g.skobeltsyn | query-driven indexing for p2p text retrieval query-driven indexing for p2p text...
TRANSCRIPT

G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
Query-Driven Indexing forQuery-Driven Indexing for P2P Text RetrievalP2P Text Retrieval
The Future of Web SearchThe Future of Web Search19.07.2007 Bertinoro, Italy19.07.2007 Bertinoro, Italy
Gleb SkobeltsynEPFL, Switzerland
June 19, 2007
Joint work with: • Toan Luu• Ivana Podnar Žarko• Martin Rajman• Karl Aberer
AlvisAlvis

DHTDHT
GoalGoal
• Our goalgoal is to achieve scalablescalable full-text retrieval with structured P2P networks (DHTs)
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
Each peer:• Provides resources (bandwidth, storage)• Searches the whole network• Publishes its own documents
22 // 2929
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
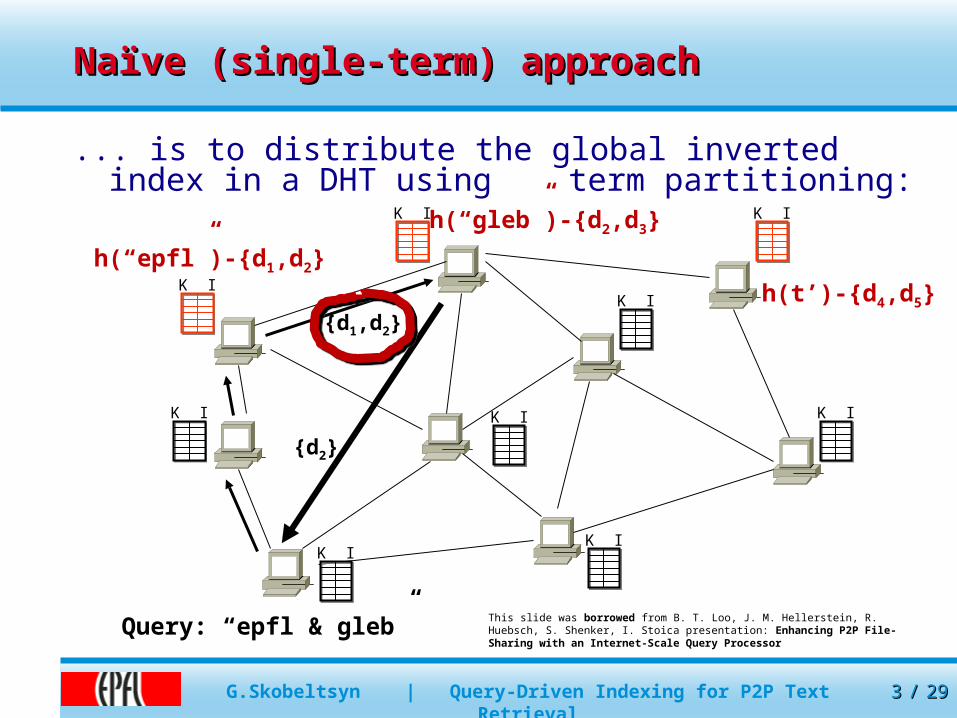
Naïve (single-term) approachNaïve (single-term) approach
... is to distribute the global inverted index in a DHT using term partitioning:
K I
K I
K I
K I
K I
K I
K I
K I
Query: “epfl & gleb”
h(“epfl”)-{d1,d2}
h(“gleb”)-{d2,d3}
h(t’)-{d4,d5}
K I
This slide was borrowed from B. T. Loo, J. M. Hellerstein, R. Huebsch, S. Shenker, I. Stoica presentation: Enhancing P2P File-Sharing with an Internet-Scale Query Processor
{d1,d2}
{d2}
33 // 2929

Single-term indexing
Multi-term indexing
term 1 posting list 1 term 2 posting list 2
term M-1 posting list M-1term M posting list M
®
®
®... ...
long posting listssm
all v
oc.
key 11 posting list 11 key 12 posting list 12
key 1i posting list 1i
®
®
®... ...
short posting lists
larg
e vo
c.
PEER 1
...
key N1 posting list N1 key N2 posting list N2
key Nj posting list Nj
®
®
®... ... PEER N
®
PEER 1
PEER N
...
Multi-term keys
Single-term vs. multi-term P2P Single-term vs. multi-term P2P indexingindexing
How to choose keys to keep a satisfactory retrieval quality?
voc. sizecould grow
exponentially!
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 44 // 2929

Multi-term indexing: frameworkMulti-term indexing: framework
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
• Each peer is responsibleresponsible for a set of keys assigned by the underlying DHT DHT using the standard hashing mechanism
• Each keykey corresponds to a term or a set of terms• Each key is assigned to a truncated posting list truncated posting list
(TPL) (TPL) that stores at most DFDFmaxmax top-ranked top-ranked document references
Distributed index contains {key,TPL} pairs
• The indexing load is handled by an optimizedoptimized DHT layer:
F. Klemm, J.-Y. Le Boudec, D. Kostic, K. AbererImproving the Throughput of Distributed Hash Tables Using Congestion-Aware Routing, in IPTPS'07 55 // 2929

Single-term indexing
Multi-term indexing
term 1 posting list 1 term 2 posting list 2
term M-1 posting list M-1term M posting list M
®
®
®... ...
long posting listssm
all v
oc.
key 11 posting list 11 key 12 posting list 12
key 1i posting list 1i
®
®
®... ...
short posting lists
larg
e vo
c.
PEER 1
...
key N1 posting list N1 key N2 posting list N2
key Nj posting list Nj
®
®
®... ... PEER N
®
PEER 1
PEER N
...
Multi-term keys
Single-term vs. multi-term P2P Single-term vs. multi-term P2P indexingindexing
How to choose keys to keep a satisfactory retrieval quality?
voc. sizecould grow
exponentially!
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 66 // 2929

Multi-term indexing techniquesMulti-term indexing techniques
• Indexing with Highly Discriminative Keys (HDKs), based on:– Scalable Peer-to-Peer Web Retrieval with Highly Discriminative Keys
I. Podnar, M. Rajman, T. Luu, F. Klemm, K. Abererin ICDE’07
– Beyond term indexing: A P2P framework for Web information retrieval I. Podnar, M. Rajman, T. Luu, F. Klemm, K. Aberer Informatica, vol. 30, no. 2, 2006.
• Query-Driven Indexing (QDI), based on:– Web Text Retrieval with a P2P Query-Driven Index
G. Skobeltsyn, T. Luu, I. Podnar Žarko, M. Rajman, K. Abererin SIGIR’07
– Query-Driven Indexing for Scalable Peer-to-Peer Text Retrieval G. Skobeltsyn, T. Luu, I. Podnar Žarko, M. Rajman, K. Aberer in Infoscale’07
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 77 // 2929
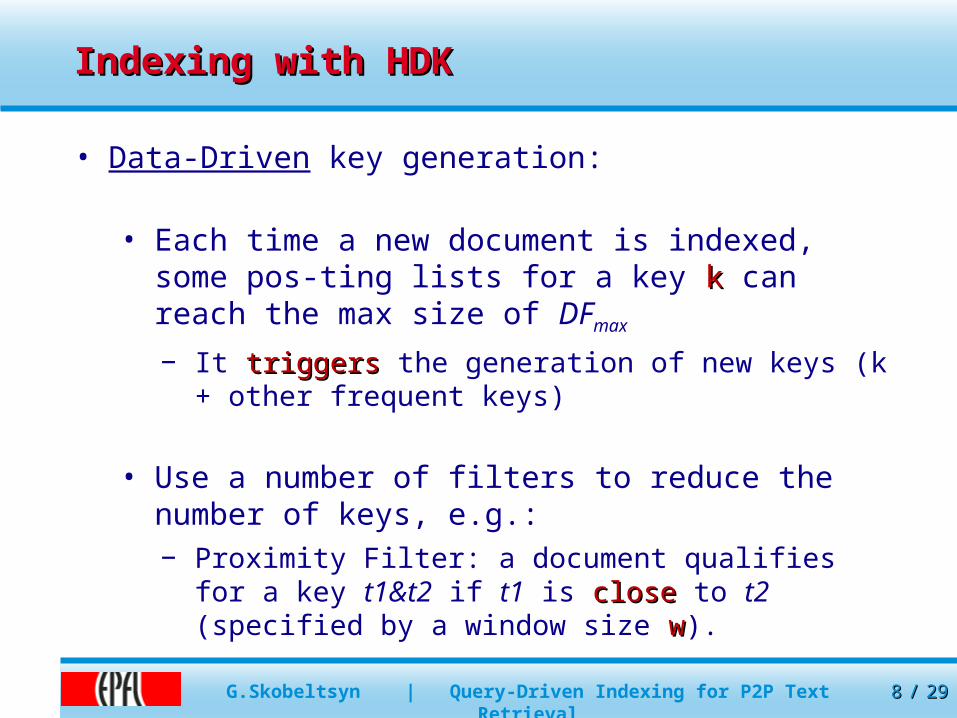
Indexing with HDKIndexing with HDK
• Data-Driven key generation:
• Each time a new document is indexed, some pos-ting lists for a key k k can reach the max size of DFmax
− It triggerstriggers the generation of new keys (k + other frequent keys)
• Use a number of filters to reduce the number of keys, e.g.:− Proximity Filter: a document qualifies for a key
t1&t2 if t1 is closeclose to t2 (specified by a window size ww).
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 88 // 2929

Indexing with HDKIndexing with HDK
• Pro’sPro’s: – ICDE’07 paper proves that the number of keys grows
linearly– Elegant key generation mechanism– Low bandwidth while query processing (PL’s of limited
size)
• Con’sCon’s:– Practically the number of keys is LARGE: 68M for 0.6M
docs– High bandwidth consumption at indexing
• ProblemProblem:– Too many keys are superfluous (almost never used)
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 99 // 2929

Query Driven IndexingQuery Driven Indexing
Lets index only what is queried!Lets index only what is queried!
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 1010 // 2929
ContentsContents
• Introduction• Single-term vs. multi term indexing• HDK approach for indexing• Query-driven approach for indexing/retrieval
– Indexing structure– Example– Scalability– Evaluation
• Conclusion
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 1111 // 2929

Query-Driven Index (QDI)Query-Driven Index (QDI)
• Query-Driven Indexing strategy solves the “Too-Many-KeysToo-Many-Keys” problem:– Avoids maintenance of superfluous keys– Generates only such keys that are requested by users– Utilizes query-log to discover such keys
• ProblemsProblems– Indexing of a new key requires a bandwidth-efficient
mechanism to obtain the top-k posting list associated with the key Smart Broadcast (ONM) Smart Broadcast (ONM) or Conventional intersection like TA, but less Conventional intersection like TA, but less
frequentfrequent
– Incomplete index causes degradation of query results quality Show that the degradation is lowShow that the degradation is low
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 1212 // 2929

Which keys to index?Which keys to index?
• Each single-term found in the document collection has to be indexed. – We call all single-term keys a basic single term indexbasic single term index.
– The posting lists are truncated at DFmax.
• A key k is non-superfluousnon-superfluous and can be activated activated iff:
– k is popular: QF(k) ≥QFmin, where QF(k) is the popularity of the key k derived from the available query log and QFmin is a parameter for our model (popularity filter).
– k contains from 2 to smax terms: 2≤|k|≤ smax, where smax is a parameter of our model (size filter).
– all immediate sub-keys of k (of size |k-1|) are indexed and their associated postings lists are truncated (redundancy filter).
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 1313 // 2929

QDI: RetrievalQDI: Retrieval
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
a b c
abc
ab bc ac
• Single term index is generated
• Process abc1) Probe Pabc
2) Probe Pab Pbc and Pac
3) Probe Pa Pb and Pc
4) Obtain top-DFmax results for a, b and c (ranked w.r.t a, b and c respectively)
5) Contact peers in the list, re-rank the obtained results w.r.t abc
6) Output top-10
• Inc. the QF for ab, bc and ac• Activate (index) ac
peer?abc nothing
?abc
nothing
nothing
nothing
?abc
+1 +1 +1
DFmax
popularpopular
1414 // 2929

QDI: Retrieval 2QDI: Retrieval 2
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
abc
ab bc ac
a b c
• Assume the frequency of b is below DFmax
• Note, how the redundancy filter would simplify the lattice in such a case(grayed nodes cannot be activated)
DFmax
abc
ab bc
1515 // 2929

QDI: Retrieval 3QDI: Retrieval 3
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
abc
ab bc ac
a b c
• Single term index is generated and ac is indexed
• Process abc1) Probe Pabc
2) Probe Pab Pbc and Pac – obtain the result for ac
3) Probe Pb and obtain the result for b
4) Contact all peers in the list to re-rank the obtained results w.r.t abc
5) Output top-10
• Inc. the QF for ab, bc and ac
peer?abc nothing
?abc
nothing
nothing
?abc
+1+1 +1
1616 // 2929

ScalabilityScalability
• The retrieval traffic is bounded by a constant due to trun-cated posting lists (depends on DFmax and a query size)
• The indexing traffic depends on the number of keys to be activated.
– The number of keys in the HDK approach (UPPER BOUND) is proven to grow linearly linearly with the number of peers, if each peer provides a limited number of documents
– The number of keys does does notnot depend on the document depend on the document collection sizecollection size but only on the size of the query log
– We can use the QFmin parameter to adjust the tradeoff:
indexing traffic <-> retrieval qualityindexing traffic <-> retrieval qualityG.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 1818 // 2929

ContentsContents
• Introduction• Single-term vs. multi term indexing• HDK approach for indexing• Query-driven approach for indexing/retrieval
– Indexing structure– Example– Scalability– Evaluation
• Conclusion
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 1919 // 2929

AOL logsAOL logs
• 17M Queries from March, April, May 2006 (92 days)• 650K anonymous user sessions• Extracted all unique queries from each user
session:
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
…2006-05-31 23:50:30 wearthbow.com native.cheyenne origin.2006-05-31 23:50:30 l6 screensaver2006-05-31 23:50:30 horses for sale in tn ky2006-05-31 23:50:30 bank of america.com2006-05-31 23:50:30 ask2006-05-31 23:50:29 del rosa lanes2006-05-31 23:50:28 www.spirit airlines.com2006-05-31 23:50:28 find holy women of the bible2006-05-31 23:50:27 trains2006-05-31 23:50:27 todaysmiricles2006-05-31 23:50:27 constition2006-05-31 23:50:26 german grocceries in las vegas nv2006-05-31 23:50:25 porn2006-05-31 23:50:25 northwest indiana2006-05-31 23:50:24 united.eprize.net2006-05-31 23:50:24 jessica laguna…
<-0.7Gb
2020 // 2929

Distribution of combinations in the AOL Distribution of combinations in the AOL logslogs
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 2121 // 2929

TREC ExperimentTREC Experiment
• WT10G collection (~1.69 M docs)• 100 TREC queries (from TREC Web Track 9 & 10)• Query statistics generated form 17M AOL
queries• Using Okapi-BM25 weighting schema to
compute ranking score• QFmin = 1, 3, 5, ∞• DFmax = 100, 500• smax=3
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
DFmax=100 DFmax=500ST-BM25
QFmin=∞ QFmin=5 QFmin=3 QFmin=1 QFmin=∞ QFmin=5 QFmin=3 QFmin=1
P@1 0.408 0.449 0.449 0.449 0.429 0.439 0.439 0.439 0.439
P@2 0.388 0.439 0.434 0.434 0.418 0.429 0.429 0.429 0.429
P@3 0.347 0.412 0.412 0.408 0.391 0.395 0.395 0.395 0.395
P@4 0.324 0.370 0.372 0.370 0.367 0.362 0.362 0.362 0.360
P@5 0.306 0.345 0.347 0.341 0.345 0.343 0.343 0.343 0.337
P@10 0.266 0.299 0.295 0.294 0.307 0.302 0.303 0.302 0.298
P@15 0.237 0.267 0.267 0.267 0.276 0.279 0.280 0.278 0.278
P@20 0.212 0.243 0.243 0.246 0.254 0.259 0.259 0.259 0.257
P@30 0.174 0.206 0.209 0.212 0.214 0.221 0.221 0.224 0.226
P@50 0.139 0.169 0.171 0.174 0.175 0.181 0.181 0.183 0.186
P@100 0.097 0.126 0.127 0.130 0.128 0.135 0.135 0.136 0.140
Precision is similar to centralized indexing
Precision is similar to centralized indexing
TREC: Precision at Top Ranked Pages (table)
2222 // 2929

Overlap experimentOverlap experiment
• Use the query-log to build the index (days 1..91)• Choose randomly 2K test queries from the day 92• Answer each test queryquery with Google and compare to the union
of top-DFmax Google results for each of its combinationsits combinations that are indexed according to the logs.
• Mimics our P2PIR system if Google’s ranking is used.• Example:
Original query
Non-superfluous (indexed) combinations
X
X
overlap@5=3/5=60%
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 2323 // 2929

Overlap exampleOverlap example
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
>id=481, q=“what did babe ruth do in the 1920”what did babe ruth do in the 1920”
“1920 babe ruth”, qf=0 ----> Ov@100= 100%
“1920 babe”, qf=0 ---------> Ov@100= 9% +++“1920 ruth”1920 ruth”, qf=1 ---------> Ov@100= 33%33% +++“babe ruth”babe ruth”, qf=495 -------> Ov@100= 69% 69%
---“1920”, qf=716 ------------> Ov@100= 1% ---“babe”, qf=3196 -----------> Ov@100= 2% ---“ruth”, qf=1653 -----------> Ov@100= 7%
Size: 192192, Keys used: 22, Overlap@100: 94%94%
• Cut-n-paste from the simulation log:
2424 // 2929

Google experiment: impact of sGoogle experiment: impact of smaxmax, , DFDFmaxmax
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
impact of Smax for all possible combinations (QFmin=0)
Impact of DFmax with QFmin=1, Smax =3
2525 // 2929

Google experiment: impact of QFGoogle experiment: impact of QFminmin
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
impact of QFmin (DFmax=600) Number of keys for different QFmin
• Does not depend on the document collection size
• HDK approach would require~65M keys for 650K documents
• Does not depend on the document collection size
• HDK approach would require~65M keys for 650K documents
• >30% of badly performing queries are misspells => real quality is higher
• >30% of badly performing queries are misspells => real quality is higher
2626 // 2929
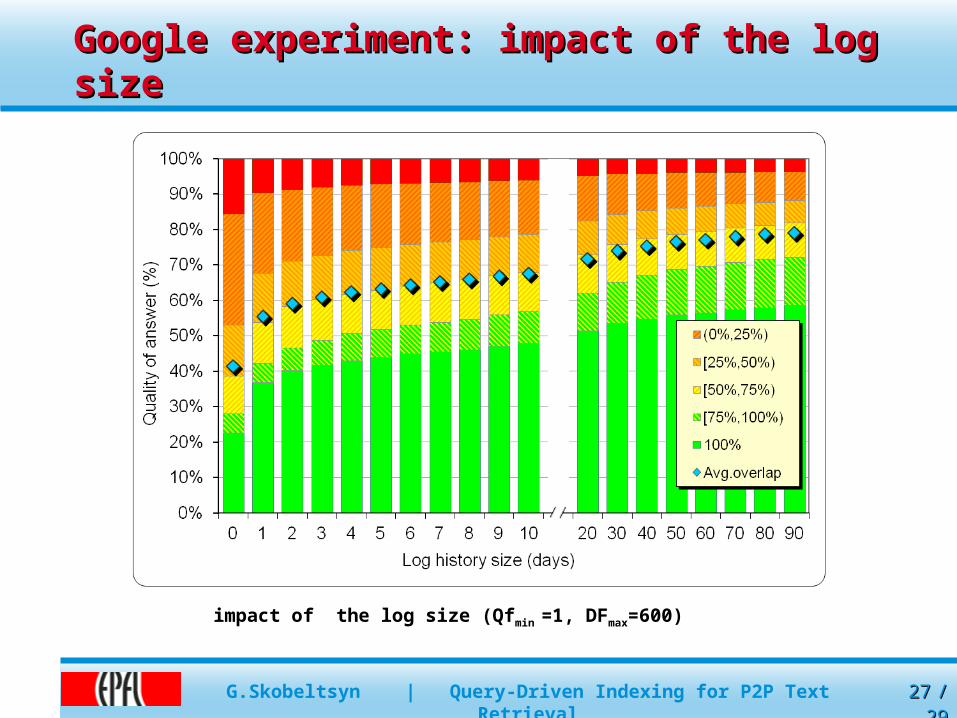
Google experiment: impact of the log Google experiment: impact of the log sizesize
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
impact of the log size (Qfmin =1, DFmax=600)
2727 // 2929

ConclusionsConclusions
• We presented the query-driven indexing strategy query-driven indexing strategy for scalable web text retrieval with structured P2P networks:– Stores posting lists in a DHT for terms andand term combinations
– Stores at most at most DFmax top document references in a posting list
– Efficiently collects the query statisticsstatistics in a distributed fashion
– Based on this statistics activates (indexes) only popularpopular keys
– Computes the result of a multi-term query based only on the index entries available at the moment – nono costly intersections
• We also showed that:– With real query-logs our approach achieves good retrieval qualitygood retrieval quality
– The QFmin parameter adjusts the traffic/quality tradeofftradeoff
G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval 2828 // 2929

G.Skobeltsyn | Query-Driven Indexing for P2P Text Retrieval
Last slideLast slide
Thank you for your attention!Questions?
2929 // 2929
AlvisP2P - to appear in July athttp://globalcomputing.epfl.ch/alvis/