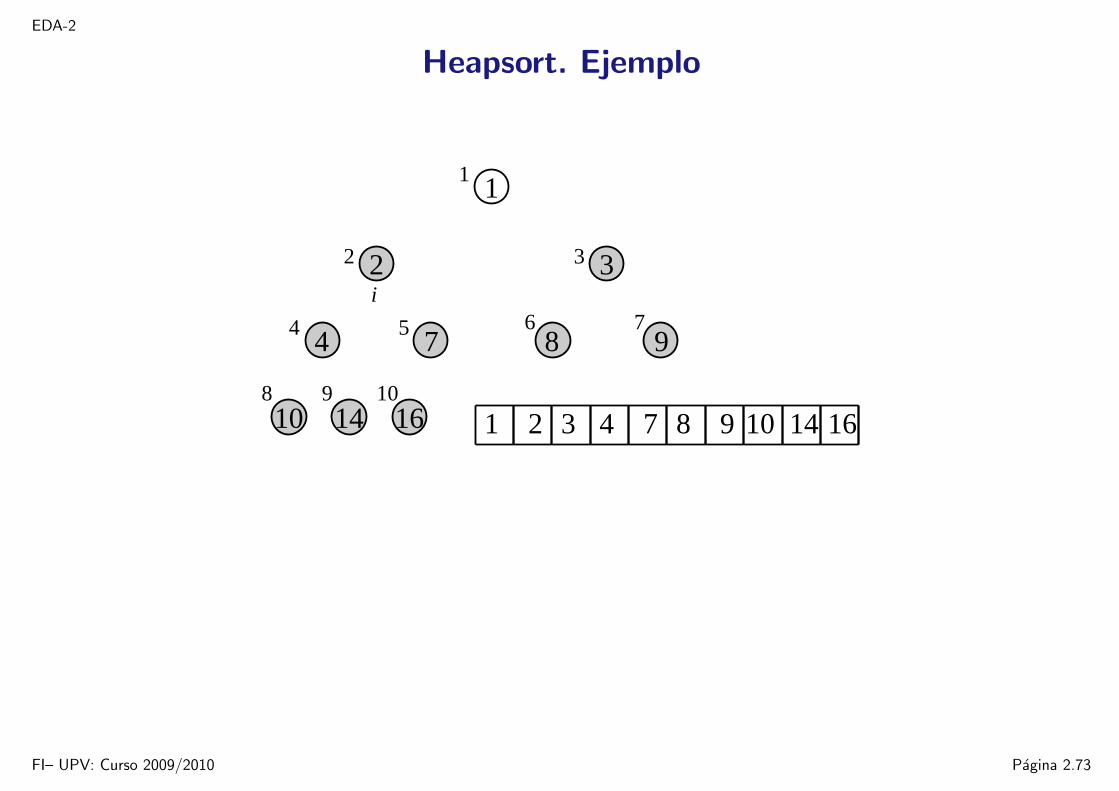
EDA-2
Heapsort. Ejemplo
16109
14
1
5
8
6 7
32
4
1
2
9
10
874
3i
1 2 4 7 8 9 10 14 163
FI– UPV: Curso 2009/2010 Pagina 2.73

EDA-2
Propiedades de Heapsort
“sort in-place” (como Quicksort; Mergesort necesita espacio adicional)
Se garantiza el coste O(n log n), independientemente de la entrada → nohay peor caso (a diferencia de Quicksort). El “precio” que hay que pagar esque realiza mas comparaciones que Quicksort, por lo que tiende a ser maslento en la practica.
Ejercicio. Traza Heapsort. Hacer una traza de Heapsort sobre el vectorA = 5, 13, 2, 25, 7, 17, 20, 8, 4.
Ejercicio. Coste Heapsort. ¿Cual es el coste de Heapsort sobre un vectorde longitud n que este ya ordenado de forma creciente? ¿Y si esta ordenado deforma decreciente? ¿Y si todos sus elementos son iguales?
FI– UPV: Curso 2009/2010 Pagina 2.74

EDA-2
Ejercicio
Disena un algoritmo para resolver el problema deencontrar el k-esimo menor elemento de un vector detalla n, con n ≥ k ≥ 1, utilizando un Heap.
FI– UPV: Curso 2009/2010 Pagina 2.75

EDA-2
Solucion (a)
1. Construir un MinHeap a partir del vector dado. Coste O(n).
2. Hacer k − 1 veces (i ındice en el bucle): borrar el mınimo delMinHeap. Coste O(log(n− i)) en cada iteracion.
3. Devolver el mınimo del MinHeap. Coste O(1).
Coste total (sin ajustar log(n− i)) es O(n+ k log n).
FI– UPV: Curso 2009/2010 Pagina 2.76

EDA-2
Solucion (b)
1. Construir un MaxHeap de tamano k con los k primeros elementos delvector dado. Coste O(k).
2. Para el resto de elementos del vector (n− k):
Si el elemento correspondiente del vector es menor que el mayorelemento del maxheap, reemplazamos ese elemento del maxheap yhacemos heapify(1).
3. Devolver el maximo del maxheap. Coste O(1).
Coste total O(k + (n− k) log k).
Nota: Ordenando elementos 2 a k del heap en el ultimo paso obtenemoslos k menores elementos con coste O(k + (n − k) log k + k log k) =O(k + n log k).
Nota: Determinar que solucion es la mejor depende de los valores de ky n.
FI– UPV: Curso 2009/2010 Pagina 2.77

EDA-2
Ejercicio(Examen Febrero 99 (1.5 puntos))
Disena un algoritmo que borre el elemento que ocu-pa la posicion i-esima en un MaxHeap. Analiza lacomplejidad temporal del algoritmo.
FI– UPV: Curso 2009/2010 Pagina 2.78

EDA-2
Solucion(Examen Febrero 99 (1.5 puntos))
1 bool max_heap::borrar(int pos) // suponemos pos es ındice correcto2 if (ocupados <= 0)3 return false;4 vector[pos] = vector[ocupados];5 ocupados--;6 while (pos > 1 && vector[pos] > vector[padre(pos)]) 7 T tmp = vector[pos];8 vector[pos] = vector[padre(pos)];9 vector[padre(pos)] = tmp;
10 pos = padre(pos);11 12 heapify(pos);13 return true;14
El coste de Heap-Delete presenta un mejor caso cuando el elemento quese coloca en la posicion i no viola la propiedad del Heap. En el peor caso,el coste es identico al del borrado del maximo, es decir, O(log n), siendon la talla del Heap.
FI– UPV: Curso 2009/2010 Pagina 2.79

EDA-2
Ejercicio
Dado un conjunto de n > 0 enteros representados en unMax-Heap, disena un algoritmo que devuelva el mınimodel conjunto, haciendo el menor numero de comparacionesposible.
FI– UPV: Curso 2009/2010 Pagina 2.80

EDA-2
Solucion
Dado que el mınimo en un Max-Heap solo puede estar en una delas hojas, empezamos a buscar en la hoja de menor ındice en elvector, esto es, a partir de bheap-size(A)/2c+ 1.
1 bool max_heap::minimo(T &elemento) 2 if (ocupados <= 0)3 return false;4 int i = padre(ocupados)+1;5 T val_min = vector[i]; i++;6 while (i <= ocupados) 7 if (vector[i] < val_min) val_min = vector[i];8 i++;9
10 elemento = val_min;11 return true;12
FI– UPV: Curso 2009/2010 Pagina 2.81
EDA-2
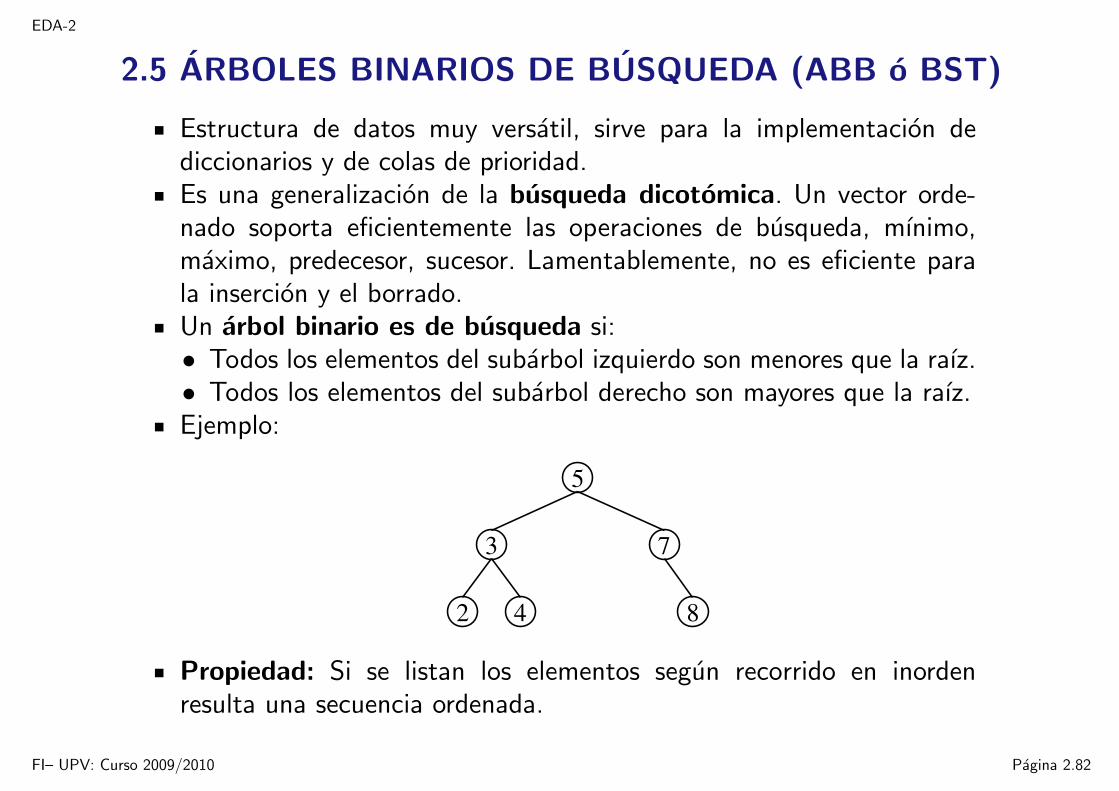
2.5 ARBOLES BINARIOS DE BUSQUEDA (ABB o BST)
Estructura de datos muy versatil, sirve para la implementacion dediccionarios y de colas de prioridad.Es una generalizacion de la busqueda dicotomica. Un vector orde-nado soporta eficientemente las operaciones de busqueda, mınimo,maximo, predecesor, sucesor. Lamentablemente, no es eficiente parala insercion y el borrado.Un arbol binario es de busqueda si:• Todos los elementos del subarbol izquierdo son menores que la raız.• Todos los elementos del subarbol derecho son mayores que la raız.Ejemplo:
5
3
2 4
7
8
Propiedad: Si se listan los elementos segun recorrido en inordenresulta una secuencia ordenada.
FI– UPV: Curso 2009/2010 Pagina 2.82

EDA-2
Operaciones con ABBs
1 class abb // clase arbol binario de busqueda2 nodo_abb *raiz;3 public:4 abb(); // constructor5 ˜abb(); // destructor6 bool maximo(int& v);7 bool minimo(int& v);8 bool buscar(int v);9 bool borrar(int v);
10 bool predecesor(int &v);11 bool sucesor(int &v);12 void insertar(int elemento);13 ;
Observa que soporta tanto operaciones de tipo diccionariocomo de cola de prioridad.
FI– UPV: Curso 2009/2010 Pagina 2.83

EDA-2
Operaciones con ABBs
1 struct nodo_abb // clase auxiliar para representar un nodo2 int valor;3 nodo_abb *izq, *der;4 // metodos5 void borrar_hijos();6 nodo_abb(int v, nodo_abb *i=0, nodo_abb *d=0);7 nodo_abb* buscar(int v);8 nodo_abb* insertar(int v);9 nodo_abb* insertar(nodo_abb* nodo);
10 nodo_abb* maximo();11 nodo_abb* minimo();12 nodo_abb* predecesor(int v);13 nodo_abb* sucesor(int v);14 ;
Si la operacion Selectop fuese importante, se anade un atributo contador que almacena eltamano de cada subarbol.
FI– UPV: Curso 2009/2010 Pagina 2.84
EDA-2
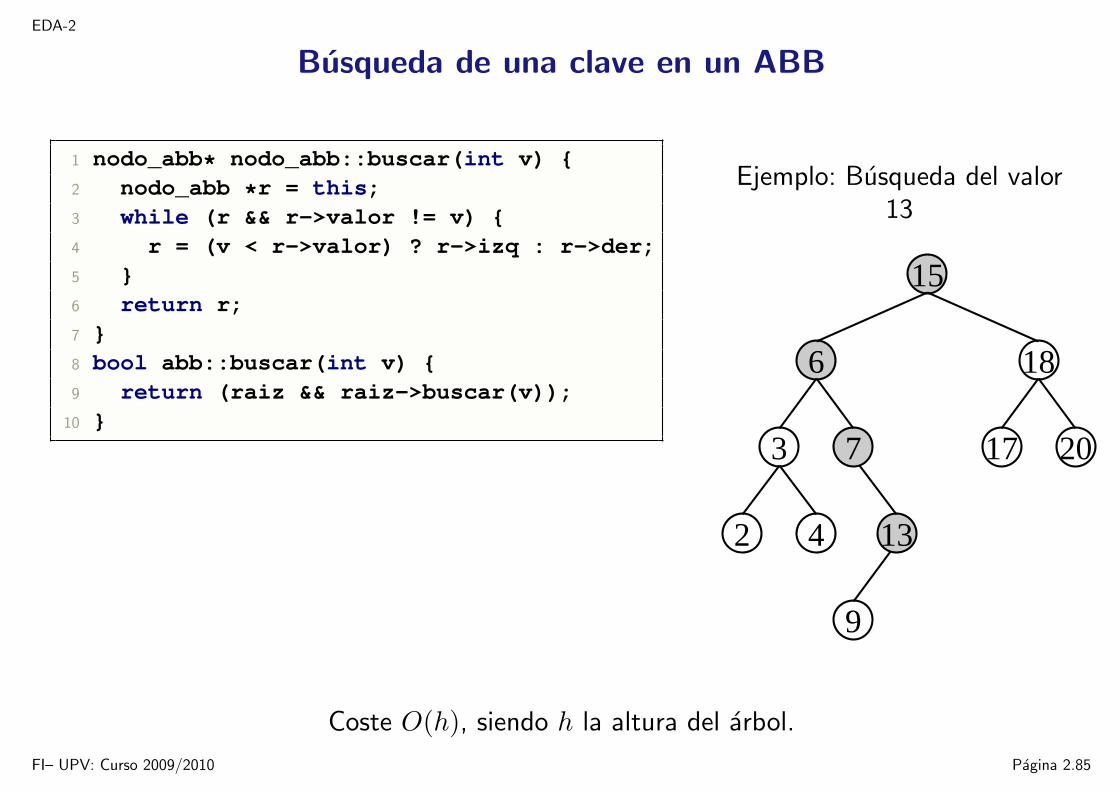
Busqueda de una clave en un ABB
1 nodo_abb* nodo_abb::buscar(int v) 2 nodo_abb *r = this;3 while (r && r->valor != v) 4 r = (v < r->valor) ? r->izq : r->der;5 6 return r;7 8 bool abb::buscar(int v) 9 return (raiz && raiz->buscar(v));
10
Ejemplo: Busqueda del valor13
15
6 18
134
73
2
9
2017
Coste O(h), siendo h la altura del arbol.
FI– UPV: Curso 2009/2010 Pagina 2.85

EDA-2
Ejercicios
Ejercicio. ABB secuencias.
Supongamos que tenemos los numeros del 1 al 1000 en un ABB y queremos buscar elnumero 363. ¿Cual de las siguientes secuencias de nodos no puede ser la secuencia denodos examinada? Escribe un programa que responda estas cuestiones.
2, 252, 401, 398, 330, 344, 397, 363
924, 220, 911, 244, 898, 258, 362, 363
925, 202, 911, 240, 912, 245, 363
2, 399, 387, 219, 266, 382, 381, 278, 363
935, 278, 347, 621, 299, 392, 358, 363
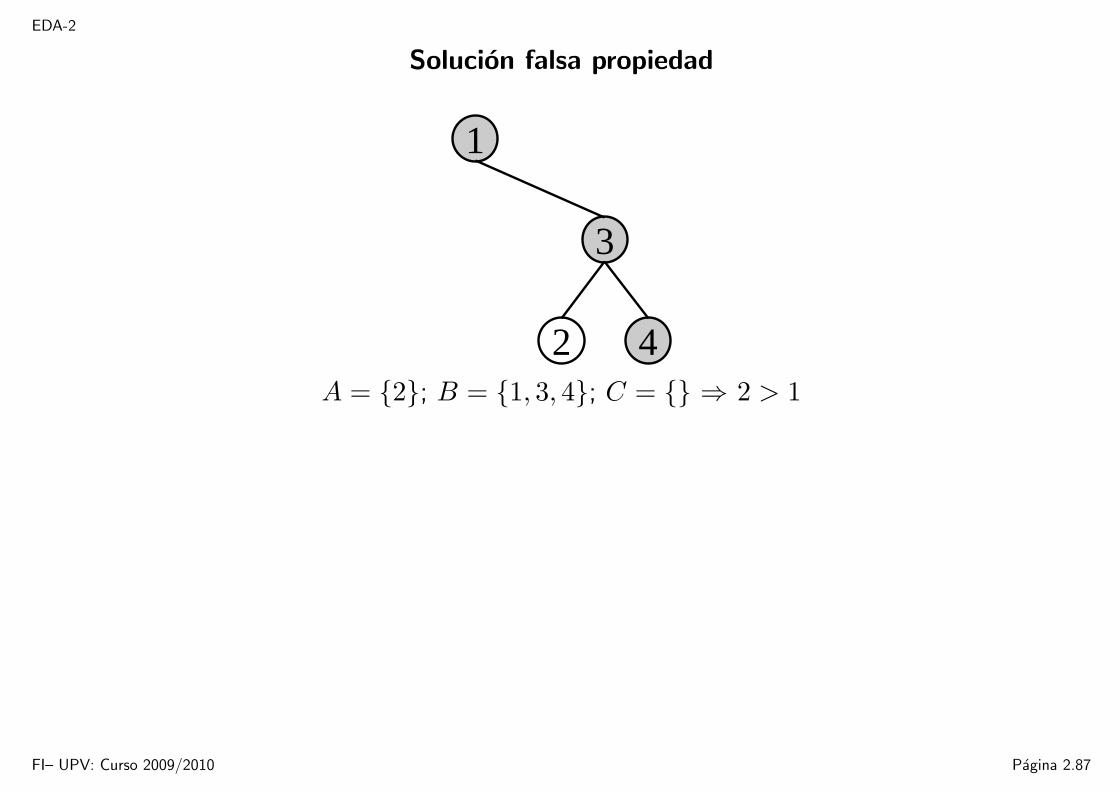
Ejercicio. Falsa propiedad.
Demuestra que la siguiente propiedad no es cierta: Supongamos que la busqueda de unelemento de clave k en un ABB termina en una hoja. Considera tres conjuntos: A, lasclaves a la izquierda del camino de busqueda; B, las claves del camino de busqueda; yC, las claves a la derecha del camino de busqueda. Encuentra un contraejemplo parademostrar que no se cumple que para cualquier a ∈ A, b ∈ B y c ∈ C, a ≤ b ≤ c.
FI– UPV: Curso 2009/2010 Pagina 2.86
EDA-2
Solucion falsa propiedad
1
3
42A = 2; B = 1, 3, 4; C = ⇒ 2 > 1
FI– UPV: Curso 2009/2010 Pagina 2.87
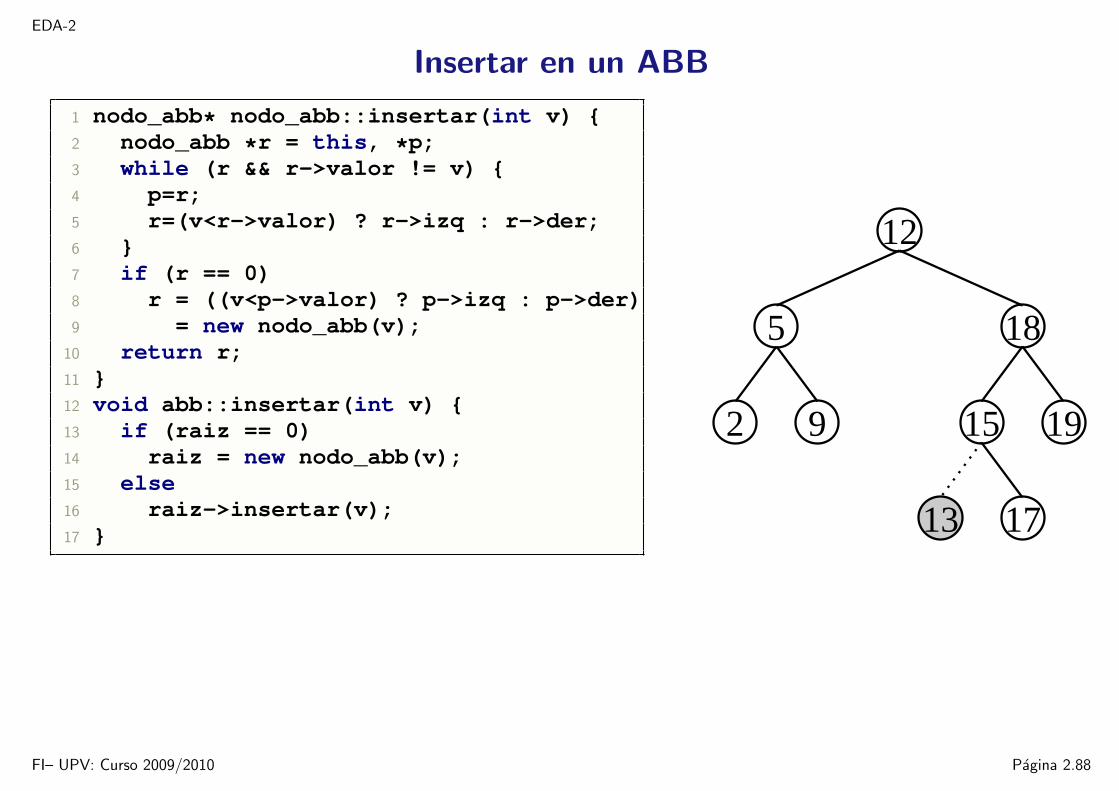
EDA-2
Insertar en un ABB
1 nodo_abb* nodo_abb::insertar(int v) 2 nodo_abb *r = this, *p;3 while (r && r->valor != v) 4 p=r;5 r=(v<r->valor) ? r->izq : r->der;6 7 if (r == 0)8 r = ((v<p->valor) ? p->izq : p->der)9 = new nodo_abb(v);
10 return r;11 12 void abb::insertar(int v) 13 if (raiz == 0)14 raiz = new nodo_abb(v);15 else16 raiz->insertar(v);17
15 19
12
5 18
92
13 17
FI– UPV: Curso 2009/2010 Pagina 2.88
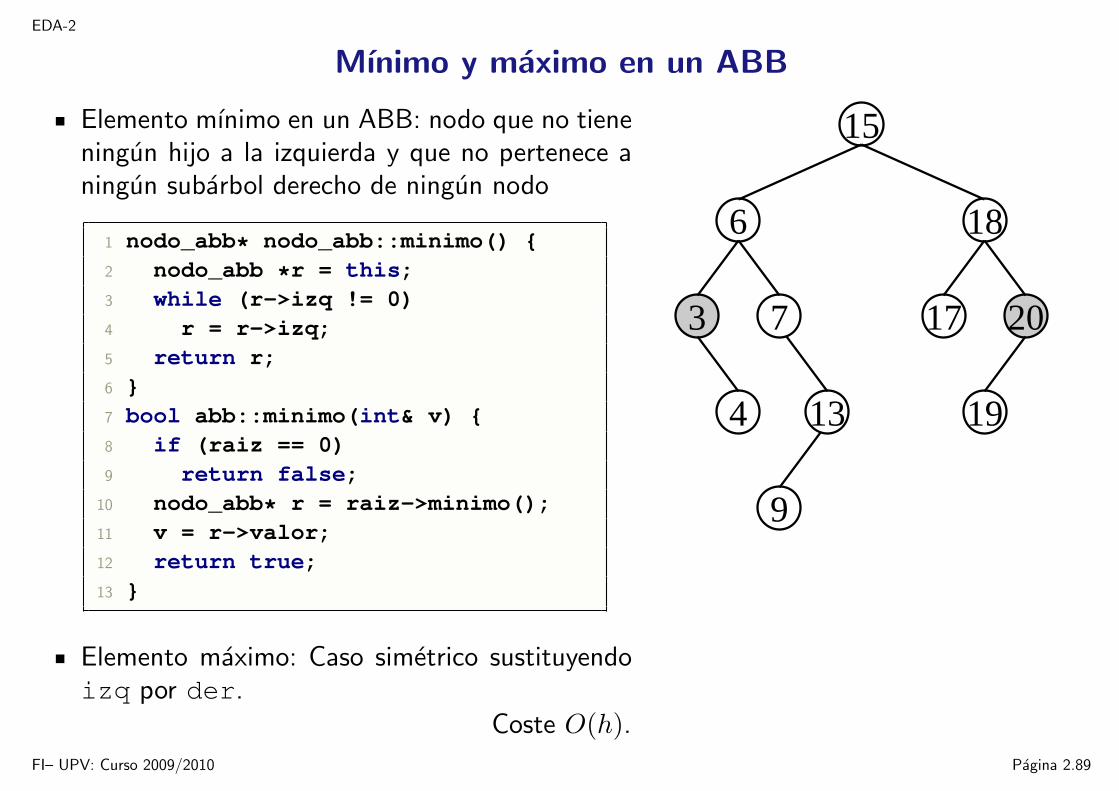
EDA-2
Mınimo y maximo en un ABB
Elemento mınimo en un ABB: nodo que no tieneningun hijo a la izquierda y que no pertenece aningun subarbol derecho de ningun nodo
1 nodo_abb* nodo_abb::minimo() 2 nodo_abb *r = this;3 while (r->izq != 0)4 r = r->izq;5 return r;6 7 bool abb::minimo(int& v) 8 if (raiz == 0)9 return false;
10 nodo_abb* r = raiz->minimo();11 v = r->valor;12 return true;13
Elemento maximo: Caso simetrico sustituyendoizq por der.
17
15
6 18
134
73
9
20
19
Coste O(h).
FI– UPV: Curso 2009/2010 Pagina 2.89
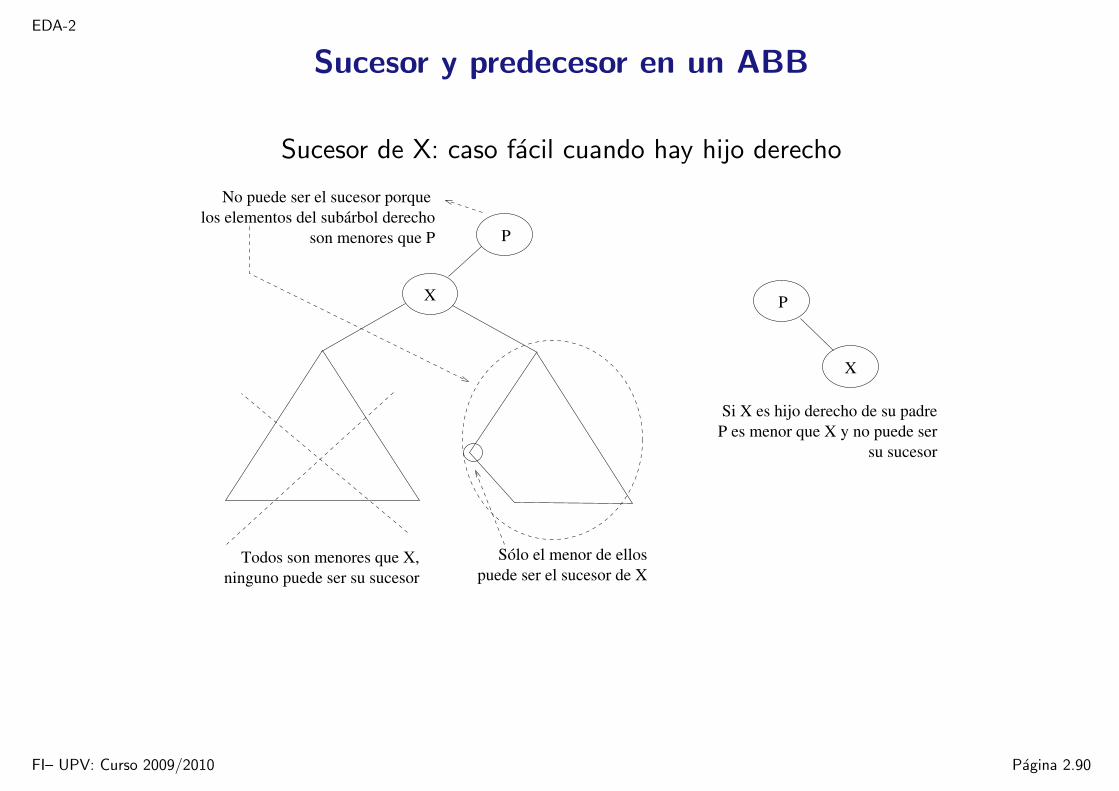
EDA-2
Sucesor y predecesor en un ABB
Sucesor de X: caso facil cuando hay hijo derecho
X
P
Todos son menores que X, Sólo el menor de ellospuede ser el sucesor de Xninguno puede ser su sucesor
No puede ser el sucesor porque
son menores que Plos elementos del subárbol derecho
X
P
Si X es hijo derecho de su padreP es menor que X y no puede ser
su sucesor
FI– UPV: Curso 2009/2010 Pagina 2.90
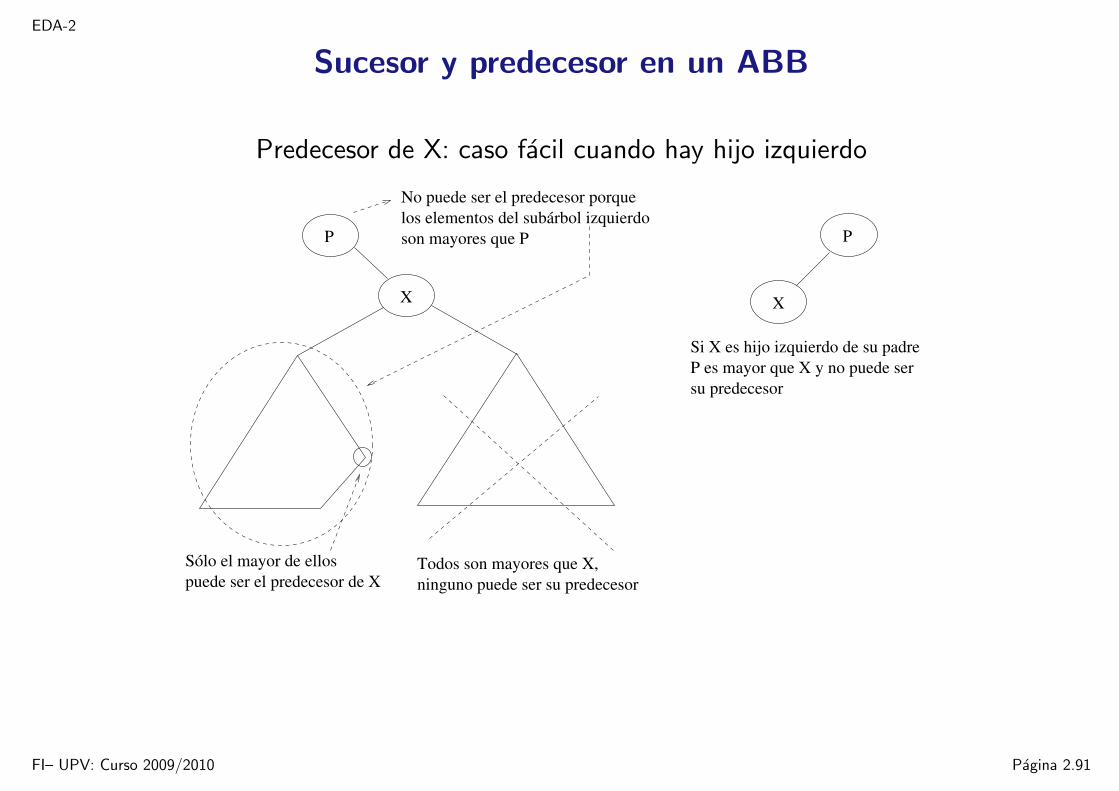
EDA-2
Sucesor y predecesor en un ABB
Predecesor de X: caso facil cuando hay hijo izquierdo
X
P
X
P
Todos son mayores que X,Sólo el mayor de ellospuede ser el predecesor de X ninguno puede ser su predecesor
No puede ser el predecesor porque
son mayores que Plos elementos del subárbol izquierdo
Si X es hijo izquierdo de su padreP es mayor que X y no puede sersu predecesor
FI– UPV: Curso 2009/2010 Pagina 2.91

EDA-2
Sucesor y predecesor en un ABB
Sucesor de X: caso menos facil cuando NO hay hijo derechoNOTA: Y es sucesor de X ↔ X es predecesor de Y
durante la búsqueda de Xtal que al bajar lo hicimos porsu hijo izquierdo
Y es el último nodo visitado
Y
buscamos su sucesorX es el elemento del cual
1 nodo_abb* nodo_abb::sucesor(int v) /* pseudo-codigo:2 Nota: este codigo se llama desde la raız3 Buscamos X, pero nos apuntamos el ultimo4 nodo tal que hay que bajar por su hijo izquierdo5 al llegar a X hay 2 casos:6
7 X tiene hijo derecho: devolvemos el minimo del subarbol derecho8 X no tiene hijo dcho: devolvemos el nodo que nos hemos apuntado */9
FI– UPV: Curso 2009/2010 Pagina 2.92
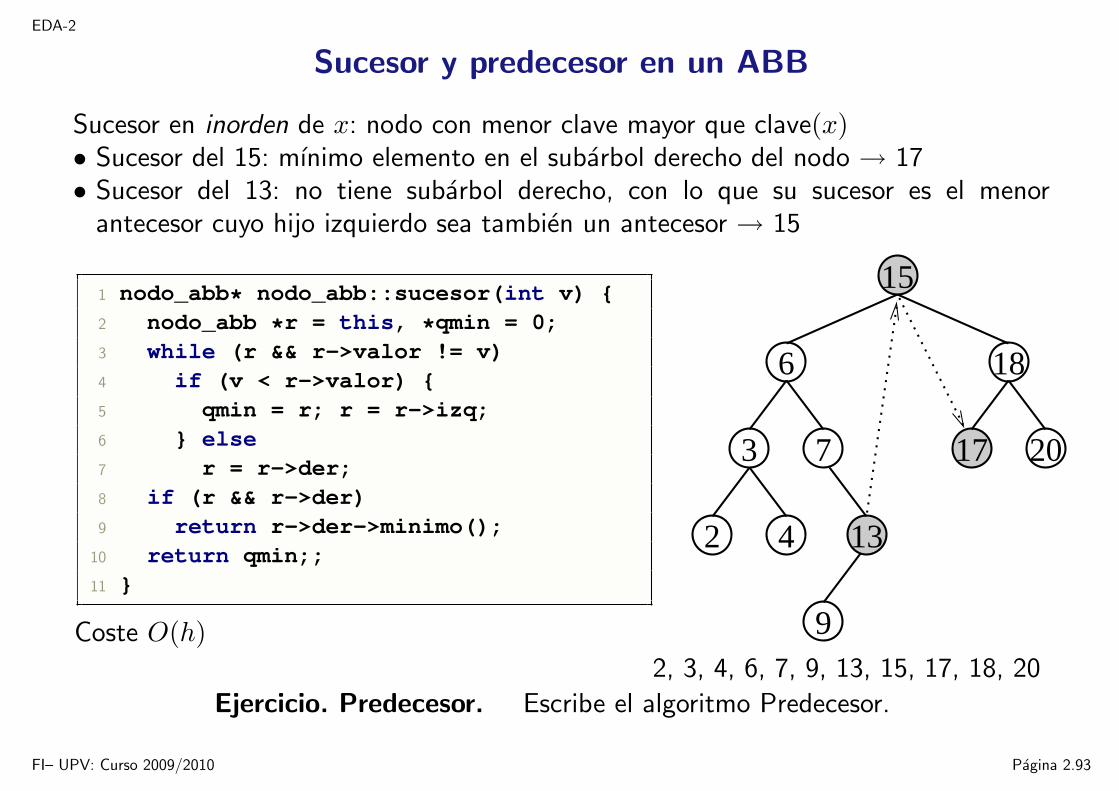
EDA-2
Sucesor y predecesor en un ABB
Sucesor en inorden de x: nodo con menor clave mayor que clave(x)• Sucesor del 15: mınimo elemento en el subarbol derecho del nodo → 17• Sucesor del 13: no tiene subarbol derecho, con lo que su sucesor es el menor
antecesor cuyo hijo izquierdo sea tambien un antecesor → 15
1 nodo_abb* nodo_abb::sucesor(int v) 2 nodo_abb *r = this, *qmin = 0;3 while (r && r->valor != v)4 if (v < r->valor) 5 qmin = r; r = r->izq;6 else7 r = r->der;8 if (r && r->der)9 return r->der->minimo();
10 return qmin;;11
Coste O(h)
15
6 18
134
73
2
9
2017
2, 3, 4, 6, 7, 9, 13, 15, 17, 18, 20
Ejercicio. Predecesor. Escribe el algoritmo Predecesor.
FI– UPV: Curso 2009/2010 Pagina 2.93
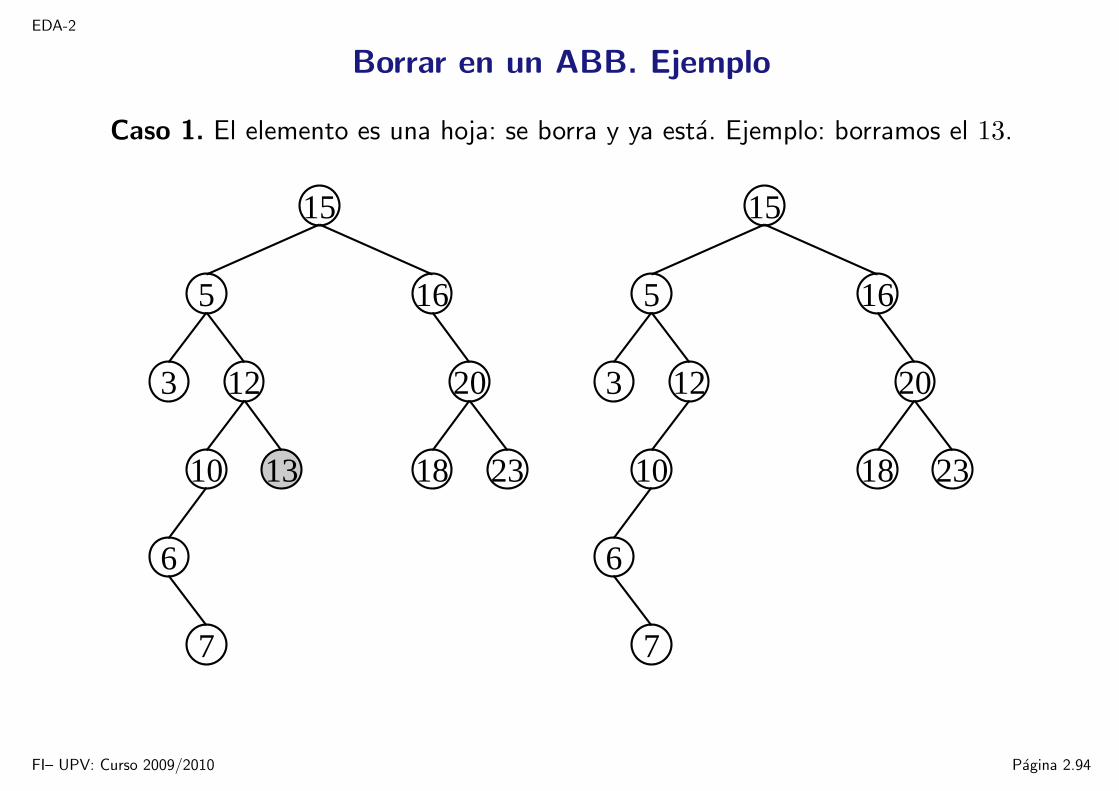
EDA-2
Borrar en un ABB. Ejemplo
Caso 1. El elemento es una hoja: se borra y ya esta. Ejemplo: borramos el 13.
12
15
5 16
3 20
10 13
6
7
18 23
15
5 16
3 20
10
6
7
18 23
12
FI– UPV: Curso 2009/2010 Pagina 2.94
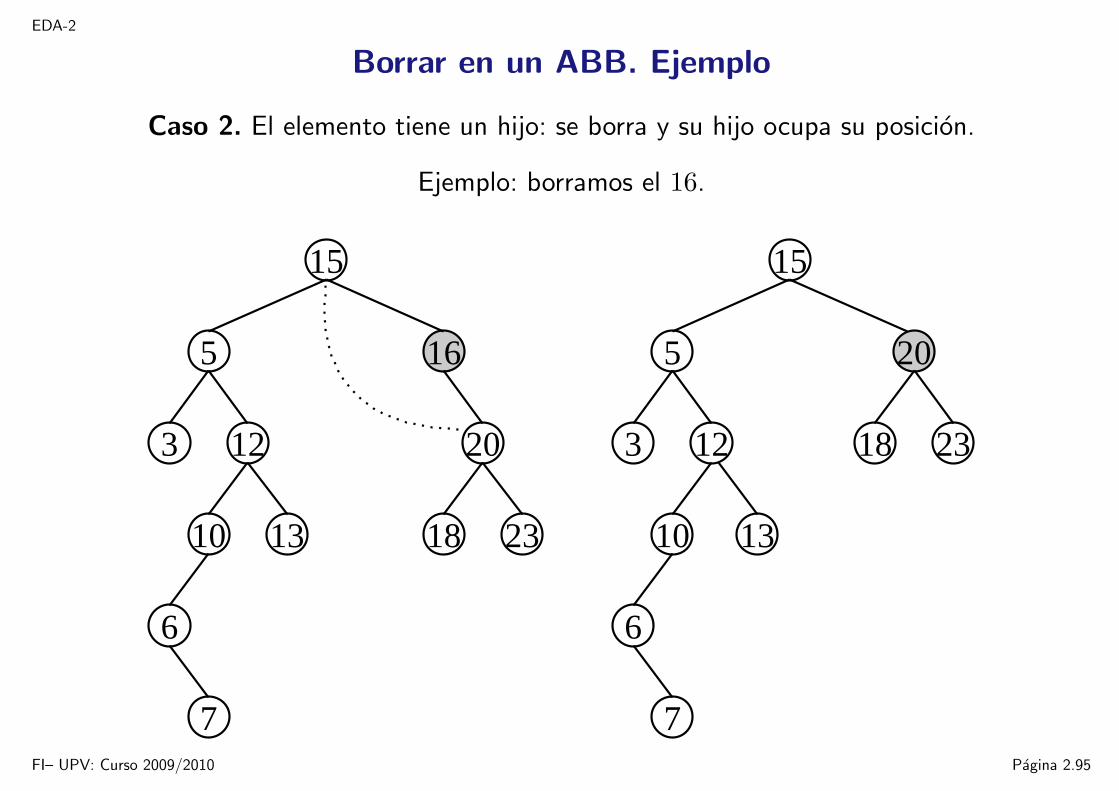
EDA-2
Borrar en un ABB. Ejemplo
Caso 2. El elemento tiene un hijo: se borra y su hijo ocupa su posicion.
Ejemplo: borramos el 16.
13 13
15
5
3
10
6
7
12
15
5 16
3 20
10
6
7
18 23
12
20
18 23
FI– UPV: Curso 2009/2010 Pagina 2.95
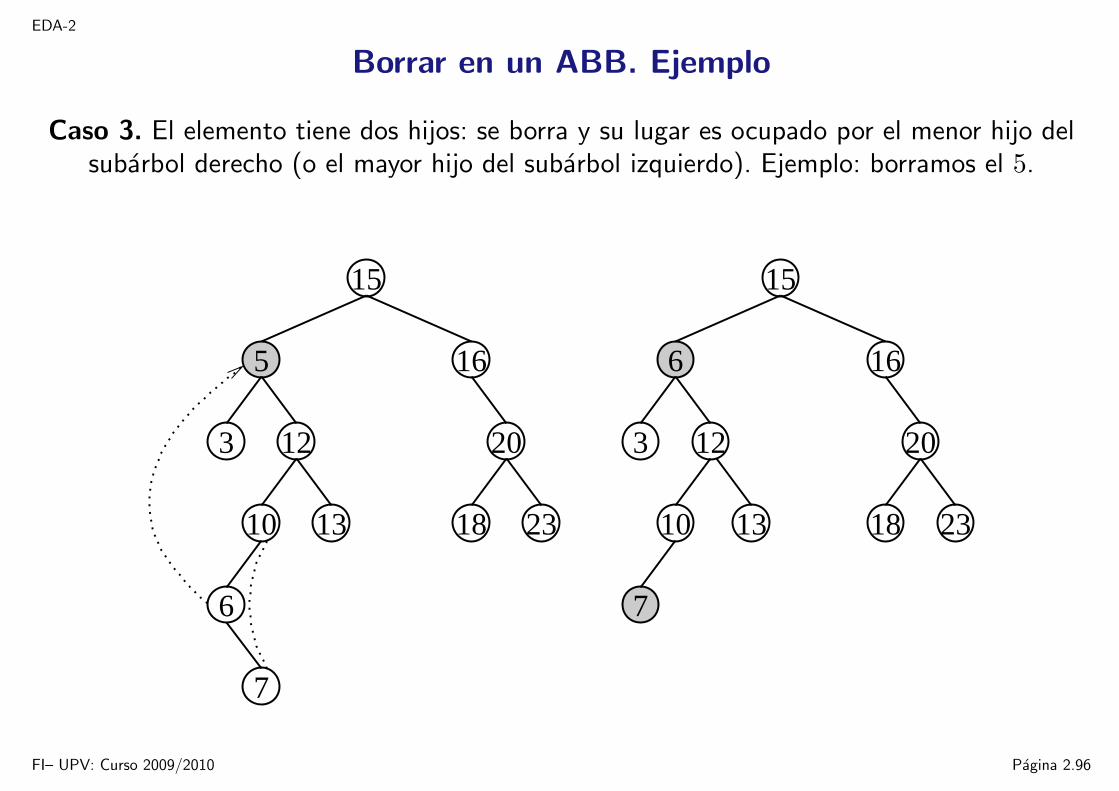
EDA-2
Borrar en un ABB. Ejemplo
Caso 3. El elemento tiene dos hijos: se borra y su lugar es ocupado por el menor hijo delsubarbol derecho (o el mayor hijo del subarbol izquierdo). Ejemplo: borramos el 5.
13 13
15
6 16
3 20
10
7
18 23
12
15
5 16
3 20
10
6
7
18 23
12
FI– UPV: Curso 2009/2010 Pagina 2.96
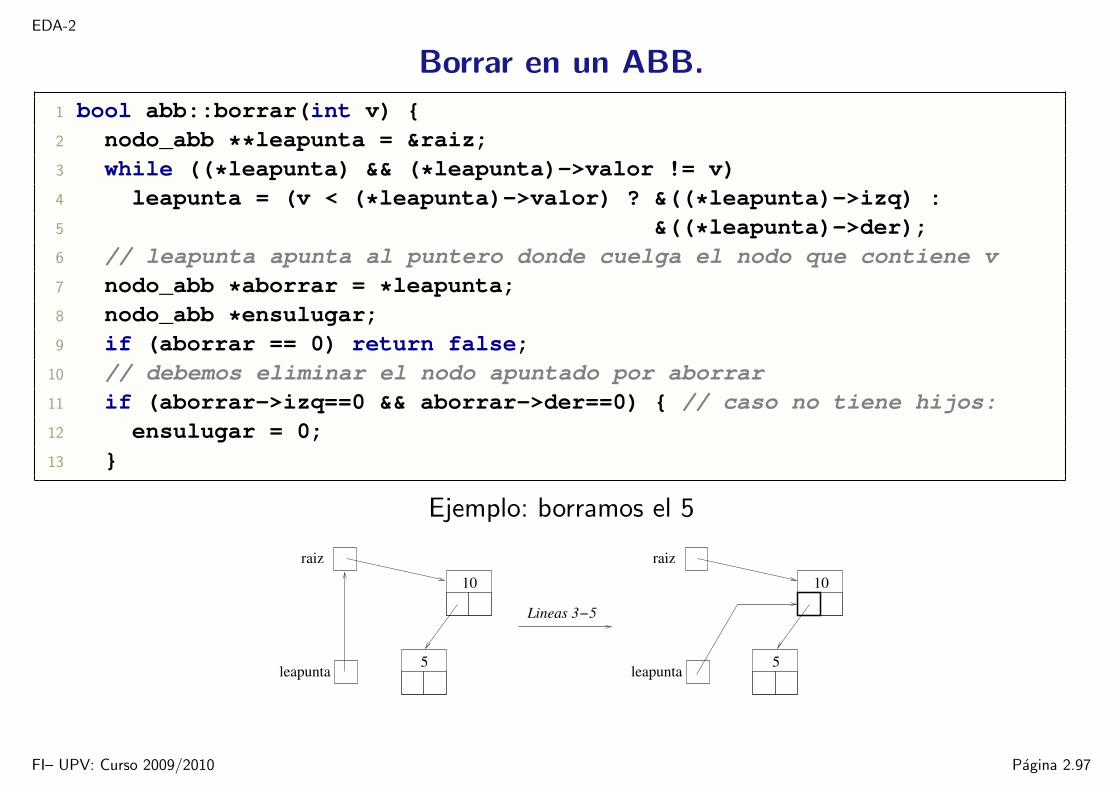
EDA-2
Borrar en un ABB.
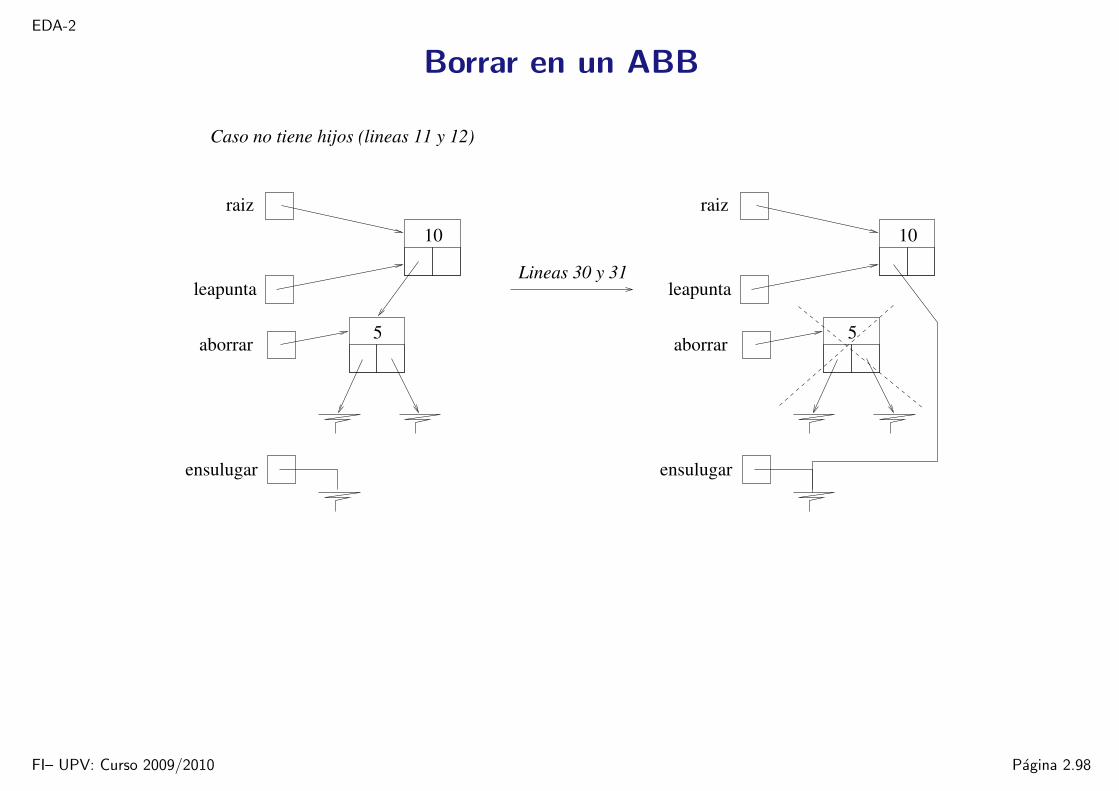
1 bool abb::borrar(int v) 2 nodo_abb **leapunta = &raiz;3 while ((*leapunta) && (*leapunta)->valor != v)4 leapunta = (v < (*leapunta)->valor) ? &((*leapunta)->izq) :5 &((*leapunta)->der);6 // leapunta apunta al puntero donde cuelga el nodo que contiene v7 nodo_abb *aborrar = *leapunta;8 nodo_abb *ensulugar;9 if (aborrar == 0) return false;
10 // debemos eliminar el nodo apuntado por aborrar11 if (aborrar->izq==0 && aborrar->der==0) // caso no tiene hijos:12 ensulugar = 0;13
Ejemplo: borramos el 5
raiz
leapunta5
10
Lineas 3−5
raiz
leapunta5
10
FI– UPV: Curso 2009/2010 Pagina 2.97
EDA-2
Borrar en un ABB
raiz
5
10
leapunta
aborrar
ensulugar
raiz
5
10
leapunta
aborrar
ensulugar
Lineas 30 y 31
Caso no tiene hijos (lineas 11 y 12)
FI– UPV: Curso 2009/2010 Pagina 2.98

EDA-2
Borrar en un ABB (cont.)
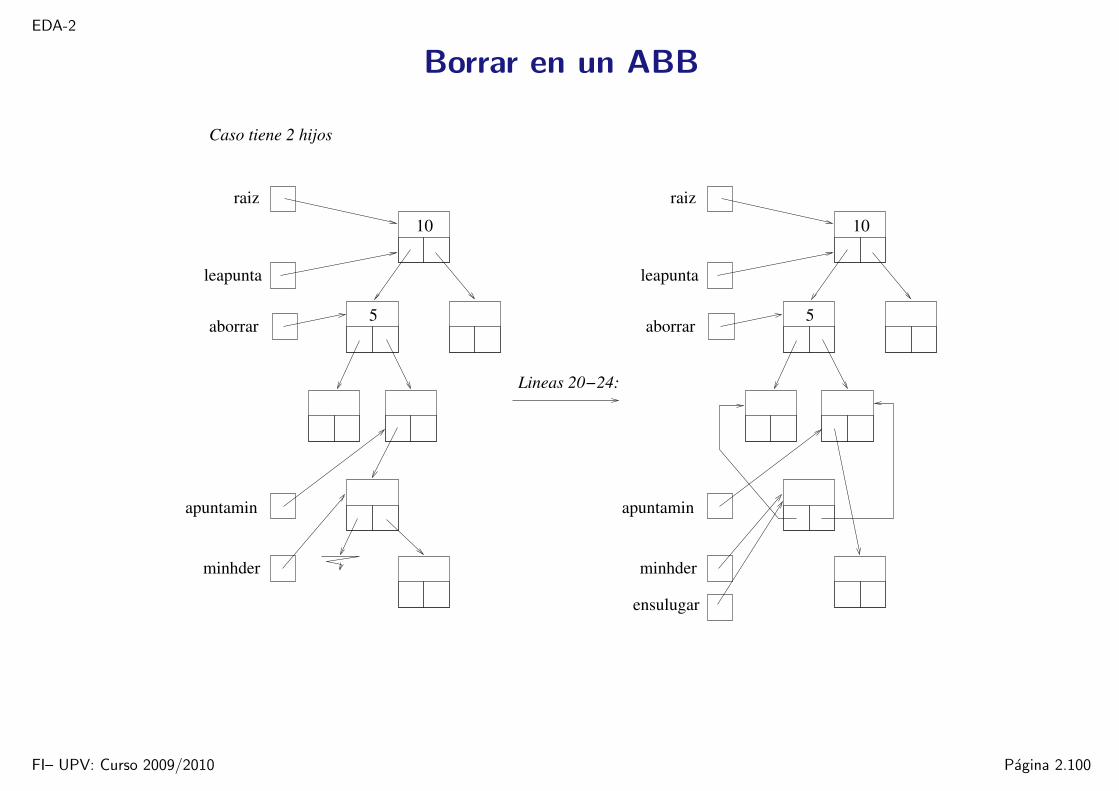
14 else if (aborrar->izq && aborrar->der) // tiene 2 hijos15 // obtenemos el minimo del hijo derecho:16 nodo_abb **apuntamin = &(aborrar->der);17 while ((*apuntamin)->izq) apuntamin = &((*apuntamin)->izq);18 nodo_abb *minhder = *apuntamin;19 // quitamos el nodo minimo del hijo derecho:20 *apuntamin = minhder->der;21 // ponemos el nodo minhder en lugar de aborrar:22 minhder->izq = aborrar->izq;23 minhder->der = aborrar->der;24 ensulugar = minhder;25 else
FI– UPV: Curso 2009/2010 Pagina 2.99
EDA-2
Borrar en un ABB
raiz
apuntamin
minhder
aborrar5
10
leapunta
Caso tiene 2 hijos
Lineas 20−24:
raiz
apuntamin
minhder
aborrar5
10
leapunta
ensulugar
FI– UPV: Curso 2009/2010 Pagina 2.100

EDA-2
Borrar en un ABB (cont.)
25 else 26 // tiene 1 solo hijo, veamos cual es:27 nodo_abb *hijo = (aborrar->izq) ? aborrar->izq : aborrar->der;28 ensulugar = hijo; // ponemos en su lugar el hijo29 30 *leapunta = ensulugar;31 delete aborrar; // nos cargamos el nodo a borrar32 return true;33
FI– UPV: Curso 2009/2010 Pagina 2.101

EDA-2
Costes de las operaciones con ABBs
Coste operaciones: O(h), siendo h la altura del ABB (h ∈ O(log n); h ∈ O(n))
La altura h esta entre O(log n) y Ω(n), donde n es el numero de elementos.
Si insertamos datos aleatoriamente se consigue una altura O(log n), pero losABB no ofrecen ese comportamiento en todas las presentaciones de datos. Existenestructuras de datos basadas en arboles que incluyen informacion y/o operacionesadicionales de cara a lograr un equilibrio en los arboles. Son los arboles balanceadosy se suelen basar en:
Efectuar “rotaciones”. Se intercambian nodos y subarboles en un arbol binario debusqueda para lograr otro equivalente (Ejemplo: arboles AVL, arboles rojo-negro).
Efectuar una “reconstruccion parcial”. Un recorrido en inorden de un ABB tienecoste y produce una secuencia ordenada que permite un arbol perfectamentebalanceado con un coste lineal con el numero de nodos reestructurados. Existentecnicas (arboles balanceados “generales”) que efectuan este tipo de reconstruc-cion en aquellas busquedas que superan una profundidad determinada. El umbraldepende de una constante multiplicada por el logaritmo del numero de nodos.Tiene coste amortizado de orden logarıtmico.
FI– UPV: Curso 2009/2010 Pagina 2.102
EDA-2
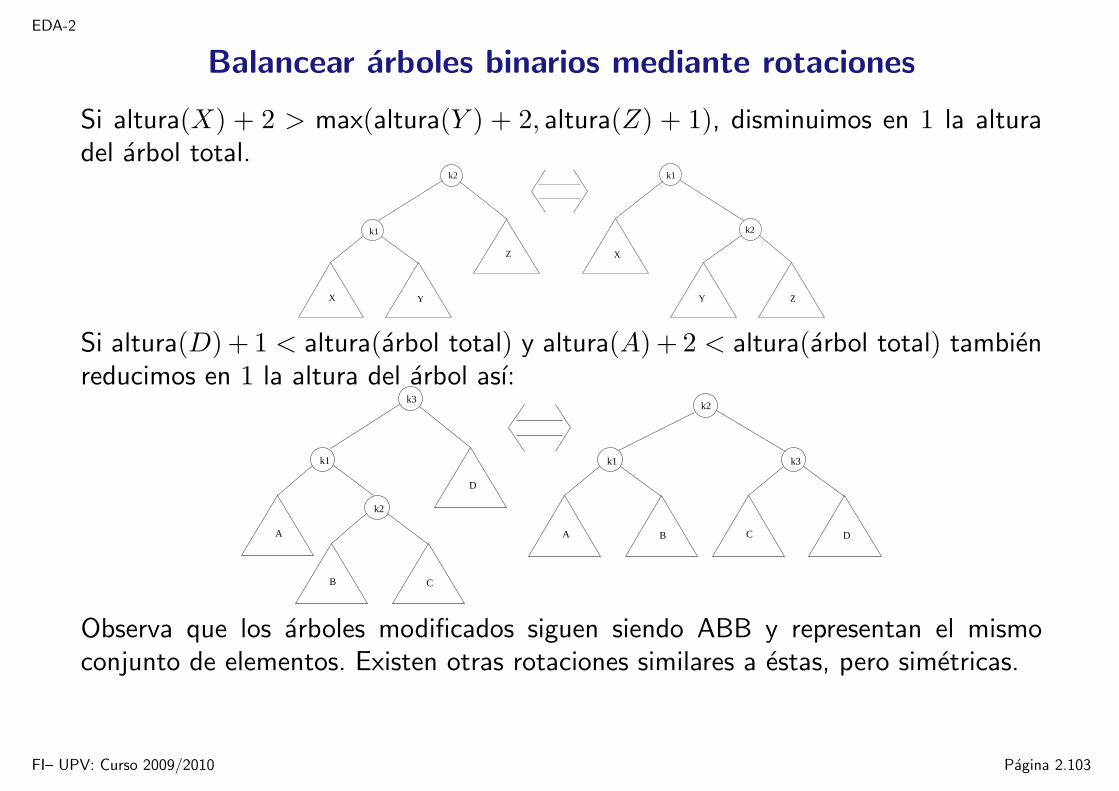
Balancear arboles binarios mediante rotaciones
Si altura(X) + 2 > max(altura(Y ) + 2, altura(Z) + 1), disminuimos en 1 la alturadel arbol total.
Y
Z
X
k1
k2
Y
X
Z
k2
k1
Si altura(D) + 1 < altura(arbol total) y altura(A) + 2 < altura(arbol total) tambienreducimos en 1 la altura del arbol ası:
CB
k2
BA
k1
DC
k3
D
k3
A
k1
k2
Observa que los arboles modificados siguen siendo ABB y representan el mismoconjunto de elementos. Existen otras rotaciones similares a estas, pero simetricas.
FI– UPV: Curso 2009/2010 Pagina 2.103