exploiting inter-class rules for focused crawling İsmail sengör altıngövde bilkent university...
Post on 20-Dec-2015
221 views
TRANSCRIPT

Exploiting Inter-Class Rules for Focused Crawling
İsmail Sengör Altıngövde
Bilkent University
Ankara, Turkey

Our Research: The Big Picture Goal: Metadata based modeling and querying of web
resources Stages:
Semi automated metadata extraction from web resources Focused crawling fits here!
Extending SQL to support ranking and text-based operations in an integrated manner
Developing query processing algorithms Prototyping a digital library application for CS
resources

Overview Motivation Background & related work Interclass rules for focused crawling Preliminary results

Motivation Crawlers a.k.a. bots,spiders, robots Goal: Fetching all the pages on the Web, to allow
succeding useful tasks (e.g., indexing) “all pages”: means somewhat 4 billion pages
today (due to Google) Requires enormous hardware and network resources Consider the growth rate & refresh rate of Web What about hidden-Web and dynamic content?

Motivation Certain applications do need such powerful
(and expensive) crawlers e.g., a general purpose search engine
And some others don’t... e.g., a portal on computer science papers, or
people homepages...

Motivation Let’s relax the problem space: “Focus” on a restricted target space of Web pages
that may be of some “type” (e.g., homepages) that may be of some “topic” (CS, quantum physics)
The “focused” crawling effort would use much less resources, be more timely, be more qualified for indexing & searching purposes

Motivation Goal: Design and implement a focused Web
crawler that would gather only pages on a particular “topic” (or class) use interclass relationships while choosing the
next page to download Once we have this, we can do many interesting
things on top of the crawled pages I plan to be around for a few more years!!!

Background: A typical crawler Starts from a set of “seed pages” Follows all hyperlinks it encounters, to
eventually traverse the entire Web Applies breadth-first search (BFS) Runs endless in cycles
to revisist modified pages to access unseen content
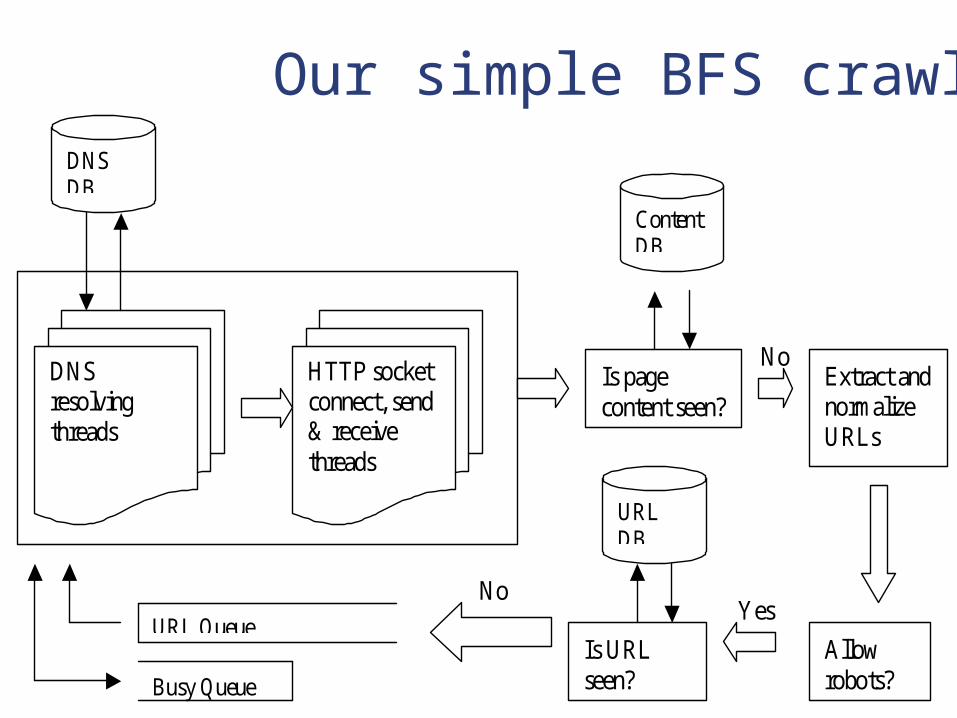
Our simple BFS crawler
No
No
Yes
HTTP socket connect, send & receive threads
DNS resolving threads
DNS DB
Is page content seen?
Extract and normalize URLs
Allow robots?
Is URL seen?
URL Queue
Busy Queue
Content DB
URL DB

Crawling issues... Multi-threading
Use separate and dedicated threads for DNS resolution and actual page downloading
Cache and prefetch DNS resolutions Content-seen test
Avoid duplicate content, e.g., mirrors Link extraction and normalization
Canonical URLs

More issues... URL-seen test
Avoid being trapped in a cycle! Hash visited URLs by MD5 algorithm and
store in a database. 2-level hashing to exploit spatio-temporal
locality Load balancing among hosts: Be polite!
Robot exclusion protocol Meta tags

Even more issues?! Our crawler is simple, since issues like
Refreshing crawled web pages Performance monitoring Hidden-Web content
are left out... And some of the implemented issues can
be still improved “Busy queue” for the politeness policy!

Background: Focused crawling
“A focused crawler seeks and acquires [...] pages on a specific set of topics representing a relatively narrow segment of the Web.” (Soumen Chakrabarti)
The underlying paradigm is Best-First Search instead of the Breadth-First Search

Breadth vs. Best First Search

Two fundamental questions Q1: How to decide whether a downloaded
page is on-topic, or not?
Q2: How to choose the next page to visit?

Early algorithms FISHSEARCH: Query driven
A1: Pages that match to a query A2: Neighborhood of the pages in the above
SHARKSEARCH: Use TF-IDF & cosine measure from IR to
determine page relevance Cho et. al.
Reorder crawl frontier based on “page importance” score (PageRank, in-links, etc.)

Chakrabarti’s crawler Chakrabarti’s focused crawler
A1: Determines the page relevance using a text classifier
A2: Adds URLs to a max-priority queue with their parent page’s score and visits them in descending order!
What is original is using a text classifier!

The baseline crawler A simplified implementation of
Chakrabarti’s crawler It is used to present & evaluate our rule
based strategy Just two minor changes in our crawler
architecture, and done!!!
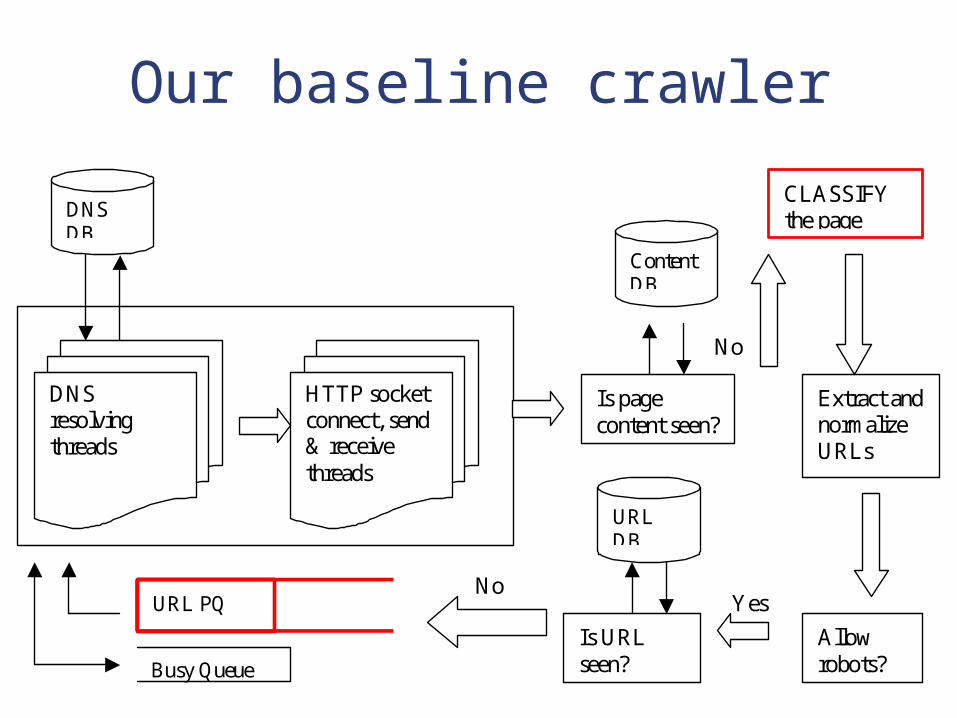
Our baseline crawler
No
No
Yes
HTTP socket connect, send & receive threads
DNS resolving threads
DNS DB
Is page content seen?
Extract and normalize URLs
Allow robots?
Is URL seen?
URL PQ
Busy Queue
Content DB
URL DB
CLASSIFY the page

The baseline crawler An essential component is text classifier
Naive-Bayes classifier called Rainbow Training the classifier
Data: Use a topic taxonomy (The Open Directory, Yahoo).
Better than modeling a negative class

Baseline crawler: Page relevance Testing the classifier
User determines focus topics Crawler calls the classifier and obtains a
score for each downloaded page Classifier returns a sorted list of classes and
scores (A 80%, B 10%, C 7%, D 1%,...)
The classifier determines the page relevance!

Baseline crawler: Visit order The radius-1 hypothesis: If page u is an on-
topic example and u links to v, then the probability that v is on-topic is higher than the probability that a random chosen Web page is on-topic.

Baseline crawler: Visit order Hard-focus crawling:
If a downloaded page is off-topic, stops following hyperlinks from this page.
Assume target is class B And for page P, classifier gives:
A 80%, B 10%, C 7%, D 1%,... Do not follow P’s links at all!

Baseline crawler: Visit order Soft-focus crawling:
obtains a page’s relevance score (a score on the page’s relevance to the target topic)
assigns this score to every URL extracted from this particular page, and adds to the priority queue
Example: A 80%, B 10%, C 7%, D 1%,... Insert P’s links with score 0.10 into PQ

Rule-based crawler: Motivation Two important observations: Pages not only refer to pages from the
same class, but also pages from other classes. e.g., from “bicycle” pages to “first aid”
pages Relying on only radius-1 hypothesis is
not enough!

Rule-based crawler: Motivation Baseline crawler can not support tunneling
“University homepages” link to “CS pages”, which link to “researcher homepages”, and which futher link to “CS papers”
Determining score only w.r.t. the similarity to the target class is not enough!

Our solution Extract rules that statistically capture
linkage relationships among the classes (topics) and guide crawler accordingly
Intuitively, we determine relationships like “pages in class A refer to pages in class B with probability X”
A B (X)

Our solution When crawler seeks for class B and page P
at hand is of class A, consider all paths from A to B compute an overall score S add links from P to the PQ with this score S
Basically, we revise radius-1 hypothesis with class linkage probabilities.
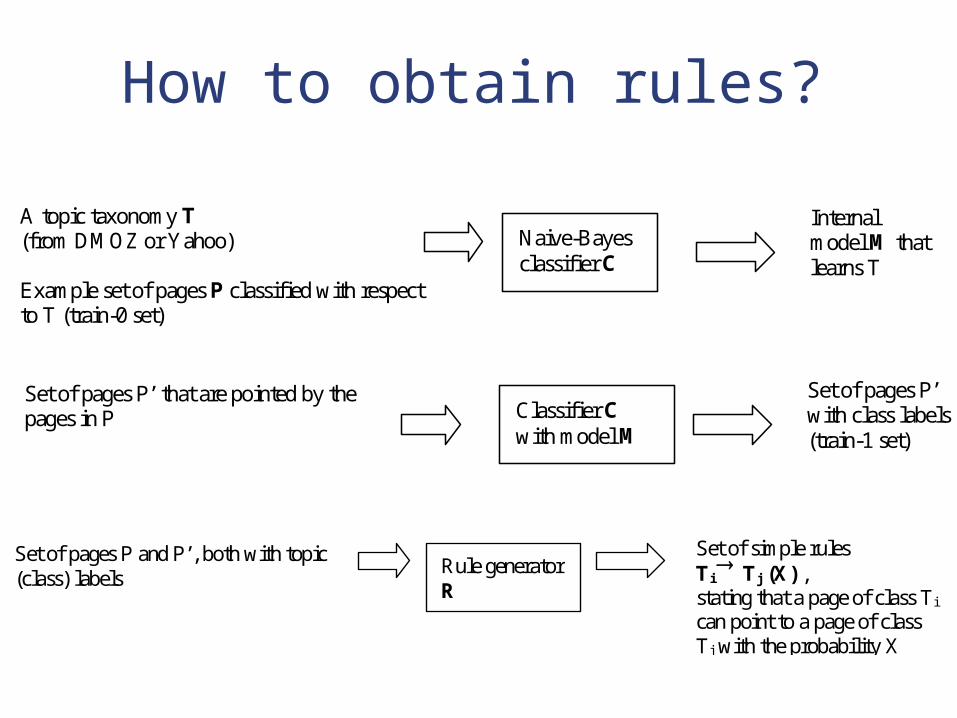
How to obtain rules?
Naive-Bayes classifier C
A topic taxonomy T (from DMOZ or Yahoo) Example set of pages P classified with respect to T (train-0 set)
Internal model M that learns T
Set of pages P’ that are pointed by the pages in P
Classifier C with model M
Set of pages P’ with class labels (train-1 set)
Set of pages P and P’, both with topic (class) labels
Rule generator R
Set of simple rules Ti
Tj (X) , stating that a page of class Ti can point to a page of class Tj with the probability X

An example scenario Assume our taxonomy have 4 classes:
department homepages (DH) course homepages (CH) personal homepages (PH) sports pages (SP)
First, obtain train-0 set Next, for each class, assume 10 pages are fetched
pointed to by the pages in train-0 set

An example scenario
The distribution of links to classes
Inter-class rules for the above distribution
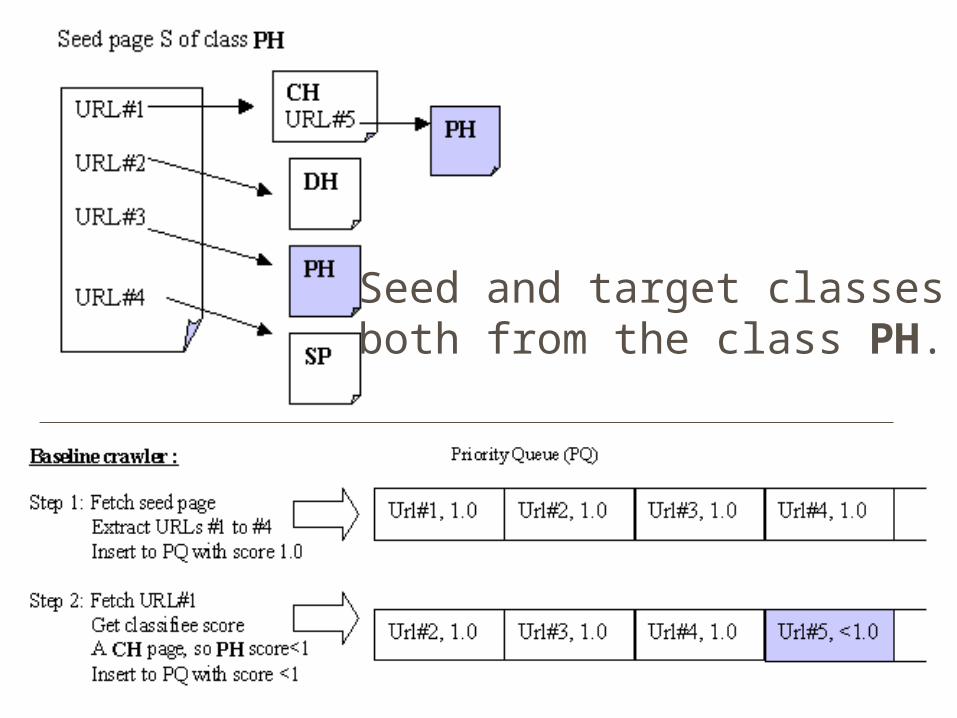
Seed and target classes are both from the class PH.
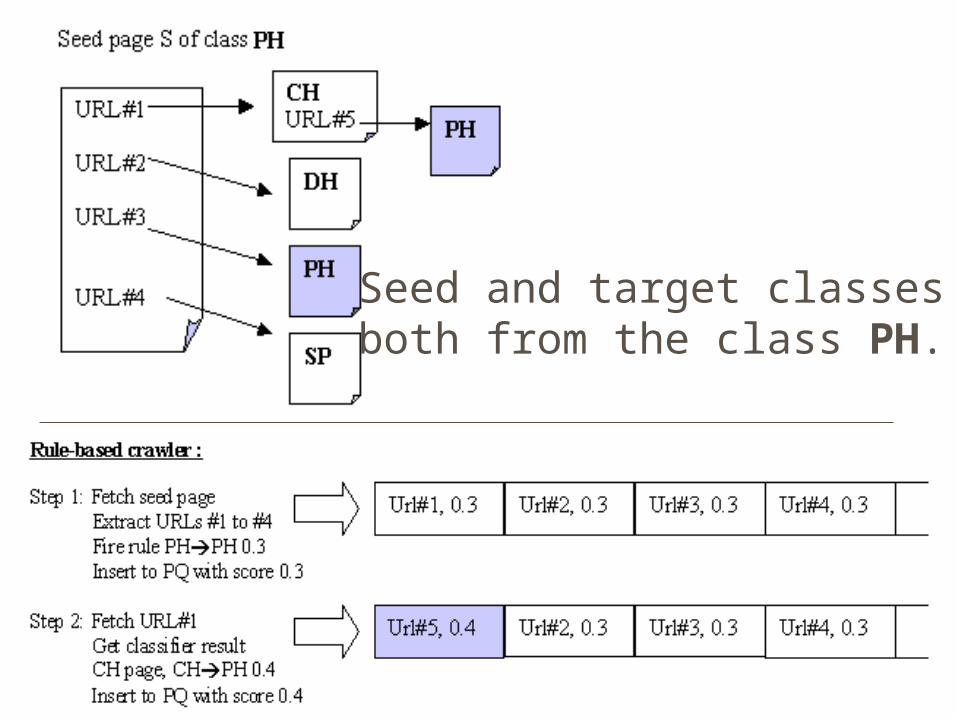
Seed and target classes are both from the class PH.

Rule-based crawlerRule-based approach succesfully uses class linkage information to revise radius-1 hypothesis to reach an immediate award

Rule-based crawler: Tunneling Rule based approach also support tunneling by a
simple application of transitivity. Consider URL#2 (of class DH)
A direct rule is: DH PH (0.1) An indirect rule is:
from DH CH (0.8) and CH PH (0.4)
obtain DH PH (0.8 * 0.4 = 0.32) And, thus DH PH (0.1 + 0.32 = 0.42)

Rule-based crawler: TunnelingObserve that
i) In effect, the rule based crawler becomes aware of a path DH CH PH, although it has only trained with paths of length 1.
ii) The rule based crawler can succesfully imitate tunneling.

Rule-based score computation Chain the rules up to some predefined MAX-
DEPTH number (e.g., 2 or 3) Merge the paths with the function SUM If no rules whatsoever, stick on soft-focus score Note that
Rule db can be represented as a graph, and For a given target class all cycle free paths
(except self loop of T) can be computed (e.g., modify BFS)
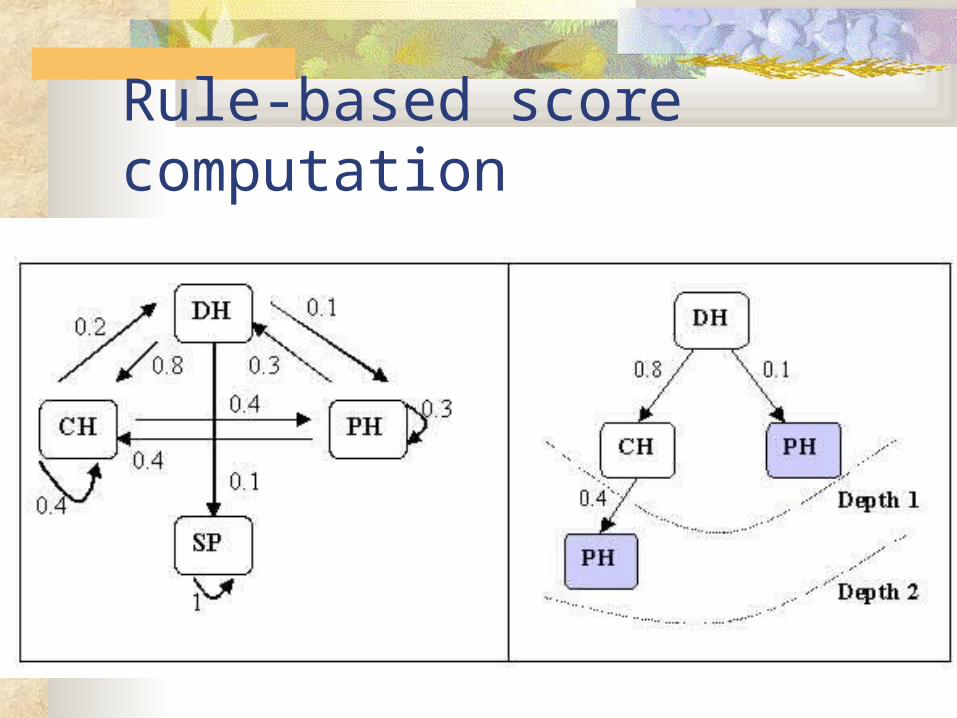
Rule-based score computation

Preliminary results: Set-up DMOZ taxonomy
leafs with more than 150 URLs 1282 classes (topics)
Train-0 set: 120K pages Train-1 set: 40K pages pointed to by 266
interrelated classes (all about science) Target topics are also from these 266
classes

Preliminary results: Set-up Harvest ratio: the average relevance of all
pages acquired by the crawler to the target topic
N
TURLlevance
HR
N
ii
1
),(Re
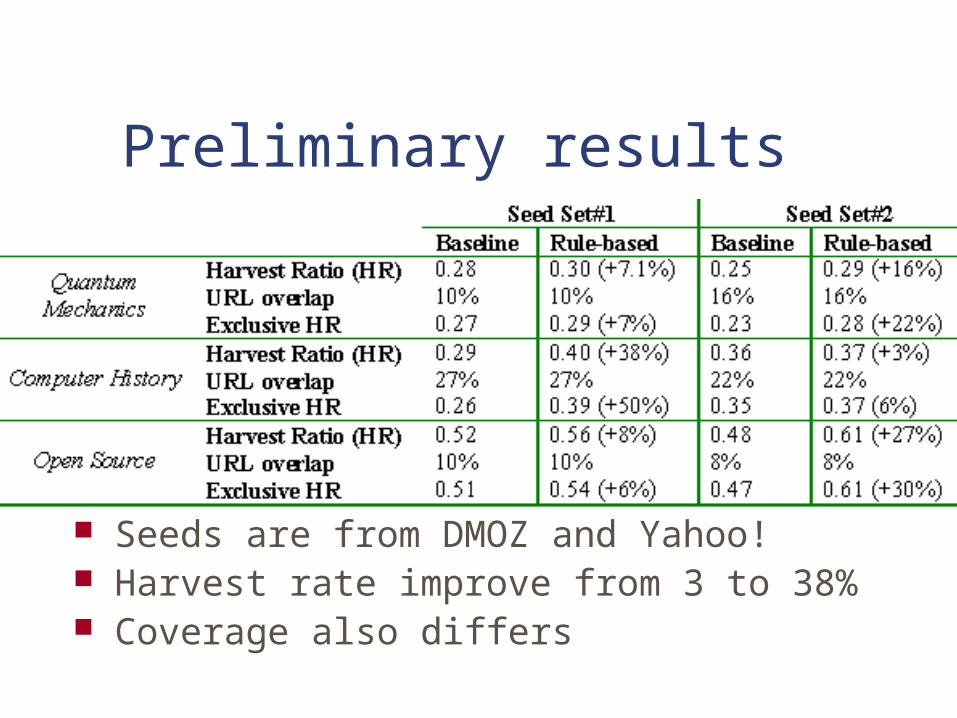
Preliminary results
Seeds are from DMOZ and Yahoo! Harvest rate improve from 3 to 38% Coverage also differs
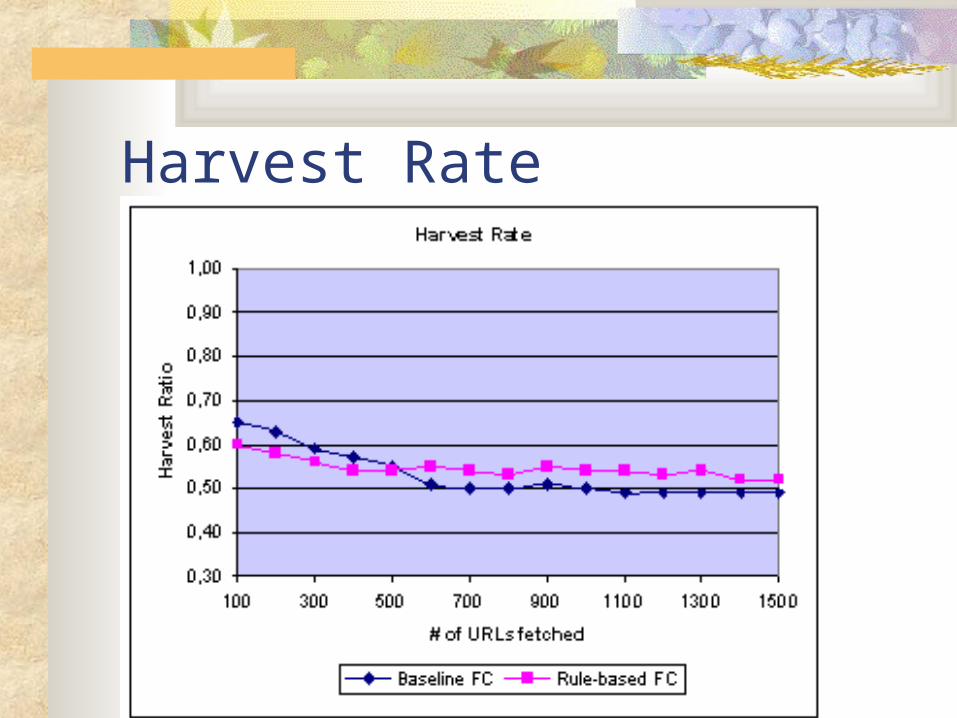
Harvest Rate

Future Work Sophisticated rule discovery techniques
(e.g., topic citation matrix of Chakrabarti et al.)
On-line refinement of the rule database Using the entire taxonomy but not only
leafs

Acknowledgments We gratefully thank Ö. Rauf Atay for the
implementation.

References I. S. Altıngövde, Ö. Ulusoy, “Exploiting Inter-
Class Rules for Focused Crawling”, IEEE Intelligent Systems Magazine, to appear.
S. Chakrabarti, “Mining the Web Discovering Knowledge from Hypertext Data.” Morgan Kaufmann Publishers, 352 pages, 2003.
S. Chakrabarti, M. H. van den Berg, and B.E. Dom, “Focused crawling: a new approach to topic-specific web resource discovery,” In Proc. of 8th International WWW Conference (WWW8), 1999.

Any questions???