european organization for nuclear research capturing, storing and using time-series data for the...
Post on 18-Dec-2015
216 views
TRANSCRIPT

European Organization For Nuclear Research
Capturing, storing and using Capturing, storing and using time-series data for the world's largest time-series data for the world's largest
scientific instrumentscientific instrument
The LHC Logging ServiceThe LHC Logging Service
By Chris Roderick
UKOUG Conference 2006, Birmingham

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 2
OutlineOutline
Introduction to CERN The LHC Logging Project LHC Logging Service Architecture LHC Logging Service Design & Implementation Database Techniques Used Lessons Learned Conclusion Questions

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 3
CERNCERN European Organization for Nuclear ResearchEuropean Organization for Nuclear Research
Founded in 1954 by 12 countries Today: 20 member states CERN does pure scientific research into the laws of nature Providing to >7000 users (particle physicists) from all over the world:
Accelerators accelerate particles to almost the speed of light Detectors make the particles visible
The birthplace of the World Wide Web

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 4
CERNCERN
Geneva Airport LHC accelerator
CERN Main site (CH)SPS accelerator
CERN 2nd site (F)
France
Switzerland
PS accelerator complex

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 5
The Large Hadron Collider (LHC)The Large Hadron Collider (LHC) Most powerful instrument ever built to investigate particles properties 27km circumference, 100m underground 4 cathedral size underground caverns hosting huge detectors The highest energy of any accelerator in the world The most intense beams of colliding particles Operating at a temperature just above absolute zero

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 6
OutlineOutline
Introduction to CERN The LHC Logging Project LHC Logging Service Architecture LHC Logging Service Design & Implementation Database Techniques Used Lessons Learned Conclusion Questions

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 7
The LHC Logging ProjectThe LHC Logging Project Need to know what’s going on in and around the LHC
Log heterogeneous time series data:Cryogenics temperatures, magnetic field strengths, power dissipation, vacuum pressures, beam intensities and positions…etc…
Integration with other services (e.g. alarms): Coherent data time-stamping Consistent identification of the data
Oracle has a long history at CERN (since 1983 version 2.3) Decision to go with latest available Oracle technology:
Oracle 9i Database Oracle Application Server Oracle Enterprise Manager
Logging Project started in 2001 First operational implementation used in autumn 2003

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 8
The LHC Logging ProjectThe LHC Logging Project Exponential increase in data volumes Stabilise after 1st year of LHC operation ~5TB per year

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 9
OutlineOutline
Introduction to CERN The LHC Logging Project LHC Logging Service Architecture LHC Logging Service Design & Implementation Database Techniques Used Lessons Learned Conclusion Questions
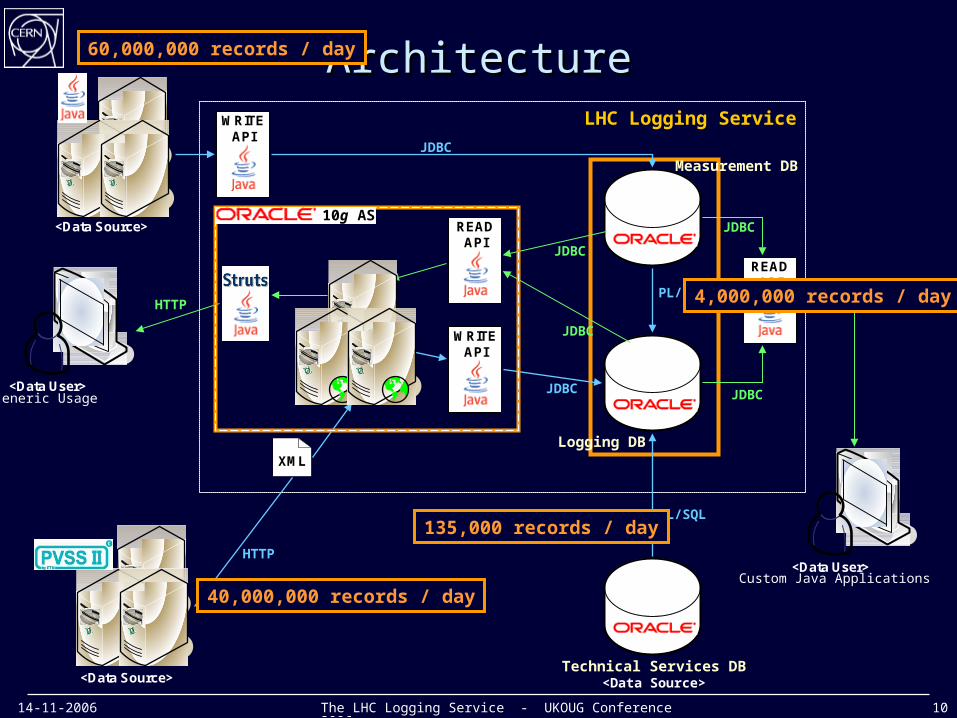
14-11-2006 The LHC Logging Service - UKOUG Conference 2006 10
LHC Logging Service
ArchitectureArchitecture
<Data Source>
<Data Source>
Logging DB
Measurement DB
Technical Services DB<Data Source>
WRITEAPI
XML
HTTP
HTTP
READAPI
WRITEAPI
READAPI
JDBC
JDBC
JDBCJDBC
JDBC
JDBC
PL/SQL
PL/SQL
<Data User>Custom Java Applications
<Data User>Generic Usage
XML Data Sending SAX parser extracts data as objects Java API loads data
10g AS
Oracle RAC Database Host 2 x SUN Fire V240 Dual 1 GHz CPU 4 GB RAM Dual internal disks Dual power supply SUN StorEdge 3510FC disk array 2-Gb fiber channel bus Dual RAID controllers 1 GB cache 12 x 146 GB 10k rpm FC disks 24 x 300 GB 10k rpm FC disks (2007) SUN Solaris 9 Veritas Volume Manager 3.5 Oracle9i Enterprise Edition Release 9.2.0.7.0
60,000,000 records / day
40,000,000 records / day
135,000 records / day
4,000,000 records / day

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 11
OutlineOutline
Introduction to CERN The LHC Logging Project LHC Logging Service Architecture LHC Logging Service Design & Implementation Database Techniques Used Lessons Learned Conclusion Questions

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 12
Metadata Tables Variables for which time
series data will be logged Users User-Variable relations
Variable groupings
Time series Tables Index-Organized Range Partitioned
Tablespace per range Timestamp data type Table per data type
Time Series DataRange Partitioned
Audit & Error Tables Error definitions Error logging Administrator notifications Audit data:
Who did what When How long it took
VARRAY of NUMBER

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 13
Partitioned Measurement DataPartitioned Measurement Data Time series data tables in Measurement Database, also implemented as
range-partitioned IOTs Benefit for administration and query performance 7 days of data are kept table may contain several billion rows Data is organized in daily range partitions Daily DBMS_JOB executes a procedure:
adding a new partition dropping oldest partition, using UPDATE GLOBAL INDEXES
(avoids the need to rebuild the global table index as an offline operation)
Today’s DataDrop Add
P-6 P-4P-5 P-3 P-2 P-1 P P+1 P+2 P+3 P+4 P+5P-7P-8
Range-Partitioned IOT Time Series Data Table

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 14
SELECT variable_id, count(*) repeating_cntFROM ( SELECT variable_id, value, LAG(value) OVER (PARTITION BY variable_id ORDER BY utc_stamp) last_value FROM data_numeric WHERE variable_id IN ( SELECT variable_id FROM meta_variable WHERE user_name = p_user_name AND datatype_name = l_dn_datatype ) AND utc_stamp >= p_start_stamp AND utc_stamp < p_end_stamp)WHERE value = last_value GROUP BY variable_id;
SELECT COUNT(*) repeating_dn_cntFROM ( SELECT value, LAG(value) OVER (PARTITION BY variable_id ORDER BY utc_stamp) last_value FROM data_numeric WHERE variable_id IN ( SELECT variable_id FROM meta_variable WHERE user_name = p_user_name AND datatype_name = l_dn_datatype ) AND utc_stamp >= p_start_stamp AND utc_stamp < p_end_stamp)WHERE value = last_value;
Automated TasksAutomated Tasks Check available storage (used space and partition creation) Check for broken jobs Gather CBO statistics Calculating system usage statistics:
No. records logged, per user, per data type during the previous day No. of repeating values

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 15
Data ExtractionData Extraction
Correlation of logged data from different systems key functional requirement
Dedicated Java Web applications based on the Apache Struts framework provide: Time series data statistics Data extraction to file, in various formats Data visualization in interactive charts

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 16

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 17
Time ScalingTime Scaling Need to correlate asynchronous data from different systems
Scale-upsummary information from finer granularity information
Scale-down finer granularity information from coarser granularity information
Since 9i, no built in PL/SQL time scaling (formerly TimeSeries cartridge)
Time-scaling functions implemented in PL/SQL using analytic functions LAG and LEAD: Scale-down Repeat Scale-down Interpolate Scale-up MIN/MAX/AVG

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 18
Time ScalingTime Scaling Accessible via PL/SQL functions, returning a TABLE (user defined SQL
Type) containing the time scaled data
TABLE data is returned row by row using the PIPELINED clause (no need to wait for the complete set of time scaled data to be derived)
Example SCALEUP Function usage:
SELECT stamp, min_value, max_value, avg_value FROM TABLE( TIME_SCALE.SCALEUP( 24288, -- ID of variable for which data is to be scaled 1, -- No. of intervals between generated timestamps 'HOUR', -- Type of interval between generated timestamps '2006-08-22 00:00:00',-- Desired start time for generated data '2006-08-22 23:59:59',-- Desired end time for generated data 'utc_stamp', -- Name of column containing the raw timestamps 'value', -- Name of column containing the raw values 'data_numeric', -- Name of table containing time series data 'variable_id' -- Name of column containing variable ID
)) ORDER BY stamp;
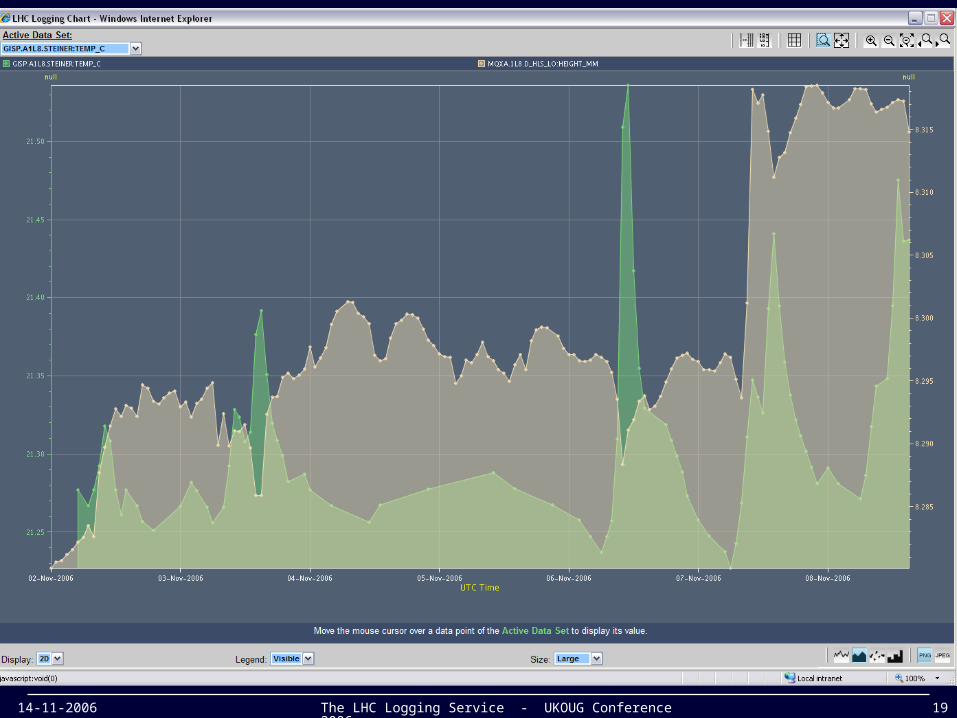
14-11-2006 The LHC Logging Service - UKOUG Conference 2006 19
Show Time Scaling in TIMBERShow Time Scaling in TIMBER

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 20
Exception HandlingException Handling
Extremely important – deals with abnormal situations System administrators quickly aware of problems Event and conditions which caused problem are captured Allows APIs to behave in a predictable manner Logging Service uses an adaptation of the exception
handling framework proposed by S. Feuerstein in Oracle Magazine (May – August 2003)
Deals with: Exception definitions (name, description, severity) Exception capturing (what, who, when, parameter values) Exception treatment (log, mask, raise) Administrator notifications (depending on severity)

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 21
OutlineOutline
Introduction to CERN The LHC Logging Project LHC Logging Service Architecture LHC Logging Service Design & Implementation Database Techniques Used Lessons Learned Conclusion Questions
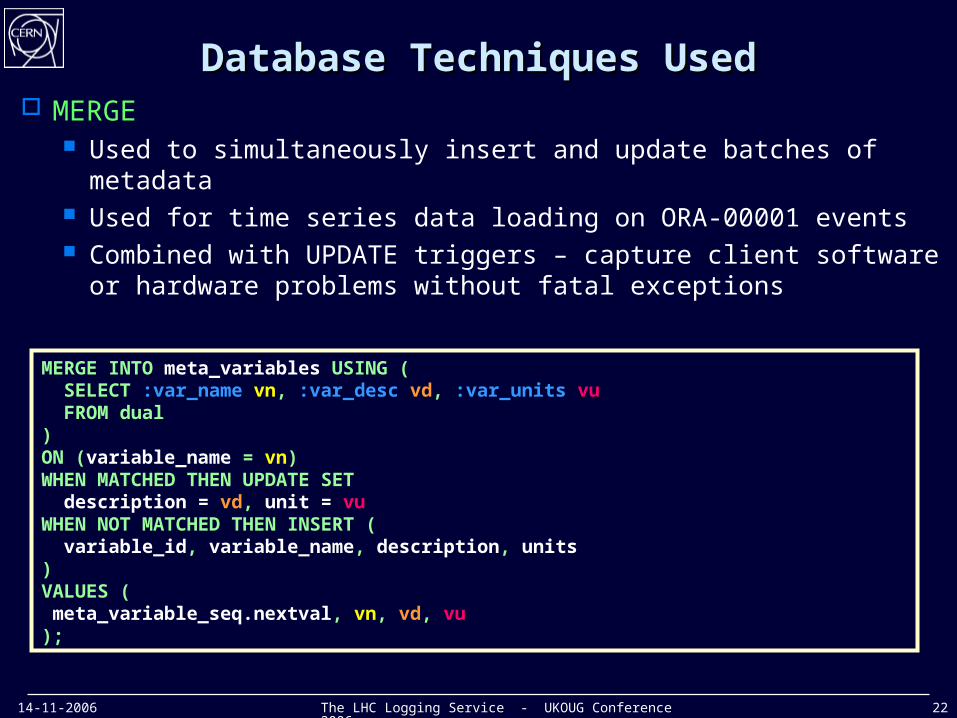
14-11-2006 The LHC Logging Service - UKOUG Conference 2006 22
Database Techniques UsedDatabase Techniques Used MERGE
Used to simultaneously insert and update batches of metadata Used for time series data loading on ORA-00001 events Combined with UPDATE triggers – capture client software or
hardware problems without fatal exceptions
MERGE INTO meta_variables USING ( SELECT :var_name vn, :var_desc vd, :var_units vu FROM dual)ON (variable_name = vn)WHEN MATCHED THEN UPDATE SET description = vd, unit = vuWHEN NOT MATCHED THEN INSERT ( variable_id, variable_name, description, units) VALUES ( meta_variable_seq.nextval, vn, vd, vu);
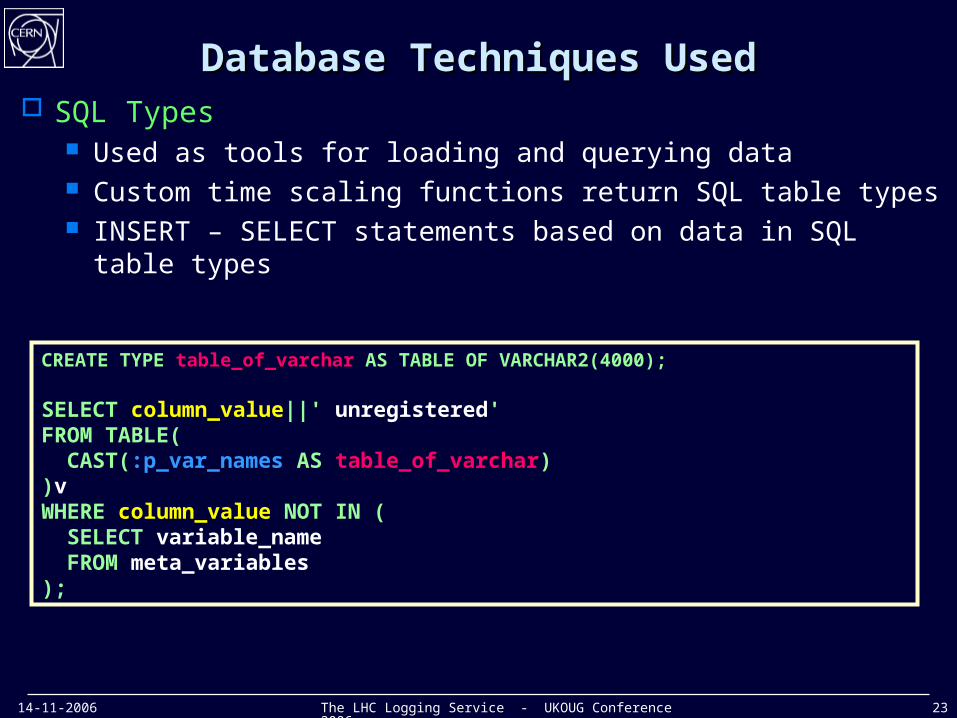
14-11-2006 The LHC Logging Service - UKOUG Conference 2006 23
Database Techniques UsedDatabase Techniques Used SQL Types
Used as tools for loading and querying data Custom time scaling functions return SQL table types INSERT – SELECT statements based on data in SQL table types
CREATE TYPE table_of_varchar AS TABLE OF VARCHAR2(4000);
SELECT column_value||' unregistered'FROM TABLE( CAST(:p_var_names AS table_of_varchar) )vWHERE column_value NOT IN ( SELECT variable_name FROM meta_variables);

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 24
Database Techniques UsedDatabase Techniques Used BULK PL/SQL
Used by PL/SQL data loading API BULK COLLECT for loading collections FORALL for inserting data Significant performance gains (depending on LIMIT clause value)
PROCEDURE LOG_LOGGING_DN IS l_data logging_data_loading.data_numeric_tab; -- Collection of logging data CURSOR c IS SELECT variable_name, utc_stamp, value FROM to_log_data_numeric;
BEGIN
OPEN c; LOOP FETCH c BULK COLLECT INTO l_data LIMIT 100; EXIT WHEN c%NOTFOUND; /* Send the data to the Logging DB 100 records at a time */ logging_data_loading.LOG_NUMERIC_DATA(l_data); END LOOP; CLOSE c;
………

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 25
Database Techniques UsedDatabase Techniques Used INTERVAL Data Types
Used in PL/SQL, SQL queries, and DBMS_JOB scheduling Add clarity to code Allow arithmetic to be carried out upon them – simplifies establishing
time elapsed between consecutive client data loading sessions
CASE /* Log the value if it is outside the fixed logging interval */
WHEN l_vars(i).last_logged + NUMTODSINTERVAL( l_vars(i).fixed_log_interval_size, l_vars(i).fixed_logging_interval_type ) < l_data(j).utc_stamp THEN INSERT INTO to_log_data_numeric (variable_name, utc_stamp, value) VALUES ( l_vars(i).variable_name, l_data(j).utc_stamp, ROUND(l_data(j).value, l_vars(i).rounding) );
WHEN …………
DBMS_JOB.INTERVAL(:job_no, 'SYSDATE + 1/24/4');VsDBMS_JOB.INTERVAL(:job_no, 'SYSDATE + INTERVAL ''15'' MINUTE');

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 26
Database Techniques UsedDatabase Techniques Used
Multi-table Inserts Used when inserting certain metadata Remove the need for procedural logic, and multiple INSERT
statements in the data loading API
INSERT FIRST WHEN dtype IN ('NUMERIC', 'NUMSTATUS', 'TEXTUAL', 'VECTORNUMERIC') THEN INTO prof_variables(user_prof_id, variable_id) VALUES (profid, varid) WHEN dtype = 'FUNDAMENTAL' THEN INTO prof_fundamentals(user_prof_id, fundamental_id) VALUES (profid, varid) SELECT :pid profid, :vid varid, :dt dtype FROM DUAL;

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 27
Database Techniques UsedDatabase Techniques Used
Analytic Functions Used for Time Scaling, Auditing, Data Derivation and Filtering Brings a new power to SQL obtain results previously only possible
using procedural code Give better performance, and reduce development time
Find old range partitions to be dropped based on convention of naming partitions as <table_alias>_PARTYYYYMMDD e.g. DN_PART20061114
SELECT table_name, partition_name FROM ( SELECT partition_name, table_name, RANK() OVER(PARTITION BY table_name ORDER BY partition_name DESC) p_rank FROM user_tab_partitions)WHERE p_rank > p_max_parts ORDER BY table_name, p_rank DESC;

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 28
OutlineOutline
Introduction to CERN The LHC Logging Project LHC Logging Service Architecture LHC Logging Service Design & Implementation Database Techniques Used Lessons Learned Conclusion Questions

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 29
Lessons LearnedLessons Learned
Handling large data volumes Range partitioned, index-organized tables
Good query performance Simplified administration
Storing arrays of numeric data using VARRAY Advantage of storing the data in it’s original order Not supported over database links (need for PL/SQL type conversion) Problematic for bulk data processing operations, where VARRAY size can
vary greatly between records No native means of comparing content of VARRAYS

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 30
Lessons LearnedLessons LearnedGetting the data access right Variety of data providers, with varying data volumes and rates
accurate CBO statistics is an ongoing challenge Combinations of skewed data and bind variable peeking Temporary fix: forcing execution paths
Impedance mismatch between OO developers and database developers Controlled database access via APIs is essential
Analytic functions – simplify development, improve performance
Knowing what’s going on, and keeping control Enterprise Manager Application Server Control 10g (9.0.4.3.0)
Intuitive, reliable, fulfils requirements for OAS administration Functionality removed / added in the subsequent version
Client and system audit data is invaluable

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 31
OutlineOutline
Introduction to CERN The LHC Logging Project LHC Logging Service Architecture LHC Logging Service Design & Implementation Database Techniques Used Lessons Learned Conclusion Questions

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 32
ConclusionConclusion The Logging Project operational Logging Service, used by an
increasing number of clients… Vital to monitor client behaviour and overall service performance Design has been validated, but the implementation continues to evolve in sync
with Oracle technology Scalability has been anticipated within the design, but additional hardware
needs to be foreseen and plugged in to meet future demands
Database tuning can be improved, particularly CBO statistics strategy
With hindsight – re-consider data storage using objects
Convinced to have followed the right path, we are looking forward to the full exploitation of the Oracle-powered logging service when CERN’s flagship LHC produces its first scientific results

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 33
QuestionsQuestions

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 34
Additional SlidesAdditional Slides
14-11-2006 The LHC Logging Service - UKOUG Conference 2006 35
The LHC Logging ProjectThe LHC Logging ProjectThe need for time-series data logging The LHC will be an installation of unprecedented complexity, with dense high-energy
particle beams that can potentially damage the equipment of the machine itself. Hundred-thousands of signals coming from equipment surveillance and beam
observation will be monitored to carefully examine the behaviour of this machine. Cryogenics temperatures, magnetic field strengths, power dissipation, vacuum
pressures, beam intensities and positions are all parameters that will influence the correct functioning and performance of the installation as a whole.
Each subsystem has its own data acquisition system to track parameter values over time. In order to be able to correlate this heterogeneous information, the data is “logged” in a central database, allowing end-users to:
Visualize and extract any data Compare over time Examine trends, Find patterns Discover unforeseen parameter relationships.
The need and value for such centralized logging was already demonstrated on previous occasions:
LEP Logging: data logging for CERN’s previous flagship accelerator, the Large Electron-Positron Collider (LEP), operated from 1989 till 2000.
LHC-string Logging: data logging from the prototype LHC magnet test stand, operated from 2001 till 2003.
LHC Logging project was launched in October 2001, and the first operational implementation was used in autumn 2003.
14-11-2006 The LHC Logging Service - UKOUG Conference 2006 36
The LHC Logging ProjectThe LHC Logging ProjectInitial system requirements Two types of clients acting as data providers:
Equipment hardware related – data is progressively and increasingly available before LHC start-up, as individual subsystems go through their hardware commissioning
Particle beam related – data will only become available when the LHC is fully commissioned with the green light to receive the first particles from the injecting accelerator chain
Rough figures on data volumes – exponential increase foreseen to stabilise after first year of beam operation at around 5TB per year
Historic data of previous years will be kept on-line in the same data store, in order to facilitate data comparison over the lifetime of the LHC
Throughput and latency performance requirements could not be quantified at project start design had to anticipate scalability
Overall software environment Java, J2EE Supervisory control and data acquisition (SCADA) systems on top of programmable logic
controllers (PLC). Heterogeneous data providers due to the specificities of the individual data acquisition
systems.

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 37
The LHC Logging ProjectThe LHC Logging ProjectIntegration with other projects The logging service is not an isolated tool to monitor the performance of
the LHC and its subsystems Functionality needs to be combined with other services to get a more
complete picture of the machine behaviour The Logging service is designed to be a steady, continuous, long-term
data capturing tool, for a wide range of clients The following services have complimentary functionality: Post-Mortem service: collects and analyzes transient recordings, i.e.
buffers of rapid data points (kilohertz range) from a set of crucial LHC subsystems, triggered by special events
Alarm service: centralizes notifications that indicate malfunctioning of any component to inform control room operators, and incite them for immediate action
Two prerequisites to allow a smooth integration of the services have been enforced: Coherent time-stamping Consistent identification of the data

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 38
Oracle Environment at CERNOracle Environment at CERN
CERN was one of the first European companies to have purchased Oracle (1983, version 2.3)
Many operational systems developed with the Oracle database as a foundation
Oracle is the standard RDBMS at CERN Database administration managed by CERN IT department Decentralized software development teams are
responsible for database & software design Hardware and system software infrastructure is
established by IT according to specific database service requirements
In general, only terminal releases of Oracle versions are deployed as operational production platforms

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 39
Oracle Environment for LHC LoggingOracle Environment for LHC Logging Starting the logging project five years before the full blown operational
use of the service – the evolution of the technology needed to be taken into account.
Strategic decisions have been made from the outset - going for the latest technology, as soon as possible:
Database technology Design and implementation details: based on Oracle9i technology Early 2007: migration to Oracle 10g Release 2, Enterprise Edition
Application Servers Java is the application software platform for all new projects. In-depth evaluation was made in 2003-2004 to compare J2EE deployment solutions Final choice: Standalone Oracle Container for Java (OC4J) or Oracle Application
Server (OAS) Logging project opted for OAS
Enterprise Manager Allows simple monitoring, diagnostics and repair of the deployed service Anticipate that these actions will be partially performed by control room operators in
the future Only OAS instances are currently monitored; complete service (including database)
could potentially be managed in the future

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 40
Development & Runtime EnvironmentsDevelopment & Runtime Environments Development Tools
JDeveloper 10.1.3 is used for all Java development, and database modelling (replacing Oracle Designer). Oracle SQLDeveloper is used for SQL and PL/SQL development.
Three runtime environments, each containing the complete setup of: Database schemas Data loading APIs Data reading APIs Application Server(s)
Development: Developing and testing features to satisfy new requirements Upgrading existing implementations to use new techniques or technologies
Test: Identical to the production environment in terms of hardware and software deployment. Used by new clients of the logging service – allowing them to validate their software against our system. Opportunity to validate behaviour of new clients – ensuring they conform to logging service requirements:
Send data in batches Send data at appropriate frequencies Filter unchanged or uninteresting data Round numeric values to appropriate precisions
Logged data is either deleted after an elapsed time, or transferred to the production environment. Production:
For clients who have passed ‘validation’ in the TEST environment, and wish to continue logging data, to be stored beyond the lifetime of the LHC machine.

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 41
DiagnosticsDiagnostics Database – ViewDB (in-house tool):
Database activity User sessions Resource consumption
Application Server – Oracle Enterprise Manager Application Server Control: Monitor application server usage and performance Access server and application log files Control application server components Edit configuration files Modify Web application runtime parameters in various OC4Js
System Usage – Audit tables, populated by the various data loading APIs, database triggers, and automated procedures which analyse logged time series data: Monitor evolution of system usage Plan for new system resources in advance Identify bad clients Track system performance Identify the causes of bursts of activity

14-11-2006 The LHC Logging Service - UKOUG Conference 2006 42
Evolution and Future DirectionEvolution and Future DirectionScalability – difficult to estimate final throughput and volume rates Not all subsystems are currently available. Fine details of data pushing capabilities of each subsystem are not known yet. Rationalization of information (e.g. filtering, data reduction) is of low priority to data providers. Peak loads may occur unexpectedly from inexperienced clients.
We can assume the eventual need to increase the resources of the service Number of application servers. Number of nodes in the database RAC cluster. Number of disks, and disk controllers.
No fundamental changes to the overall system design or the database design are foreseen.
Planned upgrades For the year 2007, an extra raw disk capacity of 7.2 TB will be installed.
Unexplored possibilities Clustering of application server hosts at software or hardware level. Automatic load balancing between the database servers. Data replication on a redundant system to ensure 100% uptime. Application notification of data modifications to avoid polling by external applications. Bringing in an Oracle consultant for system tuning.