hadoop on nutanix - protosinc.com document shows the design and scaling of hadoop mapreduce on the...
TRANSCRIPT

Hadoop on Nutanix
Reference Architecture

Copyright 2012 Nutanix, Inc.
Nutanix, Inc. 1735 Technology Drive, Suite 575 San Jose, CA 95110
All rights reserved. This product is protected by U.S. and international copyright and intellectual property laws.
Nutanix is a trademark of Nutanix, Inc. in the United States and/or other jurisdictions. All other marks and names mentioned herein may be trademarks of their respective companies.

Table of Contents
1. Executive Summary ..................................................................................... 5
2. Introduction .................................................................................................. 6
2.1. Audience ................................................................................................................ 6
2.2. Purpose ................................................................................................................. 6
3. Solution Overview ........................................................................................ 7
4. Solution Design .......................................................................................... 12
4.1. Hadoop MapReduce the Traditional Way ........................................................... 12
4.2. Hadoop MapReduce the Nutanix Way ................................................................ 14
4.3. Nutanix – Compute / Storage .............................................................................. 16
4.4. Network ................................................................................................................ 17
5. Validation & Benchmarking ........................................................................ 18
6. Further Research ....................................................................................... 20
7. Conclusion ................................................................................................. 21
8. Appendix: Configuration ............................................................................. 22
9. References ................................................................................................. 26
9.1. Table of Figures ................................................................................................... 26
9.2. Table of Tables .................................................................................................... 26
10. About the Author ........................................................................................ 27
11. About Nutanix ............................................................................................ 28
12. Acknowledgements .................................................................................... 29

This page left intentionally blank.

H
5
1. Executive Summary
The Nutanix Complete Cluster is a scalable virtualization solution for Desktop and Server, and Hadoop Virtualization. This document shows the design and scaling of Hadoop MapReduce on the Nutanix Distributed File System (NDFS). It shows the scalability of the Nutanix Complete Cluster and provides detailed performance and configuration information on the scale-out capabilities of the cluster. The Nutanix Complete Cluster consists of modular “Blocks” that include Compute, Storage and Network. This design greatly reduces cost while increasing performance and scalability. The Nutanix Distributed File System (NDFS), the core of Nutanix’s Complete Cluster, tethers high performance solid state storage directly to enterprise applications while preserving the high-capacity the SATA HDD tier provides through its adaptive information lifecycle management (ILM) capabilities. NDFS amplifies the power of server attached flash (NYSE:FIO) in the realm of enterprise virtualization by co-locating high performance, localized storage IO, and Google-like, scale-out distributed redundancy via high speed 10GbE top-of-rack switches. The base cluster ships with four industry-standard x86 servers bundled with VMware's hypervisor in a 2U, 75-lb, SAN-Free server appliance. The solution and testing provided in this document was completed with Hadoop 0.20 deployed on VMware vSphere on the Nutanix Complete Cluster.
Simplified. Software Defined. Nutanix

6 | Hadoop on Nutanix
2. Introduction
2.1. Audience
This reference architecture document is part of the Nutanix Solutions Library and is intended for use by individuals responsible for architecting, designing, managing and/or supporting Nutanix infrastructures. Consumers of this document should be familiar with concepts pertaining to VMware vSphere, Hadoop MapReduce, and Nutanix.
We have broken down this document to address to key items for each role focusing on the enablement of a successful design, implementation and transition to operation.
2.2. Purpose
This document will cover the following subject areas:
o Overview of the Nutanix solution
o Overview of Hadoop and its use-cases
o The benefits of virtualizing Hadoop on Nutanix
o Architecting a complete Hadoop MapReduce solution on the Nutanix Platform
o Design and configuration considerations when architecting a Hadoop solution on Nutanix
o Benchmarking MapReduce performance on Nutanix
If you’re looking for a high-level overview and background on the solution continue with the Solution Overview section below.
If you’re looking for the detailed solution jump HERE
H
7
3. Solution Overview
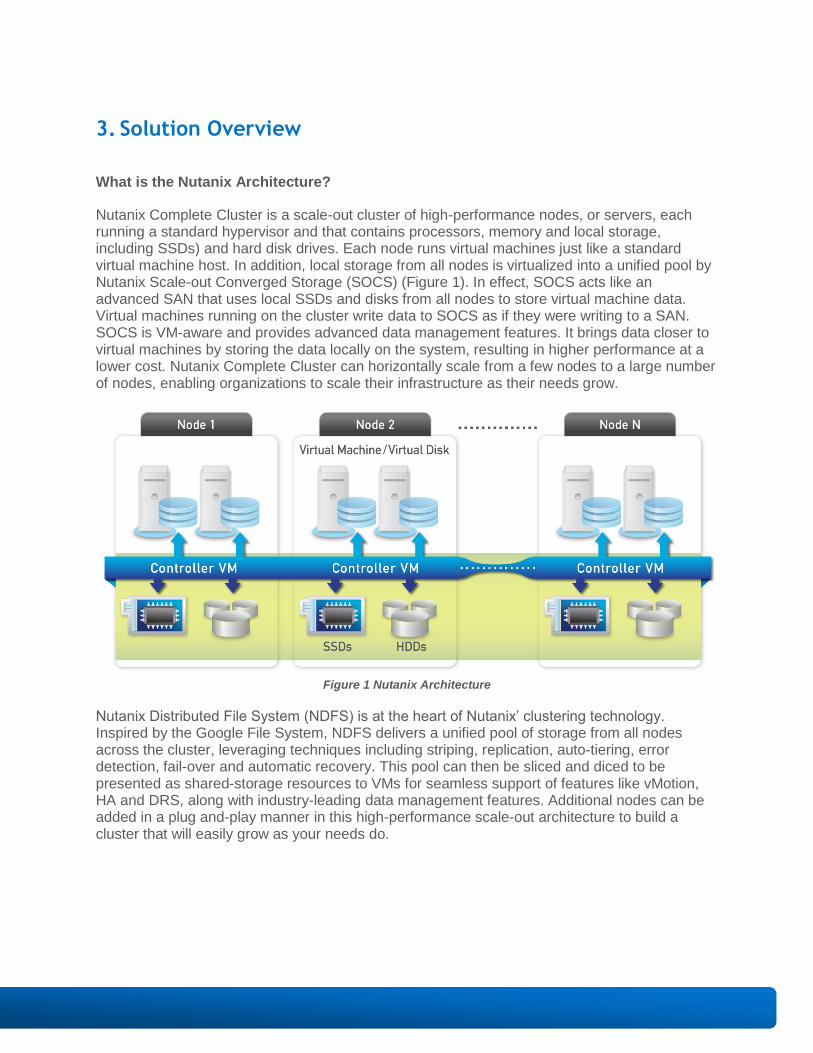
What is the Nutanix Architecture?
Nutanix Complete Cluster is a scale-out cluster of high-performance nodes, or servers, each running a standard hypervisor and that contains processors, memory and local storage, including SSDs) and hard disk drives. Each node runs virtual machines just like a standard virtual machine host. In addition, local storage from all nodes is virtualized into a unified pool by Nutanix Scale-out Converged Storage (SOCS) (Figure 1). In effect, SOCS acts like an advanced SAN that uses local SSDs and disks from all nodes to store virtual machine data. Virtual machines running on the cluster write data to SOCS as if they were writing to a SAN. SOCS is VM-aware and provides advanced data management features. It brings data closer to virtual machines by storing the data locally on the system, resulting in higher performance at a lower cost. Nutanix Complete Cluster can horizontally scale from a few nodes to a large number of nodes, enabling organizations to scale their infrastructure as their needs grow.
Figure 1 Nutanix Architecture
Nutanix Distributed File System (NDFS) is at the heart of Nutanix’ clustering technology. Inspired by the Google File System, NDFS delivers a unified pool of storage from all nodes across the cluster, leveraging techniques including striping, replication, auto-tiering, error detection, fail-over and automatic recovery. This pool can then be sliced and diced to be presented as shared-storage resources to VMs for seamless support of features like vMotion, HA and DRS, along with industry-leading data management features. Additional nodes can be added in a plug and-play manner in this high-performance scale-out architecture to build a cluster that will easily grow as your needs do.

8 | Hadoop on Nutanix
What is Hadoop?1
The Apache™ Hadoop™ project develops open-source software for reliable, scalable, distributed computing and processing of data.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of nodes using a simple programming model. It is designed to scale up from a single node to thousands of nodes, each offering local computation and storage. Rather than depending on reliable hardware to deliver high-availability and fault-tolerance, the library itself is designed to detect and handle failures at the application layer, delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Hadoop is available in a number of different distributions, some of which we’ve highlighted below: Distribution Considerations & Thoughts
Apache Hadoop o Main Hadoop open-source initiative
o Constant updates
o Lack of official support
o Lack of deployment model
Cloudera o Official Support
o Provisioning & Management (Cloudera Manager)
o Stable Releases
o Hadoop Version 0.23 in CDH4
Hortonworks o Official Support
o Provisioning & Management (Ambari)
o Stable Releases
o NameNode / Job Tracker HA
MapR o NFS / Maprfs API2
o No NameNode Table 1 Hadoop Distribution Considerations
Other related projects: Project Role
Serengeti Open-source initiative for provisioning virtual Hadoop: LINK
Apache Pig High-level data flow language: LINK
Apache Hive SQL-like language and metadata repository: LINK
Apache Zookeeper High-reliable distributed coordination service: LINK
Apache HBase Scalable record and table storage with real-time read/write access: LINK
Apache Flume Service for collecting and aggregating log and event data: LINK
Apache Sqoop Data transport engine for relational database integration: LINK

H
9
Apache Mahout Library of machine learning algorithms for Hadoop: LINK
Table 2 Hadoop Related Projects
What does Hadoop mean for my business?3
The amount of data generated in businesses is growing exponentially. Data on business transactions, customer interactions, web log data etc. is accumulating at an increasing at an unrelenting pace. Turning that data into information and actionable insights is becoming more difficult as methods based on traditional databases are generally hard to scale up to tera- or petabyte scale.
Google was one of the first companies that recognized this and developed an internal distributed compute architecture (MapReduce) and distributed file system (Google File System or GFS) that allows the massively parallel processing of large amounts of data. It scales up easily by increasing the number of computational nodes.
Hadoop is an Apache open source project that made this computational paradigm available for everyone, with Yahoo being one of its largest contributors and heavy internal user. Hadoop enables distributed parallel processing of huge amounts of data across inexpensive, commodity servers configured into Hadoop clusters. With Hadoop, no data is too big. And in today’s hyper-connected world where people and businesses are creating more and more data every day, Hadoop’s ability to grow virtually without limits means businesses and organizations can now unlock potential value from all their data.
Figure 2 Business Data Sources
To date, most organizations created their Hadoop clusters by dedicating and managing a separate set of physical compute nodes and storage. However, this created both some management and capital expense downsides.

10 | Hadoop on Nutanix
Why virtualize Hadoop nodes?
o Increased performance: Virtualized Hadoop nodes have been proven to perform better than their bare-metal cousins4
o Hardware utilization: Bare-metal Hadoop deployments average 10-20% CPU utilization, a major waste of hardware resources and datacenter space. Virtualizing Hadoop allows for better hardware utilization and flexibility
o Elastic MapReduce and scaling: Dynamic addition and removal of Hadoop nodes based on load allow you to scale based upon your current needs, not what you expect. Enable supply and demand to be in true synergy
o Allow DevOps & IT Ops to live in harmony: Big Data scientists demand performance, reliability, and a flexible scale model. IT Ops relies on virtualization to tame server sprawl, increase utilization, encapsulate workloads, manage capacity growth, and alleviate disruptive outages caused by hardware downtime. By virtualizing Hadoop, Data Scientists and IT Ops mutually achieve all objectives while preserving autonomy and independence for their respective responsibilities
o Sandboxing of jobs – Make Hadoop and Enterprise Apps play nice: Buggy MapReduce jobs can quickly saturate hardware resources, creating havoc for remaining jobs in the queue. Virtualizing Hadoop clusters encapsulates and sandboxes MapReduce jobs from other important sorting runs and general purpose workloads
o Batch Scheduling & Stacked workloads: Allow all workloads and applications to co-exist, e.g. Hadoop, Virtual Desktops and Servers. Schedule MapReduce job runs during off-peak hours to take advantage of idle night time and weekend hours that would otherwise go to waste or utilize VMware’s resource pooling features to run concurrently
o New Hadoop economics: Bare metal implementations are expensive and can spiral out of control. Downtime and underutilized CPU consequences of physical server’s workloads can jeopardize project viability. Virtualizing Hadoop reduces complexity and ensures success for sophisticated projects with a scale-out grow as you go model – a perfect fit for Big Data projects
o Service-defined tiering: Maintain and manage SLAs with resource prioritization and reservations
Why run Hadoop MapReduce on Nutanix?
o Blazing fast performance: Up to 2,000 MB/s of sequential throughput in a compact 2U 4-node cluster. A TeraSort benchmark yields 250 MB/s in the same 2U cluster
o Unified data platform: Run multiple data processing platforms along with Hadoop MapReduce on a single unified data platform (NDFS)
o High Availability: With HDFS the NameNode is a single point of failure. Nutanix has built-in high-availability and replication features to secure all pieces of Hadoop data. With Nutanix you eliminate any single points of failure
o Change Management: Maintain environmental control and separation between development, test, staging and production environments. Nutanix snapshots and fast clones can help in sharing production data with non-production jobs, without requiring full copies and unnecessary data duplication

H
11
o Business Continuity and Data Protection: If your Hadoop cluster is gradually becoming mission critical, it needs all the enterprise-grade data management features including backup and DR. With Nutanix these are already provided out of the box and can be managed the same as would be for virtual environments
o Data Archiving: Older data that is not heavily used by jobs doesn’t need to fit on the highest storage tier. With Nutanix, ILM this will automatically be moved down the tiers during times of inactivity and moved back up the tiers in time of heavy access. Along with compression this offers the ideal combination of performance along with capacity
o Flash SSDs for NoSQL: The summaries that roll up to a NoSQL database like HBase are used to run business reports and are typically memory and IOPS-heavy. Nutanix has PCIe SSD and SATA SSD tiers coupled along with dense memory capacities. With its heat-optimized tiering technology can transparently bring IOPS-heavy workloads to SSD tiers
o Enterprise-grade cluster management: An Apple-like approach to managing large clusters, including a converged GUI that serves as a single pane of glass for servers and storage, alert notifications, and bonjour mechanism to auto-detect new nodes in the cluster. Spend more time enhancing your environment, not maintaining it
o High-density Hadoop: Nutanix uses a hyperscale server architecture in which 8 sockets of Intel and up to 1TB of memory fit in a single 2U spread over 4 motherboards. Coupled with data archiving and compression, Nutanix can reduce Hadoop hardware footprints by up to 4x
o Time-sliced clusters: Like public cloud EC2 environments, Nutanix can provide a truly converged cloud infrastructure - Allowing you to run your server and desktop virtualization service along with Hadoop on a single converged cloud. Get the efficiency and savings you require with a converged cloud on a truly converged architecture
Nutanix enables you to run multiple-solutions all on the same converged infrastructure, while only enhancing performance and consolidation:
Big Data Private Cloud End-User Computing

12 | Hadoop on Nutanix
4. Solution Design
4.1. Hadoop MapReduce the Traditional Way
You should consider this approach if:
o You have strict requirements requiring HDFS
The Hadoop Architecture consists of two main services: the data layer (HDFS) and the parallel processing layer (MapReduce). HDFS is composed of two main components: 1) The NameNode and 2) the DataNode. The NameNode is responsible for all metadata operations as well as maintaining the metadata for the namespace. In the event of a NameNode failure, HDFS will be unavailable. The DataNode is responsible for the actual data I/O. In bare-metal deployment the NameNode is a single instance which can be susceptible to failure; however this can be highly available in virtual configurations. MapReduce is composed of two main components: 1) The Job Tracker and 2) the Task Tracker. The Job Tracker is responsible for the scheduling and management of job submission and queue management. The Task Tracker is responsible for the actual MapReduce and task management. In bare-metal deployments the Job Tracker is a single instance which can be susceptible to failure; however this can be again highly available in virtual configurations.
Below we show an image of how these services layers are composed and how the clients interact with them:
DataNode
TaskTracker
Node 1
HDFS
NameNodeRF=3
MapReduce
JobTracker
DataNode
TaskTracker
Node 2
DataNode
TaskTracker
Node N
Read / Write
MetaData Ops MR Job
Task Attempt Task Result
...
Replication
MetaData (Name, replicas,..)
Client
Replication
Figure 3 Hadoop Flow with HDFS

H
13
Hadoop can be deployed on Nutanix the same way as it would be deployed in any virtual scenario. In this case the DataNodes would mount VMDKs hosted on Nutanix NDFS. This does provide multiple layers of abstraction for storage as HDFS would be running on NDFS, however does provide full Hadoop functionality and the HDFS API.
Below we show the relationship between a Nutanix Node, SVM and Hadoop node. Here you can see the Hadoop node is running HDFS with VMDKs hosted on Nutanix NDFS. In addition, this also ensures all DataNode IO to its VMDKs is always going to the local SVM:
Figure 4 Hadoop Layers with HDFS
Below we show a more detailed configuration of how the Hadoop node is running HDFS on NDFS via its local SVM:
Nutanix Node2 CPU @ 8 Core (32 Logical w/ HT)
256 GB Memory
Hadoop VM 1
/mn
t/te
mp
/d
1
/mn
t/te
mp
/d
2
/mn
t/te
mp
/d
3
/mn
t/te
mp
/d
4
Ub
un
tu O
S
LSI SCSI Controller
0:0
PV-SCSI Controller
Mapred Local
Hadoop VM n
...
Mapred DFS
/had
oo
p/
loca
l/d
1
/had
oo
p/
loca
l/d
2
/had
oo
p/
loca
l/d
3
/had
oo
p/
loca
l/d
4
Nutanix SVM
Nutanix NDFS
NFSiSCSI
2TB
VM
DK
2TB
VM
DK
2TB
VM
DK
2TB
VM
DK
RF2 CTR DATA
RF1 CTR TEMP
NFS Datastore
RF2 CTR VM
NFS Datastore
/had
oo
p/
dat
a/d
1
/had
oo
p/
dat
a/d
2
/had
oo
p/
dat
a/d
3
/had
oo
p/
dat
a/d
4
NFS Datastore
/mn
t/d
ata/
d1
/mn
t/d
ata/
d2
/mn
t/d
ata/
d3
/mn
t/d
ata/
d4
2TB
VM
DK
2TB
VM
DK
2TB
VM
DK
2TB
VM
DK
Figure 5 Hadoop Node Architecture with HDFS

14 | Hadoop on Nutanix
4.2. Hadoop MapReduce the Nutanix Way
You should consider this approach if:
o You do not have strict requirements requiring HDFS
o Are looking for the best possible performance
o Are looking for a truly unified data platform
o Are looking for simplified configuration and management
Nutanix provides the ideal combination of compute and high-performance local storage; providing the best possible architecture for Hadoop and other distributed applications. Nutanix provides a highly distributed filesystem with replication out of the box; enabling us to remove the HDFS services layer and platform MapReduce directly on our native filesystem. With the Nutanix Hadoop solution you also get the benefit to run a mixed workload. Use the solution for VDI and Server Virtualization during the day and run batch MapReduce on the same environment later. Below we show an updated image of how these services layers are composed and how the clients interact with them:
SVM
TaskTracker
Node 1
MapReduce
JobTracker
SVM
TaskTracker
Node 2
SVM
TaskTracker
Node N
Read / WriteMR Job
Task Attempt Task Result
...
Replication
Client
Replication
Nutanix NDFS
Figure 6 Hadoop Flow with NDFS
As you can see from the image above, we’ve removed the HDFS services layer and have the Task Trackers interacting directly with NDFS. Nutanix has data locality and ILM logic to ensure the Task is always interacting with local data ensuring the highest possible performance. This greatly simplifies the configuration of Hadoop and quickly allows you to get to what your real focus is - efficient parallel processing of massive scale datasets.
H
15
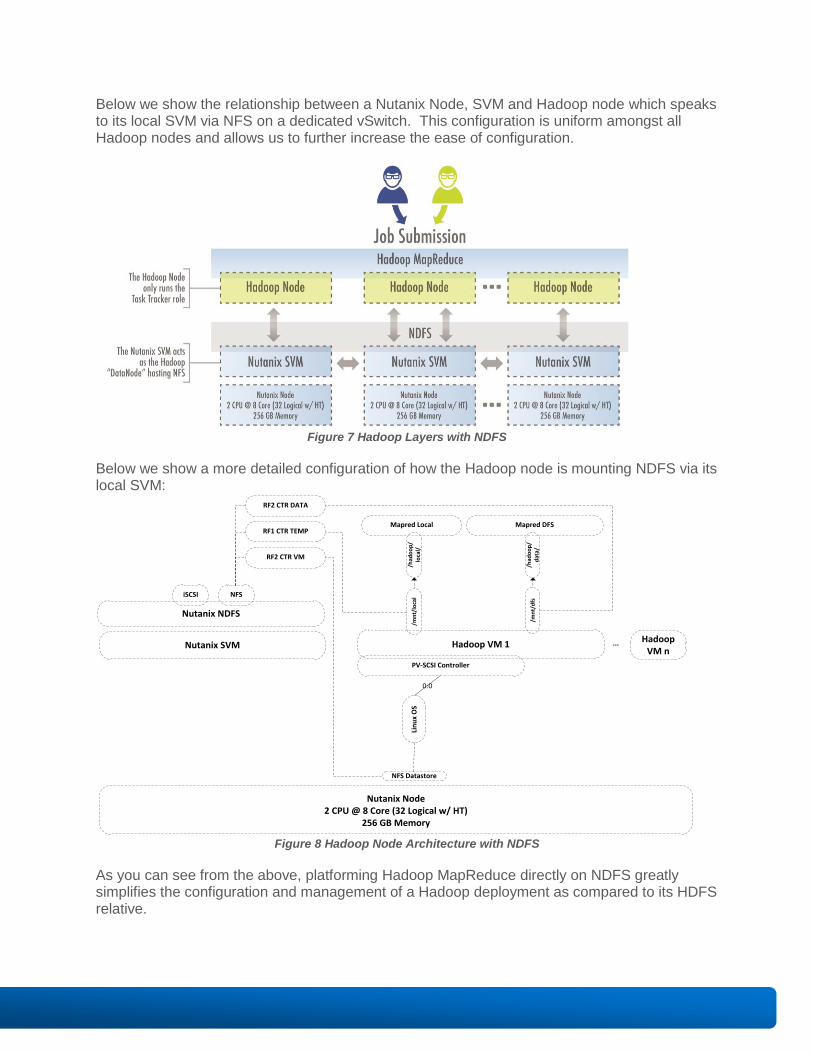
Below we show the relationship between a Nutanix Node, SVM and Hadoop node which speaks to its local SVM via NFS on a dedicated vSwitch. This configuration is uniform amongst all Hadoop nodes and allows us to further increase the ease of configuration.
Figure 7 Hadoop Layers with NDFS
Below we show a more detailed configuration of how the Hadoop node is mounting NDFS via its local SVM:
Nutanix Node2 CPU @ 8 Core (32 Logical w/ HT)
256 GB Memory
Hadoop VM 1
/mn
t/lo
cal
Lin
ux
OS
0:0
PV-SCSI Controller
Mapred Local
Hadoop VM n
...
Mapred DFS
/had
oo
p/
loca
l/
Nutanix SVM
Nutanix NDFS
NFSiSCSI
RF1 CTR TEMP
RF2 CTR DATA
RF2 CTR VM
NFS Datastore
/had
oo
p/
dat
a//m
nt/
dfs
Figure 8 Hadoop Node Architecture with NDFS
As you can see from the above, platforming Hadoop MapReduce directly on NDFS greatly simplifies the configuration and management of a Hadoop deployment as compared to its HDFS relative.
16 | Hadoop on Nutanix
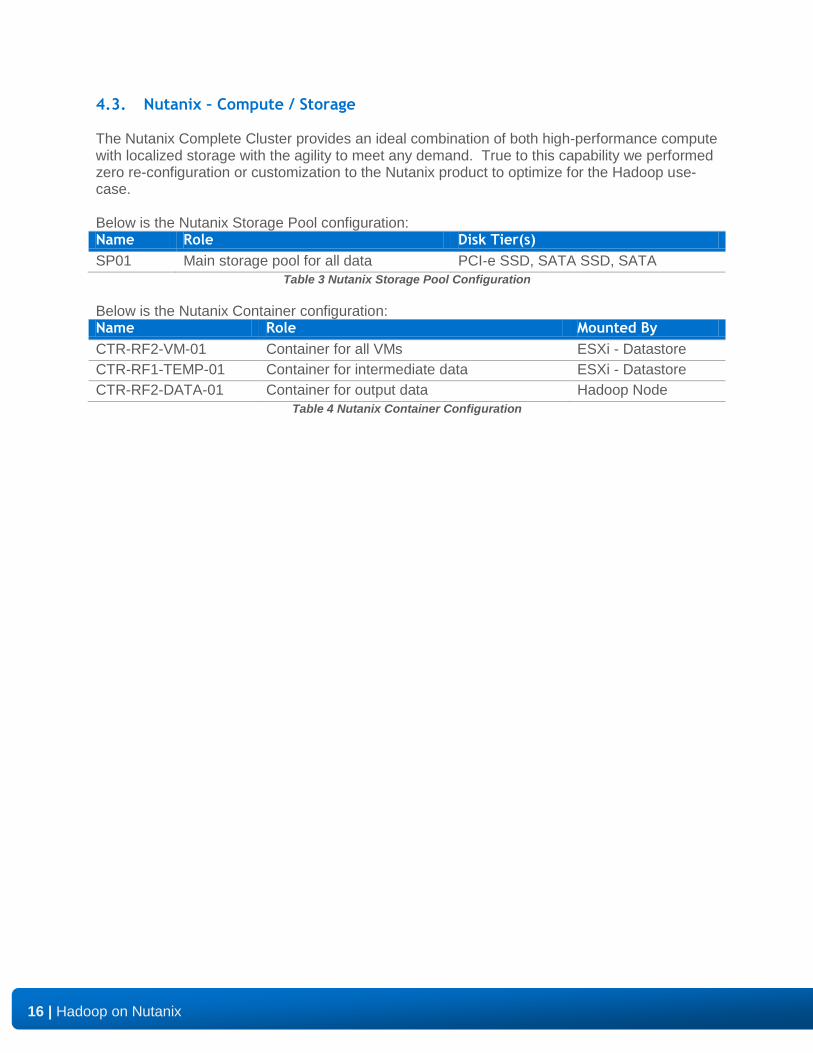
4.3. Nutanix – Compute / Storage
The Nutanix Complete Cluster provides an ideal combination of both high-performance compute with localized storage with the agility to meet any demand. True to this capability we performed zero re-configuration or customization to the Nutanix product to optimize for the Hadoop use-case. Below is the Nutanix Storage Pool configuration: Name Role Disk Tier(s)
SP01 Main storage pool for all data PCI-e SSD, SATA SSD, SATA
Table 3 Nutanix Storage Pool Configuration
Below is the Nutanix Container configuration: Name Role Mounted By
CTR-RF2-VM-01 Container for all VMs ESXi - Datastore
CTR-RF1-TEMP-01 Container for intermediate data ESXi - Datastore
CTR-RF2-DATA-01 Container for output data Hadoop Node Table 4 Nutanix Container Configuration

H
17
4.4. Network
Designed for true linear scaling, we leverage a Leaf Spine network architecture. A Leaf Spine architecture consists of two network tiers: A L2 Leaf and a L3 Spine based upon 40GbE and non-blocking switches. In this architecture you maintain consistent performance without any reduction due to scaling due to a static maximum of two hops from any node in the network. Below we show a design of a scale out Leaf Spine network architecture which provides 20Gb active throughput from each node to its L2 Leaf and scalable 80Gb active throughput from each Leaf to Spine switch. In the image below we show how a Leaf Spine architecture would scale from 1 Nutanix Complete Block to 1000s+ without any impact to available bandwidth:
Figure 9 Leaf Spine Network Architecture

18 | Hadoop on Nutanix
5. Validation & Benchmarking
The industry standard TeraSort benchmark 5was used for validating the Hadoop MapReduce job performance on the Nutanix Complete Cluster.
The solution and testing provided in this document was completed with Cloudera Hadoop 3 Update 4 (CDH3U4) MapReduce on NDFS deployed on VMware vSphere on the Nutanix Complete Cluster.
Test Environment Configuration*
Hardware:
o Storage / Compute: 2 Nutanix Complete Blocks
o Network: Arista 7050Q / 7050S Series Switches
Hadoop Node Configuration:
o OS: Ubuntu 10.04 LTS
o 1 x CDH3U4 Node per Nutanix Node
o 24 vCPU & 80 GB memory
o 4 x 2TB VMDKs for intermediate data
o 1 x NDFS mount for MapReduce Output
*More information on the configuration can be found in the Appendix
Test Execution
o Prepare input data by running TeraGen w/ N 100 Byte Keys
▫ N = 10 Billion for ~1TB
▫ N = 50 Billion for ~5TB
▫ N = 100 Billion for ~10TB
o Perform sort of data by running TeraSort w/ input data set
o Perform validation of data by running TeraValidate w/ output data set
Results
The Nutanix Hadoop Solutions provides the highest density Hadoop MapReduce performance delivering performance 2x’s faster than the previous leader (HP6) at 250MB/s sort throughput per 2U block. As the number of blocks scale the sort throughput performance scales linearly.
H
19
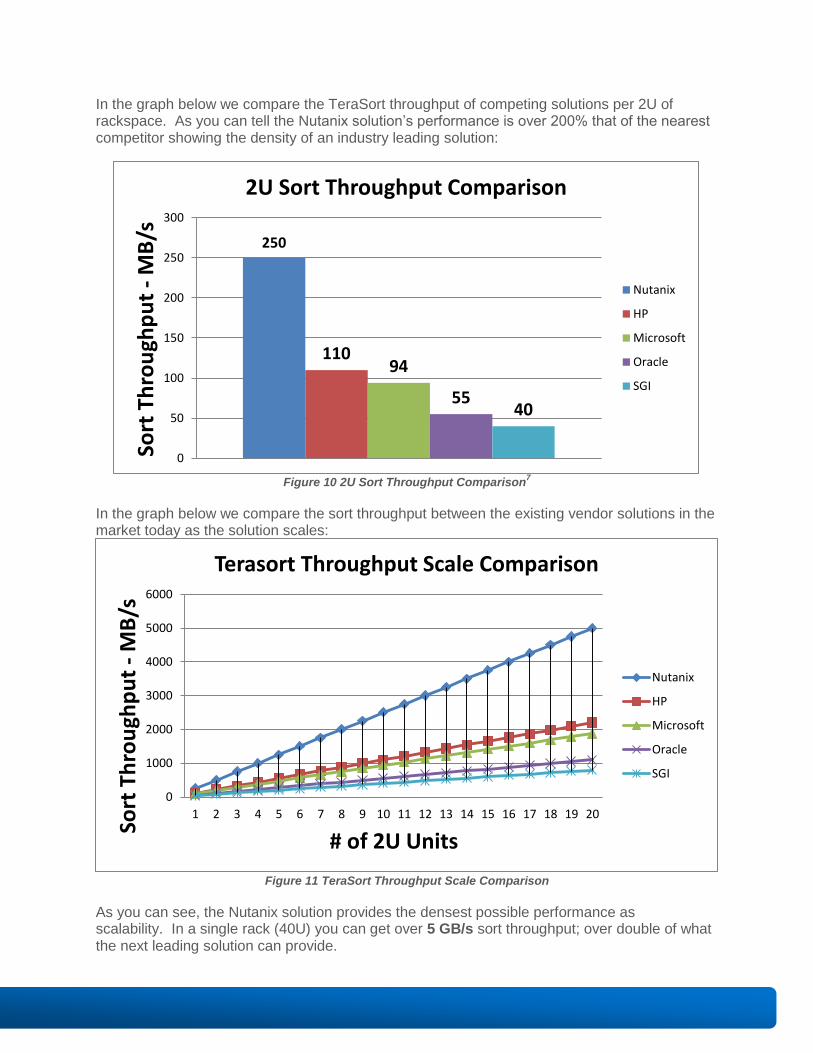
In the graph below we compare the TeraSort throughput of competing solutions per 2U of rackspace. As you can tell the Nutanix solution’s performance is over 200% that of the nearest competitor showing the density of an industry leading solution:
Figure 10 2U Sort Throughput Comparison
7
In the graph below we compare the sort throughput between the existing vendor solutions in the market today as the solution scales:
Figure 11 TeraSort Throughput Scale Comparison
As you can see, the Nutanix solution provides the densest possible performance as scalability. In a single rack (40U) you can get over 5 GB/s sort throughput; over double of what the next leading solution can provide.
250
110 94
55 40
0
50
100
150
200
250
300
Sort
Th
rou
ghp
ut
- M
B/s
2U Sort Throughput Comparison
Nutanix
HP
Microsoft
Oracle
SGI
0
1000
2000
3000
4000
5000
6000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Sort
Th
rou
ghp
ut
- M
B/s
# of 2U Units
Terasort Throughput Scale Comparison
Nutanix
HP
Microsoft
Oracle
SGI

20 | Hadoop on Nutanix
6. Further Research
As part of its continuous determination to deliver the best possible solutions, Nutanix will continue to research into the following areas:
o Performance Optimizations
o Scale Testing
o Distribution Specific Reference Architectures (i.e. Cloudera, HortonWorks, etc.)
o Deployment integrations with Project Serengeti
o API integrations and enhancements

H
21
7. Conclusion
The Nutanix Hadoop solution provides the best of many worlds: industry leading performance with the ability to run multiple mixed workloads on a single converged architecture. Of the “converged” architectures in the market today, none can truly provide the optimal configuration for all workloads; however this is changing with Nutanix. The same platform that brought you revolutionary virtual desktop performance at massive scale can do the exact same with Hadoop. Below we take a look at the various key items of the solution from key perspectives: For the Data Scientist
o Best of class MapReduce performance - Over 2x what the next leading competitor provides
o Native DFS support / integration with Nutanix Distributed File System (NDFS) - Run MapReduce without HDFS and its NameNode
o Run multiple data processing platforms on a single unified data platform (NDFS)
o Simplified Hadoop configuration and management
For IT
o Ease of integration and management - manage it the same as you do with existing virtual environments
o True linear scalability - incrementally scale your environment granularly match demand as it grows
o Datacenter consolidation and convergence around a single, simple product
For the Business leader
o Increased speed of delivery - Get rid of the long procurement cycles
o Enable IT to be a strategic department
o Standardized, Simple and Scalable
Nutanix provides a revolutionary architecture enabling you and your business for the future.

22 | Hadoop on Nutanix
8. Appendix: Configuration
Hardware
o Storage / Compute
▫ 2 x Nutanix Complete Block (8 nodes total)
▫ Node Configuration
o CPU: Intel Xeon X5650 @ 2.67 GHz
o Memory: 96 GB Memory
o Network
▫ Arista 7050Q - L3 Spine
▫ Arista 7050S - L2 Leaf
Software o Nutanix
▫ Software build 2.6
o OS
▫ Ubuntu 10.04 LTS
o Hadoop
▫ Cloudera Hadoop 3 Update 4 (CDH3U4)
VM o Hadoop Node
▫ 1 Hadoop Node per Nutanix Node (8 total)
▫ CPU: 24 vCPU
▫ Memory: 80 GB
o Storage:
▫ 1 x 20GB OS Disk on CTR-RF2-VM-01 NDFS backed NFS datastore
▫ 4 x 2TB TMP VMDKs on CTR-RF1-TEMP-01 NDFS backed NFS datastore
▫ 1 x 30TB NDFS mount to CTR-RF2-DATA-01 NDFS Container
Hadoop Configuration Example – w/ HDFS
o core-site.xml
<?xml version="1.0"?>

H
23
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://namenode:port</value>
</property>
</configuration>
o mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>jobtracker:port</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/hadoop/local/d1,/hadoop/local/d2,/hadoop/local/d3,/hadoop/local/d4</value>
</property>
</configuration>
o hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
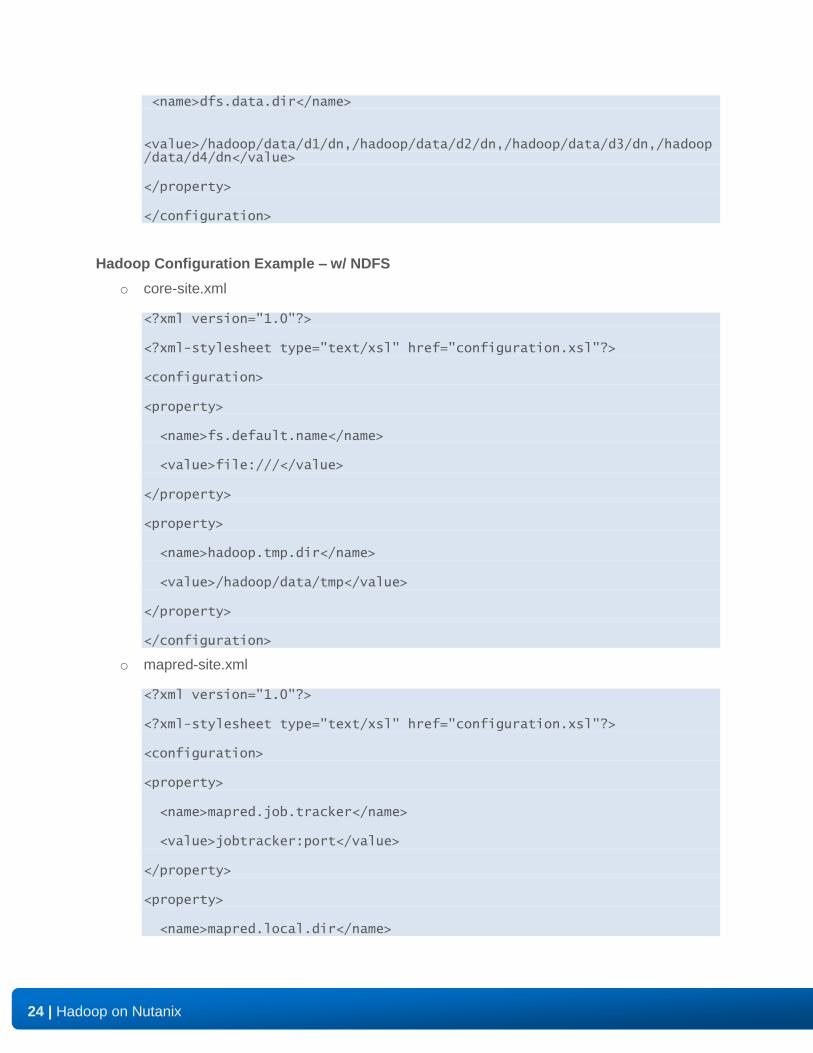
<name>dfs.name.dir</name>
<value>/hadoop/data/d1/nn,/nfsmount/dfs/nn</value>
</property>
<property>
24 | Hadoop on Nutanix
<name>dfs.data.dir</name>
<value>/hadoop/data/d1/dn,/hadoop/data/d2/dn,/hadoop/data/d3/dn,/hadoop/data/d4/dn</value>
</property>
</configuration>
Hadoop Configuration Example – w/ NDFS
o core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>file:///</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/data/tmp</value>
</property>
</configuration>
o mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>jobtracker:port</value>
</property>
<property>
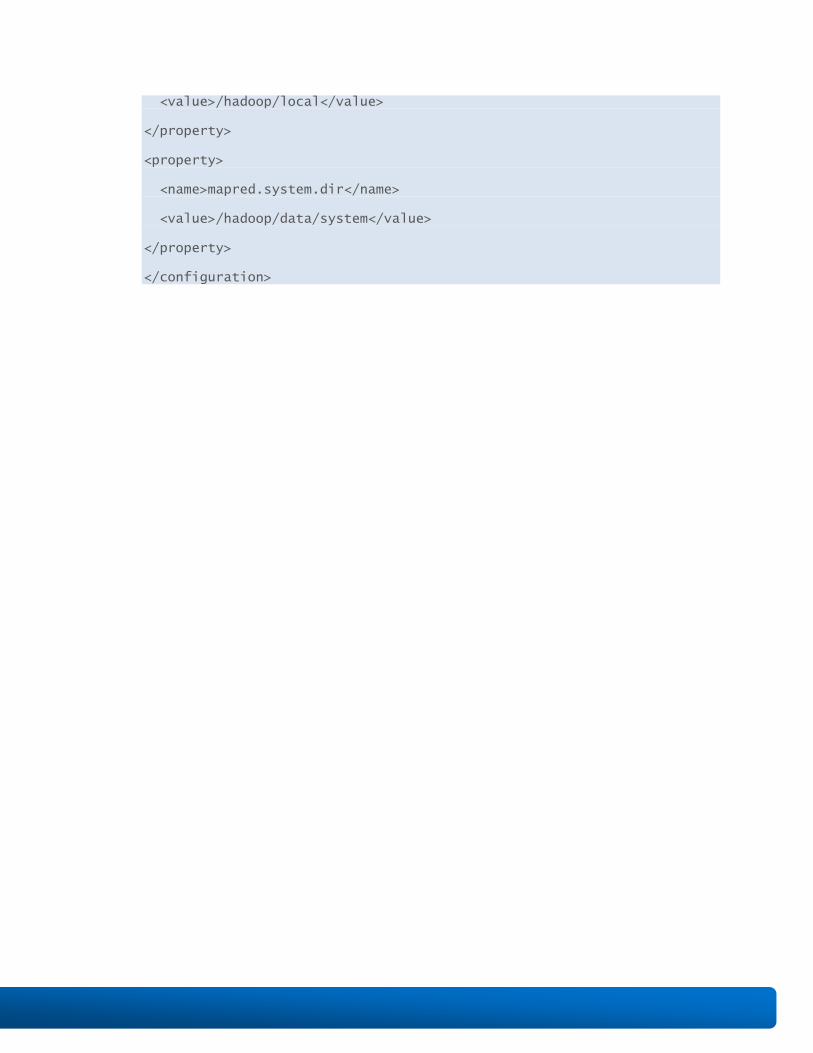
<name>mapred.local.dir</name>
H
25
<value>/hadoop/local</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/hadoop/data/system</value>
</property>
</configuration>

26 | Hadoop on Nutanix
9. References
9.1. Table of Figures
Figure 1 Nutanix Architecture ..................................................................................................... 7
Figure 2 Business Data Sources ................................................................................................ 9
Figure 3 Hadoop Flow with HDFS .............................................................................................12
Figure 4 Hadoop Layers with HDFS ..........................................................................................13
Figure 5 Hadoop Node Architecture with HDFS ........................................................................13
Figure 6 Hadoop Flow with NDFS .............................................................................................14
Figure 7 Hadoop Layers with NDFS ..........................................................................................15
Figure 8 Hadoop Node Architecture with NDFS ........................................................................15
Figure 9 Leaf Spine Network Architecture .................................................................................17
Figure 10 2U Sort Throughput Comparison ...............................................................................19
Figure 11 TeraSort Throughput Scale Comparison ...................................................................19
9.2. Table of Tables
Table 1 Hadoop Distribution Considerations .............................................................................. 8
Table 2 Hadoop Related Projects............................................................................................... 9
Table 3 Nutanix Storage Pool Configuration .............................................................................16
Table 4 Nutanix Container Configuration...................................................................................16

H
27
10. About the Author
Steven Poitras is a Solutions Architect on the Technical Marketing team at Nutanix, Inc. In his role, Steven helps design architectures combining applications with the Nutanix platform creating solutions helping solve critical business needs and requirements and disrupting the infrastructure space. Prior to joining Nutanix he was one of the key solution architects at the Accenture Technology Labs where he was focused in the Next Generation Infrastructure (NGI) & Next Generation Datacenter (NGDC) domains. In these spaces he has developed methodologies, reference architectures and frameworks focusing on the design and transformation to agile, scalable, and cost effective infrastructures which can be consumed in a "service-oriented" or cloud like manner.

28 | Hadoop on Nutanix
11. About Nutanix
Nutanix is the first company to offer a radically simple compute and storage infrastructure for implementing enterprise-class virtualization without complex and expensive external network storage (SAN or NAS). Founded in 2009 by a team that built scalable systems such as Google File System and enterprise-class systems such as Oracle Database/Exadata, Nutanix is based in San José, California, and is backed by Lightspeed Venture Partners, Khosla Ventures and Blumberg Capital.

H
29
12. Acknowledgements

30 | Hadoop on Nutanix
H
31
1 Apache Hadoop. Apache. http://hadoop.apache.org/
2 Because Hadoop isn’t Perfect: 8 ways to replace HDFS, GigaOm, http://gigaom.com/cloud/because-
hadoop-isnt-perfect-8-ways-to-replace-hdfs/ 3 A Benchmarking Case Study of Virtualized Hadoop Performance on VMware vSphere 5. VMware.
http://www.vmware.com/files/pdf/VMW-Hadoop-Performance-vSphere5.pdf 4 A Benchmarking Case Study of Virtualized Hadoop Performance on VMware vSphere 5. VMware.
http://www.vmware.com/files/pdf/VMW-Hadoop-Performance-vSphere5.pdf 5 Sort Benchmark. http://sortbenchmark.org/
6 HP Unleashes the Power of Hadoop. HP.
http://www.hp.com/hpinfo/newsroom/press_kits/2012/HPDiscover2012/Hadoop_Appliance_Fact_Sheet.pdf 7 HP Unleashes the Power of Hadoop. HP.
http://www.hp.com/hpinfo/newsroom/press_kits/2012/HPDiscover2012/Hadoop_Appliance_Fact_Sheet.pdf MinuteSort with Flat Datacenter Storage. Microsoft Research. http://sortbenchmark.org/FlatDatacenterStorage2012.pdf Sun Fire X2270 M2 Super-Linear Scaling of Hadoop Terasort and CloudBurst Benchmarks. Oracle. https://blogs.oracle.com/BestPerf/entry/20090920_x2270m2_hadoop Increased Hadoop Optimization Using Intel-based SGI Rackable Solutions. SGI. http://www.sgi.com/pdfs/4333.pdf