handling non-determinism and incompleteness. the story until now.. classical planning ...
Post on 20-Dec-2015
216 views
TRANSCRIPT

Handling non-determinism and incompleteness

The story until now..
Classical Planning Instantaneous actions Deterministic dynamics Discrete state Fully observable initial state Goals of achievement Static world
NP-Complete for poly-length plans P-SPACE Complete in general
Relax goals of achievement Partial satisfaction Planning; trajectory goals
Relax instantaneous actions Durative actions (temporal planning)
Exp-space complete if same action can be executed concurrent with itself
Relax Static World Replanning
Relax Full Observability Non-deterministic/Stochastic
Relax Determistic actions Non-deterministic/Stochastic

Non-deterministic vs. Stochastic
Non-deterministic means we know there is uncertainty but do not know the distribution of uncertainty NON-DETERMINISTIC != Uniform
distribution E.g. The agent may be in one of
{s1,….sn}. We don’t know which of them are more vs. less likely (we also don’t know that they are all equally likely)
E.g. the action a done in s can lead to {s1..sm}—no information is available on which outcomes are more likely
Stochastic is Non-deterministic + distribution information.
So stochastic means more knowledge Note that more knowledge implies
more problems are expressible and solvable (but also might mean that the computational burden on the agent increases). With non-determinism, the agent has to say whether there is a strong vs. weak plan. With stochastic actions, the agent can also talk about plans that satisfy goals with different levels of probability

Observability status of Classical planning
Classical planning can be seen either as Full observability (initial state as well as all other
states are observable) OR Complete initial state specification + No observability
If you know initial state, and you are in a static and deterministic world, you can be blind!

Sequential Plans/Contingent (conditional) Plans/Policies
As long as all the actions available to an agent are purely causative actions, the plans of that agent can be expressed simply as generalized sequences May contain partial order/concurrency. But NO branching in the plan
Once the agent has access to sensing actions, the plans of the agent should be able to express branching (Based on the sensing test, you take one branch or the other) Contingent (also called conditional) plans are directed graphs (may be acyclic or
cyclic), with the sensing actions acting as the branch points Both sequential and contingent plans can be compiled down to the general
representation of policies Policy: test?action
Fully observable case, the test can be Stateaction mapping Partially observable case, the test may be phiaction (where phi is a general function
on states) Non-observable case, the test is timeaction (where time is the clock time or
execution period; no sensing is done).

Problems, Solutions, Success Measures:3 orthogonal dimensions
Incompleteness in the initial state Un (partial) observability of states Non-deterministic actions Uncertainty in state or effects Complex reward functions
(allowing degrees of satisfaction)
Conformant Plans: Don’t look—just do Sequences
Contingent/Conditional Plans: Look, and based on what you see, Do; look again Directed acyclic graphs
Policies: If in (belief) state S, do action a (belief) stateaction tables
Deterministic Success: Must reach goal-state with probability 1 Probabilistic Success: Must succeed with probability >= k
(0<=k<=1) Maximal Expected Reward: Maximize the expected reward (an
optimization problem)

Some specific cases
1.0 success conformant planning for domains with incomplete initial states
1.0 success conformant planning for domains with non-deterministic actions
1.0 success conditional plans for fully observable domains with incompletely specified init states, and deterministic actions
1.0 success conditional plans for fully observable domains with non-deterministic actions
1.0 success conditional plans for parially observable domains with non-deterministic actions
Probabilistic variants of all the ones on the left (where we want success probability to be >= k).

Belief State Search
Planning problem: initial belief state BI and goal state BG and a set of actions ai – the objective is to find a sequence of actions [a1…ak] that when executed in the initial belief state takes the agent to some state in BG The plan is strong if every execution leads to a state in BG [probability of
success is 1] The plan is weak if some of the executions lead to a state in BG [probability
of success > 0 ] If we have stochastic actions, we can also talk about the “degree” of strength
of the plan [ 0 <= p <= 1] We will focus on STRONG plans
Search: Start with the initial belief state, BI and do progression or regression until you find a belief state B’ s.t. B’ is a subset of BG

Action Applicability Issue
Action applicability issue (what if a belief state has 100 states and an action is applicable to 90 of them?) Consider actions that are always applicable in any
state, but can leave many states unchanged. This involves modeling actions without executability
preconditions (they can have conditional effects). This ensures that the action is applicable everywhere

Generality of Belief State Rep
Size of belief states duringSearch is never greater than |BI|
Size of belief states duringsearch can be greater or less than |BI|

State Uncertainty and Actions
The size of a belief state B is the number of states in it. For a world with k fluents, the size of a belief state can be between 1 (no
uncertainty) and 2k (complete uncertainty). Actions applied to a belief state can both increase and reduce the
size of a belief state A non-deterministic action applied to a singleton belief state will lead to a
larger (more uncertain) belief state A deterministic action applied to a belief state can reduce its uncertainty
E.g. B={(pen-standing-on-table) (pen-on-ground)}; Action A is sweep the table. Effect is B’={(pen-on-ground)}
Often, a good heuristic in solving problems with large belief-state uncertainty is to do actions that reduce uncertainty
E.g. when you are blind-folded and left in the middle of a room, you try to reach the wall and then follow it to the door. Reaching the wall is a way of reducing your positional uncertainty

Conformant Planning (only game in town if sensing is not available)
Given an incomplete initial state, and a goal state, find a sequence of actions that when executed in any of the states consistent with the initial state, takes you to a goal state.
Belief State: is a set of states 2S
I as well as G are belief states (in classical planning, we already support partial goal state)
Issues: Representation of Belief States Generalizing “progression”, “regression” etc to belief states Generating effective heuristics for estimating reachability in the space of
belief states

Progression and Regression with Belief States
Given a belief state B, and an action a, progression of B over a is defined as long as a is applicable in every state s in B Progress(B,a) { progress(s,a) | s in B}
Given a belief state B, and an action a, regression of B over a is defined as long as a is regressable from every state s in B. Regress(B,a) { regress(s,a) | s in B} Non-deterministic actions complicate regression. Suppose an action a,
when applied to state s can take us to s1 or s2 non-deterministically. Then, what is the regression of s1 over a?
Strong and Weak pre-images: We consider B’ to be the strong pre-image of B w.r.t action a, if Progress(B’,a) is equal to B. We consider B’ to be a weak pre-image if Progress(B’,a) is a superset of B


Representing Belief States

What happens if we restrict uncertainty?
If initial state uncertainty can be restricted to the status of single variables (i.e., some variables are “unknown” the rest are known), then we have “conjunctive uncertainty”
With conjunctive uncertainty, we only have to deal with 3n belief states (as against 2^(2n)) Notice that this leads to loss of expressiveness (if, for example, you know that in
the initial state one of P or Q is true, you cannot express this as a conjunctive uncertainty
Notice also the relation to “goal states” in classical planning. If you only care about the values of some of the fluents, then you have conjunctive indifference (goal states, and thus regression states, are 3n).
Not caring about the value of a fluent in the goal state is a boon (since you can declare success if you reach any of the complete goal states consistent with the partial goal state; you have more ways to succeed)
Not knowing about the value of a fluent in the initial state is a curse (since you now have to succeed from all possible complete initial states consistent with the partial initial state)

Belief State Rep (cont) Belief space planners have to search in the space of full
propositional formulas!! In contrast, classical state-space planners search in the
space of interpretations (since states for classical planning were interpretations).
Several headaches: Progression/Regression will have to be done over all states
consistent with the formula (could be exponential number). Checking for repeated search states will now involve checking the
equivalence of logical formulas (aaugh..!) To handle this problem, we have to convert the belief states into some
canonical representation. We already know the CNF and DNF representations. There is another one, called Ordered Binary Decision Diagrams that is both canonical and compact
OBDD can be thought of as a compact representation of the DNF version of the logical formula

Doing Progression/Regresssion Efficiently
Progression/Regression will have to be done over all states consistent with the formula (could be exponential number). One way of handling this is to restrict the type of uncertainty allowed.
For example, we may insist that every fluent must either be true, false or unknown. This will give us just the space of conjunctive logical formulas (only 3n space).
Flip side is that we may not be able to represent all forms of uncertainty (e.g. how do we say that either P or Q is true in the initial state?)
Another idea is to directly manipulate the logical formulas during progression/regression (without expanding them into states…)
Tricky… connected to “Symbolic model checking”

Effective representations of logical formulas
Checking for repeated search states will now involve checking the equivalence of logical formulas (aaugh..!) To handle this problem, we have to convert the belief states into
some canonical representation. We already know the CNF and DNF representations. These are
normal forms but are not canonical Same formula may have multiple equivalent CNF/DNF representations
There is another one, called Reduced Ordered Binary Decision Diagrams that is both canonical and compact
ROBDD can be thought of as a compact representation of the DNF version of the logical formula


Symbolic model checking: The bird’s eye view
Belief states can be represented as logical formulas (and “implemented” as BDDs )
Transition functions can be represented as 2-stage logical formulas (and implemented as BDDs)
The operation of progressing a belief state through a transition function can be done entirely (and efficiently) in terms of operations on BDDs
Read Appendix C before next class (emphasize C.5; C.6)

Belief State Search: An Example Problem
Initial state: M is true and exactly one of P,Q,R are true
Goal: Need G
Actions:A1: M P => KA2: M Q => KA3: M R => LA4: K => GA5: L => G
Init State Formula: [(p & ~q & ~r)V(~p&q&~r)V(~p&~q&r)]&MDNF: [M&p&~q&~r]V[M&~p&~q&~r]V[M&~p&~q&r]CNF: (P V Q V R) & (~P V ~Q) &(~P V ~R) &(~Q V ~R) & M
DNF good for progression(clauses are
partial states)
CNF goodFor regression
Plan: ??

Progression & Regression
Progression with DNF The “constituents” (DNF clauses) look like partial states already. Think of
applying action to each of these constituents and unioning the result Action application converts each constituent to a set of new constituents Termination when each constituent entails the goal formula
Regression with CNF Very little difference from classical planning (since we already had partial
states in classical planning). THE Main difference is that we cannot split the disjunction into search
space Termination when each (CNF) clause is entailed by the initial state

Progression Example

Regression Search ExampleActions:A1: M P => KA2: M Q => KA3: M R => LA4: K => GA5: L => G
Initially: (P V Q V R) &
(~P V ~Q) & (~P V ~R) & (~Q V ~R) &
M
Goal State:G
G
(G V K)
(G V K V L)
A4
A1
(G V K V L V P) & M
A2
A5
A3
G or K must be true before A4For G to be true after A4
(G V K V L V P V Q) & M
(G V K V L V P V Q V R) &M
Each Clause is Satisfied by a Clause in the Initial Clausal State -- Done! (5 actions)
Initially: (P V Q V R) &
(~P V ~Q) & (~P V ~R) & (~Q V ~R) &
M
Clausal States compactly represent disjunction to sets of uncertain literals – Yet, still need heuristics for the search
(G V K V L V P V Q V R) &M
Enabling preconditionMust be true beforeA1 was applied

Conformant Planning: Efficiency Issues
Graphplan (CGP) and SAT-compilation approaches have also been tried for conformant planning Idea is to make plan in one world, and try to extend it as
needed to make it work in other worlds Planning graph based heuristics for conformant
planning have been investigated. Interesting issues involving multiple planning graphs
Deriving Heuristics? – relaxed plans that work in multiple graphs Compact representation? – Label graphs

KACMBP and Uncertainty reducing actions


Sensing Actions Sensing actions in essence “partition” a
belief state Sensing a formula f splits a belief state B to
B&f; B&~f Both partitions need to be taken to the goal
state now Tree plan AO* search
Heuristics will have to compare two generalized AND branches In the figure, the lower branch has an
expected cost of 11,000 The upper branch has a fixed sensing cost
of 300 + based on the outcome, a cost of 7 or 12,000
If we consider worst case cost, we assume the cost is 12,300
If we consider both to be equally likey, we assume 6303.5 units cost
If we know actual probabilities that the sensing action returns one result as against other, we can use that to get the expected cost…
As
A
7
12,000
11,000
300

Sensing: General observations Sensing can be thought in terms of
Speicific state variables whose values can be found OR sensing actions that evaluate truth of some boolean formula
over the state variables. Sense(p) ; Sense(pV(q&r))
A general action may have both causative effects and sensing effects Sensing effect changes the agent’s knowledge, and not the world Causative effect changes the world (and may give certain
knowledge to the agent) A pure sensing action only has sensing effects; a pure causative
action only has causative effects.

Progression/Regression with Sensing
When applied to a belief state, AT RUN TIME the sensing effects of an action wind up reducing the cardinality of that belief state basically by removing all states that are not consistent with the sensed
effects AT PLAN TIME, Sensing actions PARTITION belief states
If you apply Sense-f? to a belief state B, you get a partition of B1: B&f and B2: B&~f
You will have to make a plan that takes both partitions to the goal state Introduces branches in the plan
If you regress two belief state B&f and B&~f over a sensing action Sense-f?, you get the belief state B

Full Observability: State Space partitioned to singleton Obs. ClassesNon-observability: Entire state space is a single observation class Partial Observability: Between 1 and |S| observation classes



Hardness classes for planning with sensing
Planning with sensing is hard or easy depending on: (easy case listed first) Whether the sensory actions give us full or partial
observability Whether the sensory actions sense individual fluents
or formulas on fluents Whether the sensing actions are always applicable
or have preconditions that need to be achieved before the action can be done
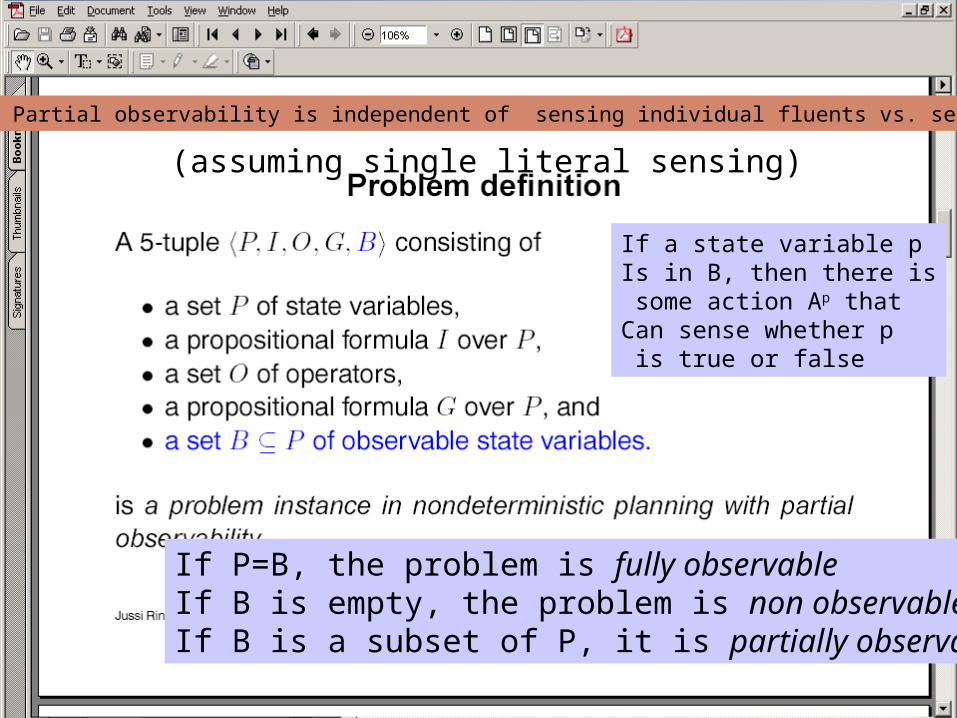
If a state variable pIs in B, then there is some action Ap thatCan sense whether p is true or false
If P=B, the problem is fully observableIf B is empty, the problem is non observableIf B is a subset of P, it is partially observable
Note: Full vs. Partial observability is independent of sensing individual fluents vs. sensing formulas.
(assuming single literal sensing)

A Simple Progression Algorithm in the presence of pure sensing actions
Call the procedure Plan(BI,G,nil) where Procedure Plan(B,G,P)
If G is satisfied in all states of B, then return P Non-deterministically choose:
I. Non-deterministically choose a causative action a that is applicable in B. Return Plan(a(B),G,P+a)
II. Non-deterministically choose a sensing action s that senses a formula f (could be a single state variable)
Let p’ = Plan(B&f,G,nil); p’’=Plan(B&~f,G,nil) /*Bf is the set of states of B in which f is true */
Return P+(s?:p’;p’’)
If we always pick I and never do II then we will produce conformantPlans (if we succeed).

Remarks on Progression with sensing actions
Progression is implicitly finding an AND subtree of an AND/OR Graph If we look for AND subgraphs, we can represent DAGS.
The amount of sensing done in the eventual solution plan is controlled by how often we pick step I vs. step II (if we always pick I, we get conformant solutions). Progression is as clue-less as to whether to do sensing and
which sensing to do, as it is about which causative action to apply Need heuristic support

Very simple ExampleA1 p=>r,~pA2 ~p=>r,p
A3 r=>g
O5 observe(p)
Problem: Init: don’t know p Goal: g
Plan: O5:p?[A1A3][A2A3]
Notice that in this case we also have a conformant plan: A1;A2;A3 --Whether or not the conformant plan is cheaper depends on how costly is sensing action O5 compared to A1 and A2

A more interesting example: MedicationThe patient is not Dead and may be Ill. The test paper is not Blue.We want to make the patient be not Dead and not IllWe have three actions: Medicate which makes the patient not ill if he is illStain—which makes the test paper blue if the patient is illSense-paper—which can tell us if the paper is blue or not.
No conformant plan possible here. Also, notice that I cannot be sensed directly but only through B
This domain is partially observable because the states (~D,I,~B) and (~D,~I,~B) cannot be distinguished

“Goal directed” conditional planning
Recall that regression of two belief state B&f and B&~f over a sensing action Sense-f will result in a belief state B
Search with this definition leads to two challenges:1. We have to combine search states into single ones (a sort of reverse AO*
operation)2. We may need to explicitly condition a goal formula in partially observable
case (especially when certain fluents can only be indirectly sensed) Example is the Medicate domain where I has to be found through B If you have a goal state B, you can always write it as B&f and B&~f for any
arbitrary f! (The goal Happy is achieved by achieving the twin goals Happy&rich as well as Happy&~rich) Of course, we need to pick the f such that f/~f can be sensed (i.e. f and ~f
defines an observational class feature) This step seems to go against the grain of “goal-directedenss”—we may not
know what to sense based on what our goal is after all!
Regression forPO case isStill notWell-understood

Very simple ExampleA1
p=>r,~pA2
~p=>r,p
A3r=>g
O5observe(p)
Problem: Init: don’t know p Goal: g
Regresssion

Handling the “combination” during regression
We have to combine search states into single ones (a sort of reverse AO* operation) Two ideas:
1. In addition to the normal regression children, also generate children from any pair of regressed states on the search fringe (has a breadth-first feel. Can be expensive!) [Tuan Le does this]
2. Do a contingent regression. Specifically, go ahead and generate B from B&f using Sense-f; but now you have to go “forward” from the “not-f” branch of Sense-f to goal too. [CNLP does this; See the example]

Need for explicit conditioning during regression (not needed for Fully Observable case)
If you have a goal state B, you can always write it as B&f and B&~f for any arbitrary f! (The goal Happy is achieved by achieving the twin goals Happy&rich as well as Happy&~rich) Of course, we need to pick the f
such that f/~f can be sensed (i.e. f and ~f defines an observational class feature)
This step seems to go against the grain of “goal-directedenss”—we may not know what to sense based on what our goal is after all!
Consider the Medicate problem. Coming from the goal of ~D&~I, we will never see the connection to sensing blue!
Notice the analogy to conditioning in evaluating a probabilistic query

Sensing: More things under the mat(which we won’t lift for now )
Sensing extends the notion of goals (and action preconditions). Findout goals: Check if Rao is awake vs. Wake up Rao
Presents some tricky issues in terms of goal satisfaction…! You cannot use “causative” effects to support “findout” goals
But what if the causative effects are supporting another needed goal and wind up affecting the goal as a side-effect? (e.g. Have-gong-go-off & find-out-if-rao-is-awake)
Quantification is no longer syntactic sugaring in effects and preconditions in the presence of sensing actions Rm* can satisfy the effect forall files remove(file); without KNOWING what are the
files in the directory! This is alternative to finding each files name and doing rm <file-name>
Sensing actions can have preconditions (as well as other causative effects); they can have cost
The problem of OVER-SENSING (Sort of like a beginning driver who looks all directions every 3 millimeters of driving; also Sphexishness) [XII/Puccini project] Handling over-sensing using local-closedworld assumptions
Listing a file doesn’t destroy your knowledge about the size of a file; but compressing it does. If you don’t recognize it, you will always be checking the size of
the file after each and every action

Paths to Perdition
Complexity of finding probability 1.0 success plans








Similar processing can be done for regression (PO planning is nothing but least-committed regression planning)
We now have yet another way of handling unsafe links --Conditioning to put the threatening step in a different world!

Sensing: More things under the mat(which we won’t lift for now )
Sensing extends the notion of goals (and action preconditions). Findout goals: Check if Rao is awake vs. Wake up Rao
Presents some tricky issues in terms of goal satisfaction…! You cannot use “causative” effects to support “findout” goals
But what if the causative effects are supporting another needed goal and wind up affecting the goal as a side-effect? (e.g. Have-gong-go-off & find-out-if-rao-is-awake)
Quantification is no longer syntactic sugaring in effects and preconditions in the presence of sensing actions Rm* can satisfy the effect forall files remove(file); without KNOWING what are the
files in the directory! This is alternative to finding each files name and doing rm <file-name>
Sensing actions can have preconditions (as well as other causative effects); they can have cost
The problem of OVER-SENSING (Sort of like a beginning driver who looks all directions every 3 millimeters of driving; also Sphexishness) [XII/Puccini project] Handling over-sensing using local-closedworld assumptions
Listing a file doesn’t destroy your knowledge about the size of a file; but compressing it does. If you don’t recognize it, you will always be checking the size of
the file after each and every action
Review

Sensing: Limited Contingency planning
In many real-world scenarios, having a plan that works in all contingencies is too hard An idea is to make a plan for some of the contingencies; and
monitor/Replan as necessary. Qn: What contingencies should we plan for?
The ones that are most likely to occur…(need likelihoods) Qn: What do we do if an unexpected contingency arises?
Monitor (the observable parts of the world) When it goes out of expected world, replan starting from that state.

Things more complicated if the world is partially observable Need to insert sensing actions to sense fluents that can only be indirectly sensed

“Triangle Tables”

This involves disjunctive goals!

Replanning—Respecting Commitments
In real-world, where you make commitments based on your plan, you cannot just throw away the plan at the first sign of failure
One heuristic is to reuse as much of the old plan as possible while doing replanning.
A more systematic approach is to 1. Capture the commitments made by the agent based on the
current plan2. Give these commitments as additional soft constraints to the
planner

Replanning as a universal antidote…
If the domain is observable and lenient to failures, and we are willing to do replanning, then we can always handle non-deterministic as well as stochastic actions with classical planning!
1. Solve the “deterministic” relaxation of the problem2. Start executing it, while monitoring the world state3. When an unexpected state is encountered, replan
A planner that did this in the First Intl. Planning Competition—Probabilistic Track, called FF-Replan, won the competition.

30 years of researchinto programming languages, ..and C++ is the result?
20 years of researchinto decision theoreticplanning, ..and FF-Replan is the result?

Models of Planning
Classical Contingent (FO)MDP
??? Contingent POMDP
??? Conformant (NO)MDP
Complete Observation
Partial
None
UncertaintyDeterministic Disjunctive Probabilistic