from pos tagging to question answering: state-of-the...
TRANSCRIPT

From POS tagging to question answering: State-of-the-art NLP results from
simple deep learning models
Christopher ManningStanford University
@chrmanning❀@stanfordnlpDL4NLP summer school 2017

I am a student <EOS> Je suis étudiant
Je suis étudiant <EOS>
1. RNN encoder-decoder networks
-0.10.3
-0.1-0.70.1
0.2 0.6 -0.1 -0.7 0.1
0.2 0.6 -0.1 -0.7 0.1
0.2 0.6 -0.1 -0.7 0.1
0.2-0.3-0.1-0.40.2
0.2 0.4 0.1 -0.5 -0.2
0.4 -0.2 -0.3 -0.4 -0.2
0.2 0.6 -0.1 -0.7 0.1
Encoder Decoder
ht = tanh(W[xt] + Uht–1 + b)
0.00.00.00.00.0
0.30.5
-0.20.1
-0.1
W
U

Gated Recurrent Unit[Cho et al., EMNLP2014; Chung, Gulcehre, Cho, Bengio, DLUFL2014]
Long Short-Term Memory [Hochreiter & Schmidhuber, NC1999; Gers, Thesis2001]
Gated Recurrent Units ≈ “LSTMs”
ht = ut � ht + (1� ut)� ht�1
h = tanh(W [xt] + U(rt � ht�1) + b)
ut = �(Wu [xt] + Uuht�1 + bu)
rt = �(Wr [xt] + Urht�1 + br)
h
t
= o
t
� tanh(ct
)
c
t
= f
t
� c
t�1 + i
t
� c
t
c
t
= tanh(Wc
[xt
] + U
c
h
t�1 + b
c
)
o
t
= �(Wo
[xt
] + U
o
h
t�1 + b
o
)
i
t
= �(Wi
[xt
] + U
i
h
t�1 + b
i
)
f
t
= �(Wf
[xt
] + U
f
h
t�1 + b
f
)
Equations of the two most widely used gated recurrent units
Basic update to memory cell (GRU h = LSTM c) is via a standard neural net layer
ht = tanh(W [xt] + U(rt � ht�1) + b)

Gated Recurrent Unit[Cho et al., EMNLP2014; Chung, Gulcehre, Cho, Bengio, DLUFL2014]
Long Short-Term Memory [Hochreiter & Schmidhuber, NC1999; Gers, Thesis2001]
Gated Recurrent Units ≈ “LSTMs”
ht = ut � ht + (1� ut)� ht�1
h = tanh(W [xt] + U(rt � ht�1) + b)
ut = �(Wu [xt] + Uuht�1 + bu)
rt = �(Wr [xt] + Urht�1 + br)
h
t
= o
t
� tanh(ct
)
c
t
= f
t
� c
t�1 + i
t
� c
t
c
t
= tanh(Wc
[xt
] + U
c
h
t�1 + b
c
)
o
t
= �(Wo
[xt
] + U
o
h
t�1 + b
o
)
i
t
= �(Wi
[xt
] + U
i
h
t�1 + b
i
)
f
t
= �(Wf
[xt
] + U
f
h
t�1 + b
f
)
Equations of the two most widely used gated recurrent units
Summing previous & new candidate hidden states gives direct gradient flow & more effective memory
ht = tanh(W [xt] + U(rt � ht�1) + b)

Gated Recurrent Unit[Cho et al., EMNLP2014; Chung, Gulcehre, Cho, Bengio, DLUFL2014]
Long Short-Term Memory [Hochreiter & Schmidhuber, NC1999; Gers, Thesis2001]
Gated Recurrent Units ≈ “LSTMs”
ht = ut � ht + (1� ut)� ht�1
h = tanh(W [xt] + U(rt � ht�1) + b)
ut = �(Wu [xt] + Uuht�1 + bu)
rt = �(Wr [xt] + Urht�1 + br)
h
t
= o
t
� tanh(ct
)
c
t
= f
t
� c
t�1 + i
t
� c
t
c
t
= tanh(Wc
[xt
] + U
c
h
t�1 + b
c
)
o
t
= �(Wo
[xt
] + U
o
h
t�1 + b
o
)
i
t
= �(Wi
[xt
] + U
i
h
t�1 + b
i
)
f
t
= �(Wf
[xt
] + U
f
h
t�1 + b
f
)
Equations of the two most widely used gated recurrent units
Bernoulli variable “gates” control how much history is kept & input is attended to
ht = tanh(W [xt] + U(rt � ht�1) + b)

Die Proteste waren am Wochenende eskaliert <EOS> The protests escalated over the weekend
0.20.6
-0.1-0.70.1
0.4-0.60.2
-0.30.4
0.2-0.3-0.1-0.40.2
0.20.40.1
-0.5-0.2
0.4-0.2-0.3-0.4-0.2
0.20.6
-0.1-0.70.1
0.20.6
-0.1-0.70.1
0.20.6
-0.1-0.70.1
-0.10.3
-0.1-0.70.1
-0.20.60.10.30.1
-0.40.5
-0.50.40.1
0.20.6
-0.1-0.70.1
0.20.6
-0.1-0.70.1
0.2-0.2-0.10.10.1
0.20.6
-0.1-0.70.1
0.10.3
-0.1-0.70.1
0.20.6
-0.1-0.40.1
0.2-0.8-0.1-0.50.1
0.20.6
-0.1-0.70.1
-0.40.6
-0.1-0.70.1
0.20.6
-0.10.30.1
-0.10.6
-0.10.30.1
0.20.4
-0.10.20.1
0.30.6
-0.1-0.50.1
0.20.6
-0.1-0.70.1
0.2-0.1-0.1-0.70.1
0.10.30.1
-0.40.2
0.20.6
-0.1-0.70.1
0.40.40.3
-0.2-0.3
0.50.50.9
-0.3-0.2
0.20.6
-0.1-0.50.1
-0.10.6
-0.1-0.70.1
0.20.6
-0.1-0.70.1
0.30.6
-0.1-0.70.1
0.40.4
-0.1-0.70.1
-0.20.6
-0.1-0.70.1
-0.40.6
-0.1-0.70.1
-0.30.5
-0.1-0.70.1
0.20.6
-0.1-0.70.1
The protests escalated over the weekend <EOS>
An LSTM encoder-decoder MT net [Sutskever et al. 2014]
Encoder:Builds up sentence meaning
Source sentence
Translation generated
Feeding in last word
Decoder
Bottleneck

I am a student <EOS> Je suis étudiant
Je suis étudiant <EOS>
A BiLSTM encoder and LSTM-with-attention decoder [Luong et al. 2015]
-0.10.3
-0.1-0.70.1
0.2 0.6 -0.1 -0.7 0.1
0.2 0.6 -0.1 -0.7 0.1
0.2 0.6 -0.1 -0.7 0.1
0.2-0.3-0.1-0.40.2
0.2 0.4 0.1 -0.5 -0.2
0.4 -0.2 -0.3 -0.4 -0.2
0.2 0.6 -0.1 -0.7 0.1
Encoder Decoder
Bilinear attention

Progress in Machine Translation[Edinburgh En-De WMT newstest2013 Cased BLEU; NMT 2015 from U. Montréal]
0
5
10
15
20
25
2013 2014 2015 2016
Phrase-based SMT Syntax-based SMT Neural MT
From [Sennrich 2016, http://www.meta-net.eu/events/meta-forum-2016/slides/09_sennrich.pdf]

IWSLT 2015, TED talk MT, English-German [Luong and Manning 2015]
9
16.16
21.84 22.67 23.42
28.18
0
5
10
15
20
25
30
Stanford Edinburgh Karlsruhe Heidelberg PJAIT
HTER (HE SET)
26%

Four big wins of Neural MT1. End-to-end training
All parameters are simultaneously optimized to minimize a loss function on the network’s output
2. Distributed representations share strengthBetter exploitation of word and phrase similarities
3. Better exploitation of contextNMT can use a much bigger context – both source and partial target text – to translate more accurately
4. More fluent text generationDeep learning text generation is much higher quality
10

Enormous success!
From first modern research attempts in 2014, neural MT has seen rapid and significant success
2017: Almost everyone is now using Neural MT in production, at least for many language pairs
11

The BiLSTM Hegemony
To a first approximation,the de facto consensus in NLP in 2017 is
that no matter what the task,you throw a BiLSTM at it, with
attention if you need information flow, and get great performance!
12

Simplicity
We still understand badly how to make good neural networks
So, it is scientifically better to see how far we can get with
very simple models
13

Talk outline
1. The BiLSTM (with attention) hegemony2. Question answering: The Stanford Attentive Reader3. Effective human-machine dialog: copying & memory4. State-of-the-art dependency parsing5. More complex futures
14

A Thorough Examination of the CNN/ Daily Mail Reading Comprehension Task
[Chen, Bolton, & Manning 2016]
• Demonstrated a simple, highly successful architecture for question answering and reading comprehension
• Known as the Stanford Attentive Reader
15
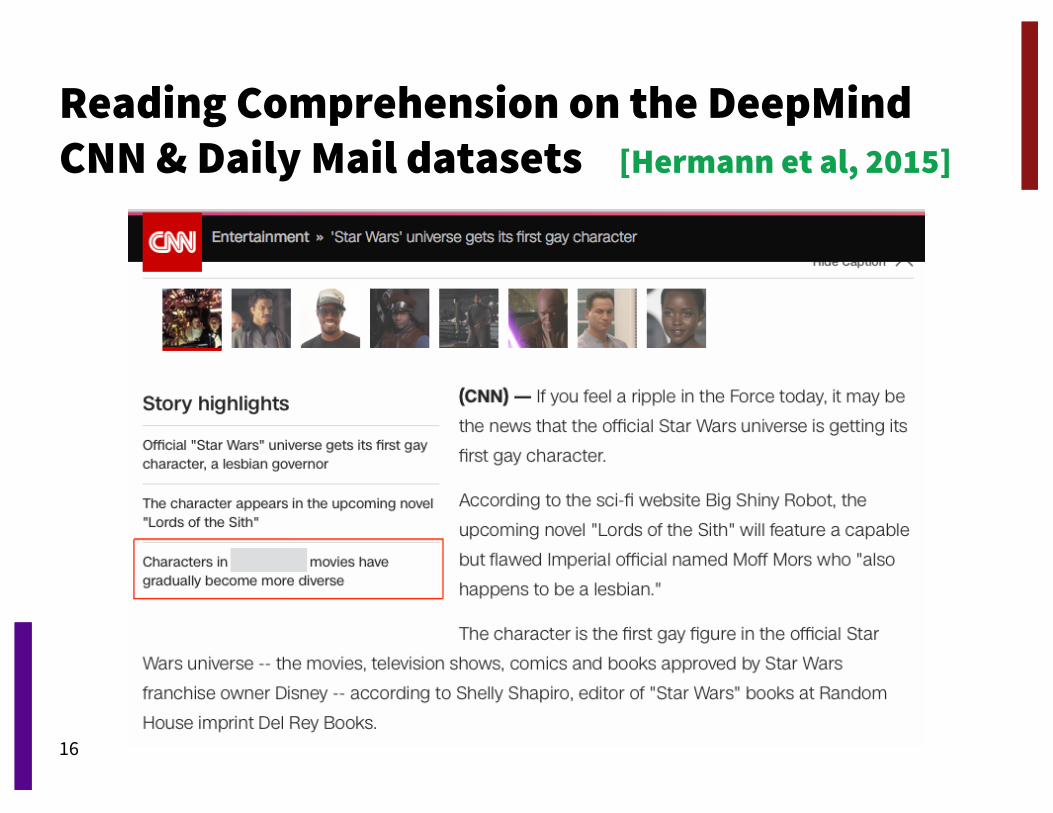
Reading Comprehension on the DeepMind CNN & Daily Mail datasets [Hermann et al, 2015]
16
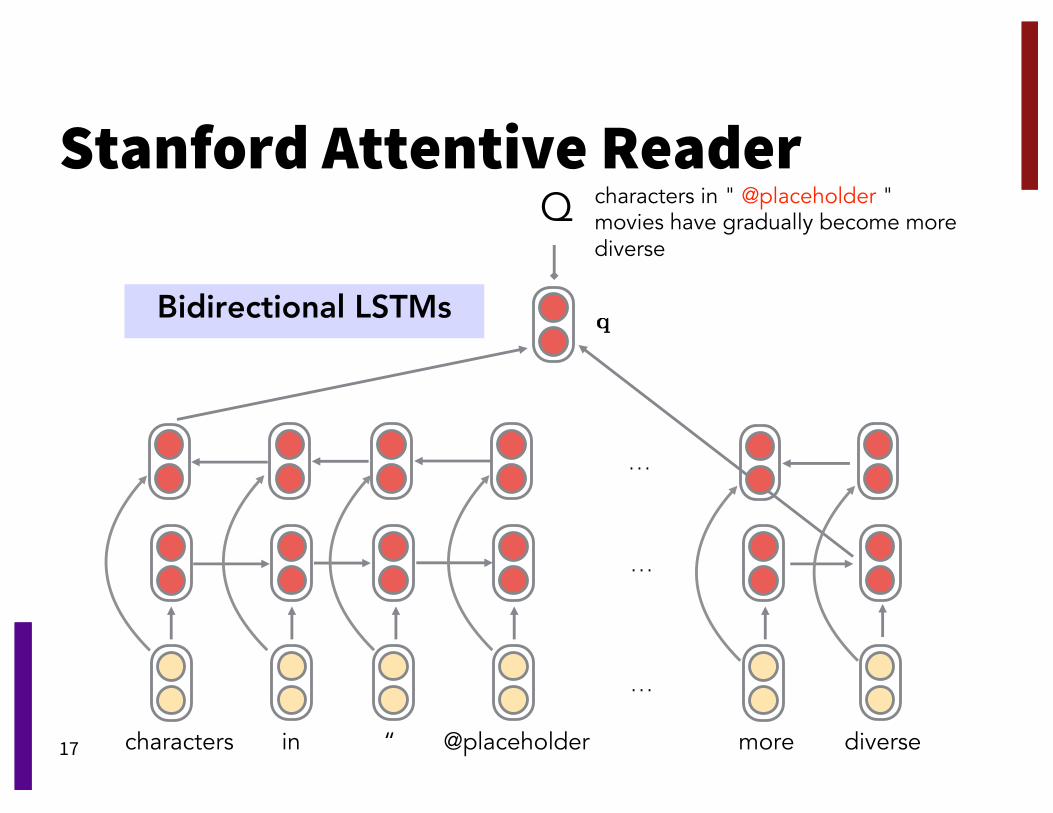
Stanford Attentive Reader
17
characters in " @placeholder " movies have gradually become more diverse
Q
Bidirectional LSTMs
characters in “ @placeholder more diverse
…
…
…

Stanford Attentive Reader
18
Q
… ……P
Bidirectional LSTMs
entity6A
characters in " @placeholder " movies have gradually become more diverse
Attention

Stanford Attentive Reader
A very simple model• Learned word embeddings feed into• Bi-directional shallow 128d GRUs for passage and question• Question representation used for soft attention over
passage with same simple bilinear attention function
• A final softmax layer predicts the answer entity• SGD, dropout (0.2), batch size = 32, hidden size = 128, …
19

20
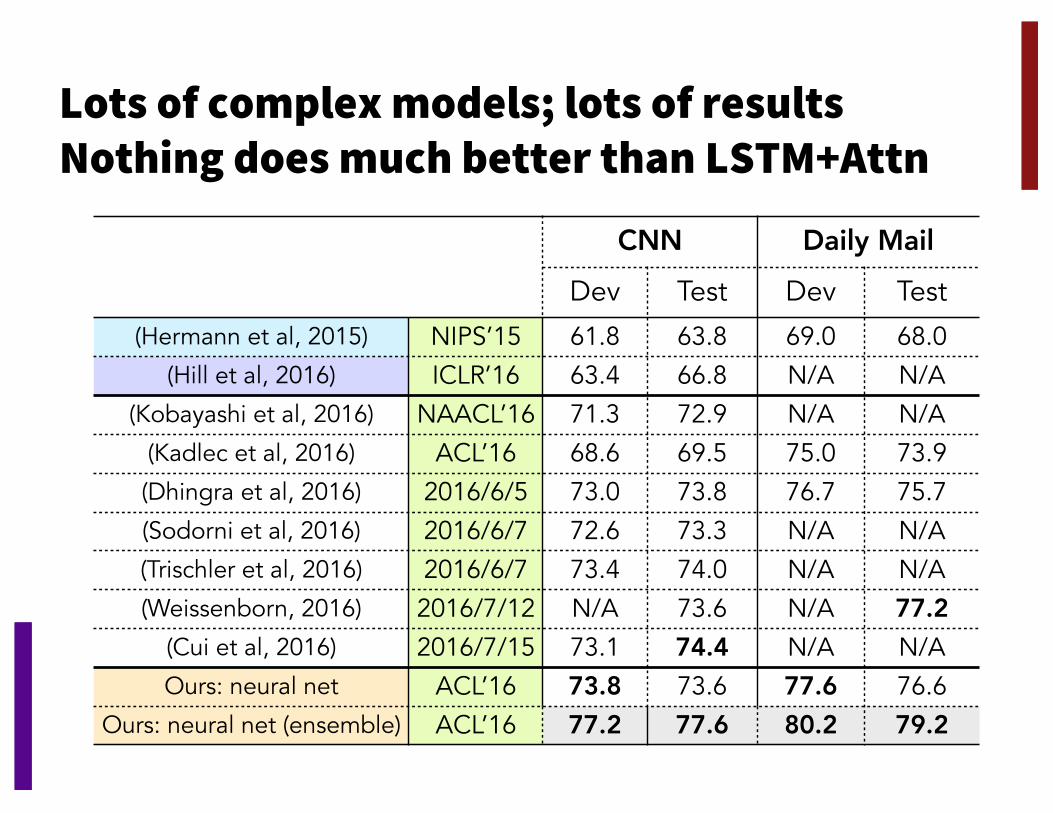
Lots of complex models; lots of resultsNothing does much better than LSTM+Attn
CNN Daily Mail
Dev Test Dev Test
(Hermann et al, 2015) NIPS’15 61.8 63.8 69.0 68.0(Hill et al, 2016) ICLR’16 63.4 66.8 N/A N/A
(Kobayashi et al, 2016) NAACL’16 71.3 72.9 N/A N/A(Kadlec et al, 2016) ACL’16 68.6 69.5 75.0 73.9(Dhingra et al, 2016) 2016/6/5 73.0 73.8 76.7 75.7(Sodorni et al, 2016) 2016/6/7 72.6 73.3 N/A N/A(Trischler et al, 2016) 2016/6/7 73.4 74.0 N/A N/A(Weissenborn, 2016) 2016/7/12 N/A 73.6 N/A 77.2
(Cui et al, 2016) 2016/7/15 73.1 74.4 N/A N/AOurs: neural net ACL’16 73.8 73.6 77.6 76.6
Ours: neural net (ensemble) ACL’16 77.2 77.6 80.2 79.2

2. DrQA: Open-domain Question Answering(Chen, et al. ACL 2017) https://arxiv.org/abs/1704.00051
22

WebQuestions (Berant et al, 2013)Q: What part of the atom did Chadwick discover? A: neutron
TREC Q: What U.S. state’s motto is “Live free or Die”? A: New Hampshire
WikiMovies (Miller et al, 2016)Q: Who wrote the film Gigli? A: Martin Brest
SQuADQ: How many of Warsaw's inhabitants spoke Polish in 1933? A: 833,500
Open-domain Question Answering
23

DocumentReader
Document Retriever
833,500
Q: How many of Warsaw's inhabitants spoke Polish in 1933?
24

Document Retriever
25
70-86% of questions we have that the answer segment appears in the top 5 articles
Traditional tf.idf
inverted index +
efficient bigram
hash

Stanford Attentive Reader++
26
Who did Genghis Khan unite before hebegan conquering the rest of Eurasia?Q
… ……P
Bidirectional LSTMs
Attention
predict start token
Attention
predict end token

SQuAD Results (single model)
27
F1
Logistic regression 51.0
Fine-Grained Gating (Carnegie Mellon U) 73.3
Match-LSTM (Singapore Management U) 73.7
DCN (Salesforce) 75.9
BiDAF (UW & Allen Institute) 77.3
Multi-Perspective Matching (IBM) 78.7
ReasoNet (MSR Redmond) 79.4
DrQA (Chen et al. 2017) 79.4
r-net (MSR Asia) [Wang et al., ACL 2017] 79.7
r-net (MSR Asia) [Jul 2017] 83.5
Human performance 91.2

Demo
29

Demo
30

Demo
31

3. Effective human-machine dialog[Eric and Manning EACL 2017, Eric and Manning SIGDIAL 2017]
Voice interfaces are starting to appear everywhere
But are often frustrating to use!How can we get them to understand us the way we talk?

Hi, what can I help you with?
Cool! Where is it?
Hmm … actually any froyo around?
I’m feeling likeItalian
There are 3 italianrestaurants nearby
No froyo, sadly, but there is a gelato cafe

A copy-augmented sequence-to-sequence + attention model[Eric and Manning EACL 2017]

New: Copy-Augmented Seq2Seq
• Add copy mechanism as an option to generator• A second attention distribution can copy a context word
• Known to improve machine translation, text summarization
• Give the system extra information about the entity type of items (restaurant, address, etc.)

Experiment
• Data: • Dialogue State Tracking Challenge 2 (DSTC2)• Restaurant Reservation Domain; 1600 Dialogues
• Train:• Seq2seq model predicts system from Wizard-of-Oz
Model Per-response Acc.Memory Net (Bordes & Weston 2016) 41.1Our model (Copy + EntType) 48.0QRN (Salesforce) 50.7

System output: seq2seq plus copyingUser: cheap restaurant in east part of town System: api call r cuisine east cheap User: <silence>System: the missing sock is a nice place in the east of town and the prices are cheap User: address System: sure, the missing sock is on [Finders Place, Newmarket Rd] User: phone number System: the phone number of the missing sock is [1223 812660]User: thank you good byeSystem: you are welcome
But only knowledge is what LSTM learned during training!

What time is mydoctor appt. ?
Your appt. is at 3pm on Thursday
Natural Language Understanding
Knowledge Base
Natural language generation
Background

Background
What time is mydoctor appt. ?
Your appt. is at 3pm on Thursday

Incorporating the KB

Representing the KBEvent Time Date Party Agenda
dinner 8pm the 13th Ana
Subject Relation Object
dinner time 8pm
dinner date the 13th
dinner party Ana
dinner agenda
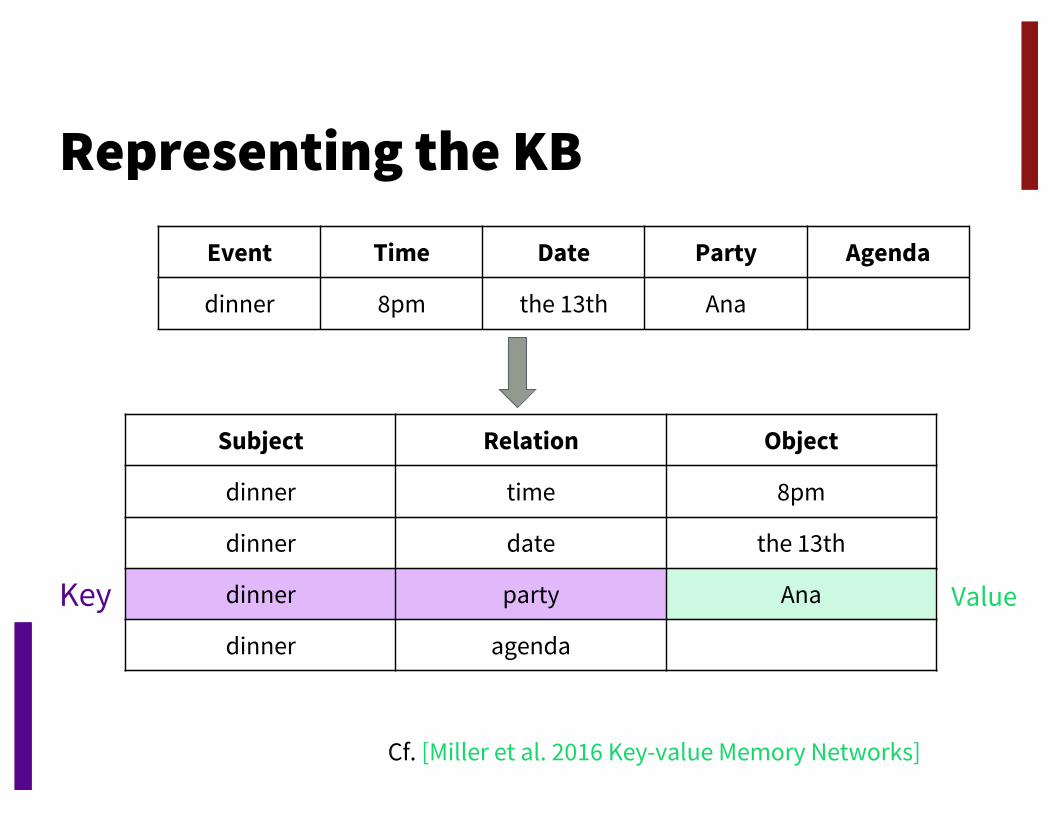
Representing the KBEvent Time Date Party Agenda
dinner 8pm the 13th Ana
Subject Relation Object
dinner time 8pm
dinner date the 13th
dinner party Ana
dinner agenda
Key Value
Cf. [Miller et al. 2016 Key-value Memory Networks]

Putting it Together
Copy
GenerateMemory retrieval

Automatic evaluation scoresData• 3000 dialogues collected
from 3 domains: calendar, weather, navigation
Baselines• Rule-based system
• Intent and state tracking to KB• Template-based NLG
• Copy-augmented Seq2Seq• Encoder-decoder LSTM• Attention model• Attention-based hard-copy
Model BLEU Entity F1
Rule-based 6.6 43.8Attn Seq2Seq 10.2 30.0KV Retr. Net 13.2 48.2Human 13.5 60.7
44

• 120 distinct scenarios, 3 dialogue domains• AMT workers paired real-time with either our
model or another worker• Assess for: Fluency, Cooperative, Human-like (1–5)
45
Human evaluation
Model Fluency Cooperative Human-like
Rule-based 3.2 3.4 2.9Copy net 2.3 2.4 2.0KV Retr. Net 3.4 3.4 3.1Human 4.0 4.0 4.0

Sample Dialogue
POI Category Traffic Info
Civic Center Parking garage
Car collision
Valero Gas station Road block
Webster Garage
Parking garage
Car collision
Trader Joes Grocery Store
Heavy
Mandarin Roots.
Chinese rest.
Moderate
Driver: I am looking for a gas station near me with the shortest route from me.
Car: The closest gas station is valero but, but there is a road block nearby.
Driver: What is the next nearest gas station?
Car: Valero is the only nearby gas station that I can find
Driver: Thanks
Car: Here to serve

Dialogue using sequence-to-sequence models
• Still not commercial quality• Currently too small domain and fragile• Commercial systems are still using simple machine learning
for understanding user queries• Followed by “templated generation” (each generated
sentence is hand-written)• Tiny exception: Google Auto-reply
• Nonetheless, a very exciting research direction!!• Aim is to give not only good task completion but human-like
naturalness and friendliness

Deep Biaffine Attention for Neural Dependency ParsingDozat and Manning (ICLR 2017, CoNLL 2017)
A simple, carefully tuned graph-based dependencyparser that gives the state of the art in parsing performance.

Dependency parsingSentence structure is shown by indicating for each word what it is a modifier or argument of, via typed dependency edges
A dependency tree can be used to guide natural language understanding – it’s almost a semantic network

Methods of Dependency Parsing
1. Dynamic programmingEisner (1996) gives a clever O(n3) algorithm, by producing parse items with heads at the ends rather than in the middle
2. Graph algorithmsEach edge is scored – McDonald et al.’s (2005) MSTParserscored dependencies independently using an ML classifier You create a Minimum Spanning Tree for a sentence
3. “Transition-based dependency parsing”Maintain stack and buffer; make greedy choices of shift/ reduce transition actions (e.g., MaltParser, Nivre et al. 2004)

Graph-based Parsing
Arc probabilityHead
root Casey hugged Kim
Dependent
Casey 0.10 − 0.85 0.05
hugged 0.80 0.15 − 0.05
Kim 0.05 0.05 0.90 −
Score putting an arc between each word pair (+ root as head)
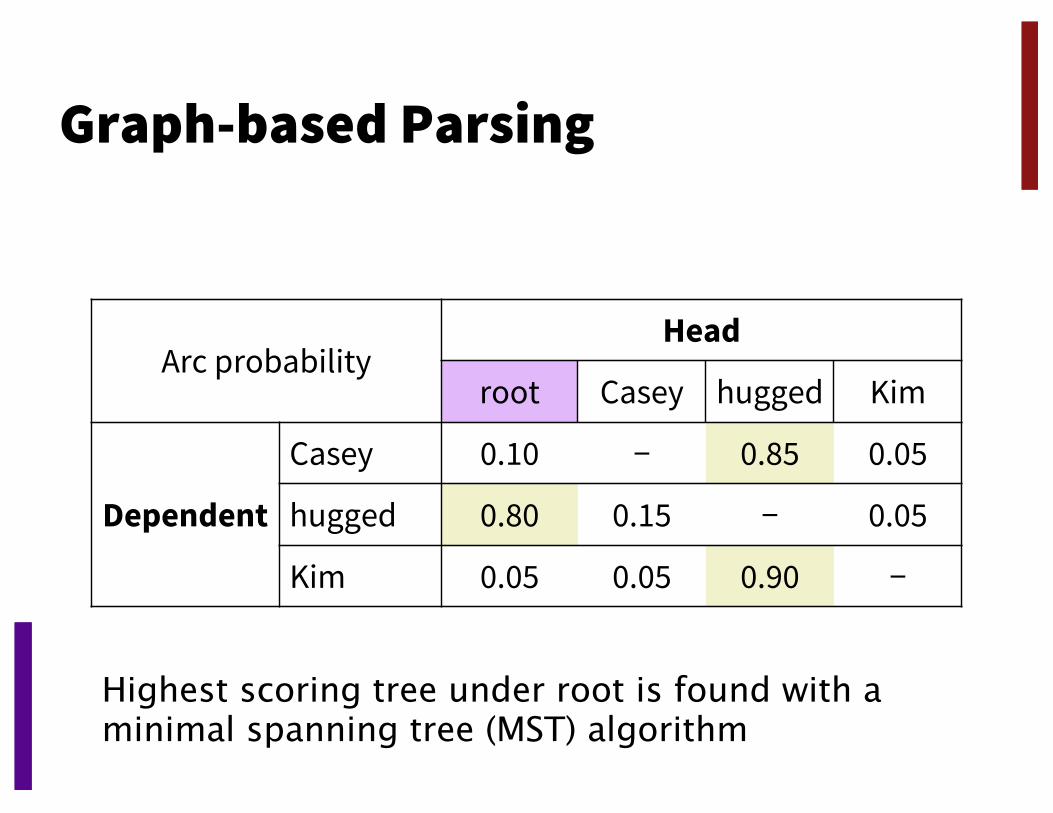
Graph-based Parsing
Arc probabilityHead
root Casey hugged Kim
Dependent
Casey 0.10 − 0.85 0.05
hugged 0.80 0.15 − 0.05
Kim 0.05 0.05 0.90 −
Highest scoring tree under root is found with a minimal spanning tree (MST) algorithm

Deep Biaffine Attention for Neural Dependency ParsingDozat and Manning (ICLR 2017)
• We use an LSTM recurrent neural network with word/tag embedding vectors as input as parsing input
• Similar to Kiperwasser & Goldberg (2016), however:• Their feedforward scorer/classifier is somewhat unintuitive
and needlessly complex• Their Representations don’t distinguish heads/dependents• Their model is relatively small and unregularized• Maybe they just didn’t tune their model very well?

Our Approach
A similar, more carefully tuned, parser with a simpler and more intuitive scorer/classifier• Idea 1: biaffine classifiers
• Arguably simpler than MLPs• More natural in this context
• Idea 2: MLP layers produce head and dependent representations between LSTM and biaffine classifier• Applying a nonlinearity helps the network remove
irrelevant information, helping to avoid overfitting• Reducing dimensionality gives speed without reducing
representational capacity of the recurrent network

Dozat and Manning (2017) base encoding architecture
55

Unlabeled arc parser
• Bidirectional LSTM over word/tag embeddings• Two separate FC ReLU layers
• One representing each token as a dependent trying to find (attend to) its head
• One representing each token as a head trying to find (be attended to by) its dependents
56

Dependencies: Biaffine Self-Attention
• H is the stacked matrix of LSTM vectors•W is the weight matrix• S represents the n x n matrix of arc scores
H(arc-head) ⊕ 1 W ⊕ b H(arc-dep) S

Graph-based Parsing
Arc probabilityHead
root Casey hugged Kim
Dependent
Casey 0.10 − 0.85 0.05
hugged 0.80 0.15 − 0.05
Kim 0.05 0.05 0.90 −

Our Approach: Biaffine models
• Typical fixed-class classification: given input vector x, do affine transformation to get a vector of scores
s = Wx + b• b provides the prior probability of each class
P(class = c)• Wx provides the likelihood of each class given the
input, P(class = c | x)• We need to extend this to variable-class classification• We don’t know how many words in a sentence• We don’t know what those words will be

Our Approach: Biaffine models
• Given words i and j with LSTM vectors ri and rj, what function captures the prior probability P(headi = j | rj) and likelihood P(headi = j | ri, rj) in the same way?• Answer: a biaffine transformation
sij = rjTWri + rj
Tw• rj
Tw provides the prior probability P(headi = j | rj)• Function words never take dependents; verbs
frequently do• rj
TWri provides the likelihood P(headi = j | ri,rj)

Labeler: LSTM
• Take the topmost BiLSTM vectors used for the unlabeled parser
• Two more separate FC ReLU layers: • One representing each token as a dependent trying to
determine its label• One representing each token as a head trying to determine
its dependents’ labels
61

Labeler: Classifier
• Biaffine layer scores possible relations for each best-head/dependent pair
• Train with softmax cross-entropy, added to the loss of the unlabeled parser
62

Initial evaluation
• Penn TreeBank converted to Stanford Dependencies, version 3.3.0• Predicted POS tags, ignoring punctuation
• Evaluation metrics• Unlabeled attachment score (UAS)• Labeled attachment score (LAS)

Parsing performance on PTB WSJ SD 3.3
Type Feat Model LASTransition-based
symb MaltParser (Nivre et al. 2006) 87.2neur Chen & Manning 2014 89.7neur Weiss et al. 2014 92.05neur Andor et al. 2016 92.79
Graph-based symb MSTParser (McDonald et al. 2005) 88.1symb TurboParser (Martins et al. 2013) 89.6neur Kipperwasser and Goldberg 2016 91.9neur Dozat and Manning 2017 94.08
64

Universal Dependencies
Part-of-speech tags
Morphological features
Dependency relations
En katt jagar rattor och moss
det nsubj conj
dobj
conj
En kat jager rotter og mus
nsubj
? dobj cc conj
A cat chases rats and mice
det nsubj dobj cc
conj
Toutefois , les filles adorent les desserts .
ADV PUNCT DET NOUN VERB DET NOUN PUNCT
Definite=Def Gender=Fem Number=Plur Definite=Def Gender=MascNumber=Plur Number=Plur Person=3 Number=Plur Number=Plur
Tense=Pres
advmod
punct
det nsubj
root
det
dobj
punct
1
http://universaldependencies.org

UD v2.0 parsing was a shared task at CoNLL 2017
Universal Guidelines Group
Release and Documentation Task ForceChief Cat Herder

Part-of-Speech Tagger: LSTM
• A possible weakness of our system was POS tagging• Can parsing be improved with better tagger?• Uses a BiLSTM (distinct from parser BiLSTM!) • Two separate FC ReLU layers:
• One for (universal) UPOS tags• One for (language particular) XPOS tags
68

Tagger: Classifiers
• Affine layers to score possible tags for each word
• Train jointly by adding softmax cross-entropy • When using in the main parser, add UPOS and XPOS
embeddings together (eltwise)
69
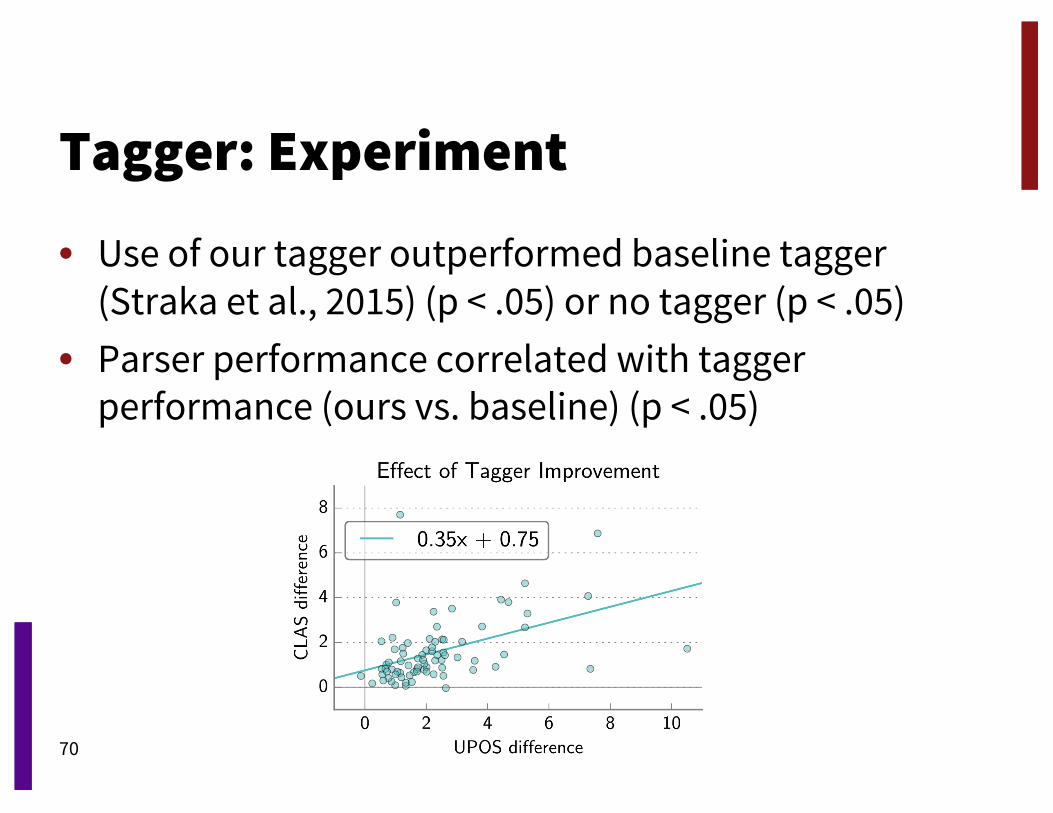
Tagger: Experiment
• Use of our tagger outperformed baseline tagger (Straka et al., 2015) (p < .05) or no tagger (p < .05)
• Parser performance correlated with tagger performance (ours vs. baseline) (p < .05)
70

Character-level model: Motivation• Many languages have complex morphology
• Grammatical functions indicated more by word form than relative location
• Rare words with highly predictive suffixes won’t be attested in the frequent word embedding matrix
• Extreme sparsity may yield low-quality pretrainedembeddings
• Idea: Compose word embeddings orthographically with a character-based embedding model
• Question: Does this improve accuracy on inflectionally rich languages?
71

Character model: LSTM
• Unidirectional LSTM over character embeddings Concatenate two sources of information:
• Linear attention over top hidden states (Cao and Rei, 2016) Final cell state (Ballesteros et al., 2015)
72

Character model: Embedding
• Linearly transform to the desired size
• When using in the parser/tagger, add with pretrainedand frequent-token embeddings (eltwise)
73

Character model: Experiment
• Systems trained with a character model outperformed models trained without (p < .05)
• Improvement correlated with morphological complexity (p < .05)
74

Details: Dropout• Lots of dropout: keep_prob is .67 throughout the whole
network• Embedding dropout
• Drop token/tag embeddings independently• When one is dropped, the other is scaled up to compensate • When both are dropped, replace with zeros• Seems to work better than random vector/UNK replacement
• Same-mask recurrent dropout (Gal and Ghahramani, 2016)• Drop input connections and recurrent connections• Drop the same connections at each recurrent timestep• Seems to work better than traditional dropout/zoneout (Krueger et al.,
2017) 75

Optimizer: Adam
• Adam optimizer (Kingma and Ba 2015) with β1 = β2 = .9 • For embedding matrices, only decay m and v
accumulators for tokens used in the minibatch• I.e., for words that are seen in the minibatch, we apply
Adam’s accumulator update rule: mt = β1mt−1 + (1 − β1)gt
vt = β2vt−1 + (1 − β2)gt2
• But for words that aren’t, we don’t update the accumulators, preventing uncommon words from decaying down to zero
• Note: this is not the behavior of most DL toolkits! 76

Hyperparameters
• Initialization • Preference for initializing to zero wherever possible• Bias terms • Final linear layers (character model, output layers) • Word/POS embeddings (other than pretrained)
• Otherwise, we use orthonormal initialization (Saxe et al., 2014)
• Recurrent Cells • LSTMs vastly outperformed GRUs and slightly outperformed
coupled input-forget LSTMs (Greff et al., 2016) • Adding a forget bias hurts performance 77
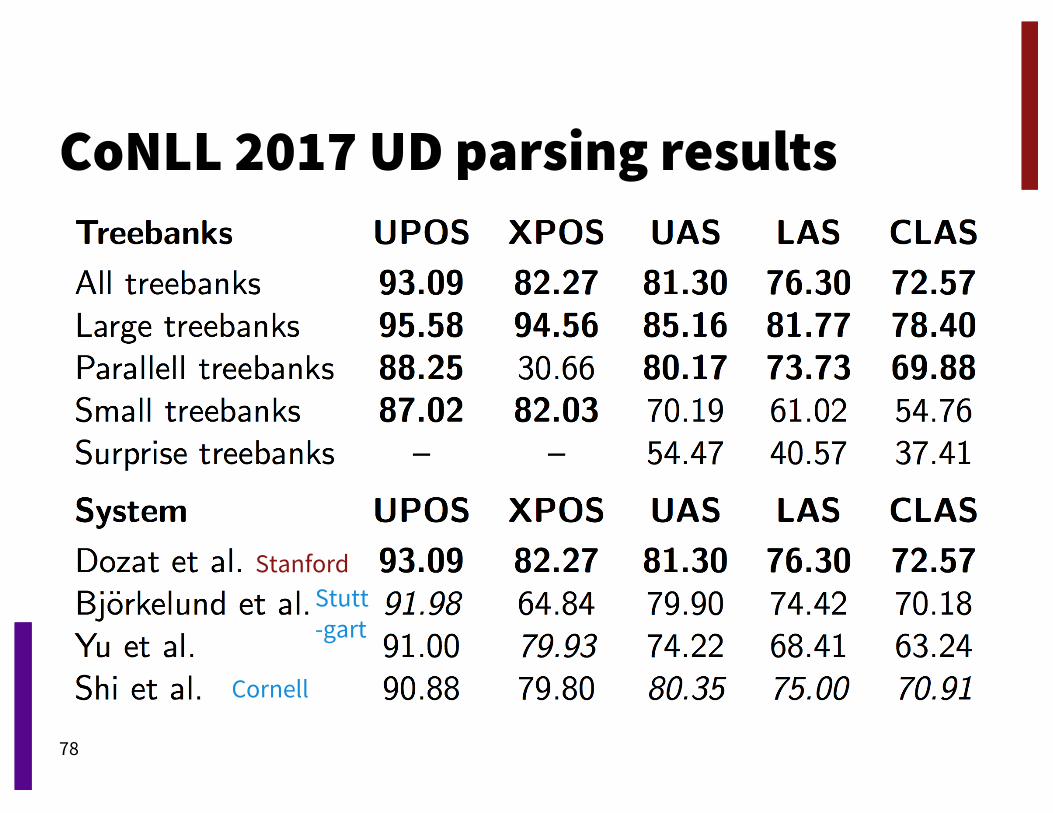
CoNLL 2017 UD parsing results
78
Stanford
Cornell
Stutt-gart

Nonprojectivity
• Our system outperforms UDPipe v1.1 (transition-based) by a larger margin on treebanks with many crossing arcs (p < .05)
• Stronger correlation for treebanks with more crossing arcs in the test set than in the training set (p < .05)
79

Good, simple models can work really well!
Is there anything more?
80

Is there anything more?
• I believe the answer is yes!• Structured memories
• Structured sentences
• But we’re still working to prove out those ideas81

Envoi
• Deep learning – distributed representations, end-to-end training, and richer modeling of state – has brought great gains to NLP
• At the moment, neural sequence models with attention are often the sweet spot of good performance, simplicity and speed
• However, I do believe that we do need more structure and modularity for language, memory, knowledge, and planning; it’ll just take some time

From POS tagging to question answering: State-of-the-art NLP results from
simple deep learning models
Christopher ManningStanford University
@chrmanning❀@stanfordnlpDL4NLP summer school 2017