highly’parallel,’lock0less,’user0space’ tcp/ip’networking ... ·...
TRANSCRIPT

Highly parallel, lock-‐less, user-‐space TCP/IP networking stack based on
FreeBSD
EuroBSDCon 2013 Malta

Networking stack
• Requirements – High throughput – Low latency – ConnecLon establishments and teardowns per second
• SoluLon – Zero-‐copy operaLon – Lock eliminaLon

Hardware plaNorm overview
• Tilera TILEncore-‐Gx card • TILE-‐Gx36 processor • 36 Lles (cores) • 4 SFP+ 10GiBi ports

MulLcore architecture overview

MulLcore architecture overview
• Local L1 and L2 caches • Distributed L3 cache – By using L2 caches of other Lles
• Memory homing – Local homing – Remote homing – Hash for homing

mPIPE • mulLcore Programmable Intelligent Packet Engine
• Packet header parsing • Packet distribuLon • Packet Buffer management • Load balancing • CalculaLng the L4 checksum on ingress and egress traffic.
• Gathering packet data potenLally sca[ered across mulLple buffers from Lles.

So\ware plaNorm overview
• Zero Overhead Linux (ZOL) – One thread assigned to one Lle – No interrupts, context switchces, syscalls
• Modified libpthreads – Standard API, no significant code change necessary except explicit affinity se`ngs
• Library for direct access to mPIPE buffers from user-‐space – Also buffer allocaLon rouLnes

Design approach • One process composed of a number of threads running on
separate Lles • Each Lle executes the same single threaded net-‐stack code. • Each Lle performs the enLre processing of incoming and
outgoing packets for a given TCP/IP connecLon (in a run-‐to-‐compleLon fashion)
• A givenTCP/IP connecLon is always processed by the same Lle (staLc flow affinity) using mPIPE flow hash funcLonality
• This approach has the following advantages: – Data structures locking avoidance inside the stack – Having smaller sets of PCBs local to each Lle speeds up lookups, creaLon etc. as they are executed in parallel on different Lles
– OpLmal Lles’ cache usage

FuncLonal parLLoning
RX/TX
TCP processing Buffer alloc/dealloc Packet queues polling
APP
Raw/naLve API calls ApplicaLon processing
Control channel
Data channel
(de)alloc channel

RX/TX Lle
• Perform TCP processing (FreeBSD rouLnes) • Poll for control messages • Poll for data packets (both ingress from mPIPE and egress from applicaLon)
• Manage allocaLon/de-‐allocaLon queues • Local Lmer Lck

Inter-‐Lle channels • Data CommunicaLon Channel – One for each TCP connecLon – Ingress and egress queues – No locks at stack endpoint – Serves ‘socketbuf’ funcLonality for the stack
• Control channel – One for each netstack Lle – Handles request like connect, listen, etc.
• Packet buffers allocaLon/free channels – One for each netstack Lle – Described in greater details on later slides

App Lle (raw/naLve API)
• Similar to socket calls – listen(), bind(), connect(), send(), receive(), etc.
• All calls always non-‐blocking • Based on polling • Provides addiLonal rouLnes for buffer manipulaLons – Necessary for zero-‐copy approach – Includes buffer allocaLon, expanding, shrinking, etc.

Socket-‐like
• Inspired by LwIP • Implemented with raw/naLve API only • Only API compaLbility – A handle returned when creaLng a socket is not a regular descriptor
• Intended as a temporary easier-‐to-‐use API for the user – Lower performance than raw/naLve API

Ensuring zero-‐copy
• Requirement – The same packet buffer seen by the hardware, networking stack and applicaLon
• SoluLon – Dedicated memory pages accessible directly by mPIPE – Buffer pools for each RX/TX Lle
• Eliminates locks on the stack side • Each buffer has to return to its original pool • AllocaLon/deallocaLon can be done only by mPIPE or RX/TX Lle

pktbuf aka mbuf
• Each packet is represented as a pktbuf (mbuf) – Fixed size buffer pools managed by the hardware – API rouLnes to manipulate pktbufs of arbitrary size consisLng of chain of fixed size buffers
• Two unidirecLonal queues – AllocaLon queue from RX/TX Lle to applicaLon Lle – De-‐allocaLon queue from applicaLon Lle to RX/TX Lle
• RX/TX Lle role – Keeping the allocaLon queue full – Keeping the de-‐allocaLon queue free

AllocaLon/de-‐allocaLon Put new or reuse buffer
AllocaLon queue
De-‐allocaLon queue
Request a new packet buffer
Free a packet buffer
Free a packet buffer
RX/TX Tile
App Tile

Ensuring no locks inside the stack
• Each Lle runs only one thread • Each TCP connecLon is handled by one Lle only
• Only single sender and/or single receiver queues – AllocaLon/deallocaLon queues – Data CommunicaLon Channel queues – Control queues

Ensuring flow affinity
• Ingress – mPIPE calculates a hash from quadruple (source and desLnaLon IP and port) of each incoming packets
– A modulo number of RX/TX Lles is taken from hash result
– Obtained number idenLfies the Lle the packet is handed over to for processing
• Egress – The same scenario while establishing a connecLon – A\er that number idenLfying the correct Lle is held within connecLon handle

Data flow example 1,2,.. -‐ Ingress A,B,… -‐ Egress

Test setup
• Modified ‘ab’ tool for connecLon establishments and finishes per second
• Infinicore hardware TCP/IP tester • Iperf and simple ‘echo’ app for throughput • Counter inside the stack for latency measurements
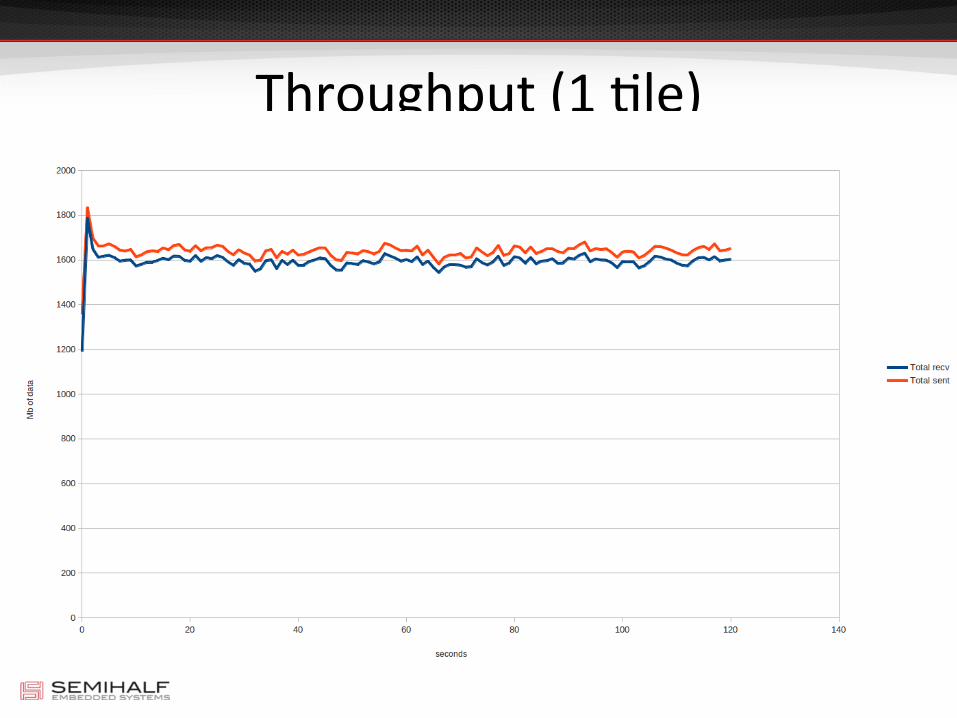
Throughput (1 Lle)

Throughput (1 Lle)

Throughput (8 Lles)

Throughput (8 Lles)

Throughput scaling

Latency

ConnecLon performance
• How many connecLons we can successfully establish and teardown in a second
• Most difficult to achieve • About 500k/s with 16 cores – Reached limit of the test environment

FreeBSD stack flexibility
• Fairly good in overall • Majority of the TCP processing easily reusable – TCP FSM, TCP CC, TCP Syncache, TCP Timers, TCP Timewait, etc.
• OpLmized for SMP – Fine grained locking

Acknowledgements • People involved in the project (all from Semihalf): – Maciej Czekaj – Rafał Jaworowski – Tomasz Nowicki – Pablo Ribalta Lorenzo – Piotr Zięcik
• Special thanks (all from Tilera): – Tom DeCanio – Jici Gao – Kalyan Subramanian – Satheesh Velmurugan

Any quesLons?