in 32 nd international conference on very large databases, seoul, korea, sept. 2006 scalable...
TRANSCRIPT

In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
Scalable Continuous Query Processing Scalable Continuous Query Processing by Tracking Hotspotsby Tracking Hotspots
Junyi Xie
joint work with
Pankaj Agarwal, Jun Yang and Hai Yu
Department of Computer Science, Duke University
Durham, North Carolina 27708, U.S.A.
2
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
result
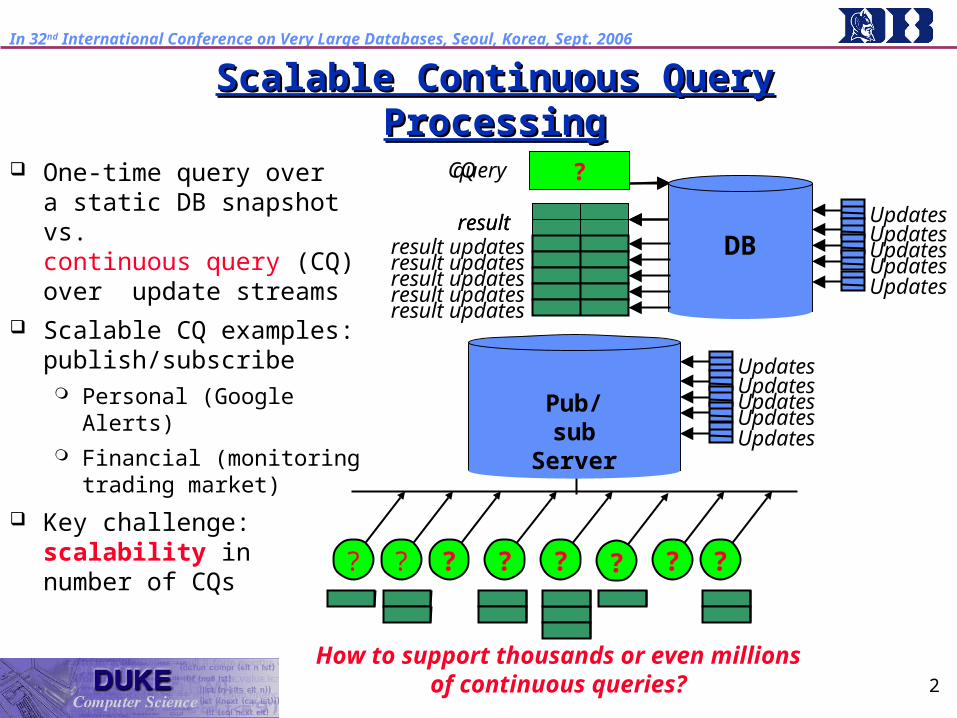
Scalable Continuous Query ProcessingScalable Continuous Query Processing
?query ?CQ
resultDBresult updates
result updatesresult updatesresult updatesresult updates
UpdatesUpdatesUpdatesUpdatesUpdates
Pub/subServer
UpdatesUpdatesUpdatesUpdatesUpdates
One-time query over a static DB snapshot vs.continuous query (CQ) over update streams
Scalable CQ examples: publish/subscribe Personal (Google Alerts) Financial (monitoring
trading market)
Key challenge: scalability in number of CQs
How to support thousands or even millions of continuous queries?
? ? ? ? ? ? ? ?

3
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
Naïve: for each incoming data update, evaluate each CQ Not scalable: linear processing cost
Idea: treat CQs as data, and use techniques such as indexing Scalability goal: sublinear processing cost
Previous work focused on simple CQs E.g., range selection CQs
Treating Queries as DataTreating Queries as Data
CQi: SELECT ID FROM Stock WHERE price > ai AND price < bi
(ID = ‘IBM’, PRICE = $75)
Interval index
CQs triggered by updates

4
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
Challenge: Complex Queries!Challenge: Complex Queries!R(A, B), S(B, C)
=2 rangeAi 2 rangeCi
Qi: (SELECTrangeAi R) JOIN (SELECTrangeCi S) Equality join + local range selection conditions
Example: matching Supply & DemandWHERE Supply.product = Demand.product AND Supply.rating 2 [7, 10]AND Demand.quantity > 1000
How do we index joins? A single interval index is not enough

5
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
Method 1: Select FirstMethod 1: Select First
Q1: (SELECTrangeA1 R) JOIN (SELECTrangeC1 S),
Q2: (SELECTrangeA2 R) JOIN (SELECTrangeC2 S),
… …
Given an insertion r(a,b) into R Find subset of CQs whose selection cond. on R is satisfied by r
Use a predicate index on all rangeAi’s
Process each such CQ Use an index on S (e.g., B-tree w/ compound key BC)
to identify S tuples with S.B = b and S.C 2 rangeCi
But what if lots of queries survive the first step?

6
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
A geometric interpretationR.A
S.C
rangeCi
rangeAi
Qi
Method 2: Join FirstMethod 2: Join First
Given an insertion r(a,b) into R Find all S tuples that join with r
Use an index on S
Process each such tuple s Use an index on all CQs
(e.g., R-tree on {rangeAi£rangeCi}) to identify Qi’s for which a 2 rangeAi and s.C 2 rangeCi
But what if lots of S tuplesjoin with r?
Space of (R JOIN S) tuples
a

7
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
Problem of Intermediate Result SizeProblem of Intermediate Result Size
Each method forces a particular processing order Method 1: select first
Cost depends on n’ (# of rangeAi’s containing a)
Method 2: join first Cost depends on m’ (# of S tuples that join with r)
Both n’ and m’ can be huge even if final output size is small
Can we make processing cost independent of n’ & m’?

8
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
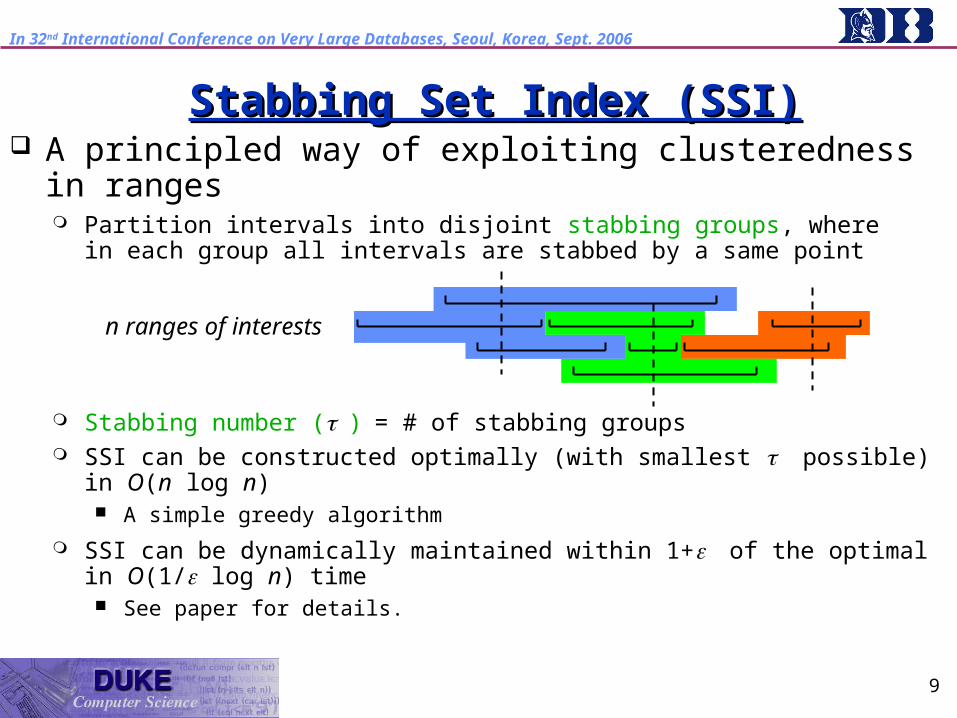
Observation: CQs (=user interests) often are naturally clustered Idea: take advantage of clusteredness in processing Stabbing Set Index (SSI): a principled method for exploiting
clusteredness in ranges Quantifies the degree of clusteredness Supports algorithms whose performance improves linearly with the
degree of clusteredness
Hotspot tracking: improves robustness of performance against unbalanced and tiny clusters Applies SSI to clusters where it is most beneficial
Three representative applications (not exhaustive) Scalably processing select-join CQs, band-join CQs Building good histograms for ranges in linear time
ContributionsContributions
9
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
A principled way of exploiting clusteredness in ranges Partition intervals into disjoint stabbing groups, where
in each group all intervals are stabbed by a same point
Stabbing number ()= # of stabbing groups SSI can be constructed optimally (with smallest possible) in O(n log
n) A simple greedy algorithm
SSI can be dynamically maintained within 1+of the optimal in O(1/ log n) time See paper for details.
Stabbing Set Index (SSI)Stabbing Set Index (SSI)
n ranges of interests

10
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
App 1: Equality Join w/ Local SelectionApp 1: Equality Join w/ Local SelectionRecall CQs: …, (SELECTrangeAi R) JOIN (SELECTrangeCi S), …
Given an insertion r(a,b) into RUse an SSI of CQs based on rangeCi’s For each stabbing group
(with common stabbing point p) Find the two points on the a line
(i.e., two S tuples joining with r) closest to p
Use an index on S (e.g., B-tree w/ compound key BC)
Find all rectangles in the group stabbed by one of the two points
Use an index (e.g., R-tree) on this stabbing group of CQs
They are precisely the triggered queries!
R.A
S.C
Space of (R JOIN S) tuples
r.a
p

11
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
App 1: Cost AnalysisApp 1: Cost Analysis SSI-based:
For each stabbing group, 3 index lookups One to get two closest points, two to get stabbed rectangles
Total: O( £ (index lookups) + output) Output cost same for all algorithms
Compare with: Select first: O(m’ £ (index lookup) + output)
m’: # of CQs with local selections satisfied by incoming R tuple
Join first: O(n’ £ (index lookup) + output) n’: # of S tuples join with incoming R tuple

12
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
App 2: Band JoinApp 2: Band JoinQi: R JOINR.B – S.B 2 rangei S
Band-join conditions
Given an insertion s(b, c) into S: BJ-D (data-outer): for each R tuple, use R.B – b to probe a query index to
find stabbed rangei’s (triggered queries) Cost increases linearly with # of R tuples
BJ-Q (query-outer): for each Qi (with rangei), perform range search with (rangei + b) over an index for R Cost increases linearly with # of CQs
BJ-MJ (merge join): merge-join R (presorted by R.B) and queries (presorted by range endpoints) Cost linear in # of CQs and # of R tuples
Same problem: cannot dodge the linearity in cost

13
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
App 2: SSI-Based ApproachApp 2: SSI-Based Approach SSI over all rangei, with two sorted lists for each stabbing group
Ones stores ranges in the group in increasing order of left endpoints The other stores in decreasing order of right endpoints Can be maintained in logarithmic time
Given an insertion s(b, c) into S:
For each stabbing group with common point p:
Probe index on R.B to get two tuples r1, r2 closest to (p + b)
Just traverse the two sorted lists until we hit r1 – b, r2 – b
Ranges traversed are precisely those triggered queries!
R index on R.B
r1 r2
p+b
p
r1–b r2–b

14
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
App 2: Cost AnalysisApp 2: Cost Analysis Observations on the SSI-based approach
Avoids tuples that do not contribute to any final result Avoids queries that are not triggered
Cost analysis For each stabbing group, just need to probe R.B index Remaining cost is linear in output size Total cost: O( £ (index lookup) + output)
Output cost same for all algorithms
Compare with: BJ-D: O((# of R tuples) £ (query index lookup) + output) BJ-Q: O((# of queries) £ (data index lookup) + output) BJ-MJ: O((# of queries) + (# of R tuples) + output)

15
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
Select-Joins: Overall ScalabilitySelect-Joins: Overall Scalability100-100K CQs; 100K-row relations
Th
rou
ghp
ut (
# o
f upd
ate
s/se
c)Only 20%
degradation
Orders-of-magnitude
improvement
16
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
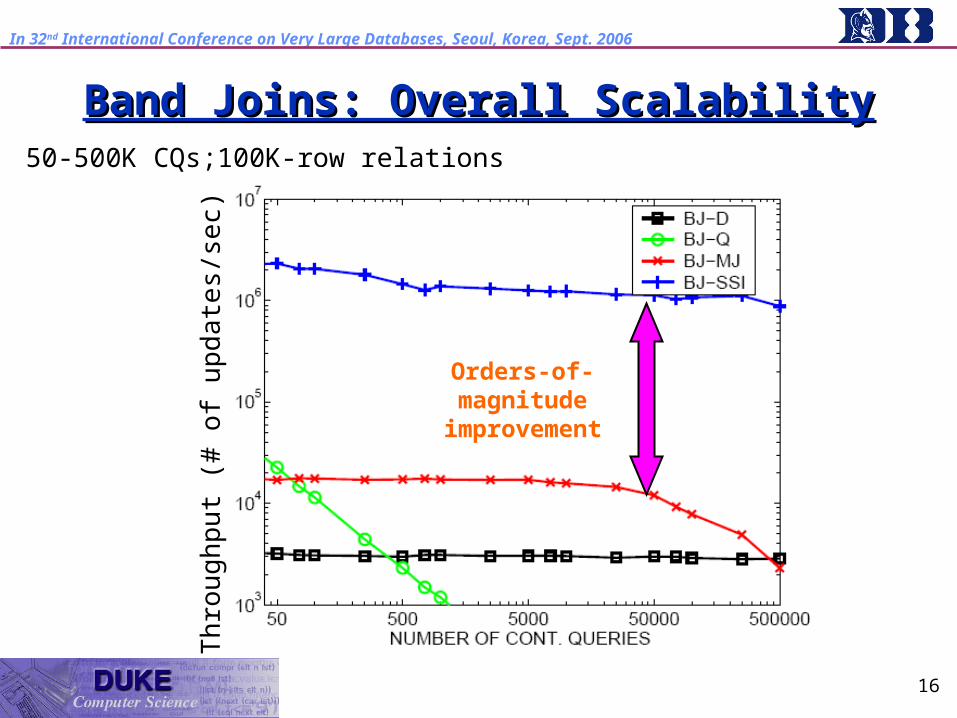
50-500K CQs;100K-row relations
Th
rou
ghp
ut (
# o
f upd
ate
s/se
c)
Orders-of-magnitude
improvement
Band Joins: Overall ScalabilityBand Joins: Overall Scalability
17
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
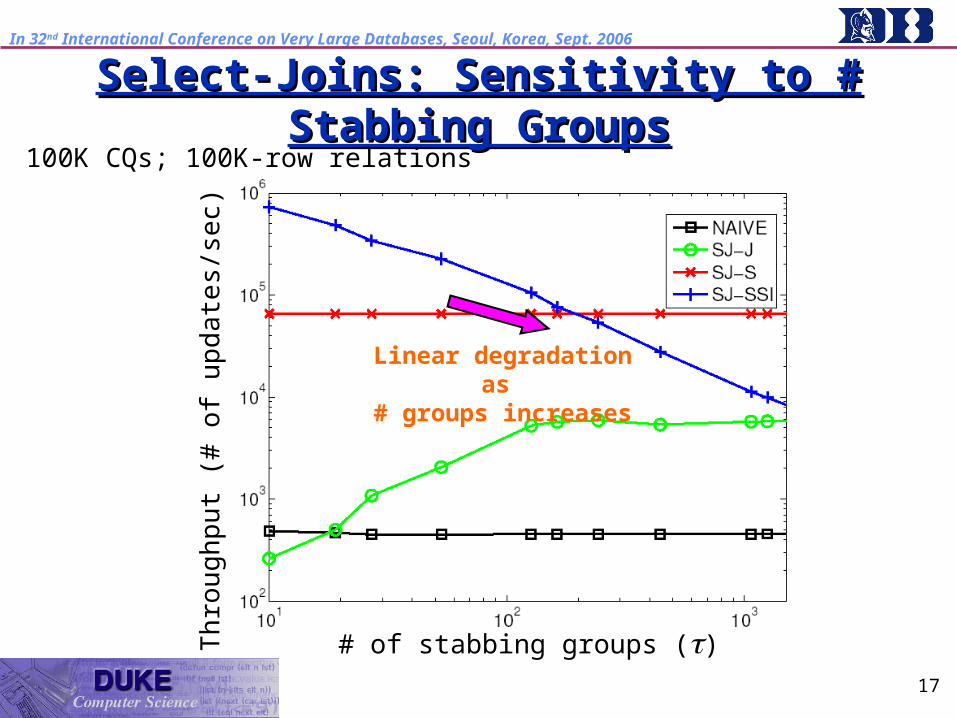
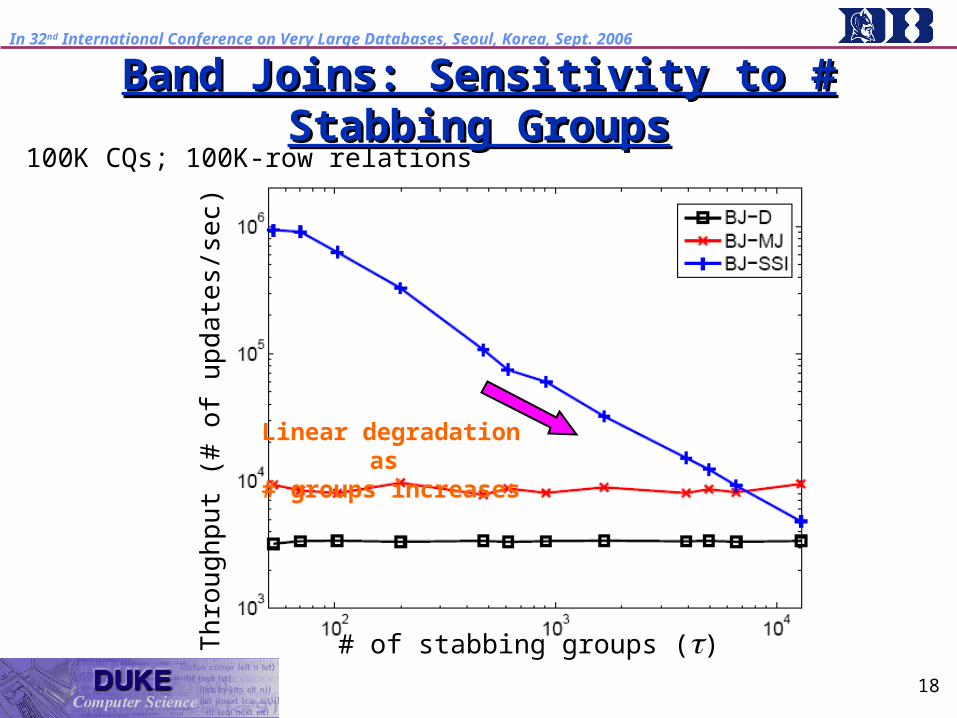
Select-Joins: Sensitivity to # Stabbing GroupsSelect-Joins: Sensitivity to # Stabbing Groups100K CQs; 100K-row relations
Linear degradation as
# groups increases
Th
rou
ghp
ut (
# o
f upd
ate
s/se
c)
# of stabbing groups ()
18
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
100K CQs; 100K-row relations
Linear degradation as
# groups increases
Band Joins: Sensitivity to # Stabbing GroupsBand Joins: Sensitivity to # Stabbing Groups
Th
rou
ghp
ut (
# o
f upd
ate
s/se
c)
# of stabbing groups ()

19
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
Lessons LearnedLessons Learned SSI-based algorithms can bring enormous benefit Though basic SSI-based algorithms are susceptible to
a large # of stabbing groups
Other experiments (see paper) Unlike previous approaches to select-joins, SJ-SSI does not have
the problem of large intermediate results Unlike previous approaches to band joins, large numbers of CQs and
large datasets have much less impact on BJ-SSI SSI has low maintenance overhead (when adding, deleting, and
updating CQs) Tiny when compared with query processing cost saved

20
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
Power law: SSI may have unbalanced stabbing groups Just a few groups may contain most of the intervals Other queries are scattered across many groups
Bad for SSI, because they increase # of groups a lot!
-hotspot: a group with at least £ total # of intervals
Use SSI to process hotspots # of -hotspots is at most 1/—processing cost becomes bounded
Using traditional algorithms on non-hotspots
Tracking HotspotsTracking Hotspots
“hot” groups “cold” groups
21
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
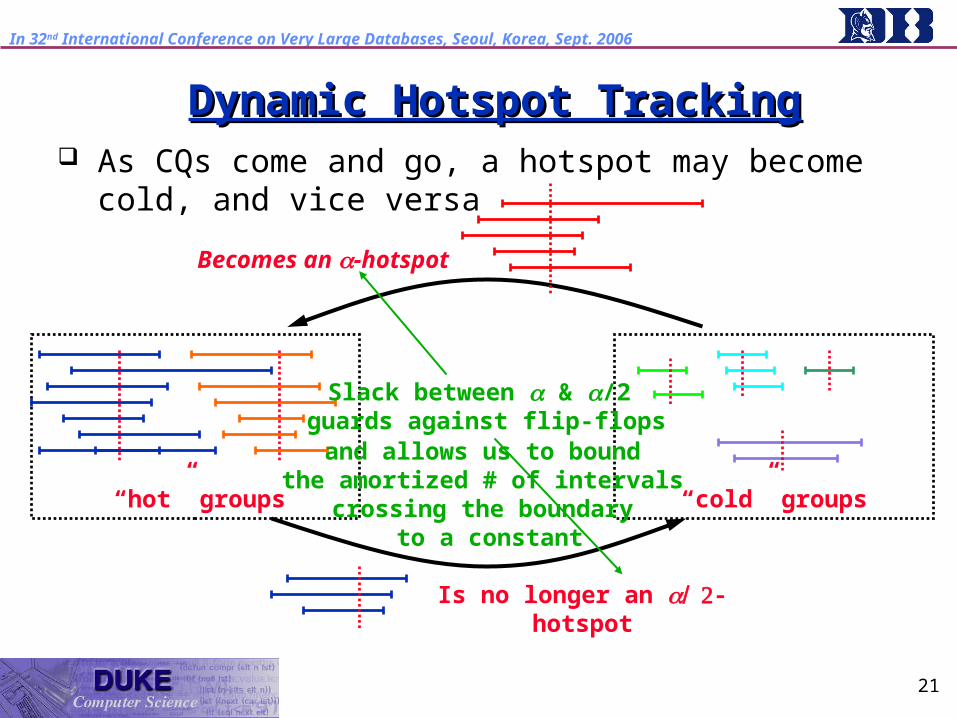
Dynamic Hotspot TrackingDynamic Hotspot Tracking As CQs come and go, a hotspot may become cold, and
vice versa
“hot” groups “cold” groups
Becomes an -hotspot
Is no longer an -hotspot
and allows us to bound the amortized # of intervals
crossing the boundary to a constant
Slack between & /2 guards against flip-flops

22
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
Effectiveness of Hotspot TrackingEffectiveness of Hotspot Tracking 500K select join CQs; adjust the concentration of
hotspots (% of intervals covered by the 500 largest groups)
Traditional: SJ-S for all CQs
Hotpot: SJ-SSI on hotspots (500 largest groups); SJ-S on non-hotspots A
vera
ge
tim
e p
er u
pd
ate
(s)
The higher the concentration, the
better the performance!

23
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
ConclusionConclusion Scalably processing a large # of CQs is essential for
apps such as pub/sub Complex CQs such as joins are much harder than filters Hope lies in exploiting clusteredness in user interests
Do so in a principled way with SSI and hotspot tracking
Future work SSI in higher dimensions Even more complex queries, e.g., aggregations, multi-way joins Data-sensitive processing with cost-based optimization
No single approach can beat others at all times
Pick best processing strategy for each incoming update on the fly
24
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
Thank you!Thank you!

25
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
Back-up slidesBack-up slides

26
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
How Doe It Work?How Doe It Work? Theorem1: Stabbing partition can be maintained with size
(1+) £ optimal size
with amortized cost
O(1/ log |# of intervals|)
Theorem2: the amortized number of intervals moving between groups is
O(1) (in fact, at most 5).
Proved by accounting argument Detail omitted

27
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
DeletionDeletionDelete an interval from a hotspot group,
Demote that group if no longer -hotspot All other hot groups are safe Promote some group in non-hotspot if necessary
Reduce bar for a group to be hot
Delete an interval from a non-hotspot group Some other non-hot group may become hot, promote them if necessary All hot groups are safe

28
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
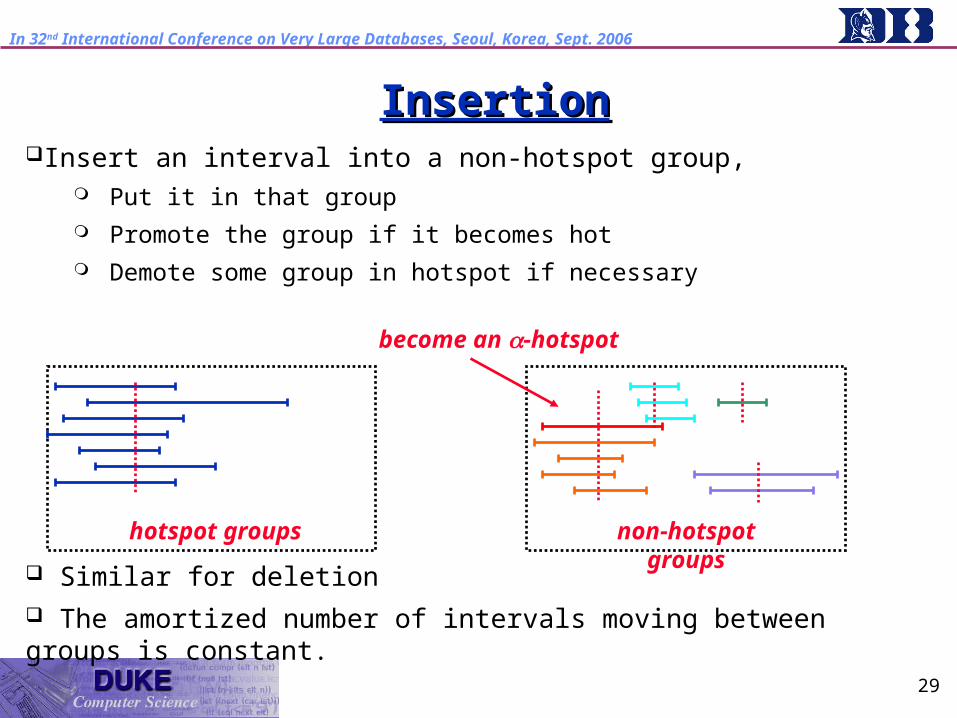
InsertionInsertion Insert an interval to a non-hotspot group
Put it in that group Demote other hot group to non-hotspot groups
Insert each interval one by one and maintain stabbing sets in non-hot groups
hotspot groups
non-hotspot groups
no longer an -hotspot
non-hotspot groups
29
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
InsertionInsertionInsert an interval into a non-hotspot group,
Put it in that group Promote the group if it becomes hot Demote some group in hotspot if necessary
Similar for deletion The amortized number of intervals moving between groups is constant.
hotspot groups
non-hotspot groups
become an -hotspot

30
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
Stabbing Set Based HistogramStabbing Set Based Histogram Histogram for intervals
Selectivity estimation: how many queries will be triggered by incoming tuple? Useful to optimization
Previous approach: dynamic programming to compute optimal histogram Quadratic time, usually not practical for large number of queries
SSI based histogram Build histogram for each stabbing set Map to the problem computing weighted k-mean clustering
Can be computed in nearly linear time: O(n) +ploy(k, 1/, log n)
Or using iterative k-mean
Need to allocate number of buckets for each set
31
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
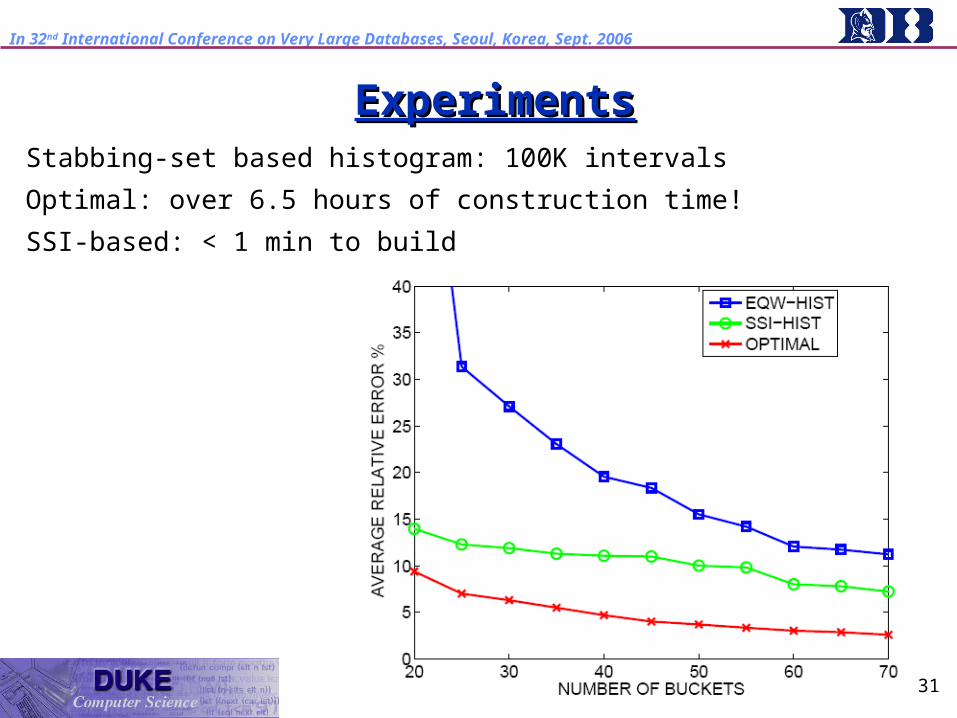
ExperimentsExperimentsStabbing-set based histogram: 100K intervals
Optimal: over 6.5 hours of construction time!
SSI-based: < 1 min to build
32
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
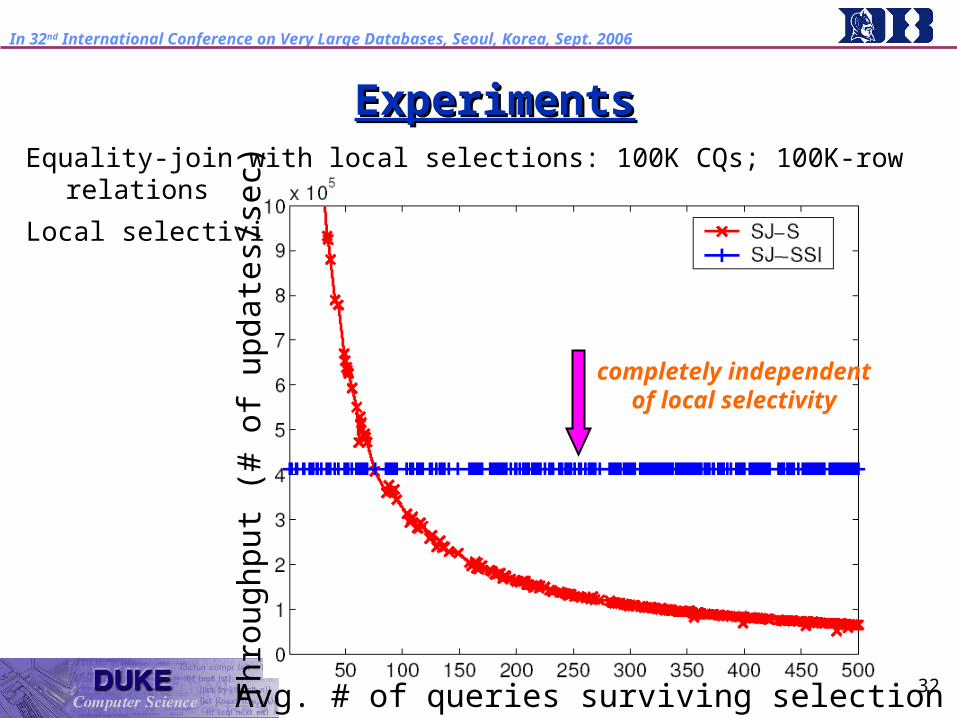
ExperimentsExperimentsEquality-join with local selections: 100K CQs; 100K-row relations
Local selectivity
Th
roug
hpu
t (#
of
upd
ate
s/se
c)
Avg. # of queries surviving selection
completely independent of local
selectivity
33
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
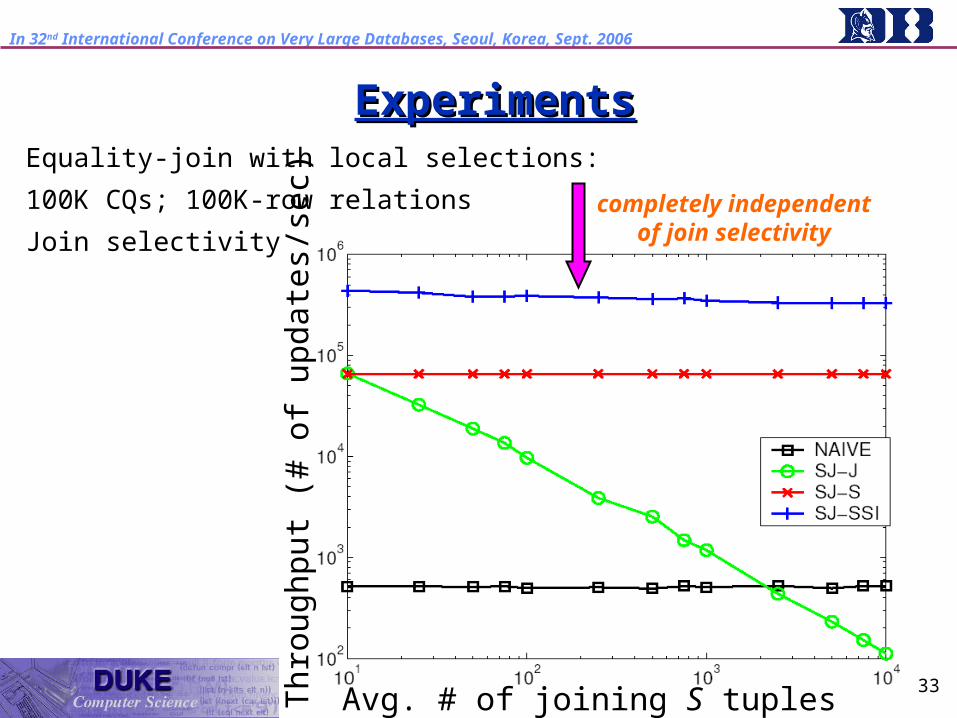
ExperimentsExperimentsEquality-join with local selections:
100K CQs; 100K-row relations
Join selectivity
Th
roug
hpu
t (#
of
upd
ate
s/se
c)
Avg. # of joining S tuples
completely independent of join
selectivity
34
In 32nd International Conference on Very Large Databases, Seoul, Korea, Sept. 2006
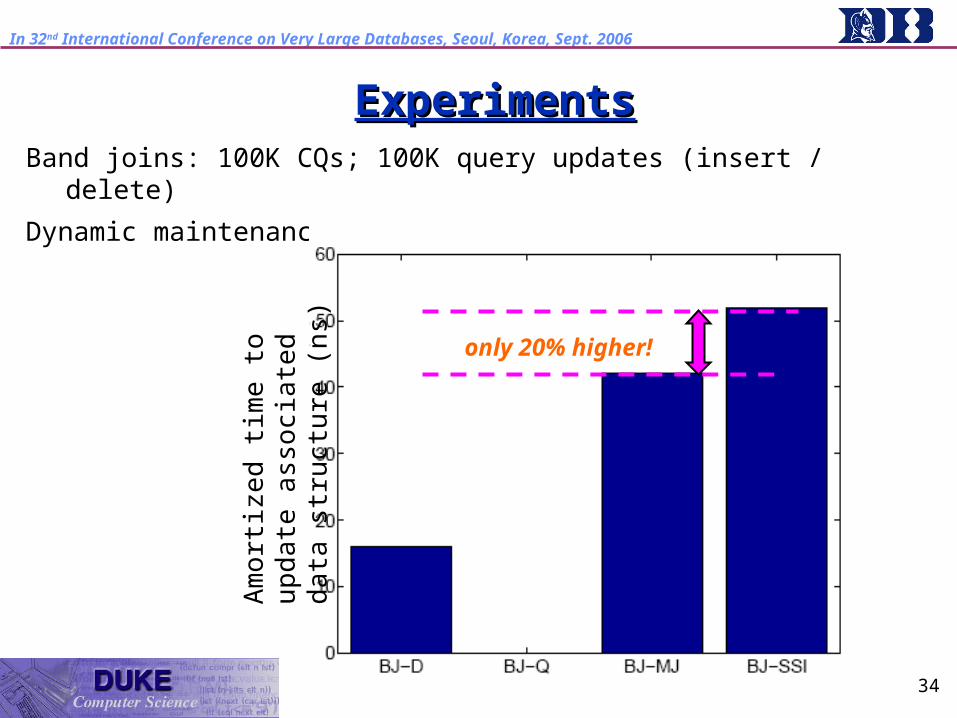
ExperimentsExperimentsBand joins: 100K CQs; 100K query updates (insert / delete)
Dynamic maintenance cost:
Am
ort
ize
d tim
e to
up
dat
e
ass
oci
ate
d d
ata
str
uct
ure
(n
s)only 20% higher!