instituto superior de engenharia do porto …paf/proj/set2004/web intelligence.pdf · relacionados,...
TRANSCRIPT

INSTITUTO SUPERIOR DE ENGENHARIA DO PORTO
DEPARTAMENTO DE INFORMÁTICA
RAMO DE COMPUTADOR E SISTEMAS
������������������������������������������������������������
Projecto 5º Ano
I020989 – José Manuel Godinho Oliveira
Orientado por Carlos Fernando da Silva Ramos
Porto, Setembro de 2004

WEB INTELLIGENCE ISEP 2004
Pág. 2
Agradecimentos Este trabalho vem concluir mais uma fase da minha vida. Foram dois
anos de esforço, onde aconteceram coisas boas e coisas más. A ajuda de todos aqueles com quem passei este tempo foi preciosa, e
por isso lhes digo: muito obrigado. Quero ainda agradecer ao meu orientador, Eng. Carlos Ramos, a forma
como se empenhou e a disponibilidade que mostrou. Obrigado também à minha mulher pela coragem e apoio que me deu
para enfrentar este desafio. A ela, e ao meu filho, dedico este projecto.

WEB INTELLIGENCE ISEP 2004
Pág. 3
Índice 1. Introdução............................................................................................................. 5
1.1 Breve descrição ............................................................................................. 5 1.2 Estrutura do trabalho ..................................................................................... 5
2. Algumas técnicas usadas ....................................................................................... 6 2.1 Data Mining - Descoberta do conhecimento em bases de dados ..................... 6 2.2 Text Mining - Descoberta do conhecimento em textos................................... 7 2.3 Web Mining .................................................................................................. 9 2.4 Interfaces Inteligentes que se adaptam (Adaptive User Interfaces) ............... 10 2.5 Agentes Inteligentes e Web Agents.............................................................. 11 2.6 Semântica da Web e Ontologias................................................................... 12
3. The Web Intelligence Consortium ....................................................................... 14 3.1 A organização.............................................................................................. 14 3.2 Centros de pesquisa e projectos ................................................................... 15
4. Web Intelligence (WI)......................................................................................... 20 4.1 O que é? ...................................................................................................... 20 4.2 Objectivo..................................................................................................... 21
5. Sistemas e Aplicações mais comuns da WI.......................................................... 26 5.1 Business Intelligence ................................................................................... 26 5.2 E-Technology.............................................................................................. 26 5.3 Intelligent Enterprise Portals........................................................................ 27 5.4 Intelligent Web Information Systems........................................................... 28 5.5 Price Dynamics and Pricing Algorithms ...................................................... 28 5.6 Measuring and Analyzing Web Merchandising and Web-Based Direct Marketing and CRM ............................................................................................... 28
6. Futuro e desafios para a WI................................................................................. 30 6.1 Novas tecnologias........................................................................................ 30 6.2 Recolha e selecção de dados para Data Mining ............................................ 30 6.3 Identificar utilizadores e recolher os seus dados com precisão ..................... 31 6.4 Integração dos vários resultados e tipos de mining....................................... 32 6.5 Privacidade.................................................................................................. 32
7. Ferramentas......................................................................................................... 33 7.1 Web Usage Mining...................................................................................... 33 7.2 Text Mining de páginas web........................................................................ 38 7.3 Web Content Mining ................................................................................... 42 7.4 Web Structure Mining ................................................................................. 43
8. Conclusão ........................................................................................................... 52 9. Dificuldades........................................................................................................ 52 10. Referências...................................................................................................... 53

WEB INTELLIGENCE ISEP 2004
Pág. 4
Índice de Figuras Figura I - Estrutura das técnicas de Web Mining ........................................................... 9 Figura II - Pesquisas na web actualmente .................................................................... 21 Figura III - O Futuro da web ....................................................................................... 22 Figura IV - Áreas envolvidas na WI............................................................................ 23 Figura V - Ecrã principal do Funnel Web Analyzer..................................................... 33 Figura VI - Tabela de análises estatísticas ................................................................... 34 Figura VII - Gráfico de visitantes................................................................................ 34 Figura VIII - Gráfico da distribuição regional ............................................................. 35 Figura IX - Tempos de acesso ao site .......................................................................... 36 Figura X - Gráfico de erros ......................................................................................... 37
Índice de Imagens Imagem 1 - Resultados da pesquisa............................................................................. 38 Imagem 2 - Texto seleccionado no TextAnalyst .......................................................... 39 Imagem 3 - Árvore de palavras relevantes................................................................... 40 Imagem 4 - Palavras relevantes da pesquisa aos resultados......................................... 41 Imagem 5 - Selecção de palavras................................................................................. 41 Imagem 6 - Portal Digesto.net.................................................................................... 42 Imagem 7 - Resultados de um query........................................................................... 44 Imagem 8 - Resultados do crawl ................................................................................ 45 Imagem 9 - Resultados do crawl com nível de profundidade ....................................... 45 Imagem 10 - Resultados ordenados ............................................................................. 46 Imagem 11 - Resultados de submitting........................................................................ 47 Imagem 12 - Resultados do matching......................................................................... 48 Imagem 13 - Resultados da pesquisa com nível 1....................................................... 50 Imagem 14 - Resultados da pesquisa com nível 2........................................................ 51
Índice de Tabelas Tabela 1 - Distribuição dos acessos por regiões........................................................... 35 Tabela 2 - Duração dos acessos ao site ........................................................................ 36 Tabela 3 - URLs falhados............................................................................................ 37

WEB INTELLIGENCE ISEP 2004
Pág. 5
1. Introdução
1.1 Breve descrição
A Internet é sem dúvida a grande responsável pela forma como, nos
dias de hoje, obtemos, tratamos e usamos a informação. No entanto, para além desta ser em grande quantidade, também pode ser apresentada em vários formatos, como por exemplo: documentos distribuídos e inter-relacionados, estruturados ou não, com textos, imagens e sons. Em 1999 Garofalakis [17] e outros previam que a maior parte do conhecimento humano estaria na Internet em 10 anos.
Entretanto, tanto conhecimento só será útil se as pessoas que o procuram o conseguirem encontrar. Embora existam muitos motores de busca, no início de 1998, Bharat e Broder [18] estimaram que, apenas 80% dos 200 milhões de páginas publicadas na Web estavam indexadas nos maiores motores (Altavista, HotBot, Excite e Infoseek).
Este problema demonstra a necessidade da existência de mecanismos de procura de informação na Internet de uma forma inteligente. Foi com este objectivo que apareceu a Web Intelligence. Em 2000, Zhong [19] definiu a WI como um campo de pesquisa que explora a Inteligência Artificial (IA) e a Tecnologia de Informação (TI) avançada para o desenvolvimento de sistemas inteligentes para a Web.
Segundo [31], WI investiga os papéis importantes que estas duas componentes têm sobre a web, preocupando-se com o impacto prático que elas terão na nova e futura geração de produtos, sistemas, serviços e actividades utilizadores na web. É a chave e o campo de investigação mais urgente da tecnologia de informação para o business intelligence.
1.2 Estrutura do trabalho
O trabalho é composto por 9 capítulos. O primeiro capítulo faz uma breve referência à Internet de hoje. O
segundo apresenta algumas técnicas mais usadas na descoberta de conhecimento. O terceiro apresenta a organização que representa e impulsiona a investigação da WI. O quarto capítulo define a própria WI e os seus objectivos. No quinto capítulo, podemos saber quais as áreas de aplicação da WI. No sexto capítulo são discutidos alguns dos desafios futuros da WI. No sétimo capítulo são apresentadas algumas ferramentas experimentadas no âmbito deste projecto. Finalmente, no oitavo e novo capítulo são apresentadas as conclusões e as dificuldades na elaboração do trabalho.

WEB INTELLIGENCE ISEP 2004
Pág. 6
2. Algumas técnicas usadas
Em 2002, Goetzel descreve a web como tendo uma “mente infantil” e acredita que nos próximos 20 anos iremos assistir ao seu crescimento e desenvolvimento para um sistema inteligente, globalmente distribuído, altamente autónomo e “capaz de voar” [30].
Esta secção apresenta as principais técnicas de inteligência artificial
utilizadas, e explica como podem ser aplicadas na Web Intelligence.
2.1 Data Mining - Descoberta do conhecimento em bases de dados
A Descoberta do Conhecimento em bases de dados (KDD) é um
processo não-trivial de identificação de padrões válidos, potencialmente úteis e compreensíveis ao utilizador [20]. A KDD é composta por algoritmos e ferramentas inteligentes que auxiliam as pessoas a analisar grandes volumes de informação para extrair conhecimento útil. Segundo Fayyad [20] Data Mining pode ser definido como a parte do processo de KDD responsável pela extracção de padrões de dados, enquanto que a descoberta do conhecimento é um processo maior, envolvendo também a interpretação dos dados. As principais técnicas de Data Mining são:
• Classificação
Esta técnica tem como objectivo relacionar os elementos com classes pré-existentes, onde é utilizada uma função para mapear os elementos com as classes [20]. As classes devem ser definidas através das suas características.
• Modelos de previsão A técnica de modelos de previsão é semelhante à de classificação, mas em vez de tentar relacionar os elementos com classes, tenta descobrir uma função matemática que descreva o comportamento de um sistema (calcular uns valores em função de outros) [21]. A finalidade é poder prever valores futuros.
• Detecção de desvios Esta técnica utiliza uma função média, representando o comportamento normal de um sistema para avaliar possíveis desvios.
• Clustering Este é o processo inverso da classificação. Nesta técnica não existem classes (não se sabe quais são as classes, quantas são nem quais as suas características), apenas elementos num universo, a partir dos quais se vão definir classes para os enquadrar. O objectivo é identificar grupos de afinidades,

WEB INTELLIGENCE ISEP 2004
Pág. 7
avaliando a similaridade entre os elementos, e agrupá-los [Han96].
• Análise de cluster Esta técnica completa a anterior, na medida em que procura características comuns entre os elementos de cada grupo. Na maioria dos mecanismos o objectivo está em identificar um conjunto de características médias para cada classe [Han96].
• Associação ou correlação Esta é a técnica mais conhecida de Data Mining. Com esta técnica verifica-se se existe alguma influência entre atributos ou valores de atributos [22]. O objectivo é encontrar dependências entre atributos ou valores de atributos através da análise de probabilidades condicionais.
• Análise de séries temporais
Esta técnica procura encontrar padrões na repetição seguida de valores.
• Evolução ou sequência de tempo
As técnicas de evolução ou sequência de tempo tentam encontrar regras de associação ou correlação entre eventos ocorridos em momentos diferentes [22].
2.2 Text Mining - Descoberta do conhecimento em textos
O objectivo do Text Mining é procurar padrões ou tendências em textos de linguagem natural, e analisar textos com objectivos específicos.
Inspirado no Data Mining, que descobre padrões proeminentes de bases de dados altamente estruturadas, o Text Mining pretende extrair conhecimento útil de texto não estruturado ou semi-estruturado. O Text Mining, também conhecido como Text Data Mining ou Knowledge Discovery from Text (KDT) é um campo inter-disciplinar que inclui, mas não é limitado por:
Information Extraction (IE) Natural Language Processing (NLP) and Computational Linguistics (CL) Machine Learning (ML) Information Retrieval (IR) Data Mining (DM) or Knowledge Discovery from Databases (KDD) Knowledge and Information Management Information Visualization O termo “Descoberta do Conhecimento em textos” foi usado pela
primeira vez por Feldman e Dragan em 1995 para designar o processo de extracção de algo de interessante em textos de artigos de revistas e jornais, mensagens de e-mail, páginas Web, etc. Nos dias de hoje, Text Mining e Text Data Mining são usados também com a mesma finalidade [23].

WEB INTELLIGENCE ISEP 2004
Pág. 8
Assim, podemos definir Text Mining como o processo de extrair padrões ou conhecimento, interessantes e não-triviais, a partir de documentos de texto [23]. As principais técnicas de Text Mining são:
• Extracção Esta técnica tem como objectivo encontrar informações específicas dentro de textos [24]. O objectivo desta área é diferente do objectivo do processamento da linguagem natural, uma vez que é mais focado e definido, extraindo tipos específicos de informação [Rillof94]. A técnica procura converter dados não estruturados em informações explícitas, normalmente armazenadas em bases de dados estruturadas.
• Categorização Esta é uma técnica básica. A categorização de textos tem como objectivo associar categorias pré-definidas aos textos [25]. Em geral, os trabalhos de categorização procuram encontrar os temas centrais de um texto.
• Análise de características ou descrição de conceitos
O objectivo é apresentar uma lista com os conceitos principais de um único texto. Geralmente os conceitos são termos ou expressões extraídos por análise estatística.
• Análise linguística Este tipo de abordagem procura descobrir informações analisando frases ao nível léxico, morfológico, sintáctico e semântico.
• Resumos Esta técnica usa as anteriores, mas com mais ênfase na produção de resumos dos textos. Resumir é a generalização das partes mais importantes de um texto [24].
• Associação entre textos Esta técnica tenta relacionar várias descobertas presentes em vários textos.
• Clustering No Text Mining a técnica de clustering é igual à usada no Data Mining, sendo que a única diferença é que a mesma é aplicada sobre palavras ou sobre conceitos. Conceitos permitem trabalhar com sinónimos ou variações lexicais.

WEB INTELLIGENCE ISEP 2004
Pág. 9
2.3 Web Mining
Web Mining é a aplicação das técnicas de Data Mining, Text Mining ou outro processo de Descoberta do Conhecimento na Web.
Os utilizadores podem tirar partido desta técnica para obter informação da Web com mais eficiência. A técnica de Web Mining pode ser dividida em 3 categorias: content mining, usage mining, e structure mining.
Figura I - Estrutura das técnicas de Web Mining
• Content Mining Web content mining descreve o processo automático de procura nas fontes de informação on-line [14], e envolve a extracção de conteúdos de dados na Web. No contexto do Web Mining, web content minig é semelhante às técnicas de Data Mining em bases de dados relacioanis, uma vez que é possível extrair conhecimento semelhante de fontes de dados não estruturadas que existem nos documentos da Web.
• Structure Mining
O objectivo desta categoria é gerar resumos sobre a estrutura de Web Sites e páginas Web. Tecnicamente, web content mining centra-se principalmente na estrutura do próprio documento, enquanto que web structure mining se preocupa em descobrir a estrutura de hyperlinks entre documentos. É com base na topologia dos hyperlinks que web structure mining vai categorizar as páginas web e gerar a informação, como por exemplo a semelhança e relacionamento emtre Web Sites diferentes. Outro dos seus objectivos é identificar documentos mais procurados. A ideia é que um hyperlink de um documento A para um documento B implica que o autor do documento A pensa que o documento B tem informação relevante.
• Usage Mining Web usage mining tenta descobrir informação útil a partir dos logs de utilização de um servidor web. Centra-se principalmente nas técnicas que podem prever o comportamento dos utilizadores, enquanto este navegam na web. M. Spiliopoulou [16]

WEB INTELLIGENCE ISEP 2004
Pág. 10
referiu uma teoria, como uma estratégia possível, para atingir o objectivo como sendo: prever o comportamento do utilizador no site, comparação entre a utilização esperada e a utilização efectiva do Web Site e ajuste do Web Site aos interesses do utilizador. Não há distinções definidas entre esta e as duas categorias anteriores. Durante o processo de preparação dos dados de wen usage mining, a categoria de web content mining e a topologia do web site são usadas como a fonte de informação, o que significa que existe interacção com as duas categorias anteriores. Esta categoria é composta por três fases: pré-processamento, descoberta de padrões e análise desses padrões [15].
Segundo [32] podemos usar web content e web usage mining para
reconfiguração de web sites. A reconfiguração é personalização e recomendação dinâmica do site, baseadas no comportamento do utilizador ao navegar.
2.4 Interfaces Inteligentes que se adaptam (Adaptive User Interfaces)
As interfaces inteligentes são truques de software que melhoram a sua
capacidade de interagir com o utilizador, construindo um modelo baseado na experiência de interacção com o utilizador [28].
As interfaces inteligentes usam técnicas de inteligência artificial para auxiliar os utilizadores, de forma a atingirem mais fácil e rapidamente o objectivo que pretendem.
A interface inteligente tem de ter sempre presente 4 tipos de informações sobre o utilizador:
• Objectivo: estado que ele pretende atingir • Plano: sequência de acções que o levam até ao estado
desejado. Estas acções são actos que a interface vai permitir que o utilizador faça.
• Capacidades: físicas e mentais do utilizador • Comportamento e preferências: forma de interagir
Os objectivos do utilizador podem ser explicitamente declarados (o
mesmo indica ao sistema qual é), ou então inferidos por mecanismos de inteligência do sistema.
Para o segundo caso, podem ser utilizadas técnicas de machine learning, que analisam o comportamento do utilizador, o histórico de navegação e as características do ambiente.
As interfaces inteligentes procuram geralmente estabelecer perfis de utilizadores e classifica-los nesses perfis, de forma a poderem mais facilmente ajuda-los. Isto pode ser conseguido descobrindo-se um perfil comum em grupos de utilizadores.
Outra forma das interfaces inteligentes entenderem as necessidades de um utilizador é interagindo com ele através do diálogo. A inteligência

WEB INTELLIGENCE ISEP 2004
Pág. 11
artificial tem uma área de estudo que é o processamento de Linguagem Natural. Este processamento pode ser feito a nível léxico, sintáctico, semântico ou pragmático.
As diferentes técnicas que compõe esta área podem ser usadas para que a interface inteligente possa entender as informações dadas pelo utilizador ou então para produzir respostas num formato mais compreensível ao mesmo.
Estas interfaces podem ser usadas para as mais variadas tarefas. A Internet é uma das áreas que mais pode beneficiar com este tipo de software. O crescimento da quantidade de informação e serviços na web faz com que seja difícil encontrar e recolher a informação que procuramos. As interfaces inteligentes que se adaptam baseadas na web permitem que os sites tenham interacção com o utilizador de forma personalizada, aumentando a capacidade de navegação do utilizador nos mais variados contextos como por exemplo comércio electrónico, ensino à distância (e-learning) ou trabalho cooperativo [28]. Os sites que se adaptam são habitualmente chamados de adaptive web sites. Estes têm a capacidade de semi-automaticamente melhorar a organização e apresentação da sua informação, aprendendo com a os padrões de acesso dos utilizadores.
2.5 Agentes Inteligentes e Web Agents
Outro aspecto da WI foca o estudo e aplicação de Agentes Inteligentes na web.
A definição de agentes é um assunto sobre o qual não existe um consenso único.
No entanto, segundo [27], os Agentes Inteligentes são sistemas automatizados (hardware ou software), contendo mecanismos de inteligência artificial, capazes de tomar decisões e melhorar o seu desempenho de forma automática.
O objectivo é permitir que a inteligência seja distribuída remotamente ou que indivíduos possam tomar decisões de forma autónoma, aumentando assim a eficiência de sistemas computacionais.
Uma definição comum de agentes inteligentes diz que os mesmos devem ter as seguintes características:
• Autonomia: trabalhar sem intervenção humana • Habilidade social: saber interagir com humanos ou outros
agentes • Capacidade de reacção: poder receber estímulos do ambiente e
responder em tempo útil • Pró-actividade: ter comportamento direccionado a um objectivo,
tomando a iniciativa da acção sem precisar de receber estímulos • Mobilidade: poder mover-se para outros ambientes • Orientado por objectivos: ser capaz de lidar com problemas
complexos. • Continuidade temporal: funcionar continuamente

WEB INTELLIGENCE ISEP 2004
Pág. 12
Existem outras pessoas, nomeadamente as ligadas à área da inteligência artificial, que definem os agentes como sendo algo mais do que aquilo que é definido anteriormente. Estes dizem que um agente tem também as seguintes características:
• Mobilidade: ser capaz de se deslocar pela rede de uma máquina
para a outra • Aprendizagem: ser capaz de alterar o seu comportamento com
base em experiências anteriores • Adaptabilidade: ser capaz de se ajustar aos métodos de trabalho
e preferências do seu utilizador • Agilidade: ser capaz de aproveitar oportunidades não previstas • Colaboração: ser capaz de analisar ordens ou instruções dadas
pelos utilizadores antes de as executar e ter noção de que estes podem cometer erros. O agente deve verificar as instruções a efectuar fazendo questões ao utilizador ou usando um modelo de utilizador pré-definido para resolver problemas deste género.
Quando existem vários Agentes Inteligentes a actuar de forma integrada
e cooperativa, o sistema é chamado de Multi-Agentes. Geralmente, cada agente inteligente possui conhecimentos próprios e diferentes. Estes indivíduos interagem entre si, partilhando informações e conhecimento para resolução de problemas mais complexos, os quais dificilmente seriam resolvidos se os agentes actuassem de maneira isolada.
Na Internet, os agentes inteligentes são designados por Web Agents e servem principalmente para explorar serviços na Web.
Os Web Agents são sistemas complexos que operam na web e nas intranets das organizações. Eles são desenhados para fazer variadas tarefas como caching e routing de informação para pesquisas, categorização, filtragem, monitorização e análise de dados. Na Internet, estes agentes percorrem web sites extraindo dados dos mesmos. Estes dados podem ser depois utilizados por ferramentas de Data Mining.
2.6 Semântica da Web e Ontologias
A web, apesar de ter muitas potencialidades, tem muitas limitações. De entre muitas outras, uma que se destaca é a dificuldade de troca de informações entre as máquinas, devido ao facto da maior parte da informação estar estruturada de forma a ser compreendida pelos humanos.
A semântica da web apareceu com Tim Berners.Lee, o inventor da world wide web, URIs, HTTP e HTML. Existe uma equipa no consórcio W3C a investigar este tema, mas no entanto ele ainda está nos seus primórdios.
Deixando de lado o problema da inteligência artificial em treinar máquinas para ter o comportamento semelhante ao humano, a abordagem da semântica da web desenvolve linguagens que permitam exprimir a informação de uma forma compreensível para as máquinas
Estas linguagens permitem criar conjuntos de informação organizada para que possa ser facilmente processada por máquinas a uma escala

WEB INTELLIGENCE ISEP 2004
Pág. 13
global. Podemos pensar nela como sendo uma forma de representar informação na web, ou como uma base de dados global [13].
Segundo [29], a chave para realização da semântica da web são as ontologias como meio de contextualizar e estruturar o conhecimento. As ontologias aumentam o nível de especificação do mesmo conhecimento, incluindo semântica nos dados, e promovem a sua troca numa forma explícita e compreensível. Ainda segundo [29], a semântica web e as ontologias estão completamente ligadas como uma valiosa plataforma de trabalho para distintas aplicações de negócio como por exemplo comércio electrónico e B2B.

WEB INTELLIGENCE ISEP 2004
Pág. 14
3. The Web Intelligence Consortium
3.1 A organização
O WIC (http://wi-consortium.org/) é uma organização internacional, sem
fins lucrativos, que se dedica à promoção da pesquisa científica e desenvolvimento industrial da área da Web Intelligence, a nível mundial. Tem ainda um papel importante na colaboração entre os centros de pesquisa em WI em todo o mundo. A sua função passa também pela organização de conferências mundiais sobre a área, onde promove mostras tecnológicas. Esta organização publica o livro e o jornal oficiais de WI, newsletters, e é responsável pelo lançamento de novas soluções industriais e standards tecnológicos [31].
As actividades principais do WIC incluem:
• Organizar conferências relacionadas com inteligência na web e em
agentes, a nível internacional e regional, como:
The IEEE/WIC International Conference on Web Intelligence and The IEEE/WIC International Conference on Intelligent Agent Technology patrocinada em conjunto por IEEE Computer Society e o WIC.
The 2003 IEEE/WIC International Joint Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT 2003) Realizada em Outubro de 13-16 de 2003 em Halifax, Canada. (www.comp.hkbu.edu.hk/WI03/ ou www.comp.hkbu.edu.hk/IAT03/ )
The 2004 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT 2004) A realizar em Setembro de 20-24 de 2004 em Beijing, China. (www.maebashi-it.org/WI04/ ou www.maebashi-it.org/IAT04/ )
• Publicar os jornais, livros e newsletters sobre web intelligence e agentes inteligentes, como:
Web Intelligence and Agent Systems É um jornal internacional e official do WIC (IOS Press)
Annual Review of Intelligent Informatics (World Scientific) É uma série de publicações oficiais do WIC.
Vários números especiais do WI-IAT foram e serão publicados em jornais internacionais, incluíndo os da IEEE Computer, Computational Intelligence (Blackwell), International Journal of Pattern Recognition and Artificial Intelligence (World Scientific),

WEB INTELLIGENCE ISEP 2004
Pág. 15
Journal of Intelligent Information Systems (Kluwer), Cognitive Systems Research journal (Elsevier), and Knowledge Based Systems (Elsevier).
Vários livros relacionados com WI-IAT foram publicados pelas editoras Springer, World Scientific, e IOS Press.
• Promover as ferramentas, sistemas e standards relacionados com web intelligence e agent intelligence.
• Estabelecer e dar apoio aos centros de pesquisa em WI e empresas
relacionadas com WI-IAT. Em todo o mundo, o WIC tem cerca de 13 centros de pesquisa em todo o mundo, sendo eles:
• WIC-Australia Research Centre • WIC-Beijing Research Centre • WIC-Canada Research Centre • WIC-France Research Centre • WIC-Hong Kong Research Centre • WIC-India Research Centre • WIC-Japan Research Centre • WIC-Korea Research Centre • WIC-Mexico Research Centre • WIC-Poland Research Centre • WIC-Spain Research Centre • WIC-UK Research Centre • WIC-US Research Centre
3.2 Centros de pesquisa e projectos
Alguns centros de pesquisa têm vindo a desenvolver projectos na área
da WI, e apresentaram este ano um relatório sobre as suas actividades nos últimos meses. Todos os projectos são interessantes, mas apenas vou fazer referência a alguns.
WIC-Beijing Research Centre
O WIC de Beijing foi criado em Fevereiro de 2003, e desde então já desenvolveu vários projectos na área de WI.
• Web-based Intelligent Tutoring System
Este projecto visa ajudar os estudantes do liceu a fazerem os seus
trabalhos de casa na área da matemática depois das aulas. O sistema recentemente foi desenhado na versão web, versão esta que permite uma

WEB INTELLIGENCE ISEP 2004
Pág. 16
maior e mais inteligente interacção com os estudantes, a disponibilização suplementar de ferramentas de resolução de problemas, e uma maior rapidez de resposta.
• Web Text Mining Systems
Nesta área, o centro de pesquisa apenas se interessa por dois tipos de
sistemas: classificação de textos na web, e web log mining. Desenvolveram dois sistemas, um de classificação de correio electrónico
e outro de classificação de textos na web. O primeiro é baseado no método de Naive-bayes e pode ser integrado em ferramentas de e-mail, como por exemplo Microsoft Outlook. O segundo, aborda várias técnicas de classificação de texto (Naive-Bayes, VSM, etc) em plataformas de Web Mining. O sistema de web log mining, é baseado nos seus próprios algoritmos de regras de associação.
WIC-Canada Research Centre
• Web-based Support Systems
Os sistemas computorizados de suporte são alvo de estudo neste centro. Muitos sistemas foram sendo estudados ao longo do tempo. Como exemplos disso temos: sistemas de suporte à decisão, sistemas de suporte ao negócio, sistemas de suporte médico, etc. No WIC-Canadá, estes sistemas estão a ser estudados de forma a serem “transportados” para o ambiente da Internet, o que nos faz chegar ao conceito de sistemas de suporte baseados na web. A investigação destes tipos de sistemas é uma evolução natural da investigação já existente. Com o aparecimento das tecnologias web e da Web Intelligence, torna-se obvio que este será uma das áreas onde será necessário investigar.
• Computacional Web Intelligence
A computação inteligente é uma sub-área da Inteligência Artificial que
foca os aspectos computacionais da inteligência e dos sistemas inteligentes. Da mesma forma, Web Intelligence computacional (CWI) estuda o lado computacional da Web Intelligence [34]. O principal objectivo da CWI é estudar as teorias e técnicas da computação e explorar as suas implicações nos sistemas de informação web inteligentes (IWIS). Espera-se que a CWI tenha um grande impacto nos sistemas inteligentes de negócio na web.
WIC-Hong Kong Research Centre
• Adaptative e-Learning Environment Via Collaboration
A importância do e-learning já à muito foi identificada e muitos sistemas on-line já foram construídos. Este projecto em Hong Kong tenta aplicar

WEB INTELLIGENCE ISEP 2004
Pág. 17
filtros colaborativos para extrair informações dos registos do aproveitamento passado dos alunos, de forma a prever alguns exercícios a propor aos mesmos.
• Optimizing Web site Usability
Este projecto tenta combinar o modelo orientado à tarefa de um site e os
dados de navegação de um utilizador num site, de forma a obter um modelo probabilístico relacionado com as tarefas de navegação.
WIC-India Research Centre
• Searching the Web
Com o objectivo de medir a qualidade dos resultados dos motores de busca, foram introduzidos métodos subjectivos, baseados no feedback dos utilizadores. Estas medidas, juntamente com ferramentas de computação, como lógica de fuzzy e algortimos genéticos, são usados para melhorar os resultados produzidos pelos motores de busca. Os dados do feedback dos utilizadores é obtido sem esforços por parte dos mesmos, porque estes são recolhidos com base no comportamento dos utilizadores face aos resultados obtidos.
• Soft computing in web mining
Esta area de invetigação visa a aplicação de lógica de fuzzy em web
page clustering e retorno de informação, redes neuronais para web page clustering e personalização, algoritmos genéticos para optimizar a pesquisa na web e a apresentação de documentos, e análise com rough set para obter informações sobre associação em dados heterogéneos.
WIC-Korea Research Centre
• Intelligente Web Information Extraction
A extracção da informação da web adopta diferentes tecnologias dependendo do tipo dos documentos alvo. Para documentos web semi-estruturados, os esquema wrapper induction tem sido o mais popular. Dois sistemas de extracção de informação da web foram implementados aplicando as técnicas de geração de wrappers: MORPHEUS e XTROS. Morpheus é um sistema de compras on-line que explora a geração de wrappers baseados em heurísticas. Xtros é um extratctor de informação de estado real que adopta técnicas de wrapper baseadas em conhecimento. Ambos os sistemas são aplicados ao domínio do comércio electrónico.
Para os documentos não estrututados, são empregadas técnicas de processamento de linguagem natural. O Posie é um sistema de extracção de informação da web que foi desenvolvido usando múltiplas estratégias de aprendizagem, aprendizagem orientada ao utilizador e aprendizagem

WEB INTELLIGENCE ISEP 2004
Pág. 18
separada do contexto. Este trabalho foi usado com sucesso em domínios como educação continua e oferta de emprego.
• Dialogue-based Web Information Retrieval
Nesta área, os investigadores estão a desenvolver as técnicas de
pergunta-resposta e gestão de diálogos que são aplicadas em information retrieval.
SiteQ é um sistema de pergunta-resposta baseado na tacnologia da linguagem natural em information retrieval. O SiteQ consegue retornar uma resposta exacta para uma pergunta, em vez de uma lista de documentos, por incorporar tecnologias como processamento de linguagem natural, information retrieval, padrões de semântica do léxico, nos recursos linguísticos.
Está a ser desenvolvido outro agente de information retrieval, que interage com sistemas de previsão de informação heterogéneos, como por exemplo sistemas de document retrieval, sistemas FAQ retrieval e sistemas de gestão de bases de dados relacionais. Como complemento, estão também a ser desenvolvidos métodos para integrar os agentes de information retrieval com interfaces de diálogo.
• Semantic Web
Nesta área, existem dois projectos a ser desenvolvidos. O primeiro,
Knowledge-based Distributed Visual Media Retrieval Framawork using Semantic Web, tem como objective recuperar e trocar dados de visual media, que estão distribuídos pela web, aplicando tecnologias Semantic Web na sua representação e recuperação. Estão a ser especialmente desenvolvidas as seguintes tecnologias:
- Padronização de metadados - Classificação sistemática - Construção de ontologias para os dados de visual media - Protocolo de recuperação para pesquisa na web de dados de visual media
Outro projecto que já foi desenvolvido com sucesso é o Semenatic Web
Service Discovery System based on na Enhanced Matchmaking Algorithm. Um motor de busca de serviços web é implementado usando várias técnicas de Semantic Web e bases de dados.
WIC-Mexico Research Centre
• Web Mining and Farming
Neste projecto, os investigadores criaram um conjunto de ferramentas (ferramentas de gestão de conteúdos) e agentes para fazer manutenção de páginas web com o curriculum individual dos investigadores. Cada produto científico é mantido como um registo separado. Um servidor central recolhe

WEB INTELLIGENCE ISEP 2004
Pág. 19
toda a informação das páginas individuais, e cria um índice. O objectivo é extrair a ontologia do curriculum de texto puro. A ideia deste projecto é trabalhar em medidas similares, mas entre documentos científicos.
• Agents in the Web
Partilha de ontologias para serviços web. A tecnologia de agentes está a
ser usada para facilitar o desenvolvimento de ambientes de serviços abertos e dinâmicos, para sistemas baseados na web. As ontologias são a peça fundamental na recuperação do conhecimento, partilha e reutilização de mecanismos usados na web ou pelos agentes.
Agentes para a computação distribuída. Agentes autónomos podem, de forma espontânea, representar utilizadores, serviços web ou dispositivos disponíveis na Internet, o que se torna num meio ubíquo para a partilha de informação. Foi desenvolvida a framework SALSA, que permite implementar agentes simples para sistemas ubicomp. Estes agentes usam uma linguagem de comunicação expressiva baseada em XML, que disponibiliza protocolos para localizar e interagir com serviços web, mesmo quando o utilizador está desligado.

WEB INTELLIGENCE ISEP 2004
Pág. 20
4. Web Intelligence (WI)
4.1 O que é?
Web Intelligence é definida pela comunidade científica como uma nova direcção de investigação e desenvolvimento, que explora as regras fundamentais e o impacto prático da inteligência artificial e das tecnologias de informação para a próxima geração de sistemas, serviços e ambientes baseados na web.
Segundo o [31], e aplicando uma definição simplista, WI explora a IA e as TI na web e Internet. É a chave o campo de investigação mais urgente das TI para o Business Intelligence.
Conceptualmente existem quatro níveis distintos na WI:
• Internet-level (communication, infrastructure, and security protocol)
A Web é vista como uma rede de computadores
– Sistemas de pré-carregamento dos dados da Web • Consiste em processos de aprendizagem adaptativa,
baseados na observação do comportamento dos utilizadores durante a navegação
• Interface-level (multimedia presentation standards)
A Web é vista como um interface de interação Homem-Internet
– Interfaces Web Inteligentes • Representações multimedia personalizadas • Processamento de dados multi-modal
Application-level Ubiquitous computing
and social intelligence utilities
Knowledge-level Information processing and management tools
Interface-level Multi-media presentation
standards
Internet-level Communications,
infrastructure, and security protocols
Support functions
Level-1
Level-2
Level-3
Level-4
Hardware
Application

WEB INTELLIGENCE ISEP 2004
Pág. 21
• Knowledge-level (information processing and management tools) A Web é vista como uma base de dados/conhecimento distribuída
– Este nível desenvolve “semantic markup languages” para representar os conteúdos semânticos da web disponíveis num formato de linguagem entendido pelas máquinas. O objectivo é fazer com que a computação baseada em agentes possa usar esta informação para fazer pesquisa, agregação, classificação, filtragem, gestão e descoberta na web.
• Application-level (ubiquitous computing and social intelligence
environments) A Web é vista como uma base para estabelecer redes sociais que
contêm comunidades de pessoas, organizações ou outras entidades, ligadas por determinadas relações sociais, como por exemplo colaboração em trabalhos, trocas de informação sobre interesses comuns, ou apenas por amizade.
– Social network intelligence ou apenas Social Intelligence – Plataformas Móveis – Acesso web de vários pontos e de vários dispositivos necessita
de personalização adaptativa. As técnicas de WI são usadas aqui para construir modelos dos interesses dos utilizadores, obtendo essa informação através do comportamento e das acções do mesmo.
4.2 Objectivo
Os motores de busca actuais estão maioritariamente desenhados para uso por parte do ser humano. Quando um utilizador faz uma pesquisa obtém uma lista com as páginas mais relevantes sobre o assunto. O utilizador tem então que ver as páginas e extrair delas, de forma “manual”, a informação que lhe interessa. Esta informação tem ainda de ser reunida de diferentes páginas, de maneira a ser extraído o conhecimento necessário.
Figura II - Pesquisas na web actualmente

WEB INTELLIGENCE ISEP 2004
Pág. 22
Por exemplo, se um utilizador quiser planear uma viagem do Porto a
Paris, necessita de pesquisar no motor de busca voos entre Porto e Paris e, da lista encontrada, escolher a página que contém o voo à melhor hora. Depois, precisa de fazer outra pesquisa para poder ter acesso a informações sobre serviços de comboios na França, e será apresentada a página dos serviços de comboios franceses. Dentro deste, é ainda necessário indicar o local de partida e de chegada e a hora, para poder saber quais os comboios e linhas que deve usar.
Isto é muito demorado e não é eficiente porque: 1. temos que localizar os serviços necessários (avião, comboio,
autocarro, etc) 2. preencher vários formulários (sempre com a mesma informação)
para podermos ter informação sobre horários, estações, linhas, etc. No final nada nos garante que a ligação que escolhemos para ir do Porto
a Paris seja a melhor em termos de preço, tempo que iremos demorar, etc.
Espera-se que a web do futuro funcione de maneira diferente.
Figura III - O Futuro da web
A futura web terá semântica associada às páginas, e os motores de
busca serão agentes inteligentes capazes de usar essa mesma semântica para fornecer melhores resultados e serviços baseados na semântica. A tarefa descrita anteriormente poderia ser simplificada por um agente que continha toda a informação sobre o utilizador (onde vive, aeroporto mais próximo, etc.) e percorria a web à procura de serviços e questionava esses mesmos serviços, evitando que o utilizador tivesse que fazer isso.
Definir o esquema semântico da pesquisa (ontologias), automaticamente
produzir as anotações semânticas (NLP, Information Extraction), retornar páginas que usam essas anotações (motores de busca semânticos), fazer a junção das informações dos diferentes locais e produzir serviços capazes de usar a semântica (e.g. agentes) para executar tarefas, está entre os objectivos da WI.

WEB INTELLIGENCE ISEP 2004
Pág. 23
Outro objectivo da WI é combinar várias áreas de forma a conseguir
criar sistemas inteligentes baseados na web.
Estes sistemas de WI podem ser aplicados por exemplo em:
• Business Intelligence • E-Technology (E-Business, E-Commerce, E-Community, E-Finance,
E-Government, E-Learning, E-Publishing, E-Science) • Intelligent Enterprise Portals • Intelligent Web Information Systems • Price Dynamics and Pricing Algorithms • Measuring and Analyzing Web Merchandising • Web-Based Direct Marketing and CRM • Web-Based EDI
A figura seguinte apresenta um esquema das áreas envolvidas nos sistemas inteligentes criados pela aplicação da WI.
Figura IV - Áreas envolvidas na WI
Knowledge Networks and Management
• Digital Library • Information and Knowledge Markets • Knowledge Community Formation and Support • Ontology Engineering • Semantic Web • Visualization of Information and Knowledge • Web-Based Decision Support • Web Regularities and Models

WEB INTELLIGENCE ISEP 2004
Pág. 24
Ubiquitous Computing and Social Network Intelligence
• Competitive Dynamics of Web Sites • Computational Societies and Markets • Dynamics of Information Sources • Reputation Mechanisms • Theories of Small World Web • Ubiquitous Learning Systems • Ubiquitous Web Access • Web-Based Cooperative Work • Web Security, Integrity, Privacy and Trust • Wireless Web Intelligence
Intelligent Human-Web Interaction
• Adaptive Web Interfaces • Multimedia Representation • Multimodal Data Processing • Science and Art of Web Design
Web Information Management
• Data Models for the Web • Integrated Exploration and Exploitation • Internet and Web-Based Data Management • Multi-Dimensional Web Databases and OLAP • Multimedia Information Management • Object Oriented Web Information Management • Personalized Information Management • Semi-Structured Data Management • Use and Management of Metadata • Web-Based Distributed Information Systems
Web Information Retrieval
• Automatic Cataloging and Indexing • Conceptual Information Extraction • Information Retrieval Support Systems • Multi-Linguistic Information Retrieval • Multimedia Retrieval • Multimodal Information Retrieval • Ontology-Based Information Retrieval
Web Agents
• Conversational Systems • E-mail Filtering and Automatic Handling • Global Information Foraging • Information Filtering

WEB INTELLIGENCE ISEP 2004
Pág. 25
• Navigation Guides • Recommender Systems • Remembrance Agents • Resource Intermediary and Coordination Mechanisms • Semantic Web Agents
Web Mining and Farming
• Data Mining and Knowledge Discovery • Learning User Profiles • Multimedia Data Mining • Text Mining • Web-Based Ontology Learning • Web-Based Reverse Engineering • Web Content Mining • Web Farming • Web Log Mining • Web Structure Mining • Web Warehousing
Emerging Web Technology
• Knowledge Grid and Grid Intelligence • Mediators and Middleware • New Web Information Description and Query Languages • Peer-to-Peer Computing • Problem Solver Markup Language (PSML) • Soft Computing (incluíndo redes neuronais, lógica fuzzy, rough sets, e
computação granular) e Uncertainty Management para WI • Web Document Prefetching • Web Inference Engine • Web Intelligence Development Tools • Web Protocols • Wisdom Web

WEB INTELLIGENCE ISEP 2004
Pág. 26
5. Sistemas e Aplicações mais comuns da WI
5.1 Business Intelligence
Business Intelligence (BI) é uma categoria de sistemas de informação de gestão, aplicações e tecnologias, que recolhem, armazenam, analisam e permitem acesso a dados, para ajudar os colaboradores das empresas a melhorar e fundamentar as decisões nos seus negócios. As actividades típicas do BI incluem suporte à decisão, processamento analítico on-line, análise estatística e Data Mining. O termo representa os sistemas que ajudam as empresas a compreender o que faz o seu negócio “girar”, e ajuda a prever o impacto futuro das decisões tomadas no presente.
Estes sistemas têm um papel importante no planeamento estratégico da empresa. Sistemas que exemplificam o BI são: definição de perfis de cliente, análises de mercado, anti-fraude, análises de contactos com clientes, segmentação de mercados, rentabilidade dos produtos, etc.
A WI permite ao BI ir mais além do que a análise e acesso aos dados da empresa.
Em [1] as empresas verificaram que tendo acesso aos conteúdos da Internet, antes que estes chegassem aos meios de comunicação tradicionais, poderiam efectivamente aumentar a sua competitividade. Esta WI inclui a enorme quantidade de informação que anda à deriva na web, como notícias, rumores, especulação e comentários públicos, que podem ter um impacto significativo na reputação, força de vendas e ultimamente nos preços de uma empresa.
Segundo Guy Greese, director de pesquisa do Aberdeen Group, muitas empresas podem tirar vantagens ao adicionar WI ao seu arsenal de informação.
“Indústrias de informação intensiva… precisam de complementar os seus serviços tradicionais de notícias com inteligência baseada na web, para actuarem em novos desenvolvimentos rapidamente”, disse Greese.
5.2 E-Technology (E-Business, E-Commerce, E-Community, E-Finance, E-Government, E-Learning, E-Publishing, E-Science, etc.)
Com o avanço dos computadores e das tecnologias ligadas à Internet, a
descoberta do conhecimento desempenha um papel importante nos sistemas de informação baseados na web. Como o e-business e o e-commerce crescem de forma muito rápida, é possível às empresas armazenar grandes quantidades de informação sobre as vendas. No entanto, isto apenas causa o crescimento desmesurado de informação, o que faz com que haja a necessidade de se criarem formas mais eficientes de se extrair conhecimento útil da mesma. Por outro lado, as pessoas começaram a verificar que o Data Mining poderia não só oferecer conhecimento sobre o comportamento dos clientes, analisando os registos de transacções passadas dos mesmos, mas também ajudar a melhorar a eficiência e qualidade das decisões de gestão a tomar.

WEB INTELLIGENCE ISEP 2004
Pág. 27
Assim, a aplicação de técnicas de Web Mining ao e-business e ao e-commerce têm como objectivo a descoberta de conhecimento novo, mais interessante e útil.
Técnicas de Web Mining ajudaram [8] a entender o perfil dos
compradores de um conjunto de sites de e-commerce. Por exemplo, descobriram que visitantes que gastam grandes quantias (heavy purchasers) pertencem a uma faixa etária mais alta, têm conhecimento do site através de notícias, possuem propriedades e carros de alto valor, visitam áreas específicas do site e repetem a compra 4 vezes ou mais. Também conseguiram descobrir que certos eventos do mundo real aumentam o tráfego em alguns sites (ex: guerras).
[9] utilizou técnicas de Web Mining para entender o comportamento do
utilizador dentro de sites de e-commerce. Descobriu que um utilizador em média visita 10 páginas, gasta 5 minutos no site e gasta 35 segundos entre páginas, enquanto que um comprador em média visita 50 páginas e gasta 30 minutos no site.
5.3 Intelligent Enterprise Portals
Os portais empresariais inteligentes permitem que todas as aplicações, informação e serviços de uma empresa sejam reunidos e apresentados num interface baseado na web. Cada colaborador ou utilizador autorizado poderá ter acesso a toda a informação e serviços que necessita para trabalhar, a partir de qualquer dispositivo capaz de ter acesso à Internet, seja fixo ou móvel.
A rápida integração destes portais no ambiente da empresa, proporciona vantagens económicas consideráveis para as empresas que funcionam de forma descentralizada.
Melhor e mais fácil acesso à informação acelera os processos vitais da empresa, enquanto que a optimização da troca de informação aumenta a cooperação e comunicação da empresa com clientes e parceiros.
A WI pode aqui ajudar a encontrar informações na Internet relacionadas com os assuntos abordados nestes portais.
Os agentes de software tornam mais fácil a procura, captação e disseminação da informação através da Internet [2]. A tecnologia dos agentes inteligentes de software modificaram a forma como a informação é capturada, armazenada, processada, usada e apresentada em portais web [3].
Os agentes inteligentes e móveis possibilitam a acessibilidade e a adaptabilidade do sistema, garantem a monitorização contínua das fontes de informação, preparação da mesma e a sua disponibilização de acordo com os pedidos dos clientes.

WEB INTELLIGENCE ISEP 2004
Pág. 28
5.4 Intelligent Web Information Systems
O interesse da WI centra-se no desenho e implementação de sistemas inteligentes no novo ambiente de Inteligência Artificial baseado na web.
Esta tendência abre caminho ao desenvolvimento de Intelligent Web Information Systems (IWIS) que são caracterizados por “pensar e agir” (como os humanos ou racionalmente).
Existem vários tipos de IWIS, e cada um serve um grupo de utilizadores ou um propósito. Estes sistemas de informação inteligentes baseados na web podem por exemplo analisar os comportamentos dos utilizadores, e em função dos resultados prever os passos que os mesmos vão seguir. Os utilizadores apresentam fortes regularidades no seu modelo de comportamento cognitivo, e portanto nas suas acções [33]. Para sermos mais precisos, segundo [33], num ambiente como a web existem fortes estatísticas sobre a regularidade e os padrões de navegação dos utilizadores. A previsão tenta identificar os mecanismos apropriados que tiram partido destas grandes quantidades de informação deixada pelos utilizadores enquanto navegam.
5.5 Price Dynamics and Pricing Algorithms
Os preços dos produtos tendem a ser temporários, ou seja, são voláteis. A própria volatilidade muda com o tempo, e estas mudanças afectam variáveis de mercado, afectando directamente o valor marginal de armazenamento, afectando uma componente do custo de produção marginal total: o custo da oportunidade de produzir o produto já em vez de esperar por mais informações sobre o preço [6].
Também nesta área a WI dá o seu contributo, traçando perfis de clientes com base em históricos de transacções, de forma a poder fornecer aos algoritmos de cálculo de preços a máxima e mais rigorosa informação.
5.6 Measuring and Analyzing Web Merchandising and Web-Based Direct Marketing and CRM
A WI pode ajudar os profissionais de marketing na difícil tarefa de
entenderem quem são os clientes, como se comportam e quais as suas preferências. Técnicas de Data Mining aplicadas sobre bases de dados de cliente ou de transacções efectuadas pelos mesmos (compras, vendas, operações bancárias, etc.) permitem extrair padrões estatísticos. Por exemplo, pode-se ter uma análise completa das distribuições de valores pelos atributos dos clientes (bairro, cidade, idade, sexo) com a finalidade de entender o perfil do cliente e assim direccionar a publicidade. Podemos também descobrir associações entre produtos adquiridos na mesma compra. Conhecimento como este pode ser utilizado em campanhas para vendas cruzadas (“cross-sales”) ou promoções.
Em especial a técnica de clustering permite encontrar grupos de clientes, de maneira a segmentar o mercado e assim elaborar campanhas específicas para cada segmento. Os clientes também podem ser agrupados

WEB INTELLIGENCE ISEP 2004
Pág. 29
por comportamento (hábitos de compra ou produtos adquiridos). Alguns autores sugerem a utilização de técnicas de clustering de mais alto nível, analisando classes de produtos comprados porque muitas vezes as marcas não se repetem mas sim os tipos de produtos.
Técnicas de Web Mining ajudam a analisar o impacto de campanhas de
marketing on-line, permitindo entender a forma como os utilizadores chegam até as compras, ou seja, de onde vêm (links de motores de busca ou banners de publicidade) e que caminho fazem até comprarem um produto (sequência de páginas visitadas).
Estas técnicas servem também para melhorar a apresentação de páginas muito visitadas.
Técnicas de Data Mining e Web Mining integradas permitem comparar
os comportamentos dos utilizadores que compraram e dos que não compraram, e extrair características comuns entre os que compraram determinado produto ou visitaram determinadas páginas.
[7] afirmam que é possível avaliar a efectividade de um site, por exemplo estudando onde se perdem clientes durante o processo de compra.
A área de marketing também se pode valer das técnicas de WI para
melhorar a publicidade e ajudar a vender produtos. A área de merchandising preocupa-se com a apresentação de produtos.

WEB INTELLIGENCE ISEP 2004
Pág. 30
6. Futuro e desafios para a WI
A Web Intelligence é uma área relativamente nova, que começa agora a ter bastantes investigadores interessados em realizar trabalho nela. A primeira conferência mundial sobre este tema foi em 2001, e desde então muitas pessoas começaram a interessar-se e a desenvolver pesquisas nesta área.
Embora neste momento, ano 2004, a WI já tenha muitas aplicações e já exista um elevado número de projectos, existem ainda alguns desafios a enfrentar.
6.1 Novas tecnologias
A WI tem de se adaptar às novas tecnologias que a cada dia aparecem.
Por exemplo, as comunicações de banda larga permite a melhoria dos métodos fazem análises, uma vez que estes poderão dar respostas em tempo real.
O uso de dispositivos móveis exigirá novos e melhores sistemas com métodos mais eficazes. Embora a “luta” pela existência de standards na indústria seja grande, cada tecnologia tem a sua maneira de interacção, o que exige do sistema inteligente um mecanismo de detecção dos recursos do utilizador e a consequente adaptação ou personalização.
O software “cliente” irá ter também avanços significativos. Estes avanços facilitarão o trabalho do utilizador e irão garantir um maior nível de segurança, uma vez que serão criadas formas de identificação mais seguras (por exemplo, íris, impressão digital, reconhecimento facial, etc.). Numa perspectiva ainda mais futurista, podemos dizer que nessa altura será possível identificar o local exacto para onde o utilizador está a olhar, ou mesmo analisar as expressões faciais e conseguir reconhecer estados de espírito do mesmo. Com o avanço das tecnologias multimédia será possível transmitir pela Internet, para além dos dois sentidos já existentes (visão e audição), os outros sentidos do corpo humano, como o olfacto, gosto e tacto
6.2 Recolha e selecção de dados para Data Mining
Uma instituição bancária descobriu que 5% dos seus clientes, que
aderiram aos serviços pela Internet, tinham nascido na mesma data, dia 1 de Janeiro. A razão deste padrão era simples: os clientes não preenchiam correctamente os formulários de adesão. Alguns utilizadores não gostavam de preencher alguns dados obrigatórios, os quais eram armazenados com os valores por defeito [9].
Este problema torna evidente a necessidade de melhorar a recolha de dados na web. Dados errados ou inconsistentes podem influenciar um processo de WI, e consequentemente gerar resultados incorrectos. Note-se que resultados incorrectos neste caso significa resultados que não espelham a realidade, mas sim o conhecimento que existe nos dados armazenados.

WEB INTELLIGENCE ISEP 2004
Pág. 31
A selecção de dados para realizar WI, também é um dos aspectos em que é necessário ter muito cuidado. Por exemplo, numa empresa de e-commerce foram utilizados os dados das transacções de clientes dos últimos 5 anos. Depois de aplicadas técnicas de WI, descobriu-se que quem compra o produto X também compra o produto Y. Esta regra tinha uma confiança de 80%, ou seja em 80% dos casos em que o cliente comprava o produto X também comprava o produto Y. Numa análise dos mesmos dados, mas desta vez ano a ano, verificou-se que nos primeiros 4 anos a mesma regra tinha confiança de 100%, enquanto que no último ano tinha confiança de 0%. Se o resultado da primeira análise fosse usado para uma campanha de markting, poderíamos estar a adoptar estratégias distorcidas e sem sentido.
A mesma empresa implementou um novo sistema de comércio electrónico via Web, mas para outro ramo de negócio. Passados seis meses da entrada em funcionamento, foi feita uma análise ao volume de vendas. A média de vendas nesses meses foi de 25%, o que ficava muito longe das expectativas. No entretanto, analisando somente o último mês, pôde-se observar que foi pelo sistema via web que foram efectuadas 45% das vendas. A análise somente da média poderia levar a uma frustração ou mesmo à decisão de descontinuar o sistema, o que estaria errado, porque a tendência era o aumento das vendas e o consequente sucesso do novo negócio.
6.3 Identificar utilizadores e recolher os seus dados com
precisão
Um grande desafio na web é conseguir identificar um utilizador. Os dados de um indivíduo ou entidade podem ser solicitados, mas nem
sempre os mesmos estão interessados em fornecê-los. No entanto, mesmo respeitando toda a legislação e direitos de
privacidade dos utilizadores é importante para as organizações saber quem é o utilizador, do que gosta, o que faz, etc. No caso da Internet, a identificação de um utilizador pode facilitá-lo na navegação, através da recomendação de produtos/serviços, personalização do ambiente, ou mesmo evitar que seja necessário pedir ou fornecer informações ao utilizador que ele já tenha dados ou recebidos.
Algumas técnicas sugeridas são o uso de cookies ou a identificação pelo endereço IP da máquina. Estas técnicas levantam duas questões: e se o utilizador mudar de máquina? E se uma máquina for usada por várias pessoas? [10]
As técnicas de WI poderiam ajudar a identificar o utilizador pelo seu comportamento, respeitando sempre o direito à privacidade.
Por exemplo, poder-se-ia observar se as mesmas páginas são vistas no início do dia (ex: notícias e e-mail), se o utilizador chega ao site sempre pelo mesmo caminho (ex: por portal da empresa, pois é o que ele conhece), se uma mesma sequência de páginas seguida à risca (utilizador experiente ou leigo) ou se ele acede através de páginas do meio do site (utilizador que conhece os atalhos).
Além de ser capaz de recolher dados sobre o utilizador, o sistema inteligente deve manter somente dados confiáveis e coerentes, o que

WEB INTELLIGENCE ISEP 2004
Pág. 32
muitas vezes não acontece por causa do utilizador, seja de propósito ou sem intenção. Algumas informações podem ser validadas através de acções concretas, como por exemplo, entrega de um prémio ou produto num endereço. Isto atesta que os dados do endereço do utilizador existem e estão correctos.
6.4 Integração dos vários resultados e tipos de mining
A WI utiliza várias técnicas e métodos de mining (Data minig, Web
Mining, Text Mining). Um melhor desempenho é atingido quando estas abordagens são utilizadas em conjunto. Por exemplo, Web Mining analisa o comportamento dos utilizadores de um site pelo log armazenado no servidor. Seria importante criar uma base de dados com estas informações e ainda acrescentar dados sobre o conteúdo das páginas com técnicas de Text Mining.
Uma técnica simples seria substituir as URL’s por palavras, temas ou conceitos presentes nas páginas web. Além de tudo isto, existem informações sobre o comportamento que não estão no log (por exemplo: compras e transacções bancárias feitas pelo utilizador). Estas informações aparecem por em bases de dados corporativas. Pode ainda acrescentar-se informações relativas à semântica da web (links semânticos e comportamento social).
[11] sugerem criar um Data Webhouse, termo análogo a DataWarehouse. O objectivo é manter todos os dados necessários à inteligência do negócio reunidos numa mesma base de dados e de forma integrada para facilitar a descoberta do conhecimento.
6.5 Privacidade
Um factor que pode inibir o avanço da WI é a questão da privacidade.
Hoje em dia é possível descobrir informações sobre pessoas sem que estas as forneçam. Estas informações são importantes para as empresas. No entanto, as acções de recolha e uso destes dados precisam de ser regidas por direitos e deveres.
Muitas pessoas não querem que os seus dados sejam recolhidos (preferem o anonimato).
Já outras não se importam, mas exigem que os dados não sejam divulgados para outros ou usados para publicidade.
[Schafer2001] sugerem que as empresas e sites divulguem explicitamente as suas políticas de privacidade (que informação está a ser recebida e qual a sua finalidade).
Está em discussão no WWW Consortium (W3C) o protocolo P3P (Platform for Privacy Preferences) que permitirá a negociação automática entre empresas e clientes.
Segundo [10], este protocolo permite aos sites publicarem as suas políticas em formatos capazes de serem lidos e entendidos por outras máquinas. Desta forma, o browser cliente pode ler e comparar estas políticas com as configurações de segurança do utilizador.

WEB INTELLIGENCE ISEP 2004
Pág. 33
7. Ferramentas
Nos capítulos anteriores são referidas várias técnicas usadas pela WI. A maior parte dos exemplos apresentados são puramente teóricos, mas existem algumas implementações destas mesmas técnicas. No âmbito deste projecto trabalhamos com algumas dessas implementações, e é neste capítulo que vamos relatar as experiências.
7.1 Web Usage Mining
Como já foi referido anteriormente, Web Mining é composto por três
áreas diferentes, mas que se complementam. Uma das áreas com mais ferramentas disponíveis é a Web Usage Mining. Existe as mais diversas ferramentas para análise de log dos servidores de páginas web, mas a maior parte delas, até ao momento, apenas fazem uma análise em termos estatísticos. A ferramenta escolhida para experimentar foi o Funnel Web Analyzer.
Para iniciar a experiência, fiz download de alguns logs de utilização de
um site. Sem qualquer tipo de pré-processamento dos dados da minha parte, iniciei a aplicação e pedi uma análise dos ficheiros que tinha feito download.
Figura V - Ecrã principal do Funnel Web Analyzer
Durante alguns segundos a aplicação processa os dados e gera um
relatório, em formato HTML, com os resultados da análise. Para se visualizar esses resultados, basta abrir o ficheiro com um
browser de Internet.
O relatório começa por apresentar alguns dados estatísticos, como outras ferramentas fazem, mas apresenta depois mais detalhe na análise, agrupando inclusive os acessos por várias categorias.

WEB INTELLIGENCE ISEP 2004
Pág. 34
Figura VI - Tabela de análises estatísticas
Uma análise mais detalhada de algumas categorias, permite ver
algumas informações mais interessantes. Categoria Demographics
Esta categoria mostra a origem e comportamento dos visitantes do site, verificando a utilização individual dos mesmos ao longo do tempo.
Figura VII - Gráfico de visitantes
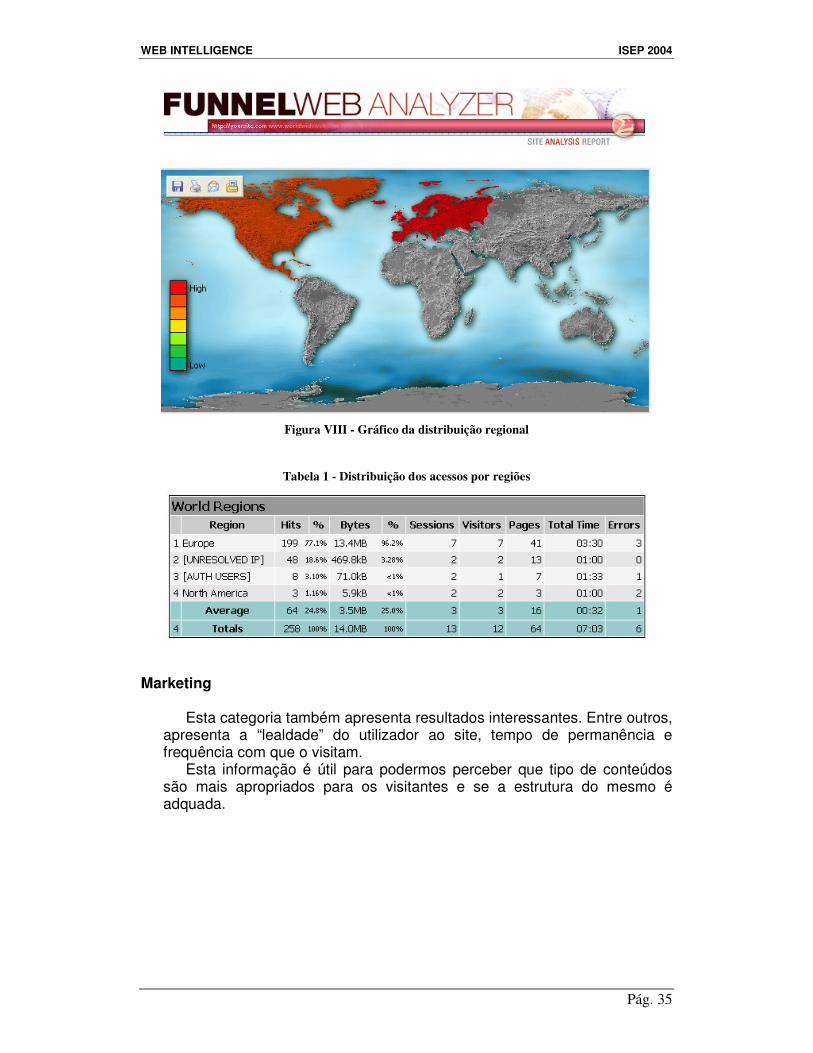
Nesta categoria podemos também ver quais as regiões de localização
dos utilizadores que mais acederam ao site.
WEB INTELLIGENCE ISEP 2004
Pág. 35
Figura VIII - Gráfico da distribuição regional
Tabela 1 - Distribuição dos acessos por regiões
Marketing
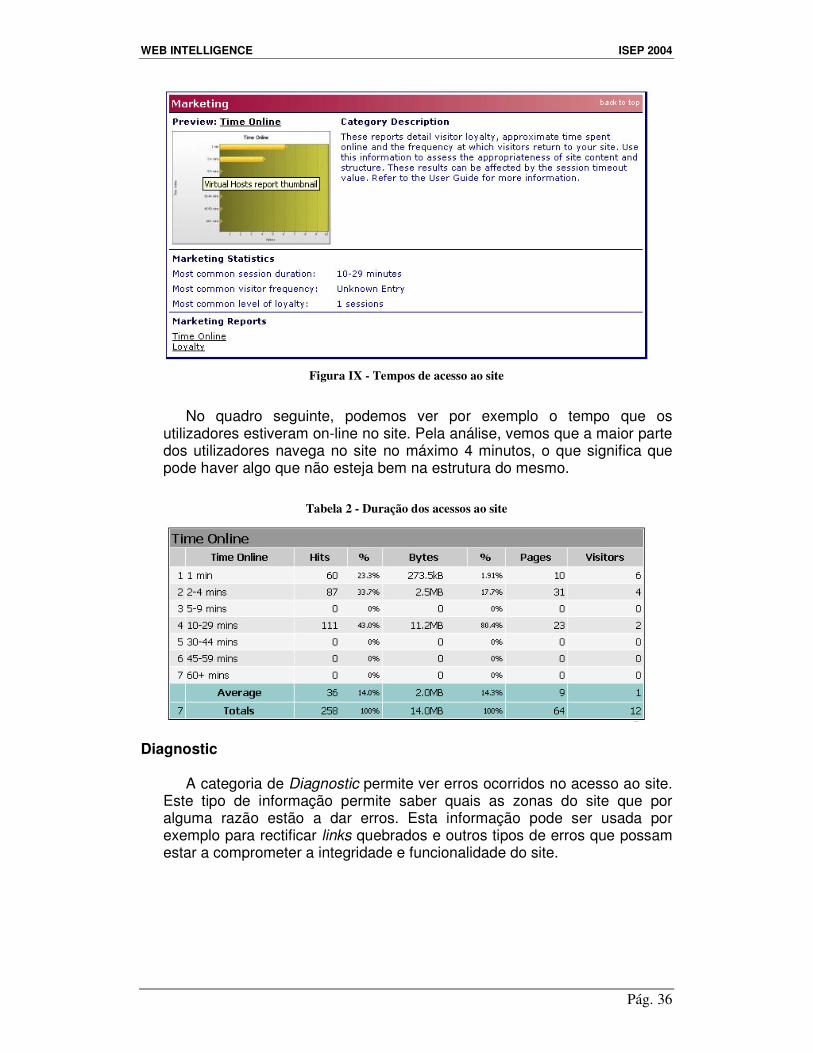
Esta categoria também apresenta resultados interessantes. Entre outros, apresenta a “lealdade” do utilizador ao site, tempo de permanência e frequência com que o visitam.
Esta informação é útil para podermos perceber que tipo de conteúdos são mais apropriados para os visitantes e se a estrutura do mesmo é adquada.
WEB INTELLIGENCE ISEP 2004
Pág. 36
Figura IX - Tempos de acesso ao site
No quadro seguinte, podemos ver por exemplo o tempo que os
utilizadores estiveram on-line no site. Pela análise, vemos que a maior parte dos utilizadores navega no site no máximo 4 minutos, o que significa que pode haver algo que não esteja bem na estrutura do mesmo.
Tabela 2 - Duração dos acessos ao site
Diagnostic
A categoria de Diagnostic permite ver erros ocorridos no acesso ao site. Este tipo de informação permite saber quais as zonas do site que por alguma razão estão a dar erros. Esta informação pode ser usada por exemplo para rectificar links quebrados e outros tipos de erros que possam estar a comprometer a integridade e funcionalidade do site.

WEB INTELLIGENCE ISEP 2004
Pág. 37
Figura X - Gráfico de erros
No quadro seguinte podemos ver quais os URLs que falharam, quando
solicitados pelo utilizador. Com a informação do quadro, sabemos facilmente quais os links que poderão não estar a funcionar bem.
Tabela 3 - URLs falhados
A aplicação tem mais categorias, nomeadamente informações sobre os sistemas mais usados no acesso, sites que mais referências têm para o site em análise, etc.
Conclusão
Este tipo de aplicações é muito útil na análise da utilização de um site. Ela permite ver não só os erros existentes no mesmo, mas também quem visita, como o faz, com que aplicações e qual o objectivo da visita. Esta informação é preciosa não só para os administradores dos sites, mas

WEB INTELLIGENCE ISEP 2004
Pág. 38
também para os departamentos de marketing das empresas proprietárias dos mesmos sites.
7.2 Text Mining de páginas web
Existem algumas ferramentas que permitem fazer Text Mining sobre documentos, facilitando a pesquisa dentro do próprio, disponibilizando resumos, palavras mais relevantes, etc. A MegaPuter, empresa que produz ferramentas para descoberta de conhecimento, tem um Add-in para o Internet Explorer que faz análises semânticas, sumários e perguntas em linguagem natural das páginas web encontradas. Enquanto estamos a navegar pelas páginas, o TextAnalyst analisa as mesmas, retornando assim a informação mais importante.
A experiência que fiz foi muito simples. No Google, pesquisei pela frase “lei da protecção dos dados pessoais”.
Imagem 1 - Resultados da pesquisa
Como é natural, os resultados foram muitos. Como o que me
interessava era a versão da lei mais ligada à informática, procurei então no TextAnalyst um resultado que se referisse a informática. A figura a seguir mostra a lista de informações mais importantes obtidas pela aplicação.

WEB INTELLIGENCE ISEP 2004
Pág. 39
Imagem 2 - Texto seleccionado no TextAnalyst
Ao seleccionarmos o texto que nos interessa, o TextAnalyst também
selecciona esse mesmo texto na página web, de forma podermos localizá-lo imediatamente.
Já dentro documento pretendido, o TextAnalyst faz de novo uma
pesquisa, de forma a retornar as informações mais importantes. O TextAnalyst apresenta os resultados das suas pesquisas em dois
painéis distintos. Num painel apresenta a rede semântica, que é usada para navegar pelos conceitos mais importantes do documento. Este painel mostra, de forma hierárquica, uma estrutura dos conceitos mais importantes. Cada conceito tem um número atribuído, de 1 a 100, que indica o grau de importância em relação ao documento inteiro. Quando carregamos num dos conceitos, todas as frases que o contêm aparecem no painel de baixo. Cada frase apresentada está ligada ao documento original, de forma a facilitar a sua localização no mesmo.

WEB INTELLIGENCE ISEP 2004
Pág. 40
Imagem 3 - Árvore de palavras relevantes
Com este tipo de ferramentas podemos também fazer perguntas em linguagem natural. Esse foi o meu próximo passo. Primeiro fiz a pergunta “o que é tratamento informático dos dados?”. O TextAnalyst cria uma estrutura com tópicos, semelhante à rede semântica. Os tópicos pais são os conceitos mais importantes que a nossa pesquisa retornou, e cada frase que contem esse conceito é mostrada no painel de visualização de texto. Cada frase está ligada com a sua localização no texto HTML original, para que seja possível ser destacada tanto no painel como no documento quando fazemos duplo click com o rato sobre a mesma.

WEB INTELLIGENCE ISEP 2004
Pág. 41
Imagem 4 - Palavras relevantes da pesquisa aos resultados
A árvore criada pode ser expandida, e em cada um dos nós podemos
ver que existem mais conceitos com pesos outros pesos. Cada nó filho apresenta um conceito que aparece nas frases onde aparece o nó pai. Um nó filho contém dois pesos. O primeiro indica a importância em relação ao nó pai e o outro em relação ao documento inteiro.
Assim, à medida que vamos descendo na árvore vamos refinando a nossa pesquisa e obtendo conceitos mais completos.
Imagem 5 - Selecção de palavras
Conclusão
As ferramentas do tipo TextAnalyst ajudam os utilizadores a terem um conhecimento mais rápido do conteúdo de um documento, bem como a encontrar mais facilmente os documentos de que precisam. No caso concreto, a ferramenta pode ajudar bastante na pesquisa em páginas com elevada quantidade de texto, e onde apenas algumas coisa nos interessam. Não será necessário ler o documento na integra, bastando apenas fazer algumas pesquisas pelas palavras que mais nos interessam.

WEB INTELLIGENCE ISEP 2004
Pág. 42
7.3 Web Content Mining
Web content mining é um processo automático que vai muito mais além
do que a simples extracção de palavras-chave. Uma vez que os documentos de texto têm uma semântica que não é compreendida pelas máquinas, algumas abordagens sugerem que se faça a reestruturação do conteúdo do documento numa representação que pode ser explorada pelas máquinas. A abordagem mais usual para explorar conteúdos de documentos é usar marcas que fazem mapeamento com um modelo de dados.
Existem duas estratégias para fazer web content mining: aquela que procura directamente os conteúdos dos documentos, e aquela que melhora os conteúdos pesquisados por outras ferramentas, como por exemplo motores de busca.
Nesta área experimentei o Digesto.net da WBSA – Web Intelligence Systems.
Digesto.Net
O Digesto é um portal de busca que faz uso de técnicas de IA para pesquisar conteúdos na web sobre matérias jurídicas.
Imagem 6 - Portal Digesto.net
Este sistema faz buscas em páginas, artigos da lei publicados na
Internet e acórdãos, distribuídos por vários organismos judiciais do Brasil. Podemos experimentar o projecto em www.digesto.net.

WEB INTELLIGENCE ISEP 2004
Pág. 43
7.4 Web Structure Mining
WebQL é uma ferramenta que permite extrair dados de qualquer fonte
de dados digital. Segundo a QL2 Software, empresa produtora, o núcleo do WebQL é uma linguagem de programação que usa uma sintaxe simples para contornar virtualmente qualquer problema de migração de dados. O WebQL é derivada do SQL padrão, mas contem extensões lógicas para poder identificar dados originários de qualquer fonte.
Como o SQL, o WebQL pode trabalhar com dados estruturados, mas o seu principal trunfo é a capacidade de processar dados não estruturados, dados encontrados em páginas web, folhas de cálculo e documentos de texto normais.
O WebQL Studio é uma aplicação com ambiente gráfico, que permite
desenvolver e distribui aplicações baseadas em WebQL. Esta ferramenta pode também ser usada para desenvolver aplicações em Java, .NET e VB6, como veremos mais à frente neste capítulo.
Podemos ter acesso à mesma em www.ql2.com, e utilizá-la por um
período de 30 dias. Infelizmente neste período experimental apenas temos acesso a uma espécie de Query Analyser que permite fazer queries e ver os seus resultados, e usar apenas 1 instância do objecto disponibilizado na API.
As experiências que efectuei com esta ferramenta foram de dois tipos.
Primeiro comecei por usá-la apenas no ambiente gráfico disponibilizado e depois, usando o API disponível para .NET, desenvolvi uma aplicação simples para criar a árvore de links de uma página web.
Experiência 1 – query simples
Na minha primeira experiência, o objectivo era ver a sintaxe da linguagem, pelo que comecei pelo mais simples:
select * from http://www.dei.isep.ipp.pt
O WebQL apresenta quase sempre os resultados de uma forma
estruturada, isto é, devolve uma tabela normal com linhas e colunas. Para o caso, são devolvidos os campos por defeito: url origem, título da página e o seu conteúdo em html. A figura seguinte mostra um exemplo do retorno da query.

WEB INTELLIGENCE ISEP 2004
Pág. 44
Imagem 7 - Resultados de um query
Como já foi dito anteriormente, o WebQL é em tudo semelhante ao SQL,
mas tem algumas extensões que fazem todo o sentido para o meio para onde foi concebido. Uma extensão muito interessante é o crawl. O crawl permite que a query entre pela página fornecida e, a partir daí, comece a testar todos os links que encontre. Teoricamente, o motor de ferramenta analisa a página dada e retorna os seus links, analisando por sua vez cada página apontada por cada link e retornando também os seus links. Este processo é recursivo, podendo por tanto tornar-se quase infinito, dada a dimensão da Internet. No entanto, esta extensão tem um parâmetro que permite parar a recursividade num determinado nível. Chama-se “depth” e pode ser usado de várias maneiras.
Vamos então fazer alguns testes com o “crawl”.
Experiência 2 – a extensão “crawl”
O primeiro objectivo é ver o resultado de um querie simples, para depois podermos definir um nível de profundidade (depth).
Os queries a executar são:
Select * from crawl of http://www.dei.isep.ipp.pt Select * from crawl of http://www.dei.isep.ipp.pt to depth 3
Como já foi dito, o primeiro query vai executar durante muito tempo, teoricamente infinito, até terminarem os links encontrados. O segundo, vai apenas fazer o crawling dos links de primeiro e segundo nível.
As imagens seguintes apresentam os resultados dos queries.

WEB INTELLIGENCE ISEP 2004
Pág. 45
Imagem 8 - Resultados do crawl
Imagem 9 - Resultados do crawl com nível de profundidade
Se analisarmos a imagem 9 vemos que passado algum tempo da query começar a executar, já está a fazer testes em links que não têm nada a ver com a página inicialmente dada, é por isso que dizemos que teoricamente a query não tem fim.

WEB INTELLIGENCE ISEP 2004
Pág. 46
A informação retornada pode servir para bastantes fins, no entanto, se
usarmos alguns campos que o WebQL nos disponibiliza, podemos obter dados com um objectivo bem definido. Por exemplo, vamos substituir as colunas a serem retornadas de * para parent_url, source_url e crawl_depth.
Nesta experiência, o objectivo é saber qual a estrutura de links da página. Depois de alterado o query temos:
select parent_url as url_pai, source_url as link, crawl_depth as nivel
from crawl of http://www.dei.isep.ipp.pt to depth 2 order by crawl_depth
Os resultados obtidos foram os seguintes:
Imagem 10 - Resultados ordenados
Se analisarmos a tabela, podemos ver que na primeira coluna temos
sempre o mesmo url origem. Isto significa que todos os links que aparecem na segunda coluna, são originários do da primeira. Portanto, temos aqui, de forma resumida, a estrutura de links da página www3.dei.isep.ipp.pt.
Se quisermos ir mais longe, podemos aumentar o nível de profundidade
e teremos uma estrutura de links mais abrangente. Por exemplo, vamos alterar o parâmetro to depth de 2 para 3. O que é que vai acontecer? O que vai acontecer é que o nosso query vai retornar os links dos links da página www3.dei.isep.ipp.pt.
Com esta experiência, tentei demonstrar a capacidade que esta
ferramenta tem de fazer web structure mining, e foi com base nisto que desenvolvi uma aplicação simples, da qual irei falar mais tarde.

WEB INTELLIGENCE ISEP 2004
Pág. 47
Experiência 3 – pesquisas múltiplas
Quando fazemos pesquisas sobre determinada matéria na Internet, temos sempre uma dificuldade: saber qual o motor de busca que nos dará melhores resultados. Para a ultrapassar geralmente fazemos pesquisas em todos eles e analisamos os resultados. Com esta terceira experiência quero mostrar uma forma mais ou menos automática de se fazer a pesquisa em todos os motores de busca que quisermos. Para que o objectivo seja cumprido, é necessário recorrermos a outra extensão que a linguagem implementa: o submitting.
Esta opção permite que o WebQL preencha os campos de um formulário HTML encontrado durante o query, com os valores fornecidos pelo utilizador. Por exemplo, se a nossa pesquisa na Internet fosse “isep”, podíamos executar o seguinte comando:
Select * from [ http://www.google.com, http://www.altavista.com ]
submitting values ‘isep’ for * to form 1
Imagem 11 - Resultados de submitting
Os resultados não são nada que nunca se tenha visto antes, isto é, são
simples pesquisas que podemos fazer nos motores de busca, mas com a particularidade de serem feitas automaticamente. O interessante é que sobre os resultados desta query, podemos fazer outra, ou então filtrar a mesma de forma a aparecerem apenas os resultados por que pesquisamos. Por exemplo, se adicionarmos mais alguns motores de busca e filtrarmos por o query pelo texto procurado temos:

WEB INTELLIGENCE ISEP 2004
Pág. 48
select unique html_to_text(CONTENT) as TITULO, url as URL_LINK from links within [http://www.google.com, http://www.altavista.com, http://www.hotbot.com, http://www.lycos.com, http://www.excite.com] submitting values 'isep' for * to form 1 where html_to_text(CONTENT) matching 'isep' or html_to_text(CONTENT) matching 'ISEP'
Imagem 12 - Resultados do matching
Neste momento, fizemos uma pesquisa nos 5 motores de busca ao
mesmo tempo, e seleccionamos apenas os resultados que continham a palavra isep.
Embora as pesquisas directas nos motores nos possam retornar textos com excertos do conteúdo dos sites encontrados, o que permite que nos enquadremos minimamente com os mesmos, esta query pode retornar resultados de todos eles ao mesmo tempo.
Como é evidente, e dado tratar-se apenas de experiências, os
resultados não são apresentados na forma mais amigável para o utilizador. Um software útil poderia ser algo que apresenta-se estes resultados de uma forma gráfica e mais “bonita”.
Esta experiência visa sobretudo mostrar que com algumas ferramentas
de web mining é possível melhorar alguns dos serviços que hoje em dia

WEB INTELLIGENCE ISEP 2004
Pág. 49
existem na Internet, bem como integrar alguns de forma a que se complementem.
Experiência 4 - Web Structure Mining – Desenvolvimento de aplicação
Para finalizar as experiências com esta ferramenta, desenvolvi uma pequena aplicação que permite ver a árvore de links de um determinado site.
O WebQL disponibiliza um API que permite executar queries e obter os
resultados e os logs de execução das mesmas. A plataforma escolhida for VB.NET, embora se possa usar a API com Java, ASP.NET e VB6 também.
A aplicação é muito simples. Tem apenas uma janela, dividida em 4
partes. Do lado esquerdo temos a árvore de links gerada, do lado direito temos um browser e uma caixa de mensagens, onde vão aparecendo os logs de execução. Em cima temos uma barra para colocação do url a pesquisar, um contador que indica o nível de profundidade a que queremos chegar e os botões de iniciar e abortar.
A implementação é simples. O WebQL disponibiliza um namespace
WebQL que tem as classes Script, Runtime e Records. Para se executar um query, é necessário criar um objecto do tipo Script, e depois executar o método CreateRuntime(), que retorna um objecto do tipo RunTime. Neste objecto chama-se o método Start() e o processamento do query começa. Existem eventos próprios no objecto que nos vão dando informação dos estado da execução, bem como das mensagens produzidas durante a mesma. Quando o processamento terminar, é lançado o evento DataReceived() que retorna um conjunto de registos com os dados. É sobre destes dados que são extraídos os resultados. Estes dados vêm no formato de uma tabela, com o número de colunas que foram especificadas no query, e tantas linhas quantos os resultados obtidos.
De seguida vamos ver alguns exemplos de execuções da aplicação para
alguns sites. Na imagem seguinte podemos ver a janela depois de executada uma
query para o site www.cnn.com, com nível de profundidade 1.

WEB INTELLIGENCE ISEP 2004
Pág. 50
Imagem 13 - Resultados da pesquisa com nível 1
No lado esquerdo temos a estrutura de links retornada. Estes são todos
os links possíveis a partir da página inicial do site www.cnn.com. Se aumentarmos o nível de profundidade para 2, verificamos que os queries demoram muito mais tempo a executar, uma vez que é necessário percorrer também os links dos links. A imagem seguinte mostra uma execução com nível de profundidade 2.

WEB INTELLIGENCE ISEP 2004
Pág. 51
Imagem 14 - Resultados da pesquisa com nível 2
A execução deste query demorou 1h 17m. Como é evidente, pelo tempo
que demora, o acesso a esta árvore não pode ser imediato, ou seja, não podemos estar a navegar e pedir a visualização da árvore, pelo menos para páginas como esta. O ideal para casos como este seria ter uma aplicação que executasse o trabalho e guardasse os resultados numa base de dados, para posterior consulta.
O objectivo desta experiência era demonstrar a facilidade com que
WebQL pode ser usado para criar software, e também um exemplo de uma aplicação da área da Web Intelligence. Podemos concluir que com este exemplo confirmamos um pouco a definição de WI: recorrer à IA e TI de forma a aplicá-las na web.

WEB INTELLIGENCE ISEP 2004
Pág. 52
8. Conclusão
Cada vez mais a Internet é um dos principais fornecedores de informação da sociedade em que vivemos. A quantidade de informação é de tal forma grande que se torna quase impossível retirar qualquer conhecimento da mesma, e a existência de semânticas diferentes entre sistemas torna ainda mais complexa a colaboração e troca de informação.
Na tentativa de automatizar os processos de descoberta de conhecimento em grandes repositórios de informação, como é o caso da web, a WI recorre à IA e às TI de forma a aplicá-las nas estruturas da Internet. A WI está a dar passos com a finalidade de desenvolver ferramentas que nos possam ajudar a criar aquilo a que poderemos chamar uma rede inteligente. Uma rede capaz de identificar as necessidades dos utilizadores e organizações e responder de forma rápida e precisa a essas mesmas necessidades.
Neste trabalho foram apresentadas as várias vertentes da WI, os níveis em que se divide, as áreas que utiliza para obter os seus resultados, áreas onde pode ser aplicada de forma a criar mais valias e desafios que terá de enfrentar com a evolução da Internet.
9. Dificuldades
Imediatamente após a apresentação da disciplina de Projecto, e o
aparecimento da primeira lista de temas possíveis, escolhi o meu. Entre os vários temas que foram apresentados, havia alguns sobre os quais tinha muito mais conhecimento, mas escolhi este precisamente por ser algo de novo para mim. Fazer este trabalho foi extremamente interessante, mas ao mesmo tempo difícil. Com o desenrolar do trabalho verifiquei que, embora o conjunto de conceitos fosse algo de novo, havia alguns que já me eram familiares de algumas disciplinas leccionadas no curso.
Uma das dificuldades que encontrei na elaboração do relatório deveu-se à quantidade de informação disponível sobre as várias áreas que compõe a WI. Na Internet existem vários artigos que falam sobre o tema, mas a maior parte da informação, e a mais “valiosa”, encontra-se nos livros dos Proceedings das conferências anuais que o WIC realiza, e nos artigos apresentados em workshops um pouco por todo o mundo. Por exemplo, só tive acesso aos proceedings da conferência de 2004, realizada de 20 a 24 de Setembro, no dia 30 de Setembro, e porque o Eng. Carlos Ramos me emprestou. No entanto penso que a maior dificuldade foi fazer a estruturação do trabalho, saber que áreas deveria abordar e a qual delas devia dar mais destaque. A componente experimental também foi difícil de realizar, principalmente porque a maior parte do software existente é comercializado e não permite o uso a título experimental.

WEB INTELLIGENCE ISEP 2004
Pág. 53
10. Referências [1] Nick Denton, CEO, Moreover The Rise of Web Intelligence May 2001 [2] Ching-Shen James DONG, Grace SauLan LOO Flexible Web-Based Decision Support System Generator (FWDSSG) Utilising Software Agents. Proceedings of the 12th International Workshop on Database and Expert Systems Applications (DEXA’01). [3] Liu J., Zhong N., Yao Y.Y., Ras Z.W. 2003. The Wisdom Web: New Challenges for Web Intelligence (WI). Journal of Intelligent Information Systems [4]Hong Tang Yu Wu J.T. Yao Gouyin Wang Y. Y. Yao
CUPTRSS: A Web-based Research Support System Office of Science and Technology, Institute of Computer Science and Technology Chongqing University of Posts and Telecommunications, China [5]Fjodor Ruzic Web and AI Convergence: Society Intelligence through Web Intelligence Institute for Informatics, Zagreb, Croatia June 2003 [6] Robert S. Pindyck VOLATILITY AND COMMODITY PRICE DYNAMICS Massachusetts Institute of Technology Cambridge, MA August 2002 [7] LEE, J. & PODLASECK, Mark. Visualization and analysis of clickstream data of online stores for understanding web merchandising. Journal of Data Mining and Knowledge Discovery, v.5, n.1/2, Janeiro de 2001. [8] KOHAVI, Ron & BECHER, Jon. E-commerce and clickstream mining tutorial. SIAM International Conference on Data Mining. Abril de 2001. [9] KOHAVI, Ron Mining e-commerce data: the good, the bad and the ugly. Simpósio Internacional de Gestão de Conhecimento e Gestão de Documentos. Curitiba, Agosto 2001

WEB INTELLIGENCE ISEP 2004
Pág. 54
[10] SRIVASTAVA, Jaideep et al Web usage mining: Discovery and applications of usage patterns from Web data. ACM SIGKDD Explorations, Janeiro de 2000 [11] KIMBALL, Ralph & MERZ, Richard. Data Webhouse: construindo o data warehouse para a WEB. Rio de Janeiro: Campus, 2000. [12] SCHAFER, J. Ben et al. E-commerce recommendation applications. Journal of Data Mining and Knowledge Discovery, Janeiro de 2001. [13] Sean B. Palmer The Semantic Web: An Introduction 2001
[14] S.K.Madria, S.S.Bhowmick, W.K.Ng, e E.P.Lim Research issues in Web data mining. Proceedings of Data Warehousing and Knowledge Discovery First International Conference, DaWaK 1999
[15] Yan Wang Web Mining and Knowledge Discovery of Usage Patterns CS 748T Project (Part I) 2000
[16] M. Spiliopoulou Data mining for the Web Proceedings of Principles of Data Mining and Knowledge Discovery Third European conference, PKDD 1999
[17] Garofalakis, Minos N. et al. Data mining and the web: past, present and future. ACM Workshop on Web Information and Data Management Kansas City, 1999
[18] Bharat, Krishna & Broder, Andrei A technique for measuring the relative size and overlap of public Web search engines Conf. on World Wide Web, 1998 (www7.scu.edu.au/programme/fullpapers/1937/com1937.htm)
[19] Zhong, N. et al. Web Intelligence (WI). Proceedings 24th IEEE International Computer, Software and Applications Conference (COMPSAC), 2000
[20] Fayyad, Usama M. et al. From data mining to knowledge discovery: an overview.

WEB INTELLIGENCE ISEP 2004
Pág. 55
Advances in Knowledge Discovery and Data Mining Menlo Park, The MIT Press, 1996
[21] Goebel, Michael and Gruenwald, Le. A survey of data mining and knowledge discovery software tools ACM SIGKDD Explorations, v.1, n.1, 1999. [Han96] Han, Jiawei et al. Intelligente query answering by knowledge discovery techniques. IEEE Transactions on Knowledge and Data Engineering, v.8, n.3, 1996.
[22] Agrawal, Rakesh. Data mining: the quest perspective. EDBT Summer School on Advances in Database Technology Gubbio-Itália, 1995
[23] Tan, Ah-Hwee Text mining: the state of the art and the challenges. Pacific-Asia Workshop on Knowledge Discovery from Advanced Databases Beijing, 1999
[24] Willet, Peter. Recent trends in hierarchic document clustering: a critical review. Information Processing & Management, v.24, n.5, 1988 [25] Yang, Yiming e Liu, Xin A re-examination of text categorization methods ACM-SIGIR Conf. on Research and Development in Information Retrieval Berkeley, 1999
[26] Riloff, Ellen e Lehnert, Wendy Information extraction as a basis for high precision text classification ACM Transactions on Information Systems, v.12, n.3, 1994.
[27] T. Berners-Lee, J. Hendler, O. Lassila The semantic web – a new form of the Web content that is meaningful to computer will unleash a revolution of new possibilities. Scientific American, 2001 (www.sciam.com/print_version.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21)
[28] Web-based Adaptive User Interfaces: Problems, Methods and Applications Fifth World Multiconference On Systemics, Cybernetics and Informatics July 22-25, 2001 Orlando, Florida USA Sheraton World Resort (http://www.ia.uned.es/~jgb/waui01/)
[29] Nuno Silva e João Rocha Semantic Web Complex Ontology Mapping Proceedings IEEE/WIC International Conference on Web Intelligence 2003 Halifax, Canada 2003
[30] Goertzel, Bem World Wide Brain

WEB INTELLIGENCE ISEP 2004
Pág. 56
The Emergence of Global WI and how it will transform the human race 2002 (http://www,goertzel.org/papers/webart.html)
[31] Web Intelligence Consortium 2003 http://wi-consortium.org/ [33] Juan D. Velasquez, Hiroshi Yasuda, Terumasa Auki Web Site Structure and Content ecomendations Proceedings IEEE/WIC/ACMs International Conference on Web Intelligence 2004 Benjing, China 2004 [34] Web-based Support Systems A Report of the WIC Canada Research Centre Proceedings IEEE/WIC/ACM International Conference on WI 2004