hardware definitions –port: point of connection –bus: interface daisy chain...
TRANSCRIPT
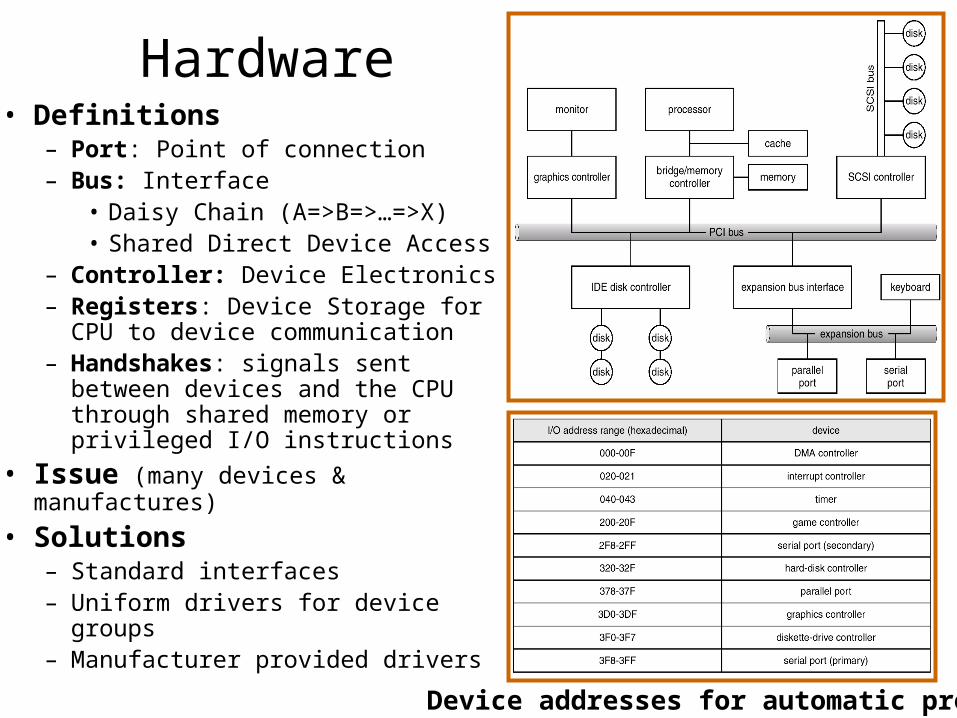
Hardware• Definitions
– Port: Point of connection– Bus: Interface
• Daisy Chain (A=>B=>…=>X)• Shared Direct Device Access
– Controller: Device Electronics– Registers: Device Storage for CPU
to device communication– Handshakes: signals sent between
devices and the CPU through shared memory or privileged I/O instructions
• Issue (many devices & manufactures)
• Solutions– Standard interfaces– Uniform drivers for device groups– Manufacturer provided drivers
Device addresses for automatic probes

CPU Device Control• Privileged I/O instructions control devices
– Interface with device command-ready, busy, and error status registers
• Direct memory I/O instructions– Ties devices to memory locations
• Memory-mapped I/O – Reserved memory addresses control a device (E.g.: monitor display)
• Simple Polling interface– Useful if device response is almost instantaneous (busy-wait)
WHILE command-ready-register = device-not-ready THEN spinIssue send or receive commandWHILE device is busy THEN spin (This is a busy wait loop) IF error and retry-count not expired THEN restart the commandRETURN I/O complete
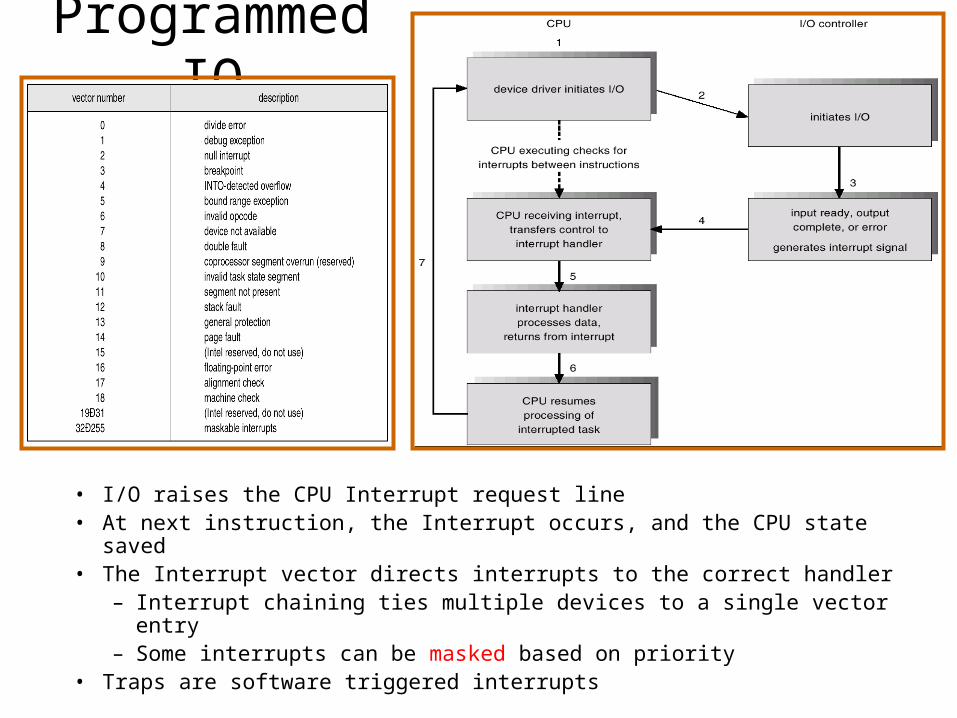
Programmed IO
• I/O raises the CPU Interrupt request line• At next instruction, the Interrupt occurs, and the CPU state saved• The Interrupt vector directs interrupts to the correct handler
– Interrupt chaining ties multiple devices to a single vector entry– Some interrupts can be masked based on priority
• Traps are software triggered interrupts
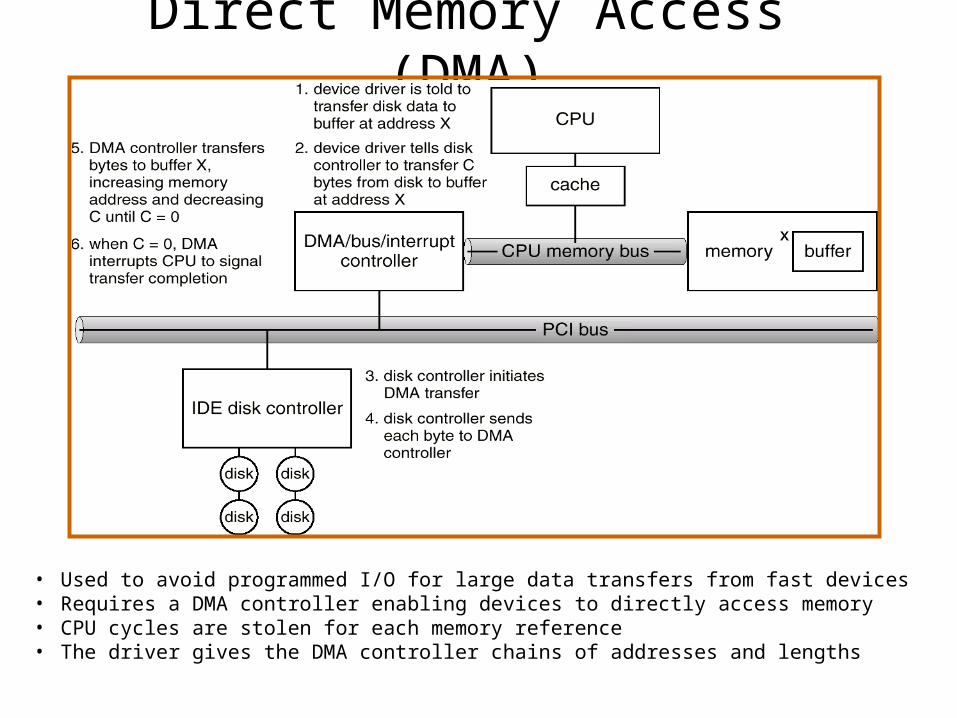
Direct Memory Access (DMA)
• Used to avoid programmed I/O for large data transfers from fast devices• Requires a DMA controller enabling devices to directly access memory• CPU cycles are stolen for each memory reference• The driver gives the DMA controller chains of addresses and lengths
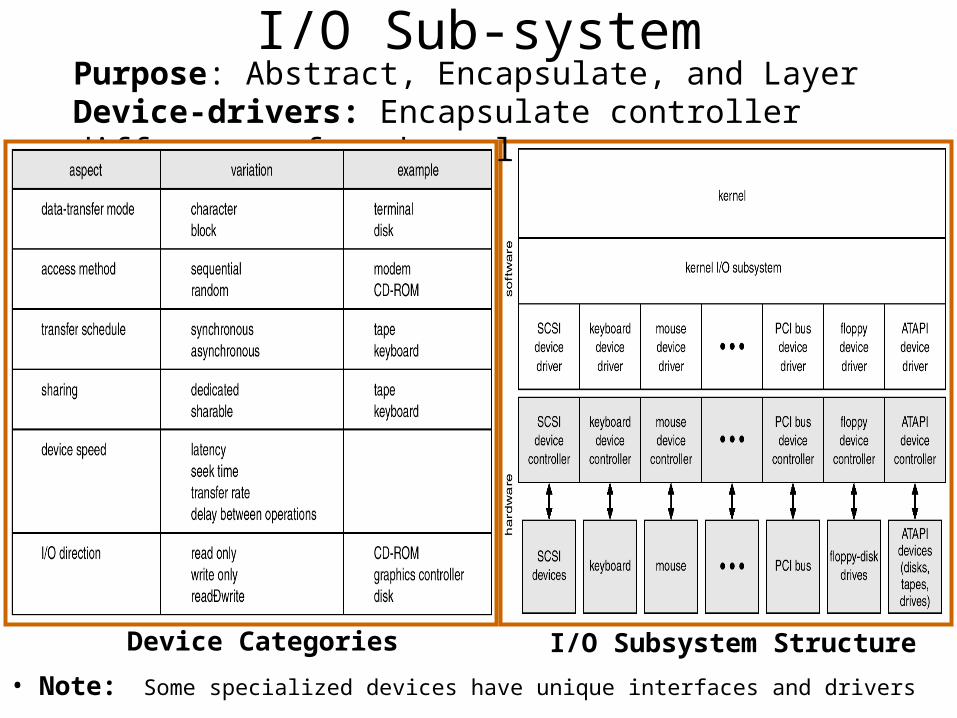
I/O Sub-system
• Note: Some specialized devices have unique interfaces and drivers
Purpose: Abstract, Encapsulate, and LayerDevice-drivers: Encapsulate controller differences from kernel
Device Categories I/O Subsystem Structure
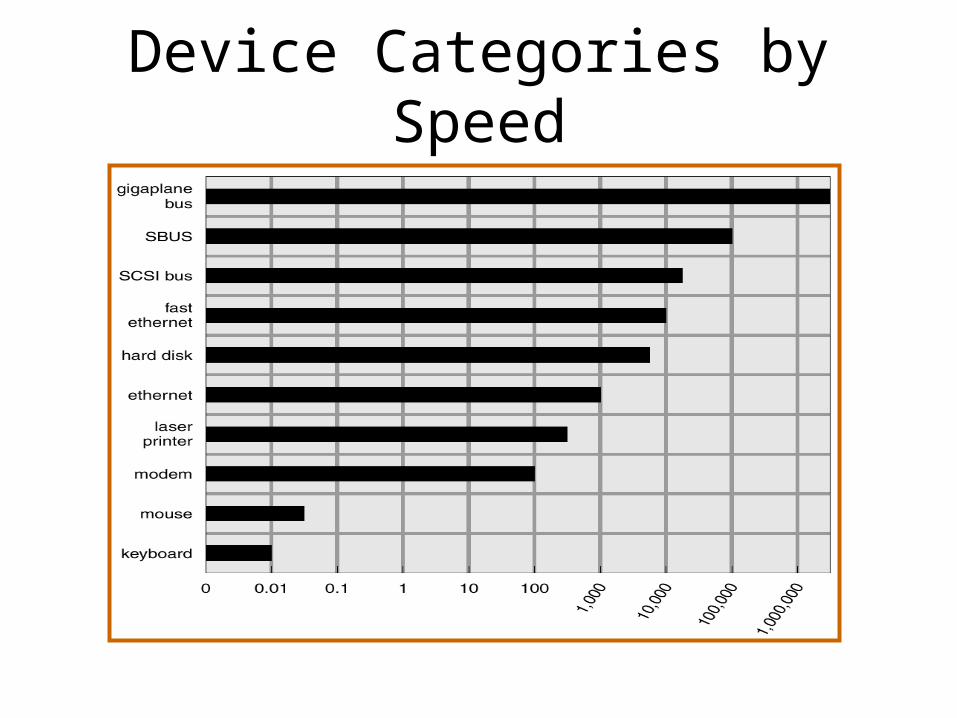
Device Categories by Speed
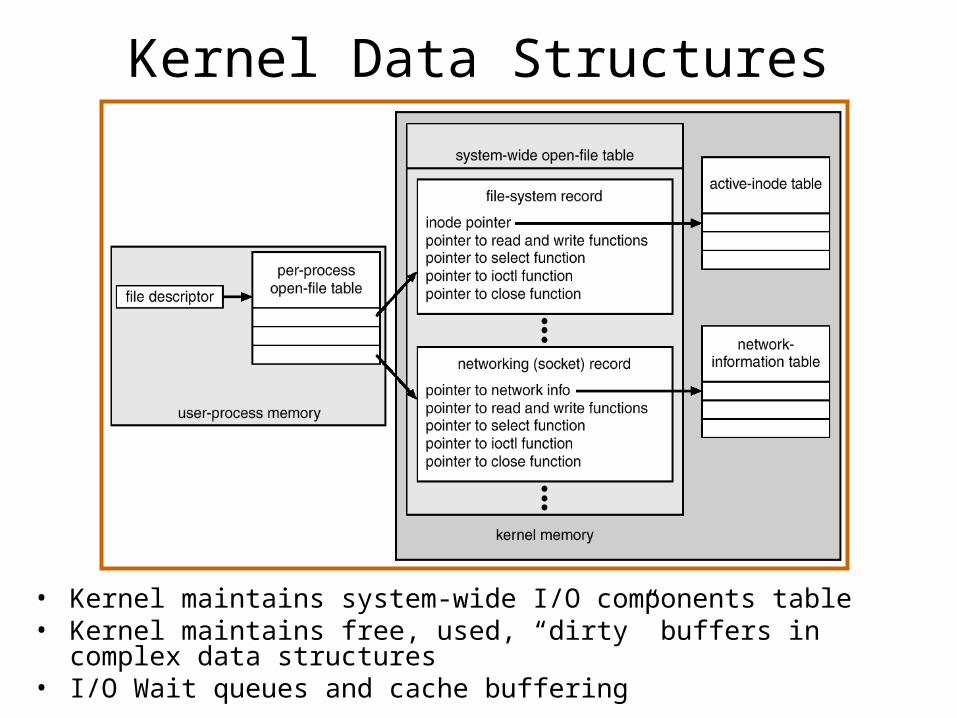
Kernel Data Structures
• Kernel maintains system-wide I/O components table• Kernel maintains free, used, “dirty” buffers in complex data structures• I/O Wait queues and cache buffering
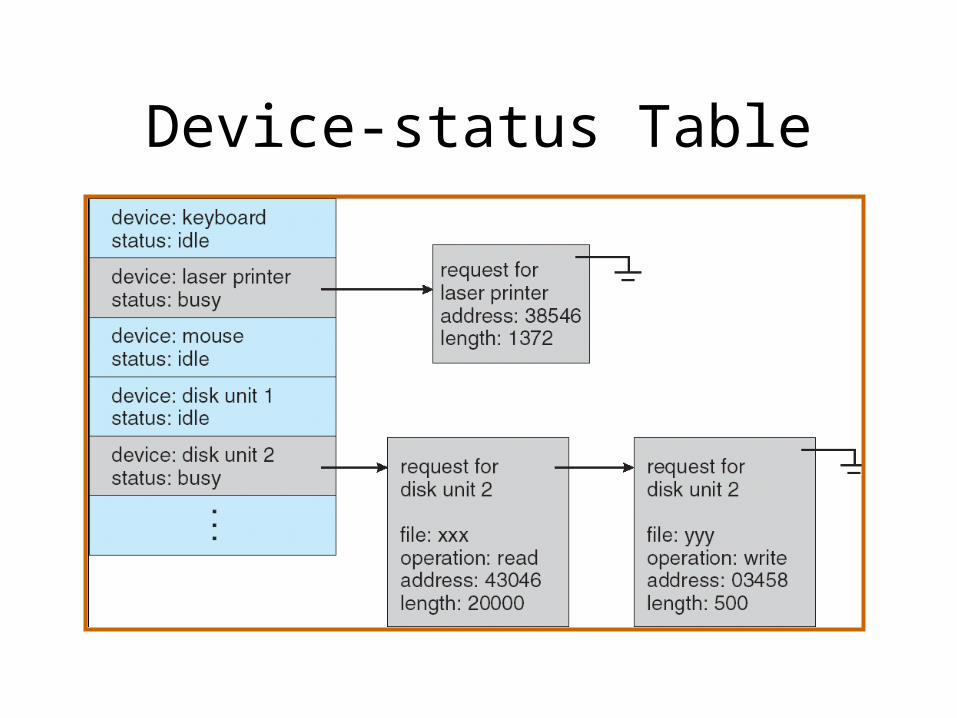
Device-status Table

Application API• Block devices include disk drives
– Commands include read, write, seek – Raw I/O or file-system access– Memory-mapped byte streams using virtual memory facilities
• Character devices (keyboards, mice, serial ports)– Commands include get, put– Libraries layered on top allow line editing (backspace etc.)
• Network devices– Incorporates protocol, flow control, and pipelining
– Separates network protocol from network operation– Includes select functionality (socket port numbers)
• Clocks and Timers for current time and elapsed time– Course grain regular interval interrupts– Programmable non-interruptible timers for fine grain resolution
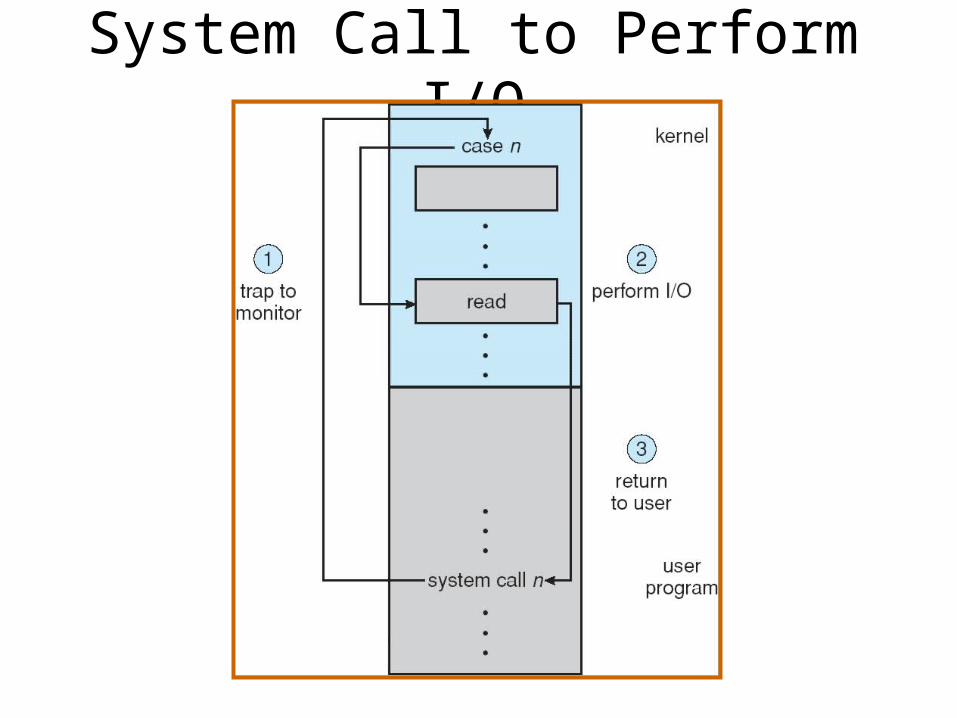
System Call to Perform I/O

Categories of OS calls
• Blocking - process suspended until I/O completed– Easy to use and understand– Insufficient for some needs
• Non-blocking - I/O call returns as much as available– User interface, data copy (OS buffered I/O)– Implemented via multi-threading– Returns quickly with count of bytes read or written
• Asynchronous - process runs while I/O executes– Difficult to use– I/O subsystem signals process when I/O completed
• Direct Application control– ioctl (on UNIX) allows applications to directly control devices– Driver testing

Additional OS I/O Subsystem Services• Caching - fast memory access to recently accessed data
– Always just a copy– Significant performance impact
• Spooling - hold output for a device– If device can serve only one request at a time – i.e., Printing
• Exclusive device reservation– System calls for allocation and de-allocation– Deadlocks are possible
• Scheduling - Ordering the I/O requests in the per-device queue– Some OSs try fairness
• Buffering - store data in OS buffers during transfers– To cope with device speed or transfer size mismatches– To maintain “copy semantics”, and dirty buffers.
• Fault processing: Recovery through retry operations, error logs• Miscellaneous: Pipes, FIFOs, packet handling, streams, queues, mailboxes
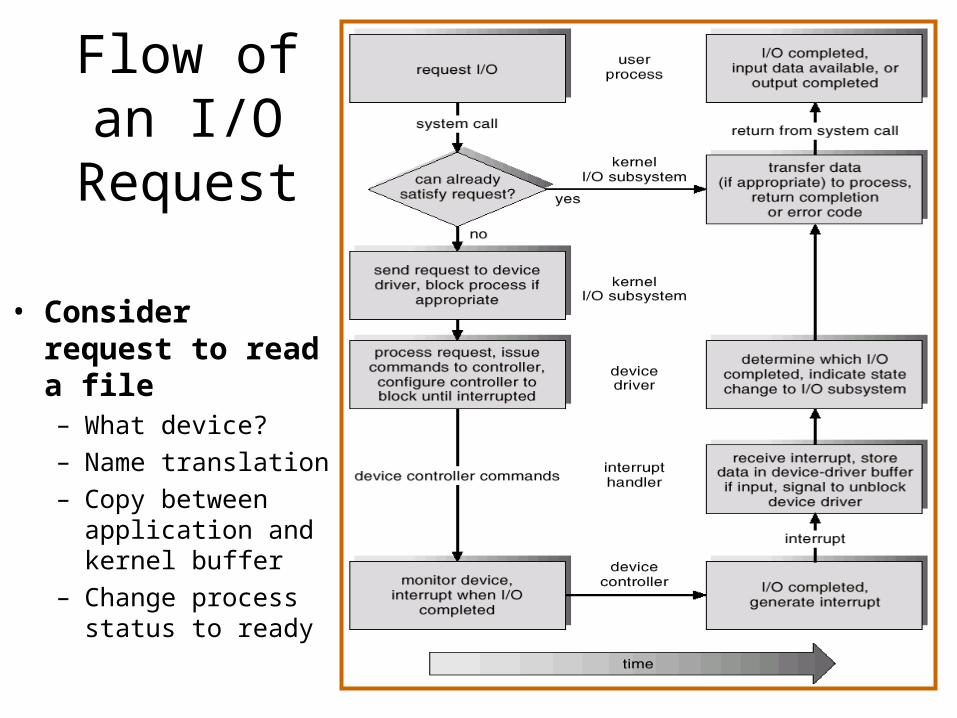
Flow of an I/O
Request
• Consider request to read a file – What device?– Name translation– Copy between
application and kernel buffer
– Change process status to ready
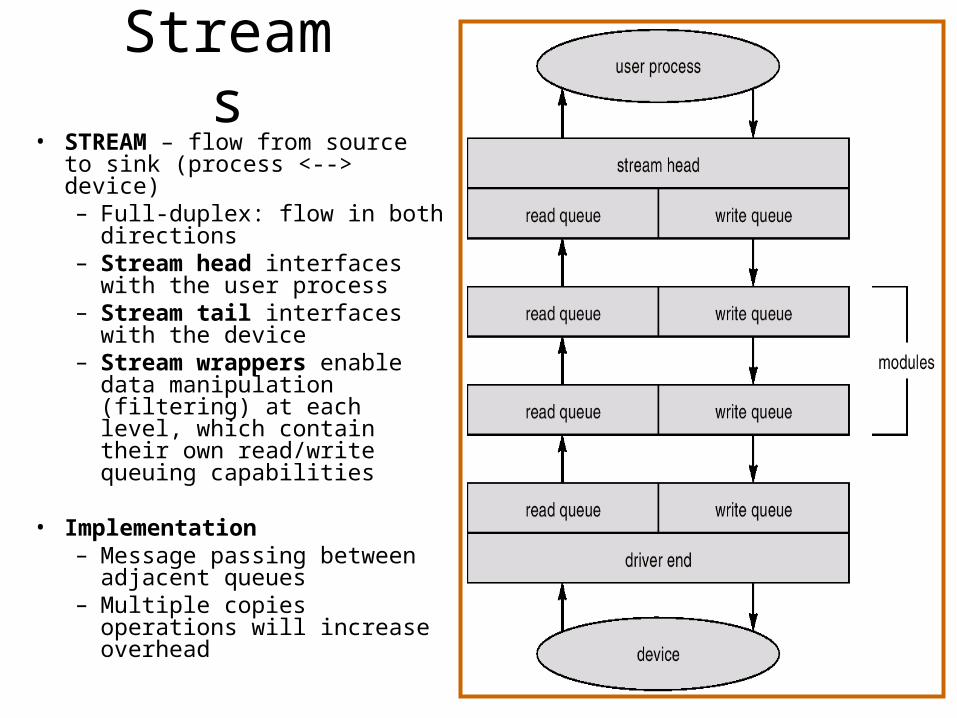
Streams• STREAM – flow from source to
sink (process <--> device)– Full-duplex: flow in both
directions– Stream head interfaces
with the user process– Stream tail interfaces with
the device– Stream wrappers enable
data manipulation (filtering) at each level, which contain their own read/write queuing capabilities
• Implementation– Message passing between
adjacent queues– Multiple copies operations
will increase overhead
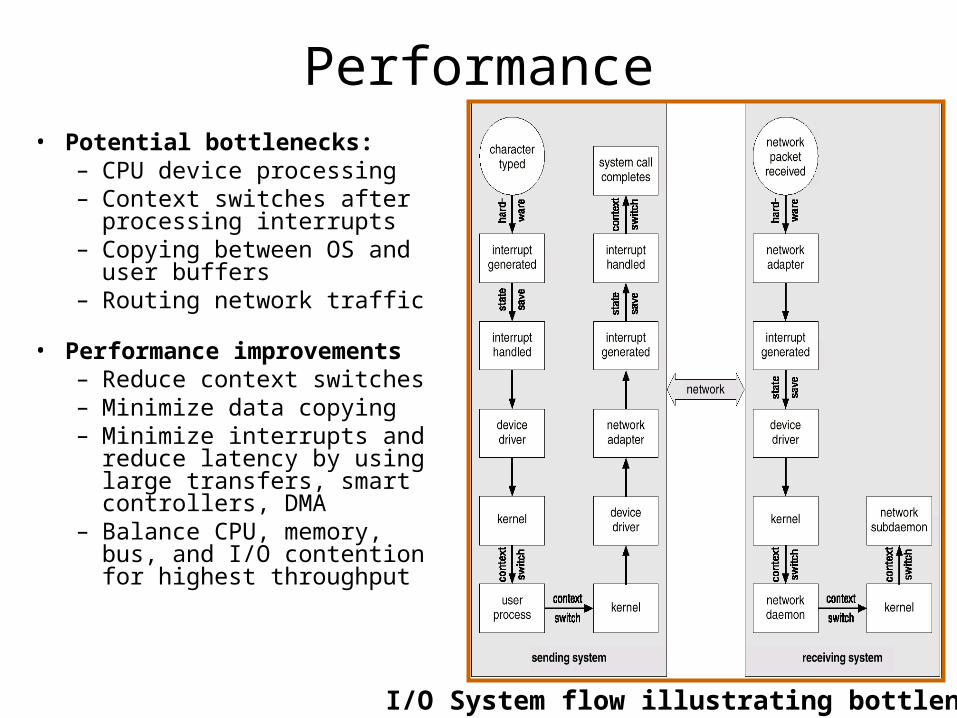
Performance• Potential bottlenecks:
– CPU device processing– Context switches after
processing interrupts– Copying between OS and
user buffers– Routing network traffic
• Performance improvements– Reduce context switches– Minimize data copying – Minimize interrupts and
reduce latency by using large transfers, smart controllers, DMA
– Balance CPU, memory, bus, and I/O contention for highest throughput
I/O System flow illustrating bottlenecks
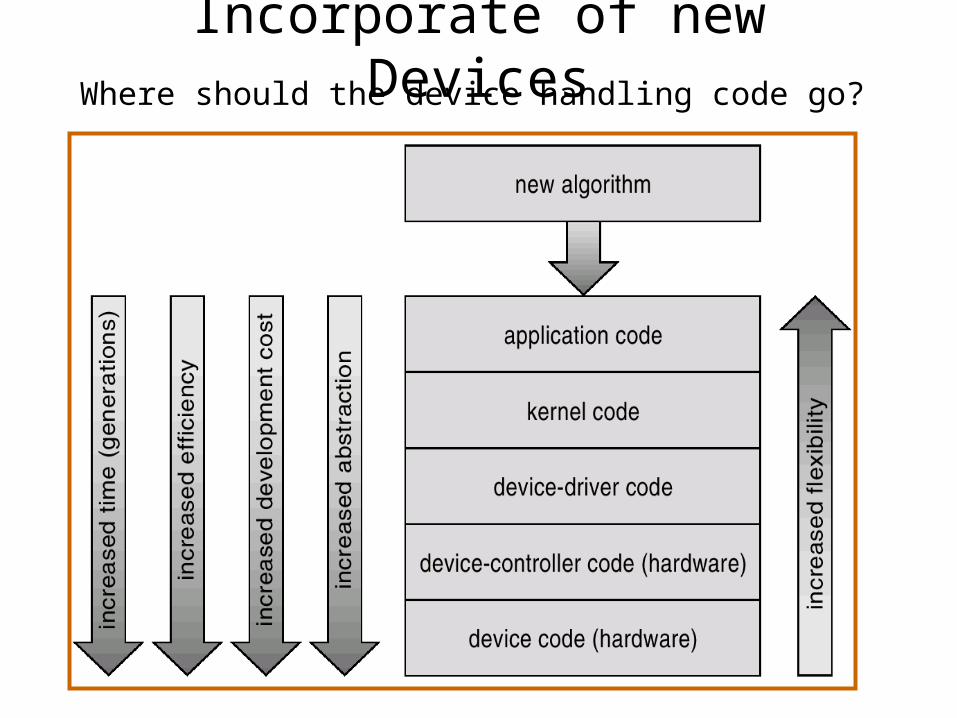
Incorporate of new DevicesWhere should the device handling code go?