gcma: guaranteed contiguous memory allocator
TRANSCRIPT

GCMA: Guaranteed Contiguous Memory AllocatorSeongJae Park1, Minchan Kim2, Heon Y. Yeom1
Seoul National University1
LG Electronics2

This work by SeongJae Park is licensed under the Creative Commons Attribution-ShareAlike 3.0 Unported License. To
view a copy of this license, visithttp://creativecommons.org/licenses/by-sa/3.0/.

These slides were presented duringEWiLi 2015 at Amsterdam
(http://syst.univ-brest.fr/ewili2015/)

TL; DR
● Contiguous Memory Allocation is a big problem of embedded system● Current solutions have weakness
○ Too expensive for embedded system, or○ Waste memory space, or○ Too slow and even fail to allocate
● GCMA, our new solution, guarantees○ Fast latency of contiguous memory allocation○ Success of contiguous memory allocation○ and Reasonable memory utilization
● That’s it! ;)

Who Wants Physically Contiguous Memory?
● Virtual Memory avoids the fragmentation problem○ Applications use virtual address; virtual address can be mapped to any physical address○ MMU do mapping of virtual address to physical address
● In Linux, it uses demand paging and reclaim
Physical MemoryApplication MMUCPU
Logical address Physical address
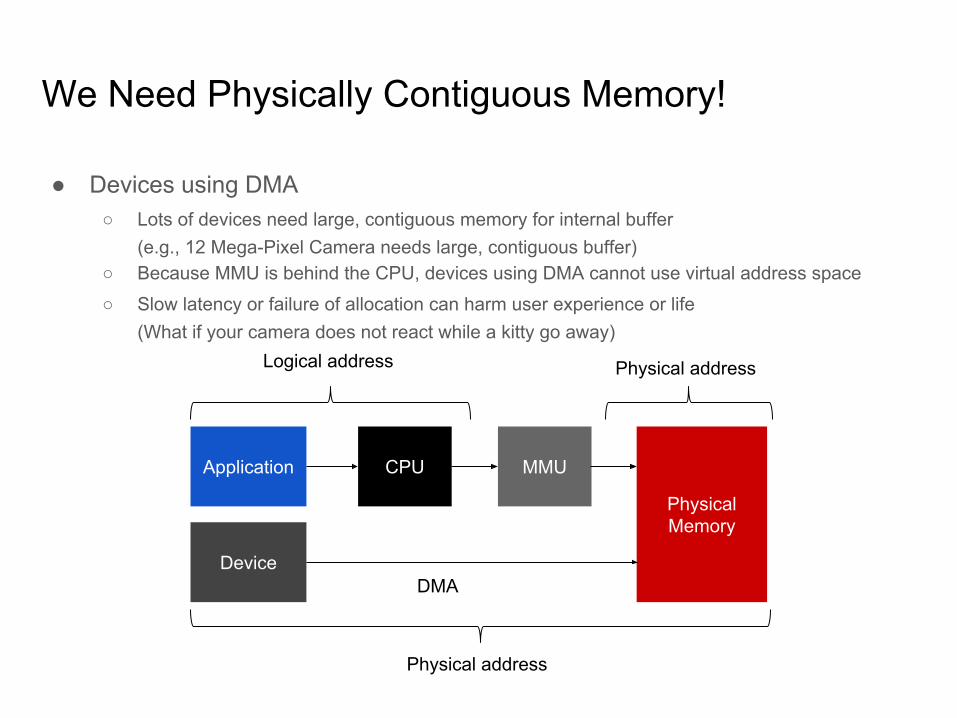
We Need Physically Contiguous Memory!
● Devices using DMA○ Lots of devices need large, contiguous memory for internal buffer
(e.g., 12 Mega-Pixel Camera needs large, contiguous buffer)○ Because MMU is behind the CPU, devices using DMA cannot use virtual address space
○ Slow latency or failure of allocation can harm user experience or life(What if your camera does not react while a kitty go away)
Physical Memory
Application MMUCPU
Logical address Physical address
DeviceDMA
Physical address

We Need Physically Contiguous Memory!
● Devices using DMA○ Lots of devices need large, contiguous memory for internal buffer
(e.g., 12 Mega-Pixel Camera needs large, contiguous buffer)○ Because MMU is behind the CPU, devices using DMA can not use virtual address space
○ Slow latency or failure of allocation can harm user experience or life(What if your camera does not react while a kitty go away)
● Huge page, System internal buffer○ Huge pages can enhance system performance by minimizing TLB miss
○ System needs contiguous memory for internal usagee.g., struct page *alloc_pages(unsigned int flags, unsigned int order);
NOTE: This research focuses on device case for embedded system, though
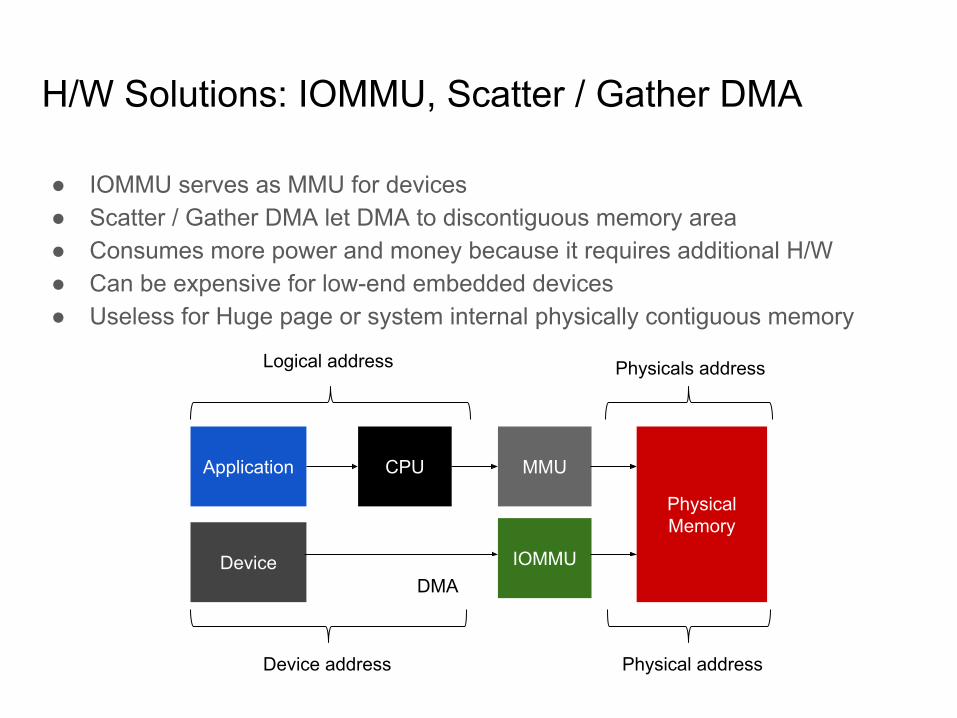
H/W Solutions: IOMMU, Scatter / Gather DMA
● IOMMU serves as MMU for devices● Scatter / Gather DMA let DMA to discontiguous memory area● Consumes more power and money because it requires additional H/W● Can be expensive for low-end embedded devices● Useless for Huge page or system internal physically contiguous memory
Physical Memory
Application MMUCPU
Logical address Physicals address
DeviceDMA
Device address
IOMMU
Physical address
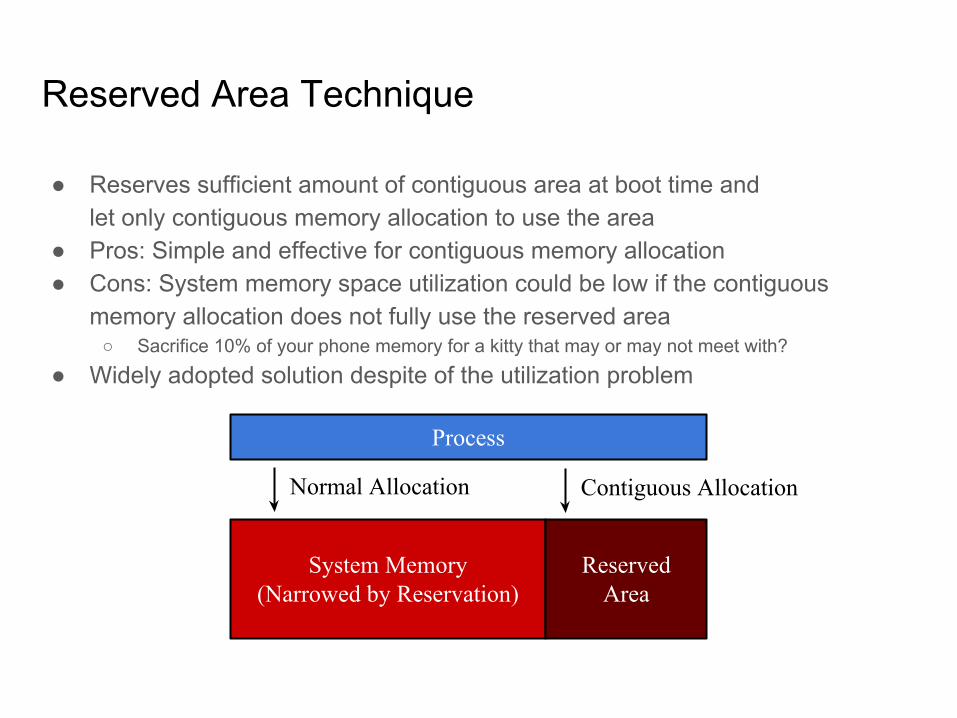
Reserved Area Technique
● Reserves sufficient amount of contiguous area at boot time andlet only contiguous memory allocation to use the area
● Pros: Simple and effective for contiguous memory allocation● Cons: System memory space utilization could be low if the contiguous
memory allocation does not fully use the reserved area○ Sacrifice 10% of your phone memory for a kitty that may or may not meet with?
● Widely adopted solution despite of the utilization problem
System Memory(Narrowed by Reservation)
ReservedArea
Process
Normal Allocation Contiguous Allocation

CMA: Contiguous Memory Allocator
● Software-based solution in mainline Linux● Generously extended version of Reserved area technique
○ Mainly focus on memory utilization○ Let movable pages to use the reserved area
○ If contig mem alloc requires pages being used for movable pages,move those pages out of reserved area and give the vacant area to contig mem alloc
○ Solves memory utilization problem because general pages are movable
● In other words, CMA gives different priority to clients of the reserved area○ Primary client: contiguous memory allocation○ Secondary client: movable page allocation
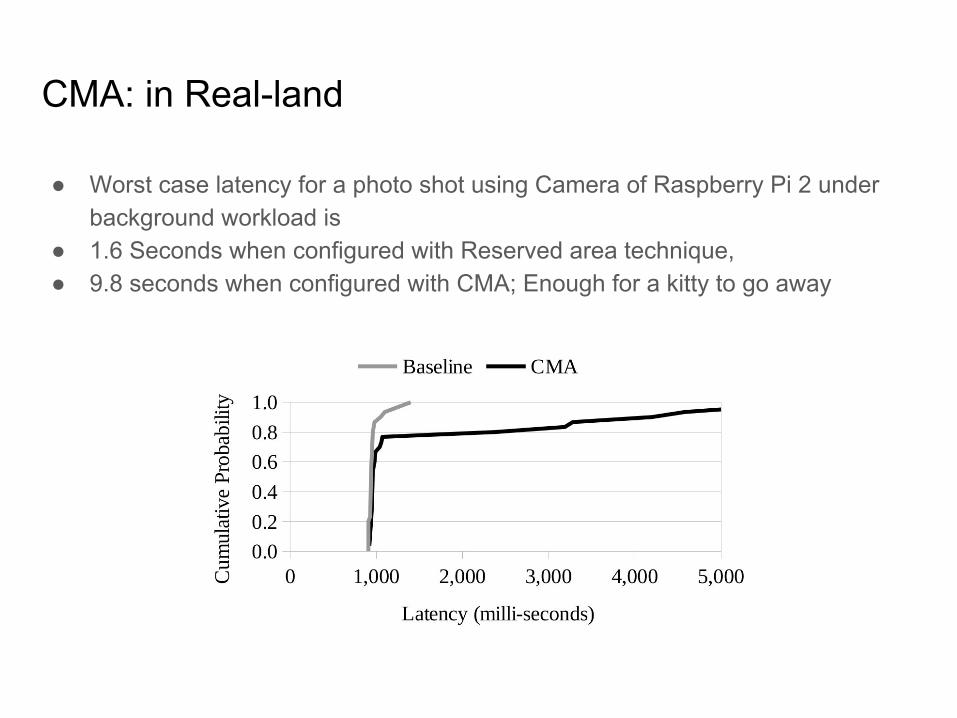
CMA: in Real-land
● Worst case latency for a photo shot using Camera of Raspberry Pi 2 under background workload is
● 1.6 Seconds when configured with Reserved area technique,● 9.8 seconds when configured with CMA; Enough for a kitty to go away
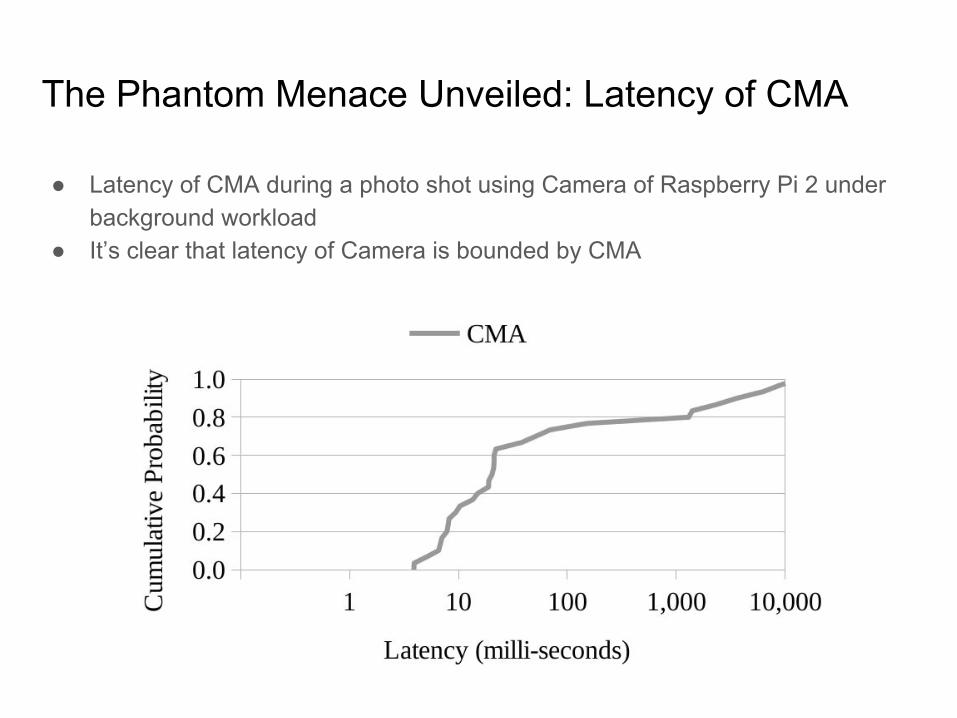
The Phantom Menace Unveiled: Latency of CMA
● Latency of CMA during a photo shot using Camera of Raspberry Pi 2 under background workload
● It’s clear that latency of Camera is bounded by CMA
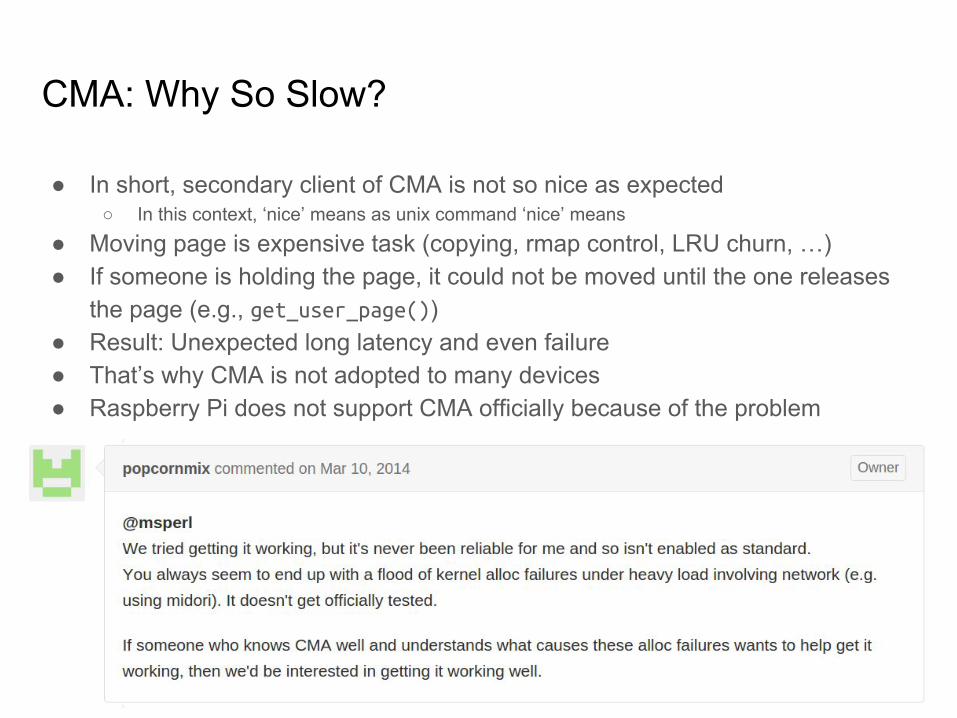
CMA: Why So Slow?
● In short, secondary client of CMA is not so nice as expected○ In this context, ‘nice’ means as unix command ‘nice’ means
● Moving page is expensive task (copying, rmap control, LRU churn, …)● If someone is holding the page, it could not be moved until the one releases
the page (e.g., get_user_page())● Result: Unexpected long latency and even failure● That’s why CMA is not adopted to many devices● Raspberry Pi does not support CMA officially because of the problem

GCMA: Guaranteed Contiguous Memory Allocator
● GCMA is a variant of CMA that guarantees○ Fast latency and success of allocation○ While keeping memory utilization as well
● Main idea is simple○ Follow primary / secondary client idea of CMA to keep memory utilization○ Select secondary client as only nice one unlike CMA
■ For fast latency, should be able to vacate the reserved area as soon as required without any task such as moving content
■ For success, should be out of kernel control■ For memory utilization, most pages should be able to be secondary client

Secondary Client of GCMA
● Last chance cache for○ pages being swapped out and○ clean pages being evicted from file cache
● Pages being swapped out to write-through swap device○ Could be discarded immediately because the contents are written through to swap device○ Kernel think it’s already swapped out○ Most anonymous pages could be swapped out
● Clean pages being evicted from file cache○ Could be discarded because the contents are in storage already○ Kernel think it’s already evicted out○ Lots of file-backed pages could be the case
● Additional pros 1: Already expected to not be accessed again soon○ Discarding secondary client pages from GCAM will not affect system performance much
● Additional pros 2: Occurs with severe workload, only○ In peaceful case, zero overhead at all
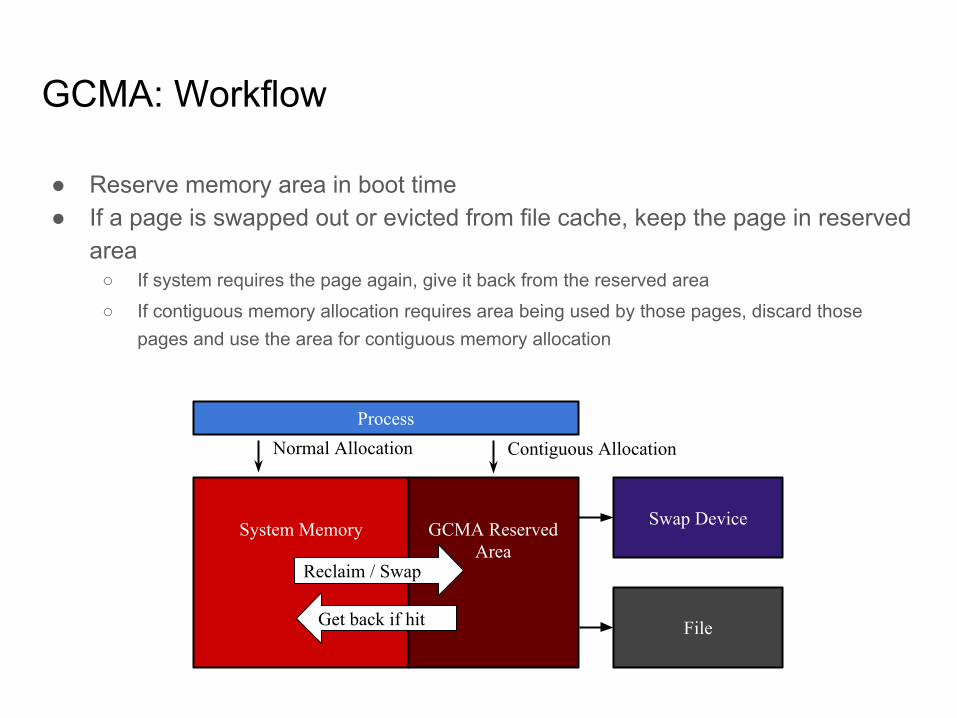
GCMA: Workflow
● Reserve memory area in boot time● If a page is swapped out or evicted from file cache, keep the page in reserved
area○ If system requires the page again, give it back from the reserved area
○ If contiguous memory allocation requires area being used by those pages, discard those pages and use the area for contiguous memory allocation
System Memory GCMA Reserved Area
Swap Device
File
ProcessNormal Allocation Contiguous Allocation
Reclaim / Swap
Get back if hit
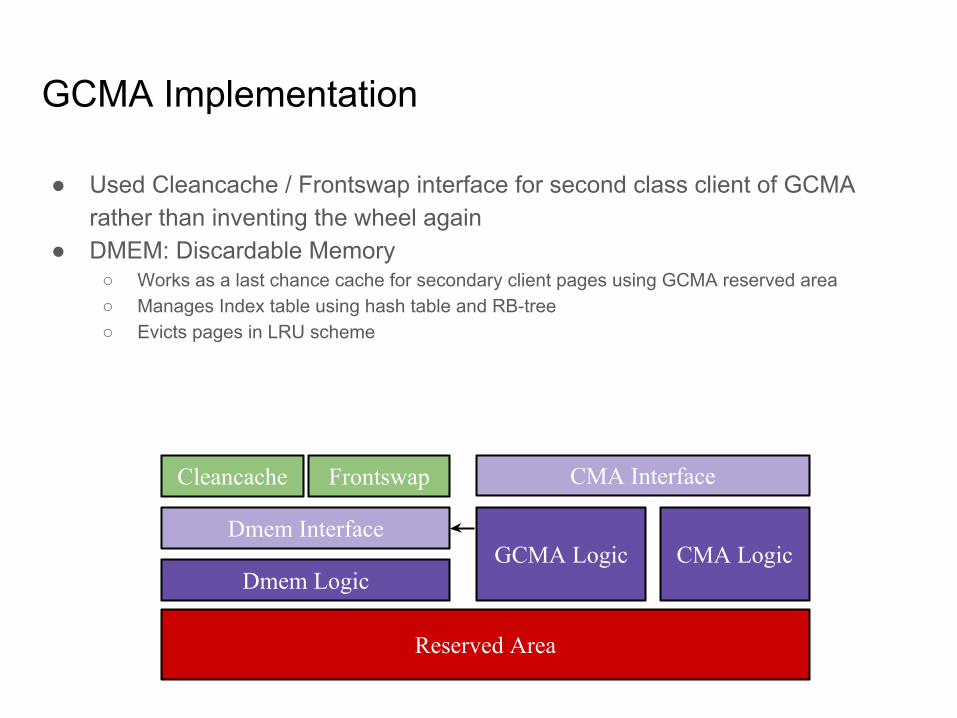
GCMA Implementation
● Used Cleancache / Frontswap interface for second class client of GCMA rather than inventing the wheel again
● DMEM: Discardable Memory○ Works as a last chance cache for secondary client pages using GCMA reserved area○ Manages Index table using hash table and RB-tree○ Evicts pages in LRU scheme
Reserved Area
Dmem LogicGCMA Logic
Dmem Interface
CMA Interface
CMA Logic
Cleancache Frontswap

GCMA Implementation: in Short
● Implemented on Linux v3.18● About 1,500 lines of code● Ported, evaluated on CuBox and Raspberry Pi 2● Available under GPL v3 at: https://github.com/sjp38/linux.
gcma/releases/tag/gcma/rfc/v2

GCMA Optimization for Write-through Swap
● Write-through swap device could consume I/O resource● GCMA recommends compressed memory block device as a swap device
○ Zram is a compressed memory block device in upstream Linux○ Google also recommends zram as a swap device for low-memory Android devices

Experimental Setup
● Device setup○ Raspberry Pi 2○ ARM cortex-A7 900 MHz * 4 cores○ 1 GiB LPDDR2 SDRAM○ Class 10 SanDisk 16 GiB microSD card
● Configurations○ Baseline: Linux rpi-v3.18.11 + 100 MiB swap +
256 MiB reserved area
○ CMA: Linux rpi-v3.18.11 + 100 MiB swap + 256 MiB CMA area
○ GCMA: Linux rpi-v3.18.11 + 100 MiB Zram swap + 256 MiB GCMA area
● Workloads○ Contig Mem Alloc: Contiguous memory allocation using CMA or GCMA○ Blogbench: Realistic file system benchmark
○ Camera shot: Repeated shot of picture using Raspberry Pi 2 Camera module with 10 seconds interval between each shot

Contig Mem Alloc without Background Workload
● Average of 30 allocations● GCMA shows 14.89x to 129.41x faster latency compared to CMA● CMA even failed once for 32,768 contiguous pages allocation even though
there is no background task
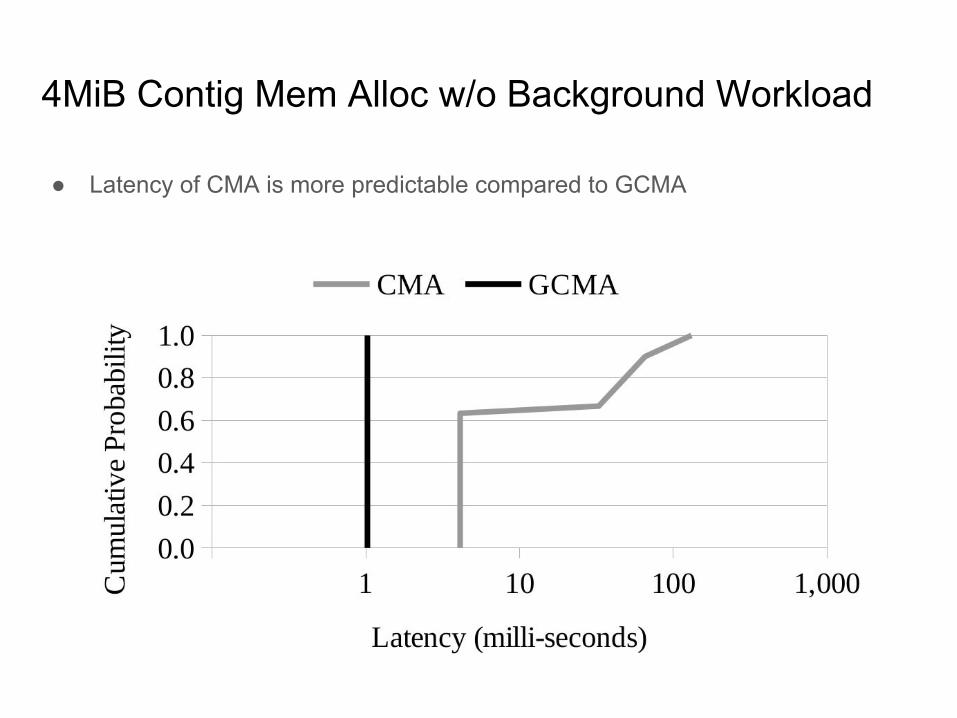
4MiB Contig Mem Alloc w/o Background Workload
● Latency of CMA is more predictable compared to GCMA
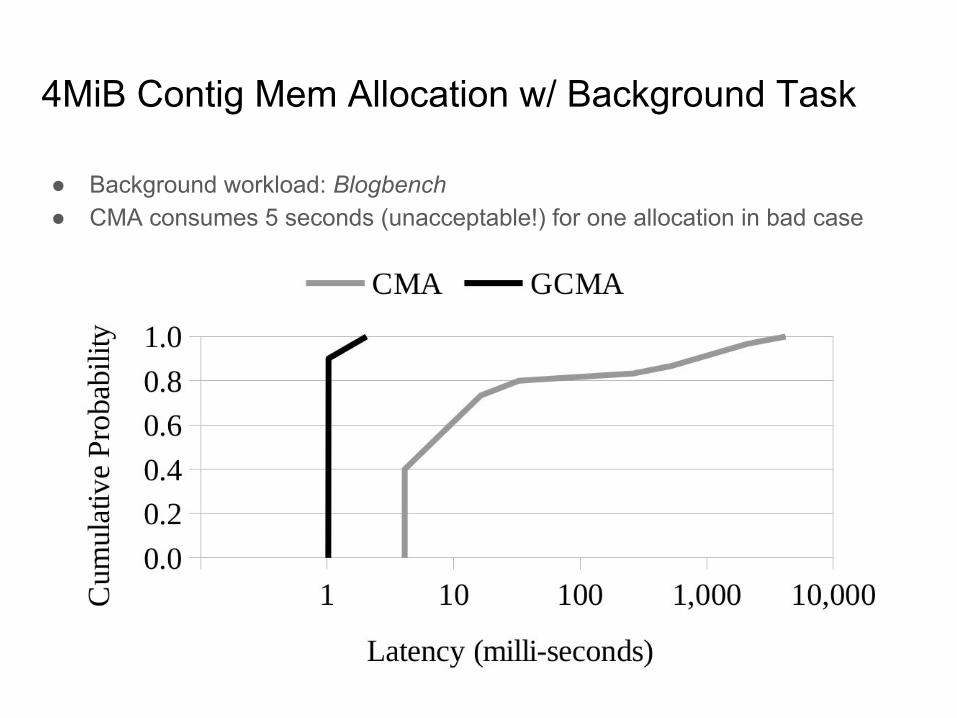
4MiB Contig Mem Allocation w/ Background Task
● Background workload: Blogbench● CMA consumes 5 seconds (unacceptable!) for one allocation in bad case
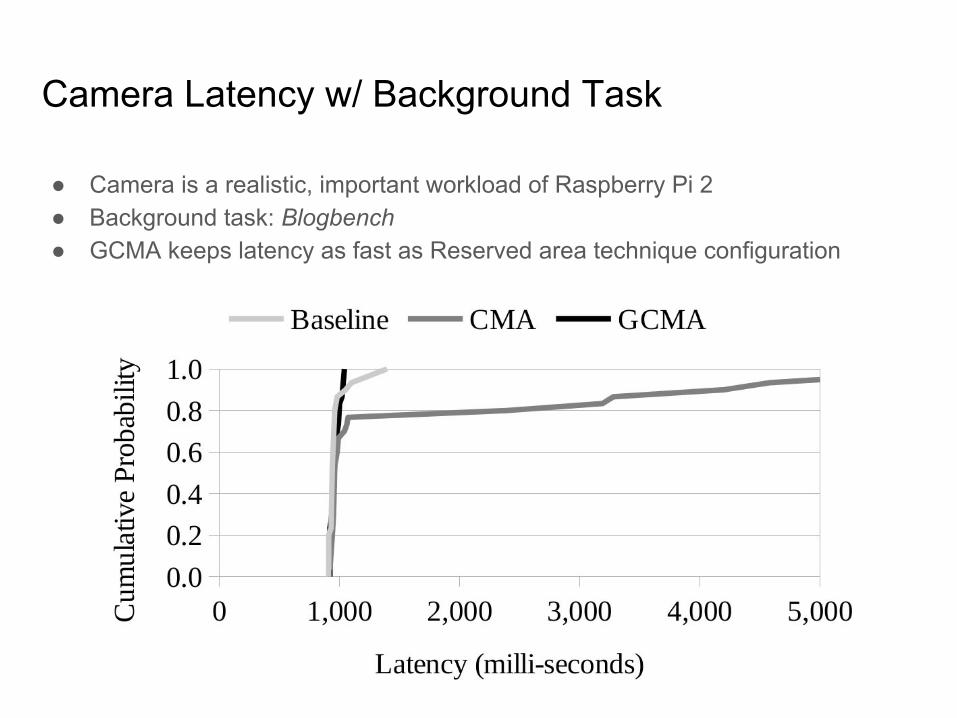
Camera Latency w/ Background Task
● Camera is a realistic, important workload of Raspberry Pi 2● Background task: Blogbench● GCMA keeps latency as fast as Reserved area technique configuration
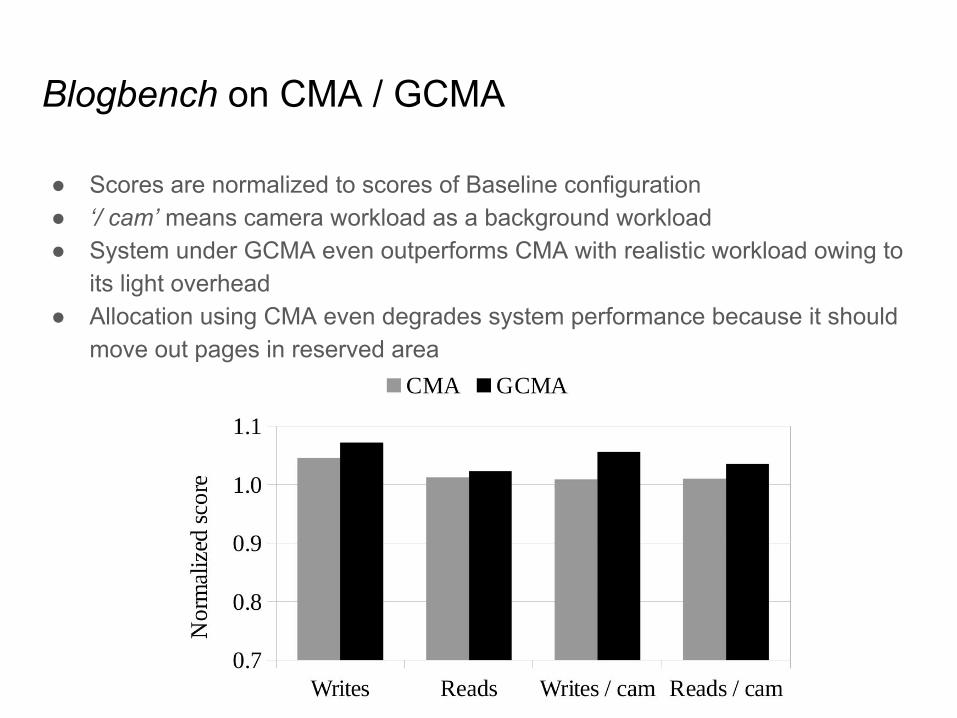
Blogbench on CMA / GCMA
● Scores are normalized to scores of Baseline configuration● ‘/ cam’ means camera workload as a background workload● System under GCMA even outperforms CMA with realistic workload owing to
its light overhead● Allocation using CMA even degrades system performance because it should
move out pages in reserved area

Conclusion
● Contiguous memory allocation is still a big problem for embedded device○ H/W solutions are too expensive○ S/W solutions like CMA is not effective○ Most system uses Reserved area technique despite of low memory utilization
● GCMA guarantees fast latency, success of allocation and reasonable memory utilization
○ Allocation latency of GCMA is as fast as Reserved area technique○ System performance under GCMA is is similar or outperforms the performance under CMA

Thank You
Any question?