hpc software development at llnl
DESCRIPTION
HPC Software Development at LLNL. Presented to College of St. Rose, Albany. Feb. 11, 2013. Todd Gamblin Cente r for Applied Scientific Computing. LLNL has some of the world’s largest supercomputers. Sequoia #1 in the world, June 2012 IBM Blue Gene/Q 96 racks, 98,304 nodes - PowerPoint PPT PresentationTRANSCRIPT

LLNL-PRES-XXXXXXThis work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract
DE-AC52-07NA27344. Lawrence Livermore National Security, LLC
HPC Software Development at LLNLPresented to College of St. Rose, Albany
Todd GamblinCenter for Applied Scientific Computing
Feb. 11, 2013

Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx2
Sequoia• #1 in the world, June 2012• IBM Blue Gene/Q • 96 racks, 98,304 nodes• 1.5 million cores• 5-D Torus network• Transactional Memory• Runs lightweight, Linux-like OS• Login nodes are Power7, but compute nodes are
PowerPC A2 cores. Requires cross-compiling.
LLNL has some of the world’s largest supercomputers

Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx3
Zin• Intel Sandy Bridge• 2,916 16-core nodes• 45,656 processors• Infiniband Fat Tree
interconnect• Commodity parts
• Runs TOSS, LLNL’s Red Hat Linux Distro
LLNL has some of the world’s largest supercomputers
Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx4
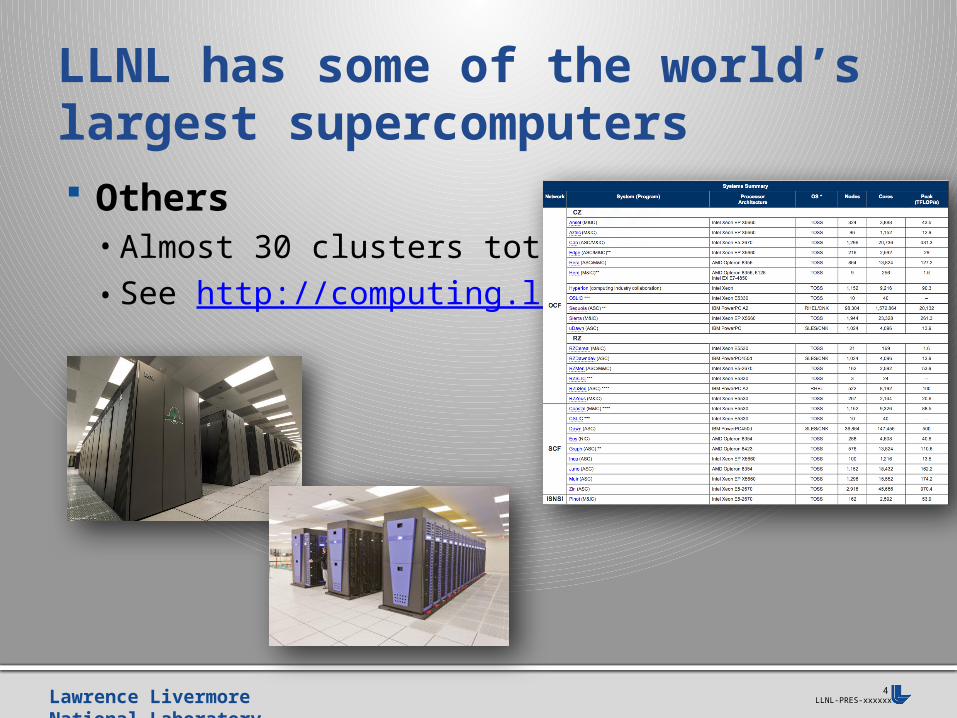
Others• Almost 30 clusters total• See http://computing.llnl.gov
LLNL has some of the world’s largest supercomputers

Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx5
Multi-physics simulations Material Strength Laser-Plasma Interaction Quantum Chromodynamics Fluid Dynamics
Lots of complicated numericalmethods for solving equations:• Adaptive Mesh Refinement (AMR)• Adaptive Multigrid• Unstructured Mesh• Structured Mesh
Supercomputers run very large-scale simulations
NIF Target
Supernova
AMR FluidInterface

Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx6
1. Code teams• Work on physics applications• Larger code teams are 20+ people
— Software developers— Applied mathematicians— Physicists
• Work to meet milestones for lab missions
Code Teams
Researchers (CASC)
Production Computing (LC)
Structure of the Lab

Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx7
2. Livermore Computing (LC)• Run supercomputing center• Development Environment Group
— Works with application teams toimprove code performance
— Knows about compilers, debuggers,performance tools
— Develops performance tools• Software Development Group
— Develops
Structure of the Lab
Code Teams
Researchers (CASC)
Production Computing (LC)

Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx8
2. Center For Applied ScientificComputing (CASC)
• Most CS Researchers are in CASC• Large groups doing:
— Performance Analysis Tools— Power optimization— Resilience— Source-to-source Compilers— FPGAs and new architectures— Applied Math and numerical analysis
Structure of the Lab
Code Teams
Researchers (CASC)
Production Computing (LC)

Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx9
Write software to measure theperformance of other software• Profiling• Tracing• Debugging• Visualization
Tools themselves need toperform well:• Parallel Algorithms• Scalability and low overhead are important
Performance Tools Research
Code Teams
Tools Resaerch(CASC)
Development Environment Group (DEG)

Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx10
Application codes are written in many languages• Fortran, C, C++, Python• Some applications have been around for 50+ years
Tools are typically written in C/C++• Tools typically run as part of an application• Need to be able to link with application environment
Non-parallel parts of tools are often in Python.• GUI• front-end scripts• some data analysis
Development Environment

Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx11
http://www.atlassian.com• Confluence Wiki• JIRA Bug Tracker• Stash git repo hosting
Several advantages for our distributed environment:• Scale to lots of users• Fine-grained permissions allow us to
stay within our security model
We’ve started using Atlassian tools for collaboration

Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx12
Parallel Applications use the MPI Library for communication
We want to measure time spent in MPI calls• Also interested in other
metrics• Semantics, parameters,
etc.
We write a lot of interposer libraries
Simple example: Measuring MPI
MPI_Library
Implements MPI_Send() Implements PMPI_Send()
ApplicationCalls MPI_Send()
MPI_LibraryImpleme
nts MPI_Sen
d()
Implements
PMPI_Send()
ApplicationCalls MPI_Send()
MPI_LibraryImpleme
nts MPI_Sen
d()
Implements
PMPI_Send()
ApplicationCalls MPI_Send()
MPI_LibraryImpleme
nts MPI_Sen
d()
Implements
PMPI_Send()
ApplicationCalls MPI_Send()
MPI_LibraryImpleme
nts MPI_Sen
d()
Implements
PMPI_Send()
ApplicationCalls MPI_Send()
. . .
Parallel Application
Single Process

Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx13
Parallel Applications use the MPI Library for communication
We want to measure time spent in MPI calls• Also interested in other
metrics• Semantics, parameters,
etc.
We write a lot of interposer libraries
Simple example: Measuring MPI
MPI_Library
Implements MPI_Send() Implements PMPI_Send()
Tool Interposer LibraryImplementsMPI_Send() Calls PMPI_Send()
ApplicationCalls MPI_Send()

Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx14
This call intercepts calls from the application It does its own measurement Then it calls the MPI library Allows us to measure time spent in particular routines
Example Interposer Codeint MPI_Bcast(void *buffer, int count, MPI_Datatype dtype, int root, MPI_Comm comm) { double start = get_time_ns();
PMPI_Bcast(buffer, count, dtype, root, comm);
double duration = get_time_ns() – start; record_time(MPI_Bcast, duration);}

Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx15
See other slide set.
Another type of problem: communication optimization
