flannick mpg workshop pooled sequencing … sequencing analysis ... target region to sequence ......
TRANSCRIPT

MPG NSG workshop I: Pooled Sequencing Analysis
Jason Flannick
Postdoctoral Fellow Altshuler Lab 02/04/10

What is pooled sequencing?
• Sequence mulIple individuals in a single lane
• No barcoding • Usually phenotype driven
2

When should you perform pooled sequencing?
• You have a (small) target region to sequence
• You want to sequence as many individuals as possible
• You can’t use indexing
• It’s too late to redesign your experiment
3

How is pooled sequencing unique?
• SNP calling more challenging – Allele frequencies close to error rates – Lose idenIty of samples
• Phenotype driven – Different (but sIll general) analyses
• Different analysis pipeline – Different SNP caller – AnnotaIon / associaIon scripts
4

Pooled sequencing analysis workflow
5
Call Ready BAM files
Coverage & Power Metrics
Syzygy
SNP calls
AnnotaIons Frequency EsImaIon
AssociaIons Burden TesIng
Syzygy ReSeq
Polyphen PDB UCSC C‐alpha
Variants for Followup Genotyping PED/MAP files
ValidaIon Metrics VbV AssociaIons Burden TesIng
PLINK C‐alpha
GATK
Picard BAM files
GATK

Produced by Pipeline
Pipeline Automates These Tasks
6
Call Ready BAM files
Coverage & Power Metrics
SNP calls
AnnotaIons Frequency EsImaIon
AssociaIons Burden TesIng
Syzygy ReSeq
Polyphen PDB UCSC C‐alpha
Variants for Followup Genotyping PED/MAP files
ValidaIon Metrics VbV AssociaIons Burden TesIng
PLINK C‐alpha
GATK
1 day 2 hrs
2 hrs
Instant
Syzygy
Picard BAM files
GATK RunIme for FHS
3 hrs
Tools provided to help

How to run your data
• OpIon 1: Your own custom analysis – Install and run Syzygy – Write own scripts to analyze annotaIons and associaIons
• OpIon 2 (recommended): Run data through pipeline – Work with designated analyst
– Required input files • Picard BAM files
• Target file • Sample to lane mapping informaIon
– Use web interface to monitor progress and access files
– Can get data out of pipeline at any point • Direct access to all intermediate and final files through Unix File System
7

Sample Output Files: ApplicaIon to T2D
8

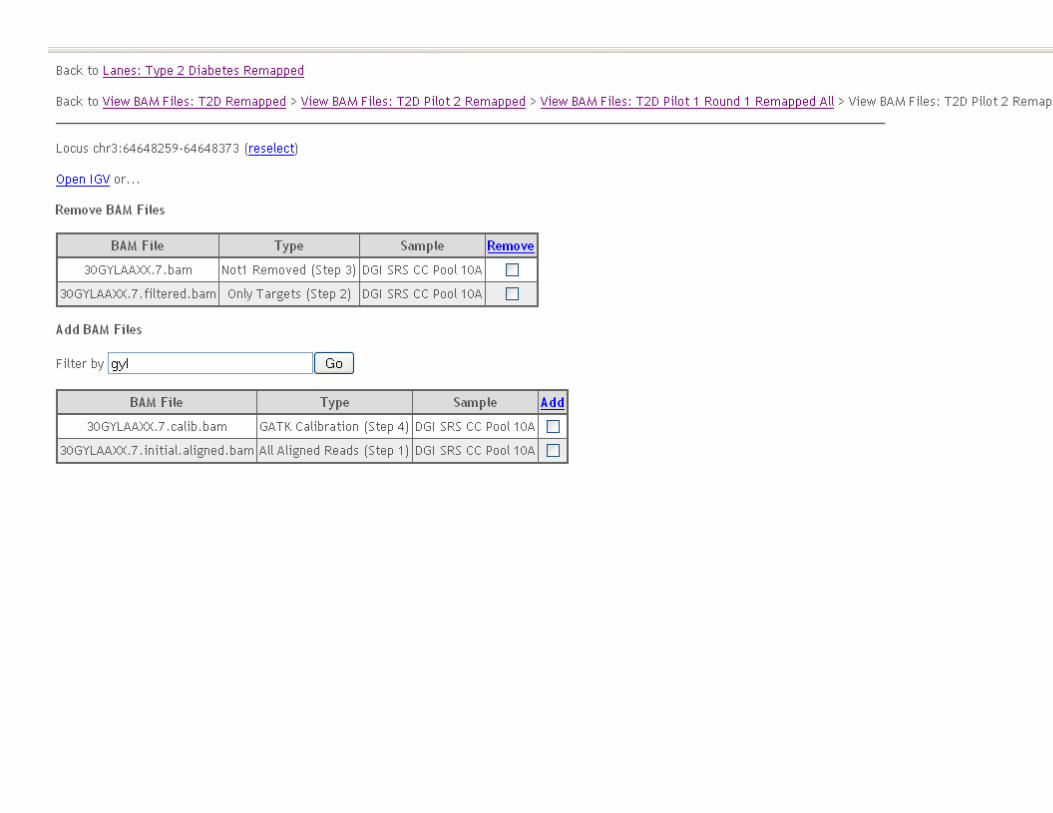


Sample Output Files: Coverage & Power Metrics
12



15

16

Sample Output Files: SNP Calls
17

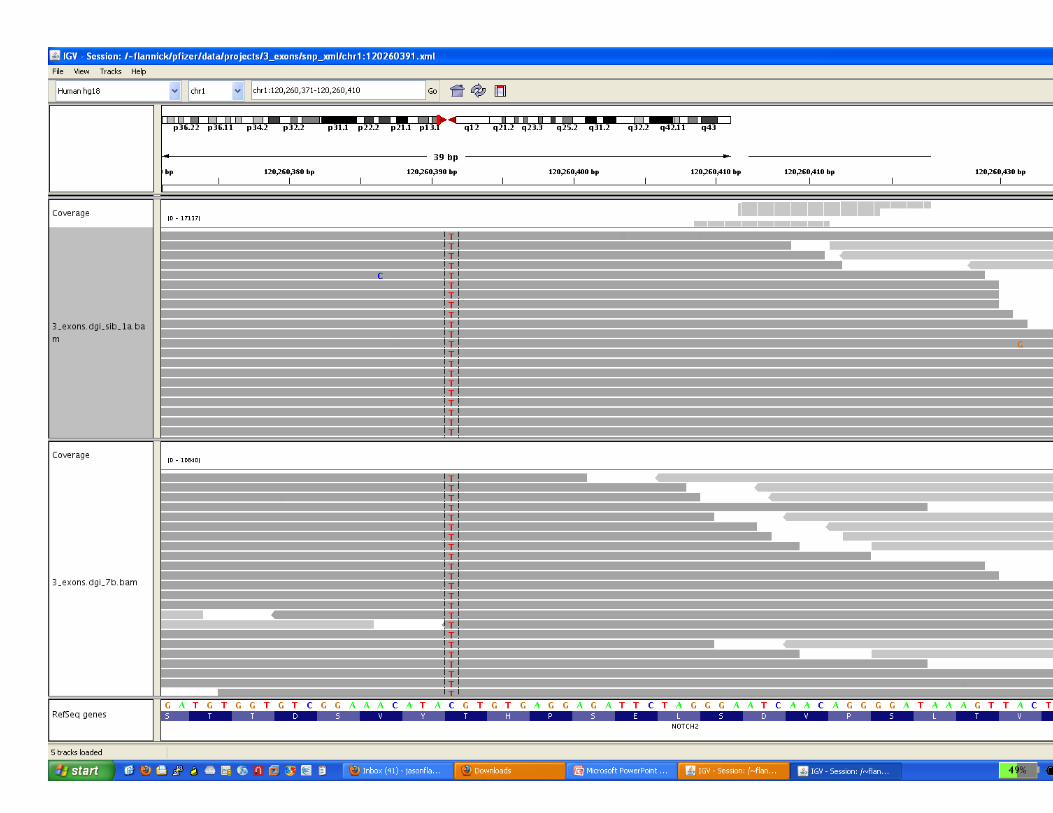


Sample Output Files: AnnotaIons & AssociaIons
21

22

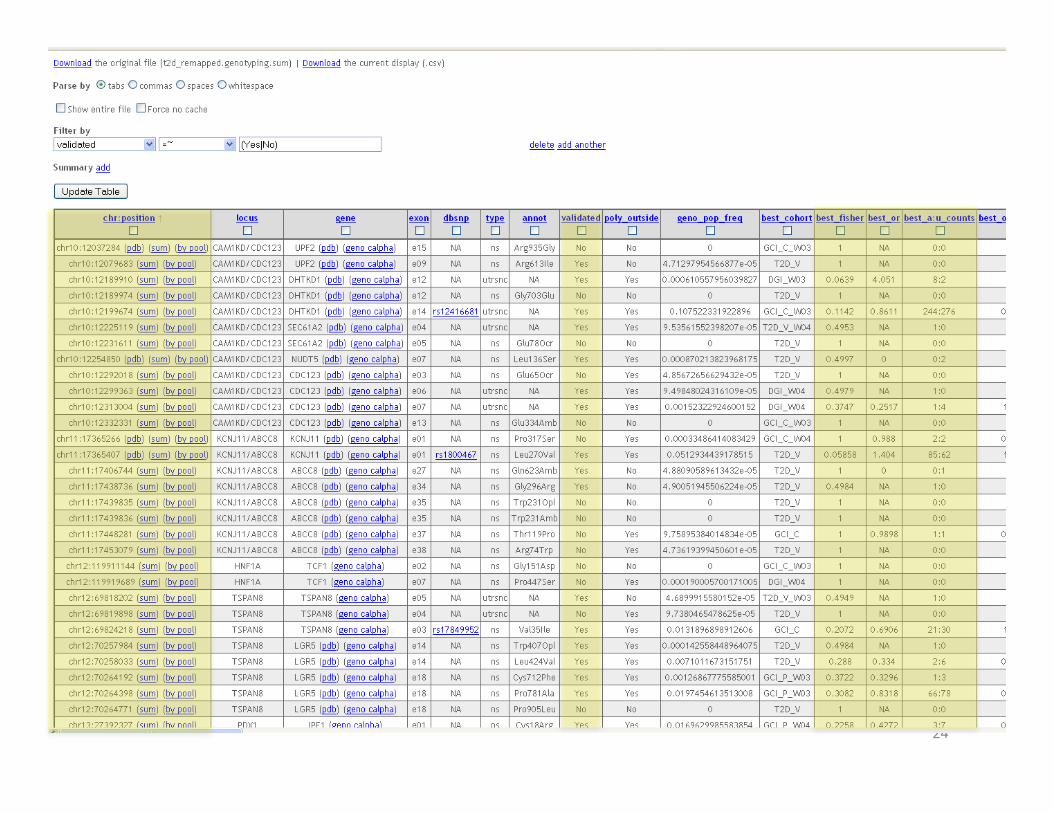
24

Summary
• Pipeline recommended for calling and analyzing pooled data
• Many tools to help analyze data, but also allows easy access to every intermediate file for custom analysis
• Designated analysts can advise on how to filter SNP calls and analyze variants for associaIon
25

Power calculator
• Available at hhp://www.broadinsItute.org/~flannick/power/
26

Overview of Syzygy
• Call SNPS – Compute error model for each locus (different from GATK)
– Perform likelihood raIo test of SNP vs. error – Filter SNPs
• Strand bias, clustered SNPs, second best base • Annotate SNPS
– ReSeq annotaIon server • Frequency esImaIon and associaIon tesIng
– Use EM to esImate case and control frequencies
– Perform chi‐squared test of associaIon for each SNP
– Perform C‐alpha test on each gene for variants with MAF < .05
27

