ext generation storage engine: forestdb: couchbase connect 2015
TRANSCRIPT

FORESTDB: NEXT GENERATION STORAGE ENGINE FOR COUCHBASE
Chiyoung SeoSoftware Architect, Couchbase Inc.

©2015 Couchbase Inc. 2
Contents Why do we need a new KV storage engine? ForestDB
HB+-Trie Write Ahead Logging (WAL) Block buffer cache Evaluation
Optimizations for Solid-State Drives (SSDs) Volume manager inside ForestDB Lightweight and I/O efficient compaction Async I/O to exploit parallel I/O capabilities from SSDs
Summary

Why do we need a new KV storage engine?

©2015 Couchbase Inc. 4
Operate on huge volumes of unstructured data
Significant amount of new data is constantly generated from hundreds of millions of users or devices
Still require high performance and scalability in managing their ever-growing database
Underlying storage engine is one of the most critical parts in database systems to provide high performance / scalability
Modern Web / Mobile/ IoT Applications

©2015 Couchbase Inc. 5
Main storage index structure in a database field
Generalization of binary search tree
Each node consists of two or more {key, value (or pointer)} pairs Fanout (or branch) degree: # of KV pairs in a node
Node size is generally fitted into multiple page size
B+Tree

©2015 Couchbase Inc. 6
03/26
B+TreeKi: ith smallest key in the nodePi: pointer corresponding to Ki
Vi: value corresponding to Ki
f: fanout degreeK1 P1 … … Kd Pd
K1 V1 K2 V2 … … Kf Vf …
Index (non-leaf) node
Leaf node
… Kj Pj … … Kl Pl
K1 P1 … … Kj PjRoot node
…
…
K1 P1 … … Kf Pf Kj Pj … … Kn Pn
…
… …
… …
Kj Vj Kk Vk … … Kn Vn
Index (non-leaf) node

©2015 Couchbase Inc. 7
Not suitable to index variable or fixed-length long keys Significant space overhead as entire key strings are indexed in
non-leaf nodes
Tree depth grows quickly as more data is loaded
I/O performance is degraded significantly as the data size gets bigger
Several variants of B+Tree were proposed LevelDB (Google) RocksDB (Facebook) TokuDB (Tokutek) WiredTiger (MongoDB)
B+Tree Limitations
04/26

©2015 Couchbase Inc. 8
Fast and scalable index structure for variable or fixed-length long keys Targeting block I/O storage devices not only SSD but also
legacy HDD
Less storage space overhead Reduce write amplification
Regardless of the pattern of keys Efficient to keys both sharing common prefix and not
sharing common prefix
Goals
06/26

ForestDB

©2015 Couchbase Inc. 10
Key-Value storage engine developed by Couchbase Caching / Storage team
Its main index structure is built from Hierarchical B+-Tree based Trie or HB+-Trie
ForestDB paper accepted for publication in IEEE Trans. On Computers
Significantly better read and write performance with less storage overhead
Support various server OSs (Centos, Ubuntu, Debian, Mac OS x, Windows) and mobile OSs (iOS, Android)
Currently Beta and 1.0 GA will be released in July Underlying storage engine for secondary index, mobile, and
key-value engine in Couchbase
ForestDB

©2015 Couchbase Inc. 11
Multi-Version Concurrency Control (MVCC) with append-only storage model
Write-Ahead Logging (WAL)
A value can be retrieved by its sequence number or disk offset in addition to a key
Custom compare function to support a customized key order
Snapshot support to provide different views of database
Rollback to revert the database to a specific point
Ranged iteration by keys or sequence numbers
Transactional support with read_committed or read_uncommitted isolation level
Multiple key-value instances per database file
Manual or auto compaction configured per database file
Main Features

ForestDB: Main Index Structure

©2015 Couchbase Inc. 13
Trie (prefix tree) whose node is B+Tree A key is split into the list of fixed-size chunks (sub-string of the
key)
HB+Trie (Hierarchical B+Tree based Trie)
Variable length key: Fixed size (e.g. 4-byte)a83jgls83jgo29a…
07/26Lexicographical ordered traversal
Search using Chunk1
Document
B+Tree (Node of HB+Trie)
Node of B+Tree
Chunk1Chunk2Chunk3 …
a83j gls8 3jgo …
Search using Chunk2
Search using Chunk3 07/26

©2015 Couchbase Inc. 14
Prefix Compression
08/26
As original trie, each node (B+Tree) is created on-demand (except for root node)
Example: Chunk size = 1 byte
1stInsert ‘aaaa’
B+Tree using 1st
chunk as key

©2015 Couchbase Inc. 15
Prefix Compression
1stInsert ‘aaaa’
aaaaa
Distinguishable by first chunk ‘a’
08/26
As original trie, each node (B+Tree) is created on-demand (except for root node)
Example: Chunk size = 1 byte B+Tree using 1st
chunk as key

©2015 Couchbase Inc. 16
Prefix Compression
Distinguishable by
first chunk ‘b’
B+Tree using 1st
chunk as key
08/26
As original trie, each node (B+Tree) is created on-demand (except for root node)
Example: Chunk size = 1 byte
Insert ‘bbbb’
aaaa
1st
abbbb
b

©2015 Couchbase Inc. 17
Prefix Compression
B+Tree using 1st
chunk as key
08/26
As original trie, each node (B+Tree) is created on-demand (except for root node)
Example: Chunk size = 1 byte
Insert ‘aaab’
aaaa
1st
abbbb
bCannot
distinguish using first chunk
‘a’

©2015 Couchbase Inc. 18
Prefix Compression
Insert ‘aaab’
aaaaCannot distinguish
using first chunk ‘a’ First
distinguishable chunk: 4th
B+Tree using 1st
chunk as key
08/26
As original trie, each node (B+Tree) is created on-demand (except for root node)
Example: Chunk size = 1 byte
1st
abbbb
b
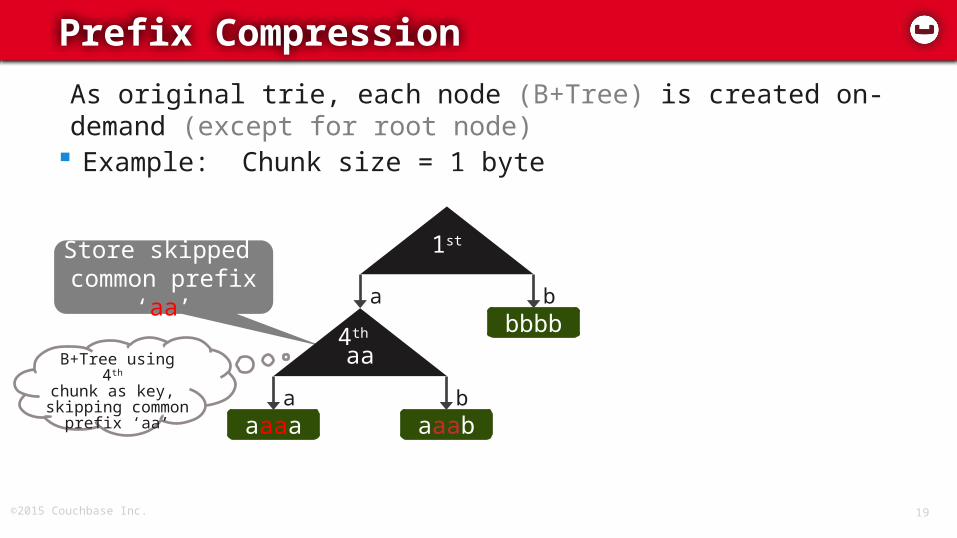
©2015 Couchbase Inc. 19
Prefix Compression
Store skipped common prefix
‘aa’
08/26
As original trie, each node (B+Tree) is created on-demand (except for root node)
Example: Chunk size = 1 byte
1st
abbbb
b
4th aa
aaaaa
aaabb
B+Tree using 4th chunk as key,
skipping common prefix ‘aa’
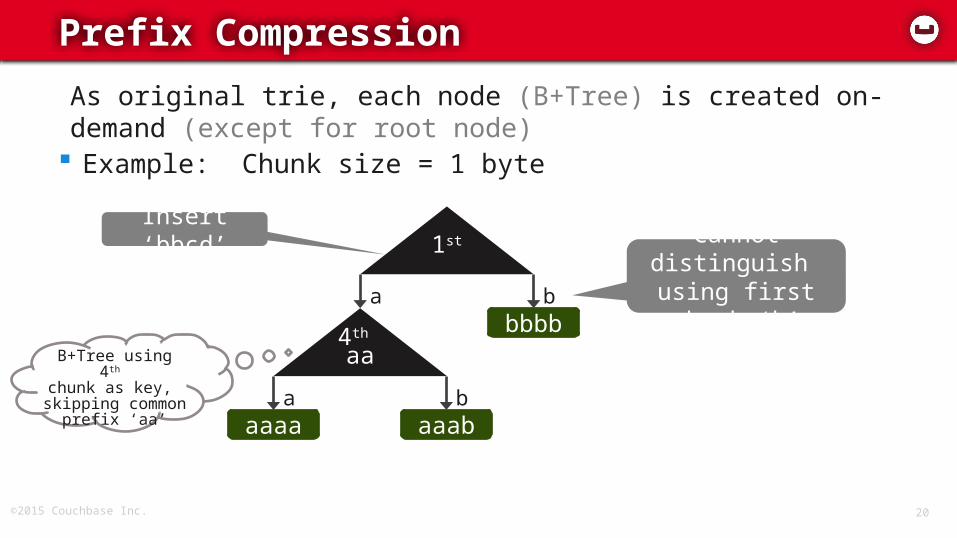
©2015 Couchbase Inc. 20
Prefix Compression
08/26
As original trie, each node (B+Tree) is created on-demand (except for root node)
Example: Chunk size = 1 byte
1st
abbbb
b
4th aa
aaaaa
aaabb
Insert ‘bbcd’ Cannot distinguish
using first chunk ‘b’
B+Tree using 4th chunk as key,
skipping common prefix ‘aa’

©2015 Couchbase Inc. 21
Prefix Compression
1st
abbbb
b
4th aa
aaaaa
aaabb
Insert ‘bbcd’ Cannot distinguish
using first chunk ‘b’
First distinguishable
chunk: 3rd
B+Tree using 4th chunk as key,
skipping common prefix ‘aa’
08/26
As original trie, each node (B+Tree) is created on-demand (except for root node)
Example: Chunk size = 1 byte

©2015 Couchbase Inc. 22
Prefix Compression
1st
a b
4th
aa
aaaaa
aaabb
3rd b
bbbb bbcdb c
Store skipped common prefix
‘b’
B+Tree using 3rd chunk as key,
skipping common prefix ‘b’
08/26
As original trie, each node (B+Tree) is created on-demand (except for root node)
Example: Chunk size = 1 byte

©2015 Couchbase Inc. 23
Benefits
When keys are sufficiently long & uniform random (e.g., UUID or hash value)
When keys have common prefixes (e.g., secondary index keys)
Example: Chunk size = 4 bytes
1st
Insert a83jfl2iejzm302k,dpwk3gjrieorigje,z9382h3igor8eh4k,283hgoeir8goerha,023o8f9o8zufisue
a83jfl2iejzm30
2k
a8 dpwk3gjrieorig
je
dp z9382h3igor8eh
4k
z9283hgoeir8goer
ha
28023o8f9o8zufis
ue
02
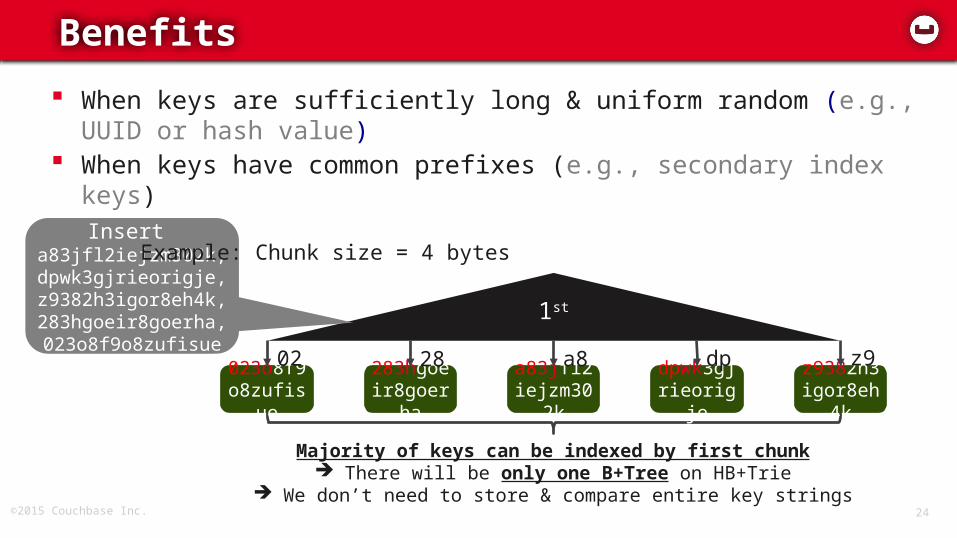
©2015 Couchbase Inc. 24
Benefits
09/26
1st
Insert a83jfl2iejzm302k,dpwk3gjrieorigje,z9382h3igor8eh4k,283hgoeir8goerha,023o8f9o8zufisue
a83jfl2iejzm30
2k
a8 dpwk3gjrieorig
je
dp z9382h3igor8eh
4k
z9283hgoeir8goer
ha
28023o8f9o8zufis
ue
02
Majority of keys can be indexed by first chunk There will be only one B+Tree on HB+Trie
We don’t need to store & compare entire key strings
When keys are sufficiently long & uniform random (e.g., UUID or hash value)
When keys have common prefixes (e.g., secondary index keys)
Example: Chunk size = 4 bytes

©2015 Couchbase Inc. 25
ForestDB maintains two index structures HB+Trie: key index Sequence B+Tree: sequence number (8-byte integer) index Retrieve the file offset to a value using key or sequence number
ForestDB Index Structures
DB file Doc Doc Doc Doc Doc Doc …
HB+Trie
B+Tree
key
Sequence number
11/26

ForestDB: Write Ahead Logging
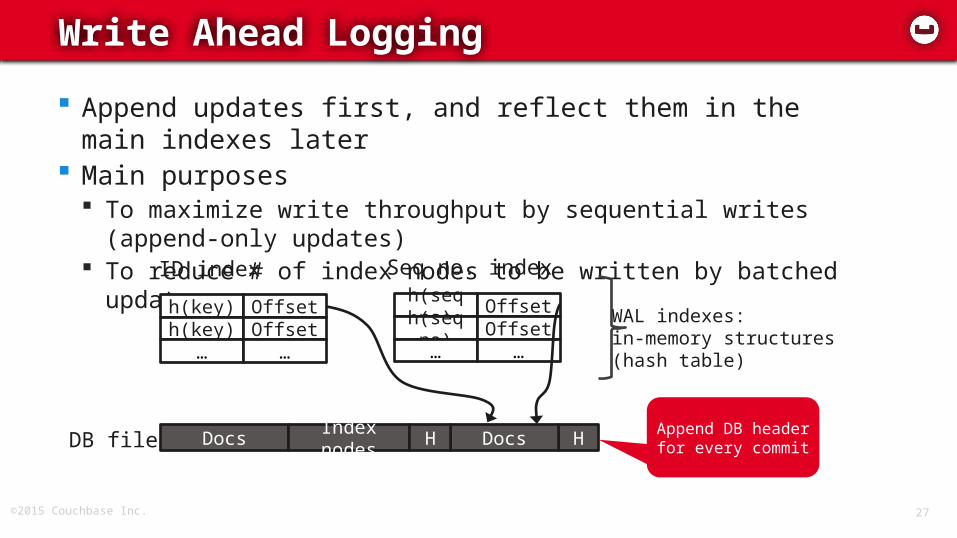
©2015 Couchbase Inc. 27
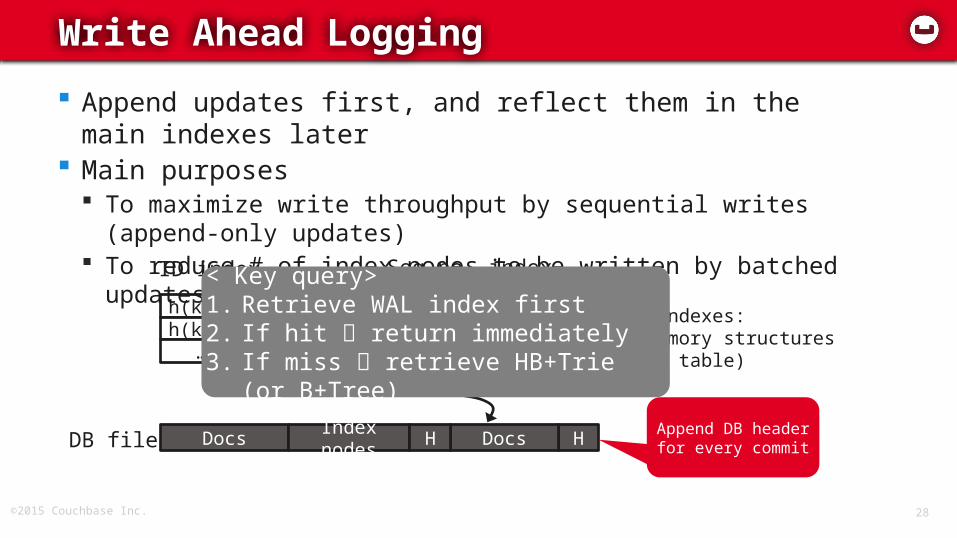
Append updates first, and reflect them in the main indexes later
Main purposes To maximize write throughput by sequential writes (append-
only updates) To reduce # of index nodes to be written by batched updates
Write Ahead Logging
Append DB headerfor every commitHDocsDB file Docs Index nodes
h(key)h(key)
…
OffsetOffset
…
h(seq no)h(seq no)…
OffsetOffset
…
ID index Seq no. index
WAL indexes:in-memory structures(hash table)
H
©2015 Couchbase Inc. 28
Append DB headerfor every commitHDocsDB file Docs Index nodes
h(key)h(key)
…
OffsetOffset
…
h(seq no)h(seq no)…
OffsetOffset
…
ID index Seq no. index
WAL indexes:in-memory structures(hash table)
H15/26
Append updates first, and reflect them in the main indexes later
Main purposes To maximize write throughput by sequential writes (append-
only updates) To reduce # of index nodes to be written by batched updates
Write Ahead Logging
< Key query>1. Retrieve WAL index first2. If hit return immediately3. If miss retrieve HB+Trie (or
B+Tree)

ForestDB: Block Cache

©2015 Couchbase Inc. 30
ForestDB has its own block cache layer Managed on a block basis Give higher priority to index node blocks than data
blocks Provide an option to bypass the OS page cache
Block Cache
HB+Trie (or Seq Index) WAL Index
Block Cache Layer
Block read/write
DB File (on File System)
File read/write (if cache miss/eviction occurs)

©2015 Couchbase Inc. 31
18/26
Global LRU list for database files that are currently opened
Separate AVL tree for each file to keep track of dirty blocks
Separate hash table for each file with a key (block_id) and a value (pointer to a cache entry in either the clean LRU list or AVL tree)
Block Cache
File LRU list
File 4
File 2
File 1
File 5
hash(BID)hash(BID)
…
ptrptr…
AVL-tree
Block Block
Hash table
Block Block Block Block
Dirty blocks
Clean LRU list
…
…

ForestDB: Compaction

©2015 Couchbase Inc. 33
Manual compaction Performed by calling the compact public API manually
Daemon compaction A single daemon thread inside ForestDB manages the
compaction automatically Support the additional API that allows the application to
retain the stale data up to a given snapshot marker A Compactor thread can interleave with a writer thread
Compaction

ForestDB: Evaluation

©2015 Couchbase Inc. 35
Evaluation Environments 64-bit machine running Centos 6.5 Intel Xeon 2.00 GHz CPU (6 cores, 12 threads) 32GB RAM and Crucial M4 SSD
Data Key size 32 bytes and value size 1KB Load 100M items Logical data size 100GB total
ForestDB Performance

©2015 Couchbase Inc. 36
LevelDB Compression is disabled Write buffer size: 256 MB (initial load), 4 MB (otherwise) Buffer cache size: 8 GB
RocksDB Compression is disabled Write buffer size: 256 MB (initial load), 4 MB (otherwise) Maximum number of background compaction threads: 8 Maximum number of background memtable flushes: 8 Maximum number of write buffers: 8 Buffer cache size: 8 GB (uncompressed)
ForestDB Compression is disabled WAL size: 4,096 documents Buffer cache size: 8 GB
KV Storage Engine Configurations
©2015 Couchbase Inc. 37
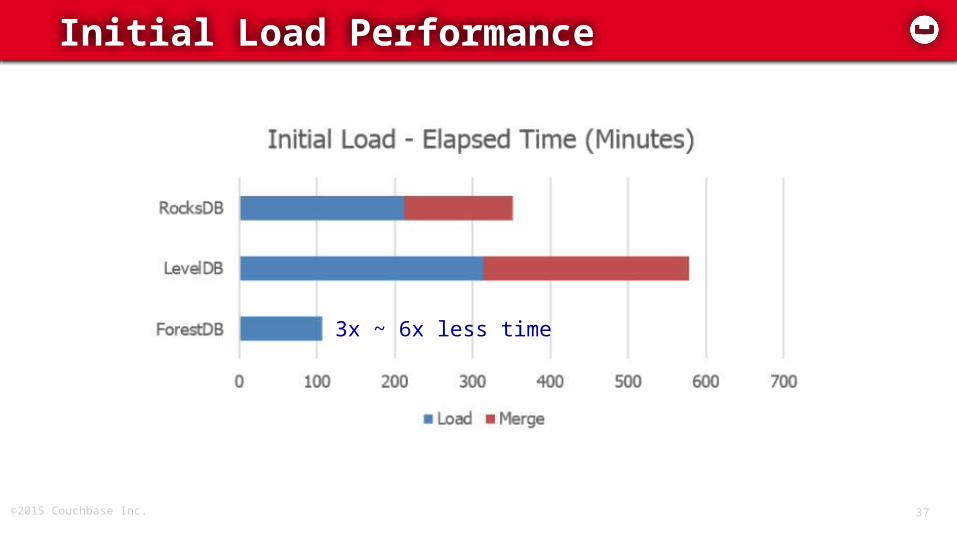
Initial Load Performance
3x ~ 6x less time

©2015 Couchbase Inc. 38
Initial Load Performance
4x less write overhead

©2015 Couchbase Inc. 39
Read-Only Performance
1 2 4 80
5000
10000
15000
20000
25000
30000
Throughput
ForestDB LevelDB RocksDB
# reader threads
Ope
ratio
ns p
er s
econ
d
2x ~ 5x
©2015 Couchbase Inc. 40
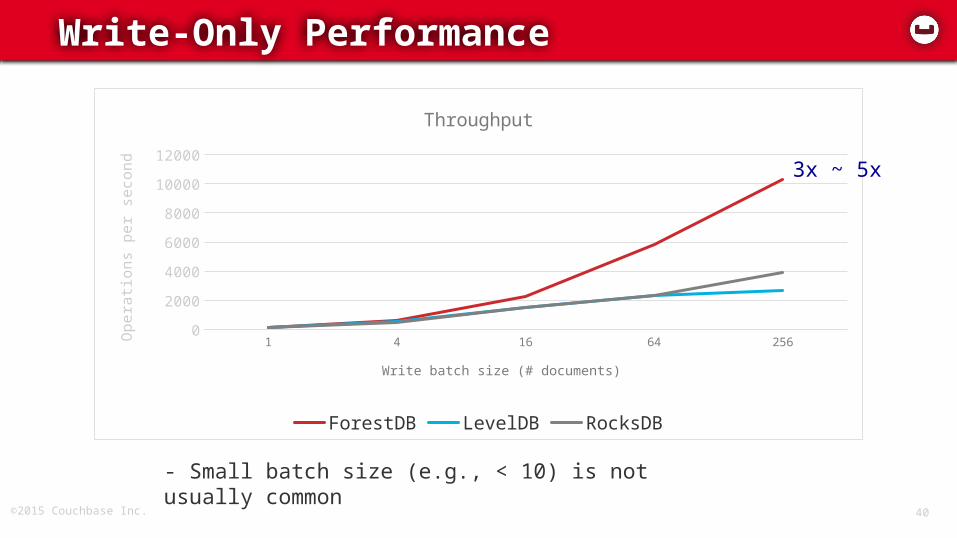
Write-Only Performance
1 4 16 64 2560
2000
4000
6000
8000
10000
12000
Throughput
ForestDB LevelDB RocksDB
Write batch size (# documents)
Ope
ratio
ns p
er s
econ
d
- Small batch size (e.g., < 10) is not usually common
3x ~ 5x

©2015 Couchbase Inc. 41
Write-Only Performance
1 4 16 64 2560
50
100
150
200
250
300
350
400
450
Write Amplification
ForestDB LevelDB RocksDB
Write batch size (# documents)
Writ
e am
plifi
catio
n(N
orm
aliz
ed t
o a
sing
le d
oc s
ize)
ForestDB shows 4x ~ 20x less write amplification

©2015 Couchbase Inc. 42
Mixed Workload Performance
1 2 4 80
2000
4000
6000
8000
10000
12000
Mixed (Unrestricted) Performance
ForestDB LevelDB RocksDB
# reader threads
Ope
ratio
ns p
er s
econ
d
2x ~ 5x

Optimizations for Solid-State Drives
Please join the deep dive session tomorrow presented by Prof. Sang-Won
Lee and Sundar Sridharan

©2015 Couchbase Inc. 44
26/26
OS File System Stack Overhead
SSD SSD SSD
Block I/O Interface (SATA, PCIe)
OS File System
Page Cache
Meta Data Mgmt
Database Storage Engine
SSD SSD SSD
Block I/O Interface (SATA, PCIe)
Database Storage Engine
… Buffer Cache
Typical Database Storage Stack
Advanced Database Storage Stack
Volume Manager

©2015 Couchbase Inc. 45
Required for append-only storage model Garbage collect stale data blocks
Use significant disk I/O bandwidth Read the entire database file and write all valid blocks
into a new file
Affect other performance metrics Regular read / write performance drops significantly
Database Compaction

©2015 Couchbase Inc. 46
Adapt the SSD Flash Translation Layer (FTL) to provide the new API SHARE Avoid copying non-stale physical blocks from the old file
to the new file Leverage Btrfs (B-tree file system) Copy-On-Write
(COW) Allow us to share non-stale physical blocks between the
old file and new file Much less write amplification and extend the SSD
lifespan
Compaction Optimization

©2015 Couchbase Inc. 47
Exploit async I/O library (e.g., libaio) to better utilize the parallel I/O capabilities by SSDs
Performance boost in various operations Multi-Get API to fetch multiple documents at once Reading non-stale blocks from the old file for compaction Traversing secondary indexes when documents satisfying
a query predicate are located in different blocks
Utilizing Parallel I/O Channels on SSDs
©2015 Couchbase Inc. 48
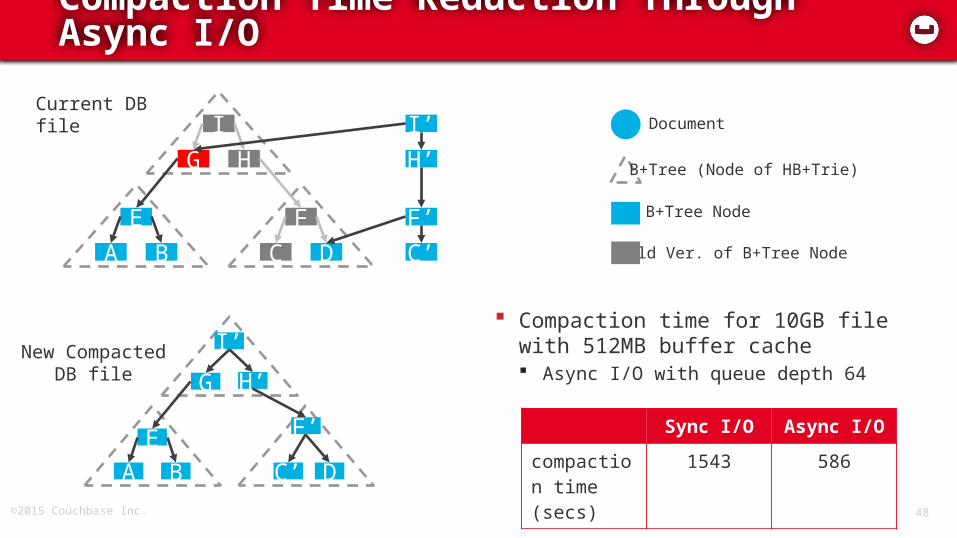
Compaction Time Reduction Through Async I/O
Document
B+Tree (Node of HB+Trie)
B+Tree Node
Old Ver. of B+Tree Node
I
G H
E
A B
F
C D C’
F’
H’
I’
G
EA B DC’
F’
H’
I’
Current DB file
New CompactedDB file
Compaction time for 10GB file with 512MB buffer cache Async I/O with queue depth 64
Sync I/O Async I/O
compaction time (secs)
1543 586

Summary

©2015 Couchbase Inc. 50
ForestDB Compacted main index structure built from HB+-Trie High-performance, space efficiency, and scalability
Various optimizations for Solid-State Drives Compaction Volume manager Exploiting parallel I/O channels on SSDs
ForestDB integrations Couchbase Server secondary index Couchbase Lite Couchbase Server KV engine Couchbase full-text search engine
Summary
