fairness and learning: an experimental examinationmyweb.fsu.edu/djcooper/research/fair.pdf ·...
TRANSCRIPT

Fairness and Learning:An Experimental Examination
David J. CooperDepartment of Economics
Weatherhead School of ManagementCase Western Reserve University
10900 Euclid AvenueCleveland, OH 44106
Carol Kraker StockmanGraduate School of Public Health
University of Pittsburgh130 DeSoto Street, A664
Pittsburgh, PA [email protected]
September 11, 2002
The authors would like to thank the National Science Foundation for financial support. We would like tothank Ido Erev, John Kagel, Jim Rebitzer, Al Roth, David Schkade, Bob Slonim, John Van Huyck, JimWarnick, an anonymous editor, two anonymous referees, and seminar participants at Alabama, Case WesternReserve, the Cleveland Federal Reserve, Oberlin, Ohio State, Pittsburgh, Purdue, Texas A&M, Tufts, theSEA meetings, and the ESA meetings for their helpful comments. The usual caveat applies.
Abstract: Over the last twenty years, experimental economists have identified a wide variety of games inwhich subjects display “other-regarding” behavior in violation of standard game theoretic predictions. Thetwo primary approaches to explaining this behavior can be characterized as the “fairness hypothesis” and the“learning hypothesis.” Both hypotheses provide an adequate explanation of behavior in existing experiments,but the two approaches rely on very different interpretations of the factors underlying subjects’ behavior. Inthis paper, we examine experiments with a step-level public goods game designed to distinguish between thefairness and learning hypotheses. We find that neither approach provides an adequate explanation of theexperimental data by itself. We propose a model which synthesizes the fairness and learning hypotheses.Using econometric analysis, we demonstrate that this model provides a significantly better fit to theexperimental data.
JEL: C72, C91, C92, D64

1Well known examples include the ultimatum game (Roth, 1995), the dictator game (Roth, 1995), VCMpublic goods games without thresholds (Ledyard, 1995), experimental labor markets (Fehr, Kirchler, andWeichbold, 1998), and trust games (Berg, Dickhaut, & McCabe, 1995).
2It is somewhat of a misnomer to refer to the “fairness” hypothesis, since the theory encompasses a widevariety of emotions such as envy, spite, and reciprocity. The “interpersonal comparisons” hypothesis wouldbe a more accurate (if unwieldy) characterization of this approach.
3See also Falk and Fischbacher (1998), Levine (1998), and Charness and Rabin (2000).
1
I. Introduction: Over the last twenty years, experimental economists have identified a wide variety
of games in which subjects display “other-regarding” behavior that violates standard game theoretic
predictions.1 Explaining these results has become a major focus of experimental economics and the related
areas of economic theory. The two primary approaches to explaining this anomalous behavior can be
characterized as the “fairness hypothesis” and the “learning hypothesis.” The fairness hypothesis maintains
the assumption of full rationality but eliminates the equivalence between monetary payoffs and utility, instead
allowing a player’s utility to depend on the payoffs of others.2 Sophisticated versions of this approach, such
as Bolton and Ockenfels (2000) and Fehr and Schmidt (1999), give unified explanations of results from a
wide variety of experiments.3 The learning hypothesis takes the opposite approach, relaxing the assumption
of full rationality but maintaining the equivalence between monetary payoffs and utility. Under the learning
hypothesis, players have bounded rationality, only gradually learning to behave optimally. As shown by Roth
and Erev (1995) and Binmore, Gale, and Samuelson (1995), the learning hypothesis also provides a unified
explanation of results from a wide variety of experiments. Although both hypotheses provide an adequate
explanation of existing experimental data, the two approaches rely on very different interpretations of the
factors underlying subjects’ behavior. As such, there exists a need for experimental work which allows us
to determine whether subjects’ behavior is best explained by the fairness hypothesis, the learning hypothesis,
or a synthesis of both approaches.
This paper examines experiments with a three player sequential step-level public goods game. We
focus on the behavior of “critical” third players – third players whose decisions determine whether or not the
public good will be provided. This case is of particular interest because critical third players face no strategic
uncertainty. The game creates a strong tension between monetary payoffs and fairness for critical third

4The MCS game was first introduced in a simultaneous form by Van de Kragt, Orbell and Dawes (1983)and in a sequential form by Erev and Rapoport (1990).
2
players. Applying the fairness and learning hypotheses to this game allows us to make sharp predictions
about the observed behavior of critical third players. In particular, existing models of fairness, static by their
very nature, predict no change in behavior over time, while existing learning models predict that
contributions by critical third players, a strictly dominant strategy, must increase over time. Our results
unequivocally indicate that neither approach can explain the experimental data by itself – we observe
consistent movements in critical third players’ play, including a strong decrease in the contribution rate for
one of the treatments. We propose a model which synthesizes the fairness and learning hypotheses. Using
maximum likelihood analysis, we show that this hybrid model provides a better explanation for our data than
either a pure fairness or learning approach.
To the best of our knowledge, our data set is unique in showing robust movement away from a
dominant strategy. The existing experimental literature on other-regarding behavior generally reports no
observable dynamics, in part due to the relatively small number of repetitions typically employed. To the
extent that any dynamics are observed, they involve movement towards a dominant strategy.
We initially viewed our MCS game experiments as a contest between the fairness and learning
hypotheses, but discovered that neither approach is wholly satisfactory. Rather than saying both approaches
are wrong, it would be more accurate to say that both are partially right. By synthesizing the best features
of the fairness and learning hypotheses, our model hopefully not only improves our ability to fit the current
experimental data, but also improves our ability to understand interactions between learning and fairness.
II. The MCS Game, the Experimental Design, and Predicted Results: The Minimal Contributing
Set (MCS) game we study is a 3-person step-level public goods game.4 Each player is given an initial
endowment of 12 tokens. Players sequentially choose whether or not to contribute to provision of a public
good. Contribution is a binary choice; players choose to either contribute or not contribute, and a
predetermined cost of contribution is deducted from a player’s initial endowment following contribution. The
public good is provided if at least 2 of the 3 players contribute. If the public good is provided, then each of

3
the players receives an additional 18 tokens regardless of whether he contributed to the public good. Costs
of contribution are deducted regardless of whether or not the public good is provided. Players are given
perfect information – they know all players’ payoff tables and the moves of preceding players.
The pre-set cost associated with contribution for player i is ci tokens, i 0 {1,2,3}, where the index
gives the player’s position in the game (Player 1 moves first, Player 2 moves second, and Player 3 moves
third). We use three different cost structures, as summarized in Table 1. Only one cost structure is used in
any given experimental session. We will refer to the treatments by the cost structure, giving us the “3/6/9
treatment,” the “1/3/9 treatment,” and the “1/3/16 treatment.” Note that costs of contribution are increasing
in player’s position for all three treatments. Although payoffs for all treatments are set so that all players earn
more money if the public good is provided (ci < 18, œ i), each player earns more if he can free-ride on the
contributions of the other players.
Restricting our attention to pure strategy equilibria, and assuming that utility is a function solely of
a player’s monetary payoff, the MCS game has four Nash equilibria. In one equilibrium none of the players
contribute and the public good is not provided. In the remaining three equilibria exactly two of the three
players contribute and the public good is provided. Only the equilibrium in which the last two players
contribute is a subgame perfect equilibrium.
The position contingent contribution costs and the sequential nature of the game create tension
between payoff maximization and other-regarding preferences. Consider the position of a “critical” third
player – a third player who knows that exactly one of the two preceding players has contributed. A critical
third player knows that the public good will be provided if and only if he contributes. If this player cares
solely about his monetary payoffs, he should always contribute. However, this player also knows that a
preceding player with a lower cost of contribution has not contributed and will free-ride on provision of the
public good. We can easily imagine that a critical third player might resent this, and therefore not contribute
to punish the earlier player who did not contribute. A critical third player must also consider that his decision
to contribute or not contribute affects the preceding individual who did contribute, an individual whom he
may wish to help. Thus, the desire to maximize one’s own monetary payoffs, the desire to punish free riders,

4
and the desire to reward other contributors all can affect the behavior of critical third players. The resulting
behavior depends on which of these forces carries the greatest weight.
The three different cost structures are designed to place differing emphasis on maximizing one’s own
payoffs versus fairness for critical third players. Compare the 3/6/9 treatment with the 1/3/9 treatment. In
both cases, the monetary benefits of contributing are identical for critical third players. However, in the 1/3/9
treatment the preceding players’ costs of contribution are lower. Holding the identity of the contributing
player fixed, we would expect a critical third player to feel greater resentment when the non-contributing
player’s cost of contribution is lowered. A critical third player should also be less concerned about harming
a player who has contributed when that player’s cost of contribution is reduced. We therefore would expect
fairness considerations to play a greater role in the 1/3/9 treatment than the 3/6/9 treatment, lowering
contribution rates by critical third players. Likewise, compare the 1/3/9 treatment with the 1/3/16 treatment.
While the costs of contribution are identical for Player 1s and Player 2s across the two treatments, the cost
of contribution has increased for Player 3s in the 1/3/16 treatment. Since the monetary incentives to
contribute have been reduced, we expect fairness considerations to play a more important role in determining
the choices of critical third players in the 1/3/16 treatment than in the 1/3/9 treatment. We therefore anticipate
lower contribution rates by critical third players in the 1/3/16 treatment than in the 1/3/9 treatment.
By their very nature, existing models of fairness predict no change in the behavior of critical third
players over time. These are all models in which individuals have fixed utility functions over their own
payoffs and the payoffs of others. Since there is no uncertainty about other players’ payoffs to be resolved
for critical third players, there is no reason for their behavior to change.
The preceding arguments have all been made on an intuitive basis, but can also be placed on a more
formal footing. For example, we can apply Bolton and Ockenfels’ (2000) ERC model, a leading model of
fairness, to the MCS game. Bolton and Ockenfels model a player’s utility from a game as a function of his
monetary payoff and his payoff share. The latter term captures a player’s concern with fairness. Making
some standard assumptions, we prove the following two propositions. The proofs are available from the
authors upon request.

5
Proposition 1: If an individual ever contributes as a critical third player in the 1/3/9 treatment, they must
always contribute as a critical third player in the 3/6/9 treatment.
Proposition 2: If an individual ever contributes as a critical third player in the 1/3/16 treatment, they must
always contribute as a critical third player in the 1/3/9 treatment.
It follows from these propositions that the ERC model predicts contribution rates by critical third
players to be non-increasing as we go from the 3/6/9 treatment to the 1/3/9 treatment and then to the 1/3/16
treatment. Because a player’s utility function only depends on his own monetary payoff and the monetary
payoffs of the other two players, information which is known to a critical third player, the ERC model
predicts no systematic change over time in contribution rates by critical third players.
Our predictions for the MCS game are not driven by the fine details of the ERC model, and wouldn’t
change if a different model of fairness was used. For example, Proposition 1 and Proposition 2 can both be
proved using Fehr and Schmidt’s (1999) model of fairness, competition, and cooperation. Copies of these
alternative proofs are also available from the authors upon request.
The predictions of a reinforcement learning model (with reinforcements equal to monetary payoffs)
are quite different than those of a fairness model. While we put off a detailed description of the reinforcement
learning model of Roth and Erev until Section V, a brief intuitive explanation of what the model predicts is
useful in reading the experimental results. Reinforcement learning models can be summarized in a single
sentence: Strategies that do well should be played more frequently over time. A learning model by its very
nature makes no predictions about the initial distribution of play – learning models predict the evolution of
play given a starting distribution of strategies. With monetary reinforcements, play should move in the
direction of increased monetary payoffs. Since it is a strictly dominant strategy to contribute as a critical third
player regardless of the treatment, we expect that the contribution rate for third players will increase (on
average) over time regardless of the treatment. However, we do expect that the rate of increase will be slower
in the 1/3/16 treatments than in the other two since the reinforcement for contributing is smaller in this
treatment.

6
To summarize, both a pure fairness approach and pure learning approach make strong predictions
about the data. Considering fairness by itself, we predict that contribution rates by critical third players
should be decreasing as we move from the 3/6/9 treatment to the 1/3/9 treatment and then the 1/3/16
treatment. A fairness only approach predicts no change over time in contribution rates. A learning model
with no fairness component makes no predictions about the starting distribution of strategies across the three
treatments, but predicts that contribution rates should be rising for critical third players in all three cases. It
also predicts that the rate of increase will be slowest in the 1/3/16 treatment.
III. Experimental Procedures: Four replications of each of the three cells of the design have been run
using a total of 234 subjects. Between fifteen and twenty-four subjects participated in each session and each
subject was allowed to take part in only one session. Subjects were recruited from the University of
Pittsburgh undergraduate population using newspaper ads, posters, and electronic bulletin board postings.
The average session lasted about 1½ hours, and the average subject earned about $15, including a $5
participation fee. These earnings were adequate to ensure a steady supply of subjects.
Before the beginning of a session, instructions were read aloud to all subjects. Subjects were also
given a written copy of the instructions and of the payoff tables. All substantive questions about the
instructions were answered out loud to ensure common knowledge. Subjects were asked to complete a short
payoff quiz to verify their ability to read the payoff tables.
Each session consisted of forty periods of play of the sequential MCS Game. Subjects were told the
number of periods to be played. We randomly determined each subject’s player position (Player 1, Player
2, or Player 3) before the first round of play. A subjects’ position remained unchanged throughout the course
of the session. Subjects knew their own position and that there were an equal number of subjects in each
position, but did not know the position of any other subject. At the beginning of each round of play, we
randomly and anonymously assigned subjects to three person groups containing one subject for each position.
The instructions emphasized that the three person groups would be randomly rematched in every round. This
was intended to preserve the one-shot strategic character of the MCS game. After each round of play,
subjects were informed of the decisions made and the payoffs earned by the other members of their group.

7
Subjects were given record sheets on which to record their outcomes. While we did not require subjects to
fill out the record sheet, we observed that most did.
To avoid any framing effects, neutral terms were used wherever possible. For example, players were
asked to choose between “X” and “Y” rather than “contribute” and “don’t contribute.” No explicit mention
was ever made of “provision” or “public goods”. Instead, the payoff table refers solely to “your choice” and
“total number of other players choosing X.”
Subjects were paid privately, in cash, based on their token earnings in two periods randomly chosen
from the forty periods of play. Each token was worth $0.30 to subjects.
IV. Experimental Data: Figure 1 shows the evolution of contribution rates for Player 1s, Player 2s
contingent on Player 1's decision, and critical Player 3s. Our data analysis concentrates on the choices of
critical third players. Unlike other players, third players face no uncertainty about the play of others. We
therefore don’t need to worry about the unobservable beliefs of subjects in analyzing their behavior. Only
for third players can we make strong predictions about how behavior should vary across treatment and across
time and draw strong conclusions about the effects of fairness and learning on subjects’ behavior.
After sorting themselves out over the first few rounds, contribution rates by critical third players are
decreasing as the asymmetry of costs increases. These differences emerge early -- aggregating over the first
ten periods, the contribution rates by critical third players are 82%, 76%, and 73% in the 3/6/9, 1/3/9, and
1/3/16 treatments respectively -- and increase over time. For the 3/6/9 and 1/3/9 treatments, the contribution
rate for critical third players rises over time, reaching 90% and 83% respectively for the final ten periods. In
the 1/3/16 treatment, the contribution rate for critical third players falls substantially over time, dipping to
50% in periods 21-30 and then rebounding somewhat to 60% in the final ten periods. This decline in
contribution rates is not due to anomalous behavior in a single session – for all four sessions of the 1/3/16
treatment the contribution rate by critical third players was lower in the final ten periods than in the initial
ten periods.
Rather than capturing a substantive feature of subjects’ behavior such as reputation building, the late

5We can also refute the reputation hypothesis by looking at play by critical third players in the 40th period. Since this is the last period of play, there is nothing to be gained by maintaining a reputation. None theless, only 8 of 15 critical third players in the 40th period of the 1/3/16 treatment contribute to the publicgood. By way of comparison, 20 out of 20 critical third players contributed in the 40th period of the 3/6/9treatment and 13 out of 14 critical third players contributed in the 40th period of the 1/3/9 treatment.
8
increase of the contribution rate for critical third players in the 1/3/16 treatment illustrates the deceptive
effects of aggregation over sessions. In later periods of the experiment, the probability of being a critical third
player is endogenous. If learning by the first two players moves them towards strategies with higher expected
payoffs, there will be positive correlation between the initial probability that critical third players contribute
in a session and the probability that third players are critical in later periods. It follows that observations of
critical third players in later periods are more likely to come from sessions in which critical third players tend
to contribute. This aggregation effect biases estimated changes in the contribution rate for critical third
players upwards.
The rise in contribution rates for 1/3/16 critical third players in the final ten periods is largely due to
the aggregation effect described above. When contribution rates are broken down by session, no clear pattern
of change emerges over the second half of the experiment, but the percentage of observations coming from
sessions with relatively high contribution rates rises steadily over time. As such, we see little support for the
hypothesis that reputation effects are driving our results.5
To control for individual effects (and for the aggregation effects), we examine the behavior of critical
third players using probit analysis with a random effects specification. This analysis is summarized in Table
2. Each observation corresponds to a play of the game for which the third player was critical. For all three
models the dependent variable is the critical third player’s decision (0 = don’t contribute, 1 = contribute).
The random effects term is significant at the 1% level in all three regressions, but is not reported in Table 2
since it is of little economic significance.
Model 1 is a baseline regression looking for general differences between the treatments. The only
regressors are dummy variables for treatment (Payoff 3/6/9=1 if 3/6/9 treatment, 0 otherwise; Payoff
1/3/16=1 if 1/3/16 treatment, 0 otherwise). Using the 1/3/9 treatment as a base, this regression finds that

6Throughout this paper, all tests of significance for individual parameters are two tailed z-tests. All tests ofjoint significance use a log likelihood ratio test.
7To test this hypothesis, we reran Model 2 with the 1/3/16 treatment as the base. The parameter estimate forperiod is -.0295 with a standard error of .0063. This parameter is significant at the 1% level.
9
contribution rates are higher in the 3/6/9 treatment and lower in the 1/3/16 treatment with both dummies
significant at the 1% level.6
Model 2 adds a regressor for the period in which the decision was made as well as two variables
which interact period with a treatment dummy (period 3/6/9 and period 1/3/16). Once again the treatment
dummies are significant at the 1% level, indicating that statistically significant differences between treatments
are present from the beginning of play. Jointly, the three new variables are significant at the 1% level (P2 =
31.756, 3 d.f., p < .01). The parameter for period is positive and significant at the 5% level, while the period
3/6/9 parameter is not significant at any standard level. Together, these parameters indicate that contribution
rates are rising in the 3/6/9 and 1/3/9 treatments with the difference between the two treatments remaining
roughly constant. The parameter for period 1/3/16 is negative and significant at the 1% level. Additionally,
the overall rate of change in 1/3/16 sessions is negative and significant at the 1% level, indicating that
contribution rates are falling significantly over time in the 1/3/16 treatment.7
Model 3 adds four new variables to the regression. These additions are chosen to test secondary
predictions of the fairness and learning hypotheses. Whocon is a dummy variable indicating which of the
preceding two players contributed (whocon = 1 if the first player contributed, 0 otherwise). Under general
conditions, the fairness hypothesis predicts that critical third players should contribute more frequently if
Player 2 has contributed than if Player 1 has contributed. (Formal proofs using either the Bolton-Ockenfels
model or the Fehr and Schmidt model are available from the authors upon request.) This prediction holds
regardless of treatment, so no interactions with the treatment dummies are included in the regression. Chance
gives the percentage of previous periods in which the third player has been critical. In a reinforcement
learning model without fairness (reinforcements equal monetary payoffs), the contribution rate by critical
third players should be positively correlated with chance. Intuitively, the more opportunities you have had

10
to learn that contributing yields higher payoffs than not contributing, the more likely you should be to
contribute. When the reinforcement includes a fairness component, the model predicts that more chances to
be critical should accelerate learning but not affect the direction. Since contribution rates by critical third
players move in different directions in the different treatments, the variable chance is interacted with the
treatment dummies to generate the variables chance 3/6/9 and chance 1/3/16.
The results for Model 3 indicates that which player contributed prior to Player 3 does not have any
significant effect on a critical third player’s decision. The three chance variables are not jointly significant
at any standard level (P2 = 4.46, 3 d.f., p > .10). Examined individually, only the parameter estimate for
chance 1/3/16 is significant even at the 10% level. The positive sign of the parameter estimate for chance
1/3/16 does not fit with any sort of reinforcement learning model, given that contribution rates for critical
third players in the 1/3/16 sessions decrease over time.
Overall, the regression results reinforce our observations from Figure 1. Both the level of
contribution rates for critical third players and the direction of change for these contribution rates depend on
the asymmetry of contribution costs. For the treatments with relatively symmetric costs (3/6/9 and 1/3/9
treatments), contribution rates for critical third players are relatively high and rise over time. For the
treatment with relatively asymmetric costs (1/3/16 treatment), critical third player contribution rates are
initially low and fall over time.
The experimental results can only be partially explained by the existing theories of fairness. The
initial differences in play by critical third players between treatments are consistent with the predictions of
fairness models like the Bolton-Ockenfels ERC model. However, these initial differences are quite small,
only becoming economically significant with the passage of time. The existing models of fairness are static
in nature, and therefore cannot track the dynamics.
A pure learning approach also fails to explain all of the major features of the data. As noted
previously, such an approach predicts a rising contribution rate for critical third players in all three treatments,
when in fact the contribution rate falls sharply in the 1/3/16 treatment.

8See Cooper and Feltovich (1996), Cheung and Friedman (1997), Erev and Roth (1998), Salmon (1998),Camerer and Ho (1999), Blume, DeJong, Neumann, and Savin (1999), and Feltovich (2000).
11
V. Learning and Fairness: While neither the pure fairness hypothesis nor the pure learning hypothesis
captures all of the major features of the experimental data, both are able to explain some of the major features.
While unable to explain the changes in subjects’ behavior, the pure fairness hypothesis does correctly predict
that contribution rates for critical third players are decreasing as the costs of contribution become more
asymmetric. Likewise, while unable to predict the decrease in contribution rates for critical third players in
the 1/3/16 treatment, the pure learning hypothesis correctly predicts that behavior will change over time with
the differences between treatments growing. These partial successes suggest that a hybrid model synthesizing
the best of the fairness and learning hypotheses might fit the data well.
This section presents a reinforcement learning model and explores whether the addition of fairness
to the model improves its ability to fit the data. Because the dynamics generated by the learning model are
probabilistic in nature and sensitive to how the learning model is specified, the model must be formally
specified and appropriate econometric tests must be applied to cleanly reject the null hypothesis of pure
learning in favor of a hybrid between learning and fairness.
The Learning Model: We use a variation of the reinforcement learning model developed by Roth and Erev
(1995). There exist a wide variety of learning models in the literature, and which of these best tracks the
behavior of experimental subjects remains an open question.8 Our concern is not to determine whether the
reinforcement learning model is the best model of learning, but rather to study whether or not the observed
data is best explained by a learning model that allows for fairness considerations. The reinforcement learning
model is particularly well suited to this purpose since it has been used previously to study similar issues and
is easily modified to incorporate fairness considerations. We strongly conjecture that our conclusions will
hold for any learning model which puts increased weight over time on strategies that do well.
The reinforcement learning model studies how behavior changes over time for a population of
individuals who are repeatedly matched in small groups to play a game. Individuals are assumed to always

12
play the same role within this game, but the groups matched with each other change from round to round.
Formally, consider an N player normal form game. Let Mi be the number of strategies available to the i-th
player. In round t, the j-th individual in the i-th role has propensity qijt(m) for choosing his m-th strategy.
The probability of the j-th individual in the i-th role choosing his m-th strategy in round t is obtained by
dividing the associated propensity for this strategy by the sum of the propensities in round t.
(eq. 1)p (m)
q (m)
qijt ij
t
ijt
=∑=
( )µµ 1
Mi
In round t, each individual is randomly assigned N - 1 opponents, then chooses his strategy based on
his round-t probabilities. Let Fijt 0 {1,2, . . . , Mi} be the strategy chosen by the j-th individual in the i-th role
in round t. Monetary payoffs are determined the strategies chosen by all N individuals in a matching. Let
rijt be the reinforcement received by the j-th individual in the i-th role in round t. For the learning model
without fairness, this reinforcement is equal to the individual’s monetary payoff. For the hybrid model with
fairness, the reinforcement is a function of the individual’s monetary payoff and the size of his payoff relative
to the payoffs of others. An individual’s propensities are updated by multiplying all propensities by a
“forgetting” parameter * and then adding his reinforcement to his propensity for choosing his realized
strategy. Equation 2 gives the formula for updating the propensity of the realized strategy – for all other
strategies, the rijt term is dropped. By assumption, 0 # * # 1.
(eq. 2)( ) ( )q s q s rijt 1
ijt
ijt
ijt
ijt+ = +δ
To help pick up the individual effects in the data, we modify the model by adding an autocorrelation
parameter psame. This “inertia” parameter allows for the possibility that the draws are not independent across
periods, but instead correlated. The addition of this parameter affects how strategies are selected in each
period. With probability psame, the same strategy is chosen in period t as was chosen in period t - 1 (Fijt = Fij
t-1).
Otherwise, the formula in (eq. 1) is used to pick a new strategy. In other words, (eq. 1) now gives the
probability for each strategy being used subject to the individual choosing a new strategy.

9For example, suppose the first two players contribute. Suppose the third player would not have contributedif he had been critical. With normal form strategies, this choice gets reinforced even though it was neverimplemented. No reinforcement takes place with behavioral strategies.
10The frequency of contribution for third players when both preceding players contribute is 3.1% in the3/6/9 treatment, 13.2% in the 1/3/9 treatment, and 3.2% in the 1/3/16 treatment. The frequency ofcontribution for third players when neither preceding player contributes is 4.2% in the 3/6/9 treatment,18.7% in the 1/3/9 treatment, and 1.5% in the 1/3/16 treatment.
13
Fitting the reinforcement learning model: Before fitting parameters for the reinforcement learning model, we
must make some decisions as to how the model will be formulated for the MCS game. The model is written
down in terms of normal form strategies, but can be equally well stated in terms of behavioral strategies. For
an extensive form game like the MCS game, this might seem like a more natural choice. However, to give
the pure learning hypothesis its best possible chance, we use normal form strategies. This decision increases
the probability of a decline in critical third players’ contribution rates as observed in the 1/3/16 treatment.
The two approaches differ on the critical issue of whether or not third players reinforce the decision they
would have made if they had been critical even when they are not critical. Using normal form strategies
allows this sort of “accidental” reinforcement while using behavioral strategies does not.9 As a neutral force,
accidental reinforcement works against the natural direction of the dynamic. Since contributing is a dominant
strategy for critical third players with no fairness considerations, the natural direction of the dynamic is
towards increasing contribution rates. Thus accidental reinforcement works to our benefit if we are trying
to generate decreasing contribution rates.
In this paper, the model will only be fit for third players since this is the primary focus. Results on
fitting the model for Players 1 and 2 are available from the authors upon request. In the full normal form
game, Player 3s have sixteen available strategies. To make the estimation less unwieldy, the strategy set is
simplified by forcing third players to choose the same action whenever they are not critical. In other words,
a third player who is not critical cannot condition his strategy on whether both or neither of the previous
players have contributed. Given that contribution rates are about the same in both cases, and given the low
proportion of contributions observed in either case, this assumption is unlikely to have any substantial effect
on our conclusions.10 The remaining eight strategies tell a Player 3 what action to take when not critical,

14
r3 1 2 3i
1 2 3( , , )π π π π α
ππ π π
= −+ +
−
3 0 13
* min , (Eq.3)
critical following a contribution by Player 1, or critical following a contribution by Player 2.
We fit two variations of the reinforcement learning model to the data for third players using standard
maximum likelihood techniques. In the first version of the model, the learning model without fairness,
reinforcements equal the players’ monetary payoffs. In the second version, we incorporate fairness into the
learning model by using a version of Bolton and Ockenfel’s ERC model to generate the reinforcements. In
particular, the reinforcements for the learning model with fairness are given by equation 3. Let Bi be the
monetary payoff for the i-th player. Note that if " = 0, we get the learning model without fairness.
The results of the maximum likelihood estimation are contained in Table 3. All Player 3 observations
were used in fitting the models. Separate initial propensities are fit for each of the three treatments. Given
that the inclusion of psame probably does not fully control for individual effects in the data, the standard errors
have been corrected for clustering using techniques due to Moulton (1986) and White (1994). The initial
propensities are of little economic interest, and hence are not reported.
The critical parameter in the maximum likelihood estimation is ", the weight put on fairness in the
reinforcement function. Even after correcting the standard errors for clustering, we can reject the null
hypothesis that " = 0 at the 1% level using either a z-test (z = 3.34, p < .01) or a log-likelihood ratio test (P2
= 11.91, 1 d.f., p < .01). Adding fairness to the reinforcement function significantly improves the model’s
ability to fit the data. This improvement does not depend on the precise details of how fairness is added to
the reinforcements. We have done analogous analysis using several alternative specifications of the ERC
model and several specifications of the Fehr-Schmidt model, and get identical qualitative results. The details
of these additional fitting exercises are available upon request.
The ability of the reinforcement learning model with fairness to better fit the data follows from the
basic properties of the model. Reinforcement learning models tends to move in the direction of higher
reinforcements. Because contributing always provides a higher monetary payoff for critical third players,

11For " > 14.7, a critical third player in the 1/3/16 treatment always receives greater reinforcement from notcontributing than from contributing. For the 1/3/9 treatment, a critical third player always receives greaterreinforcement from contributing than not contributing if " < 127.1. For the 3/6/9 treatment, a critical thirdplayer always receives greater reinforcement from contributing than not contributing if " < 140.4.
15
the learning model without fairness is strongly predisposed toward rising contribution rates. This makes it
difficult for the model to track the falling contribution rates in the 1/3/16 treatment. With fairness added to
the reinforcement function, it becomes possible for not contributing when critical to generate a higher
reinforcement than contributing. For the fitted value of ", this is indeed the case for the 1/3/16 treament, but
not for the other two treatments.11 The model therefore can track both the rising contribution rate for critical
third players in the 3/6/9 and 1/3/9 treatments and the falling contribution rate in the 1/3/16 treatment.
The preceding argument should make it clear why use of reinforcement learning versus some other
learning model is not an essential ingredient of the hybrid model. What make the hybrid model work is its
ability to change which strategy is dominant in the 1/3/16 treatment. As long as the learning model has the
tendency of moving towards a dominant strategy, the specifics of the dynamics aren’t crucial.
VI. Conclusions and Discussion: This paper has presented experiments with a sequential step-level
public goods game, the MCS game. It explores whether the observed data can best be explained by the pure
fairness hypothesis, the pure learning hypothesis, or some combination of both approaches. While neither
approach by itself captures the major features of the data, a hybrid model that combines the dynamics of the
learning hypothesis with the sensitivity to relative payoffs of the fairness hypothesis provides a significantly
better fit for the experimental data. In particular, this model is consistent with declining contribution rates
for critical third players in the 1/3/16 treatment.
The novelty of our work comes from two sources, one empirical and one theoretical. Empirically,
we find strong movement towards a dominated strategy, a unique result as far as we know. For the most part,
games with other-regarding behavior yield no discernable dynamics. One case for which strong dynamics
are typically observed is in VCM public goods games without a threshold (Ledyard, 1995, pp. 146-148).
However, these dynamics involve movement towards the dominant strategy of not contributing. Only

12 The observed dynamics in VCM public goods games do not allow us to reject the pure fairnesshypothesis in any substantive manner. Because VCM games are simultaneous play games, subjects facestrategic uncertainty. It is consistent with the fairness hypothesis to build a model in which players arecompletely rational and have other-regarding preferences, but have to learn about the preferences (and byextension play) of others. Such a Bayesian learning model can fully explain the observed dynamics inVCM public goods games. Because critical third players in MCS games face no strategic uncertainty, asimilar approach cannot explain the observed changes in contribution rates over time.
Roth and Slonim (1998) and Cooper, Feltovich, Roth, and Zwick (2000) report learning byproposers in ultimatum games. As with VCM public goods games, these changes can be explained as aresponse to uncertainty about responders’ preferences.
16
because of the significant shift in the 1/3/16 treatment away from the dominant strategy of contributing for
critical third players can we reject the pure learning hypothesis.12
The primary theoretical innovation of this paper is driven by the empirical results. The data make
it clear that fairness and learning do not act in isolation, but instead interact with each other. This suggest
the need to develop a theory that incorporates both fairness and learning and allows us to model the
interaction between these two factors. Our hybrid model, the reinforcement learning model with fairness,
takes a first step towards building a unified theory of fairness and learning.
An important implication of the learning model with fairness is that fairness and learning are not
distinctly separate phenomena, but instead must be considered as aspects of a unified whole. Understanding
the dual nature of subjects’ behavior allows us to reconcile the contradictory conclusions reached by earlier
papers comparing the fairness and learning hypotheses. Two preceding papers have studied variants of the
ultimatum game to compare these hypotheses. Abbink, Bolton, Sadrieh, and Tang (1997) conclude that
punishment is a better explanation of responder behavior than learning. They find clear evidence that fairness
matters for responders and no firm evidence of learning by responders. In contrast, Cooper, Feltovich, Roth,
and Zwick (2000) find support for the pure learning hypothesis. Their main treatment effect is in the direction
predicted by the pure learning hypothesis and they find strong evidence that responders’ actions respond to
their past experience as a learning model predicts. Within the framework of our hybrid model, these opposing
results can happen quite naturally. Trying to discern the relative importance of fairness and learning from
a single experiment is closely akin to the famous anecdote about blind men trying to determine the nature of
an elephant by feeling a single body part. Depending on exactly which experiment is considered, different

13In fact, Cooper et al fit a hybrid model analogous to ours to their data in the working paper version of theirtext. Even though it isn’t necessary to explain the main treatment effect, they find that the learning modelwith fairness provides a significantly better fit for the data.
14Suppose we concede the dubious point that subjects would have a 30% error rate in early periods. If playin the last half of the experiment accurately reflects subjects’ true preferences, there is approximately a 50-50 split between subjects that prefer to contribute as critical third players in the 1/3/16 treatment and thosewho prefer to not contribute. Since random errors are presumably unbiased, it is equally likely that a playerthat intended to contribute would accidentally choose to not contribute as vice versa. Thus, even with ahigh rate of random errors, the contribution rate for critical third players should be roughly 50% in the earlyperiods. This is clearly not the case.
15For reviews of the literature on constructive preferences, see Payne, Bettman, and Johnson (1992), Slovic(1995), and Bettman, Luce and Payne (1998). For attempts to build a theory of constructive preferences,see Bettman, Luce, and Payne (1998) and Payne, Bettman, and Schkade (forthcoming).
17
conclusions will be reached about the relative importance of fairness and learning.13
We speculate that the learning model with fairness captures something about the behavioral
foundations of critical third players’ choices. Unlike many settings where strong dynamics are observed, it
is somewhat puzzling that the behavior of critical third players changes so dramatically. After all, what is
there to learn for a critical third player? Usually when strong learning effects are observed, subjects face
either substantial uncertainty about parameters of the game or substantial strategic uncertainty. Neither of
these conditions applies to critical third players in the MCS game. In settings which involve fairly complex
optimization problems, we observe learning because subjects must develop a good heuristic for solving the
difficult maximization problem. This scarcely applies to critical third players who face a straightforward
binary choice. We cannot even justify the observed dynamics through a decrease in random errors. The
relatively weak increases in contribution rates for critical third players in the 3/6/9 and 1/3/9 treatments might
be attributed to a decrease in random errors, but it hard to square the strong decrease in contribution rates for
critical third players in the 1/3/16 treatment with a decrease in random errors.14 Just about the only thing left
that subjects could be learning is their preferences. Indeed, recent advances in cognitive psychology suggest
that subjects will not enter our experiment with well-formed preferences.
Economists typically assume that preferences are an innate characteristic of individuals, and hence
stable. Over the past few decades, cognitive psychologists have largely abandoned this rigid view of
preferences in favor of the more flexible notion of constructive preferences.15 The basic idea can be

18
summarized as follows. Individuals are not assumed to carry around pre-specified preferences in their heads.
They cannot simply look up the appropriate preferences from some master list when faced with a novel
problem. At best, individuals may have well defined attitudes towards the primary attributes of a novel
problem. However, they lack any coherent notion of how these attitudes combine into a single preference
measure. Instead, preferences must be constructed on the spot.
The concept of constructive preferences applies naturally to the decision facing inexperienced
subjects who are critical third players in the MCS game. The primary attributes of their choices are monetary
payoffs and fairness. Contributing to the public good generates higher monetary payoffs but lower fairness.
Presumably most subjects know that (ceteris paribus) they prefer outcomes that are more fair to outcomes that
are less fair. They also can be assumed to prefer outcomes that (ceteris paribus) give higher monetary payoffs
to those that give lower monetary payoffs. However, we speculate that subjects lack a complete preference
ordering over combinations of fairness and monetary payoffs and must construct said preferences as needed.
Put simply, rather than entering our experiment knowing how they feel about tradeoffs between fairness and
monetary payoffs, we suspect that our subjects must learn their preferences. In particular, many critical third
players in the 1/3/16 treatment realize with experience that they prefer a slightly lower monetary payoff with
equal relative payoffs over a slightly higher monetary payoff with very unequal relative payoffs.
Given this story, the reinforcement learning model with fairness is natural approach to capturing the
process of critical third players resolving their preferences. Consider the position of a subject playing as a
third player in the 1/3/16 treatment. He is in an unfamiliar environment facing a problem he’s never seen
before. He must resolve a difficult tradeoff between fairness and monetary considerations. We might
reasonably expect that he will be somewhat confused. While it is possible that our subject uses a very
sophisticated strategy for resolving his confusion, it seems at least as plausible that he muddles along before
settling on a strategy that seems to do well. This is essentially the learning strategy of a reinforcement
learner.
Our current experiments do not allow us to directly confirm this conjecture that changes in the

19
choices of critical third players reflect the construction of preferences. More generally, they do not allow us
to state with any certainty that the reinforcement learning model with fairness is the best possible method of
synthesizing fairness and learning, to determine the best possible specification for this model, or to determine
the range of settings in which the hybrid model is applicable. In future work with the MCS game and other
related games, we plan to explore these issues.

20
References
Abbink, Klaus; Bolton, Gary E.; Sadrieh, A. and Tang, F. "Adaptive Learning versus Punishment inUltimatum Bargaining." Mimeo, Penn State University, 1997.
Berg, Joyce; Dickhaut, John W. and McCabe, Kevin A. "Trust, Reciprocity and Social History." Games andEconomic Behavior, July 1995, 10(1), pp. 122-42.
Bettman, James R.; Luce, Mary Frances and Payne, John W. "Constructive Consumer Choice Processes."Journal of Consumer Research, December 1998, 25(3), pp. 187-217.
Binmore, Ken; Gale, John and Samuelson, Larry. "Learning to be Imperfect: The Ultimatum Game." Gamesand Economic Behavior, January 1995, 8(1), pp. 56-90.
Blume, A.; DeJong, D.V.; Neumann, G.R. and Savin, N.E. "Inferring Learning Rules from ExperimentalGame Data." Working paper, University of Iowa,1999.
Bolton, Gary E. and Ockenfels, A. "ERC: A Theory of Equity, Reciprocity, and Competition." AmericanEconomic Review, March 2000, 90(1), pp.166-93.
Camerer, C. and Ho, T. H. "Experience-Weighted Attraction Learning in Normal Form Games."Econometrica, July 1999, 67(4), pp. 827-874.
Charness, Gary and Matthew Rabin, "Social Preferences: Some Simple Tests and a New Model," workingpaper, University of California-Berkeley, 2000.
Cheung, Yin Won and Friedman, Daniel. "Individual Learning in Normal Form Games: Some LaboratoryResults." Games and Economic Behavior, April 1997, 19(1), pp. 46-79.
Cooper, David J. and Feltovich, Nick. "Reinforcement-Based Learning vs. Bayesian Learning: AComparison." Working paper, University of Pittsburgh, 1996.
Cooper, David J.; Feltovich, Nick; Roth, Alvin E. and Zwick, Rami. "Relative versus Absolute Speed ofAdjustment in Strategic Environments: Responder Behavior in Ultimatum Games." Working paper,Case Western Reserve University, 2000.
Erev, Ido and Rapoport, Amnon. "Provision of Step-Level Public Goods: The Sequential ContributionMechanism." Journal of Conflict Resolution, September 1990, 34(3), pp. 401-25.
Erev, Ido and Roth, A.E. "Predicting How People Play Games: Reinforcement Learning in ExperimentalGames with Unique, Mixed Strategy Equilibria." American Economic Review, September 1998,88(4), pp. 848-881.
Falk, Armin and Fischbacher, Urs. "An Eye for an Eye, a Tooth for a Tooth: A Theory of Reciprocity."Mimeo, University of Zurich, 1998.

21
Fehr, Ernst; Kirchler, Erich; Weichbold, Andreas and Gachter, Simon. "When Social Norms OverpowerCompetition: Gift Exchange in Experimental Labor Markets." Journal of Labor Economics, April1998, 16(2), pp. 324-51.
Fehr, Ernst and Schmidt, K. "A Theory of Fairness, Competition, and Cooperation." Quarterly Journal ofEconomics, August 1999, 114(3), pp. 817-68.
Feltovich, Nicholas. "Reinforcement-Based vs. Beliefs-Based Learning Models in ExperimentalAsymmetric-Information Games." Econometrica, May 2000, 68(3), pp. 605-41.
Ledyard, John O. "Public Goods: A Survey of Experimental Research," in John H. Kagel and Alvin E. Roth,eds., The Handbook of Experimental Economics. Princeton: Princeton University Press, 1995.
Levine, David K. "Modeling Altruism and Spitefulness in Experiments." Review of Economic Dynamics, July1998, 1(3), pp. 593-622.
Moulton, Brent, "Random Group Effects and the Prevision of Regression Estimates," Journal ofEconometrics,1986, 32, 385-397.
Payne, John W.; Bettman, James R. and Johnson, Eric J. "Behavioral Decision Research: A ConstructiveProcessing Approach." Annual Review of Psychology, 1992, 43, pp. 87-131.
Payne, John W.; Bettman, James R. and Schkade, David A. "Measuring Constructed Preferences: Towardsa Building Code." forthcoming Journal of Risk and Uncertainty.
Roth, Alvin E. "Bargaining Experiments," in John H. Kagel and Alvin E. Roth, eds., The Handbook ofExperimental Economics. Princeton: Princeton University Press, 1995.
Roth, Alvin E. and Erev, Ido. "Learning in Extensive-Form Games: Experimental Data and Simple DynamicModels in the Intermediate Term." Games and Economic Behavior, January 1995, 8(1), pp. 164-212.
Roth, Alvin E. and Slonim, Robert. "Learning in High Stakes Ultimatum Games: An Experiment in theSlovak Republic." Econometrica, May 1998, 66(3), pp. 569-96.
Salmon, T.C. "An Evaluation of Econometric Models of Adaptive Learning." forthcoming Econometrica.
Slovic, Paul. "The Construction of Preference." American Psychologist, May 1995, 50(5), pp. 364-371.
Van de Kragt; Alphons J.; Orbell, John M. and Dawes, Robyn M. "The Minimal Contributing Set as aSolution to Public Goods Problems." American Political Science Review, March 1983, 77(1), pp.112-22.
White, H. Estimation, Inference and Specification Analysis. New York: Cambridge University Press, 1994.

Figure 1
Contribution Rates by Player 1s
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1-5 6-10 11-15 16-20 21-25 26-30 31-35 36-40Periods
Con
tribu
tion
Rat
e
3/6/9 Treatment 1/3/9 Treatment 1/3/16 Treatment
Contribution Rates by Player 2sContingent on Player 1s Contributing
0
0.1
0.2
0.3
0.4
0.5
0.6
1-5 6-10 11-15 16-20 21-25 26-30 31-35 36-40Periods
Con
tribu
tion
Rat
e
3/6/9 Treatment 1/3/9 Treatment 1/3/16 Treatment
Contribution Rates by Player 2sContingent on Player 1 Not Contributing
0.5
0.6
0.7
0.8
0.9
1
1-5 6-10 11-15 16-20 21-25 26-30 31-35 36-40Periods
Con
tribu
tion
Rat
e
3/6/9 Treatment 1/3/9 Treatment 1/3/16 Treatment
Contribution Rates by Critical Third Players
0.4
0.5
0.6
0.7
0.8
0.9
1
1-5 6-10 11-15 16-20 21-25 26-30 31-35 36-40Periods
Con
tribu
tion
Rat
e
3/6/9 Treatment 1/3/9 Treatment 1/3/16 Treatment

Table 1Summary of Contribution Costs by Treatment
Player 1 Player 2 Player 3
3/6/9 Treatment 3 6 9
1/3/9 Treatment 1 3 9
1/3/16 Treatment 1 3 16

Table 2Results of Probits for Critical Third Players
1.960 ** 1.678 ** 2.145 **
(0.163) (0.219) (-0.507)0.987 ** 0.832 ** 0.240(.232) (0.357) (0.606)-0.903 ** -0.955 ** -1.643 **
(.154) (0.297) (0.561)0.014 * 0.012 *
(0.007) (0.007)0.007 0.008
(0.010) (0.010)-0.043 ** -0.041 **
(0.010) (0.009)0.095-0.095-0.787(0.634)0.670
(0.640)1.012 +
(0.671)Log-likelihood -643.24 -627.37 -625.12
** indicates significance at the 1% level* and + indicate significance at the 5 and 10% levels, respectively( ) standard errors
Model 1 Model 2 Model 3
Constant
Payoff 3/6/9
Payoff 1/3/16
Period
Chance 3/6/9
Chance 1/3/16
Period 3/6/9
Period 1/3/16
Whocon
Chance
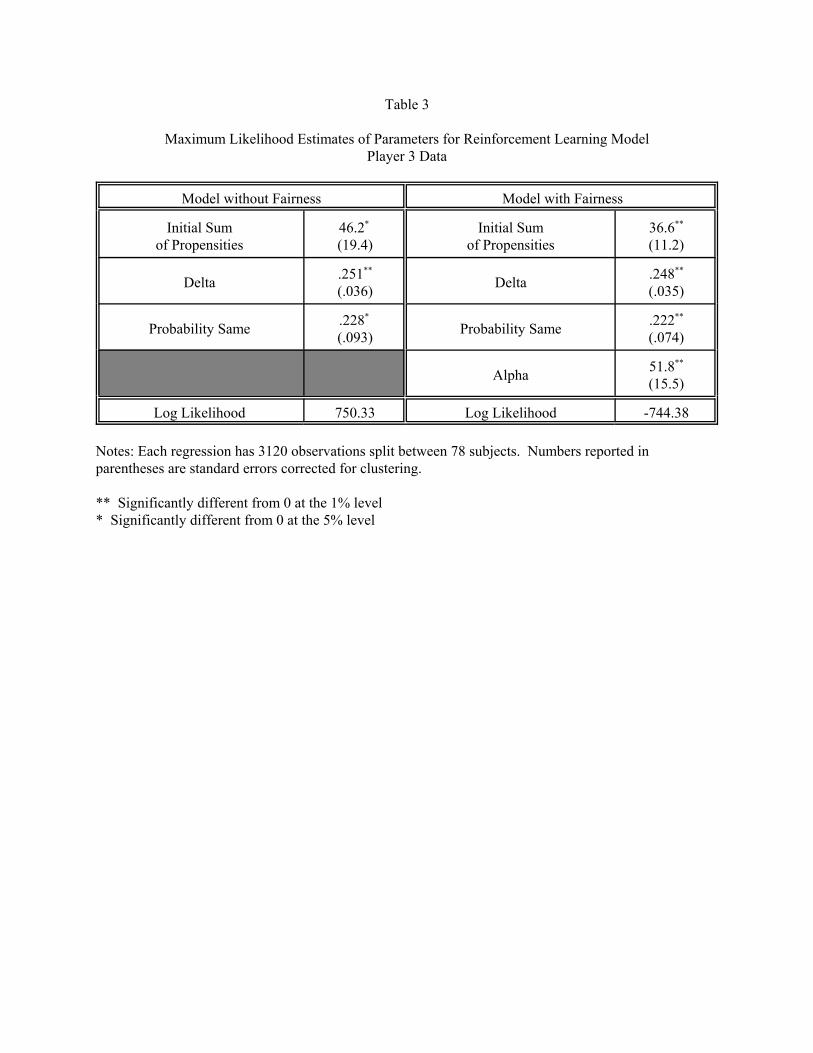
Table 3
Maximum Likelihood Estimates of Parameters for Reinforcement Learning ModelPlayer 3 Data
Model without Fairness Model with Fairness
Initial Sumof Propensities
46.2*
(19.4)Initial Sum
of Propensities36.6**
(11.2)
Delta .251**
(.036) Delta .248**
(.035)
Probability Same .228*
(.093) Probability Same .222**
(.074)
Alpha 51.8**
(15.5)
Log Likelihood 750.33 Log Likelihood -744.38
Notes: Each regression has 3120 observations split between 78 subjects. Numbers reported inparentheses are standard errors corrected for clustering.
** Significantly different from 0 at the 1% level* Significantly different from 0 at the 5% level