genomics and gene recognition - computer science: …predrag/classes/2004falli400/lecture... ·...
TRANSCRIPT

Genomics and Gene Recognition
Genes and Blue Genes
November 3, 2004

Eukaryotic Gene Structure
• eukaryotic genomes are considerably more complex than those of prokaryotes– eukaryotic cells have organelles →
a variety of chemical environments can exist within a cell
– each cell type typically has a distinct pattern of gene expression (even though the same DNA)
– there is a significant portion of introns and intergenic space whose role is mostly unknown
• eukaryotic cells (nuclei) almost always contain two copies of chromosomes animal cell

Chromosome Structure
• a very long, continuous piece of DNA• contains many genes, regulatory elements
and other intervening nucleotide sequences
• the uncondensed DNA exists in a quasi-ordered structure inside the nucleus
• it wraps around histones (structural proteins)
• this composite material is called chromatin
(1) Chromatid
(2) Centromere
(3) Short arm
(4) Long arm.
sheer size and diversity of regulation and functions make eukaryotic DNA very hard to annotate

Eukaryotic Genomes

Transcription in Eukaryotes
• much more complex than in prokaryotes– a typical mammalian cell has
1,500 times as much DNA than the cell of E. Coli
– DNA wrapped around histoneswhich limits access of transcription regulatory proteins to promoters
– eukaryotic transcription requires “factors” that can recognize the chromatin so that the transcription machinery can access promoters

What is Transcription Factor?
• transcription factor is a complex of about 10 proteins
• transcriptional regulation coordinates metabolic activity, cell division, embryonic development
• transcription start is enabled by– promoters– enhancers– response elements

Promoters
• promoters of eukaryotic genes that encode proteins are defined by modules of short conserved sequences (e.g. TATA box, CAAT box, GC box)– CAAT box is usually located around position –80– GC box usually contains sequence GGGCGG or its complement– GC box is usually found upstream of ‘housekeeping genes’ – genes
that encode proteins commonly present in all cells and essential to normal function (they are expressed at relatively stable level in all cells)
• sets of various sequence modules are embedded in the upstream region of genes they collectively define the promoter
• every (almost) eukaryotic gene has its own promoter• RNA polymerase II is responsible for the transcription of the
protein coding genes

Promoters

Enhancers
• also called upstream activation sequences, or UASs• enhancers are additional regulatory sequences and they assist
transcription initiation• differ from promoters
– location of enhancers is not fixed• they may be several thousand nucleotides away from the promoter• sometimes downstream from the gene
– bidirectional sequences• function in either orientation• can be removed and then reinserted in a different orientation without
loss of function
• enhancers are also evolutionarily conserved• enhancers are promiscuous
– stimulate transcription from any nearby promoter
• enhancer recognition depends on transcription factors

Promoters and Enhancers
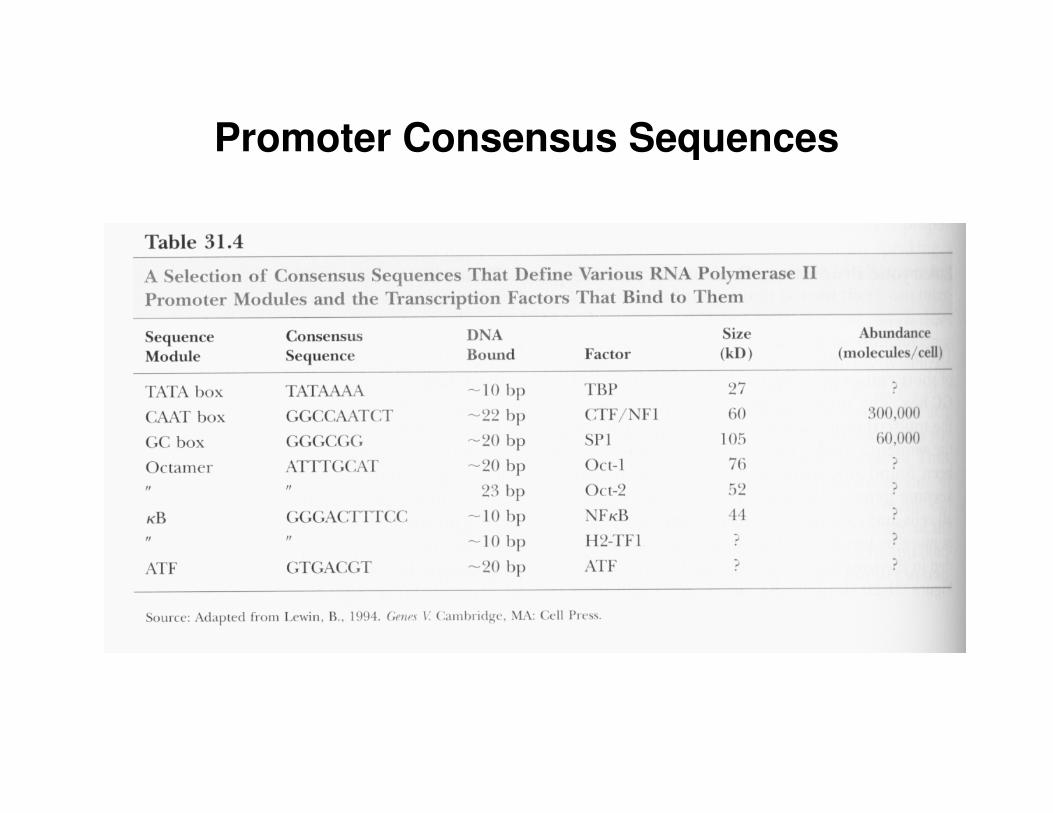
Promoter Consensus Sequences

Response Elements
• response elements are promoter modules in genes responsive to common regulation
• found in the promoter regions of genes whose transcription is activated in response to a sudden increase in environment– temperature -> heat shock proteins– toxic heavy metals -> metal response elements
• heat shock element sequences are recognized by a specific transcription factor (HSTF)– located at about +15 from the transcription start site of genes whose
expression is dramatically enhanced– consensus sequence for HSE is about 14bp long and it can be in
introns too
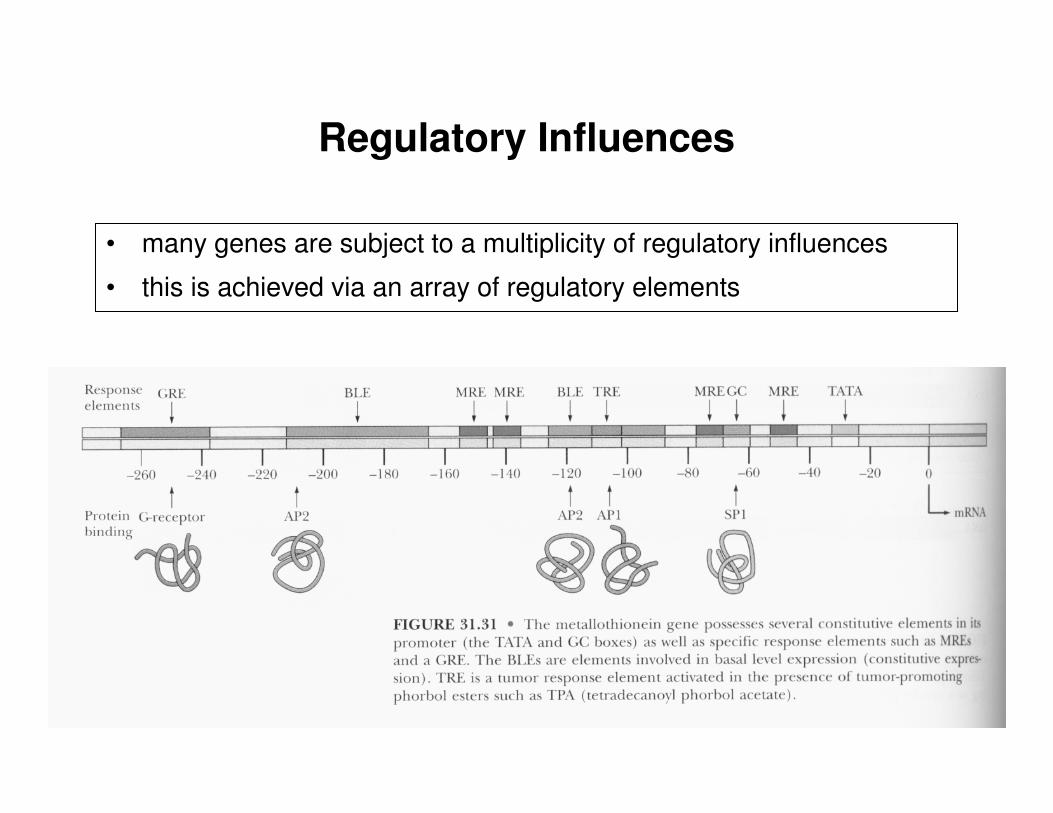
Regulatory Influences
• many genes are subject to a multiplicity of regulatory influences
• this is achieved via an array of regulatory elements

RNA Polymerases
• there are 3 RNA polymerases in eukaryotic proteins• RNA polymerases I and II are involved in transcribing RNA
molecules• RNA polymerase II transcribes protein coding genes
• RNA polymerase II DOES NOT directly recognize promoters– this task is carried out by transcription factors (e.g. TATA-binding
proteins)– there are at least 12 TATA associated factors that bind to the
nucleotide sequence in specific order
• transcription initiation site starts with an initiator sequence– typically about 6 nucleotides long
• subtle differences in transcription factors are known to exist among different cell types
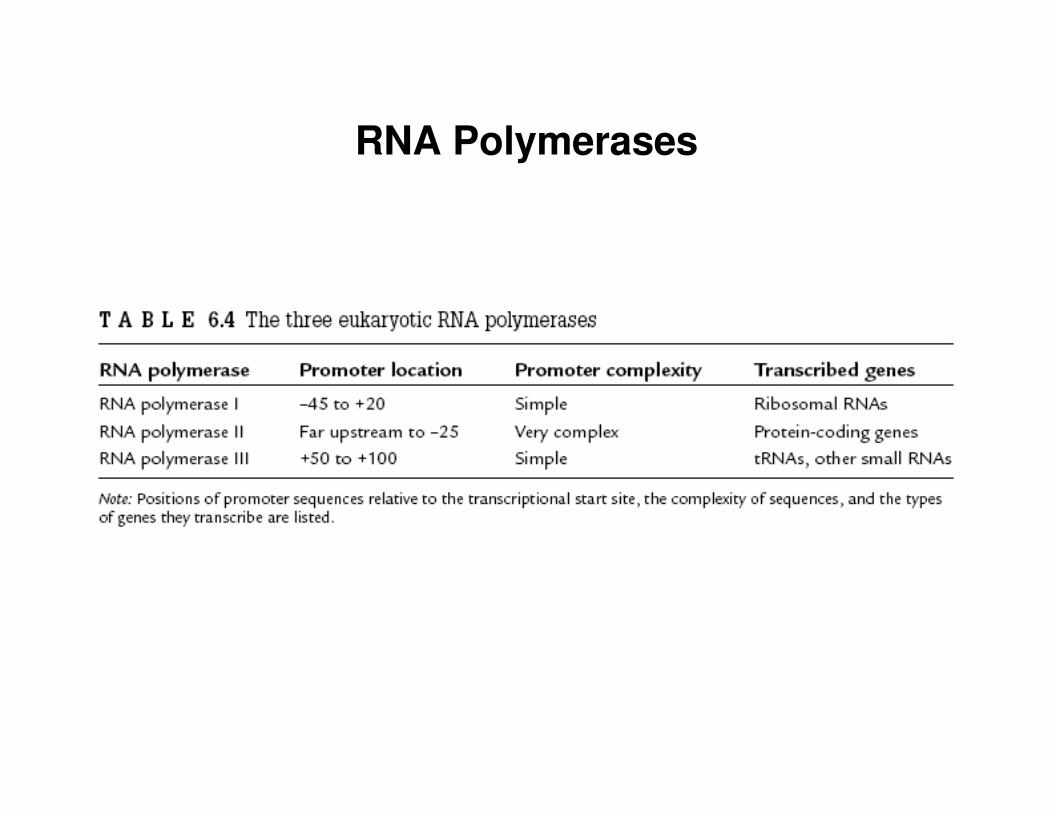
RNA Polymerases

Transcription Factors
• majority of transcription factors are sequence-specific DNA-binding proteins– recognize consensus
sequences, e.g. TATA box– recognize enhancers

DNA Looping
• because transcription must respond to a variety of regulatory signals, multiple proteins are essential for appropriate regulation of gene expression
• these regulatory proteins are the sensors of cellular circumstances– how do they work?– they communicate this information by binding at specific nucleotide
sequences
• DNA is a linear molecule so there is little space for all these proteins to bind– all these sites are near transcription initiation site
• DNA looping enables additional proteins to interact with RNA polymerase II initiation complex
• DNA loping expands the repertoire of transcriptional regulation mechanism

DNA Looping

Post-Transcriptional Modification of mRNA
• transcription and translation are separated in eukaryotes
• transcription occurs on DNA in the nucleus• translation occurs on ribosomes in the cytoplasm
• transcript must move from nucleus into cytoplasm– on its way, pre-mRNA undergoes processing– this primary transcript (hnRNA) is converted into mature mRNA
• each mRNA encodes ONLY ONE protein (monocistronic RNAs)– in prokaryotes, some are polycistronic

Post-Transcriptional Processing of mRNA
• prior to processing hnRNAs are capped and poly-adenylated
• Capping– a set of chemical alterations at the 5’ end of all hnRNAs
• Poly-adenylation– the process of replacing the 3’ end of an hnRNA with approximately 250
A’s that are NOT spelled out in the nucleotide sequence of a gene– exception: histones lack poly-A tail
• Splicing– removal of often large segments from the interior of hnRNA

Introns and Exons
• most genes in higher eukaryotes are split into coding and non-coding regions– coding regions – exons– non-coding regions – introns
• introns are removed from the primary transcript in the process called splicing
• tRNA and rRNA also get spliced!!!
• Example:– yeast actin gene has only one intron 309bp long, after the 3rd amino
acid– chicken ovalbumin gene has 8 exons and 7 introns

Introns and Exons
“mosaic molecules consisting of sequences complementary to several non-contiguous
segments of the viral genome”
Quote from: Adenovirus amazes at Cold Spring Harbor (1977) Nature 268: 101-104.
“The notion of the cistron, the genetic unit of function that one thought corresponded to a polypeptide chain, now must be replaced by that of a transcription unit containing regions
which will be lost from the mature messenger -- which I suggest we call introns (for intragenic regions) -- alternating with regions which will be expressed -- exons. The gene is a
mosaic: expressed sequences held in a matrix of silent DNA, an intronic matrix”.
Gilbert, W. (1978) Why genes in pieces? Nature 271: 501

Open Reading Frames (ORFs)
• predicting genes is more difficult than in prokaryotes– splice sites are hard to predict– detecting sufficiently long ORFs is not enough to detect a gene– alternative splicing even further complicates the issue
• ORFs would be useful in eukaryotes ONLY if we had algorithms that could accurately predict splice sites
• splice sites are very hard to predict, they are tissue specific– there are at least 8 different splice signals– GU-AG rule is the most common– introns are at least 60bp long (to be able to accommodate splicing)– introns can be tens of thousands of nucleotides long
• exons– vary in length between about 100 and 2,000bp

Introns and Exons
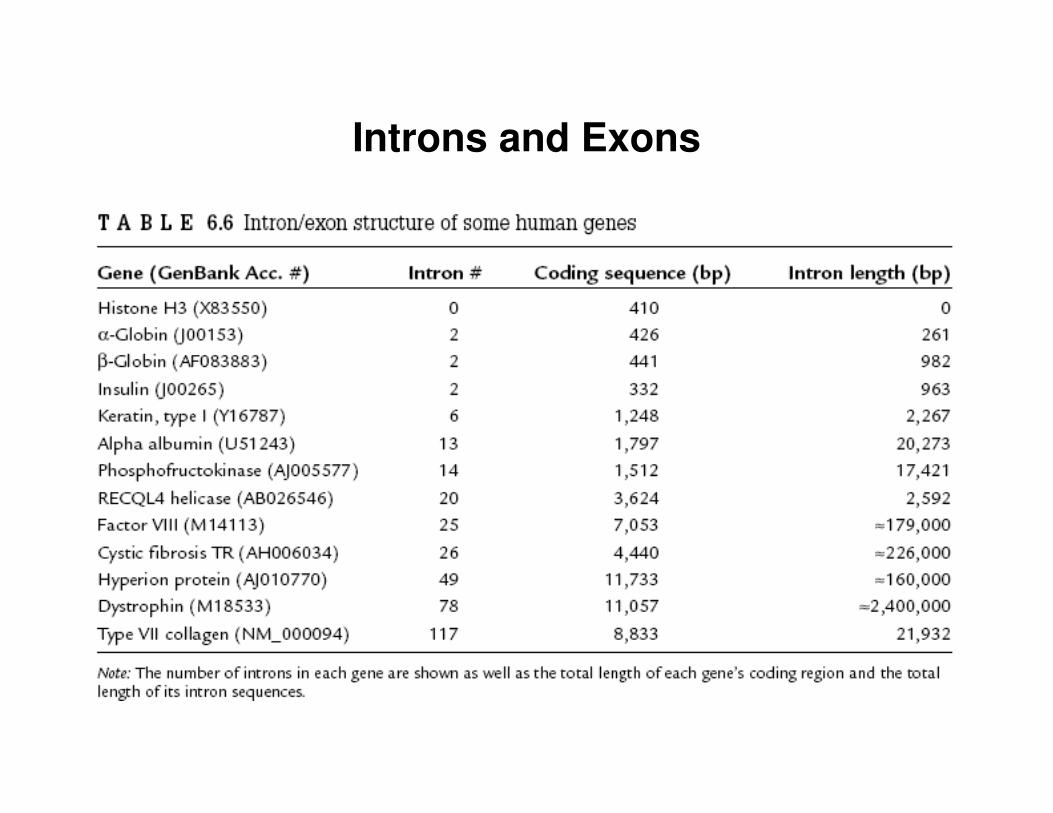
Introns and Exons

Alternative Splicing
• majority of eukaryotic genes appear to be processed into a single mRNA, but...
• 20-40% of human genes give rise to to more than one mRNA sequence
• how?– via alternative splicing
• alternative splicing depends on a cell type and environmental circumstances
• splicing apparatus itself is made from a variety of snRNAs and several proteins
• variations in splice junctions may reflect specific recognition

Alternative Splicing

GC Content in Eukaryotic Genomes
• overall, GC content does not vary as widely as in prokaryotes• however, there is a large-scale variation of GC content within
eukaryotic genomes
• it is very important for gene recognition algorithms– eukaryotic ORFs are much harder to recognize– there is a useful correlation between genes, upstream promoter regions,
codon choices, gene length, gene density and GC regions are involved
• GC rich regions are termed CpG islands and they are very underrepresented as compared to other dinucleotides within DNA sequences
• CpG islands occur frequently at the 5’ ends of genes (-1,500 to +500) with the level of GC content as predicted by chance

CpG Islands

CpG Islands

• analysis shows ~45,000 of CpG islands• about half of these islands are housekeeping genes • many remaining CpG islands are associated with promoters of
tissue specific genes• CpG islands are rarely found in gene-free regions
– the reasons are chemical modifications of CpG’s into CpA’s and TpG’s– transcription requires un-methylated DNA
• methylation and acetylation of histones– help process of transcription– histones lose affinity to bind DNA and thus the chromatin becomes less
tightly packed– the areas become more accessible to RNA polymerases
CpG Islands

Codon Usage Bias
• every organism prefers to use some triplets over others (to code for the same amino acid)
• Example– in yeast Arg is frequently encoded by AGA (48%) although there are
four other codons (CGC, CGA, CGG, AGG)– fruit flies use CGA in 33% of the cases
• How do they occur– consequence of the abundance of tRNAs within the organism– consequence of the avoiding of stop codons

Transposons
• insertion sequences; jumping genes
• mobile genetic material that can be moved from one location of agene and be inserted at another
• the movement occurs due to the presence of an enzyme which is encoded within transposon itself– transposase enzyme coded by one or two genes– it catalyses its transposition from one part of the genome to another– the enzyme genes are surrounded by “repeat segments”
• transposition– conservative – the number of copies of the repeat does not change– replicative – copy number increases
• transposons are more common in bacteria, but are known to exist in eukaryotes as well (~1,000 transposons in human genome)

Repetitive Elements
• many DNA regions contain repetitive sequences• typically, large repetitive chunks are divided into
– tandemly repeated DNA– repeats that are interspersed throughout the genome
• tandemly repeated DNA– satellites– minisatellites and/or microsatellites
• Example: – 5’ CTCTCTCTCT 3’ sequence in which the repeat unit is ‘CT’– 5’ ATTCGATTCGATTCG 3’ sequence; the repeat unit is ‘ATTCG’

Tandem Repeats
• Satellite DNA– long, simple sequences (up to 10mbp) with skewed nucleotide
compositions– repeating fragments of up to 2,000bp
• Minisatellite DNA– not so long as satellites (up to 20kbp)– copies of sequences of up to 25bp
• Microsatellite DNA– shorter than minisatellites (up to 150bp)– up to 100 copies of sequences of up to 5bp (typically 2-3)– “TAGTAGTAGTAGTAGTAGTAG..."
• Example: humans, ‘CA’ repeats– occur once every 10,000bp– make 0.5% of human genome

Interspersed Repeats
• scattered randomly throughout genomes• propagated by the synthesis of an RNA intermediate - process
called retrotransposition
• there are three steps in retrotransposition– an RNA copy of the transposon is transcribed by RNA polymerase
(regular transcription step)– RNA copy is converted into a DNA molecule by reverse transcriptase– reverse transcriptase inserts the DNA copy somewhere else in the
genome
• reverse transcriptase may be acquired through viral infections

Eukaryotic Gene Density
• very small
• in the human genome:– 3% of DNA codes for genes– 27% of DNA are promoters, introns, and pseudogenes– 70% of DNA ??? – often called ‘junk DNA’
• unique sequences• repetitive sequences
• genes are far apart– the average distance between genes is about 65,000bp– in E. Coli the average distance between genes is about 120bp