identifying extracellular plant proteins based on frequent subsequences of amino acids y. wang, o....
Post on 19-Dec-2015
218 views
TRANSCRIPT

Identifying Extracellular Plant Proteins Based on
Frequent Subsequences of Amino Acids
Y. Wang, O. Zaiane, R. Goebel

2
Introduction
Protein: linear sequence of amino acidsProtein subcellular localization Plant: nuclear, cytoplamic,
mitochondria, extracellular, …
Intracellular vs. Extracellular Sequence information alone Class imbalance Transparency

3
Related Word
N-terminal sorting signalsAmino acid compositionLexical analysisIntegrative approachSubsequence methods

4
Predicting Extracellular Proteins
Feature ExtractionSupport Vector MachineBoostingFrequent Pattern Method

5
Feature Extraction
Frequent subsequences: subsequences that occur in more than a certain percentage of extracellular proteins Strong discriminative power Perform similar functions via
relationed biochemical mechanism Capture local similarity
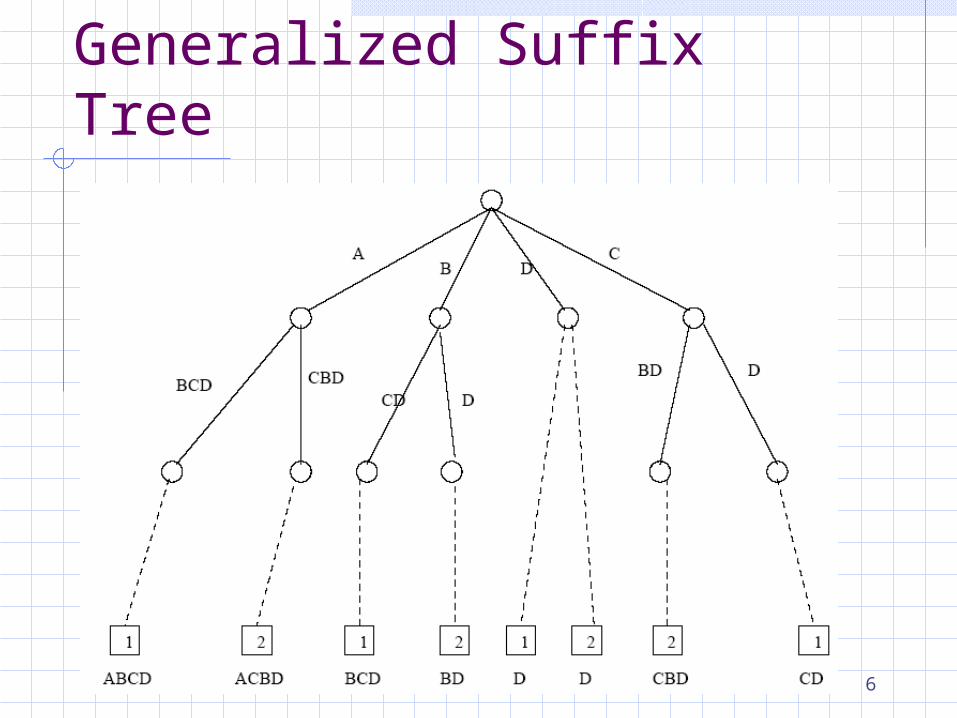
6
Generalized Suffix Tree

7
Support Vector Machine
Input data represented as feature vectorsFind a linear separator that separate the data and maximize the marginKernel function: nonlinear separator

8
SVM for extracellular protein prediction
Data Transformation(sequencevector) Frequent subsequences as features Transform protein sequence as binary
vectors
Kernel Functions Linear kernel Polynomial kernel RBF kernel

9
Boosting
Iterative algorithms to improve weak classifierDifferent weighted distribution of examples in each iterationIncrease the weights of incorrectly classified examples, and decrease the weights of correctly classified ones

10
AdaBoost

11
Frequent Pattern Method
Frequent pattern: *X1*X2*…*Xn* extracellular X1,X2,…Xn are frequent
subsequences “*” can be substituted to zero or up to
MaxGap amino acids when matching a protein sequence

12
FOIL algorithm

13
Z-number
:accuracy of rule R
:support of rule R

14

15
Experiments
Dataset(PASub project at UofA) Plant: 3293 proteins, 171 extracellular
Five-cross validation

16
Evaluation Matrix
Overall accuracy is not good enoughF-measure

17
Result(SVM with subsequence)

18
Result(Boosting with subsequence)

19
Result(Frequent Pattern)
MinLen=3
Min_gain=0.1
03.08.0
MinSup=5%
MinConf=80%
MaxGap=300

20
Result(SVM with composition)

21
Result(Boosting with composition)

22
Cross Comparision

23
SVM with combined features

24
Boosting with combined features

25
Effects of MinLen on SVM

26
Effects of MinLen on boosting

27
Conclusion
Presented three methods for identifying extracellular proteins based on frequent subsequence of amino acidsSVM achieves the best resultFSP method provides easily interpretable rules

28
Future Work
Use for information about proteins (e.g., structure, function, …)Integrating amino acid composition into FSP methodIncorporate more biological knowledge