faculty of natural and computational science …
TRANSCRIPT

FACULTY OF NATURAL AND COMPUTATIONAL SCIENCE
DEPARTMENT OF COMPUTER SCIENCE
POST GRADUATE PROGRAM
TITLE: MINIMALLY SUPERVISED MACHINE LEARNING WORD SENSE
DISAMBIGUATES TO AMHARIC TEXT
PREPARED BY: - AKLOG EJGU
SUBMITTED TO DR. TESFA TEGEGNE

ii
Name and signature of Members of the Examining Board
Name Title Signature Date
________________________ Chairperson ___________ ________
________________________ Advisor ___________ ________
________________________ Examiner ___________ ________

iii
Declaration
I declare that the thesis is my original work and has not been presented for a degree
in any other University.
_________________
Date _________________
This thesis has been submitted for examination with my approval as university
advisor.
_________________
Date _________________

xix
Acknoweldgement
Above all. I would like to think God for his invaluable helps in my entire life span. Next , I would like
to express my sincere appreciation to Dr. Tesfa Tegegne for advising thesis. I appreciate the conti-
nuous support and timely advice he has given me, his encouragement helped shape the direction of my
work. He has continuously encouraged me and bifheartedly guided me on semisupervised machine
learning approach.
I would like to express my gratitude to my best friend ato Lemma Misganewufor his valuable sugges-
tions and helpful comments. I wish to thank my colleagues in computer science department. Finally I
wish thank my parents specially my wife W/o Betelhem Adane for their types of the document and also
continuous encouragement and support.

xx
List of Acronyms and Abbrevations
NLP Natural language process
MT Machine Translation
WSD word sense disambiguation
NBC British natural corpus
RBFN Radial basis function network
IR Information retrieval
LM Language model
SMT Statistical machine translation
LP Labele propagation
EM Expectation maximization
SSL Semisupervised learning
TP True positive
TN True negative
FN False negative
FP False positive

xxi
Table of Contents
Acknowledgment………………………………………………………………………….…………xix
List of Acronyms and Abbreviation………………………………………………… ………………..xx
List of Tables………………………………………………………………………….........................xxv
List of Figures…………………………………………………………………………………............xxvi
List of Appendixes………………………………………………………………………….…...........xxvii
Abstruct ……………………………………………………………………………………………….xxvii
CHAPTER ONE………………………………………………………………………………………………………………..1
INTRODUCTION…………………………………………………………………………….…………1
1.1.Background .................................................................................................................................. 1
1.2.Statement of the problem study ..................................................................................................... 3
1.3.Objective of the study ................................................................................................................... 5
1.3.1.General objective of the study .................................................................................................... 5
1.3.2.Specific objective of the study ................................................................................................... 5
1.4.Scope and limitation of the work ................................................................................................... 6
1.5.Significance of the study ............................................................................................................... 6
1.6.Methodology ................................................................................................................................ 6
1.6.1.Literature review ........................................................................................................................ 6
1.6.2.Data set collection and preparation ............................................................................................. 7
1.6.3.Tools and techniques .................................................................................................................. 8
1.7.Experimentation............................................................................................................................ 8
1.7.1.Data processing .......................................................................................................................... 8

xxii
1.7.2.Training and testing ................................................................................................................... 9
1.7.3.Evaluation techniques ................................................................................................................ 9
1.8.Financial cost ................................................................................................................................ 9
1.9.summary ..................................................................................................................................... 10
1.10.Thesis Organization .................................................................................................................. 11
CHAPTER TWO.............................................................................................................................................................. 12
LITERATURE REVIEW ................................................................................................................................................ 12
Introduction ...................................................................................................................................................................... 12
2.1. Word sense disambiguation work ............................................................................................... 13
2.2. Steps in word sense disambiguation ........................................................................................... 14
2.2.1. Choose of word sense ............................................................................................................. 14
2.2.2 External of knowledge of source .............................................................................................. 14
2.2.3 Representation of context ......................................................................................................... 14
2.2.4 Selection of classification approach ......................................................................................... 15
2.3. Natural language processing (NLP) ............................................................................................ 15
2.4. word sense disambiguation of application .................................................................................. 15
2.4.1. Information retrieval ............................................................................................................... 16
2.4.2. Word sense disambiguation for text mining............................................................................. 17
2.4.3. Machine translation ................................................................................................................. 18
2.5 word sense disambiguation ......................................................................................................... 19
2.5.1. Corpus based method .............................................................................................................. 19
2.5.2 Knowledge –based approach .................................................................................................... 19

xxiii
2.5.3. Supervised learning method .................................................................................................... 20
2.5.4. Minimally supervised learning method ................................................................................... 21
2.3.4.1 Bootstrapping algorithm ........................................................................................................ 22
2.3.4.2 Yarowsky bootstrapping algorithm........................................................................................ 23
2.3.4.3. Bilingual bootstrapping methods ......................................................................................... 24
2.3.4.4. Graph based minimally algorithm ........................................................................................ 24
2.6. Unsupervised learning method ................................................................................................... 23
2.7. Hybrid Techniques ..................................................................................................................... 23
2.8. Related empirical investigation .................................................................................................. 24
2.8.1 Global research tasks ......................................................................................................... 24
2.8.1.1 Bayesian networks ................................................................................................... 24
2.8.1.2 Radial basis function (RBF) ....................................................................................... 25
2.8.1.3 Hierarchical Clustering Techniques ........................................................................ 26
2.9. Local research Tasks ................................................................................................................. 28
CHAPTER THREE.......................................................................................................................................................... 31
WORD SENSE DISAMBIGUATION IN AMHARIC LANGUAGE .................................................................................. 31
3.1. Amharic language ...................................................................................................................... 31
3.2. Amharic witting system ........................................................................................................... 32
3.3. Amharic punctuation marks ....................................................................................................... 33
3.4. Amharic morphology ................................................................................................................. 34
3.5 ambiguities in Amharic ............................................................................................................... 35
3.5.1 orthographic ambiguities .......................................................................................................... 35
3.5.2. Referential ambiguity .............................................................................................................. 36

xxiv
3.5.3 syntactic (structural ) ambiguity ............................................................................................... 36
3.5.4. phonological ambiguity ........................................................................................................... 37
3.5.5. lexical ambiguity..................................................................................................................... 37
3.5.5.1 homonymy ............................................................................................................................ 37
3.5.5.2 Categorical ambiguity ........................................................................................................... 37
3.5.5.3. Homophone affixes .............................................................................................................. 38
3.5.5.4. Synonymy ............................................................................................................................ 38
CHAPTER FOUR ............................................................................................................................................................ 39
Data collection or preparation and implementation design ................................................................................................... 39
4.1 data collection ........................................................................................................................... 39
4.2. Preprocessing techniques and algorithms ................................................................................... 40
4.2.1 Tokenization ............................................................................................................................ 40
4.2.2 Stop word removal ................................................................................................................... 41
4.2.3.Stemming ................................................................................................................................ 41
4.2.5.Normalization .......................................................................................................................... 42
Types of normalization ..................................................................................................................................................... 43
4.2.6.Preparing machine readable data ........................................................................................... 44
CHAPTER FIVE .............................................................................................................................................................. 49
EXPERIMENTATION AND DISCUSSION EVALUATION............................................................................................. 49
5.1Experimentation setup for supervised........................................................................................... 50
5.1.1Bayes Net test ........................................................................................................................... 53
5.1.2. RBF network .......................................................................................................................... 64

xxv
5.2. Experimentations setup for semi supervised ............................................................................ 75
5.2.1 Bayes net test .......................................................................................................................... 76
5.2.2. RBF network test .................................................................................................................... 83
Discussions ........................................................................................................................................................................ 89
5.3. Compared of classification algorithm ......................................................................................... 89
5.4. Compared of supervised and semi-supervised ............................................................................ 90
CONCLUSION AND RECOMMENDATION .............................................................................................................. 95
6.1.Conclusion .................................................................................................................................. 96
6.2. Recommendation ....................................................................................................................... 98
REFERENCE ................................................................................................................................. 103
List of Tables
Table1.1 cost of the research work ..................................................................................................... 9
Table 3.1 an assumption regularity of letter shapes drive for various character.................................. 32
Table 3.2 Amharic punctuation marks............................................................................................... 34
Table 4.1 Ambiguous words sentences ............................................................................................. 39
Table 4.2 Amharic characters with identical sound ........................................................................... 43
Table 4.3 sample data set ................................................................................................................. 44
Table 4.4. confusion matrix for two class (A and B) ........................................................................ 46
Table 5.1. experimentation setup ...................................................................................................... 51
Table 5.2. compared of algorithm at different class level .................................................................. 75
Table 5.3 accuracy performance to satisfied at various levels of class using bayes net. ..................... 82
Table 5.4 accuracy performance to satisfied at various levels of class using RBF network ............... 88

xxvi
Table 5.5 performance evaluation at different classes stages. ........................................................... 89
Table 5.6 results using minimally supervised learning:- bayes net and RBF network algorithm........ 91
Table 5.7. results using minimally supervised learning:- bayes net ,RBF network and Hierarchica algorithm
(3-3 window………………………………………………………..91
List of Figure
Figure 2.1 ......................................................................................................................................... 27
Fig 4.1. Architecture for the proposed WSD system ......................................................................... 49
Figure 5.1 confusion matrix three classes or sense using bayesNet. ................................................... 54
Figure 5.2 confusion matrix three classes or sense using bayesNet…………………...………49
Figure 5.3 confusion matrix for nine classes using bayes net. ............................................................ 57
Figure 5.4 confusion matrix for twelve classes using bayes net. ....................................................... 59
Figure 5.5 confusion matrix for fifteen classes using bayes net. ....................................................... 62
Figure 5.6 confusion matrix for three classes RBF network.............................................................. 65
Figure 5.7 confusion matrix for six classes RBF network. ................................................................ 66
Figure 5.8 confusion matrix for nine classes RBF network. .............................................................. 68
Figure 5.9 confusion matrix for twelve classes RBF network. ............................................................................................. 70
Figure 5.10 confusion matrix for fifteen classes RBF network. ........................................................ 73
Figure 5.11 confusion matrix for three classes using bayes net ......................................................... 76
Figure5. 12 confusion matrix for six classes or sense of using bayes net ........................................... 78
Figure 5. 13 confusion matrix for nine classes using bayes net ......................................................... 79
Figure 5.14 confusion matrix for twelve classes using bayes net ...................................................... 80
Figure 5.15 confusion matrix for fifteen classes using bayes net ....................................................... 82
Figure 5.15 confusion matrix for three classes of sense using RBF network ...................................... 83

xxvii
Figure 5. 17 confusion matrix for six classes or sense using RBF network ........................................ 84
Figure 5.18 confusion matrix for nine classes of using RBF network ................................................ 85
Figure 5.19 confusion matrix for twelve classes using RBF network ............................................... 86
Figure 5.20 confusion matrix for fifteen classes of sense using RBF network .................................. 88
Figure 5.21 performance evaluation different classification algorithm and different class levels ....... 90
List of appendixes
Apppendixes Amharic Alphabetic A ................................................................................................................................. 108
Apppendixes Amharic Engilsh translation B .................................................................................................................... 108

xxviii
Abstract
The main objective of this thesis was to design word sense disambiguation (WSD) minimally final
model for Amharic words semi- upervised learning is half way between the supervised and unsuper-
vised learning. In addition to unlabeled data, the algorithm is provided with some supervision informa-
tion but not necessarily for all example data. Due to the unavailability of Amharic word net. Only five
words and have their fifteen classes or senses were selected. These words were mesal, ras, yemigeba,
gb, kena, a different data sets using three meanings or sense of words were prepared for the develop-
ment of this Amharic WSD prototype. The final classification work was done on fully labeled training
set using RBF network and bayes net classification algorithms on weka package.
Key words : word sense disambiguation, semi-supervised learning bayes net and RBF network.

1
CHAPTER ONE
INTRODUCTION
1.1. Background Word sense disambiguation (WSD) is process of determining the actual sense of words in a given con-
text. The task word sense disambiguation consists of assigning the most important meaning to a poly-
semous word within a given context. Applications like machine translation, knowledge acquisition,
common sense reasoning, ambiguities semantics and other require knowledge about Amharic word
meaning and also WSD is considered essential for all the applications(Rou Mihalcea and Ehsalforu-
zue)[1]. Word sense disambiguation is the problem of selecting a sense for a word from a set of prede-
fined possibilities. Word sense discrimination is the problem of dividing the usage of a word into differ-
ent meaning, without regard to any particular existing sense inventory [2]. Ambiguity rarely a problem
for human in their current communication or information interchanges. Many words in Amharic lan-
guage have more than one lexical sense or meanings unless only one of them represent in appeared con-
text so that word sense disambiguation studies with the selected true sense (i.e. meaning)of words in a
given document. Word sense disambiguation is a problem in computational linguistics [3]. Word sense
disambiguation is appropriate problem application in domain of natural language processing (NLP).
Machine translation (MT) cannot work without few form of disambiguation. Alike the other languages,
Amharic word have many ambiguous words as an example “ራስ” whchic has three meanings in differ-
ent context such as “to yourself”, “to head”, “to moisture”. It has three different meanings or senses.
Thus, studing Amharic word sense disambiguation is very important to identify the meanings (senses)
of a word based on the context in a sentence or prhase.
With the developing world and business people move from one country to other and state to state. Cur-
rently,huge amont of data are computerized, many of websites and blogs consists of the relevant infor-
mation. When we require accessing this information the challenge is understanding of the text. To over-
come this challenges, it is vital to develop a technology ; however, natural language processing system is
not developed and it lacks resouces and tools..
Amharic has been one of the under-resourced languages both in terms of electronic resources and natu-
ral language processing tools to access favourable conditions that information technology has brought
(Atelach Alemu and Lars, 2010).

2
According to Getahun (2012) word sense disambiguates is a systematically and technically will be pre-
pare to minimizes or decreases word ambiguous supervised method requires external label thetraining
data which take effort(not cheap) , costly , subjective and time consume. Solomon (2011) studied to ex-
amine using the same dataset and target words tested by Solomon (2010) and unsupervised learning
techniques get in significance poor accuracy and produce outcome that are not satisfying for many ap-
plications and always drive sets of word sense that are not to humans. Getahun (2012) his studied ex-
amined both supervised and unsupervised techniques with together. It attempt to the label and unlabeled
data training. It have their own limitations to goals of a good classification and cluster result even if se-
misupervised techniques has used to minimize knowledge acquisition bottleneck and to improve poor
performance but also has a limitation which is identical problems by making use of many unlabelled and
labeled data training. Agerie (2013) tried to test the result of ensemble learning algorithm to solve un-
solved problem in the previous works of word sense disambiguation. It improves the better performance
using by classifier algorithm. They still needs different amount of annotation (zha 2005; chapplle etal,
2006; valchas, 2010) [20] It introduces a new method for solving the Amharic ambiguous word in text.
The technique can be thinks as minimally supervised learning word sense disambiguates, it desire to
solve unsolved problem in Amharic word more than two meaning within a given context. And also im-
proving better performance by using graph based algorithm. Word sense disambiguation has always a
hot research issue of natural language processing (NLP) (according to Jinqwen zhan,Yamin chen) [25]
Word sense disambiguation , automatically identifying the meaning ambiguous word in a context and
which should be solve the problem in word sense disambiguation. Because it used to a little data set for
training purpose and generalization the concept learning from the training corpus.
Natural language most common way to interaction with each other but it is not simply understand all the
language. To known the different language machine translation (MT) is needed. Machine translation is
the most important application which helps to know any other languages in very poor time and cost. Re-
late to the context some challenge are faced by researchers like word ambiguous which have identical
means, few words spelled various and also different meanings. Therefore word sense disambiguation is
used to understand the correct meaning of the word with respect to context in which that is used [23]
(Manoj chandak). As a result that we used to higher education and 9-12 grades in English language ex-
cept Amharic course (Gunnar Eriksson) [20]. In general Ethiopia there are nations and nation nationali-
ties. Therefore Amharic is the official language of the federal government in Ethiopia and also

3
the south region and Amhara region. Amharic is it has the mother tongue more than 20 million and
second language 5 million people the information communication media used to Amharic language.
Amharic language has many rich words, phrases, sentences; morphology, lexical, acoustic, semantics
word and also their own Fidel’s stand itself like ሀ it is not develop perfectly to deliver the information of
the society. So that there are some Amharic text documented, publishes, report researches, music’s,
films, comedy, news, magazines, poetry and web pages are available for Amharic language.
1.1. Statement of the problem study Word sense disambiguation(WSD) is an open challenge natural languages process(NLP) which governs
the process of to determine which sense of a word(i.e. meaning) is used in a sentence when word has
multiple meaning(polysemy). To date, there are many research works on word sense disambiguation
have been done in English and a lot of other languages like that Chinese, Japanese, French and Spanish
to developing . Many natural language process (NLP) such that text summarization, information retriev-
al, machine translation, information extraction and question and answer. Practically outcome of these
investigates show that the performance of the system considers higher after word sense disambiguation
is applied to them. The study by the Fail (2009), for instance, demonstrated a machine translation system
for two various languages (English and Persian) with a word sense disambiguation system combine with
it. This attempt to show that disambiguation process by using understanding decision trees accepted a
better precision in detecting the correct translation of ambiguities words. The study by Gonzalo et al
(1998) also showed the ability for word sense disambiguation to improve the performance of informa-
tion retrieval system. In locally the Amharic language word sense disambiguation has been studied us-
ing three machine learning techniques in the previous years. At the beginning time Solomon (2010), at-
tempted to supervise learning techniques by using Bayesian classifier. It takes the total amount of 10 45
English sense sample from British natural corpus (NBC) for five correct words, and an investigated de-
veloped word sense disambiguation size from 70 to 80%. The second investigate Solomon (2011) at-
tempted to unsupervised machine learning techniques using identical data set and target words attempt
by Solomon(2010). However the performance of the system potentiated by the second investigated was
not higher to that of the first study, it revealed promising outcome. Getahun (2012) as far as tried to test
the result of semi supervised learning to resolve the gab of the two individual techniques; i.e. the re-
quired for manually annotated corpus for supervised techniques and less performance of unsupervised
techniques. Agerie (2013) tried to examine the result of ensemble learning algorithm to solve the gab of

4
the previous work on the Amharic word sense disambiguation. It was improve the performance by using
the ensemble algorithm. The local investigates showed that outcome they were promising. Their works
were lowest toword sense disambiguation in Amharic language which is poor privilege language in au-
tomated natural language process systems. However this contribution there is investigates have some
problem. Firstly all the local word sense disambiguation investigates target word only two meanings
within given context in Amharic text each. With this not consider for more than two meaning in ambigu-
ities target words employed, it is challenge to come up with a model can solve the ambiguity problem.
Secondly, it had some problem to build much labeled data sets, which is improve to be time consuming
and expensive. Techniques, which can be make a model by employing an integrated of few annotated
data and more unlabeled instance the performance should be consider. Thirdly the decision tree as base
classifier for Ad boost and Bagging are some problem. So that a good involve other poor base classifier
like graph based or bayes net and RBF network to benefit from their ability in finding in a data that can
be important complex tasks such as word sense disambiguation.
Taking in to consideration this limitation, the researchers indicates for further investigates that employ
other machine learning techniques with a good dataset and target words. Based on the limitation ex-
plored in the local investigates reviews, the current study show to employ minimally supervised learning
techniques is effectively, improving the performance by using a graph based(Bayes net) algorithm, radi-
al basis function network (RBF network) and hierarchical cluster algorithm. The limitation related to
limited dataset and target words by a way of addressing and RBF network algorithm gained more atten-
tion from the research attention from the research community and currently achieve performance close
to the state of the art. The current study consists five target words and whose means more than two
meaning is within a given context collected from various Amharic resource like 5-8 grade text book. For
this advantage, this investigates tests to address the following research question.
Can a minimally supervised techniques improve the performance of Amharic word sense disam-
biguation using RBF network?
Which of minimally supervised learning approach brings best performance for our dataset?
How the cluster by Hierarchical solving for the Amharic ambiguous word?
What tools and algorithm are better for word sense disambiguation in Amharic text such as clas-
sification, association rule mining, hierarchical cluster, bayes net algorithm, algorithm(RBF
network) and cluster ?

5
How to study with the word sense disambiguation with in Amharic text to effectively, efficiently
and scalable minimally supervised machine tasks?
How to get simply a train corpus in Amharic languages word sense disambiguation?
How to select the train ambiguous word in Amharic word sense disambiguation?
How to compare with the minimally and supervised approach the Amharic languages word
sense disambiguation corpus?
What is the application of minimally supervised machine learning techniques in Amharic lan-
guages?
1.2. Objective of the study
1.3.1. General objective of the study
The general objective of this thesis is to design and develop Word Sense Disambiguation systems for
Amharic text. to study the application of minimally supervised machine learning techniques to word
sense disambiguation of Amharic texts.
1.3.2. Specific objective of the study
Based on the general objective, the study attempts to address the following specific objectives.
The ambiguous words study to in Amharic understanding to word sense disambiguation in the
language;
“acquire training and test data set(corpus)”;
The compression of the different selected to the algorithm in the activity of minimally supervised
WSD for Amharic words;
Develop and train word sense disambiguation prototype used to the selects minimally super-
vised machine algorithm;
Build and train the Amharic document(corpus);
To summarization and recommendation.
To provides a common sense word reasoning by minimally training data.
To provides ambiguities semantic in the content of Amharic text to word sense disambiguation in
the language.
It provides to resource study Amharic language for the

6
1.4. Scope and limitation of the work There are minimally supervised, supervised and unsupervised machine learning approach for the word
disambiguation in this case to time constraints ,analysis result, to train test, only five minimally super-
vised machine learning algorithm are used to build and evaluation the word sense disambiguation. Not
available sense annotated and linguistics corpus; the investigation is limit to the experimentation of five
ambiguous words.
1.5. Significance of the study
The outcome of this investigation was assumption to produce experiment approve that demon-
strate distinguish application areas of minimal machine learning approach to word sense disam-
biguation of Amharic texts.
It gives for the future researches.
The study in the area of natural language processing specially in speech processing.
Understanding to communicate social media and information interchange like email and face
book, information retrieval, information fetch, grammatical rule analysis, machine translation
from Amharic language to anther languages or other language to Amharic language, extract the
information, text processing, text to speech translation, to in the Google or search engine by Am-
haric texts.
It used to thematic analysis as those requirement word sense disambiguation is complement.
The readers easily understand for the concept in the Amharic text.
It contribute to develop the human language in Amharic language area requires word sense dis-
ambiguation.
It gives to sufficient information and resources for the researcher or reader requires word sense
disambiguates from Amharic text.
It gives a resource to study for the student in Amharic language.
1.6. Methodology
1.6.1. Literature review In the literature review of the word sense disambiguation (WSD) is review and discussion. The
related literatures from different resources such as journal, magazine, books, news, internet etc. it
will be reviewed to understand with one word sense disambiguation to other in the command and

7
non command. Word sense disambiguates researches with focus on machine learning approach,
which is used in this study. As well as machine learning algorithms that that are tested to perform
well for word sense disambiguation research including minimally supervised algorithm.
The topic include as the following
The word sense disambiguation in both foreign and local languages
It will be used to different machine learning techniques and the advantage and disadvan-
tages
Use to different cluster algorithm and their application in machine learning techniques
Amharic ambiguous word, Amharic writing system, quotation mark and used to syntactic
architecture
1.6.2. Data set collection and preparation
Under this study, minimally supervised approach is select to develop a prototype or model.Under this
technique an important number of sense examples are acquired to make training possible for the algo-
rithm, which is challenged to gain for Amharic text. In other language such as German, France and Eng-
lish the available of word sense disambiguation thesis. After review appears literatures, techniques that
used to monolingual of another languages for requires sense. The collection or the corpus used in this
study was lastly used in research on supervised and unsupervised word sense disambiguation for Amhar-
ic .based on Solomon Assemu on English corpus is used to requires sense for instance in Amharic cor-
pus ambiguous words and the example are translate to Amharic. In the case to lack Amharic words am-
biguous words required, translate and annotation of sense for example for this thesis, the researcher used
the corpus and ambiguous word choose prepare to organize that fix this research direction Solomon As-
semu(2011) use five ambiguous words choose by a linguistic expert from a lists of homonyms collected.
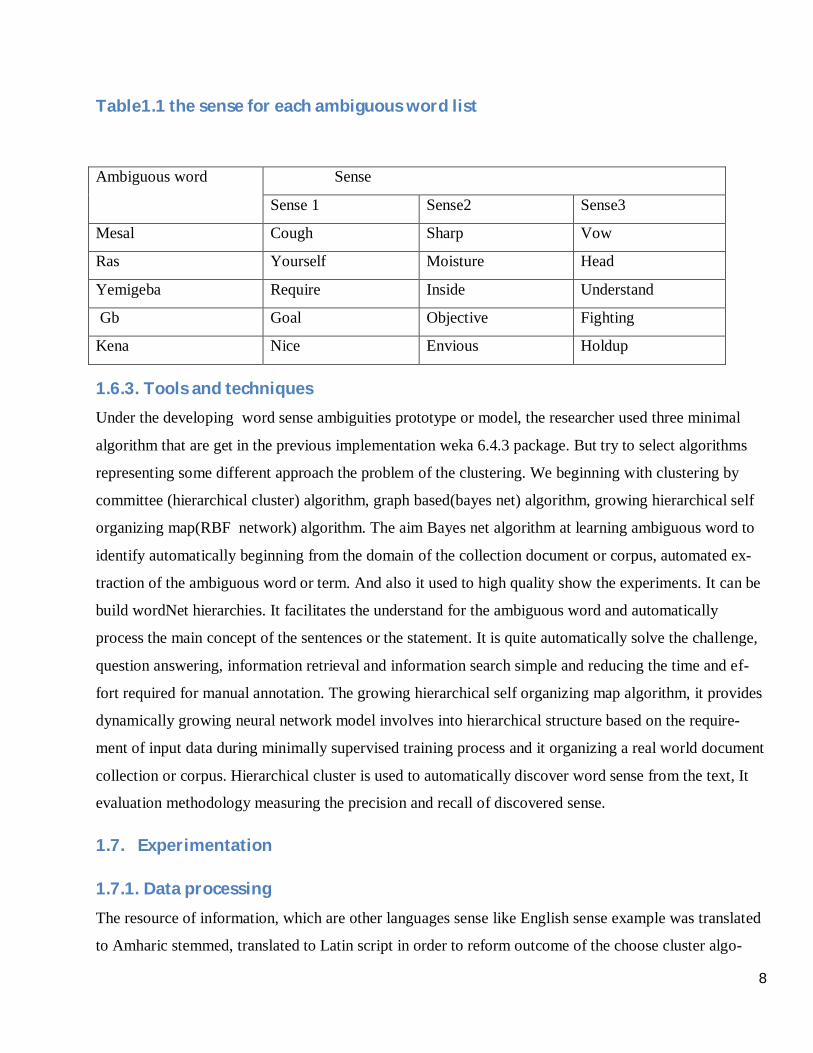
The selected words are መሳል (mesal), ግብ (gb), ቀና (kena), ራስ(ras), የሚገባ(yemigeba). As well as
to the basic words their difference is considered. The conclusion of the sense for each ambiguous word
is the following table1.
8
Table1.1 the sense for each ambiguous word list
Ambiguous word Sense
Sense 1 Sense2 Sense3
Mesal Cough Sharp Vow
Ras Yourself Moisture Head
Yemigeba Require Inside Understand
Gb Goal Objective Fighting
Kena Nice Envious Holdup
1.6.3. Tools and techniques Under the developing word sense ambiguities prototype or model, the researcher used three minimal
algorithm that are get in the previous implementation weka 6.4.3 package. But try to select algorithms
representing some different approach the problem of the clustering. We beginning with clustering by
committee (hierarchical cluster) algorithm, graph based(bayes net) algorithm, growing hierarchical self
organizing map(RBF network) algorithm. The aim Bayes net algorithm at learning ambiguous word to
identify automatically beginning from the domain of the collection document or corpus, automated ex-
traction of the ambiguous word or term. And also it used to high quality show the experiments. It can be
build wordNet hierarchies. It facilitates the understand for the ambiguous word and automatically
process the main concept of the sentences or the statement. It is quite automatically solve the challenge,
question answering, information retrieval and information search simple and reducing the time and ef-
fort required for manual annotation. The growing hierarchical self organizing map algorithm, it provides
dynamically growing neural network model involves into hierarchical structure based on the require-
ment of input data during minimally supervised training process and it organizing a real world document
collection or corpus. Hierarchical cluster is used to automatically discover word sense from the text, It
evaluation methodology measuring the precision and recall of discovered sense.
1.7. Experimentation
1.7.1. Data processing The resource of information, which are other languages sense like English sense example was translated
to Amharic stemmed, translated to Latin script in order to reform outcome of the choose cluster algo-

9
rithm. In the experimentation there is no require to split the information into learn the training and test
sets for evaluation because of minimally supervised of clustering algorithm.
1.7.2. Training and testing The system or the software is learn and train for five ambiguous word a collection of un notated neces-
sary for the ambiguous word to created model. A total of five experiments cover using “class to cluster”
the different method and characteristic to evaluate and values to train the model. In general the cluster
by committee or hierarchical algorithm performance measuring using the accuracy of the result.
1.7.3. Evaluation techniques Us explain our techniques (minimally supervised machine learning method) using a resources of sense
tagged corpus. In the case of supervised and un supervised machine, sense tagged corpus it used to in-
duce classify and then train to categorized the test data where as un supervised techniques the sense
tagged corpus used to carry out an evaluation of the discovery of the group sense. However the minimal-
ly supervised techniques using a little annotated data within the evaluation sense data. The tools used to
processing clustering depend on the cluster mode one select. At this mode weka beginning avoids the
class attribute and operation the clustering and during the test level it allocate classes to the clusters de-
pend on the maximum values of the class attribute within each cluster. According to the above methods
its prediction accuracy and precision were use to measure how well it has been able to generalize the
clustering result.
1.8. Financial cost
Table1.2 Here is the detail expected total cost for the research conducted.
NO Materials Price (birr)
1 Stationary material 1600
2 Software tools 400
3 Communication 2100
4 Secretarial service 2000
5 Data gather, corpus prepara-
tion
6000
Total cost 12,100

10
1.9. summary Word sense disambiguation deals with the actual word sense in a given context. To properly identify
sense of words one must known common sense facts. More over sometimes the common sense need to
disambiguate such word pronouns in case having anaphora’s the text. There are different applications in
natural language process like machine translation, speech recognition etc. it needs the word sense dis-
ambiguation. Currently the important of computer technology to the internet out come a big collection of
information to indicate the data requires the society. The natural languages ambiguities will be challeng-
ing due to lack of natural languages processing system in many languages. Amharic language is one of
lack of resources and natural languages processing tool to favorable conditions that information. In Am-
haric text there are different problem in the context. While Amharic document or text translates one lan-
guage to other languages lose concept or idea of the reader from Amharic text or document and also
have different problems occurred like that of text summarization, text analysis, machine translation and
also common sense word reasoning and ambiguities semantics. The aim of this study to develop and
train word sense disambiguates prototype or model to select minimally supervised techniques and build
the Amharic documents or corpus. The main concept is this thesis investigates to using minimally su-
pervised machine because of it used to a little data to train represent to the whole corpus. The advantag-
es of this work gives to the future research work and study of the area of natural languages processing
specially word sense processing ,understand to communicate social media and information interchange
like email. It also contributes to develop the human languages in Amharic language area requires word
sense disambiguation. The compression of selected to the algorithm in the activity of minimally super-
vised WSD for Amharic words. Under the developing word sense disambiguation models, the research
used three minimally algorithm that are get in the previous implementation weka 6.4 package and java.
Like the selected approach cluster by committee ( hierarchical cluster), graph based algorithm ( bayes
net algorithm) and growing hierarchical self organizing map algorithm (RBF network) and also to eva-
luate our techniques (minimally supervised machine learning techniques) using a resource of senses
tagged corpus.

11
1.10. Thesis Organization
This thesis is organized into six chapters: Chapter 1 - Introduction; Chapter 2- Literature Review; Chap-
ter 3 – The Amharic Language and its Writing system; Chapter 4 - Methodology Chapter-5 Experiment
and Performance Evaluation and Chapter 6 – Conclusion and Recommendations. Chapter one includes
background, statement of the problem, objectives of the study, scope, applications of the study and
methodology. Chapter 2 discuses different text classification approaches, document preprocessing and
representation, overview of the different classification and clustering algorithms and evaluation tech-
niques. Chapter 3 gives highlight about Amharic writing system. Chapter 4 discusses details of metho-
dology adopted and chapter 5 presents the experimental results and findings of the study. In chapter 6
summarizes findings of this study and recommendations are given for further research

12
CHAPTER TWO
LITERATURE REVIEW
Introduction
Automatically word sense disambiguates (WSD) have been an important area of research for early 1950,
during that when a language started to be changed by using computers (Navigli, 2009). In 1960, Bar-
Hilled (1960) implementation the challenge of word sense disambiguation (WSD) on machine transla-
tion (MT). For 1966, based on progress was being built in the area of knowledge representation, more
over the following accidentally of semantic networks, which were automatically the applied to sense
disambiguation due to the 1970 the challenge of word sense disambiguates was researched with artificial
intelligence techniques targeting language understanding (wilks, 1975’) even though, generalizing the
outcome was challenge, means because of the lack of a big amount of machine- readable knowledge. It
was since 1980’ that word sense disambiguation reached a back point following the release of high-
scale lexical sources which could immediately techniques for knowledge extraction. The 1990 led to the
massive statistically techniques and established of periodic revolution campaigns of word sense disam-
biguation system (wilks et al, 1990)
Since 1990 behind few of the problems related to word sense disambiguation (like that of alignment of
parallel translations) was thoroughly addressed, the problem of WSD taken the middle phase, and it is
start to be sequence showed as one of the advantage hazard in NLP (IDe & veron’s, 1998). Word sense
disambiguation (WSD) is a “intermediate task” which is does not an end itself. Replaced, it is an impor-
tant task that required being one level or other to completely most NLP task (wilks & stevenso, 1996). It
is an important in language understanding application consisting message understanding and man-
machine interaction. It is also helpful & needed in few conditions for application whose main target lan-
guage understanding information retrieval, speech processing, and machine translation etc. word sense
disambiguation have been determined as artificial intelligence complete problem (nallery, 1988). In a
sense it is a difficult which able be resolved only by being solved all hazards in artificial inelegancy like
that of the representation of common sense and encyclopedia knowledge.

13
2.1. Word sense disambiguation work In language a word able have much various senses or means that take out refer the context in which they
occur. The task of word sense disambiguation is calculably to identify the right sense to ambiguities
words according to a rounding context. for example mesal (መሳል) in Amharic able be either mean
‘cough’, ‘sharp’, ‘vow’ according to the context of the document. Solving these types of ambiguities is
a main task for human which is not needs more effort. Human have a detail understanding of language
and its uses. They have also a wide range and conscious clearing of the real world. As outcome of that,
they can parameterize the meaning of each word in a text forceless. Although create expand knowledge-
base which able be used by computers (machine) to clearly the world and cause about word means basi-
cally, is still not completely work in NLP(Ng ‘ang’ a, 2005).
Word sense disambiguation (WSD) can be countered in various conditions in a text (Navigl; 2009) For
instance it could be at a lexical stage where a word can have two or more means or at the part of speech
stage where a lexical object or item can take one of different grammatically roles in a statement, due to
alignment of a preposition on various words which yields various means. Bakx (2006) determined two
different of the generic word sense disambiguation (WSD) works. The beginning is lexical examples
(target word sense disambiguation) where a system is needed to disambiguate the limited element of tar-
get words times existing one per statement. The other is the whole words word sense disambiguation,
where a system is known to not complex or disambiguates a all known class words in a text (i.e.., ad-
verbs, adjectives, noun, verb). Target word sense disambiguation can be controlled by minimally super-
vised system as they can be trained using a many of hand unlabeled example (training set) and applied to
graphical representation a set of labeled instance (attempt set). The whole word sense disambiguates on
the other way needs broad-coverage system switch really on complete coverage knowledge sources ,
whose exist must be corrected.
Xiao in zhu (2005) a good graph should response us prior knowledge about the domain current time, it is
design is more of an art than science. It is the operation is responsibility to feed a good graph-based
semi-supervised learning algorithm, in order to assume useful result.” Presently graph-based semi-
supervised learning method have attracted great attention” graph- based technologies beginning with a
graph nodes are the labeled and unlabeled data points and (weight) edges response the identical of
nodes. It techniques enjoy a good feature from spectral graph theory [31].

14
2.2. Steps in word sense disambiguation The work of sense disambiguation has four main elements (Navigli, 2009), the selection of word sense
(i.e. classes), the use of knowledge resources, the representation of context, and choose of an automatic
classification techniques.
2.2.1. Choose of word sense Identifying the sense the approved definition (meanings) in a given text of a words is the first key point
level or step in WSD, a sense source portion s the area of a meaning of a word into its sense. Word sense
does not counter zed, so that, minimize to limit counter a set of intermediate, every encoding different
meaning. The main cause of these hazards is of that language is automatically which change and devel-
op with time. In addition to that it is very challenge to determine the range of meanings is close to each
other.
2.2.2 External of knowledge of source Knowledge is a basic part of word sense disambiguation. Knowledge source give data which are impor-
tant to comminute sense with words they can differ from document of texts, either annotated or unla-
beled with word sense, to machine- readable, thesauri, glossaries, dictionaries, etc.
2.2.3 Representation of context Text is a complex or unstructured source of information to build this complex formats comfortable (But
it does not important all steps).Tokenization is the process of breaking a stream of text up into taken
(usually words). Part of speech tagging, also known as grammatical tagging, is process of representing a
grammatical classified(word, adjective, adverb, noun etc) to each word Stemming, that is the decrease of
morphological different of a word to their main work Chunking, which includes of separating a text in
cynically corrected parts (e.g.[the bar] NLP(was problem) )VP, orderly the noun phrase and the verb
phrase of the sample.Parsing or syntactic analysis is the process of analyzing a string of tags target to determine
the syntactic structure of a statement.

15
2.2.4 Selection of classification approach
Choice of a classification (techniques) is the last step in the word sense disambiguation tasks. Most of
the techniques to the solution of word ambiguity stem from the area of machine learning, domain from
techniques with strong supervision to syntactic and structural pattern identify methods.
2.3. Natural language processing (NLP)
The growth and convert of computing multilingual information and telecommunication has output in
the accidental of enormous volumes of information in electronics media (Ng ‘ung’ a, 2005). Although
the previous this gathering of information was assigned in other way that is comfort more for human
users than computer system. This has automated the development of technologies that would supports
quickly and efficiently access this information via computer systems. In this case natural language
processing (NLp) is one of the best advantage tools and approaches that increase the implementation of
natural language based interact to computer systems, available communication in natural language be-
tween man and machine. These approach also available people to arrange, extract and use the know-
ledge consisted of the large gather of natural language electronic data. However, NLp is very difficult
tasks. One of the main reason for this is the ambiguity of natural language ; meaning is summarize var-
ious in nature, and this build it very challenge to determine what the sense of a word actually
are(Kilgarriff, 1997)
2.4. word sense disambiguation of application
However there are many problems comminutes to it, word sense disambiguation is an entire concept to
the success of most other natural language process (NLp) applications. It has been determined as an es-
sential center work that could important improves outcome of applications like that of, speech recogni-
tion, document classification, text summarization, question answering, information extraction, machine
translation.

16
2.4.1.Information retrieval
Word sense disambiguation (WSD) is the task of determine the precision meaning of a term in con-
text.As the main semantic clearing of tasks at the lexical step, word sense disambiguation is the basic
hazard in natural language process. It can be potential used as a part of in more application, like that of
machine translation, speech recognition, information retrieval (IR). In the application of word sense dis-
ambiguation to, MT research has seen that the combining word sense disambiguation essential ways im-
portant improve the performance of MT (chan et al, 2007; carpuat and Wu, 2007). In the application to
IR word sense disambiguation able be bring two types of important. The first one query to IR word
sense disambiguation able is bringing two types of important. The first one query may consist is ambi-
guous word (term), which has different meanings. The ambiguities these of these request word can hurt
retrieval correction. Determining the precision meanings of ambiguous words in two queries and docu-
ments can help improve retrieval correct. The second also query word may have tightly associated
meaning” with other words does not in the query”, building use of these relation between words can im-
prove retrieval recall.
In addition to information retrieval system can be potentially important from the precision meaning of
words given by word sense disambiguation system. Even though in the previous of studies of the usage
of word sense disambiguation (WSD) in information retrieval, multiple researches arrived at conflicting
observation and summarize. Some of the previous research showed detail in retrieval performance by
using (krovetz and croft, 1992, Voorhees, 1993), some of other tested showed improve by combiner
word sense in information retrieval (schuitze, and Pedersen, 1995; Gonzalo et al…, 1998; Stokoe et al,
2003; Kim et al, 2004). So that (zhizhong and HNee Tou Ng) was tried to attempt the use of word sense
to improve the performance of information retrieval. This task an approach the sense for short queries
those incorporate word senses into the language modeling (LM) technique to information retrieval
(Ponte and croft, 1998), and utilize sense similarity relate to further the performance. The data set ob-
serves the supervised word senses disambiguation result to others word sense disambiguation base lines
and important improves information retrieval.
Multiple works tested to disambiguation word in the queries and documents with the sense pre-
identified sense inventories, and then used the sense to task ordering and retrieval. Voorhees (1993) used
different relation word Net (Miller, 1990) to ambiguities the different nouns in a text. The result of both

17
Voorhees and Wallis are appreciating as it could seem reasonable that if ambiguity were resolved, in-
formation retrieval performance was used to increase.
Many the previous investigation have analyze the benefit of and the problem of applying word sense
disambiguation to information retrieval, Krorez and croft (1992) investigated the sense link between
words in a query and the document collection. They conclude that the important of word sense disam-
biguation in information retrieval are not as expected. Because query words have skewd sense distribu-
tion and gather result from other query already performs some disambiguation. Sanderson (1994; 2000)
used to known artificial word ambiguity in order to study the effect of sense ambiguity an information
retrieval. His summarize because the effective of word sense disambiguation performance high accuracy
of word sense disambiguation is an important requirements to achieve improve.
2.4.2. Word sense disambiguation for text mining
In recent years, the important increase in using the web and the improvements of the quality and fast of
the internet have transferred our communities into one that based on the strongly on the fast access to
information. The huge amount of data that is generated by this process of interactions assign significant-
ly information that accumulate daily and that is stored inform of text document, database etc. the retriev-
al this information is does not and easy as a result that the data mining approach were growth for extrac-
tion information and knowledge that the represented in design or concepts that are sometimes not ob-
vious. Word sense disambiguation there were determined a domain of linguistic idea like that of as a
choose or domain information that are relevant in resolving the ambiguities of words (Damiel I et al)
these feature are called linguistic knowledge sources. a recently word sense disambiguation system re-
ports does not mention these resources but rather current poor levels properties like that of “big of
words” n-grams “ used in disambiguation algorithms one of the reasons being that the proper-
ties(coding), creating more than one source knowledge [40] the purpose of the recent research paper talk
about the source of knowledge and to clearly the related between source knowledge , properties and lex-
ical resource of used in word sense disambiguation knowledge source level abstraction of linguistic and
semantics properties which are important for resolving. Ambiguities words like that of the domain for
individual words (sports, poetry, etc).

18
2.4.3. Machine translation
Machine translation (MT) is the work of work of immediately deciding which target language term the
most essential equivalent is a source language term in context. The large problem of MT although is
that, the translation of one language into other effect in a very multiple form than that of the original
(Dagon and Itai,). This is mainly, Dagan and Itai note, due to the current of multiple equal translations
relation for words in the target language relation for each word of the source language. In addition, the
source language is itself known multiple optional senses for a target word which makes the work of ma-
chine translation (MT) more complex. In this way, word sense disambiguation works helps in deciding
which target language term is the most essential equal of source language word in context unfortunately,
word sense disambiguation is a very challenge work by itself. It can even become more difficult when it
is applied in machine translation with two very divergent languages.
As Dagan and Itai (1994) not multiple linguist step were used to deal with word sense disambiguation
for machine translation consisting pragmatic, semantic and syntactic. As reported by the researchers the
syntactic approach is not expensive compute, bout one of not in the sequence condition when the differ-
ence sense of the word observation the identical syntactic properties, having the identical part of speech
and even the identical sub-part frame. Substantial application of semantic or pragmatic knowledge about
the term or word and its context needs compiling big amount of knowledge, the important of which for
implementation application of a wide domain has not late been proven. In addition to like approaches
sometimes does not reflect word usages.
The task and important of word sense disambiguation (WSD) models in statistical machine translation
(SMT) have been tested by researcher (Chan et al, 2007; Dagan and Itai, 1994; vickrey et al, 2005).
Chan et al (2oo5). Combine a word sense disambiguation (WSD). It system into a state –of-the-art hie-
rarchical phrase- based machine translation (MT) and observed for the beginning time combining a word
sense disambiguation system improves the performance of the state – of- the art statistical machine
translation system on an actual translation task. In addition that they showed that the improved, they
showed is statistically important, identically, Corpuat and Wu (2007) observed for the beginning time
that incorporating the predetermined of word sense disambiguation system within the typical phrase.
Based chinese-english statistical machine translation model consist improve translation quality Across
different Chinese- English test set.

19
2.5 word sense disambiguation
There are different ways techniques word sense disambiguation’s (WSD) hazards according on how
disambiguation knowledge source or information needed(Ng’ang’ a,2005); corpus-based approaches,
knowledge- based approaches, ,explicit lexicon, where the important data about the machine learning
approaches can be divided into unsupervised , supervised, and minimally supervised approach. More
over in detail discussed the following approach.
2.5.1. Corpus based method
Corpus- based method provide an optional strategy to overcome the lexical a question lack observed in
knowledge – based approaches by giving information. The important for word sense disambiguates are
directly from textual information. On this method the work of disambiguation is done by training statis-
tical or machine learning language sample on corpus. Researchers in the field of word sense disambigua-
tion have a previous to corpora to help expand the coverage of existing system as much as boot strap or
train new systems. These methods have also important from match research in machine learning and sta-
tistical techniques, and especially, in their application to corpora, making it possible to gain disambigua-
tion data from information automatically. As well as, the success with which statically method have
been applied to other NLP task like speech recognition, parsing balanced that they can also used for dis-
ambiguation task(Ng’ang’a 2005) . If one selection to task with corpus-based approach, the possible
means used for disambiguating sense of terms are distribution and context words (Gaustad, 2001`).
Spread information senses. Collection information if got from context words which are got to the correct
and the left of ambiguous words.
2.5.2 Knowledge –based approach
Knowledge based word sense disambiguation is task by service the knowledge hold in machine readable
dictionaries in the form of word Net , thesaurus, lexicon, semantic ontology’s to identify the sense of

20
words in context (Navigli, 2009) this method may also grammar rules or other way code rules. Currently
most dictionaries built exist in machine readable dictionary format. These consist English dictionary,
collines, and long man dictionary for ordinary contemporary English; the surges which increase similar
data such as get; the saurus; and semantic networks which add many semantics link like word net, euro
word net (shorma, 2008). Lesk (1986) was one of the beginning researchers who experiment to use these
types of machine readable resources for (WSD). We task was according on the shown that essential of a
sentence is based on cohesions of the words in it; this means that the selection of one sense in text is a
function of the senses of words close to it. He devised an algorithm that selection the right sense of a
word by computationally the word obstacle between the context sentence and the dictionary means of
the term in question. A major hindrance to dictionary-based approach like that of those depends on
leak’s phenomena is their concept based on identically in terming or wording between texts MRD. As
stated by Montoya et al (2005) their important are that; they remove the required for a big amount of
training date and they have a large coverage as they are using large-scale knowledge resources. The ha-
zards with them some times have poor performance than their supervised optional, dictionaries meaning
are sometimes very short to incorporate an obstacle from which lack set of show can be got. Even
though their well structured information and added vocabulary coverage, recoded knowledge sources. In
addition to suffer from restriction is domain –specific coverage and in copying with the known of new
words. In other way to dictionary – based approach is the adequate of a for mentioned machine readable
resource in most language.
2.5.3. Supervised learning method
Supervised word sense disambiguation use machine learning approach is for detail a classifier from
sense annotated data sets. The training data set consists a collection of sample statement with manually
tagged target words. Using this data set the word sense disambiguation system implement the classifica-
tion work and identify the assure sense to each example of the target word (Solomon, 2010). The trained
classifier system then will be used to indicator a cute seen sample to one of a limit number of sense.

21
2.5.4. Minimally supervised learning method
The semi-supervised or minimally supervised methods are obtaining robust because of their can be gain
by with only a little amount of annotated known data while always outperforming totally unsupervised
techniques on a huge data set. Minimally supervised method for word sense disambiguation in words of
exploiting unlabeled data in learning categories based on what is used for supervision in learning
process. The resources or lexicon, to disambiguation word senses are immediately generated sense-
tagged corpus (Lesk, 1986, Lin, 1997; Mccarthy et al, 2004; Yarowsky, 1992). Exploiting the various
between mapping of terms meaning in various language by the use of mono language corpora (for in-
stance parallel corpora or untagged one language or mono lingual corpora in two language) Brown et al,
1991; Dagan and Itai; 1994; Daib and Resnik, 2002; Li and Li, 2004; Ng et al, 2003.
Bootstrapping sense tagged seed examples to outcome the lack of acquisition of a huge sense tagged da-
ta (Hearst, 1991; Karor and Edelman, 1991; Mihalcea; Park et al, 200; Yarowsky, 1995). “Bootstrapping
algorithm used semi supervised learning method for word sense disambiguation”. It tasks by iteratively
classifying unlabeled instance and adding confidential classified examples into labeled data set using
model learned from augmented labeled data set in the previous iteration. It ability to obtained that the
affinity data among unlabeled samples is not fully explored this bootstrapping process. Bootstrapping is
according on a local consistency assumption; instance close to labeled instance within identical class
will have similar labels, which also the suggestion underlining more supervised learning method like
KNN.
In this section include promising families of graph based minimally supervised learning algorithm are
introduced, which can effectively combine unlabeled data with labeled in learning process by exploit-
ing cluster structure in data. “Labeled propagation algorithm is a graph based semi supervised learning
algorithm” (LP algorithms) (Zhu and Ghahramani, 2002) for word sense disambiguation, which tasks
by assigning labeled and unlabeled examples as a vertices in a connected graph, then iteratively propa-
gation labeled data from any vertex to neighbor or nearby vertices through weight edges, finally infer-
ring the labels of unlabeled instance after this propagation process convergence. Compared with boot-
strapping, level propagation is according to a global consistency suggestion, intuitively, if there at least
one labeled instance in each cluster that include of identical examples, then unlabeled instance will
have the identical labels as labeled examples in the identical by propagating the labeled information of

22
any examples to nearby examples on their proximity. So that in this section to describe the bootstrap-
ping algorithm and graph based approach: Labeled propagation algorithm.
2.3.4.1 Bootstrapping algorithm
To identify the partly of overcome the knowledge acquision lack. Some algorithm have been divided
for making classifier when only a some annotated instance are exist together with a large amount of an
annotated data. These algorithm are always known as bootstrapping algorithm (Abney 2002, 2004);
among them, us ability high light co-training (Blum and Mitcheel 1998), and self training (Nigam and
Ghan, 2000). In detail, co- training algorithm tasks by learning to complementary classifier for the clas-
sification work train on a few beginning set of labeled examples which are then used to annotated new
unlabeled examples. From this new instance only the most confident forecasting are added to the set of
labeled examples. Each classifier and the process repeats. The complementary classifier are build by as-
sumption to various views of the data (i.e. to various properties codification), which should be satiation
independent given the process label. In multiple natural language process works, co- training has given
moderate improved with respect to not using additional unlabeled examples. One important aspect of co-
training includes on the use of various shows to train various classification during the repeat process.
While Blum and Mitchell (1998) stated the situation independent of the view as need, Abney (2002)
views that this needs ability are relaxed. In addition Clark et al (2003) views that easily retraining on the
whole newly labeled data can be in few case, yield comparable outcome to accepted according to co-
training, with only a fraction of computational cost. Self training beginning with a set of labeled data
and makes a unique classifier (three are no several of data), which is then used on the unlabeled data.
Only those examples with confidence score more certain threshold is consists in the labeled set. The
classifier is re-trained and ordering iterated. Note the classifier use its own forecasting to teach itself.
The order is also called self-teaching. Self training has been applied to multiple NLp works. Yarowsky
(1995) uses self training for word sense disambiguation. Self training is a hyper algorithm, and is hard to
analyze in general. Mihalcea (2004) introduce a new bootstrapping scheme that combines co-training
with more voting, with the result of smoothing strapping learning curves and improve the average of
performance. Although, this method assumes a comparison spread of class between both labeled and
unlabeled data. At each repetition the class distribution of class between both labeled and unlabeled da-
ta. Class between already labeled instance and newly add examples. This needs know a priori the distri-

23
bution of meaning classes in the unlabeled corpus, which seems unreality. Pham et al(2005) also at-
tempted with the many of co-training variants on the senseval-2 lexical sample and all- words works,
consisting the ones in Mihalcea (2004), however the main co-training algorithm do not give any impor-
tant more using only labeled examples all the sophisticated co-training different found advantage im-
provements(taking naïve bayes as the base learning method). The best reported algorithm was spectral
graph transduction co-training.
2.3.4.2 Yarowsky bootstrapping algorithm
The yarowsky algorithm (yarowsky 1995) was probably, one of the beginning an over successful appli-
cation of the bootstrapping method to natural language process works. The yarowsky algorithm is easily
and incremental algorithm which, require for a huge training set by real on a relation avoid few number
of example of each meaning for each lexeme of interest. These label example are used as seeds to train
on start classifier using any of the supervised learning approach (decision lists, in this a single case).
This start classifier then used to filter bigger training sets from the remaining untagged corpus. Only
those examples that are categorized with the confidence over a certain threshold are kept as additional
training instance for the next repetition. The algorithm iteration this retraining and re-labeling order until
change (i.e. when no changes are showed from the previous repetition). The original of these methods
lies in its can to create a bigger training set from a few set of seeds regarding the initial seed set; Ya-
rowsky (1995) discussed multiple optional automatic manually supervised orders. This initial labeling
may have very low coverage (and therefore, low recall) but it is assumed to have extremely high correc-

24
tion. As repetition proceeds, the set of training instance tends to increase, while the pool of unlabeled
example shirks. In the word of a performance, recall improve with iterations while correct tends to re-
duce slightly, conceptually at convergence most of the instance will be labeled with high confidence.
2.3.4.3. Bilingual bootstrapping methods
A new approach for word sense disambiguation, one that using machine learning approach called bilin-
gual bootstrapping. In learning to disambiguate word to be translated, bilingual bootstrapping build use
of a little amount of classified data and a big amount of unclassified in both the source and the target
language. The information in two languages should be from identical domain but are not needed to be
correctly in parallel. It repeats builds classifiers in the two languages on the base of classified data in
both languages in parallel by iteratively the following two steps. Building a classifier for each of the
languages is the base of categorized data in both languages Used the constructed classifiers for each
language to classifier unclassified data of the language. We can use classified data in both languages.
We can use classified data in both languages in step 1, because words in on language have translation
in the other and us ability to translation data from one language into another. It boosts the performance
of the classifier by classifying of unclassified data in the languages and by interchanging data respect-
ing classified data between the two languages. The performance of bilingual bootstrapping been at-
tempt evaluated in word transfer disambiguation, and all of their outcome show that the bilingual boot-
strapping in related between the ambiguous words in the language.
2.3.4.4. Graph based minimally algorithm
This algorithm tasks by assigning unlabeled and labeled examples as vertices in connected graph, the
propagating the labeled data from any vertex to nearby vertices through weighted edges iteratively, fi-
nally inferring the labels of unlabeled instance after the propagation process coverage’s, in labels propa-
gation algorithm (zhu and Ghahroman; 2002) labeled data of any vertex in a graph is propagate to near-
by vertices through weighted edges until a global stable stage is successful. Bigger edge weight allows
labeled to moves through simple. So that closer instance, much likely they have identical labeled (the
global consistency assumption). In labeled propagation process, the smooth labeled through unlabeled

25
data. With this push from labeled instance, the class surrounding will be pushed through edge with large
weights and settle in gabs along edges with weights. If the information structures fix the classification
goal the labeled propagation (LP) algorithm can use these unlabelled information to help learning classi-
fication plane. The following LP algorithm:

23
2.4. Unsupervised learning method
Unsupervised learning neither did not really on labeled training text nor is they build use of every ma-
chine- readable sources such as dictionaries, ontology thesauri (Gale et al, 1992). They are prototype to
result the knowledge acquisition problem showed in the case of supervised word sense disambiguation.
They do so by requiring contextual data directly from un-annotated raw text and by inducing meanings
from text using a few identical measures (Lin, 1997). They can to induce word sense from input text by
clustering word exist and then classifying new exist into the induced clusters. Navigli (2009) condition
of not important of these techniques saying as they do not re al on labeled data, they perform word sense
difference, that is, they aim to division the existing of term into a number of classes by identifying for
any to exist whether they have to the same sense or not. Consequently, these approaches may not dis-
cover clusters equal to the traditional meaning a dictionary sense inventory. For this case, their evolu-
tions is sometimes more difficult.
2.5. Hybrid Techniques
Hybrid techniques are a real on disambiguation information gain from both corpora and explicit know-
ledge base (Navigli, 2009). The target of hybrid approach is to build use of the strong of the single tech-
niques as much as to result special limitation related with a singular techniques and a result improving
word sense disambiguation precision. They perform on a knowledge driven, corpus-supported there,
service more over information as can be from various resources Luks (1995) system is an example of a
hybrid techniques that combines information in MRD meanings with statistical information gained from
raw corpora. His uses textual meanings of sense from the document to identify for word sense disam-
biguation, his corpus to compute arrived information score between these related senses. Bootstrapping
system is other better example for hybrid approach initial data comes from an explicit knowledge re-
source which is then augmented with information from corpora. The unsupervised learning reported by
Yarowsky (1995) can be based as a bootstrapping algorithm. In these techniques the researcher defines a
little many of initially meaning for every of sense of a word the initial can also derived from dictionary

24
definition or lexicons such as word net synsets. His then uses the initial meanings to classify the better
cases in corpus. Decision list are used to learn conclude according on the corpus example that have be-
fore been classified; this process is iteratively to the corpus, classifying more example. Learning follow
in this way until all corpus examples of the ambiguous words has been classified.
2.6. Related empirical investigation
There are suggested many of tasks make to resolve word sense disambiguation (WSD) and associated
classification problems the global. These research tasked were transferred in various language using var-
ious machine system methods. In sections, detail reviewed of main implementation or empirical tasks
that inform the current investigate are given. The review and focus on task done in global on word sense
disambiguation using graph based algorithm. It also reviews to attempted investigation that evaluates the
performance of classification and algorithm. The section will be detail tested available tasks transferred
implying corpus based approach.
2.6.1 Global research tasks
2.6.1.1 Bayesian networks
Graph based semi-supervised learning algorithm have been a better used to exact class- example pairs
from large unstructured text gathering (Fernando peneira). Graph based semi-supervised learning algo-
rithm have a goal early successfully in class-example acquisition, there is no investigation compared
various graph based semi-supervised learning algorithm on this work. It address this gab with this a se-
ries of attempt compare in the previous graph based semi-supervised algorithm on a graph constructed
from multiple source (metaweb technologies, 2009; Banko et al, 2007). It studies whether semantic data
in the form of example-attribute edges drive from an independent knowledge base (Suchanek et al,
2007) can improve class examples acquisition the institution back this that example that share attributes
are more similar to belong to the same class. We practical that example-attribute is edge important im-

25
prove the precision of a class instance extraction. It is the gap between to the last investigates partici-
pated proprietary data sets (Van Durme and pasca 2008); Talakdor et al, 2008; pennacc hiott and pantel,
2009), all of our attempt use publicly available dataset.
It include Bayesian networks are probabilistic graphical models and are represented by their structure
and parameters. Structure is given by a directed acyclic graph and it encodes the dependency relation-
ships between domain variables whereas parameters of the network are conditional probability distribu-
tions which are associated with its nodes. A Bayesian network like other probabilistic graphical models
encodes joint probability distribution of a set of random variables and could be used to answer all possi-
ble inference queries on these variables. Bayesian networks have already been applied successfully to a
large number of problems in machine learning and pattern recognition and are well known for their
power and potential of making valid predictions under uncertain situations. But in our knowledge there
are only a few methods which use Bayesian networks for graphic symbol recognition. Recently Barrat et
al. have used the naïve bayes classifier in a ‘pure’ statistical manner for graphic symbol recognition.
Their system use three shape descriptors (Generic Fourier Descriptor, Zernike descriptor and R-
Signature 1D) and applies dimensionality reduction for extracting the most relevant and decimating fea-
ture to formulate the feature vector(Muhammed Muzzami Luguman et al ,2009).
2.6.1.2 Radial basis function (RBF)
Radial basis function (RBF) Network RBF Network (RBFN) trains a radial basis function network,
which is a type neural network. The network has three layers: an input layer with a node for each
attribute; a hidden layer where each node has a Gaussian radial basis function as activation function,
created using a clustering method called KMeans (Martin, 1995); and an output layer containing a node
for each class with sigmoid as activation function. Radial basis function network (RBF network) is type
of feed forward network with a long history in machine learning. RBF regress or trains or regression
model(Eibe Frank (2014))

26
2.6.1.3 Hierarchical Clustering Techniques Hierarchical clustering algorithms produce a cluster hierarchy named a dendrogram (Berkhin, 2002).
These algorithms can be categorized as divisive (top-down) and agglomerative (bottomup) (Jain, 1999)
(Berkhin, 2002). We discuss these approaches in the following sub-sections.
Divisive Hierarchical Clustering
Divisive algorithms start with one cluster of all documents and at each iteration split the most appropri-
ate cluster until a stopping criterion such as a requested number k of clusters is achieved.
A method to implement a divisive hierarchical algorithm is described by Kaufman and Rousseeuw. In
this technique in each step the cluster with the largest diameter is split, i.e. the cluster containing the
most distant pair of meanings . As we use sense similarity instead of distance as a proximity measure,
the cluster to be split is the one containing the least similar pair of meanings. Within this cluster the doc-
ument with the least average similarity to the other ambiguous words is removed to form a new single-
ton cluster. The algorithm proceeds by iteratively assigning the documents in the cluster being split to
the new cluster if they have greater average similarity to the documents in the new cluster (Kang, 2003).
Agglomerative Hierarchical Clustering Agglomerative clustering algorithms start with each sense in a
separate cluster and at each iteration merge the most similar clusters until the stopping criterion is met.

27
They are mainly categorized as single-link, complete-link and average-link depending on the method
they define inter-cluster similarity.
Single-link The single-link method defines the similarity of two clusters Ci and Cj as the similarity of
the two most similar meanings (Arzucan, 2002):
Figure 2.2 shows a possible dendrogram produced by an agglomerative hierarchical algorithm. At the
topmost level of the dendrogram, we have a single cluster containing all elements. Using a similarity
threshold, we can extract a clustering of the data by cutting the dendrogram according to this threshold.
Then, each connected component of the dendrogram forms a cluster. For example, assuming that the
best clustering in the 2-dimensional space of Figure consists of small tight clusters, the dotted line in (b)
gives a good threshold for this data resulting in three clusters: {A, E, C}, {H, I} and {D, B, G, F}. The
problem with any threshold is that on some data sets, a particular threshold will be good but on another
data set, it will fail. For example, in Figure 2.2, if the similarity threshold was just a little higher, we
would have five clusters with elements C and D in separate clusters.
2.2. Figure 2.1

28
2.7. Local research Tasks
There are some research tasks done using various approaches apart with the goal of patterning a proto-
type for Amharic word sense disambiguation. At the beginning researcher who attempt word sense dis-
ambiguation for Amharic language was Teshome (1999). He has investigated the use of word sense dis-
ambiguation according to on semantic vector to improve the performance of an information retrieval
system sampled for Amharic correct text. He attempted his own algorithm based on distributional hypo-
thesis i.e. terms with identical meanings tend to exist in identical contexts. The outcome his find show
that the recall and precision of the information retrieval was 82% and 58% orderly with word sense dis-
ambiguation combine to it
Especially from the above tasks, there are four tasks done by Solomon (2010), Solomon (2011), Geta-
hun (2012) and Hagerie (2013). These tasks were translated partly using corpus based techniques by im-
plementing various machines learning algorithm. Solomon (2010) tried to study the application of su-
pervised machine learning approach to immediately require disambiguation data from Amharic corpus.
He used the number of 1,045 English sense sample gathered from British national corpus for five main
words metrat (መጥራት), mesal ( መሳል), atena (አጠና),mesasat (መሳሳት),keretse (ቀረጻ) his to disam-
biguate terms. These sense samples were translate to Amharic, manually annotated and preprocessed to
build them ready for the attempted. His implied Naïve Byes supervised classifier algorithm from weka
package tool using 10-fold cross validation. As the beginning task to demonstrate corpus based ap-
proaches for Amharic language, the investigate language goal increase the outcome. The classifier out-
come shows that within the range of 70% to 80%.
The second investigate by Solomon (2011) implied unsupervised machine learning approaches on the
identical data set as the last researcher to immediately decide the correct sense of an ambiguous word
based on its left and right context. For his investigate, the researcher used to identical set of target words
and identically data set used by Solomon (2010). In he attempted, his implied five cluster algorithm (av-
erage, complete link, expectation maximization (EM), hierarchical agglomerative link: single and simple
k means on weka 3.7.9 package. “Cluster to cluster” evaluation model was selection to learn the choose
algorithms in the preprocessed data set. In the test, a text window surrounding ambiguous words of ±10
parts or words was build first and then existence of the target word is noted in a characteristic vector for

29
each direction corresponding to various words. Then a Euclidian distance function, which is default in a
weka package, was used for measuring identical between contexts. The main advantage of this test was
to evaluate and compare with each other the performance of those cluster algorithms on Amharic text.
As well as that the researcher also tried to determine how stemming, stop word removal and window
size influence the performance of the models. The accuracy scores required (using three –three and two-
two window size) from the algorithm indicate: 51.9- 58.3% for single link, 54.4-71.1% for complete link
65.1-79.4% for simple k means and 67.9-76.9% for EM and cluster algorithm. The outcome also shows
that stemming important increased the accuracy of the outcome. It is also decisive to selection the bal-
ance window size to get the better outcome on this test three-three word window was obtained most im-
portant window size for Expectation Maximization and simple k means and two –two word window for
agglomerative single and complete link clustering algorithms. As compare the accuracy outcome re-
quired by Solomon (2010) according to supervised learning techniques (70.1% to 83.2%), the unsuper-
vised algorithms scored lesser accuracy values. The researcher, although, correctly values that outcome
required is still increased based sense annotated dataset is not used to prototype the system based on
clustering algorithms. The above two researcher have indicated that some problems in common. They
are the problem of lack of standard sense annotated corpus and other machine readable language re-
sources such that glossaries and thesauri, for Amharic language. They also showed the limitation of the
approach they used. So that the supervised learning techniques acquire enough manually labeled training
data, the unsupervised learning approach techniques outcome in to mini accurate model as it is not make
from manually sense tagged corpus.
So that both researchers recommended future investigates that implies various word sense disambigua-
tion techniques on more ambiguous words therefore a better natural languages known could be target for
Amharic language. Based on their future direction, Getahun (2012) examined to patter a word sense dis-
ambiguation prototype model using semi-supervised machine learning approach to the gap between the
limitations showed in the last investigate. The attempted was conducted on five ambiguous Amharic
verbs: etena (አጠና), derse (ደረሰ), tensa (ተነሳ), ale (አለ) and bela (በላ)with the total corpus size of (0,
3) sentences. The corpus with combine of more unlabeled samples with some seeds examples. The com-
bine of clustering and classification algorithms was used to develop the prototype models. The unsuper-
vised approach was applied at the beginning to the data in order to make some assumption about the
spread of the data and these suggestions are remarked using supervised algorithms. Two clustering algo-
rithms, k-means and expected algorithm implied to cluster sentences in to senses. And five classification

30
algorithms (Ad boost, Bagging, Naïve bays, SMO and AD tree) were then applied on average, AD tree
scored the highest accuracy of 88.47%. Comparing the outcome with last researches done using super-
vised and unsupervised is techniques recognizly. The researcher takes to have improved Solomon (2010)
by 11.5% and that of Solomon (2011) 28.36%.
Agerie (2013) tried to study the application of ensemble supervised machine learning approaches clas-
sifiers and implied that two algorithm that can be to create ensemble of min- model which would parti-
cipated in making the final model. She used the total of 1770 number of sentences from the Amharic
websites. For eight words ale (አለ), atena (አጠና), bela (በላ), derese (ደረሰ), akebere (አከበረ), kerbe
(ቀረበ), melese (መለሰ), tenesa (ተነሳ) her to disambiguates these sense examples were there translate to
Amharic to optimal window size seems to be related the number of sense an ambiguous terms has and
the size of the training data set used. She employed ensemble supervised classification algorithm from
weka package tools using 10 folds cross validation. The result indicate the optimal window size to be
two on which algorithms score maximum 78.75% for Random forest alone, 79.70% for Ad boost and
80.46% Bagging based on these experiment improvement in performance. However there is some prob-
lems occurs are not consider more than two sense target words and also this approach takes time and ex-
pensive by employing a combination of some annotated data many unlabeled examples with reasonable
performance should be considered.
The current investigate is identically to the work done by Getahun (2012) in that it uses minimally su-
pervised machine learning approach. However, the present work differs from Getahun in its selection of
algorithm and also corpus prepared. Getahun employed that the combination of classification and clus-
tering algorithms was used to develop the prototype model. Whereas the current investigate the selection
ambiguous words have more than two or three classes or senses and improve the performance the sense
or classes of the ambiguous words integrate cluster and classification algorithm using to develop the
minimal final model.The present study also use of a minimally corpus size within three meaning of five
target words.

31
CHAPTER THREE
WORD SENSE DISAMBIGUATION IN AMHARIC LANGUAGE
Ethiopia is linguistically different nation nationalities where more than 80 language are used in daily
communication, however many language are spoken in Ethiopia. So that Amharic is the dominant in that
it is spoken as a mother tongue by a language segment of the people and it is the most common learned
second language the country(Tesema et al 2010).
3.1. Amharic language
Amharic language is a semantic language of the Afro-Asiatic language groups that is relation Hebrew,
Syrian and Arabic (Argew and Asker, 2007). Next to Arabic , it the second most spoken semantic lan-
guage with around 28 million speakers (Gasser and Wondwosen, 2012). Amharic is the working lan-
guage of the Ethiopia federal government and some regional state in Ethiopia (like that of Amhara na-
tional regional state and Southern nation nationalities and people regional state). It also a day to day lan-
guage of churches, market place ,university and schools in addition ), it is the medium for written scripts
consists novels, primary school texts, magazines, news paper, official and legal documents and other
printed materials(Bloor , 1995). Amharic is a linguistically rich language with its own writing system,
although few has been with respects to developing its computational linguistic resources. As well as dig-
ital information is present being produced in Ethiopia (Guesser and Wondosson 2012 ) but the means to
get interchange and disseminate . this information is not yet established adequately. The attribute which
contribute to this problem include lack of digital libraries facilities and central information repositories
inadequate resources for electronic publication of journal and books and archive collection and docu-
mentation. The challenge to access information have future led to low expectations and under material
of existing information resource.

32
3.2. Amharic witting system
Amharic , a syllabic language , uses a script which derived the Geez alphabet . this script is known by
the name Fidel (ፊደል) in Amharic. It writing system works on the basic of thirty three base symbol or-
ganized in seven horizontal ‘orders’, represent seven values, for each base symbols. The first order is the
normal reference term for each base symbol. The other six orders represent various forms of the base
symbol (resulted from combining with various vawels) (Boolr, 1995). These seven classes are known by
their ethopic name as Geez (ግዕዝ) , kaeb (ከዕብ), sals(ሳልስ), rabe( ራብዕ), hams(ሃምሳ), sads (ሳድስ),
sabe(ሳብዕ). In order. Show the table 3.1
Table 3.1 there is an assumption regularity of letter shapes drive for various charac-
ter
1 2 3 4 5 6 7
ሰ ሱ ሲ ሳ ሴ ስ ሶ
Se Su Si Sa Sie S so
መ ሙ ሚ ማ ሜ ም ሞ
Me Mu Mi Ma Mie M mo
ጠ ጡ ጢ ጣ ጤ ጥ ጦ
Te Tu Ti Ta Tie T tu
ከ ኩ ኪ ካ ኬ ክ ኮ
Ke Ku Ki Ka Kie K ko
ፈ ፉ ፊ ፋ ፌ ፍ ፎ
Fe Fu Fi Fa Fie F Fo
As can be seen on table 3.1 there is an assumption regularity of letter shapes drive for various charac-
ters (link in ጠ and መ) although, there is standard formula to predict the shape in entire system (Fi-
del). We can show some inconsistency in the case of some characters (like in መ and ፈ). These deriva-

33
tion of each base symbols in to seven different forms produces 231 (33x7) major symbols. As well as to
these symbols, Amharic has 44 additional different for labialized consonants (plus vowel), that is syl-
lables involving consonants with lip- rounding, for example mwa(ሟ), twa (ቷ), chwa (ጯ) etc, Yacob
and Firdyiwek (1997) presented for full ASCII representation for Amharic alphabets as current in Ap-
pendix
Amharic alphabets are one reasons of ambiguities in the language these include repeat of symbol with
the some pronunciation and physical/ visual identical symbols. For instance ‘He’ can be represent as ‘ሀ’
, ‘ሐ’, ‘ኀ’, and ‘ኸ’ these for the symbols, when they are pronounced, the have common sound in a word,
but their usage in writing can variation in meaning. There are also few characters which look like in
their physical representation which can cause ambiguity for the reader. ሸ vs ቨ and ጥ vs ኘ can be ob-
serve as a sample for this problem. However Amharic is in the same semantic family as Arabic and He-
brew , its character are written read from left to right. The witting system makes on different between
lower and upper case letter and has no conventional cursive form (Bloor, 1995). Specially from its
unique word construction structure, Amharic language also demonstrates its own syntactic structure to
make sentences. Its syntactic structure in general follows a subject object-verb (sov) order .
3.3. Amharic punctuation marks
In addition to its alphabets, Amharic also has its own numbers ( twenty symbols, even though not large
used now a days ) and its their punctuation system with eight symbols as shown in table 3.2 (Bjorn and
Samuel, 2005) in the host days, word ranges were indicate by
Two vertically placed dots like a colon called ‘hulet netb’(ሁለት ነጥብ). But this traditional not contin-
ued gradually after printing in Amharic become common practice. Letter spaces are current used instead
of hulet netb particularly on printed documents. Although people still use ሁለት ነጥብ in their hand
writing, a sentence completely is indicated by four dots called arat netb(አራት ነጥብ)a practice
which still continuous (Yohannes, 2007). The other punctuation marks in Amharic lan-
guage are ‘derb serez’(ድርብ ሰረዝ)which roughly corresponds roughly to a comma. Even though
usage of this tags may not necessary agree with English usage (Leslau, 2000) question mark (?) is used

34
to end interrogative sentences as used by English language literatures show that three dots (…) have been
used in place of question mark in the previous days. Quotes (ትምህርተ ጥቅስ) are sometimes represent
as in the French styles << … >> and are parentheses (ቅንፍ) and exclamation mark (ቃል አጋኖ) are in
the roman system (…) and ! (Bloor, 1995).
Table 3.2 Amharic punctuation marks
Name Hulet
netm
Arat
netb
Derb
serez
Netela
serez
Question
mark
Quotation
mark
Exclamation
mark
parenthesis
Sign : :: ፤ ፣ ? <<>> ! ()
3.4. Amharic morphology
Amharic is one of the morphologically rich and complex languages. It is a more inflectional and quite
dialectally diversified (Asker et al 2009). Amharic like other semantic languages like that of Arabic, ex-
hibits the root pattern morphological idea (Marcha, 2010). A root is a set of consonant which has a basic
lexical meanings. The design include a set of vowels which are added among the consonant of a root to
form as well as to this non concatenative morphological feature, Amharic words as various affixes to
create ineffectual and derivational word forms. For Amharic such as most other languages, verbs have
the most difficult morphology. More over to lexical information, the morphemes in an Amharic verb
convey subject and object person, number, and gender; tense, aspect, and mood; different derivational
division such as polarity, reciprocal, passive and causative (negative or affirmative); and arrange of pre-
position and conjunctions. (wondwosson and Gass 2012). All these process make Amharic morphologi-
cal analysis more difficult.
Few Amharic adverbs can be derived from adjectives. Nouns are originate from other basic nouns, ad-
jectives, stems, roots and the infinitive form of a verb by affixation and intercalation. Case, number, de-
finiteness, and gender affixes inflect nouns. Adjectives derived from nouns , stems or verbal roots by
adding a prefix or a suffix. In addition, adjectives can also formed from compounding like nouns, adjec-
tive are inflected for gender, number, and case (Martha, 2010). The Amharic vocabulary is very big

35
mainly as a result of the afore mentioned big number of morphological forms each word have. In Am-
haric morphology, each word can be expanded into a large number of forms. If we consider the case of
verbs we notice that it has more than one thousand various forms (Mesifn 2008). Amharic morphology
is thus another cause of ambiguity in the course of NLP. These ambiguity in the word have the same suf-
fix or prefix. The word betoch (ቤቶች) which outcome from additions of plural suffix och (ኦች) can be
taken as a good example. In segmenting the word betoch (ቤቶች) in to its singular form and suffix, it
would be ambiguous identify the singular form of the word. Because either it can be (በሬ) or (ቤት). it is
recommended to attempted each component morphemes of a word carefully to determine the classes of
each morpheme to clarify where the source of ambiguity comes from.
3.5 ambiguities in Amharic
Ambiguity in language is divided in two main types (Krovetz and craft , 1992) syntactical and lexical
ambiguity. Lexical ambiguity is determined as the presence of two or more possible meanings within a
single word. Syntactic ambiguity on the other hand consider the semantic shifts created when the order
of words have more than one grammatical relationship in a given context. Although ambiguity in vari-
ous languages are no limited to only to these types. Solomon (2010) determine the various types of am-
biguities which can occur in Amharic language including orthographic, lexical, phonological, structural,
referential and semantic
3.5.1 orthographic ambiguities
Orthographic ambiguities is outcome from germinate and sounds. The ambiguity can be resolved using
context. However it might be more challenge such in the following example
Mobile yiseral(ሞባይሉ ይሰራል)
The word “yiseral” is the reason of ambiguity. The sentences is ambiguity between the followings.
1. The mobile works (“yseral”)
2. The mobile will be repaired (“yiseral”)

36
3.5.2. Referential ambiguity
Referential ambiguity up when a word or phrase could, in the context of a single sentence, refer two or
more futures or things. Sometimes the context tell us which meanings is perfectly, but when it does not
we may selection the wrong means, this kinds of ambiguity normally occurs in Amharic pronouns when
they come with more than one antecedent in a sentences. For exampleAbebe tru wutet slemiyameta ter-
gaga(አበበ ጥሩ ዉጤት ስለሚያመጣ ተረጋጋ) the above sentences becomes ambiguous us the follow-
ing two meanings.
1. Abebe is relieved since he get a good result and see
2. The getting of Abebe relied some one
3.5.3 syntactic (structural ) ambiguity
Syntactic ambiguity outcome when a consistent of a syntactic has more than one possible. By a syntactic
we mean the way structure consistent are arranged. The following is an example of such ambiguity.
Bemiketlew samnt endemtmeta kal gebtalech (በሚቀጥለዉ ሳምንት እንደምትመጣ ቃል ገብታለች)
The above sentence understand in two ways
1. She promised that she would be coming for the next week (በሚቀጥለዉ ሳምንት እንደምትመጣ
ቃል ገብታለች)
2. On a discussion held for next week, she promised that she would coming(በቀጣይ ሳምንት
እነደገለፀችዉ በቀጠሮዉ መሰረት ትመጣለች )
The position of ‘wik’ in the sentence brings ambiguity to the meanings of the sentences. If the time ad-
verb ‘wik’ is positioned as seen in the next sentence. Endemtmeta bemiktlewu samnt kal gebtalch
(በሚቀጥለዉ ሳምንት እንደምትመጣ ቃል ገብታለች). the sentences becomes clearer referring the
second meaning in the above. In any case, it requires a close examination of the context to decide the
meaning of these types of ambiguity sentences.

37
3.5.4.phonological ambiguity
Interpretation of voice sounds within and from start to end words may cause ambiguity phonological
ambiguity exist when a speaker pronounce by creating stop sound . talking using stop and without stop
result into sense ambiguity. An example of the following show this type of ambiguity in a sentences.
Berasew neber (በራ-ሰዉ ነበር) in this sentences when there is a stop between ‘bera’
And ‘sew’ and whereas, when it is read without stop it means that moisture.
3.5.5. lexical ambiguity
As stated in the previous section, lexical ambiguity means to reason where there are two or more sense
for a lexical unit. This lexical unit may there to identical or various parts of speech division. The various
factors that cause lexical ambiguity include: Affixes, categorical, homonymy, synonymy and homo-
phonous.
3.5.5.1 homonymy
Homonymy is the condition of a given words having the identical phonological form. But with various
meanings which will cause ambiguity. For example, the word terda (ተረዳ) have more than one meaning
these include understand, fund, in the sentence abebe yetemarewn terda (አበበ አጥንቶ ተረዳ), terda
means understand. Whereas kebede genzeb tereda (ከበደ ገንዘብ ተረዳ) the word terda means funds.
3.5.5.2 Categorical ambiguity
A word is categorical ambiguous when it has the identical phonological and homographic form but be-
longs to various classes e.g.‘Tla metach’ (ጥላ- መጣች) is ambiguous because tla has two meanings
which serve as a noun means umbrella and as a verb (means fight) the sentence would have the follow-
ings two meanings depending on the context and on the role of the word as a noun or as a verb

38
1. Umbrella was ready for it (serving as noun)
2. She is coming the fighting (serving as a verb)
3.5.5.3.Homophone affixes
The types of ambiguities outcome affixes are used for various word classes the word can be morpholog-
ically analyzed into separate morphemes: the root, suffix and prefix. Since the meaning each morphemes
remains the same across words it creates identical words are difficult understand. E.g. the definiteness
marker (u-/ is phonetically the same with the third person genitive possive suffix / -u/ hence, nouns like
begu (በጉ) is ambiguous between the definite reading ‘the sheep’ or the passive reading ‘his sheep’.
3.5.5.4. Synonymy
Synonymy are words are words that posses identical or related meanings. Synonymy can be any part of
speech (like that of preposition, adverb, adjective, verb, nouns) as well as both words are with the iden-
tical part of speech. Although synonyms might not has correctly the identical meanings in all contexts.
On the other hand words they might not be used alternately in sentence. For example, the English ‘stick’
can be translated in to Amharic words dula (ዱላ),betr (በትር), these two words are synonymous refer-
ring in rural area watch to domestic animal and protect when fighting the people each other but the
usage of these words in sentences depends on the context show the examples below to show how these
words are used in these two sentences.
1. Alemu watch the caw with stick ; stick takes the meaning of ‘betr’
2. Kebede protect the fighting person with stick ; stick takes the meaning of ‘dula’
The present study in detail on lexical ambiguity of words. It deals with five homonymous
Amharic verbs with three sense each.

39
CHAPTER FOUR
DATACOLLECTION OR PREPARATION AND IMPLEMENTATION DESIGN
This study aim to model Amharic word sense disambiguation using minimally supervised machine
learning towards that, different processing and data collection works have been performed , various tools
and parameters were chosen to be used for experiment and over system architecture have been proposed.
4.1 data collection
In Amharic language there is no context base wordnet (repository) and sense annotated corpus, in this
investigate we entail to attempt on the existing labeled data sets that are taken in the previous research-
ers (Agerie,2013,Getahun,2012,Solomon,2011,Solomon,2010) for the ambiguous word (mesal). To sup-
port the existing data set, the researcher collected data for the fouradditional ambiguous words.
Ras(ራስ),gb(ግብ),yemigeba(የሚገባ) and kena (ቀና) list of selected ambiguous words with respective
size and sense of their data set is shown in table 1. Thedata collection for these new words done from the
following internet resources((citation) http:// www.ethiopian reporter.com, www.ertagov.com, addisa-
dimass news.com (Agerie, 2013), Amharic voa news.com, Amharic bible, Amhara bzuhan megenagna
and bekur news. The researcher collects sentence from different domains to coverage the possible con-
texts the ambiguous words can be situated.
To collect the data set a great deal of time is invested. The different and derivation of the target words
used to search the sentence has been selected carefully. Repeated sentences were also removed as much
as possible. In general, the researcher has managed to collect 204 sentence for the word ራስ(ras), 199
sentence for ቀና(kena), 200 sentence for the word ግብ (gb),201 sentence የሚገባ(yemigeba). These sen-
tence were collected by searching the target word on Amharic web sites. In situations where the sen-
tences were short, phrases preceding and following the selected sentences were included.
Table 4.1 Ambiguous words sentences
Ambiguous
Words
Amharic re-
presentation
Sense one Sense two Sense three Number of
sentence
Mesal መሳል Cough Vow Sharp 220

40
Ras ራስ yourself moisture Head 204
Yemigeba የሚገባ Require Inside Understand 201
Gb ግብ Goal Objective Fight 200
Kena ቀና Nice Envious Holdup 199
Total 1025
4.2. Preprocessing techniques and algorithms
In order to prepare the row data gathered for the machine learning tool (weka), some start preprocessing
works were performed including tokenization, stop word removal,stemming and normalization. These
preprocessing works were done using program codes written python software.The details of the prepro-
cessing tasks are explained below.
4.2.1 Tokenization
Tokenization is the first work performed in preprocessing the collected data. Tokenization is the process
of splitting a sentence into words (tokens) so as to get context words for disambiguation purpose (Solo-
mon, 2010) the main works in tokenization is removal of punctuation and spacing (single space between
words). The common punctuation marks seen in the statement include comma,fuli stop, semico-
lon,exclamation point,slash,quotation mark, hyphen, colon, dash, period, parentheses and apostropheand
compound words were very difficult for tokenization tasks. Various writers represent compoundwords
in various forms. Forexample the word ‘wet-bet’ was represented as a single word ‘ወጥ u?ƒ’ or even
separated by the hyphen as ‘ወጥ-ቤት’ tokenizing the last two representations. Tokenization was also
challenging in that double spaces were instantiated or created between words,as a result of the tokeniza-
tion.

41
4.2.2 Stop word removal
Stop word removal is the process of removing commonly occurring words which have discriminating
power for the ambiguous words (Yohannes,2007).These words comprise non-content bearing word like
preposition, articles, conjunction, numerals and names(including name of place and person ). The com-
monly shown stop words in the collected sentence includeወደ, የ, አቶ, ይህ, ነዉ, ብቻ, ናቸዉ, ላይ,
ዉስጥ, ወይም, ግን, ነገርግን, በ, እና, ለ, ና, ይህን, ይሄ,@ ያኛዉ. In some condition , some stop
words near the target words provides expressive and consistent information to the sense of target words.
In such conditions, these stop words are kept in the corpus since they can discriminate the meaning of
the ambiguous words from the other meaning. For instance, stop word ‘በ’ discriminate the target word
‘ቀና’. If’ቀ’is followed by the word n it always specify the meaning of approach rather than present.
The use of በ in such context can be illustrated in the following phrase: በሚስቱ ቀና, በስራ k“,
በህዝቡ< ሃሰብ ቀና keeping this condition in mind, separate stop word sets were used for each ambi-
guous and each meaning. The stop word removal algorithm is presented in Algorithm 4.1
1. Open corpus and stop word list
2. While not end of corpus file is reached do
Read terms
For each term in the file
If term in stop word list then
Remove term
End if
End for
3. End while
4. Close files
Algorithm 4.1 stop word removal
4.2.3. Stemming

42
Stemming is a method used to minimize morphological variants of a word into its root word (Yohanes,
2007). This tasks is an important task for Amharic text preprocessing due to the morphological increases
and complexity of the language. As discussed in chapter three, Amharic language make use of prefix-
ing, suffixing and infixing to create various word forms. Stemming is so the removal of these affixes to
obtain the stem or root forms. For this thesis, stem is performed for both the target words and words in
the rest of the corpus. For example the ambiguous word መሳል word is obtained as a result of stem-
ming of the following words ሲስል, በመሳል, አሳሳል, ሲያስል, ከተሳለ, ከምትስሉት, ከመሳል,
የመናስለዉ, በሚስለዉ, በማሳል, በስዕል, እንደሚሳል, ባይሳልም etc 4.2 shows the algorithm used for stemming
1. open corpus, exception list and stop word list
2. write not end of corpus file is reached do
read terms
for each term in the file
if term starts with prefix
if term not in exception file list then
remove prefix
end if
end if
if term end with suffix
if term not in exception file list then
remove prefix
end if
end if
end for
3. find while
4. close file
4.2.5. Normalization

43
In Amharic language normalization is make normal, especially cause to form to astandared or normal.
To make (a text or language) regular and consistent especially with respect to spellingor style.
Types of normalization
1. Amharic has different characters that represents same sound phoneme. These are grouped in two
as different alphabet that share the same sound and the same sound for the first and fourth order
alphabets(Betelhem,2002). Normalization in Amharic language has to be done to convert differ-
ent form of Amharic letter (fidel) that have the same sound to one some form (Yohannes,2007),
for instance, fidel like that of አ, ዐ, ዓ converted to one common› table 4.2 lists many Amharic
characters which find normalization. Normalization has been done both for the base symbols
and for the respective derivatives. That mean all identical sound fidel are normalized to one sin-
gle form. Tokenization slaves in accuracy problem that can be caused by spelling difference of
the identical word like ስእል, ሥዕል
The code used for transliteration work was written by Ermias Abebe
Table 4.2 Amharic characters with identical sound
Various character
With the same sound Normalized form
ሀ ሐ ኀ ሀ(he)
ሰ ሠ ሰ(se)
ዐ አ አ(A)
ç ፀ ፀ(Tse)
2. Numbers in Amharic text writing are usually represented in three ways using Alphabetical
words, Arabic numerals and ethiopic numerals (Seid and Mulugeta, 2009). For example አንድ, 1,
3. The other normalization task was converting the abbreviation into their respective detail form.
Amharic abbreviation are written using the character “/” for word slash, “.” or dot for example
ት/ቤት or ት.ቤት and መ/ቤት መ.ቤት

44
4. The other normalization process involves compound word. It is might be written as one or sepa-
rated by space in texts that do not use the Amharic word separater for example compound words
like “ቤተ ክርስቲያን”/ ‘bete krstiyan’ which means church and “ወጥ ቤት”/ wet bet which
means kitchen are normalize into one word as “ቤተክርስቲያን” and “ወጥቤት”.
5. The last problem is related to writing of affixes different formats. As in ዘግባአለች፤ዘግባለች/
zegbaalech’, ‘zegbalech’ which all that means she has reported. This solved during the stemming
process, as the seffixes “ለች” and “አለች” are removed the same root word is extracted for both
words.
4.2.4 Preparing machine readable data The final step in preprocessing is to get the ambiguous words aligned the center column and the sur-
rounding words (word context) to the left and of the target word. Data with different bag size were
marked for each ambiguous word. A maximum of ten window size were prepared by removing columns
from extreme ends of the wider window size data sets.Shown in table 4.3 is a typical example of the
prepared data
Table 4.3 sample data set for ቀና with three window size and three meanings in the
context
L3 L2 L1 Target R1 R2 R3 Class
Ljoch Tru Na Kena Endi Honu Memker Nice
Saytan Melkam Sra Kena Amelekakt Ye Lewum Envious
Hilemariam Wede China Kena Africa Form Tsatefe Hold up
Ya Le Tchit Kena Snetbeb Liyadig Ayicilm Nice
Bal Be mistu Kena Le Meftat Wesene Envious s
Hyiwete Ye Gemerwu Kana Memhr Shon New Nice
The formatted data shown in table 4.3 finally was converted to Arff(Attribute relation file format) that is
readable by weka. Ingeneral the preprocessing work and data collection were very challenging and time

45
taking.Data collection was fully manual. As well as internet connection was very slow by the time we
attempted to collect the data. The python code, which was used to do stemming, was not effective as ex-
pected. First it is not adequate to cover all word various(verities) in the language; secondly it introduced
invalid words in to the corpus in the process of removing affixes and replacing them with new ones. To
challenge this, we had to do stemming work automatically a single for target words and context words
which contribute much in the disambiguation processstop word removal, tokenization, and normaliza-
tion were compared easier than stemming since they participate removal of specific character from the
corpus. Eventhough, there were some correction still needed to be done manually. More over the above
listed challenge, inconsistently in Amharic writing system has also contribute a lot to the problem. For
instance
Some Amharic words have various spelling due to the difference in their pronunciation in dif-
ferent parts of country.
Example ‘tsebay’ is found writers as ፀባይ or as ጠባይ
Different writers in different spelling for the same sound.
For example ‘tahsas’ is found written as ታህሳስ or as ታሳስ
‘ayiroplan’ is found written as አዉሮፕላን or as አይሮፕላን
Various in using affixes applied to identical word
For instance beayer is found written as በአየር or as ባየር
Some words were represented as abbereviation
For example beale is found written as በአል or as ባል
In consistent usage of compound words
For example ‘betekrstian’ is found written as ቤተ-ክርስቲያን or as ቤተክርስቲያን or as ቤተ
ክርስቲያን
4.2. Training and data set
Once all the important work were done on the corpus, training the sample and evaluating it were fol-
lowed. To do that, 10-fold cross validation is used and supplied tes t used. Cross validation is a method
for assessing how the result of a statistical analysis will generalize to an independent data set. It is main-
ly used to predict and estimate how the truth a predictive model will perform in practice (Mclachlan et
al, 2004).

46
In n – fold cross validation, the original sample is partitioned into n sub-samples of the n sub- samples
(example), a particular sub- sample is retained as the validation data. For testing the model and the re-
maining n-1 sub- samples are used as training data. The cross validation process is then repeated n times
(the fold), with each of the n sub-samples used exactly once as validation data the n result from the fold
then can be averaged (or compined) to produce a single estimation. The importance of this techniques
over repeat random sub-sampling is that all shows are used for both training and validation, and each
shows is used for validation exactly once. Ten-fold cross-validation is commonly used by researchers
and in our experiment too, n is chosen to be 10 (also default value on weka).
4.3. Selected algorithms for the experiments
For this experiment, minimally supervised learning techniques are implemented by using graph
base(Bayes net) algorithm , clustering by committee(Hierarchical cluster) algorithm and high growing
hierarchical self-organizing map(RBF network) algorithm found in weka 3.6. package.
4.4. Performance measures
The performance measures of classification algorithm is sometimes measured by parameters
such as accuracy, recall, precision and f-measures. These performance parameters are the func-
tion of the number of correctly and incorrectly classified instance. Which are obtained on the
confusion matrix analyzes how well an algorithm classifier instance in their corresponding
classes. Table below demonstrate the confusion matrix for two classes (A and B).
Table 4.4 confusion matrix for two class (A and B)

47
Node A B
A True positive False negative
B False negative True negative
The value listed in the table are described as below
True positive- actual positive instance which are correctly labeled as positive
True negative- actual negative instance which are correctly labeled as negative
False positives – negative instance that are incorrectly labeled as positive
False negatives – positive instance that are incorrectly labeled as negative
From these given values, the performance parameters can be calculate as follows.
Precision (positive predictive value) proportion of predicated positives which are actual positives
Precision = TP/(Tp + Fp)
Recall: proportion of actual positives which are predicated positive
Recall = Tp(Tp + Fn)
Accuracy : the percentage of correctly classified instance is often called accuracy or sample accuracy.
Predictive accuracy has always been used as the main and often only evaluation criterion for the
predictive performance of Bayes net and RBF network algorithm (Ankita sati 2013) better performance
other algorithm like monolingual boot strapping algorithm. This study as well employed accuracy to be
the only performance measure.
4.5. System Architecture
Finally the system architecture is designed to represent the end to end process of the disambiguation
work. Fig 4.1 shows the architecture of the proposed Amharic word sense disambiguation system. As
can be seen on the diagram, the system takes in raw collection of sentences consists one ambiguous

48
word each. These sentence are then preprocessed like that of tokenization, stop word removal,stemming
and normalization are performed. Then Amharic word sense translated, ordered and labeled in such a
way that they can be readable the machine learning tool (weka). This preprocessed and labeled data are
then used to model the WSD system. Minimally supervised algorithm label propagation are applied to
build the model. It adapted from (Hagerie welde, 2013 and Getahun wassie,2012)
Sentence with ambiguous
word

49
Fig 4.1. Architecture for the proposed WSD system
CHAPTER FIVE
EXPERIMENTATION AND DISCUSSION EVALUATION

50
As discussed in section 2.5.4 the semi supervised learning which combines supervised and unsupervised
method by exploiting(xiaojin and hyail,2008). It uses both labeled and unlabelled training data together
to improve WSD accuracy(Bartsz and Maciej, 2013). The combination of many unlabelled and some
labeled seeds examples improve performance with less effort (Getahun et al, 2012). The experiment of
minimally supervised algorithm method using selected algorithm was conducted on the five Amharic
WSD data sets following semi supervised classification assumption. The result of the experiment shown
in table 6. Ten fold cross validation is used for evaluating and creating predictive model. discusses the
results obtained from the experiment. This is due to appropriates of 10-fold cv for small datasets we
used in this experiment. it is because it performs the training 10 times increasing the training dataset by
tenfold.
The experiment are performed based on the concepts discussed in the chapter four. The experiments
were done using two classification and one clustering algorithms are bayesNet and radial basis function
( RBF) network classification and hierarchical cluster algorithm. As we used radial basis function net
work classification algorithm given excellent performance of kernel- base classifiers such as support
vector machine, which are often applied with an RBF kernel that corresponds to Gaussian basis function
with a fixed global variance (Eibe Frank, 2014). In the other algorithm as we used bayes net classifica-
tion algorithm have been applied success full to a large number of problems in machine learning an d
pattern recognition and are well known for their power and potential of making valid prediction under
uncertain situations(Muhammed Muzzamile Luqman et al). as well as we employed that used to hierar-
chical cluster algorithm it produce a nested partitioning of the data element by merging or splitting clus-
ters (Endmonton, Alberta,2003). Based on result obtained from these classification and clustering algo-
rithm are discussed and a compared of these classification algorithm RBF network algorithm better than
bayes net algorithm. For this study five classifier namely mesal, kena, ras, yemigeba and gb will be
trained for each ambiguous words with their corresponding data sets are defined in chapter four of this
thesis. In this chapter the experiment procedures with the analysis of the experiment result will be pre-
sented.
5.1 Experimentation setup for supervised
For supervised experiment the researcher the same data with semi supervised shown table 3, a total of
15 classes and 1025 sentences were used in the experimentation process. The all sentence are labeled to

51
its pre-defined classes with the corresponding provided by itself . To test the performance of RBF net-
work and bayesNet algorithm at increasing number of classes and sentences, the different pre-defined
number of classes and corresponding pre- classified sentence were used to conduct the experiments.
The 15 categories were divided to into five and the experiment were done on 3, 6, 9, 12 and 15 number
of classes using 220, 420, 624, 826 and 1025 sentence respectively as shown table3. The first experi-
ment was done on three classes: ‘cough’, ‘vow’ and ‘sharp’ that contain different number of sentence
items were selected. The second experiment was performed on six classes: ‘cough’, ‘vow’, ‘sharp’,
‘yourself’, ‘moisture’ and ‘head’. The third experiment was performed on nine classes : ‘cough’, ‘vow’,
‘sharp’, ‘yourself’, ‘moisture’, ‘head’, ‘require’, ‘inside’ and ‘understand’. The fourth experiment was
performed on twelve classes: ‘cough’, ‘vow’, ‘sharp’, ‘yourself’, ‘moisture’, ‘head’, ‘require’, ‘inside’,
‘understand’, ‘goal’, ‘objectives’ and ‘fight’. The fifth experiment was performed on fifteen classes
:‘cough’, ‘vow’, ‘sharp’, ‘yourself’, ‘moisture’, ‘head’, ‘require’, ‘inside’, ‘understand’, ‘goal’, ‘objec-
tives’ and ‘fight’, ‘nice’, ‘envious’, ‘holdup’ and ‘holdup’.
Table 5.1. experimentation setup
Experiment No. ambiguous
words
List o of class used Number of
sentences
Algorithm used
On three of
class
1 1. Cough 44 1. Bayes
Net 2. Vow 69

52
3. Sharp 107 2. RBF
network
Total 220 1. Bayes
Net
2. RBF
network
On six of
classes
2
1. Cough 44
2. Vow 69
3. Sharp 107
4. Yourself 116
5. Moisture 36
6. Head 48
Total 420
On nine of
classes
3
1. Cough 44 1. Bayes
Net
2. RBF
network
2. Vow 69
3. Sharp 107
4. Yourself 116
5. Moisture 36
6. Head 48
7. Require 102
8. Inside 80
9. understand 22
Total 624
On twelve of
classes
4
1. cough 44 1. Bayes
Net
2. RBF
network
2. Vow 69
3. Sharp 107
4. Yourself 116
5. Moisture 36
6. Head 48
7. Require 102
8. Inside 80
9. understand 22
10. goal 22
53
11. objective 144
12. fight 36
Total 826
On fifteen of
classes
5
1. cough 44 1. Bayes
Net
2. RBF
network
2. Vow 69
3. Sharp 107
4. Yourself 116
5. Moisture 36
6. Head 48
7. Require 102
8. Inside 80
9. understand 22
10. goal 22
11. objective 144
12. fight 36
13. nice 101
14. envious 21
15. holdup 77
Total 1025
5.1.1 Bayes Net test
As in chapter two Bayes Net is one of the simple algorithm of machine learning. It is probabilistic
graphic models and represented by their structure and parameters. Structure is a given by a directed a
cyclic graph and it encodes the dependency relationships between domain variables where as parameters
of the network are conditional probability distributions which are associated with its node. The test re-
sults for the bayes net classifier is discussed in the following sections. Three classes ‘cough’, ‘vow’,
‘sharp’, contain different number of sentence items were selected. Where 220 sentence items were used.
The classification accuracy for this test can be shown using confusion matrix. A confusion matrix con-

54
tain a column and row where the row is a actual categories and column is predicted number of sentence
classified to the corresponding classes. The following confusion matrix details are for the three classes.
=== Stratified cross-validation ===
=== Summary ===
Ten cross validation
Correctly Classified Instances 174 81.09 %
Incorrectly Classified Instances 46 18.91 %
=== Confusion Matrix ===
a b c <-- classified as
36 2 6 | a = cough
9 56 4 | b = vow
12 13 82 | c = sharp
Figure 5.1 confusion matrix three classes or sense using bayesNet. The first row indicates that 36 sentences are classified correctly as the category ‘cough’, 8 sentence from
this category are misclassified as other category 2 as ‘vow’ and 6 as ‘sharp’. The second row indicates 9
sentence from the class ‘vow’ are classified incorrectly to the class ‘cough’; 56 sentence are classified
correctly ; 4 sentence classified incorrectly to the class of category ‘sharp’. The third row indicates 12
sentence from the class of category ‘cough’; 13 sentence from the class of ‘sharp’ are classified incor-
rectly to the category ‘vow’. 82 sentence are classified correctly in the class of category. As we can ob-
served from the above experiments output the algorithm classified 81.09% of the sentence correctly and
18.91% of the sentence incorrectly. This is correctly classified are 174 out 220.
Experiment on six classes
Six classes ‘cough’, ‘vow’, ‘sharp’, ‘yourself’, ‘moisture’ and ‘head’ contain various number of sen-
tence items were selected. Where 420 sentences items were used. The classification accuracy for this

55
experiment can be showing using confusion matrix contain a column and where the raw is a classes. The
following confusion matrix details for the six classes or senses.
=== Stratified cross-validation ===
=== Summary ===
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 336 80 %
Incorrectly Classified Instances 84 20 %
=== Confusion Matrix ===
A b c d e f <-- classified as
31 2 11 0 0 0 | a = cough
4 58 7 0 0 0 | b = vow
5 11 91 0 0 0 | c = sharp
0 0 0 97 4 15 | d = yourself
0 0 0 1 25 10 | e = moisture
0 0 0 11 3 34 | f = head
Figure 5.2 confusion matrix for six classes using bayes net.
The first row indicates that 31 sentences are classified correctly as the category ‘cough’ , 13 sen-
tence from this category are misclassified as other category 2 as ‘vow’, 11 as ‘sharp’, 0 as ‘yourself’, 0
as ‘moisture’, 0 as ‘head’. The second row indicates 4 sentences from the class ‘vow’ are classified in-
correctly to the class ‘cough’; 58 sentences are classified correctly as the category ‘vow’; 7 sentence
classified incorrectly to the category ‘sharp’, 0 sentence classified incorrectly to the category ‘yourself’,
0 sentence classified incorrectly to the category ‘moisture’ and 0 sentence classified incorrectly to the
category ‘head’. The third row indicates 5 sentence from the class ‘sharp’ are classified incorrectly to
the class of ‘cough’, 11 sentence from the class ‘sharp’ are classified incorrectly to the class of ‘vow’;
91 sentence are classified correctly as the category ‘sharp’; 0 sentence classified incorrectly to the class
‘yourself’, 0 sentence classified incorrectly to the class ‘moisture’ and 0 sentence classified incorrectly

56
to the class ‘head’. The fourth row indicates 0 sentences from this category are misclassified as the cate-
gory 0 as ‘cough’, ‘vow’, ‘sharp’; 97 sentence are classified correctly as the category ‘yourself’; 19
sentence from this category incorrectly as the other category 4 as ‘moisture’, 15 as ‘head’. The fifth row
indicates 1 sentence classified incorrectly as the category 0 as ‘cough’, ‘vow’, ‘sharp’ and as 1 ‘your-
self’. 25 sentence are classified correctly as the category ‘moisture’. 10 sentence classified incorrectly in
to the category ‘head’. The sixth row indicates 14 sentence from this category misclassified as other
category 0 as ‘cough’, 0 as ‘vow’, 0 as ‘sharp’, 11 as ‘yourself’, 3 as ‘moisture’ ;34 sentence are classi-
fied correctly as the category ‘head’. As we can observed from the above experiment result the algo-
rithm classified 80% of the sentence correctly and 20% of the sentence incorrectly. The highest confu-
sion (11) happened between cough and sharp.
Experiment on nine classes
Nine classes ‘cough’, ‘vow’, ‘sharp’, ‘yourself’, ‘moisture’, ‘head’, ‘require’, ‘inside’, and ‘understand’
are contain different number sentence items were selected. Where 604 sentence showing using confu-
sion matrix contain column and row where the row is a classes. The following confusion matrix details
for the nine classes.
Time taken to build model: 0 seconds
=== Stratified cross-validation ===
=== Summary ===

57
=== Stratified cross-validation ===
Ten cross validation
=== Summary ===
Correctly Classified Instances 453 72.5962 %
Incorrectly Classified Instances 171 27.4038 %
=== Confusion Matrix ===
a b c d e f g h I <-- classified as
30 2 12 0 0 0 0 0 0 | a = cough
2 58 9 0 0 0 0 0 0 | b = vow
3 11 93 0 0 0 0 0 0 | c = sharp
0 0 0 101 1 14 0 0 0 | d = yourself
0 0 0 6 20 10 0 0 0 | e = moisture
0 0 0 16 2 30 0 0 0 | f = head
0 0 0 1 0 0 56 27 18 | g = require
0 0 0 0 0 0 22 49 9 | h = inside
0 0 0 0 0 0 3 3 16 | i = understand
Figure 5.3 confusion matrix for nine classes using bayes net.
The first row indicates that 30 sentences are classified correctly as the category ‘cough’; 14 sentence
from this category are misclassified as other category 2 as ‘vow’, 12 as ‘sharp’, 0 as ‘yourself’, 0 as
‘moisture’, 0 as ‘head’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’. The second row indicates 2 sen-
tence from the class ‘vow ’ are classified incorrectly to the class ‘cough’; 58 sentence are classified cor-
rectly as the category ‘vow’; 9 sentence from this category are incorrectly as other category 9 as
‘sharp’, 0 as ‘yourself’, 0 as ‘moisture’, 0 as ‘head’, 0 as ‘head’, 0 as ‘require’, 0 as ‘understand’, 0 as
‘inside’. The third row indicates 3 sentence from the class ‘vow’ are classified incorrectly to the class
‘cough’ and 11 sentence from the class ‘sharp’ are classified incorrectly to the class ‘vow’; 93 sentence

58
are classified correctly as the category ‘sharp’; 0 sentence from this category are misclassified as other
category 0 as ‘yourself’, 0 as ‘moisture’, 0 as ‘head’, 0 as ‘require’, 0 as ‘understand’, 0 as inside. The
fourth row indicates 0 sentence in this category are misclassified as other category 0 as ‘cough’, 0 as
‘vow’, 0 as ‘sharp’; 101 sentence are classified correctly as the category ‘yourself’; 15 sentence from
this category are misclassified as other 1 as ‘moisture’, 14 as ‘head’, 0 as ‘require’, 0 as ‘inside’, and 0
as ‘understand’. The fifth row indicates 6 sentence in this category are misclassified as other category 0
as ‘cough’, 0 as ‘vow’, 0 as ‘sharp’ and 6 as ‘yourself’; 20 sentence are classified correctly as the cate-
gory ‘moisture’; 10 sentence are classified incorrectly category as 10 as ‘head’, 0 as ‘require’, 0 as ‘in-
side’, 0 as ‘understand’. The sixth row indicates 18 sentence in this category are misclassified as other
category 0 as ‘cough’, 0 as ‘vow’, 0 as ‘sharp’, 16 as ‘yourself’, 2 as ‘moisture’; 30 sentence are classi-
fied correctly as the category ‘head’; 0 sentence are classified incorrectly category as 0 ‘require’, 0 as
‘inside’, 0 as ‘understand’. The seventh row indicates 1 sentence in this category are misclassified as
other category 0 as ‘cough’, 0 as ‘vow’, 0 as ‘sharp’, 1 as ‘yourself’, 0 as ‘moisture’, 0 as ‘head’; 56 sen-
tence are classified correctly as the category ‘require’; 45 sentence are classified incorrectly category 27
as ‘inside’ and 18 as ‘understand’. The eighth row indicates 22 sentences in this category are misclassi-
fied as other category 0 as ‘cough’, 0 as ‘vow’, 0 as ‘sharp’, 0 as ‘yourself’, 0 as ‘moisture’, 0 as ‘head’,
22 as ‘require’; 49 sentences are classified correctly as the category ‘inside’; 9 sentence are classified
incorrectly as ‘understand’. The ninth row indicates 6 sentence are misclassified category as 0 as
‘cough’, 0 as ‘vow’, 0 as ‘sharp’, 0 as ‘yourself’, 0 as ‘moisture’, 0 as ‘head’, 3 as ‘require’ and 3 as
‘inside’; 16 sentence are correctly as the category ‘understand’. As we can observed from the above ex-
periment result the algorithm classified 72.59% of the sentence correctly and 27.40% of the sentence
incorrectly. The highest confusion (27) happened between require and inside.
Experiment on twelve classes
Twelve classes ‘cough’, ‘vow’, ‘sharp’, ‘yourself’, ‘moisture’, ‘head’, ‘require’, ‘inside’, ‘under-
stand’, ‘goal’, ‘objective’ and ‘fight’ are contain different number sentence items were selected. Where
826 sentence showing using confusion matrix contain column and row where the row is a classes. The
following confusion matrix details for the twelve classes.

59
=== Stratified cross-validation ===
=== Summary ===
Ten cross validation
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 630 76.27 %
Incorrectly Classified Instances 196 23.73 %
=== Confusion Matrix ===
a b c d e f g h i j k l <-- classified as
30 2 12 0 0 0 0 0 0 0 0 0 | a = cough
1 54 14 0 0 0 0 0 0 0 0 0 | b = vow
3 10 94 0 0 0 0 0 0 0 0 0 | c = sharp
0 0 0 104 1 11 0 0 0 0 0 0 | d = yourself
0 0 0 8 22 6 0 0 0 0 0 0 | e = moisture
0 0 0 17 3 28 0 0 0 0 0 0 | f = head
0 0 0 0 0 0 62 38 2 0 0 0 | g = require
0 0 0 0 0 0 24 54 2 0 0 0 | h = inside
0 0 0 0 0 0 4 7 11 0 0 0 | i = understand
0 0 0 0 0 0 0 0 0 5 15 2 | j = goal
0 0 0 0 0 0 0 0 0 0 137 7 | k = objective
0 0 0 0 0 0 0 0 0 0 7 29 | l = fight
Figure 5.4 confusion matrix for twelve classes using bayes net.

60
The first row indicates that 30 sentence are classified correctly as the category ‘cough’; 14 sentence
from this category are misclassified as other category 2 as ‘vow’, 12 as ‘sharp’, 0 as ‘yourself’, 0 as
‘moisture’, 0 as ‘head’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as ‘goal’, ‘objective’ and ‘fight’.
The second row indicates 1 sentence from the class ‘vow’ are classified incorrectly to the class ‘cough’;
54 sentence are classified correctly as the category ‘vow’; 14 sentence from this category are misclassi-
fied as other category 14 as ‘sharp’, 0 as ‘yourself’, 0 as ‘moisture’, 0 as ‘head’, 0 as ‘require’, 0 as ‘in-
side’, 0 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’. The third row indicates 13 sentence
are misclassified as other category 3 as ‘cough’ and 10 as ‘vow’; 94 sentence are classified correctly as
the category ‘sharp’; 0 sentence from this category are misclassified as other category 0 as ‘yourself’, 0
as ‘moisture’, 0 as ‘head’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and
0 as ‘fight’.The fourth row indicates 0 sentence are misclassified as other category 0 as ‘cough’, 0 as
‘vow’ and 0 as sharp;104 sentence are classified correctly as the category ‘yourself’; 13 sentence from
this category are misclassified as other category 1 as ‘moisture’, 11 as ‘head’, 0 as ‘require’, 0 as ‘in-
side’, 0 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’. The fifth row indicates 8 sentence
are misclassified as other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp and 8 as ‘yourself ’;22 sentence
are classified correctly as the category ‘moisture’; 6 sentence from this category are misclassified as
other category 6 as ‘head’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’
and 0 as ‘fight’. The sixth row indicates 20 sentence are misclassified as other category 0 as ‘cough’, 0
as ‘vow’ , 0 as sharp, 17 as ‘yourself and 3 as moisture ’;28 sentence are classified correctly as the cate-
gory ‘head’; 0 sentence from this category are misclassified as other category 0 as ‘require’, 0 as ‘in-
side’, 0 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’. The seventh row indicates 0 sen-
tence are misclassified as other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as
moisture and 0 as ‘head ’;62 sentence are classified correctly as the category ‘require’; 40 sentence from
this category are misclassified as other category 38 as ‘inside’, 2 as ‘understand’, 0 as ‘goal’, 0 as ‘ob-
jective’ and 0 as ‘fight’. The eighth row indicates 24 sentence are misclassified as other category 0 as
‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘your elf , 0 as moisture and 0 as ‘head ’, 24 as ‘require’;54 sen-
tence are classified correctly as the category ‘inside’; 2 sentence from this category are misclassified as
other category 2 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’. The ninth row indicates
11 sentence are misclassified as other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0
as moisture and 0 as ‘head ’, 4 as ‘require’, 7 ‘inside’;11 sentence are classified correctly as the catego-
ry ‘understand’; 2 sentence from this category are misclassified as other category 0 as ‘goal’, 0 as ‘ob-

61
jective’ and 0 as ‘fight’.The tenth row indicates 0 sentence are misclassified as other category 0 as
‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘require’, 0 as ‘in-
side’, 0 as ‘understand’ ;5 sentence are classified correctly as the category ‘goal’; 17 sentence from this
category are misclassified as other category 15 as ‘objective’ and 2 as ‘fight’.The eleventh row indi-
cates 0 sentence are misclassified as other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself
, 0 as moisture and 0 as ‘head ’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as goal ;137 sentence
are classified correctly as the category ‘objective’; 7 sentence from this category are misclassified as
other category 7 as ‘fight’. The twelveth row indicates 7 sentence are misclassified as other category
0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘require’, 0 as
‘inside’, 0 as ‘understand’, 0 as goal and 7 as ‘objective’ ;29 sentence are classified correctly as the cat-
egory ‘fight’. As we can shown from the above experiment result the algorithm classified 76.27% of the
sentence correctly and 23.73% of the sentence incorrectly. The highest confusion (38) happened be-
tween require and understand. These shows more related the classes.
Experiment on fifteen classes
Fifteen classes ‘cough’, ‘vow’, ‘sharp’, ‘yourself’, ‘moisture’, ‘head’, ‘require’, ‘inside’, ‘understand’,
‘goal’, ‘objective’ , ‘fight’, ‘nice’ and ‘envious’ contain different number sentence items were selected.
Where 1025 sentence showing using confusion matrix contain column and row where the row is a
classes. The following confusion matrix details for the fifteen classes.
=== Stratified cross-validation ===
=== Summary ===

62
=== Summary ===
Ten cross validation
Correctly Classified Instances 762 74.3415 %
Incorrectly Classified Instances 263 25.6585 %
=== Confusion Matrix ===
a b c d e f g h i j k l m n o <-- classified as
27 2 15 0 0 0 0 0 0 0 0 0 0 0 0 | a = cough
1 54 14 0 0 0 0 0 0 0 0 0 0 0 0 | b = vow
1 13 93 0 0 0 0 0 0 0 0 0 0 0 0 | c = sharp
0 0 0 106 1 9 0 0 0 0 0 0 0 0 0 | d = yourself
0 0 0 6 23 7 0 0 0 0 0 0 0 0 0 | e = moisture
0 0 0 19 0 29 0 0 0 0 0 0 0 0 0 | f = head
0 0 0 0 0 0 61 40 1 0 0 0 0 0 0 | g = require
0 0 0 0 0 0 25 52 3 0 0 0 0 0 0 | h = inside
0 0 0 0 0 0 5 10 7 0 0 0 0 0 0 | i = understand
0 0 0 0 0 0 0 0 0 5 15 2 0 0 0 | j = goal
0 0 0 0 0 0 0 0 0 0 138 6 0 0 0 | k = objective
0 0 0 0 0 0 0 0 0 0 7 29 0 0 0 | l = fight
0 0 0 0 0 0 0 0 0 0 0 0 92 0 9 | m = nice
0 0 0 0 0 0 0 0 0 0 0 0 13 2 6 | n = envious
0 0 0 0 0 0 0 0 0 0 0 0 30 3 44 | o = holdup
Figure 5.5 confusion matrix for fifteen classes using bayes net. The first row indicates that 27 sentence are classified correctly as the category ‘cough’; 17 sentence
from this category are misclassified as other category 2 as ‘vow’, 15 as ‘sharp’, 0 as ‘yourself’, 0 as
‘moisture’, 0 as ‘head’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as ‘goal’, ‘objective’ , ‘fight’, 0
as ‘nice’, 0 as ‘envious ‘and 0 as ‘holdup’. The second row indicates 1 sentence from the class ‘vow’ are
classified incorrectly to the class ‘cough’; 54 sentence are classified correctly as the category ‘vow’; 14
sentence from this category are misclassified as other category 14 as ‘sharp’, 0 as ‘yourself’, 0 as ‘mois-
ture’, 0 as ‘head’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as
‘fight’, 0 as ‘nice’, 0 as ‘envious’ and 0 as ‘holdup’. The third row indicates 14 sentence are misclassi-

63
fied as other category 1 as ‘cough’ and 13 as ‘vow’; 93 sentence are classified correctly as the category
‘sharp’; 0 sentence from this category are misclassified as other category 0 as ‘yourself’, 0 as ‘mois-
ture’, 0 as ‘head’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as
‘fight’, 0 as ‘nice’, 0 as ‘envious ‘and 0 as ‘holdup’.The fourth row indicates 0 sentence are misclassi-
fied as other category 0 as ‘cough’, 0 as ‘vow’ and 0 as sharp;106 sentence are classified correctly as
the category ‘yourself’; 10 sentence from this category are misclassified as other category 1 as ‘mois-
ture’, 9 as ‘head’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as
‘fight’, 0 as ‘nice’, 0 as ‘envious ‘and 0 as ‘holdup’. The fifth row indicates 6 sentence are misclassified
as other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp and 6 as ‘yourself ’;23 sentence are classified
correctly as the category ‘moisture’; 7 sentence from this category are misclassified as other category 7
as ‘head’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’, 0
as ‘nice’, 0 as ‘envious ‘and 0 as ‘holdup’. The sixth row indicates 19 sentence are misclassified as
other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 19 as ‘yourself and 0 as ‘moisture ’;29 sentence
are classified correctly as the category ‘head’; 0 sentence from this category are misclassified as other
category 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’, 0
as ‘nice’, 0 as ‘envious’ and 0 as ‘holdup’. The seventh row indicates 0 sentence are misclassified as
other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’;61
sentence are classified correctly as the category ‘require’; 41 sentence from this category are misclassi-
fied as other category 40 as ‘inside’, 1 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’, 0 as
‘nice’, 0 as ‘envious’ and 0 as ‘holdup’. The eighth row indicates 25 sentence are misclassified as other
category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 25 as ‘re-
quire’;53 sentence are classified correctly as the category ‘inside’; 3 sentence from this category are
misclassified as other category 3 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’, 0 as
‘nice’, 0 as ‘envious’ and 0 as ‘holdup’. The ninth row indicates 5 sentence are misclassified as other
category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘re-
quire’, 5 ‘inside’;10 sentence are classified correctly as the category ‘understand’; 7 sentence from this
category are misclassified as other category 7 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’, 0 as ‘nice’, 0 as
‘envious’ and 0 as ‘holdup’.The tenth row indicates 5 sentence are misclassified as other category 0 as
‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘require’, 0 as ‘in-
side’, 5 as ‘understand’ ;10 sentence are classified correctly as the category ‘goal’; 7 sentence from this
category are misclassified as other category 7 as ‘objective’ and as ‘fight’, 0 as ‘nice’, 0 as ‘envious’

64
and 0 as ‘holdup’.The eleventh row indicates 0 sentence are misclassified as other category 0 as
‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘require’, 0 as ‘in-
side’, 0 as ‘understand’, 0 as goal ;138 sentence are classified correctly as the category ‘objective’; 6
sentence from this category are misclassified as other category 6 as ‘fight’, 0 as ‘nice’, ‘envious’, ‘hol-
dup’. The twelveth row indicates 7 sentence are misclassified as other category 0 as ‘cough’, 0 as
‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘un-
derstand’, 0 as goal and 7 as ‘objective’ ;29 sentence are classified correctly as the category ‘fight’; 0
sentence from this category misclassified as other category 0 as ‘nice’, 0 as ‘envious’, 0 as ‘holdup’. The
thirteenth row indicates 0 sentence are misclassified as other category 0 as ‘cough’, 0 as ‘vow’ , 0 as
sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as
goal , 0 as ‘objective’ and 0 as ‘fight’ ;92 sentence are classified correctly as the category ‘nice’; 9 sen-
tence from this category misclassified as other category 0 as ‘envious’, and 9 as ‘holdup’. The four-
teenth row indicates 13 sentence are misclassified as other category 0 as ‘cough’, 0 as ‘vow’ , 0 as
sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as
goal , 0 as ‘objective’, 0 as ‘fight’ and 13 as nice ;2 sentence are classified correctly as the category
‘envious’; 6 sentence from this category misclassified as other category 6 as ‘holdup’.The fifteenth
row indicates 33 sentence are misclassified as other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as
‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as goal , 0 as
‘objective’, 0 as ‘fight’ 0 as ‘nice’ and ‘envious’ ;44 sentence are classified correctly as the category
‘holdup’. As we can observed from the above experiment result the algorithm classified 74.34% of the
sentence correctly and 25.66% of the sentence incorrectly. The highest confusion (40) happened be-
tween require and understand. These shows more related the classes.
5.1.2. RBF network
Radial basis function (RBF) network have supervised training of Gaussian in weka. It is a type of feed
forward network with a long history in machine learning. RBF regresses trains or regression model
(Muhammad Muzzamil luquman (2009)). Which algorithm supports growth high hierarchical self or-
ganize map. The key to successfully implementation of these networks to find suitable centers for Gaus-
sian function. “the important of the radial basis function network is that its finds the input output map
using local approximates”(Animut Belay(2012)). Three classes ‘cough’, ‘vow’, ‘sharp’ are contain dif-

65
ferent number of sentence items were selected. Where 220 sentence items were used. The classification
accuracy for this test can be shown using confusion matrix. A confusion matrix contain a column and
row where the row is a actual categories and column is predicted number of sentence classified to the
corresponding classes. The following confusion matrix details are for the three classes.
=== Stratified cross-validation ===
=== Summary ===
Ten cross validation
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 150 68.1818 %
Incorrectly Classified Instances 70 31.8182 %
=== Confusion Matrix ===
a b c <-- classified as
21 11 12 | a = cough
5 50 14 | b = vow
10 18 79 | c = sharp
Figure 5.6 confusion matrix for three classes RBF network.
The first row indicates that 21 sentences are classified correctly as the category ‘cough’, 23 sentence
from this category are misclassified as other category 11 as ‘vow’ and 12 as ‘sharp’. The second row
indicates 5 sentence from the class ‘vow’ are classified incorrectly to the class ‘cough’; 50 sentence are
classified correctly ; 14 sentence classified incorrectly to the class of category ‘sharp’. The third row in-
dicates 28 sentence from the class of category ‘cough’; 10 sentence from the class of ‘sharp’ are classi-
fied incorrectly to the category ‘vow’ and 18 sentence from the class of category ‘vow’ are classified to
the category ‘sharp’; 79 sentence are classified correctly as the category. As we can observed from the
above experiment result the algorithm classified 68.18% of the sentence correctly and 36.67% of the
sentence incorrectly. The highest confusion (18) happened between sharp and vow. These confusion
shows more related the classes.

66
Experiment on six classes
Six classes ‘cough’, ‘vow’, ‘sharp’, ‘yourself’, ‘moisture’ and ‘head’ contain various number of sen-
tence items were selected. Where 420 sentences items were used. The classification accuracy for this
experiment can be showing using confusion matrix contain a column and where the raw is a classes. The
following confusion matrix details for the six classes or senses.
=== Stratified cross-validation ===
=== Summary ===
Ten cross validation
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 266 63.3333 %
Incorrectly Classified Instances 154 36.6667 %
=== Confusion Matrix ===
a b c d e f <-- classified as
25 4 12 1 0 2 | a = cough
6 49 12 0 0 2 | b = vow
6 20 75 1 0 5 | c = sharp
0 4 0 70 6 36 | d = yourself
0 1 0 9 16 10 | e = moisture
0 0 1 13 3 31 | f = head
Figure 5.7 confusion matrix for six classes RBF network.
The first row indicates that 25 sentences are classified correctly as the category ‘cough’ , 18 sentence
from this category are misclassified as other category 4 as ‘vow’, 12 as ‘sharp’, 1 as ‘yourself’, 0 as
‘moisture’, 2 as ‘head’. The second row indicates 6 sentences from the class ‘vow’ are classified incor-
rectly to the class ‘cough’; 49 sentences are classified correctly as the category ‘vow’; 14 sentence clas-

67
sified incorrectly to the category 12 as ‘sharp’, 0 as sentence classified incorrectly to the category
‘yourself’, 0 sentence classified incorrectly to the category ‘moisture’ and 2 sentence classified incor-
rectly to the category ‘head’. The third row indicates 26 sentence from the class category are misclassi-
fied as other 6 as ‘cough’ and 20 as ‘vow’; 75 sentence are classified correctly as the category ‘sharp’;
6 sentence classified incorrectly to the class 1 as ‘yourself’, 0 as ‘moisture’,5 as ‘head’. The fourth row
indicates 4 sentences from this category are misclassified as the category 0 as ‘cough’, 4 as ‘vow’, 0
‘sharp’; 70 sentence are classified correctly as the category ‘yourself’; 44 sentence from this category
incorrectly as the other category 6 as ‘moisture’, 36 as ‘head’. The fifth row indicates 10 sentence clas-
sified incorrectly as the category 0 as ‘cough’, 1 as ‘vow’, 0 as ‘sharp’ and as 9 ‘yourself’. 16 sentence
are classified correctly as the category ‘moistures’. 10 sentence classified incorrectly in to the category
‘head’. The sixth row indicates 17 sentence from this category misclassified as other category 0 as
‘cough’, 0 as ‘vow’, 1 as ‘sharp’, 13 as ‘yourself’, 3 as ‘moisture’ ;31 sentence are classified correctly
as the category ‘head’ As we can shown from the above experiment result the algorithm classified
63.33% of the sentence correctly and 36.67% of the sentence incorrectly. The highest confusion (20)
happened between sharp and vow. These shows more related the classes.
Experiment on nine classes
Nine classes ‘cough’, ‘vow’, ‘sharp’, ‘yourself’, ‘moisture’, ‘head’, ‘require’, ‘inside’, and ‘understand’
are contain different number sentence items were selected. Where 604 sentence showing using confu-
sion matrix contain column and row where the row is a classes. The following confusion matrix details
for the nine classes.
=== Stratified cross-validation ===
=== Summary ===

68
Ten cross validation
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 342 54.8077 %
Incorrectly Classified Instances 282 45.1923 %
=== Confusion Matrix ===
a b c d e f g h i <-- classified as
26 5 8 3 0 2 0 0 0 | a = cough
6 54 5 2 0 1 0 1 0 | b = vow
25 4 55 1 0 2 0 0 0 | c = sharp
0 1 0 69 14 29 1 2 0 | d = yourself
0 0 0 5 21 7 0 3 0 | e = moisture
0 0 0 15 2 30 0 1 0 | f = head
0 1 6 0 0 10 38 47 0 | g = require
0 0 1 0 0 6 26 47 0 | h = inside
0 0 1 1 0 3 6 9 2 | i = understand
Figure 5.8 confusion matrix for nine classes RBF network.
The first row indicates that 26 sentences are classified correctly as the category ‘cough’; 18 sentence
from this category are misclassified as other category 5 as ‘vow’, 8 as ‘sharp’, 3 as ‘yourself’, 0 as
‘moisture’, 2 as ‘head’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’. The second row indicates 6 sen-
tence from the class ‘vow ’ are classified incorrectly to the class ‘cough’; 54 sentence are classified cor-
rectly as the category ‘vow’; 9 sentence from this category are incorrectly as other category 5 as
‘sharp’, 2 as ‘yourself’, 0 as ‘moisture’, 1 as ‘head’, 1 as ‘require’, 0 as ‘understand’, 0 as ‘inside’. The
third row indicates 29 sentence from the class ‘vow’ are classified incorrectly to the class 25 as ‘cough’
and 4 sentence from the class ‘sharp’ are classified incorrectly to the class ‘vow’; 55 sentence are classi-
fied correctly as the category ‘sharp’; 3 sentence from this category are misclassified as other category 1
as ‘yourself’, 0 as ‘moisture’, 2 as ‘head’, 0 as ‘require’, 0 as ‘understand’, 0 as inside. The fourth row
indicates 1 sentence in this category are misclassified as other category 0 as ‘cough’, 1 as ‘vow’, 0 as
‘sharp’; 69 sentence are classified correctly as the category ‘yourself’; 46 sentence from this category

69
are misclassified as other 14 as ‘moisture’, 29 as ‘head’, 1 as ‘require’, 2 as ‘inside’, and 0 as ‘under-
stand’. The fifth row indicates sentence in this category are misclassified as other category 0 as ‘cough’,
0 as ‘vow’, 0 as ‘sharp’ and 5 as ‘yourself’; 21 sentence are classified correctly as the category ‘mois-
ture’; 10 sentence are classified incorrectly category as 7 as ‘head’, 0 as ‘require’, 3 as ‘inside’, 0 as ‘un-
derstand’. The sixth row indicates 17 sentence in this category are misclassified as other category 0 as
‘cough’, 0 as ‘vow’, 0 as ‘sharp’, 15 as ‘yourself’, 2 as ‘moisture’; 30 sentence are classified correctly as
the category ‘head’; 0 sentence are classified incorrectly category as 1 ‘require’, 0 as ‘inside’, 0 as ‘un-
derstand’. The seventh row indicates 17 sentence in this category are misclassified as other category 0 as
‘cough’, 1 as ‘vow’, 6 as ‘sharp’, 0 as ‘yourself’, 0 as ‘moisture’, 10 as ‘head’; 38 sentence are classified
correctly as the category ‘require’; 47 sentence are classified incorrectly category 47 as ‘inside’ and 0 as
‘understand’. The eighth row indicates 33 sentences in this category are misclassified as other category
0 as ‘cough’, 0 as ‘vow’, 1 as ‘sharp’, 0 as ‘yourself’, 0 as ‘moisture’, 6 as ‘head’, 26 as ‘require’; 47
sentences are classified correctly as the category ‘inside’; 0 sentence are classified incorrectly as ‘under-
stand’. The ninth row indicates 20 sentence are misclassified category as 0 as ‘cough’, 0 as ‘vow’, 1 as
‘sharp’, 1 as ‘yourself’, 0 as ‘moisture’, 3 as ‘head’, 6 as ‘require’ and 9 as ‘inside’; 2 sentence are cor-
rectly as the category ‘understand’. As we can shown from the above experiment result the algorithm
classified 54.80% of the sentence correctly and 45.20% of the sentence incorrectly. The highest confu-
sion (47) happened between require and inside. These shows more related the classes.
Experiment on twelve classes
Twelve classes ‘cough’, ‘vow’, ‘sharp’, ‘yourself’, ‘moisture’, ‘head’, ‘require’, ‘inside’, ‘understand’,
‘goal’, ‘objective’ and ‘fight’ are contain different number sentence items were selected. Where 826
sentence showing using confusion matrix contain column and row where the row is a classes. The fol-
lowing confusion matrix details for the twelve classes.
=== Stratified cross-validation ===
=== Summary ===

70
Ten cross validation
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 467 56.5375 %
Incorrectly Classified Instances 359 43.4625 %
=== Confusion Matrix ===
a b c d e f g h i j k l <-- classified as
22 8 10 0 0 1 0 2 1 0 0 0 | a = cough
4 39 25 0 0 1 0 0 0 0 0 0 | b = vow
19 9 73 0 0 0 0 4 2 0 0 0 | c = sharp
2 0 0 55 5 47 0 1 6 0 0 0 | d = yourself
0 0 0 6 19 10 0 1 0 0 0 0 | e = moisture
0 0 0 8 2 36 0 0 1 1 0 0 | f = head
0 0 0 0 0 40 33 18 11 0 0 0 | g = require
0 0 0 0 0 28 10 33 9 0 0 0 | h = inside
0 0 0 0 0 12 1 3 6 0 0 0 | i = understand
0 0 0 0 0 4 0 0 0 12 6 0 | j = goal
0 0 1 0 0 7 0 0 2 14 120 0 | k = objective
0 0 0 0 1 5 0 1 0 5 5 19 | l = fight
Figure 5.9 confusion matrix for twelve classes RBF network.
The first row indicates that 22 sentence are classified correctly as the category ‘cough’; 22 sentence
from this category are misclassified as other category 8 as ‘vow’, 10 as ‘sharp’, 0 as ‘yourself’, 0 as
‘moisture’, 1 as ‘head’, 0 as ‘require’, 2 as ‘inside’, 1 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0
as ‘fight’. The second row indicates 4 sentence from the class ‘vow’ are classified incorrectly to the
class ‘cough’; 39 sentence are classified correctly as the category ‘vow’; 25 sentence from this catego-
ry are misclassified as other category 25 as ‘sharp’, 0 as ‘yourself’, 0 as ‘moisture’, 1 as ‘head’, 0 as ‘re-
quire’, 0 as ‘inside’, 0 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’. The third row indi-
cates 28 sentence are misclassified as other category 9 as ‘cough’ and 19 as ‘vow’; 73 sentence are clas-
sified correctly as the category ‘sharp’; 6 sentence from this category are misclassified as other category

71
0 as ‘yourself’, 0 as ‘moisture’, 0 as ‘head’, 4 as ‘require’, 2 as ‘inside’, 0 as ‘understand’, 0 as ‘goal’, 0
as ‘objective’ and 0 as ‘fight’.The fourth row indicates 2 sentence are misclassified as other category 2
as ‘cough’, 0 as ‘vow’ and 0 as sharp;55 sentence are classified correctly as the category ‘yourself’; 59
sentence from this category are misclassified as other category 5 as ‘moisture’, 47 as ‘head’, 0 as ‘re-
quire’, 1 as ‘inside’, 6 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’. The fifth row indi-
cates 7 sentence are misclassified as other category 1 as ‘cough’, 0 as ‘vow’ , 0 as sharp and 6 as ‘your-
self ’;19 sentence are classified correctly as the category ‘moisture’; 11 sentence from this category are
misclassified as other category 10 as ‘head’, 0 as ‘require’, 1 as ‘inside’, 0 as ‘understand’, 0 as ‘goal’,
0 as ‘objective’ and 0 as ‘fight’. The sixth row indicates 10 sentence are misclassified as other category
0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 8 as ‘yourself and 2 as moisture ’;36 sentence are classified cor-
rectly as the category ‘head’; 2 sentence from this category are misclassified as other category 0 as
‘require’, 0 as ‘inside’, 1 as ‘understand’, 1 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’. The seventh row
indicates 40 sentence are misclassified as other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as
‘yourself , 0 as moisture and 40 as ‘head ’;33 sentence are classified correctly as the category ‘require’;
29 sentence from this category are misclassified as other category 18 as ‘inside’, 11 as ‘understand’, 0
as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’. The eighth row indicates 38 sentence are misclassified as
other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 28 as ‘head ’, 10
as ‘require’;33 sentence are classified correctly as the category ‘inside’; 9 sentence from this category
are misclassified as other category 9 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’. The
ninth row indicates 16 sentence are misclassified as other category 0 as ‘cough’, 0 as ‘vow’ , 0 as
sharp, 0 as ‘yourself , 0 as moisture and 12 as ‘head ’, 1 as ‘require’, 3 ‘inside’;6 sentence are classified
correctly as the category ‘understand’; 0 sentence from this category are misclassified as other category
0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’.The tenth row indicates 4 sentence are misclassified as other
category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 4 as ‘head ’, 0 as ‘re-
quire’, 0 as ‘inside’, 0 as ‘understand’ ;12 sentence are classified correctly as the category ‘goal’; 6 sen-
tence from this category are misclassified as other category 6 as ‘objective’ and 0 as ‘fight’.The ele-
venth row indicates 24 sentence are misclassified as other category 0 as ‘cough’, 0 as ‘vow’ , 1 as
sharp, 0 as ‘yourself , 0 as moisture and 7 as ‘head ’, 0 as ‘require’, 0 as ‘inside’, 2 as ‘understand’, 14
as goal ;120 sentence are classified correctly as the category ‘objective’; 0 sentence from this category
are misclassified as other category 0 as ‘fight’. The tewelveth row indicates 12 sentence are misclassi-
fied as other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 1 as moisture and 5 as ‘head

72
’, 0 as ‘require’, 1 as ‘inside’, 0 as ‘understand’, 5 as goal and 5 as ‘objective’ ;19 sentence are classi-
fied correctly as the category ‘fight’. As we can observed from the above experiment result the algo-
rithm classified 56.54% of the sentence correctly and 43.46% of the sentence incorrectly. The highest
confusion (25) happened between vow and sharp. These shows more related the classes.
Experiment on fifteen classes
Fifteen classes ‘cough’, ‘vow’, ‘sharp’, ‘yourself’, ‘moisture’, ‘head’, ‘require’, ‘inside’, ‘under-
stand’, ‘goal’, ‘objective’ , ‘fight’, ‘nice’ and ‘envious ‘are contain different number sentence items
were selected. Where 1025 sentence showing using confusion matrix contain column and row where the
row is a classes. The following confusion matrix details for the fifteen classes.
=== Stratified cross-validation ===
=== Summary ===
Ten cross validation
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 550 53.6585 %
Incorrectly Classified Instances 475 46.3415 %
=== Confusion Matrix ===
a b c d e f g h i j k l m n o <-- classified as
24 2 10 5 0 3 0 0 0 0 0 0 0 0 0 | a = cough
10 45 12 0 0 1 0 0 1 0 0 0 0 0 0 | b = vow
22 16 61 1 0 2 0 0 5 0 0 0 0 0 0 | c = sharp
2 0 0 54 7 45 0 0 5 0 2 1 0 0 0 | d = yourself
0 0 0 2 16 12 0 0 3 2 0 0 0 1 0 | e = moisture
0 0 0 10 3 33 0 0 1 0 1 0 0 0 0 | f = head
0 0 0 0 0 33 26 32 11 0 0 0 0 0 0 | g = require

73
0 0 0 0 0 23 5 42 10 0 0 0 0 0 0 | h = inside
0 0 0 0 0 7 0 5 10 0 0 0 0 0 0 | i = understand
0 0 0 0 0 2 0 0 2 7 7 4 0 0 0 | j = goal
0 0 0 0 0 10 0 0 0 7 119 8 0 0 0 | k = objective
0 0 0 0 0 2 0 0 1 1 4 28 0 0 0 | l = fight
1 1 0 0 0 8 0 1 3 0 0 1 63 22 1 | m = nice
1 1 0 0 0 0 0 0 2 0 0 0 4 12 1 | n = envious
0 0 0 0 0 8 0 0 12 1 0 0 12 34 10 | o = holdup
Figure 5.10 confusion matrix for fifteen classes RBF network.
The first row indicates that 24 sentence are classified correctly as the category ‘cough’; 20 sentence
from this category are misclassified as other category 2 as ‘vow’, 10 as ‘sharp’, 5 as ‘yourself’, 0 as
‘moisture’, 3 as ‘head’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 0 as ‘goal’, ‘objective’ , ‘fight’, 0
as ‘nice’, 0 as ‘envious’ and 0 as ‘holdup’. The second row indicates 10 sentence from the class ‘vow’
are classified incorrectly to the class ‘cough’; 45 sentence are classified correctly as the category
‘vow’; 14 sentence from this category are misclassified as other category 12 as ‘sharp’, 0 as ‘yourself’, 0
as ‘moisture’, 1 as ‘head’, 0 as ‘require’, 0 as ‘inside’, 1 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and
0 as ‘fight’, 0 as ‘nice’, 0 as ‘envious’ and 0 as ‘holdup’. The third row indicates 38 sentence are mis-
classified as other category 22 as ‘cough’ and 16 as ‘vow’; 61 sentence are classified correctly as the
category ‘sharp’; 8 from this category are misclassified as other category 0 as ‘yourself’, 1 as ‘mois-
ture’, 0 as ‘head’, 2 as ‘require’, 0 as ‘inside’, 0 as ‘understand’, 5 as ‘goal’, 0 as ‘objective’ and 0 as
‘fight’, 0 as ‘nice’, 0 as ‘envious’ and 0 as ‘holdup’.The fourth row indicates 2 sentence are misclassi-
fied as other category 2 as ‘cough’, 0 as ‘vow’ and 0 as sharp;54 sentence are classified correctly as
the category ‘yourself’; 53 sentence from this category are misclassified as other category 7 as ‘mois-
ture’, 45 as ‘head’, 0 as ‘require’, 0 as ‘inside’, 5 as ‘understand’, 0 as ‘goal’, 2 as ‘objective’ and 1 as

74
‘fight’, 0 as ‘nice’, 0 as ‘envious’ and 0 as ‘holdup’. The fifth row indicates 2 sentence are misclassified
as other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp and 2 as ‘yourself ’;16 sentence are classified
correctly as the category ‘moisture’; 18 sentence from this category are misclassified as other category
12 as ‘head’, 0 as ‘require’, 0 as ‘inside’, 3 as ‘understand’, 2 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’,
0 as ‘nice’, 1 as ‘envious’ and 0 as ‘holdup’. The sixth row indicates 13 sentence are misclassified as
other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 10 as ‘yourself and 3 as moisture ’;33 sentence are
classified correctly as the category ‘head’; 2 sentence from this category are misclassified as other cate-
gory 0 as ‘require’, 0 as ‘inside’, 1 as ‘understand’, 0 as ‘goal’, 1 as ‘objective’ and 0 as ‘fight’, 0 as
‘nice’, 0 as ‘envious’ and 0 as ‘holdup’. The seventh row indicates 33 sentence are misclassified as oth-
er category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 33 as ‘head ’;26 sen-
tence are classified correctly as the category ‘require’; 43 sentence from this category are misclassified
as other category 32 as ‘inside’, 26 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’, 0 as
‘nice’, 0 as ‘envious’ and 0 as ‘holdup’. The eighth row indicates 28 sentence are misclassified as other
category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 23 as ‘head ’, 5 as ‘re-
quire’;42 sentence are classified correctly as the category ‘inside’; 3 sentence from this category are
misclassified as other category 3 as ‘understand’, 0 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’, 0 as
‘nice’, 0 as ‘envious’ and 0 as ‘holdup’. The ninth row indicates 5 sentence are misclassified as other
category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘re-
quire’, 5 ‘inside’;10 sentence are classified correctly as the category ‘understand’; 7 sentence from this
category are misclassified as other category 7 as ‘goal’, 0 as ‘objective’ and 0 as ‘fight’, 0 as ‘nice’, 0 as
‘envious’ and 0 as ‘holdup’.The tenth row indicates 5 sentence are misclassified as other category 0 as
‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘require’, 0 as ‘in-
side’, 5 as ‘understand’ ;10 sentence are classified correctly as the category ‘goal’; 7 sentence from this
category are misclassified as other category 7 as ‘objective’ and as ‘fight’, 0 as ‘nice’, 0 as ‘envious’
and 0 as ‘holdup’.The eleventh row indicates 0 sentence are misclassified as other category 0 as
‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘require’, 0 as ‘in-
side’, 0 as ‘understand’, 0 as goal ;138 sentence are classified correctly as the category ‘objective’; 6
sentence from this category are misclassified as other category 6 as ‘fight’, 0 as ‘nice’, ‘envious’, ‘hol-
dup’. The tewelveth row indicates 7 sentence are misclassified as other category 0 as ‘cough’, 0 as
‘vow’ , 0 as sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘require’, 0 as ‘inside’, 0 as ‘un-
derstand’, 0 as goal and 7 as ‘objective’ ;29 sentence are classified correctly as the category ‘fight’; 0

75
sentence from this category misclassified as other category 0 as ‘nice’, 0 as ‘envious’, 0 as ‘holdup’. The
thirteenth row indicates 15 sentence are misclassified as other category 1 as ‘cough’, 1 as ‘vow’ , 0 as
sharp, 0 as ‘yourself , 0 as moisture and 8 as ‘head ’, 0 as ‘require’, 1 as ‘inside’, 3 as ‘understand’, 0 as
goal , 0 as ‘objective’ and 1 as ‘fight’ ;63 sentence are classified correctly as the category ‘nice’; 22
sentence from this category misclassified as other category 21 as ‘envious’, and 1 as ‘holdup’. The four-
teenth row indicates 7 sentence are misclassified as other category 1 as ‘cough’, 1 as ‘vow’ , 0 as
sharp, 0 as ‘yourself , 0 as moisture and 0 as ‘head ’, 0 as ‘require’, 0 as ‘inside’, 2 as ‘understand’, 0 as
goal , 0 as ‘objective’, 0 as ‘fight’ and 4 as nice ;12 sentence are classified correctly as the category
‘envious’; 1 sentence from this category misclassified as other category 6 as ‘holdup’.The fifteenth
row indicates 66 sentence are misclassified as other category 0 as ‘cough’, 0 as ‘vow’ , 0 as sharp, 0 as
‘yourself , 8 as moisture , 0 as ‘head ’, 0 as ‘require’, 12 as ‘inside’, 1 as ‘understand’, 0 as goal , 0 as
‘objective’, 12 as ‘fight’ 34 as ‘nice’ and ‘envious’ ;10 sentence are classified correctly as the category
‘holdup’. As we can observed from the above experiment result the algorithm classified 53.66% of the
sentence correctly and 46.34% of the sentence incorrectly. The highest confusion (42) happened be-
tween inside and understand. These shows more related the classes.
Table 5.2. compared of algorithm at different class level
Number of sense or class Bayes net
Accuracy (%)
RBF network
Accuracy (%)
3 81% 68.18%
6 80% 63.33%
9 72.59% 54.80%
12 76.27% 56.54%
15 74.34% 53.66%
As shown in table above bayes net archived the highest performance in term of accuracy.
5.2. Experimentations setup for semi supervised

76
Learning as shown in table 3 a total of 15 sense or classes and 1025 sentences were used in the experi-
mentation process. The list of pre-defined classes with the corresponding sentence were used is already
provided. To test the performance of bayes net and RBF network classification algorithm at increasing
number of sense or classes and sentence, the various pre-defined number of sense or classes and the
corresponding pre-classified sentence were to conduct the experiments. The pre-defined classes or sense
were organized in the condition that each classes of sense are not related. That means classes that have
great identically have smaller probability to be selected at the same time. The 15 classes or senses using
,220, 420, 624, 826, and 1025 sentences respectively as shown in table 3
5.2.1 Bayes nettest Three classes or senses ‘cough’, ‘vow’ and ‘sharp’ within the target of ‘mesal’ that contain different
number of sentence item were selected; were 220 sentence items were used. The classification accuracy
for this test can be shown using confusion matrix include column and row where the column is predicate
and the row is actual categories number of sentences classified to the corresponding senses or classes.
The following confusion matrix details are for the three sense or classes with in the target word.
Time taken to build model: 0 seconds
=== Evaluation on test set ===
=== Summary ===
Correctly Classified Instances 218 99.0909 %
Incorrectly Classified Instances 2 0.9091 %
Total Number of Instances 220
=== Confusion Matrix ===
a b c <-- classified as
43 0 1 | a = cough
0 68 1 | b = vow
0 0 107 | c = sharps
2.3. Figure 5.11 confusion matrix for three classes using bayes net

77
The first row indicate that’s that 43 sentences are classified of sense correctly as the category ‘cough’; 1
sentences from this category are misclassified of sense as other category’s as ‘vow’ and 1 as ‘sharp’.
The second row indicates 0 sentence from the category ‘vow’ are not incorrectly to the category
‘cough’; 68 sentences are classified of correctly and 1 sentence are classified of sense of sentence are
incorrectly to the category ‘vow’. The third row indicates o sentences from the category of ‘sharp’ are
classified of sense ‘cough’ ; 0 sentence from the category sharp are classified of sense ‘vow’ and 107
sentence are classified correctly to the category of ‘sharp’. Therefore, correctly classified sense of sen-
tence items are 218 out of 220 and the average accuracy is 99.09% . the highest confusion (1) between
cough and sharp. This shows that more related of have of the classes or it have a lot in common.
Experiment on six categories
The second experiment was performed on six categories ‘cough’, ‘vow’ ‘sharp’, ‘yourself’ , ‘moisture’,
and ‘head’
Time taken to build model: 0.01 seconds
=== Evaluation on test set ===
=== Summary ===
Correctly Classified Instances 417 99.2857 %
Incorrectly Classified Instances 3 0.7143 %
Total Number of Instances 420
=== Confusion Matrix ===
a b c d e f <-- classified as
43 0 1 0 0 0 | a = cough
0 68 1 0 0 0 | b = vow
0 0 107 0 0 0 | c = sharp
0 0 0 116 0 0 | d = yourself
0 0 0 1 35 0 | e = moisture

78
0 0 0 0 0 48 | f = head
Figure5. 12 confusion matrix for six classes or sense of using bayes net
As we can see from the above experiment result the algorithm classified 99.2857of the sentence correct-
ly and 0.7143% of the sentence incorrectly. The highest confusion (1) happened between cough and
vow. These shows more the classes of sense.
Experiment on nine categories
The second experiment was performed on six categories ‘cough’, ‘vow’ ‘sharp’, ‘yourself’ , ‘moisture’,
and ‘head’ , ‘require’, ‘inside’ and ‘understand’.

79
Time taken to build model: 0.01 seconds
=== Evaluation on test set ===
=== Summary ===
Correctly Classified Instances 621 99.5192 %
Incorrectly Classified Instances 3 0.4808 %
Total Number of Instances 624
=== Confusion Matrix ===
a b c d e f g h i <-- classified as
43 0 1 0 0 0 0 0 0 | a = cough
0 68 1 0 0 0 0 0 0 | b = vow
0 0 107 0 0 0 0 0 0 | c = sharp
0 0 0 116 0 0 0 0 0 | d = yourself
0 0 0 1 35 0 0 0 0 | e = moisture
0 0 0 0 0 48 0 0 0 | f = head
0 0 0 0 0 0 102 0 0 | g = require
0 0 0 0 0 0 0 80 0 | h = inside
0 0 0 0 0 0 0 0 22 | i = understand
Figure 5. 13 confusion matrix for nine classes using bayes net As we can observed from the above experiment result the algorithm classified 99.5192 % of the sen-
tence correctly and 0.4808 %of the sentence incorrectly. The highest confusion (1) happened between
cough and vow. These shows more the classes of sense.
Experiment on twelve categories
The second experiment was performed on six categories’ of sense ‘cough’, ‘vow’ ‘sharp’, ‘yourself’ ,
‘moisture’, and ‘head’ , ‘require’, ‘inside’ and ‘understand’. ‘goal’, ‘objective’, and ‘fight’.

80
Time taken to build model: 0.01 seconds
=== Evaluation on test set ===
=== Summary ===
Correctly Classified Instances 820 99.2736 %
Incorrectly Classified Instances 6 0.7264 %
Total Number of Instances 826
=== Confusion Matrix ===
a b c d e f g h i j k l <-- classified as
42 0 2 0 0 0 0 0 0 0 0 0 | a = cough
0 68 1 0 0 0 0 0 0 0 0 0 | b = vow
0 0 107 0 0 0 0 0 0 0 0 0 | c = sharp
0 0 0 116 0 0 0 0 0 0 0 0 | d = yourself
0 0 0 1 35 0 0 0 0 0 0 0 | e = moisture
0 0 0 0 0 48 0 0 0 0 0 0 | f = head
0 0 0 0 0 0 102 0 0 0 0 0 | g = require
0 0 0 0 0 0 0 80 0 0 0 0 | h = inside
0 0 0 0 0 0 0 0 22 0 0 0 | i = understand
0 0 0 0 0 0 0 0 0 21 1 0 | j = goal
0 0 0 0 0 0 0 0 0 0 144 0 | k = objective
0 0 0 0 0 0 0 0 0 0 1 35 | l = fight
Figure 5.14 confusion matrix for twelve classes using bayes net
As we can shown from the above experiment result the algorithm classified 99.2736 % of the sentence
correctly and 0.7264 %of the sentence incorrectly. The highest confusion (1) happened between goal
and objective. These shows more related the classes .

81
Experiment on fifteen categories
The second experiment was performed on six categories : ‘cough’, ‘vow’ ‘sharp’, ‘yourself’, ‘moisture’,
and ‘head’ , ‘require’, ‘inside’ and ‘understand’. ‘goal’, ‘objective’, and ‘fight’ , ‘nice’. ‘envious’ and
‘holdup’
Time taken to build model: 0.01 seconds
=== Evaluation on test set ===
=== Summary ===
Correctly Classified Instances 1017 99.2195 %
Incorrectly Classified Instances 8 0.7805 %
Total Number of Instances 1025
=== Confusion Matrix ===
a b c d e f g h i j k l m n o <-- classified as
42 0 2 0 0 0 0 0 0 0 0 0 0 0 0 | a = cough
0 68 1 0 0 0 0 0 0 0 0 0 0 0 0 | b = vow
0 0 107 0 0 0 0 0 0 0 0 0 0 0 0 | c = sharp
0 0 0 116 0 0 0 0 0 0 0 0 0 0 0 | d = yourself
0 0 0 1 35 0 0 0 0 0 0 0 0 0 0 | e = moisture
0 0 0 0 0 48 0 0 0 0 0 0 0 0 0 | f = head
0 0 0 0 0 0 102 0 0 0 0 0 0 0 0 | g = require
0 0 0 0 0 0 0 80 0 0 0 0 0 0 0 | h = inside
0 0 0 0 0 0 0 0 22 0 0 0 0 0 0 | i = understand
0 0 0 0 0 0 0 0 0 22 0 0 0 0 0 | j = goal
0 0 0 0 0 0 0 0 0 0 144 0 0 0 0 | k = objective
0 0 0 0 0 0 0 0 0 0 1 35 0 0 0 | l = fight
0 0 0 0 0 0 0 0 0 0 0 0 101 0 0 | m = nice

82
0 0 0 0 0 0 0 0 0 0 0 0 1 20 0 | n = envious
0 0 0 0 0 0 0 0 0 0 0 0 2 0 75 | o = holdup
Figure 5.15 confusion matrix for fifteen classes using bayes net
As we can see from the above experiment result the algorithm classified 99.2195 % of the sentence cor-
rectly and 0.7805 %of the sentence incorrectly. The highest confusion (2) happened between cough and
sharp. These shows the classes have in common.
Table 5.3 accuracy performance to satisfied at various levels of class using bayes
net.
Number of classes or sense Accuracy performance
3 99.09%
6 99.28%
9 99.52%
12 99.27%
15 99.23%
Table 5.2 accuracy performance to satisfied at various levels of class using bayes net from the above ta-
ble, the highest accuracy is 99.52% and lowest accuracy is 99.09% when the number of classes three and

83
one respectively. From this we can conclude that when the number of class or sense increase the accura-
cy increase goes in vise verse.
5.2.2. RBF network test Experiment on three categories
The second experiment was performed on three categories ‘cough’, ‘vow’ and ‘sharp’ within one target
word ‘mesal’
Time taken to build model: 0.1 seconds
=== Evaluation on test set ===
=== Summary ===
Correctly Classified Instances 219 99.818 %
Incorrectly Classified Instances 1 0.8182 %
Total Number of Instances 220
=== Confusion Matrix ===
a b c <-- classified as
43 0 1 | a = cough
0 68 1 | b = vow
1 1 105 | c = sharp
Figure 5.15 confusion matrix for three classes of sense using RBF network As we can observe from the above experiment result the algorithm classified 98.818 % of the sentence
correctly and 0.8182 %of the sentence incorrectly. The highest confusion (1) happened between cough
and sharp. These shows more related the classes of sense.
Experiment on six categories’
The second experiment was performed on three categories ‘cough’, ‘vow’ and ‘sharp’ , ‘yourself’,
‘moisture’ and ‘head’.

84
=== Evaluation on test set ===
=== Summary ===
Correctly Classified Instances 419 99.8095 %
Incorrectly Classified Instances 1 0.1905 %
Total Number of Instances 420
=== Confusion Matrix ===
a b c d e f <-- classified as
44 0 0 0 0 0 | a = cough
0 68 1 0 0 0 | b = vow
0 1 106 0 0 0 | c = sharp
0 0 0 115 0 1 | d = yourself
0 0 0 0 36 0 | e = moisture
0 0 0 2 0 46 | f = head
2.4. Figure 5. 17 confusion matrix for six classes or sense using RBF network
As we can observed from the above experiment result the algorithm classified 99.8095 % of the sen-
tence correctly and 0.1905 %of the sentence incorrectly. The highest confusion (1) happened between
vow and sharp. These shows more related the classes of sense.
Experiment on nine categories
The second experiment was performed on three categories ‘cough’, ‘vow’ and ‘sharp’ , ‘yourself’,
‘moisture’, ‘head’, ‘require’, ‘inside ‘and ‘understand’.

85
=== Evaluation on test set ===
=== Summary ===
Correctly Classified Instances 619 99.1987 %
Incorrectly Classified Instances 5 0.8013 %
Total Number of Instances 624
=== Confusion Matrix ===
a b c d e f g h i <-- classified as
44 0 0 0 0 0 0 0 0 | a = cough
0 68 1 0 0 0 0 0 0 | b = vow
0 1 106 0 0 0 0 0 0 | c = sharp
0 0 0 115 0 1 0 0 0 | d = yourself
0 0 0 0 36 0 0 0 0 | e = moisture
0 0 0 2 0 46 0 0 0 | f = head
0 0 0 0 0 0 102 0 0 | g = require
0 0 0 0 0 0 0 80 0 | h = inside
0 0 0 0 0 0 0 0 22 | i = understand
Figure 5.18 confusion matrix for nine classes of using RBF network
As we can observed from the above experiment result the algorithm classified 99.1987 % of the sen-
tence correctly and 0.8013 %of the sentence incorrectly. The highest confusion (1) happened between
vow and sharp. These shows more related the classes of sense.
Experiment on twelve categories
The second experiment was performed on three categories ‘cough’, ‘vow’ , ‘sharp’ , ‘yourself’, ‘mois-
ture’, ‘head’, ‘require’, ‘inside’, ‘understand’, ‘goal’, ‘objective’ and ‘fight’.

86
=== Evaluation on test set ===
=== Summary ===
Correctly Classified Instances 821 98.80 %
Incorrectly Classified Instances 5 1.19 %
Total Number of Instances 826
=== Detailed Accuracy By Class ===
=== Confusion Matrix ===
a b c d e f g h i j k l <-- classified as
44 0 0 0 0 0 0 0 0 0 0 0 | a = cough
0 68 1 0 0 0 0 0 0 0 0 0 | b = vow
0 1 106 0 0 0 0 0 0 0 0 0 | c = sharp
0 0 0 116 0 0 0 0 0 0 0 0 | d = yourself
0 0 0 0 36 0 0 0 0 0 0 0 | e = moisture
0 0 0 0 0 48 0 0 0 0 0 0 | f = head
0 0 0 0 0 0 102 0 0 0 0 0 | g = require
0 0 0 0 0 0 0 80 0 0 0 0 | h = inside
0 0 0 0 0 0 0 0 22 0 0 0 | i = understand
0 0 0 0 0 0 0 0 0 22 0 0 | j = goal
0 0 0 0 0 0 0 0 0 0 144 0 | k = objective
0 0 0 0 0 0 0 0 0 0 0 36 | l = fight
2.5. Figure 5.19 confusion matrix for twelve classes using RBF network

87
As we can shown from the above experiment result the algorithm classified 98.80% of the sentence cor-
rectly and 1.19 %of the sentence incorrectly. The highest confusion (1) happened between vow and
sharp. These shows more related the classes of sense.
Experiment on fifteen categories of sense
The second experiment was performed on three categories’ ‘cough’, ‘vow’ , ‘sharp’ , ‘yourself’, ‘mois-
ture’, ‘head’, ‘require’, ‘inside ‘and ‘understand’, ‘goal’, ‘objective’ and ‘fight’.
=== Evaluation on test set ===
=== Summary ===
Correctly Classified Instances 1021 98.1818 %
Incorrectly Classified Instances 41.8182 %
Total Number of Instances 1025
=== Confusion Matrix ===
a b c d e f g h i j k l m n o <-- classified as
44 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | a = cough
0 69 0 0 0 0 0 0 0 0 0 0 0 0 0 | b = vow
0 0 107 0 0 0 0 0 0 0 0 0 0 0 0 | c = sharp
0 0 0 116 0 0 0 0 0 0 0 0 0 0 0 | d = yourself
0 0 0 0 36 0 0 0 0 0 0 0 0 0 0 | e = moisture
0 0 0 0 0 48 0 0 0 0 0 0 0 0 0 | f = head
0 0 0 0 0 0 102 0 0 0 0 0 0 0 0 | g = require
0 0 0 0 0 0 0 80 0 0 0 0 0 0 0 | h = inside
0 0 0 0 0 0 0 0 22 0 0 0 0 0 0 | i = understand
0 0 0 0 0 0 0 0 0 22 0 0 0 0 0 | j = goal
0 0 0 0 0 0 0 0 0 0 144 0 0 0 0 | k = objective
0 0 0 0 0 0 0 0 0 0 0 36 0 0 0 | l = fight
0 0 0 0 0 0 0 0 0 0 0 0 101 0 0 | m = nice

88
0 0 0 0 0 0 0 0 0 0 0 0 0 21 0 | n = envious
0 0 0 0 0 0 0 0 0 0 0 0 0 0 77 | o = holdup
Figure 5.20 confusion matrix for fifteen classes of sense using RBF network
As we can see from the above experiment result the algorithm classified 98.8 % of the sentence correctly
and 1.1818%of the sentence incorrectly.
2.6. Table 5.4 accuracy performance to satisfied at various levels of class using
RBF network
Number of classes or senses Accuracy performance
3 99.81%
6 99.80%
9 99.19%
12 98.80%
15 98.18%

89
Table 5 accuracy performance to satisfied at various levels of class using RBF network from the above
table, the highest accuracy is 99.8% and lowest accuracy is 98.18% when the number of classes five and
one respectively. From this we can conclude that when the number of class or sense increase the accura-
cy also increase goes in reverse way
Discussions
The algorithm used in the experimentation presented in this thesis were implemented from weka pack-
age. These algorithm were selected to contains different set of paradigms, where high compute efficien-
cy. according to the above experiments results. According to the above experiment results. We can un-
derstand see that the highest accuracy is 99.8% and the lowest 99.52 when the number of classes or
sense five and three respectively. In fact the highest accuracy have to RBF network and bayes net with
the percentage of 99.8% and 99.52 respectively. Finally when the sense of the ambiguous words were
increase the performance also increase.
5.3. Compared of classification algorithm
In this thesis various classification algorithm were used. The performance of each sentence classifica-
tion bayes net and RBF network were compared using their accuracy. Table below shows the compari-
son of the classification results obtained by bayes net and RBF network for 3,6,9,12 and 15 classes .
Table 5.5 performance evaluation at different classes stages.
Number of classes or senses RBF network Bayesnet
3 99.81% 99.09%
6 99.80% 99.28%
9 99.19% 99.52%
12 98.80% 99.27%
15 98.18% 99.23%
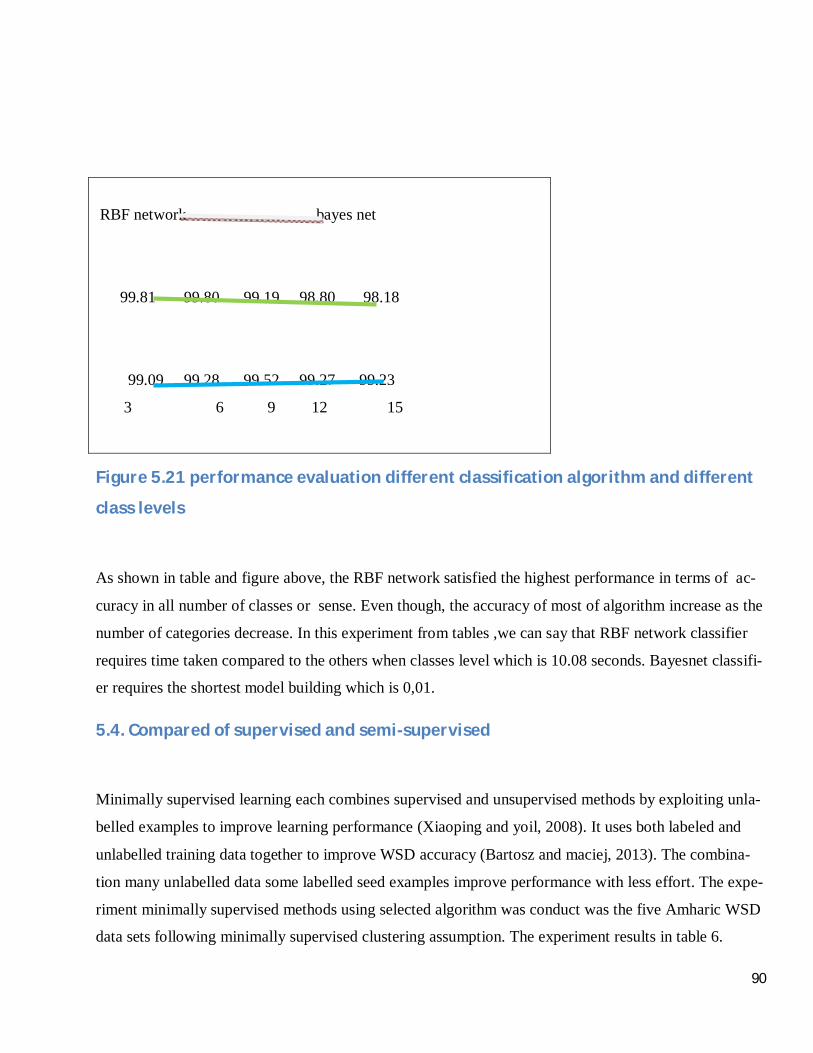
90
RBF network bayes net
99.81 99.80 99.19 98.80 98.18
99.09 99.28 99.52 99.27 99.23
3 6 9 12 15
Figure 5.21 performance evaluation different classification algorithm and different
class levels
As shown in table and figure above, the RBF network satisfied the highest performance in terms of ac-
curacy in all number of classes or sense. Even though, the accuracy of most of algorithm increase as the
number of categories decrease. In this experiment from tables ,we can say that RBF network classifier
requires time taken compared to the others when classes level which is 10.08 seconds. Bayesnet classifi-
er requires the shortest model building which is 0,01.
5.4. Compared of supervised and semi-supervised
Minimally supervised learning each combines supervised and unsupervised methods by exploiting unla-
belled examples to improve learning performance (Xiaoping and yoil, 2008). It uses both labeled and
unlabelled training data together to improve WSD accuracy (Bartosz and maciej, 2013). The combina-
tion many unlabelled data some labelled seed examples improve performance with less effort. The expe-
riment minimally supervised methods using selected algorithm was conduct was the five Amharic WSD
data sets following minimally supervised clustering assumption. The experiment results in table 6.

91
Table 5.6 results using minimally supervised learning:- bayes net and RBF network
algorithm.
Machine learning ap-
proach
Ambiguous word Bayes net RBF network
Supervised 3 81% 68.18%
6 80% 63.33%
9 72.59% 54.80%
12 76.27% 56.54%
15 74.34% 53.66%
Average 80.22% 99.37%
minimally supervised 3 99.09% 99.81%
6 99.28% 99.80%
9 99.52% 99.19%
12 99.27% 98.80%
15 99.23% 98.18%
Average 99.09% 99.64%
Table 5.6 performance comparison of semi supervised and supervised performance. As observed expe-
rimentation results above , all the results of semi supervised classification approach is more than super-
vised learning approach. So that, this shows that minimally supervised ambiguous words classification
is important better than supervised ambiguous word classification.
Table 5.7. results using minimally supervised learning:- bayes net ,RBF network and
Hierarchical algorithm(3-3 window)
Machine learning
approach
Ambiguous
words
RBF network Bayes net Hierarchical
Supervised Mesal 78% 79% 78.80%

92
Ras 58.5% 72.5% 81.50%
Yemigeba 47.62% 49% 81.16%
Kena 56% 58% 81.30%
Gb 76.5% 75.5% 81.55%
Average 67% 61% 81%
Semi supervised Mesal 68% 87.55% 99.9%
Ras 68.5% 68.5% 99.8%
Yemigeba 51.9% 43.33% 99.75%
Gb 54% 65% 99.5%
Kena 74% 75.5% 99.4%
Average 73.9% 67.9% 99.67%
Table 5.6 performance comparison of minimally supervised and supervised performance as observed
experimental results above, all the results of semi supervised classification approach is quite greater
more than supervised machine learning approach. Therefore, this indicates that minimally supervised
ambiguous words classification is significantly better than supervised ambiguous word classification.
Minimally supervised learning method using bayes net improves purely supervised method such as
naïve bayes. Apply RBF network algorithm on WSD task performance gives good results in accura-
cy(Yarowsky, 2008), likewise in this thesis I got the average performance results of Bayes net, RBF
network and Hierarchical algorithm are 73.9% , 67.9% and 99.967%. the current experiment results
shown a that better performance than the previous related research because of the recent thesis were
used more than two three ambiguous words.
An English corpus (British national corpus) was used to acquire sentences which contain the ambiguous
words and these sentences (collected in English) were translated to Amharic by the researcher assisted
by English-Amharic. An English equivalent of ambiguous word was used as a query word to extract
sentence from the English corpus. As can be understood the data collection tasks pass through a lot of
steps including translation from Amharic to English and vice versa.
At look at the overall observed of the result, however shows that best performance is achieved smaller
window sizes. Finding of different related investigates globally (e.g., Leacock et al, 1998) and locally

93
worked for Amharic language Especially from the above tasks, there are four tasks done by Solomon
(2010), Solomon (2011), Getahun (2012) and Hagerie (2013). These tasks were translated partly using
corpus based techniques by implementing various machines learning algorithm. Solomon (2010) tried
to study the application of supervised machine learning approach to immediately require disambigua-
tion data from Amharic corpus. He used the number of 1,045 English sense sample gathered from Brit-
ish national corpus for five main words metrat (መጥራት), mesal ( መሳል), atena (አጠና),mesasat
(መሳሳት),keretse (ቀረጻ) his to disambiguate terms. These sense samples were translate to Amharic,
manually annotated and preprocessed to build them ready for the attempted. His implied Naïve Byes
supervised classifier algorithm from weka package tool using 10-fold cross validation. As the begin-
ning task to demonstrate corpus based approaches for Amharic language, the investigate language goal
increase the outcome. The classifier outcome shows that within the range of 70% to 80%. The second
investigate by Solomon (2011) implied unsupervised machine learning approaches on the identical data
set as the last researcher to immediately decide the correct sense of an ambiguous word based on its left
and right context. For his investigate, the researcher used to identical set of target words and identically
data set used by Solomon (2010). In he attempted, his implied five cluster algorithm (average, complete
link, expectation maximization (EM), hierarchical agglomerative link: single and simple k means on
weka 3.7.9 package. “Cluster to cluster” evaluation model was selection to learn the choose algorithms
in the preprocessed data set. In the test, a text window surrounding ambiguous words of ±10 parts or
words was build first and then existence of the target word is noted in a characteristic vector for each
direction corresponding to various words. Then a Euclidian distance function, which is default in a we-
ka package, was used for measuring identical between contexts. The main advantage of this test was to
evaluate and compare with each other the performance of those cluster algorithms on Amharic text. As
well as that the researcher also tried to determine how stemming, stop word removal and window size
influence the performance of the models. The accuracy scores required (using three –three and two-
two window size) from the algorithm indicate: 51.9- 58.3% for single link, 54.4-71.1% for complete
link 65.1-79.4% for simple k means and 67.9-76.9% for EM and cluster algorithm. The outcome also
shows that stemming important increased the accuracy of the outcome. It is also decisive to selection
the balance window size to get the better outcome on this test three-three word window was obtained
most important window size for Expectation Maximization and simple k means and two –two word
window for agglomerative single and complete link clustering algorithms. As compare the accuracy
outcome required by Solomon (2010) according to supervised learning techniques (70.1% to 83.2%),

94
the unsupervised algorithms scored lesser accuracy values. The researcher, although, correctly values
that outcome required is still increased based sense annotated dataset is not used to prototype the sys-
tem based on clustering algorithms. The above two researcher have indicated that some problems in
common. They are the problem of lack of standard sense annotated corpus and other machine readable
language resources such that glossaries and thesauri, for Amharic language. They also showed the limi-
tation of the approach they used. So that the supervised learning techniques acquire enough manually
labeled training data, the unsupervised learning approach techniques outcome in to mini accurate model
as it is not make from manually sense tagged corpus.
So that both researchers recommended future investigates that implies various word sense disambigua-
tion techniques on more ambiguous words therefore a better natural languages known could be target for
Amharic language. Based on their future direction, Getahun (2012) examined to patter a word sense
disambiguation prototype model using semi-supervised machine learning approach to the gap between
the limitations showed in the last investigate. The attempted was conducted on five ambiguous Amharic
verbs: etena (አጠና), derse (ደረሰ), tensa (ተነሳ), ale (አለ) and bela (በላ) with the total corpus size of (0,
3) sentences. The corpus with combine of more unlabeled samples with some seeds examples. The com-
bine of clustering and classification algorithms was used to develop the prototype models. The unsuper-
vised approach was applied at the beginning to the data in order to make some assumption about the
spread of the data and these suggestions are remarked using supervised algorithms. Two clustering algo-
rithms, k-means and expected algorithm implied to cluster sentences in to senses. And five classification
algorithms (Ad boost, Bagging, Naïve bays, SMO and AD tree) were then applied on average, AD tree
scored the highest accuracy of 88.47%. Comparing the outcome with last researches done using super-
vised and unsupervised is techniques recognizly. The researcher takes to have improved Solomon (2010)
by 11.5% and that of Solomon (2011) 28.36%.Agerie (2013) tried to study the application of ensemble
supervised machine learning approaches classifiers and implied that two algorithm that can be to create
ensemble of min- model which would participated in making the final model. She used the total of 1770
number of sentences from the Amharic websites. For eight words ale(አለ), atena (አጠና), bela (በላ), de-
rese (ደረሰ), akebere (አከበረ), kerbe (ቀረበ), melese (መለሰ), tenesa (ተነሳ) her to disambiguates these
sense examples were there translate to Amharic to optimal window size seems to be related the number
of sense an ambiguous terms has and the size of the training data set used. She employed ensemble su-
pervised classification algorithm from weka package tools using 10 folds cross validation. The result

95
indicate the optimal window size to be two on which algorithms score maximum 78.75% for Random
forest alone, 79.70% for Ad boost and 80.46% Bagging based on these experiment improvement in per-
formance. However there is some problems occurs are not consider more than two sense target words
and also this approach takes time and expensive by employing a combination of some annotated data
many unlabeled examples with reasonable performance should be considered.
The current investigate is identically to the work done by Getahun (2012) in that it uses minimally su-
pervised machine learning approach. However, the present work differs from Getahun in its selection of
algorithm. Getahun employed that the combination of classification and clustering algorithms was used
to develop the prototype model. Whereas the current investigate the selection ambiguous words have
more than two or three classes or senses and improve the performance the sense or classes of the ambi-
guous words integrate cluster and classification algorithm using to develop the minimal final model.
The present study also use of a minimally corpus size within three meaning of five target words.
As also observed from the experiment result when the number of classes decrease the performance also
increase. Finally find this indicates semi supervised approach by Bayes net, RBF network and hierar-
chical cluster for word sense disambiguous are significantly better than supervised approach to word
sense disambiguous . Because of more than two or three classes of ambiguous words trained were
used in this thesis.
CHAPTER SIX
CONCLUSION AND RECOMMENDATION

96
6.1 Conclusion Word sense disambiguation deals with actual word sense in given context . to properly identify sense of
words one must known common sense facts. Amharic language of one of lack o resourcesand natural
language processingtool to favorable conditions that information .in Amharic text there are different
problem in the context while Amharic document or text translate one language to other languages lose
concept or idea of the reader from Amharic text or document and alsohave different problems occurred
like that of text summarization ,text analysis. the aim of this studyto develop and train word sense dis-
ambiguate prototype to select minimally supervised techniques.there are some research works done us-
ing different techniques apart with the objective of designing prototype for Amharic word sense disam-
biguation for Amharic language . the researcher recommended future study that employs different word
disambiguation techniques on more ambiguous words there for natural language known could be target
for Amharic language. the current study use of minimally corpus wit in three meaning of five target
word.
Ethiopia is linguistically various nation nationalities where more than 80 language are used in daily
communication. Amharic language is semanticlanguage of afro-Asiatic language groups. There are dif-
ferent types of ambiguities which are occur in Amhariclanguage includes orthographic, lexical, phono-
logical ,structural,referential and semantic. In order to prepare the row data collection for the machine
learning tool(weka).the final step in preprocessing is to get the ambiguous word lined the center column
and the surrounding words (word context)to the left and the target word .once all the advantage word
were done on the corpus, training the sample and evaluating it were followed. To do that, 10-fold cross
validation is used and supplied used. The performance measures of classification algorithm and cluster
algorithm is sometimes measured by parameters such as accuracy, recall, precision and f-measures.
These performance parameters are the function of the number of correctly classified incorrectly. The
experiment were done using two classification and cluster algorithms. Bayes net and RBF network and
also hierarchical cluster algorithm. Generally find this indicates semi supervised approach by bayes net
,RBF network and hierarchical cluster for word sense disambiguous is important better than supervised
approach to word sense disambiguous and more than two or three sense of ambiguous word trained is
better t achieved than two ambiguous words in terms of performance.
Based the experiment done in this study the following concluding remarks made

97
As the number of sentence and class increase the accuracy produced by different classifi-
er,Bayes net and RBF network, become decrease and requires relatively high computational
requirements. Moreover it is learnt that considering categories with equal number of text items
increase the performance of the classifier.
The best result gained by bayes net classifier three categories data (81% and 68%) and the
least performance is shown on the fifteen categories data (72.59% and 53.66%) respectively.
Compaired to RBF networks classifier methods obtain a result good.
All the classification algorithm bayesnet and RBF network achieved better classification accu-
racy in supervised than supervised. So that we can say that applying semi-supervised word
sense disambiguous better than supervised approach.

98
6.2. Recommendation
This study shows the potential application of semi-supervised machine learning techniques to the analy-
sis of word sense disambiguous Amharic texts is both crucial and feasible. How ever, recommendation
for further research are forwarded to improve the performance of sense or meaning classification and to
explore all algorithms and application of semisupervised sense classification especially for local lan-
guage.
This study considered three sense or classes ambiguous word. Bu tmany words in Amharic
language have more than three sense .it is also challenge to represent the WSD model only by
using five target words. Further researchers should be done to prototype Amharic WSD system
targeting words with more than three as well as with multiple sense ambiguous.
Further researchers can also compared the perform a once of semi-supervised approaches with
the unsupervised approach and two steps approaches using the same evaluation methods.
In this study shown the words repeat it self in the context of sentence. So it is difficult to sense
the repeated word. Further researchers should be done to be model Amharic WSD system tar-
geting words with repeat itself words of sense.
As the researcher knowledge, there is no standard corpus open for researchers to apply differ-
ent machine language. further researcher should be done take much time on their work and ex-
plore more if standard corpus is prepared for Amharic word sense disambiguous experiment.
REFERENCE

99
Rada, M. and Ehsanul, F. (2005) Minimally Supervised Word Sense Disambiguation for All Words
in Open Text Department of Computer Science University of North T exas.
Eneko, A. (2008) Word Sense Disambiguation Using Conceptual Density Lengoaia eta Sistema
Informatikoak saila. Euskal Herriko Universitatea.
Solomon, A. (2011) unsupervised machine learning approach for word sense disambiguation to
Amharic words Addis Ababa university school of graduate studies
School of information science June,
Michael, D. et al (2009) The Growing Hierarchical Self-Organizing Map Institut für Softwaretechnik,
Technische Universität Wien.
Getahun, W. (2012) A Word Sense Disambiguation Model for Amharic Words using Semi Super-
vised Learning Paradigm Science, Technology and Arts Research Journal Sci. Technol. Arts Res.
Roberto, N.(1999) A Graph-based Algorithm for Inducing Lexical Taxonomies from Scratch
Dipartimento di Informatica Sapienza Universit ` a di Roma.
Patrick, P. and Dekang, L. (2000) Discovering Word Senses from Text University of Alberta
Department of Computing Science
Tessema. M, et al (2003) The Need for Amharic WordNet Computer Science Department IS&T Di-
vision Ministry Finance and Economic, Addis Ababa University UN ECA Development, Ethiopia
Solomon, T. A . (2011) Amharic Speech Recognition: Past, Present and Future Proceedings of the
16th International Conference of Ethiopian Studied.
Daniel, Y. (2005) Developments towards an Electronic Amharic Corpus TALN Ge’ez Frontier Foun-
dation.
Hagerie, W. (2013) ensemble classifiers applied to Amharic word sense disambiguation A Thesis
Submitted to the School of Graduate Studies of AAU in Partial Fulfillment of the Requirements for the
Degree of Master of Science in Information Science .
Steven , A. (2002) Understanding the Yarowsky Algorithm University of Michigan.

100
Roberto, N. (2009) Word Sense Disambiguation: A Survey University `a di Roma La Sapien.
Chang, et al (1996) combining machine readable lexical resources and Bilingual corpora for broad
word sense disambiguation Department of Computer Science National Tsing Hua University Hsinchu
30043, Taiwan, ROC
Michele, B. and Oren E. (2007) The Tradeoffs between Open and Traditional Relation Extraction
Turing Center University of Washington Computer Science and Engineering
Gerard , E. B (2006) Machine Learning Techniques for Word Sense Disambiguation For the ob-
tention of the PhD Degree at the Universitat Politµecnica de Catalunya Barcelona
Judita , P. (2006) Probabilistic word sense disambiguation Analysis and techniques for combining
knowledge sources 15 JJ Thomson Avenue Cambridge CB3 0FD
United Kingdom
Blum, M . (1998) Combining Labeled and Unlabeled Data with Co-Training School of Computer
Science Carnegie Mellon University Pittsburgh, PA 15213-3891
Marine C. W. U (2007) How Phrase Sense Disambiguation outperforms Word Sense Disambiguation
for Statistical Machine Translation [email protected] [email protected]
Human Language T echnology Center HKUST Department of Computer Science and Engineering Uni-
versity of Science and Technology, Clear Water Bay, Hong Kong
Patrick , A. P. (2003) Clustering by Committee A thesis submitted to the Faculty of Graduate Studies
and Research in partial fulfillment of the requirements for the degree of Doctor of Philosophy Depart-
ment of Computing Science Edmonton, AlbertaSpring
Tomuro et al (2002) Clustering Using Feature Domain Similarity to Discover Word Senses for Adjec-
tives DePaul University, School of Computer Science, Telecommunications and Information Systems,
Chicago, IL 60604 USA {tomuro,lytinen}@cs.depaul.edu
Zheng, Y. N. (1998) Learning model order from labeled and unlabeled datafor partially supervised
classification, with application to word sense disambiguation” Institute for Infocomm Research, Mail

101
Box B023, 21 Heng Mui Keng Terrace, Singapore 119613, Singapore Department of Computer Science,
National University of Singapore
Chew , L. T. et al (2010) Word Sense Disambiguation Using Label Propagation Based Semi-
Supervised Learning Institute for Infocomm Research 21 Heng Mui Keng Terrace 119613 Singapore
zniu, dhji}@i2r.a-star.edu.sg
Massimiliano, C. (1992) Broad-Coverage Sense Disambiguation and Information Extraction with a Su-
per sense Sequence Tagger Inst. of Cognitive Science and Technology
Italian National Research Council [email protected].
Mirna, A. and C. J. van Rijsbergen(2001) Phrase Identification in Cross-Language Information Re-
trieval Department of Computing Science University of Glasgow Glasgow G12 8QQ, Scotland
mirna, keith}@dcs.gla.ac.uk
Partha , P. T.(2001) Experiments in Graph-based Semi-Supervised Learning Methods for
Class-Instance Acquisition Search Labs, Microsoft Research Mountain View, CA 94043
Fernando , G. et al (2009) Improving Supervised Sense Disambiguation with Web-Scale Selectors Uni-
versity of Pennsylvania, Philadelphia, PA USA,University of Central Florida, Orlando, FL USAhan-
[email protected], [email protected], [email protected]
William, G. et al (2008) Estimating Upper and Lower Bounds on the Performance of Word-Sense
disambiguation Programs AT&T Bell Laboratories 600 Mountain Ave. Murray Hill, NJ 07974
Niladri ,S. D. (2001) Polysemy and Homonymy: A Conceptual Labyrinth
Linguistic Research Unit Indian Statistical Institute, Kolkata Email: [email protected]

102
Paul, C. and Graeme H.(2007) Automatic identification of words with novel but infrequent senses
Department of Computer Science University of Toronto {pcook,gh}@cs.toronto.edu
Paramveer S. D. (1991) Metric Learning for Graph-based Domain Adaptation Computer and Informa-
tion Science, University of Pennsylvania, U.S.A [email protected]
Gholam, R. H. and Anoop S. (1996) Analysis of Semi-Supervised Learning with the Yarowsky Algo-
rithm School of Computing Science Simon Fraser University{ghaffar1,anoop}@cs.sfu.ca
Marti A. H. (1992) Automatic Acquisition of Hyponyms from Large Text Corpora
Computer Science Division, 571 Evans Hall University of California, Berkeley
Berkeley, CA 94720b and XeroxPalo Alto Research Center [email protected]
Steve, L. (1993) A Hybrid Approach to Word Sense Disambiguation Neural Clustering with Class
Labeling Department of Computer Science, University of Jyv¨askyl¨a, Finland, [email protected], Fa-
culty of Telematics, University of Colima, Mexico,
Bartosz, B. and, Wojciech M. (1999) Evaluation of Clustering Algorithms for Polish Word Sense Dis-
ambiguation Institute of Informatics, Wrocław University of Technology, Polandbar-
[email protected], [email protected]
Jen Nan , C. (2002) Topical Clustering of MRD Senses Based on Information Retrieval Techniques
National Tsing Hua University
Andres, M. et al (2003) Combining Knowledge- and Corpus-based Word-Sense-Disambiguation Me-
thods Dept. of Software and Computing Systems University of Alicante, Spain
Rada , M. (2005) Using Wikipedia for Automatic Word Sense Disambiguation
Department of Computer Science University of North Texas [email protected]
Mike, M. (1997) Distant supervision for relation extraction without labeled data
Stanford University / Stanford, CA 94305

103
Ping, C. al (1999) A Fully Unsupervised Word Sense Disambiguation Method Using Dependency
Knowledge Dept. of Computer and Math. Sciences University of Houston-Downtown [email protected]
Simone, P. P. (2007) Knowledge-rich Word Sense Disambiguation Rivaling Supervised Systems
Department of Computational Linguistics Heidelberg University
Partha, P. T. (2001) New Regularized Algorithms for Transductive Learning
University of Pennsylvania, USA
Partha, P. T. (2009) “Topics in Graph Constr uction for Semi-Supervised Learning” University of Penn-
sylvania
Judita, P. ( 2006) Probabilistic word sense disambiguation Analysis and techniques for combining
knowledge sources 15 JJ Thomson Avenue Cambridge CB3 0FD United Kingdom
Amar , S. (1994) Graph-based Semi-Supervised Learning Algorithms for NLP
Google Research [email protected]
Ms. Ankita Sat (2013) Semi-Supervised Learning Methods for Word Sense Disambiguation
IOSR Journal of Computer Engineering (IOSR-JCE) (M.Tech Student, Banasthali Vidyapith, Banastha-
li, Jaipur, India) e-ISSN: 2278-0661, p- ISSN: 2278-8727Volume 12, Issue 4 (Jul. - Aug. 2013), PP 63-
68 www.iosrjournals.org
Jason, E. and Damianos K. (2003) Bootstrapping Without the Boot Center for Language and Speech
Processing Johns Hopkins University, Baltimore, MD 2
{eisner,damianos}@jhu.edu
Tou , H. N. et al (2002) Word Sense Disambiguation with Semi-Supervised Learning
Department of Computer Science National University of Singapore
Ellen , M. (1996)Voorhees Disambiguating Highly Ambiguous Words Siemens Corporate Research

104
Muhammed, M. L. et al (2009) Graphic Symbol Recognition using Graph Based Signature and
Bayesian Network Classifier Université François Rabelais de Tours, Laboratoire d'Informatique .
Patrick A .P. (2009) Clustering by Committee UNIVERSITY OF ALBERTA
Eibe Frank (2014) Fully Supervised Training of Gaussian Radial Basis Function Networks Department
of Computer Science University of Waikato July 2,
APPENDIX A. The Amharic alphabet ('fidel') adopted from Dawkins and Yacob [65].
1 ሀ ሁ ሂ ሃ ሄ ህ ሆ
he Hu hi ha He H ho
2 ለ ሉ ሊ ላ ሌ ል ሎ ሏ
Le Lu li la Le L Lo lwa
3 ሐ ሑ ሒ ሓ ሔ ሕ ሖ ሗ
he Hu hi ha He H ho
4 መ ሙ ሚ ማ ሜ ም ሞ ሟ
me Mu mi ma me M mo mwa
5 ሰ ሱ ሲ ሳ ሴ ስ ሶ ሷ
Se Su si sa Se S So swa
6 ረ ሩ ሪ ራ ሬ ር ሮ ሯ
Re Ru ri ra Re R Ro Rwa
7 ሠ ሡ ሢ ሣ ሤ ሥ ሦ ሧ
Se Su si sa Se S So
8 ሸ ሹ ሺ ሻ ሼ ሽ ሾ ሿ
she Shu shi sha she Sh sho
9 ቀ ቁ ቂ ቃ ቄ ቅ ቆ ቈ ቍ ቋ ቌ ቍ
qe Qu qi qa qe Q qo qwe qwu qwa qwe qwi
10 በ ቡ ቢ ባ ቤ ብ ቦ ቧ
be Bu bi Ba be B bo bwa
105
11 ቨ ቩ ቪ ቫ ቬ ቭ ቮ ቯ
ve Vu vi va ve V Vo vwa
12 ተ ቱ ቲ ታ ቴ ት ቶ ቷ
te Tu ti ta te T To twa
13 ቸ ቹ ቺ ቻ ቼ ች ቾ ቿ
ce Cu ci ca ce C Co cwa
14 ኀ ኁ ኂ ኃ ኄ ኅ ኆ ኈ ኊ ኋ ኌ ኍ
he Hu hi ha he H ho hwe hwu hwa hwe hwi
15 ነ ኑ ኒ ና ኔ ን ኖ ኗ
ne Nu ni na ne N no nwa
16 ኘ ኙ ኚ ኛ ኜ ኝ ኞ ኟ
ne Nu ni na ne N no nwa
17 አ ኡ ኢ ኣ ኤ እ ኦ
xe Xu xi xa xe X Xo
18 ከ ኩ ኪ ካ ኬ ክ ኮ ኰ ኲ ኳ ኴ ኵ
ke Ku ki ka ke K ko kwe kwu kwa kwe kwi
19 ኸ ኹ ኺ ኻ ኼ ኽ ኾ ዃ
he Hu hi ha he H ho hwa
20 ወ ዉ ዊ ዋ ዌ ው ዎ
we Wu wi wa we W wo
21 ዐ ዑ ዒ ዓ ዔ ዕ ዖ
xe Xu xi xa xe X Xo
22 ዘ ዙ ዚ ዛ ዜ ዝ ዞ ዟ
ze Zu zi za ze Z Zo zwa
23 ዠ ዡ ዢ ዣ ዤ ዥ ዦ ዧ
ze Zu zi za ze Z Zo zwa
24 ደ ዱ ዲ ዳ ዴ ድ ዶ ዷ
de Du di da de D do dwa
25 የ ዩ ዪ ያ ዬ ይ ዮ ywa

106
ye Yu yi ya ye Y Yo
26 ጀ ጁ ጂ ጃ ጄ ጅ ጆ ጇ
je Ju ji ja je J Jo jua
27 ገ ጉ ጊ ጋ ጌ ግ ጎ ጓ
ge Gu gi ga ge G Go gwa
28 ጠ ጡ ጢ ጣ ጤ ጥ ጦ ጧ
te Tu ti ta te T To twa
29 ጨ ጩ ጪ ጫ ጬ ጭ ጮ ጯ
ce Cu ci ca ce C Co cwa
30 ጰ ጱ ጲ ጳ ጴ ጵ ጶ
pe Pu pi pa pe P po
31 ፀ ፁ ፂ ፃ ፄ ፅ ፆ
te Tu ti ta te T To
32 ጸ ጹ ጺ ጻ ጼ ጽ ጾ ጿ
te Tu ti ta te T To twa
33 ፈ ፉ ፊ ፋ ፌ ፍ ፎ ፏ
fe Fu fi fu fe F Fo
34 ፐ ፑ ፒ ፓ ፔ ፕ ፖ ፗ
1. I made a vow to St.Gabriel to fast for two days
ለቀዱስ ገብርኤል ሁለት ቀን ለመፆም ተሳልኩ፡፡
2. Over and above this, men might vow individuals or possessions to God as a thank-offering.
ከዚህ በተጨማሪ ወንዶች ሰዎችን ወይም ያላቸውን ንብረት እግዚያብሔርን ለማመስገን ይሳሉ ነበር፡፡
3. This harmony might be expressed as an offering which accompanies a vow of some kind or as a
thank-offering or free-will offering.
ይህ ስምምነት የሚገለፀው የሆነ ነገር በፍቃደኝነት ለመስጠት ወይም ለማመስገ ንበመሳል ነው፡፡

107
4. Jacob vowed a vow, saying, “If God will be with me, and will keep me in this way that I go,
and will give me bread to eat, and clothing to put on, so that I come again to my father’s house in
peace, and Yahweh will be my God,
ያእቆብ እግዚአብሔር በሄድኩበት ከጠበቅከኝ፣የምበላውን እና የምለብሰውን ከሰጠኽኝ፣ወደ
አባቴ ቤት እመለሳለው እግዚአብሔርም አምላኬ ይሁናል ብሎ ተሳለ፡፡
5. I am the God of Bethel, where you vowed a vow to me. Now arise, get out from this land, and re-
turn to the land of your birth.
እኔ ስለት የተሳልክልኝ የቤቴልሔም አምላክ ነኝ፤ አ ሁን ከዚህ ምድር ተነሳና ወደ ተወለድክበት ምድር
ተመለስ፡፡
7. Now, after years of hard work, we are in sight of immunizing all the world's children against po-
lio, tuberculosis, diphtheria, whooping cough, tetanus and measles.
ከብዙ ጠነካራ ሥራ በኋላ ሁሉንም ያዓለም ሕፃናት ከፖሊዮ፣የሳንባ ነቀርሳ፣የጉሮሮ በሽታ፣የትክትክ
ሳል፣ቲታነስ እና ኩፍኝ ክትባት መስጠት ችለናል፡፡
8. In the United Kingdom, parents are advised to have their children immunised against diphtheria,
tetanus, polio, whooping cough, measles and rubella .
በእንግሊዝወላጆችልጆቻቸውን ከጉሮሮ በሽታ፣ቲታነስ፣ፖሊዮ፣የትክትክ ሳል፣ኩፍኝ፣ሩቤ ላ
የሚከላከል ክትባት እነዲያስከትቡተ መከሩ፡፡
9. The days of being forced to get out of it on cough medicine are well behind.
የሳል መድኃኒት አልቆ የምንቸገርበት ጊዜ አልፏል፡፡
10. Greenough and colleagues showed that babies who did not require respiratory support had a
high prevalence of wheeze and cough in the first year of life.
ግሪኖፍ እና ጓደኞቹየ መተንፈሻ አካላት እርዳታ የማያስፈልጋቸው ህፃናት ማቃተትና ሳል በመጀመሪያ
ዓመታቸው እንደሚያጋጥማቸው አሳዪ፡፡
11. The commonest symptom for the disease is coughing persistently, with frequent chest infection.
የበሽታው የተለመዱ ምልክቶች በተደጋጋሚ መሳል እና የሚደጋገም የደረት ህመም ናቸው፡፡
12. Charlton applied a sharp knife, carving it into steaks in the kitchen.
ቻርልተን ማብስያ ቤት ውስጥ ጥብሱን ለመክተፍ የተሳለ ቢላ ተጠቀመ፡፡
13. A terrific place to have breakfast in, not a knife sharp enough to cut a lemon.

108
ቁርስ ለመብላት የማይመች ቦታ ነው፤ሎሚ ለመቁረጥ የሚሆን እንኳን የተሳለ ቢላ የለም፡፡
14. The film's sharp sword has many edges.
ፊልሙ ላይ ያሉት የተሳሉ ጎራዴዎች ብዙ ጠርዞች አላቸው፡፡
15. ‘Even now, the memories are sharp as broken glass.
አሁንም ትዝታዎቹ ልክ እንደተሰበረ ብርጭቆ የተሳሉ ናቸው፡፡
16. Again do not round over the sharp edges when sanding.
አሁንም አሸዋ ስታፈስ በተሳሉ ጠርዞች ላይ አትዙር፡፡