february 22, 2010 connectionist models of language
TRANSCRIPT

February 22, 2010
Connectionist Models of LanguageConnectionist Models of Language

Artificial neural network modelsArtificial neural network models
Inspired by computation in the brain:– Large number of simple, similar processing units– Massively parallel processing– Numerical (rather than symbolical) operations– Learning by adaptation of synaptic weights– No separation between knowledge (‘competence’) and
processing (‘performance’)
But usually not a neurobiological theory In Cognitive Science, also called ‘connectionism’
or ‘parallel distributed processing’ (PDP)

A model neuronA model neuronMcCulloch & Pitts (1943)McCulloch & Pitts (1943)
First formalization of neurons, extreme simplification:− Vector of input activations: x = (x0, …, xn)
− Vector of synaptic weights: w = (w0, …, wn)
− A single output activation: y
x1 w1
x2
xn
...w2
wn
y
x0 w0

input activations (from other units or external)
x1 wi,1
x2
xn
...wi,2
wi,n
neuron neuron ii
wix yi = f(wix)
x0 = 1
wi,0
A model neuronA model neuroninput activationinput activation

constant input (bias activation)
x1 wi,1
x2
xn
...wi,2
wi,n
wix yi = f(wix)
x0 = 1
wi,0
neuron neuron ii
A model neuronA model neuronbias inputbias input

x1 wi,1
x2
xn
...wi,2
wi,n
wix yi = f(wix)
x0 = 1
wi,0
connections with (positive or negative) weights
neuron neuron ii
A model neuronA model neuronconnections/synapsesconnections/synapses

x1 wi,1
x2
xn
...wi,2
wi,n
wix yi = f(wix)
x0 = 1
wi,0
total input to neuron i
xwi
n
jjijxw
0
neuron neuron ii
A model neuronA model neurontotal inputtotal input

x1 wi,1
x2
xn
...wi,2
wi,n
wix yi = f(wix)
x0 = 1
wi,0
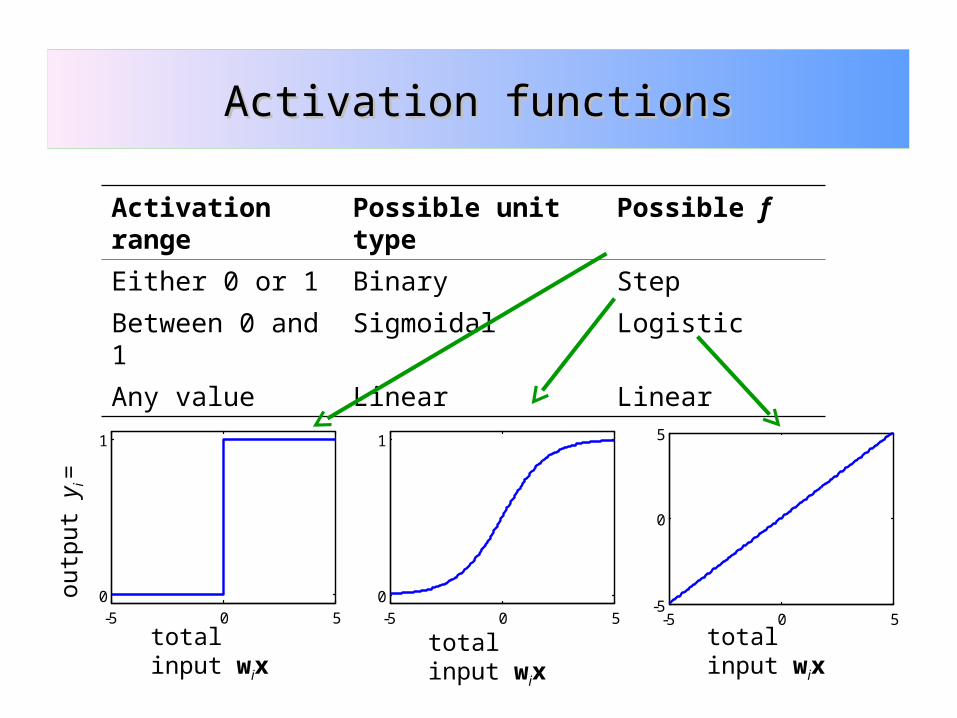
The neuron’s output activation is a function f (the activation function) of its total input:
neuron neuron ii
A model neuronA model neuronoutput activationoutput activation
)( xwii fy
-5 0 50
1
ou
tput
y i =
f(
wix
)
total input wix
-5 0 50
1
total input wix
-5 0 5-5
0
5
total input wix
Activation range
Possible unit type
Possible f
Either 0 or 1 Binary Step
Between 0 and 1
Sigmoidal Logistic
Any value Linear Linear
Activation functionsActivation functions

x0 = 1x1
x2
w0
w1
w2
y
Single neuron exampleSingle neuron example
Make the neuron detect if x1 > x2
So, compute the function:
21
21
if0
if1
xx
xxy
w0 = 0
w1 = 1w2 = −1
x0 = 1
x1
x2
y3
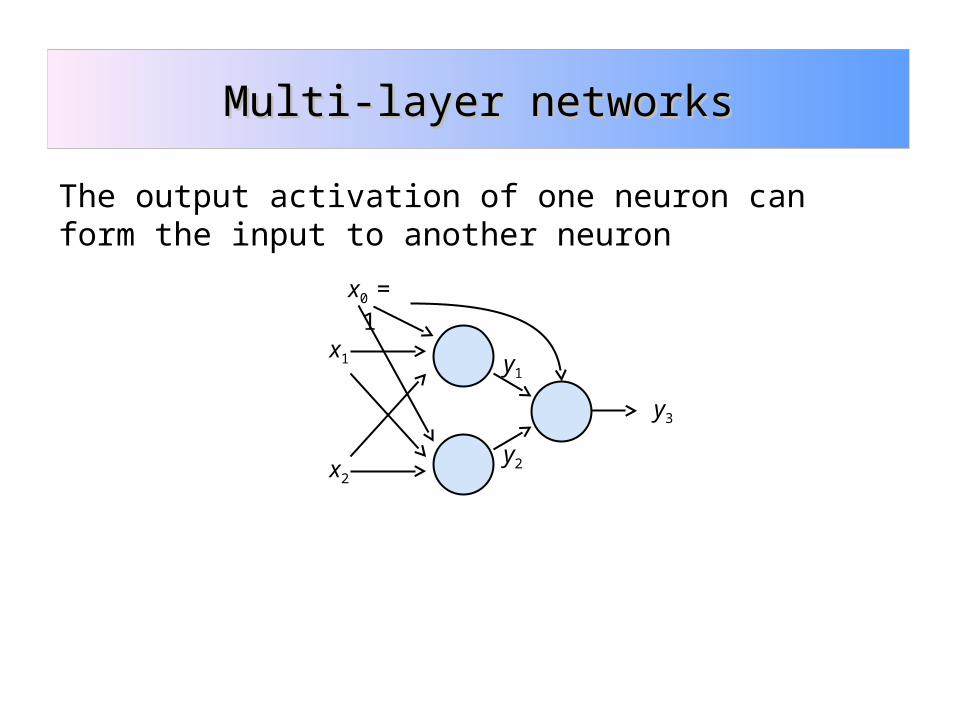
Multi-layer networksMulti-layer networks
The output activation of one neuron can form the input to another neuron
y1
y2

h1 h2
y2y1 y3
h3
Whid
inputs
…
… x1 x2 xninputs
hidden neurons
output neurons
= hidden layer
output layer
A two-layer feedforward network
Wout
…
x
h
y
x0
Multi-layer networksMulti-layer networks

With enough hidden units, a two-layer feedforward network can compute any function (i.e., any mapping from inputs x to outputs y) with arbitrary precision
Caveats:1. We don’t know in advance how many hidden units are needed
2. The required number of hidden units can be very large
3. How to find the right connection weights? Just trying all possible combinations is not feasible
Multi-layer networksMulti-layer networks

We have N training examples, which are pairs of input vectors and target outputvectors: (x1, t2), …, (xN, tN)
The desired output for input xi is target ti , but the actual output is yi . The error for example i is:
Find connection weights Whid and Wout that minimize the total error:
Finding proper connection weightsFinding proper connection weights

Gradient descentGradient descent
Each set of connection weights results in a particular total error E. With just two weights, we have a 3D error landscape:
w1 w2
Tota
l err
or
For any given set of weights, we can compute E. But in practice, we can’t know what the full error landscape looks like.
Starting at a random position, how to find the lowest point?
Change weights to follow the steepest descent and find at least a local minimum.

The Backpropagation algorithmThe Backpropagation algorithm(Rumelhart, Hinton, & Williams, 1986)(Rumelhart, Hinton, & Williams, 1986)
Take a feedforward network with one or more hidden layers, and a set of training examples
Start with random (small) connection weights For each training example i:
– Process training input xi to get output yi.
– Compare yi to the target ti .
– Which changes to Wout and h will maximally reduce the difference between yi and ti ? Adjust Wout accordingly.
– Which changes to Whid will lead to the desired change in h? Adjust Whid accordingly.
Repeat until bored (or satisfied)

In theory, a two-layer feedforward network can compute any function. But what does it do in practice?
With enough training, enough hidden units, and a lucky choice of initial connection weights, all training examples can be learned ‘perfectly’.
Generalization: good performance on items that were not used for training.
Generalization shows that the network did not just store all the training examples, but discovered an underlying pattern/regularity/system.
But how can the network know the target outputs for items that were not used for training?
GeneralizationGeneralization

0 0.5 10
0.5
1
input
outp
ut
0 0.5 10
0.5
1
input
outp
ut
= training example
What to do with a new input?
What is the underlying function?
We can never be sure!
new input
GeneralizationGeneralization

0 0.5 10
0.5
1
input
outp
ut
0 0.5 10
0.5
1
input
outp
ut
0 0.5 10
0.5
1
input
outp
ut
0 0.5 10
0.5
1
input
outp
ut
0 0.5 10
0.5
1
input
outp
ut
good sample
sparse sample
bad sample
0 0.5 10
0.5
1
input
outp
ut
0 0.5 10
0.5
1
input
outp
ut
= training example= sine function= network output
Which sample characterizes human language acquisition?
Which sample characterizes human language acquisition?
(Lack of) generalization(Lack of) generalization

Fodor & Pylyshyn (1988):− Language is systematic: If you can understand “Mary
likes Susan” you can also understand “Susan likes Mary”
− Systematicity can only be explained by a symbol system: a compositional syntax/semantics
− Neural networks are not symbolic, so they cannot explain systematicity
Marcus (1998):− A model of language processing must use variables to
explain generalization (e.g., “Mary likes x”) − Neural networks do not provide variables− So, connectionist models do not generalize enough
Critique of connectionismCritique of connectionism

Temporal sequence processing
When perceiving language, the signal develops over time and is processed incrementally
How to do this in a feedforward neural network? The network has long-term memory (connection
weights), but no short-term memory
Whid
input
hidden layer
output layer
Wout
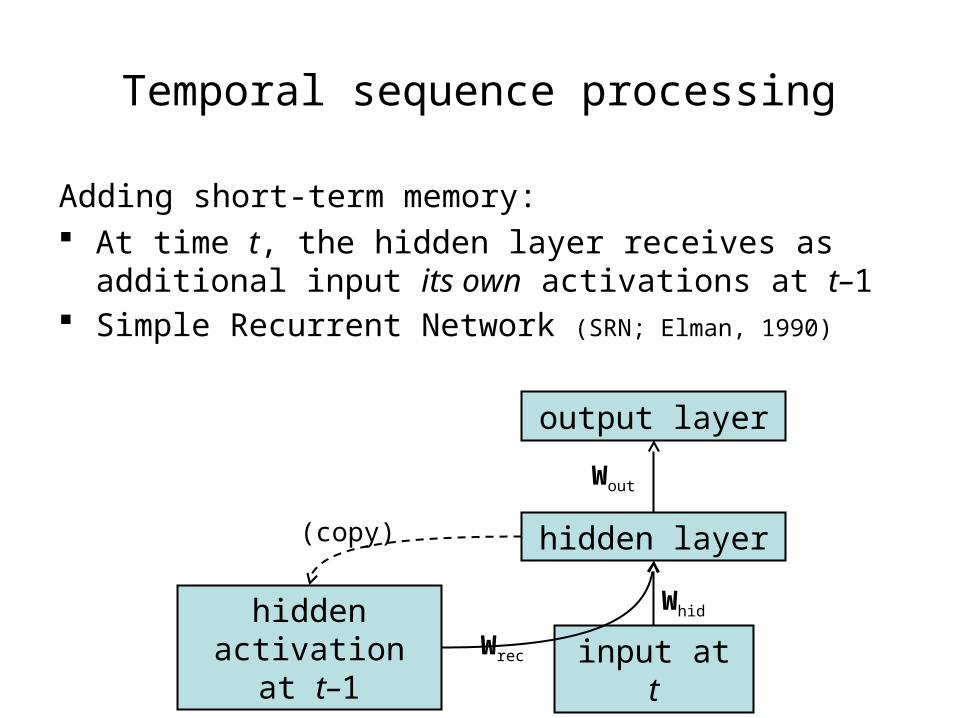
Temporal sequence processing
Adding short-term memory: At time t, the hidden layer receives as additional
input its own activations at t–1 Simple Recurrent Network (SRN; Elman, 1990)
Whid
input at t
hidden layer
output layer
Wout
hidden activation at t–
1
(copy)
Wrec

Simulating sentence comprehension
Input: temporal sequence of words (e.g., man hugs tree)
Target output: a representation of the meaning of the sentence (somehow encoded as an activation vector)− Conceptual structure: Agent = man
Patient = treeAction = hug
− Mental model: analogical representation of the state-of-affairs described by the sentence
Connectionist models of sentence-to-meaning mappings:− To conceptual structure: Miikulainen & Dyer (1991), Desai
(2002, 2007)
− To mental model: Nenov & Dyer (1994), Frank, Haselager & v. Rooij (2009)
Generalization, but (so far) not able to explain much about human sentence comprehension

Non-semantic sentence processing
Most common task in SRN sentence processing: to predict the upcoming word
t Training input Target output
1 the woman
2 woman sees
3 sees the
4 the man
5 man . [end]
6 . [end] the

SRNs and next-word prediction
Standard approach:− Sentences from a simplified language (hand-
crafted probabilistic grammar)− One input per word− One output per word
Correct prediction is hardly ever possible, so only grammatical prediction is required
If word i is likely to come next, the activation of output unit i should be high (and vice versa)
If the network generalizes well, it learned “something” about the grammar

SRNs and next-word predictionElman (1991)
SRN learned next-word prediction on a simple language
Lexicon (each word = 1 network input/output unit)
– 10 nouns: John, Mary, boy(s), girl(s), …– 12 verbs: transitive (feed), intransitive (live),
either (see)– 1 relative pronoun: who– 1 end-of-sentence marker
Sentences– simple: girl feeds dogs.
John lives.– relative clause: dogs who chase cat see girl.
dogs who cats chase see girl.– multiple embeddings: boys who girls who dogs chase see hear.

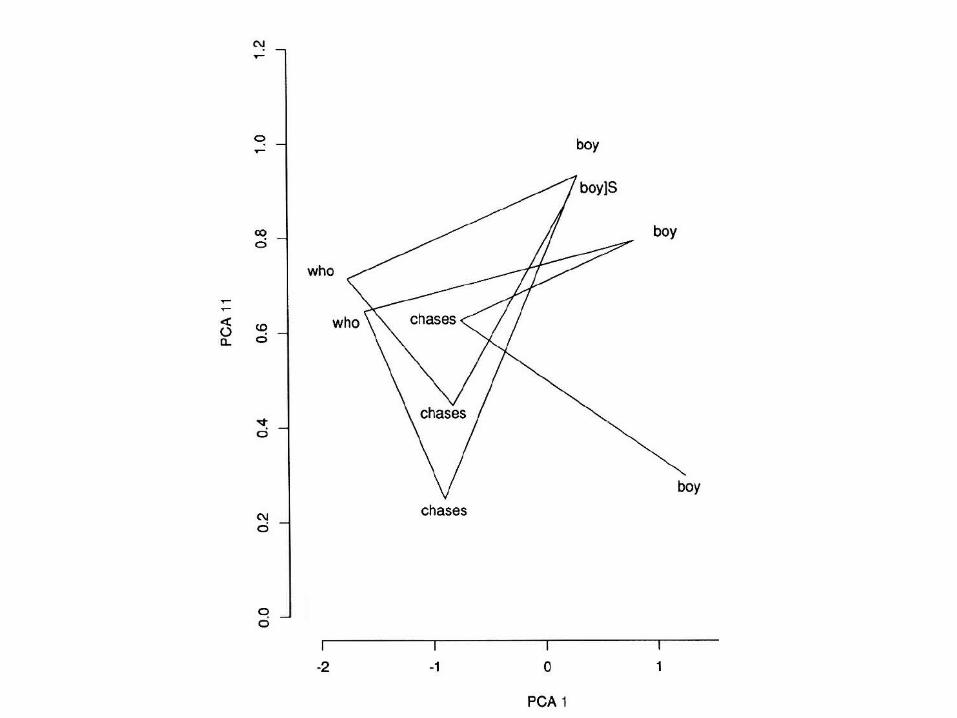
Output activation during processing of: boys who Mary chases feed cats

What do such simulations explain about human sentence processing?
Analyze the network’s internal representations of (sequences of) words
Each input (word sequence) results in a vector of activation values in the hidden layer(s). Or equivalently: points in high-dimensional state space(s).
Methods of analysis− Hierarchical cluster analysis (HCA)− Principal component analysis (PCA)
Network analysis

Take the set of vectors you’re interested in Split this into two sets, such that the average
distance within each set is minimal, and the average distance between the two sets is maximal (other criteria also possible)
Repeat for each set until you’re down to single vectors
Hierarchical Cluster Analysis

Hierarchical Cluster AnalysisA two-dimensional example
0 0.5 10
0.5
1
a
bc
de
f
g
h
i
j
k
l
m
n
op
q
r
s
t
activation hidden unit 1
activ
atio
n hi
dden
uni
t 2

Hierarchical Cluster AnalysisThe dendrogram
e h k r p c a i b l m q t f g j s d o n
0.1
0.2
0.3
0.4
Euc
lidea
n di
stan
ce
vector

(Elman, 1990)

Project the state space onto a space with fewer (usually two) dimensions
Find directions that retain most information. These do not need to coincide with the state-space’s dimensions
In particular: find the set of dimensions in which the variance in data is maximal
PCA1, PCA2, PCA3, … are the dimensions with most, 2nd most, 3rd most,… variance in the data
Principal Component Analysis

0 0.5 1
-0.2
0
0.2
a
b
c
d
e
fgh
i
jk
lm
n
o
p
q
r
s
t
PCA1
PC
A2
Principal Component AnalysisA two-dimensional example
0 0.5 10
0.5
1
a
bc
de
f
g
h
i
j
k
l
m
n
op
q
r
s
t
i a rp md
PCA1
PCA2
PCA1
PC
A2
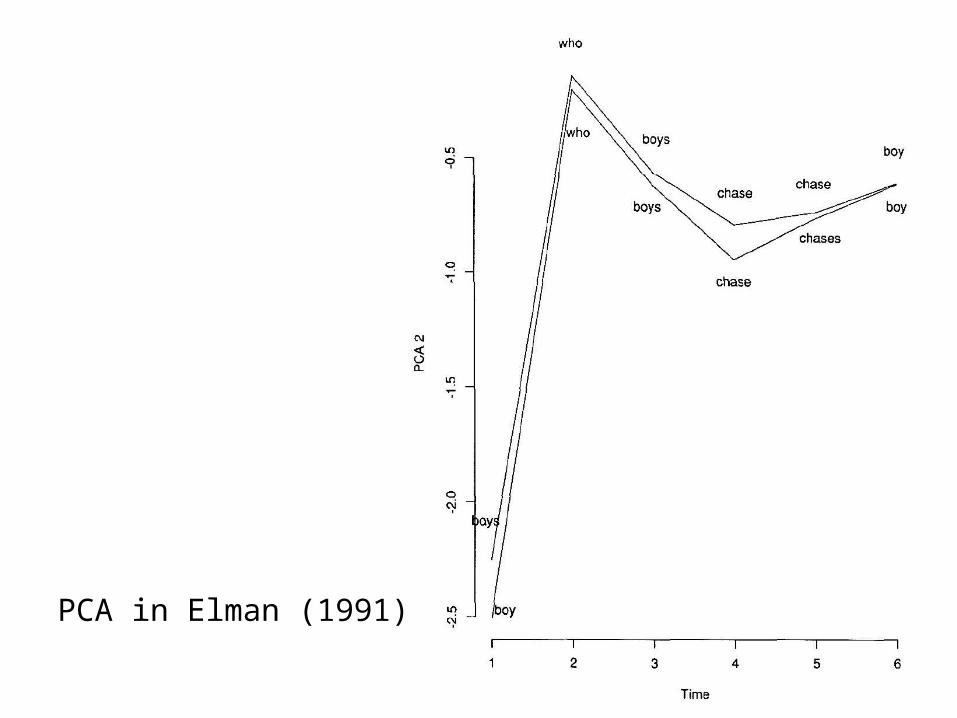
PCA in Elman (1991)

Relation to the DOP approach
Differences:− No structural analysis (i.e., no parsing)− Examples are not stored explicitly− No ‘productive units’; Non-compositional
representations− No explicit word categories (but regions in a state
space that develops during training)
Similarities:− Importance of frequencies/probabilities− No restrictions on relevant fragments− Every learned example affects the model

Assignment IV
On Blackboard, under “Lecture 4” Construct (on paper) a neural network that can
recognize different vowels Hand in the completed assignment the latest on
Friday February 26 at 6pm By e-mail to [email protected]