high performance computation --- a practical introduction chunlin tian naoc beijing 2011
TRANSCRIPT

High Performance Computation --- A Practical
IntroductionChunlin Tian
NAOC Beijing 2011

Outline
Parallelization techniques OpenMP: do-loop based MPI: communication Auto-parallelization, CUDA
Remark:– It is at introduction level– It is NOT a comprehensive introduction

Introduction Speed up the computing Mathematic, physics, computation Hardware
– number of CPU– size of memory– CPU : multi-processer vs. cluster; GPU– Memory: distributed vs. shared
Software– Auto-parallelization by compiler– OpenMP– MPI– Cuda
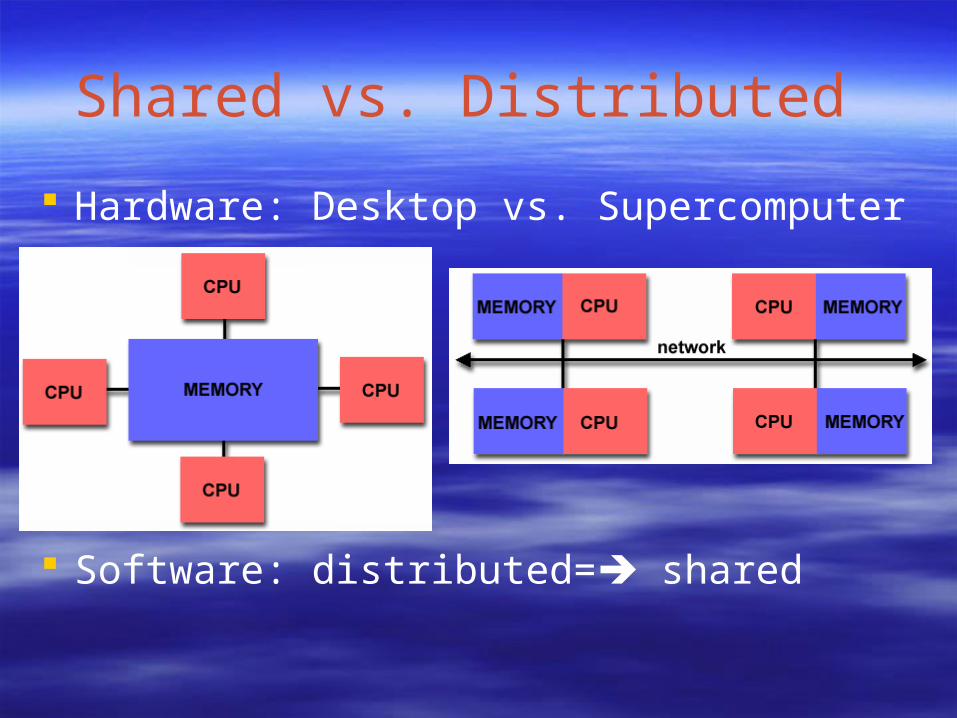
Shared vs. Distributed
Hardware: Desktop vs. Supercomputer
Software: distributed= shared

Auto-parallelizationAuto-parallelization
Easy to employEasy to employ– Set environment variableSet environment variable
setenvsetenv OMP_NUM_THREADSOMP_NUM_THREADS 22
– Compiler optionsCompiler options pgf77 pgf77 –mp–mp –static–static … … … … ifort ifort –parallel–parallel … … … …
Not smart enoughNot smart enough– Only efficient for dual core CPUOnly efficient for dual core CPU– Some time even slower than the single threadSome time even slower than the single thread

OpenMP-introductionOpenMP-introduction
Open MOpen Multi-ulti-PProcessingrocessing– An API supporting multi-platform An API supporting multi-platform sharedshared memory memory
multiprocessing programming. multiprocessing programming. – It consists of a set of compiler directives, library It consists of a set of compiler directives, library
routines and environment variables.routines and environment variables.– History:History:
– 1997, version 1.0 in Fortran1997, version 1.0 in Fortran– 1998, version 1.0 in C, C++1998, version 1.0 in C, C++– 2000 ,version 2.0 in Fortran2000 ,version 2.0 in Fortran– 2002, version 2.0 in C, C++2002, version 2.0 in C, C++– 2005, version 2.5 in Fortran, C, C++2005, version 2.5 in Fortran, C, C++– 2008, version 3.0 in Fortran, C, C++ …2008, version 3.0 in Fortran, C, C++ …
– Compilers: GNU, Intel, IBM, PGI, MS … Compilers: GNU, Intel, IBM, PGI, MS …
Coding with OpenMPCoding with OpenMP
Step 1: define parallel regionStep 1: define parallel region Step 2: define the types of the variablesStep 2: define the types of the variables Step 3: mark the Step 3: mark the do-loopsdo-loops to be paralleled to be paralleled Remark: Remark:
– you can parallel your code (parts by parts) you can parallel your code (parts by parts) incrementally. incrementally.
– The number of parallel regions should be as The number of parallel regions should be as less as possible.less as possible.

Example of OpenMP code !$omp parallel !$omp& default (shared) !$omp& private (tmp) !$omp do• do i=1,nx• tmp=a(i)**2+b(i)**2• tmp=sqrt(tmp)• c(i)=a(i)/tmp• d(i)=b(i)/tmp• enddo !$omp end do !$omp single• write(*,*)maxval(c),
maxval(b)
!$omp end single !$omp do do j=1,ny tmp=a(j)**2+b(j)**2 tmp=sqrt(tmp) c(j)=b(j)/tmp d(j)=a(j)/tmp enddo !$omp end do !$omp end parallel
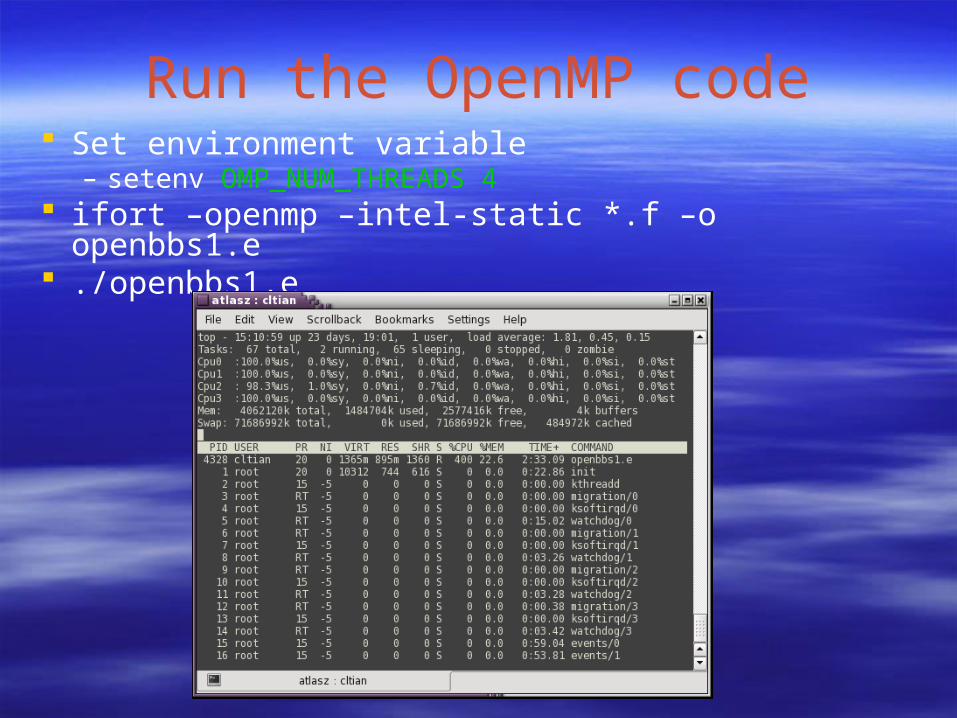
Run the OpenMP code Set environment variable
– setenv OMP_NUM_THREADS 4 ifort –openmp –intel-static *.f –o openbbs1.e ./openbbs1.e

Scalability of OpenMP code
Ideally it should be linear.
But the initializing, finalizing, and synthesis etc. takes time.
MPI Message Pass Interface
– A specification for an API that allows many computers to communicate with one another.
– Language-independent protocol, programmer interface, semantic specification
– History: 1994 May, version 1.0, the final report of MPIF 1995 June, version 1.1 1997 July, version 1.2, MPI-1; 2.0 MPI-2 2008 May, version 1.3 2008 June, version 2.1 2009 Sept., version 2.2
Remark:– Open MPI ≠ OpenMP– MPICH, HP MPI, Intel MPI, MS MPI, …

Coding with MPICoding with MPI
1: determine the number of blocks1: determine the number of blocks 2: define virtual CPU topology2: define virtual CPU topology 3: define the parallel region3: define the parallel region 4: assign tasks to different threads.4: assign tasks to different threads. 5: communication between threads.5: communication between threads. 6: manage the threads: 6: manage the threads:
master-slavemaster-slave non-masternon-master

Example of MPI codingExample of MPI coding Include ‘mpi.h’Include ‘mpi.h’ nx=100, ny=100 nx=100, ny=100 !number of grids!number of grids mx=2, my=5 mx=2, my=5 !number of blocks!number of blocks call MPI_INIT(ierr) call MPI_INIT(ierr) !initialize the parallelization!initialize the parallelization call MPI_COMM_RANK(MPI_COMM_WORLD,myid,ierr) call MPI_COMM_RANK(MPI_COMM_WORLD,myid,ierr) !get id!get id … … … … … … …… … … … … … … call MPI_Finalize(ierr) call MPI_Finalize(ierr) !finalize the parallelization!finalize the parallelization myidmyidmyidx,myidymyidx,myidythe IDs of myid’s neighbours the IDs of myid’s neighbours !virtual topology!virtual topology call MPI_SEND(vb,nx*2, MPI_REAL8, call MPI_SEND(vb,nx*2, MPI_REAL8,
receiverid,tag,MPI_COMM_WORLD,ierr) receiverid,tag,MPI_COMM_WORLD,ierr) !send data!send data call MPI_RECV(va,nx*2,MPI_REAL8, senderid, tag, call MPI_RECV(va,nx*2,MPI_REAL8, senderid, tag,
MPI_COMM_WORLD,ierr) MPI_COMM_WORLD,ierr) !receive data!receive data

CPU Virtual TopologyCPU Virtual Topology
1. each thread has a unique ID;1. each thread has a unique ID; 2. each thread has more than one neighbors;2. each thread has more than one neighbors; 3. cpus can be arranged as one- or multi- 3. cpus can be arranged as one- or multi-
dimensional array;dimensional array; 4. the topology should be as simple as 4. the topology should be as simple as
possible.possible.

MPI CommunicationMPI Communication
Point-point: one CPU to one CPU Point-point: one CPU to one CPU Collective: Collective:
– one to multiple: broadcast; scatter; gather; one to multiple: broadcast; scatter; gather; reduce, etc. reduce, etc.
BlockBlock– Send and then check the receiving bufferSend and then check the receiving buffer
Non-blockNon-block– Send and returnSend and return
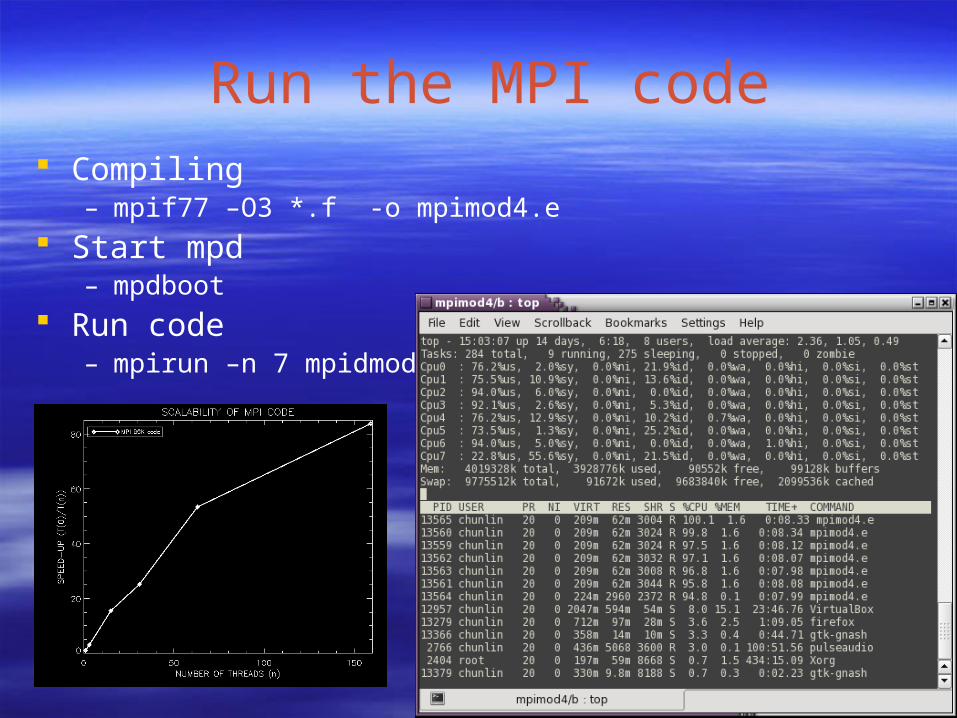
Run the MPI code Compiling
– mpif77 –O3 *.f -o mpimod4.e Start mpd
– mpdboot Run code
– mpirun –n 7 mpidmode.4
CUDA what's next ?
GPU-SUPERCOMPUTING
It is do-loop based method.Do-loop <==> cuda subroutine

SummarySummary
ParallelizationParallelization Three levels of parallelizationThree levels of parallelization
(compiler, OpenMP, MPI)(compiler, OpenMP, MPI) Employment: Easy <---> DifficultEmployment: Easy <---> Difficult Scalability: inefficient <---> efficient? Scalability: inefficient <---> efficient?
Principle Principle Do-loop based parallelizationDo-loop based parallelization Massage passing Massage passing