grab: fast and accurate sensor processing for cashier-free ...cashier-free shopping systems. a...
TRANSCRIPT

Grab: Fast and Accurate Sensor Processing forCashier-Free Shopping
Xiaochen LiuUniversity of Southern California
Yurong JiangLinkedIn*
Kyu-Han KimHewlett-Packard Labs
Ramesh GovindanUniversity of Southern California
ABSTRACTCashier-free shopping systems like Amazon Go improve shop-ping experience, but can require significant store re-design. Inthis paper, we propose Grab, a practical system that leveragesexisting infrastructure and devices to enable cashier-free shop-ping. Grab needs to accurately identify and track customers,and associate each shopper with items he or she retrievesfrom shelves. To do this, it uses a keypoint-based pose trackeras a building block for identification and tracking, developsrobust feature-based face trackers, and algorithms for associ-ating and tracking arm movements. It also uses a probabilisticframework to fuse readings from camera, weight and RFIDsensors in order to accurately assess which shopper picks upwhich item. In experiments from a pilot deployment in a retailstore, Grab can achieve over 90% precision and recall evenwhen 40% of shopping actions are designed to confuse thesystem. Moreover, Grab has optimizations that help reduceinvestment in computing infrastructure four-fold.
1 INTRODUCTIONWhile electronic commerce continues to make great strides,in-store purchases are likely to continue to be important inthe coming years: 91% of purchases are still made in physicalstores [40, 41] and 82% of millennials prefer to shop in thesestores [39]. However, a significant pain point for in-storeshopping is the checkout queue: customer satisfaction dropssignificantly when queuing delays exceed more than fourminutes [10]. To address this, retailers have deployed self-checkout systems (which can increase instances of shoplifting[7, 24, 30]), and expensive vending machines.
The most recent innovation is cashier-free shopping, inwhich a networked sensing system automatically (a) identi-fies a customer who enters the store, (b) tracks the customerthrough the store, (c) and recognizes what they purchase. Cus-tomers are then billed automatically for their purchases, anddo not need to interact with a human cashier or a vendingmachine, or scan items by themselves. Over the past year,several large online retailers like Amazon and Alibaba [1, 35]
* The work was done at Hewlett-Packard Labs.
have piloted a few stores with this technology, and cashier-free stores are expected to take off in the coming years [9, 36].Besides addressing queue wait times, cashier-free shoppingis expected to reduce instances of theft, and provide retailerswith rich behavioral analytics.
Not much is publicly known about the technology behindcashier-free shopping, other than that stores need to be com-pletely redesigned [1, 8, 35] which can require significantcapital investment (§2). In this paper, we ask: Is cashier-freeshopping viable without having to completely redesign stores?To this end, we observe that many stores already have, orwill soon have, the hardware necessary to design a cashier-free shopping system: cameras deployed for in-store security,sensor-rich smart shelves [37] that are being deployed bylarge retailers [21] to simplify asset tracking, and RFID tagsbeing deployed on expensive items to reduce theft. Our paperexplores the design and implementation of a practical cashier-free shopping system called Grab1 using this infrastructure,and quantifies its performance.
Grab needs to accurately identify and track customers, andassociate each shopper with items he or she retrieves fromshelves. It must be robust to visual occlusions resulting frommultiple concurrent shoppers, and to concurrent item retrievalfrom shelves where different types of items might look similar,or weigh the same. It must also be robust to fraud, specificallyto attempts by shoppers to confound identification, tracking,or association. Finally, it must be cost-effective and havegood performance in order to achieve acceptable accuracy:specifically, we show that, for vision-based tasks, slower than10 frames/sec processing can reduce accuracy significantly(§4).Contributions. An obvious way to architect Grab is to usedeep neural networks (DNNs) for each individual task incashier-free shopping, such as identification, pose tracking,gesture tracking, and action recognition. However, theseDNNs are still relatively slow and many of them cannotprocess frames at faster than 5-8 fps. Moreover, even if they
1A shopper only needs to grab items and go.
arX
iv:2
001.
0103
3v1
[cs
.CV
] 4
Jan
202
0

have high individual accuracy, their effective accuracy wouldbe much lower if they were cascaded together.
Grab’s architecture is based on the observation that, forcashier-free shopping, we can use a single vision capabil-ity (body pose detection) as a building block to perform allof these tasks. A recently developed DNN library, Open-Pose [28] accurately estimates body "skeletons" in a video athigh frame rates.
Grab’s first contribution is to develop a suite of lightweightidentification and tracking algorithms built around these skele-tons (§3.1). Grab uses the skeletons to accurately determinethe bounding boxes of faces to enable feature-based facedetection. It uses skeletal matching, augmented with colormatching, to accurately track shoppers even when their facesmight not be visible, or even when the entire body might notbe visible. It augments OpenPose’s elbow-wrist associationalgorithm to improve the accuracy of tracking hand move-ments which are essential to determining when a shopper maypickup up items from a shelf.
Grab’s second contribution is to develop fast sensor fusionalgorithms to associate a shopper’s hand with the item that theshopper picks up (§3.2). For this, Grab uses a probabilisticassignment framework: from cameras, weight sensors andRFID receivers, it determines the likelihood that a given shop-per picked up a given item. When multiple concurrent suchactions occur, it uses an optimization framework to associatehands with items.
Grab’s third contribution is to improve the cost-effectiveness of the overall system by multiplexing multiplecameras on a single GPU (§3.3). It achieves this by avoidingrunning OpenPose on every frame, and instead using alightweight feature tracker to track the joints of the skeletonbetween successive frames.
Using data from a pilot deployment in a retail store, weshow (§4) that Grab has 93% precision and 91% recall evenwhen nearly 40% of shopper actions were adversarial. Grabneeds to process video data at 10 fps or faster, below which ac-curacy drops significantly: a DNN-only design cannot achievethis capability (§4.4). Grab needs all three sensing modalities,and all of its optimizations: removing an optimization, or asensor, can drop precision and recall by 10% or more. Finally,Grab’s design enables it to multiplex up to 4 cameras perGPU with negligible loss of precision.
2 APPROACH AND CHALLENGESCashier-free shopping systems. A cashier-free shoppingsystem automatically determines, for every customer in ashop, what items the customer has picked from the shelves,and directly bills each customer for those items. Cashier-freeshopping is achieved using a networked system containingseveral sensors that together perform three distinct functions:identifying each customer, tracking each customer through
3) RFID: Signal blockagea) Vision: Similar packages 2) Weight: Similar weight
RFID Blocking
Figure 1: Real-world challenges in identifying items. a) Differ-ent items with similar packages; b) Different items with similarweight; c) Occluded RFID tags that would be hard to read at acheckout gate.
the shop, and identifying every item pickup or item dropoffon a shelf to accurately determine which items the customerleaves the store with.
These systems have several requirements. First, they mustbe non-intrusive in the sense that they must not require cus-tomers to wear or carry sensors or any form of electronicidentification, since these can detract from the shopping expe-rience. Second, they must be robust to real-world conditions(Figure 1), in being able to distinguish between items that arevisually similar or have other similarities (such as weight),as well as to be robust to occlusion. Third, they must be ro-bust to fraud: specifically, they must be robust to attemptsby shoppers to circumvent or tamper with sensors used toidentify customers, items and the association between cus-tomers and items. Finally, they must be cost-effective: theyshould leverage existing in-store infrastructure to the extentpossible, while also being computationally efficient in orderto minimize computing infrastructure investments.Today’s cashier-free shopping systems. Despite widespreadreports of cashier-free shopping deployments [1, 8, 33, 35],not much is known about the details of their design, but theyappear to fall into three broad categories.
Vision-Only. This class of systems, exemplified by [23,33], identifies customers and items, and tracks customers,only using cameras. It trains a deep learning model to recog-nize customers and objects, and uses this to bill them. How-ever, such a system can fail to distinguish between items thatlook similar (Figure 1(a)) especially when these items aresmall in the image (occupy a few pixels), or items that areoccluded by other objects (Figure 1(c)) or by the customer.
Vision and Weight. Amazon Go [1] uses both camerasand weight sensors on shelves, where the weight sensor canbe used to identify when an item is removed from a shelfeven if it is occluded from a camera. One challenge such asystem faces is the ability to discriminate between items ofsimilar weight (Figure 1(b)). Moreover, their design requiresa significant redesign of the store: user check-in gates, anarray of cameras on the ceiling and the shelf, and additional
2

sensors at the exit [2, 22]. Finally, Amazon Go also reportedlyencounters issues when shoppers put back items randomly [3].
Vision and RFID. The third class of approaches, used byTaobao Cafe [35] and Bingo Box [8], does not track shopperswithin the store, but uses vision to identify customers andRFID scanners at a checkout gate that reads all the items beingcarried by the customer. Each object needs to be attachedwith an RFID tag, and users have to queue at the checkoutgate. This approach has drawbacks as well: RFID tags can beexpensive relative to the price of some items [29], and RFIDreaders are known to have trouble when scanning tags thatare stacked, blocked, or attached to conductors [72, 76, 77].Approach and Challenges. While all of these approaches arenon-intrusive, it is less clear how well they satisfy other re-quirements: robustness to real-world conditions and to fraud,and cost-effectiveness. In this paper, with a goal towards un-derstanding how well these requirements can be met in prac-tice, we explore the design, implementation, and evaluationof a cashier-free shopping system called Grab, which com-bines the three technologies described above (vision, weightscales, and RFID). At a high-level, Grab combines advancesin machine vision, with lightweight sensor fusion algorithmsto achieve its goals. It must surmount four distinct challenges:(a) how to identify customers in a lightweight yet robust man-ner; (b) how to track customers through a store even when thecustomer is occluded by others or the customer’s face is notvisible in a camera; (c) how to determine when a customer haspicked up an item, and which item the customer has pickedup, and to make this determination robust to concurrent itemretrievals, customers putting back items, and customers at-tempting to game the system in various ways; (d) how tomeet these challenges in a way that minimizes investments incomputing infrastructure.
3 GRAB DESIGNGrab addresses these challenges by building upon a vision-based keypoint-based pose tracker DNN for identification andtracking, together with a probabilistic sensor fusion algorithmfor recognizing item pickup actions. These ensure a com-pletely non-intrusive design where shoppers are not requiredto scan item codes or pass through checkout gates while shop-ping. Grab consists of four major components (Figure 2).
Identity tracking recognizes shoppers’ identities and trackstheir movements within the store. It includes efficient andaccurate face and body pose detection and tracking, adaptedto work well in occluded environments, and to deal withcorner cases in body pose estimation that can increase errorin item pickup detection (§3.1).
Action recognition uses a probabilistic algorithm to fusevision, weight and RFID inputs to determine item pickupor dropoff actions by a customer (§3.2). This algorithm is
Smart Shelf
Shopper
Identity Tracking
GPU Multiplexing
Action Recognition
Output
User: Alice
Bought:Coke x 1Cups x 1
CustomerRegistration
Figure 2: Grab is a system for cashier-free shopping and hasfour components: registration, identity tracking, action recog-nition, and GPU multiplexing.
Pose Detection Face
Detection & Matching
Keypoint-based Pose Tracking
Optimized Limb
Association
Alice
Figure 3: Grab’s identity tracking module uses a feature-basedface detector and uses key-point base pose tracking.
designed to be robust to real-world conditions and to theft.When multiple users pickup the same type of item simulta-neously, the algorithm must determine which customer takeshow many items. It must be robust to: customers concealingitems or to attempts to tamper with the sensors (e.g., replacingan expensive item with an identically weighted item).
GPU multiplexing enables processing multiple cameras ona single GPU (§3.3). DNN-based video processing usuallyrequires a dedicated GPU for each video stream for reasonableperformance. Retail stores need tens of cameras, and Grabcontains performance optimizations that permit it to multiplexthe processing of multiple streams on a single GPU, therebyreducing cost.
Grab also has a fourth, offline component, registration.Customers must register once online before their first storevisit. Registration involves taking a video of the customer toenable matching the customer subsequently (§3.1), in additionto obtaining information for billing purposes. If the identitytracking component detects a customer who has not registered,she may be asked to register before buying items from thestore.
3.1 Identity trackingIdentity tracking consists of two related sub-components (Fig-ure 3). Shopper identification determines who the shopper isamong registered users. A related sub-component, shoppertracking, determines (a) where the shopper is in the store ateach instant of time, and (b) what the shopper is doing at eachinstant.
3

Requirements and Challenges. In designing Grab, we re-quire first that customer registration be fast, even though it isperformed only once: ideally, a customer should be able to reg-ister and immediately commence shopping. Identity trackingrequires not just identifying the customer, but also detectingeach person’s pose, such as hand position and head position.These tasks have been individually studied extensively in thecomputer vision literature. More recently, with advances indeep learning, researchers in computer vision have developeddifferent kind of DNNs for people detection [70, 79, 81], facedetection [14, 93] and hand gesture recognition [48, 89].
Each of these detectors performs reasonably well: e.g.,people detectors can process 35 frames per second (fps), facedetectors can process 30 fps, and hand recognizers can runat 12 fps. However, Grab requires all of these components.Dedicating a GPU for each component is expensive: recallthat a store may have several cameras (Grab proposes to re-purpose surveillance cameras for visual recognition tasks,§1), and using one GPU per detection task per camera isundesirable (§2) as it would require significant investment incomputing infrastructure.
The other option is to run these on a single GPU per camera,but this would result in lower frame rates. Lower frame ratescan miss shopper actions: as §4.4 shows, at frame rates lowerthan 10 fps, Grab’s precision and recall can drop dramatically.This highlights a key challenge we face in this paper: design-ing fast end-to-end identity tracking algorithms that do notcompromise accuracy.Approach. In this paper, we make the following observation:we can build end-to-end identity tracking using a state-of-the-art pose tracker. Specifically, we use, as a building block,a keypoint based body pose tracker, called OpenPose [28].Given an image frame, OpenPose detects keypoints for eachhuman in the image. Keypoints identify distinct anatomicalstructures in the body (Figure 4(a)) such as eyes, ears, nose,elbows, wrists, knees, hips etc. We can use these skeletons foridentification, tracking and gesture recognition. OpenPoserequires no pose calibration (unlike, say, the Kinect [46]), so itis attractive for our setting, and is fast, achieving up to 15 fpsfor body pose detection. (OpenPose also has modes where itcan detect faces and hand gestures using many more keypointsthan in Figure 4(a), but using these reduces the frame ratedramatically, and also has lower accuracy for shoppers faraway from the camera).
However, fundamentally, since OpenPose operates onlyon a single frame, Grab needs to add identification, trackingand gesture recognition algorithms on top of OpenPose tocontinuously identify and tracks shoppers and their gestures.The rest of this section describes these algorithms.
Original skeleton output Frontal face bounding box
Bounding box w/o direction adjustment
Bounding box w/ direction adjustment
(b) (c)
(e)(d)
(a)
Figure 4: (a) Sample OpenPose output. (b,c,d,e) Grab’s ap-proach adjusts the face’s bounding box using the keypoints de-tected by OpenPose. (The face shown is selected from Open-Pose project webpage [28])
Shopper Identification. Grab uses fast feature-based facerecognition to identify shoppers. While prior work has ex-plored other approaches to identification such as body fea-tures [43, 49, 94] or clothing color [73], we use faces be-cause (a) face recognition has been well-studied by visionresearchers and we are likely to see continued improvements,(b) faces are more robust for identification than clothingcolor, and (c) face features have the highest accuracy in largedatasets (§5).
Feature-based face recognition. When a user registers,Grab takes a video of their face, extracts features, and buildsa fast classifier using these features. To identify shoppers,Grab does not directly use a face detector on the entire im-age because traditional HAAR based detectors [69] can beinaccurate, and recent DNN-based face detectors such asMTCNN [93] can be slow. Instead, Grab identifies a face’sbounding box using keypoints from OpenPose, specifically,the five keypoints of the face from the nose, eyes, and ears(Figure 4(b)). Then, it extracts features from within the bound-ing box and applies the trained classifier.
Grab must (a) enable fast training of the classifier sincethis step is part of the registration process and registrationis required to be fast (§3.1), (b) must robustly detect thebounding box for different facial orientations relative to thecamera to avoid classification inaccuracy.
Fast Classification. Registration is performed once foreach customer. During registration, Grab extracts featuresfrom the customer’s face. To do this, we evaluated severalface feature extractors [15, 44, 85], and ultimately selectedResNet-34’s feature extractor [15] which produces a 128-dimension feature vector, performs best in both speed andaccuracy (§4.6).
With these features, we can identify faces by comparingfeature distances, build classifiers, or train a neural network.After experimenting with these options, we found that a knearest neighbor (kNN) classifier, in which each customer
4

is trained as a new class, worked best among these choices(§4.6). Grab builds one kNN-based classifier for all customersand uses it across all cameras.
Tightening the face bounding box. During normal opera-tion, Grab extracts facial features after drawing a boundingbox (derived from OpenPose keypoints) around each cus-tomer’s face. Grab infers the face’s bounding box width usingthe distance between two ears, and the height using the dis-tance from nose to neck. This works well when the face pointstowards the camera (Figure 4(c)), but can result in an inac-curate bounding box when a customer faces slightly awayfrom the camera (Figure 4(d)). This inaccuracy can degradeclassification performance.
To obtain a tighter bounding box, we estimate head pitchand yaw using the keypoints. Consider the line between thenose and neck keypoints: the distance of each eye and ear key-point to this axis can be used to estimate head yaw. Similarly,the distance of the nose and neck keypoints to the axis be-tween the ears can be used to estimate pitch. Using these, wecan tighten the bounding box significantly (Figure 4(e)). Toimprove detection accuracy (§4) when a customer’s face is notfully visible in the camera, we also use face alignment [44],which estimates the frontal view of the face.Shopper Tracking. A user’s face may not always be visiblein every frame, since customers may intentionally or other-wise turn their back to the camera. However, Grab needs to beable to identify the customer in frames where the customer’sface is not visible, for which it uses tracking. Grab assumesthe use of existing security cameras, which, if placed cor-rectly, make it unlikely that a customer can evade all camerasat all times (put another way, if the customer is able to do this,the security system’s design is faulty).
Skeleton-based Tracking. Existing human trackers usebounding box based approaches [68, 75, 82, 90, 92], whichcan perform poorly in in-store settings with partial orcomplete occlusions (Figure 5(a)). We quantify this in§4.4 with the state-of-the-art bounding box based tracker,DeepSort [92], but Figure 5 demonstrates this visually.
Instead, we use the skeleton generated by OpenPose todevelop a tracker that uses geometric properties of the bodyframe. We use the term track to denote the movements ofa distinct customer (whose face may or may not have beenidentified). Suppose OpenPose identifies a skeleton in a frame:the goal of the tracker is to associate the skeleton with anexisting track if possible. Grab uses the following to trackcustomers. It tries to align each keypoint in the skeleton withthe corresponding keypoint in the last seen skeleton in eachtrack, and selects that track whose skeleton is the closestmatch (the sum of match errors is smallest). Also, as soon asit is able to identify the face, Grab associates the customer’sidentity with the track (to be robust to noise, Grab requires
To be updated
a) Bounding box tracking result b) Our tracking result
Figure 5: Bounding-box based approaches (b) have troubletracking multiple users in crowds, but our approach (a) workswell in these settings.
that the customer’s face is identified in 3 successive frames).To work well, the tracking algorithm needs to correctly handlepartial and complete occlusions.
Dealing with Partial Occlusions. When a shopper’s bodyis not completely visible (e.g., because she is partially ob-scured by another customer, Figure 5(b)), OpenPose can onlygenerate a subset of the key points. In this case, Grab matchesonly on the visible subset. However, with significant occlu-sions, very few key points may be visible. In this case, Grabattempts to increase matching confidence using the color his-togram of the visible upper body area. However, if the twomatching approaches (color and skeletal) conflict with eachother, Grab skips matching attempts until subsequent frameswhen this process is repeated.
Dealing with Complete Occlusions. In some cases, a shop-per may be completely obscured by another. Grab uses lazytracking (Figure 6) in this case. When an existing track dis-appears in the current frame, Grab checks if, in the previousframe, the track was close to the edge of the image, in whichcase it assumes the customer has moved out of the camera’sfield of view and deletes the track. Otherwise, it marks thetrack as blocked. When the customer reappears in a subse-quent frame, it reactivates the blocked track.Shopper Gesture Tracking. Grab must recognize the armsof each shopper in order to determine which item he or shepurchases (§3.2). OpenPose has a built-in limb associationalgorithm, which associates shoulder joints to elbows, andelbows to wrists. We have found that this algorithm is a littlebrittle in our setting: it can miss an association (Figure 7(a)),or mis-associate part of a limb of one shopper with another(Figure 7(b)).
How limb association in OpenPose works. OpenPose firstuses a DNN to associate with each pixel confidence valueof it being part of an anatomical key point (e.g., an elbow,or a wrist). During image analysis, OpenPose also generatesvector fields (called part affinity fields [47]) for upper-armsand forearms whose vectors are aligned in the direction ofthe arm. Having generated keypoints, OpenPose then esti-mates, for each pair of keypoints, a measure of alignmentbetween an arm’s part affinity field, and the line between
5

Approach A is close, B is far
A B A
B B A
Occlusion B no longer detectedKeep B’s track after A
ResumeUpdate B with new detection
Frame 2Frame 1 Frame 3
Figure 6: When a shopper is occluded by another, Grab resumestracking after the shopper re-appears in another frame (lazytracking).
Connection Failure Wrong Assignment
(a) (b)
Figure 7: OpenPose can (a) miss an assignment between elbowand wrist, or (b) wrongly assign one person’s joint to another.
the keypoints (e.g., elbow and wrist). It then uses a bipartitematching algorithm to associate the keypoints.
Improving limb association robustness. One source ofbrittleness in OpenPose’s limb association is the fact thatthe pixels for the wrist keypoint are conflated with pixels inthe hand (Figure 7(a)). This likely reduces the part affinityalignment, causing limb association to fail. To address this,for each keypoint, we filtered outlier pixels by removing pix-els whose distance from the mediod [78] was greater than the85th percentile.
The second source of brittleness is that OpenPose’s limbassociation treats each limb independently, resulting in caseswhere the key point from one person’s elbow may get associ-ated with another person’s wrist (Figure 7(b)). To avoid thisfailure mode, we modify OpenPose’s limb association algo-rithm to treat one person’s forearms or upper-arms as a pair(Figure 8). To identify forearms (or upper-arms) as belong-ing to the same person, we measure the Euclidean distanceED(.) between color histograms F (.) belonging to the twoforearms, and treat them as a pair if the distance is less thanan empirically-determined threshold thresh. Mathematically,we formulate this as an optimization problem:
maxi, j
∑i ∈E
∑j ∈W
Ai, jzi, j
s.t.∑j ∈W
zi, j ≤ 1 ∀i ∈ E,∑i ∈E
zi, j ≤ 1 ∀j ∈W ,
ED(F (i, j), F (i ′, j ′)) < thresh ∀j, j ′ ∈W i, i ′ ∈ E
Person A
(a) (b)
Person B
w0 w1 w’0
e2e1e0
ElbowWrist
Figure 8: OpenPose associates limb joints using bipartite match-ing.where E andW are the sets of elbow and wrist joints, and
Ai, j is the alignment measure between the i-th elbow and thej-th wrist, while zi, j is an indicator variable indicating connec-tivity between the elbow and the wrist. The third constraintmodels whether two elbows belong to the same body, usingthe Euclidean distance between the color histograms of thebody color. This formulation reduces to a max-weight bipar-tite matching problem, and we solve it with the Hungarianalgorithm [67].
Tag RSSIMatching
Visual Feature
Matching
Output
User: Alice
Bought:Coke x 1Cups x 1
Customer Pose Tracks
Proximity Event
Detection
Weight Change
Matching
Figure 9: Grab recognizes the items a shopper picks up byfusing vision with smart-shelf sensors including weight andRFID.
3.2 Shopper Action RecognitionWhen a shopper is being continuously tracked, and their handmovements accurately detected, the next step is to recognizehand actions, specifically to identify item(s) which the shop-per picks up from a shelf. Vision-based hand tracking alone isinsufficient for this in the presence of multiple shoppers con-currently accessing items under variable lighting conditions.Grab leverages the fact that many retailers are installing smartshelves [18, 37] to deter theft. These shelves have weightsensors and are equipped with RFID readers. Weight sensorscannot distinguish between items of similar weight, whilenot all items are likely to have RFID tags for cost reasons.So, rather than relying on any individual sensor, Grab fusesdetections from cameras, weight sensors, and RFID tags torecognize hand actions.Modeling the sensor fusion problem. In a given cameraview, at any instant, multiple shoppers might be reachingout to pick items from shelves. Our identity tracker (§3.1)tracks hand movement, the goal of the action recognition
6

(X, Y, Z)
World coordinates
Camera coordinates
(x, y)XYZ
xy
(Xc, Yc, Zc)
Transform
Figure 10: When the shopper’s hand is obscured, Grab infersproximity to shelves by determining when a shoppers anklejoint is near a shelf.
problem is to associate each shopper’s hand with the item heor she picked up from the shelf. We model this associationbetween shopper’s hand k and item m as a probability pk,mderived from fusing cameras, weight sensors, and RFID tags(Figure 9).pk,m is itself derived from association probabilitiesfor each of the devices, in a manner described below. Giventhese probabilities, we then solve the association problemusing a maximum weight bipartite matching. In the followingparagraphs, we discuss details of each of these steps.Proximity event detection. Before determining associationprobabilities, we need to determine when a shopper’s handapproaches a shelf. This proximity event is determined usingthe identity tracker module’s gesture tracking (§3.1). Know-ing where the hand is, Grab uses image analysis to determinewhen a hand is close to a shelf. For this, Grab requires aninitial configuration step, where store administrators specifycamera view parameters (mounting height, field of view, reso-lution etc.), and which shelf/shelves are where in the cameraview. Grab uses a threshold pixel distance from hand to theshelf to define proximity, and its identity tracker reports startand finish times for when each hand is within the proximityof a given shelf (a proximity event).
In some cases, the hand may not be visible. In these cases,Grab estimates proximity using the skeletal keypoints iden-tified by OpenPose (§3.1). Specifically, Grab knows, fromthe initial configuration step, the camera position (includingits height), its orientation, and its field of view. From this,and simple geometry, it can estimate the pixel position of anypoint on the visible floor. In particular, it can estimate thepixel location of a shopper’s ankle joint (Figure 10), and usethis to estimate the distance to a shelf. When the ankle jointis occluded, we extrapolate its position from the visible partof the skeleton to estimate the position.Association probabilities from the camera. When a prox-imity event starts, Grab starts tracking the hand and any itemin the hand. It uses the color histogram of the item to classifythe item. To ensure robust classification, Grab performs (Fig-ure 11(a)) (a) background subtraction to remove other itemsthat may be visible and (b) eliminates the hand itself from theitem by filtering out pixels whose color matches typical skin
colors. Grab extracts a 384 dimension color histogram fromthe remaining pixels.
During an initial configuration step, Grab requires storeadministrators to specify which objects are on which shelves.Grab then builds, for each shelf (a single shelf might contain10-15 different types of items), builds a feature-based kNNclassifier (chosen both for speed and accuracy). Then, duringactual operation, when an item is detected, Grab runs thisclassifier on its features. The classifier outputs an orderedlist of matching items, with associated match probabilities.Grab uses these as the association probabilities from the cam-era. Thus, for each hand i and each item j, Grab outputs thecamera-based association probability.Association probabilities from weight sensors. In principle,a weight sensor can determine the reduction in total weightwhen an item is removed from the shelf. Then, knowing whichshopper’s hand was closest to the shelf, we can associate theshopper with the item. In practice, this association needs toconsider real-world behaviors. First, if two shoppers concur-rently remove two items of different weights (say a can ofPepsi and a peanut butter jar), the algorithm must be able toidentify which shopper took which item. Second, if two shop-pers are near the shelf, and two cans of Pepsi were removed,the algorithm must be able to determine if a single shoppertook both, or each shopper took one. To increase robustnessto these, Grab breaks this problem down into two steps: (a) itassociates a proximity event to dynamics in scale readings,and (b) then associates scale dynamics to items by detectingweight changes.
Associating proximity events to scale dynamics. Weightscales sample readings at 30 Hz. At these rates, we haveobserved that, when a shopper picks up an item or deposits anitem on a shelf, there is a distinct "bounce" (a peak when anitem is added, or a trough when removed) because of inertia(Figure 11(b)). If d is the duration of this peak or trough, andd ′ is the duration of the proximity event, we determine theassociation probability between the proximity event and thepeak or trough as the ratio of the intersection of the two tothe union of the two. As Figure 11(b) shows, if two shopperspick up items at almost the same time, our algorithm is ableto distinguish between them. Moreover, to prevent shoppersfrom attempting to confuse Grab by temporarily activatingthe weight scale with a finger or hand, Grab filters out scaledynamics where there is high frequency of weight change.
Associating scale dynamics to items. The next challenge isto measure the weight of the item removed or deposited. Evenwhen there are multiple concurrent events, the 30 Hz samplingrate ensures that the peaks and troughs of two concurrentactions are likely distinguishable (as in Figure 11(b)). In thiscase, we can estimate the weight of each item from the sensorreading at the beginning of the peak or trough ws and the
7

Background subtraction
Original image with hand detection
Hand Elimination
VisualFeatures
(a)
Proximity Threshold
Hand-A Hand-B
Weight Drop 1
Weight Drop 2
(b) (c)Figure 11: (a) Vision based item detection does background subtraction and removes the hand outline. (b) Weight sensor readings arecorrelated with hand proximity events to assign association probabilities. (c) Tag RSSI and hand movements are correlated, which helpsassociate proximity events to tagged items.
reading at the end we . Thus |ws −we | is an estimate of theitem weight w . Now, from the configuration phase, we knowthe weights of each type of item on the shelf. Define δ j as|w −w j | wherew j is the known weight of the j-th type of itemin the shelf. Then, we say that the probability that the itemremoved or deposited was the j-th item is given by 1/δj∑
i (1/δi ) .This definition accounts for noise in the scale (the estimatesfor w might be slightly off) and for the fact that some itemsmay be very similar in weight.
Combining these association probabilities. From thesesteps, we get two association probabilities: one associating aproximity event to a peak or trough, another associating thepeak or trough to an item type. Grab multiplies these two toget the probability, according to the weight sensor, that handi picked item j.Association probabilities from RFID tag. For items whichhave an RFID tag, it is trivial to determine which item wastaken (unlike with weight or vision sensors), but it is stillchallenging to associate proximity events with the correspond-ing items. For this, we leverage the fact that the tag’s RSSIbecomes weaker as it moves away from the RFID reader.Figure 11(c) illustrates an experiment where we moved anitem repeatedly closer and further away from a reader; no-tice how the changes in the RSSI closely match the distanceto the reader. In smart shelves, the RFID reader is mountedon the back of the shelf, so that when an object is removed,its tag’s RSSI decreases. To determine the probability that agiven hand caused this decrease, we use probability-basedDynamic Time Warping [45], which matches the time seriesof hand movements with the RSSI time series and assignsa probability which measures the likelihood of associationbetween the two. We use this as the association probabilityderived from the RFID tag.Putting it all together. In the last step, Grab formulates an as-signment problem to determine which hand to associate withwhich item. First, it determines a time window consisting of aset of overlapping proximity events. Over this window, it first
uses the association probabilities from each sensor to definea composite probability pk,m between the k-th hand and them-th item: pk,m is a weighted sum of the three probabilitiesfrom each sensor (described above), with the weights beingempirically determined.
Then, Grab formulates the assignment problem as an opti-mization problem:
maxk,m
∑pk,mzk,m
s.t.∑k ∈H
zk,m ≤ 1 ∀m ∈ I ,∑l ∈It
zk,l ≤ ul ∀k ∈ H
where H is the set of hands, I is the set of items, and It isthe set of item types, and zk,m is an indicator variable thatdetermines if hand k picked up item m. The first constraintmodels the fact that each item can be removed or depositedby one hand, and the second models the fact that sometimesshoppers can pick up more than one item with a single hand:ul is a statically determined upper bound on the number ofitems of the l-th item that a shopper can pick up using a singlehand (e.g., it may be physically impossible to pick up morethan 3 bottles of a specific type of shampoo). This formulationis a max-weight bipartite matching problem, which we canoptimally solve using the Hungarian [67] algorithm.
3.3 GPU MultiplexingBecause retailer margins can be small, Grab needs to mini-mize overall costs. The computing infrastructure (specifically,GPUs) is an important component of this cost. In what wehave described so far, each camera in the store needs a GPU.
Grab actually enables multiple cameras to be multiplexedon one GPU. It does this by avoiding running OpenPose onevery frame. Instead, Grab uses a tracker to track joint posi-tions from frame to frame: these tracking algorithms are fastand do not require the use of the GPU. Specifically, supposeGrab runs OpenPose on frame i. On that frame, it computes
8

Figure 12: ORB features from each joint bounding box aretracked across successive frames to permit multiplexing theGPU across multiple cameras.
ORB [84] features around every joint (Figure 12(a)): ORBfeatures can be computed faster than previously proposedfeatures like SIFT and SURF. Then, for each joint, it identi-fies the position of the joint in frame i + 1 by matching ORBfeatures between the two frames. Using this it can reconstructthe skeleton in frame i + 1 without running OpenPose on thatframe.
Grab uses this to multiplex a GPU over N different cameras.It runs OpenPose from a frame on each camera in a round-robin fashion. If a frame has been generated by the k-thecamera, but Grab is processing a frame from another (say, them-th) camera, then Grab runs feature-based tracking on theframe from the k camera. Using this technique, we show thatGrab is able to scale to using 4 cameras on one GPU withoutsignificant loss of accuracy (§4).
4 EVALUATIONWe now evaluate the end-to-end accuracy of Grab and explrethe impact of each of our optimizations on overall perfor-mance. 2
4.1 Grab ImplementationWeight-sensing Module. To mimic weight scales on smartshelves, we built scales costing $6, with fiberglass boardsand 2 kg, 3 kg, 5G kg pressure sensors. The sensor output isconverted by the SparkFun HX711 load cell amplifier [19]to digital serial signals. An Arduino Uno Micro Control Unit(MCU) [6] (Figure 13(a)-left) batches data from the ADCsand sends it to a server. The MCU has nine sets of serialTx and Rx so it can collect data from up to nine sensorssimultaneously. The sensors have a precision of around 510 g,with an effective sampling rate of 30 Hz3.RFID-sensing Module. For RFID, we use the SparkFunRFID modules with antennas and multiple UHF passive RFIDtags [32] (Figure 13(a)-right). The module can read up to 150tags per second and its maximum detection range is 4 m with
2Demo video of Grab: https://vimeo.com/2452741923The HX711 can sample at 80 Hz, but the Arduino MCU, when used with severalweight scales, limits the sampling rate to 30 Hz.
a) b)
RFID Antenna
RFID Module
Arduino MCU
RFID Tag
Weight Scale
ADCArduino
MCU
(a) (b)Figure 13: (a) Left: Weight sensor hardware, Right: RFID hard-ware; (b) Grab sample output.
and antenna. The RFID module interfaces with the ArduinoMCU to read data from tags.Video input. We use IP cameras [4] for video recording. Inour experiments, the cameras are mounted on merchandiseshelves and they stream 720p video using Ethernet. We alsotried webcams and they achieved similar performance (detec-tion recall and precision) as IP cameras.Identity tracking and action recognition. These modulesare built on top of the OpenPose [28] library’s skeleton detec-tion algorithm. As discussed earlier, we use a modified limbassociation algorithm. Our other algorithms are implementedin Python, and interface with OpenPose using a boost.pythonwrapper. Our implementation has over 4K lines of code.
4.2 Methodology, Metrics, and DatasetsIn-store deployment. To evaluate Grab, we collected tracesfrom an actual deployment in a retail store. For this tracecollection, we installed the sensors described above in twoshelves in the store. First, we placed two cameras at the endsof an aisle so that they could capture both the people’s poseand the items on the shelves. Then, we installed weight scaleson each shelf. Each shelf contains multiple types of items,and all instances of a single item were placed on a single shelfat the beginning of the experiment (during the experiment,we asked users to move items from one shelf to another totry to confuse the system, see below). In total, our shelvescontained 19 different types of items. Finally, we placed theRFID reader’s antenna behind the shelf, and we attachedRFID tags to all instances of 8 types of items.Trace collection. We then recorded five hours worth of sensordata from 41 users who registered their faces with Grab. Weasked these shoppers to test the system in whatever way theywished to (Figure 13(b)). The shoppers selected from amongthe 19 different types of items, and interacted with the items(either removing or depositing them) a total of 307 times.Our cameras saw an average of 2.1 shoppers and a maximumof 8 shoppers in a given frame. In total, we collected over10GB of video and sensor data, using which we analyze Grab’performance.Adversarial actions. During the experiment, we also askedshoppers to perform three kinds of adversarial actions. (1)
9

Item-switching: The shopper takes two items of similar coloror similar weight and then puts one back, or takes one itemand puts it on a different scale; (2) Hand-hiding: The shop-per hides the hand from the camera and grabs the item; (3)Sensor-tampering: The shopper presses the weight scale withtheir hand. Of the 307 recorded actions, nearly 40% were ad-versarial: 53 item-switching, 34 hand-hiding, and 31 sensor-tampering actions.Metrics. To evaluate Grab’s accuracy, we use precision andrecall. In our context, precision is the ratio of true positivesto the sum of true positives and false positives. Recall is theratio of true positives to the sum of true positives and falsenegatives. For example, suppose a shopper picks items A, B,and C, but Grab shows that she picks items A, B, D, and E. Aand B are correctly detected so the true positives are 2, but Cis missing and is a false negative. The customer is wronglyassociated with D and E so there are 2 false positives. In thisexample, recall is 2/3 and precision is 2/4.
4.3 Accuracy of GrabOverall precision and recall. Figure 14(a) shows the preci-sion and recall of Grab, and quantifies the impact of usingdifferent combinations of sensors: using vision only (V Only),weight only (W only), RFID only (R only) or all possiblecombinations of two of these sensors. Across our entire trace,Grab achieves a recall of nearly 94% and a precision of over91%. This is remarkable, because in our dataset nearly 40%of the actions are adversarial (§4.2). We dissect Grab failuresbelow and show how these are within the loss margins thatretailers face today due to theft or faulty equipment.
Using only a single sensor4 degrades recall by 12-37%and precision by 16-36% (Figure 14(a)). This illustrates theimportance of fusing readings from multiple sensors for as-sociating proximity events with items (§3.2). The biggestloss of accuracy comes from using only the vision sensorsto detect items. RFID sensors perform the best, since RFIDcan accurately determine which item was selected5. Even so,an RFID-only deployment has 12% lower recall and 16%lower precision. Of the sensor combinations, using weightand RFID sensors together comes closest to the recall perfor-mance of the complete system, losing only about 3% in recall,but 10% in precision.Adversarial actions. Figure 14(b) shows precision and recallfor only those actions in which users tried to switch items.In these cases, Grab is able to achieve nearly 90% precisionand recall, while the best single sensor (RFID) has 7% lower
4For computing the association probabilities §3.2. Cameras are still used for identitytracking and proximity event detection.5In general, since RFID is expensive, not all objects in a store will have RFID tags. Inour deployment, a little less than half of the item types were tagged, and these numbersare calculated only for tagged items.
recall and 13% lower precision, and the best 2-sensor combi-nation (weight and RFID) has 5% lower precision and recall.As expected, using a vision sensor or weight sensor alonehas unacceptable performance because the vision sensor can-not distinguish between items that look alike and the weightsensor cannot distinguish items of similar weight.
Figure 14(c) shows precision and recall for only those ac-tions in which users tried to hide the hand from the camerawhen picking up items. In these cases, Grab estimates prox-imity events from the proximity of the ankle joint to the shelf(§3.2) and achieves a precision of 80% and a recall of 85%.In the future, we hope to explore cross-camera fusion to bemore robust to these kinds of events. Of the single sensors,weight and RFID both have more than 24% lower recall andprecision than Grab. Even the best double sensor combinationhas 12% lower recall and 20% lower precision.
Finally, Figure 14(d) shows precision and recall only forthose items in which the user trying to tamper with the weightsensors. In these cases, Grab is able to achieve nearly 87%recall and 80% precision. RFID, the best single sensor, hasmore than 10% lower precision and recall, while predictably,vision and RFID have the best double sensor performancewith 5% lower recall and comparable precision to Grab.
In summary, Grab has slightly lower precision and recallfor the adversarial cases and these can be improved withalgorithmic improvements, its overall precision and recallon a trace with nearly 40% adversarial actions is over 91%.When we analyze only the non-adversarial actions, Grab hasa precision of 95.8% and a recall of 97.2%.Taxonomy of Grab failures. Grab is unable to recall 19of the 307 events in our trace. These failures fall into twocategories: those caused by identity tracking, and those byaction recognition. Five of the 19 failures are caused either bywrong face identification (2 in number), false pose detection(2 in number) (Figure 13(c)), or errors in pose tracking (one).The remaining failures are all caused by inaccuracy in actionrecognition, and fall into three categories. First, Grab usescolor histograms to detect items (§3.2), but these can be sensi-tive to lighting conditions (e.g., a shopper takes an item fromone shelf and puts it in another when the lighting condition isslightly different) and occlusion (e.g., a shopper deposits anitem into a group of other items which partially occlude theitems). Incomplete background subtraction can also reducethe accuracy of item detection. Second, our weight scaleswere robust to noise but sometimes still could not distinguishbetween items of similar, but not identical, weight. Third,our RFID-to-proximity event association failed at times whenthe tag’s RFID signal disappeared for a short time from thereader, possibly because the tag was temporarily occluded by
10

Figure 14: Grab has high precision and recall across our entire trace (a), relative to other alternatives that only use a subset of sensors(W: Weight; V: Vision; R: RFID), even under adversarial actions such as (b) Item-switching; (c) Hand-hiding; (d) Sensor-Tampering.
other items. Each of these failure types indicates directions orfuture work for Grab.Contextualizing the results. From the precision/recall re-sults, it is difficult to know if Grab is within the realm offeasibility for use in today’s retail stores. Grab’s failures fallinto two categories: Grab associates the wrong item with ashopper, or it associates an item with the wrong shopper. Thefirst can result in inventory loss, the second in overcharging acustomer. A survey of retailers [27] estimates the inventoryloss ratio (if a store’s total sales are $100, but $110 worthof goods were taken from the store, the inventory loss rateis 10%) in today’s stores to be 1.44%. In our experiments,Grab’s failures result in only 0.79% inventory loss. Anotherstudy [34] suggests that faulty scanners can result in up to3% overcharges on average, per customer. In our experiments,we see a 2.8% overcharge rate. These results are encouragingand suggest that Grab may be with the realm of feasibility,but larger scale experiments are needed to confirm this. Ad-ditional investments in sensors and cameras, and algorithmimprovements, could further improve Grab’s accuracy.
4.4 The Importance of EfficiencyGrab is designed to process data in near real-time so thatcustomers can be billed automatically as soon as they leavethe store. For this, computational efficiency is important tolower cost (§4.5), but also to achieve high processing rates inorder to maintain accuracy.Impact of lower frame rates. If Grab is unable to achieve ahigh enough frame rate for processing video frames, it canhave significantly lower accuracy. At lower frame rates, Grabcan fail in three ways. First, a customer’s face may not be visi-ble at the beginning of the track in one camera. It usually takesseveral seconds before the camera can capture and identifythe face. At lower frame rates, Grab may not capture frameswhere the shopper’s face is visible to the camera, so it might
Figure 15: Grab needs a frame rate of at least 10 fps for suf-ficient accuracy, reducing identity switches and identificationdelay.
take longer for it to identify the shopper. Figure 15(a) showsthat this identification delay decreases with increasing framerate approaching sub-second times at about 10 fps. Second,at lower frame rates, the shopper moves a greater distancebetween frames, increasing the likelihood of identity switcheswhen the tracking algorithm switches the identity of the shop-per from one registered user to another. Figure 15(b) showsthat the ratio of identity switches approaches negligible val-ues only after about 8 fps. Finally, at lower frame rates, Grabmay not be able to capture the complete movement of thehand towards the shelf, resulting in incorrect determinationof proximity events and therefore reduced overall accuracy.Figure 15(c) shows precision6 approaches 90% only above10 fps.Infeasibility of a DNN-only architecture. In §3 we arguedthat, for efficiency, Grab could not use separate DNNs fordifferent tasks such as identification, tracking, and action6In this and subsequent sections, we focus on precision, since it is lower than recall(§4.3), and so provides a better bound on Grab performance.
11
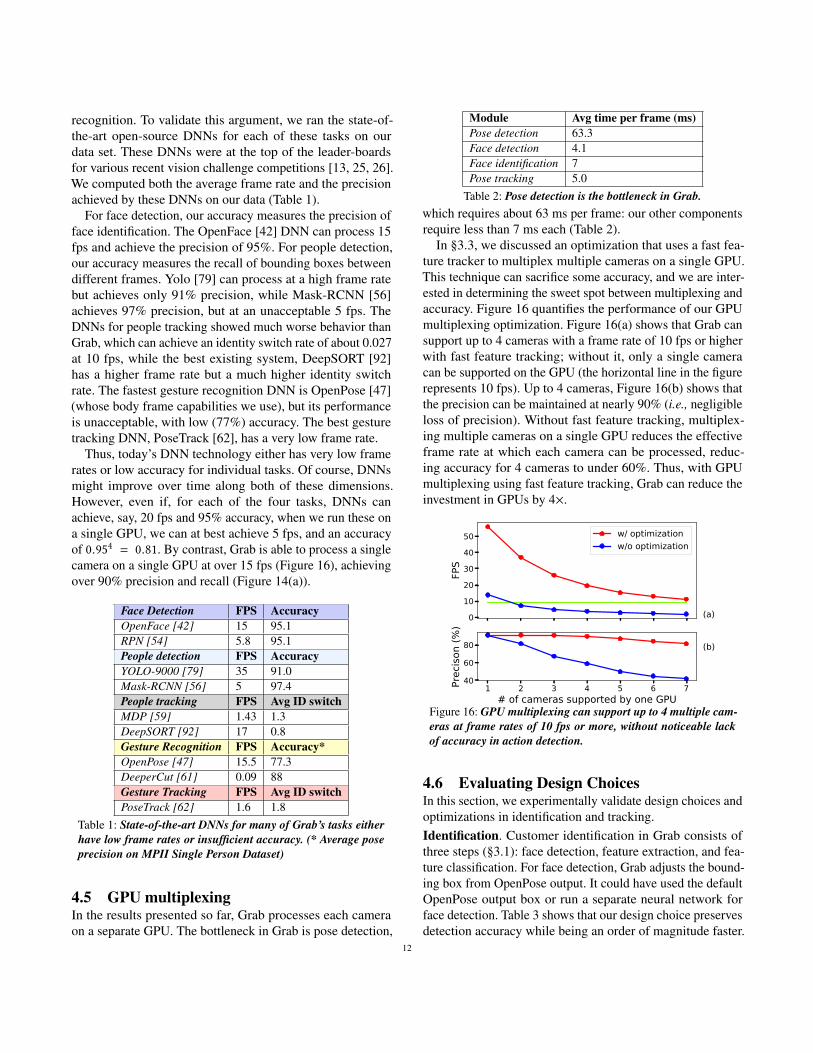
recognition. To validate this argument, we ran the state-of-the-art open-source DNNs for each of these tasks on ourdata set. These DNNs were at the top of the leader-boardsfor various recent vision challenge competitions [13, 25, 26].We computed both the average frame rate and the precisionachieved by these DNNs on our data (Table 1).
For face detection, our accuracy measures the precision offace identification. The OpenFace [42] DNN can process 15fps and achieve the precision of 95%. For people detection,our accuracy measures the recall of bounding boxes betweendifferent frames. Yolo [79] can process at a high frame ratebut achieves only 91% precision, while Mask-RCNN [56]achieves 97% precision, but at an unacceptable 5 fps. TheDNNs for people tracking showed much worse behavior thanGrab, which can achieve an identity switch rate of about 0.027at 10 fps, while the best existing system, DeepSORT [92]has a higher frame rate but a much higher identity switchrate. The fastest gesture recognition DNN is OpenPose [47](whose body frame capabilities we use), but its performanceis unacceptable, with low (77%) accuracy. The best gesturetracking DNN, PoseTrack [62], has a very low frame rate.
Thus, today’s DNN technology either has very low framerates or low accuracy for individual tasks. Of course, DNNsmight improve over time along both of these dimensions.However, even if, for each of the four tasks, DNNs canachieve, say, 20 fps and 95% accuracy, when we run these ona single GPU, we can at best achieve 5 fps, and an accuracyof 0.954 = 0.81. By contrast, Grab is able to process a singlecamera on a single GPU at over 15 fps (Figure 16), achievingover 90% precision and recall (Figure 14(a)).
Face Detection FPS AccuracyOpenFace [42] 15 95.1RPN [54] 5.8 95.1People detection FPS AccuracyYOLO-9000 [79] 35 91.0Mask-RCNN [56] 5 97.4People tracking FPS Avg ID switchMDP [59] 1.43 1.3DeepSORT [92] 17 0.8Gesture Recognition FPS Accuracy*OpenPose [47] 15.5 77.3DeeperCut [61] 0.09 88Gesture Tracking FPS Avg ID switchPoseTrack [62] 1.6 1.8
Table 1: State-of-the-art DNNs for many of Grab’s tasks eitherhave low frame rates or insufficient accuracy. (* Average poseprecision on MPII Single Person Dataset)
4.5 GPU multiplexingIn the results presented so far, Grab processes each cameraon a separate GPU. The bottleneck in Grab is pose detection,
Module Avg time per frame (ms)Pose detection 63.3Face detection 4.1Face identification 7Pose tracking 5.0
Table 2: Pose detection is the bottleneck in Grab.which requires about 63 ms per frame: our other componentsrequire less than 7 ms each (Table 2).
In §3.3, we discussed an optimization that uses a fast fea-ture tracker to multiplex multiple cameras on a single GPU.This technique can sacrifice some accuracy, and we are inter-ested in determining the sweet spot between multiplexing andaccuracy. Figure 16 quantifies the performance of our GPUmultiplexing optimization. Figure 16(a) shows that Grab cansupport up to 4 cameras with a frame rate of 10 fps or higherwith fast feature tracking; without it, only a single cameracan be supported on the GPU (the horizontal line in the figurerepresents 10 fps). Up to 4 cameras, Figure 16(b) shows thatthe precision can be maintained at nearly 90% (i.e., negligibleloss of precision). Without fast feature tracking, multiplex-ing multiple cameras on a single GPU reduces the effectiveframe rate at which each camera can be processed, reduc-ing accuracy for 4 cameras to under 60%. Thus, with GPUmultiplexing using fast feature tracking, Grab can reduce theinvestment in GPUs by 4×.
Figure 16: GPU multiplexing can support up to 4 multiple cam-eras at frame rates of 10 fps or more, without noticeable lackof accuracy in action detection.
4.6 Evaluating Design ChoicesIn this section, we experimentally validate design choices andoptimizations in identification and tracking.Identification. Customer identification in Grab consists ofthree steps (§3.1): face detection, feature extraction, and fea-ture classification. For face detection, Grab adjusts the bound-ing box from OpenPose output. It could have used the defaultOpenPose output box or run a separate neural network forface detection. Table 3 shows that our design choice preservesdetection accuracy while being an order of magnitude faster.
12

For feature extraction, we compared our ResNet face featureswith another face feature (FaceNet), with a neural net gener-ated body feature, and with a body color histogram. Table 4shows that our approach has the highest accuracy. Finally, forfeature classification, we tried three approaches: comparingfeatures’ cosine distance, using kNN, or using a simple neuralnetwork. Their re-training time7, running speed, and accu-racy, are shown in Table 5. We can see that kNN has the bestaccuracy with retraining overhead of 2 s and classificationoverhead less than 2 ms.
Speed (ms/img) Accuracy (%)Adjusted box (Grab) 4.1 95.1Original box from pose <1 83.0Box from DNN model 93 95.1
Table 3: Adjusting the face bounding box in Grab has compara-ble accuracy to a neural network based approach, while havingsignificantly lower overhead.
Method AccuracyGrab’s model (ResNet) 95.1%FaceNet 89.4%Body deep feature 51.2%Color histogram 31.7%
Table 4: Grab’s ResNet based face features have the highestaccuracy.
Tracking. Replacing our pose tracker with a bounding boxtracker [92] can result in below 50% precision. Removing thelimb association optimization drops precision by about 11%,and removing the optimization that estimates proximity whenthe hand is not visible reduces precision by over 7%. Finally,removing lazy tracking, which permits accurate tracking evenin the presence of occlusions can reduce precision by over15%. Thus, each optimization is necessary to achieve highprecision.
5 RELATED WORKWe are not aware of published work on end-to-end design andevaluation of cashier-free shopping.Commercial cashier-free shopping systems. Amazon Gowas the first set of stores to permit cashier-free shopping.Several other companies have deployed demo stores, includ-ing Standard Cognition [33], Taobao [35], and Bingobox [8].Amazon Go and Standard Cognition use deep learning andcomputer vision to determine shopper-to-item association([2, 17, 22, 23]). Amazon Go does not use RFID [2, 22]but needs many ceiling-mounted cameras. Imagr[20] uses acamera-equipped cart to recognize the items put into the cartby the user. Alibaba and Bingobox use RFID reader to scanall items held by the customer at a "checkout gate" ([11, 12]).Grab incorporates many of these elements in its design, but7Fast re-training is essential to minimize the time the customer needs to wait betweenregistration and shopping.
Cosine Dist kNN Neural NetRetraining latency (s) 0 2.1 68.6Classification latency (ms) 0.1* 1.9 10.7Accuracy (%) 75.6 95.1 92.8Table 5: Grab’s kNN-based algorithm has highest accuracywhile having low retraining and classification latency. (* Co-sine distance runtime is 0.1 ms per person)
uses a judicious combination of complementary sensors (vi-sion, RFID, weight scales).
Person identification. Person (re)-identification hasused face features and body features. Body-feature-basedre-identification [43, 49, 94] can achieve the precision of upto 80%, insufficient for cashier-free shopping. Proprietaryface feature based re-identification [5, 16, 31, 38] can reach99% precision. Recent academic research using face featureshas achieved an accuracy of more than 95% on publicdatasets, but such systems are either unavailable [50, 55, 95]or too slow [74, 91]. Grab uses fast feature-based facere-identification with comparable accuracy while using apose tracker to accurately bound the face (§3.1).
People tracking. Bounding box based trackers [71, 83, 92]can track shopper movement, but can be less effective incrowds (§4.4) since they do not detect limbs and hands. Somepose trackers [60, 63] can do pose detection and trackingat same time, but are too slow for Grab (§4.4) which usesa skeleton-based pose tracker both for identity tracking andgesture recognition.
Action detection. Action detection is an alternative ap-proach to identifying shopping actions. Publicly availablestate-of-the-art DNN-based solutions [52, 57, 65, 88] havenot yet been trained for shopping actions, so their precisionand recall in our setting is low.
Item detection and tracking. Prior work has explored itemidentification using Google Glass [53] but such devices arenot widely deployed. RFID tag localization can be used foritem tracking [64, 86, 87] but that line of work does notconsider frequent tag movements, tag occlusion, or otheradversarial actions. Vision-based object detectors [51, 56,80] can be used to detect items, but need to be trained forshopping items and can be ineffective under occlusions andpoor lighting (§4.3). Single-instance object detection scalesbetter for training items but has low accuracy [58, 66].
6 CONCLUSIONCashier-free shopping systems can help improve the shoppingexperience, but pose significant design challenges. Grab is acashier-free shopping system that uses a skeleton-based posetracking DNN as a building block, but develops lightweightvision processing algorithms for shopper identification andtracking, and uses a probabilistic matching technique forassociating shoppers with items they purchase. Grab achieves
13

over 90% precision and recall in a data set with up to 40%adversarial actions, and its efficiency optimizations can reduceinvestment in computing infrastructure by up to 4×. Muchfuture work remains including obtaining results from longer-term deployments, improvements in robust sensing in theface of adversarial behavior, and exploration of cross-camerafusion to improve Grab’s accuracy even further.
REFERENCES[1] Amazon Go. https://www.amazon.com/b?node=16008589011.[2] Amazon Go is Finally a Go. https://www.geekwire.com/2018/check-
no-checkout-amazon-go-automated-retail-store-will-finally-open-public-monday/.
[3] Amazon’s Store of the Future is Delayed. https://www.cnet.com/news/amazon-go-so-far-is-a-no-show-now-what/.
[4] Amcrest 720P Security Wireless IP Camera. https://amcrest.com/amcrest-720p-wifi-video-security-ip-camera-pt.html.
[5] Apple Face ID. https://support.apple.com/en-us/HT208108.[6] Arduino Uno MCU. https://store.arduino.cc/usa/arduino-uno-rev3.[7] Big Y to Eliminate All Self Checkout Kiosks. http://www.masslive.com/business-
news/index.ssf/2011/09/big_y_to_eliminate_all_self-checkout_kio.html.[8] Bingobox. https://www.techinasia.com/china-version-amazon-go-bingobox-
funding.[9] Cashier Free Shopping is the Trend. https://www.thirdchannel.com/mind-the-
store/adopting-new-technologies-in-store.[10] Checkout Time Limit Around Four Minutes. http://www.retailwire.com/
discussion/checkout-time-limit-around-four-minutes/.[11] China’s Brick-and-Mortar Stores Fight Back with Tech. https://medium.com/
transforming-retail/as-ecommerce-steamrolls-retail-chinas-brick-and-mortar-/stores-fight-back-with-tech-a1b97da1d494.
[12] China’s Convenience Stores No Longer Need People. http://technode.com/2017/07/04/chinas-convenience-stores-no-longer-need-people-bingobox/.
[13] COCO Challenge. http://cocodataset.org/.[14] DLIB Library. https://github.com/davisking/dlib.[15] Face Feature with Deep Neural Network. https://github.com/ageitgey/face_
recognition/.[16] Face Recognition Using Amazon Rekognition. https://aws.amazon.com/blogs/
machine-learning/build-your-own-face-recognition-service-using-amazon-rekognition/.
[17] How ’Amazon Go’ works. https://www.geekwire.com/2016/amazon-go-works-technology-behind-online-retailers-/groundbreaking-new-grocery-store/.
[18] How Smart Shelf Technology is Reshaping the Retail Industry. https://www.datexcorp.com/smart-shelf-technology-reshaping-retail-industry/.
[19] HX711 ADC chip. https://www.sparkfun.com/products/13879.[20] Imagr. http://www.imagr.co/.[21] In Retail Small is Big. https://www.rangeme.com/blog/in-retail-small-is-big/.[22] Inside Amazon Go. https://www.nytimes.com/2018/01/21/technology/inside-
amazon-go-a-store-of-the-future.html.[23] Is The End Of The Checkout Near? https://www.forbes.com/sites/neilstern/2017/
08/25/is-the-end-of-the-checkout-near/#59e87b145d21.[24] Making Self-Checkout Work: Learning From Albertsons. https:
//www.forbes.com/sites/bryanpearson/2016/12/06/making-self-checkout-work-learning-from-albertsons/#5324dc8c7c11.
[25] MOT: Multiple Object Tracking Benchmark. https://motchallenge.net/.[26] MPII Human Pose Dataset. http://human-pose.mpi-inf.mpg.de/.[27] NATIONAL RETAIL SECURITY SURVEY 2018. https://nrf.com/resources/
retail-library/national-retail-security-survey-2018.[28] OpenPose. https://github.com/CMU-Perceptual-Computing-Lab/openpose.[29] RFID tags. https://www.sparkfun.com/products/14147.[30] Self-Checkout at Walmart Results in More Theft Charges. http:
//www.amacdonaldlaw.com/blog/2014/03/self-checkout-at-wal-mart-results-in-more-theft-charges.shtml.
[31] Sighthound Face Recognition Performance. https://www.sighthound.com/technology/face-recognition/benchmarks/pubfig200.
[32] Sparkfun RFID Module and Antenna. https://www.sparkfun.com/products/14066,https://www.sparkfun.com/products/14131.
[33] Standard Cognition. https://www.standardcognition.com/.[34] Supermarket Scanner Errors. https://abcnews.go.com/GMA/ConsumerNews/
avoid-costly-supermarket-grocery-store-scanner-mistakes/story?id=11619157.[35] Taobao Cashier-Free Demo Store. http://mashable.com/2017/07/12/taobao-
china-store/#57OXUGTQVaqg.[36] Why Retailers Must Adopt a Technology Mind-set. http://www.mckinsey.
com/~/media/mckinsey/dotcom/client_service/bto/pdf/mobt32_10-13_niemeierinterview_r5.ashx.
[37] Will Smart Shelves Ever be Smart Enough for Kroger and Other Retail-ers? http://www.retailwire.com/discussion/will-smart-shelves-ever-be-smart-enough-for-kroger-and/-other-retailers/.
[38] Yitu Wins the 1st Place in Identification Accuracy. https://www.sighthound.com/technology/face-recognition/benchmarks/pubfig200.
[39] Online and In-store Shopping: Competition or Complements? http://genyu.net/2014/12/09/online-and-in-store-shopping-competition-or-complements/, 2017.
[40] Study Finds Shoppers Prefer Brick-And-Mortar Stores to Amazon andEBay. https://www.forbes.com/sites/barbarathau/2014/07/25/report-amazons-got-nothing-on-brick-and-mortar-stores/#7557597262d0, 2017.
[41] The Retailer’s Dilemma: a Brick-and-Mortar or Brand Problem. https://go.forrester.com/ep06-the-retailers-dilemma/, 2017.
[42] B. Amos, B. Ludwiczuk, and M. Satyanarayanan. Openface: A General-purposeFace Recognition Library with Mobile applications. CMU School of ComputerScience, 2016.
[43] S. Bai, X. Bai, and Q. Tian. Scalable person re-identification on supervisedsmoothed manifold. In CVPR, 2017.
[44] T. Baltrušaitis, P. Robinson, and L.-P. Morency. Openface: an Open Source FacialBehavior Analysis toolkit. In Applications of Computer Vision (WACV), 2016IEEE Winter Conference on, 2016.
[45] M. A. Bautista, A. Hernández-Vela, V. Ponce, X. Perez-Sala, X. Baró, O. Pu-jol, C. Angulo, and S. Escalera. Probability-based Dynamic Time Warping forGesture Recognition on Rgb-d data. In Advances in Depth Image Analysis andApplications. Springer, 2013.
[46] M. K. bin Mohd Sidik, M. S. bin Sunar, I. bin Ismail, M. K. bin Mokhtar, et al. AStudy on Natural Interaction for Human Body Motion Using Depth Image data.In Digital Media and Digital Content Management (DMDCM), 2011 Workshopon, 2011.
[47] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh. Realtime Multi-person 2d PoseEstimation Using Part Affinity fields. In CVPR, number 2, 2017.
[48] T.-Y. Chen, M.-Y. Wu, Y.-H. Hsieh, and L.-C. Fu. Deep Learning for IntegratedHand Detection and Pose estimation. In Pattern Recognition (ICPR), 2016 23rdInternational Conference on, 2016.
[49] W. Chen, X. Chen, J. Zhang, and K. Huang. Beyond triplet loss: a deep quadrupletnetwork for person re-identification. In Proc. CVPR, 2017.
[50] X. Chen. Face Recognition with Contrastive Convolution. In Proceedings of theEuropean Conference on Computer Vision (ECCV), pages 118–134, 2018.
[51] Y. Chen, W. Li, C. Sakaridis, D. Dai, and L. Van Gool. Domain Adaptive FasterR-cnn for Object Detection in the Wild. In Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition, pages 3339–3348, 2018.
[52] A. Dave, O. Russakovsky, and D. Ramanan. Predictive-corrective Networks forAction detection. arXiv preprint arXiv:1704.03615, 2017.
[53] K. Ha, Z. Chen, W. Hu, W. Richter, P. Pillai, and M. Satyanarayanan. TowardsWearable Cognitive assistance. In Proceedings of the 12th annual internationalconference on Mobile systems, applications, and services, 2014.
[54] Z. Hao, Y. Liu, H. Qin, J. Yan, X. Li, and X. Hu. Scale-aware Face detection.In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2017.
[55] M. Hayat, S. H. Khan, N. Werghi, and R. Goecke. Joint Registration and Repre-sentation Learning for Unconstrained Face identification. In Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition, 2017.
[56] K. He, G. Gkioxari, P. Dollár, and R. Girshick. Mask R-cnn. In Computer Vision(ICCV), 2017 IEEE International Conference on, 2017.
[57] F. C. Heilbron, W. Barrios, V. Escorcia, and B. Ghanem. Scc: Semantic ContextCascade for Efficient Action detection. In IEEE Conference on Computer Visionand Pattern Recognition (CVPR), 2017.
[58] D. Held, S. Thrun, and S. Savarese. Robust Single-view Instance recognition. InRobotics and Automation (ICRA), 2016 IEEE International Conference on, 2016.
[59] R. Henschel, L. Leal-Taixé, D. Cremers, and B. Rosenhahn. Improvements toFrank-wolfe Optimization for Multi-detector Multi-object tracking. CoRR, 2017.
[60] E. Insafutdinov, M. Andriluka, L. Pishchulin, S. Tang, E. Levinkov, B. Andres,and B. Schiele. Articulated Multi-person Tracking in the wild. In CVPR, 2017.
[61] E. Insafutdinov, L. Pishchulin, B. Andres, M. Andriluka, and B. Schiele. Deep-ercut: A deeper, stronger, and Faster Multi-person Pose Estimation model. InEuropean Conference on Computer Vision, 2016.
[62] U. Iqbal, A. Milan, and J. Gall. Posetrack: Joint Multi-person Pose Estimationand tracking. In IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2017.
[63] U. Iqbal, A. Milan, and J. Gall. Posetrack: Joint Multi-person Pose Estimationand tracking. In IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2017.
[64] C. Jiang, Y. He, X. Zheng, and Y. Liu. Orientation-aware Rfid Tracking withCentimeter-level Accuracy. In Proceedings of the 17th ACM/IEEE InternationalConference on Information Processing in Sensor Networks, pages 290–301. IEEEPress, 2018.
[65] V. Kalogeiton, P. Weinzaepfel, V. Ferrari, and C. Schmid. Action tubelet detectorfor spatio-temporal action localization. In ICCV, 2017.
14

[66] L. Karlinsky, J. Shtok, Y. Tzur, and A. Tzadok. Fine-grained Recognition ofThousands of Object Categories with Single-example training. In Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[67] H. W. Kuhn. The Hungarian Method for the Assignment problem. Naval Re-search Logistics (NRL), 1955.
[68] L. Leal-Taixé, A. Milan, I. Reid, S. Roth, and K. Schindler. Motchal-lenge 2015: Towards a Benchmark for Multi-target tracking. arXiv preprintarXiv:1504.01942, 2015.
[69] R. Lienhart and J. Maydt. An Extended Set of Haar-like Features for RapidObject detection. In Image Processing. 2002. Proceedings. 2002 InternationalConference on, 2002.
[70] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg.Ssd: Single Shot Multibox detector. In European conference on computer vision,2016.
[71] X. Liu, Y. Jiang, P. Jain, and K.-H. Kim. Tar: Enabling Fine-grained Targeted Ad-vertising in Retail Stores. In Proceedings of the 16th Annual International Con-ference on Mobile Systems, Applications, and Services, pages 323–336. ACM,2018.
[72] F. Lu, X. Chen, and T. Y. Terry. Performance Analysis of Stacked Rfid tags. InRFID, 2009 IEEE International Conference on, 2009.
[73] W. Lu and Y.-P. Tan. A Color Histogram Based People Tracking system. In Cir-cuits and Systems, 2001. ISCAS 2001. The 2001 IEEE International Symposiumon, 2001.
[74] I. Masi, S. Rawls, G. Medioni, and P. Natarajan. Pose-aware Face Recognition inthe wild. In Proceedings of the IEEE Conference on Computer Vision and PatternRecognition, 2016.
[75] A. Milan, L. Leal-Taixé, I. Reid, S. Roth, and K. Schindler. Mot16: A Benchmarkfor Multi-object tracking. arXiv preprint arXiv:1603.00831, 2016.
[76] F. Nekoogar and F. Dowla. Ultra-wideband Radio Frequency Identification Sys-tems. Springer Science & Business Media, 2011.
[77] P. V. Nikitin and K. Rao. Performance Limitations of Passive Uhf Rfid sys-tems. In Antennas and Propagation Society International Symposium 2006, IEEE,2006.
[78] H.-S. Park and C.-H. Jun. A Simple and Fast Algorithm for K-medoids clustering.Expert systems with applications, 2009.
[79] J. Redmon and A. Farhadi. YOLO9000: better, faster, stronger. CoRR, 2016.[80] J. Redmon and A. Farhadi. Yolov3: An Incremental Improvement. arXiv preprint
arXiv:1804.02767, 2018.[81] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-cnn: Towards Real-time Object
Detection with Region Proposal networks. In Advances in neural informationprocessing systems, 2015.
[82] E. Ristani and C. Tomasi. Tracking Multiple People Online and in Real time. InAsian Conference on Computer Vision, 2014.
[83] E. Ristani and C. Tomasi. Features for Multi-target Multi-camera Tracking andRe-identification. arXiv preprint arXiv:1803.10859, 2018.
[84] E. Rublee, V. Rabaud, K. Konolige, and G. Bradski. Orb: An Efficient Alternativeto Sift or surf. In Proceedings of the 2011 International Conference on ComputerVision, ICCV ’11, 2011.
[85] F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A Unified Embedding forFace Recognition and clustering. In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition, 2015.
[86] L. Shangguan, Z. Yang, A. X. Liu, Z. Zhou, and Y. Liu. Relative Localization ofRfid Tags using Spatial-temporal Phase profiling. In NSDI, 2015.
[87] L. Shangguan, Z. Zhou, and K. Jamieson. Enabling Gesture-based Interactionswith objects. In Proceedings of the 15th Annual International Conference onMobile Systems, Applications, and Services, MobiSys ’17, 2017.
[88] S. Sun, Z. Kuang, L. Sheng, W. Ouyang, and W. Zhang. Optical Flow Guided Fea-ture: A Fast and Robust Motion Representation for Video Action Recognition. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR)(June2018), 2018.
[89] A. Tang, K. Lu, Y. Wang, J. Huang, and H. Li. A Real-time Hand Posture Recog-nition System Using Deep Neural networks. ACM Transactions on IntelligentSystems and Technology (TIST), 2015.
[90] S. Tang, M. Andriluka, B. Andres, and B. Schiele. Multiple People Tracking byLifted Multicut and Person Re-identification. 2017.
[91] L. Tran, X. Yin, and X. Liu. Disentangled Representation Learning Gan for Pose-invariant Face recognition. In CVPR, number 6, 2017.
[92] N. Wojke, A. Bewley, and D. Paulus. Simple Online and Realtime Tracking witha Deep Association metric. arXiv preprint arXiv:1703.07402, 2017.
[93] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao. Joint Face Detection and Alignment Us-ing Multitask Cascaded Convolutional networks. IEEE Signal Processing Letters,2016.
[94] H. Zhao, M. Tian, S. Sun, J. Shao, J. Yan, S. Yi, X. Wang, and X. Tang. Spindlenet: Person Re-identification with Human Body Region Guided Feature Decom-position and fusion. In Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition, 2017.
[95] J. Zhao, Y. Cheng, Y. Xu, L. Xiong, J. Li, F. Zhao, K. Jayashree, S. Pranata,S. Shen, J. Xing, et al. Towards Pose Invariant Face Recognition in the Wild. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni-tion, pages 2207–2216, 2018.
15