hdp @ md anderson - data management platform,...
TRANSCRIPT

Vamshi Punugo- & Bryan Lari
MD Anderson Cancer Center
June 2016
HDP @ MD ANDERSON
Star1ng the Hadoop Journey at a Global Leader
in Cancer Research

Agenda
• About MD Anderson
• Big Data Program
• Our Hadoop Implementa9on
• Lessons Learned
• Next Steps

• Who we are – One of the worlds largest centers devoted exclusively to cancer care
– Created by the Texas legislature in 1941
– Named one of the na9on's top two hospitals for cancer care every
year since the survey began in 1990
• Mission – MD Anderson’s mission is to eliminate cancer in Texas, the na9on
and the world through excep9onal programs that integrate pa9ent
care, research and preven9on.
About MD Anderson
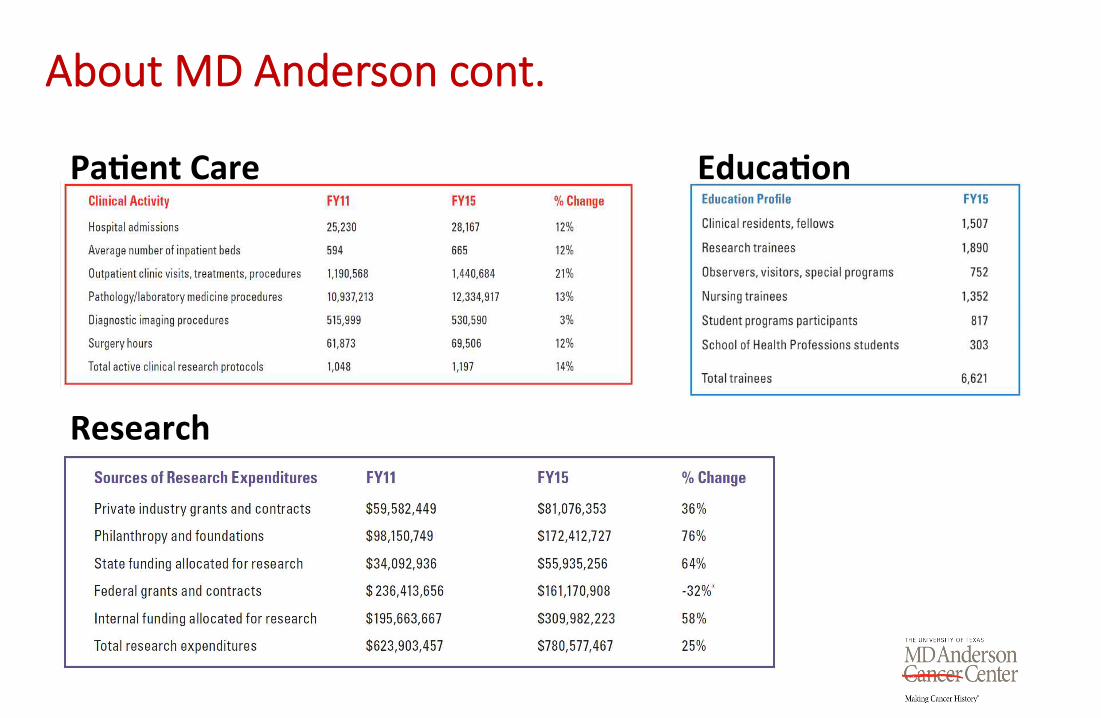
About MD Anderson cont.
Pa-ent Care Educa-on
Research

Moon Shots Program
• Launched in 2012 – to make a giant leap for pa9ents
• Accelera9ng the pace of conver9ng scien9fic discoveries into
clinical advances that reduce cancer deaths
• Transdisciplinary team‐science approach
• Transforma9ve professional plaSorms
List of Moon Shots
12 Total Moon Shots
B‐cell Lymphoma Lung Cancer
Breast Cancer Melanoma
Colorectal Cancer Multiple Myeloma
Glioblastoma Ovarian Cancer
HPV‐Related Cancers Pancreatic Cancer
Leukemia (CLL, MDS, AML) Prostate Cancer
hTp://www.cancermoonshots.org


Volume
Variety
Velocity
Veracity
Gulf of Mexico Analogy

Goals of Big Data Program • Data driven organiza9on
• All “types” of data
• “Access” for all customers
• Clinicians
• Researchers
• Administra9ve / Opera9onal
• Enable discovery of “insights”
• Improve pa9ent care
• Increase research discoveries
• Improve opera9ons
• Govern data like an asset
• Provide a plaSorm / environment to enable all these things
To provide the right informa1on to the right people at the right 1me with the right tools
Goal data
insight

Insights
Make big data addi1ve and build upon founda1on

What are we doing today?
• FIRE Enterprise Data Warehouse
• Natural Language Processing (NLP)
• Data Governance
• Hadoop NoSQL
• Cogni9ve Compu9ng
• Data Visualiza9on
• Evolving our PlaSorm / Architecture
• Iden9fying big data use cases
• Training & Skills

• Federated Ins9tu9onal Repor9ng Environment
• Centralized data repository suppor9ng analy9cs, decision making, and business intelligence
• Central repository for historical and opera9onal data
• Break‐down data silos
Enterprise Repository Source Systems
Dashboards
KPI’s
Analytic
Reports
Analytics & Reporting
Discoveries
Improve
Patient Care
Quality / Perf
Improvements
Genomic
FIRE Program
Radiology
Labs
Epic / Clarity
Legacy Systems
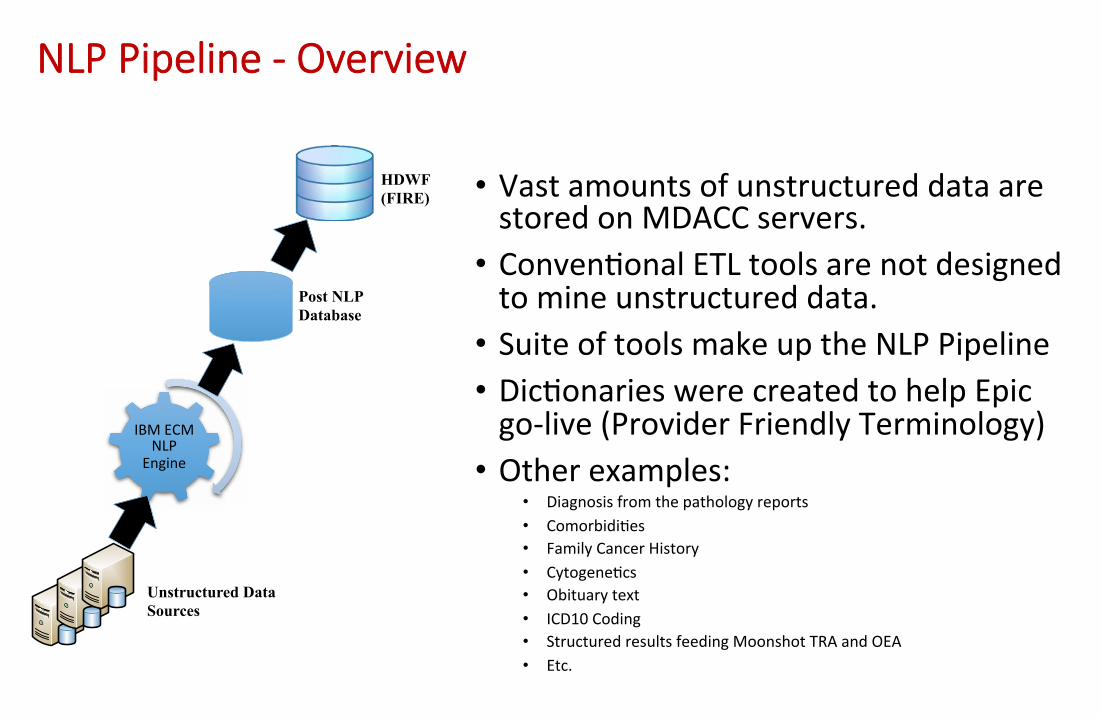
• Vast amounts of unstructured data are stored on MDACC servers.
• Conven9onal ETL tools are not designed to mine unstructured data.
• Suite of tools make up the NLP Pipeline
• Dic9onaries were created to help Epic go‐live (Provider Friendly Terminology)
• Other examples: • Diagnosis from the pathology reports
• Comorbidi9es
• Family Cancer History
• Cytogene9cs
• Obituary text
• ICD10 Coding
• Structured results feeding Moonshot TRA and OEA
• Etc.
IBM ECM NLP
Engine
Unstructured Data
Sources
Post NLP
Database
HDWF
(FIRE)
NLP Pipeline ‐ Overview
Enterprise Business
Clinical Big Data
Peoplesod
Systems of Record
Systems of Reporting
Systems of Insights
Kronos
Point of Sale
Volunteer Services
Rotary House
MyHR
UTPD
Facili9es
Clinic Sta9on
Epic
Lab
GE IDX
Cerner
CARE
EPM
Hyperion
Oracle Business Intelligence
Smart View
Web Analy9cs
FIRE
EIW
Business Objects
Crystal
Hyperion Interac9ve Repor9ng
TwiTer
UPS
Center for Disease Control
The Weather Channel
Youtube
oracle.com Yelp!
Reuters
U.S. Census
Medical Devices
Medical Equipment
Building Controls
Campus Video
Real‐9me Loca9on Service
Wayfinding
Data
Visualiza9on
Ad Hoc
Cogni9ve
Compu9ng
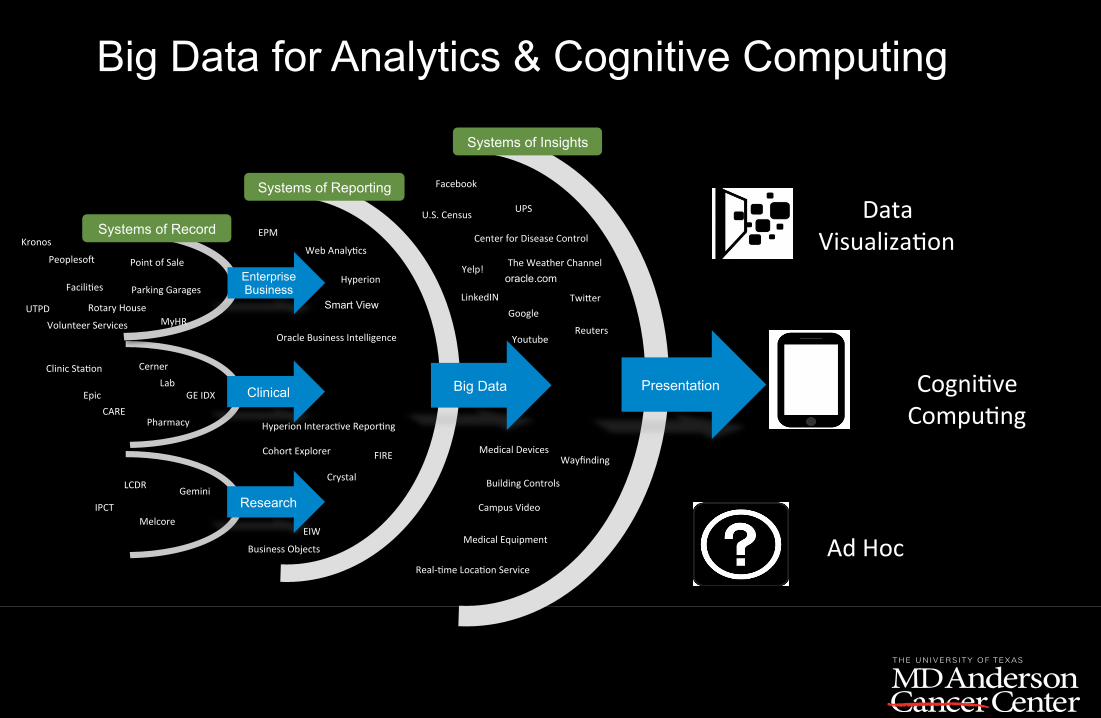
Big Data for Analytics & Cognitive Computing
Presentation
Cohort Explorer
Parking Garages
Pharmacy
Research
LCDR
Melcore
Gemini
IPCT
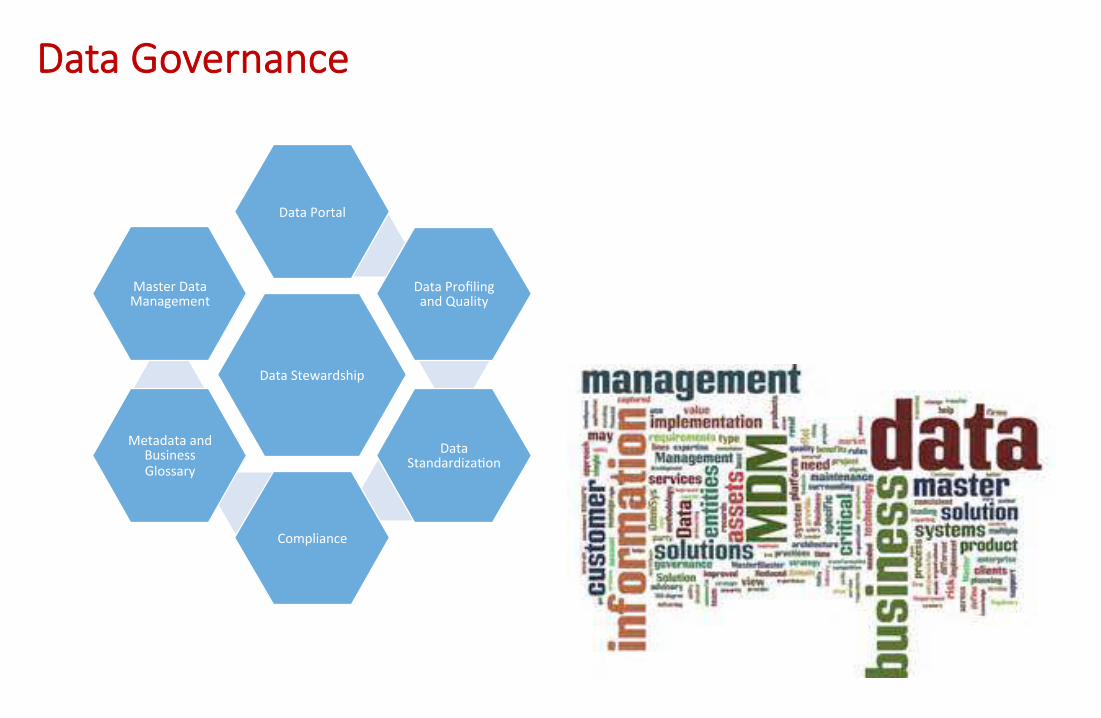
Data Governance
Data Stewardship
Data Portal
Data Profiling and Quality
Data Standardiza9on
Compliance
Metadata and Business Glossary
Master Data Management
Data Repository
Dashboards
KPI’s
Analytic
Reports
Analytics & Informatics
Discoveries
Improve
Patient Care
Quality / Perf
Improvements
Data Mgt & Operations
Data Lake
Data Discovery Profiling
Standards / Quality
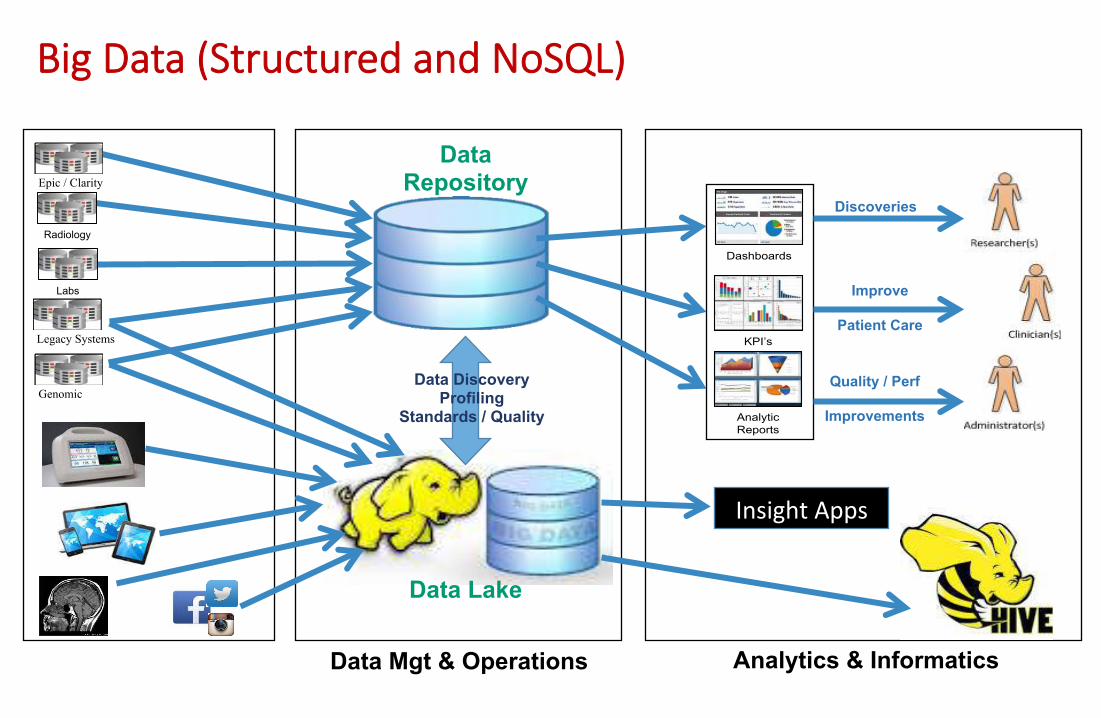
Big Data (Structured and NoSQL)
Insight Apps
Genomic
Radiology
Labs
Epic / Clarity
Legacy Systems
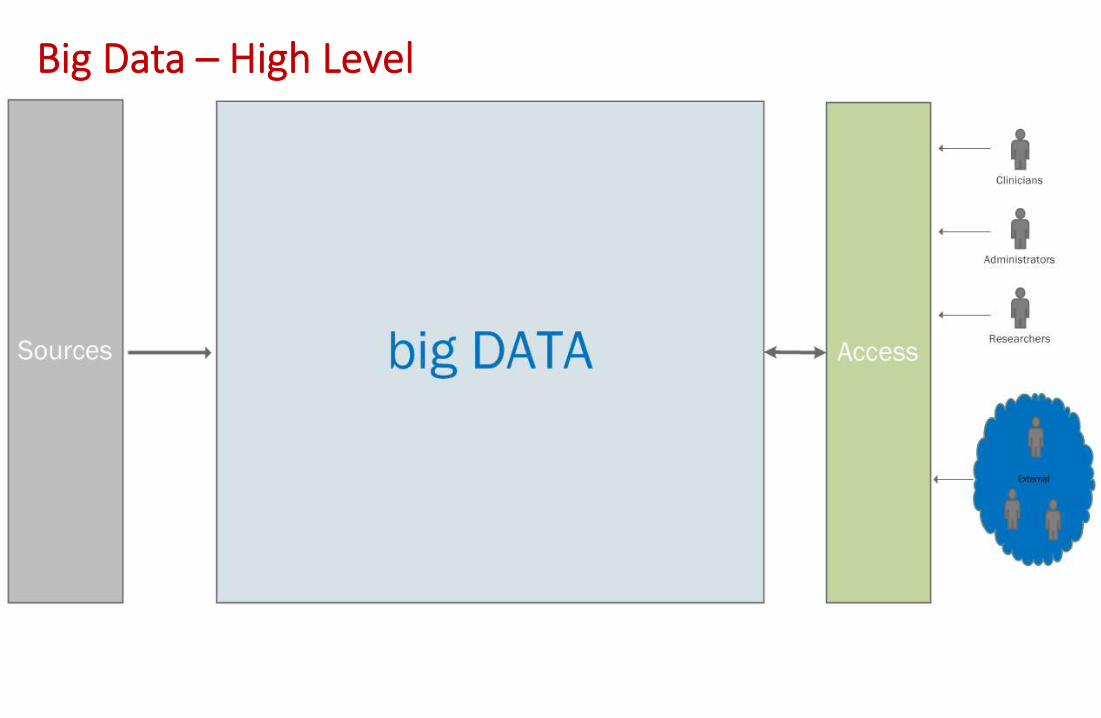
Big Data – High Level

Big Data Technical Architecture

Our Hadoop Implementa1on
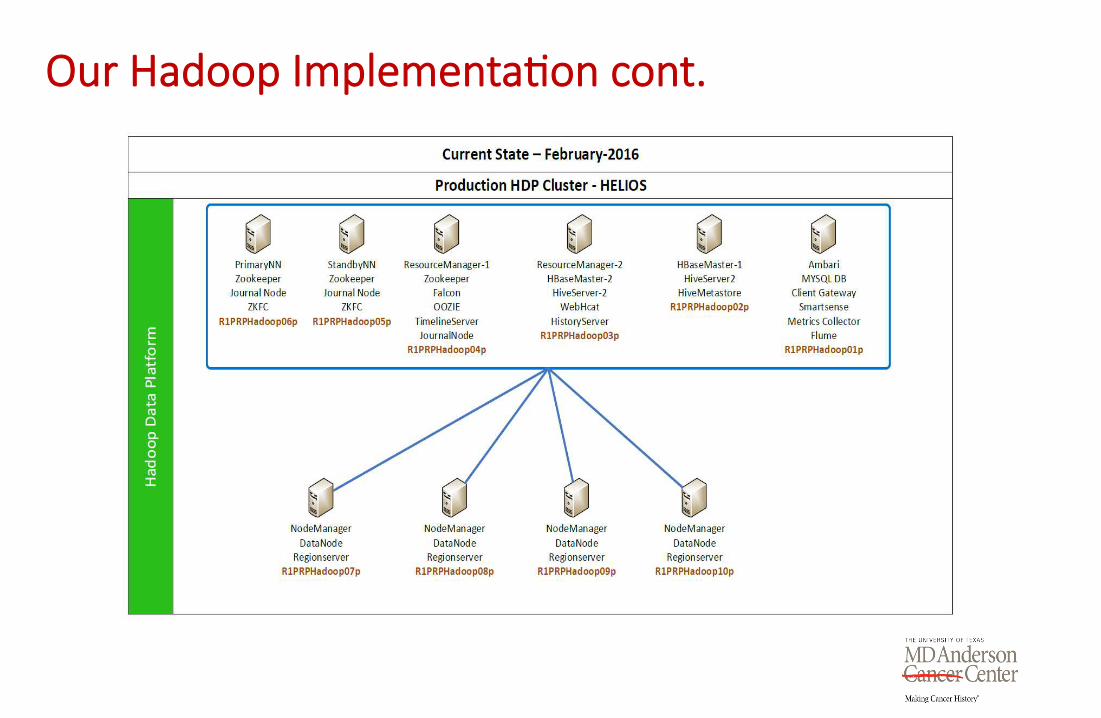
Our Hadoop Implementa1on cont.
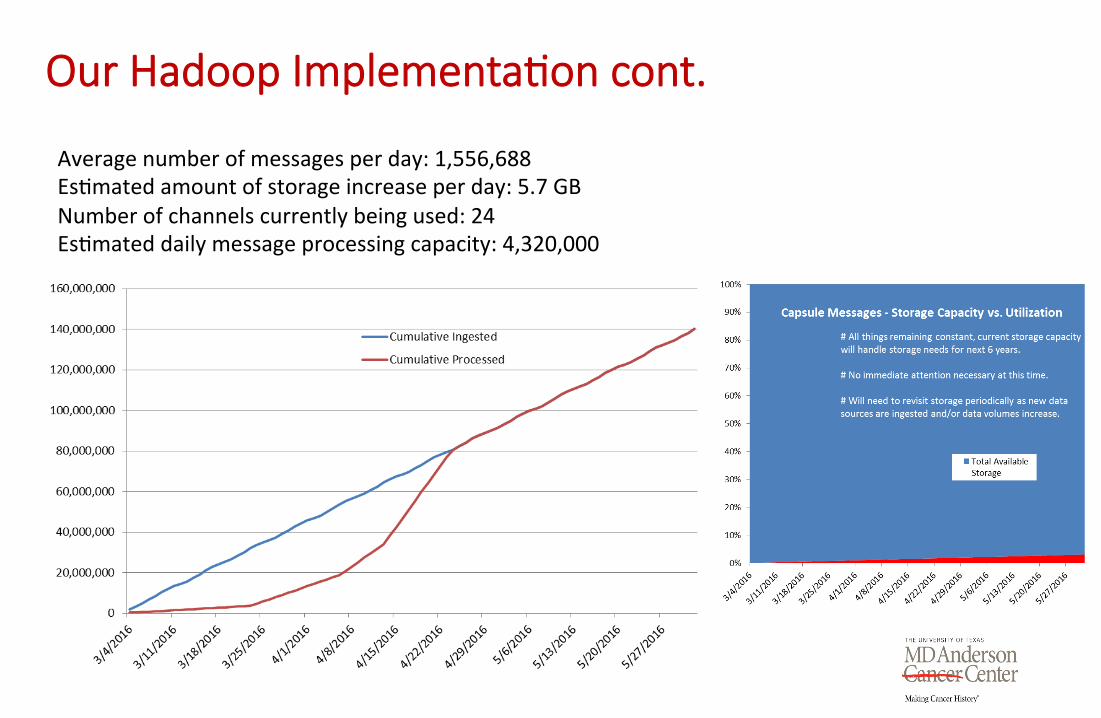
Our Hadoop Implementa1on cont.
Average number of messages per day: 1,556,688
Es9mated amount of storage increase per day: 5.7 GB
Number of channels currently being used: 24
Es9mated daily message processing capacity: 4,320,000
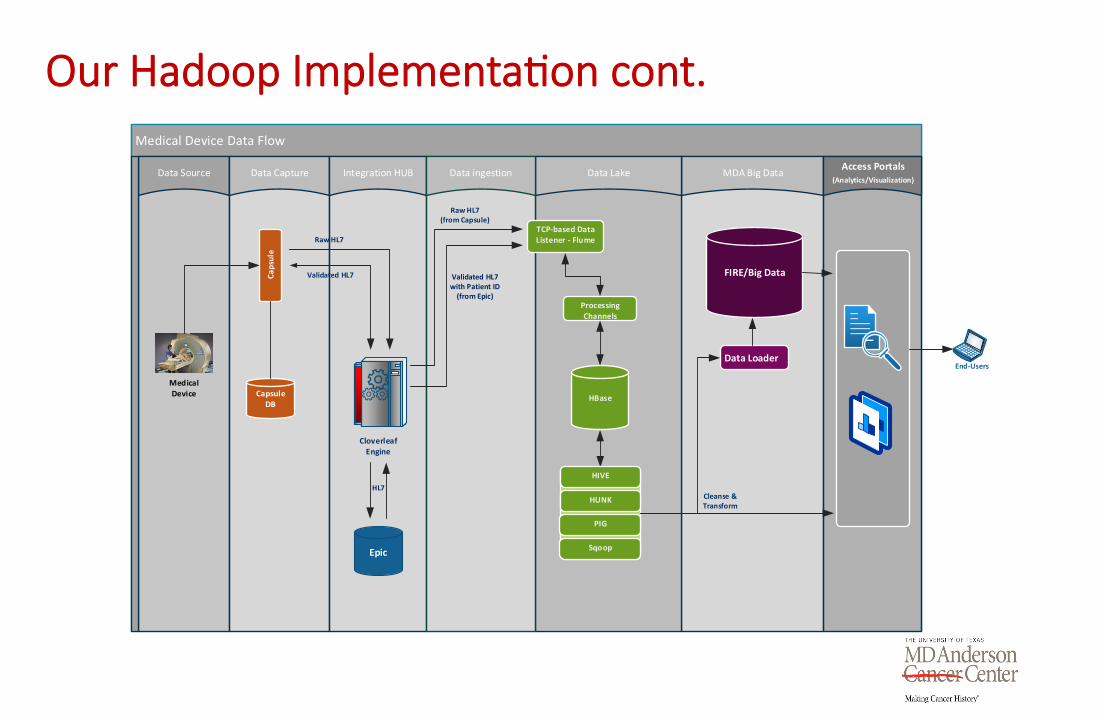
Our Hadoop Implementa1on cont.
Medical Device Data Flow
Data Source Data Capture MDA Big DataData LakeAccess Portals
(Analytics/Visualization)Integration HUB Data ingestion
Processing
Channels
HBase
Data Loader
Capsule
Capsule
DB
Medical
Device
End‐Users
FIRE/Big Data
Cloverleaf
Engine
Epic
TCP‐based Data
Listener ‐ Flume
HIVE
PIG
HUNK
Sqoop
Validated HL7
with Patient ID
(from Epic)
HL7
Raw HL7
(from Capsule)
Cleanse &
Transform
Raw HL7
Validated HL7

Our Hadoop Implementa1on cont.
Developer
Workstation/Sandbox
SVN
(source control server)
Bamboo
(build server)
HDP Dev ClusterHDP QA Cluster
HDP Prod Cluster
Daily Checkin/Checkout
Development Cycle
On Dev Lead Approval:
Build, Unit Test, Deploy & Tag
On Successful UAT
& Release Approval:
Deploy Per
Last Successful
Build Tag
Smoke Test
Before Updating Task status
Periodic Integration & Validation:
Build, Unit Test
& Notify On Error
Development
Cycle
Deployment
Cycle

process
1. It’s complex
2. It’s a journey
3. Leverage exis9ng strengths
4. Collaborate openly
5. Learn from experts
6. One cluster – mul9ple use cases
7. Follow best prac9ces
Lessons Learned – what went well
people

1. Con9nue to expand/evolve our plaSorm
2. Ingest more data and data types
3. Iden9fy high value use cases
4. Develop/Train people with new skills
Next Steps

Train People with new Skills Accessing data
Compu9ng data
Visualizing data
Insights &
Cogni9ve Compu9ng
