from exploration to planning cornelius weber and jochen triesch frankfurt institute for advanced...
Post on 21-Dec-2015
214 views
TRANSCRIPT

From Exploration to Planning
Cornelius Weber and Jochen TrieschFrankfurt Institute for Advanced StudiesGoethe University Frankfurt, Germany
18th International Conference on Artificial Neural Networks3d - 6th September 2008, Prague
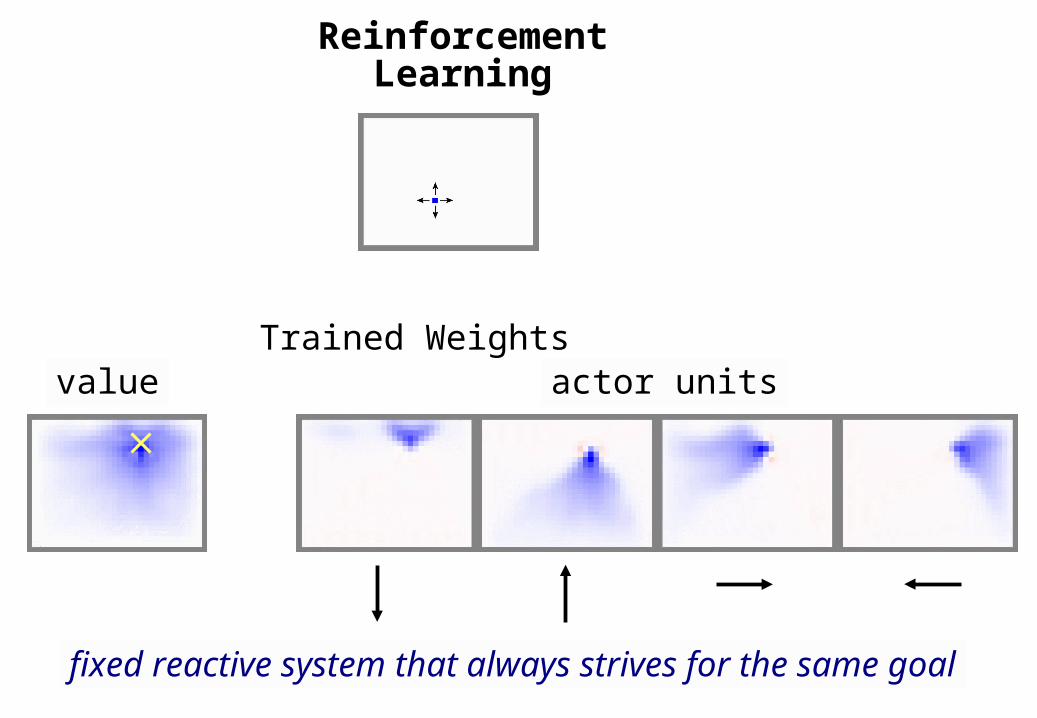
Reinforcement Learning
value actor units
fixed reactive system that always strives for the same goal
Trained Weights

reinforcement learning does not use the exploration phase
to learn a general model of the environment
that would allow the agent to plan a route to any goal
so let’s do this
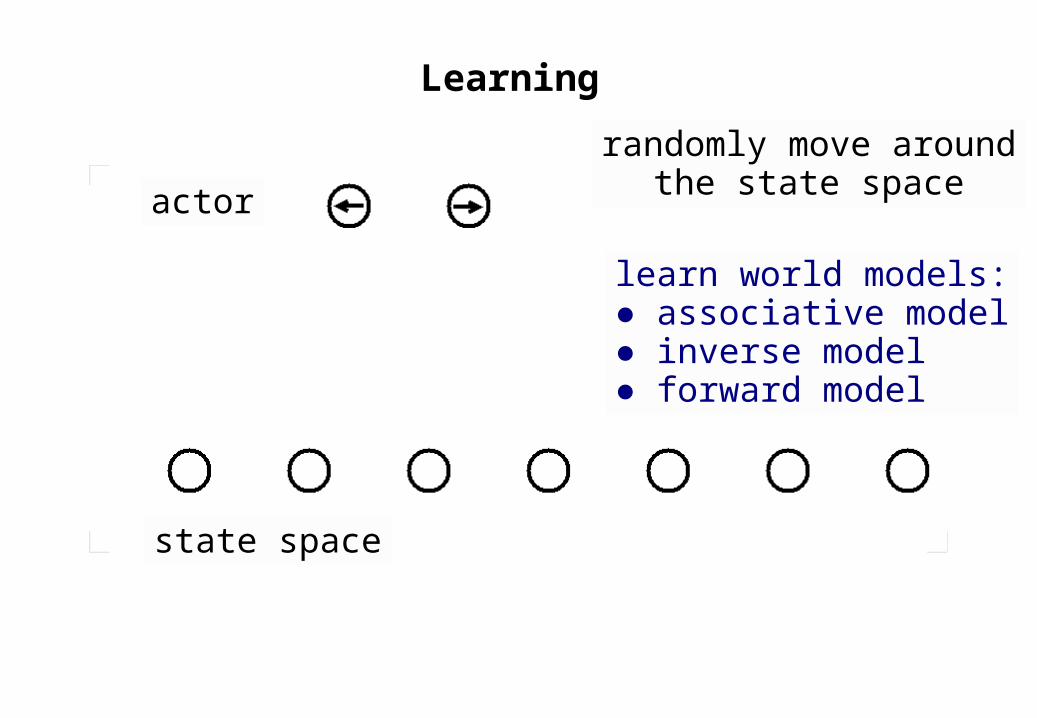
Learning
actor
state space
randomly move aroundthe state space
learn world models:● associative model● inverse model● forward model
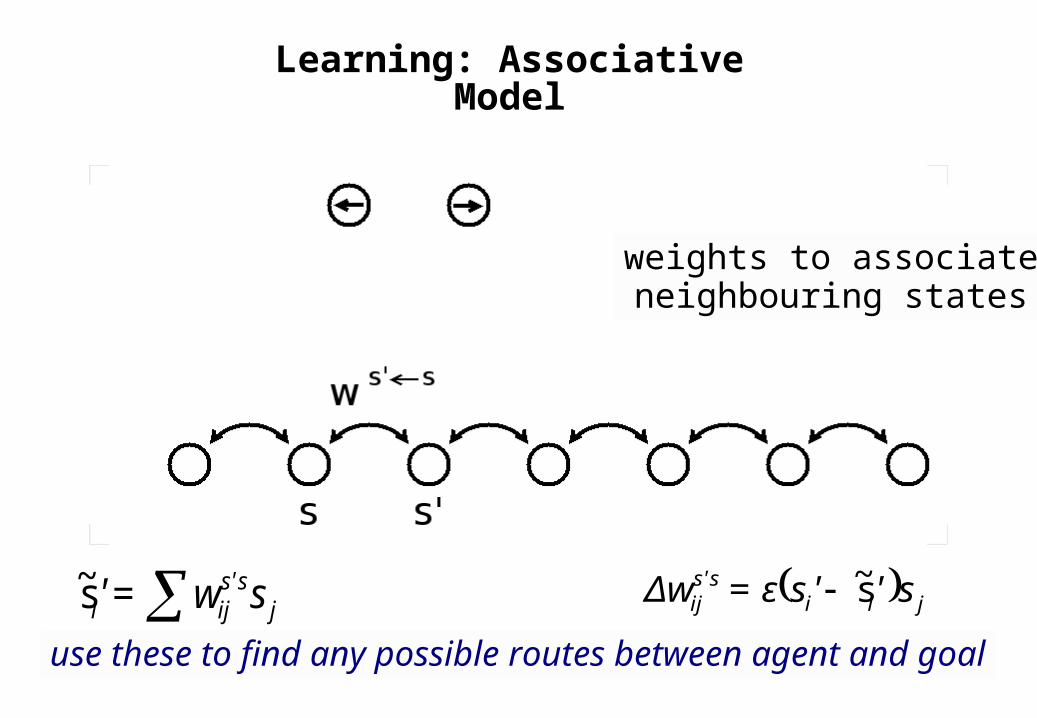
Learning: Associative Model
weights to associateneighbouring states
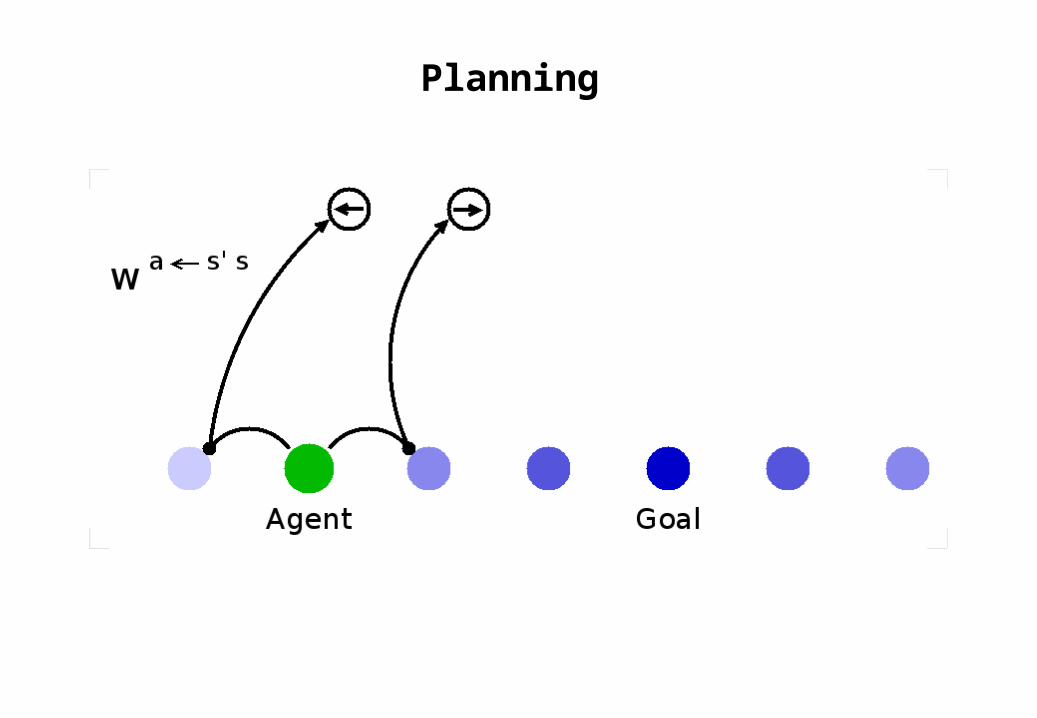
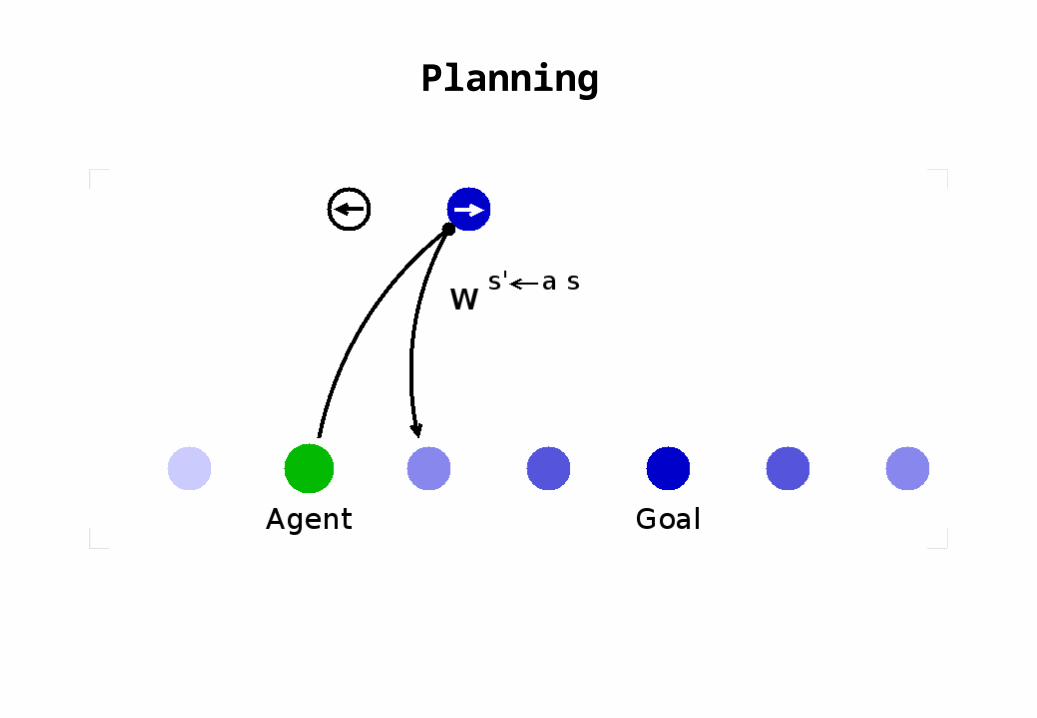
use these to find any possible routes between agent and goalj
ss'iji sw=' s~ jii
ss'ij s''sε=Δw s~
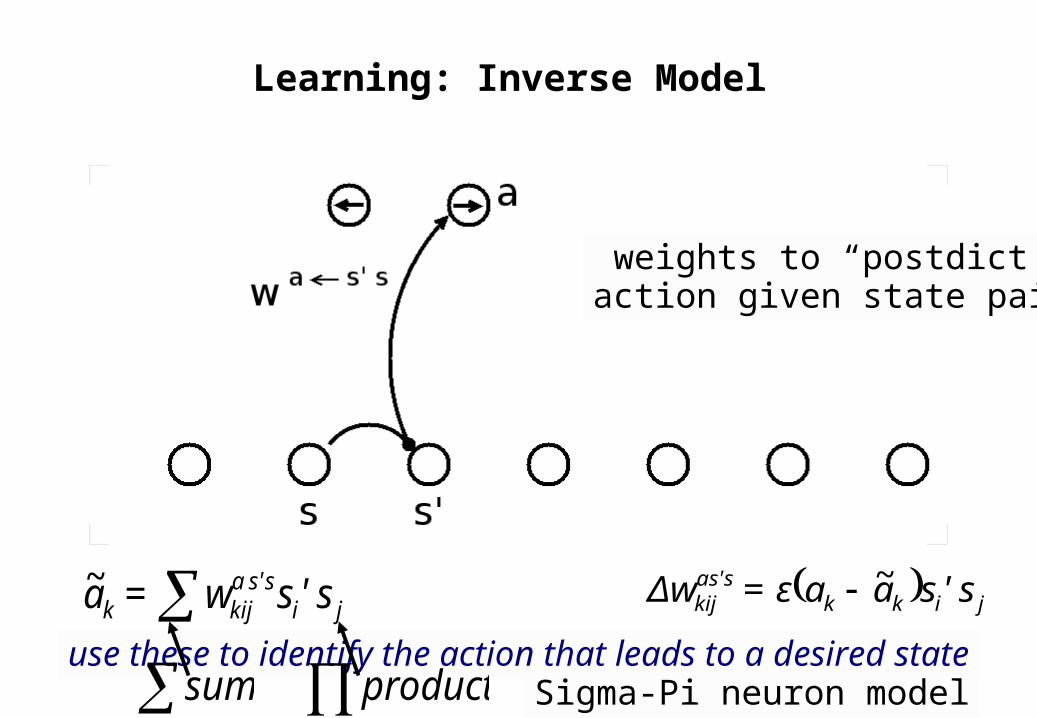
Learning: Inverse Model
weights to “postdict”action given state pair
use these to identify the action that leads to a desired stateji
s s'akijk s'sw=a ~ jikk
sas'kij s'saaε=Δw ~
sum product Sigma-Pi neuron model
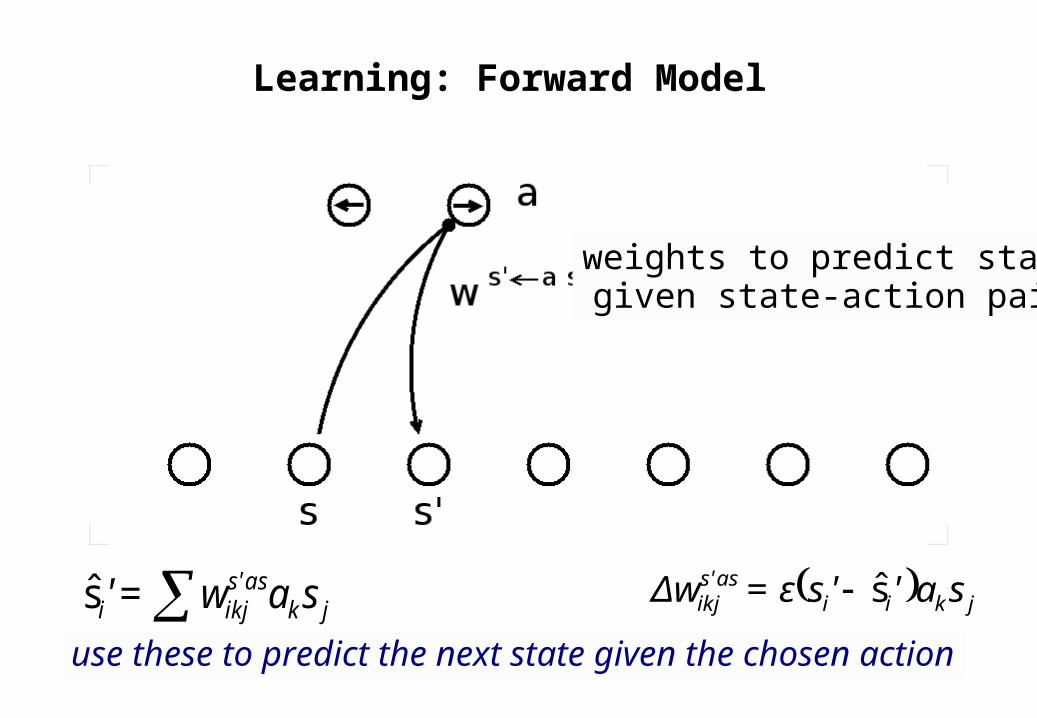
Learning: Forward Model
weights to predict stategiven state-action pair
use these to predict the next state given the chosen actionjk
ass'ikji saw=' s jkii
ass'ikj sa''sε=Δw s
Planning

Planning

Planning

Planning
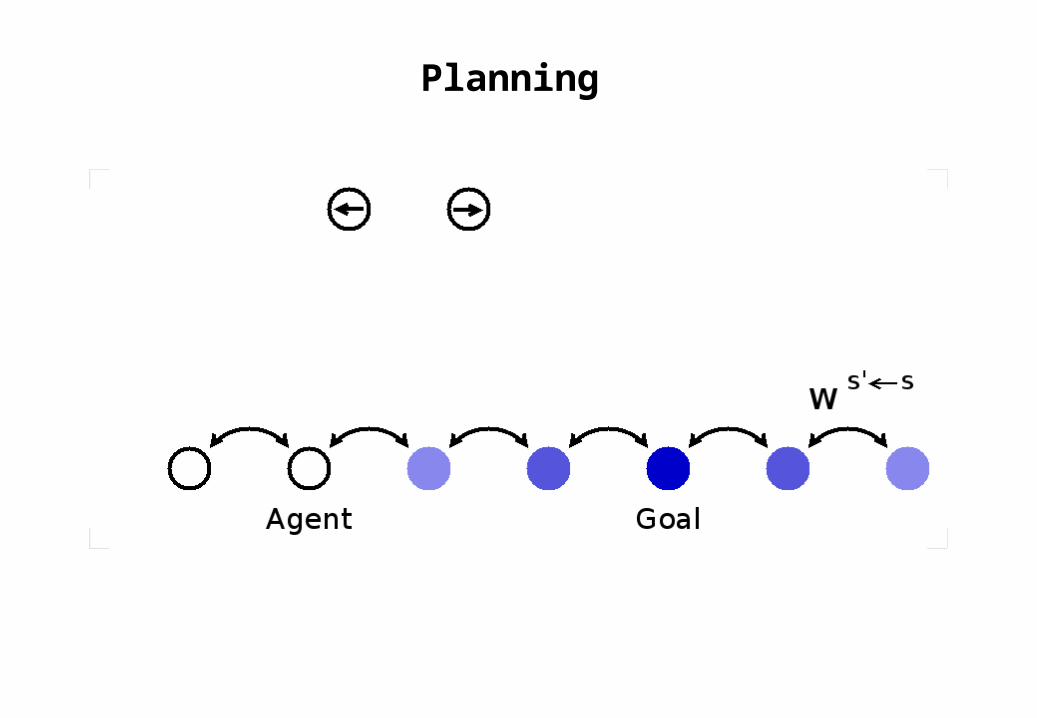
Planning

Planning

Planning
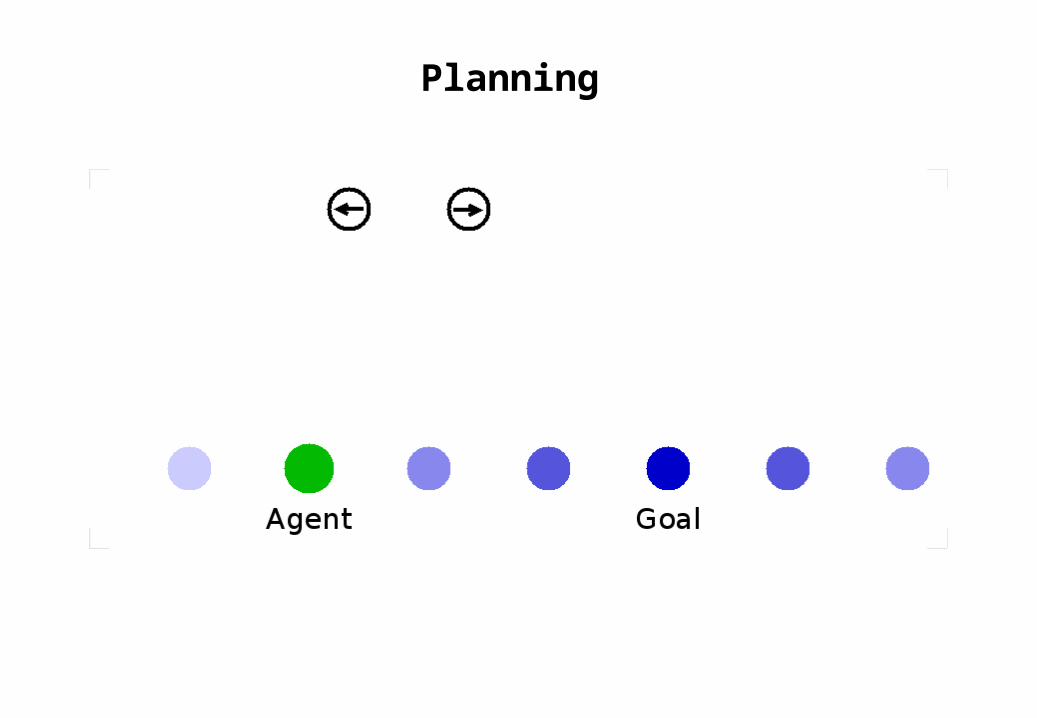
Planning
Planning

Planning

Planning
Planning

Planning

Planning
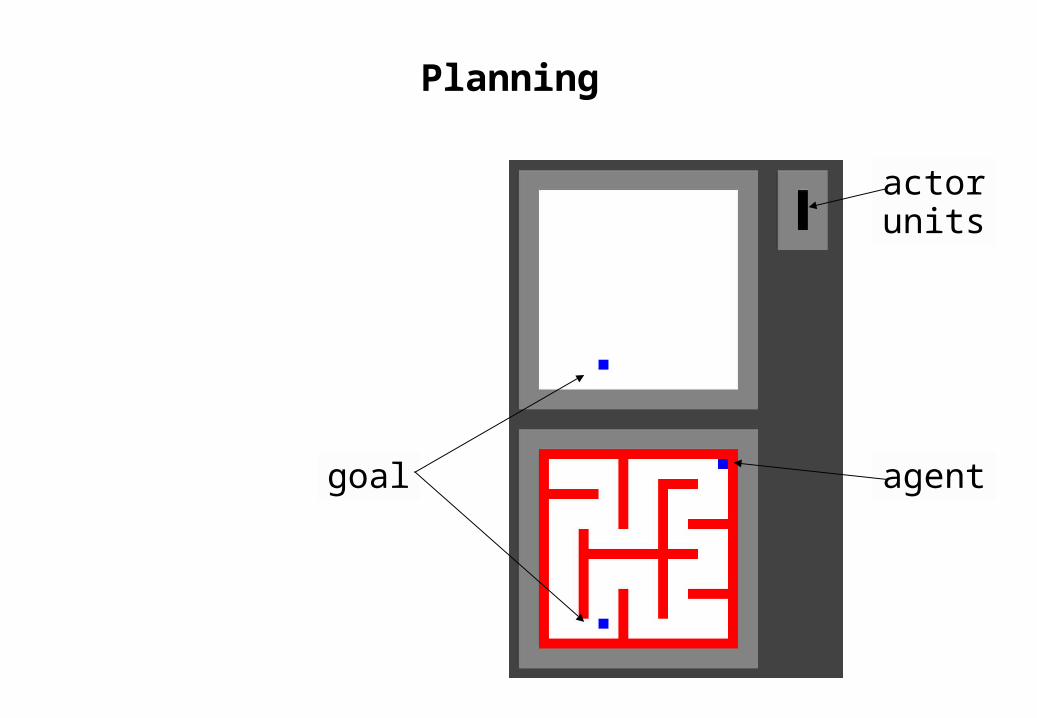
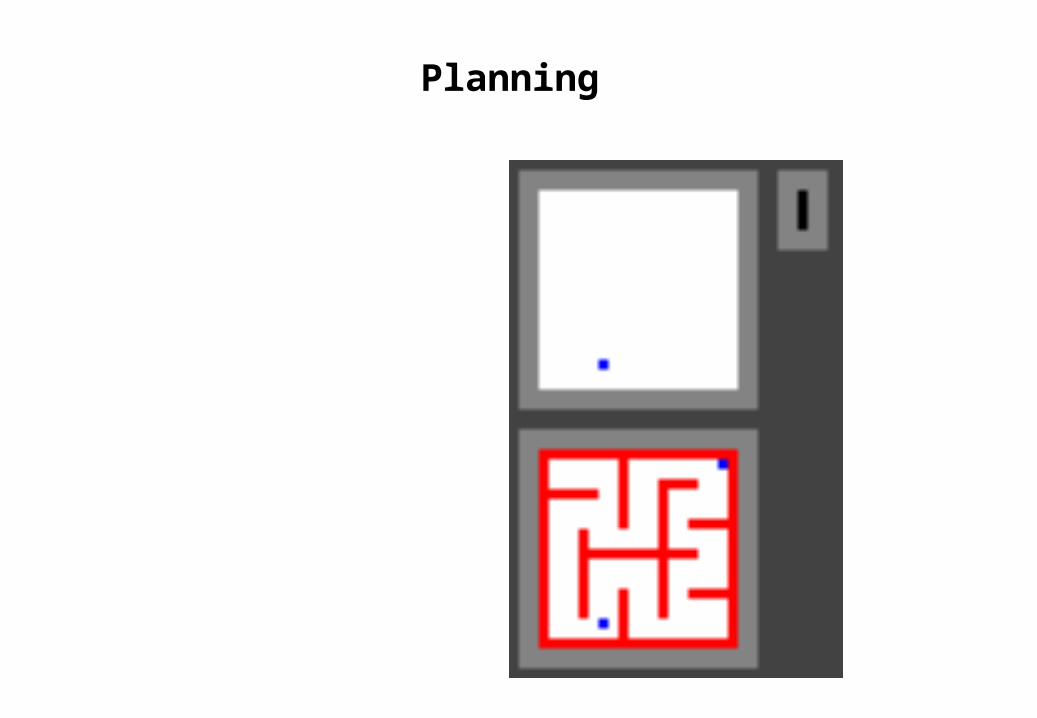
Planning
goal
actorunits
agent
Planning

Planning
Planning

Discussion
- reinforcement learning ... if no access to full state space
- previous work ... AI-like planners assume links between states
- noise ... wide “goal hills” will have flat slopes
- shortest path ... not taken; how to define?
- biological plausibility ... Sigma-Pi neurons; winner-take-all
- to do: embedding ... learn state space from sensor input
- to do: embedding ... let the goal be assigned naturally
- to do: embedding ... hand-designed planning phases

Acknowledgments
Collaborators:
Jochen Triesch FIAS J-W-Goethe University Frankfurt
Stefan Wermter University of Sunderland
Mark Elshaw University of Sheffield