ideology and brand consumption...
TRANSCRIPT

Ideology and Brand Consumption
Supplement
Romana Khan, Kanishka Misra, Vishal Singh
June 27, 2011
This document is the supplement to the paper ‘Ideology and Brand Consumption’. In
section 1.1, we describe the data used in the project in detail. Section 1.2 discusses the
methodology and in Section 3 we provide various robustness checks to our analysis.
1 Materials and Methods
1.1 Data Description
Our objective in this article is to examine whether traits associated with a conservative ide-
ology such as preference for tradition and status quo, uncertainty avoidance, and skepticism
to new experiences get manifested in routine purchase decisions. Our empirical strategy re-
lies on relating measures of brand consumption to county level measures of conservativeness.
Our analysis combines four key sources of data: (1) Retail Sales Data, (2) Religion Data, (3)
Political Voting Data, and (4) Demographics.
1.1.1 Retail Sales Data
The consumer packaged goods (CPG) data is an academic dataset provided by IRI (Bron-
nenberg, Kruger, and Mela, 2008). It provides UPC-level weekly store sales data for 26 CPG
industries across 47 U.S. markets, spanning a period of 6 years from 2001 to 2006. The
categories analyzed cover a wide range of industries, including both edible (e.g. soup) and
non-edible (e.g. paper towels) products. As CPG categories, the products studied are func-
tional, providing personal consumption utility, with limited scope to serve as a signal of social
status or make a statement about individual personality. There are 416 counties represented
in the data, which cover 47% of the total US population. There are 1,860 stores from 135
1

major chains. Our measures of brand consumption and new product trial are computed from
this store level sales data.
Brand Reliance - Private Label Market Share In CPG categories, a key distinc-
tion is between national and private label brands1. Despite their dramatic growth over the
past few decades, industry reports and academic research in marketing suggest that gener-
ics are perceived by consumers as riskier and of lower quality than national brands (Erdem
and Valenzuela, 2004; ADWEEK, 2000). Since a major function of branding is to lower
uncertainty and simplify decision making (Aaker, 1991), we might expect that, controlling
for other socio-economic factors, aspects of conservative values such as preference for tra-
dition and convention, and lower tolerance for ambiguity and complexity may get reflected
in higher reliance on national brands as opposed to generics. To test this empirically, our
key measure is the market share of the private label brand (PLShare), measured at the store
level within each category, for each year. While the average PLShare is 16%, figure 1 shows
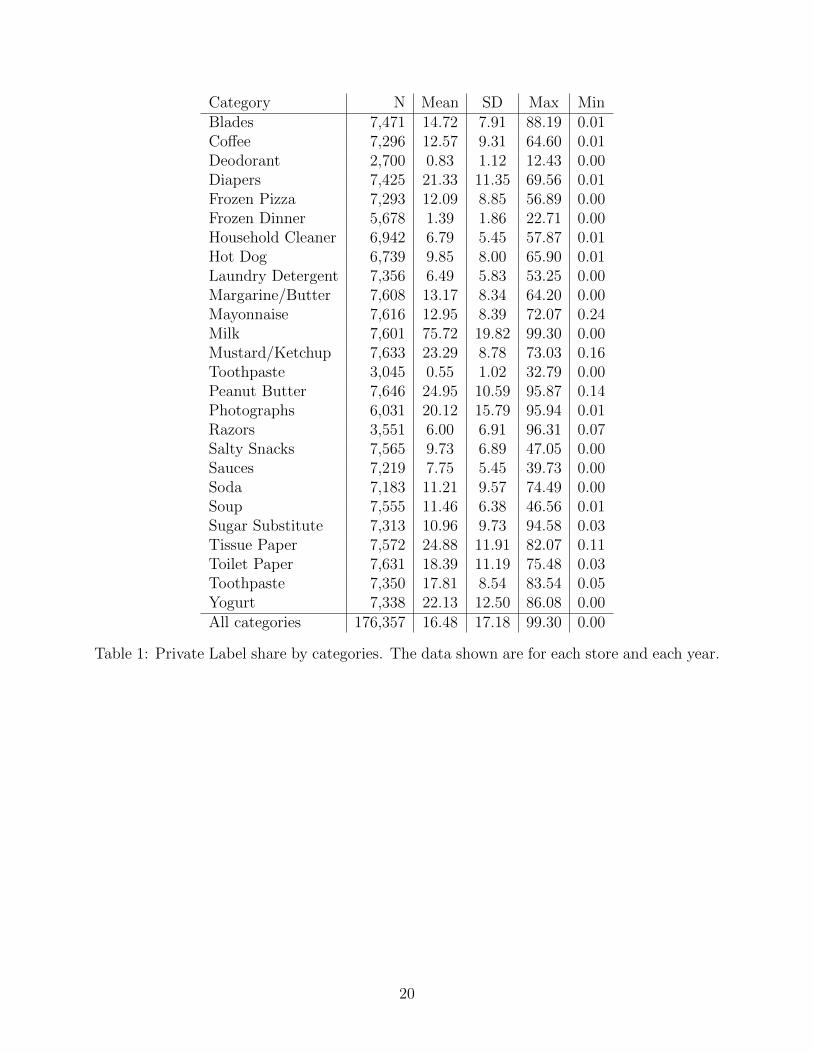
that there is considerable variation across categories, stores and years. Table 1 shows the
summary statistics for PLShare for each category. There is a large degree of heterogeneity
across categories, ranging from an average PLShare of 76% in milk to 0.55% in toothpaste.
Furthermore, within each category we observe significant variation across stores and mar-
kets. For example, in 20 of the 26 categories the maximum PLshare observed across stores
exceeds 50%. Given the large variation, it is necessary to control for category effects and
chain identity as the private label quality may vary across chains and categories.
[Figure 1 about here.]
[Table 1 about here.]
New Brand Market Share Our second key measure is new brand market share. The
CPG industry is characterized by frequent introductions of new products, ranging from new
brands to minor modifications of existing products (e.g. a new flavor). We hypothesize
that personality traits associated with conservative ideology, such as skepticism towards new
experiences, might get reflected in lower acceptance and penetration of new products. To
measure new product penetration, we first create a data set to identify all new product
introductions from 2002 to 2004. (Since we observe data for only a few months in 2001 and
2006, we use the years 2002 to 2004 to identify the new product introductions.) We use the
market share of the new product in the year following launch as our key dependent variable. In
all, we observe 4,151 new product launches across our 26 categories. The summary statistics
1Private labels are often called store brands or generics. We use these terms interchangeably in this article.
2

for new product market share by category is shown in table 2. On average we observe
approximately 6.6 (ranges from 0 to 122) new product launches every year in a county across
all categories. The average new product share is 1.3%, however there is a large degree of
heterogeneity across counties and categories. The distribution of all new product market
shares is shown in figure 2.
[Table 2 about here.]
[Figure 2 about here.]
1.1.2 Measures of Religiosity
Religiosity is a complex, multi-dimensional construct. It encompasses the various levels at
which religion impacts people, including their cognitive values and beliefs, affective feelings of
spirituality and commitment, and behaviors such as prayer and church attendance. The As-
sociation of Religion Data Archives (ARDA) compiles data on religious activity at the county
level. It collects information on church membership, adherence, and number of congregations
at the county level, and then provides further detail by breaking it down to the denomination
level. Our measures of religiosity are constructed from data contained in the 2000 report.
The primary measure of religiosity used in the empirical application is Adherence. The defi-
nition of adherents is quite stringent, counting only full members of religious denominations
and non-members who attend services regularly. As such, it serves as a relatively accurate
measure of the population that is truly engaged in religious activity, rather than including
those who might identify with a particular denomination but not actively practice or engage
with the religion through participation.
The summary statistics for our measures of religiosity are provided in table 3. This table
provides the mean and standard deviations for all counties in the US and the mean and stan-
dard deviation of the counties that overlap with IRI data and are included in our analysis.
The in-sample mean of Adherence is 50% (which matches the mean across all US counties
53%) with a standard deviation of 13%. Figure 3 shows the distribution of Adherence for the
421 counties represented in the sample. The minimum is 19%, with a few counties showing
100% Adherence. In the robustness checks below, we use two alternate measures of reli-
giosity. First, the ARDA data provides measures of Adherence at the denomination level.
Specifically, we know the number of adherents in each county who identify as Evangelical
Protestant, Mainline Protestant, Catholic, Jewish and Islamic. This allows us to investigate
whether and how the impact of religiosity on brand consumption varies across the denomi-
nations. For the second robustness measure, we use the number of religious establishments
in a county from the 2000 County Business Patterns report published by the U.S. Census
3

Bureau. The Census Bureau collects information on the number of religious establishments
defined as “those establishments primarily engaged in operating religious organizations, such
as churches, religious temples, and monasteries and/or establishments primarily engaged in
administering an organized religion or promoting religious activities.” As discussed below,
our results are robust to these alternate definitions of religiosity.
[Table 3 about here.]
[Figure 3 about here.]
1.1.3 Political Voting
To measure political voting behavior, we use county level outcomes from presidential elections
between 1980 and 2004 (available at http://uselectionatlas.org). Rather than rely on any
particular election, our main measure of political conservatism is the average percentage
of Republican votes in all elections between 1980 and 2004 (7 presidential elections). As
a robustness check, we also consider just 2004 presidential election as this coincides most
closely with our sales data.
The summary statistics for our measures of Republican are provided in table 4. This table
provides the mean and standard deviation for all counties in the US and for the counties that
overlap with IRI data and are included in our analysis. The in-sample mean of Republican
vote is 55% (which matches the mean across all US counties 57%) with a standard deviation
of 11%. For the 2004 presidential election, we find that the counties with IRI data have a
lower percentage of Republican votes than the entire sample. Note importantly, the 61%
does not reflect the national average votes for George Bush in the 2004 election (51%), this
is because the 61% is the average across counties (these two number would be the same only
if the number of voters in the each county were the same). Figure 4 shows the distribution of
Republican for the 421 counties represented in the sample, displaying significant variation.
[Table 4 about here.]
[Figure 4 about here.]
Evaluating Religiosity and Republican as measures of conservativeness In addi-
tion, for the preliminary analysis in the paper we consider the biannual American national
election studies (ANES) survey data from 1948 to 2008. These data are available on-line
(http://www.electionstudies.org/). Raw correlations in these data show that religious belief
(r = 0.17, p value < 0.0001) and Republican political preference (r = 0.39, p value < 0.0001)
4

are significantly correlated with self-reported measures of conservative ideology. However,
the correlation between religious belief and political preference is not significantly different
from zero (r = -0.00, p value = 0.789), suggesting that both variables capture some aspects of
conservative values independent of each other. Interestingly, for Evangelical Protestant and
Mainline Protestant, we find a significant correlation between religious adherence (defined
by the scale ”how often do you go to church”) and Republican preference (r = 0.06 and 0.07
respectively, both have p <0.0001).
The correlations of religiosity and Republican in our data are shown in table 5. We find a
low overall correlation between the main measure of Republican and religiosity (adherence).
To visualize this, consider the plot of the raw data for the 421 counties in figure 4. Similar
to the ANES survey, we also observe a significant positive correlation between Evangelical
Protestant adherence and Republican voting.
[Table 5 about here.]
[Figure 5 about here.]
1.1.4 Demographics
Finally we incorporate an extensive set of demographic variables to control for other factors
that might impact brand consumption. These data are obtained from the US Census. The
variables included are (a) Income - average income, (b) Elderly - percent of the population
over 65, (c) Unemployed - percent unemployed, (d) Education - average number of years of
education, (e) HHsize - average household size, (f) Black - % African American population
and (g) Metro - an indicator for stores in large metropolitan areas. Descriptive statistics for
these measure are shown in table 6, which as before compares the statistics for the US with
our analysis sample. We note that metropolitan areas are over represented in the IRI sample,
and therefore we see on average a higher income and higher % African American population.
[Table 6 about here.]
In addition to demographic variables we include controls for marketing mix activity and
a rich set of fixed effects to control for every combination of chain, category, and year.
This accounts for the fact that chains may differ in the quality of private label in different
categories.
5

1.2 Methodology
1.2.1 Main model
In this paper our main model is of the following form:
log
(sr,ch,ct,s,y
1 − sr,ch,ct,s,y
)= αch,ct,s,y + βrelReligiosityr + βrepRepublicanr + γXr + εr,ch,ct,s,y (1)
Where r represents a store, ch represents a chain, ct represents a category, s represent a US
state, y represents a year. sr,ch,ct,s,y is the market share of the private label (or new product),
where the transformation to log( s1−s
) ensures support on the real line. αch,ct,s,y represents a
rich set of fixed effects for every combination of chain, category (or brand for new products),
state and year. This is important for our application as the quality of private labels can
vary across categories and chains. Religiosityr is the religious adherence in the store r’s
county; Republicanr is the average percentage of votes of the Republican party between
1980 and 2004 in the store r’s county. Our two main variables of interest are βrel and βrep
which capture the impact of the two measures of conservatism on private label (new product)
share. Xr contains the demographic variables such as income, employment and household
size for store r’s county. γ estimates the impact of these demographics on private label (new
product) share. The error term εr,ch,ct,s,y contains all other variation and is assumed to be
i.i.d. normal in our application. It is important to note that by incorporating a rich set
of fixed effects, other parameters in the regression are identified based on the variation in
market shares between stores that belong to the same retail chain serving different counties.
Thus, βrel and βrep capture the net impact of conservativeness after controlling for a variety
of socio-economic characteristics, marketing mix variables, and a robust set of fixed effects
that absorb any differences in product quality across retail chains.
1.2.2 Quantile regression
There are a few potential problems that could arise in using a least squares estimate (LS).
First, LS can give additional weight to outliers which can skew the estimates. Second, LS
only provides estimates in the central location rather then the entire distribution. In other
words, a least squares model assumes a homogeneous response to all independent variables
while this response can be heterogeneous. Therefore LS provides estimates of the average
impact of religiosity and Republican voting that may not be true for the entire distribution
of stores. Third, LS makes strong assumptions about the error term structure which could
be heteroskedastic. As a robustness check, we also estimate quantile regressions that can
account for each of these (see Koenker, 2005; Hao and Naiman, 2007). The main difference
6

between the two approaches is that LS estimates parameters at the conditional (conditional
on independent variables) mean where as a quantile regression estimates the parameters
at different conditional quantiles (e.g. median) of the private label (new product) share
distribution. As discussed below, our estimates are robust to these potential problems with
a linear model, and that for all quantiles of the conditional distribution of private label (new
product) share the estimate of Republican and religiosity are significant and negative (i.e.
consistent with the LS estimates).
2 SOM Text: Main Results
In this section we provide further details (displaying all controls) of our main results provided
in the main text. We will discuss the results for the private label share and the new product
share in subsections 2.1 and 2.2.
2.1 Private Label share
The complete main results for the pooled model are provided in Table 7. These represent the
results estimated by pooling our data from all categories. Here we find that the coefficients
associated with both religiosity and Republican are negative and statistically significant,
indicating that market shares for generics are significantly lower in conservative counties. It
is important to note that these estimates are identified based on the variation in market shares
between stores that belong to the same retail chain serving different counties. Thus, they
capture the net impact of conservativeness after controlling for a variety of socio-economic
characteristics, marketing mix variables, and a robust set of 47,232 fixed effects that absorb
any differences in product quality across retail chains. The detailed category level results
are shown in table 8 below. The category level results are quite telling. In 20 out of the 26
categories, the effect of religiosity on generic brand penetration is negative and statistically
significant. For six categories the effect is insignificant, and there is not a single category
where religious counties are associated with higher market shares for generics. In 17 out
of the 26 categories, the effect of republican on generic brand penetration is negative and
statistically significant. For 7 categories the effect is insignificant, and for only 2 are the
estimates positive. These two categories are Toothpaste and Milk. Note that these are
somewhat unusual categories, Toothpaste has extremely low market share for generics (0.5%)
and Milk has very large market share (over 75%).
[Table 7 about here.]
7

[Table 8 about here.]
2.2 New product share
The complete main results for the pooled model are provided in Table 9. We find that the
coefficients associated with both religiosity and Republican are negative and statistically sig-
nificant, indicating that market shares for new products are significantly lower in conservative
counties. It is important to note that these estimates are identified based on the variation in
market shares for the same brands across different counties within a state. They capture the
net impact of conservativeness after controlling for a variety of socio-economic characteristics,
marketing mix variables, and a robust set of 53,389 fixed effects that absorb any differences
in brands and states. The detailed category level results are shown in table 10 below. Across
the two measures of conservatism, 32 out of the 52 estimates are negative and statistically
significant implying that the effect of religiosity and republican on new product penetration
is negative. All the remaining estimates are insignificant, and there is not a single estimate
that is positive and statistically significant.
[Table 9 about here.]
[Table 10 about here.]
3 SOM Text: Robustness Checks
In this section we provide robustness checks to our main results by using alternate definitions
for religiosity and voting. In addition, we provide estimates from quantile regressions. We
will discuss the results for the private label share and the new product share in subsections
3.1 and 3.2.
3.1 Private Label share
3.1.1 Alternate Definition of Religiosity
In our main results, we define religiosity as adherence in a county using data provided by
ARDA. To ensure these results are not driven any particular measure of religiosity, we use
additional data from the County Business Patterns from the 2000 Census. The religiosity
measure based on this data is the number of religious organizations per 100,000 residents.
The results are shown in table 11. As seen from table 11, our main results are replicated
using this new measure of religiosity.
8

[Table 11 about here.]
As a second robustness check, we test whether our results are robust across different
religious denominations. The results are shown in table 12. We find significant negative
estimates for Protestant, Catholic, Jewish and Islam and our estimates are directionally con-
sistent though insignificant for Evangelical and all ‘other’ religions. As pointed out earlier,
there is high correlation between the Evangelical Protestants adherence and Republican po-
litical support. To test this we run the same model without the Republican parameter and
do indeed find that coefficient for Evangelical is negative and significant. These results are
shown in second column of table 12.
[Table 12 about here.]
3.1.2 Alternate Definition of Republican
In our main results, we define Republican based on the average voting outcome for all elections
from 1980 to 2004. We test if our results are robust to the other measure of Republican -
2004 election results. The results are shown in table 13. We find that our main results are
replicated.
[Table 13 about here.]
3.1.3 Quantile Regression
The results of the quantile regression are shown in figure 6. In these charts the solid line rep-
resents the quantile regression estimates and the shaded area represents the 95% confidence
interval. The dotted line shows the least squares model and the blue lines show the 95%
confidence interval for these estimates. Figure 6 shows that for the entire distribution of pri-
vate label share we find both religion and Republican have a significant and negative impact.
Hence, our main OLS estimates are not driven by outliers or other model misspecification.
[Figure 6 about here.]
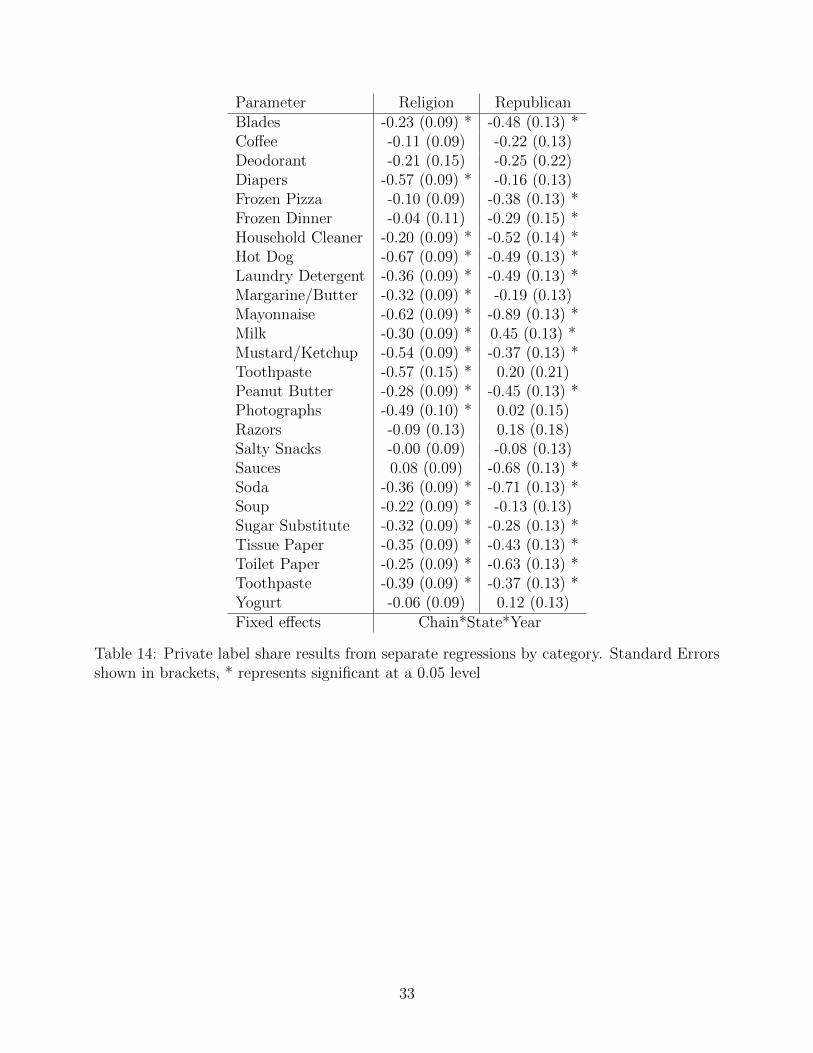
3.1.4 Separate regressions by category
In our main results (table 8) we estimate our category level effects with assuming the same
impact of marketing mix and demographic variables across categories. To show this does
not impact our results, we run a robustness check where we run separate regressions for each
category. The results are shown in table 14 (for brevity the estimates of the controls are not
shown). Consistent with our main results in table 8 we find that 33 of the 52 estimates are
9

negative and statistically significant. Only one is positive and significant (the estimate of
Republican on generic milk share) and the rest are not significant.
[Table 14 about here.]
3.2 New Products
3.2.1 Alternate Definition of Religiosity
Results for new product market share using the alternate definition of religiosity are reported
in table 15. As with Private Label shares, we find our main results are replicated.
[Table 15 about here.]
Next, we test the robustness of results to different denominations of religion. The results
are shown in table 16. We find significant negative estimates for Protestant, Catholic, Jewish
and Islam. As in the Private Label case, we do not find significant results for Evangelical and
believe this is due to the correlation with Republican voting. Again, to test this we rerun our
main regression without the Republican variable and find that the Evangelical coefficient is
significant and negative.
[Table 16 about here.]
3.2.2 Alternate Definition of Republican
The results using voting outcomes for 2004 presidential elections are shown in table 17. We
find our main results are replicated.
[Table 17 about here.]
3.2.3 Quantile Regression
The results of the quantile regression are shown in figure 7. In these charts the solid line rep-
resents the quantile regression estimates and the shaded area represents the 95% confidence
interval. The dotted line shows the least squares model and the blue lines show the 95% con-
fidence interval for these estimates. As with the private label regression, these charts show
that for the entire distribution of new product share we find both religion and Republican
have a significant and negative impact.
[Figure 7 about here.]
10

3.2.4 Launch date
We provide one final robustness check with regards to the definition of the new product. In
the data we observe that several of the new products are launched at a regional rather than a
national level. Here we consider two alternate measures for new products. First, rather than
considering the share of the new product in the year after launch, we use the share in 2005
as our main dependent variable. The results are shown in the first column of table 18, and
we find that our results are replicated. Second, we consider only “major” launches (those
brands that were launched nationwide at the same time). This definition reduces the number
of new products in the data from 4,151 to 1,350. The second column of table 18 shows that
we still get very similar results with the reduced dataset.
[Table 18 about here.]
3.2.5 Separate regressions by category
In our main results (table 10) we estimate our category level effects with assuming the same
impact of marketing mix and demographic variables across categories. To show this does
not impact our results, we run a robustness check where we run separate regressions for each
category. The results are shown in table 19 (for brevity the estimates of the controls are not
shown). Consistent with our main results in table 10 we find that 25 of the 52 estimates
are negative and statistically significant. The rest are not significant. Not one estimate is
positive and statistically significant.
[Table 19 about here.]
11

References
Aaker, D. A. (1991): “Managing Brand Equity,” Free Press.
ADWEEK (2000): “Why risk prevents switching to Private Labels,” July 10.
Bronnenberg, B., M. Kruger, and C. Mela (2008): “The IRI Marketing Data Set,”
Marketing Science, 27, 745–748.
Erdem, T., and A. Valenzuela (2004): “Performance of Store Brands,” Journal of
Marketing Research, 41(1), 208–227.
Hao, L., and D. Q. Naiman (2007): “Quantile Regression,” SAGE publications.
Koenker, R. (2005): “Quantile Regression,” Cambridge University Press.
12

Figure 1: Distribution of PL share across all categories, stores and years
13
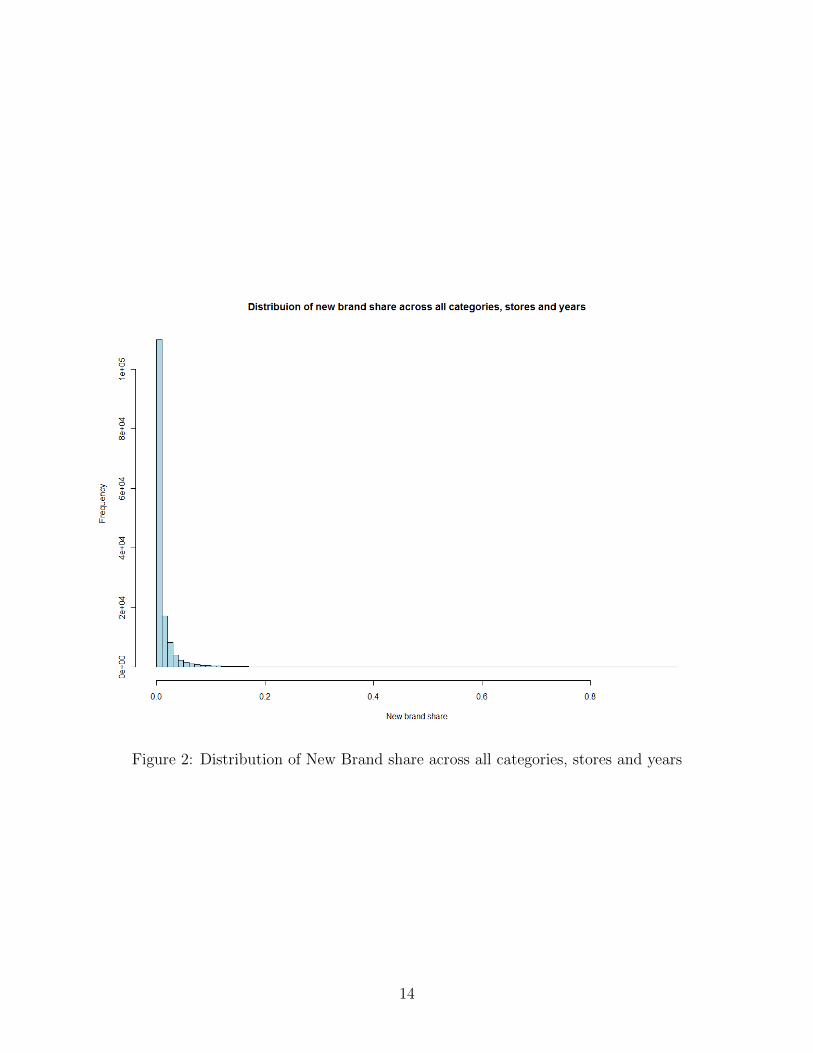
Figure 2: Distribution of New Brand share across all categories, stores and years
14
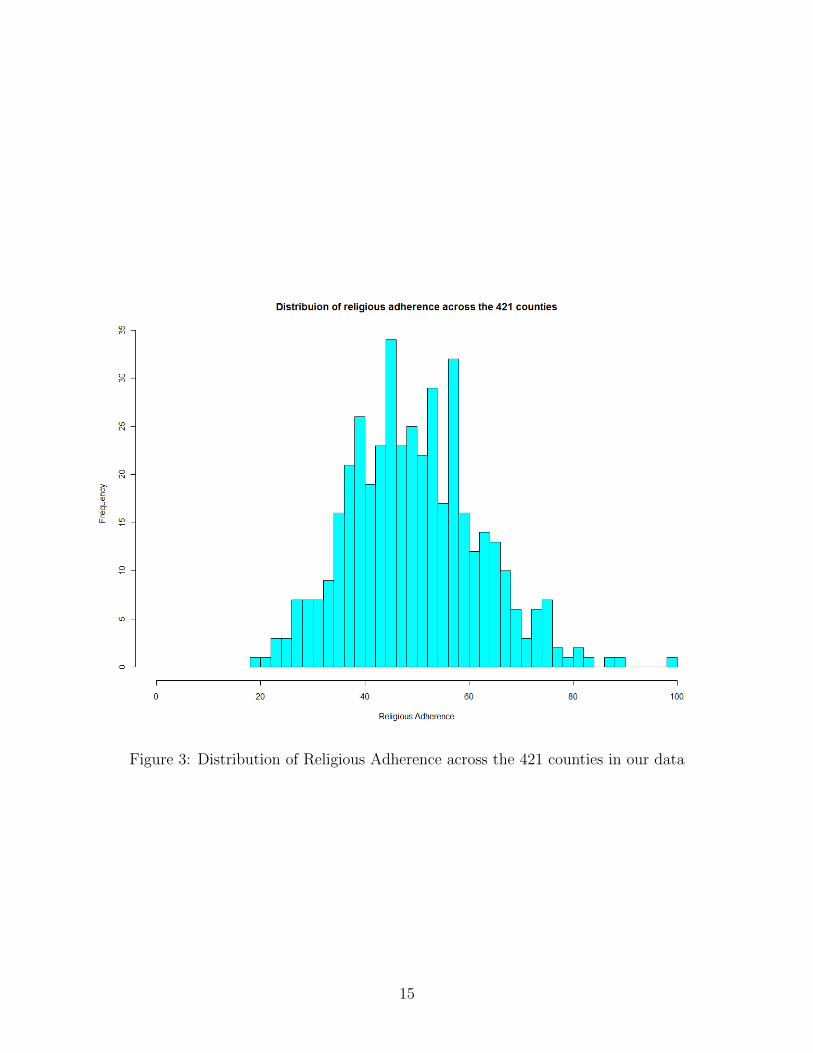
Figure 3: Distribution of Religious Adherence across the 421 counties in our data
15

Figure 4: Distribution of Percentage votes for the Republican party across the 421 countiesin our data
16
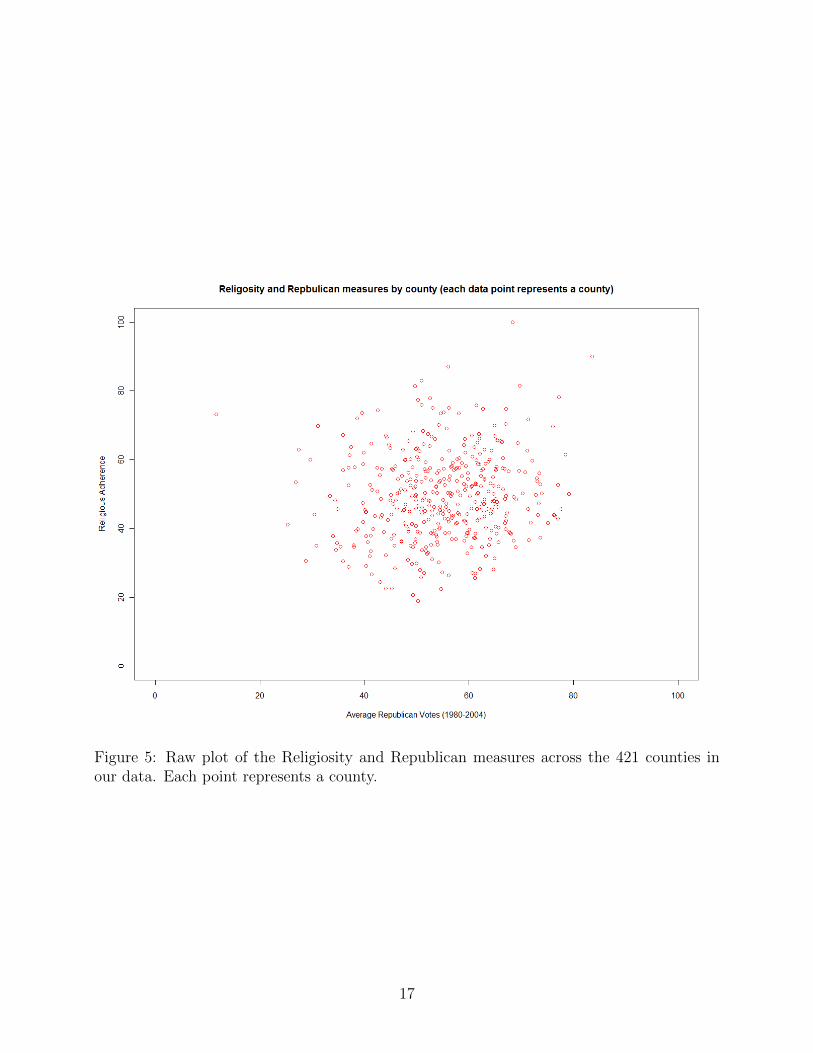
Figure 5: Raw plot of the Religiosity and Republican measures across the 421 counties inour data. Each point represents a county.
17
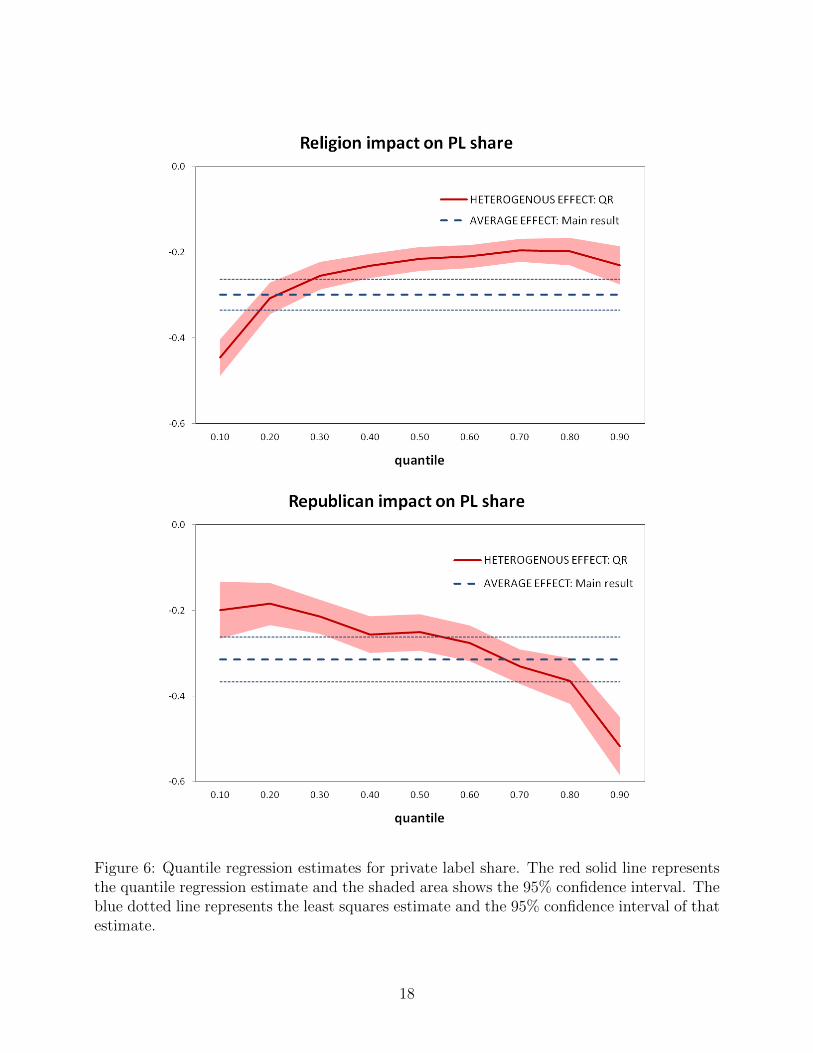
Figure 6: Quantile regression estimates for private label share. The red solid line representsthe quantile regression estimate and the shaded area shows the 95% confidence interval. Theblue dotted line represents the least squares estimate and the 95% confidence interval of thatestimate.
18

Figure 7: Quantile regression estimates for new product share. The red solid line representsthe quantile regression estimate and the shaded area shows the 95% confidence interval. Theblue dotted line represents the least squares estimate and the 95% confidence interval of thatestimate.
19
Category N Mean SD Max MinBlades 7,471 14.72 7.91 88.19 0.01Coffee 7,296 12.57 9.31 64.60 0.01Deodorant 2,700 0.83 1.12 12.43 0.00Diapers 7,425 21.33 11.35 69.56 0.01Frozen Pizza 7,293 12.09 8.85 56.89 0.00Frozen Dinner 5,678 1.39 1.86 22.71 0.00Household Cleaner 6,942 6.79 5.45 57.87 0.01Hot Dog 6,739 9.85 8.00 65.90 0.01Laundry Detergent 7,356 6.49 5.83 53.25 0.00Margarine/Butter 7,608 13.17 8.34 64.20 0.00Mayonnaise 7,616 12.95 8.39 72.07 0.24Milk 7,601 75.72 19.82 99.30 0.00Mustard/Ketchup 7,633 23.29 8.78 73.03 0.16Toothpaste 3,045 0.55 1.02 32.79 0.00Peanut Butter 7,646 24.95 10.59 95.87 0.14Photographs 6,031 20.12 15.79 95.94 0.01Razors 3,551 6.00 6.91 96.31 0.07Salty Snacks 7,565 9.73 6.89 47.05 0.00Sauces 7,219 7.75 5.45 39.73 0.00Soda 7,183 11.21 9.57 74.49 0.00Soup 7,555 11.46 6.38 46.56 0.01Sugar Substitute 7,313 10.96 9.73 94.58 0.03Tissue Paper 7,572 24.88 11.91 82.07 0.11Toilet Paper 7,631 18.39 11.19 75.48 0.03Toothpaste 7,350 17.81 8.54 83.54 0.05Yogurt 7,338 22.13 12.50 86.08 0.00All categories 176,357 16.48 17.18 99.30 0.00
Table 1: Private Label share by categories. The data shown are for each store and each year.
20

New product shareCategory New launches N Mean SD Max MinBlades 83 5,881 1.94 2.12 30.39 0.00Coffee 254 4,137 1.02 4.21 60.80 0.00Deodorant 148 10,923 0.94 1.31 17.56 0.00Diapers 22 1,856 4.41 5.43 41.91 0.00Frozen Pizza 39 1,099 3.35 7.78 68.03 0.00Frozen Dinner 183 10,221 1.20 1.84 35.18 0.00Household Cleaner 117 4,721 1.05 3.15 41.68 0.00Hot Dog 133 3,228 1.73 3.56 50.87 0.00Laundry Detergent 180 2,047 2.16 5.14 42.25 0.00Margarine/Butter 61 1,790 2.29 5.17 43.27 0.00Mayonnaise 56 1,949 2.07 4.13 30.72 0.00Milk 78 1,906 1.86 6.84 68.54 0.00Mustard/Ketchup 192 2,905 1.31 8.26 95.62 0.00Toothpaste 209 4,832 0.82 4.23 64.79 0.00Peanut Butter 29 571 6.18 9.66 51.55 0.00Photographs 45 1,821 2.08 6.68 55.42 0.00Razors 30 4,016 7.96 6.13 75.00 0.01Salty Snacks 708 19,345 0.28 1.08 28.57 0.00Sauces 504 18,208 0.55 1.17 26.08 0.00Soda 301 10,876 0.53 1.61 28.88 0.00Soup 244 6,128 0.84 2.47 41.16 0.00Sugar Substitute 45 1,100 4.20 8.19 60.90 0.00Tissue Paper 38 1,211 3.14 5.77 37.25 0.00Toilet Paper 162 10,214 1.30 1.94 38.43 0.00Toothpaste 150 12,313 1.01 1.81 31.71 0.00Yogurt 140 6,770 1.31 2.41 50.25 0.00All categories 4,151 150,068 1.29 3.45 95.62 0.00
Table 2: New product launches by category
21

All data (n = 2,980) IRI data (n = 421)Variable Mean SD Mean SDAdherence 53.24 17.96 49.59 12.62Evangelical Protestant Adherence 23.14 16.92 17.75 14.75Mainline Protestant Adherence 14.43 11.4 11.7 6.04Catholic Adherence 13.49 14.64 17.25 15.32Jewish Adherence 0.23 1.14 1.04 2.5Islam Adherence 0.08 0.35 0.36 0.78Other Adherence 1.97 8.44 1.5 6.78Religious establishments (census) 52.61 101.92 169.83 200.44
Table 3: Mean and standard deviation of religiosity variables and the IRI data.
22
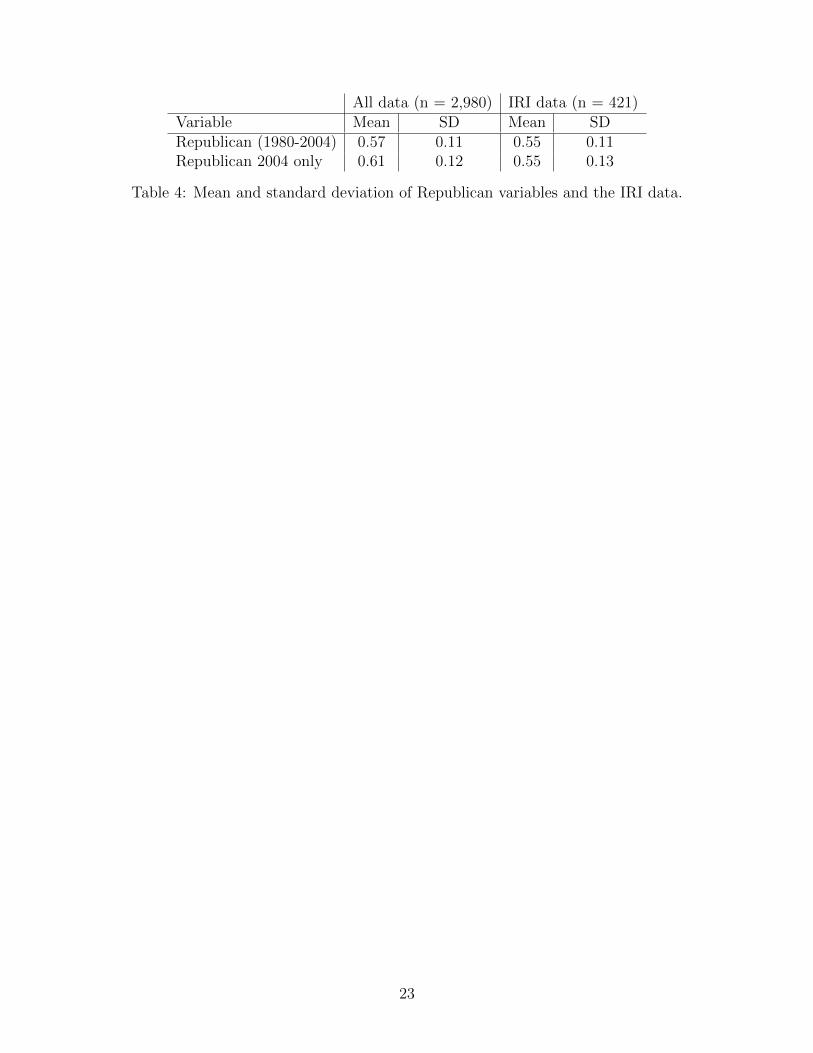
All data (n = 2,980) IRI data (n = 421)Variable Mean SD Mean SDRepublican (1980-2004) 0.57 0.11 0.55 0.11Republican 2004 only 0.61 0.12 0.55 0.13
Table 4: Mean and standard deviation of Republican variables and the IRI data.
23

Religiosity Republican (1980-2004) Republican 2004 onlyAdherence 0.12 0.15Evangelical Protestant Adherence 0.43 0.54Mainstream Protestant Adherence 0.13 0.14Catholic Adherence -0.37 -0.44Jewish Adherence -0.3 -0.36Islam Adherence -0.4 -0.42Other Adherence 0.17 0.16
Table 5: Correlation between the republican and the religiosity variables.
24

Variable All data (n = 2,980) IRI data (n = 421)Mean SD Mean SD
Median Income ($K) 41.81 9.54 51.15 12.16Elderly 14.85 4.10 12.28 2.75% Unemployed 5.73 2.63 5.43 2.14Education 12.47 0.86 13.03 1.01Average HH size 2.63 0.22 2.66 0.18% African American 8.65 14.46 12.76 15.32Metropolitan 0.34 0.47 0.76 0.42
Table 6: Mean and standard deviation of demographics in the 2004 census and the IRI data.
25

Parameter EstimateReligion -0.30 (0.02) *Republican -0.31 (0.03) *Promotion 0.15 (0.01) *Feature 0.16 (0.03) *Display 0.59 (0.01) *Income -6.5E-6 (2.8E-7) *Elderly 7.5E-4 (1.0E-3)Unemployed -0.01 (0.00) *Education 0.01 (0.00) *HH size -1.5E-3 (1.5E-2)Black -2.3E-3 (2.3E-4) *Metro -0.03 (0.01) *Fixed effects Chain*State*Year*CategoryObservations 176,357
Table 7: Private label share main results. Standard Errors shown in brackets, * representssignificant at a 0.05 level
26
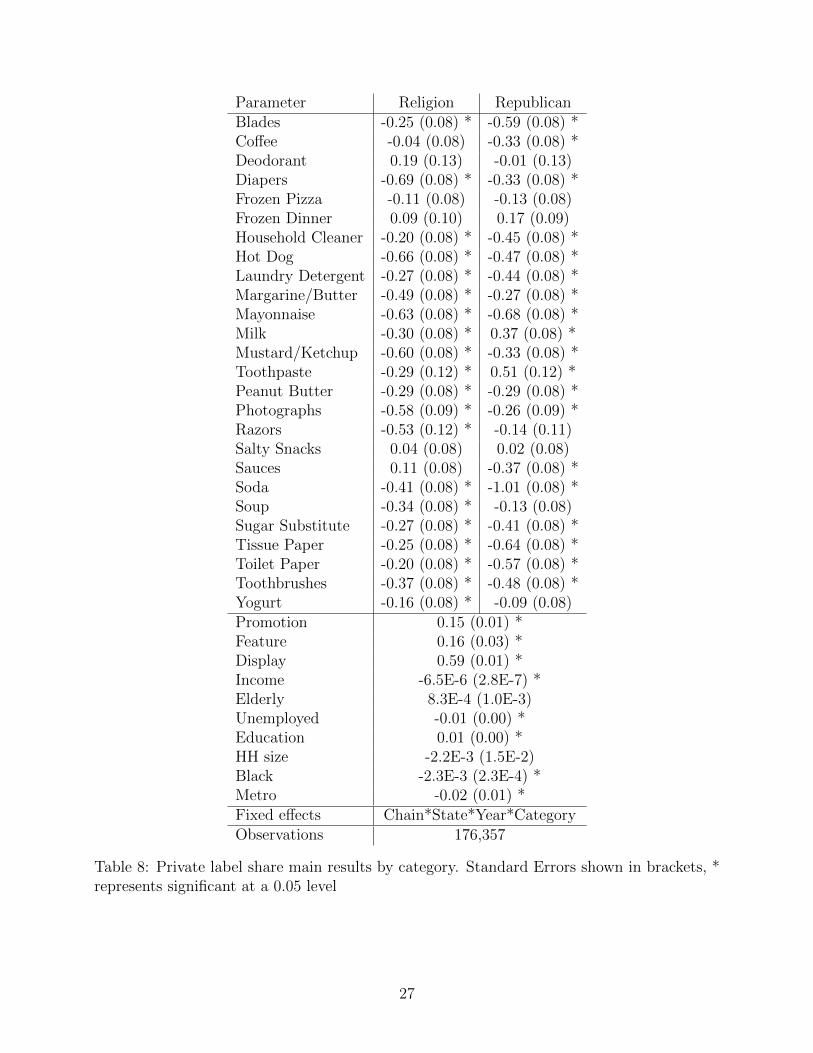
Parameter Religion RepublicanBlades -0.25 (0.08) * -0.59 (0.08) *Coffee -0.04 (0.08) -0.33 (0.08) *Deodorant 0.19 (0.13) -0.01 (0.13)Diapers -0.69 (0.08) * -0.33 (0.08) *Frozen Pizza -0.11 (0.08) -0.13 (0.08)Frozen Dinner 0.09 (0.10) 0.17 (0.09)Household Cleaner -0.20 (0.08) * -0.45 (0.08) *Hot Dog -0.66 (0.08) * -0.47 (0.08) *Laundry Detergent -0.27 (0.08) * -0.44 (0.08) *Margarine/Butter -0.49 (0.08) * -0.27 (0.08) *Mayonnaise -0.63 (0.08) * -0.68 (0.08) *Milk -0.30 (0.08) * 0.37 (0.08) *Mustard/Ketchup -0.60 (0.08) * -0.33 (0.08) *Toothpaste -0.29 (0.12) * 0.51 (0.12) *Peanut Butter -0.29 (0.08) * -0.29 (0.08) *Photographs -0.58 (0.09) * -0.26 (0.09) *Razors -0.53 (0.12) * -0.14 (0.11)Salty Snacks 0.04 (0.08) 0.02 (0.08)Sauces 0.11 (0.08) -0.37 (0.08) *Soda -0.41 (0.08) * -1.01 (0.08) *Soup -0.34 (0.08) * -0.13 (0.08)Sugar Substitute -0.27 (0.08) * -0.41 (0.08) *Tissue Paper -0.25 (0.08) * -0.64 (0.08) *Toilet Paper -0.20 (0.08) * -0.57 (0.08) *Toothbrushes -0.37 (0.08) * -0.48 (0.08) *Yogurt -0.16 (0.08) * -0.09 (0.08)Promotion 0.15 (0.01) *Feature 0.16 (0.03) *Display 0.59 (0.01) *Income -6.5E-6 (2.8E-7) *Elderly 8.3E-4 (1.0E-3)Unemployed -0.01 (0.00) *Education 0.01 (0.00) *HH size -2.2E-3 (1.5E-2)Black -2.3E-3 (2.3E-4) *Metro -0.02 (0.01) *Fixed effects Chain*State*Year*CategoryObservations 176,357
Table 8: Private label share main results by category. Standard Errors shown in brackets, *represents significant at a 0.05 level
27

Parameter EstimateReligion -0.41 (0.03) *Republican -0.46 (0.04) *Display 0.01 (0.00) *Feature 0.02 (0.00) *Promotion 0.03 (0.00) *Income -8.9E-7 (4.4E-7) *Elderly 0.01 (0.00) *Unemployed -0.02 (0.00) *Education -0.03 (0.00) *HH size 0.22 (0.02) *Black -0.01 (0.00) *Metro -0.11 (0.01) *Fixed effects Brand * State * YearObservations 150,068
Table 9: New brand share main results. Standard Errors shown in brackets, * representssignificant at a 0.05 level
28

Parameter Religion RepublicanBlades -0.35 (0.11) * -0.43 (0.12) *Coffee -0.77 (0.08) * -0.54 (0.08) *Deodorant -0.30 (0.09) * -0.51 (0.10) *Diapers -1.03 (0.16) * -0.56 (0.17) *Frozen Pizza -0.38 (0.09) * -0.51 (0.09) *Frozen Dinner -0.38 (0.20) -0.67 (0.21) *Household Cleaner -0.75 (0.30) * 0.04 (0.31)Hot Dog -0.49 (0.09) * -0.52 (0.10) *Laundry Detergent -0.52 (0.14) * -0.87 (0.14) *Margarine/Butter -0.43 (0.18) * -0.15 (0.18)Mayonnaise -1.27 (0.26) * -0.45 (0.27)Milk -0.26 (0.24) -0.65 (0.25) *Mustard/Ketchup 0.11 (0.24) -0.14 (0.24)Toothpaste -0.53 (0.25) * -0.35 (0.25)Peanut Butter 0.02 (0.19) -0.83 (0.20) *Photographs -0.51 (0.15) * -0.36 (0.15) *Razors -0.17 (0.48) -0.04 (0.46)Salty Snacks -0.09 (0.22) -0.55 (0.23) *Sauces -0.14 (0.13) -0.60 (0.14) *Soda -0.05 (0.07) -0.62 (0.08) *Soup 0.03 (0.13) -0.10 (0.13)Sugar Substitute -0.52 (0.32) -0.03 (0.32)Tissue Paper -0.28 (0.29) -0.18 (0.28)Toilet Paper -0.57 (0.09) * -0.32 (0.10) *Toothbrushes -0.72 (0.08) * -0.19 (0.09) *Yogurt -0.22 (0.11) * -0.52 (0.12) *Display 0.01 (0.00) *Feature 0.02 (0.00) *Promotion 0.03 (0.00) *Income -8.4E-7 (4.4E-7)Elderly 0.01 (0.00) *Unemployed -0.02 (0.00) *Education -0.03 (0.00) *HH size 0.22 (0.02) *Black -0.01 (0.00) *Metro -0.11 (0.01) *Fixed effects Brand * State * YearObservations 150,068
Table 10: New brand share main results by category. Standard Errors shown in brackets, *represents significant at a 0.05 level
29

Parameter EstimateReligion -8.2E-5 (5.0E-6) *Republican -0.34 (0.03) *Promotion 0.15 (0.01) *Feature 0.16 (0.03) *Display 0.59 (0.01) *Income -7.6E-6 (2.7E-7) *Elderly -0.01 (0.00) *Unemployed -0.01 (0.00) *Education 0.01 (0.00) *HH size -0.03 (0.01) *Black -1.3E-3 (2.3E-4) *Metro -0.03 (0.01) *Fixed effects Chain*State*Year*CategoryObservations 176,357
Table 11: Private label share results are robust to religiosity measure. The religion measurehere is the number of religious establishments from the Census. Standard Errors shown inbrackets, * represents significant at a 0.05 level
30
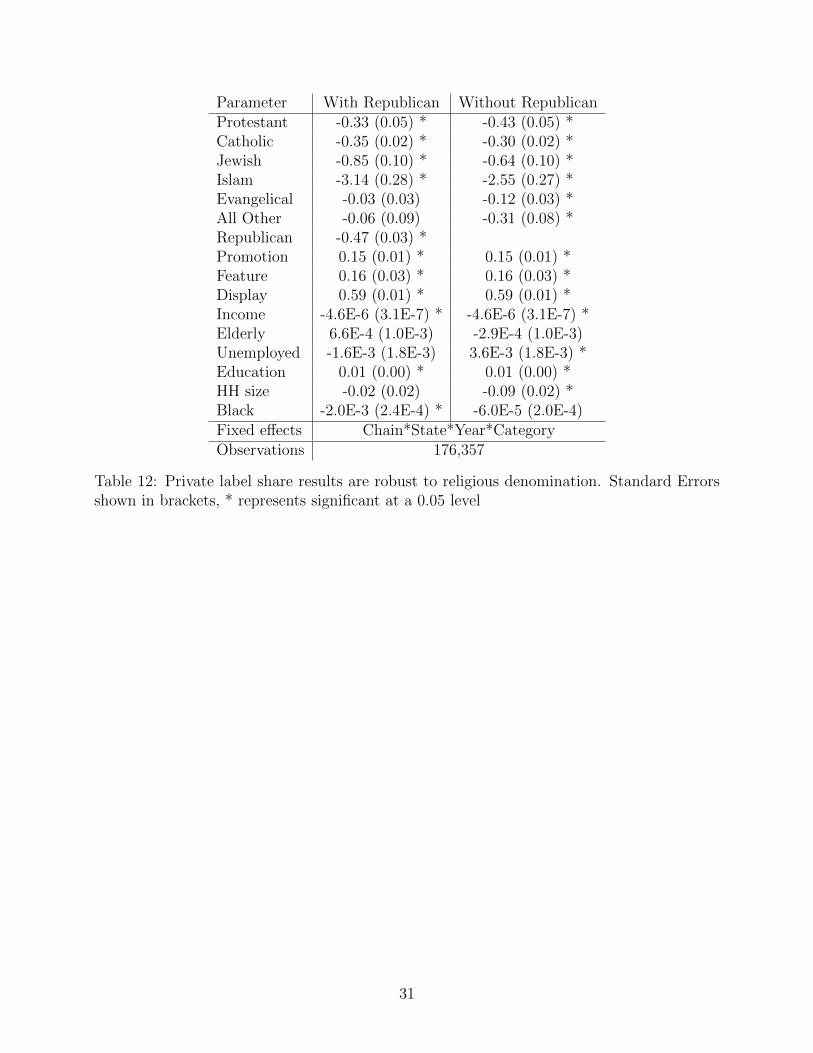
Parameter With Republican Without RepublicanProtestant -0.33 (0.05) * -0.43 (0.05) *Catholic -0.35 (0.02) * -0.30 (0.02) *Jewish -0.85 (0.10) * -0.64 (0.10) *Islam -3.14 (0.28) * -2.55 (0.27) *Evangelical -0.03 (0.03) -0.12 (0.03) *All Other -0.06 (0.09) -0.31 (0.08) *Republican -0.47 (0.03) *Promotion 0.15 (0.01) * 0.15 (0.01) *Feature 0.16 (0.03) * 0.16 (0.03) *Display 0.59 (0.01) * 0.59 (0.01) *Income -4.6E-6 (3.1E-7) * -4.6E-6 (3.1E-7) *Elderly 6.6E-4 (1.0E-3) -2.9E-4 (1.0E-3)Unemployed -1.6E-3 (1.8E-3) 3.6E-3 (1.8E-3) *Education 0.01 (0.00) * 0.01 (0.00) *HH size -0.02 (0.02) -0.09 (0.02) *Black -2.0E-3 (2.4E-4) * -6.0E-5 (2.0E-4)Fixed effects Chain*State*Year*CategoryObservations 176,357
Table 12: Private label share results are robust to religious denomination. Standard Errorsshown in brackets, * represents significant at a 0.05 level
31

Parameter EstimateReligion -0.30 (0.02) *Republican -0.24 (0.02) *Promotion 0.15 (0.01) *Feature 0.17 (0.03) *Display 0.59 (0.01) *Income -6.6E-6 (2.8E-7) *Elderly 1.3E-3 (1.0E-3)Unemployed -0.01 (0.00) *Education 0.01 (0.00) *HH size -0.01 (0.01)Black -2.6E-3 (2.5E-4) *Metro -0.03 (0.01) *Fixed effects Chain*State*Year*CategoryObservations 176,357
Table 13: Private label share results are robust to republican measure. Republican measurehere is the 2004 election results. Standard Errors shown in brackets, * represents significantat a 0.05 level
32
Parameter Religion RepublicanBlades -0.23 (0.09) * -0.48 (0.13) *Coffee -0.11 (0.09) -0.22 (0.13)Deodorant -0.21 (0.15) -0.25 (0.22)Diapers -0.57 (0.09) * -0.16 (0.13)Frozen Pizza -0.10 (0.09) -0.38 (0.13) *Frozen Dinner -0.04 (0.11) -0.29 (0.15) *Household Cleaner -0.20 (0.09) * -0.52 (0.14) *Hot Dog -0.67 (0.09) * -0.49 (0.13) *Laundry Detergent -0.36 (0.09) * -0.49 (0.13) *Margarine/Butter -0.32 (0.09) * -0.19 (0.13)Mayonnaise -0.62 (0.09) * -0.89 (0.13) *Milk -0.30 (0.09) * 0.45 (0.13) *Mustard/Ketchup -0.54 (0.09) * -0.37 (0.13) *Toothpaste -0.57 (0.15) * 0.20 (0.21)Peanut Butter -0.28 (0.09) * -0.45 (0.13) *Photographs -0.49 (0.10) * 0.02 (0.15)Razors -0.09 (0.13) 0.18 (0.18)Salty Snacks -0.00 (0.09) -0.08 (0.13)Sauces 0.08 (0.09) -0.68 (0.13) *Soda -0.36 (0.09) * -0.71 (0.13) *Soup -0.22 (0.09) * -0.13 (0.13)Sugar Substitute -0.32 (0.09) * -0.28 (0.13) *Tissue Paper -0.35 (0.09) * -0.43 (0.13) *Toilet Paper -0.25 (0.09) * -0.63 (0.13) *Toothpaste -0.39 (0.09) * -0.37 (0.13) *Yogurt -0.06 (0.09) 0.12 (0.13)Fixed effects Chain*State*Year
Table 14: Private label share results from separate regressions by category. Standard Errorsshown in brackets, * represents significant at a 0.05 level
33

Parameter EstimateReligion -5.9E-4 (1.2E-5) *Republican -0.46 (0.04) *Display 0.01 (0.00) *Feature 0.02 (0.00) *Promotion 0.03 (0.00) *Income -1.4E-6 (4.4E-7) *Elderly 0.01 (0.00) *Unemployed -0.01 (0.00) *Education -0.01 (0.00) *HH size 0.12 (0.02) *Black -2.2E-3 (3.4E-4) *Metro -0.10 (0.01) *Fixed effects Brand * State * YearObservations 150,068
Table 15: New Product share results are robust to religiosity measure. The religion measurehere is the number of religious establishments from the Census. Standard Errors shown inbrackets, * represents significant at a 0.05 level
34

Parameter With Republican Without RepublicanProtestant -0.26 (0.07) * -0.47 (0.07) *Catholic -0.51 (0.04) * -0.41 (0.03) *Jewish -1.57 (0.13) * -1.29 (0.12) *Islam -4.44 (0.49) * -3.63 (0.46) *Evangelical -2.2E-3 (4.2E-2) -0.11 (0.04) *All Other 0.35 (0.15) * 0.08 (0.14)Republican -0.75 (0.05) *Display 0.01 (0.00) * 0.01 (0.00) *Feature 0.02 (0.00) * 0.02 (0.00) *Promotion 0.03 (0.00) * 0.03 (0.00) *Income 2.8E-6 (5.0E-7) * 2.7E-6 (4.8E-7) *Elderly 0.02 (0.00) * 0.01 (0.00) *Unemployed -0.02 (0.00) * 2.0E-3 (2.5E-3)Education -0.03 (0.00) * -0.03 (0.00) *HH size 0.27 (0.02) * 0.13 (0.02) *Black -4.7E-3 (3.5E-4) * -2.5E-3 (3.0E-4) *Metro -0.12 (0.01) * -0.09 (0.01) *Fixed effects Brand * State * YearObservations 150,068
Table 16: New Product share results robust to religious denomination. Standard Errorsshown in brackets, * represents significant at a 0.05 level
35

Parameter EstimateReligion -0.41 (0.03) *Republican -0.14 (0.03) *Display 0.01 (0.00) *Feature 0.02 (0.00) *Promotion 0.03 (0.00) *Income -4.1E-7 (4.5E-7)Elderly 0.01 (0.00) *Unemployed -0.01 (0.00) *Education -0.03 (0.00) *HH size 0.17 (0.02) *Black -4.9E-3 (3.5E-4) *Metro -0.10 (0.01) *Fixed effects Brand * State * YearObservations 150,068
Table 17: New Product share results are robust to republican measure. Republican measurehere is the 2004 election results. Standard Errors shown in brackets, * represents significantat a 0.05 level
36

Parameter 2005 Share National launchesReligion -0.40 (0.03) * -0.42 (0.05) *Republican -0.51 (0.04) * -0.70 (0.07) *Display 0.01 (0.00) * 0.01 (0.00) *Feature 0.01 (0.00) * 0.02 (0.00) *Promotion 0.03 (0.00) * 0.04 (0.00) *Income -1.5E-6 (4.4E-7) * -1.1E-6 (1.0E-6)Elderly 0.01 (0.00) * 0.02 (0.00) *Unemployed -0.02 (0.00) * -0.02 (0.00) *Education -0.03 (0.00) * -0.04 (0.01) *HH size 0.21 (0.02) * 0.22 (0.04) *Black -0.01 (0.00) * -0.01 (0.00) *Metro -0.10 (0.01) * -0.11 (0.01) *Fixed effects Brand * State * YearObservations 147,919 35,557
Table 18: New Product share defined as share in 2005 and national launches. StandardErrors shown in brackets, * represents significant at a 0.05 level
37

Parameter Religion RepublicanBlades -0.20 (0.13) -0.09 (0.20)Coffee -0.58 (0.08) * -0.52 (0.13) *Deodorant -0.26 (0.10) * -0.34 (0.16) *Diapers -0.98 (0.18) * -0.52 (0.27)Frozen Pizza -0.28 (0.10) * -0.62 (0.15) *Frozen Dinner -0.19 (0.23) -0.07 (0.36)Household Cleaner -1.30 (0.33) * 0.28 (0.51)Hot Dog -0.47 (0.10) * -0.56 (0.15) *Laundry Detergent -0.69 (0.16) * -0.76 (0.23) *Margarine/Butter -0.30 (0.19) -0.99 (0.30) *Mayonnaise -0.87 (0.28) * -1.04 (0.44) *Milk -0.21 (0.27) -0.44 (0.42)Mustard/Ketchup 0.10 (0.25) -0.86 (0.39) *Toothpaste -0.61 (0.26) * -0.37 (0.39)Peanut Butter -0.03 (0.21) -1.46 (0.31) *Photographs -0.78 (0.16) * -1.01 (0.25) *Razors -0.72 (0.54) -0.02 (0.78)Salty Snacks -0.22 (0.25) -0.31 (0.39)Sauces 0.06 (0.16) -0.33 (0.24)Soda -0.39 (0.08) * -0.64 (0.12) *Soup -0.23 (0.14) -0.11 (0.21)Sugar Substitute -0.64 (0.34) 0.62 (0.52)Tissue Paper -0.26 (0.31) 0.21 (0.47)Toilet Paper -0.47 (0.10) * -0.38 (0.16) *Toothpaste -0.64 (0.09) * -0.02 (0.14)Yogurt 0.01 (0.13) -0.04 (0.19)Fixed effects Brand * State * Year
Table 19: New Product share results from separate regressions by category. Standard Errorsshown in brackets, * represents significant at a 0.05 level
38