grundlagen der rechnerarchitektur - universität paderborn · 2 architecture of parallel computer...
TRANSCRIPT
1
Architecture of Parallel Computer Systems WS15/16 J.Simon 1
Grundlagen der Rechnerarchitektur
Architecture of Parallel Computer Systems WS15/16 J.Simon 2
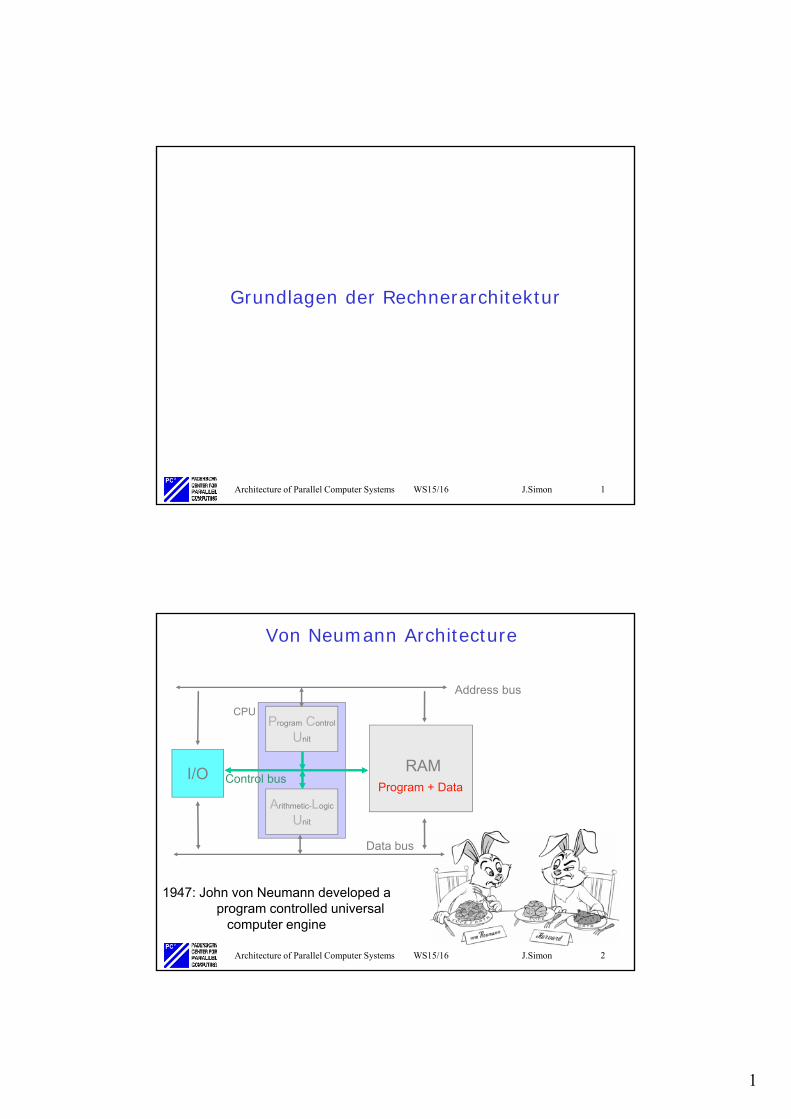
Von Neumann Architecture
1947: John von Neumann developed a program controlled universal
computer engine
I/O
Address bus
Data bus
Program + Data
RAM
CPU
Arithmetic-Logic
Unit
Program Control
Unit
Control bus

2
Architecture of Parallel Computer Systems WS15/16 J.Simon 3
The von Neumann Computer
Simple Operation
c = a + b
1. Get first instruction2. Decode: Fetch a3. Fetch a to internal register4. Get next instruction5. Decode: fetch b6. Fetch b to internal register7. Get next instruction8. Decode: add a and b (c in register)9. Do the addition in ALU10.Get next instruction11.Decode: store c in main memory12.Move c from internal register to main memory Execution is strong sequential
Architecture of Parallel Computer Systems WS15/16 J.Simon 4
Nach wie vor eingesetzte Architektur
Prozessor(CPU)
Hauptspeicher Controller Controller
GerätGerät Gerät
Daten-BusAdress-BusKontroll-Bus

3
Architecture of Parallel Computer Systems WS15/16 J.Simon 5
Prozessor• Grundelemente eines Prozessors sind
– Rechenwerk: führt die arithmetischen und die logischen Operationen aus
– Steuerwerk: stellt Daten für das Rechenwerk zur Verfügung, d.h. holt die Befehle aus dem Speicher, koordiniert den internen Ablauf
– Register: Speicher mit Informationen über die aktuelle Programmbearbeitung, z.B.
• Rechenregister, Indexregister• Stapelzeiger (stack pointer)• Basisregister (base pointer)• Befehlszähler (program counter, PC)• Unterbrechungsregister,…
• Moderne Prozessoren bestehen aus Prozessorkernen und Caches
• Jeder Prozessorkern hat mehrere Rechenwerke (Funktionseinheiten)
Steuerwerk
Befehlsdekodierungund Ablaufsteuerung
PC, Befehlsregister,Zustandsregister
Rechenwerk
Gleitkommaeinheit
Register R1 - Rn
CPU CPU
L1-$ L1-$
L2-$
…
Prozessorkern
Prozessor
arithmetische/logische Einheitarithmetische/logische Einheit
Gleitkommaeinheit
Architecture of Parallel Computer Systems WS15/16 J.Simon 6
Hauptspeicher
• Hauptspeicher (Arbeitsspeicher):– flüchtige Speicherung der aktiven Programme und
der dazugehörigen Daten• typische Größe derzeit bei PCs
– 4 GByte bis 64 GByte• Organisation des Speichers
– Folge aus Bytes, auf die einzeln lesend oder schreibend zugegriffen werden kann (Random Access Memory, RAM)
– theoretische Größe des Speichers wird durch die Breite des Adressbusses festgelegt
• Virtualisierung des Speichers– einheitliche logische Adressräume– effizienter Nutzung des physischen Speichers
0123
.
.
.
max

4
Architecture of Parallel Computer Systems WS15/16 J.Simon 7
Daten-CacheDie Geschwindigkeit des Hauptspeichers ist zu gering für die Rechenleistung der Prozessoren
Einsatz von Cache-Speichern notwendig
Block-Offset:00000 00010 …
00001 00011 11111
Prozessor CacheHaupt-speicher
Adresse
DatenDaten
Adresse
Adress-Tag*
Datenblock
Cache-LineByte ……
…
Byte Byte Byte Byte10010
1100
11010110
Index:
000
001
010
011
100
101
110
111
1001000000011
Adresse:
Architecture of Parallel Computer Systems WS15/16 J.Simon 8
Assoziativität eines Caches
Direct-mapped Cache 2-Way Set-Associative Cache
V Tag Datenblock
Tag Index Block-Offset
HIT Datenwort oder -Byte
2k
Lines
/k
/t
=
/ t
/b V Tag Datenblock
Tag Index Block-Offset
HIT Datenwort oder -Byte
/k
/t
=
/ t
/b
V Tag Datenblock
=

5
Architecture of Parallel Computer Systems WS15/16 J.Simon 9
Cache-Aufbau und Charakteristika• Cache-Lines (Blockgröße z.B. 64 Bytes)• Caches deutlich kleiner als Hauptspeicher
mapping von HS-Blöcken notwendig– direct mapped jeder Block wird auf festen Bereich
abgebildet– fully associate Block kann überall im Cache abgelegt
werden– m-way set associative:
• Block kann beliebig in einer Menge von m Cache-Lines abgelegt werden
• Replacement: zufällig oder LRU• verallgemeinert die beiden anderen Prinzipien
• Weitere Charakteristika:– Latenzzeit– Bandbreite– Kapazität des Caches
Architecture of Parallel Computer Systems WS15/16 J.Simon 10
Cache-Miss-Typen• Compulsory-Miss:
– auch cold-start-miss genannt– erster Zugriff auf Block führt zu einem Cache-Miss
• Capacity-Miss:– Cache nicht groß genug für alle benötigten Blöcke– Cache-Miss ist aufgetreten, obwohl der Block schon
einmal im Cache war und verdrängt wurde• Conflict-Miss:
– Adresskollision– auch collision-miss oder interferences-miss genannt– „Capacity-Miss“ der durch eine zu geringe Assoziativität
des Caches oder zu große Blöcke begründet ist– „Ping-Pong“ Effekt möglich

6
Architecture of Parallel Computer Systems WS15/16 J.Simon 11
Compulsory-Misses• Problem:
– Noch nicht genutzte Daten sind typischerweise nicht im Cache
– Folge: erster Zugriff auf Daten potentiell sehr teuer• Optimierung:
– größere Cache-Lines (räumliche Lokalität nutzen)• erhöht Latenzzeit bei Cache-Miss• kann Anzahl der Conflict-Misses erhöhen
– Prefetching• Datenwort laden bevor es tatsächlich benötigt wird• Überlappung von Berechnungen und Ladeoperationen• nur sinnvoll bei nicht-blockierenden Caches• Varianten
– nächstes Datenwort laden (unit stride access)– wiederkehrende Zugriffsmuster erkennen und laden (stream
prefetch)– Zeigerstrukturen laden
Architecture of Parallel Computer Systems WS15/16 J.Simon 12
Strategien beim Design
• Latenzzeit bei Hit und Miss reduzieren– Multi-Level-Cache– Speicherzugriffe überlappend ausführen (Pipelining)– diverse andere Hardwaretechniken (s. „Computer
Architecture: A …“
• Cache-Trefferrate erhöhen– Hardware-Techniken– Datenzugriffstransformationen– Daten-Layout-Transformationen
• Latenzzeit verdecken– Out-of-Order Execution– Multithreading

7
Architecture of Parallel Computer Systems WS15/16 J.Simon 13
Speicherhierarchien
• Memory WallDer Unterschied zwischen Prozessor- und Speichergeschwindigkeit wird immer größer
• Leistungsfähigere Speicherhierarchien notwendig– Größere Speicherkapazitäten
• kleinere Fertigungsstrukturen nutzbar– Höhere Frequenzen
• Steigerung beschränkt durch die „Physik“– Breitere Datenpfade
• beschränkt durch Parallelität in der Anwendung– Mehr Speicherebenen
• Potentiell auf mehreren Ebenen nachfolgende Misses
Architecture of Parallel Computer Systems WS15/16 J.Simon 14
Beispiel: Highend Server IBM Power E870
• Modell: IBM Power E870
• 4 bis 8 Power8 Prozessormodule (je 8-10 Kerne)– max. 64 Prozessorkerne 4.0 GHz– max. 80 Prozessorkerne 4.2 GHz
• Shared-memory, NUMA-Architektur– max. 4 TByte DDR3-1600

8
Architecture of Parallel Computer Systems WS15/16 J.Simon 15
Beispiel: Highend Server IBM Power E880
• Modell: IBM Power E880
• 4 bis 16 Power8 Prozessormodule (je 8-12 Kerne)– max. 128 Prozessorkerne 4.3 GHz– max. 192 Prozessorkerne 4.0 GHz
• Shared-memory, NUMA-Architektur– max. 4 TByte DDR3-1600
Architecture of Parallel Computer Systems WS15/16 J.Simon 16
IBM Power8• Chip with 12 cores• Core clock rate 2.5 – 5.0 GHz• Massive multithreaded chip with 96 hw-
threads• Each core with
– 64 kB L1 D-cache– 32 kB L1 I-cache– 512 kB SRAM L2-cache
• 96 MB eDRAM shared L3-cache– 8 MB per core
• Up to 128 MB eDRAM off-chip L4-cache• On-chip memory controller
– Ca. 1 TByte memory– ~ 230 GByte/s
• 4.2 billion transistors, 22nm• Available 5/2014 Power8 Chip
Power8 Core

9
Architecture of Parallel Computer Systems WS15/16 J.Simon 17
Power8 Caches
• L2: 512 kB 8 way per core• L3: 96 MB (12 x 8MByte 8 way bank)• “NUCA” cache policy (Non-Uniform Cache Architecture)
– Scalable bandwidth and latency– Migrate “Hot” lines to local L2, then local L3 (replicate L2 contained footprint)
• Chip Inteconnect: 150 GB/s x 12 segments per direction = 3.6 TB/s
Architecture of Parallel Computer Systems WS15/16 J.Simon 18
POWER8 Memory Buffer Chip
10
Architecture of Parallel Computer Systems WS15/16 J.Simon 19
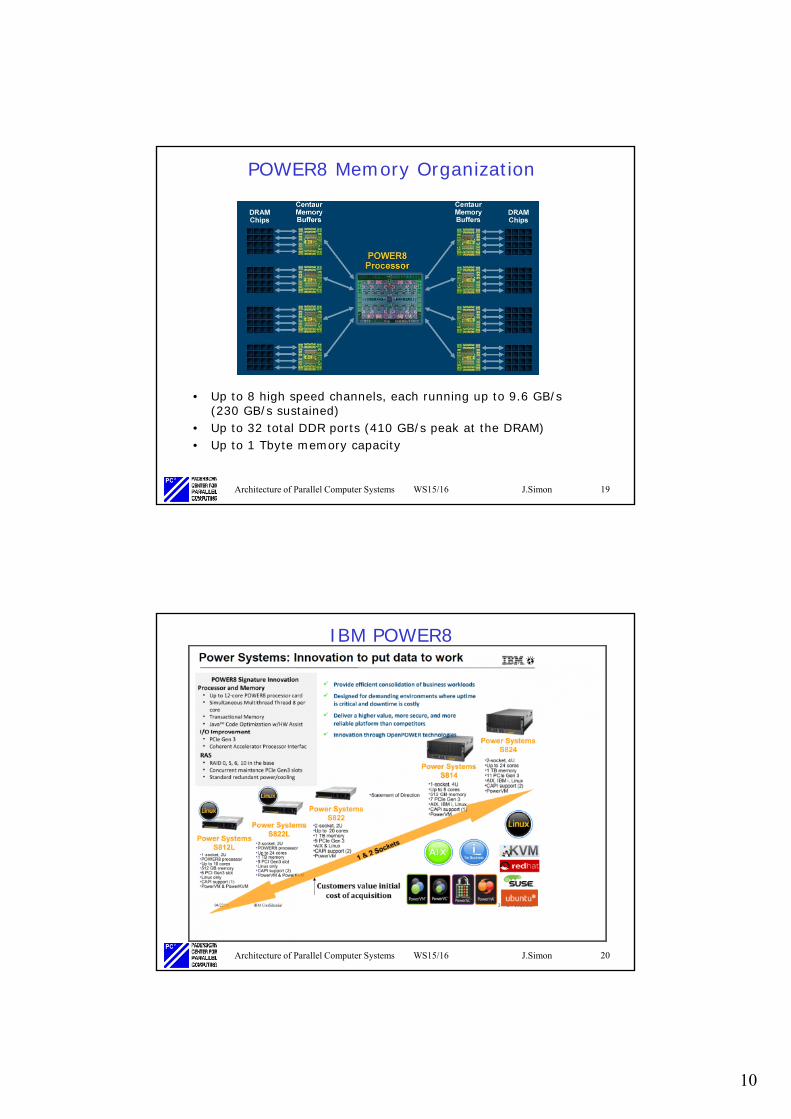
POWER8 Memory Organization
• Up to 8 high speed channels, each running up to 9.6 GB/s (230 GB/s sustained)
• Up to 32 total DDR ports (410 GB/s peak at the DRAM)• Up to 1 Tbyte memory capacity
Architecture of Parallel Computer Systems WS15/16 J.Simon 20
IBM POWER8
11
Architecture of Parallel Computer Systems WS15/16 J.Simon 21
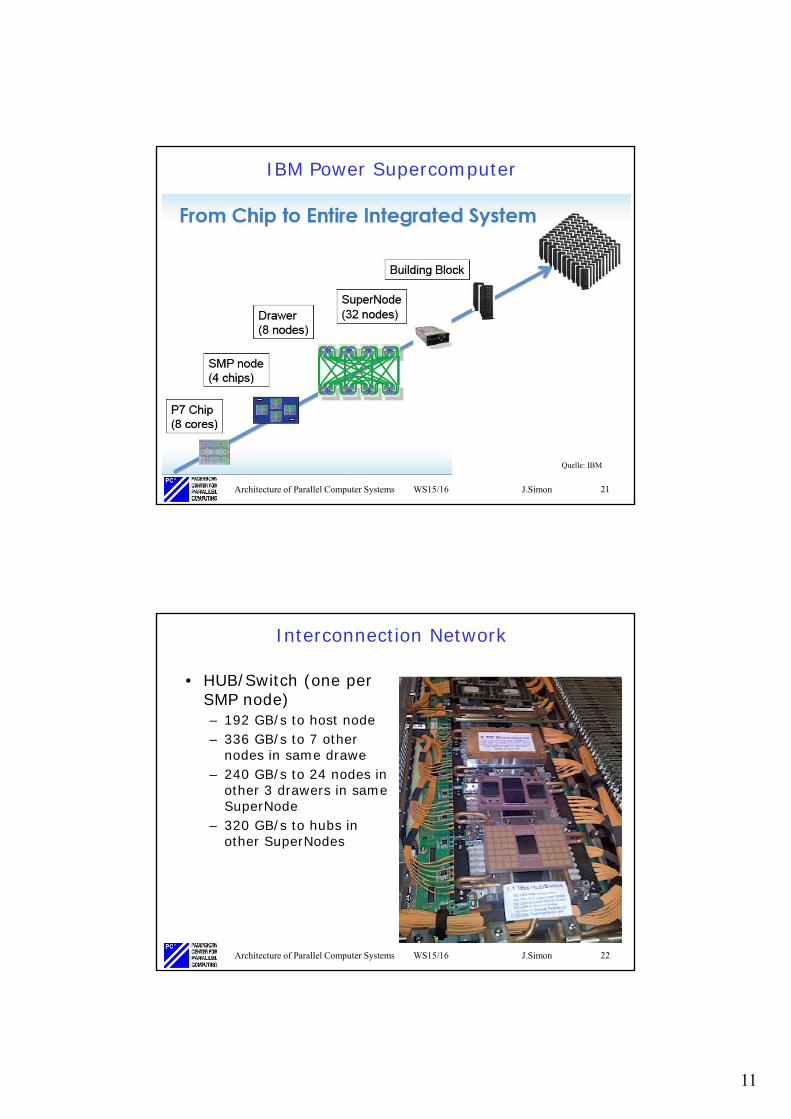
IBM Power Supercomputer
Quelle: IBM
Architecture of Parallel Computer Systems WS15/16 J.Simon 22
Interconnection Network
• HUB/Switch (one per SMP node)– 192 GB/s to host node– 336 GB/s to 7 other
nodes in same drawe– 240 GB/s to 24 nodes in
other 3 drawers in same SuperNode
– 320 GB/s to hubs in other SuperNodes

12
Architecture of Parallel Computer Systems WS15/16 J.Simon 23
Speicherhierarchie: Beispiel IBM Power E870 (Power8)
1 8MB per Core x 102 shared by 10 Cores2 shared by 80 Cores
Swap Space on SSD > X * 500 GByte/s < 1 ms
Swap Space on Harddisk >> X * 200 MByte/s ~5 ms
Remote Main Memory3 8192 GByte 230 GByte/s < 1 µs
Lokal Main Memory2 1024 GByte 230 GByte/s < 90 ns
3. Level Cache1 80 MByte 150 GByte/s < 30 ns
2. Level Cache 512 kByte 150 GByte/s 4 ns
1. Level Cache 64 kByte 75 GByte/s 1 ns
Register 256 Byte 120 GByte/s 0.2 ns
CPU Kapazität Bandbreite Latenz
Buffer Cache2 128 Mbyte ? ?
Architecture of Parallel Computer Systems WS15/16 J.Simon 24
OpenPOWER
Compared to IBM products• Broader Market• Bigger Ecosystem• Platform for innovation• Main focus on Linux
• Tyan– TN71-BP012– One Power8 processor– 32 DIMMs ECC DDR3-1600

13
Architecture of Parallel Computer Systems WS15/16 J.Simon 25
Beispiel: Intel E5-2600v3 „Haswell“• max. 18 cores per processor,
– max. 3.2 GHz (turbo 3.8GHz)• 22 nm, 2.6 – 5.7 billion transistors• 256 bit AVX SIMD units• per core
– 32 kByte L1-D-Cache, 8-way– 256 kByte L2-Cache, 8-way– 64 Byte Cache-Lines
• 20 - 45 MByte L3-Cache• Memory controller
– 4 memory channels, DDR4-2133• MESIF cache coherence protocol• Quick Path Interconnect (QPI)
– Bidirektionaler Link– 20 Bits, 8 GT/s, 20 GByte/s
• PCIe 3.0 on-chip
Architecture of Parallel Computer Systems WS15/16 J.Simon 26
Haswell EP Configurations
14
Architecture of Parallel Computer Systems WS15/16 J.Simon 27
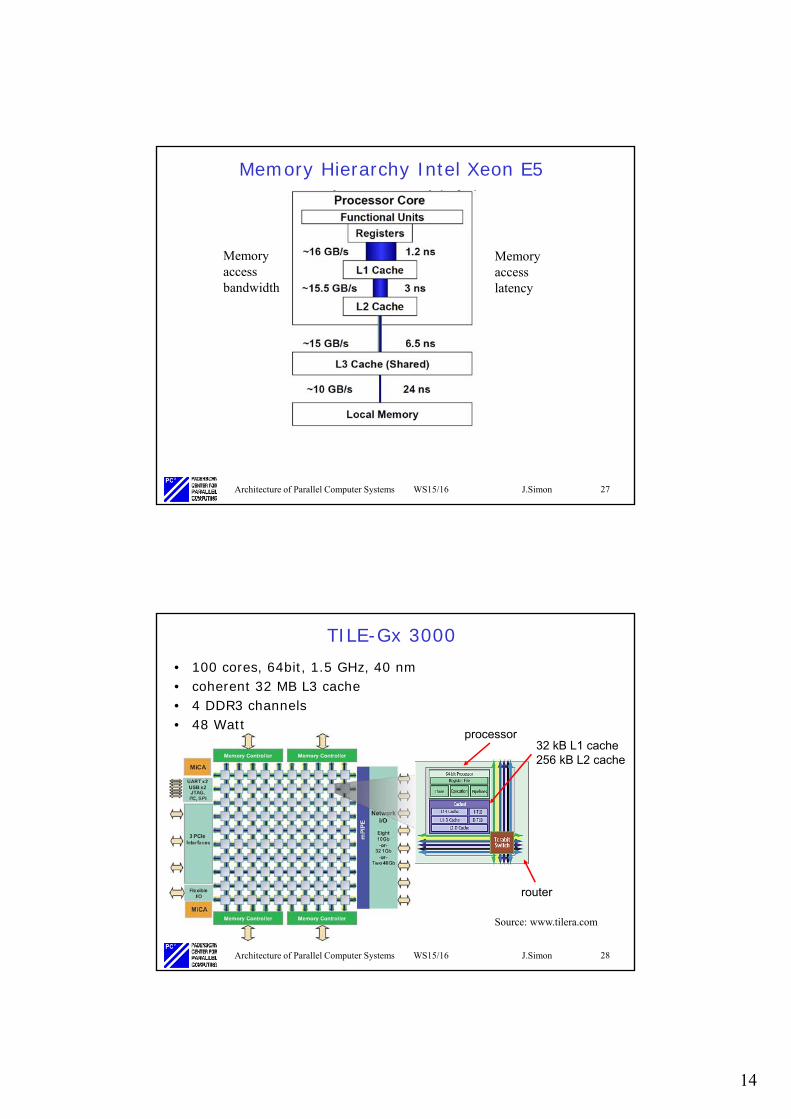
Memory Hierarchy Intel Xeon E5
Memory accesslatency
Memory accessbandwidth
Architecture of Parallel Computer Systems WS15/16 J.Simon 28
TILE-Gx 3000• 100 cores, 64bit, 1.5 GHz, 40 nm• coherent 32 MB L3 cache• 4 DDR3 channels• 48 Watt
Source: www.tilera.com
processor32 kB L1 cache256 kB L2 cache
router

15
Architecture of Parallel Computer Systems WS15/16 J.Simon 29
nVidia Maxwell GPUGPU GM107Max. number of shader-processors 640
Clock rate 1.020 MHzBoost clock rate 1.085 MHzGFLOPs 1305,6CUDA interface 5.0Shared Memory / SM 64 kBRegister File Size 256 kBActive Blocks / SM 32Textur units 40
Texel fill rate 40,8 GTexel/Sek.
Memory clock rate 1.350 MHzMemory bandwidth 86,4 GByte/sROPs 16L2-Cache size 2 MBNumber of transistors 1.87 billionChip size 148 mm2
Fabrication 28 nmTDP 60 Watt
Architecture of Parallel Computer Systems WS15/16 J.Simon 30
nVIDIA „PASCAL“
• Next generation GPU• 3D „stacked“ memory
– ~16 GByte• Some modules also with
new NVLink– ~80 GByte/s bandwidth– PCIe Gen3 < 16 GByte/s
• Planed for 2016
PCIe switch
mem
16
Architecture of Parallel Computer Systems WS15/16 J.Simon 31
Accelerators become part of the Processor
• Floating-Point Unit– 1978
• Intel 8086 + Intel 8087 Math-Co processor (16 Bit)– 1989
• Intel i486 with integrated floating-point units (32 bit)• Vector Unit
– 1993• CM5 with Sparc processor + Vector Unit Accelerators (MBUS)
– 1995• Intel Pentium P55C with MMX instructions
– 1996• Motorola PowerPC with AltiVec
• Stream Processing– 2006
• Workstation + GPU graphic card (PCI)– 2011
• Intel HD Graphics 3000 with integrated GPU (OpenCL)
Architecture of Parallel Computer Systems WS15/16 J.Simon 32
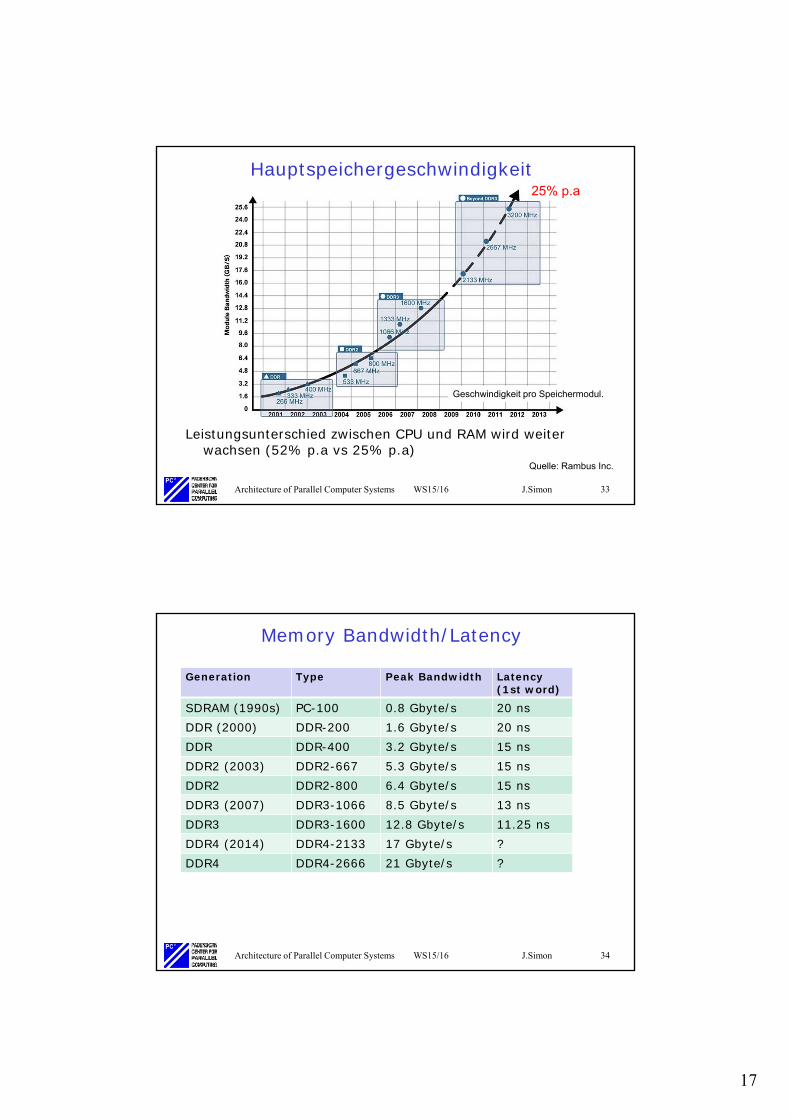
Leistungsentwicklung eines Prozessorkerns
• Von 1986 bis 2002 ca. 50% Leistungszuwachs pro Jahr• Derzeit Einzelprozessorleistung langsamer zunehmend• Höherer Leistungszuwachs nur noch über Erhöhung der
Anzahl an Prozessor(kerne) möglich
52% /year
25% /year
17
Architecture of Parallel Computer Systems WS15/16 J.Simon 33
Hauptspeichergeschwindigkeit
Quelle: Rambus Inc.
Geschwindigkeit pro Speichermodul.
Leistungsunterschied zwischen CPU und RAM wird weiter wachsen (52% p.a vs 25% p.a)
25% p.a
Architecture of Parallel Computer Systems WS15/16 J.Simon 34
Memory Bandwidth/Latency
Generation Type Peak Bandwidth Latency(1st word)
SDRAM (1990s) PC-100 0.8 Gbyte/s 20 nsDDR (2000) DDR-200 1.6 Gbyte/s 20 nsDDR DDR-400 3.2 Gbyte/s 15 nsDDR2 (2003) DDR2-667 5.3 Gbyte/s 15 nsDDR2 DDR2-800 6.4 Gbyte/s 15 nsDDR3 (2007) DDR3-1066 8.5 Gbyte/s 13 nsDDR3 DDR3-1600 12.8 Gbyte/s 11.25 nsDDR4 (2014) DDR4-2133 17 Gbyte/s ?DDR4 DDR4-2666 21 Gbyte/s ?

18
Architecture of Parallel Computer Systems WS15/16 J.Simon 35
Trends• „Power Wall“
– Energieaufnahme / Kühlung– Lösungen
• geringere Taktfrequenzen• mehr Ausführungseinheiten
• „Memory Wall“– Speicherbandbreite u. Latenz– Lösungen
• bessere Speicherhierarchien u. Anbindung an CPUs• Latency-Hidding
• „ILP Wall“– Beschränkte Parallelität im sequentiellen Instruktionsstrom– Lösungen
• mehr Parallelität in Programmen erkennen (Compiler)• mehr explizite Parallelität in Programmen
(Programmiersprachen)
Architecture of Parallel Computer Systems WS15/16 J.Simon 36
Teil 3:Architekturen paralleler
Rechnersysteme

19
Architecture of Parallel Computer Systems WS15/16 J.Simon 37
Einfache Definition Parallelrechner
George S. Almasi, IBM Thomas J. Watson Research Center
Allan Gottlieb, New York University, 1989
„ A parallel computer is a collection of processing elements that communicate and cooperate to solve large problems fast.”
Architecture of Parallel Computer Systems WS15/16 J.Simon 38
Rechnerarchitektur
Eine Rechnerarchitektur ist bestimmt durch ein Operationsprinzip für die Hardware und die Struktur ihres Aufbaus aus den einzelnen Hardware-Betriebsmitteln
(Giloi 1993)
OperationsprinzipDas Operationsprinzip definiert das funktionelle Verhalten der Architektur durch Festlegung einer Informationsstruktur und einer Kontrollstruktur.
Hardware-StrukturDie Struktur einer Rechnerarchitektur ist gegeben durch Art und Anzahl der Hardware-Betriebsmittel und deren verbindenden Kommunikationseinrichtungen.

20
Architecture of Parallel Computer Systems WS15/16 J.Simon 39
... in anderen Worten
Operationsprinzip
• Vorschrift über das Zusammenspiel der Komponenten
Aufbau
• Einzelkomponenten• Struktur der Verknüpfung der
Komponenten
• Grundlegende Strukturbausteine sind– Prozessor (CPU), als aktive Komponente zur Ausführung von
Programmen,– Hauptspeicher (ggf. hierarchisch strukturiert, …),– Übertragungsmedium zur Verbindung der einzelnen
Architekturkomponenten,– Steuereinheiten für Anschluss und Kontrolle von Peripherie-
geräten und– Geräte, als Zusatzkomponenten für Ein- und Ausgabe von
Daten sowie Datenspeicherung.
Architecture of Parallel Computer Systems WS15/16 J.Simon 40
Parallelrechner
• Operationsprinzip:– gleichzeitige Ausführung von Befehlen– sequentielle Verarbeitung in bestimmbaren Bereichen
• Arten des Parallelismus:– Explizit: Die Möglichkeit der Parallelverarbeitung wird
a priori festgelegt. Hierzu sind geeignete Datentypen bzw. Datenstrukturen erforderlich, z.B. Vektoren (lineare Felder) samt Vektoroperationen.
– Implizit: Die Möglichkeit der Parallelverarbeitung ist nicht a priori bekannt. Durch eine Datenabhängigkeitsanalyse werden die parallelen und sequentiellen Teilschritte des Algorithmus zur Laufzeit ermittelt.

21
Architecture of Parallel Computer Systems WS15/16 J.Simon 41
Strukturelemente von Parallelrechnern
• Parallelrechner besteht aus einer Menge von Verarbeitungselementen, die in einer koordinierten Weise, teilweise zeitgleich, zusammenarbeiten, um eine Aufgabe zu lösen
• Verarbeitungselemente können sein:– spezialisierte Einheiten, wie z.B. die Pipeline-Stufen eines
Skalarprozessors oder die Vektor-Pipelines der Vektoreinheit eines Vektorrechners
– gleichartige Rechenwerke, wie z.B. die Verarbeitungselemente eines Feldrechners
– Prozessorknoten eines Multiprozessorsystems– vollständige Rechner, wie z.B. Workstations oder PCs
eines Clusters– selbst wieder ganze Parallelrechner oder Cluster
Architecture of Parallel Computer Systems WS15/16 J.Simon 42
Grenzbereiche von Parallelrechnern
• eingebettete Systeme als spezialisierte Parallelrechner• Superskalar-Prozessoren, die feinkörnige Parallelität
durch Befehls-Pipelining und Superskalar-Technik nutzen
• Mikroprozessoren arbeiten als Hauptprozessor teilweise gleichzeitig zu einer Vielzahl von spezialisierten Einheiten wie der Bussteuerung, DMA-,Graphikeinheit, usw.
• Ein-Chip-Multiprozessor• mehrfädige (multithreaded) Prozessoren führen
mehrere Kontrollfäden überlappt oder simultan innerhalb eines Prozessors aus
• VLIW- (Very Long Instruction Word)- Prozessor

22
Architecture of Parallel Computer Systems WS15/16 J.Simon 43
Klassifikation von Parallelrechnern
• Klassifikation nach Flynn, d.h. Klassifikation nach der Art der Befehlsausführung
• Klassifikation nach der Speicherorganisation und dem Adressraum
• Konfigurationen des Verbindungsnetzwerks
• Varianten an speichergekoppelte Multiprozessorsysteme
• Varianten an nachrichtengekoppelte Multiprozessorsysteme
Architecture of Parallel Computer Systems WS15/16 J.Simon 44
Klassifikation nach FlynnZweidimensionale Klassifizierung mit Kriterium Anzahl der Befehls- und Datenströme– Rechner bearbeitet zu einem Zeitpunkt einen oder mehrere
Befehle– Rechner bearbeitet zu einem Zeitpunkt einen oder mehrere
Datenwerte
Damit vier Klassen von Rechnerarchitekturen– SISD: Single Instruction, Single Data
Ein Befehl verarbeitet einen Datensatz. (herkömmliche Rechnerarchitektur eines seriellen Rechners)
– SIMD: Single Instruction, Multiple DataEin Befehl verarbeitet mehrere Datensätze, z.B. N Prozessoren führen zu einem Zeitpunkt den gleichen Befehl aber mit unterschiedlichen Daten aus.
– MISD: Multiple Instruction, Single DataMehrere Befehle verarbeiten den gleichen Datensatz. (Diese Rechnerarchitektur ist nie realisiert worden.)
– MIMD: Multiple Instruction, Multiple DataUnterschiedliche Befehle verarbeiten unterschiedliche Datensätze. (Dies ist das Konzept fast aller modernen Parallelrechner.)

23
Architecture of Parallel Computer Systems WS15/16 J.Simon 45
SISD Architektur• Klassische Struktur eines seriellen Rechners:
Nacheinander werden verschiedene Befehle ausgeführt, die z.B. einzelne Datenpaare verknüpfen
Verarbeitungs-Einheit
A(1) + B(1)
A(2) B(2)
• Moderne RISC (Reduced Instruction Set Computer) Prozessoren verwenden Pipelining: – Mehrere Funktionseinheiten, die gleichzeitig aktiv sind. – Operationen sind in Teiloperationen unterteilt. – In jedem Takt kann eine Funktionseinheit (z.B. Addititionseinheit) eine
neue Operation beginnen. – D.h. hohe interne Parallelität nutzbar
Architecture of Parallel Computer Systems WS15/16 J.Simon 46
SIMD Architektur (Prozessorarray)• Mehrere Prozessoren führen zu einem Zeitpunkt den gleichen
Befehl aus• Rechner für Spezialanwendungen (z.B. Bildverarbeitung,
Spracherkennung) • I.A. sehr viele Prozessorkerne (tausende Kerne in einem System ) • Beispiele: Graphikprozessoren, Numerische Coprozessoren
X[1]-Y[1]
C[1]*D[1]
A[1]+B[1]
Prozessor 1
…
X[2]-Y[2]
C[2]*D[2]
A[2]+B[2]
Prozessor 2
…
X[3]-Y[3]
C[3]*D[3]
A[3]+B[3]
Prozessor 3
…
X[4]-Y[4]
C[4]*D[4]
A[4]+B[4]
Prozessor 4
…
• Mittlerweile auch innerhalb einzelner Funktionseinheiten zu finden

24
Architecture of Parallel Computer Systems WS15/16 J.Simon 47
MIMD Architektur
Mehrere Prozessoren führen unabhängig voneinander unterschiedliche Instruktionen auf unterschiedlichen Daten aus:
…call subx=y…
Prozessor 1
…
…do i = 1,na(i)=b(i)end doT = sin(r)…
Prozessor 2
…
…t = 1/xcall sub1n=100…
Prozessor 3
…
…z=a(i)x=a(1)/tb=0.d0…
Prozessor 4
…
• Fast alle aktuellen Systeme entsprechen dieser Architektur.
Architecture of Parallel Computer Systems WS15/16 J.Simon 48
Speicherorganisation und Adressraum
globaler Adressraumlokaler Adressraum
zent
rale
Spe
iche
rorg
anis
atio
nve
rtei
lteSpe
iche
rorg
anis
atio
n
Speicher ist allen CPUs direkt zugänglich;Programme laufen in unterschiedlichemAdressraum und kommunizieren über MessagePassing oder UNIX-Pipes (eher theoretisch,sonst nur bei Partitionierung des Adressraums)
Speicher ist allen CPUs direkt zugänglich beiKonstanter Latenzzeit (z.B. Cray Y-MP)
Zugriff auf anderen CPUs zugeordneteSpeicher nur über explizites Message Pasing;sehr hohe Latenzzeit (z.B. PC-Cluster)
Zugriff auf anderen CPUs zugeordneteSpeicher direkt möglich bei variablerLatenzzeit (z.B. Cray T3E)
Speicher
CPU
Verbindungsnetzwerk
Speicher
CPU
Speicher
CPU
…
…
Verbindungsnetzwerk
Speicher
CPU
Speicher
CPU
…
…
Speicher
CPU
Speicher
CPU CPU … CPU
Speicher
CPU CPU … CPU

25
Architecture of Parallel Computer Systems WS15/16 J.Simon 49
Konfiguration der Verbindungsnetzwerke
Prozessor Prozessor
Verbindungsnetz
gemeinsamer Speicher
Globaler Speicher räumlich verteilter Speicher
Ver
teilt
er A
dres
srau
mG
emei
nsam
er A
dres
srau
m
Leer
Prozessor Prozessor
Verbindungsnetz
lokalerSpeicher
lokalerSpeicher
SMP Symmetrischer Multiprozessor DSM Distributed-shared-memory-Multiprozessor
Prozessor Prozessor
Verbindungsnetz
lokalerSpeicher
lokalerSpeicher
send receive
Nachrichtengekoppelter (Shared-nothing-)Multiprozessor
Architecture of Parallel Computer Systems WS15/16 J.Simon 50
Arten von Multiprozessorsystemen• Bei speichergekoppelten Multiprozessorsystemen besitzen alle
Prozessoren einen gemeinsamen Adressraum.Kommunikation und Synchronisation geschehen über gemeinsame Variablen.– symmetrisches Multiprozessorsystem (SMP): ein globaler
Speicher– Distributed-Shared-Memory-System (DSM): gemeinsamer
Adressraum trotz räumlich verteilter Speichermodule• Beim nachrichtengekoppelten Multiprozessorsystem besitzen alle
Prozessoren nur räumlich verteilte Speicher und prozessorlokale Adressräume.Die Kommunikation geschieht durch Austausch von Nachrichten.– Massively Parallel Processors (MPP), eng gekoppelte Prozessoren– Verteiltes Rechnen in einem Workstation-Cluster.– Grid-/Cloud-Computing: Zusammenschluss weit entfernter
Rechner

26
Architecture of Parallel Computer Systems WS15/16 J.Simon 51
Speichergekoppelte Multiprozessorsysteme
• Alle Prozessoren besitzen einen gemeinsamen Adressraum;Kommunikation und Synchronisation geschieht über gemeinsame Variablen.
• Uniform-Memory-Access-Modell (UMA):– Alle Prozessoren greifen in gleichermaßen auf einen
gemeinsamen Speicher zu. Insbesondere ist die Zugriffszeit aller Prozessoren auf den gemeinsamen Speicher gleich.Jeder Prozessor kann zusätzlich einen lokalen Cache-Speicher besitzen. Typische Beispiel: die symmetrischen Multiprossorsysteme (SMP)
• Nonuniform-Memory-Access-Modell (NUMA):– Die Zugriffszeiten auf Speicherzellen des gemeinsamen
Speichers variieren je nach dem Ort, an dem sich die Speicherzelle befindet.Die Speichermodule des gemeinsamen Speichers sind physisch auf die Prozessoren aufgeteilt.
– Typische Beispiele: Distributed-Shared-Memory-Systeme.
Architecture of Parallel Computer Systems WS15/16 J.Simon 52
Nachrichtengekoppelte Multiprozessorsysteme
• Uniform-Communication-Architecture-Modell(UCA):Zwischen allen Prozessoren können gleich lange Nachrichten mit einheitlicher Übertragungszeit geschickt werden.
• Non-Uniform-Communication-Architecture-Modell (NUCA):Die Übertragungszeit des Nachrichtentransfers zwischen den Prozessoren ist je nach Sender- und Empfänger-Prozessor unterschiedlich lang.

27
Architecture of Parallel Computer Systems WS15/16 J.Simon 53
Speicher- vs. Nachrichtenkopplung
• Distributed-Shared-Memory-Systeme sind NUMAs: Die Zugriffszeiten auf Speicherzellen des gemeinsamen Speichers variieren je nach Ort, an dem sich die Speicherzelle befindet.– cc-NUMA (Cache-coherent NUMA): Cache-Kohärenz wird
über das gesamte System gewährleistet, z.B. SGI Origin, HP Superdome, IBM Regatta
– ncc-NUMA (Non-Cache-coherent NUMA): Cache-Kohärenz wird nur innerhalb eines Knoten gewährleistet, z.B. Cray T3E, SCI-Cluster
– COMA (Cache-only-Memory-Architecture): Der Speicher des gesamten Rechners besteht nur aus Cache-Speicher. Nur in einem kommerziellen System realisiert (ehemalige Firma KSR)
• Nachrichten gekoppelte Multiprozessorsysteme sind NORMAs (No-remote-memory-access-Modell) oder Shared-nothing-Systeme, z.B. IBM SP, HP Alpha Cluster
Architecture of Parallel Computer Systems WS15/16 J.Simon 54
Zugriffszeit-/Übertragungszeit-Modell
single processorsingle address space
multiple processorsshared address space multiple processors
message passingUMA
NUMA
UCA
NUCA
Tim
e of
dat
a ac
cess
Con
veni
ence
of pr
ogra
mm
ing
cc-NUMA
ncc-NUMA

28
Architecture of Parallel Computer Systems WS15/16 J.Simon 55
Zusammenfassung: Klassifizierung
• Befehls- und Datenströme
• Speicherorganisation
• Verbindungsnetzwerke– Weitere Details später in der Vorlesung