informatica training
TRANSCRIPT



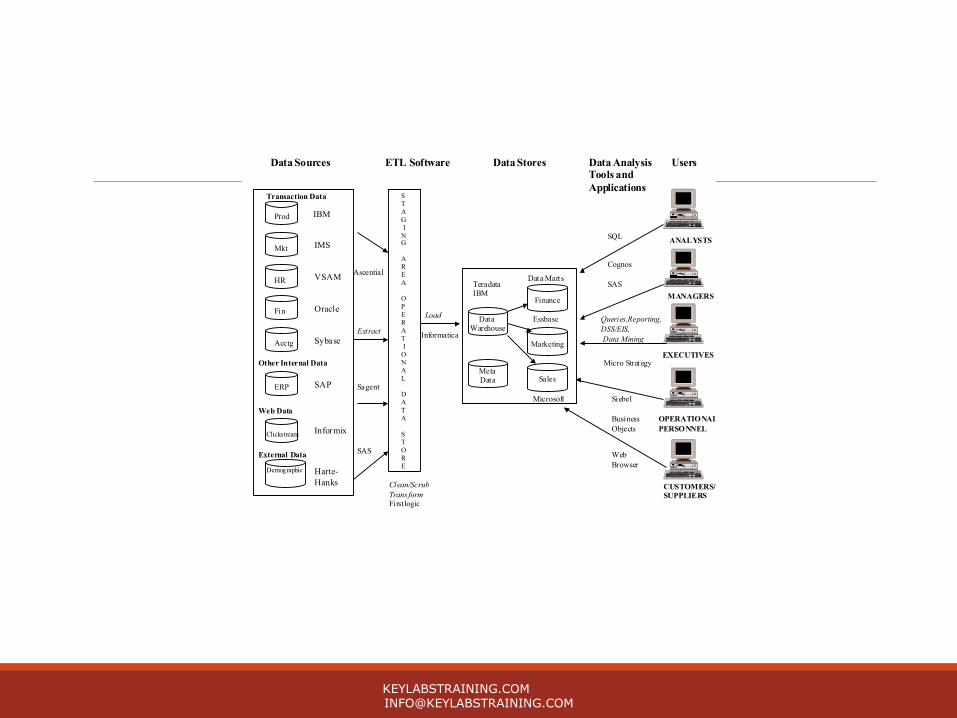
Data Warehousing Data warehousing is the entire process of data extraction, transformation, and loading of data to the warehouse and the access of the data by end users and applications
KEYLABSTRAINING.COM [email protected]

Data Mart A data mart stores data for a limited number of subject areas, such as marketing and sales data. It is used to support specific applications.
An independent data mart is created directly from source systems.
A dependent data mart is populated from a data warehouse.
KEYLABSTRAINING.COM [email protected]
Prod
Mkt
HR
Fin
Acctg
Data Sources
Transaction Data
IBM
IMS
VSAM
Oracle
Sybase
ETL Software Data Stores Data AnalysisTools and Applications
Users
Other Internal Data
ERP SAP
Clickstream Informix
Web Data
External Data
Demographic Harte-Hanks
STAG ING
AREA
OPERAT IONAL
DATA
STORE
Ascential
Extract
Sagent
SAS
Clean/ScrubTrans formFirstlogic
Load
Informatica
Data MartsTeradataIBM
Data Warehouse
Meta Data
Finance
Marketing
Sales
Essbase
Microsoft
ANALYSTS
MANAGERS
EXECUTIVES
OPERATIONAL PERSONNEL
CUSTOMERS/SUPPLIERS
SQL
Cognos
SAS
Queries,Reporting,DSS/EIS, Data Mining
Micro Strategy
Siebel
BusinessObjects
WebBrowser
KEYLABSTRAINING.COM [email protected]

Sample ETL Tools DataStage from IBM Software
SAS System from SAS Institute
Informatica
Oracle Data Integrator
Abinito
Data Manager From Cognos—IBM
Cubeware
KEYLABSTRAINING.COM [email protected]

Components Of Informatica
Repository Manager
Powercenter Designer
Workflow Manager
Workflow Monitor
KEYLABSTRAINING.COM [email protected]

Informatica provides the following integrated components:
• Informatica repository. The Informatica repository is at the center of the Informatica suite. You create a set of metadata tables within the repository database that the Informatica applications and tools access. The Informatica Client and Server access the repository to save and retrieve metadata.
• Informatica Client. Use the Informatica Client to manage users, define sources and targets, build mappings and mapplets with the transformation logic, and create sessions to run the mapping logic. The Informatica Client has three client applications: Repository Manager, Designer, and Workflow Manager.
• Informatica Server. The Informatica Server extracts the source data, performs the data transformation, and loads the transformed data into the targets.
KEYLABSTRAINING.COM [email protected]
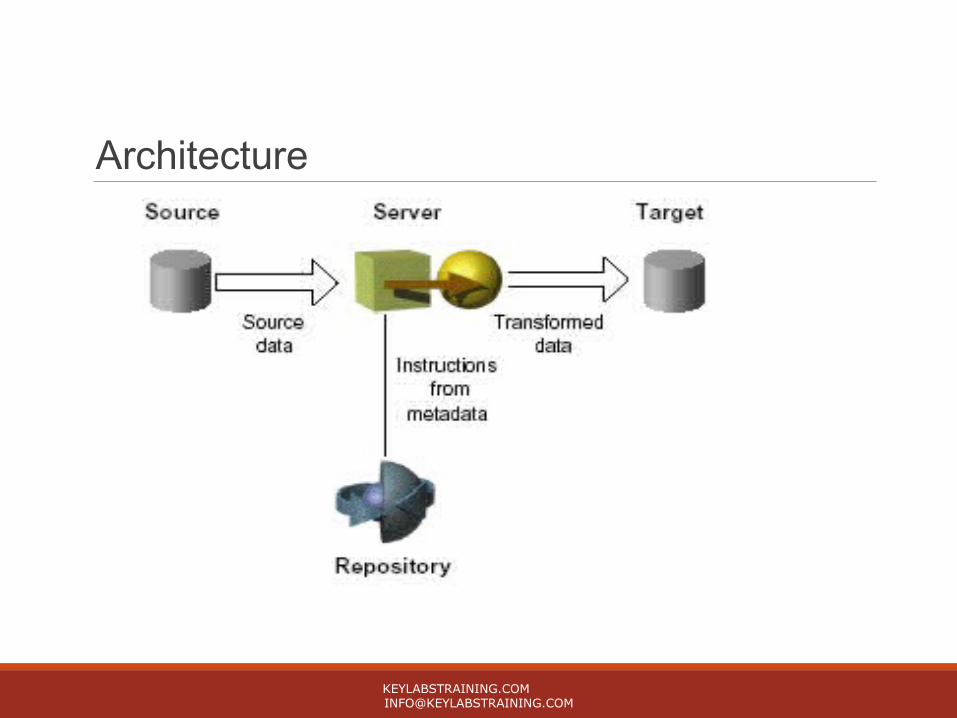

Process FlowInformatica Server moves the data from source to target based on the workflow and metadata stored in the repository.
A workflow is a set of instructions how and when to run the task related to ETL.
Informatica server runs workflow according to the conditional links connecting tasks.
Session is type of workflow task which describes how to move the data between source and target using a mapping.
Mapping is a set of source and target definitions linked by transformation objects that define the rules for data transformation.
KEYLABSTRAINING.COM [email protected]

Sources
Power Mart and Power Center access the following sources:
• Relational. Oracle, Sybase, Informix, IBM DB2, Microsoft SQL Server, and Teradata.
• File. Fixed and delimited flat file, COBOL file, and XML.
• Extended. If you use Power Center, you can purchase additional Power Connect products to access business sources such as PeopleSoft, SAP R/3, Siebel, and IBM MQSeries.
• Mainframe. If you use Power Center, you can purchase Power Connect for IBM DB2 for faster access to IBM DB2 on MVS.
• Other. Microsoft Excel and Access.
KEYLABSTRAINING.COM [email protected]

TargetsPower Mart and Power Center can load data into the following targets:
• Relational. Oracle, Sybase, Sybase IQ, Informix, IBM DB2, Microsoft SQL Server, and Teradata.
• File. Fixed and delimited flat files and XML.
• Extended. If you use Power Center, you can purchase an integration server to load data into SAP BW. You can also purchase Power Connect for IBM MQSeries to load data into IBM MQSeries message queues.
• Other. Microsoft Access.
You can load data into targets using ODBC or native drivers, FTP, or external loaders.
KEYLABSTRAINING.COM [email protected]

General Flow of InformaticaStep 1: Creating Repository ,creating folders ,Creating users and assign permission in Repository Manager, so as to work in the client tools.
Step 2:Connecting to the repository from the designer. importing source and target tables , creation of mappings.
Step 3 : Creation of Workflow through workflow Manager which has different tasks connected between them. In that ,session is the task which is pointing to a mapping created in the designer.
KEYLABSTRAINING.COM [email protected]

Repository
The Informatica repository is a set of tables that stores the metadata you create using the Informatica Client tools. You create a database for the repository, and then use the Repository Manager to create the metadata tables in the database.
You add metadata to the repository tables when you perform tasks in the Informatica Client application such as creating users, analyzing sources, developing mappings or mapplets, or creating sessions. The Informatica Server reads metadata created in the Client application when you run a session. The Informatica Server also creates metadata such as start and finish times of a session or session status.
Contd :-
KEYLABSTRAINING.COM [email protected]

Repository Contd..When you use Power Center, you can develop global and local repository to share metadata:
Global repository. The global repository is the hub of the domain. Use the global repository to store common objects that multiple developers can use through shortcuts. These objects may include operational or application source definitions, reusable transformations, mapplets, and mappings.
Local repositories. A local repository is within a domain that is not the global repository. Use local repositories for development. From a local repository, you can create shortcuts to objects in shared folders in the global repository. These objects typically include source definitions, common dimensions and lookups, and enterprise standard transformations. You can also create copies of objects in non-shared folders.
KEYLABSTRAINING.COM [email protected]
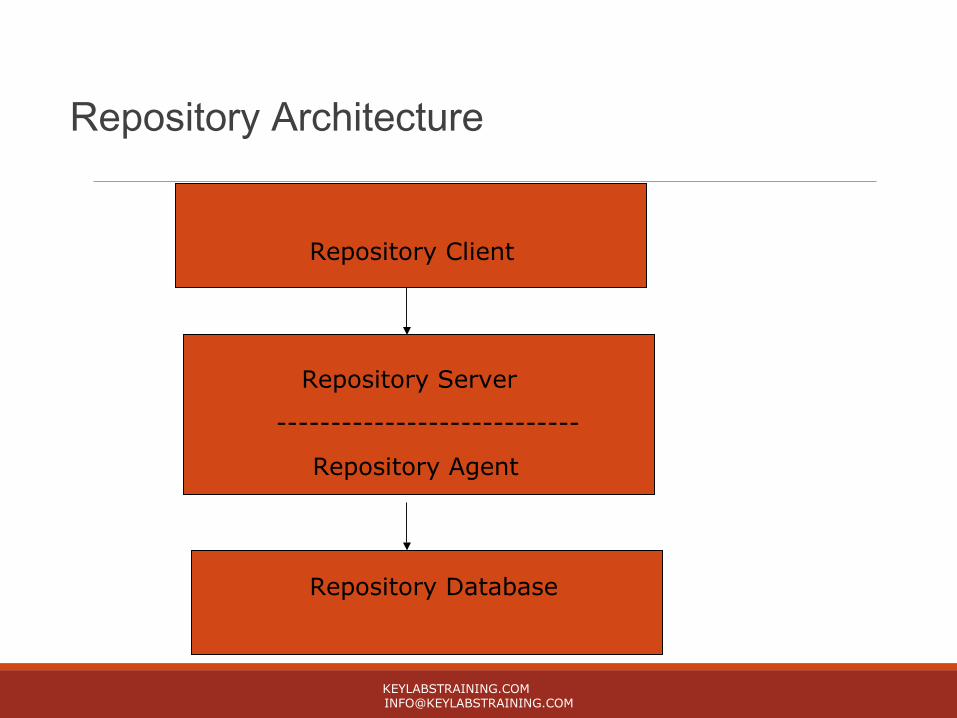
Repository Architecture
KEYLABSTRAINING.COM [email protected]
Repository Client
Repository Server
----------------------------
Repository Agent
Repository Database

Creating a RepositoryTo create Repository
1. Launch the Repository Manager by choosing Programs-Power Center (or Power Mart) Client-Repository Manager from the Start Menu.
2. In the Repository Manager, choose Repository-Create Repository.
Note: You must be running the Repository Manager in Administrator mode to see the Create Repository option on the menu. Administrator mode is the default when you install the program.
3. In the Create Repository dialog box, specify the name of the new repository, as well as the parameters needed to connect to the repository database through ODBC.
KEYLABSTRAINING.COM [email protected]

Working with Repository..
By default 2 users will be created in the repository . Database user used to connect to the repository. Administrator User.
By default 2 Groups will be created PublicAdministrators.These groups and users cannot be deleted from the repository . The
administrator group has only read privilege for other user groups.
KEYLABSTRAINING.COM [email protected]

Working with Repository contd..
Informatica tools include two basic types of security:
• Privileges. Repository-wide security that controls which task or set of tasks a single user or group of users can access. Examples of these are Use Designer, Browse repository , Session operator etc.
• Permissions. Security assigned to individual folders within the repository. You can perform various tasks for each privilege. Ex :- Read , Write and Execute.
KEYLABSTRAINING.COM [email protected]

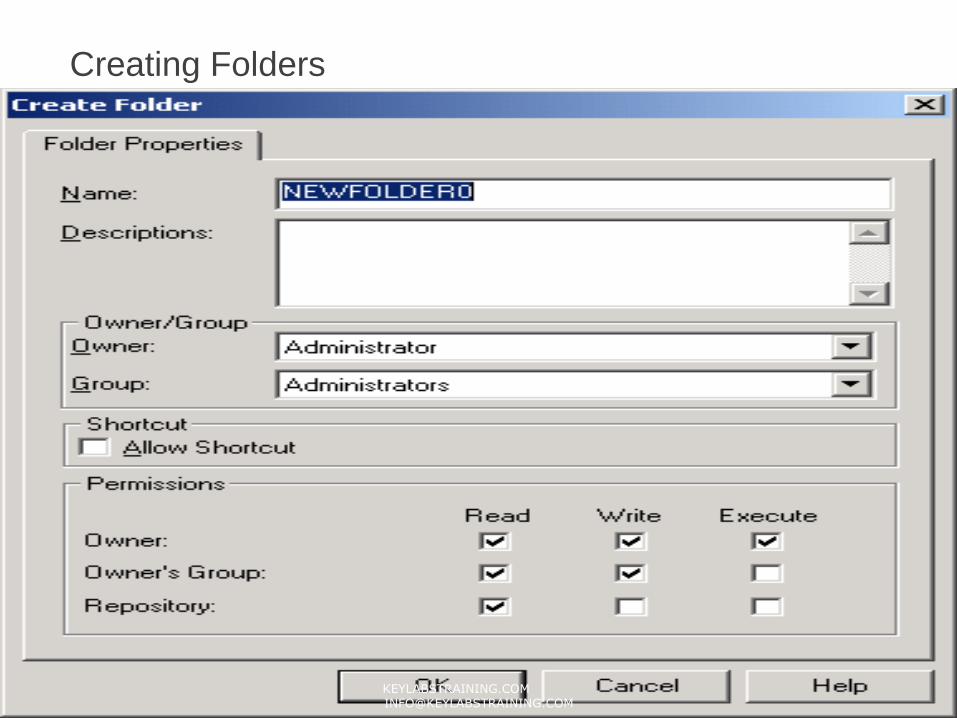
FoldersFolders provide a way to organize and store all metadata in the repository, including mappings, schemas, and sessions. Folders are designed to be flexible, to help you organize your data warehouse logically. Each folder has a set of properties you can configure to define how users access the folder. For example, you can create a folder that allows all repository users to see objects within the folder, but not to edit them. Or you can create a folder that allows users to share objects within the folder.
Shared Folders
When you create a folder, you can configure it as a shared folder. Shared folders allow users to create shortcuts to objects in the folder. If you have reusable transformation that you want to use in several mappings or across multiple folders, you can place the object in a shared folder.
For example, you may have a reusable Expression transformation that calculates sales commissions. You can then use the object in other folders by creating a shortcut to the object.
KEYLABSTRAINING.COM [email protected]

Folder PermissionsPermissions allow repository users to perform tasks within a folder. With folder permissions, you can control user access to the folder, and the tasks you permit them to perform.
Folder permissions work closely with repository privileges. Privileges grant access to specific tasks while permissions grant access to specific folders with read, write, and execute qualifiers.
However, any user with the Super User privilege can perform all tasks across all folders in the repository. Folders have the following types of permissions:
• Read permission. Allows you to view the folder as well as objects in the folder.
• Write permission. Allows you to create or edit objects in the folder.
• Execute permission. Allows you to execute or schedule a session or batch in the folder.
KEYLABSTRAINING.COM [email protected]

Other Features of Repository Manager Viewing , removing Locks
Adding Repository
Backup and Recovery of Repository
Taking Metadata reports like Completed Sessions details , List of reports on Jobs , session , workflow etc
KEYLABSTRAINING.COM [email protected]


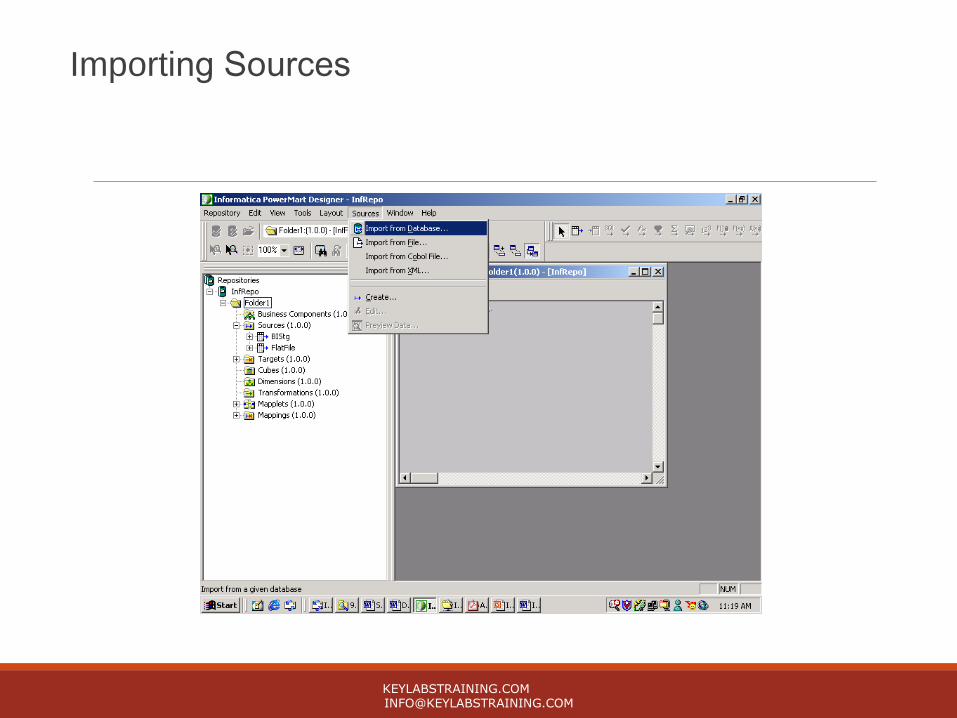
Working with DesignerConnecting to the repository using User id and password.
Accessing the folder
Importing the source and target tables required for mapping.
Creation of mapping
KEYLABSTRAINING.COM [email protected]

Tools provided by DesignerSource Analyzer: Importing Source definitions for Flat file, XML, COBOL and relational Sources.
Warehouse Designer: Use to Import or create target definitions.
Transformation Developer: Used to create reusable transformations
Mapplet Designer: Used to create mapplets
Mapping Designer: Used to create mappings
KEYLABSTRAINING.COM [email protected]
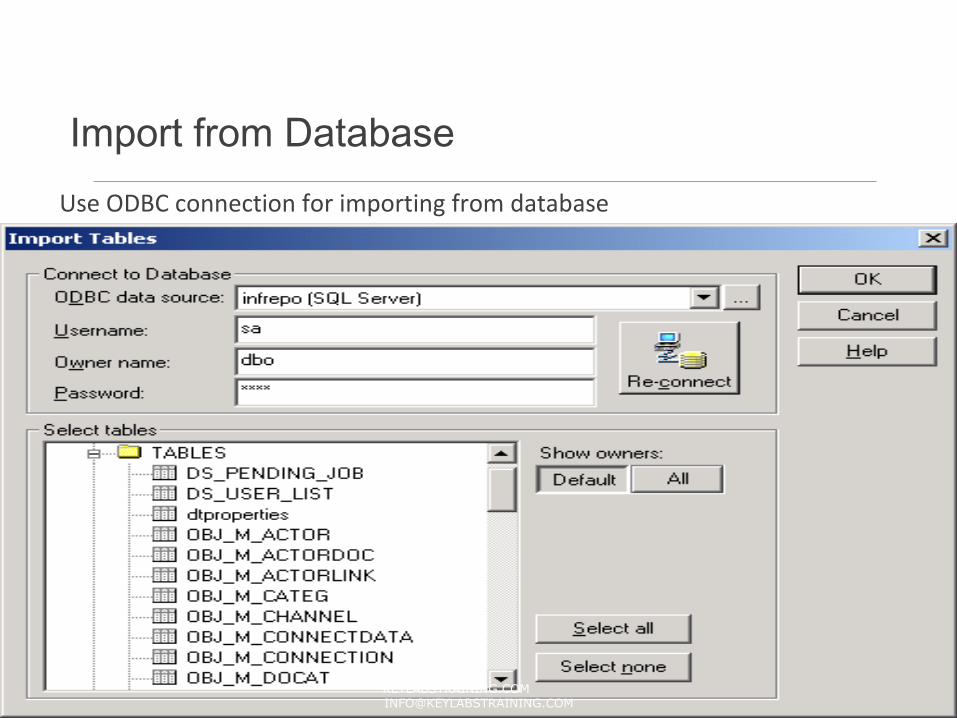
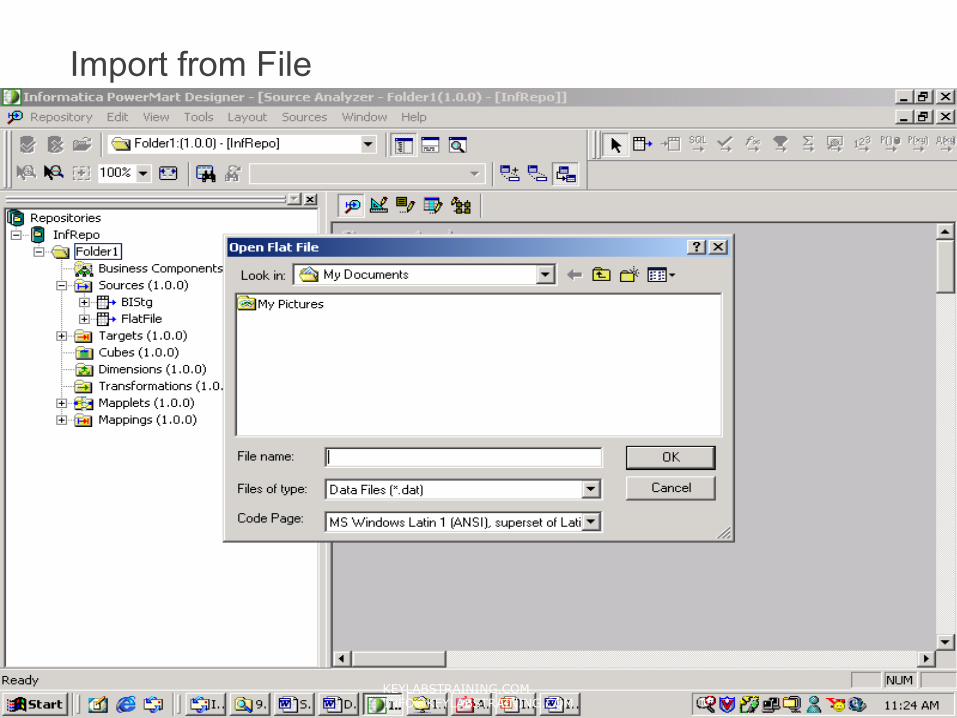
Import from DatabaseUse ODBC connection for importing from database
KEYLABSTRAINING.COM [email protected]

KEYLABSTRAINING.COM [email protected]
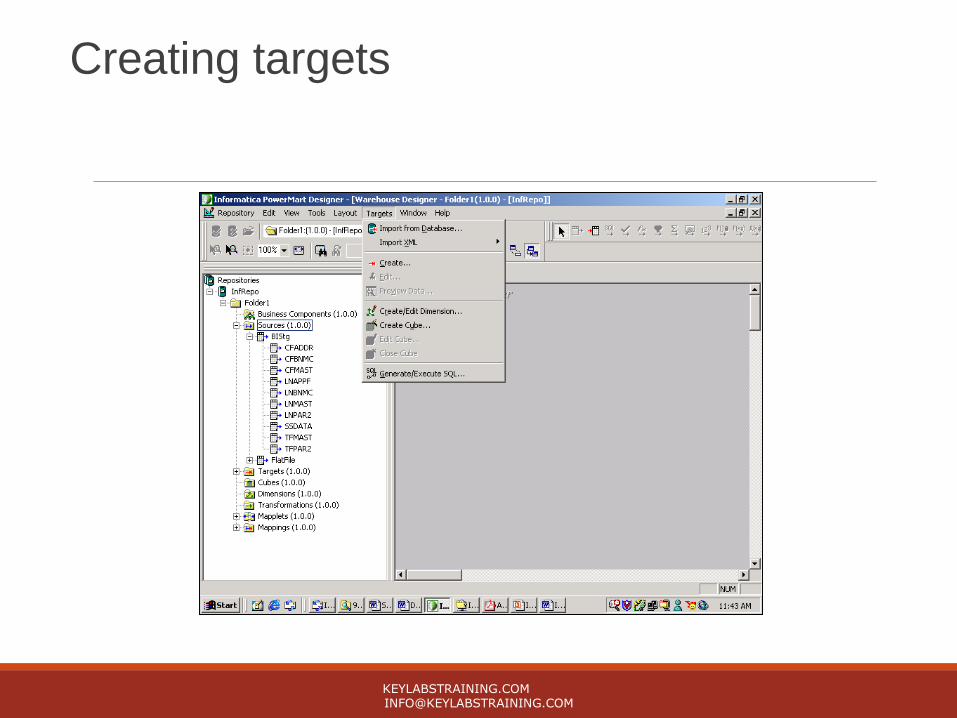
Creating TargetsYou can create target definitions in the Warehouse Designer for file and relational sources. Create definitions in the following ways:
• Import the definition for an existing target. Import the target definition from a relational target.
• Create a target definition based on a source definition. Drag one of the following existing source definitions into the Warehouse Designer to make a target definition: o Relational source definition o Flat file source definition o COBOL source definition
• Manually create a target definition. Create and design a target definition in the Warehouse Designer.
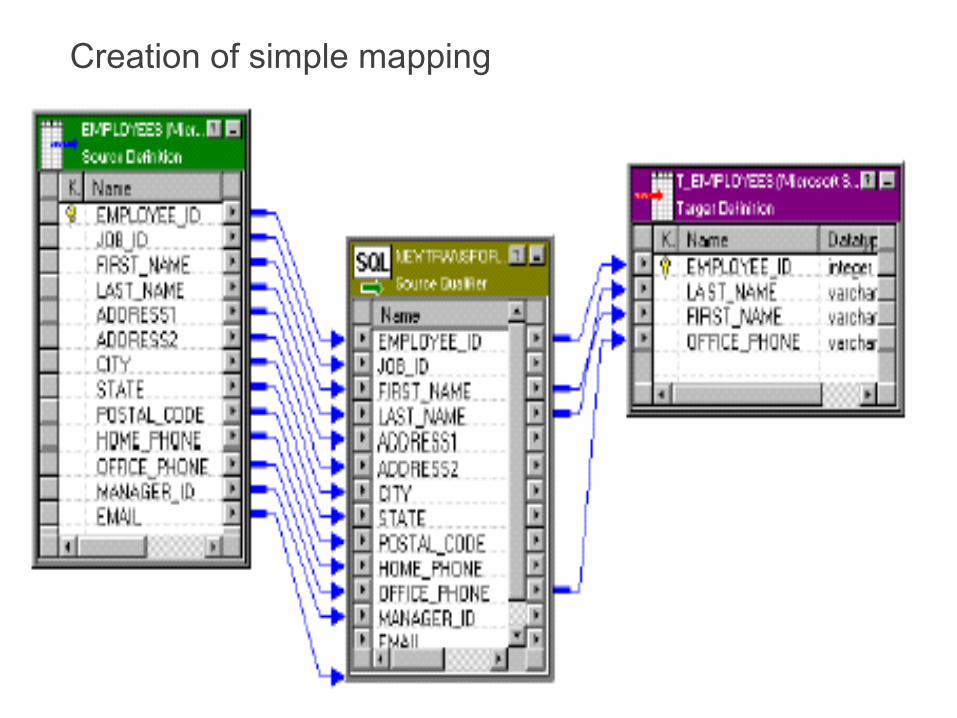

Creation of simple mapping Switch to the Mapping Designer.
Choose Mappings-Create.
While the workspace may appear blank, in fact it contains a new mapping without any sources, targets, or transformations.
In the Mapping Name dialog box, enter <Mapping Name> as the name of the new mapping and click OK.
The naming convention for mappings is m_MappingName.
In the Navigator, under the <Repository Name> repository and <Folder Name> folder, click the Sources node to view source definitions added to the repository.
Contd..
KEYLABSTRAINING.COM [email protected]
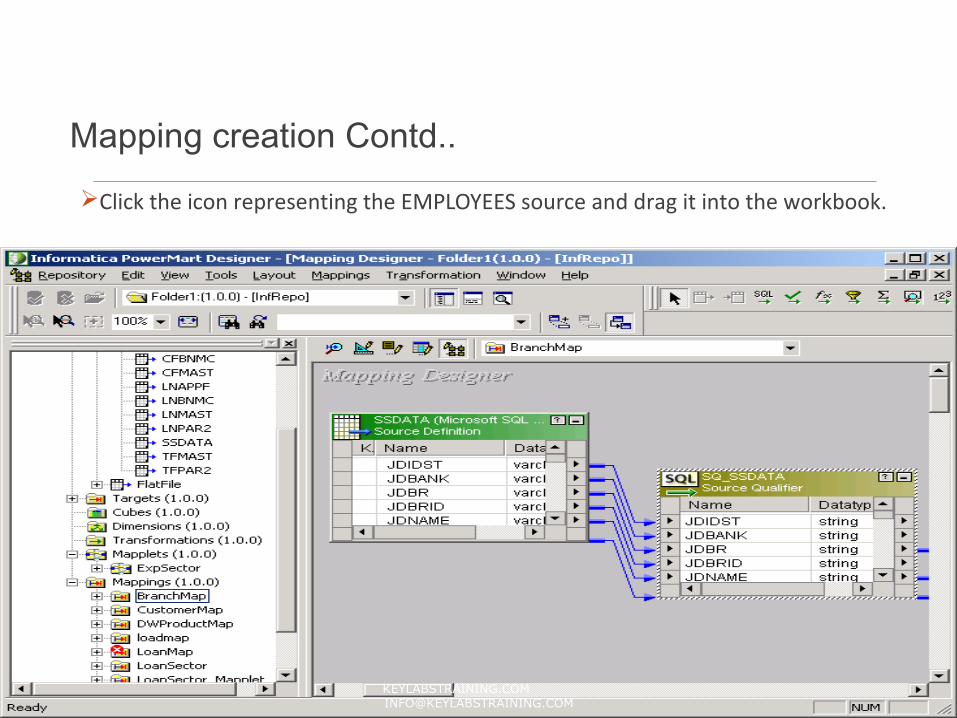
Mapping creation Contd..
Click the icon representing the EMPLOYEES source and drag it into the workbook.
KEYLABSTRAINING.COM [email protected]

Mapping creation Contd..
The source definition appears in the workspace. The Designer automatically connects a Source Qualifier transformation to the source definition. After you add the target definition, you connect the Source Qualifier to the target.
Click the Targets icon in the Navigator to open the list of all target definitions.
Click and drag the icon for the T_EMPLOYEES target into the workspace.
The target definition appears. The final step is connecting the Source Qualifier to this target definition.
KEYLABSTRAINING.COM [email protected]
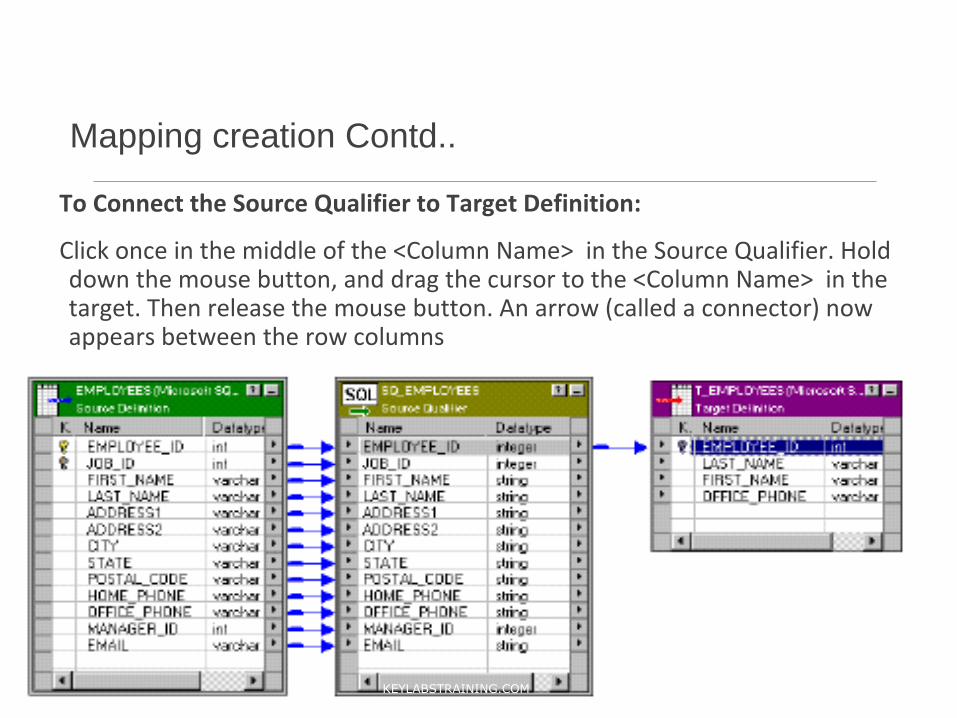
Mapping creation Contd..
To Connect the Source Qualifier to Target Definition:
Click once in the middle of the <Column Name> in the Source Qualifier. Hold down the mouse button, and drag the cursor to the <Column Name> in the target. Then release the mouse button. An arrow (called a connector) now appears between the row columns
KEYLABSTRAINING.COM [email protected]


TransformationsA transformation is a repository object that generates, modifies, or passes data
The Designer provides a set of transformations that perform specific functions
Data passes into and out of transformations through ports that you connect in a mapping or mapplet
Transformations can be active or passive
KEYLABSTRAINING.COM [email protected]

TransformationsActive transformations
Aggregator performs aggregate calculationsFilter serves as a conditional filterRouter serves as a conditional filter (more than one filters)Joiner allows for heterogeneous joinsSource qualifier represents all data queried from the source
Passive transformations
Expression performs simple calculationsLookup looks up values and passes to other objectsSequence generator generates unique ID valuesStored procedure calls a stored procedure and captures return valuesUpdate strategy allows for logic to insert, update, delete, or reject
data
KEYLABSTRAINING.COM [email protected]

Transformations Contd..Create the transformation. Create it in the Mapping Designer as part of a
mapping, in the Mapplet Designer as part of a Mapplet, or in the Transformation
Developer as a reusable transformation.
Configure the transformation. Each type of transformation has a unique set of
options that you can configure.
Connect the transformation to other transformations and target definitions.
Drag one port to another to connect them in the mapping or Mapplet .
KEYLABSTRAINING.COM [email protected]

Expression TransformationYou can use the Expression transformations to calculate values in a single row before you write to the target.
For example, you might need to adjust employee salaries, concatenate first and last names, or convert strings to numbers.
You can use the Expression transformation to perform any non-aggregate calculations.
You can also use the Expression transformation to test conditional statements before you output the results to target tables or other transformations.
KEYLABSTRAINING.COM [email protected]

Expression Transformation
Calculating Values
To use the Expression transformation to calculate values for a single row, you must include the
following ports:
Input or input/output ports for each value used in the calculation. For example,
when calculating the total price for an order, determined by multiplying the unit price by
the quantity ordered, the input or input/output ports. One port provides the
unit price and the other provides the quantity ordered.
Output port for the expression. You enter the expression as a configuration option for the
output port. The return value for the output port needs to match the return value of
the expression.
Variable Port : Variable Port is used like local variable inside Expression Transformation ,
which can be used in other calculations
KEYLABSTRAINING.COM [email protected]

Source Qualifier Transformation
Every mapping includes a Source Qualifier transformation,
representing all the columns of information read from a
source and temporarily stored by the Informatica Server. In
addition, you can add transformations such as a calculating
sum, looking up a value, or generating a unique ID that modify
information before it reaches the target.
KEYLABSTRAINING.COM [email protected]

Source Qualifier Transformation
When you add a relational or a flat file source definition to a mapping, you need to connect it to a Source Qualifier transformation.
The Source Qualifier represents the records that the Informatica Server reads when it runs a session. You can use the Source Qualifier to perform the following tasks:
• Join data originating from the same source database. You can join two or more tables with primary-foreign key relationships by linking the sources to one Source Qualifier.
• Filter records when the Informatica Server reads source data. If you include a filter condition, the Informatica Server adds a WHERE clause to the default query.
• Specify an outer join rather than the default inner join. If you include a user-defined join, the Informatica Server replaces the join information specified by the metadata in the SQL query.
• Specify sorted ports. If you specify a number for sorted ports, the Informatica Server adds an ORDER BY clause to the default SQL query.
• Select only distinct values from the source. If you choose Select Distinct, the Informatica Server adds a SELECT DISTINCT statement to the default SQL query.
• Create a custom query to issue a special SELECT statement for the Informatica Server to read source data. For example, you might use a custom query to perform aggregate calculations or execute a stored procedure
KEYLABSTRAINING.COM [email protected]

Configuring Source Qualifier Transformation
To configure a Source Qualifier:
• In the Designer, open a mapping. • Double-click the title bar of the Source Qualifier. • In the Edit Transformations dialog box, click Rename, enter a
descriptive name for the transformation, and click OK. The naming convention for Source Qualifier transformations is SQ_TransformationName,.
• Click the Properties tab.
KEYLABSTRAINING.COM [email protected]

Configuring Source Qualifier
Option Description
SQL QueryDefines a custom query that replaces the default query the Informatica Server uses
to read data from sources represented in this Source Qualifier
User-Defined Join
Specifies the condition used to join data from multiple sources represented in the same Source Qualifier transformation
Source Filter Specifies the filter condition the Informatica Server applies when querying records.
Number of Sorted Ports
Indicates the number of columns used when sorting records queried from relational sources. If you select this option, the Informatica Server adds an ORDER BY to the default query when it reads source records. The ORDER BY includes the number of ports specified, starting from the top of the Source Qualifier.
When selected, the database sort order must match the session sort order.
Tracing LevelSets the amount of detail included in the session log when you run a session
containing this transformation.
Select Distinct Specifies if you want to select only unique records. The Informatica Server includes a SELECT DISTINCT statement if you choose this option.
KEYLABSTRAINING.COM [email protected]

Joiner Transformation
While a Source Qualifier transformation can join data originating from a common source database, the Joiner transformation joins two related
heterogeneous sources residing in different locations or file systems. The combination of sources can be varied. You can use the following sources:
• Two relational tables existing in separate databases • Two flat files in potentially different file systems • Two different ODBC sources • Two instances of the same XML source • A relational table and a flat file source • A relational table and an XML source
If two relational sources contain keys, then a Source Qualifier transformation can easily join the sources on those keys. Joiner transformations typically combine information from two different sources that do not have matching keys, such as flat file sources.
The Joiner transformation allows you to join sources that contain binary data.
KEYLABSTRAINING.COM [email protected]

Creating a Joiner TransformationTo create a Joiner Transformation:
• In the Mapping Designer, choose Transformation-Create. Select the Joiner transformation. Enter a name for the Joiner. Click OK. The naming convention for Joiner transformations is JNR_TransformationName. Enter a description for the transformation. This description appears in the Repository Manager, making it easier for you or others to understand or remember what the transformation does.
• The Designer creates the Joiner transformation. Keep in mind that you cannot use a Sequence Generator or Update Strategy transformation as a source to a Joiner transformation.
• Drag all the desired input/output ports from the first source into the Joiner transformation. The Designer creates input/output ports for the source fields in the Joiner as detail fields by default. You can edit this property later.
• Select and drag all the desired input/output ports from the second source into the Joiner transformation. The Designer configures the second set of source fields and master fields by default.
• Double-click the title bar of the Joiner transformation to open the Edit Transformations dialog box. • Select the Ports tab. • Click any box in the M column to switch the master/detail relationship for the sources. Change the
master/detail relationship if necessary by selecting the master source in the M column.
KEYLABSTRAINING.COM [email protected]
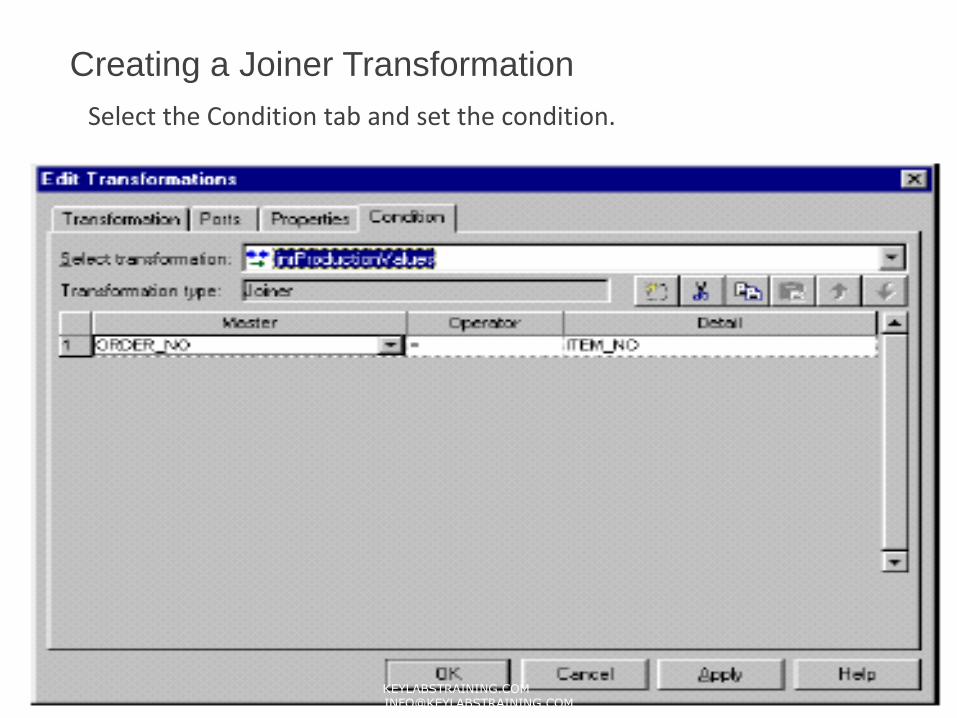
Creating a Joiner Transformation
Select the Condition tab and set the condition.
KEYLABSTRAINING.COM [email protected]

Configuring Joiner transformation
Joiner Setting Description
Case-Sensitive String Comparison
If selected, the Informatica Server uses case-sensitive string comparisons when performing joins on string columns.
Cache Directory
Specifies the directory used to cache master records and the index to these records. By default, the caches are created in a directory specified by the server variable $PMCacheDir. If you override the directory, be sure there is enough disk space on the file system. The directory can be a mapped or mounted drive.
Join TypeSpecifies the type of join: Normal, Master Outer, Detail Outer, or Full Outer.
KEYLABSTRAINING.COM [email protected]

Used to look up data in a relational table, view, synonym or Flat File.
It compares Lookup transformation port values to lookup table column values based on the lookup condition.
Connected Lookups
Receives input values directly from another transformation in the pipeline
For each input row, the Informatica Server queries the lookup table or cache based on the lookup ports and the condition in the transformation
Passes return values from the query to the next transformation
Un Connected Lookups
Receives input values from an expression using the
:LKP (:LKP.lookup_transformation_name (argument, argument, ...)) reference qualifier to call the lookup and returns one value.
With unconnected Lookups, you can pass multiple input values into the transformation, but only one column of data out of the transformation
KEYLABSTRAINING.COM [email protected]
Lookup Transformation

Lookup Transformation
You can configure the Lookup transformation to perform different types of
lookups. You can configure the transformation to be connected or unconnected, cached or uncached:
Connected or unconnected. Connected and unconnected transformations receive input and send output in
different ways.
Cached or uncached. Sometimes you can improve session performance by caching the lookup table. If you
cache the lookup table, you can choose to use a dynamic or static cache. By default, the lookup cache
remains static and does not change during the session. With a dynamic cache, the Informatica
Server inserts rows into the cache during the session. Informatica recommends that you cache the target
table as the lookup. This enables you to look up values in the target and insert them if they do not exist.
KEYLABSTRAINING.COM [email protected]

Diff bet Connected & Unconnected Lookup
Connected lookup Unconnected lookup
1) Receives input values directly from of a the pipe line transformation.
Receives input values from the result of LKP expression within other transformation.
2) U can use a dynamic or static cache U can use a static cache.
3) Cache includes all lookup columns used in the mapping.
Cache includes all lookup out put ports.
4) Support user defined default values Does not support user defined default values
KEYLABSTRAINING.COM [email protected]

Diff between Static & Dynamic Cache
Static Cache Dynamic Cache
1) U can not insert or update the cache
U can insert rows into the cache as u pass to the target
2) The Informatica Server does not update the cache while it processes the Lookup transformation
The Informatica Server dynamically inserts data into the lookup cache and passes data to the target table.
KEYLABSTRAINING.COM [email protected]

Update Strategy TransformationWhen you design your data warehouse, you need to decide what type of information to store in targets. As part of
your target table design, you need to determine whether to maintain all the historic data or just the most recent changes.
For example, you might have a target table, T_CUSTOMERS, that contains customer data. When a customer address changes, you may want to save the original address in the table, instead of updating that portion of the customer record. In this case, you would create a new record containing the updated address, and preserve the original record with the old customer address. This illustrates how you might store historical information in a target table. However, if you want the T_CUSTOMERS table to be a snapshot of current customer data, you would update the existing customer record and lose the original address.
The model you choose constitutes your update strategy, how to handle changes to existing records. In Power Mart and Power Center, you set your update strategy at two different levels:
• Within a session. When you configure a session, you can instruct the Informatica Server to either treat all records in the same way (for example, treat all records as inserts), or use instructions coded into the session mapping to flag records for different database operations.
• Within a mapping. Within a mapping, you use the Update Strategy transformation to flag records for insert, delete, update, or reject.
KEYLABSTRAINING.COM [email protected]

Setting up Update Strategy at Session Level
During session configuration, you can select a single database operation for all records. For the Treat Rows As setting, you have the following options:
Setting Description
InsertTreat all records as inserts. If inserting the record violates a primary or foreign key constraint in the database, the Informatica Server rejects the record.
Delete
Treat all records as deletes. For each record, if the Informatica Server finds a corresponding record in the target table (based on the primary key value), the Informatica Server deletes it. Note that the primary key constraint must exist in the target definition in the repository.
Update
Treat all records as updates. For each record, the Informatica Server looks for a matching primary key value in the target table. If it exists, the Informatica Server updates the record. Again, the primary key constraint must exist in the target definition.
Data Driven
The Informatica Server follows instructions coded into Update Strategy transformations within the session mapping to determine how to flag records for insert, delete, update, or reject. If the mapping for the session contains an Update Strategy transformation, this field is marked Data Driven by default. If you do not choose Data Driven setting, the Informatica Server ignores all
Update Strategy transformations in the mapping.KEYLABSTRAINING.COM [email protected]
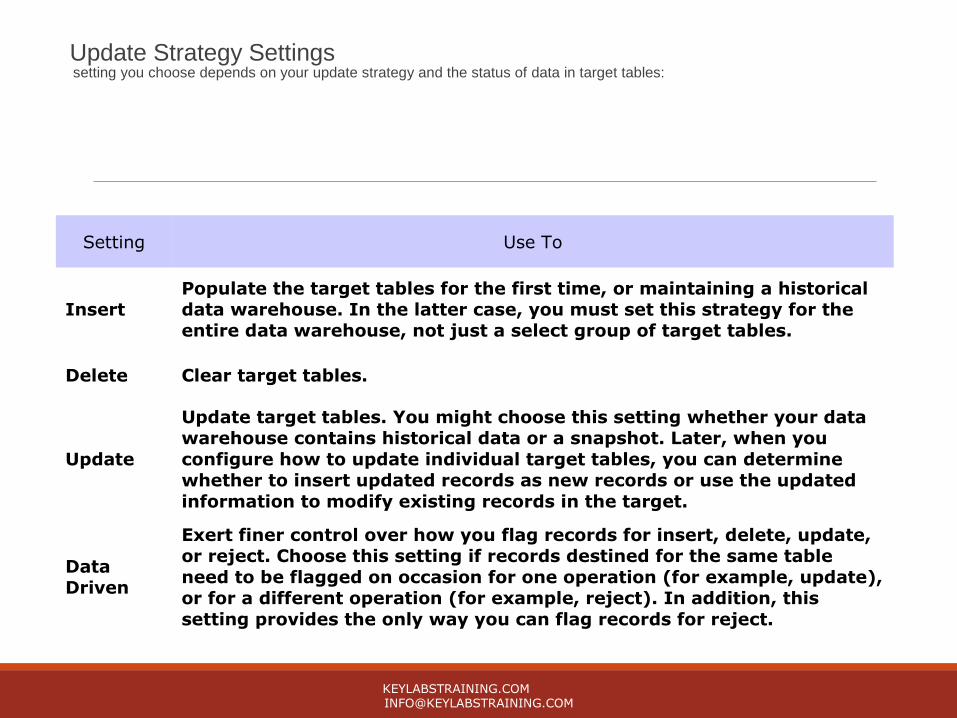
Update Strategy Settings setting you choose depends on your update strategy and the status of data in target tables:
Setting Use To
InsertPopulate the target tables for the first time, or maintaining a historical data warehouse. In the latter case, you must set this strategy for the entire data warehouse, not just a select group of target tables.
Delete Clear target tables.
Update
Update target tables. You might choose this setting whether your data warehouse contains historical data or a snapshot. Later, when you configure how to update individual target tables, you can determine whether to insert updated records as new records or use the updated information to modify existing records in the target.
Data Driven
Exert finer control over how you flag records for insert, delete, update, or reject. Choose this setting if records destined for the same table need to be flagged on occasion for one operation (for example, update), or for a different operation (for example, reject). In addition, this setting provides the only way you can flag records for reject.
KEYLABSTRAINING.COM [email protected]

Informatica Online Training By Keylanstraining.com
Ph:+91-9550645679(IND).
KEYLABSTRAINING.COM [email protected]