gpfs%fpo’...
TRANSCRIPT

2011 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved.
GPFS-‐FPO A Cluster File System for Scale-‐Out Applica8ons
Dinesh Subhrave. IBM Research

2011 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved.
2
Mo8va8on: SANs are built for latency not bandwidth Advantages of using GPFS: r High scale (thousands of nodes,
petabytes of storage), high performance, high availability, data integrity,
r POSIX seman.cs, workload isola.on, enterprise features (security, snapshots, backup/restore, archive, asynchronous caching and replica.on)
Challenges: r Adapt GPFS to shared nothing clusters r Maximize applica.on performance
rela.ve to cost r Failure is common, network is a
boMleneck
SAN
I/O boMleneck
Tradi.onal architecture
Shared nothing environment
Scale out performance
1 server -‐> 1 GBps
100 servers-‐> 100 GBps
0
200
400
600
800
1000
Seq w
rite
Seq r
ead
Rand
om Re
ad
Rand
om W
rite
Backw
ard Re
ad
Record
rewrite
Stride
Read
gpfs-‐san gpfs-‐snc
GPFS-‐FPO: Mo8va8on

2011 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved.
3
Mul.ple Block Sizes
InfoSphere Big Insights
POSIX Map Reduce, Cloud
Disaster Recovery
Node N
MetadataN
SAN
Node 1
Data 1
Metadata1
Solid State Disks
Cache Node 2
Metadata2
Local or Rack AMached Disks
Cache Cache
Replicated metadata: No single point of failure
Mul.-‐.ered storage with automated policy-‐based migra.on
Data 2 Data N
Smart Caching
Data Layout Control
High Scale: 1000 nodes, PBs of data
GPFS-‐FPO: Architecture
2011 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved.
4
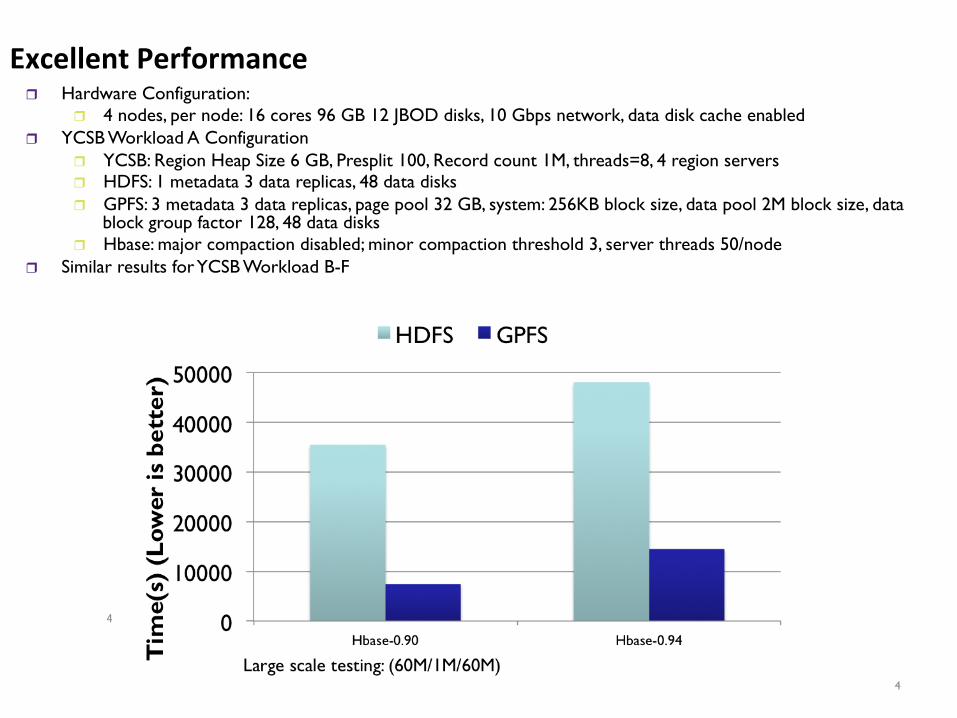
r Hardware Configuration: r 4 nodes, per node: 16 cores 96 GB 12 JBOD disks, 10 Gbps network, data disk cache enabled
r YCSB Workload A Configuration r YCSB: Region Heap Size 6 GB, Presplit 100, Record count 1M, threads=8, 4 region servers r HDFS: 1 metadata 3 data replicas, 48 data disks r GPFS: 3 metadata 3 data replicas, page pool 32 GB, system: 256KB block size, data pool 2M block size, data
block group factor 128, 48 data disks r Hbase: major compaction disabled; minor compaction threshold 3, server threads 50/node
r Similar results for YCSB Workload B-F
4
Excellent Performance
2011 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved. 5
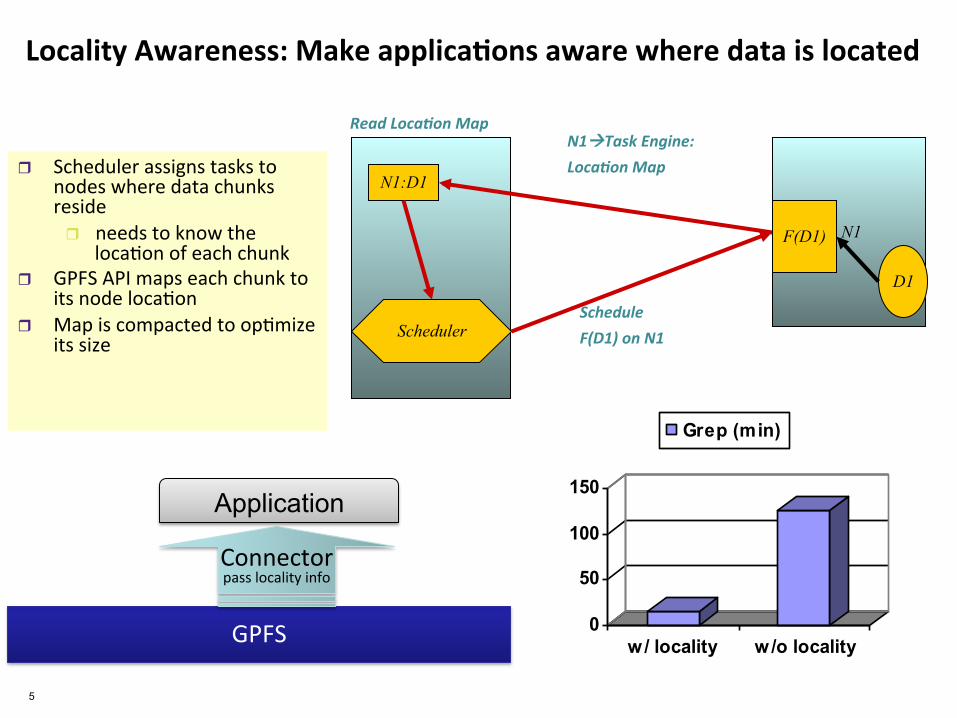
Locality Awareness: Make applica8ons aware where data is located
r Scheduler assigns tasks to nodes where data chunks reside r needs to know the
loca.on of each chunk r GPFS API maps each chunk to
its node loca.on r Map is compacted to op.mize
its size
N1
D1
N1:D1 N1Task Engine: Loca1on Map
Scheduler
Read Loca1on Map
Schedule F(D1) on N1
F(D1)
GPFS
Connector pass locality info
0
50
100
150
w/ locality w/o locality
Grep (min)
Application
2011 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved. 6
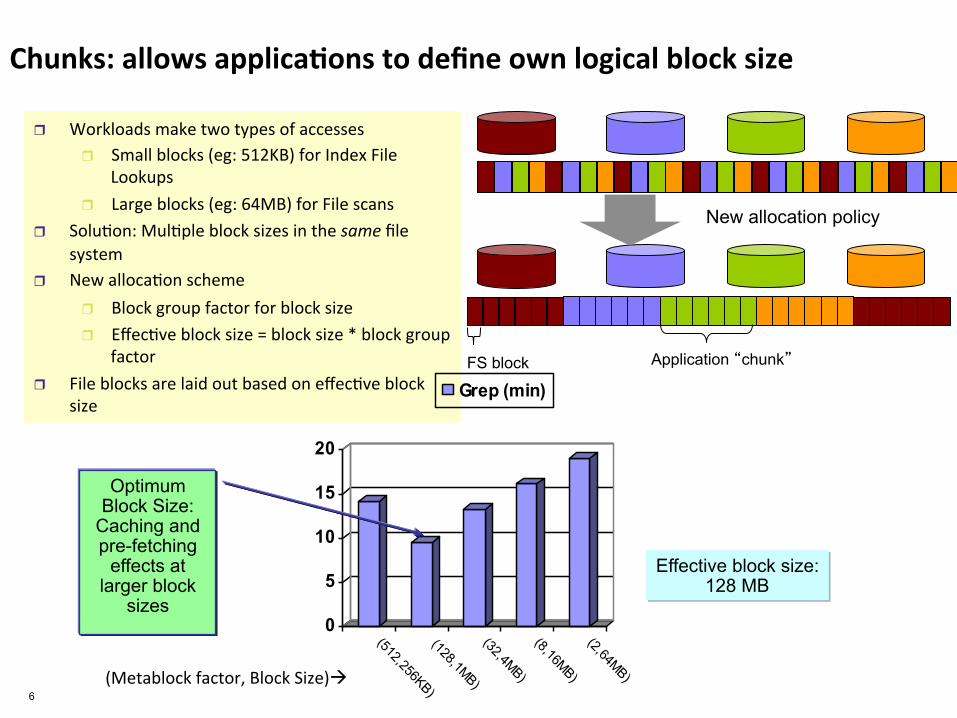
Chunks: allows applica8ons to define own logical block size
r Workloads make two types of accesses r Small blocks (eg: 512KB) for Index File
Lookups r Large blocks (eg: 64MB) for File scans
r Solu.on: Mul.ple block sizes in the same file system
r New alloca.on scheme r Block group factor for block size r Effec.ve block size = block size * block group
factor r File blocks are laid out based on effec.ve block
size
Application “chunk” FS block
New allocation policy
0
5
10
15
20
(512,256KB)
(128,1MB)
(32,4MB)
(8,16MB)
(2,64MB)
Grep (min)
(Metablock factor, Block Size)à
Optimum Block Size:
Caching and pre-fetching
effects at larger block
sizes
Effective block size: 128 MB

2011 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved. 7
Write Affinity: Allow applica8ons to dictate layout
r Wide striping with mul.ple replicas: r No locality of data in a
par.cular node r Bad for commodity
architectures due to excessive network traffic
r Write Affinity for a file or a set of files on a given node r All relevant files will be
allocated on the node, near a node or in the same rack
r Configurability of replicas r Each replica can be configured
for either wide striping or write affinity
N1
File
N2
N3
Read File 1
Wide striped layout: Read over local disk + network
N1
N2
N3
N4
Read File 1
Write affinity layout: Read over only local disk
N1
N2
N3
N4
Read File 1
Write affinity and wide striping with replica8on: Read over only local disk, recover from wide striped replica
Parallel Recovery
0
5
10
15
20
25
30
35
WriteAffinity WideStriping
TeraGen (min)

2011 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved.
r Observa.on r Data is suited for GPFS-‐FPO r Metadata is suited for regular GPFS
r Make alloca.on type a storage pool property r Metadata pool: no write affinity r Data pools: write affinity
r GPFS-‐FPO: distributed metadata r No single point of failure but too many
metadata nodes r Increases probability of any 3 metadata
nodes going down à loss of data r Assumes replica.on=3
r Typical metadata profile in GPFS-‐FPO r One or two metadata nodes per rack
(failure domain) r Random access paMerns
Hybrid alloca8on: treat metadata and data differently
Metadata: No write affinity
Rack 1 Rack 2 Rack 3
Data: Write Affinity

2011 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved. 9
Pipelined Replica8on: Efficient replica8on of data
Disk 1 Disk 2 Disk 3 Disk 4 Disk 5
Node 1 Node 2 Node 3 Node 4 Node 5
N1
Client
N2
N3
B0
B1 B2
Write Write Pipeline
0
10
20
30
40
S ing le -‐ s o ur c e P ip e l ined
TeraGen(min)
r Higher Degree of replica.on r Pipelining for lower latency
r Single source does not u.lize the bandwidth effec.vely
r Able to saturate 1 Gbps Ethernet link

2011 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved. 10
Fast Recovery: Recover quickly from disk failures
r Handling failures is policy driven r Incorporated node failure and
disk failure triggers r Policy-‐based recovery
r Restripe on a node failure or disk failure
r Alterna.vely, rebuild the disk when the disk is replaced
r Fast recovery r Incremental recovery
r Keep track of changes during failure and recover what is needed
r Distributed restripe r Restripe load is spread
out over all the nodes r Quickly figure out what
blocks are needed to be recovered when a node fails
N1 N1 N1
File
N2
N3
Well replicated file N2 rebooted: Writes go to N1 and N3
N2 comes back and catches up by copying missed writes from N1 and N3 in parallel
N2
N3
N2
N3
New write
Copy Deltas
0
5
10
15
20
0 1 2
Grep(Min)
Failed Nodes

2011 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved.
11
File System GPFS-FPO HDFS MapR
Robust No single point of failure
NameNode vulnerability
No single point of failure
Data Integrity High Evidence of data loss New file system
Scale Thousands of nodes Thousands of nodes Hundreds of nodes
POSIX Compliance Full – supports a wide range of applications
Limited Limited
Data Management Security, Backup, Replication
Limited Limited
MapReduce Performance
Good Good Good
Workload Isolation Supports disk isolation
No support Limited support
Traditional Application Performance
Good Poor performance with random reads and writes
Limited
Comparison with HDFS and MapR

2011 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved.
r 4Q12 : GA r 1H13 :
r WAN Caching r Advanced Write Affinity r KVM Support
r 1Q14: r Integrate with Platform Computing Scheduler:
DirectShuffle r Encryption r Disaster Recovery
12
RoadMap

2011 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved.
http://almaden.ibm.com