introducing bioinformatics databases
DESCRIPTION
Introducing Bioinformatics Databases. Tan Tin Wee/Victor Tong/Susan Moore Dept of Biochemistry NUS Mohammad Asif Khan Perdana University Graduate School of Medicine. Sources of Biological Knowledge. Past: textbooks, monographs, books, journals. - PowerPoint PPT PresentationTRANSCRIPT

Introducing Bioinformatics DatabasesTan Tin Wee/Victor Tong/Susan Moore
Dept of Biochemistry
NUS
Mohammad Asif Khan
Perdana University Graduate School of Medicine


Sources of Biological Knowledge Past: textbooks, monographs, books, journals.
Today: online accessible databasesKeyword searchable, e.g. Google.
Every class of biological molecule has at least a few databases associated with it.
Every area of biology, biotechnology, medicine and life science research will have some kind of database associated with it.
Must be aware and familiar with MAJOR databases
Must be able to discover NEW databases and master them as and when they appear.

Biological knowledge today! STORED digitallyAlmost critical biological data, information, knowledge is currently stored in computers
ACCESSIBLE globallyAll current critical biological knowledge is publicly accessible via the Internet network of computers
SHARED extensivelyMost research data is exchanged via the Internet today if not publicly and free, then shared among international collaborators
PUBLISHED onlineMost scientific journals are now published with a digital version accessible online, free open access or for a subscription fee paid by the individual or by the institution
10 years ago, this was not so. There has been tremendous change.

UNSTOPPABLE DATA GROWTH
2005 2008
Growth of GenBankDNA Sequence
(2005 – 2009)>100,000,000 sequences
Exponential IncreaseNext Gen Sequencing
Technologies
100
90
80
70
60
100
90
80
70
60
http://www.ncbi.nlm.nih.gov/Genbank/genbankstats.html
Growth of PDBProtein and MacromolecularStructuresDriven by various StructuralGenomics initiatives such asProtein Structure Initiativehttp://www.nigms.nih.gov/Initiatives/PSI
JCSGhttp://www.jcsg.org/
http://www.pdb.org/pdb/statistics/contentGrowthChart.do?content=total&seqid=100

RELENTLESS INCREASE IN DATABASESMichael Y. Galperin and Guy R. Cochrane (2009) Nucl. Acids Res. 37:D1-D4 . Nucleic Acids Research annual Database Issue and the NAR online Molecular Biology Database Collection in 2009 (doi:10.1093/nar/gkn942) http://nar.oxfordjournals.org/cgi/content/full/37/suppl_1/D1
A lot of dataA lot of databases
What do they mean?
Most of the data begins to make sense if they areIntegrated
But many plans to integratethese databases have failed

7
Biological Databases – examples and general considerations
Biological databases – what they are; purpose
Some general considerations Sample databases

8
Biological databasesMany (but not all) definitions of “database” include:
- Storage of data on a computer in an organized way- Provision for searching and data extraction.
By these definitions web pages, books, journal articles, text files, and spreadsheet files cannot be considered as databases
Purposes of biological databases:
1. To disseminate biological data and information2. To provide biological data in computer-readable form3. To allow analysis of biological data

9
But first…a few terms Database Record: “A collection of related data, arranged in fields and treated as a unit. The data for each [item] in a database make up a record.” www.d.umn.edu/lib/reference/skills/vocab.html
Field: “the part of a record reserved for a particular type of data…” www.amberton.edu/VL_terms.htm

10
Example from the “Grocery Shopping Database”:
Date: 18/08/2006Item: White breadStore: Dover Provision
Price: $1.29
A record
FieldsA different view of the first “record”:
Field Values

11
Some features of Biological Databases Data/information…
Stored in records according to some predetermined structure/format
+/- evidence +/- unique identifiers +/- additional annotation +/- DB Xrefs (cross references)

Authoritative and Reliable Most biological databases are from authoritative and reliable sources, however…
Not all Websites and Databases are reliable. Not all data and information stored in authoritative and reliable websites or databases are accurate or correct, or up-to-date
Nevertheless, most of them are useful and instructive
Many of them contain valuable information and knowledge
Identification of authority and Evaluation of reliability – very important
Every serious scientist must be critical of the information they read, whether online or not.

Discoverability
Most publications, books and courses include online references – Web address (URL)e.g. http://www.pdb.org/ for protein structural data
Most useful resources are also listed and taught in courses, or spread by word of mouth.
Most databases are searchable by appropriate keywords and their authority determined by their web addresses, the institutions behind the databases or the authors’ reputation
Most databases have full details of their content and how to use them.

14
NAR Database Categories List
From: http://nar.oxfordjournals.org

TABLE OF NAR DATABASES ISSUEhttp://en.wikipedia.org/wiki/Biological_databasehttp://www.oxfordjournals.org/nar/database/c/ Nucleotide Sequence Databases RNA sequence databases Protein sequence databases Structure Databases Genomics Databases (non-vertebrate) Metabolic and Signaling Pathways Human and other Vertebrate Genomes Human Genes and Diseases Microarray Data and other Gene Expression Databases Proteomics Resources Other Molecular Biology Databases Organelle databases Plant databases Immunological databases Bibliographic databases

Database of Biological Databases
Alphabetical order http://www.oxfordjournals.org/nar/database/a/
Categoryhttp://www3.oup.co.uk/nar/database/cap/

Human Genome Project – DNA sequence
Microarray – RNA expression and levels
Proteomics – protein expression and concentration in cells
Structural proteomics or genomics – protein structure (and function)
Functional genomics- protein function
Information flow in Biology

Examples of Major Bioinformatics Resources
Browsing databases NCBI Entrezhttp://www.ncbi.nlm.nih.gov/sites/gquery
EBI Ensembl http://www.ensembl.org/index.html
Retrieving sequences SRS - Sequence Retrieval System http://srs.ebi.ac.uk/
ExPASy – Expert Protein Analysis System – Proteomics server http://au.expasy.org/

Bibliographic Information
PubMed and Medline Recent National Institutes of Health USA policy
Google Scholar Web of Science and Science Citation Index Online journals
SuperTier Top Journals – Nature, Science, Cell, PNAS, etc.
Open access journals Public Library of Science PLoS
Biomed Central

20
Literature - PubMed
Citations and abstracts for articles from approx. 5000 (not all!) biomedical journals
Text searching to identify citations of interest
Links to full-text articles (free or otherwise)
More than 16,000,000 records*
* 16000000 As of Dec 29 2005. PubMed News. http://www.ncbi.nlm.nih.gov/feed/rss.cgi?ChanKey=PubMedNews

21
Literature – PubMed
p53 cancer
PMID: Unique ID for this record
Bibliographic Information
(Journal name, date, volume, issue, page numbers)
Article Title
Authors

22
AbstractPlus view - PubMed

STORING YOUR OWN BIBLIOGRAPHIC INFORMATIONOnline Wizfolio: http://www.wizfolio.comSoftware: ENDNOTE or REFMAN

Genetic and Genomic Databases
From sequencing of specific genes or genomic sequence of entire genomes
Data are prepared, annotated and stored in databases Genbank, NCBI DDBJ, NIG EBI/EMBL
Making Deposits http://www.ncbi.nlm.nih.gov/Genbank/update.html Bankit Sequin

25
Nucleic Acid Databases
Include: GenBank DDBJ EMBL
RefSeq
•Archives of Primary data
•Exchange data amongst themselves
Summary/Integration of primary data

26
GenBank
Data from: Individual laboratories Sequencing centres
Any organism Individual records may be incomplete or inaccurate Eg: sequencing errors Eg: incomplete sequences
NCBI Handbook

27
Searching Entrez Nucleotide for human p53

28
p53 Genbank record: GI 48094186

29
p53 Genbank record: HEADER
Data sources
Organismal Source
Identifiers, Version, Definition Line

30
p53 Genbank record: FEATURES
Cross-References to Other DBs
Protein product

31
p53 Genbank record: SEQUENCE

32
The linked protein record: GenBank GenPept

33
Links from p53 GenPept record
Available links vary from one record to another

34
With so many records how do we know which one to work with?
They may: Come from different source databases
eg DDBJ, GenBank, EMBL (nucleotide) Have the same or different sequence information Single changes in nucleotides/amino acids Incomplete sequence
Have variable extra annotation Eg: Signal peptide; domains; DB XRefs etc

35
The RefSeq Project
Goal: a “comprehensive, integrated, non-redundant set of sequences, including genomic DNA, transcript (RNA), and protein products, for major research organisms.” http://www.ncbi.nlm.nih.gov/RefSeq/index.html
Info from: Predictions from genomic sequence Analysis of GenBank Records Collaborating databases

36
RefSeq:
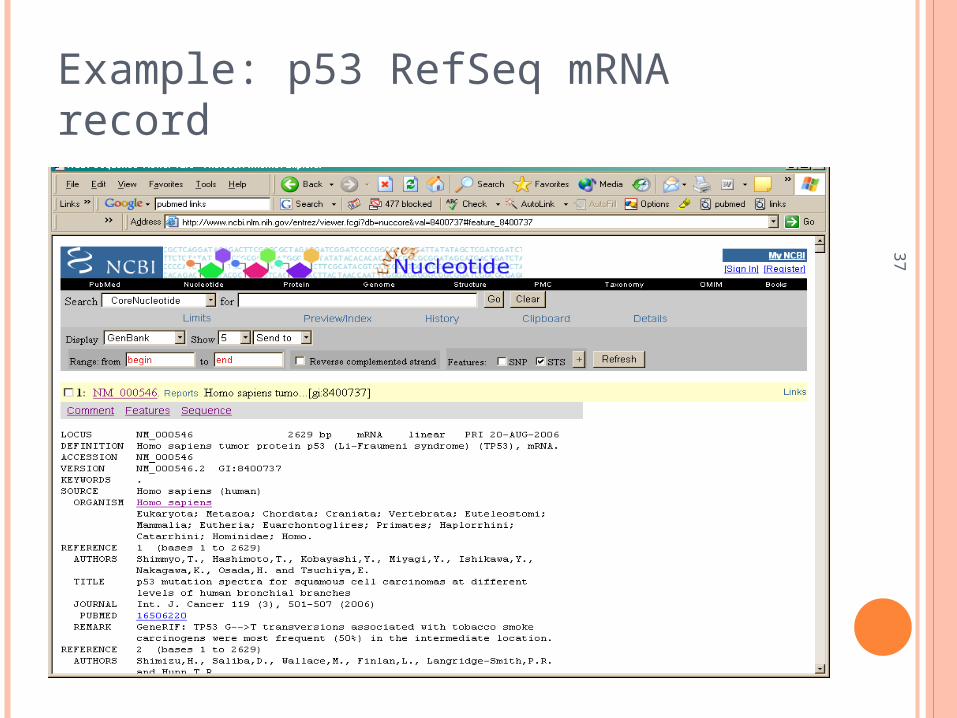
37
Example: p53 RefSeq mRNA record
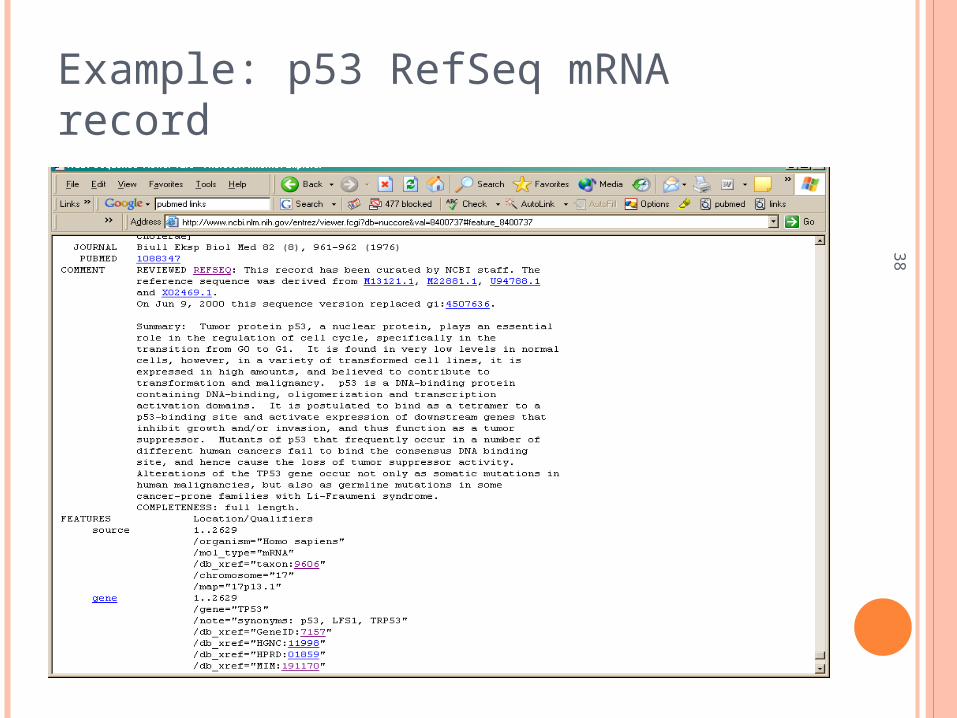
38
Example: p53 RefSeq mRNA record

39
p53 RefSeq mRNA features

40
p53 RefSeq mRNA features continued

41
p53 RefSeq mRNA features continued

42
p53 RefSeq mRNA features include…
Links: GeneID – locus and display of genomic, mRNA and protein
sequences; extensive additional annotation OMIM – Online Mendelian Inheritance in Man – disease information CDD – conserved protein domain HGNC – official nomenclature for human genes HPRD – Human Protein Reference Database
CDS (CoDing Sequence) Gene Ontology terms applied to the protein Nucleotide sequence range of translated product Translation – the protein sequence Link to RefSeq Protein record
Other features – sequence ranges refer to the nucleotide Nuclear Localization Signal Polyadenylation site etc

43
p53 RefSeq Protein
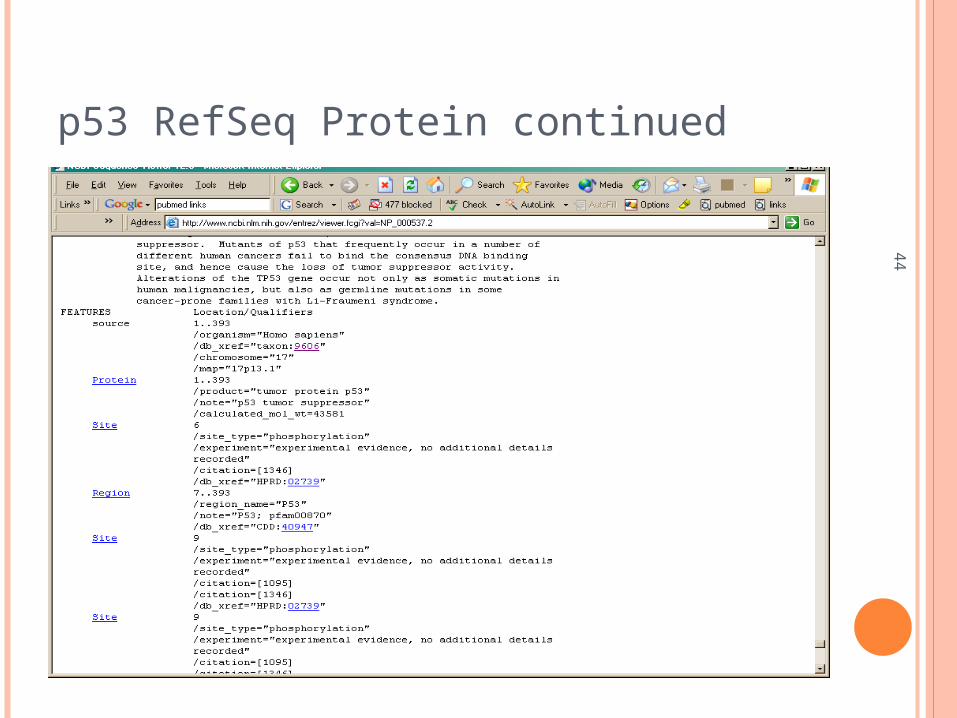
44
p53 RefSeq Protein continued

45
p53 RefSeq Protein continued
Sequence ranges in features refer to the amino acid sequence

46
Interpreting RefSeq identifiers
Genomic DNA NC_123456 - complete genome, complete chromosome, complete plasmid
NG_123456 - genomic region NT_123456 - genomic contig
mRNA - NM_123456 Protein - NP_123456 Gene and protein models from genome annotation projects:
XM_123456 - mRNA XR_123456 - RNA (non-coding transcripts) XP_123456 - protein

47
RefSeq status Validated Reviewed Provisional--------------- Predicted Model Inferred Genome Annotation
Most confident
Least confident

48
Protein Database – Swiss-Prot
SWISS-PROT
A curated database of protein sequences
• Trained biologists extract and analyze relevant evidence from scientific publications
• Post translational modifications, sequence variations, functions, etc
TrEMBL = Translated EMBL
UniProtKB = Swiss-Prot + TrEMBL

49
Protein Database – Swiss-Prot
SWISS-PROT
A curated database of protein sequences
• Trained biologists extract and analyze relevant evidence from scientific publications
• Post translational modifications, sequence variations, functions, etc
TrEMBL = Translated EMBL
UniProtKB = Swiss-Prot + TrEMBL

50
Structures: PDB
Three-dimensional structures of biomolecules
Image: Eric Martz
RasMol Gallery. http://www.umass.edu/microbio/rasmol/galmz.htm (Accessed Aug 16, 2006)
51
PDB

52
Results Summary Page

53
PDB – Structure Summary

54
PDB Structure Summary continued

55
Interactions: BIND
Physical and genetic interaction data Curated from published experimental evidence
All organisms Physical interactions span all molecule types: Protein-Protein Protein-RNA Protein-DNA Protein-Small Molecule Etc
Details characterizing the interaction – eg binding sites
p53 AP2Alpha

56
p53 protein-protein interactions in BIND – query results

57
A BIND interaction record

58
BIND interaction statistics - protein

59
Function and pathways databases - KEGG
Several interconnected databases including:
• PATHWAY contains info on metabolic and regulatory networks.
• 40,568 pathways generated from 301 reference pathways
• GENES contains information on genes and proteins.
• LIGAND contains information on chemical compounds and reactions involved in cellular processes.

60
Searching KEGG Genes

61
Linking from Gene to Pathways

62
KEGG Human Cell Cycle Pathway

63
SUMMARY: Biological databases – examples and general considerations
Scope and sample records from selected databases: Pubmed, Genbank, RefSeq, PDB, BIND, KEGG
Primary archival databases vs. derived databases Relative numbers of database records
Pubmed > RefSeq > Interactions > Structures > Reference Pathways

64
Extracting data from the databases
Databases have variable means of accessing and working with the data
Keyword (simple) searches +/- query by ID (eg PMID) +/- advanced queries – Boolean; field-
specific +/- different views of the data +/- ways to export or store your
results +/- visualization
Getting the data

65
A problem with keyword searches
Matches in potentially irrelevant parts of the record
Eg: if we ONLY want records describing the sequence of p53 and we do a keyword search of Entrez Nucleotide with p53:
p53 is mentioned in a GeneRIF.

66
Biological databases: PDB Advanced Query – Field Specific

67
PDB Advanced Query – Boolean Field Specific Query
Molecule Name: p53 AND Ligand Name: zinc
“Match ALL of the following conditions”

68
PDB Custom Reports

69
Selecting fields for PDB Custom Reports

70
PDB Custom Report

71
PDB Custom Report – Save report in CSV (comma separated value)

72
Views: GenBank Flat File vs FASTA

73
Getting the data
Large-scale analyses large-scale data retrieval Querying through the web interface may be ineffective
Some DBs also have programming interfaces
Many DBs also store their data at their FTP sites can download entire datasets for programmatic manipulation
Eg: Flat Files parse into tables

74
Eg of KEGG API
http://www.genome.jp/kegg/soap/

75
Extracting the data - summary
Understanding database records allows us to query more effectively
Saving our results allows us to manipulate them offline
Different views are suited for different purposes
The web interface is not the only way to extract data

76
Limitations of databases…
May have redundant information May be incomplete May have errors May not be actively updated
Including new data Including corrections to old data Including updates of info from other DBs

77
Where does the data and additional annotation come from?
Direct deposition of data eg PDB, Genbank
Manually extracted from the literature eg BIND, SwissProt, old Genbank
Text-mining Automatically extracting biological information from the literature using computer programs
Electronic Annotation Eg automated assignment of GO terms to proteins based on sequence similarity
All can be +/- human validation

78
Redundancy and Incompleteness in Biological Databases We’ve already seen redundancy WITHIN databases… Eg multiple entries for human p53 in Genbank
And…there can be multiple databases for a single data type. Eg: SwissProt – RefSeq Protein Eg: BIND – MINT – DIP – HPRD etc

79
Redundancy and incompleteness:
Overlap of human protein-protein interactions between 2 databases
It is likely that NEITHER of these databases is complete
DIP: the Database of Interacting Proteins
1049 interactions
HPRD: Human Protein Reference Database
24385 interactions
• 73% overlap (Gandhi et al, Nature Genetics 38, 285-293 (2006)

80
Incomplete primary databases
Not all published observations have been curated into databases
Not all experimental observations have been published
Not all experiments have been conducted yet
Not all experiments can make all possible observations

81
Striving for complete datasets and minimal redundancy
Eg GenBank – DDBJ – EMBL
Eg for interaction data: IMEx – International Molecular Exchange consortium
BIND, DIP, MINT, IntAct, MPact, BioGRID Share curation (data entry + checking) workload in a non-redundant fashion
Curate according to common standards Exchange data using the PSI MI exchange format

82
Errors
Can include, but are not limited to: Typographical errors
Impact on keyword searches?? Incorrect interpretation of source data Experimental errors Text mining not validated by a human Incorrect automated analysis
(eg predicting mRNAs from genomic sequence)

83
Error example: A retracted record
GI 4504946, RefSeq mRNA for water buffalo alpha-lactalbumin:

84
Retracted record:NM_002289.1 vs NM_002289.2
Re-interpretation of genomic sequence different mRNA, same protein

85
So:
1) Search multiple databases2) Where possible, verify by
consulting the evidence Eg: For crucial information – go back
to the original publication
3) Keep a record of unique IDs, DB versions used
4) Search using appropriate identifiers (eg from CVs – see next section) where possible

86
Standard Nomenclature and Controlled Vocabularies Standard Nomenclature Limited computational value of free text
CVs and Ontologies - Definitions Grocery Shopping example Gene Ontology NCBI Taxonomy
87
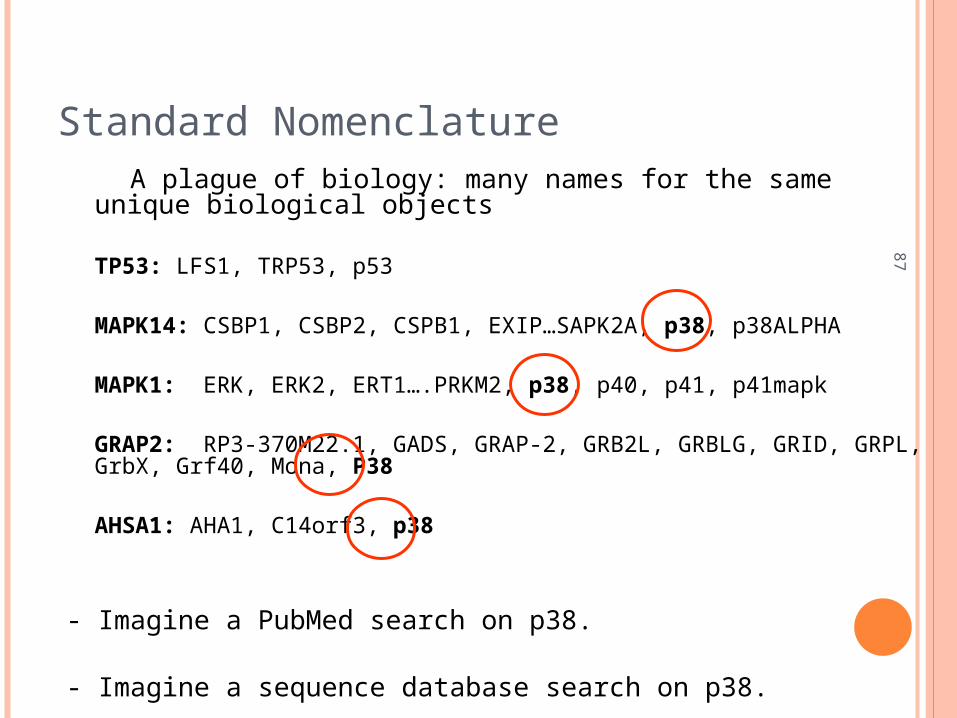
Standard Nomenclature A plague of biology: many names for the same unique biological objects
TP53: LFS1, TRP53, p53
MAPK14: CSBP1, CSBP2, CSPB1, EXIP…SAPK2A, p38, p38ALPHA
MAPK1: ERK, ERK2, ERT1….PRKM2, p38, p40, p41, p41mapk
GRAP2: RP3-370M22.1, GADS, GRAP-2, GRB2L, GRBLG, GRID, GRPL, GrbX, Grf40, Mona, P38
AHSA1: AHA1, C14orf3, p38
- Imagine a PubMed search on p38.
- Imagine a sequence database search on p38.

88
Standard nomenclature
1) Use identifiers! When referring to database entries that
you have used When querying databases.
2) Include the “official gene name” when describing your researcheg HUGO Gene Nomenclature Committee approved name: HGNC:1189, “AHSA1”

89
Limited Computational Value of Free Text
Text mining vs human interpretation of free text: Humans win!
Which would be easier for a computer to assess?
1. MoleculeA was found in the cytoplasm, whereas MoleculeB was not; rather it continued to accumulate in the nucleus.
2. MoleculeACellPlace: CytoplasmMoleculeBCellPlace: Nucleus

90
Controlled Vocabularies and Ontologies
Define: controlled vocabulary (CV) “a set of official descriptors assigned to a particular entry in a database, illustrating the relationship between synonyms and preferred usage terms.”truncated from: www.library.appstate.edu/tutorial/glossary/glossary.html
Define: ontology “specification of a conceptualisation of a knowledge domain. An ontology is a controlled vocabulary that describes objects and the relations between them in a formal way…”
truncated from: members.optusnet.com.au/~webindexing/Webbook2Ed/glossary.htm

91
These terms are sometimes used interchangeably in bioinformatics
We will think of ontologies as “hierarchical CVs that specify relationships”

92
Example from the “grocery shopping database”
CV: we might use different words for the same thing Bread – le pain – das Brot
Ontology: we can formally classify our concepts of bread

93
A sample (and simple) ontology for bread
others are possible…
Grain product
Breakfast cerealBread
Synonyms:Le pain, das Brot
Loaf bread Flat bread
Roti Prata Pita NaanWhite breadSynonym:
WonderBread

94
The Gene Ontology
What: A database of terms to describe gene (or gene product) information
Terms are applied to gene products
Why: 1) So we can use a common language to describe the same biological observations
2) So that we can compute on these observations

95
GO – the 3 aspects of describing genes and their products
Cellular Component ~ where it is in the cell (can also be extracellular) – eg nucleus
Molecular Function ~ actions of the gene product at a molecular level – eg catalysis, binding
Biological Process~ biological events mediated by ordered assemblies of molecular functions – eg signal transduction
An Introduction to the Gene Ontology. http://www.geneontology.org/GO.doc.shtml
96
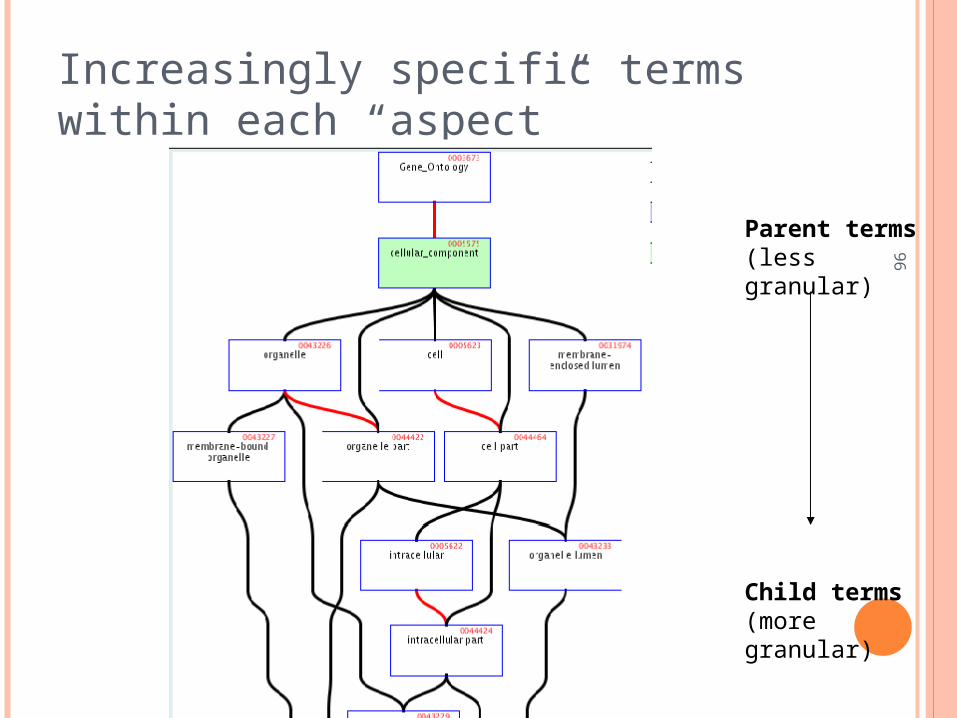
Increasingly specific terms within each “aspect”
Parent terms (less granular)
Child terms (more granular)

97
p53 Cellular Component annotation from RefSeq Protein record cytoplasm [pmid 7720704]; insoluble fraction [pmid 12915590]; mitochondrion [pmid 12667443]; nuclear matrix [pmid 11080164]; nucleolus [pmid 12080348]; nucleoplasm [pmid 11080164] [pmid 12915590]; nucleus [pmid 7720704]
In general, the most specific (most “granular”) term possible is applied, given the evidence.

98
A GO term record: Nuclear Matrix

99
“Nuclear matrix” in tree view (QuickGO)
Less granular term

100
Grouping entries by less granular terms
Eg: ProteinA nucleusProteinB nuclear matrixProteinC mitochondria
Can group by A COMMON PARENT TERM:
”Intracellular Membrane-Bound Organelle”

101
Eg PDB: Browse by Cellular Component
“Show me all of the structures where one or more of the molecules can reside in an intracellular membrane-bound organelle”

102
NCBI Taxonomy: Homo sapiens

103
NCBI Taxonomy: class Mammalia

104
Grouping entries by less granular terms: NCBI Taxonomy Eg2: Trying to draw global patterns about host-virus interactions
“Find me all of the protein-protein interactions where one protein is from a virus and the other protein is from a mammal”

105

106
Value of CVs/Ontologies in querying Increased ability to retrieve specific records Eg: return all the records that have the exact GO term “Nuclear Matrix” in them
Grouping observations at multiple levels Eg: return all the records that have the GO term “nucleus”, or any of its child terms

107
Summary of L2
Contents of some databases: PubMed, GenBank, RefSeq, etc
Databases have limitations Understanding database records allows us to query more effectively
Controlled Vocabularies can make queries more powerful