hadoop - how it works
TRANSCRIPT

Ing. Vladimír Hanušniak
University of Žilina, March 2014

Brief review
Parallel processing
Hadoop ◦ HDFS (Hadoop Distributed File System)
◦ MapReduce
Example
2

Brief review
Parallel processing
Hadoop ◦ HDFS (Hadoop Distributed File System)
◦ MapReduce
Example
3
4
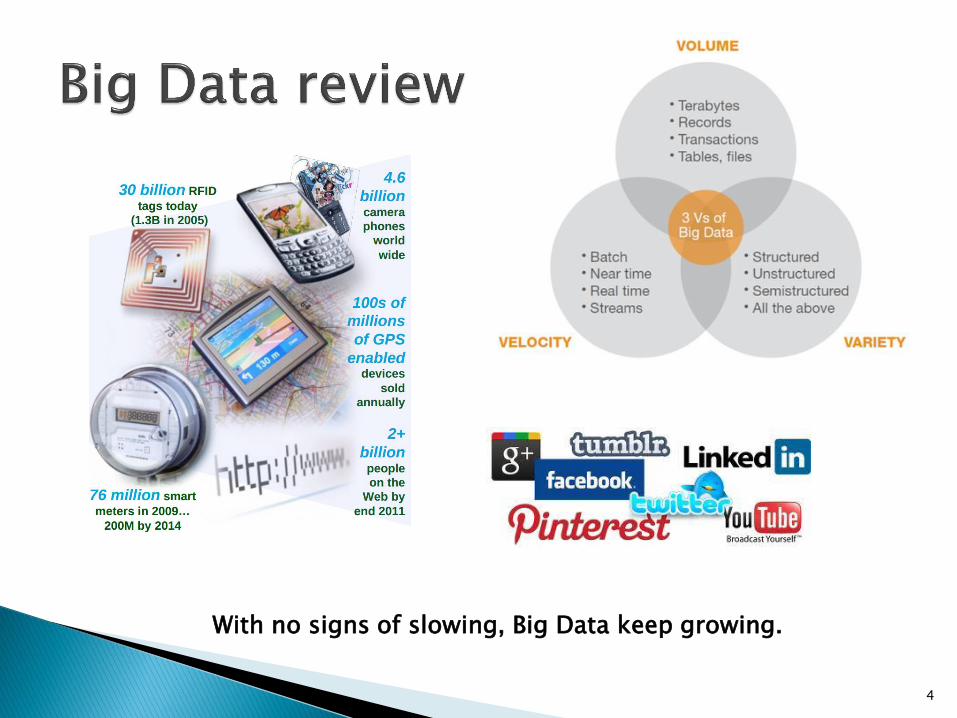
With no signs of slowing, Big Data keep growing.

5
X-ray – 30MB
3D CT scan – 1GB
3D MRI – 150MB
Mammograms – 120MB
Growing – 20-40%/year
Preemies health ◦ University of Ontario & IBM ◦ 16 different data streams ◦ 1260 data points per second
Early treatment

Data structure and storage
Analytical methods & Processing power
Needed parallelization
6

Brief review
Parallel processing
Hadoop ◦ HDFS (Hadoop Distributed File System)
◦ MapReduce
Example
7

Task decomposition (HPC Uniza) ◦ Computationally expensive task
◦ Move the data to processing
◦ Execution order
◦ Shared data storage
8

Slow HDD read spead !!!
HDD reading speed ~100MB/s ◦ Read 1000GB => 10000s (166,6 min)
100 parallel reading machines => 1,6 min
9

Data decomposition (Hadoop) ◦ Data has regular structure (type, size)
◦ Move processing to data
10

Brief review
Parallel processing
Hadoop ◦ HDFS (Hadoop Distributed File System)
◦ MapReduce
Example
11

Hadoop – framework for processing BigData
Two main components: ◦ HDFS
◦ MapReduce
Thousands of nodes in
cluster
12

Distributed fault-tolerant file system designed to run on commodity hardware
Main characteristics ◦ Scalability
◦ High availability
◦ Large files
◦ Common hardware
◦ Streeming data access - write once read many times
13

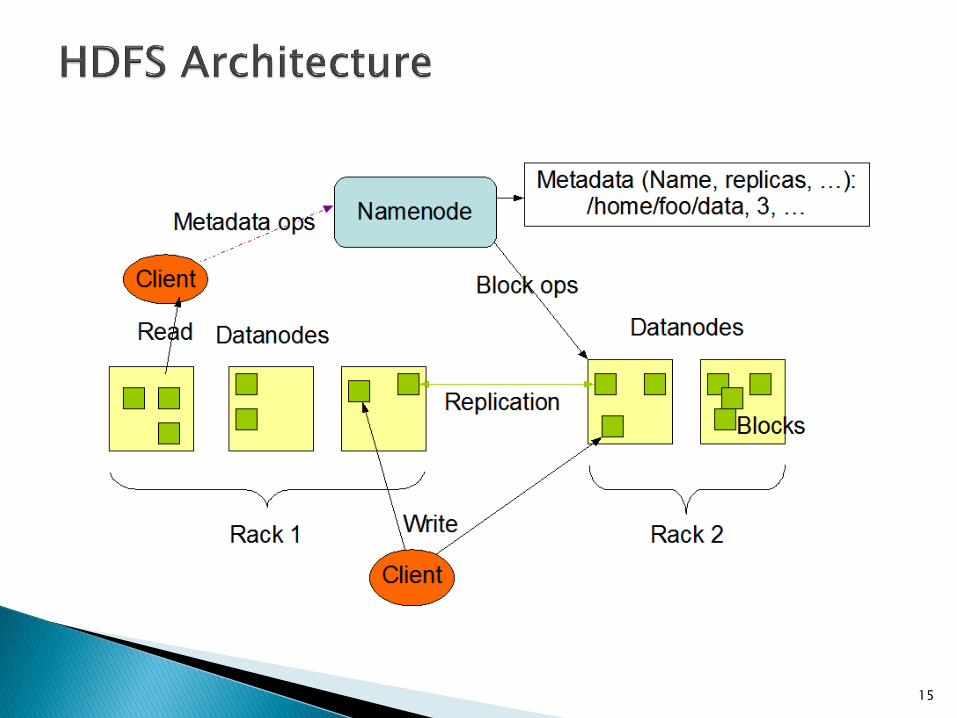
NameNode ◦ Master
◦ Control storage
◦ Store metadata about files
Name, path, size, block size, block IDs, ...
DataNode ◦ Slave
◦ Store data in blocks
14
15

Files are stored in blocks ◦ Large files are split
Size: 64, 128, 256 MB …
Stored in NameNode memory ◦ Limit factor
150 bytes per file/directory or block object ◦ 3GB of memory = 10 million one blocks files.
16

Seek time - 10ms seek time
Block size - 100 MB 1% of
Transfer rate - 100 MB/s transfer time
Number of Map & Reduce Jobs depends on block size
17

18

19

First – same node, client
Second – off-rack
Third – same rack, different node
Next… - random nodes (tries to avoid placing too many replicas on the same rack)
20

Brief review
Parallel processing
Hadoop ◦ HDFS (Hadoop Distributed File System)
◦ MapReduce
Example
21
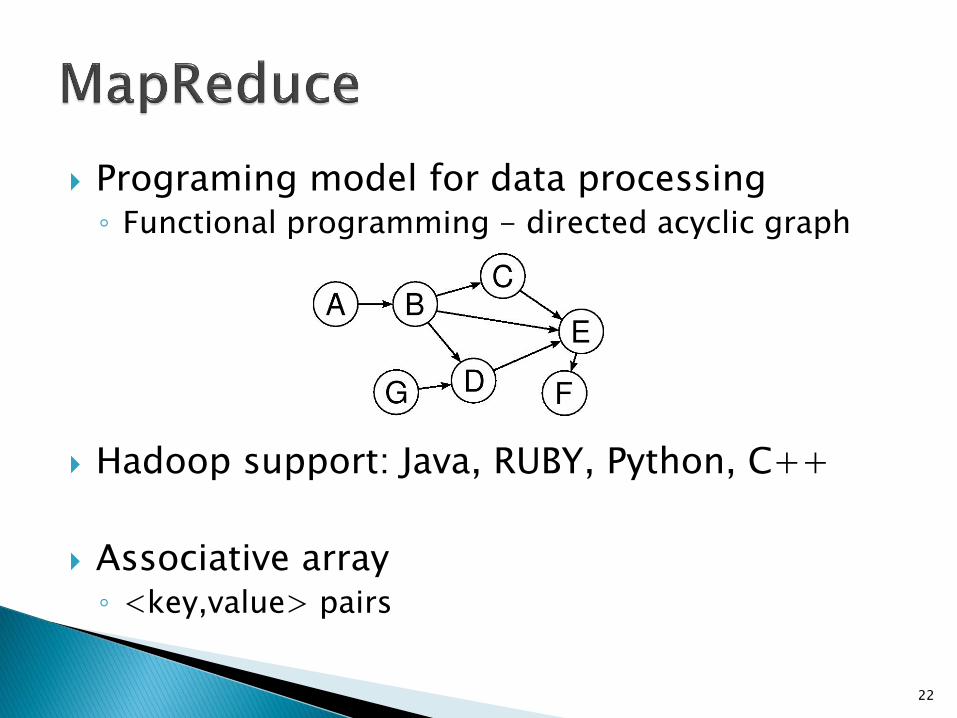
Programing model for data processing ◦ Functional programming - directed acyclic graph
Hadoop support: Java, RUBY, Python, C++
Associative array ◦ <key,value> pairs
22

Job - unit of work ◦ Input data
◦ Map & Reduce program
◦ Configuration information
Job is divided into task ◦ Map tasks
◦ Reduce tasks
23

Job tracker ◦ Coordinates all jobs by scheduling tasks to run on
task trackers
◦ Keeps job progress records
◦ Reschedule task in case of fails
Task trackers ◦ Run tasks
◦ Send progress report to Jobtracker
24

25

Hadoop divide input to MapReduce job into fixed-size piece of work – input split
Create one map per split ◦ Run user define map function
Split size tends to be the size of an HDFS block
26

Data locality optimization ◦ Run the map task on a node where the input data
resides in HDFS.
◦ Data-local (a), rack-local (b), and off-rack (c) map tasks.
27

Output - <Key, Value> pairs
Write to local disk – NOT to HDFS !!! ◦ Map output is processed by reduce tasks to
produce final output
◦ No replicas needed
Sort <Key, Value> pairs
If node fails before reduce –> map again
28

TaskTracker read region files remotely (RPC)
Invoke Reduce function (aggregate)
Output is stored in HDFS
Don’t have the advantage of data locality ◦ Input to reduce – output from all mappers
29

30

Minimize the data transferred between map and reduce tasks
Run on the map output
“Reduce on Map side”
max(0, 20, 10, 25, 15) = max(max(0, 20, 10), max(25, 15)) = max(20, 25) = 25
mean(0, 20, 10, 25, 15) = 14
mean(mean(0, 20, 10), mean(25, 15)) = mean(10, 20) = 15
31

Java (RUBY, Python, C++) ◦ Good for programmers
Pig ◦ Scripting language with a focus on dataflows. ◦ Use Pig Latin language ◦ Allow merging, filtering, applying functions
Hive ◦ Use HiveQL - similar to SQL (use Facebook) ◦ Provides a database query interface
Hbase
32

33

Brief review
Parallel processing
Hadoop ◦ HDFS (Hadoop Distributed File System)
◦ MapReduce
Example
34

(0, 0067011990999991950051507004...9999999N9+00001+99999999999...) (106, 0043011990999991950051512004...9999999N9+00221+99999999999...) (212, 0043011990999991950051518004...9999999N9-00111+99999999999...) (318, 0043012650999991949032412004...0500001N9+01111+99999999999...) (424, 0043012650999991949032418004...0500001N9+00781+99999999999...)
Data Set
Find the maximum temperature by year
1901 - 317 1902 - 244 1903 - 289 1904 - 256 1905 - 283 ...
35

#!/usr/bin/env bash for year in all/* do echo -ne `basename $year .gz`"\t" gunzip -c $year | \ awk '{ temp = substr($0, 88, 5) + 0; q = substr($0, 93, 1); if (temp !=9999 && q ~ /[01459]/ && temp > max) max = temp } END { print max }' done % ./max_temperature.sh 1901 317 1902 244 1903 289 1904 256 1905 283 ...
36

37
Run parts of the program in parallel ◦ Process different years in different processes
Problems ◦ Non equal-size pieces
◦ Combining partial results need processing time
◦ Single machine processing limit
◦ Long processing time

38

39

40

41
42
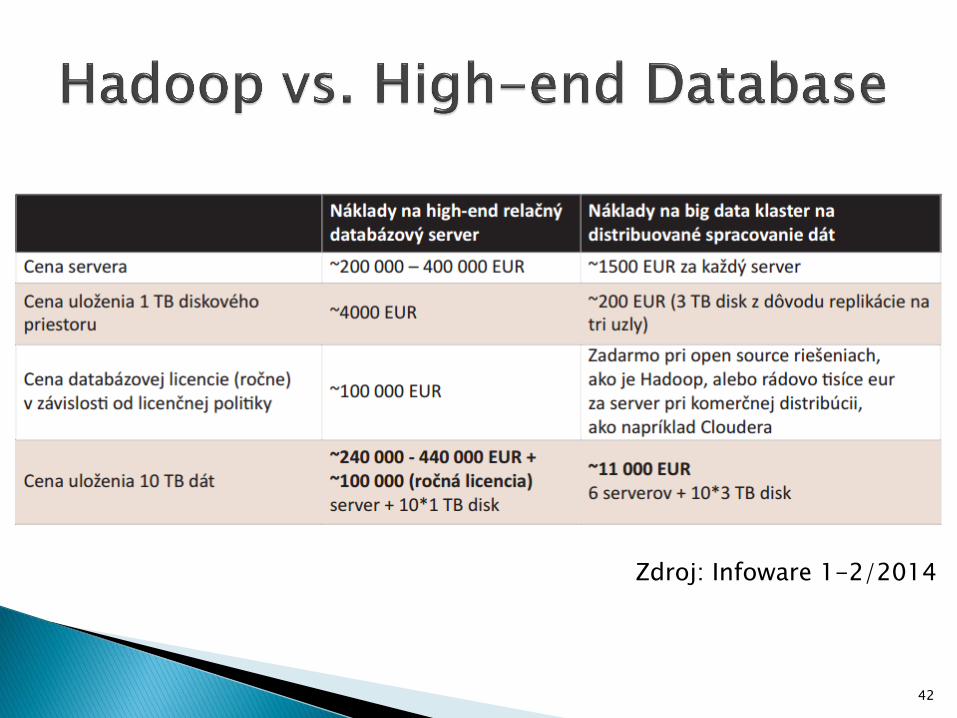
Zdroj: Infoware 1-2/2014

43

Hadoop: The Definitive Guide, 3rd Edition ◦ http://it-ebooks.info/book/635/
Big Data: A Revolution That Will Transform How We Live, Work, and Think
http://hadoop.apache.org/
http://architects.dzone.com/articles/how-hadoop-mapreduce-works
44