hw set5 - sites.stat.washington.edu
TRANSCRIPT





hw_lec12_1Show that in the ANOVA decomposition for the RCBD model, the cross-term between the 2nd and 3rd terms is zero. I.e. show that
Hint: this requires only 2 or 3 lines of algebra; and don't forget that
The point is to show that the cross-terms are zero, and to get practice with the dot-bar notation.


hw_lec12_3: In problem 4.3, a) perform anova to compute a p-value from an F test of whether the 4 chemicals have an effect on strength, treating the data as if they were collected in a CRD. by hand b) Repeat part a, but with an RCBD, with Bolts as the block factor. by hand.c) Produce two residual plots: residuals versus y_hat, and residuals vs. y, (just to see why the latter is not recommended), for the residuals from the CRD design.d) Repeat part c, but for RCBD.e) Make qq plots for the CRD and RCBD residuals. Comment
y = matrix(c( # rows = treatment, col = block 73, 68, 74, 71, 67, 73, 67, 75, 72, 70, 75, 68, 78, 73, 68, 73, 71, 75, 75, 69), nrow=4,byrow=T)
# a) CRD a = 4 n = 5 N = n*a means = apply(y,1,mean) # 70.6 71.4 72.4 72.6 vars = apply(y,1,var) # 9.3 9.3 19.3 6.8 Note: unequal vars! grand.mean = mean(means) SS_treatment = n*sum((means - grand.mean)^2) SS_E = (n-1)*sum(vars) MS_treatment = SS_treatment/(a-1) # 4.316667 MS_E = SS_E/(N-a) # 11.175 F_obs = MS_treatment/MS_E # 0.3862789 pf(F_obs, df1=a-1, df2=N-a, 0, lower.tail = FALSE) # 0.764377
# Cannot reject H0 (that all 4 tau's are zero) in favor of H1.
# b) RCBD a = 4 b = 5 row.means = apply(y,1,mean) # 70.6 71.4 72.4 72.6 col.means = apply(y,2,mean) # 73.50 68.50 75.50 72.75 68.50 SS_treatment = b*sum((row.means - grand.mean)^2) SS_block = a*sum((col.means - grand.mean)^2) resid2 = (t(t(y - row.means) - col.means + grand.mean)) # Note t( t() ) SS_E = sum( resid2^2 ) MS_treatment = SS_treatment/(a-1) # 4.316667 MS_block = SS_block/(b-1) # 39.25 MS_E = SS_E/((a-1)*(b-1)) # 1.816667 F_obs = MS_treatment/MS_E # 2.376147 pf(F_obs, df1=a-1, df2=(a-1)*(b-1), 0, lower.tail = FALSE) # 0.1211445
# Cannot reject H0 (that all 4 tau's are zero) in favor of H1.

# The conclusion to part a is this: assuming the design is CRD (when we know it's not), and applying an anova F-test, does NOT allow us to find the treatment effect. Part b tells us that doing an F test that acknowledges the existing RCBD design is still not capable of finding the treatement effect, but it does have a lower p-value.
# c) residual for CRD resid.crd = y - row.means # residuals vs. y_hat: plot(rep(row.means,5), resid.crd, xlab="y_hat", ylab="residual") abline(h=0)
# residuals vs. y: (not recommended) plot(as.vector(y), resid.crd, xlab="y", ylab="residual") abline(h=0)
# The residual plots look adequate, except for the 2nd one # which is why it is not recommended.
# d) residual for RCBD
resid.rcbd = t(t(y - row.means) - col.means + grand.mean)
plot(rep(row.means,5), as.vector(resid.rcbd), xlab="row.means",ylab="residual") abline(h=0)
plot(as.vector(y), as.vector(resid.rcbd), xlab="row.means", ylab="residual") abline(h=0)
# This time both residual plots look adequate.
# e) qq plots fo CRD and RCBD
qqnorm(resid.crd) # consistent with normal qqnorm(resid.rcbd) # consistent with normal.

hw_lec13_1: In problem 4.3, In an RCBD design with one treatment and one block factor, we know how to test the treatment effect (and the block effect). The tests are based on an F-test, where F is MS_treatment/MSE (or MS_block/MSE). However, I have also mentioned that those tests are equivalent to another set of F tests which are based on the SSE's obtained from a full model and two reduced models. Let's confirm! For the data in problem 4.3, do the following (all by R):a) Write code to produce the anova table for the full model. Record/save the value of SSE. Also, save the F-ratios for the treatment and block effects in the full anova table.b) Write code to develop the reduced model that excludes the treatment factor. Record/save the value of SSE. c) Write code to develop the reduced model that excludes the block factor. Record/save the value of SSE. d) Show that by computing the appropriate differences and ratios of SSE in parts a, b, and c, you can compute the same F ratios you saved in the anova table of the full model in part a. Pay attention to dfs.
y.matrix = matrix(c( # rows = treatment, col = block 73, 68, 74, 71, 67, 73, 67, 75, 72, 70, 75, 68, 78, 73, 68, 73, 71, 75, 75, 69), nrow=4,byrow=T) y = t(y.matrix) y = as.vector(y)
a = 4 b = 5 A = as.factor(rep(c(1:a),each=b)) B = as.factor(rep(c(1:b),a))
# a) lm.1 = lm(y ~ A + B) temp = summary.aov(lm.1) SSE_mu_tau_beta = temp[[1]][3,2]
# Df Sum Sq Mean Sq F value Pr(>F) # A 3 12.95 4.32 2.376 0.121 # B 4 157.00 39.25 21.606 2.06e-05 ***# Residuals 12 21.80 1.82
# b) lm.reducedB = lm(y ~ B ) tempB = summary.aov(lm.reducedB) SSE_mu_beta = tempB[[1]][2,2]
# Df Sum Sq Mean Sq F value Pr(>F)# B 4 157.00 39.25 16.94 1.95e-05 ***# Residuals 15 34.75 2.32
# c) lm.reducedA = lm(y ~ A ) tempA = summary.aov(lm.reducedA) SSE_mu_tau = tempA[[1]][2,2] # Df Sum Sq Mean Sq F value Pr(>F)# A 3 12.95 4.317 0.386 0.764# Residuals 16 178.80 11.175

# d) FA_numer = (SSE_mu_beta - SSE_mu_tau_beta) / (a-1) FA_denom = SSE_mu_tau_beta/((a-1)*(b-1)) FA = FA_numer/FA_denom # 2.376147 = in part a FB_numer = (SSE_mu_tau - SSE_mu_tau_beta) / (b-1) FB_denom = SSE_mu_tau_beta/((a-1)*(b-1)) FB = FB_numer/FB_denom # 21.6055 = in part a
# Although I did not ask you to do this, you can see that the p-values are the same too:
pf(FA, df1=a-1, df2=(a-1)*(b-1), 0, lower.tail = FALSE) # 0.1211445 = in part a pf(FB, df1=b-1, df2=(a-1)*(b-1), 0, lower.tail = FALSE) # 2.059181e-05 = in part a

hw_lect13_2: The number of LS's is given in Table 4.13 . They are generated by switching 2 rows and/or 2 cols of 1 LS. Generate the twelve 3x3 possible LS's. Try to show HOW you did things, by showing what you switched.
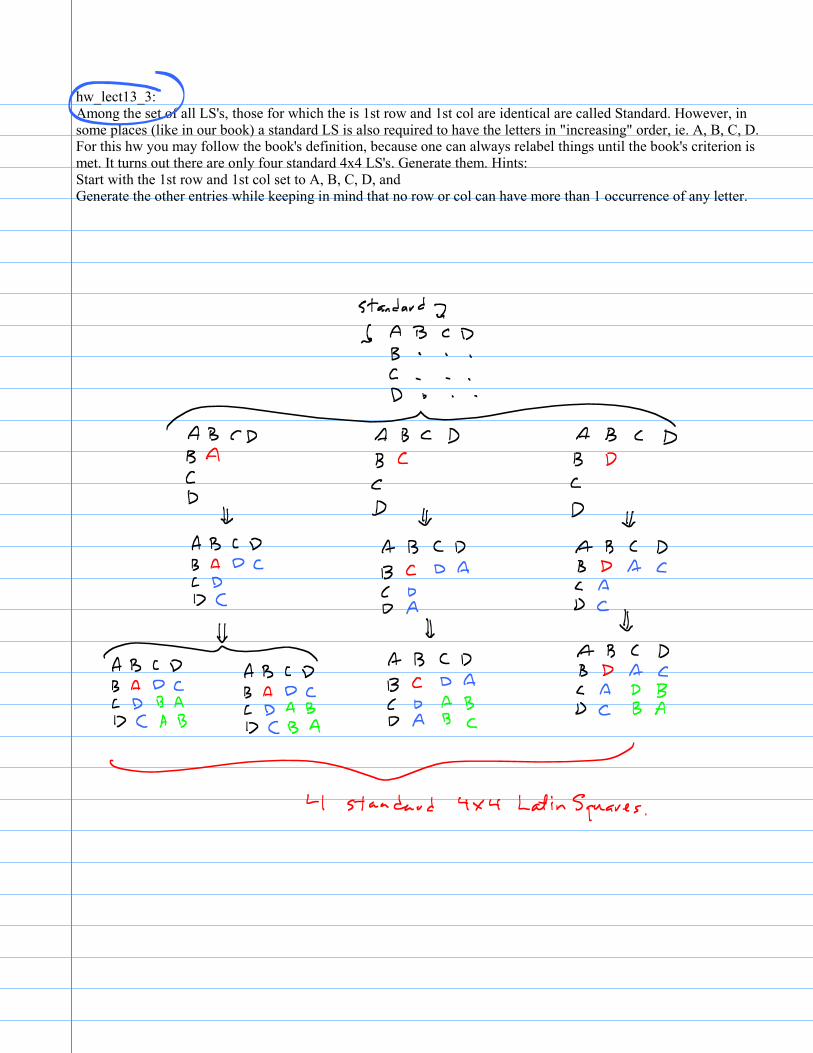
hw_lect13_3: Among the set of all LS's, those for which the is 1st row and 1st col are identical are called Standard. However, in some places (like in our book) a standard LS is also required to have the letters in "increasing" order, ie. A, B, C, D. For this hw you may follow the book's definition, because one can always relabel things until the book's criterion is met. It turns out there are only four standard 4x4 LS's. Generate them. Hints:Start with the 1st row and 1st col set to A, B, C, D, andGenerate the other entries while keeping in mind that no row or col can have more than 1 occurrence of any letter.