final presentation tong wang. 1.automatic article screening in systematic review 2.compression...
TRANSCRIPT

Final Presentation
Tong Wang

1. Automatic Article Screening in Systematic Review
2. Compression Algorithm on Document Classification

Automatic Article Screening
• Review Question: Vitamin C for preventing and treating common cold?
• Data set: 17 References articles.664 Not references articles.

Problem Definition
• Input : document d classes(c1 = Reference, c2 = not a reference)• Output: predicted class of d• Goal: find all articles belong to c1(Reference)

Build Features
• “Bag of Words” assumption: the order of words in a document can be neglected
• Preprocessing: tokenization, lemma, remove stop words, remove some part of speech.
• Need a step: Name Entity Recognizer(NER), it labels sequences of words which are the name of things. It is implemented by linear chain Conditional Random Field(CRF)

Build features
• Vector space model• Extract vocabulary over all articles.• Each document can be represented by a vector,
value in each dimension is the word frequency in this article
• N = size of vocabulary w1, w2, w3, w4… wNd1 1 0 2 0 … 0d2 0 1 0 0 … 0

Naïve Bayes

Logistic Regression

Discuss
• Define loss matrix, give high penalty for false negative.
• Another way is to use Cosine distance to compute similarity between articles. Wiki def:
• Use other nlp probability model, like LSA, LDA

Compression
• The basic idea is the data contains patterns that occur with a certain regularity will be compressed more efficiently
• It is generally inexpensive
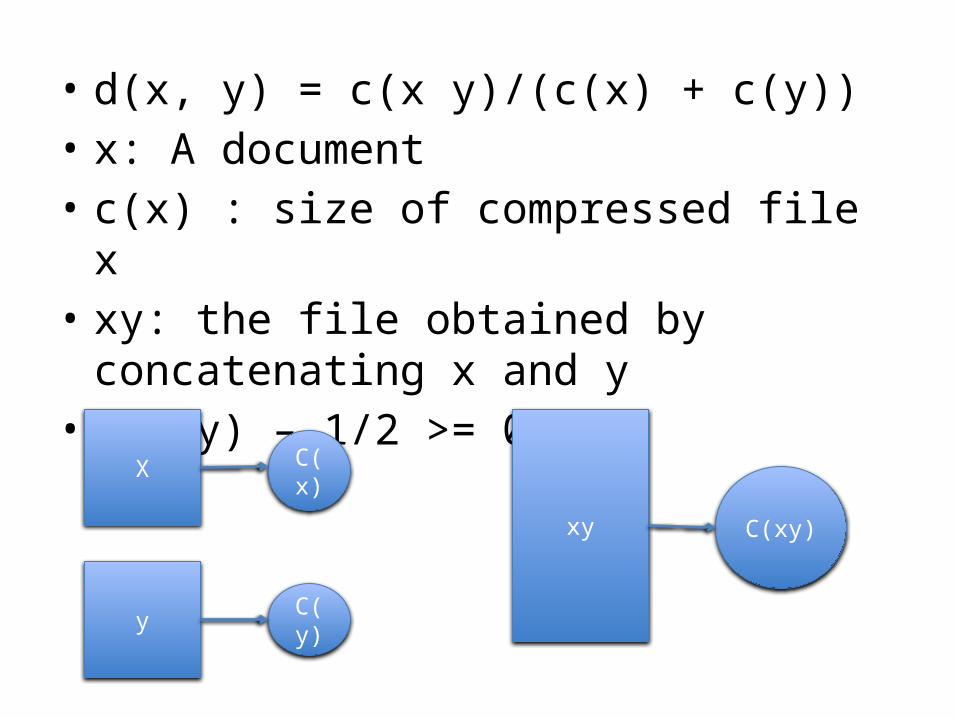
• d(x, y) = c(x y)/(c(x) + c(y))• x: A document • c(x) : size of compressed file x• xy: the file obtained by concatenating x and y• d(x,y) – 1/2 >= 0
X
y
xy
C(x)
C(y)
C(xy)

Compression Matrix
a1 a2 a3 a4….b1 d(b1, a1) d(b1, a2)b2 d(b2, a1) d(b2, a2)b3b4…

Experiments
• Two groups of drug review(ADHD) articles.• Two groups of machine learning articles.• Each group has 15 articles• Intuitively d(ADHD, ADHD) < d(ADHD, machine learning)d(machine learning, machine learning) < d(ADHD, machine learning)


Future work
• More experiments• Compare cosine(x, y) and d(x, y)