heterogenous persistence
TRANSCRIPT

Heterogeneous PersistenceA guide for the modern DBA
Marcos AlbeJervin RealRyan LoweLiz Van Dijk

Introduction
Hello everyone

Introduction
MySQL everyone?

Introduction
Memcached?

Agenda● Introduction● Why a single DBMS is not enough● What makes a DBMS● Different flavors of DMBS● Top picks

Why one DBMS is not enough
"If you feel things are not efficient in your code, is likely that you are suffering of poor data structures choice/design" ~ Anonymous

Why one DBMS is not enough● Different data structures● Different access patterns● Different consistency and durability requirements.● Different scaling needs● Different budgets● Theoretical fundamentalism

Why one DBMS is not enough
A more concrete exampleOLAP -vs- OLTP

OLAP -vs- OLTP

PROs CONs
● No SPOF● Workload optimized services● Easier to scale*
● Additional complexity● Operational needs (additional
staffing)● Cost ($$$)*

La Carte● Key Value Stores
○ Memcached○ MemcacheDB○ Redis○ Riak KV○ Cassandra○ Amazon's DynamoDB
● Graph○ Neo4J○ OrientDB○ Titan○ Virtuoso○ ArangoDB
● Relational○ MySQL○ PostgreSQL
● Time Series○ InfluxDB○ Graphite○ OpenTSDB○ Blueflood○ Prometheus
● Columnar○ Vertica○ Infobright○ Amazon RedShift○ Apache HBase
● Document○ MongoDB○ Couchbase
● Fulltext○ Sphinx○ Lucene/Solr

What makes a DB?

General Criteria● Specialty● Cost● API/Interfaces● Scalability● CAP● ACID● Secondary Features

What makes a DBMS: General● Licensing● Language support● OS support● Community & workforce● Tools ecosystem

● Data Architecture○ Logical data model ○ Physical data model
● Standards adherence (where defined)● Atomicity● Consistency● Isolation● Durability● Referential integrity● Transactions● Locking ● Crash recovery● Unicode support
What makes a DBMS: Fundamental Features

● Interface / connectors / protocols● Sequences / auto-incrementals / atomic counters● Conditional entry updates● MapReduce● Compression● In-memory● Availability● Concurrency handling● Scalability● Embeddable● Backups
What makes a DBMS: Fundamental Features cont.

● CRUD● Union ● Intersect ● JOIN (inner, outer)● Inner selects ● Merge joins ● Common Table Expressions ● Windowing Functions ● Parallel Query● Subqueries● Aggregation● Derived tables
What makes a DBMS: querying capabilities

● Cursors● Triggers● Stored procedures● Functions● Views● Materialized views● Virtual columns● UDF● XML/JSON/YAML support
What makes a DBMS: programmatic capabilities

● Database (tables size sum)● Number of Tables● Tables individual size ● Variable length column size● Row width ● Row columns count● Row count● Column name● Blob size● Char● Numeric● Date (min / max)
What makes a DBMS: sizing limits

● B-Tree● Full text indexing● Hash● Bitmap● Expression● Partials● Reverse● GiST● GIS indexing● Composite keys● Graph support
What makes a DBMS: indexing

● Replication● Failover● Clustering● CAP choice
What makes a DBMS: high availability

Partitioning
● Range● Hash● Range+hash● List● Expression● Sub-partitioning
Sharding
● By key● By table
What makes a DBMS: scalability

● Integer● Floating point● Decimal● String● Binary● Date/time● Boolean● Binary● Set● Enumeration● Blob● Clob● JSON/XML/YAML (as native types)
What makes a DBMS: supported data types

● Authentication methods● Access Control Lists● Pluggable Authentication Modules support● Encryption at-rest● Encryption over the wire● User proxy
What makes a DBMS: security features

● Data organization model: unstructured, semi-structured, structured● Data model (schema) stability: Static? Stable? Dynamic? Highly dynamic? ● Writes: append-only; append mostly; updates only; updates mostly● Reads: full scans; range scans; multi-range scans; point reads;● Reads by age: new only; new mostly; old only; old mostly; whole range● Reads by complexity: simple, related, deeply-nested relations, ....?
What makes a DBMS: workload

ACID vs BASE
● Atomic● Consistent● Isolated● Durable
● Basic Availability● Soft-state● Eventual Consistency

CAP Theorem
● Consistency● Availability● Partitioning

Relational Databases

Relational Databases

Relational Databases: write anomalies

Relational Databases: write anomalies

Relational Databases: normalization

Relational Databases: normalization

Relational Databases: query language
results = new Array();table = open(‘mydata’);while (row = table.fetch()) { if (row.x > 100) { results.push(row); } }

Relational Databases: query language
SELECT * FROM mydata WHERE x > 100;

Relational Databases: JOINsSELECT o.order_id AS Order, CONCAT(c.customer_name, “ (“, c.customer_email, “)”) as Customer, GROUP_CONCAT(i.item_name), SUM(item_price)FROM orders AS oJOIN order_items AS oi ON oi.order_id = o.order_idJOIN items AS i ON i.item_id = oi.item_idJOIN customers AS c ON c.customer_id = o.customer_id

Relational Databases: good use cases● Highly-structured data with complex querying needs
● Projects that need very high data durability and guarantees of database-level consistency and integrity
● Simple projects with limited data growth and limited amount of entities
● Projects that require PCI/DSS, HIPPA or similar security requirements
● Analysis of portions of larger BigData stores
● Projects where duplicated data volumes would be a problem

Relational Databases: bad use cases● Unstructured data
● Deep Hierarchies / Nested -> XML
● Deep recursion:
● Ever-growing datasets; Projects that are basically logging data
● Projects recording time-series
● Reporting on massive datasets

Relational Databases: bad use cases● Projects supporting extreme concurrency
● Projects supporting massive data intake
● Queues
● Cache storage

PROs CONs
● Very mature● Abundant workforce● ACID guarantees● Referential integrity● Highly expressive query language● Ubiquitous
● Rigid schema● Difficult to scale horizontally● Expensive writes● JOIN bombs

Relational Databases: MySQL

● Well known / mature / extensive documentation
● GPLv2 + commercial license for OEMs, ISVs and VARs
● Client libraries for about every programming language
● Many different engines
● SQL/ACID impose scalability limits
● Asynchronous / Semi-synchronous / Virtually synchronous replication
● Can be AP or CP depending on replication model
Relational Databases: MySQL

PROs CONs
● Open source● Mature and ubiquitous● ACID ● Choice of AP or CP● Highly available● Abundant tooling and expertise● General purpouse; Likely good to
start anything you want.
● Difficult to shard● Replication issues● Not 100% standard compliant● Storage engines imposed
limiations● General purpouse; No single
bullet solutions for scaling!

Relational Databases: PostgreSQL

● Mature / adequate documentation
● PostgreSQL License (similar to BSD/MIT)
● Client libraries for about every programming language
● Highly Standards Compliant
● SQL/ACID impose scalability limits
● Asynchronous / Semi-synchronous
● Virtually synchronous replication via 3rd party
● Can be AP or CP depending on replication model`
Relational Databases: PostgreSQL

PROs CONs
● Open source● Mature and stable● ACID● Lots of advanced features● Vacuum
● Difficult to shard● Operations feel like an
afterthought● Less forgiving● Vacuum

K/V Stores

CRUD
● CREATE● READ● UPDATE● DELETE

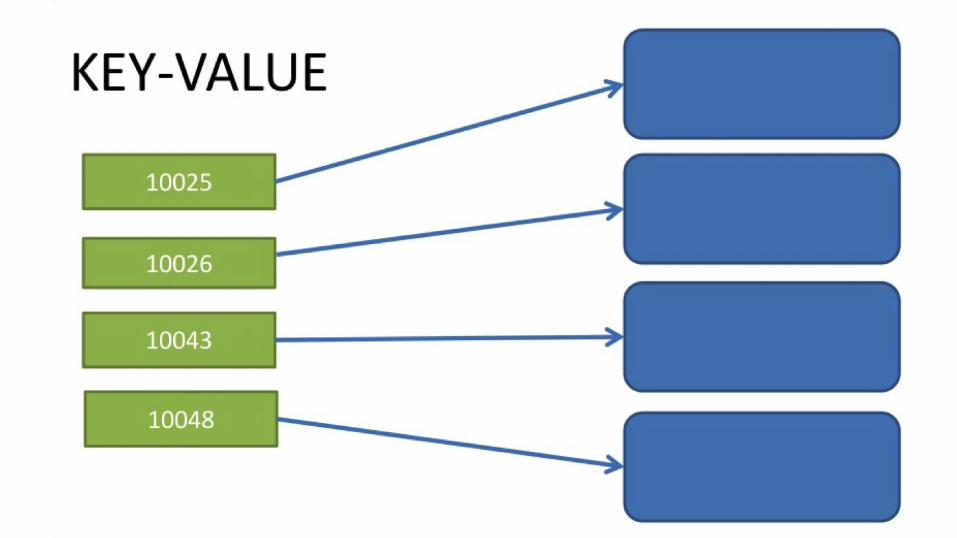
HASHING● Computers: 0, 1, 2, …, n - 1, n● Key Value Pair: (k, v)
(k, v) => hash(k) mod n




THUNDERING HERD

CONSISTENT HASHING

CONSISTENT HASHING

K/V Stores - Good Use Cases
● Lots of data● Object cache in front of RDBMS● High concurrency● Massive small-data intake● Simple data access patterns

K/V Stores - Good Use Cases
● Lots of data○ Usually easily horizontally scalable
● Object cache in front of RDBMS● High concurrency● Massive small-data intake● Simple data access patterns

K/V Stores - Good Use Cases
● Lots of data● Object cache in front of RDBMS
○ Memcached, anyone?
● High concurrency● Massive small-data intake● Simple data access patterns

K/V Stores - Good Use Cases
● Lots of data● Object cache in front of RDBMS● High concurrency
○ Very simple locking model
● Massive small-data intake● Simple data access patterns

K/V Stores - Good Use Cases
● Lots of data● Object cache in front of RDBMS● High concurrency● Massive small-data intake● Simple data access patterns

K/V Stores - Good Use Cases
● Lots of data● Object cache in front of RDBMS● High concurrency● Massive small-data intake● Simple data access patterns
○ CRUD on PK access

K/V Stores - Bad Use Cases
● Durability and consistency*● Complex data access patterns● Non-PK access*● Operations*

K/V Stores - Bad Use Cases
● Durability and consistency*● Complex data access patterns● Non-PK access*● Operations*

K/V Stores - Bad Use Cases
● Durability and consistency*● Complex data access patterns*● Non-PK access*● Operations*

K/V Stores - Bad Use Cases
● Durability and consistency*● Complex data access patterns● Non-PK access*● Operations*

K/V Stores - Bad Use Cases
● Durability and consistency*● Complex data access patterns● Non-PK access*● Operations*
○ Complex systems fail in complex ways

SIMPLE FAILURE

COMPLICATED FAILURE

EXAMPLE K/V STORES
● Memcached● MemcacheDB● Redis*● Riak KV● Cassandra*● Amazon DynamoDB*

EXAMPLE K/V STORES
● Memcached● MemcacheDB● Redis*● Riak KV● Cassandra*● Amazon DynamoDB*

EXAMPLE K/V STORES
● Memcached● MemcacheDB● Redis*● Riak KV● Cassandra*● Amazon DynamoDB*

EXAMPLE K/V STORES
● Memcached● MemcacheDB● Redis*● Riak KV● Cassandra*● Amazon DynamoDB*

EXAMPLE K/V STORES
● Memcached● MemcacheDB● Redis*● Riak KV● Cassandra*● Amazon DynamoDB*

EXAMPLE K/V STORES
● Memcached● MemcacheDB● Redis*● Riak KV● Cassandra*● Amazon DynamoDB*

EXAMPLE K/V STORES
● Memcached● MemcacheDB● Redis*● Riak KV● Cassandra*● Amazon DynamoDB*

PROs CONs
● Highly scalable● Simple access patterns
● Operational complexities● Limited access patterns

Key Value Stores - Questions?

Columnar Databases

Columnar Data Layout● Row-oriented ● Column-oriented
001:10,Smith,Joe,40000;
002:12,Jones,Mary,50000;
003:11,Johnson,Cathy,44000;
004:22,Jones,Bob,55000;
...
10:001,12:002,11:003,22:004;
Smith:001,Jones:002,Johnson:003,Jones:004;
Joe:001,Mary:002,Cathy:003,Bob:004;
40000:001,50000:002,44000:003,55000:004;
...

Columnar Data Layout● Row-oriented Read Approach
What we want to read
Read Operation
Memory Page
1 2
3
4
10 Smith Bob 40000
12 Jones Mary 50000
11 Johnson Cathy 44000

Columnar Data Layout● Column-oriented Read Approach
What we want to read
Read Operation
Memory Page
1 2
3
4
10 12 11 22
Smith Jones Johnson
Joe Mary Cathy Bob

Columnar Databases - Considerations● Buffering and compression can help to reduce the impact of writes, but
they should still be avoided when possible○ Usually, an ETL process should be put in place to prepare data for analysis in a column-based
format
● Covering Indexes in row-based stores could provide similar benefits, but only up to a point → index maintenance work can become too expensive
● Column-based stores are self-indexing and more disk-space efficient● SQL can be used for most column-based stores

Columnar Databases - Considerations● Buffering and compression can help to reduce the impact of writes, but they
should still be avoided when possible○ Usually, an ETL process should be put in place to prepare data for analysis in a column-based
format
● Covering Indexes in row-based stores could provide similar benefits, but only up to a point → index maintenance work can become too expensive
● Column-based stores are self-indexing and more disk-space efficient● SQL can be used for most column-based stores

Columnar Databases - Considerations● Buffering and compression can help to reduce the impact of writes, but they
should still be avoided when possible○ Usually, an ETL process should be put in place to prepare data for analysis in a column-based
format
● Covering Indexes in row-based stores could provide similar benefits, but only up to a point → index maintenance work can become too expensive
● Column-based stores are self-indexing and more disk-space efficient● SQL can be used for most column-based stores

Columnar Databases - Considerations● Buffering and compression can help to reduce the impact of writes, but they
should still be avoided when possible○ Usually, an ETL process should be put in place to prepare data for analysis in a column-based
format
● Covering Indexes in row-based stores could provide similar benefits, but only up to a point → index maintenance work can become too expensive
● Column-based stores are self-indexing and more disk-space efficient● SQL can be used for most column-based stores

● Suitable for read-mostly or read-intensive, large data repositories
● Good for full table / large range reads.
● Good for unstructured problems where “good” indexes are hard to forecast
● Good for re-creatable datasets
● Good for structured data
Columnar Database - Good use cases

● Suitable for read-mostly or read-intensive, large data repositories
● Good for full table / large range reads.
● Good for unstructured problems where “good” indexes are hard to forecast
● Good for re-creatable datasets
● Good for structured data
Columnar Database - Good use cases

● Suitable for read-mostly or read-intensive, large data repositories
● Good for full table / large range reads.
● Good for unstructured problems where “good” indexes are hard to forecast
● Good for re-creatable datasets
● Good for structured data
Columnar Database - Good use cases

● Suitable for read-mostly or read-intensive, large data repositories
● Good for full table / large range reads.
● Good for unstructured problems where “good” indexes are hard to forecast
● Good for re-creatable datasets
● Good for structured data
Columnar Database - Good use cases

● Suitable for read-mostly or read-intensive, large data repositories
● Good for full table / large range reads.
● Good for unstructured problems where “good” indexes are hard to forecast
● Good for re-creatable datasets
● Good for structured data
Columnar Database - Good use cases

● Not good for “SELECT *” queries or queries fetching most of the columns
● Not good for writes
● Not good for mixed read/write
● Bad for unstructured data
Columnar Database - Bad use cases

● Not good for “SELECT *” queries or queries fetching most of the columns
● Not good for writes
● Not good for mixed read/write
● Bad for unstructured data
Columnar Database - Bad use cases

● Not good for “SELECT *” queries or queries fetching most of the columns
● Not good for writes
● Not good for mixed read/write
● Bad for unstructured data
Columnar Database - Bad use cases

● Not good for “SELECT *” queries or queries fetching most of the columns
● Not good for writes
● Not good for mixed read/write
● Bad for unstructured data
Columnar Database - Bad use cases

Columnar Database - Examples● InfoBright (ICE)● Vertica● Amazon Redshift● Apache HBase

Columnar Database - Examples● InfoBright (ICE)● Vertica● Amazon Redshift● Apache HBase

Columnar Database - Examples● InfoBright (ICE)● Vertica● Amazon Redshift● Apache HBase

Columnar Database - Examples● InfoBright (ICE)● Vertica● Amazon Redshift● Apache HBase
○ https://www.percona.com/live/data-performance-conference-2016/sessions/solr-how-index-10-billion-phrases-mysql-and-hbase

Columnar - Questions?

Graph Databases


Graph Databases - Good Use Cases
● Highly Connected Data● Millions or Billions of Records● Re-Creatable Data Set● Structured Data

Graph Databases - Good Use Cases
● Highly Connected Data○ Network & IT Operations, Recommendations, Fraud Detection, Social Networking, Identity &
Access Management, Geo Routing, Insurance Risk Analysis, Counter Terrorism
● Millions or Billions of Records● Re-Creatable Data Set● Structured Data


Graph Databases - Good Use Cases
● Highly Connected Data● Millions or Billions of Records
○ Relational databases can also solve this problem at a smaller scale
● Re-Creatable Data Set● Structured Data

Graph Databases - Good Use Cases
● Highly Connected Data● Millions or Billions of Records● Re-Creatable Data Set
○ Keep as much as possible outside of the critical path
● Structured Data

Graph Databases - Good Use Cases
● Highly Connected Data● Millions or Billions of Records● Re-Creatable Data Set● Structured Data
○ You cannot graph a relationship unless you can define it

Graph Databases - Bad Use Cases
● Unstructured Data● Non-Connected Data● Highly Concurrent RW Workloads● Anything in the Critical OLTP Path*● Ever-Growing Data Set

Graph Databases - Bad Use Cases
● Unstructured Data○ You cannot graph a relationship if you cannot define it
● Non-Connected Data● Highly Concurrent Workloads● Anything in the Critical OLTP Path*● Ever-Growing Data Set

Graph Databases - Bad Use Cases
● Unstructured Data● Non-Connected Data
○ Graphiness is important here
● Highly Concurrent Workloads● Anything in the Critical OLTP Path*● Ever-Growing Data Set

Graph Databases - Bad Use Cases
● Unstructured Data● Non-Connected Data● Highly Concurrent RW Workloads
○ Performance breaks down
● Anything in the Critical OLTP Path*● Ever-Growing Data Set

Graph Databases - Bad Use Cases
● Unstructured Data● Non-Connected Data● Highly Concurrent Workloads● Anything in the Critical OLTP Path*
○ I'm not only talking about writes here
● Ever-Growing Data Set

Graph Databases - Bad Use Cases
● Unstructured Data● Non-Connected Data● Highly Concurrent RW Workloads● Anything in the Critical OLTP Path*● Ever-Growing Data Set

Example Graph Databases
● Neo4j● OrientDB● Titan● Virtuoso● ArangoDB

Example Graph Databases
● Neo4j● OrientDB● Titan● Virtuoso● ArangoDB

Example Graph Databases
● Neo4j● OrientDB● Titan● Virtuoso● ArangoDB

Example Graph Databases
● Neo4j● OrientDB● Titan● Virtuoso● ArangoDB

Example Graph Databases
● Neo4j● OrientDB● Titan● Virtuoso● ArangoDB

Example Graph Databases
● Neo4j● OrientDB● Titan● Virtuoso● ArangoDB


THE CODE

PROs CONs
● Solves a very specific (and hard) data problem
● Learning curve not bad for developer usage
● Data analysts’ dream
● Very little operational expertise for hire● Little community and virtually no tooling for
administration and operations.● Big mismatch in paradigm vs RDBMS;
Hard to switch for DBAs.● Hard/Expensive to scale horizontally● Writes are computationally expensive

Graph Databases - Questions?

Time Series

ID: {timestamp, value}
db1-threads: {1460928171, 6}

Time Series - Good Use Cases
● Uh … Time Series Data● Write-mostly (95%+) - Sequential Appends● Rare updates, rarer still to the distant past● Deletes occur at the opposite end (the beginning)● Data does not fit in memory

Time Series - Good Use Cases
● Uh … Time Series Data● Write-mostly (95%+) - Sequential Appends● Rare updates, rarer still to the distant past● Deletes occur at the opposite end (the beginning)● Data does not fit in memory

Time Series - Good Use Cases
● Uh … Time Series Data● Write-mostly (95%+) - Sequential Appends● Rare updates, rarer still to the distant past● Deletes occur at the opposite end (the beginning)● Data does not fit in memory

Time Series - Good Use Cases
● Uh … Time Series Data● Write-mostly (95%+) - Sequential Appends● Rare updates, rarer still to the distant past● Deletes occur at the opposite end (the beginning)● Data does not fit in memory

Time Series - Good Use Cases
● Uh … Time Series Data● Write-mostly (95%+) - Sequential Appends● Rare updates, rarer still to the distant past● Deletes occur at the opposite end (the beginning)● Data does not fit in memory

Time Series - Good Use Cases
● Uh … Time Series Data● Write-mostly (95%+) - Sequential Appends● Rare updates, rarer still to the distant past● Deletes occur at the opposite end (the beginning)● Data does not fit in memory

Time Series - Bad Use Cases
● Uh … Not Time Series Data● Small data

Example Time Series Databases
● InfluxDB● Graphite● OpenTSDB● Blueflood● Prometheus

Example Time Series Databases
● InfluxDB● Graphite● OpenTSDB● Blueflood● Prometheus


Example Time Series Databases
● InfluxDB● Graphite● OpenTSDB● Blueflood● Prometheus

Example Time Series Databases
● InfluxDB● Graphite● OpenTSDB● Blueflood● Prometheus

Example Time Series Databases
● InfluxDB● Graphite● OpenTSDB● Blueflood● Prometheus

Example Time Series Databases
● InfluxDB● Graphite● OpenTSDB● Blueflood● Prometheus

PROs CONs
● Solves a very specific (big) data problem● Well-defined and finite data access
patterns
● Terrible query semantics

Time Series - Questions?

Document Stores

Document Stores: Document Oriented

Document Stores: Document Oriented

Document Stores: Flexible Schema

Document Stores: Flexible Schema

Document Stores: Flexible Schema

Document Stores: Flexible Schema

Document Stores: Flexible Schema

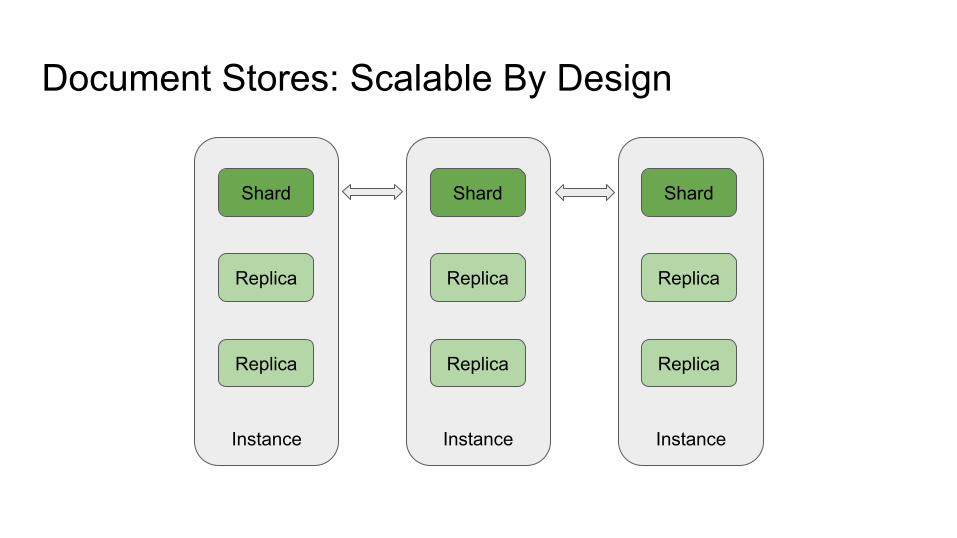
ShardShardShard
Document Stores: Scalable by Design
Primary Primary Primary
Replica Replica Replica
Replica Replica Replica
InstanceInstanceInstance
Document Stores: Scalable By Design
Shard Shard Shard
Replica Replica Replica
Replica Replica Replica

Document Stores

Document Stores: MongoDB

Document Stores: MongoDB● Sharding and replication for dummies!● Pluggable storage engines for distinct workloads.● Excellent compression options with PerconaFT, RocksDB, WiredTiger● On disk encryption (Enterprise Advanced)● In-memory storage engine (Beta)● Connectors for all major programming languages● Sharding and replica aware connectors● Geospatial functions● Aggregation framework● .. a lot more except being transactional

Document Stores: MongoDB● Sharding and replication for dummies!● Pluggable storage engines for distinct workloads.● Excellent compression options with PerconaFT, RocksDB, WiredTiger● On disk encryption (Enterprise Advanced)● In-memory storage engine (Beta)● Connectors for all major programming languages● Sharding and replica aware connectors● Geospatial functions● Aggregation framework● .. a lot more except being transactional

Document Stores: MongoDB● Sharding and replication for dummies!● Pluggable storage engines for distinct workloads.
○ Different locking behaviors● Excellent compression options with PerconaFT, RocksDB, WiredTiger● On disk encryption (Enterprise Advanced)● In-memory storage engine (Beta)● Connectors for all major programming languages● Sharding and replica aware connectors● Geospatial functions● Aggregation framework● .. a lot more except being transactional

Document Stores: MongoDB● Sharding and replication for dummies!● Pluggable storage engines for distinct workloads.● Excellent compression options with PerconaFT, RocksDB, WiredTiger● On disk encryption (Enterprise Advanced)● In-memory storage engine (Beta)● Connectors for all major programming languages● Sharding and replica aware connectors● Geospatial functions● Aggregation framework● .. a lot more except being transactional

Document Stores: MongoDB● Sharding and replication for dummies!● Pluggable storage engines for distinct workloads.● Excellent compression options with PerconaFT, RocksDB, WiredTiger● On disk encryption (Enterprise Advanced)● In-memory storage engine (Beta)● Connectors for all major programming languages● Sharding and replica aware connectors● Geospatial functions● Aggregation framework● .. a lot more except being transactional

Document Stores: MongoDB● Sharding and replication for dummies!● Pluggable storage engines for distinct workloads.● Excellent compression options with PerconaFT, RocksDB, WiredTiger● On disk encryption (Enterprise Advanced)● In-memory storage engine (Beta)● Connectors for all major programming languages● Sharding and replica aware connectors● Geospatial functions● Aggregation framework● .. a lot more except being transactional

Document Stores: MongoDB● Sharding and replication for dummies!● Pluggable storage engines for distinct workloads.● Excellent compression options with PerconaFT, RocksDB, WiredTiger● On disk encryption (Enterprise Advanced)● In-memory storage engine (Beta)● Connectors for all major programming languages● Sharding and replica aware connectors● Geospatial functions● Aggregation framework● .. a lot more except being transactional

Document Stores: MongoDB● Sharding and replication for dummies!● Pluggable storage engines for distinct workloads.● Excellent compression options with PerconaFT, RocksDB, WiredTiger● On disk encryption (Enterprise Advanced)● In-memory storage engine (Beta)● Connectors for all major programming languages● Sharding and replica aware connectors● Geospatial functions● Aggregation framework● .. a lot more except being transactional

Document Stores: MongoDB● Sharding and replication for dummies!● Pluggable storage engines for distinct workloads.● Excellent compression options with PerconaFT, RocksDB, WiredTiger● On disk encryption (Enterprise Advanced)● In-memory storage engine (Beta)● Connectors for all major programming languages● Sharding and replica aware connectors● Geospatial functions● Aggregation framework● .. a lot more except being transactional

Document Stores: MongoDB● Sharding and replication for dummies!● Pluggable storage engines for distinct workloads.● Excellent compression options with PerconaFT, RocksDB, WiredTiger● On disk encryption (Enterprise Advanced)● In-memory storage engine (Beta)● Connectors for all major programming languages● Sharding and replica aware connectors● Geospatial functions● Aggregation framework● .. a lot more except being transactional

Document Stores: MongoDB● Sharding and replication for dummies!● Pluggable storage engines for distinct workloads.● Excellent compression options with PerconaFT, RocksDB, WiredTiger● On disk encryption (Enterprise Advanced)● In-memory storage engine (Beta)● Connectors for all major programming languages● Sharding and replica aware connectors● Geospatial functions● Aggregation framework● .. a lot more except being transactional

● Catalogs● Analytics/BI (BI Connector on 3.2)● Time series
Document Stores: MongoDB > Use Cases

● Catalogs● Analytics/BI (BI Connector on 3.2)● Time series
Document Stores: MongoDB > Use Cases

● Catalogs● Analytics/BI (BI Connector on 3.2)● Time series
Document Stores: MongoDB > Use Cases

Document Stores: Couchbase

Document Stores: Couchbase● MongoDB - more or less● Global Secondary Indexes is exciting which produces localized secondary
indexes for low latency queries (Multi Dimensional Scaling)● Drop in replacement for Memcache

Document Stores: Couchbase● MongoDB - more or less● Global Secondary Indexes is exciting which produces localized
secondary indexes for low latency queries (Multi Dimensional Scaling)● Drop in replacement for Memcache

Document Stores: Couchbase● MongoDB - more or less● Global Secondary Indexes is exciting which produces localized secondary
indexes for low latency queries (Multi Dimensional Scaling)● Drop in replacement for Memcache

Document Stores: Couchbase > Use Cases● Internet of Things (direct or indirect receiver/pipeline)● Mobile data persistence via Couchbase Mobile i.e. field devices with unstable
connections and local/close priximity ingestion points● Distributed K/V store

Document Stores: Couchbase > Use Cases● Internet of Things (direct or indirect receiver/pipeline)● Mobile data persistence via Couchbase Mobile i.e. field devices with
unstable connections and local/close priximity ingestion points● Distributed K/V store

Document Stores: Couchbase > Use Cases● Internet of Things (direct or indirect receiver/pipeline)● Mobile data persistence via Couchbase Mobile i.e. field devices with unstable
connections and local/close priximity ingestion points● Distributed K/V store

Document Store: Questions?

Fulltext Search

Fulltext Search: Inverted Index

Fulltext Search: Search in a Box

Fulltext Search: Optimized Out● Optimized to take data out - little optimizations for getting data in
https://flic.kr/p/abeTEw

Fulltext Search: Structured/Non-Structured Data

Fulltext Search

Fulltext Search: Elasticsearch● Lucene based● RESTful interface - JSON in, JSON out● Flexible schema● Automatic sharding and replication (NDB like)● Reasonable defaults● Extension model● Written in Java, JVM limitation applies i.e. GC● ELK - Elasticsearch+Logstash+Kibana

Fulltext Search: Elasticsearch● Lucene based● RESTful interface - JSON in, JSON out● Flexible schema● Automatic sharding and replication (NDB like)● Reasonable defaults● Extension model● Written in Java, JVM limitation applies i.e. GC● ELK - Elasticsearch+Logstash+Kibana

Fulltext Search: Elasticsearch● Lucene based● RESTful interface - JSON in, JSON out● Flexible schema● Automatic sharding and replication (NDB like)● Reasonable defaults● Extension model● Written in Java, JVM limitation applies i.e. GC● ELK - Elasticsearch+Logstash+Kibana

Fulltext Search: Elasticsearch● Lucene based● RESTful interface - JSON in, JSON out● Flexible schema● Automatic sharding and replication (NDB like)● Reasonable defaults● Extension model● Written in Java, JVM limitation applies i.e. GC● ELK - Elasticsearch+Logstash+Kibana

Fulltext Search: Elasticsearch● Lucene based● RESTful interface - JSON in, JSON out● Flexible schema● Automatic sharding and replication (NDB like)● Reasonable defaults● Extension model● Written in Java, JVM limitation applies i.e. GC● ELK - Elasticsearch+Logstash+Kibana

Fulltext Search: Elasticsearch● Lucene based● RESTful interface - JSON in, JSON out● Flexible schema● Automatic sharding and replication (NDB like)● Reasonable defaults● Extension model● Written in Java, JVM limitation applies i.e. GC● ELK - Elasticsearch+Logstash+Kibana

Fulltext Search: Elasticsearch● Lucene based● RESTful interface - JSON in, JSON out● Flexible schema● Automatic sharding and replication (NDB like)● Reasonable defaults● Extension model● Written in Java, JVM limitation applies i.e. GC● ELK - Elasticsearch+Logstash+Kibana

Fulltext Search: Elasticsearch● Lucene based● RESTful interface - JSON in, JSON out● Flexible schema● Automatic sharding and replication (NDB like)● Reasonable defaults● Extension model● Written in Java, JVM limitation applies i.e. GC● ELK - Elasticsearch+Logstash+Kibana

Fulltext Search: Elasticsearch > Use Cases● Logs Analysis - ELK Stack i.e. Netflix● Full Text search i.e. Github, Wikipedia, StackExchange, etc● https://www.elastic.co/use-cases

Fulltext Search: Elasticsearch > Use Cases● Logs Analysis - ELK Stack i.e. Netflix● Full Text search i.e. Github, Wikipedia, StackExchange, etc● https://www.elastic.co/use-cases

Fulltext Search: Elasticsearch > Use Cases● Logs Analysis - ELK Stack i.e. Netflix● Full Text search i.e. Github, Wikipedia, StackExchange, etc● https://www.elastic.co/use-cases
○ Sentiment analysis○ Personalized experience○ etc

● Lucene based● Quite cryptic query interface - Innovator’s Dilemma● Support for SQL based query on 6.1● Structured schema, data types needs to be predefined● Written in Java, JVM limitation applies i.e. GC● Near realtime indexing - DIH, ● Rich document handling - PDF, doc[x]● SolrCloud support for sharding and replication
Fulltext Search: Solr

● Lucene based● Quite cryptic query interface - Innovator’s Dilemma● Support for SQL based query on 6.1● Structured schema, data types needs to be predefined● Written in Java, JVM limitation applies i.e. GC● Near realtime indexing - DIH, ● Rich document handling - PDF, doc[x]● SolrCloud support for sharding and replication
Fulltext Search: Solr

● Lucene based● Quite cryptic query interface - Innovator’s Dilemma● Support for SQL based query on 6.1● Structured schema, data types needs to be predefined● Written in Java, JVM limitation applies i.e. GC● Near realtime indexing - DIH, ● Rich document handling - PDF, doc[x]● SolrCloud support for sharding and replication
Fulltext Search: Solr

● Lucene based● Quite cryptic query interface - Innovator’s Dilemma● Support for SQL based query on 6.1● Structured schema, data types needs to be predefined● Written in Java, JVM limitation applies i.e. GC● Near realtime indexing - DIH, ● Rich document handling - PDF, doc[x]● SolrCloud support for sharding and replication
Fulltext Search: Solr

● Lucene based● Quite cryptic query interface - Innovator’s Dilemma● Support for SQL based query on 6.1● Structured schema, data types needs to be predefined● Written in Java, JVM limitation applies i.e. GC● Near realtime indexing - DIH, ● Rich document handling - PDF, doc[x]● SolrCloud support for sharding and replication
Fulltext Search: Solr

● Lucene based● Quite cryptic query interface - Innovator’s Dilemma● Support for SQL based query on 6.1● Structured schema, data types needs to be predefined● Written in Java, JVM limitation applies i.e. GC● Near real-time indexing - DIH, ● Rich document handling - PDF, doc[x]● SolrCloud support for sharding and replication
Fulltext Search: Solr

● Lucene based● Quite cryptic query interface - Innovator’s Dilemma● Support for SQL based query on 6.1● Structured schema, data types needs to be predefined● Written in Java, JVM limitation applies i.e. GC● Near realtime indexing - DIH, ● Rich document handling - PDF, doc[x]● SolrCloud support for sharding and replication
Fulltext Search: Solr

● Lucene based● Quite cryptic query interface - Innovator’s Dilemma● Support for SQL based query on 6.1● Structured schema, data types needs to be predefined● Written in Java, JVM limitation applies i.e. GC● Near realtime indexing - DIH, ● Rich document handling - PDF, doc[x]● SolrCloud support for sharding and replication
Fulltext Search: Solr

● Search and Relevancy○ https://www.percona.com/live/data-performance-conference-2016/sessions/solr-how-index-10-
billion-phrases-mysql-and-hbase
● Recommendation Engine● Spatial Search
Fulltext Search: Solr > Use Cases

● Search and Relevancy● Recommendation Engine● Spatial Search
Fulltext Search: Solr > Use Cases

● Search and Relevancy● Recommendation Engine● Spatial Search
Fulltext Search: Solr > Use Cases

● Structured data ● MySQL protocol - SphinxQL● Durable indexes via binary logs● Realtime indexes via MySQL queries● Distributed index for scaling● No native support for replication i.e. via rsync ● Very good documentation● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search

● Structured data ● MySQL protocol - SphinxQL● Durable indexes via binary logs● Realtime indexes via MySQL queries● Distributed index for scaling● No native support for replication i.e. via rsync ● Very good documentation● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search

● Structured data ● MySQL protocol - SphinxQL● Durable indexes via binary logs● Realtime indexes via MySQL queries● Distributed index for scaling● No native support for replication i.e. via rsync ● Very good documentation● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search

● Structured data ● MySQL protocol - SphinxQL● Durable indexes via binary logs● Realtime indexes via MySQL queries● Distributed index for scaling● No native support for replication i.e. via rsync ● Very good documentation● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search

● Structured data ● MySQL protocol - SphinxQL● Durable indexes via binary logs● Realtime indexes via MySQL queries● Distributed index for scaling● No native support for replication i.e. via rsync ● Very good documentation● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search

● Structured data ● MySQL protocol - SphinxQL● Durable indexes via binary logs● Realtime indexes via MySQL queries● Distributed index for scaling● No native support for replication i.e. via rsync ● Very good documentation● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search

● Structured data ● MySQL protocol - SphinxQL● Durable indexes via binary logs● Realtime indexes via MySQL queries● Distributed index for scaling● No native support for replication i.e. via rsync ● Very good documentation● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search

● Structured data ● MySQL protocol - SphinxQL● Durable indexes via binary logs● Realtime indexes via MySQL queries● Distributed index for scaling● No native support for replication i.e. via rsync ● Very good documentation● Fastest full indexing/reindexing
Fulltext Search: Sphinx Search

● Real time full text + basic geo functions● Above with with dependency or to simplify access with SphinxQL or even
Sphinx storage engine for MySQL
Fulltext Search: Sphinx Search > Use Cases

● Real time full text + basic geo functions● Above with with dependency or to simplify access with SphinxQL or
even Sphinx storage engine for MySQL
Fulltext Search: Sphinx Search > Use Cases

Search - Questions?

Docker Is Your Friend

Relational
● https://github.com/docker-library/mysql ● https://github.com/docker-library/postgres
Key Value
● https://github.com/docker-library/memcached ● https://github.com/docker-library/redis ● https://github.com/docker-library/cassandra● https://github.com/hectcastro/docker-riak (https://docs.docker.
com/engine/examples/running_riak_service/)
Docker Is Your Friend

Graph
● https://github.com/neo4j/docker-neo4j ● https://github.com/orientechnologies/orientdb-docker ● https://github.com/arangodb/arangodb-docker ● https://github.com/tenforce/docker-virtuoso (non official)● https://hub.docker.com/r/itzg/titandb/~/dockerfile/ (non official)● https://github.com/phani1kumar/docker-titan (non official)
Full Text
● https://github.com/docker-solr/docker-solr/ ● https://github.com/stefobark/sphinxdocker
Docker Is Your Friend

Docker Is Your FriendTime series
● https://github.com/tutumcloud/influxdb (non official)● https://hub.docker.com/r/sitespeedio/graphite/ (non official)● https://github.com/rackerlabs/blueflood/tree/master/demo/docker ● https://hub.docker.com/r/petergrace/opentsdb-docker/ (non-official)● https://hub.docker.com/r/opower/opentsdb/ (non-official)● https://prometheus.io/docs/introduction/install/#using-docker● https://github.com/prometheus/prometheus/blob/master/Dockerfile● Both via http://opentsdb.net/docs/build/html/resources.html

Docker Is Your FriendDocument
● https://github.com/docker-library/mongo/ ● https://hub.docker.com/r/couchbase/server/~/dockerfile/
Columnar
● http://www.infobright.org/index.php/download/download-pentaho-ice-integrated-virtual-machine/ ● https://github.com/meatcar/docker-infobright/blob/master/Dockerfile ● https://github.com/vertica/docker-vertica
