guidelines on commercial and open dataset attestation .../media/imda/files/industry...
TRANSCRIPT

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 1 of 60
GUIDELINES ON COMMERCIAL AND OPEN DATASET ATTESTATION (CODA) SCHEME
Prepared by : CODA Working Group Version : 1.0, Apr 2016

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 2 of 60
Document Change Log
Document Name: IMDA Guidelines on Commercial and Open Dataset Attestation
Version Summary of Change Updated By/ Date
Reviewed By/ Date
Approved By/ Date
1.0 Initiation of CODA document

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 3 of 60
Contents Page
Foreword 4
0 Introduction and objectives 6
1 Scope 7
2 Normative references 7
3 Definitions and abbreviated terms 7
4 Approach for scheme development 9
5 Scheme requirements 12
6 Scheme tiers 14
7 Conformance process 15
8 Attestation process 16
9 Implementation considerations 17
10 Future considerations 20
Annexes
A List of CODA requirements 21
B CODA questionnaire 26
Tables
1 Tier 1 requirements 21
2 Tier 2 requirements 21
3 Tier 3 requirements 22
4 Tier 4 requirements 24
Figures
1 Overview of the CODA Scheme 7
2 Synthesis of additional requirements on top on ODC 11
3 Interoperability mapping between ODC and CODA 12
4 Comparison of use cases between tiers 15
5 Illustration of the use of badges for tiers administered via an online platform 18
6 Illustration of the attestation process administered via an online platform 19

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 4 of 60
Foreword
The Commercial and Open Dataset Attestation (CODA) Working Group (WG) is initiated by the National Cloud Computing Office at the Info-communications Media Development Authority (IMDA) to assist in the preparation of this guideline, comprises the following experts who contribute in their individual capacity:
Chair: Chen Yew Nah (Zeles) Deputy Chair: Lee Hing Yan (IMDA) Member: Chris Chin/James Liu (Singapore Computer Society) Member: Fred Sim (Singapore IT Federation) Member: Oliver Chen/Raymond Chan (DataKind) Member: Lim May-Ann/Magnus Young (Asia Cloud Computing Association) Member: Samantha Fok/Adeline Lim (IMDA)
The Focus Group appointed by IMDA to assist in providing professional insights, verification and endorsement of these Guidelines includes the following experts:
Fabio La Mola (IMS Health) Lim Huishan (SPH) Ng Peng Khim & Joan Tay (DBS) Angela Xu (Great Eastern) Roy Goh (Merck) Daryl Peh (IBM) Henry Cheng (SMRT) Daniel Ong (Tableau) Pablo Kotey (Standard Chartered) Edwin Law (Grab) Lim Siow Cheng (EZ-Link) Lau Shih Hor (Elixir Technology) Usman Haque (Umbrellium) Mike Davie (DataStreamX) William Lai (Amicus) Sun Wenting (Adplusplatform) Erel Rosenberg (DFRC) Anthony Chong (ESRI Singapore) Ghanshyam Ahuja (JamiQ) Yong Kai Chin (Sense Infosys) Lek Hsiang Hui (Standices) Chan Chi-Loong (VSlashR) Priyanka Grover (IHIS) Varoon Rajani (Blazeclan) Mohammad Zaki bin Ariffin (CAAS) Jane Lo (Finboxx) Larry Liu & Andy Liu (Alibaba) Vincent Soh (EDF) Judy Yuen (Compcierge Asia) Kew Yoke Ling (Kewmann Data) Vinod Arya (Optumum Solutions)

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 5 of 60
Disclaimer The information provided in these Guidelines for Commercial and Open Dataset Attestation Scheme is for general information purposes only. The Guidelines for Commercial and Open Dataset Attestation Scheme is provided “AS IS” without any express or implied warranty of any kind. Whilst the Working Group (defined above), Info-communications Media Development Authority of Singapore (IMDA) and/or individual contributors thereof have made every reasonable effort to ensure that the information contained herein are obtained from reliable sources and that any opinions and/or conclusions drawn there from are made in good faith, to the extent not prohibited by law, the Working Group and IMDA, and their respective employees, agents and/or assigns shall not be responsible or liable for reliance by any person on the information, opinions and/or conclusions contained herein. The Working Group and IMDA, and their respective employees, agents and/or assigns shall not be liable for any direct, indirect, incidental or consequential losses arising out of the use of the Guidelines for Commercial and Open Dataset Attestation Scheme. The Working Group and IMDA are entitled to add, delete or change any information in the Guidelines for Commercial and Open Dataset Attestation Scheme at any time at their absolute discretion without giving any reasons. Copyright © 2016 Info-communications Development Authority Singapore. All rights reserved.

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 6 of 60
Guidelines for Commercial and Open Dataset Attestation (CODA) Scheme
0 Introduction and objectives
0.1 Introduction The exponential growth of data and acceleration of technological advance is causing fundamental shifts in the way decision-makers think about business problems, driving entrepreneurial innovation, opening up new business opportunities and creating new jobs. As organisations and governments continue to leverage data and technology to drive strategic business and social objectives, these benefits and opportunities cannot be effectively realised in the absence of highly trusted, reliable and usable datasets. To drive an effective data economy, the Ministry of Communications and Information has announced, in its Infocomm Media 2025 Report, an initiative to create a trusted data marketplace where public and private sector datasets are made available to help generate new applications, products and services. A dataset attestation scheme can help to instil trust and confidence in the use of data within a data marketplace.
0.2 Objectives The overall objective of the Commercial and Open Dataset Attestation (CODA) scheme is to instil trust and confidence in the use of data through providing a standardised framework to assess a dataset’s metadata and the associated data publishing process. The scheme aims to improve data users’ level of trust on a dataset, through the description of opportunities and restrictions on the dataset, the amount of effort needed to process the dataset, the amount of support that can be reasonably expected, as well as the availability of enterprise level support. For data providers, the scheme is a structure to provide transparency on their datasets, and is a guide to improve data sharing and monetisation.
The scheme proposes a questionnaire which data providers fill up for each dataset that they want attested. Based on a data provider’s responses to the questionnaire, datasets are assigned an appropriate tier, which can be used by data users to identify datasets that fit their needs. This process is referred to as the conformance process for data providers. After a tier has been assigned to a particular dataset, data users of the dataset can provide feedback to testify to or invalidate the declared conformance made by the data provider. This process is referred to as the attestation process for data users.

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 7 of 60
Figure 1 – Overview of the CODA Scheme
1 Scope This document provides recommendations for the development of the CODA scheme. It:
suggests key requirements that the assessment of the datasets will be based on;
suggests a tiered structure that will be used to classify datasets into their appropriate tiers;
provides recommendations on conformance and attestation processes for the scheme.
2 Normative references There are no normative references in this document.
3 Definitions and abbreviated terms For the purpose of this guideline document, the following definitions and abbreviated terms apply:
3.1 API Application Programming Interface (API) refers to the set of routines and protocols which facilitates access to data of an application, a database or other services. Refer to Open Data Handbook1 for more information on API.
1 http://opendatahandbook.org/glossary/en/terms/api/

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 8 of 60
3.2 Commercial data Commercial data refers to data that have restrictions imposed on access, reuse or redistribution. Data may be accessible only to specific groups of users or organisations. There may also be restrictions on the reuse and redistribution of the data under non-open licenses.
3.3 Data provider A data provider is a service provider that enables data availability on demand to other external data providers or data users whether for free or at a fee. It includes data owners (primary data source) who create or collect their own data, as well as data aggregators (secondary data source) who collect data from multiple primary data providers.
3.4 Data user A data user is an entity or organisation involved in accessing data from data providers, whether for free or with a fee, for the purpose of internal use to conduct research, analysis, to create value-added services from the data and/or for decision-making, except for selling of the data itself. This includes some data aggregators that make use of data from data providers to carry out their business activities.
3.5 Database dump A database dump is an output of data from the database, which can be used to back up or restore a database in the event of data loss.
3.6 Dataset A dataset is a collection of digitally accessible data, published or curated by a single source, and available for access or download in one or more formats.
3.7 Licence A licence is the explicit permission given by the licence holder to someone else to access, reuse and redistribute the licensed work.
3.8 Machine-readability Machine-readability refers to whether a document or dataset is in a format which can be easily processed by a computer in a way that is informative or useful. For example, a word-processing document containing tables of data is not considered machine-readable as a computer would not be able to easily access and transform the data in the tables without customised computer programs. Digitally accessible data may not necessarily be machine-readable, as is the case for scanned documents. Refer to “A Primer on Machine Readability for Online Documents and Data”2 and Open Data Handbook3 for more information on machine-readability.
3.9 Open data Open data refers to data that anyone can access, use and share. Open data is data with an open license. Refer to Open Data Handbook4 for more information on open data.
2 https://www.data.gov/developers/blog/primer-machine-readability-online-documents-and-data
3 http://opendatahandbook.org/glossary/en/terms/machine-readable/ 4 http://opendatahandbook.org/glossary/en/terms/open-data/

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 9 of 60
3.10 Open licence An open license allows the following, without discrimination, without charge, for any purpose:
Free use of the licensed data or content
Redistribution of the licensed data or content
Modification of the licensed data or content, and the distribution of the derived work under the same terms as the original license
Separation of part of the licensed data or content for use, redistribution and modification
Compilation of the licensed data or content together with other works for distribution, without placing any restrictions on the other works
Refer to Open Definition5 for more information on open licenses.
4 Approach for scheme development To develop the CODA scheme, a scan of existing data sharing frameworks and related references was conducted, in order for relevant requirements to be synthesised into the new CODA scheme. One of the existing schemes, the Open Data Certificate (ODC) by Open Data Institute (ODI), is taken as the base reference scheme for CODA. The rationale for this referencing and considerations for interoperability with the ODC are described in this section. Interoperability between ODC and CODA refers to how data sets with an ODC tier can obtain a CODA tier and vice versa.
4.1 Existing frameworks and references Existing frameworks relevant to the scheme were identified and referenced in the development of the scheme. These frameworks include:
Open Data Institute’s (ODI) Open Data Certificate (ODC) – an online tool developed to assess and recognise the sustainable publication of quality open data
5-Star Open Data – a rating system for linked open data developed by Tim Berners-Lee
Sunlight Foundation’s Open Data Policy Guidelines – a set of guidelines created to address what data should be public, how to make data public, and how to implement an open data policy
Technical reference for data versioning (TR55 : 2016) – a technical reference that provides a set of best practices in data versioning
Technical reference for data quality metrics (TR41 : 2015) – a technical reference recommending a baseline set of industry-agnostic data quality metrics
Technical reference for data as a service (DaaS) application programming interface (API) design and implementation (TR33 : 2013) – a technical reference that defines a set of best practices in the design and implementation of APIs
ISO 8000, Data quality – an ISO standard on data quality
IDA’s data management policy
Data Catalog Vocabulary (DCAT) – a Resource Description Framework (RDF) vocabulary designed to facilitate interoperability between data catalogues published on the web
Creative Commons – a non-profit organisation which has released several free copyright-licenses to the public, allowing content creators to communicate the rights which they reserved or waived for the benefit of recipients or other creators
Open Data Commons – an Open Knowledge Foundation project that launched the Public Domain Dedication and License (PDDL) open license to help others provide and use open data
Singapore Copyright Act
Singapore Patent Act
Personal Data Protection Act (PDPA)
5 http://opendefinition.org/od/2.1/en/

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 10 of 60
4.2 Proposed choice of framework as primary reference for CODA scheme The ODC is proposed as the primary reference in the development of the CODA scheme with the following considerations:
a) Intent – ODC was developed to assess and recognise the sustainable publication of quality open data, which is similar to the intent of the CODA scheme.
b) Coverage – ODC covers a wide range of areas, including data quality, usage and support, legal rights, conformance and attestation processes. Other frameworks cover only a subset of these areas, and can be used to further enhance CODA scheme in areas which the ODC does not address.
c) Compatibility – ODC builds upon existing frameworks like opendefinition.org, 5-Star Open Data,
Sunlight principles and DCAT. This is aligned with the CODA scheme’s requirement on interoperability.
d) Adoption – ODC has been adopted widely in the UK; Approximately 150,000 data certificates
were issued at end of 2015. Some adopters include:
UK national government
Greater London Authority
Australia Queensland Office of National Statistics
UK Data Service
Besides providing a rounded assessment of how effective the data provider is in sharing a dataset for ease of reuse, the certificate also acts as a reference sheet containing information of interest to users of a dataset. It represents a clear quality mark for users looking for assurances around how well the data is published.
In developing the CODA scheme, the ODC was used as the base framework. Existing frameworks and feedback from industry players were also used to supplement the CODA scheme. Elements of the ODC that may not be relevant for commercial data, or not easily achievable by data providers and could thus potentially hinder adoption were identified. Of these elements, the requirements for independent auditing of anonymisation and privacy were assessed to have the greatest impact on adoption. However, all identified elements are still incorporated in the CODA scheme to maintain interoperability.

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 11 of 60
Figure 2 – Synthesis of additional considerations on top on ODC
4.3 Interoperability considerations
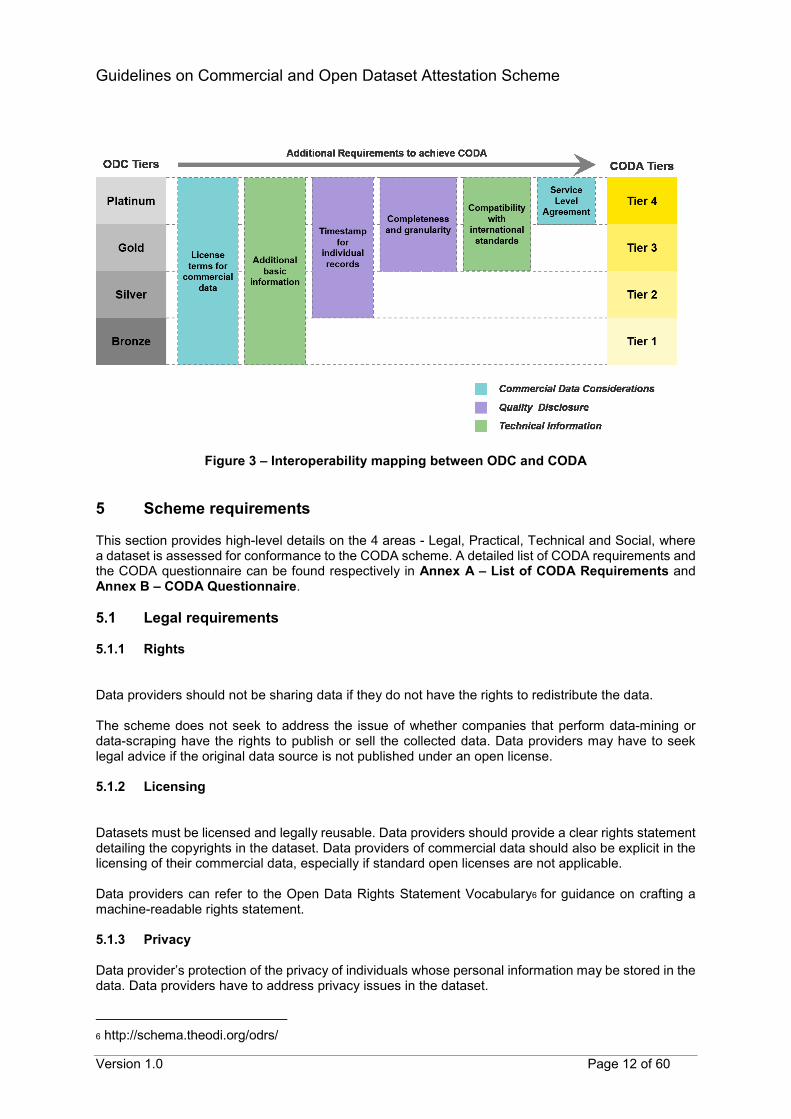
To maintain interoperability between the CODA scheme and ODC, all requirements, requirement categories and the corresponding tiered structure from ODC are incorporated into the scheme. The CODA tiering scheme (Tier 1 to 4) also follows a similar structure to the ODC tiering scheme (Bronze, Silver, Gold and Platinum). For both schemes, four tiers are used; each increasing tier indicates that all of the requirements of the previous tier have been fulfilled, along with additional requirements that qualify the dataset for the current tier. Additional requirements specific to the CODA scheme are categorised in each of the four tiers to adhere to the ODC tiered structure. This allows data providers who are on the CODA scheme to easily obtain an ODC certification. Data providers already with an ODC certificate for their dataset can obtain a similar tier in the CODA scheme by fulfilling the additional requirements in the scheme. Building the CODA scheme on top of ODC eliminates the need to maintain a complex mapping between ODC and CODA. It also allows flexibility in adopting any future changes to the ODC scheme as it matures. The figures below illustrate the interoperability mapping between ODC and CODA.
Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 12 of 60
Figure 3 – Interoperability mapping between ODC and CODA
5 Scheme requirements
This section provides high-level details on the 4 areas - Legal, Practical, Technical and Social, where a dataset is assessed for conformance to the CODA scheme. A detailed list of CODA requirements and the CODA questionnaire can be found respectively in Annex A – List of CODA Requirements and Annex B – CODA Questionnaire.
5.1 Legal requirements 5.1.1 Rights Data providers should not be sharing data if they do not have the rights to redistribute the data. The scheme does not seek to address the issue of whether companies that perform data-mining or data-scraping have the rights to publish or sell the collected data. Data providers may have to seek legal advice if the original data source is not published under an open license. 5.1.2 Licensing Datasets must be licensed and legally reusable. Data providers should provide a clear rights statement detailing the copyrights in the dataset. Data providers of commercial data should also be explicit in the licensing of their commercial data, especially if standard open licenses are not applicable. Data providers can refer to the Open Data Rights Statement Vocabulary6 for guidance on crafting a machine-readable rights statement. 5.1.3 Privacy Data provider’s protection of the privacy of individuals whose personal information may be stored in the data. Data providers have to address privacy issues in the dataset.
6 http://schema.theodi.org/odrs/

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 13 of 60
The CODA scheme does not ensure the anonymity of datasets. The onus lies on the data providers to ensure that each individual dataset that is placed on the scheme complies with the relevant laws like the PDPA.
5.2 Practical requirements 5.2.1 Searchability Extent to which data providers help data users search for the data. Datasets should be accessible and discoverable on the web (can be linked to from other web pages). 5.2.2 Accuracy Extent to which data providers keep their data up to date. Dataset should be time-stamped or kept up to date. If there are multiple versions of the dataset, data providers should implement a version control process. Data providers can refer to the Technical Reference for Dataset Versioning (TR55 : 2016) 5.2.3 Quality Level of reliance which data users can place on the data. Quality issues in the data should be documented. Data providers should also provide information on the granularity and completeness of their datasets. The scheme does not assess the quality of the dataset’s content as the perception of quality depends on individual use cases. Instead, the scheme assesses the quality of how the data is constructed and if there are any quality control processes in place to detect invalid data values. 5.2.4 Guarantees Extent to which data users can depend on the data’s availability. Data should be available for at least a year, and data provider should guarantee timeliness of updates to the dataset. Regular backups of the data should also be taken. Datasets which have to be purchased by data users are recommended to have Service Level Agreements that provide guarantees on the user support, data timeliness and data availability. Refer to “Global Reference Architecture (GRA) Information Sharing Enterprise Service-Level Agreement”7 for a sample Service Level Agreement on data sharing services.
5.3 Technical requirements 5.3.1 Locations Options where data users can access the data. There should be a single consistent Uniform Resource Indicator (URI) for downloading the data. 5.3.2 Formats Data should be available in open standard, machine-readable and content-appropriate formats, disclosing compatibility with international standards where applicable. URLs should also be used as identifiers within the data.
7 https://it.ojp.gov/GIST/60/Global-Reference-Architecture--GRA--Information-Sharing-Enterprise-Service-Level-Agreement

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 14 of 60
5.3.3 Trust Level of trust that data users can put in the source of the data. Data providers should provide machine-readable documentation on the provenance of the data, to indicate to data users how the data was created and processed.
5.4 Social requirements 5.4.1 Documentation Extent of documentation given by data providers to help data users understand the context and content of the data. Documentation and machine-readable metadata should be provided. 5.4.2 Support Channels which data providers can use to communicate with data users. Social media accounts should be used to promote the data. Forums, mailing lists should also be available to facilitate discussions and updates on the data. There should also be dedicated teams to build user community around the use of the dataset. 5.4.3 Services Provision of access to tools that data users may need to work with the data. Data providers should provide a list of recommended tools that data providers can use to work with the data.
6 Scheme tiers Four tiers are achievable in this scheme, with each tier having incremental requirements to fulfil. A high-level description of the different tiers is provided below. A detailed list of the incremental requirements for each tier can be found in Annex A – List of CODA Requirements.
6.1 Tier 1 Data is licensed, accessible and legally reusable.
6.2 Tier 2 In addition to meeting the Tier 1 requirements, the data is documented in a machine-readable format, reliable and offers ongoing support from the publisher via a dedicated communication channel. 6.3 Tier 3 In addition to meeting the Tier 2 requirements, the data is published in an open standard machine-readable format, has guaranteed regular updates, offers greater support, documentation, and includes a machine-readable rights statement. Datasets with personally-identifiable information also have to be independently audited on the anonymisation process and privacy risk assessment.
6.4 Tier 4 In addition to meeting the Tier 3 requirements, the data has machine-readable provenance documentation, uses unique identifiers in the data, and the publisher has a communications team building a data user community.

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 15 of 60
Figure 4 – Comparison of use cases between tiers
7 Conformance process The conformance process refers to how a dataset is assessed for conformance to the requirements of the scheme, and subsequently assigned an appropriate tier based on the assessment results.
7.1 Self-declared conformance The proposed approach is self-declared conformance, where data providers answer a questionnaire on the datasets that they wish to place onto the CODA scheme. Based on the responses given, an appropriate tier will be assigned for the particular dataset. For the purposes of tracking and accountability, it is recommended for data providers to be issued formal documentation on the assigned tier for each dataset, and for data users to be provided a means of verifying the authenticity of each dataset’s assigned tier and to view the data providers’ questionnaire responses.
7.2 Questionnaire structure The questionnaire comprises a combination of multiple-choice and open-ended questions, addressing requirements in 4 key aspects as described in Clause 5. Each question in the questionnaire has an accompanying description to guide data providers in providing the most suitable response for their dataset, and also educate on best practices. A summary on the requirements that data providers need to fulfil to achieve each tier will help data providers understand how they can achieve their desired tier. The questionnaire can either be sorted categorically such that all questions are grouped according to their relevant areas, like legal rights or privacy issues. Alternatively, the questions can be ordered such that data users would encounter questions required for the lowest tier first before the questions required for the higher tiers.

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 16 of 60
7.3 Validity of dataset tier
Imposing a validity period on the dataset tier is recommended as this would encourage data providers to maintain conformance of their datasets to the scheme, and ensures that the assessment of the dataset stays current and relevant. The validity period of the dataset tier can be tracked and a re-conformance process triggered upon expiry. A default validity period of one year is recommended, which is in line with the ODC scheme, and deviations from this default period can be considered for static datasets which are not updated or changed after introduction into the market.
7.4 Amendment of responses Data providers may want to amend their responses subsequently, and it is suggested that any amendment triggers a re-assessment of the dataset and refreshes the validity period of the dataset tier. It may also be worthwhile to maintain a change log of these amendments and re-assigned tiers so that data users would be able to identify the datasets that were affected.
7.5 Changes in scheme requirements To cater for changes in the scheme requirements after implementation, a possible approach would be to notify data providers of the upcoming change and allow a transitional period for data providers to make the necessary changes to their data sets or processes before the new requirements are effected. Tiers on all existing datasets can be set to expire when the new requirements are in place to ensure that no dataset has an assigned tier based on the superseded requirements. To achieve a tier from the scheme again, data providers would have to go through the conformance process under the new requirements.
8 Attestation process The attestation process refers to the process where data users verify data providers’ declared conformance of their datasets to the CODA scheme.
8.1 Controlled crowd-sourced review Eligible attesters (data users) should be allowed to verify the declared conformance made by the data providers. These attesters help to create a community around the dataset. An attester authentication process needs to be in place to ensure review accountability, preventing parties with malicious intent from providing inaccurate ratings and feedback irresponsibly. This can be done by requiring attesters to register with the CODA administrators before submission of reviews, and to limit review submission to parties that have used the data.
8.2 Feedback from users Attesters should be required to register with the CODA administrators to provide feedback on the data provider’s responses to specific questions. It can be made mandatory for attesters to indicate the specific area or response that feedback is directed at. This guided feedback process would encourage attesters to provide targeted and specific feedback instead of making generalised statements which may not be as constructive.
8.3 Response from data providers To address attesters’ feedback, data providers can choose to correct their responses to the questionnaire so that it more accurately reflects the nature of the dataset. This correction will update the assessment of the dataset and the dataset’s corresponding tier. Alternatively, data providers can

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 17 of 60
provide clarifications to the attesters’ feedback. Capturing the feedback and associated responses in a chronological order would also help both data providers and data users understand the changes made to the dataset over time.
8.4 Scheme administration Administrators of the scheme should have the authority to revoke any tiers assigned to a dataset if it is deemed that the responses to the questionnaire are untrue and compromises the integrity of the scheme. A means of arbitration for disputes should also be available. This can be carried out either by the administrator or an independent third party.
9 Implementation considerations The following questions may help to provide some guidance on the selection of an appropriate platform or approach for implementing the CODA scheme.
How will the questionnaire be made available to data providers?
Where can data users find out more about data providers’ questionnaire responses for the datasets?
How will responses to the questionnaire be assessed?
How can data users verify the authenticity of a dataset’s tier?
How will data users provide rating and feedback on the dataset, using the questionnaire responses as a benchmark?
Can data users use the scheme to seek legal recourse from data providers? The sections below detail some of the recommendations that may help to address some of the questions raised above.
9.1 CODA platform The CODA scheme can be hosted on an online platform to facilitate the administration of the questionnaire. This provides greater accessibility to the questionnaire for data providers. Likewise, responses to the questionnaire for each dataset will also be made readily accessible to data users.
9.2 Real-time assessment Assessment of the questionnaire responses can be automated and performed real-time as the data provider progresses through the questionnaire. The data provider can be provided with an indication on the tier that has been achieved with the current responses, and how far the provider is from achieving the next tier. With real-time assessment, data providers can choose not to proceed further with the questionnaire if the desired tier has been achieved. Automated input validation checks can be considered for some of the open-ended questions, with associated warnings if the entry is invalid (e.g. check for valid URLs).
9.3 Auto-assessment feature Including an auto-assessment feature on the CODA platform can help to partially, if not fully, assess a dataset based on a standard metadata document indicated by the data provider. This would reduce the time required for data providers to complete the questionnaire, and facilitates the assessment process for data providers with multiple datasets.

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 18 of 60
9.4 Authenticity of the dataset’s tier and badge
The dataset’s tier can take the form of a badge, which data providers can embed on their website. This badge, which shows the tier and the dataset ID, is linked to the CODA platform, where users can obtain more information about the relevant datasets. Alternatively, users will be able to search on the CODA platform using the dataset ID to obtain the same information. To verify the authenticity of the badge, users can cross-reference details provided by the data publisher on CODA platform against the details on the data publisher’s website and the provided dataset. The figure below illustrates how badges can be authenticated by data users via an online platform.
Figure 5 – Illustration of the use of badges for tiers administered via an online platform
9.5 Administration of crowd-sourced attestation It is also recommended that an online platform be used to host the ratings and feedback mechanism for the scheme. This helps to provide transparency and accessibility to both data providers and data users, allowing both parties to provide guided feedback and responses without too much involvement of an intermediary to process the inputs. Review accountability should be established so as to prevent sabotaging, and this can be done by requiring attesters to register on the CODA platform before they can be allowed to submit reviews. To limit the submission of reviews to parties that have used the data, a unique token can be generated by the data provider when users download the data, and required as a mandatory input for any rating and feedback to be considered valid. The figure below illustrates how crowd-sourced attestation can be administered via an online platform.

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 19 of 60
Figure 6 – Illustration of the attestation process administered via an online platform
9.6 Ratings provided by data users By allowing data users to provide ratings as part of feedback, the ratings can be aggregated into an overall score to reflect the degree of self-declared conformance made by data providers. The aggregated rating can be used by data users to refine their search for the appropriate datasets. Once a dataset has received a number of ratings and feedback from users, the dataset can be tagged as “community-verified” to differentiate from datasets which are only “self-verified” and have yet to receive any ratings and feedback.
9.7 Independent audit on anonymisation process and privacy risk assessment To achieve Tier 3 or Tier 4, data providers have to acknowledge that independent audits have been performed on their anonymisation process and privacy risk assessment if the dataset contains personally-identifiable information. These requirements are also part of the ODC base requirements for Gold and Platinum tiers. In ODC however, data providers are not required to provide the details of the audit performed. As ODC does not provide specific details on these audits, if audit guidelines are to be provided for the CODA scheme, the following points are suggested for consideration:
To provide a list of independent parties whose audits are recognised by the scheme
A consistent audit approach and methodology may be required if there are more than one independent party who can perform these audits for the purposes of the scheme.
Alignment of the above requirements with ODC’s requirements would be necessary to ensure consistency and interoperability
9.8 Independent assessment on conformance of dataset to the scheme A potential implementation option is to also allow an independent party to assess the data provider’s responses to the questionnaire. The independent assessment would provide more assurance on the accuracy of the disclosure and conformance to the requirements than the attestations provided by the data users. The following are some suggestions on the responsibilities of the independent party performing the assessment:

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 20 of 60
Assess the accuracy of the questionnaire responses based on evidence submitted by the data provider.
Correct the questionnaire responses based on evidence submitted by the data provider.
Re-assess questionnaire responses against scheme requirements and re-assign the appropriate tier.
There is also a need to consider the following points in designing the independent assessment mechanism:
Eligibility criteria for independent parties conducting the assessments should be clearly defined and the panel of independent assessors have to be appointed by the CODA administrators.
Independent parties need to be incentivised to provide such assessment services. This could be in the form of monetary fees, which may deter data providers from participating in the scheme if they were to bear the cost.
Administrators of the scheme may need to grant the power to revoke and re-assign tiers to the independent parties performing the assessment. Alternatively, administrators can revoke and re-assign tiers based on the assessment results.
9.9 Role of the scheme in contractual agreements between data providers and data users With the CODA scheme being self-declarative in nature, the scheme on its own should not be used as a legally binding contract between data providers and data users. Instead, any tiers assigned by the scheme should be used to guide data users’ expectations of the dataset. It should be explicitly made known that data users should not use the scheme to seek any legal recourse against the data providers, and any contractual agreements between both parties are not within the scope of the scheme.
10 Future considerations There are areas in the CODA scheme which may require additional considerations in the future. These areas are discussed in detail below.
10.1 Industry-specific context The scheme currently does not provide any industry-specific contexts on data sharing. However, there may be a need to consider industry-specific regulations in future as data sharing becomes more prevalent.
10.2 Changes to legal frameworks Due to technological advancements and market developments, legal frameworks may change over time . For example, proposed changes to the Copyright Regime in Singapore has been put up for public consultation in 2016. There may also be upcoming changes to existing legislation and guidelines, like the PDPA. These changes may affect various aspects of the scheme, such as the rights, licensing and privacy requirements. It is recommended that the scheme take into consideration such developments so as to stay current and relevant.

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 21 of 60
Annex A (informative)
List of CODA requirements
This annex provides a summary of the CODA requirements at each tier for data providers.
A.1 Tier 1 requirements This table summarises the requirements that are required to achieve Tier 1. Requirements marked with an asterisk (*) are requirements in addition to those identified from ODC.
Table 1 –Tier 1 requirements
Area Requirements
General Provide the following information on the dataset o data title o name of data provider o type of release (e.g. one-off, data series, API) o *description o *release date (service start date for APIs)
*Indicate if data users have to pay for the dataset
*Indicate categories and keywords of the data for better discoverability
Legal – Rights Acknowledge legal rights to provide the data. If data provider does not have clear legal rights over the data and
o some of the data was extracted or derived from another data, the other data must be published as open data
o some of the data was crowdsourced and copyrighted, provider must have a contributor license agreement
Legal – Licensing
Indicate licenses which data and content are licensed under, or provide a waiver
Technical – Locations
Provide a URL which allows users to access the data
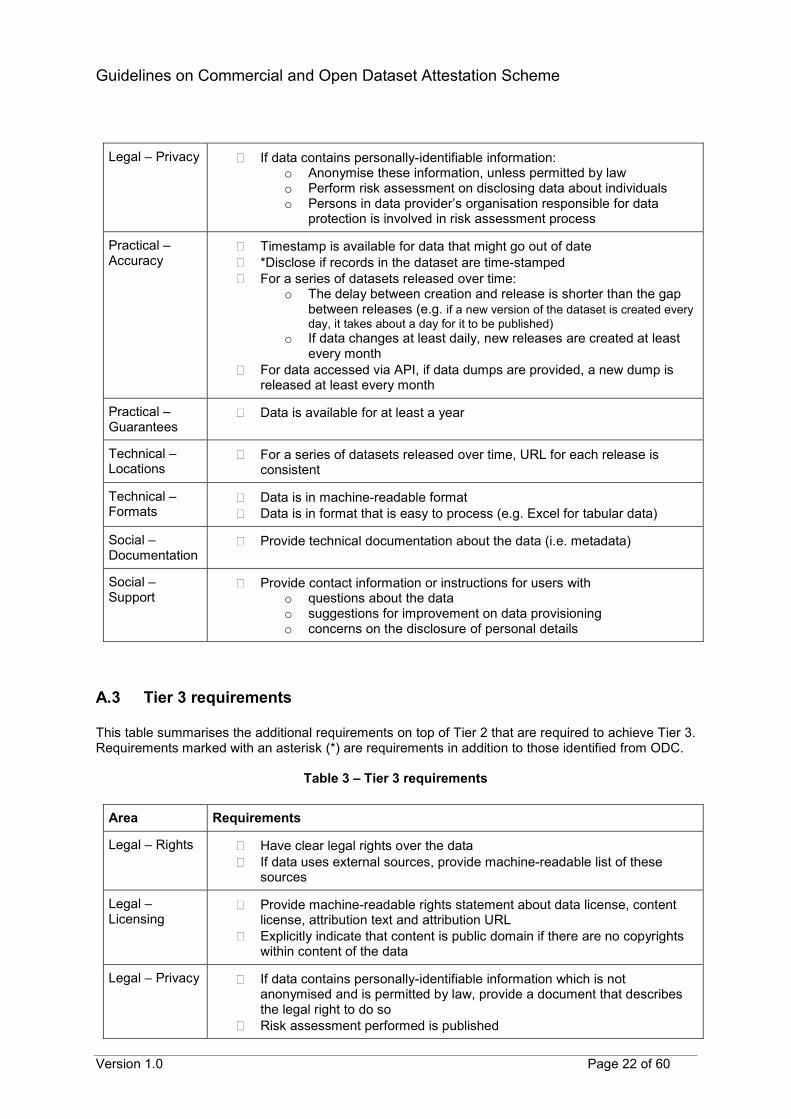
A.2 Tier 2 requirements
This table summarises the additional requirements on top of Tier 1 that are required to achieve Tier 2. Requirements marked with an asterisk (*) are requirements in addition to those identified from ODC.
Table 2 –Tier 2 requirements
Area Requirements
Legal – Rights If data provider does not have clear legal rights over the data, describe risks that users might encounter when using the data
If data uses external sources, provide document which describes source of data
Legal – Licensing
Publish rights statement on reusing data (license, attribution requirements, and a statement about relevant copyright)
Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 22 of 60
Legal – Privacy If data contains personally-identifiable information: o Anonymise these information, unless permitted by law o Perform risk assessment on disclosing data about individuals o Persons in data provider’s organisation responsible for data
protection is involved in risk assessment process
Practical – Accuracy
Timestamp is available for data that might go out of date
*Disclose if records in the dataset are time-stamped
For a series of datasets released over time: o The delay between creation and release is shorter than the gap
between releases (e.g. if a new version of the dataset is created every
day, it takes about a day for it to be published) o If data changes at least daily, new releases are created at least
every month
For data accessed via API, if data dumps are provided, a new dump is released at least every month
Practical – Guarantees
Data is available for at least a year
Technical – Locations
For a series of datasets released over time, URL for each release is consistent
Technical – Formats
Data is in machine-readable format
Data is in format that is easy to process (e.g. Excel for tabular data)
Social – Documentation
Provide technical documentation about the data (i.e. metadata)
Social – Support
Provide contact information or instructions for users with o questions about the data o suggestions for improvement on data provisioning o concerns on the disclosure of personal details
A.3 Tier 3 requirements This table summarises the additional requirements on top of Tier 2 that are required to achieve Tier 3. Requirements marked with an asterisk (*) are requirements in addition to those identified from ODC.
Table 3 – Tier 3 requirements
Area Requirements
Legal – Rights Have clear legal rights over the data
If data uses external sources, provide machine-readable list of these sources
Legal – Licensing
Provide machine-readable rights statement about data license, content license, attribution text and attribution URL
Explicitly indicate that content is public domain if there are no copyrights within content of the data
Legal – Privacy If data contains personally-identifiable information which is not anonymised and is permitted by law, provide a document that describes the legal right to do so
Risk assessment performed is published

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 23 of 60
Practical – Findability
Provide at least one URL which links users to the data from data provider’s website
Provide at least one URL which shows that the data appears within a list of similar data (e.g. data repository like data.gov.sg)
Provide URL of at least one document that references the data (e.g. blog posts)
Practical – Accuracy
For one-off data and unchanging data access via API, the data does not contain time-sensitive information
For a series of datasets released over time: o The delay between creation and release is shorter than half the
gap between releases (e.g. if a new version of the dataset is created
every day, it takes less than half a day for it to be published) o If data changes at least daily, new releases are created at least
every week
For data accessed via API: o a new data dump is released within a week of any change to the
data o Errors in the data are corrected
Practical – Quality
*Disclose quality metrics of the dataset in the following areas: o Completeness:
▪ Disclose fields that can have empty values
▪ Disclose fields that have been anonymised
▪ Disclose filters that have been applied on parent data source
o Granularity:
▪ Disclose how data aggregation is performed, if any
Provide documentation on known quality issues with the data
Practical – Guarantees
Regular offsite backups are taken
For data accessed via API, provide documentation on guarantees about service availability
Data is available for a couple of years
Technical – Locations
For a series of datasets released over time: o Provide a single URL linking to the most recent release of the
dataset o Provide a machine-readable document that lists all releases of the
data
For data accessed via API: o Provide a single URL allowing data users to download the most
recent data dump o Provide a machine-readable document describing the service or
entry point for the API
Technical – Formats
Data is in standard open format
Data is in format that is easy to analyse (e.g. CSV for tabular data)
Data includes identifiers which can be resolved via online services or as URLs
*Disclose fields that conform to international standards (e.g. country codes, currency codes, dates and times)

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 24 of 60
Social – Documentation
Provide machine-readable metadata on data (e.g. using DCAT)
If metadata about individual files are provided, metadata should include: o title o description o release date o modification date o link to rights statement related to the data
Provide documentation on the data vocabulary or schema if they are used
Provide documentation on codes if values in the data are encoded
Social – Support
Provide a list of social media accounts which users can reach the data provider on
Provide a designated forum where users can discuss about the data
Provide instructions for users to request for correction of data
Provide a mailing list or feed to notify users on the correction of data

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 25 of 60
A.4 Tier 4 requirements This table summarises the additional requirements on top of Tier 3 that are required to achieve Tier 4. Requirements marked with an asterisk (*) are requirements in addition to those identified from ODC.
Table 4 – Tier 4 requirements
Area Requirements
Legal – Licensing
Machine-readable rights statement includes copyright statement, copyright year and copyright holder
Explicitly indicate that content is public domain if there are no copyrights within content of the data
Practical – Accuracy
For a series of datasets released over time: o The delay between creation and release should be minimal or
none (e.g. if a new version of the dataset is created every day, it takes
less than a few minutes for it to be published) o If data changes at least daily, new releases are created at least
every day
For data accessed via API, a new data dump is released within a day of any change to the data
Practical – Quality
Provide documentation to describe the quality control process
Practical – Guarantees
For data accessed via API, provide an information page about the current status of the service
Data is part of day-to-day operations and is available long-term
* For datasets which have to be purchased, provide Service Level Agreement which guarantees:
o user support, o data timeliness, and o data availability
Technical – Locations
For data accessed via API: o Provide dated URLs to allow users to download a series of data
dumps o Provide a list of available data dumps in a machine-readable form
(e.g. a feed)
Technical – Formats
Data is in data formats designed specifically for the content (e.g. SDMX or Data Cube for statistics data)
Reliable third party URLs are used as identifier within the data, where available
Technical – Trust
Provide machine-readable provenance for the data
Provide mechanism to allow users to verify integrity of the data
Social – Support
Provide URL to an active team that builds the data user community
Social – Services
Provide a list of tools that can be used with the data

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 26 of 60
Annex B (informative)
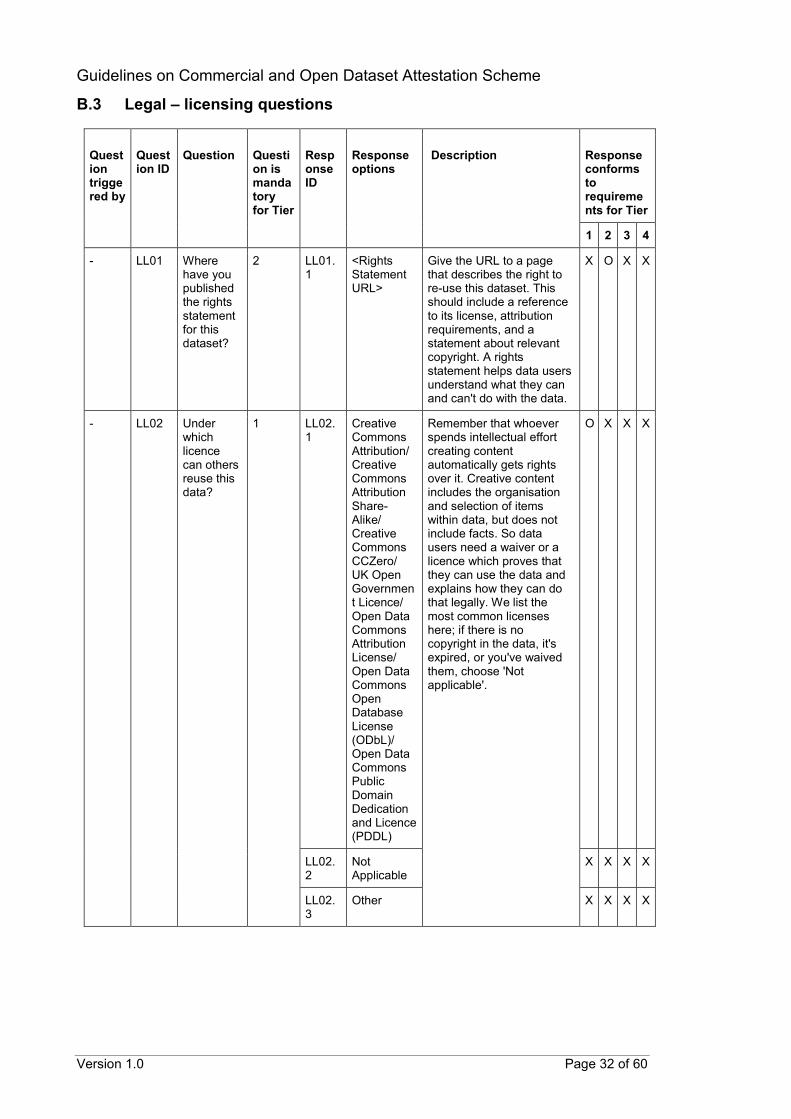
CODA questionnaire The following tables provide details of the proposed questions that can help to assess the conformance of datasets to the scheme’s requirements. The proposed questions are organised by requirement areas instead of by tiers. This is because the available responses to a question can qualify the dataset for more than one tier. Each proposed question has been assigned a unique identifier (Question ID). Corresponding response options have also been assigned unique identifiers (Response ID) with similar naming conventions. As the number of questions may be voluminous, follow-up questions can be hidden from the data provider and revealed after appropriate responses have been selected. The suggested triggering of follow-up questions is detailed in the subsequent tables (Question triggered by). Questions that can be triggered by multiple responses may require at least one or all relevant responses to be have been selected before being revealed. To guide the data provider in selecting the most appropriate response for their datasets, suggested descriptions can also be provided for specific questions or responses. These have also been included in the subsequent tables (Description). The last column in the table provides details on whether a response confirms to the scheme’s requirements for each tier. An “O” indicates that the response conforms to a requirement for that specific tier. An “X” indicates that the response still qualifies the dataset for that tier even though there is no specific requirement at that tier. A blank indicates that the response does not qualify the dataset for that specific tier. Questions marked with an asterisk (*) are questions in addition to those identified from ODC.
B.1 General questions
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
- G01 Where is the data described?
2 G01.1 <Dataset URL>
You should have a web page that offers documentation about the data you publish so that everyone can understand its context, content and utility.
O O X X
- G02 What's this data called?
1 G02.1 <Data Title>
Provide an unambiguous and descriptive name for your data that identifies what's unique about it. This helps data users quickly find your data.
O X X X
- G03 Who publishes this data?
1 G03.1 <Data Publisher>
Give the name of the organisation who publishes this data. It’s probably who you work for unless you’re doing this on behalf of someone else.
O X X X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 27 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
- G04 What is the website of the publisher?
N/A G04.1 <Publisher URL>
Provide the URL for the publisher’s website. This helps us to group data from the same organisation together, regardless of where the data is stored.
X X X X
- G05 What kind of release is this?
1 G05.1 A one-off release of a single dataset
This is a single file and you don’t currently plan to publish similar files in the future.
O X X X
G05.2 A one-off release of a set of related datasets
This is a collection of related files about the same data and you don’t currently plan to publish similar collections in the future.
O X X X
G05.3 Ongoing release of a series of related datasets
This is a sequence of datasets with planned periodic updates in the future.
O X X X
G05.4 A service or API for accessing open or commercial data
This is a live web service that exposes your data to programmers through an interface they can query.
O X X X
- *G06 What is the data about?
1 G06.1 <Data description>
Please provide basic description of the content and objective of your dataset.
O X X X
- *G07 Will this data be released as open data?
1 G07.1 No X X X X
G07.2 Yes X X X X
G07.1 *G08 Do users have to pay to use this data?
1 G08.1 No O X X X
G08.2 Yes O X X X
- *G09 What is the release date of the data (service start date for APIs)?
1 G09.1 <Release date>
O X X X
- *G10 1 G10.1 Economy O X X X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 28 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
Which categories does the theme of the data fall under? Select all that apply.
G10.2 Environment
This is to facilitate ease of discovery of your dataset.
O X X X
G10.3 Society O X X X
G10.4 Technology O X X X
G10.5 Finance O X X X
G10.6 Infrastructure
O X X X
G10.7 Health O X X X
G10.8 Energy O X X X
G10.9 Education O X X X
G10.10
Work O X X X
- *G11 What are the keywords of the data?
1 G11.1 <Keywords entry field>
Data users can find your data based on these keyword tags on our website.
O X X X
B.2 Legal – rights questions
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
- LR01 Do you have rights to publish this data as open data?
1 LR01.1
Yes, you have the rights to publish this data as open or commercial data
If your organisation didn't originally create or gather this data then you might not have the right to publish it. If you’re not sure, check with the data owner because you will need their permission to publish it.
X X O X
LR01.2
No, you don't have the rights to publish this data as open or commercial data

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 29 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
LR01.3
You're not sure if you have the rights to publish this data as open or commercial data
X X
LR01.4
The rights in this data are complicated or unclear
X X
LR01.1 or LR01.3
LR02 Was all this data originally created or gathered by you?
1 LR02.1
No, it uses external sources
If any part of this data was sourced outside your organisation by other individuals or organisations then you need to give extra information about your right to publish it
X X X X
LR02.2
Yes O X X X
LR02.1
LR03 Where do you describe sources of this data?
2 LR03.1
<Data Sources Documentation URL>
Give a URL that documents where the data was sourced from (its provenance) and the rights under which you publish the data. This helps data users understand where the data comes from
X O X X
LR01.4
LR04 Where do you detail the risks users might encounter if they use this data?
2 LR04.1
<Risk Documentation URL>
It can be risky for data users to use data without a clear legal right to do so. For example, the data might be taken down in response to a legal challenge. Give a URL for a page that describes the risk of using this data.
X O X X
LR01.3 and LR02.1
LR05 Was some of this data extracted or calculated from other data?
1 LR05.1
No An extract or smaller part of someone else's data still means your rights to use it might be affected. There might also be legal issues if you analysed their data to produce new results from it.
O X X X
LR05.2
Yes X X X X
LR05.2
LR06 Are all sources of
1 LR06.1
No You're allowed to republish someone else's data if it's
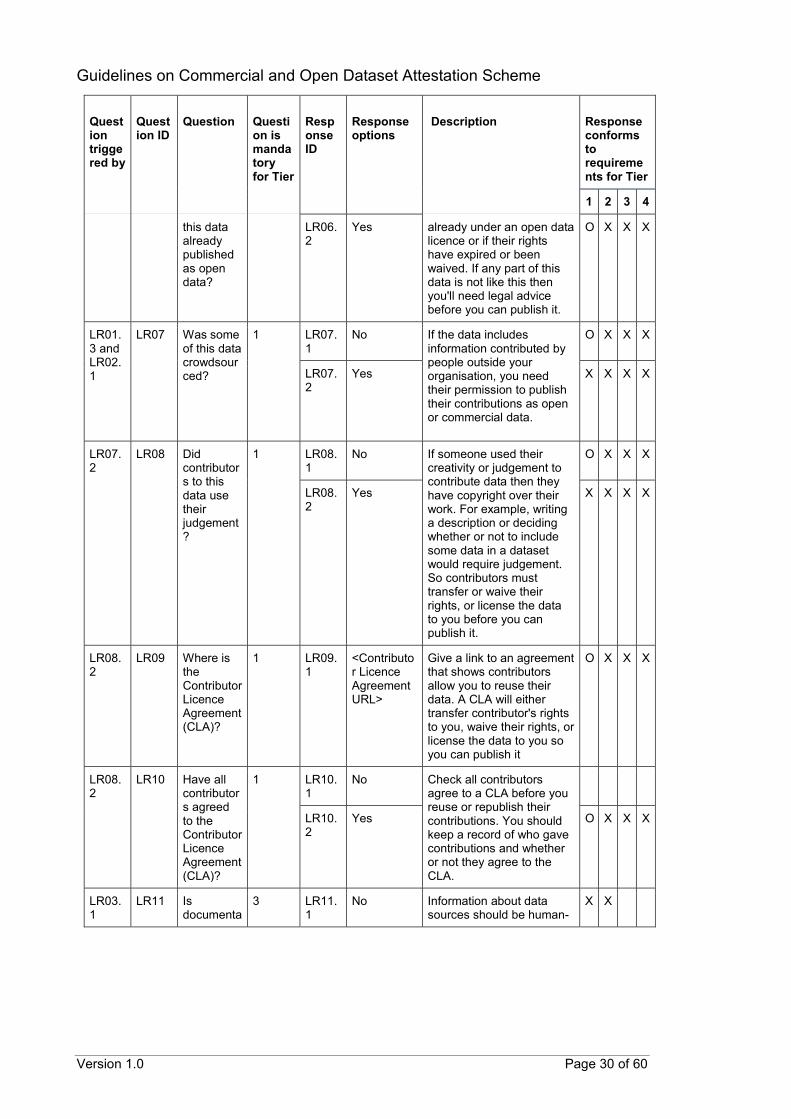
Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 30 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
this data already published as open data?
LR06.2
Yes already under an open data licence or if their rights have expired or been waived. If any part of this data is not like this then you'll need legal advice before you can publish it.
O X X X
LR01.3 and LR02.1
LR07 Was some of this data crowdsourced?
1 LR07.1
No If the data includes information contributed by people outside your organisation, you need their permission to publish their contributions as open or commercial data.
O X X X
LR07.2
Yes X X X X
LR07.2
LR08 Did contributors to this data use their judgement?
1 LR08.1
No If someone used their creativity or judgement to contribute data then they have copyright over their work. For example, writing a description or deciding whether or not to include some data in a dataset would require judgement. So contributors must transfer or waive their rights, or license the data to you before you can publish it.
O X X X
LR08.2
Yes X X X X
LR08.2
LR09 Where is the Contributor Licence Agreement (CLA)?
1 LR09.1
<Contributor Licence Agreement URL>
Give a link to an agreement that shows contributors allow you to reuse their data. A CLA will either transfer contributor's rights to you, waive their rights, or license the data to you so you can publish it
O X X X
LR08.2
LR10 Have all contributors agreed to the Contributor Licence Agreement (CLA)?
1 LR10.1
No Check all contributors agree to a CLA before you reuse or republish their contributions. You should keep a record of who gave contributions and whether or not they agree to the CLA.
LR10.2
Yes O X X X
LR03.1
LR11 Is documenta
3 LR11.1
No Information about data sources should be human-
X X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 31 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
tion about the sources of this data also in machine-readable format?
LR11.2
Yes readable so data users can understand it, as well as in a metadata format that computers can process. When everyone does this it helps other data users find out how the same open data is being used and justify its ongoing publication.
X X O X
Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 32 of 60
B.3 Legal – licensing questions
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
- LL01 Where have you published the rights statement for this dataset?
2 LL01.1
<Rights Statement URL>
Give the URL to a page that describes the right to re-use this dataset. This should include a reference to its license, attribution requirements, and a statement about relevant copyright. A rights statement helps data users understand what they can and can't do with the data.
X O X X
- LL02 Under which licence can others reuse this data?
1 LL02.1
Creative Commons Attribution/ Creative Commons Attribution Share-Alike/ Creative Commons CCZero/ UK Open Government Licence/ Open Data Commons Attribution License/ Open Data Commons Open Database License (ODbL)/ Open Data Commons Public Domain Dedication and Licence (PDDL)
Remember that whoever spends intellectual effort creating content automatically gets rights over it. Creative content includes the organisation and selection of items within data, but does not include facts. So data users need a waiver or a licence which proves that they can use the data and explains how they can do that legally. We list the most common licenses here; if there is no copyright in the data, it's expired, or you've waived them, choose 'Not applicable'.
O X X X
LL02.2
Not Applicable
X X X X
LL02.3
Other X X X X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 33 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
- LL03 Is there any copyright in the content of this data?
1 LL03.1
No, the data only contains facts and numbers
There is no copyright in factual information. If the data does not contain any content that was created through intellectual effort, there are no rights in the content.
X X X X
LL03.2
Yes, and the rights are all held by the same person or organisation
Choose this option if the content in the data was all created by or transferred to the same person or organisation.
X X X X
LL03.3
Yes, and the rights are held by different people or organisations
In some data, the rights in different records are held by different people or organisations. Information about rights needs to be kept in the data too.
X X X X
LL02.2
LL04 Why doesn't a licence apply to this data?
1 LL04.1
There is no copyright in this data
Copyright only applies to data if you spent intellectual effort creating what's in it, for example, by writing text that's within the data, or deciding whether particular data is included. There's no copyright if the data only contains facts where no judgements were made about whether to include them or not.
O X X X
LL04.2
Copyright has expired
Copyright lasts for a fixed amount of time, based on either the number of years after the death of its creator or its publication. You should check when the content was created or published because if that was a long time ago, copyright might have expired.
O X X X
LL04.3
Copyright has been waived
This means no one owns copyright and anyone can do whatever they want with this data.
X X X X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 34 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
LL04.3
LL05 Which waiver do you use to waive copyright in the data?
1 LL05.1
Creative Commons CCZero / Open Data Commons Public Domain Dedication and License (PDDL)
You need a statement to show data users that copyright has been waived, so they understand that they can do whatever they like with this data. Standard waivers already exist like PDDL and CCZero but you can write your own with legal advice.
O X X X
LL05.2
Other X X X X
LL05.2
LL06 Where is the waiver for the copyright in the data?
1 LL06.1
<Waiver URL>
Give a URL to your own publicly available waiver so data users can check that it does waive copyright in the data.
O X X X
LL03.1
LL07 Is the content of the data marked as public domain?
3 LL07.1
No Content can be marked as public domain using the Creative Commons Public Domain Mark. This helps data users know that it can be freely reused
X X
LL07.2
Yes X X O X
LL03.2
LL08 Under which licence can others reuse content?
1 LL08.1
Creative Commons Attribution/ Creative Commons Attribution Share-Alike/ Creative Commons CCZero/ UK Open Government Licence
Remember that whoever spends intellectual effort creating content automatically gets rights over it but creative content does not include facts. So data users need a waiver or a licence which proves that they can use the content and explains how they can do that legally. We list the most common licenses here; if there is no copyright in the content, it's expired, or you've waived them, choose 'Not applicable'.
O X X X
LL08.2
Not Applicable
X X X X
LL08.3
Other X X X X
LL03.3
LL09 Where are the rights and licensing of the content explained?
1 LL09.1
<Content Rights Description URL>
Give the URL for a page where you describe how someone can find out the rights and licensing of a piece of content from the data.
O X X X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 35 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
LL08.2
LL10 Why doesn't a licence apply to the content of the data?
1 LL10.1
There is no copyright in the content of this data
Copyright only applies to content if you spent intellectual effort creating it, for example, by writing text that's within the data. There's no copyright if the content only contains facts.
O X X X
LL10.2
Copyright has expired
Copyright lasts for a fixed amount of time, based on either the number of years after the death of its creator or its publication. You should check when the content was created or published because if that was a long time ago, copyright might have expired.
O X X X
LL10.3
Copyright has been waived
This means no one owns copyright and anyone can do whatever they want with this data.
X X X X
LL10.3
LL11 Which waiver do you use to waive copyright in the data?
1 LL11.1
Creative Commons CCZero
You need a statement to show data users you've done this, so they understand that they can do whatever they like with this data. Standard waivers already exist like CCZero but you can write your own with legal advice.
O X X X
LL11.2
Other X X X X
LL11.2
LL12 Where is the waiver for the copyright?
1 LL12.1
<Waiver URL>
Give a URL to your own publicly available waiver so data users can check that it does waive your copyright.
O X X X
LL02.3
LL13 What is the name of the licence?
1 LL13.1
<Licence Name>
If you use a different licence, we need its name so data users can identify it.
O X X X
LL02.3
LL14 Where is the licence?
1 LL14.1
<Licence URL>
Give a URL to the licence, so data users can check the licensing terms.
O X X X
LL02.3 and
LL15 Is the licence an
1 LL15.1
No If you aren't sure what an open licence is then read

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 36 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
*G07.2
open licence?
LL15.2
Yes the Open Knowledge Definition’s definition. Next, choose your licence from the Open Definition Advisory Board open licence list. If a licence isn't in their list, it's either not open or hasn't been assessed yet.
O X X X
LL08.3
LL16 What is the name of the licence?
1 LL16.1
<Licence Name>
If you use a different licence, we need its name so data users can identify it.
O X X X
LL08.3
LL17 Where is the licence?
1 LL17.1
<Licence URL>
Give a URL to the licence, so data users can check the licensing terms.
O X X X
LL08.3 and *G07.2
LL18 Is the licence an open licence?
1 LL18.1
No If you aren't sure what an open licence is then read the Open Knowledge Definition’s definition. Next, choose your licence from the Open Definition Advisory Board open licence list. If a licence isn't in their list, it's either not open or hasn't been assessed yet.
LL18.2
Yes O X X X
LL01.1
LL19 Does your rights statement include machine-readable versions of the following? Select all that apply.
3 LL19.1
Data license
It's good practice to embed information about rights in machine-readable formats so data users can automatically attribute this data back to you when they use it.
X X O X
LL19.2
Content license
X X O X
LL19.3
Attribution text
X X O X
LL19.4
Attribution URL
X X O X
LL19.5
Copyright Notice or Statement
X X X O
LL19.6
Copyright year
X X X O
LL19.7
Copyright holder
X X X O
B.4 Legal – privacy questions
Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 37 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
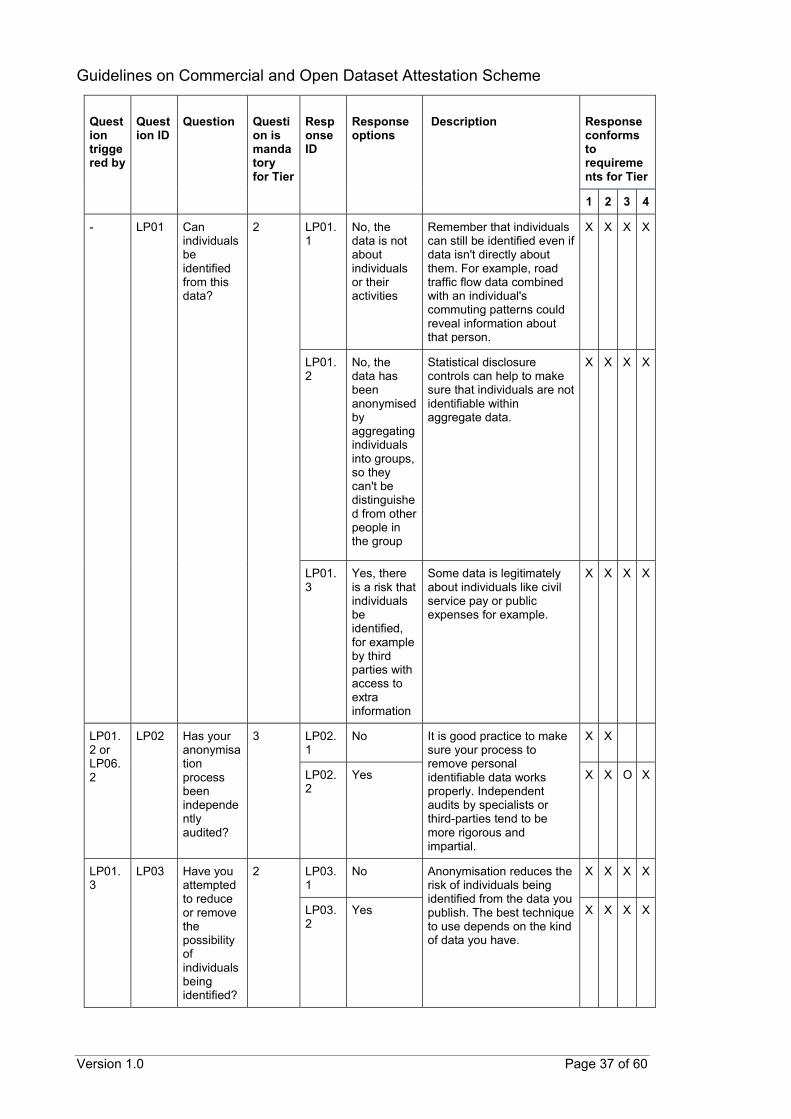
- LP01 Can individuals be identified from this data?
2 LP01.1
No, the data is not about individuals or their activities
Remember that individuals can still be identified even if data isn't directly about them. For example, road traffic flow data combined with an individual's commuting patterns could reveal information about that person.
X X X X
LP01.2
No, the data has been anonymised by aggregating individuals into groups, so they can't be distinguished from other people in the group
Statistical disclosure controls can help to make sure that individuals are not identifiable within aggregate data.
X X X X
LP01.3
Yes, there is a risk that individuals be identified, for example by third parties with access to extra information
Some data is legitimately about individuals like civil service pay or public expenses for example.
X X X X
LP01.2 or LP06.2
LP02 Has your anonymisation process been independently audited?
3 LP02.1
No It is good practice to make sure your process to remove personal identifiable data works properly. Independent audits by specialists or third-parties tend to be more rigorous and impartial.
X X
LP02.2
Yes X X O X
LP01.3
LP03 Have you attempted to reduce or remove the possibility of individuals being identified?
2 LP03.1
No Anonymisation reduces the risk of individuals being identified from the data you publish. The best technique to use depends on the kind of data you have.
X X X X
LP03.2
Yes X X X X
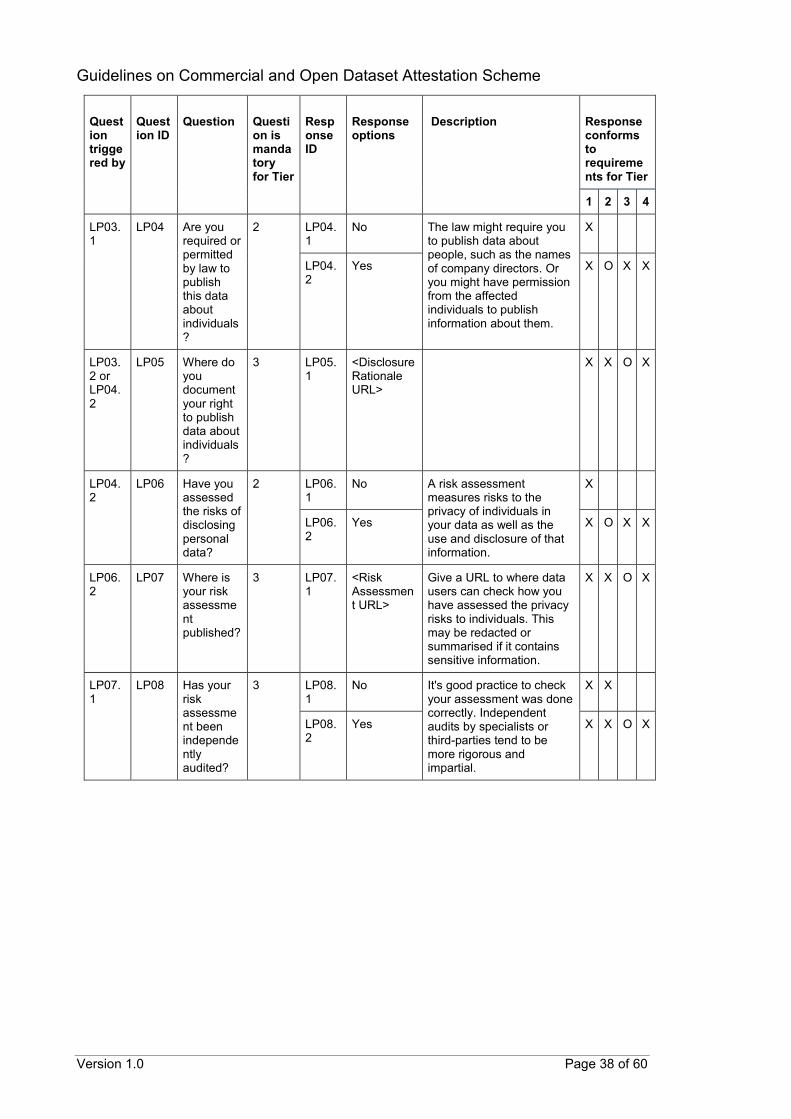
Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 38 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
LP03.1
LP04 Are you required or permitted by law to publish this data about individuals?
2 LP04.1
No The law might require you to publish data about people, such as the names of company directors. Or you might have permission from the affected individuals to publish information about them.
X
LP04.2
Yes X O X X
LP03.2 or LP04.2
LP05 Where do you document your right to publish data about individuals?
3 LP05.1
<Disclosure Rationale URL>
X X O X
LP04.2
LP06 Have you assessed the risks of disclosing personal data?
2 LP06.1
No A risk assessment measures risks to the privacy of individuals in your data as well as the use and disclosure of that information.
X
LP06.2
Yes X O X X
LP06.2
LP07 Where is your risk assessment published?
3 LP07.1
<Risk Assessment URL>
Give a URL to where data users can check how you have assessed the privacy risks to individuals. This may be redacted or summarised if it contains sensitive information.
X X O X
LP07.1
LP08 Has your risk assessment been independently audited?
3 LP08.1
No It's good practice to check your assessment was done correctly. Independent audits by specialists or third-parties tend to be more rigorous and impartial.
X X
LP08.2
Yes X X O X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 39 of 60
B.5 Practical – searchability questions
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
- PF01 Is there a link to your data from your main website?
3 PF01.1
No Data can be found more easily if it is linked to from your main website.
X X
PF01.2
Yes X X O X
PF01.2
PF02 Which page on your website links to the data?
1 PF02.1
<Web page URL>
Give a URL on your main website that includes a link to this data.
X X O X
- PF03 Is your data listed within a collection?
3 PF03.1
No Answer yes if this dataset has been registered somewhere else (e.g. as part of a group or collection of related datasets). This helps make your data more discoverable.
X X
PF03.2
Yes X X O X
PF03.2
PF04 Where is it listed?
1 PF04.1
<Listing URL>
Give a URL where this data is listed within a relevant collection. For example, data.gov.sg (if it's SG public sector data) or a URL for search engine results.
X X O X
- PF05 Is this data referenced from your own publications?
3 PF05.1
No Have you included direct links to this dataset in any of your own publications or communication channels? These could be reports, press releases, blog posts, presentations or any publication that helps to provide context to your data and encourages data users to discover and understand the data better.
X X
PF05.2
Yes X X O X
PF05.2
PF06 Where is your data referenced?
1 PF06.1
<Reference URL>
Give a URL to a document that cites or references this data.
X X O X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 40 of 60
B.6 Practical – accuracy questions
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
G05.1 or G05.2 or PA07.1
PA01 Will your data go out of date?
2 PA01.1
Yes, this data will go out of date
For example, a dataset of bus stop locations will go out of date over time as some are moved or new ones created.
X
PA01.2
Yes, this data will go out of date over time but it’s time stamped
For example, population statistics usually include a fixed timestamp to indicate when the statistics were relevant.
X O
PA01.3
No, this data does not contain any time-sensitive information
For example, the results of an experiment will not go out of date because the data accurately reports observed outcomes.
X X X X
G05.3 PA02 Does this data change at least daily?
2 PA02.1
No Tell data users if the underlying data changes on most days. When data changes frequently it also goes out of date quickly, so data users need to know if you also update it frequently and quickly too.
X X X X
PA02.2
Yes X X X X
G05.3 PA03 How long is the delay between when you create a dataset and when you publish it?
2 PA03.1
Longer than the gap between releases
For example, if you create a new version of the dataset every day, choose this if it takes more than a day for it to be published.
X
PA03.2
About the same as the gap between releases
For example, if you create a new version of the dataset every day, choose this if it takes about a day for it to be published.
X O
PA03.3
Less than half the gap between releases
For example, if you create a new version of the dataset every day, choose this if it takes less than twelve hours for it to be published.
X X O
PA03.4
There is minimal or no delay
Choose this if you publish within a few seconds or a few minutes.
X X X O

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 41 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
PA02.2
PA04 What type of dataset series is this?
4 PA04.1
Regular copies of a complete database
Choose if you publish new and updated copies of your full database regularly. When you create database dumps, it's useful for data users to have access to a feed of the changes so they can keep their copies up to date.
X X X X
PA04.2
Regular aggregates of changing data
Choose if you create new datasets regularly. You might do this if the underlying data can't be released or if you only publish data that's new since the last publication.
X X X X
PA04.1
PA05 Is a feed of changes available?
4 PA05.1
No Tell data users if you provide a stream of changes that affect this data, like new entries or amendments to existing entries. Feeds might be in RSS, Atom or custom formats.
X X X
PA05.2
Yes X X X O
PA02.2
PA06 How often do you create a new release?
2 PA06.1
Less than once a month
This determines how out of date this data becomes before data users can get an update.
X
PA06.2
At least every month
X O
PA06.3
At least every week
X X O
PA06.4
At least every day
X X X O
G05.4 PA07 Does the data behind your API change?
2 PA07.1
No, the API gives access to unchanging data
Some APIs just make accessing an unchanging dataset easier, particularly when there's lots of it.
X X X X
PA07.2
Yes, the API gives access to changing data
Some APIs give instant access to more up-to-date and ever-changing data
X X X X
G05.4 PA08 Do you also
3 PA08.1
No A dump is an extract of the whole dataset into a file
X X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 42 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
publish dumps of this dataset?
PA08.2
Yes that data users can download. This lets data users do analysis that's different to analysis with API access.
X X O X
PA07.2 and PA08.2
PA09 How frequently do you create a new database dump?
2 PA09.1
Less frequently than once a month
Faster access to more frequent extracts of the whole dataset means data users can get started quicker with the most up-to-date data.
X
PA09.2
At least every month
X O
PA09.3
Within a week of any change
X X O
PA09.4
Within a day of any change
X X X O
G05.4 PA10 Will your data be corrected if it has errors?
3 PA10.1
No It's good practice to fix errors in your data especially if you use it yourself. When you make corrections, data users need to be told about them.
X X
PA10.2
Yes X X O X
- *PA11 Are the records in the dataset timestamped?
2 PA11.1
No A timestamp on each record informs the user of the temporal information (creation, change, etc.) corresponding to the record.
X
PA11.2
Yes X O X X
PA11.2
*PA12 What is the time zone of the timestamp?
1 PA12.1
<Dropdown on a list of available time zones>
X O X X
B.7 Practical – quality questions

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 43 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
- PQ01 Where do you document issues with the quality of this data?
3 PQ01.1
<Data Quality Documentation URL>
Give a URL where data users can find out about the quality of your data. Data users accept that errors are inevitable, from equipment malfunctions or mistakes that happen in system migrations. You should be open about quality so data users can judge how much to rely on this data.
X X O X
- PQ02 Where is your quality control process described?
4 PQ02.1
<Quality Control Process Description URL>
Give a URL for data users to learn about ongoing checks on your data, either automatic or manual. This reassures them that you take quality seriously and encourages improvements that benefit everyone.
X X X O
- *PQ03 Are there empty fields or attributes in the data?
3 PQ03.1
No Informs users on whether to expect any empty fields or attributes in the dataset.
X X X X
PQ03.2
Yes X X X X
PQ03.2
*PQ04 Where do you describe the fields or attributes that have empty values?
3 PQ04.1
<Empty values description entry field>
Provide a URL where you describe the fields or attributes with empty values for users' understanding of them.
X X O X
- *PQ05 Are there fields or attributes that are anonymised?
3 PQ05.1
No Informs users on whether data has been intentionally removed of personal information.
X X X X
PQ05.2
Yes X X X X
PQ05.2
*PQ06 Where do you describe the fields or attributes that have been anonymised?
3 PQ06.1
<Anonymised fields description entry field>
Informs users on what are the fields or attributes that have been anonymised and the reason for that, so that the users can take that into account when they are processing the data.
X X O X
- *PQ07 Is the data filtered
3 PQ07.1
No X X X X
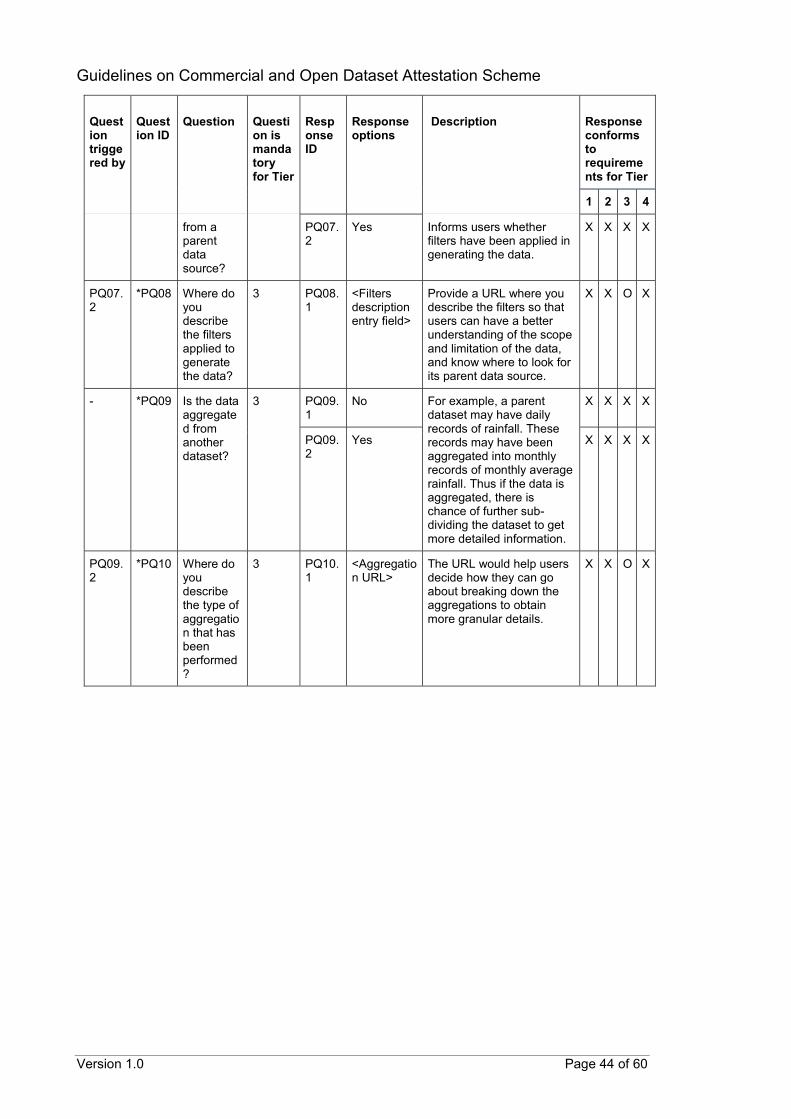
Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 44 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
from a parent data source?
PQ07.2
Yes Informs users whether filters have been applied in generating the data.
X X X X
PQ07.2
*PQ08 Where do you describe the filters applied to generate the data?
3 PQ08.1
<Filters description entry field>
Provide a URL where you describe the filters so that users can have a better understanding of the scope and limitation of the data, and know where to look for its parent data source.
X X O X
- *PQ09 Is the data aggregated from another dataset?
3 PQ09.1
No For example, a parent dataset may have daily records of rainfall. These records may have been aggregated into monthly records of monthly average rainfall. Thus if the data is aggregated, there is chance of further sub-dividing the dataset to get more detailed information.
X X X X
PQ09.2
Yes X X X X
PQ09.2
*PQ10 Where do you describe the type of aggregation that has been performed?
3 PQ10.1
<Aggregation URL>
The URL would help users decide how they can go about breaking down the aggregations to obtain more granular details.
X X O X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 45 of 60
B.8 Practical – guarantees questions
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
- PG01 Do you take offsite backups?
3 PG01.1
No This may be done automatically by your IT team or webmaster. If you are using a managed portal software solution then this should be provided as part of your Service Level Agreement.
X X
PG01.2
Yes X X O X
- PG02 How long will this data be available for?
2 PG02.1
It might disappear at any time
X
PG02.2
It's available experimentally but should be around for another year
X O
PG02.3
It's in your medium-term plans so should be around for a couple of years
X X O
PG02.4
It's part of your day-to-day operations so will stay published for a long time
X X X O
G05.4 PG03 Where do you describe any guarantees about service availability?
3 PG03.1
<Service Availability Documentation URL>
Give a URL for a page that describes what guarantees you have about your service being available for data users to use. For example you might have a guaranteed uptime of 99.5%, or you might provide no guarantees.
X X O X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 46 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
G05.4 PG04 Where do you give information about the current status of the service?
4 PG04.1
<Service Status URL>
Give a URL for a page that tells data users about the current status of your service, including any faults you are aware of.
X X X O
G08.2 *PG05 Do you have explicitly stated Service Level Agreement (SLA) for data users to agree on?
4 PG05.1
No Determines if the services and supports promised by data providers can be guaranteed of delivering.
X X X
PG05.2
Yes X X X O
PG05.2
*PG06 Where do you state the Service Level Agreement (SLA) for your data?
4 PG06.1
<SLA URL> Provide the URL to the SLA for users’ perusal.
X X X O
PG05.2
*PG07 Does your Service Level Agreement (SLA) provide guarantees in the following areas? Select all that apply.
4 PG07.1
User support (e.g. contact information)
Your SLA should fulfil all three areas in order to qualify for Tier 4.
If there are guarantees in areas other than the 3 options listed, please specify.
X X X O
PG07.2
Data timeliness (e.g. Update frequency, time frame)
X X X O
PG07.3
Data availability (e.g. uptime, downtime)
X X X O
PG07.4
Others X X X X
B.9 Technical – locations questions
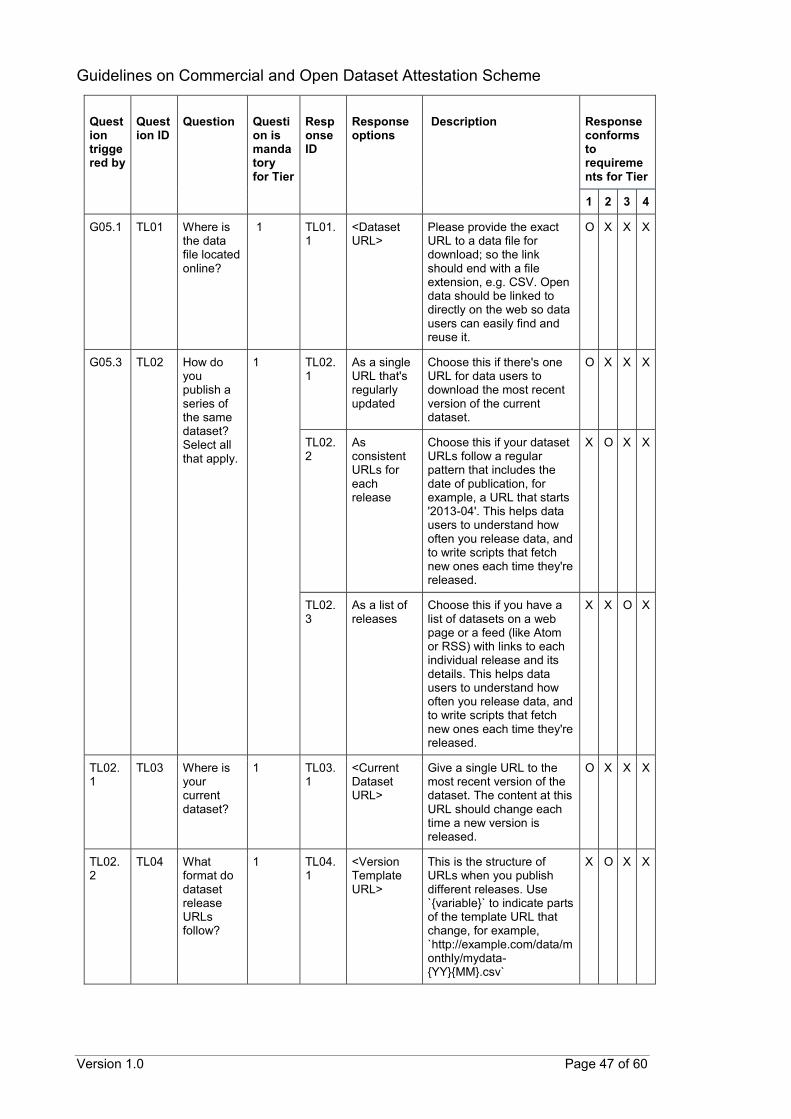
Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 47 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
G05.1 TL01 Where is the data file located online?
1 TL01.1
<Dataset URL>
Please provide the exact URL to a data file for download; so the link should end with a file extension, e.g. CSV. Open data should be linked to directly on the web so data users can easily find and reuse it.
O X X X
G05.3 TL02 How do you publish a series of the same dataset? Select all that apply.
1 TL02.1
As a single URL that's regularly updated
Choose this if there's one URL for data users to download the most recent version of the current dataset.
O X X X
TL02.2
As consistent URLs for each release
Choose this if your dataset URLs follow a regular pattern that includes the date of publication, for example, a URL that starts '2013-04'. This helps data users to understand how often you release data, and to write scripts that fetch new ones each time they're released.
X O X X
TL02.3
As a list of releases
Choose this if you have a list of datasets on a web page or a feed (like Atom or RSS) with links to each individual release and its details. This helps data users to understand how often you release data, and to write scripts that fetch new ones each time they're released.
X X O X
TL02.1
TL03 Where is your current dataset?
1 TL03.1
<Current Dataset URL>
Give a single URL to the most recent version of the dataset. The content at this URL should change each time a new version is released.
O X X X
TL02.2
TL04 What format do dataset release URLs follow?
1 TL04.1
<Version Template URL>
This is the structure of URLs when you publish different releases. Use `{variable}` to indicate parts of the template URL that change, for example, `http://example.com/data/monthly/mydata-{YY}{MM}.csv`
X O X X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 48 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
TL02.3
TL05 Where is your list of dataset releases?
1 TL05.1
<Version List URL>
Give a URL to a page or feed with a machine-readable list of datasets. Use the URL of the first page which should link to the rest of the pages.
X X O X
G05.4 TL06 Where is the endpoint for your API?
1 TL06.1
<Endpoint URL>
Give a URL that's a starting point for data users’ scripts to access your API. This should be a service description document that helps the script to work out which services exist.
O X X X
PA08.2
TL07 How do you publish database dumps? Select all that apply.
3 TL07.1
As a single URL that's regularly updated
Choose this if there's one URL for data users to download the most recent version of the current database dump.
X X O X
TL07.2
As consistent URLs for each release
Choose this if your database dump URLs follow a regular pattern that includes the date of publication, for example, a URL that starts '2013-04'. This helps data users to understand how often you release data, and to write scripts that fetch new ones each time they're released.
X X X O
TL07.3
As a list of releases
Choose this if you have a list of database dumps on a web page or a feed (such as Atom or RSS) with links to each individual release and its details. This helps data users to understand how often you release data, and to write scripts that fetch new ones each time they're released.
X X X O
TL07.1
TL08 Where is the current database dump?
1 TL08.1
<Current Dump URL>
Give a URL to the most recent dump of the database. The content at this URL should change each time a new database dump is created.
X X O X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 49 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
TL07.2
TL09 What format do database dump URLs follow?
1 TL09.1
<Dump Template URL>
This is the structure of URLs when you publish different releases. Use `{variable}` to indicate parts of the template URL that change, for example, `http://example.com/data/monthly/mydata-{YY}{MM}.csv`
X X X O
TL07.3
TL10 Where is your list of available database dumps?
1 TL10.1
<Dump List URL>
Give a URL to a page or feed with a machine-readable list of database dumps. Use the URL of the first page which should link to the rest of the pages.
X X X O
PA05.2
TL11 Where is your feed of change?
1 TL11.1
<Change Feed URL>
Give a URL to a page or feed that provides a machine-readable list of the previous versions of the database dumps. Use the URL of the first page which should link to the rest of the pages.
X X X O
B.10 Technical – formats questions
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
- TF01 Is this data machine-readable?
2 TF01.1
No Data users prefer data formats which are easily processed by a computer, for speed and accuracy. For example, a scanned photocopy of a spreadsheet in PDF format would not be machine-readable but a CSV file would be.
X
TF01.2
Yes X O X X
- TF02 Is this data in a
3 TF02.1
No Open standards are created through a fair,
X X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 50 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
standard open format?
TF02.2
Yes transparent and collaborative process. Anyone can implement them and there’s lots of support so it’s easier for you to share data with more data users. For example, XML, CSV and JSON are open standards.
X X O X
- TF03 What kind of data is being provided as part of this dataset? Select all that apply.
N/A TF03.1
Human-readable documents
Checklist, may choose more than one option Choose this if your data is meant for human consumption. For example; policy documents, white papers, reports and meeting minutes. These usually have some structure to them but are mostly text.
X X X X
TF03.2
Statistical data like counts, averages and percentages
Choose this if your data is statistical or numeric data like counts, averages or percentages. Like census results, traffic flow information or crime statistics for example.
X X X X
TF03.3
Geographic information, such as points and boundaries
Choose this if your data can be plotted on a map as points, boundaries or lines.
X X X X
TF03.4
Other kinds of structured data
Choose this if your data is structured in other ways. Like event details, railway timetables, contact information or anything that can be interpreted as data, and analysed and presented in multiple ways.
X X X X
TF03.1
TF04 What formats are your human-readable documents published in? (for this dataset)
2 TF04.1
Formats which describe semantic structure like HTML, Docbook or Markdown
These formats label structures like chapters, headings and tables that make it easy to automatically create summaries like tables of contents and glossaries. They also make it easy to apply different styles to the document so its appearance changes.
X X O X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 51 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
TF04.2
Formats which describe information on formatting like OOXML or PDF
These formats emphasise appearance like fonts, colours and positioning of different elements within the page. These are good for human consumption, but aren't as easy for data users to process automatically and change style.
X O
TF04.3
Formats which aren't meant for documents like Excel, JSON or CSV
These formats better suit tabular or structured data
X
TF03.2
TF05 What formats are your statistical data published in? (for this dataset)
2 TF05.1
Formats which expose the structure of statistical hypercube data like SDMX or Data Cube
Individual observations in hypercubes relate to a particular measure and a set of dimensions. Each observation may also be related to annotations that give extra context. Formats like SDMX and Data Cube are designed to express this underlying structure.
X X X O
TF05.2
Formats which treat statistical data as a table like CSV
These formats arrange statistical data within a table of rows and columns. This lacks extra context about the underlying hypercube but is easy to process.
X X O
TF05.3
Formats which focus on the format of tabular data like Excel
Spreadsheets use formatting like italic or bold text, and indentation within fields to describe its appearance and underlying structure. This styling helps data users to understand the meaning of your data but makes it less suitable for computers to process.
X O
TF05.4
Formats which aren't meant for statistical or tabular data like Word or PDF
These formats don't suit statistical data because they obscure the underlying structure of the data.
X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 52 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
TF03.3
TF06 What formats are your geographic data published in? (for this dataset)
2 TF06.1
Formats which are designed for geographic data like KML or GeoJSON
These formats describe points, lines and boundaries, and expose structures in the data which make it easier to process automatically.
X X X O
TF06.2
Formats which keep data structured like JSON, XML or CSV
Any format that stores normal structured data can express geographic data too, particularly if it only holds data about points.
X O
TF06.3
Formats which aren't designed for geographic data like Word or PDF
These formats don't suit geographic data because they obscure the underlying structure of the data.
X
TF03.4
TF07 What formats are your structured data files published in? (for this dataset)
2 TF07.1
Formats which are designed for structured data like JSON, XML, Turtle or CSV
These formats organise data into a basic structure of things which have values for a known set of properties. These formats are easy for computers to process automatically.
X O
TF07.2
Formats which aren't designed for structured data like Word or PDF
These formats don't suit this kind of data because they obscure its underlying structure.
X
- TF08 Does your data use persistent identifiers?
3 TF08.1
No Data is usually about real things like schools or roads or uses a coding scheme. If data from different sources use the same persistent and unique identifier to refer to the same things, data users can combine sources easily to create more useful data. Identifiers might be GUIDs, DOIs or URLs.
X X
TF08.2
Yes X X O X
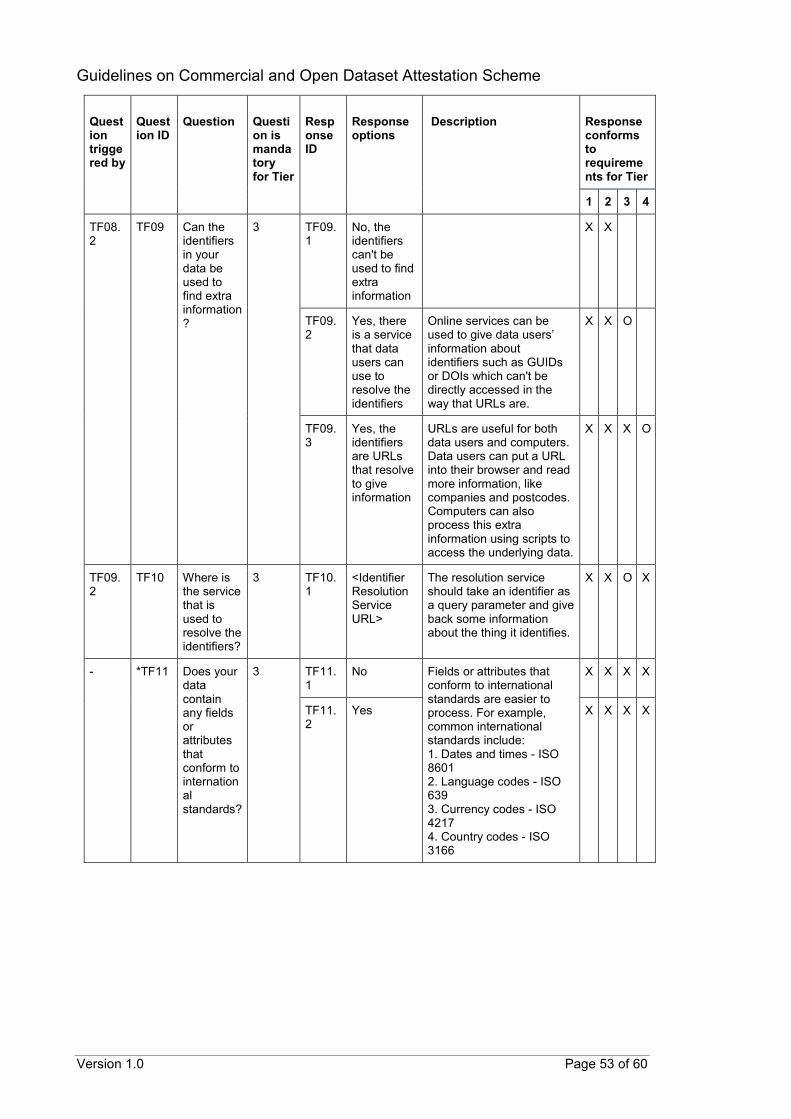
Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 53 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
TF08.2
TF09 Can the identifiers in your data be used to find extra information?
3 TF09.1
No, the identifiers can't be used to find extra information
X X
TF09.2
Yes, there is a service that data users can use to resolve the identifiers
Online services can be used to give data users’ information about identifiers such as GUIDs or DOIs which can't be directly accessed in the way that URLs are.
X X O
TF09.3
Yes, the identifiers are URLs that resolve to give information
URLs are useful for both data users and computers. Data users can put a URL into their browser and read more information, like companies and postcodes. Computers can also process this extra information using scripts to access the underlying data.
X X X O
TF09.2
TF10 Where is the service that is used to resolve the identifiers?
3 TF10.1
<Identifier Resolution Service URL>
The resolution service should take an identifier as a query parameter and give back some information about the thing it identifies.
X X O X
- *TF11 Does your data contain any fields or attributes that conform to international standards?
3 TF11.1
No Fields or attributes that conform to international standards are easier to process. For example, common international standards include: 1. Dates and times - ISO 8601 2. Language codes - ISO 639 3. Currency codes - ISO 4217 4. Country codes - ISO 3166
X X X X
TF11.2
Yes X X X X
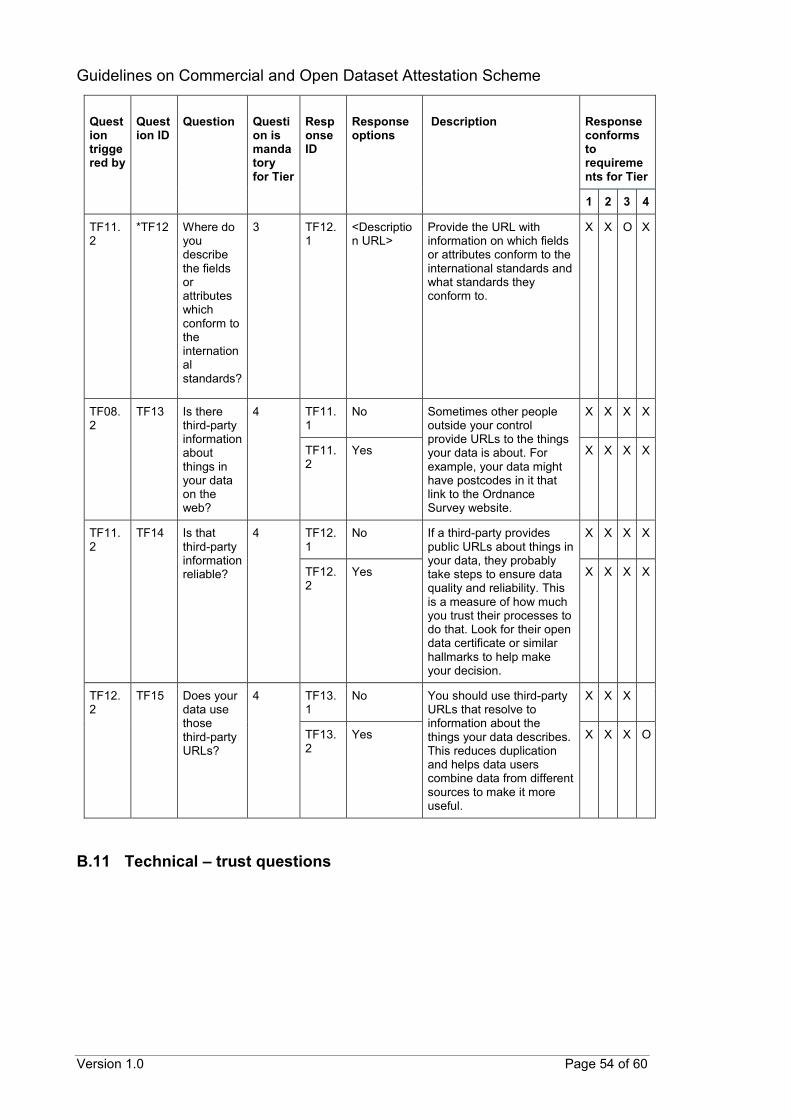
Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 54 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
TF11.2
*TF12 Where do you describe the fields or attributes which conform to the international standards?
3 TF12.1
<Description URL>
Provide the URL with information on which fields or attributes conform to the international standards and what standards they conform to.
X X O X
TF08.2
TF13 Is there third-party information about things in your data on the web?
4 TF11.1
No Sometimes other people outside your control provide URLs to the things your data is about. For example, your data might have postcodes in it that link to the Ordnance Survey website.
X X X X
TF11.2
Yes X X X X
TF11.2
TF14 Is that third-party information reliable?
4 TF12.1
No If a third-party provides public URLs about things in your data, they probably take steps to ensure data quality and reliability. This is a measure of how much you trust their processes to do that. Look for their open data certificate or similar hallmarks to help make your decision.
X X X X
TF12.2
Yes X X X X
TF12.2
TF15 Does your data use those third-party URLs?
4 TF13.1
No You should use third-party URLs that resolve to information about the things your data describes. This reduces duplication and helps data users combine data from different sources to make it more useful.
X X X
TF13.2
Yes X X X O
B.11 Technical – trust questions
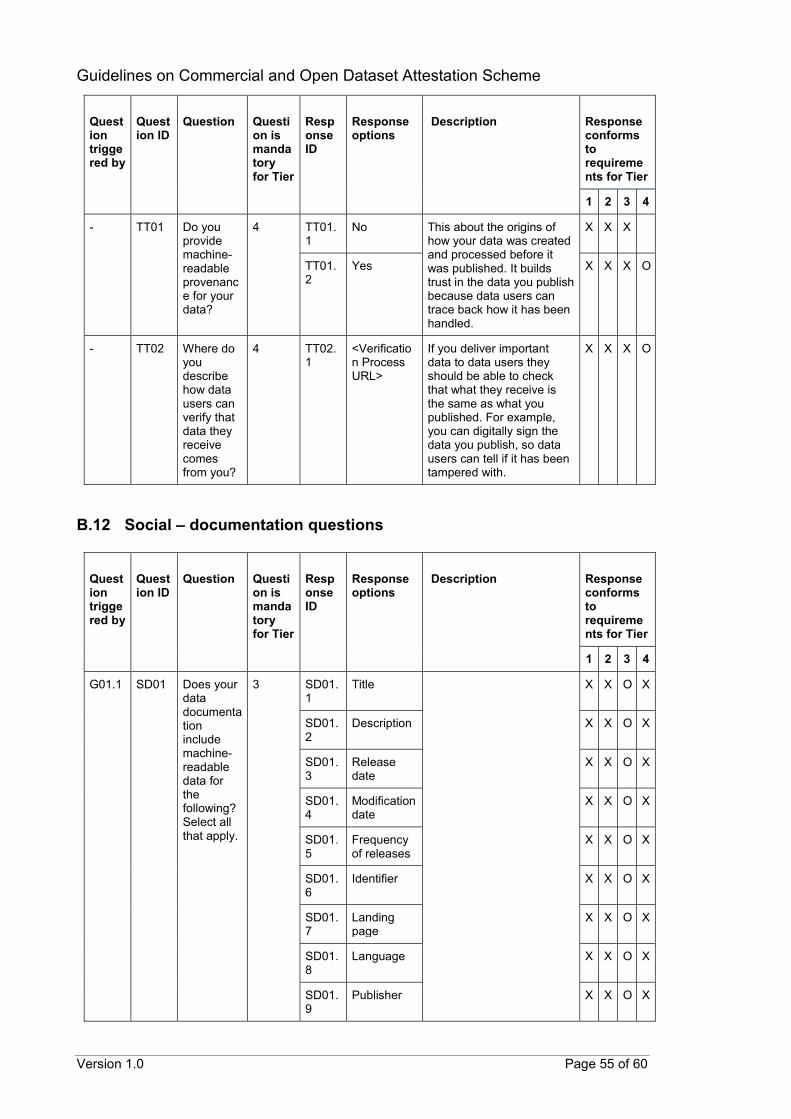
Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 55 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
- TT01 Do you provide machine-readable provenance for your data?
4 TT01.1
No This about the origins of how your data was created and processed before it was published. It builds trust in the data you publish because data users can trace back how it has been handled.
X X X
TT01.2
Yes X X X O
- TT02 Where do you describe how data users can verify that data they receive comes from you?
4 TT02.1
<Verification Process URL>
If you deliver important data to data users they should be able to check that what they receive is the same as what you published. For example, you can digitally sign the data you publish, so data users can tell if it has been tampered with.
X X X O
B.12 Social – documentation questions
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
G01.1 SD01 Does your data documentation include machine-readable data for the following? Select all that apply.
3 SD01.1
Title X X O X
SD01.2
Description X X O X
SD01.3
Release date
X X O X
SD01.4
Modification date
X X O X
SD01.5
Frequency of releases
X X O X
SD01.6
Identifier X X O X
SD01.7
Landing page
X X O X
SD01.8
Language X X O X
SD01.9
Publisher X X O X
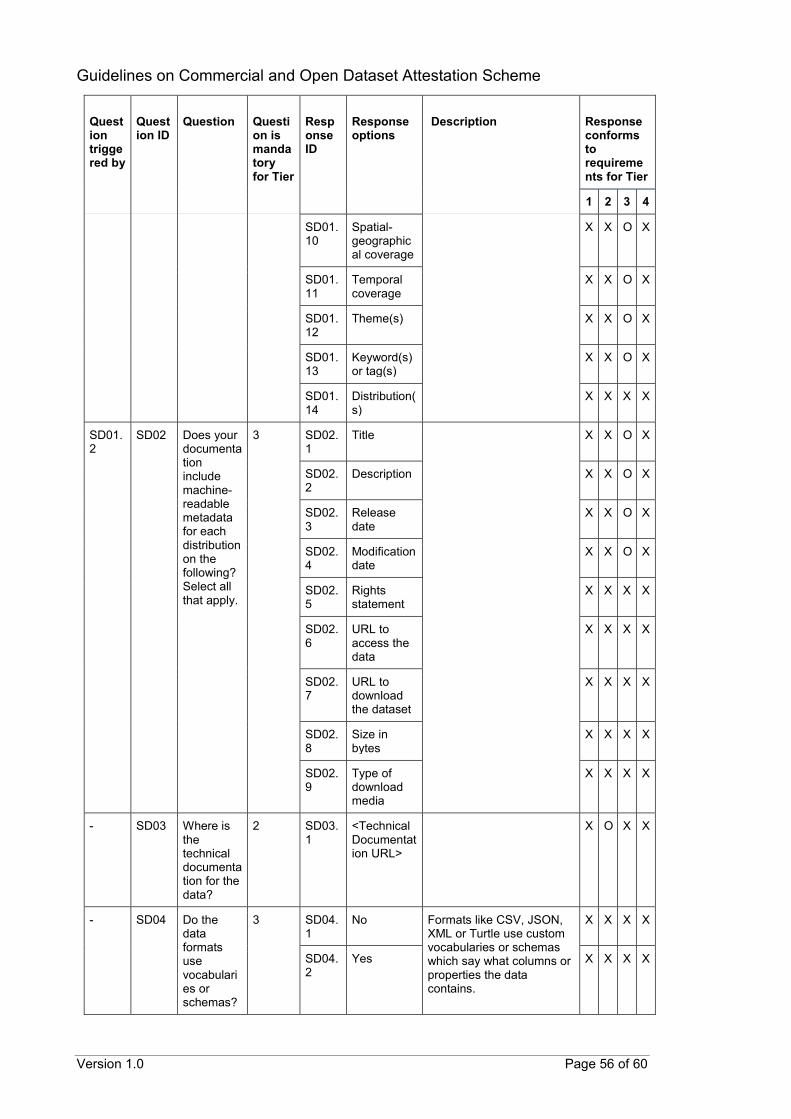
Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 56 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
SD01.10
Spatial-geographical coverage
X X O X
SD01.11
Temporal coverage
X X O X
SD01.12
Theme(s) X X O X
SD01.13
Keyword(s) or tag(s)
X X O X
SD01.14
Distribution(s)
X X X X
SD01.2
SD02 Does your documentation include machine-readable metadata for each distribution on the following? Select all that apply.
3 SD02.1
Title X X O X
SD02.2
Description X X O X
SD02.3
Release date
X X O X
SD02.4
Modification date
X X O X
SD02.5
Rights statement
X X X X
SD02.6
URL to access the data
X X X X
SD02.7
URL to download the dataset
X X X X
SD02.8
Size in bytes
X X X X
SD02.9
Type of download media
X X X X
- SD03 Where is the technical documentation for the data?
2 SD03.1
<Technical Documentation URL>
X O X X
- SD04 Do the data formats use vocabularies or schemas?
3 SD04.1
No Formats like CSV, JSON, XML or Turtle use custom vocabularies or schemas which say what columns or properties the data contains.
X X X X
SD04.2
Yes X X X X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 57 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
SD04.2
SD05 Where is documentation about your data vocabularies?
3 SD05.1
<Schema Documentation URL>
X X O X
- SD06 Are there any codes used in the data?
3 SD06.1
No If your data uses codes to refer to things like geographical areas, spending categories or diseases for example, these need to be explained to data users.
X X X X
SD06.2
Yes X X X X
SD06.2
SD07 Where are any codes in your data documented?
3 SD07.1
<Codelist Documentation URL>
X X O X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 58 of 60
B.13 Social – support questions
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
- SS01 Where can data users find out how to contact someone with questions about this data?
2 SS01.1
<Contact Documentation>
Provide the link (URL) to the webpage containing the contact details of the person(s) responsible for, or could respond to questions about, this data.
X O X X
- SS02 Where can data users find out how to improve the way your data is published?
2 SS02.1
<Improvement Suggestions URL>
X O X X
- SS03 Where can data users find out how to contact someone with questions about privacy?
2 SS03.1
<Confidentiality Contact Documentation>
Provide the link to the webpage containing the contact details for reporting a privacy related issue with the data, i.e. when the data has not been fully anonymised, so it is possible to draw personal identifying information from it.
X O X X
- SS04 Do you use social media to connect with those who use your data?
3 SS04.1
No X X
SS04.2
Yes X X O X
SS04.2
SS05 Which social media accounts can data users reach you on?
1 SS05.1
<Social Media URL>
Give URLs to your social media accounts, like your Twitter or Facebook profile page.
X X O X
- SS06 Where should data users discuss this dataset?
3 SS06.1
<Forum of Mailing List URL>
This could be the webpage for the dataset itself if data users can post a comment to have a discussion, or a dedicated forum on a data portal or publisher’s website.
X X O X

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 59 of 60
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
PA10.2
SS07 Where can data users find out how to request corrections to your data?
3 SS07.1
<Correction Instructions URL>
Give a URL where data users can report errors they spot in your data.
X X O X
PA10.2
SS08 Where can data users find out how to get notifications of corrections to your data?
3 SS08.1
<Correction Notification URL>
Give a URL where you describe how notifications about corrections are shared with data users.
X X O X
- SS09 Do you have anyone who actively builds a community around this data?
4 SS09.1
No A community engagement team will engage through social media, blogging, and arrange hackdays or competitions to encourage data users to use the data.
X X X
SS09.2
Yes X X X O
SS09.2
SS10 Where is their home page?
1 SS10.1
<Community Engagement Team Home Page URL>
X X X O
B.14 Social – services questions
Question triggered by
Question ID
Question
Question is mandatory for Tier
Response ID
Response options
Description
Response conforms to requirements for Tier
1 2 3 4
- SSV01
Where do you list tools to work with your data?
4 SSV01.1
<Tool URL> Give a URL that lists the tools you know or recommend data users can use when they work with your data.
X X X O

Guidelines on Commercial and Open Dataset Attestation Scheme
Version 1.0 Page 60 of 60
Bibliography
SN Reference document Reference source
1 Open Data Handbook’s glossary
http://opendatahandbook.org/glossary/
2 A Primer on Machine Readability for Online Documents and Data
https://www.data.gov/developers/blog/primer-machine-readability-online-documents-and-data
3 Open Definition v2.1 http://opendefinition.org/od/2.1/en/
4 Open Data Rights Statement Vocabulary
http://schema.theodi.org/odrs/
5 Global Reference Architecture (GRA) Information Sharing Enterprise Service-Level Agreement
https://it.ojp.gov/GIST/60/Global-Reference-Architecture--GRA--Information-Sharing-Enterprise-Service-Level-Agreement