hardness-aware restart policies yongshao ruan, eric horvitz, & henry kautz ijcai 2003 workshop...
TRANSCRIPT

Hardness-Aware Restart Policies
Yongshao Ruan, Eric Horvitz, & Henry Kautz
IJCAI 2003 Workshop on Stochastic Search

Randomized Restart Strategies for Backtrack SearchRandomized Restart Strategies for Backtrack Search
Simple idea: randomize branching heuristic, restart with new seed if solution is not found in a reasonable amount of time
Effective on a wide range of structured problems (Luby 1993, Gomes et al 1997)
Issue: when to restart?

Complete Knowledge of RTD
P(t)
t
D
T*
* argmin ( )
( ) ( | )( )t
tt
tE T t E T T t T
P T t
T E T
Luby (1993): Optimal policy uses fixed cutoff
where is the
length of complete run (without c
sin utgle off)

No Knowledge of RTD
1, 1, 2, 1, 1, 2, 4, ...
(log *)O T
Luby (1993): of cutoffs
is within of the fixed optimal policy for the
unknown d
Universal sequence
In
istribution
- 1-2 orders of mapra gnictice tude
Can we do better? Information about progress of the
current run (looking good?) Partial knowledge of RTD

Answers (UAI 2001) – Can predict a particular run’s time to
solution (very roughly) based on features of the solver’s trace during an initial window
(AAAI 2002) – Can improve time to solution by immediately pruning runs that are predicted to be long
Scenario: You know RTD of a problem ensemble. Each run is from a different randomly-selected problem. Goal is solve some problem as soon as possible (i.e., you can skip ones that look hard).
In general: optimal policy is to set cutoff conditionally on value of observed features.
LongLongShortShortObservation horizonObservation horizon
Median run timeMedian run time

Answers (continued)
(CP 2002) – Given partial knowledge about an ensemble RTD, the optimal strategy uses the information gained from each failed run to update its beliefs about the shape of the RTD.
Scenario: There is a set of k different problem ensembles, and you know the ensemble RTD of each. Nature chooses one of the ensembles at random, but does not tell you which one. Each run is from a different randomly-chosen problem from that ensemble. Your goal is to solve some problem as soon as possible.
In general: cutoffs change for each run.

Answers (final!)
(IJCAI 2003 Workshop) – The unknown RTD of a particular problem instance can be approximated by the RTD of a sub-ensemble
Scenario: You are allowed to sample a problem distribution and consider various ways of clustering instances that have similar instance RTD’s. Then you are given a new random instance and must solve it as quickly as possible (i.e., you cannot skip over problems!)
Most realistic?

Partitioning ensemble RTD by instance median run-times
Ensemble RTD
Instance median < ensemble median
Instance median > ensemble median

MSE versus number of clusters

Computing the restart strategy Assume that the (unknown) RTD of the
given instance is well-approximated by the RTD of one of the clusters
Strategy depends upon your state of belief about which cluster that is
Formalize as an POMDP: State = state of belief Actions = use a particular cutoff K Effect = { solved, not solved }

Solving Bellman equation:
Solve by dynamic programming (ouch!)
* *( ) min{ ( , ) ( ' | , ) ( ')}t
V s R s t P s s t V s
Probability that running with cutoff t in state s fails (resulting
in state s’)
Optimal expected time to
solution from belief state s
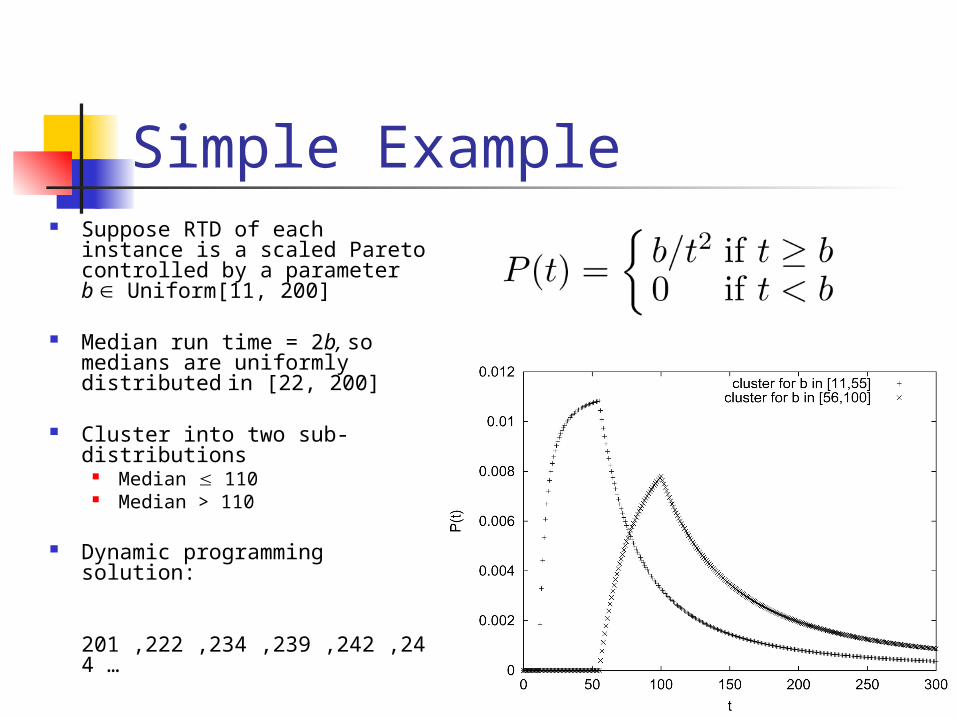
Simple Example Suppose RTD of each
instance is a scaled Pareto controlled by a parameter b Uniform[11, 200]
Median run time = 2b, so medians are uniformly distributed in [22, 200]
Cluster into two sub-distributions
Median 110 Median > 110
Dynamic programming solution:
201 ,222 ,234 ,239 ,242 ,244 …
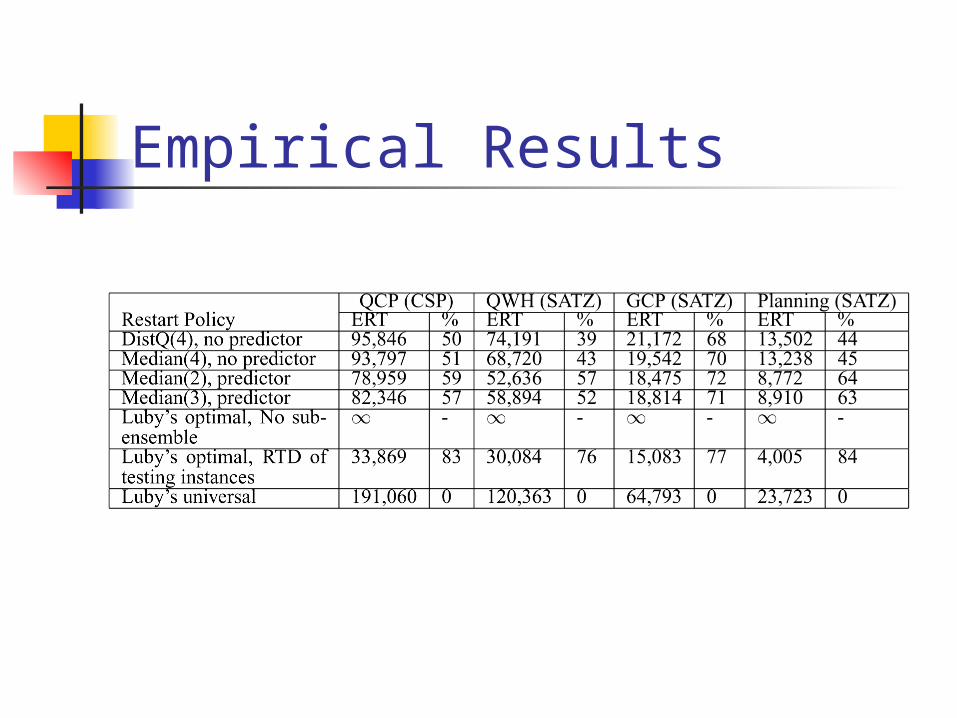
Empirical Results

Summary Last piece in basic mathematics for
optimal restarts with partial information
See paper for details of incorporating observations
RTD alone gives log speedup over Luby universal (still can be significant)
Unlimited potential for speedup with more accurate run-time predictors!