intelligent web topics search using early detection and data analysis by yixin yang presented by...
TRANSCRIPT

Intelligent Web Topics Search Using Early Detection and Data Analysis
Intelligent Web Topics Search Using Early Detection and Data Analysis
by Yixin Yang
Presented by
Yixin Yang
(Advisor Dr. C.C. Lee)
Presented by
Yixin Yang
(Advisor Dr. C.C. Lee)
July 30, 2003

Outline
1. Introduction and Background2. Related Work3. Our Approach4. System Architecture5. Crawl Algorithms and Implementation6. Experimental result7. Conclusions and Future Work

Introduction and Background

General-purpose search engine
Problem with General-purpose search engine :
These search engines lack the capabilities of finding the relevant web sites for a giving specific topic
General-purpose search engine: designed to crawl and index the web, get pages as many as possible

Topic-specific Search Engine
Topic-specific search engine: focuses on one or a limited number of topics, get topic-related pages as fast as possible without deviating to unrelated pages.
To help the topic-specific search engines to crawl the related hyperlinks, the relevant topics should provide to topic-specific search engines in advance.

Topic-specific Search Engine Sample
Internet directories like Yahoo!, or topic-specific search engine like MathSearch offer higher quality, they construct a hierarchy for topic, but they require intensive human efforts (hierarchy will be maintained by humans to update )
Google rates sites based on how frequently someone links to a page -- the more links, the more relevant. Essentially, it harnesses human judgment.

Topic-specific Search Engine Sample (cont.)
Focused Crawler utilizes both web link structure information and content similarity (based on document classification), but this system unnecessarily visits too many irrelevant pages.

Metadata in Web Documents•Metadata of a page x, is the description about the page, x, furnished by other page y, that hyperlink to x.
•Analogy: Citation in a research paper
x
y1
y2
y3

Metadata in HTML
1. Anchor (<a>) tags2. Image (<img>) tags3. Map and Area tags4. Frame tags
Each of tags have attributes associated with them.Anchor and Area: name, title, alt, href…Image: alt, src, dynsrc, lowsrc…
• Anchor text (<a ..>text</a>)
Four kinds of Hyperlinks in HTML document

Metadata Experiment by J. Yi and N. Sundaresan
• Studied a sample set of 20, 000 HTML pages, and 206,000 hyperlink references • Showed anchor text are most frequently used and reliable
Metadata Type Hyperlinks Pages
ALT tag 1890 (0.9%) 281 (1.5%)
Anchor Text 147745 (72%) 14320 (76%)
HREF 176412 (85%) 16313 (87%)
NAME 5487 (27%) 779 (4.1%)
ONMOUSEOVER 9383 (4.5%) 1523 (8.1%)
Surrounding Text 49183 (24%) 8424 (45%)
Title 885 (0.4%) 249 (1.3%)

Target topics, Candidate topics and Relevant topics
Target Topics: the topics that may consist of many sub-topics.
Relevant Topics: the topics that related to a target topic.
Candidate Topics: the topics that potentially relevant to a target topic.

Related Work

Recent Research in Topic-specific Search Engine :Topic Expansion Algorithm
Presented by Jeonghee Yi and Neel Sundaresan
Discovers relevant topics of a given topic Does not need to visit unnecessary web
pages and does not need intensive human effort.

Recent Research in Topic-specific Search Engine :Topic Expansion Algorithm ( cont.)
Four steps in Topic Expansion Algorithm:1. Collects large number of Web pages2. Extracts words from the text that is contained
inside HTML document tags 3. Selects some words that are potentially relevant
to the target topic.4. Uses a formula and a relationship-based
architecture for finding the relation between words to refine and return the relevant topics.

What is confidence? A good way to explain confidence is using
association rule. An association rule is an expression X
=>Y, where X and are sets of items. The intuitive meaning of such a rule is that transaction in database which contain the items in X also contain the items in Y.

Formula By J. Yi and N. Sundaresan

Recent Research in Topic-specific Search Engine :Topic Expansion Algorithm ( cont.)
Topic Expansion Algorithm does not need to visit unnecessary web pages and does not need intensive human effort. But it still needs :
much human involvement to update the architecture
many web pages of Web sites crawling

Our Research

Our Approach Uses early detection and data analysis
techniques for detecting and analyzing candidate topics
Add Stop Word Filter, Candidate topic Selector, Candidate topic filter to the typical web crawler
Simplify the formula used by J. Yi and N. Sundaresan

Formula we used:
cMAXco
co
to
cor *
c o : th e n u m b er o f t im es a c an d id a te to p ic co -o ccu r r ed w ith th e ta r g e t to p ic
to : th e to ta l o ccu r t im es fo r a c an d id a te to p ic MAXco : th e m a x im n u m b er o f c o am o n g a ll c an d id a te to p ic s
r : th e fi l ter in g m e tr ic c : th e u ser -d e fin ed th r e sh o ld
T h is fo r m u la is u sed to d e te rm in e ea ch can d id a te to p ic is m or e r e la ted to ta r g e t
to p ic o r o th er to p ic s . c o /to i s u sed to d e te rm in e h o w d eep a c an d id a te to p ic r e la ted to o th e r to p ic s . I f c o / to i s sm a lle r , m ean s th i s c an d id a te to p ic is m o r e r e la ted to o th e r to p ic s . c o /M a xc o i s u sed to d e te rm in e th e d eg r ee o f r e la t io n sh ip b e tw een a c an d id a te to p ic
an d th e ta r g e t to p ic .

System Architecture

System Architecture

Components in Our System Web Crawler Page Parser Stop Word Filter Candidate Topic Selector Candidate Topic Filter Relevant Term Database

Crawl Algorithms and Implementation

Crawl Algorithms: just like the typical Web Crawler Starts with a (set of)
predefined web URLs
and downloads them Breath-first-search Uses Recursion

This system: add something inside typical web crawler

Implementation : Language and Technology
Java Programming Language Java HTTP Request Java AWT and Swing Java Database Connectivity (JDBC)
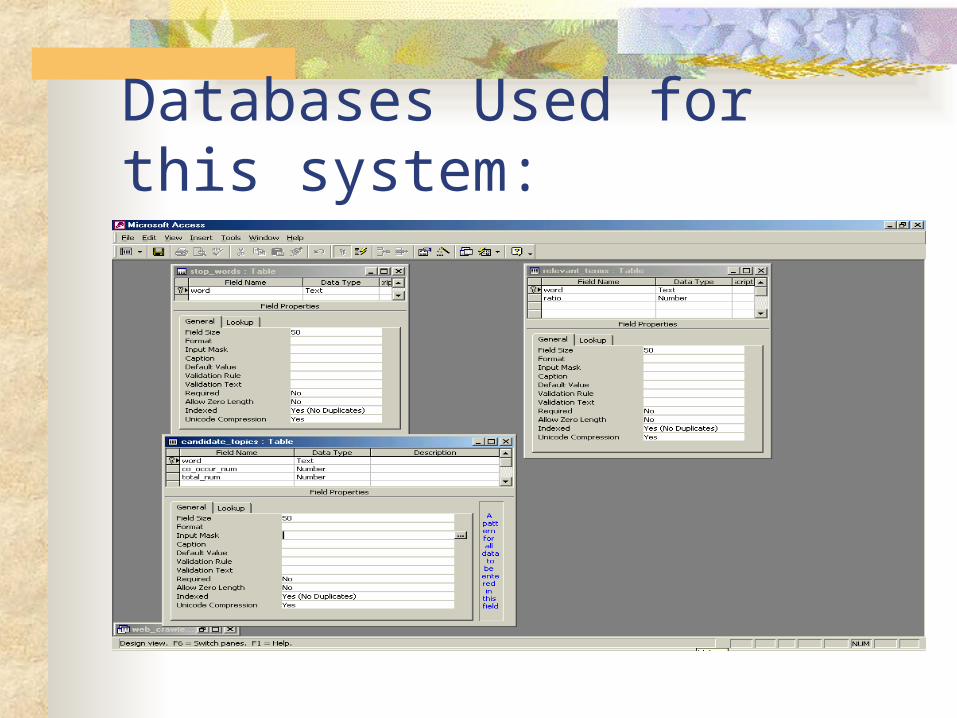
Databases Used for this system:

10 components implemented for this system:
WebCrawler HttpPage HTMLparser CandidateTopicFilter CandidateTopicSelector, StopWordFilter, StopWordsTable, Tokens.DoStat, DBAccess

Important Components HTMLparser
Parses HTML pages and Extracts the Meta data.Uses javax.swing.test.html parser package to parse the HTML page.Get the text inside <A> tags
StopWordsTableWhen start the whole application, read the stop words from Database “stop_words” table and put every word into a Hash table.

Important Components (cont.) StopWordFilter
Reads the words extracted from Metadata one by one, if a token can also be found in “stop_words” hush table, remove this word.

Important Components (cont.) CandidateTopicSelector
Reads one string (tokens) processed by Stop word filter
The attribute “total_num” for every word (except target topic) increase one
if find target topic inside this string,
the attribute “co_occur_num” for every word inside this string (except target topic) also increase one

Important Components (cont.) CandidateTopicFilter
Check every words inside the “candidate_topics” table, and calculate every words by this formula:
if words meet the requirement,put these words to “relevant_terms” table.

Formula we used:
cMAXco
co
to
cor *
c o : th e n u m b er o f t im es a c an d id a te to p ic co -o ccu r r ed w ith th e ta r g e t to p ic
to : th e to ta l o ccu r t im es fo r a c an d id a te to p ic MAXco : th e m a x im n u m b er o f c o am o n g a ll c an d id a te to p ic s
r : th e fi l ter in g m e tr ic c : th e u ser -d e fin ed th r e sh o ld
T h is fo r m u la is u sed to d e te rm in e ea ch can d id a te to p ic is m or e r e la ted to ta r g e t
to p ic o r o th er to p ic s . c o /to i s u sed to d e te rm in e h o w d eep a c an d id a te to p ic r e la ted to o th e r to p ic s . I f c o / to i s sm a lle r , m ean s th i s c an d id a te to p ic is m o r e r e la ted to o th e r to p ic s . c o /M a xc o i s u sed to d e te rm in e th e d eg r ee o f r e la t io n sh ip b e tw een a c an d id a te to p ic
an d th e ta r g e t to p ic .

Experimental result

Run Application This system can run on MS-DOS Prompt
application from any windows system such as Windows XP, Windows ME etc.
You must install and set up Microsoft Access database before run this system.
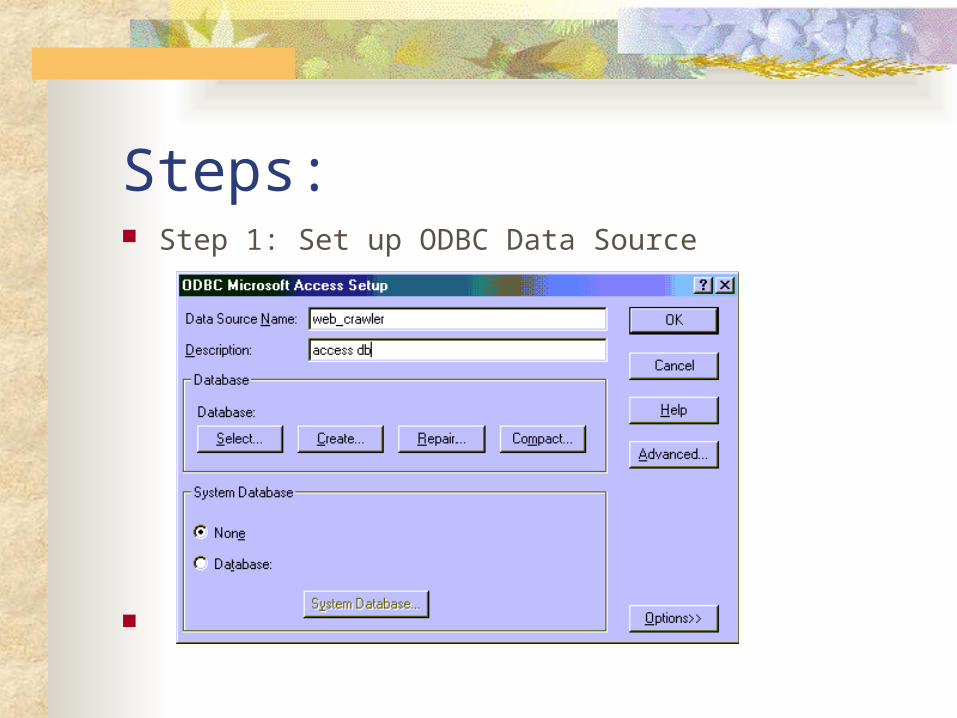
Steps: Step 1: Set up ODBC Data Source

Steps (cont.) Step 2: Start the Java application in MS-DOS
Prompt console

Steps (cont.) Step 3: Enter the start URL and target topic in
java application
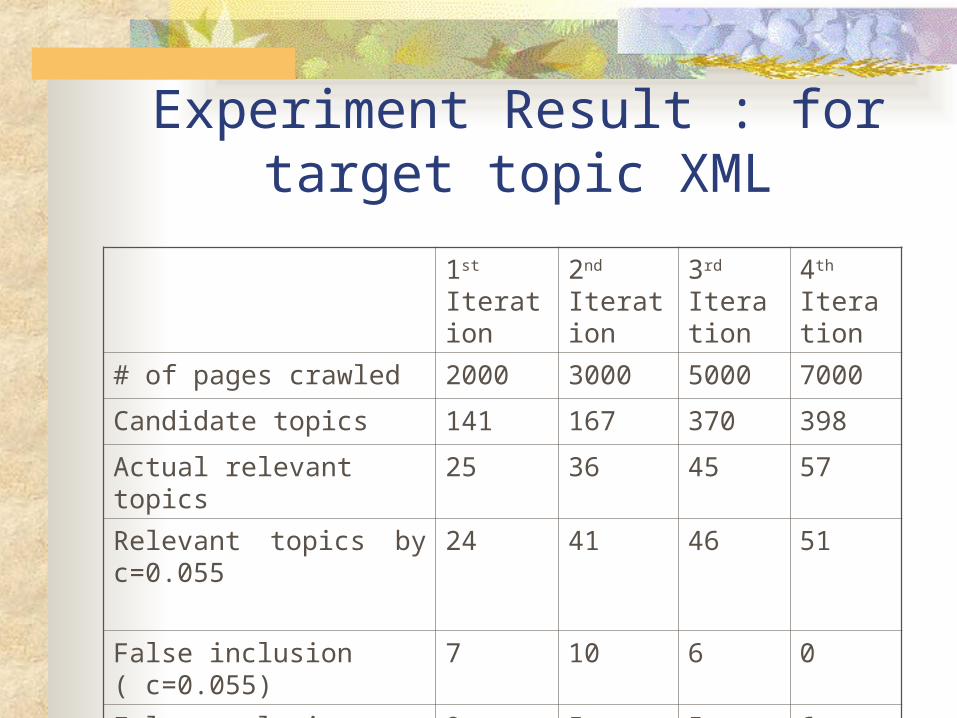
Experiment Result : for target topic XML
1st Iteration
2nd Iteration
3rd Iteration
4th Iteration
# of pages crawled 2000 3000 5000 7000
Candidate topics 141 167 370 398
Actual relevant topics 25 36 45 57
Relevant topics by c=0.055 24 41 46 51
False inclusion ( c=0.055) 7 10 6 0
False exclusion (c=0.055) 9 5 5 6

Compared to Topic Expansion Algorithm, this system also has: Lower number of web pages crawled
Other system : crawled 34,000 web pages to get 49 relevant topics out of 54 actual relevant topics
Our system : crawled 17,000 web pages and get 51 relevant topics out of 57 actual relevant topics
Don’t need a relation-based architecture
Other system : most of them need a relationship-based hierarchy and update the hierarchy every time.
Our system : Use stop word table instead

Conclusions Use early detection and data analysis
techniques for detecting and analyzing candidate topics. Improves crawl performance – visiting less
number of web pages makes the system more efficient
Less human involvement - no need to create a relationship-based hierarchy

Future Work
Adapt other character set such as Chinese,Korean, Japanese.
Need to find a better way to detect the new born words and find their relevance to a specific topic.

Questions
?