information and coding theory transmission over noisy channels. channel capacity, shannon’s...
TRANSCRIPT

Information and Information and Coding TheoryCoding Theory
Transmission over noisy channels. Transmission over noisy channels. Channel capacity, Shannon’s theorem.Channel capacity, Shannon’s theorem.
Juris Viksna, 2015

Information transmission

Noisy channel
In practice channels are always noisy (sometimes this could be ignored).There are several types of noisy channels one can consider.We will restrict attention to binary symmetric channels.

Noisy channel - the problemAssume BSC with probability of transmission error p.
In this case we assume that we have already decided on the optimal string of bits for transmission - i.e. each bit could have value 1 or 0 with equal probabilities ½.
We want to maximize our chances to receive a message without errors, to do this we are allowed to modify the message that we have to transmit.
Usually we will assume that message is composed of blocks of m bits each, and we are allowed to replace a given m bit blockwith an n bit block of our choice (likely we should have n m :)
Such replacement procedure we will call a block code.
We also would like to maximize the ratio R=m/n.

Entropy - reminder of some definitions
Conditional entropy
Mutual information
Binary entropy function

Entropy (summarized)
Relations between entropies, conditional entropies, joint entropy and mutual information.
[Adapted from D.MacKay]

How could we characterize noisy channels?
Noisy channelyixi
Assume xiWe have received some yiWhat we can infer about xi from yi?
If error probability is 0, we will have H(X|y=bk)=0If (for BSC) error probability is ½, we will have H(X|y=bk)=H(X)
[Adapted from D.MacKay]

How could we characterize noisy channels?
Noisy channelyixi
If error probability is 0, we will have H(X|y=bk)=0If (for BSC) error probability is ½, we will have H(X|y=bk)=H(X)
I(X;Y) seems a good parameter to characterize the channel[Adapted from D.MacKay]

Channel capacity
Noisy channelyixi
[Adapted from D.MacKay]
For simplicity we will restrict our attention only to BSC (so will assume uniform distribution). The distribution however usually can not be ignored for “real channels”, due to e.g. higher probabilities for burst errors etc.

Channel capacity for BSC
Assuming error probability p and probabilities of transmission of both 0 and 1 to be ½,we will have:
P(1|y=0) = p, P(0|y=0)=1pH(X|y=0) = p log p (1p)log(1p) = H2(p)H(X|y=1) = p log p (1p)log(1p) = H2(p)H(X|Y) = 1/2 H(X|y=0) + 1/2 H(X|y=1) = H2(p) Thus C(Q) = I(X;Y) = H2(1/2) H2(p) = 1 H2(p)This value will be in interval [0,1] [Adapted from D.MacKay]

Block and bit error probabilities
[Adapted from D.MacKay]
The computation of probability of block error pB is relatively simple.
If we have a code that guarantees to correct any t errors we should have:
inin
tiB pp
i
np
)1(
1

Block and bit error probabilities
[Adapted from D.MacKay]
The computation of probability of bit error pb in general is complicated. It is not enough to know only code parameters (n,k,t), but also weight distribution of code vectors.
However, assuming code is completely “random” we can argue that any non-corrected transmission of block of length n leads to selection of randomly chosen message of length k.
It remains to derive pb from the equation above
ikb
ib
k
i
inin
ti
ppi
kpp
i
n
)1()1(11

Shannon's theoremTheorem (Shannon, 1948):
1. For every discrete memoryless channel, the channel capacity
has the following property. For any ε > 0 and R < C, for large enoughN, there exists a code of length N and rate R ≥ R and a decodingalgorithm, such that the maximal probability of block error is ≤ ε.
2. If a probability of bit error pb is acceptable, rates up to R(pb) are achievable, where
and H2(pb) is the binary entropy function
3. For any pb, rates greater than R(pb) are not achievable. [Adapted from www.wikipedia.org]

Shannon Channel Coding Theorem
[Adapted from D.MacKay]

Shannon's theorem - a closer look
If a probability of bit error pb is acceptable, rates up to R(pb) are achievable, where
and H2(pb) is the binary entropy function
For any pb, rates greater than R(pb) are not achievable.
Thus, if we want pb to get as close to 0 as possible, we still need onlycodes with rates that are just below C.
[Adapted from www.wikipedia.org]

Shannon’s theorem
[Adapted from D.MacKay]
Actually we will prove only the first (and the correspondingly restricted third) part of this result - that with rates below C we can achieve as low transmission error as we wish (if pb 0 then 1H2(pb)1).
Still, this is probably the most interesting/illustrative case.
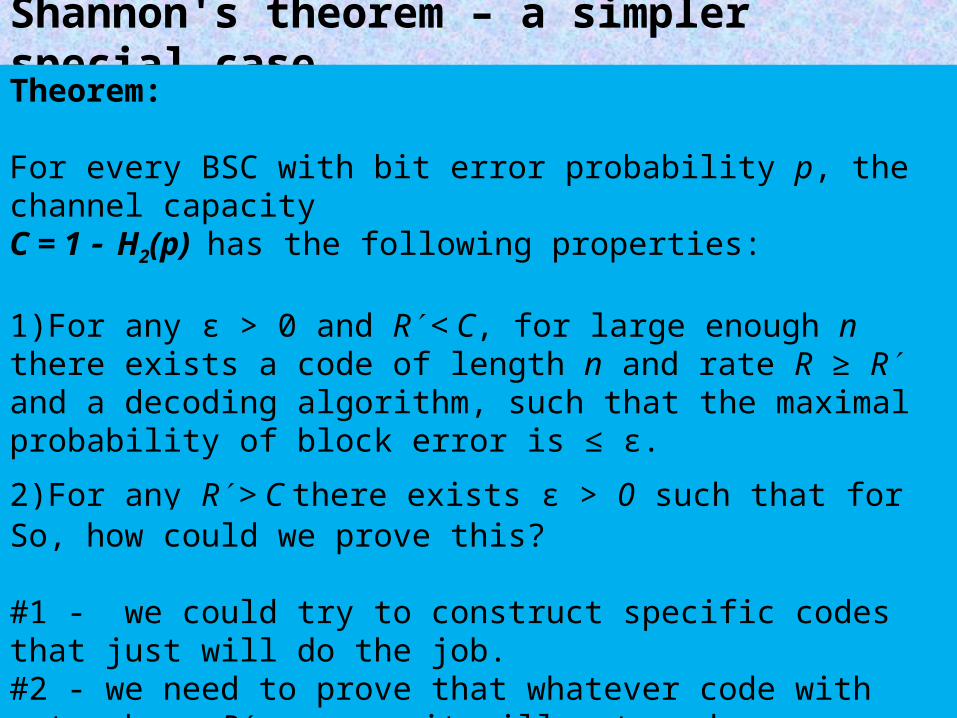
Shannon's theorem – a simpler special caseTheorem:
For every BSC with bit error probability p, the channel capacity C = 1 H2(p) has the following properties:
1)For any ε > 0 and R < C, for large enough n there exists a code of length n and rate R ≥ R and a decoding algorithm, such that the maximal probability of block error is ≤ ε.
2)For any R > C there exists ε > 0 such that for any code with rate R ≥ R probability of block error is ≥ ε.
So, how could we prove this?
#1 - we could try to construct specific codes that just will do the job.#2 - we need to prove that whatever code with rate above R we use, it will not work.

Entropy argument?
Noisy channelyx
To transmit xX without errors we need to receive H(X) bits.
The length of vectors from X (transmitted) is n bits and H(X) = k.The length of vectors from Y (received) is n bits and H(Y) n.Rate R = k/n.Capacity C = I(X;Y) = H(X) H(X|Y) = 1 H2(p).If n bits are transferred we receive nC information bits about X.To receive enough bits for error-less decoding we should have nC k, i.e. C k/n = R.
Well almost ok, provided we ”know” that entropy measures information...
p

Achievability - how to prove?
We could assume that we have a perfect code with rate R=k/n.
From Hamming inequality we could compute the number t oferrors that code can correct.
Then we could check whether the probability of t errors in blocksof length n will not exceed pB.
In principle this probably could be done....
2k messages
2n codewords
t
i
nk
i
n0
22

Achievability - how to prove?
Still, we are not that sure that perfect codes should exist...
Probably we can try to use for encoding set of randomly chosen verticesand hope that this will work well enough?
[Adapted from D.MacKay]

Probabilities of errors
Noisy channelyx
p – probability that a single bit will be changed.pn – an average number of changed bits in block of length n.(1–p)n – probability that there were no transmission errors.
– probability of exactly i transmission errors.
p
ini ppi
n
)1(

Binomial distribution
ini ppi
nixp
)1()(
n=20, p = 0.1, 0.5, 0.8

Shannon’s theorem - achievabilityLet n > k be decided upon later. Pick the encoding function E: {0,1}k{0,1}n at random, i.e. for every m{0,1}k, E(m) is chosen uniformly at random from {0,1}n, independently of all other choices.
Note, that we don’t fix encoding, retransmission of m likely will use different E(m).
The decoding function D: {0,1}n{0,1}k works as follows:
Given y{0,1}n, we find (non-constructively) the x{0,1}k such that distance d(y,E(m)) is minimized. This m is value of D(y).
[Adapted from M.Sudan]
B(y,r) – ball with center at y and radius r, i.e. set of all vectors z from {0,1}n with d(y,z) r.
Let m be given. For D(y) m we must have at least one of the following:
1)y B(E(m),r) (more than r errors in transmission)2)There exists m m with E(m) B(y,r). (possibility of wrong decoding)

Shannon’s theorem - achievabilityB(y,r) – ball with center at y and radius r, i.e. set of all vectors z from {0,1}n with d(y,z) r.
Let m be given. For D(y) m we must have at least one of the following:
1)y B(E(m),r) (more than r errors in transmission)2)There exists m m with E(m) B(y,r). (possibility of wrong decoding)
r
r
E(m)
E(m)
y
y
If we want to achieve arbitrarily lowblock error probability, we need to achieve arbitrarily low probabilities forboth of these events.
So, what value of r should we chose?

Binomial distributionini pp
i
nixp
)1()(
p – probability that a single bit will be changed.pn – an average number of changed bits in block of length n.
The probability to have exactly pn errors approaches 0 with increase of n, however it turns out the same happens with the probability to have number of errors that differs “too much” from pn. (This actually already implies that we should chose r pn).

Chernoff bound
A somewhat simplified version (but still sufficient for our purposes):
Assume we flip a coin n times, coin is such that with probability p it falls a “head” (denoted by 1) and with probability 1p it falls a “tail” (denoted by 0).
After the n flips the average number of 1-s will be pn. Although the probability that the number N of 1-s is exactly pn is small, so is the probability that N significantly deviates from pn. This is the result stated by Chernoff bound:
For an arbitrary small >0 the probability P that number of heads N differs form the mean value pn by more than (p+)n is smaller than 2/2pn.
This means that P0 if n.
Although not particularly difficult, we will omit the proof of this result here.

Chernoff boundX1,X2,...,Xn – independent random variables.X = X1+X2+...+ Xn.E[Xi] – expectation of Xi. = E[X] = E[X1] +E[X2] +...+ E[Xn] – expectation of X.
Theorem (Chernoff bound, ~1958):
For any > 0: P(X > (1+)) 2/2.
We will just be interested in special case where p(Xi=1) = p, p(Xi=0) = 1pand E(Xi) = p, E(X) =np. This gives us inequality:
P(X > (1+)pn) 2/2pn, i.e. for any chosen > 0 probability to have more than (1+)pn errors approaches 0 with increasing n. Essentially this allows us to chose r=(p+)n with arbitrarily small and be sure that probability y B(E(m),r) can be made arbitrarily small by choosing sufficiently large n.
Note. The result above is one of alternative versions the Chernoff bound is being stated; coefficients in the inequality also can be improved.

Chernoff boundTheorem (Chernoff bound):
For any > 0: P(X > (1+)) 2/2.
Proof?
Somewhat technical, but can be obtained by considering Yi =etXi, applying a familiar (an introductory result from probability theory course :) Markov’s inequalityP(X a) E[X]/a:
P(X > (1+)) = P(etX > e ((1+))) P(X > (1+)) < E[etX]/e ((1+))
and using the fact that ex < 1+x.
(This leads to somewhat more complicated expression of Chernoff bound, which then can be easily bounded from above by 2/2).

Shannon’s theorem - achievability
We fix the “number of errors” as r=(p+)n and for each y attempt to decode it to m such that yB(E(m),r).
To show that we can get arbitrarily small error probability we need to show that two following probabilities can be made arbitrarily small by choosing a sufficiently large length n of the code:
1) Probability that the number of errors have exceeded r (so decoding fails by definition);2) Probability that y falls within intersection of B(E(m),r) with another B(E(m),r) (thus a possibility to decode y wrongly as m).
[Adapted from M.Sudan]
Let m be given. For D(y) m we must have at least one of the following:
1)y B(E(m),r) (more than r errors in transmission)2)There exists m m with E(m) B(y,r). (possibility of wrong decoding)

Shannon’s theorem - achievability
Why we should chose r=(p+)n?
1) the average error rate is pn, however for any >0 the probability to get more than (p+)n errors approaches 0 with increasing n. Thus a good (and probably the only) way to bring the probability of event #1 to 0. Note that this part of the proof works regardless of code rate R.
There is no relation between this and the desired error probability - just that we need a value >0 to prove the part #1 and then can chose it as small as we wish for it to be ignored in proof of part #2.
[Adapted from M.Sudan]
Let m be given. For D(y) m we must have at least one of the following:
1)y B(E(m),r) (more than r errors in transmission)2)There exists m m with E(m) B(y,r). (possibility of wrong decoding)

Shannon’s theorem - achievability
Why we should chose r=(p+)n?
2) the probability of event #2 is dependent form n, r and k. So this is from where we will get the estimate for error rate. It will turn out that the probability of event #2 will approach 0 with increasing n, if we chose R=k/n<1H2(p) and a sufficiently small (which we are free to do). This essentially will mean that good codes exist provided that R<C.
[Adapted from M.Sudan]
Let m be given. For D(y) m we must have at least one of the following:
1)y B(E(m),r) (more than r errors in transmission)2)There exists m m with E(m) B(y,r). (possibility of wrong decoding)

Shannon’s theorem - achievability
So, the Chernoff bound guaranties that probability of event #1 can be achieved to be arbitrarily small for any > 0 and r=(p+)n, if we take n to be sufficiently large.
What about the probability for the event #2?
Let m be given. For D(y) m we must have at least one of the following:
1)y B(E(m),r) (more than r errors in transmission)2)There exists m m with E(m) B(y,r). (possibility of wrong decoding)

By definition vol(B(y,r))= . We will show that vol(B(y,pn)) 2H(p)n.
This will give error probability P 2H(p)nn+k.
Thus for R=k/n < 1H(p) we have P0 if n.
Shannon’s theorem - achievabilityHow to estimate the probability of event #2?
Denote the number of vectors in distance r from y by vol(B(y,r)). The probability to decode y wrongly to one particular m is vol(B(y,r))/2n. The probability to decode y wrongly to any vector is vol(B(y,r))/2nk.
r
r
E(m)
E(m)
y
ri i
n
...0

B(y,r) – ball with center at y and radius r, i.e. set of all vectors z from {0,1}n with d(y,z) r.
vol(B(y,r)) = |{z {0,1}n | d(y,z) r}|.
We obviously have:
But a bit surprisingly it turns out that vol(B(y,pn)) 2H(p)n
The value obviously does not depend from 0, thus let consider vol(B(0,pn)) = vol(B(pn)).
Volume of Hamming balls
r
i i
nryBvol
0)),((
pn
i i
npnyBvol
0)),((

Theorem (volume of Hamming balls):
B(r) – ball in n dimensional binary vector space with center at 0 and radius r, i.e. B(r) = {z {0,1}n | w(z) r}. Let p < 1/2 and H2(p) = p log p (1 p) log (1 p).
Then for large enough n:
1.Vol(B(pn)) 2H2(p)n
2.Vol(B(pn)) 2H2(p)n o(n)
Here f(n)o(n) for any c >0 we have f(n) < cn for all large n limn f(n)/n = 0.
Volume of Hamming balls

Vol(B(pn)) 2H2(p)n ? Consider (an obvious) equality 1 = (p + (1p))n.
Volume of Hamming balls
[Adapted from A.Rudra]
npHpn
i
nppnpn
i
pn
npn
i
i
npn
i
inipn
i
inin
i
n
i
npp
i
n
p
pp
i
n
p
pp
i
n
ppi
n
ppi
n
pp
)(
0
)1(
0
0
0
0
0
22)1(
1)1(
1)1(
)1(
)1(
))1((1
Thus:
1 Vol(B(pn))/2H2(p)n
Vol(B(pn)) 2H2(p)n

Shannon’s theorem - achievabilityThe probability to decode y wrongly to one particular m is vol(B(y,r))/2n. The probability to decode y wrongly to any vector is vol(B(y,r))/2nk.
We have chosen r=(p+)n and need to have vol(B(y,r))/2nkn 0We also assume that rate R = k/n = 1 H2(p) < C = 1 H2(p)
P(error #2) = vol(B(y,r))/2nk 2H2(p+)n/2nk = 2H2(p+)n/2nn+nH2(p)+n = 2n(H2(p+) H2(p) ) 0,n 0
r
r
E(m)
E(m)
y
We have vol(B(n,pn)) 2H2(p)n.
Probability P of incorrect decoding?
For k/n <1H2(p) we have P < 2 cn, where c>0. So, by choosingsufficiently large n we can get P as small as we wish.

Shannon’s theorem - achievability
Are we done?Almost. We have proved that m will likely be decoded correctly. What about other messages?
[Adapted from M.Sudan]

Theorem (volume of Hamming balls):
B(r) – ball in n dimensional binary vector space with center at 0 and radius r, i.e. B(r) = {z {0,1}n | w(z) r}. Let p < 1/2 and H2(p) = p log p (1 p) log (1 p).
Then for large enough n:
1.Vol(B(pn)) 2H2(p)n OK2.Vol(B(pn)) 2H2(p)n o(n) still need to prove this
Here f(n)o(n) for any c >0 we have f(n) < cn for all large n limn f(n)/n = 0.
Volume of Hamming balls

Volume of Hamming balls
[Adapted from A.Rudra]
Stirling’s formula:
More precisely:
))/1(1(2! nOe
nnn
n
nn
nn
ee
nnne
e
nn 12/1)112/(1 2!2
)(2)1(2
1
)1(
1
)1(2
1
)/)1(()/(
)/(
)!)1(()!(
!))((
)())1(12/(1)12/(1)112/(1)1(
))1(12/(1)12/(1)112/(1)1(
0
2 nenpppp
enppenpepn
en
nppn
n
pn
n
i
npnBvol
npHnppnnnppn
nppnnnppn
n
pn
i

Volume of Hamming balls
[Adapted from A.Rudra]
since
Thus:
)(2)()/)1(()/(
)/())(( )(
)1(02 nn
enpepn
en
pn
n
i
npnBvol npH
nppn
npn
i
)()())1(12/(log)112/(log2/)log)1log(log(log
))1(12/(1)12/(1)112/(1
222
)1(2
1)(
nonfnppenenpp
nppnnenpp
n
0/)(lim
0)))1(12/(log)112/(log2/)log)1log(log(log)(
nnf
and
nppenenppnf
n
)()()(
022 2)(2))(( nonpHnpHpn
in
pn
n
i
npnBvol

Volume of Hamming balls (a simplified proof)A simpler estimate for n! (can be easily proven by induction):
Then:
nn
e
nnen
e
n
!
)()(
log2log2)1log(log)(22)1(
22)1(
0
2
2
2
22)1(
1
)1(
1
)1(
1
)/)1(()/(
)/(
)!)1(()!(
!))((
nonpH
neppnpHnppn
nppn
n
pn
i
enpppp
enppenpepn
en
nppn
n
pn
n
i
npnBvol

Shannon's theorem – a simpler special caseTheorem:
For every BSC with bit error probability p, the channel capacity C = 1 H2(p) has the following properties:
1)For any ε > 0 and R < C, for large enough n there exists a code of length n and rate R ≥ R and a decoding algorithm, such that the maximal probability of block error is ≤ ε.
2)For any R > C there exists ε > 0 such that for any code with rate R ≥ R probability of block error is ≥ ε.
#1 - we could construct specific codes that just will do the job. OK#2 - we need to prove that whatever code with rate above R we use, it will not work. Still need to prove this.

Shannon’s theorem - unachievability
[Adapted from M.Sudan]
A draft of simple proof by M.Sudan. Does it work and can we fill-in the details?

Shannon’s theorem - unachievabilityAssume we have code with rate R = k/n > C = 1 H2(p).Then R = k/n = 1 H2(p)+ for some > 0.
“The usual” approach:
1)Show than with some probability c > 0 (independent of n) the number of errors in single block transmission will exceed the expected value pn.
2)Probability to have i < pn errors in specific places is pi(1p)ni, probability to have j > pn errors in specific places is pj(1p)nj. Since p<½ and (1 p) >½ we have pi(1p)ni >pj(1p)nj.
3)To achieve arbitrarily small block errors therefore we need to correct
almost errors.
pni i
ncpnBvolc
...0
))((

Shannon’s theorem - unachievabilityR = k/n = 1 H2(p)+ for some > 0.
3)To achieve arbitrarily small block errors therefore we need to correct
almost errors.
4)This applies to 2k vectors, thus we need to have almost distinct vectors of length n.
5)This leads to:
i.e. to a contradiction.
nnonnnopnHnnpnHnnonpHk
pni
k ccci
nc 222222 )())(1()()()()()()(
...0
222
pni
k
i
nc
...0
2
pni i
ncpnBvolc
...0
))((

Shannon’s theorem - unachievabilityr
..................
The vector space with 2n elements should be partitioned in 2k disjoint
parts containing elements each. Thus:
pni i
n
...0
pni i
n
...0
pni i
n
...0
pni i
nc
...0
nnonnnopnHnnpnHnnonpHk
pni
k ccci
nc 222222 )())(1()()()()()()(
...0
222

Shannon’s theorem - unachievabilityR = k/n = 1 H2(p)+ for some > 0.
1)P(number of errors > pn) > c for some c>0.
2)P(i < pn errors) > P(i > pn errors) (assuming known error bits).
3)For pB0 we must correct almost errors.
4)Thus we need almost distinct vectors of length n.
5)This gives a contradiction:
Are all these steps well justified?
pni i
ncpnBvolc
...0
))((
pni
k
i
nc
...0
2
nnonnnopnHnnpnHnnonpHk
pni
k ccci
nc 222222 )())(1()()()()()()(
...0
222
The are some difficulties with #1 – whilst it is a very well known fact, it is difficult to give a simple proof for it

Binomial distributionLet Xi be independent random values, with p(Xi=0) = p and
p(Xi=1) = 1p. What can we say about ?
ni
in XS...1
sns pps
nsxp
)1()(

Probability density function:
Or, in more general form:
In this case is expected value and 2 variance.
Normal distribution
2
2
1
2
1)(
xex
2
2
2
)(2
2
1),,(
x
ex
),(~ 2NX

Central limit theorem (CLT)X1,X2,...,Xn – independent random variables with expected values and variances 2.Sn = X1+X2+...+ Xn.
Theorem (Central Limit Theorem):
A binomial distribution is just a special case with p(Xi=1) = p, p(Xi=0) = 1p, = pn and 2 = np(1 p).
This gives us P(number of errors > pn)n 1/2.
Should be familiar from probability theory course Short proofs are known, but require mastering some techniques first.
t
nn dxxtSP ),,()( 2

Direct computation of median
Median cn,p is defined as follows:
cn,p = min{c = 0…n| Bn,c(p) > ½}
It turns out that np/2 ≤ cn,p ≤ np/2.
inic
icn pp
c
npB
)1()(
0,
[Adapted from R.Gob]

Direct computation of median
We just need also a few inequalities:
[Adapted from R.Gob]
mnmmnm qqpp
nmqp
)1()1(
2/,

Unachievability – the lengths of codesTo prove that for codes with R = k/n > C = 1 H2(p) an arbitrarily small error probability can not be achieved we used assumption that we can take the length n of code to be as large as we wish.
Apparently OK, if we have to prove the existence of codes, however have we shown that there are no good codes R > C if n is small?
Formally not yet, however, provided a “good” code with R > C and length n exists, just by used repeated code we can obtain code with same rate for any length sn.
Thus, if there are no “good” codes with large length, there can not be “good” codes with any length n.