hierarchical qr factorization algorithms for multi-core
TRANSCRIPT

Hierarchical QR factorizationalgorithms for multi-core clustersystems
Jack DongarraMathieu FavergeThomas HeraultJulien LangouYves RobertUniversity of Tennessee Knoxville, USAUniversity of Colorado Denver, USAEcole Normale Supérieure de Lyon, FranceJUNE 29, 2012

• reducing communication◦ in sequential◦ in parallel distributed
• increasing parallelism(or reducing the critical path, reducing synchronization)
Tall and Skinny matricesMinimizing communication in parallel distributed (29)Minimizing communication in hierarchichal parallel distributed (6)Minimizing communication in sequential (1)
Rectangular matricesMinimizing communication in sequential (2)Maximizing parallelism on multicore nodes (30)Parallelism+communication on multicore nodes (2)Parallelism+communication on distributed+multicore nodes (13)Scheduling on multicore nodes (4)
Julien Langou | University of Colorado Denver Hierarchical QR | 2 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Outline
Tall and Skinny matricesMinimizing communication in parallel distributed (29)Minimizing communication in hierarchichal parallel distributed (6)Minimizing communication in sequential (1)
Rectangular matricesMinimizing communication in sequential (2)Maximizing parallelism on multicore nodes (30)Parallelism+communication on multicore nodes (2)Parallelism+communication on distributed+multicore nodes (13)Scheduling on multicore nodes (4)
Julien Langou | University of Colorado Denver Hierarchical QR | 3 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
ReduceAlgorithms:Introduc4onTheQRfactoriza4onofalongandskinnymatrixwithitsdatapar44onedver4callyacrossseveralprocessorsarisesinawiderangeofapplica4ons.
A1
A2
A3
Q1
Q2
Q3
R
Input:Aisblockdistributedbyrows
Output:QisblockdistributedbyrowsRisglobal
Julien Langou | University of Colorado Denver Hierarchical QR | 4 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Exampleofapplica3ons:inblockitera3vemethods.
a) initera3vemethodswithmul3pleright‐handsides(blockitera4vemethods:)
1) Trilinos(SandiaNa4onalLab.)throughBelos(R.Lehoucq,H.Thornquist,U.Hetmaniuk).
2) BlockGMRES,BlockGCR,BlockCG,BlockQMR,…
b) initera3vemethodswithasingleright‐handside
1) s‐stepmethodsforlinearsystemsofequa4ons(e.g.A.Chronopoulos),
2) LGMRES(Jessup,Baker,Dennis,U.ColoradoatBoulder)implementedinPETSc,
3) RecentworkfromM.HoemmenandJ.Demmel(U.CaliforniaatBerkeley).
e) initera3veeigenvaluesolvers,
1) PETSc(ArgonneNa4onalLab.)throughBLOPEX(A.Knyazev,UCDHSC),
2) HYPRE(LawrenceLivermoreNa4onalLab.)throughBLOPEX,
3) Trilinos(SandiaNa4onalLab.)throughAnasazi(R.Lehoucq,H.Thornquist,U.Hetmaniuk),
4) PRIMME(A.Stathopoulos,Coll.William&Mary),
5) AndalsoTRLAN,BLZPACK,IRBLEIGS.
Julien Langou | University of Colorado Denver Hierarchical QR | 5 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
ReduceAlgorithms:Introduc4onExampleofapplica3ons:
a) inlinearleastsquaresproblemswhichthenumberofequa4onsisextremelylargerthanthenumberofunknowns
b) inblockitera4vemethods(itera4vemethodswithmul4pleright‐handsidesoritera4veeigenvaluesolvers)
c) indenselargeandmoresquareQRfactoriza4onwheretheyareusedasthepanelfactoriza4onstep
Julien Langou | University of Colorado Denver Hierarchical QR | 6 of 103
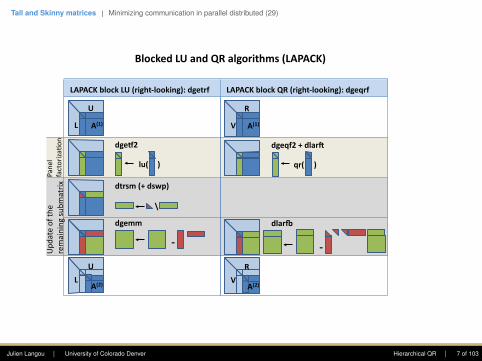
Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
BlockedLUandQRalgorithms(LAPACK)
‐
lu( )
dgeK2
dtrsm(+dswp)
dgemm
\
L
U
A(1)
A(2)L
U
‐
qr( )
dgeqf2+dlarQ
dlarR
V
R
A(1)
A(2)V
R
LAPACKblockLU(right‐looking):dgetrf LAPACKblockQR(right‐looking):dgeqrf
Upd
ateofth
eremainingsub
matrix
Pane
lfactoriza4
on
Julien Langou | University of Colorado Denver Hierarchical QR | 7 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
BlockedLUandQRalgorithms(LAPACK)
‐
lu( )
dgeK2
dtrsm(+dswp)
dgemm
\
L
U
A(1)
A(2)L
U
LAPACKblockLU(right‐looking):dgetrf
Upd
ateofth
eremainingsub
matrix
Pane
lfactoriza4
on
Latencybounded:morethannbAllReduceforn*nb2ops
CPU‐bandwidthbounded:thebulkofthecomputa4on:n*n*nbopshighlyparalleliable,efficientandsaclable.
Julien Langou | University of Colorado Denver Hierarchical QR | 8 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Paralleliza3onofLUandQR.
Parallelizetheupdate:• Easyanddoneinanyreasonablesoeware.• Thisisthe2/3n3termintheFLOPscount.• CanbedoneefficientlywithLAPACK+mul4threadedBLAS
‐
dgemm
‐
lu( )
dgeK2
dtrsm(+dswp)
dgemm
\
L
U
A(1)
A(2)L
U
Julien Langou | University of Colorado Denver Hierarchical QR | 9 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Paralleliza3onofLUandQR.
Parallelizetheupdate:• Easyanddoneinanyreasonablesoeware.• Thisisthe2/3n3termintheFLOPscount.• CanbedoneefficientlywithLAPACK+mul4threadedBLAS
Parallelizethepanelfactoriza3on:• Notanop4oninmul4corecontext(p<16)• Seee.g.ScaLAPACKorHPLbuts4llbyfartheslowestandthebojleneckofthecomputa4on.
Hidethepanelfactoriza3on:• Lookahead(seee.g.HighPerformanceLINPACK)• DynamicScheduling
lu( )
dgeK2
‐
dgemm
lu( )
dgeK2
Julien Langou | University of Colorado Denver Hierarchical QR | 10 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Hidingthepanelfactoriza4onwithdynamicscheduling.
TimeCourtesyfromAlfredoBujari,UTennessee
Julien Langou | University of Colorado Denver Hierarchical QR | 11 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Whataboutstrongscalability?
Julien Langou | University of Colorado Denver Hierarchical QR | 12 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Whataboutstrongscalability?N=1536
NB=64
procs=16
CourtesyfromJakubKurzak,UTennessee
Julien Langou | University of Colorado Denver Hierarchical QR | 13 of 103
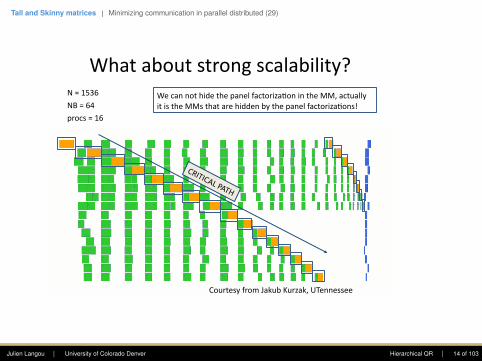
Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Whataboutstrongscalability?N=1536
NB=64
procs=16
Wecannothidethepanelfactoriza4onintheMM,actuallyitistheMMsthatarehiddenbythepanelfactoriza4ons!
CourtesyfromJakubKurzak,UTennessee
Julien Langou | University of Colorado Denver Hierarchical QR | 14 of 103
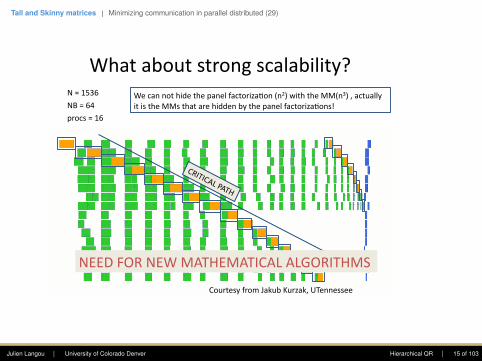
Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Whataboutstrongscalability?N=1536
NB=64
procs=16
Wecannothidethepanelfactoriza4on(n2)withtheMM(n3),actuallyitistheMMsthatarehiddenbythepanelfactoriza4ons!
NEEDFORNEWMATHEMATICALALGORITHMS
CourtesyfromJakubKurzak,UTennessee
Julien Langou | University of Colorado Denver Hierarchical QR | 15 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Anewgenera4onofalgorithms?Algorithmsfollowhardwareevolu3onalong3me.
LINPACK(80’s)(Vectoropera4ons)
Relyon‐Level‐1BLASopera4ons
LAPACK(90’s)(Blocking,cachefriendly)
Relyon‐Level‐3BLASopera4ons
Julien Langou | University of Colorado Denver Hierarchical QR | 16 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Anewgenera4onofalgorithms?Algorithmsfollowhardwareevolu3onalong3me.
LINPACK(80’s)(Vectoropera4ons)
Relyon‐Level‐1BLASopera4ons
LAPACK(90’s)(Blocking,cachefriendly)
Relyon‐Level‐3BLASopera4ons
NewAlgorithms(00’s)(mul4corefriendly)
Relyon‐aDAG/scheduler‐blockdatalayout‐someextrakernels
Thosenewalgorithms‐haveaverylowgranularity,theyscaleverywell(mul4core,petascalecompu4ng,…)‐removesalotsofdependenciesamongthetasks,(mul4core,distributedcompu4ng)‐avoidlatency(distributedcompu4ng,out‐of‐core)‐relyonfastkernelsThosenewalgorithmsneednewkernelsandrelyonefficientschedulingalgorithms.
Julien Langou | University of Colorado Denver Hierarchical QR | 17 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
2005‐2007:Newalgorithmsbasedon2Dpar44onning:
– UTexas(vandeGeijn):SYRK,CHOL(mul4core),LU,QR(out‐of‐core)– UTennessee(Dongarra):CHOL(mul4core)– HPC2N(Kågström)/IBM(Gustavson):Chol(Distributed)
– UCBerkeley(Demmel)/INRIA(Grigori):LU/QR(distributed)– UCDenver(Langou):LU/QR(distributed)
A3rdrevolu4onfordenselinearalgebra?
Julien Langou | University of Colorado Denver Hierarchical QR | 18 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
• reducing communication◦ in sequential◦ in parallel distributed
• increasing parallelism(or reducing the critical path, reducing synchronization)
We start with reduction communication in parallel distributed in the tall andskinny case.
Julien Langou | University of Colorado Denver Hierarchical QR | 19 of 103
Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
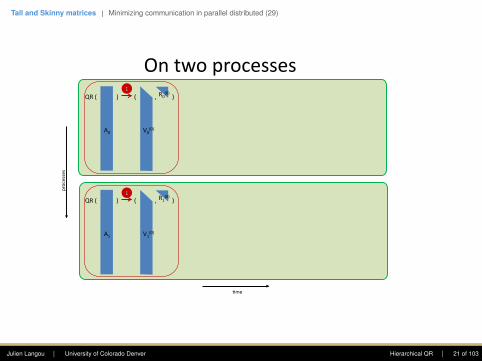
Ontwoprocesses
A0 Q0
A1 Q1
processes
4me
Julien Langou | University of Colorado Denver Hierarchical QR | 20 of 103
Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
OntwoprocessesR0(0)( , )QR( )
A0 V0(0)
R1(0)( , )QR( )
A1 V1(0)
processes
4me
Julien Langou | University of Colorado Denver Hierarchical QR | 21 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
OntwoprocessesR0(0)( , )QR( )
A0 V0(0)
)R0(0)
R1(0)
R1(0)( , )QR( )
A1 V1(0)
processes
4me
(
Julien Langou | University of Colorado Denver Hierarchical QR | 22 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
OntwoprocessesR0(0)( , )QR( )
A0 V0(0)
R0(1)( , )QR( )R0(0)
R1(0)
V0(1)
V1(1)
R1(0)( , )QR( )
A1 V1(0)
processes
4me
Julien Langou | University of Colorado Denver Hierarchical QR | 23 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
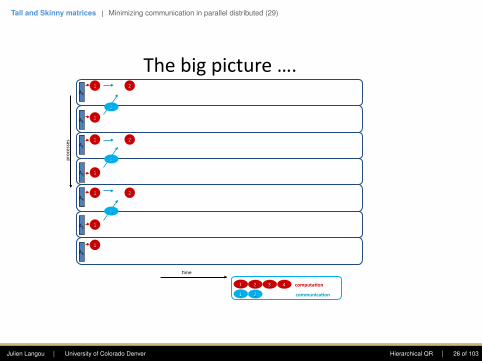
Thebigpicture….
A1
A2
A3
A4
A5
A6
Q0
Q4
Q1
Q5
Q6
Q3
Q2
R
R
R
R
R
R
R
A QR4me
processes
A0
Julien Langou | University of Colorado Denver Hierarchical QR | 24 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
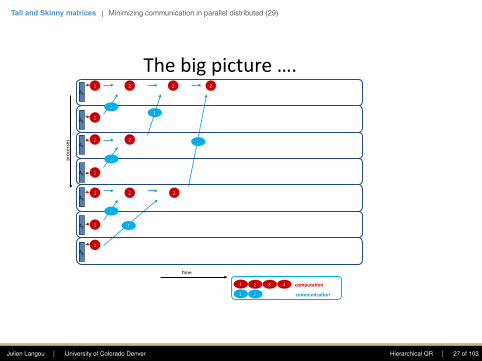
Thebigpicture….
A1
A2
A3
A4
A5
A6
4me
processes
communica3on
computa3on
A0
Julien Langou | University of Colorado Denver Hierarchical QR | 25 of 103
Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Thebigpicture….
A1
A2
A3
A4
A5
A6
4me
processes
communica3on
computa3on
A0
Julien Langou | University of Colorado Denver Hierarchical QR | 26 of 103
Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Thebigpicture….
A1
A2
A3
A4
A5
A6
4me
processes
communica3on
computa3on
A0
Julien Langou | University of Colorado Denver Hierarchical QR | 27 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Latencybutalsopossibilityoffastpanelfactoriza4on.
• DGEQR3istherecursivealgorithm(seeElmrothandGustavson,2000),DGEQRFandDGEQR2aretheLAPACKrou4nes.
• TimesincludeQRandDLARFT.
• RunonPen4umIII.
QRfactoriza3onandconstruc3onofTm=10,000
PerfinMFLOP/sec(Timesinsec)
n DGEQR3 DGEQRF DGEQR2
50 173.6 (0.29) 65.0 (0.77) 64.6 (0.77)
100 240.5 (0.83) 62.6 (3.17) 65.3 (3.04)
150 277.9 (1.60) 81.6 (5.46) 64.2 (6.94)
200 312.5 (2.53) 111.3 (7.09) 65.9 (11.98)
m=1000,000,thexaxisisn
MFLOP/sec
Julien Langou | University of Colorado Denver Hierarchical QR | 28 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
QandR:Strongscalability
0
100
200
300
400
500
600
700
800
32 64 128 256
ReduceHH(QR3)
ReduceHH(QRF)
ScaLAPACKQRF
ScaLAPACKQR2
Inthisexperiment,wefixtheproblem:m=1,000,000andn=50.Thenweincreasethenumberofprocessors.BlueGeneL
frost.ncar.edu
#ofprocessors
MFLOPs/sec/proc
Julien Langou | University of Colorado Denver Hierarchical QR | 29 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
communication :: TSQR :: parallel caseWhenonlyRiswanted
processes
4me
R0(0)( )QR( )
A0
R0(1)( )
QR( )R0
(0)R1
(0)
R1(0)( )QR( )
A1
R2(0)( )QR( )
A2
R2(1)( )
QR( )R2
(0)R3
(0)
R3(0)( )QR( )
A3
R( )QR( )
R0(1)
R2(1)
Considerarchitecture: parallel case: P processing unitsproblem: QR factorization of a m-by-n TS matrix (TS = m/P ≥ n)(main) assumption: the operation is “truly” parallel distributed⇒ answer: binary treetheory:
TSQR ScaLAPACK-like Lower bound
# flops 2mn2
P + 2n3
3 log P 2mn2
P − 2n3
3P Θ(
mn2
P
)# words n2
2 log P n2
2 log P n2
2 log P# messages log P 2n log P log P
Julien Langou | University of Colorado Denver Hierarchical QR | 30 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Any tree does.
WhenonlyRiswanted:TheMPI_Allreduce
InthecasewhereonlyRiswanted,insteadofconstruc4ngourowntree,onecansimplyuseMPI_Allreducewithauserdefinedopera4on.Theopera4onwegivetoMPIisbasicallytheAlgorithm2.Itperformstheopera4on:
Thisbinaryopera4onisassocia3veandthisisallMPIneedstouseauser‐definedopera4ononauser‐defineddatatype.Moreover,ifwechangethesignsoftheelementsofRsothatthediagonalofRholdsposi4veelementsthenthebinaryopera4onRfactorbecomescommuta3ve.
Thecodebecomestwolines:
lapack_dgeqrf( mloc, n, A, lda, tau, &dlwork, lwork, &info );
MPI_Allreduce( MPI_IN_PLACE, A, 1, MPI_UPPER,
LILA_MPIOP_QR_UPPER, mpi_comm);
QR ( )R1R2
R
Julien Langou | University of Colorado Denver Hierarchical QR | 31 of 103

Tall and Skinny matrices | Minimizing communication in parallel distributed (29)
Flat Binary tree
parallelism
+me
parallelism
+me
A weird tree
parallelism
+me
parallelism
+me
Another weird tree
Julien Langou | University of Colorado Denver Hierarchical QR | 32 of 103

Tall and Skinny matrices | Minimizing communication in hierarchichal parallel distributed (6)
Outline
Tall and Skinny matricesMinimizing communication in parallel distributed (29)Minimizing communication in hierarchichal parallel distributed (6)Minimizing communication in sequential (1)
Rectangular matricesMinimizing communication in sequential (2)Maximizing parallelism on multicore nodes (30)Parallelism+communication on multicore nodes (2)Parallelism+communication on distributed+multicore nodes (13)Scheduling on multicore nodes (4)
Julien Langou | University of Colorado Denver Hierarchical QR | 33 of 103

Tall and Skinny matrices | Minimizing communication in hierarchichal parallel distributed (6)
Latency (ms) Orsay Toulouse Bordeaux SophiaOrsay 0.07 7.97 6.98 6.12Toulouse 0.03 9.03 8.18Bordeaux 0.05 7.18Sophia 0.06
Throughput (Mb/s) Orsay Toulouse Bordeaux SophiaOrsay 890 78 90 102Toulouse 890 77 90Bordeaux 890 83Sophia 890
Julien Langou | University of Colorado Denver Hierarchical QR | 34 of 103
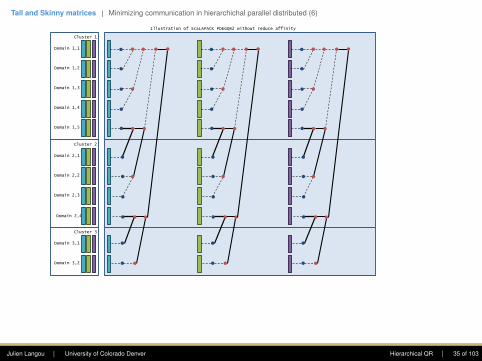
Tall and Skinny matrices | Minimizing communication in hierarchichal parallel distributed (6)
Domain 2,4
Domain 1,1
Domain 1,2
Domain 1,3
Cluster 1
Domain 1,4
Domain 1,5
Domain 2,1
Domain 2,2
Domain 2,3
Cluster 2
Domain 3,1
Domain 3,2
Cluster 3
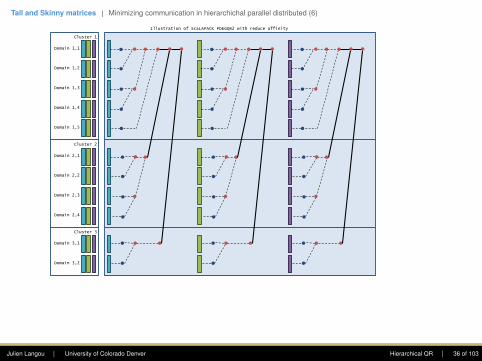
Illustration of ScaLAPACK PDEGQR2 without reduce affinity
Julien Langou | University of Colorado Denver Hierarchical QR | 35 of 103
Tall and Skinny matrices | Minimizing communication in hierarchichal parallel distributed (6)
Domain 1,1
Domain 1,2
Domain 1,3
Cluster 1
Domain 1,4
Domain 1,5
Domain 2,1
Domain 2,2
Domain 2,3
Cluster 2
Domain 2,4
Domain 3,1
Domain 3,2
Cluster 3
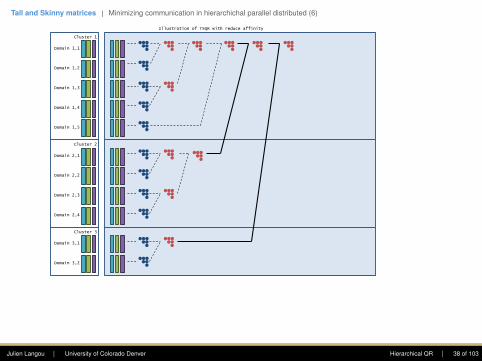
Illustration of ScaLAPACK PDEGQR2 with reduce affinity
Julien Langou | University of Colorado Denver Hierarchical QR | 36 of 103

Tall and Skinny matrices | Minimizing communication in hierarchichal parallel distributed (6)
Domain 1,1
Domain 1,2
Domain 1,3
Cluster 1
Domain 1,4
Domain 1,5
Domain 2,1
Domain 2,2
Domain 2,3
Cluster 2
Domain 2,4
Domain 3,1
Domain 3,2
Cluster 3
Illustration of TSQR without reduce affinity
Julien Langou | University of Colorado Denver Hierarchical QR | 37 of 103
Tall and Skinny matrices | Minimizing communication in hierarchichal parallel distributed (6)
Domain 1,1
Domain 1,2
Domain 1,3
Cluster 1
Domain 1,4
Domain 1,5
Domain 2,1
Domain 2,2
Domain 2,3
Cluster 2
Domain 2,4
Domain 3,1
Domain 3,2
Cluster 3
Illustration of TSQR with reduce affinity
Julien Langou | University of Colorado Denver Hierarchical QR | 38 of 103

Tall and Skinny matrices | Minimizing communication in hierarchichal parallel distributed (6)
Using 4 clusters of 32 processors.
104 105 106 107100
101
102
103
m
GF
lop/
sec
Classical Gram−SchmidtPerformance for pg = 1, 2 or 4 clusters, pc = 32 nodes per cluster, m varies (x−axis), n = 32
m = 8.e+06
m = 16.e+06
1 cluster, 9.27 GFlops/sec
2 clusters, 17.19 GFlops/sec
4 clusters, 28.19 GFlops/sec
experimentsmodel
104 105 106 107100
101
102
103
m
GF
lop/
sec
TSQR−binary−treePerformance for pg = 1, 2 or 4 clusters, pc = 32 nodes per cluster, m varies (x−axis), n = 32
m = 2.e+5
m = 5.e+5
1 cluster, 24.20 GFlops/sec
2 clusters, 48.25 GFlops/sec
4 clusters, 96.20 GFlops/secexperimentsmodel
Two effects at once: (1) avoiding communication with TSQR, (2) tuning of thereduction tree
Julien Langou | University of Colorado Denver Hierarchical QR | 39 of 103

Tall and Skinny matrices | Minimizing communication in sequential (1)
Outline
Tall and Skinny matricesMinimizing communication in parallel distributed (29)Minimizing communication in hierarchichal parallel distributed (6)Minimizing communication in sequential (1)
Rectangular matricesMinimizing communication in sequential (2)Maximizing parallelism on multicore nodes (30)Parallelism+communication on multicore nodes (2)Parallelism+communication on distributed+multicore nodes (13)Scheduling on multicore nodes (4)
Julien Langou | University of Colorado Denver Hierarchical QR | 40 of 103

Tall and Skinny matrices | Minimizing communication in sequential (1)
Considerarchitecture: sequential case: one processing unit with cache of size (W )problem: QR factorization of a m-by-n TS matrix (TS = m ≥ n and W ≥ 3
2 n2)⇒ answer: flat treetheory:
flat tree LAPACK-like Lower bound# flops 2mn2 2mn2 Θ(mn2)
# words 2mn m2n2
2W 2mn# messages 3mn
Wmn2
2W2mnW
Julien Langou | University of Colorado Denver Hierarchical QR | 41 of 103

Rectangular matrices | Minimizing communication in sequential (2)
Outline
Tall and Skinny matricesMinimizing communication in parallel distributed (29)Minimizing communication in hierarchichal parallel distributed (6)Minimizing communication in sequential (1)
Rectangular matricesMinimizing communication in sequential (2)Maximizing parallelism on multicore nodes (30)Parallelism+communication on multicore nodes (2)Parallelism+communication on distributed+multicore nodes (13)Scheduling on multicore nodes (4)
Julien Langou | University of Colorado Denver Hierarchical QR | 42 of 103
Rectangular matrices | Minimizing communication in sequential (2)
5000 10000 15000 20000 25000 30000 350000
10
20
30
40
50
60
70
80
90
100
n (matrix size)
perc
ent o
f CP
U p
eak
perf
orm
ance
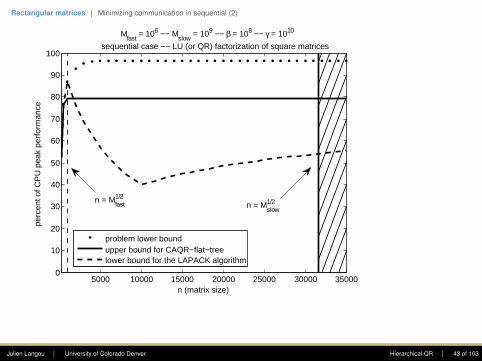
Mfast
= 106 −− Mslow
= 109 −− β = 108 −− γ = 1010
sequential case −− LU (or QR) factorization of square matrices
n = Mfast1/2
n = Mslow1/2
problem lower boundupper bound for CAQR−flat−treelower bound for the LAPACK algorithm
Julien Langou | University of Colorado Denver Hierarchical QR | 43 of 103
Rectangular matrices | Minimizing communication in sequential (2)
100 101 102 103 104 105 106 107100
101
102
( #
of s
low
mem
ory
refe
renc
es )
/ (p
robl
em lo
wer
bou
nd)
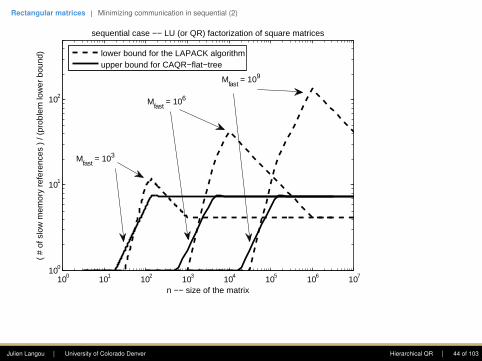
n −− size of the matrix
sequential case −− LU (or QR) factorization of square matrices
Mfast
= 103
Mfast
= 106
Mfast
= 109
lower bound for the LAPACK algorithmupper bound for CAQR−flat−tree
Julien Langou | University of Colorado Denver Hierarchical QR | 44 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Outline
Tall and Skinny matricesMinimizing communication in parallel distributed (29)Minimizing communication in hierarchichal parallel distributed (6)Minimizing communication in sequential (1)
Rectangular matricesMinimizing communication in sequential (2)Maximizing parallelism on multicore nodes (30)Parallelism+communication on multicore nodes (2)Parallelism+communication on distributed+multicore nodes (13)Scheduling on multicore nodes (4)
Julien Langou | University of Colorado Denver Hierarchical QR | 45 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Mission
Perform the QR factorization of an initial tiled matrix A on a multicore platform.
time
Julien Langou | University of Colorado Denver Hierarchical QR | 46 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
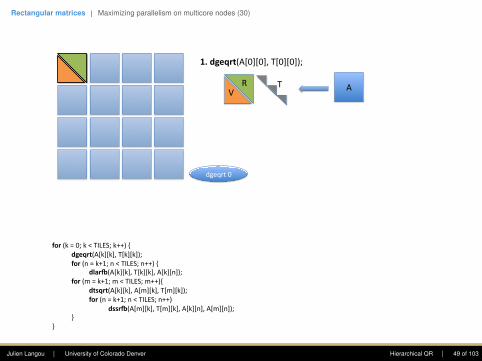
for(k=0;k<TILES;k++){dgeqrt(A[k][k],T[k][k]);for(n=k+1;n<TILES;n++){ dlar+(A[k][k],T[k][k],A[k][n]);for(m=k+1;m<TILES;m++){ dtsqrt(A[k][k],A[m][k],T[m][k]); for(n=k+1;n<TILES;n++) dssr+(A[m][k],T[m][k],A[k][n],A[m][n]);}
}
Julien Langou | University of Colorado Denver Hierarchical QR | 47 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
for(k=0;k<TILES;k++){dgeqrt(A[k][k],T[k][k]);for(n=k+1;n<TILES;n++){ dlar+(A[k][k],T[k][k],A[k][n]);for(m=k+1;m<TILES;m++){ dtsqrt(A[k][k],A[m][k],T[m][k]); for(n=k+1;n<TILES;n++) dssr+(A[m][k],T[m][k],A[k][n],A[m][n]);}
}
1.dgeqrt(A[0][0],T[0][0]);
VR AT
dgeqrt0
Julien Langou | University of Colorado Denver Hierarchical QR | 48 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
for(k=0;k<TILES;k++){dgeqrt(A[k][k],T[k][k]);for(n=k+1;n<TILES;n++){ dlar+(A[k][k],T[k][k],A[k][n]);for(m=k+1;m<TILES;m++){ dtsqrt(A[k][k],A[m][k],T[m][k]); for(n=k+1;n<TILES;n++) dssr+(A[m][k],T[m][k],A[k][n],A[m][n]);}
}
1.dgeqrt(A[0][0],T[0][0]);
VR AT
dgeqrt0
Julien Langou | University of Colorado Denver Hierarchical QR | 49 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
for(k=0;k<TILES;k++){dgeqrt(A[k][k],T[k][k]);for(n=k+1;n<TILES;n++){ dlar+(A[k][k],T[k][k],A[k][n]);for(m=k+1;m<TILES;m++){ dtsqrt(A[k][k],A[m][k],T[m][k]); for(n=k+1;n<TILES;n++) dssr+(A[m][k],T[m][k],A[k][n],A[m][n]);}
}
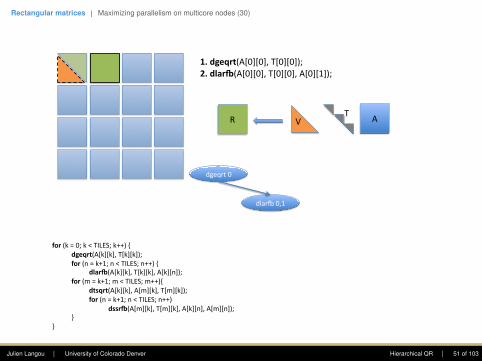
1.dgeqrt(A[0][0],T[0][0]);2.dlar+(A[0][0],T[0][0],A[0][1]);
V A
dgeqrt0
TR
dlarB0,1
Julien Langou | University of Colorado Denver Hierarchical QR | 50 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
for(k=0;k<TILES;k++){dgeqrt(A[k][k],T[k][k]);for(n=k+1;n<TILES;n++){ dlar+(A[k][k],T[k][k],A[k][n]);for(m=k+1;m<TILES;m++){ dtsqrt(A[k][k],A[m][k],T[m][k]); for(n=k+1;n<TILES;n++) dssr+(A[m][k],T[m][k],A[k][n],A[m][n]);}
}
1.dgeqrt(A[0][0],T[0][0]);2.dlar+(A[0][0],T[0][0],A[0][1]);
V A
dgeqrt0
TR
dlarB0,1
Julien Langou | University of Colorado Denver Hierarchical QR | 51 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
for(k=0;k<TILES;k++){dgeqrt(A[k][k],T[k][k]);for(n=k+1;n<TILES;n++){ dlar+(A[k][k],T[k][k],A[k][n]);for(m=k+1;m<TILES;m++){ dtsqrt(A[k][k],A[m][k],T[m][k]); for(n=k+1;n<TILES;n++) dssr+(A[m][k],T[m][k],A[k][n],A[m][n]);}
}
1.dgeqrt(A[0][0],T[0][0]);2.dlar+(A[0][0],T[0][0],A[0][1]);3.dlar+(A[0][0],T[0][0],A[0][2]);4.dlar+(A[0][0],T[0][0],A[0][3]);
V A
dgeqrt0
TR
dlarB0,3dlarB0,2dlarB0,1
Julien Langou | University of Colorado Denver Hierarchical QR | 52 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
for(k=0;k<TILES;k++){dgeqrt(A[k][k],T[k][k]);for(n=k+1;n<TILES;n++){ dlar+(A[k][k],T[k][k],A[k][n]);for(m=k+1;m<TILES;m++){ dtsqrt(A[k][k],A[m][k],T[m][k]); for(n=k+1;n<TILES;n++) dssr+(A[m][k],T[m][k],A[k][n],A[m][n]);}
}
1.dgeqrt(A[0][0],T[0][0]);2.dlar+(A[0][0],T[0][0],A[0][1]);3.dlar+(A[0][0],T[0][0],A[0][2]);4.dlar+(A[0][0],T[0][0],A[0][3]);
V A
dgeqrt0
TR
dlarB0,3dlarB0,2dlarB0,1
Julien Langou | University of Colorado Denver Hierarchical QR | 53 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
for(k=0;k<TILES;k++){dgeqrt(A[k][k],T[k][k]);for(n=k+1;n<TILES;n++){ dlar+(A[k][k],T[k][k],A[k][n]);for(m=k+1;m<TILES;m++){ dtsqrt(A[k][k],A[m][k],T[m][k]); for(n=k+1;n<TILES;n++) dssr+(A[m][k],T[m][k],A[k][n],A[m][n]);}
}
1.dgeqrt(A[0][0],T[0][0]);2.dlar+(A[0][0],T[0][0],A[0][1]);3.dlar+(A[0][0],T[0][0],A[0][2]);4.dlar+(A[0][0],T[0][0],A[0][3]);5.dtsqrt(A[0][0],A[1][0],T[1][0]);
dgeqrt0
dlarB0,3dlarB0,2dlarB0,1
V
R
A
TR
dtsqrt1,0
Julien Langou | University of Colorado Denver Hierarchical QR | 54 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
for(k=0;k<TILES;k++){dgeqrt(A[k][k],T[k][k]);for(n=k+1;n<TILES;n++){ dlar+(A[k][k],T[k][k],A[k][n]);for(m=k+1;m<TILES;m++){ dtsqrt(A[k][k],A[m][k],T[m][k]); for(n=k+1;n<TILES;n++) dssr+(A[m][k],T[m][k],A[k][n],A[m][n]);}
}
1.dgeqrt(A[0][0],T[0][0]);2.dlar+(A[0][0],T[0][0],A[0][1]);3.dlar+(A[0][0],T[0][0],A[0][2]);4.dlar+(A[0][0],T[0][0],A[0][3]);5.dtsqrt(A[0][0],A[1][0],T[1][0]);
dgeqrt0
dlarB0,3dlarB0,2dlarB0,1
V
R
A
TR
dtsqrt1,0
Julien Langou | University of Colorado Denver Hierarchical QR | 55 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
for(k=0;k<TILES;k++){dgeqrt(A[k][k],T[k][k]);for(n=k+1;n<TILES;n++){ dlar+(A[k][k],T[k][k],A[k][n]);for(m=k+1;m<TILES;m++){ dtsqrt(A[k][k],A[m][k],T[m][k]); for(n=k+1;n<TILES;n++) dssr+(A[m][k],T[m][k],A[k][n],A[m][n]);}
}
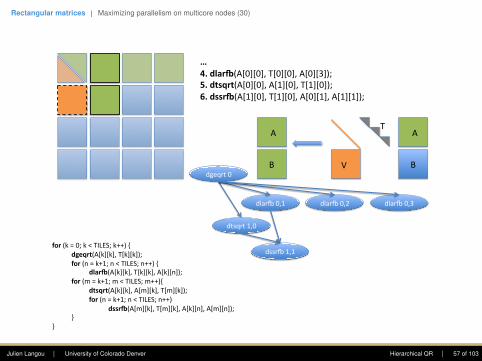
…4.dlar+(A[0][0],T[0][0],A[0][3]);5.dtsqrt(A[0][0],A[1][0],T[1][0]);6.dssr+(A[1][0],T[1][0],A[0][1],A[1][1]);
dgeqrt0
dlarB0,3dlarB0,2dlarB0,1
V
A
B
T
dtsqrt1,0
A
B
dssrB1,1
Julien Langou | University of Colorado Denver Hierarchical QR | 56 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
for(k=0;k<TILES;k++){dgeqrt(A[k][k],T[k][k]);for(n=k+1;n<TILES;n++){ dlar+(A[k][k],T[k][k],A[k][n]);for(m=k+1;m<TILES;m++){ dtsqrt(A[k][k],A[m][k],T[m][k]); for(n=k+1;n<TILES;n++) dssr+(A[m][k],T[m][k],A[k][n],A[m][n]);}
}
…4.dlar+(A[0][0],T[0][0],A[0][3]);5.dtsqrt(A[0][0],A[1][0],T[1][0]);6.dssr+(A[1][0],T[1][0],A[0][1],A[1][1]);
dgeqrt0
dlarB0,3dlarB0,2dlarB0,1
V
A
B
T
dtsqrt1,0
A
B
dssrB1,1
Julien Langou | University of Colorado Denver Hierarchical QR | 57 of 103
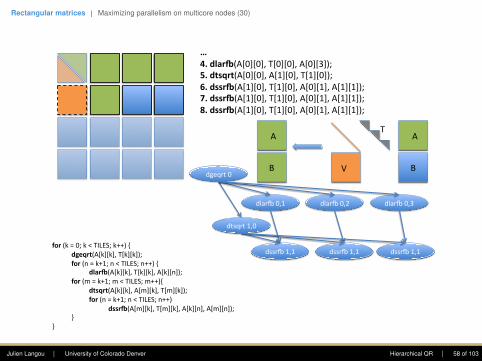
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
for(k=0;k<TILES;k++){dgeqrt(A[k][k],T[k][k]);for(n=k+1;n<TILES;n++){ dlar+(A[k][k],T[k][k],A[k][n]);for(m=k+1;m<TILES;m++){ dtsqrt(A[k][k],A[m][k],T[m][k]); for(n=k+1;n<TILES;n++) dssr+(A[m][k],T[m][k],A[k][n],A[m][n]);}
}
…4.dlar+(A[0][0],T[0][0],A[0][3]);5.dtsqrt(A[0][0],A[1][0],T[1][0]);6.dssr+(A[1][0],T[1][0],A[0][1],A[1][1]);7.dssr+(A[1][0],T[1][0],A[0][1],A[1][1]);8.dssr+(A[1][0],T[1][0],A[0][1],A[1][1]);
dgeqrt0
dlarB0,3dlarB0,2dlarB0,1
V
A
B
T
dtsqrt1,0
A
B
dssrB1,1 dssrB1,1 dssrB1,1
Julien Langou | University of Colorado Denver Hierarchical QR | 58 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
the input. The T matrix is stored separately.
DTSQRT: The kernel performs the QR factoriza-tion of a matrix built by coupling the R factor,produced by DGEQRT or a previous call to DT-SQRT, with a tile below the diagonal tile. Thekernel produces an updated R factor, a squarematrix V containing the Householder reflectorsand the matrix T resulting from accumulatingthe reflectors V . The new R factor overrides theold R factor. The block of reflectors overridesthe square tile of the input matrix. The T ma-trix is stored separately.
DLARFB: The kernel applies the reflectors calcu-lated by DGEQRT to a tile to the right of thediagonal tile, using the reflectors V along withthe matrix T .
DSSRFB: The kernel applies the reflectors calcu-lated by DTSQRT to two tiles to the right of thetiles factorized by DTSQRT, using the reflectorsV and the matrix T produced by DTSQRT.
Naive implementation, where the full T matrixis built, results in 25 % more floating point opera-tions than the standard algorithm. In order to mini-mize this overhead, the idea of inner-blocking is used,where the T matrix has sparse (block-diagonal) struc-ture (Figure 10) [32, 33, 34].
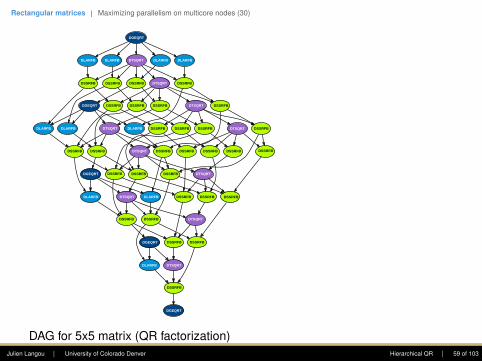
Figure 10: Inner blocking in the tile QR factorization.
Figure 11 shows the pseudocode of the tile QR fac-torization. Figure 12 shows the task graph of the tileQR factorization for a matrix of 5⇥5 tiles. Orders ofmagnitude larger matrices are used in practice. Thisexample only serves the purpose of showing the com-plexity of the task graph, which is noticeably higherthan that of Cholesky factorization.
Figure 11: Pseudocode of the tile QR factorization.
DGEQRT
DGEQRT
DGEQRT
DGEQRT
DGEQRT
DLARFBDLARFB DLARFB DLARFB
DLARFB DLARFB DLARFB
DLARFB DLARFB
DLARFB
DTSQRT
DTSQRT
DTSQRT
DTSQRTDTSQRT
DTSQRT
DTSQRT
DTSQRT
DTSQRT
DTSQRT
DSSRFBDSSRFB DSSRFB DSSRFB
DSSRFB DSSRFB DSSRFB DSSRFB
DSSRFB DSSRFB DSSRFB DSSRFB
DSSRFB DSSRFB DSSRFB DSSRFB DSSRFB DSSRFB DSSRFB
DSSRFB DSSRFB DSSRFB
DSSRFB DSSRFB DSSRFB
DSSRFB DSSRFB
DSSRFB DSSRFB
DSSRFB
Figure 12: Task graph of the tile QR factorization(matrix of size 5 ⇥ 5 tiles).
10
DAG for 5x5 matrix (QR factorization)Julien Langou | University of Colorado Denver Hierarchical QR | 59 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
f o r ( i = 0 ; i < p ; i ++ ) {DSCHED dpotrf ( dsched , ’L ’ , nb [ i ] , A[ i ] [ i ] , nb [ i ] , i n f o ) ;f o r ( j = i +1 ; j < p ; j ++ )
DSCHED dtrsm ( dsched , ’R ’ , ’L ’ , ’T ’ , ’N’ , nb [ j ] , nb [ i ] , 1 . 0 , A[ i ] [ i ] , nb [ i ] , A[ j ] [ i ] , nb [ j ] ) ;f o r ( j = i +1 ; j < p ; j ++ ) {
f o r ( k = i +1 ; k < j ; k++ ) {DSCHED dgemm( dsched , ’N’ , ’T ’ , nb [ j ] , nb [ k ] , nb [ i ] , �1, A[ j ] [ i ] , nb [ j ] , A[ k ] [ i ] , nb [ k ] , 1 , A[ j ] [ k ] , nb [ j ] ) ;
DSCHED dsyrk ( dsched , ’L ’ , ’N’ , nb [ j ] , nb [ i ] , �1.0 , A[ j ] [ i ] , nb [ j ] , + 1 . 0 , A[ j ] [ j ] , nb [ j ] ) ;}}
Fig. 9. Tile Cholesky factorization that calls the scheduled core linear algebra operations.
1 :1
2 : 2 0
1 0 : 5 8
1 1 : 7 4
1 2 : 7 4
1 3 : 7 5
1 4 : 9 0
3 : 2 0
1 5 : 9 0
1 6 : 9 1
1 7 : 1 0 5
1 8 : 1 0 5
1 9 : 1 0 6
2 0 : 1 1 9
2 1 : 1 1 8
2 2 : 1 0 0
2 3 : 1 1 1
2 4 : 9 3
2 5 : 9 3
4 : 2 1
2 6 : 8 7
2 7 : 8 6
2 8 : 7 1
2 9 : 8 0
3 0 : 6 5
3 1 : 6 5
3 2 : 6 0
3 3 : 5 9
3 4 : 4 7
3 5 : 5 4
3 6 : 4 2
5 : 3 9
3 7 : 4 2
3 8 : 3 8
3 9 : 3 7
4 0 : 2 8
4 1 : 3 3
4 2 : 2 4
4 3 : 2 4
4 4 : 2 1
4 5 : 2 0
4 6 : 1 4
4 7 : 1 7
6 : 3 9
4 8 : 1 1
4 9 : 1 1
5 0 : 9
5 1 : 8
5 2 : 5
5 3 : 6
5 4 : 3
5 5 : 3
5 6 : 2
5 7 : 1
5 8 : 1
7 : 4 0
8 : 5 7
9 : 5 7
Fig. 10. DAG for a LU factorization with 20 tiles (block size 200and matrix size 4000). The size of the DAG grows very fast with thenumber of tiles.
more tasks until some are completed. The usage of awindow of tasks has implications in how the loops of anapplication are unfolded and how much look ahead isavailable to the scheduler. This paper discusses some ofthese implication in the context of dense linear algebraapplications.
d) Data Locality and Cache Reuse: It has beenshown in the past that the reuse of memory cachescan lead to a substantial performance improvement inexecution time. Since we are working with tiles of datathat should fit in the local caches on each core, wehave provided the algorithm designer with the abilityto hint the cache locality behavior. A parameter in a call(e.g., Fig. 7) can be decorated with the LOCALITYflag in order to tell the scheduler that the data item(parameter) should be kept in cache if possible. Aftera computational core (worker) executes that task, thescheduler will assign by-default any future task usingthat data item to the same core. Note that the workstealing can disrupt the by-default assignment of tasksto cores.
The next section studies the performance impact ofthe locality flag and the window size on the LL and RLvariants of the three tile factorizations.
V. EXPERIMENTAL RESULTS
This section describes the analysis of dynamicallyscheduled tile algorithms for the three factorizations (i.e.,Cholesky, QR and LU) on different multicore systems.The tile sizes for these algorithm have been tuned and
are equal to b = 200.
A. Hardware Descriptions
In this study, we consider two different shared memoryarchitectures. The first architecture (System A) is aquad-socket, quad-core machine based on an Intel XeonEMT64 E7340 processor operating at 2.39 GHz. Thetheoretical peak is equal to 9.6 Gflops/s per core or 153.2Gflops/s for the whole node, composed of 16 cores. Thepractical peak (mesured by the performance of a GEMM)is equal to 8.5 Gflops/s per core or 136 Gflops/s forthe 16 cores. The level-1 cache, local to the core, isdivided into 32 kB of instruction cache and 32 kB of datacache. Each quad-core processor is actually composed oftwo dual-core Core2 architectures and the level-2 cachehas 2⇥4 MB per socket (each dual-core shares 4 MB).The machine is a NUMA architecture and it providesIntel Compilers 11.0 together with the MKL 10.1 vendorlibrary.
The second system (System B) is an 8 sockets, 6core AMD Opteron 8439 SE Processor (48 cores total@ 2.8Ghz) with 128 Gb of main memory. Each corehas a theoretical peak of 11.2 Gflops/s and the wholemachine 537.6 Gflops/s. The practical peak (mesured bythe performance of a GEMM) is equal to 9.5 Gflops/sper core or 456 Gflops/s for the 48 cores. There arethree levels of cache. The level-1 cache consist of 64kB and the level-2 cache consist of 512 kB. Each socketis composed of 6 cores and the level-3 cache has 6 MB48-way associative shared cache per socket. The machineis a NUMA architecture and it provides Intel Compilers11.1 together with the MKL 10.2 vendor library.
B. Performance Discussions
In this section, we evaluate the effect of the windowsize and the locality feature on the LL and RL tilealgorithm variants.
The nested-loops describing the tile LL variant codesare naturally ordered in a way that already promoteslocality on the data tiles located on the panel. Fig. 11shows the effect of the locality flag of the scheduleron the overall performance of the tile LL Choleskyvariant. As expected, the locality flag does not reallyimprove the performances when using small window
DAG for 20x20 matrix (QR factorization)
f o r ( i = 0 ; i < p ; i ++ ) {DSCHED dpotrf ( dsched , ’L ’ , nb [ i ] , A[ i ] [ i ] , nb [ i ] , i n f o ) ;f o r ( j = i +1 ; j < p ; j ++ )
DSCHED dtrsm ( dsched , ’R ’ , ’L ’ , ’T ’ , ’N’ , nb [ j ] , nb [ i ] , 1 . 0 , A[ i ] [ i ] , nb [ i ] , A[ j ] [ i ] , nb [ j ] ) ;f o r ( j = i +1 ; j < p ; j ++ ) {
f o r ( k = i +1 ; k < j ; k++ ) {DSCHED dgemm( dsched , ’N’ , ’T ’ , nb [ j ] , nb [ k ] , nb [ i ] , �1, A[ j ] [ i ] , nb [ j ] , A[ k ] [ i ] , nb [ k ] , 1 , A[ j ] [ k ] , nb [ j ] ) ;
DSCHED dsyrk ( dsched , ’L ’ , ’N’ , nb [ j ] , nb [ i ] , �1.0 , A[ j ] [ i ] , nb [ j ] , + 1 . 0 , A[ j ] [ j ] , nb [ j ] ) ;}}
Fig. 9. Tile Cholesky factorization that calls the scheduled core linear algebra operations.
1 :1
2 : 2 0
1 0 : 5 8
1 1 : 7 4
1 2 : 7 4
1 3 : 7 5
1 4 : 9 0
3 : 2 0
1 5 : 9 0
1 6 : 9 1
1 7 : 1 0 5
1 8 : 1 0 5
1 9 : 1 0 6
2 0 : 1 1 9
2 1 : 1 1 8
2 2 : 1 0 0
2 3 : 1 1 1
2 4 : 9 3
2 5 : 9 3
4 : 2 1
2 6 : 8 7
2 7 : 8 6
2 8 : 7 1
2 9 : 8 0
3 0 : 6 5
3 1 : 6 5
3 2 : 6 0
3 3 : 5 9
3 4 : 4 7
3 5 : 5 4
3 6 : 4 2
5 : 3 9
3 7 : 4 2
3 8 : 3 8
3 9 : 3 7
4 0 : 2 8
4 1 : 3 3
4 2 : 2 4
4 3 : 2 4
4 4 : 2 1
4 5 : 2 0
4 6 : 1 4
4 7 : 1 7
6 : 3 9
4 8 : 1 1
4 9 : 1 1
5 0 : 9
5 1 : 8
5 2 : 5
5 3 : 6
5 4 : 3
5 5 : 3
5 6 : 2
5 7 : 1
5 8 : 1
7 : 4 0
8 : 5 7
9 : 5 7
Fig. 10. DAG for a LU factorization with 20 tiles (block size 200and matrix size 4000). The size of the DAG grows very fast with thenumber of tiles.
more tasks until some are completed. The usage of awindow of tasks has implications in how the loops of anapplication are unfolded and how much look ahead isavailable to the scheduler. This paper discusses some ofthese implication in the context of dense linear algebraapplications.
d) Data Locality and Cache Reuse: It has beenshown in the past that the reuse of memory cachescan lead to a substantial performance improvement inexecution time. Since we are working with tiles of datathat should fit in the local caches on each core, wehave provided the algorithm designer with the abilityto hint the cache locality behavior. A parameter in a call(e.g., Fig. 7) can be decorated with the LOCALITYflag in order to tell the scheduler that the data item(parameter) should be kept in cache if possible. Aftera computational core (worker) executes that task, thescheduler will assign by-default any future task usingthat data item to the same core. Note that the workstealing can disrupt the by-default assignment of tasksto cores.
The next section studies the performance impact ofthe locality flag and the window size on the LL and RLvariants of the three tile factorizations.
V. EXPERIMENTAL RESULTS
This section describes the analysis of dynamicallyscheduled tile algorithms for the three factorizations (i.e.,Cholesky, QR and LU) on different multicore systems.The tile sizes for these algorithm have been tuned and
are equal to b = 200.
A. Hardware Descriptions
In this study, we consider two different shared memoryarchitectures. The first architecture (System A) is aquad-socket, quad-core machine based on an Intel XeonEMT64 E7340 processor operating at 2.39 GHz. Thetheoretical peak is equal to 9.6 Gflops/s per core or 153.2Gflops/s for the whole node, composed of 16 cores. Thepractical peak (mesured by the performance of a GEMM)is equal to 8.5 Gflops/s per core or 136 Gflops/s forthe 16 cores. The level-1 cache, local to the core, isdivided into 32 kB of instruction cache and 32 kB of datacache. Each quad-core processor is actually composed oftwo dual-core Core2 architectures and the level-2 cachehas 2⇥4 MB per socket (each dual-core shares 4 MB).The machine is a NUMA architecture and it providesIntel Compilers 11.0 together with the MKL 10.1 vendorlibrary.
The second system (System B) is an 8 sockets, 6core AMD Opteron 8439 SE Processor (48 cores total@ 2.8Ghz) with 128 Gb of main memory. Each corehas a theoretical peak of 11.2 Gflops/s and the wholemachine 537.6 Gflops/s. The practical peak (mesured bythe performance of a GEMM) is equal to 9.5 Gflops/sper core or 456 Gflops/s for the 48 cores. There arethree levels of cache. The level-1 cache consist of 64kB and the level-2 cache consist of 512 kB. Each socketis composed of 6 cores and the level-3 cache has 6 MB48-way associative shared cache per socket. The machineis a NUMA architecture and it provides Intel Compilers11.1 together with the MKL 10.2 vendor library.
B. Performance Discussions
In this section, we evaluate the effect of the windowsize and the locality feature on the LL and RL tilealgorithm variants.
The nested-loops describing the tile LL variant codesare naturally ordered in a way that already promoteslocality on the data tiles located on the panel. Fig. 11shows the effect of the locality flag of the scheduleron the overall performance of the tile LL Choleskyvariant. As expected, the locality flag does not reallyimprove the performances when using small window
Julien Langou | University of Colorado Denver Hierarchical QR | 60 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
0 500 1000 1500 2000 2500 3000 3500 40000
20
40
60
80
100
120
140
160
180
200Tile QR Factorization −− 3.2 GHz CELL Processor
Matrix Size
Gflo
p/s
SSSRFB PeakTile QR
Figure 5: Performance of the tile QR factorization in single precision on a 3.2GHz CELL processor with eight SPEs. Square matrices were used. The solidhorizontal line marks performance of the SSSRFB kernel times the numberof SPEs (22.16 × 8 = 177 [Gflop/s]).
28
Performance of the tile QR factorization in single precision on a 3.2 GHz CELL processor with eight SPEs. Square matrices were used. Solid horizontal linemarks performance of the SSSRFB kernel times the number of SPEs (22.16 × 8 = 177 [Gflop/s]).“The presented implementation of tile QR factorization on the CELL processor allows for factorization of a 4000–by–4000 dense matrix in single precision inexactly half of a second. To the author’s knowledge, at present, it is the fastest reported time of solving such problem by any semiconductor deviceimplemented on a single semiconductor die.”
Jakub Kurzak and Jack Dongarra, LAWN 201 – QR Factorization for the CELLProcessor, May 2008.
Julien Langou | University of Colorado Denver Hierarchical QR | 61 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Perform the QR factorization of an initial tiled matrix A.
time
Our tool:
Givens’ rotations:(cos θ − sin θsin θ cos θ
)
Julien Langou | University of Colorado Denver Hierarchical QR | 62 of 103
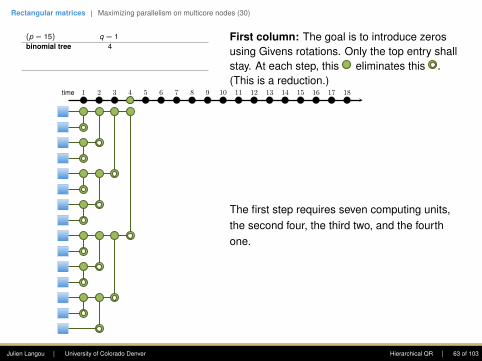
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
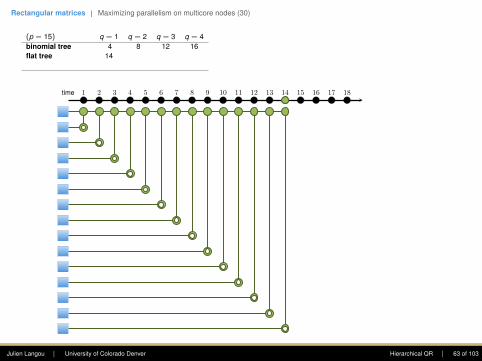
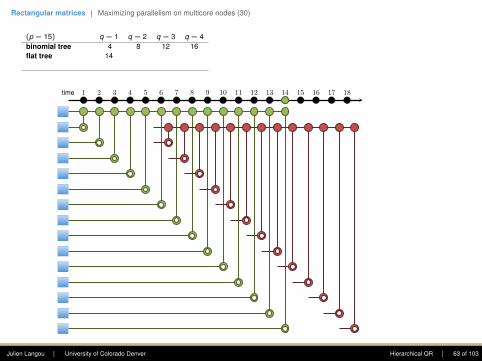
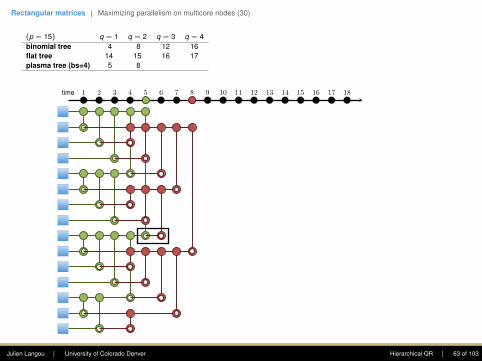
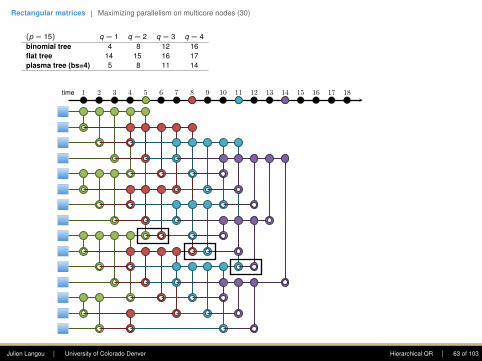
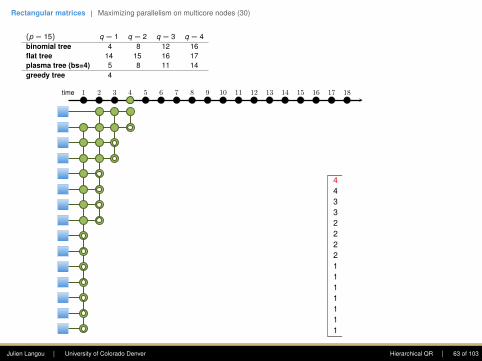
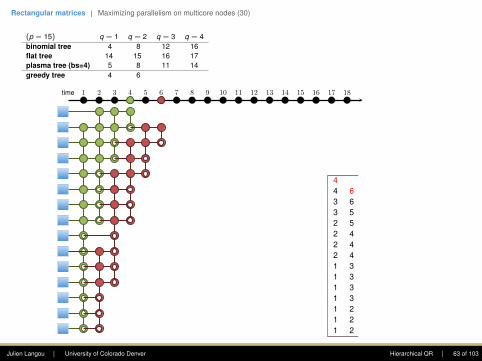
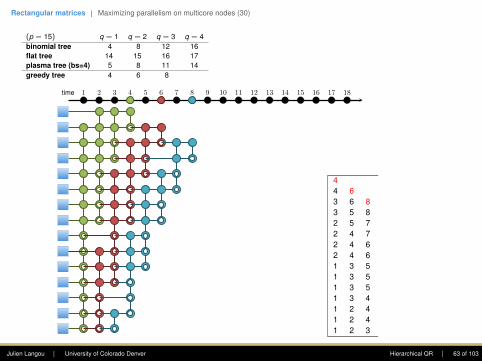
(p = 15) q = 1
q = 2 q = 3 q = 4
binomial tree 4
8 12 16flat tree 14 15 16 17plasma tree (bs=4) 5 8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.
Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1
q = 2 q = 3 q = 4
binomial tree 4
8 12 16
flat tree 14
15 16 17plasma tree (bs=4) 5 8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2
q = 3 q = 4
binomial tree 4
8 12 16
flat tree 14
15 16 17plasma tree (bs=4) 5 8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2
q = 3 q = 4
binomial tree 4 8
12 16
flat tree 14
15 16 17plasma tree (bs=4) 5 8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2
q = 3 q = 4
binomial tree 4 8
12 16
flat tree 14
15 16 17plasma tree (bs=4) 5 8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103
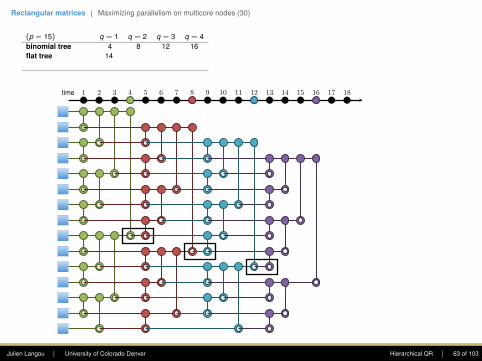
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14
15 16 17plasma tree (bs=4) 5 8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14
15 16 17plasma tree (bs=4) 5 8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14
15 16 17plasma tree (bs=4) 5 8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14 15
16 17plasma tree (bs=4) 5 8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14 15 16 17
plasma tree (bs=4) 5 8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14 15 16 17plasma tree (bs=4) 5
8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.
Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14 15 16 17plasma tree (bs=4) 5
8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14 15 16 17plasma tree (bs=4) 5 8
11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14 15 16 17plasma tree (bs=4) 5 8 11 14
greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14 15 16 17plasma tree (bs=4) 5 8 11 14greedy tree 4
6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14 15 16 17plasma tree (bs=4) 5 8 11 14greedy tree 4 6
8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14 15 16 17plasma tree (bs=4) 5 8 11 14greedy tree 4 6 8
10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14 15 16 17plasma tree (bs=4) 5 8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
(p = 15) q = 1 q = 2 q = 3 q = 4binomial tree 4 8 12 16flat tree 14 15 16 17plasma tree (bs=4) 5 8 11 14greedy tree 4 6 8 10
First column: The goal is to introduce zerosusing Givens rotations. Only the top entry shallstay. At each step, this eliminates this .(This is a reduction.)
The first step requires seven computing units,the second four, the third two, and the fourthone.Note: one point of the plasma tree is to (1)enhance parallelism in the rectangular case, (2)increase data locality (when working within adomain).
44 63 6 83 5 8 102 5 7 102 4 7 92 4 6 92 4 6 81 3 5 81 3 5 71 3 5 71 3 4 61 2 4 61 2 4 51 2 3 5
• Flat tree - Sameh and Kuck (1978).
• Plasma tree - Hadri et al. (2010). Note: thatbinomial tree corresponds to bs = 1, andflat tree to bs = p.
• Greedy - Modi and Clarke (1984), Cosnardand Robert (1986).
• Cosnard and Robert (1986) proved that nomatter the shape of the matrix (i.e., p andq), Greedy was optimal.
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 63 of 103
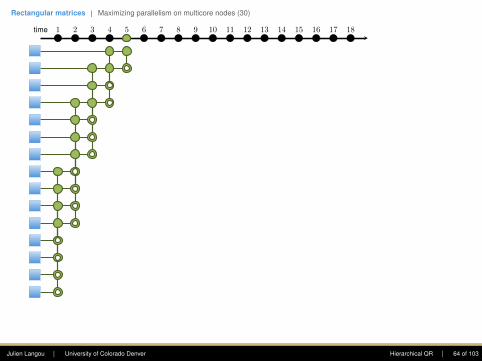
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 64 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 65 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 66 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 67 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
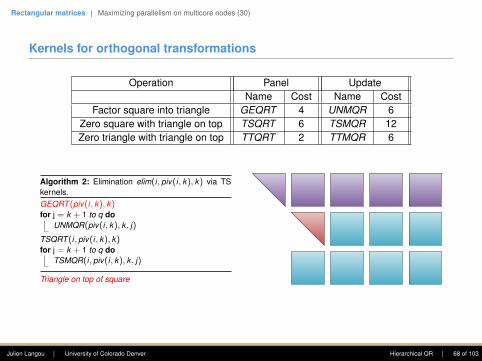
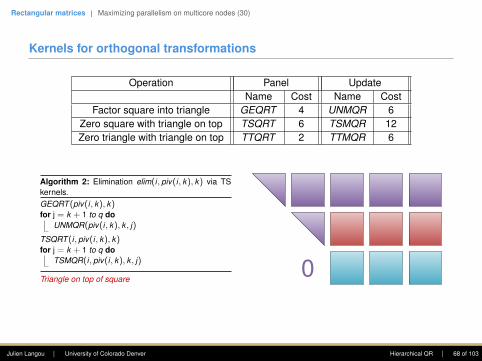
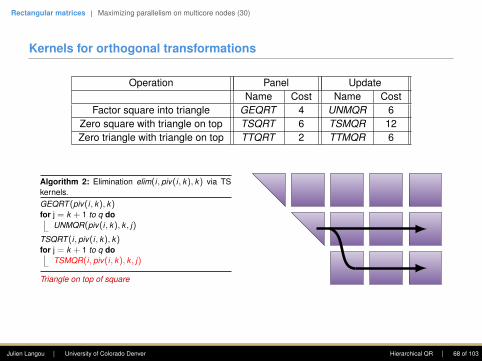
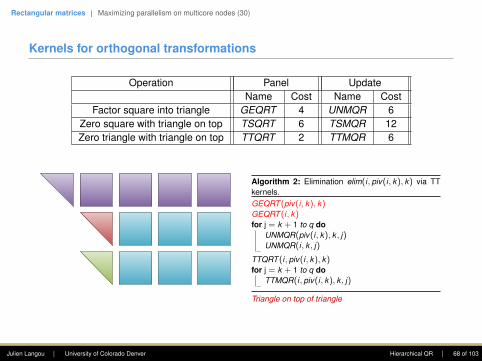
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 1: Elimination elim(i, piv(i, k), k) via TSkernels.GEQRT (piv(i, k), k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)
TSQRT (i, piv(i, k), k)for j = k + 1 to q do
TSMQR(i, piv(i, k), k , j)
Triangle on top of square
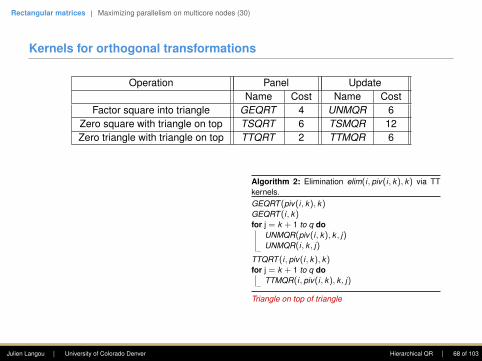
Algorithm 2: Elimination elim(i, piv(i, k), k) via TTkernels.GEQRT (piv(i, k), k)GEQRT (i, k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)UNMQR(i, k , j)
TTQRT (i, piv(i, k), k)for j = k + 1 to q do
TTMQR(i, piv(i, k), k , j)
Triangle on top of triangle
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
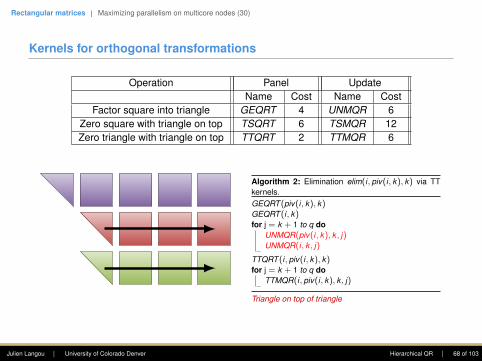
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 2: Elimination elim(i, piv(i, k), k) via TSkernels.GEQRT (piv(i, k), k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)
TSQRT (i, piv(i, k), k)for j = k + 1 to q do
TSMQR(i, piv(i, k), k , j)
Triangle on top of square
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 2: Elimination elim(i, piv(i, k), k) via TSkernels.GEQRT (piv(i, k), k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)
TSQRT (i, piv(i, k), k)for j = k + 1 to q do
TSMQR(i, piv(i, k), k , j)
Triangle on top of square
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 2: Elimination elim(i, piv(i, k), k) via TSkernels.GEQRT (piv(i, k), k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)
TSQRT (i, piv(i, k), k)for j = k + 1 to q do
TSMQR(i, piv(i, k), k , j)
Triangle on top of square
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 2: Elimination elim(i, piv(i, k), k) via TSkernels.GEQRT (piv(i, k), k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)
TSQRT (i, piv(i, k), k)for j = k + 1 to q do
TSMQR(i, piv(i, k), k , j)
Triangle on top of square
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 2: Elimination elim(i, piv(i, k), k) via TSkernels.GEQRT (piv(i, k), k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)
TSQRT (i, piv(i, k), k)for j = k + 1 to q do
TSMQR(i, piv(i, k), k , j)
Triangle on top of square0
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 2: Elimination elim(i, piv(i, k), k) via TSkernels.GEQRT (piv(i, k), k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)
TSQRT (i, piv(i, k), k)for j = k + 1 to q do
TSMQR(i, piv(i, k), k , j)
Triangle on top of square
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 2: Elimination elim(i, piv(i, k), k) via TTkernels.GEQRT (piv(i, k), k)GEQRT (i, k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)UNMQR(i, k , j)
TTQRT (i, piv(i, k), k)for j = k + 1 to q do
TTMQR(i, piv(i, k), k , j)
Triangle on top of triangle
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 2: Elimination elim(i, piv(i, k), k) via TTkernels.GEQRT (piv(i, k), k)GEQRT (i, k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)UNMQR(i, k , j)
TTQRT (i, piv(i, k), k)for j = k + 1 to q do
TTMQR(i, piv(i, k), k , j)
Triangle on top of triangle
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 2: Elimination elim(i, piv(i, k), k) via TTkernels.GEQRT (piv(i, k), k)GEQRT (i, k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)UNMQR(i, k , j)
TTQRT (i, piv(i, k), k)for j = k + 1 to q do
TTMQR(i, piv(i, k), k , j)
Triangle on top of triangle
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 2: Elimination elim(i, piv(i, k), k) via TTkernels.GEQRT (piv(i, k), k)GEQRT (i, k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)UNMQR(i, k , j)
TTQRT (i, piv(i, k), k)for j = k + 1 to q do
TTMQR(i, piv(i, k), k , j)
Triangle on top of triangle
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 2: Elimination elim(i, piv(i, k), k) via TTkernels.GEQRT (piv(i, k), k)GEQRT (i, k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)UNMQR(i, k , j)
TTQRT (i, piv(i, k), k)for j = k + 1 to q do
TTMQR(i, piv(i, k), k , j)
Triangle on top of triangle
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
0
Algorithm 2: Elimination elim(i, piv(i, k), k) via TTkernels.GEQRT (piv(i, k), k)GEQRT (i, k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)UNMQR(i, k , j)
TTQRT (i, piv(i, k), k)for j = k + 1 to q do
TTMQR(i, piv(i, k), k , j)
Triangle on top of triangle
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103
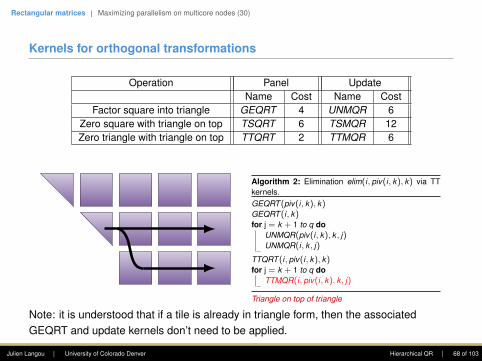
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 2: Elimination elim(i, piv(i, k), k) via TTkernels.GEQRT (piv(i, k), k)GEQRT (i, k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)UNMQR(i, k , j)
TTQRT (i, piv(i, k), k)for j = k + 1 to q do
TTMQR(i, piv(i, k), k , j)
Triangle on top of triangle
Note: it is understood that if a tile is already in triangle form, then the associatedGEQRT and update kernels don’t need to be applied.
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103
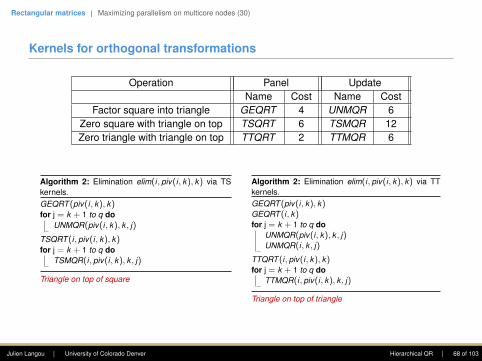
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Kernels for orthogonal transformations
Operation Panel UpdateName Cost Name Cost
Factor square into triangle GEQRT 4 UNMQR 6Zero square with triangle on top TSQRT 6 TSMQR 12Zero triangle with triangle on top TTQRT 2 TTMQR 6
Algorithm 2: Elimination elim(i, piv(i, k), k) via TSkernels.GEQRT (piv(i, k), k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)
TSQRT (i, piv(i, k), k)for j = k + 1 to q do
TSMQR(i, piv(i, k), k , j)
Triangle on top of square
Algorithm 2: Elimination elim(i, piv(i, k), k) via TTkernels.GEQRT (piv(i, k), k)GEQRT (i, k)for j = k + 1 to q do
UNMQR(piv(i, k), k , j)UNMQR(i, k , j)
TTQRT (i, piv(i, k), k)for j = k + 1 to q do
TTMQR(i, piv(i, k), k , j)
Triangle on top of triangle
Julien Langou | University of Colorado Denver Hierarchical QR | 68 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
The analysis and coding is a little more complex ...time 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80 82 84 86 88 90 92 94 96 98 100 102 104 106 108 110 112 114 116 118 120 122 124 126 128 130 132 134 136 138 140 142
Julien Langou | University of Colorado Denver Hierarchical QR | 69 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
TheoremNo matter what elimination list (any combination of TT, TS) is used the totalweight of the tasks for performing a tiled QR factorization algorithm is constantand equal to 6pq2 − 2q3.
Proof:
L1 :: GEQRT = TTQRT + q
L2 :: UNMQRT = TTMQRT + (1/2)q(q − 1)
L3 :: TTQRT + TSQRT = pq − (1/2)q(q + 1)
L4 :: TTMQR + TSMQR = (1/2)pq(q − 1) − (1/6)q(q − 1)(q + 1)
Define L5 as 4L1 + 6L2 + 6L3 + 12L4 and we get
L5 :: 6pq2 − 2q3 = 4GEQRT + 12TSMQRT + 6TTMQRT + 2TTQRT + 6TSQRT + 6UNMQRT
L5 :: = total # of flops
Note: Using our unit task weight of b3/3, with m = pb, and n = qb, we obtain 2mn2 − 2/3n3 flopswhich is the exact same number as for a standard Householder reflection algorithm as found inLAPACK or ScaLAPACK.
Julien Langou | University of Colorado Denver Hierarchical QR | 70 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
TheoremFor a tiled matrix of size p × q, where p ≥ q. The critical path length ofFLATTREE is
2p + 2 if p ≥ q = 1
6p + 16q − 22 if p > q > 1
22p − 24 if p = q > 1
time 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64
2nd Row 3rd Row 4th Row 2nd Column 3nd Column
Initial: 10 Fill the pipeline: 6(p− 1) Pipeline: 16(q − 2) End: 4
Julien Langou | University of Colorado Denver Hierarchical QR | 71 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Greedy tree on a 15x4 matrix. (Weighted on top, coarse below.)time 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80 82 84 86 88 90 92 94 96 98 100 102 104 106 108 110 112 114 116 118 120 122 124 126 128 130 132
time 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Julien Langou | University of Colorado Denver Hierarchical QR | 72 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
TheoremFor a tiled matrix of size p × q, where p ≥ q. Given the time for any coarsegrain algorithm, COARSE(p,q), the corresponding weighted algorithm timeWEIGHTED(p,q) is
10 ∗ (q − 1) + 6 ∗ COARSE(p, q − 1) + 4 + 2 ≤ WEIGHTED(p, q)
≤ 10∗(q−1)+6∗COARSE(p, q−1)+4+2∗(COARSE(p, q)−COARSE(p, q−1))
Julien Langou | University of Colorado Denver Hierarchical QR | 73 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
TheoremWe can prove that the GRASAP algorithm is optimal.
Julien Langou | University of Colorado Denver Hierarchical QR | 74 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Platform
All experiments were performed on a 48-core machine composed of eighthexa-core AMD Opteron 8439 SE (codename Istanbul) processors running at2.8 GHz. Each core has a theoretical peak of 11.2 Gflop/s with a peak of 537.6Gflop/s for the whole machine.
Experimental code is written using the QUARK scheduler.
Results are tested with ‖I − QT Q‖ and ‖A− QR‖/‖A‖. Code has beenwritten in real and complex arithmetic, single and double precision.
Julien Langou | University of Colorado Denver Hierarchical QR | 75 of 103
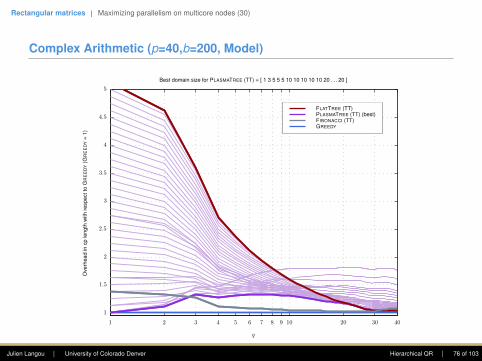
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Complex Arithmetic (p=40,b=200, Model)
FLATTREE (TT)PLASMATREE (TT) (best)FIBONACCI (TT)GREEDY
Best domain size for PLASMATREE (TT) = [ 1 3 5 5 5 10 10 10 10 10 20 . . . 20 ]O
verh
ea
din
cp
len
gth
with
resp
ectto
GR
EE
DY
(GR
EE
DY
=1
)
q
1 2 3 4 5 6 7 8 9 10 20 30 40
1
1.5
2
2.5
3
3.5
4
4.5
5
Julien Langou | University of Colorado Denver Hierarchical QR | 76 of 103
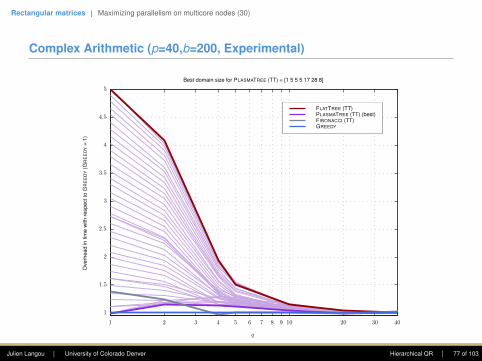
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Complex Arithmetic (p=40,b=200, Experimental)
FLATTREE (TT)PLASMATREE (TT) (best)FIBONACCI (TT)GREEDY
Best domain size for PLASMATREE (TT) = [1 5 5 5 17 28 8]O
verh
ea
din
tim
ew
ith
resp
ectto
GR
EE
DY
(GR
EE
DY
=1
)
q
1 2 3 4 5 6 7 8 9 10 20 30 40
1
1.5
2
2.5
3
3.5
4
4.5
5
Julien Langou | University of Colorado Denver Hierarchical QR | 77 of 103
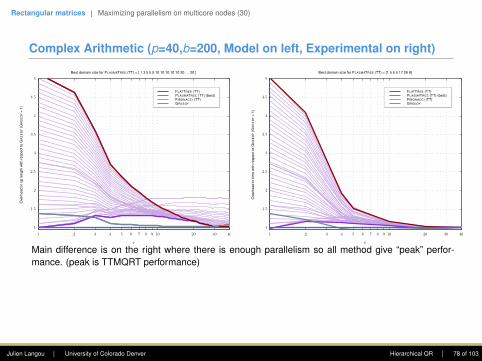
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Complex Arithmetic (p=40,b=200, Model on left, Experimental on right)
FLATTREE (TT)PLASMATREE (TT) (best)FIBONACCI (TT)GREEDY
Best domain size for PLASMATREE (TT) = [ 1 3 5 5 5 10 10 10 10 10 20 . . . 20 ]
Ove
rhe
ad
incp
len
gth
with
resp
ectto
GR
EE
DY
(GR
EE
DY
=1
)
q
1 2 3 4 5 6 7 8 9 10 20 30 40
1
1.5
2
2.5
3
3.5
4
4.5
5
FLATTREE (TT)PLASMATREE (TT) (best)FIBONACCI (TT)GREEDY
Best domain size for PLASMATREE (TT) = [1 5 5 5 17 28 8]
Ove
rhe
ad
intim
ew
ith
resp
ectto
GR
EE
DY
(GR
EE
DY
=1
)
q
1 2 3 4 5 6 7 8 9 10 20 30 40
1
1.5
2
2.5
3
3.5
4
4.5
5
Main difference is on the right where there is enough parallelism so all method give “peak” perfor-mance. (peak is TTMQRT performance)
Julien Langou | University of Colorado Denver Hierarchical QR | 78 of 103

Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Complex Arithmetic (p=40,b=200)
FLATTREE (TT)PLASMATREE (TT) (best)FIBONACCI (TT)GREEDY
Best domain size for PLASMATREE (TT) = [1 5 5 5 17 28 8]G
FL
OP
/s
q
1 2 3 4 5 6 7 8 9 10 20 30 400
20
40
60
80
100
120
140
160
Julien Langou | University of Colorado Denver Hierarchical QR | 79 of 103
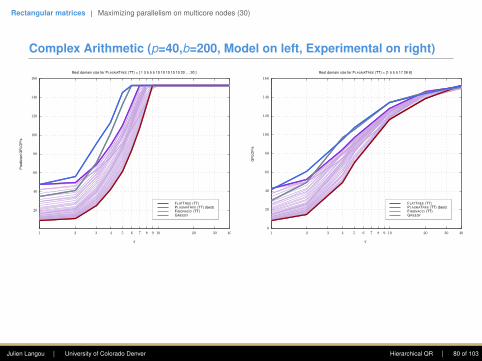
Rectangular matrices | Maximizing parallelism on multicore nodes (30)
Complex Arithmetic (p=40,b=200, Model on left, Experimental on right)
FLATTREE (TT)PLASMATREE (TT) (best)FIBONACCI (TT)GREEDY
Best domain size for PLASMATREE (TT) = [ 1 3 5 5 5 10 10 10 10 10 20 . . . 20 ]
Pre
dic
ted
GF
LO
P/s
q
1 2 3 4 5 6 7 8 9 10 20 30 40
20
40
60
80
100
120
140
160
FLATTREE (TT)PLASMATREE (TT) (best)FIBONACCI (TT)GREEDY
Best domain size for PLASMATREE (TT) = [1 5 5 5 17 28 8]
GF
LO
P/s
q
1 2 3 4 5 6 7 8 9 10 20 30 400
20
40
60
80
100
120
140
160
Julien Langou | University of Colorado Denver Hierarchical QR | 80 of 103

Rectangular matrices | Parallelism+communication on multicore nodes (2)
Outline
Tall and Skinny matricesMinimizing communication in parallel distributed (29)Minimizing communication in hierarchichal parallel distributed (6)Minimizing communication in sequential (1)
Rectangular matricesMinimizing communication in sequential (2)Maximizing parallelism on multicore nodes (30)Parallelism+communication on multicore nodes (2)Parallelism+communication on distributed+multicore nodes (13)Scheduling on multicore nodes (4)
Julien Langou | University of Colorado Denver Hierarchical QR | 81 of 103

Rectangular matrices | Parallelism+communication on multicore nodes (2)
Factor Kernelscode name # flops
GEQRT 4
TTQRT 2
TSQRT 6
• We work on square b-by-b tiles.• The unit for the task weights is b3/3.• Each of our tasks is O(b3) computation for O(b2) communication.• ⇒ Thanks to this surface/volume effect, we can neglect in a first
approximation communication and focus only on the parallelism.
Julien Langou | University of Colorado Denver Hierarchical QR | 82 of 103

Rectangular matrices | Parallelism+communication on multicore nodes (2)
Using TT KernelsGEQRT
GEQRT TTQRT
Total # of flops: (sequential time)
2 * GEQRT + TTQRT = 2 * 4 + 2 = 10
Critical Path Length: (parallel time)
GEQRT + TTQRT = 4 + 2 = 6
Using TS Kernels
GEQRT TSQRTTotal # of flops: (sequential time)
GEQRT + TSQRT = 4 + 6 = 10
Critical Path Length: (parallel time)
GEQRT + TSQRT = 4 + 2 = 10
One remarkable outcome is that the total number of flops is 10b3/3. If we consider the number offlops for a standard LAPACK algorithm (based on standard Householder transformation), we wouldalso obtain 10b3/3.
Julien Langou | University of Colorado Denver Hierarchical QR | 83 of 103

Rectangular matrices | Parallelism+communication on multicore nodes (2)
TSQRT (in)GEQRT (in)TTQRT (in)GEQRT +TTQRT (in)GEMM (in)TSQRT (out)GEQRT (out)TTQRT (out)GEQRT +TTQRT (out)GEMM (out)
GF
LO
P/s
tile size
100 200 300 400 500 6000
1
2
3
4
5
6
7
8
9
10
The TS kernels (factorization and update) are more efficient than the TT ones due a variety of reasons.(Better vectorization, better volume-to-surface ratio.)
Julien Langou | University of Colorado Denver Hierarchical QR | 84 of 103

Rectangular matrices | Parallelism+communication on multicore nodes (2)
Real Arithmetic (p=40,b=200, Model on left, Experimental on right)
FLATTREE (TS)PLASMATREE (TS) (best)FLATTREE (TT)PLASMATREE (TT) (best)FIBONACCI (TT)GREEDY
Best domain size for PLASMATREE (TS) = [ 1 1 1 1 5 5 5 5 5 5 10 ... 10 ]Best domain size for PLASMATREE (TT) = [ 1 3 5 5 5 10 10 10 10 10 20 ... 20 ]
Pre
dic
ted
GF
LO
P/s
q
1 2 3 4 5 6 7 8 9 10 20 30 40
50
100
150
200
250
FLATTREE (TS)PLASMATREE (TS) (best)FLATTREE (TT)PLASMATREE (TT) (best)FIBONACCI (TT)GREEDY
Best domain size for PLASMATREE (TS) = [1 3 6 11 12 18 32]Best domain size for PLASMATREE (TT) = [1 3 10 5 17 27 19]
GF
LO
P/s
q
1 2 3 4 5 6 7 8 9 10 20 30 400
50
100
150
200
250
⇒ Motivates the introduction of a TS-level. Square 1-by-1 tiles are grouped in a larger rectangulartiles of size a-by-1 which is eliminated in a TS fashion. The regular TT algorithm is then applied onthe rectangular tiles.
pros: recover performance of TS levelcons: introduce a tuning parameter (a)
Julien Langou | University of Colorado Denver Hierarchical QR | 85 of 103
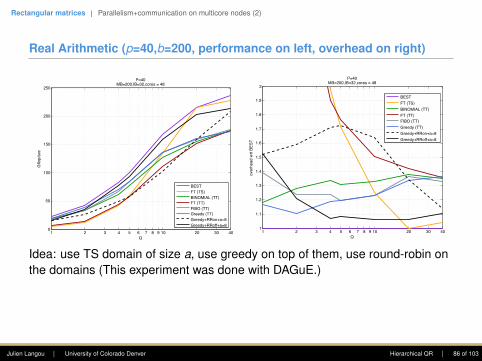
Rectangular matrices | Parallelism+communication on multicore nodes (2)
Real Arithmetic (p=40,b=200, performance on left, overhead on right)
1 2 3 4 5 6 7 8 9 10 20 30 400
50
100
150
200
250
Q
Gflo
p/se
c
P=40MB=200,IB=32,cores = 48
BESTFT (TS)BINOMIAL (TT)FT (TT)FIBO (TT)Greedy (TT)Greedy+RRon+a=8Greedy+RRoff+a=8
1 2 3 4 5 6 7 8 9 10 20 30 401
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Q
over
head
wrt
BEST
P=40MB=200,IB=32,cores = 48
BESTFT (TS)BINOMIAL (TT)FT (TT)FIBO (TT)Greedy (TT)Greedy+RRon+a=8Greedy+RRoff+a=8
Idea: use TS domain of size a, use greedy on top of them, use round-robin onthe domains (This experiment was done with DAGuE.)
Julien Langou | University of Colorado Denver Hierarchical QR | 86 of 103
Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Outline
Tall and Skinny matricesMinimizing communication in parallel distributed (29)Minimizing communication in hierarchichal parallel distributed (6)Minimizing communication in sequential (1)
Rectangular matricesMinimizing communication in sequential (2)Maximizing parallelism on multicore nodes (30)Parallelism+communication on multicore nodes (2)Parallelism+communication on distributed+multicore nodes (13)Scheduling on multicore nodes (4)
Julien Langou | University of Colorado Denver Hierarchical QR | 87 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Outline
Three goals:
1. minimize the number of local communication
2. minimize the number of parallel distributed communication
3. maximize the parallelism within a node
Julien Langou | University of Colorado Denver Hierarchical QR | 88 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Hierarchical trees
Julien Langou | University of Colorado Denver Hierarchical QR | 89 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Hierarchical trees
Julien Langou | University of Colorado Denver Hierarchical QR | 89 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Hierarchical trees
Julien Langou | University of Colorado Denver Hierarchical QR | 89 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Hierarchical algorithm layout
Global view Local view
LegendP0
P1
P2
0 local TS1 local TT2 domino3 global tree
Julien Langou | University of Colorado Denver Hierarchical QR | 90 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Outline
Three goals:
1. minimize the number of local communication
2. minimize the number of parallel distributed communication
3. maximize the parallelism within a node
Four hierarchical trees
1. TS level :: flat treeeliminate some tiles with TS kernels
2. node level :: flat/greedy/binary/fibonacci treeeliminate remaining non coupled tiles locally
3. local level :: domino treetake care of the coupling between local computation and distributedcomputations
4. distributed level :: flat/greedy/binary/fibonacci treehigh level, reduce tiles to one in parallel distributed
Julien Langou | University of Colorado Denver Hierarchical QR | 91 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Hierarchical trees
Julien Langou | University of Colorado Denver Hierarchical QR | 92 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Hierarchical trees
Julien Langou | University of Colorado Denver Hierarchical QR | 92 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Hierarchical trees
Julien Langou | University of Colorado Denver Hierarchical QR | 92 of 103
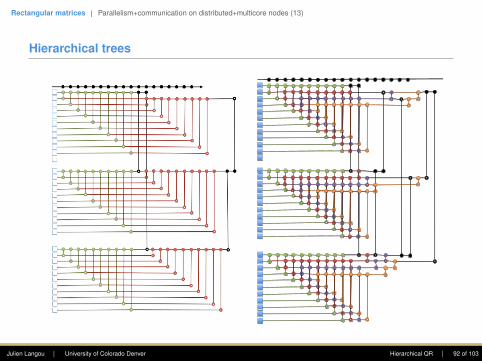
Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Hierarchical trees
Julien Langou | University of Colorado Denver Hierarchical QR | 92 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Platform
Cluster Edel from Grid5000, Grenoble• 60 nodes• 2 Nehalem Xeon E5520 at 2.27GHz per node (8 cores)• 24 GB per node• Infiniband 20G network• Theoretical peak performance:
◦ 9.08 GFlop/s per core◦ 72.64 GFlop/s per node◦ 4.358 TFlop/s for the whole machine
Julien Langou | University of Colorado Denver Hierarchical QR | 93 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Putting the results in perspective
Peak:Peak performance of a core is 9.08 GFlops/sec.x8 for a node gives 72.64 GFlops/sec.x60 for the parallel distributed platform gives 4358.4 Gflops/sec.Kernels: (one core)The TSMQR kernel performs at 7.21 GFlops/sec. (This is 79.41% of peak).The TTMQR kernel performs at 6.28 GFlops/sec. (This is 69.17% of peak).In shared memory on a node: (one node, eight cores)Flat tree TS gets 76.8% of peak with 55.83 GFlops/sec.Flat tree TT gets 66.4% of peak with 48.22 GFlops/sec.Our parallel distributed code: (sixty nodes, 480 cores)The parallel distributed on 60 nodes we top at 3 TFlop/sec, that’s 68.8% ofpeak.
Julien Langou | University of Colorado Denver Hierarchical QR | 94 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Influence of TS kernels and trees (N=4480)
0
500
1000
1500
2000
2500
4480 8960 17920 35840 71680 143360 286720
Pe
rfo
rma
nce
(G
Flo
p/s
)
M
High-Level Treea=1, greedya=4, greedy
a=8, greedya=1, binary
a=4, binarya=8, binary
0
500
1000
1500
2000
2500
4480 8960 17920 35840 71680 143360 286720
Pe
rfo
rma
nce
(G
Flo
p/s
)
M
High-Level Tree (continued)a=1, flata=4, flat
a=8, flata=1, fibonacci
a=4, fibonaccia=8, fibonacci
Influence of the TS level size with fixed local reduction tree.(Left: Greedy, Right: Flat)
Julien Langou | University of Colorado Denver Hierarchical QR | 95 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Influence of TS kernels and trees (N=4480)
0
500
1000
1500
2000
2500
4480 8960 17920 35840 71680 143360 286720
Pe
rfo
rma
nce
(G
Flo
p/s
)
M
High-Level Treea=1, greedya=4, greedy
a=8, greedya=1, binary
a=4, binarya=8, binary
0
500
1000
1500
2000
2500
4480 8960 17920 35840 71680 143360 286720
Pe
rfo
rma
nce
(G
Flo
p/s
)
M
High-Level Tree (continued)a=1, flata=4, flat
a=8, flata=1, fibonacci
a=4, fibonaccia=8, fibonacci
Influence of the TS level size with fixed local reduction tree.(Left: Greedy, Right: Flat)
⇒ a has to be adapted to the matrix size
Julien Langou | University of Colorado Denver Hierarchical QR | 95 of 103
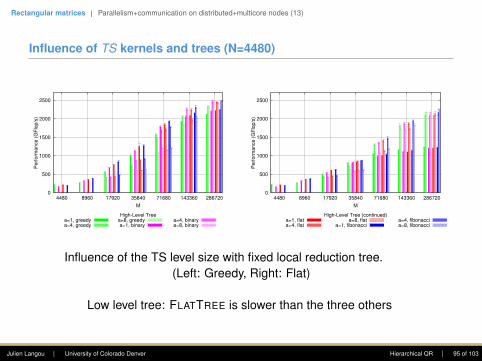
Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Influence of TS kernels and trees (N=4480)
0
500
1000
1500
2000
2500
4480 8960 17920 35840 71680 143360 286720
Pe
rfo
rma
nce
(G
Flo
p/s
)
M
High-Level Treea=1, greedya=4, greedy
a=8, greedya=1, binary
a=4, binarya=8, binary
0
500
1000
1500
2000
2500
4480 8960 17920 35840 71680 143360 286720
Pe
rfo
rma
nce
(G
Flo
p/s
)
M
High-Level Tree (continued)a=1, flata=4, flat
a=8, flata=1, fibonacci
a=4, fibonaccia=8, fibonacci
Influence of the TS level size with fixed local reduction tree.(Left: Greedy, Right: Flat)
Low level tree: FLATTREE is slower than the three others
Julien Langou | University of Colorado Denver Hierarchical QR | 95 of 103
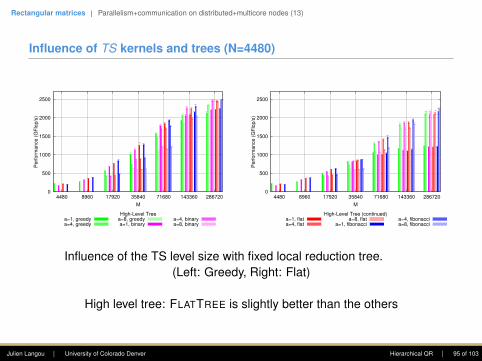
Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Influence of TS kernels and trees (N=4480)
0
500
1000
1500
2000
2500
4480 8960 17920 35840 71680 143360 286720
Pe
rfo
rma
nce
(G
Flo
p/s
)
M
High-Level Treea=1, greedya=4, greedy
a=8, greedya=1, binary
a=4, binarya=8, binary
0
500
1000
1500
2000
2500
4480 8960 17920 35840 71680 143360 286720
Pe
rfo
rma
nce
(G
Flo
p/s
)
M
High-Level Tree (continued)a=1, flata=4, flat
a=8, flata=1, fibonacci
a=4, fibonaccia=8, fibonacci
Influence of the TS level size with fixed local reduction tree.(Left: Greedy, Right: Flat)
High level tree: FLATTREE is slightly better than the others
Julien Langou | University of Colorado Denver Hierarchical QR | 95 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Influence of the domino
0
500
1000
1500
2000
2500
3000
17920 35840 71680 143360 286720
Performance (GFlop/s)
M
Low-Level Treew/o domino: flat
fibonaccigreedybinary
w/ domino: flatfibonacci
greedybinary
Figure: Influence of the low-level tree and thedomino optimization.
0
20
40
60
80
100
120
140
160
180
200
17920 35840 71680 143360 286720
Num
ber
of
task
s (x
10
00
)
M
w/o domino: GEQRT+UNMQR TT kernels TS kernels
w/ domino:
0
10
20
30
40
50
60
70
80
90
100
17920 35840 71680 143360 286720
Perc
enta
ge o
f each
cate
gory
of
task
s
M
w/o domino: GEQRT+UNMQR TT kernels TS kernels
w/ domino:
N=4480, P=15, Q=4, MB=280, a=4, High level tree set to Fibonacci
Julien Langou | University of Colorado Denver Hierarchical QR | 96 of 103

Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Scaling experiments (N=4480, M varies)
0
500
1000
1500
2000
2500
3000
0 50000 100000 150000 200000 250000 300000
Perf
orm
ance (
GF
lop/s
)
M (N=4,480)
Theoretical Peak: 4358.4 GFlop/s
Scalapack[BBD+10][SLHD10]
HQR
P=15, Q=4, MB=280, FIBONACCI/FIBONACCI,a=4, domino enabled
matrix is [16-100]x16 tiles
Julien Langou | University of Colorado Denver Hierarchical QR | 97 of 103
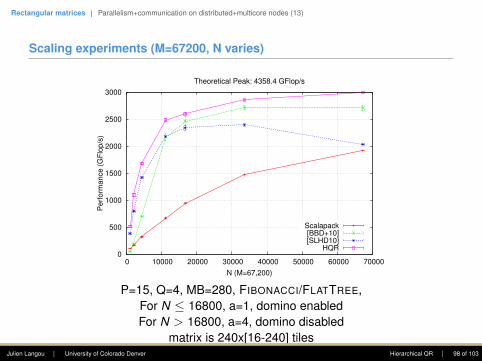
Rectangular matrices | Parallelism+communication on distributed+multicore nodes (13)
Scaling experiments (M=67200, N varies)
0
500
1000
1500
2000
2500
3000
0 10000 20000 30000 40000 50000 60000 70000
Perf
orm
ance (
GF
lop/s
)
N (M=67,200)
Theoretical Peak: 4358.4 GFlop/s
Scalapack[BBD+10][SLHD10]
HQR
P=15, Q=4, MB=280, FIBONACCI/FLATTREE,For N ≤ 16800, a=1, domino enabledFor N > 16800, a=4, domino disabled
matrix is 240x[16-240] tilesJulien Langou | University of Colorado Denver Hierarchical QR | 98 of 103

Rectangular matrices | Scheduling on multicore nodes (4)
Outline
Tall and Skinny matricesMinimizing communication in parallel distributed (29)Minimizing communication in hierarchichal parallel distributed (6)Minimizing communication in sequential (1)
Rectangular matricesMinimizing communication in sequential (2)Maximizing parallelism on multicore nodes (30)Parallelism+communication on multicore nodes (2)Parallelism+communication on distributed+multicore nodes (13)Scheduling on multicore nodes (4)
Julien Langou | University of Colorado Denver Hierarchical QR | 99 of 103

Rectangular matrices | Scheduling on multicore nodes (4)
We consider a n–by–n matrix with nb–by–nb tiles, and set n = t ∗ nb.We take for unit of flops nb3/3.This makes n and nb disappears from our problem.The number total of flops in Cholesky is
t3.
The length of the critical path is9t − 10.
Therefore on p threads, the execution time of Cholesky is at least
max(t3
p, 9t − 10 ).
This is our first lower bound for any execution time. (So in particular for the optimal execution time.)
0 20 40 60 80 100 1200
5
10
15
20
25
30
35
40
45
50
p, # of threads
spee
dup
scalability with t=20
lower bound #1
Note: the expected speedup is therefore less than this dashed line. (The lower bound in timebecomes a upper bound in speedup.)
Julien Langou | University of Colorado Denver Hierarchical QR | 100 of 103
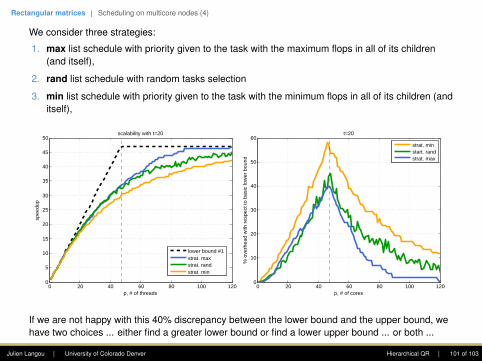
Rectangular matrices | Scheduling on multicore nodes (4)
We consider three strategies:
1. max list schedule with priority given to the task with the maximum flops in all of its children(and itself),
2. rand list schedule with random tasks selection
3. min list schedule with priority given to the task with the minimum flops in all of its children (anditself),
0 20 40 60 80 100 1200
5
10
15
20
25
30
35
40
45
50
p, # of threads
spee
dup
scalability with t=20
lower bound #1strat. maxstrat. randstrat. min
0 20 40 60 80 100 1200
10
20
30
40
50
60t=20
p, # of cores
% o
verh
ead
with
res
pect
to b
asic
low
er b
ound
strat. minstart. randstrat. max
If we are not happy with this 40% discrepancy between the lower bound and the upper bound, wehave two choices ... either find a greater lower bound or find a lower upper bound ... or both ...
Julien Langou | University of Colorado Denver Hierarchical QR | 101 of 103
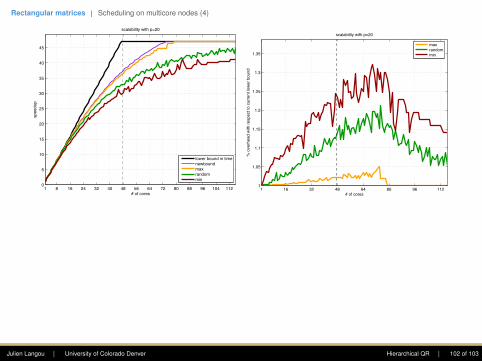
Rectangular matrices | Scheduling on multicore nodes (4)
1 8 16 24 32 40 48 56 64 72 80 88 96 104 1120
5
10
15
20
25
30
35
40
45
# of cores
spee
dup
scalability with p=20
lower bound in timenewboundmaxrandommin
1 16 32 48 64 80 96 1121
1.05
1.1
1.15
1.2
1.25
1.3
1.35
scalability with p=20
# of cores
% o
verh
ead
with
resp
ect t
o cu
rrent
low
er b
ound
maxrandommin
Julien Langou | University of Colorado Denver Hierarchical QR | 102 of 103

Rectangular matrices | Scheduling on multicore nodes (4)
1 8 16 24 32 40 48 56 64 72 80 88 96 104 1120
5
10
15
20
25
30
35
40
45
# of cores
spee
dup
scalability with p=20
lower bound in timenewboundmaxrandommin
1 16 32 48 64 80 96 1121
1.05
1.1
1.15
1.2
1.25
1.3
1.35
scalability with p=20
# of cores
% o
verh
ead
with
resp
ect t
o cu
rrent
low
er b
ound
maxrandommin
If we are not happy with this 5% discrepancy between the lower bound and theupper bound, we have two choices ... either find a greater lower bound or finda lower upper bound ... or both ...
Julien Langou | University of Colorado Denver Hierarchical QR | 103 of 103

Rectangular matrices | Scheduling on multicore nodes (4)
• reducing communication◦ in sequential◦ in parallel distributed
• increasing parallelism(or reducing the critical path, reducing synchronization)
Tall and Skinny matricesMinimizing communication in parallel distributed (29)Minimizing communication in hierarchichal parallel distributed (6)Minimizing communication in sequential (1)
Rectangular matricesMinimizing communication in sequential (2)Maximizing parallelism on multicore nodes (30)Parallelism+communication on multicore nodes (2)Parallelism+communication on distributed+multicore nodes (13)Scheduling on multicore nodes (4)
Julien Langou | University of Colorado Denver Hierarchical QR | 104 of 103

|
شكرا!Julien Langou | University of Colorado Denver Hierarchical QR | 105 of 103