infosphere change data capture (icdc) in a heterogeneous
TRANSCRIPT

Infosphere Change Data Capture (iCDC)
in a Heterogeneous Database Environment
Dan Kowal
Staples, Inc.Staples, Inc.
Session Code: D08
Thu, May 02, 2013 (8:00 AM – 9:00 AM | Platform: DB2 for LUW - II

Click to edit Master title style
First things first. . .Who is this guy?
• DB2 Database Engineer for LUW and Iseries
at Staples (13 years).
• Life Before Staples:
• DB2 Partner in Charge for a Boston based independent consulting firm
2
• DB2 Partner in Charge for a Boston based independent consulting firm
• Regional Services Manager for a major ERP Vendor
• Custom Application Development
• “Old School” (that’s an accurate picture of my desk above)
• Motto – Keep it simple. It’ll get complicated all by itself.

Click to edit Master title style
A Little Background. . . Business SideInventing the Office Superstore
Staples Brief History• Founded 1986 in Brighton, Massachusetts
• Originated the office superstore concept
• Canada operation initiated in 1991 (as The Business Depot)
• Moved to new corporate headquarters in Framingham, MA, in 1998
• Coined “That Was Easy” in 2003 marketing campaign
3
• Coined “That Was Easy” in 2003 marketing campaign
• Acquired Corporate Express in 2008 to expand B2B business
The Business• Leader in the Office supplies and services marketplace: $25B in sales (2012)
• Number 2 online retailer (behind the Brazilian river. . .)
• Markets include consumers (>2000 retail stores in 26 countries) and businesses via
Contract and Delivery
The Future• Expanding the business by supplying everything a SMB needs – products, services,
and technology

Click to edit Master title style
DB2 at StaplesA brief history…
Staples’ DB2 History• iSeries - native mode / SQL ~ 2000
• 1998-1999 design for Data Warehouse began
• First DB2: Version 5.2 EEE on AIX in 1999
• Websphere Commerce implemented in 2005
4
Current DB2 Application Portfolio• Several implementations of Websphere Commerce Server (Staples.Com, Staples
Advantage, Canadian “Advantage”)
• Enterprise Operational Data Store (~ 4TB)
• Enterprise Data Warehouse (DPF, ~25TB)
• Enterprise Customer Hub (includes IBM MDM database, ~2TB)
• Retail Transaction Management System (~2TB)
• IBM Portal (The Hub)
• Miscellaneous “tool” metadata (e.g. WBI, Tivoli Monitoring, ILMT)
• Most non-package DB2 is 9.7 FP6; packages 9.5, various FPs

Click to edit Master title style
DB2 Infrastructure. . . And ancillary tools
Staples DB2 Infrastructure• Unix (AIX, mostly 6.1) and some Linux (RHEL, et al) for smaller less critical apps
• EMC storage
• Symantec NetBackup data protection (backup/restore)
Supporting players
5
Supporting players
• Quest Foglight monitoring; Performance Analysis tool in test
• Quest Toad for DB2
• InfoSphere Change Data Capture
• SQL Replication
• WLM and OPM in Data Warehouse
• Storage Optimization in Data Warehouse and 1 Large OLTP
• Informatica for data movement and transformation
• Reporting tools: MicroStrategy, Brio, Cognos

Click to edit Master title style
The Problem. . .Data Integration across Heterogeneous DBMS
New Single Source for Enterprise Order Management data: • IBM/Sterling/Yantra (COM) on Oracle 11g – 2 Node RAC
• Tuned to Support OLTP not batch processing
• Needed to offload Reporting/Feeds
6
Oracle (OLTP)
DB2 (ODS)
EODS – Enterprise Operational Data Store (DB2 9.7)• Provides a store for granular reporting from a rolling 5 months of history
• Feeds 10 other Critical Enterprise Systems
• Data aggregated for load into the Enterprise Data Warehouse (DB2 DPF)
Integration between COM and EODS first implemented as a service• Too many groups needed to make a change (over 10)
• Changes required up to a 16 week lead time
• Viewed as too inflexible to keep up with changing requirements

Click to edit Master title style
Publishing Framework(The part we wanted to replace)
7
COM
EODS Receiver
WBI
EODS Shredders
EODS
COM
WBI
EDW
Other Applications
We had a substantial
investment in the DB2
backend processes that
we didn’t want to have
to rework

Click to edit Master title style
Objective:Reduce Development Time using a Change Data Capture Tool
• Needed to be able to source from Oracle to DB2
• RFP Sent to 5 Vendors
• Short List
• Oracle Golden Gate
8
• Oracle Golden Gate
• IBM Infosphere Change Data Capture
• POC
• Copied Production Data to QA Performance
• Ran Replication under Peak Load

Click to edit Master title style
The Choice. . . InfoSphere Change Data Capture
POC findings:
• GoldenGate “script” oriented, weak GUI
• iCDC has strong GUI, not much scripting
• iCDC had a refresh Feature -- Golden Gate didn’t
9
I see DC!!!
Decision was made to go with iCDC based on
• Better GUI/shorter learning curve
• No requirement for taking an outage on the source
to refresh the data
Caveat to replication neophytes – POC shortfall
• Should have spent more time on large table refresh
• Maintenance of replication environment not considered

Click to edit Master title style
An Aside on Why You Might Choose. . . InfoSphere Change Data Capture
IBM’s Replication Solutions:
• SQL Replication
• Q Replication
• iCDC
• Now all packaged under one product code as:
• InfoSphere Data Replication
10
• InfoSphere Data Replication
• Some folks would want to include HADR for completeness
iCDC Strengths:
• Best GUI
• Easy to use (does a pretty good job of managing itself)
• Good throughput
• Latency better than SQL Replication; not as good as Q Rep
• Broadest selection of sources and targets
• No triggers on heterogeneous sources or Federation needed for targets
• Flexibility: transformation options, multiple subscriptions, etc.

Click to edit Master title style
Building a Team. . .
Development Team executed POC . . . BUT
• For infrastructure work they didn’t have permissions/skills
• Support structure for off-hours not as robust as DBA teams
• Provided support resources as needed (several developers trained)
DB2 DBA Team chosen* to “own” iCDC
11
DB2 DBA Team chosen* to “own” iCDC
• Assumed more work on Target side (SQL tuning, etc.)
• They had the permissions and skills
• Their management was willing
• “Problems” tended to show up on the target not
the source
• Oracle DBA Team provided DBA support - (Source side)
* Having both strong Oracle and DB2 skills would have come in handy.
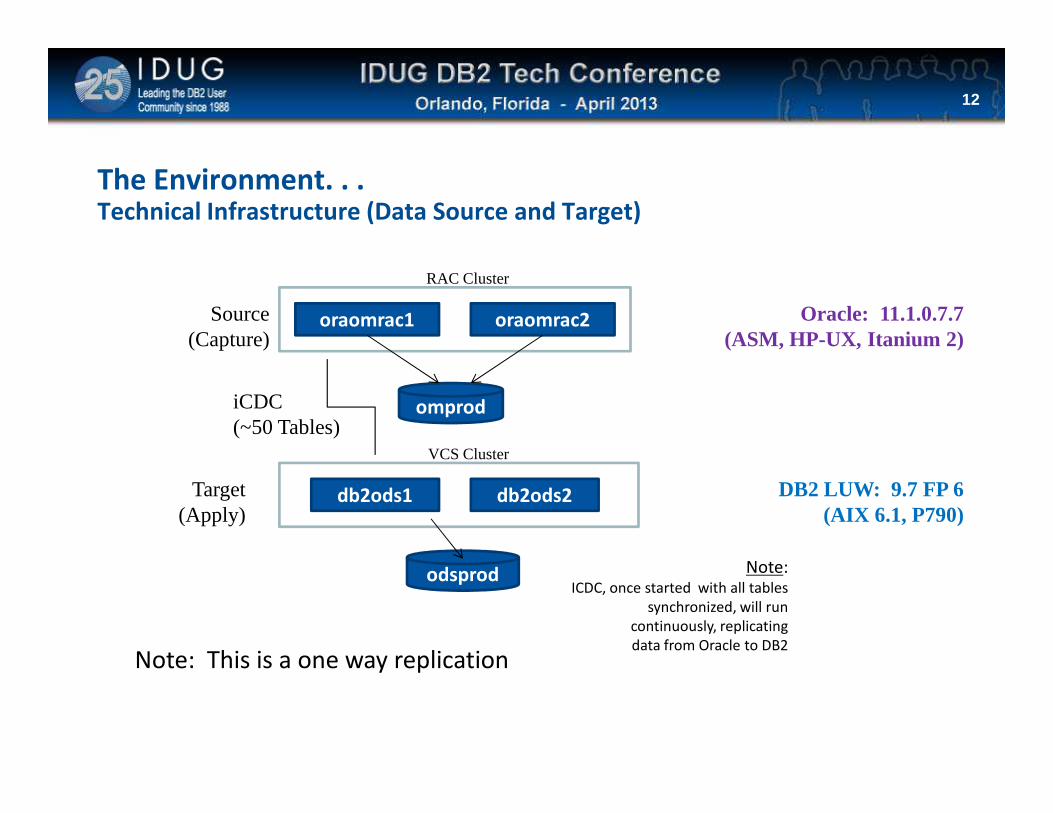
Click to edit Master title style
The Environment. . .Technical Infrastructure (Data Source and Target)
12
omprod
oraomrac1 oraomrac2Source(Capture)
iCDC
RAC Cluster
Oracle: 11.1.0.7.7(ASM, HP-UX, Itanium 2)
omprod
Target(Apply)
iCDC(~50 Tables)
db2ods1 db2ods2
VCS Cluster
odsprod Note: ICDC, once started with all tables
synchronized, will run
continuously, replicating
data from Oracle to DB2
DB2 LUW: 9.7 FP 6(AIX 6.1, P790)
Note: This is a one way replication

Click to edit Master title style
The Product Architecture. . .Overview of iCDC Components
13
Source DB
Logs
Log Reader Refresh
TCP/IP)
Metadata
Source DB
Admin AgentCapture Engine1 2
3Data Store Management
Console
Windows TCP/IP)
Target DB
1. (mirror) Scrape the log for current subscriptions on Source Database
2. (refresh) Export data to .del files, load on target, and rebuild indexes
3. Capture engine pushes data to the target engine
4. Apply agent updates Target Database
Access Server
Apply Agent
MetadataAdmin AgentTarget Engine
4
Data StoreBookmark tracked here
Windows Server

Click to edit Master title style
Creating the Initial Environment (QAT). . . Defining the Data to be Replicated
Building the subscription(s):
• What tables needed to be replicated? 50 (of 700 source tables)
• What columns on those tables? Everything but LOBs
14
Transform?
• Any transformations from source to target?
• No, other than Oracle to DB2 data types
• Use GUI (Management Console) to build subscription(s)
• Needed target data to reflect source data, so mappings were straightforward
• Several ways to build an initial set of table mappings:• If your first subscription, select tables from source dictionary/catalog and create
mappings via the Management Console
• Else, promote an existing subscription that has table mappings you wish and edit
Transform?
Column selection?
Table selection?

Click to edit Master title style
Creating the Initial Environment. . . Populating the data
Mirroring/Refresh Options:
• Once your subscription is built with table mappings, transformations (if any), etc.,
populate target tables (if not already populated)
• iCDC has three replication modes:
• REFRESH, CONTINUOUS, SCHEDULED END
15
• REFRESH, CONTINUOUS, SCHEDULED END
• REFRESH is used to bulk load the empty target tables or reload them• Serial operation (one table after another); you determine the order
• Multiple subscriptions can be used for parallel refreshes
• REFRESH can be FULL or DIFFERENTIAL and each of those may be subset using
a WHERE clause• E.G. You might choose to only replicate 3 months of table history to the target
[NOTE: we used subset refresh extensively to fill gaps in data when replication was
down; additionally, it forms a key part of our recovery strategy]• After REFRESH, (mirror) CONTINUOUS is used to keep tables in sync
• SCHEDULED END mode enables replication up to a user-specified point-in-time

Click to edit Master title style
Other Options
• Row filtering: replicate only the rows you wish
• Apply Method • Standard
• Adaptive Apply • Intelligently apply data (e.g. enable upserts)
• Conflict Detection and Resolution (for standard apply)
16
iCDC• Conflict Detection and Resolution (for standard apply)• Source wins
• Target wins
• Largest or smallest value wins (e.g. higher or lower timestamp)
• User exit handles choice and content
Source Rows Target Rows
iCDC
iCDC

Click to edit Master title style
View the from Management Console . . . Monitoring the Mirroring
17

Click to edit Master title style
Testing and Learning from Non-Prod
• Initial issues with missing logs (the tip of the iceberg)
My least favorite error message:
“IBM InfoSphere Change Data Capture daemon has encountered an error message.
Redo log file information not found. The Oracle database does not contain valid redo log
file information corresponding to the log position '390294105097.0.0.0.0.0'. . .“
18
file information corresponding to the log position '390294105097.0.0.0.0.0'. . .“
• Here’s the problem….
• iCDC works with committed transactions
• Oracle logs (including those for uncommitted transactions) were deleted as part
of the backup.
• Solution (two parts)
• Oracle DBAs created script to monitor and kill transactions inactive for more
than an hour
• Oracle DBAs increased the retention of archive logs to 12 hours before
deletion (via RMAN to NetBackup tape)

Click to edit Master title style
Missing Logs (cont.)
• Despite all this – “phantom” SCNs still caused problems
• Cause not known, problem doesn’t surface until subscription needs to be restarted
and shows up as usually a very old missing log
• Bookmarks (kept on the target) in TS_BOOKMARK table
19
• Look like this:
003080041C2B50E4F0041C2B548CE01000100003ECE0178010041C2B548CE…
• Decoded on the source side they look like this:
• Restart Position indicates oldest open transaction (maybe..)

Click to edit Master title style
Fix the Bogus Logs
• dmdisablecontinuouscapture -I nomsquat1
• dmclearstagingstore -I nomsquat1
• ./dmshowbookmark -I cdc_odsq2 -s CDC_QAT8 (target side)0003080041C2B50E4F0041C2B548CE01000100003ECE0178010041C2B548CE01000100003ECE017801000
• dmdecodebookmark -I nomsquat1 -b
20
• dmdecodebookmark -I nomsquat1 -b 0003080041C2B50E4F0041C2B548CE01000100003ECE0178010041C2B548CE01000100003ECE0178010000
• ./dmsetbookmark -I nomsquat1 -s CDC_QAT8 -l
'282438872020;282439534798.1.1.16078.376.1;282439534798.1.1.16078.376.1.0'
• Restart from the console
• dmenablecontinuouscapture -I nomsquat1

Click to edit Master title style
Normal iCDC operations
• iCDC normally runs great – Our results in production:
• 99.9% uptime
• Average 3 second or less latency
• Reliable replication of every record in the subscription
21
• Reliable replication of every record in the subscription
• 50 million + transactions replicated per day.
• The Staging Store
• iCDC works by scraping logs into the “Staging Store”
• Staging store normally exists in memory
• Records are written from memory via TCP-IP to the source and applied

Click to edit Master title style
Protecting against Target Side outages
• Extending the Staging store
• By enabling “continuous capture”, staging store contents can be written
to disk protecting against a target side outage.
• Efficient use of disk as compared to increasing archive log space
22
Efficient use of disk as compared to increasing archive log space
• No need to replicate the space across the RAC nodes
• 100 GB of file space gave us 24 more hours of protection in production
at peak usage
• Creating a Persistent Subscription
• Option on Subscription creation will attempt to restart mirroring
automatically in case of a communications failure

Click to edit Master title style
When Bad Things happen to Good Systems…
• Source side processing can go down for the following reasons:
• Uncontrolled Alter DDL against mirrored tables
• Parsing Engine Crashes
• Source DB Crashes
• Hardware/OS issues
23
• Hardware/OS issues
• Sometimes recovery is as easy as restarting the instance
and/or subscription.
• If the staging store is intact CDC will restart mirroring, if not…
• iCDC will attempt to rebuild the staging store from the available logs
• “Early Diagnosis is the key to successful recovery”

Click to edit Master title style
Resolving Operational Issues--Monitoring
Monitoring/alerting solutions• iCDC does include monitoring features
• We didn’t want to rely on the tool to monitor itself
• Implemented scripts to monitor iCDC Instance availability on the source
and target (alerts DBAs if down)
• Created CDC_HEARTBEAT Table
24
• Created CDC_HEARTBEAT Table • Included in all subscriptions
• Script on source side updates table every 5 minutes
• Script on target side wakes up every 15 minutes -- queries last update on
source and row update time on target
• If last source update greater than 16 minutes, alert sent to OVO (directs
alert to DBA team and Global Operations Management )
• If source update within 30 minutes but target update > 15 min behind
source, we assume we have a latency issue (warning sent)

Click to edit Master title style
Resolving Operational Issues—Monitoring (continued)
• Simple one-row table with key, text field, timestamps:
CREATE TABLE "DLVRY10"."CDC_HEARTBEAT" (
"ID" DECIMAL(31,0) NOT NULL,
"TXT" VARCHAR(40),
"LAST_UPDATE" TIMESTAMP,
"ROW_INSERT_TMS" TIMESTAMPDEFAULT ,
"ROW_UPDT_TMS" TIMESTAMP)
25
"ROW_UPDT_TMS" TIMESTAMP)
IN "DLY10_DATA_D16K_03"
INDEX IN "DLY10_IND16K_003";
ALTER TABLE "DLVRY10"."CDC_HEARTBEAT"
ADD CONSTRAINT "CDC_HEARTBEAT_PK" PRIMARY KEY
("ID");
Target-side table shows rough latency

Click to edit Master title style
Sample “System Down” Message(Incident Ticket also automatically opened and assigned )
-----Original Message-----
From: DB2 QA Perf Instance Account
Sent: Wednesday, February 27, 2013 2:30 PM
To: EDWDB2DBAResources
Subject: ICDC is down on ODSQAPDB and Current Latency is 40 Minutes
26
Subject: ICDC is down on ODSQAPDB and Current Latency is 40 Minutes
Refer DBA KB -
http://wiki.cexp.com:7001/twikix/pub/DBA/DB2SupportKEDB/CDC-
Missing_log_Recovery.doc
Note: Key business partners are also on distribution

Click to edit Master title style
Recovery Clearing the staging store
• Recovery generally implies that the staging store has become
corrupted
• Bring down the source instance
• Disable continuous capture, if it is in use
27
• Disable continuous capture, if it is in use
• Run dmclearstagingstore – to clean out .ss and txq. files
• Restart the source instance

Click to edit Master title style
Recovery Re-establishing the starting position
• Re-establishing the Bookmarks – if you do it “by the book”
• iCDC keeps track of the oldest open SCN and the most current SCN
• Kept on the target system
• Must be re-set to begin recovery
28
• Must be re-set to begin recovery
• To Reset the Bookmark Position
• All tables in the subscription must be in “Refresh Parked” Status
• Tables must then set to “Mirror Active” Mode
• A new table capture point must be established
• Normally requires an exclusive lock on the source tables
• On a busy system, this can be very difficult to obtain

Click to edit Master title style
Recovery Avoiding the need for Exclusive locks
• Locks are required to turn Oracle supplemental logging off/on
• Supplemental logging is a requirement for mirroring
• Configure the Subscription as “Read Only” to keep iCDC from
attempting to reset supplemental logging when bookmarks are
29
attempting to reset supplemental logging when bookmarks are
being re-established.
• Benefit: Exclusive Locks are not required to reset the bookmarks
• Downside:
• Certain columns in the log are not available to a read only subscription
• Example: Server, User, Source RRN...
• Supplemental logging (table level) must be configured by the Oracle DBA
when new tables are to be added to a subscription.

Click to edit Master title style
Recovery/RefreshUsing iCDC GUI Functionality
• iCDC has several methods for Refreshing tables.
The two most important are:
• Full Refresh – i.e. refresh the entire table
• Will normally invoke the load Utility
30
• Will normally invoke the load Utility
• Indexes dropped at the beginning of the Load and rebuilt at the end.
• The table is unavailable during refresh process.
• Subset Refresh
• JDBC refresh based on a where clause supplied by the user.
• Generally preferable to the full refresh
• Requires timestamps to be effective

Click to edit Master title style
Recovery Time – Ain’t on your side
• Recovery time is exponentially proportional to the length of the outage
• Recovering from the staging store is much faster than refreshing
(done outside the source DBMS engine)
• If Refresh is the only option, use subset refresh with timestamps where
31
Sorry Mick
• If Refresh is the only option, use subset refresh with timestamps where
possible
• With Oracle Read Consistency, the more records you have to read, the
slower the process becomes
• OLTP tuning is not compatible with long running queries
• Create indexes over the timestamp columns on both source and target

Click to edit Master title style
Elaborating on the Subset Refresh with Continuous Capture Solution. . .
Timeline:
32
R S T U V
Set subscription to
refresh_subscr
CC_subscr
•This subscription will run continuous capture (on source) while refresh is executing (target subscription is stopped)
• dmenablecontinuouscapture (for instance)• mirror_end_on_error = false (set this back to true when mirroring passes start point of refresh)
•This subscription will refresh tables • use a WHERE clause to identify the data (timestamp) range for subset refresh
Mirror Refresh and mark capture pointMark capture point and
enable continuous capture
Refresh finishes and mirroring kicks in; processes log activity stacked in staging store
Continuous Capture writes log records to staging store (requires sufficient disk allocation

Click to edit Master title style
Example from Management Console. . . REFRESH in progress
Sample Refresh slide – 1 in Process
33

Click to edit Master title style
RecoveryHow do you know you’re right?
• For the same reasons large queries don’t run well in the OLTP
environment, we needed a simple measurement to prove the
recovery was successful
34
recovery was successful
• By comparing record counts from source and target systems
for records created during the outage/refresh period, we have
a pretty reliable indicator of how well the refresh worked.
• Not always perfect – sometimes the target has more records
than the source – highest number wins.
• We run this check daily – normally ties out 100%

Click to edit Master title style
Resolving Volume-related Issues
• When we moved to Performance environment (more data),
refresh of large, wide tables became an issue
• Met with iCDC field expert: “most shops go outside the tool for
large refreshes, e.g. ETL”
• While we wrestled with ETL development resources• Opened dialog with IBM Toronto Lab iCDC Center of Excellence
35
• Opened dialog with IBM Toronto Lab iCDC Center of Excellence
• Excellent help with alternative scenarios
• Back at the ranch, our ETL tester was running into some issues:• Oracle Read Consistency for single SELECT slowed with time
• Huge updates filled the DB2 primary log

Click to edit Master title style
Resolving Volume-related Issues (continued)
• Solutions:• Broke the Oracle SELECT into multiple smaller statements
• Created parallel writers to get around index update performance
• Used Informatica pipelining to create parallel writers, but managed
them to avoid filling logs
• After much testing, determined on largest, widest tables, well-
36
• After much testing, determined on largest, widest tables, well-
tuned Informatica load could perform 2-3 times faster• 8 Tables fell into the large, wide category
• “Still haven’t found what I’m looking for”• Data pump equivalent that writes to delimited files.

Click to edit Master title style
The IBM relationship . . . working through performance challenges
• IBM help via the CoE invaluable during our challenges
• Provided alternative refresh solutions via iCDC
• Fast-tracked suggested solutions to PMRs we had opened
• Provided in-depth education on the tool
37
• Provided in-depth education on the tool
• Shared other customer approaches (e.g. using scripted
dmshowlogdependencies command to determine log flight risks)
• Dedicated resources did not stop at “here’s a solution, have fun.”

Click to edit Master title style
InfoSphere Change Data Capture. . . . . . A retrospective look
38
The Pros and the Cons of InfoSphere Change Data CaptureWhat we SELECT: What we'd INSERT/UPDATE/DELETE:
The support we receive from the iCDC CoE (Glen Sakuth et al) More flexible licensing model (sometimes nullifies choice)
Ease of use (nice GUI) Product naming (InfoSphere Data Replication is a start. . . )Ease of use (nice GUI) Product naming (InfoSphere Data Replication is a start. . . )
Redbook ("Smarter Business: Dynamic Information with IBM
InfoSphere Data Replication CDC") Need "production readiness" documentation
Number of data sources and targets Scripting language (e.g. for subscription promotion, recreation)
Fewer things to break replication
Subscription compare utility?

Click to edit Master title style
Key Learnings
39
Don’t underestimate the
complexity of replication
Start developing known
Understand business requirements up front (latency, sensitivity to outages, ability to absorb change)
Build sufficient testing and validation time into Start developing known
production implementation solutions as early as possible:
Log retention Monitoring/AlertingData validationEngage IBM Replication
CoE and field experts early
validation time into development schedules
(expect resistance)

Click to edit Master title style
Other Learnings
• iSeries to Teradata
• iCDC reads iSeries journals, ships log records to “target” server
• Flat files at target published based on # transactions or time
• Flat files processed by TPUMP or ETL to load to Teradata
• Useful Information Sources:
40
• Useful Information Sources:
• iCDC Redbook: http://www.redbooks.ibm.com/abstracts/sg247941.html?Open
• IBM Replication Overview: http://www.thefillmoregroup.com/blog/wp-
content/uploads/2012/02/Changes-and-Choices-Replication-Presentation-
Final2.pdf
• IBM Data Replication (5725-E30) announcement: http://www-01.ibm.com/common/ssi/rep_ca/8/897/ENUS212-118/ENUS212-118.PDF
• iCDC Knowledge Center for Version 6.5:http://publib.boulder.ibm.com/infocenter/cdc/v6r5m0/index.jsp Second Topic

Dan KowalStaples, Inc.
Session D08
Infosphere Change Data Capture (iCDC)
Evaluate my session online:
www.idug.org/na2013/eval
Infosphere Change Data Capture (iCDC)in a Heterogeneous Database Environment