information theory 1ee322 al-sanie. introduced by claude shannon. shannon (1948), information...
TRANSCRIPT

EE322 Al-Sanie1
Information Theory

EE322 Al-Sanie2
• Introduced by Claude Shannon. Shannon (1948) ,
Information theory, The Mathematical theory of Communication
• Claude Shannon: April 30, 1916 - February 24, 2001

EE322 Al-Sanie3
• What is the irreducible complexity below which a signal cannot be compressed ?
Entropy • What is the ultimate transmission rate for
reliable communication over noisy channel? Channel capacity
• Two foci: a) data compression and b) reliablecommunication through noisy channels.

EE322 Al-Sanie4
Amount of Information
• Before the event occurs, there is an amount of uncertainty.
• When the event occurs there is an amount of surprise.
• After the occurrence of the event, there is gain in the amount of information, the essence of which of which may be viewed as the resolution of uncertainty.
• The amount of information is related to the inverse of probability of occurrence.

EE322 Al-Sanie5
• The amount of information is related to the inverse of probability of occurrence.
• The base of the logarithm is arbitrary. It is the standard practice today to use a logarithm to base 2.
Uncertainty Surprise Probability Information
𝐼∝ 1𝑝
𝐼= log(1𝑝) = −log (𝑝)
𝐼= log2(1𝑝) = −log2(𝑝) bit

EE322 Al-Sanie6
Discrete Source• The discrete source is a source that emits symbols from a
finite alphabet
• The source output is modeled as discrete random variable S which takes one symbol of the alphabet with probabilities
• Of course, this set of probabilities must satisfy the condition
𝑃ሺ𝑆= 𝑠𝑘ሻ= 𝑝𝑘, 𝑘 = 0,1,2,…,𝐾− 1
𝑝𝑘 = 1𝐾−1𝑘=0

EE322 Al-Sanie7
Example of Discrete Source
Analog source Sampler Quantizer

EE322 Al-Sanie8
• Discrete memoryless source: If the symbol emitted by the source during successive signaling intervals are statistically independent.• We define the amount of information gained
after observing the event S=sk, which occurs with probability pk, as:
𝐼ሺ𝑠𝑘ሻ= log2( 1𝑝𝑘) = −log2 𝑝𝑘 𝑓𝑜𝑟 𝑘 = 0,1,…,𝐾− 1

EE322 Al-Sanie9
Properties of amount of information:
If we are absolutely certain of the outcome of an event, even before it occurs, there is no information gained.
.
The event yields a gain of information (or no information) but never a loss of information..
The event with lower probability of occurrence has the higher information.
For statistically independent events sk and sl.
𝐼ሺ𝑠𝑘ሻ= 0 𝑓𝑜𝑟 𝑝𝑘 = 1
𝐼ሺ𝑠𝑘ሻ≥ 0 𝑓𝑜𝑟 0 ≤ 𝑝𝑘 ≤ 1
𝐼ሺ𝑠𝑘ሻ> 𝐼ሺ𝑠𝑖ሻ 𝑓𝑜𝑟 𝑝𝑘 < 𝑝𝑖 𝐼ሺ𝑠𝑘𝑠𝑙ሻ= 𝐼ሺ𝑠𝑘ሻ+ 𝐼(𝑠𝑙)

EE322 Al-Sanie10
Entropy (The average information content per source symbol)
• Consider discrete memoryless source that emits symbols from a finite alphabet
• The amount of information I(sk) is a discrete random variable that takes on values I(s0), I(s1), …, I(sK-1) with probabilities p0, p1, …, pK-1 respectively.

EE322 Al-Sanie11
• The mean of I(sk) over the source alphabet is given by
• H is called the entropy of a discrete memoryless source. It is a measure of the average information content per source symbol.
𝐻= 𝐸ሾ𝐼ሺ𝑠𝑘ሻሿ = 𝑝𝑘 𝐼ሺ𝑠𝑘ሻ
𝐾−1𝑘=0
= 𝑝𝑘 log2( 1𝑝𝑘𝐾−1𝑘=0 )

EE322 Al-Sanie12
ExampleA source emits one of four symbols s0, s1, s2, and s3 with
probabilities ½, ¼, 1/8, and 1/8, respectively. The successive symbols emitted by the source are statistically independent.
p0=1/2 p1=1/4 p2=1/8 p3=1/8
I(s0)=1 I(s1)=2 I(s2)=3 I(s3)=3

EE322 Al-Sanie13
Properties of the entropy
• .where K is the number of Symbols• H=0 if pk=1 and pi=0 for i≠k.
• H=log2(K) if pk=1/K
maximum uncertainty when all symbols occur with the same probabilities
0 ≤ 𝐻≤ log2 𝐾

EE322 Al-Sanie14
Example: Entropy of Binary Memoryless Source
• Consider a binary source for which symols 0 occurs with probability p0 and symbol 1 with probability p1=1-p0.
𝐻= 𝑝𝑘 log2( 1𝑝𝑘𝐾−1𝑘=0 ) = −𝑝0 log2 𝑝0 − 𝑝1 log2 𝑝1
=−𝑝0 log2 𝑝0 − (1− 𝑝0) log2(1− 𝑝0)

EE322 Al-Sanie15
Entropy function H(p0) of binary source.
H=0 when p0=0H=0 when p0=1H=1 when p0=0.5 (equally likely symbols)

EE322 Al-Sanie16
Extension of Discrete Memoryless Source
• It is useful to consider blocks rather than individual symbols, with each block consisting of n successive symbols.
• We may view each block as being produced by extended source with Kn symbols, where K is the number of distinct symbols in the alphabet of the original source.
• The entropy of the extended source is

EE322 Al-Sanie17
Example: Entropy of Extended source

EE322 Al-Sanie18
The entropy of the extended source:

EE322 Al-Sanie19
Source Coding
• Source Coding is an efficient representation of symbols generated by the discrete source.
• The device that performs source coding is called source encoder.
• Source code:• Assign short code words to frequent symbols• Assign long code word to rare source symbols

EE322 Al-Sanie20

EE322 Al-Sanie21
Example: Source code (Huffman code) for English alphabet

22
• The source encoder should satisfy the following:
1. The code words produced by the encoder are in binary form.
2. The source code is uniquely decodable, so that the original source symbols can be reconstructed from the encoded binary sequence.
Source encoder
Source decoder
sk
Binary code
word
Binary code
wordsk

EE322 Al-Sanie23
Discrete Source
Source encoder Modulator Channel Demodulator Source
decoder

EE322 Al-Sanie24
ExampleA source emits one of four symbols s0, s1, s2, and s3 with
probabilities ½, ¼, 1/8, and 1/8, respectively. The successive symbols emitted by the source are statistically independent.
Consider the following source code for this source:
The average code word length
codeword p symbol
0 1/2 s0
10 1/4 s1
110 1/8 s2
111 1/8 s3

25
• Compare the two source codes (I and II) for the pervious source
• If the source emits symbols with symbol rate 1000 symbols /s.
• If we use code I: average bit rate=1000X1.75=1750 bits/s
• If we use code II: average bit rate=1000X2=2000 bits/s
EE322 Al-Sanie
codeword for code I
p symbol
0 1/2 s0
10 1/4 s1
110 1/8 s2
111 1/8 s3
codeword for code II
p symbol
00 1/2 s0
01 1/4 s1
10 1/8 s2
11 1/8 s3

EE322 Al-Sanie26
• Let the binary code word assigned to symbol sk by the encoder has length lk, measured in bits.
• We define the average code-word length of the source encoder (the average number of bits per symbol) as
• What is the minimum value of ? • The answer to this question is in Shannon’s
first theorem “The source Coding Theorem”
𝐿ത= 𝑝𝑘 𝑙𝑘𝐾−1𝑘=0

EE322 Al-Sanie27
Source Coding Theorem
• Given a discrete memoryless source of entropy H, the average code-word length for any distortionless source encoding scheme is bounded as:
• The minimum length • The efficiency of the source encoder:
𝐿ത ≥ 𝐻 𝐿ത𝑚𝑖𝑛 = 𝐻
𝜂 = 𝐻𝐿ത

EE322 Al-Sanie28
Example: The previous example

EE322 Al-Sanie29
Uniquely Decodable Source Code • A code is said to be uniquely decodable (U.D.) if the
original symbols can be recovered uniquely from sequences of encoded bits.
• The source code should be uniquely decodable code.
Source encoder
Source decoder
sk
Binary code
word
Binary sequence
sk

EE322 Al-Sanie30
Examplecodeword symbol
00 s0
00 s1
11 s2
codeword symbol
0 s0
1 s1
11 s2
codeword symbol
00 s0
01 s1
11 s2
This code is not UD because the symbols s0 and s1 have the same code words
This code is not UD:the sequence: 1 1 1 … can be decoded as1 1 1 …→ s1 s1 s1 or1 1 1 …→ s1 s2 or1 1 1 …→ s2 s1
This code is UD code

EE322 Al-Sanie31
Prefix-free Source Codes• A prefix-free code: is a code in which no
codeword is a prefix of any other codeword.• Example:
codeword symbol
0 s0
10 s1
110 s2
111 s4
codeword symbol
0 s0
01 s1
011 s2
0111 s4
Prefix-free Code Not Prefix-free Code

EE322 Al-Sanie32
• A prefix-free code has the important property that it is always uniquely decodable. But the converse in not necessarily true.
• Prefix-free → UD• UD not necessarily prefix-free• Example: UD but not prefix-free
codeword symbol
0 s0
01 s1
011 s2
0111 s4

EE322 Al-Sanie33
• Prefix-free codes have the advantage of being instantaneously decodable, i.e., a symbol can be decoded by the time the last bit in it is reached.
• Example:
codeword symbol
0 s0
10 s1
110 s2
111 s4
The sequence 1011111000 …. is decoded as s1 s3 s2 s0 s0 …

EE322 Al-Sanie34
Huffman Code• Huffman is an important prefix-free source code.• The Huffman encoding algorithm proceeds as follows:1. The source symbols are listed in order of decreasing
probability. The two source symbols of lowest probability are assigned a 0 and a 1.
2. These two source symbols are regarded as being combined into a new symbol with probability equal to the sum of the two probabilities. The probability of the new symbol is placed in the list in accordance with its value.
3. The procedure is repeated until we are left with a final list of two symbols for which a 0 and 1 are assigned.
4. The code word for each symbol is found by working backward and tracing the sequence of 0 and 1.

EE322 Al-Sanie35
Example: Huffman code
• A source emits one of four symbols s0, s1, s2, and s3 with probabilities ½, ¼, 1/8, and 1/8, respectively.
S0 1/2
S1 1/4
S2 1/8
S3 1/8
0
0
0
1
1
1
codeword p symbol
0 1/2 s0
10 1/4 s1
110 1/8 s2
111 1/8 s3

EE322 Al-Sanie36
Example: The previous example

EE322 Al-Sanie37
Example: Huffman code

EE322 Al-Sanie38

EE322 Al-Sanie39
Example: Huffman code
S1
S2
S3
S4
S5
S6
S7
s8
00 s1
010 s2
011 s3
100 s4
101 s5
110 s6
1110 S7
1111 s8

EE322 Al-Sanie40
Discrete memoryless channel

EE322 Al-Sanie41
Discrete memoryless channels• A discrete memoryless channel is a statistical model
with an input X and an output Y that is a noisy version of X; both X and Y are random variables.
• Every unit of time, the channel accepts an input symbol X selected from an alphabet and in response it emits an output symbol Y from an alphabet .
• The channel is said to be discrete when both of the alphabets and have finite size.
• It said to be memoryless when the current output symbol depends only on current input symbol and not any of the previous ones.

EE322 Al-Sanie42
• The input alphabet:• The output alphabet:
• The transition probabilities:

EE322 Al-Sanie43
• The event that the channel input X=xj occurs with probability
• The joint probability distribution of random variable X and Y is given by
• The probabilities of output symbols

EE322 Al-Sanie44
Example: Binary Symmetric Channel (BSC)• It is a special case of the discrete memoryless
channel with J=K=2.• The channel has two input symbols x0=0 and x1=1.
• The channel has two output symbols y0=0 and y1=1.
• The channel is symmetric the probability of receiving 1 if a 0 is sent is the same as the probability of receiving a 0 if a 1 is sent. i.e
• P(y=1/x=0)=P(y=0/x=1)=p
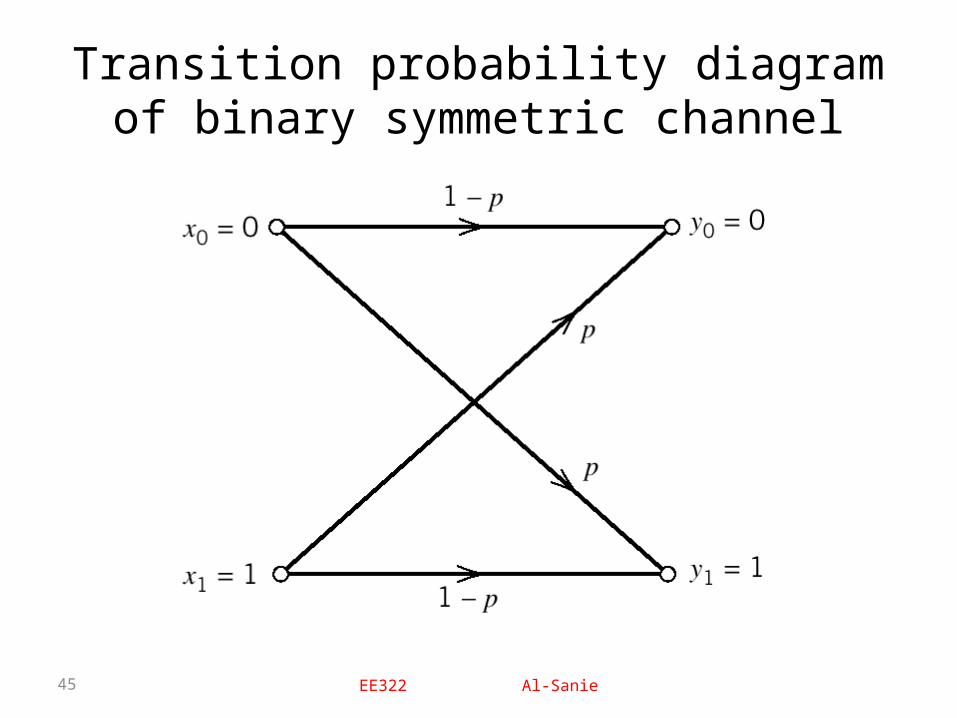
EE322 Al-Sanie45
Transition probability diagram of binary symmetric channel

EE322 Al-Sanie46
Information Capacity Theorem (Shannon’s third theorem)• The information capacity of a continuous
channel of bandwidth B Hertz, perturbed by additive white Gaussian noise of power spectral density No/2 and limited in bandwidth to B is given by
Where P is the average transmitted signal power. And NoB= σ2 =noise power
𝐶= 𝐵 log2൬1+ 𝑃𝑁𝑜𝐵൰ 𝑏𝑖𝑡𝑠/𝑠𝑒𝑐𝑜𝑛𝑑

EE322 Al-Sanie47
• The dependence of C on B is linear, whereas its dependence on signal-to-noise ratio P/NoB is logarithmic.
• Accordingly it is easier to increase the capacity of a channel by expanding bandwidth than increasing the transmitted power for a prescribed noise variance.
𝐶= 𝐵 log2൬1+ 𝑃𝑁𝑜𝐵൰ 𝑏𝑖𝑡𝑠/𝑠𝑒𝑐𝑜𝑛𝑑

EE322 Al-Sanie48
• The channel capacity theorem implies that we can transmit information at the rate of C bits per second with arbitrarily small probability of error by employing sufficiently complex encoding system.
• It is not possible to transmit at a rate higher than C by any encoding system without a definite probability of error.
• Hence, the channel capacity defines the fundamental limit on the rate of error-free transmission for power-limited, band-limited Gaussian channel.

EE322 Al-Sanie49
• If Rb≤C it is possible to transmit with small probability of error by employing sufficiently complex encoding system.
• If Rb>C it is not possible to transmit with definite probability of error.

EE322 Al-Sanie50
Implications of the information Capacity Theorem
• Consider an ideal system that transmits data at bit rate Rb equal to the information capacity C. Rb=C
• The average transmitted power may expressed as
• But
𝑃= 𝐸𝑏𝑇𝑏 = 𝐸𝑏 𝑅𝑏 = 𝐸𝑏 𝐶
𝐶= 𝐵 log2൬1+ 𝑃𝑁𝑜𝐵൰ 𝑏𝑖𝑡𝑠/𝑠𝑒𝑐𝑜𝑛𝑑 𝐶𝐵= log2൬1+ 𝐸𝑏𝑁𝑜 𝐶𝐵൰

EE322 Al-Sanie51
• A plot o bandwidth efficiency Rb/B versus Eb/No is called the bandwidth efficiency diagram. (Figure in next slide).
• The curve labeled “capacity boundary” corresponds to the ideal system for which Rb=C.
𝐶𝐵= log2൬1+ 𝐸𝑏𝑁𝑜 𝐶𝐵൰
𝐸𝑏𝑁𝑜 = 2𝐶/𝐵 − 1𝐶/𝐵

EE322 Al-Sanie52
Bandwidth-efficiency diagram.

EE322 Al-Sanie53
• Based on the previous figure, we make the following observations:
1. For infinite bandwidth, the ratio Eb/No approaches the limiting value
This value is called the Shannon limit.2. The capacity boundary curve (Rb=C) separate two
regions Rb<C :error-free transmission is possible
Rb>C: error-free transmission is not possible
- =1.6 dB

EE322 Al-Sanie54
a) Comparison of M-ary PSK against the ideal system for Pe 105 and increasing M. (b) Comparison of M-ary FSK against the ideal system for Pe 10 5 and
increasing M.