intel® intel®®®parallel composerparallel composer · pdf...
TRANSCRIPT

IntelIntelIntelIntel®®®® Parallel ComposerParallel ComposerParallel ComposerParallel Composer
Stephen Blair-ChappellIntel Compiler Labs

4/16/20092
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
IntelIntelIntelIntel®®®® Parallel ComposerParallel ComposerParallel ComposerParallel Composer
CODE & DEBUG PHASECODE & DEBUG PHASECODE & DEBUG PHASECODE & DEBUG PHASE
� Easier, faster parallelism for Windows* apps
� C/C++ compiler and advanced threaded libraries
� Built-in parallel debugger
� Supports OpenMP*
� Save time and increase productivity
Develop effective applications with a C/C++ compiler and comprehensive threaded libraries

4/16/20093
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Key Features of ComposerKey Features of ComposerKey Features of ComposerKey Features of Composer� Extensions for parallelism
– Simple concurrent functionality (__task/__taskcomplete)
– Vectorization support for SSE2/SSE3/SSSE3/SSE4 instruction set
– OpenMP™ 3.0
– Seamless integration into MS Visual Studio*
– Intel® Parallel Debugger Extensions - A Plug-in to Visual Studio*
– Intel® Threading Building Blocks
– C++ lambda function support (enables simpler interfacing with Intel®TBB)
– Intel® Integrated Performance Primitives
– Integrated array notation, data-parallel Intel® IPP functions
� Parallel build (/MP) feature
� Diagnostics to help develop parallel programs (/Qdiag-enable:thread)
� Threading tutorials with sample code

4/16/20094
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
IntelIntelIntelIntel®®®® Parallel ComposerParallel ComposerParallel ComposerParallel ComposerExtend parallel debugging capabilitiesExtend parallel debugging capabilitiesExtend parallel debugging capabilitiesExtend parallel debugging capabilities
Data race
detection
Allows filtering to control amount of data collected
Serializes parallel regions without recompilation
Adds a new class of “data breakpoints”
Adds window to visualize logs

5
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
5
Compiler Pro 11.0
Composer Future Intel Compiler
Full C and C++ Support √ √ √
Fortran Support √ No Fortran √
Fortran 2003 Support Several features No Fortran 2003 Many more features
__task/__taskcomplete No Parallel Exploration
√ √
OpenMP 3.0 √ √ √
Valarray Specializations √ √ √
Lambda Functions √ √ √
Intel® Threading Building Blocks √ √ √
Intel® Integrated Performance Primitives √ √ √
Intel® Math Kernel Library √ No √
C++ Parallel Debug Plug-in with SSE/vector window and OpenMP parallelism window (Windows Only)
No Windows Debugger
√ √
GUI Debugger with SSE/vector window and OpenMP parallelism window (Linux Only)
√ No Linux debugger √
Code Coverage Utility √ √ √
Test Select Utility √ √ √
Full Fortran Interoperability √ √, except when IPO used
√
Decimal Floating-point √ √ √

Section 2Section 2Section 2Section 2New FeaturesNew FeaturesNew FeaturesNew Features
Concurrent FunctionailtyNew C++0x FeaturesDebugger Extensions

7
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
Concurrent Functionality - Idea
• The parallel programming extensions are intended for quickly getting a program parallelized without learning a great deal about APIs
• A few keywords and the program is parallelized
• If the constructs are not powerful enough in terms of data control then there may be a need to look into other more comprehensive parallel programming methodologies, such as OpenMP.

8
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
Concurrent Functionality
• Introduction of novel C/C++ language extensions to make parallel programming easier
• There are four new keywords introduced used as statement prefixes:
__taskcomplete, __task, __par, and __critical.
• To benefit from the parallelism afforded by these keywords the switch /Qpar must be used
• The runtime system will manage the actual degree of parallelism

9
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
Concurrent Functionality - example
__taskcomplete {
__task f_sum(500, a, b, c); __task f_sum(500, a+500, b+500, c+500);
}
f_sum(1000, a, b, c);
int a[1000], b[1000], c[1000];
void f_sum ( int length, int *a, int *b, int *c )
{
int i;
for (i=0; i<length; i++)
{
c[i] = a[i] + b[i];
}
}
Serial call
Parallel call

4/16/200910
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
New C++0x FeaturesNew C++0x FeaturesNew C++0x FeaturesNew C++0x Features
New C++0x features enabled by switch:
/Qstd=c++0x (Win)
– lambda functions
– static assertions
– RVALUE references
– C99-compliant preprocessor
– __func__ predefined identifier
– variadic templates
– Extern templates
… and some more

4/16/200911
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
C++0x: FuturesC++0x: FuturesC++0x: FuturesC++0x: Futures
� Future - a mechanism used to provide values that will be accessed in the future and resolved to another value asynchronously
� The definition of futures does not specify if the computation of the given expression starts immediately or when the result is requested
� Futures are realized in the Intel® Compiler by templates
intel::future<Page*> future_page;
do { // on user click
if (user clicked NEXT) {
page = future_page.get();//Wait for next page to finish loading
} else {
future_page.cancel(); //user clicked END, speculation wasted
break;
}
} while (1);

4/16/200912
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
C++0x: Lambda FunctionsC++0x: Lambda FunctionsC++0x: Lambda FunctionsC++0x: Lambda Functions
� A lambda abstraction defines an unnamed function
� Lambda functions in C++ provides:
– treat functions as first class objects
– composing functions inline
– treating functions as class objects
– Enhances concurrent code, as it is possible to pass around code chunks like objects
– Ability to pass code as parameter
� Defines the <> operator
std::vector<int> someList;int total = 0;std::for_each(someList.begin(),someList.end(), <>(int x) : [&total](total += x));std::cout << total;

4/16/200913
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
VALARRAY methods accelerated VALARRAY methods accelerated VALARRAY methods accelerated VALARRAY methods accelerated by Intelby Intelby Intelby Intel®®®® IPPIPPIPPIPP
� C++ standard template (STL) container class for arrays consisting of array methods for high performance computing
� The operations are designed to exploit low level hardware features, for example vectorization
� In order to take full advantage of valarray, you need an optimizing C++ compiler that recognizes valarray as an intrinsic type and replaces such types by Intel® IPP library calls
// Create a valarray of ints.
valarray_t::value_type ibuf[10] = {0,1,2,3,4,5,6,7,8,9};valarray_t vi(ibuf, 10);
// Create a valarray of bools for a mask.
maskarray_t::value_type mbuf[10] = {1,0,1,1,1,0,0,1,1,0};maskarray_t mask(mbuf,10);
// Double the values of the masked array
vi[mask] += static_cast<valarray_t> (vi[mask]);

IntelIntelIntelIntel®®®® Parallel ComposerParallel ComposerParallel ComposerParallel ComposerDebugger ExtensionsDebugger ExtensionsDebugger ExtensionsDebugger Extensions

15
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
• Shared Data Access Detection
• Break on Thread Shared Data Access
• Re-entrant Function Detection
• SIMD SSE Debugging Window
• Enhanced OpenMP* Support
• Serialize OpenMP threaded application execution on the fly
• Insight into thread groups, barriers, locks, wait lists etc.
Key Features

16
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
Shared Data Access Detection
• Shared data access is a major problem in multi-threaded applications� Can cause hard to diagnoseintermittent program failure
� Tool support is required fordetection
• Technology built on:� Code Instrumentation by Intel compiler
� Debug runtime library (RTL) thatcollects data access traces and triggers debugger tool
� Add-on that reports and visualizesRTL events while debugging
� The combination enables a large variety of additional debug usecases
Visual Studio or IDB
Intel Debug Runtime
GUI
sGUI Extension
Debug Engine
Debugger Extension
CompilerInstrumentedApplication
Memory AccesInstrumentation
Normaldebugging
RTLevents

17
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
Shared Data Access Detection
�Breakpoint model(stop on detection)
�GUI extensions showresults & link to source
�Filter capabilities to hide false positives
• New powerful databreakpoint types
�Stop when 2nd threadaccesses specificaddress
�Stop on read fromaddress
Key User Benefit: A simplified feature to detect shared data accesses from multiple threads
Data sharing detection is part of overall debug process

18
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
Shared Data Access Detection - Filtering
�Data Filter�Specific data itemsand variables can beexcluded
�Code Filter� Functions can beexcluded
�Source files can beexcluded
�Address ranges canbe excluded,
Data sharing detection is selective

19
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
Re-Entrant Call Detection• Automatically halts execution when a function is executed by more than one thread at any given point in time.
• Allows to identify reentrancy requirements/problems for multi-threaded applications

20
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
Enhanced OpenMP* Debugging Support
•Dedicated OpenMP runtimeobject - informationWindows � OpenMP Task and Spawn Tree lists
� Barrier and Lock information
� Task Wait lists
� Thread Team worker lists
• Serialize Parallel Regions� Change number of parallel threadsdynamically during runtime to 1 or N (all)
� Verify code correctness for serialexecution vs. Parallel execution
� Identify whether a runtime issue isreally parallelism related
User benefit: Detailed execution state information for OpenMP applications (deadlock detection). Influences execution behavior without recompile!

21
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
OpenMP*Task Details

22
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
Parallel Debug Plug-In
• Allows Filtering to control amount of data collected
• Adds window to visualize logs
• Can serialize parallel regions
23
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
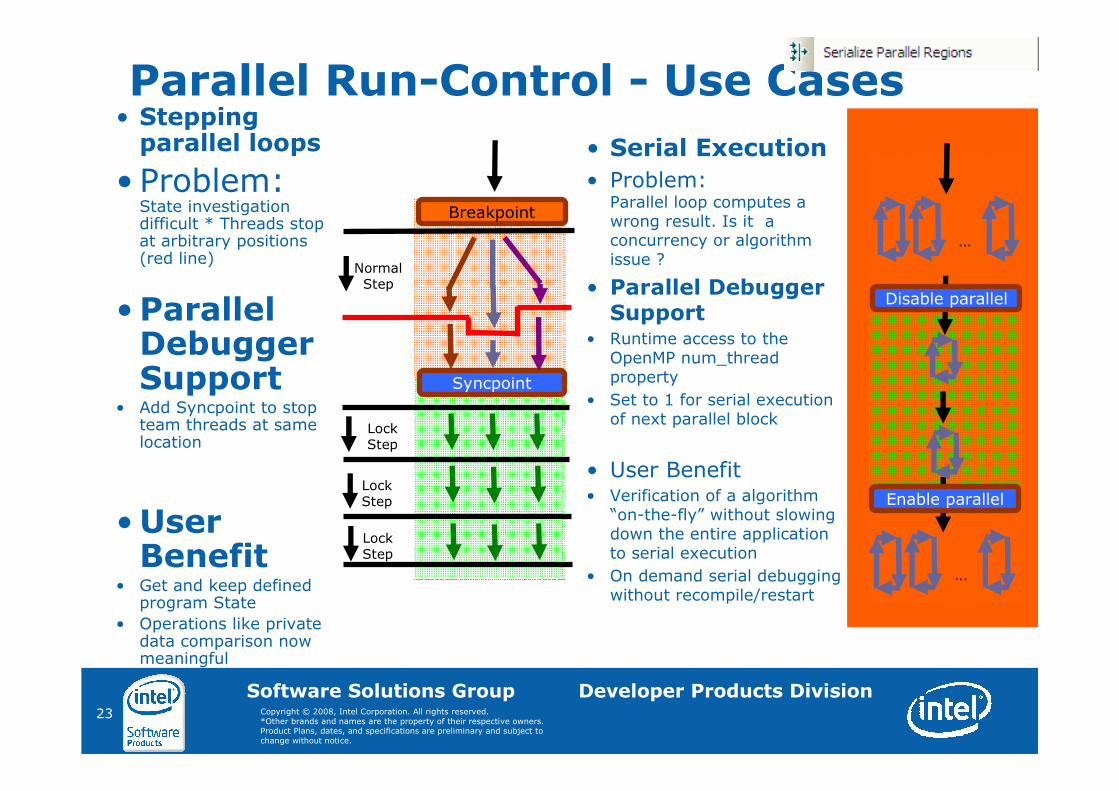
Parallel Run-Control - Use Cases• Stepping parallel loops
• Problem:State investigation difficult * Threads stop at arbitrary positions (red line)
•Parallel Debugger Support
• Add Syncpoint to stop team threads at same location
•User Benefit
• Get and keep defined program State
• Operations like private data comparison now meaningful
Syncpoint
Breakpoint
Normal Step
LockStep
LockStep
LockStep
• Serial Execution
• Problem:Parallel loop computes a wrong result. Is it a concurrency or algorithm issue ?
• Parallel Debugger Support
• Runtime access to the OpenMP num_threadproperty
• Set to 1 for serial execution of next parallel block
• User Benefit• Verification of a algorithm “on-the-fly” without slowing down the entire application to serial execution
• On demand serial debugging without recompile/restart
…
Disable parallel
…
Enable parallel

24
Software Solutions Group Developer Products DivisionCopyright © 2008, Intel Corporation. All rights reserved.
*Other brands and names are the property of their respective owners.Product Plans, dates, and specifications are preliminary and subject to
change without notice.
SIMD SSE Debugging Window
� SIMD Window (new)
� Supports evaluation of arbitrary length expressions.
� SSE Registers display of variables used for SIMD operations
� In-depth insight into data parallelization and vectorization.

Section 3Section 3Section 3Section 3Creating Parallel CodeCreating Parallel CodeCreating Parallel CodeCreating Parallel Code

4/16/200926
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Implementing Parallelism Implementing Parallelism Implementing Parallelism Implementing Parallelism –––– Different MethodsDifferent MethodsDifferent MethodsDifferent Methods
� Automatic
– Via Compiler
– No Code Changes
� Programming
– OpenMP
– Native Threads• Win32
• POSIX
– Threading Building Blocks
– MPI
� Using Parallel-enabled Libraries
– MKL
– IPPThree ways of achieving Parallelism
Automatic
Programming
Libraries

4/16/200927
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Auto ParallelismAuto ParallelismAuto ParallelismAuto Parallelism
Loop-level parallelism automatically supplied by the compiler

4/16/200928
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
AutoAutoAutoAuto----parallelization parallelization parallelization parallelization
� Auto-parallelization: Automatic threading of loops without having to manually insert OpenMP* directives.
– Compiler can identify “easy” candidates for parallelization, but large applications are difficult to analyze.
-par_report[n]
-parallel
Mac*
-par_report[n]
-parallel
Linux*
/Qpar_report[n]
/Qparallel
Windows*

4/16/200929
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Optimisation Results Optimisation Results Optimisation Results Optimisation Results –––– pi applicationpi applicationpi applicationpi application
4.64.64.64.60.2030.2030.2030.203autoautoautoauto----vecvecvecvec. & auto. & auto. & auto. & auto----par.par.par.par.
1.81.81.81.80.5160.5160.5160.516autoautoautoauto----parallelismparallelismparallelismparallelism
2.52.52.52.50.3750.3750.3750.375autoautoautoauto----vectorisationvectorisationvectorisationvectorisation
11110.9380.9380.9380.938default default default default
SpeedupTime Taken (secs)Optimisation

4/16/200930
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Sample implementations of Parallel ProgrammingSample implementations of Parallel ProgrammingSample implementations of Parallel ProgrammingSample implementations of Parallel Programming
POOP – Parallel Object Oriented Programming
*Other names and brands may be claimed as the property of others.
MPI

No ThreadsNo ThreadsNo ThreadsNo Threads
The Sample Application

4/16/200932
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Our running Example: Our running Example: Our running Example: Our running Example: The PI programThe PI programThe PI programThe PI programNumerical IntegrationNumerical IntegrationNumerical IntegrationNumerical Integration
∫4.0
(1+x2)dx = π
0
1
∑∑∑∑ F(xi)∆x ≈≈≈≈ ππππi = 0
N
Mathematically, we know that:
We can approximate the
integral as a sum of
rectangles:
Where each rectangle has
width ∆x and height F(xi) at the middle of interval i.
F( x
) =
4. 0
/(1+
x2)
4.0
2.0
1.0
X0.0

Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
PI Program: PI Program: PI Program: PI Program: The sequential programThe sequential programThe sequential programThe sequential program
static long num_steps = 100000;double step;void main (){ int i; double x, pi, sum = 0.0;
step = 1.0/(double) num_steps;
for (i=1;i<= num_steps; i++){x = (i-0.5)*step;sum = sum + 4.0/(1.0+x*x);
}pi = step * sum;
}}

Native ThreadsNative ThreadsNative ThreadsNative Threads

4/16/200935
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Threads and Parallel ProgrammingThreads and Parallel ProgrammingThreads and Parallel ProgrammingThreads and Parallel Programming
� Operating Systems 101:
– Process: A unit of work managed by an OS with its own address space (the heap) and OS managed resources.
– Threads: resources within a process that execute the instructions in a program. They have their own program counter and a private memory region (a stack) but share the other resources within the process … including the heap.
� Threads are the natural unit of execution for parallel programs on shared memory hardware.
� The threads share memory so data structures don’t have to be torn apart into distinct pieces.

4/16/200936
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Programming with Native ThreadsProgramming with Native ThreadsProgramming with Native ThreadsProgramming with Native Threads
� The OS provides an API for creating, managing, and destroying threads.
– Windows* threading API
– Posix threads (on Linux)
� Advantages of threads libraries:
– The thread library gives you detailed control over the threads.
� Disadvantage of thread libraries:
– The thread library REQUIRES that you take detailed control over the threads.
*Other names and brands may be claimed as the property of others.

Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Win32 APIWin32 APIWin32 APIWin32 API#include <windows.h>
#define NUM_THREADS 2
HANDLE thread_handles[NUM_THREADS];
CRITICAL_SECTION hUpdateMutex;
static long num_steps = 100000;
double step;
double global_sum = 0.0;
void Pi (void *arg)
{
int i, start;
double x, sum = 0.0;
start = *(int *) arg;
step = 1.0/(double) num_steps;
for (i=start;i<= num_steps;
i=i+NUM_THREADS){
x = (i-0.5)*step;
sum = sum + 4.0/(1.0+x*x);
}
EnterCriticalSection(&hUpdateMutex);
global_sum += sum;
LeaveCriticalSection(&hUpdateMutex);
}
void main ()
{
double pi; int i;
DWORD threadID;
int threadArg[NUM_THREADS];
for(i=0; i<NUM_THREADS; i++) threadArg[i] = i+1;
InitializeCriticalSection(&hUpdateMutex);
for (i=0; i<NUM_THREADS; i++){
thread_handles[i] = CreateThread(0, 0,
(LPTHREAD_START_ROUTINE) Pi,
&threadArg[i], 0, &threadID);
}
WaitForMultipleObjects(NUM_THREADS,
thread_handles, TRUE,INFINITE);
pi = global_sum * step;
printf(" pi is %f \n",pi);
}

Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Win32 thread library: Win32 thread library: Win32 thread library: Win32 thread library: ItItItIt’’’’s not as bad as it looks s not as bad as it looks s not as bad as it looks s not as bad as it looks #include <windows.h>
#define NUM_THREADS 2
HANDLE thread_handles[NUM_THREADS];
CRITICAL_SECTION hUpdateMutex;
static long num_steps = 100000;
double step;
double global_sum = 0.0;
void Pi (void *arg)
{
int i, start;
double x, sum = 0.0;
start = *(int *) arg;
step = 1.0/(double) num_steps;
for (i=start;i<= num_steps;
i=i+NUM_THREADS){
x = (i-0.5)*step;
sum = sum + 4.0/(1.0+x*x);
}
EnterCriticalSection(&hUpdateMutex);
global_sum += sum;
LeaveCriticalSection(&hUpdateMutex);
}
void main ()
{
double pi; int i;
DWORD threadID;
int threadArg[NUM_THREADS];
for(i=0; i<NUM_THREADS; i++) threadArg[i] = i+1;
InitializeCriticalSection(&hUpdateMutex);
for (i=0; i<NUM_THREADS; i++){
thread_handles[i] = CreateThread(0, 0,
(LPTHREAD_START_ROUTINE) Pi,
&threadArg[i], 0, &threadID);
}
WaitForMultipleObjects(NUM_THREADS,
thread_handles, TRUE,INFINITE);
pi = global_sum * step;
printf(" pi is %f \n",pi);
}
Setup multi-threading support
Define the work each thread
will do and pack it into a
function
Setup arguments, book
keeping, and launch the
threads
Wait for all the threads to finish
Compute
and print
final answer
Update the
final answer
one thread at
a time

Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Win32 APIWin32 APIWin32 APIWin32 API#include <windows.h>
#define NUM_THREADS 2
HANDLE thread_handles[NUM_THREADS];
CRITICAL_SECTION hUpdateMutex;
static long num_steps = 100000;
double step;
double global_sum = 0.0;
void Pi (void *arg)
{
int i, start;
double x, sum = 0.0;
start = *(int *) arg;
step = 1.0/(double) num_steps;
for (i=start;i<= num_steps;
i=i+NUM_THREADS){
x = (i-0.5)*step;
sum = sum + 4.0/(1.0+x*x);
}
EnterCriticalSection(&hUpdateMutex);
global_sum += sum;
LeaveCriticalSection(&hUpdateMutex);
}
void main ()
{
double pi; int i;
DWORD threadID;
int threadArg[NUM_THREADS];
for(i=0; i<NUM_THREADS; i++) threadArg[i] = i+1;
InitializeCriticalSection(&hUpdateMutex);
for (i=0; i<NUM_THREADS; i++){
thread_handles[i] = CreateThread(0, 0,
(LPTHREAD_START_ROUTINE) Pi,
&threadArg[i], 0, &threadID);
}
WaitForMultipleObjects(NUM_THREADS,
thread_handles, TRUE,INFINITE);
pi = global_sum * step;
printf(" pi is %f \n",pi);
}

Threading Building BlocksThreading Building BlocksThreading Building BlocksThreading Building Blocks

4/16/200941
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Featured ComponentsFeatured ComponentsFeatured ComponentsFeatured Components
Generic Parallel Algorithmsparallel_for
parallel_reducepipeline
parallel_sortparallel_whileparallel_scan
Concurrent Containersconcurrent_hash_mapconcurrent_queueconcurrent_vector
Task Scheduler

4/16/200942
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Concurrent Containers Concurrent Containers Concurrent Containers Concurrent Containers
� Library provides highly concurrent containers
– STL containers are not concurrency-friendly: attempt to modify them concurrently can corrupt container
– Standard practice is to wrap a lock around STL containers
• Turns container into serial bottleneck
� Library provides fine-grained locking or lockless implementations
– Worse single-thread performance, but better scalability.
– Can be used with the library, OpenMP, or native threads.

4/16/200943
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Generic Programming for C++ developersGeneric Programming for C++ developersGeneric Programming for C++ developersGeneric Programming for C++ developers
� Best known example is C++ STL
� Enables distribution of broadly-useful high-quality algorithms and data structures
� Write best possible algorithm with fewest constraints
– Do not force particular data structure on user
– Classic example: STL std::sort
� Instantiate algorithm to specific situation
– C++ template instantiation, partial specialization, and inlining make resulting code efficient

4/16/200944
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
template <typename Range, typename Body>void parallel_for(const Range& range, const Body &body);
� Requirements for parallel_for Body
� parallel_for partitions original range into subranges, and deals out subranges to worker threads in way that:
– Balances load
– Uses cache efficiently
– Scales
Apply the body to subrange.
void Body::operator() (Range& subrange) const
DestructorBody::~Body()
Copy constructorBody::Body(const Body&)

4/16/200945
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Serial ExampleSerial ExampleSerial ExampleSerial Example
� static void SerialUpdateVelocity() {� for( int i=1; i<UniverseHeight-1; ++i )� #pragma ivdep� for( int j=1; j<UniverseWidth-1; ++j ) � V[i][j] += (S[i][j] - S[i][j-1] + T[i][j] - T[i-1][j])*M[i];� }
Intel® TBB product has complete serial and parallel versions of seismic wave simulation.

4/16/200946
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Parallel VersionParallel VersionParallel VersionParallel Version
struct UpdateVelocityBody {void operator()( const blocked_range<int>& range ) const {int end = range.end();for( int i= range.begin(); i<end; ++i ) {
#pragma ivdepfor( int j=1; j<UniverseWidth-1; ++j ) V[i][j] += (S[i][j] - S[i][j-1] + T[i][j] - T[i-1][j])*M[i];}
}};
void ParallelUpdateVelocity() {parallel_for( blocked_range<int>( 1, UniverseHeight-1, GrainSize ),
UpdateVelocityBody() );}
Task
Establishes grain sizePattern
blue = original codered = provided by TBBblack = boilerplate for library

4/16/200947
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
tasks available to thieves
Task scheduler exampleTask scheduler exampleTask scheduler exampleTask scheduler example
Split range...
.. recursively...
...until ≤ grainsize.

4/16/200948
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
TBB ClassTBB ClassTBB ClassTBB Class
class ParallelPi
{
public:
double pi;
ParallelPi(): pi(0) {}
ParallelPi(ParallelPi &body, Split):pi(0) {}
void operator()(const tbb::blocked_range<int> &r)
{
for(int i = r.begin(); i != r.end(); ++i)
{
float x = Step * ((float)i-0.5);
pi += 4.0 / (1.0 + x*x);
}
}
void join(ParallelPi &body) { pi += body.pi; }
};

4/16/200949
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
TBB ClassTBB ClassTBB ClassTBB Class
int main()
{
ParallelPi Pi;
parallel_reduce(
tbb::blocked_range<int>(0, INTERVALS, 100),
Pi
);
printf(“Pi = %f\n”, Pi.pi/INTERVALS);
}

Section 5Section 5Section 5Section 5Expressing Parallelism Using the Expressing Parallelism Using the Expressing Parallelism Using the Expressing Parallelism Using the
Intel CompilerIntel CompilerIntel CompilerIntel Compiler
Stephen Blair-ChappellTechnical Consulting Engineer
Intel Compiler Labs

4/16/200951
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMPOpenMPOpenMPOpenMP
A deeper dive into OpenMP

4/16/200952
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
What is What is What is What is OpenMPOpenMPOpenMPOpenMP™™™™ ????
Portable, Shared Memory Multi-processing API– Fortran 77, Fortran 90, C, and C++– Multi-vendor support, for both Unix and Windows
� Standardizes loop-level parallelism
� Supports coarse-grained parallelism
� Combines serial and parallel code in single source– No need for separate source code revision
� See www.openmp.org for standard documents, tutorials, sample code
� Intel is premier member of OpenMP Review Board

Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Parallel APIs: Parallel APIs: Parallel APIs: Parallel APIs: OpenMP*OpenMP*OpenMP*OpenMP*
omp_set_lock(lck)
#pragma omp parallel for private(A, B)
#pragma omp critical
C$OMP parallel do shared(a, b, c)
C$OMP PARALLEL REDUCTION (+: A, B)
call OMP_INIT_LOCK (ilok)
call omp_test_lock(jlok)
setenv OMP_SCHEDULE “dynamic”
CALL OMP_SET_NUM_THREADS(10)
C$OMP DO lastprivate(XX)
C$OMP ORDERED
C$OMP SINGLE PRIVATE(X)
C$OMP SECTIONS
C$OMP MASTERC$OMP ATOMIC
C$OMP FLUSH
C$OMP PARALLEL DO ORDERED PRIVATE (A, B, C)
C$OMP THREADPRIVATE(/ABC/)
C$OMP PARALLEL COPYIN(/blk/)
Nthrds = OMP_GET_NUM_PROCS()
!$OMP BARRIER
OpenMP: An API for Writing Multithreaded ApplicationsOpenMP: An API for Writing Multithreaded Applications
•• A set of compiler directives and library routines for A set of compiler directives and library routines for
parallel application programmersparallel application programmers
•• Makes it easy to create multithreaded (MT) Makes it easy to create multithreaded (MT)
programs in Fortran, C and C++programs in Fortran, C and C++
•• Standardizes last 15 years of SMP practiceStandardizes last 15 years of SMP practice

4/16/200954
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMP ArchitectureOpenMP ArchitectureOpenMP ArchitectureOpenMP Architecture
� Fork-Join Model
� Worksharing constructs
� Synchronization constructs
� Directive/pragma-based parallelism
� Extensive API for finer control
4/16/200955
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
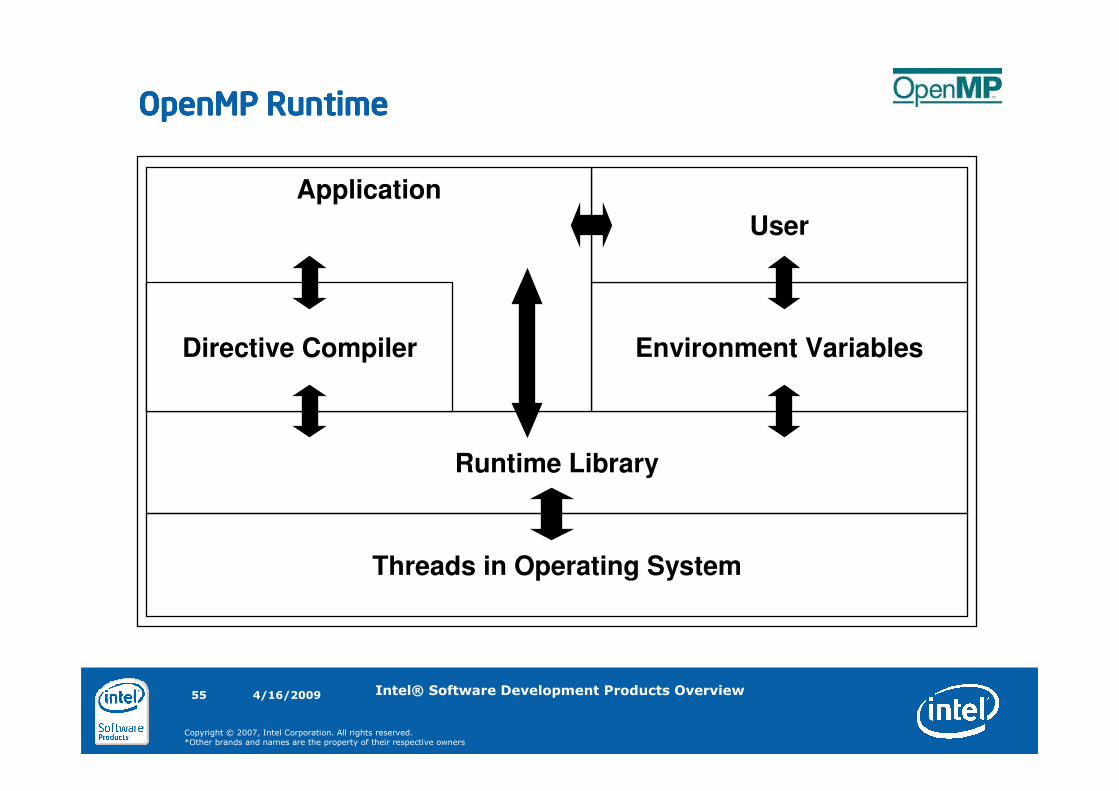
OpenMP RuntimeOpenMP RuntimeOpenMP RuntimeOpenMP Runtime
Threads in Operating System
Runtime Library
Environment Variables
User
Application
Directive Compiler

4/16/200956
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMPOpenMPOpenMPOpenMP Programming Model: Programming Model: Programming Model: Programming Model:
Fork-Join Parallelism: �Master thread spawns a team of threads as needed.
�Parallelism added incrementally until performance are met: i.e. the sequential program evolves into a parallel program.
Parallel RegionsMaster Thread in red
A Nested
Parallel region
A Nested
Parallel region
Sequential PartsSequential PartsSequential PartsSequential Parts*Other names and brands may be claimed as the property of others.

4/16/200957
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Intel Compiler Switches for Intel Compiler Switches for Intel Compiler Switches for Intel Compiler Switches for OpenMPOpenMPOpenMPOpenMP
� OpenMP™ support
– /Qopenmp
– /Qopenmp_report{0|1|2}
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
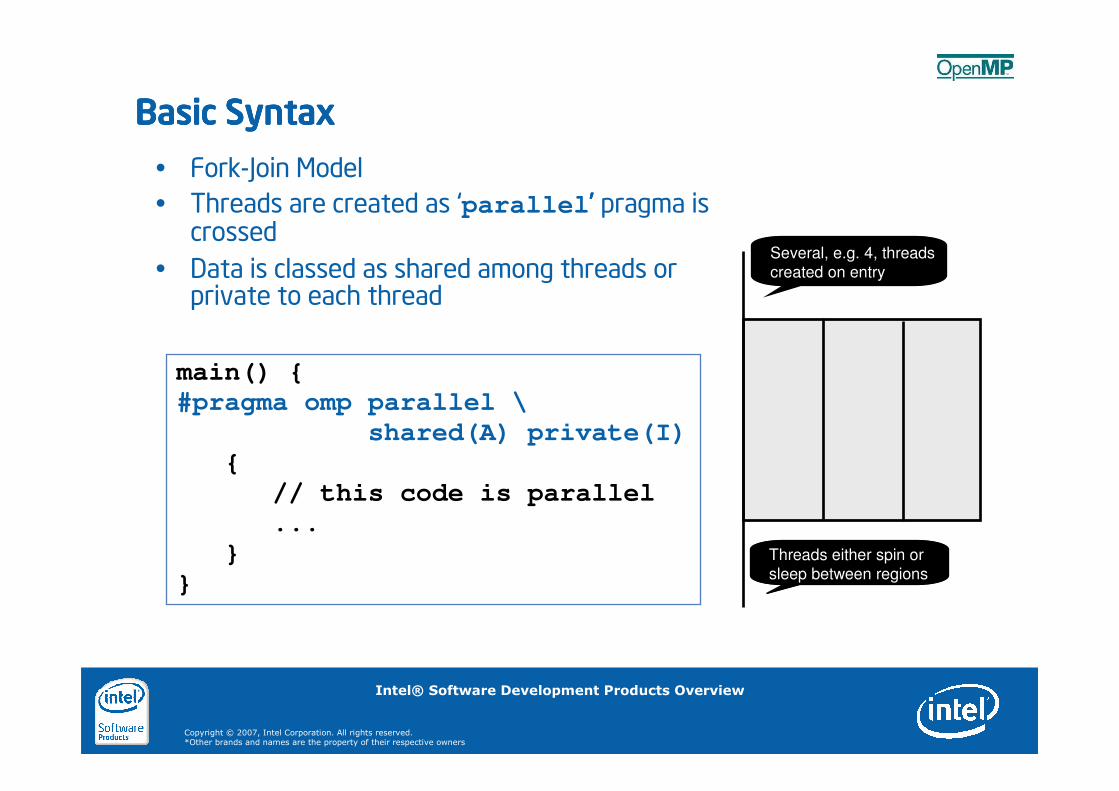
Basic SyntaxBasic SyntaxBasic SyntaxBasic Syntax
� Fork-Join Model
� Threads are created as ‘parallel’’’’ pragma is crossed
� Data is classed as shared among threads or private to each thread
Several, e.g. 4, threads
created on entry
Threads either spin or
sleep between regions
main() {
#pragma omp parallel \
shared(A) private(I)
{
// this code is parallel
...
}
}

4/16/200959
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Hello WorldHello WorldHello WorldHello World
� This program runs on three threads: � Prints this:
Hello World
Hello World
Hello World
Iter: 1
Iter: 2
Iter: 3
Iter: 4
Goodbye World
Goodbye World
Goodbye World
Void main()
#pragma omp parallel
{
printf(“Hello World\n”);
#pragma omp for
for(i=0;i<=4;i++) {
printf(“Iter: %d”, I);
}
printf(“Goodbye World\n”);
}

Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Parallel Loop ModelParallel Loop ModelParallel Loop ModelParallel Loop Model
� Threads are created
� Data is classified as shared or private
A is shared
Parallel For
I=1
I=2
I=3
I=4
I=5
I=6
A
Iterations
distributedacross threads
Barrier at end
Threads either spin or
sleep between regions
void* work(float* A) {
#pragma omp parallel for \
shared(A) private(i)
for(i=1; i<=12; i++) {
/* Iterations divided
* among threads
*/
}
}

4/16/200961
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Data Scope AttributesData Scope AttributesData Scope AttributesData Scope Attributes
� The default status can be modified with
default (shared | none)
� Scoping attribute clauses
shared(varname,…………)
private(varname,…………)

4/16/200962
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
The Private ClauseThe Private ClauseThe Private ClauseThe Private Clause
� Reproduces the variable for each thread
• Variables are un-initialized; C++ object is default constructed
• Any value external to the parallel region is undefined
void* work(float* c, int N) {
float x, y; int i;
#pragma omp parallel for private(x,y)
for(i=0; i<N; i++) {
x = a[i]; y = b[i];
c[i] = x + y;
}
}

4/16/200963
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Example: Dot ProductExample: Dot ProductExample: Dot ProductExample: Dot Product
float dot_prod(float* a, float* b, int N)
{
float sum = 0.0;
#pragma omp parallel for shared(sum)
for(int i=0; i<N; i++) {
sum += a[i] * b[i];
}
return sum;
}
What is Wrong?What is Wrong?

4/16/200964
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Protect Shared DataProtect Shared DataProtect Shared DataProtect Shared Data
� Must protect access to shared, modifiable data
float dot_prod(float* a, float* b, int N)
{
float sum = 0.0;
#pragma omp parallel for shared(sum)
for(int i=0; i<N; i++) {#pragma omp critical
sum += a[i] * b[i];
}
return sum;
}

4/16/200965
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMP* Critical ConstructOpenMP* Critical ConstructOpenMP* Critical ConstructOpenMP* Critical Construct
float R1, R2;
#pragma omp parallel
{ float A, B;
#pragma omp for
for(int i=0; i<niters; i++){
B = big_job(i);
#pragma omp critical
consum (B, &R1);
A = bigger_job(i);
#pragma omp critical
consum (A, &R2);
}
}
Threads wait their turn –
at a time, only one calls consum() thereby
protecting R1 and R2 from race conditions.
Naming the critical constructs is optional, but may increase
performance.
(R1_lock)
(R2_lock)
� #pragma omp critical [(lock_name)]
� Defines a critical region on a structured block

4/16/200966
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMP* Reduction ClauseOpenMP* Reduction ClauseOpenMP* Reduction ClauseOpenMP* Reduction Clause
� reduction (op : list)
� The variables in “list” must be shared in the enclosing parallel region
� Inside parallel or work-sharing construct:
• A PRIVATE copy of each list variable is created and initialized depending on the “op”
• These copies are updated locally by threads
• At end of construct, local copies are combined through “op” into a single value and combined with the value in the original SHARED variable

4/16/200967
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Reduction ExampleReduction ExampleReduction ExampleReduction Example
� Local copy of sum for each thread
� All local copies of sum added together and stored in “global” variable
#pragma omp parallel for reduction(+:sum)
for(i=0; i<N; i++) {
sum += a[i] * b[i];
}
4/16/200968
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
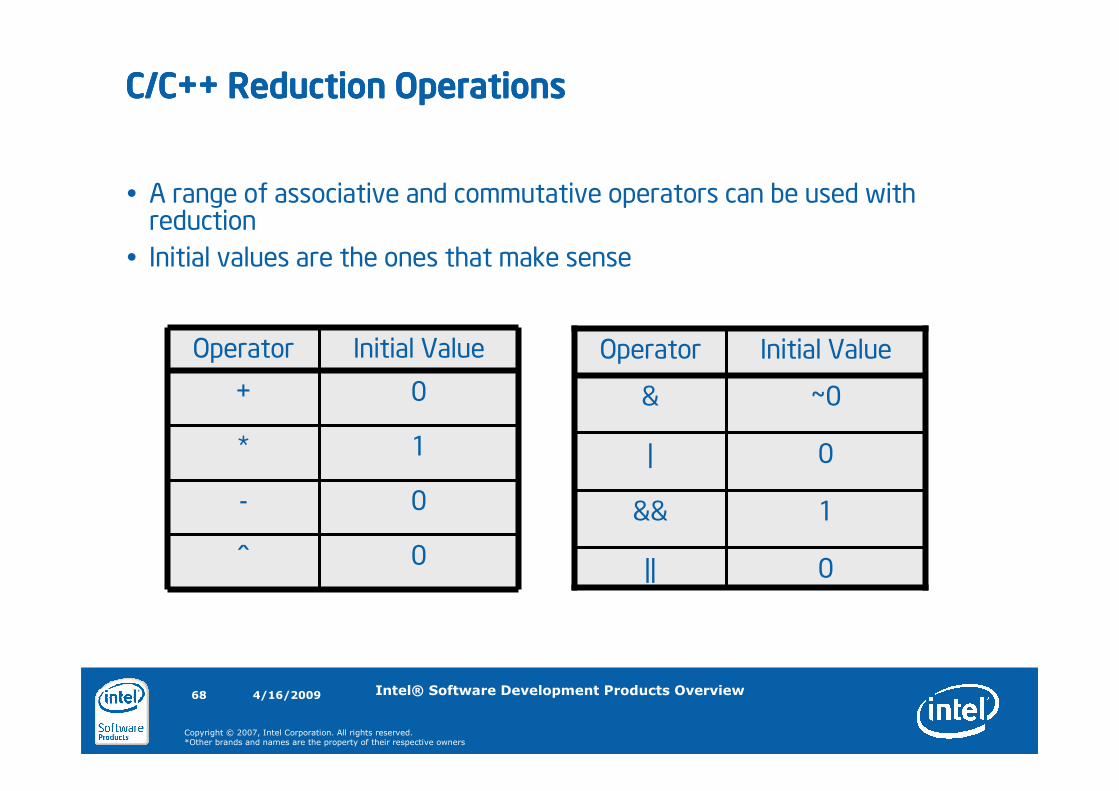
� A range of associative and commutative operators can be used with reduction
� Initial values are the ones that make sense
C/C++ Reduction OperationsC/C++ Reduction OperationsC/C++ Reduction OperationsC/C++ Reduction Operations
0^
0-
1*
0+
Initial ValueOperator
0||
1&&
0|
~0&
Initial ValueOperator

4/16/200969
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Schedule ClauseSchedule ClauseSchedule ClauseSchedule Clause
#pragma omp parallel for schedule (static, 8)
for( int i = start; i <= end; i += 2 )
{
if ( TestForPrime(i) ) gPrimesFound++;
}
� Iterations are divided according to schedule statement

Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMPOpenMPOpenMPOpenMPParallel for with a reductionParallel for with a reductionParallel for with a reductionParallel for with a reduction
#include <omp.h>
static long num_steps = 100000;
double step;
#define NUM_THREADS 2
void main ()
{
int i;
double x, pi, sum = 0.0;
step = 1.0/(double) num_steps;
omp_set_num_threads(NUM_THREADS);
#pragma omp parallel for reduction(+:sum) private(x)
for (i=1;i<= num_steps; i++)
{
x = (i-0.5)*step;
sum = sum + 4.0/(1.0+x*x);
}
pi = step * sum;
}
*Other names and brands may be claimed as the property of others.

4/16/200971
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMP FOR-schedule schemas
� schedule clause defines how loop iterations assigned to threads
� Compromise between two opposite goals:
– Best thread load balancing
– With minimal controlling overhead
N
N/2
C
f
single thread
schedule(static)
schedule(dynamic, c)
schedule(guided, f)

4/16/200972
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Iterative Iterative Iterative Iterative worksharingworksharingworksharingworksharing versus code replicationversus code replicationversus code replicationversus code replication
� Iterative worksharing -- prints ‘Hello World’ 10 times, regardless of the number of threads:
� Code replication -- assuming a team of 4 threads, prints ‘Hello World’ 40 times:
#pragma omp parallel for
for( int i = 1,i< 10;i++)
{
printf(“Hello World\n”);}
#pragma omp parallel
for( int i = 1,i< 10;i++)
{
printf(“Hello World\n”);}

4/16/200973
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Parallel SectionsParallel SectionsParallel SectionsParallel Sections
� Independent sections of code can execute concurrently
Serial Parallel
#pragma omp parallel sections
{
#pragma omp section
phase1();
#pragma omp section
phase2();
#pragma omp section
phase3();
}

4/16/200974
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Implicit BarriersImplicit BarriersImplicit BarriersImplicit Barriers
� Several OpenMP constructs have implicit barriers:
do
for
single
sections
� Unnecessary barriers hurt performance
� Suppress them, when safe, with nowait
!$omp do
[...]
!$omp end do nowait
#pragma omp for nowait
for(...)
[...];
!$omp sections
[...]
!$omp end sections nowait
#pragma omp single nowait
{ [...] }

4/16/200975
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Static and Dynamic ExtentStatic and Dynamic ExtentStatic and Dynamic ExtentStatic and Dynamic Extent
� Static extent or lexical extent is the code that is lexically within the parallel/end parallel directive
� Dynamic extent includes the static extent and the entire call tree of any subroutine or function called in the static extent.
� OpenMP directives in the dynamic extent of a parallel region are called orphaned directives
� An orphaned worksharing construct behaves as if the construct was within the lexical extent – the work is divided across thread team
– The only difference is that slightly different data scoping rules apply.

4/16/200976
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Static and Dynamic Extent Static and Dynamic Extent Static and Dynamic Extent Static and Dynamic Extent
Program main
!$omp parallel <-| Static extent
call foo |<-|
!$omp end parallel <-| |
End |
+ |
| Dynamic extent
Subroutine foo <-| |
!$omp do !orphaned | |
do i = 1,100 | |
enddo |<-|
!$omp end do |
Call X !also dynamic |
End subroutine foo <-|

4/16/200977
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Communication and data scopeCommunication and data scopeCommunication and data scopeCommunication and data scope
� In OpenMP every variable has a scope that is either shared or private
� By default, all variables have shared scope
� Data scoping clauses that can appear on parallel constructs:
– The shared and private clauses explicitly scope specific variables
– The firstprivate and lastprivate clauses perform initialization and finalization of private variables
– The default clause changes the default scoping rules when variables are not explicitly scoped
– The reduction clause explicitly identifies reduction variables

4/16/200978
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Communication and data scopeCommunication and data scopeCommunication and data scopeCommunication and data scope
� Each thread has a private stack used for automatic variables
� For all other program variables, the parallel constructs can scope each variable as shared, private, or reduction
� Private variables need to be initialized at the start of a parallel construct. The firstprivate clause will initialize from the global instance
� For parallelized loops, the lastprivate clause will update the global instance from the private value computed with the last iteration

4/16/200979
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Communication and data scopeCommunication and data scopeCommunication and data scopeCommunication and data scope
� Variables default to shared scope, except for these cases:– Loop index variables to which a parallel do or parallel forapplies default to private
– Locals variables in subroutines in the dynamic extent default toprivate unless they are marked with the save attribute (Fortran) or as static (C/C++)
� Data scoping clauses only apply to the named variables within the lexical extent
– Global variables in orphaned constructs are shared by default, regardless of the attribute in the lexical extent
– Automatic (stack allocated) variables in orphaned constructs arealways private
– Formal parameters to a subroutine in the dynamic extent acquire their scope from that of the actual variables in the caller’s context

4/16/200980
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
Environment VariablesEnvironment VariablesEnvironment VariablesEnvironment Variables� Standard Environment Variables– OMP_SCHEDULE
• Runtime schedule and optional iteration chunk size– OMP_NUM_THREADS
• Number of worker threads; defaults to number of processors– OMP_DYNAMIC
• Enables dynamic adjustment of the number of threads – OMP_NESTED
• Enables nested parallelism
� Intel Extension Environment Variables– KMP_ALL_THREADS
• Maximum number of threads in a parallel region– KMP_BLOCKTIME
• Thread wait time before sleeping at the end of a parallel region– KMP_LIBRARY
• Runtime execution mode: throughput (default) for multi-user systems, turnaround for a dedicated (single user) system
– KMP_STACKSIZE
• Worker thread stack size

4/16/200981
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
SynchronizationSynchronizationSynchronizationSynchronization
� Two kinds of synchronization– Mutual exclusion synchronization for exclusive access to data by only one thread at a time
– Event synchronization for imposing a thread execution order
� Most commonly used synchronization directives– Data synchronization gives a thread exclusive access to a shared variable• !$omp critical
an arbitrarily large block of structured code
• !$omp end critical
• !$omp atomic
a single assignment that updates a scalar variable
– Event synchronization signals the occurrence of an event that all threads must synchronize their execution on• !$omp barrierspecifies a point in the program where each thread must wait for all other threads to arrive
� Other less-frequently used synchronization directives!$omp master, !$omp flush, !$omp ordered

4/16/200982
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
The Workqueuing ModelThe Workqueuing ModelThe Workqueuing ModelThe Workqueuing Model
� Work units need not be all known or pre-computed at the beginning of construct (e.g.: while loops and recursive functions)
� taskq specifies an environment (the queue)task specifies the units of work (dynamic)
� One thread executes the taskq block, enqueuing each task it encounters
� All other threads dequeue and execute work from the queue
� Intel-specific extension to OpenMP* 2.5
– Has been accepted in new 3.0 version ( to be released Q2/08)
4/16/200983
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
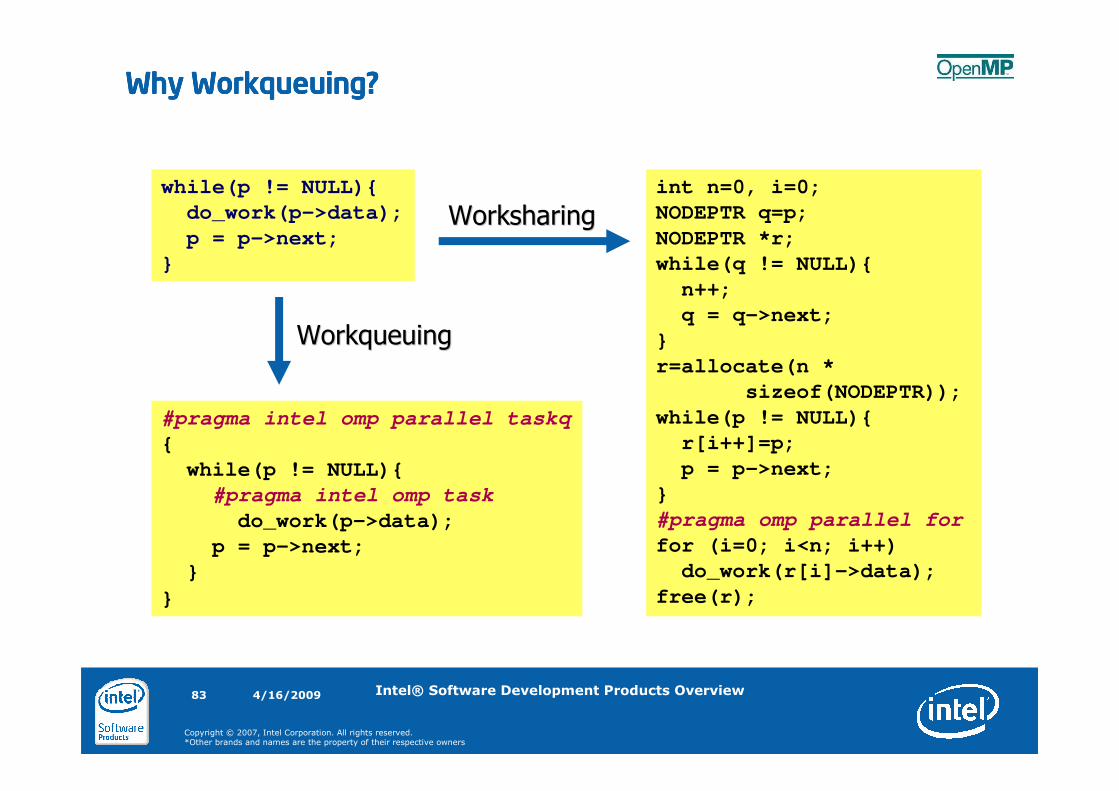
Why Workqueuing?Why Workqueuing?Why Workqueuing?Why Workqueuing?
while(p != NULL){
do_work(p->data);
p = p->next;
}
int n=0, i=0;
NODEPTR q=p;
NODEPTR *r;
while(q != NULL){
n++;
q = q->next;
}
r=allocate(n *
sizeof(NODEPTR));
while(p != NULL){
r[i++]=p;
p = p->next;
}
#pragma omp parallel for
for (i=0; i<n; i++)
do_work(r[i]->data);
free(r);
WorksharingWorksharing
WorkqueuingWorkqueuing
#pragma intel omp parallel taskq
{
while(p != NULL){
#pragma intel omp task
do_work(p->data);
p = p->next;
}
}

4/16/200984
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMPOpenMPOpenMPOpenMP* 3.0 Support * 3.0 Support * 3.0 Support * 3.0 Support
� IntelIntelIntelIntel®®®® Compilers 11.0 for C++ and Compilers 11.0 for C++ and Compilers 11.0 for C++ and Compilers 11.0 for C++ and FortanFortanFortanFortan will be fully complaint to will be fully complaint to will be fully complaint to will be fully complaint to OpenMPOpenMPOpenMPOpenMP* 3.0* 3.0* 3.0* 3.0
– Standard not release yet Standard not release yet Standard not release yet Standard not release yet • Very likely May 08 !Very likely May 08 !Very likely May 08 !Very likely May 08 !
– Draft at Draft at Draft at Draft at www.openmp.orgwww.openmp.orgwww.openmp.orgwww.openmp.org
– Four major extensions:Four major extensions:Four major extensions:Four major extensions:• Tasking for unstructured parallelismTasking for unstructured parallelismTasking for unstructured parallelismTasking for unstructured parallelism
• Loop collapsingLoop collapsingLoop collapsingLoop collapsing
• Enhanced loop scheduling controlEnhanced loop scheduling controlEnhanced loop scheduling controlEnhanced loop scheduling control
• Better support for nested parallelismBetter support for nested parallelismBetter support for nested parallelismBetter support for nested parallelismand for all who waited and for all who waited and for all who waited and for all who waited ………… eventually allow unsigned eventually allow unsigned eventually allow unsigned eventually allow unsigned intintintint for loop index variable for loop index variable for loop index variable for loop index variable ☺☺☺☺

4/16/200985
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMPOpenMPOpenMPOpenMP* 3.0 Tasking* 3.0 Tasking* 3.0 Tasking* 3.0 TaskingMaybe the most relevant new featureMaybe the most relevant new featureMaybe the most relevant new featureMaybe the most relevant new feature
� A task has
– Code to execute
– A data environment (it owns its data)
– An assigned thread that executes the code and uses the data� Two activities: packaging and execution
– Each encountering thread packages a new instance of a task (code and data)
– Some thread in the team executes the task at some later time� A task is nothing really new to OpenMP
– Implicitly each PARALLEL directive creates ‘tasks’ but they have been transparent objects
– OpenMP* 3.0 makes ‘tasking’ explicit

4/16/200986
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMPOpenMPOpenMPOpenMP* 3.0 Tasking * 3.0 Tasking * 3.0 Tasking * 3.0 Tasking ---- DefinitionsDefinitionsDefinitionsDefinitions
� Task construct – task directive plus structured block
� Task – the package of code and instructions for allocating data created when a thread encounters a task construct
� Task region – the dynamic sequence of instructions produced by the execution of a task by a thread
� ####pragmapragmapragmapragma ompompompomp task [task [task [task [clause[[,][[,][[,][[,]clause] ...] ] ...] ] ...] ] ...] structured-block
� Where <clause> is one of
� if (if (if (if (expression) ) ) )
� untieduntieduntieduntied
� shared (shared (shared (shared (list))))
� private (private (private (private (list) ) ) )
� firstprivatefirstprivatefirstprivatefirstprivate ((((list))))
� default( shared default( shared default( shared default( shared | none none none none ))))

4/16/200987
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMP* 3.0 Tasking ExampleOpenMP* 3.0 Tasking ExampleOpenMP* 3.0 Tasking ExampleOpenMP* 3.0 Tasking ExamplePostorder Tree TraversalPostorder Tree TraversalPostorder Tree TraversalPostorder Tree Traversal
� void postorder(node *p)
� {
� if (p->left)
� #pragma omp task
� postorder(p->left);
� if (p->right)
� #pragma omp task
� postorder(p->right);
� #pragma omp taskwait // wait for descendants
� process(p->data);
� }
� Parent task suspended until children tasks complete
Task scheduling pointThreads may switch to
execute other tasks

4/16/200988
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMPOpenMPOpenMPOpenMP* 3.0 * 3.0 * 3.0 * 3.0 –––– Enhanced Schedule ControlEnhanced Schedule ControlEnhanced Schedule ControlEnhanced Schedule Control
� Made schedule(runtime) more useful now
– can get/set it with library routinesomp_set_schedule()
omp_get_schedule()
– allow implementations to use their own schedule kinds
� Adds a new schedule kind AUTO which gives full freedom to the runtime to determine the scheduling of iterations to threads
� Allows C++ random access iterators as loop control variables in parallel loops

4/16/200989
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMPOpenMPOpenMPOpenMP* 3.0 Loop Collapsing * 3.0 Loop Collapsing * 3.0 Loop Collapsing * 3.0 Loop Collapsing
� Allow collapsing of perfectly nested loops
� Will form a single loop and then parallelize that
� Scheduling of combined iteration space follows the order of the original, sequential execution
!$omp parallel do collapse(2)
do i=1,n
do j=1,n
.....
end do
end do

4/16/200990
Copyright © 2007, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners
Intel® Software Development Products Overview
OpenMPOpenMPOpenMPOpenMP 3.0 : Nested Parallelism3.0 : Nested Parallelism3.0 : Nested Parallelism3.0 : Nested Parallelism
� Better support for nested parallelism
� Per-thread internal control variables
– Allows, for example, calling omp_set_num_threads()inside a parallel region.
– Controls the team sizes for next level of parallelism
� Library routines to determine depth of nesting, IDs of parent/grandparent etc. threads, team sizes of parent/grandparent etc. teams
� omp_get_active_level()
� omp_get_ancestor(level)
� omp_get_teamsize(level)