hiding sensitive association rules
TRANSCRIPT

Hiding sensitive association rules .
Under the guidance of Sri G.SridharAssistant
ProfessorPresented by:
P.Vinay Reddy(11016T1013)
Y.Bharath(11016T0982)G.Divya(11016T0997)
K.Rashmika(11016T0998)

Outline1. Introduction2. Scope and application3.Problem formulation4. Modification schemes for rule hiding5. Implementation steps6. Flow diagram7. Apriori algorithm8.Requirements

The security of the large database that containscertain crucial information, it will become aserious issue when sharing data to the networkagainst unauthorized access. Privacy preservingdata mining is a new research trend in privacydata for data mining and statistical database.Association analysis is a powerful tool fordiscovering relationships which are hidden in largedatabase. Association rules hiding algorithms getstrong and efficient performance for protectingconfidential and crucial data. Data modificationand rule hiding is one of the most important
Introduction

Data mining:Generally, data mining (sometimes called data or knowledge discovery) is the process of analyzing data from different perspectives and summarizing it into useful information.
Data: Data are any facts, numbers, or text that can be processed by a computer.
Association rule:Association rules are if/then statements that help uncover relationships between data in a transactional database.
Terminology

Itemset : an itemset is a set of products(items) Support : support of an itemset I is defined as the percentage of transactions that contain I
in the entire database transactionsDenoted as Sup( I ).
Frequent itemset : if the support of itemset I is not lower than a minimum support threshold(MST) then I is called as frequent itemset.Confidence of an association rule X -> Y : probability that Y occurs given that X occurs.
Terminology(cont…)

Scope and Application
• Shopping centers use association rules toincrease sales.
• Amazon use association rules torecommend an items based oncurrent item you are browsing.
• Google auto-complete.• customer’s consumption analysis.

Problem formulationLet M={i1,i2,…in} and D ={t1,t2,…tm}, where every tj is a subset of M, be the set of all distinct items and the transaction database, respectively. Each transaction tj isassociated with a unique identifier called TID and can be represented as a bit-vector b1b2 . . . bn, where bk=1 if ik ∈ tj.Association rule miningInclude XY if 1.Sup X U Y≥
MST and2.
Conf XY≥ MCTAssociation Rule Hiding
To hide XY we have to make 1.Sup X U Y<MST and
2. Conf

Modification schemes for rule hiding
Scheme1: Deletion of items.if X U Y is deleted
1.Sup X U Y and2. Conf XY will be decreased.
Scheme2: Insertion of items.Conf XY can be reduced by inserting X into
a transaction that doesn’t contain Y in it.

Implementation steps
1. Define minimum support threshold and minimum confidence threshold
2. By applying Apriori algorithm on this transaction database we get
frequent itemset and strong rules3. From these we select some rules to hide
which are called sensitive rules.4. We strategically employee one of the above mentioned schemes to hide strong rules.
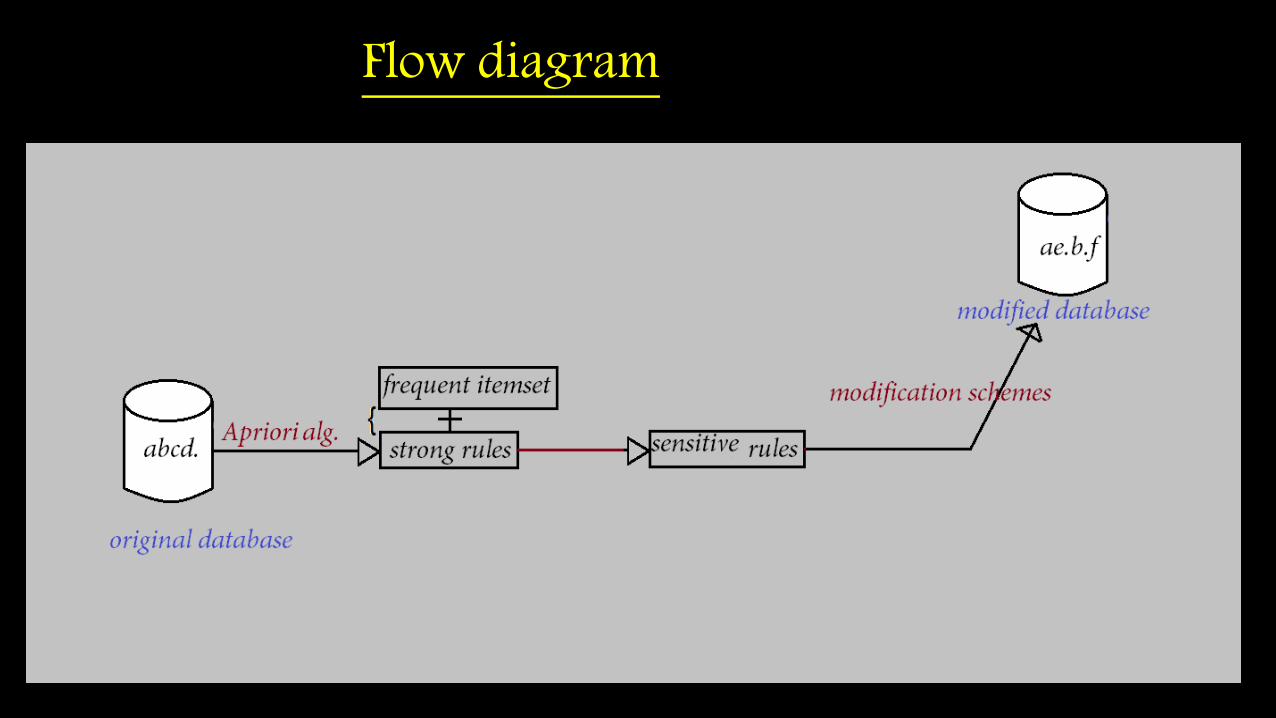
Flow diagram

The Apriori algorithm:It is a classic algorithm used in data mining forlearning association rules. It is no where ascomplex as it sounds, on the contrary it is verysimple.
For example consider following transaction tableTransaction ID Items Bought
T1 {Mango, Onion, Nintendo, Key-chain, Eggs, Yo-yo}
T2 {Doll, Onion, Nintendo, Key-chain, Eggs, Yo-yo}
T3 {Mango, Apple, Key-chain, Eggs}
T4 {Mango, Umbrella, Corn, Key-chain, Yo-yo}
T5 {Corn, Onion, Onion, Key-chain, Ice-cream, Eggs}
For simplicity consider M=mangoO=onion and so on…

k-itemset : a set of k items. E.g.{beer, cheese, eggs} is a 3-itemset{cheese} is a 1-itemset{honey, ice-cream} is a 2-itemset
support: an itemset has support s% if s% of the recordsin the DB contain that itemset.
Lk
Terminology
Ck -K itemset candidates- Frequent K-itemset

The Apriori algorithm
1. Find all frequent 1-itemsets2. For (k = 2 ; while Lk-1 is non-empty;
k++)3. {Ck = apriori-gen(Lk-1)4. For each c in Ck, initialise
c.count to zero5. For all records r in the DB6. {Cr = subset(Ck, r); For each c in
Cr , c.count++ }

Transaction ID Items Bought
T1 {M, O, N, K, E, Y }
T2 {D, O, N, K, E, Y }
T3 {M, A, K, E}
T4 {M, U, C, K, Y }
T5 {C, O, O, K, I, E}
So original transactional database will be as follows.
1.Find all item sets with specified minimal support(coverage).
2. Use these item sets to generate interesting rules.
Let minimum support count be 3
Example

Step 1:
Count number of transactions in which each item occur and tabulate them as below.
Item Support count
M 3
O 3
N 2
K 5
E 4
Y 3
D 1
A 1
U 1
C 2
I 1
Example(cont…)

Step 2:Remove all the item sets that are bought less than 3 times because minimum support count is assumed as 3.So above table will be changed toItem Support count
M 3
O 3
K 5
E 4
Y 3
These are the single items that are most frequently bought.
Example(cont…)

Step 3:Now take each possible pair of items and count how many times each item pair is being bought together.
Now our table turns as Item Pairs Support count
MO 1
MK 3
ME 2
MY 2
OK 3
OE 3
OY 2
KE 4
KY 3
EY 2
Totally C(n,2)=n(n-1)/2 item pairs will be possible.
As n=5 here 5(4)/2=10 pairs exist.
Example(cont…)

Step 4: Repeat same procedure i.e, remove all the item pairs with support count < 3 and now we are left with
Item Pairs Support count
MK 3
OK 3
OE 3
KE 4
KY 3
These are the pair of item sets that are bought more frequently.
Example(cont…)

Step 5:
To make set of three items we need one more rule termed as self-join.
It simply means, from the Item pairs in the above table, we find two pairs with the same first Alphabet, so we get
1. OK and OE, this gives OKE
2. KE and KY, this gives KEY
Item Set Support count
OKE 3
KEY 2
Here 3-itemset OKE is bought 3 times. So, OKE is 3-item set bought more frequently.
Example(cont…)

Hardware specifications1. Pentium IV
processor2. 256MB RAM3. 40GB Hard
disk

Software specificationsOperating System : windows 2000 and above
versionsJdk kit : Jdk1.7Front end : Java

Thank You