introduction
DESCRIPTION
Introduction. Social networking services are a fast-growing business nowadays Facebook, Twitter, Google+, LiveJournal, YouTube, … When users participate in online social network activities, people’s privacy suffers potential serious threat Create personal portfolio, post current location, … - PowerPoint PPT PresentationTRANSCRIPT

Structure based Data De-anonymization of Social Networks and Mobility Traces
Structure based Data De-anonymization of Social Networks and Mobility Traces
Shouling Ji, Weiqing Li, and Raheem Beyah Georgia Institute of Technology
Mudhakar SrivatsaIBM T. J. Watson Research Center
Jing S. HeKSU
Presenter: Qin Liu, Chinese University of Hong Kong

Ji et al. Structure based Data De-anonymization
Introduction
• Social networking services are a fast-growing business nowadays– Facebook, Twitter, Google+, LiveJournal, YouTube, …
• When users participate in online social network activities, people’s privacy suffers potential serious threat– Create personal portfolio, post current location, …
• Countermeasures– Naïve anonymization: removing “Personally Identifiable Information (PII)”
– Edge modification
– k-anonymity and its varients
• Still vulnerable to powerful structure-based de-anonymization attacks– Narayanan-Shmatikov attack (IEEE S&P 2009)
– Srivatsa-Hicks attack (ACM CCS 2012)
– Others

Ji et al. Structure based Data De-anonymization
Narayanan-Shmatikov attack (IEEE S&P 2009)• Anonymized data: Twitter (crawled in late 2007)
– A microblogging service
– 224K users, 8.5M edges
• Auxiliary data: Flicker (crawled in late 2007/early 2008)– A photo-sharing service
– 3.3M users, 53M edges
• Result: 30.8% of the users are successfully de-anonymized
Twitter Flicker
User mapping
HeuristicsEccentricityEdge directionalityNode degreeRevisiting nodesReverse match

Ji et al. Structure based Data De-anonymization
Srivatsa-Hicks (ACM CCS 2012)• Anonymized data
– Mobility traces: St Andrews, Smallblue, and Infocom 2006
• Auxiliary data– Social networks: Facebook, and DBLP
• De-anonymize mobility traces using corresponding social networks
• Over 80% users can be successfully de-anonymized

Ji et al. Structure based Data De-anonymization
Other structural de-anonymization attacks• Backstrom et al. attack (WWW 2007)
– Both active attacks and passive attacks
• Narayanan et al. attack (IJCNN 2011)– A simplified version Narayanan-Shmatikov attack (IEEE S&P 2009)
– For breaching link privacy
• Pedarsani et al. attack (Allerton 2013)– A Bayesian method based attack

Ji et al. Structure based Data De-anonymization
Limitations of existing attacks• Not scalable
– E.g., Backstrom et al. attack (WWW 2007) needs to create Sybil users before anonymized data release, which is not controllable or scalable
– E.g., Srivatsa-Hicks attack (CCS 2012) has a complexity of O(k!n3), k is the number seeds, which is not scalable
• High computational cost– E.g., Narayanan-Shmatikov attack (S&P 2009) has a complexity of O(nk+n4)
• Not general– E.g., Narayanan-Shmatikov attack (S&P 2009) is designed for directed graph
– E.g., Pedarsani et al. attack (Allerton 2013) is good for sparse graphs but bad for dense graphs

Ji et al. Structure based Data De-anonymization
Our contributions• Defined and mesured three de-anonymization metrics
– Strucutral similarity, relative distance similarity, and inheritance similarity
• Proposed a Unified Similarity (US) based De-Anonymization (DA) framework– Iteratively de-anonymize data with accuracy guarantee
• Generalized DA to an Adaptive De-Anonymization (ADA) framework– To de-anonymize large-scale data without the knowledge on the overlap size between the
anonymized data and the auxiliary data
• Applied the proposed de-anonymization attacks to real world datasets– Successfully de-anonymized three mobility traces: At Andrews, Infocom06, and Smallblue
– Successfully de-anonymized three social network datasets: ArnetMiner, Google+, and Facebook

Ji et al. Structure based Data De-anonymization
Outline
• Background• Preliminaries and Model• De-anonymization• Generalized Scalable De-anonymization• Experiments• Conclusion and Future Work

Ji et al. Structure based Data De-anonymization
Preliminaries and Model• Anonymized data graph
• Auxiliary data graph
• Attack Model– A de-anonymization attack is a mapping of users from the anonymized graph to the
auxiliary graph, i.e.,
Ji et al. Structure based Data De-anonymization
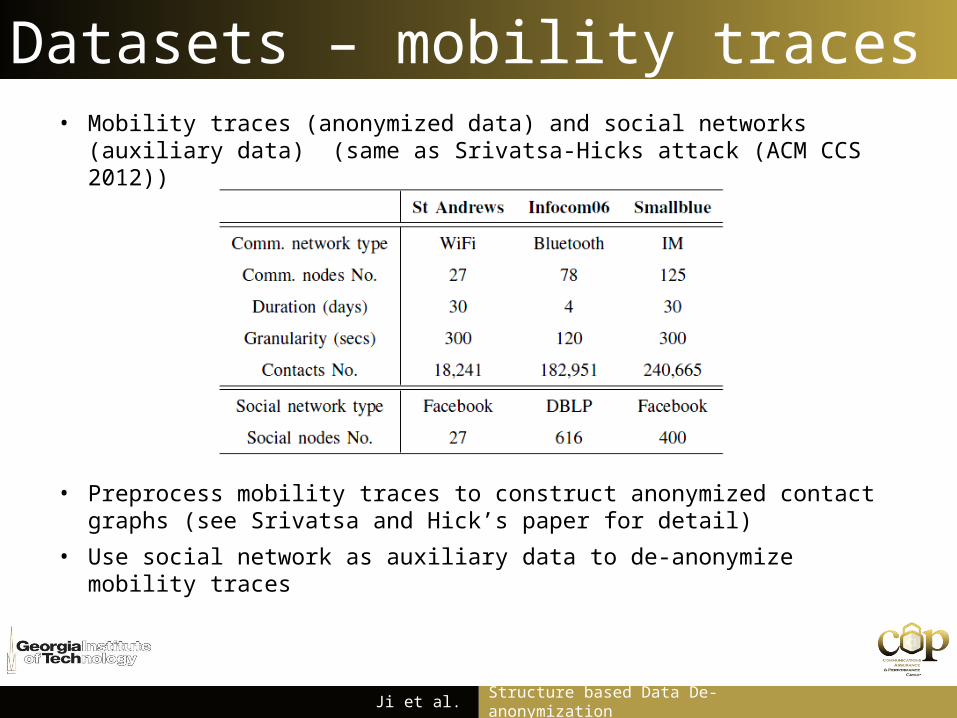
Datasets – mobility traces• Mobility traces (anonymized data) and social networks (auxiliary data)
(same as Srivatsa-Hicks attack (ACM CCS 2012))
• Preprocess mobility traces to construct anonymized contact graphs (see Srivatsa and Hick’s paper for detail)
• Use social network as auxiliary data to de-anonymize mobility traces

Ji et al. Structure based Data De-anonymization
Datasets – social networks• ArnetMiner
– A coauthor network
– A weighted graph with weight indicating the number of coauthored papers
– 1,127 authors and 6,690 “coauthor” relationships
• Google+– Two Google+ datasets crawled on July 19 and August 6 in 2011, denoted by JUL and
AUG, respectively
– JUL: 5,200 users, 7,062 connections
– AUG: 5,200 users, 7,813 connections
• Facebook– 63,731 users
– 1,269,502 friend relationships

Ji et al. Structure based Data De-anonymization
Outline
• Background• Preliminaries and Model• De-anonymization• Generalized Scalable De-anonymization• Experiments• Conclusion and Future Work

Ji et al. Structure based Data De-anonymization
De-anonymization• High-Level Description
– Seed selection
– Mapping propagation
• Seed selection– Identify a small number of seed mappings from the anonymized graph to the auxiliary
graph
– Bootstrap the de-anonymization
• Mapping propagation – De- anonymize the anonymized graph using multiple similarity measurements

Ji et al. Structure based Data De-anonymization
Mapping Propagation• Metrics
– Structural Similarity
– Relative Distance Similarity
– Inheritance Similarity
– Unified Similarity
• We also defined the weighted version of these metrics by considering the weights on edges
• Propagation framework

Ji et al. Structure based Data De-anonymization
Structural Similarity• Degree centrality
– The number of ties that a node has in a graph

Ji et al. Structure based Data De-anonymization
Structural Similarity• Closeness centrality
– How close a node is to others nodes in a graph

Ji et al. Structure based Data De-anonymization
Structural Similarity• Betweenness centrality
– A node’s global structural importance within a graph

Ji et al. Structure based Data De-anonymization
Structural Similarity• Defined as the cosine similarity between two nodes’ degree, closeness,
and betweenness centralities

Ji et al. Structure based Data De-anonymization
Relative Distance Similarity• Defined as the cosine similarity between two nodes’ distance vectors to
seeds

Ji et al. Structure based Data De-anonymization
Inheritance Similarity• Characterize the knowledge provided by current mapping results
– Two nodes have more common mapped neighbors will have high inheritance similarity score

Ji et al. Structure based Data De-anonymization
Unified Similarity (US)• Considering the structural similarity, relative distance similarity, and
inheritance similarity
Weights US
Structural similarity
Relative distance similarity
Inheritance similarity

Ji et al. Structure based Data De-anonymization
US based De-Anonymization (DA) Framework
• Step 1: seed identification by existing techniques
• Step 2: calculate two candidate node sets Ca and Cu from the anonymized graph and the auxiliary graph, respectively
• Step 3: calculate the US of each user from Ca to every user in Cu, and construct a weighted bipartite graph from Ca and Cu based on the calculated US scores
• Step 4: Seek a maximum weighted bipartite matching
• Step 5: Decide whether to accept a node de-anonymization result in the bipartite mathching
• Go to step 2 if the end condition is not reached

Ji et al. Structure based Data De-anonymization
Outline
• Background• Preliminaries and Model• De-anonymization• Generalized Scalable De-anonymization• Experiments• Conclusion and Future Work

Ji et al. Structure based Data De-anonymization
Generalized Scalable De-anonymization
• Core Matching Subgraph (CMS)

Ji et al. Structure based Data De-anonymization
Adaptive De-Anonymization (ADA)
Identify initial CMS
Run DA on initial CMS
Update CMS or End

Ji et al. Structure based Data De-anonymization
Outline
• Background• Preliminaries and Model• De-anonymization• Generalized Scalable De-anonymization• Experiments• Conclusion and Future Work
Ji et al. Structure based Data De-anonymization
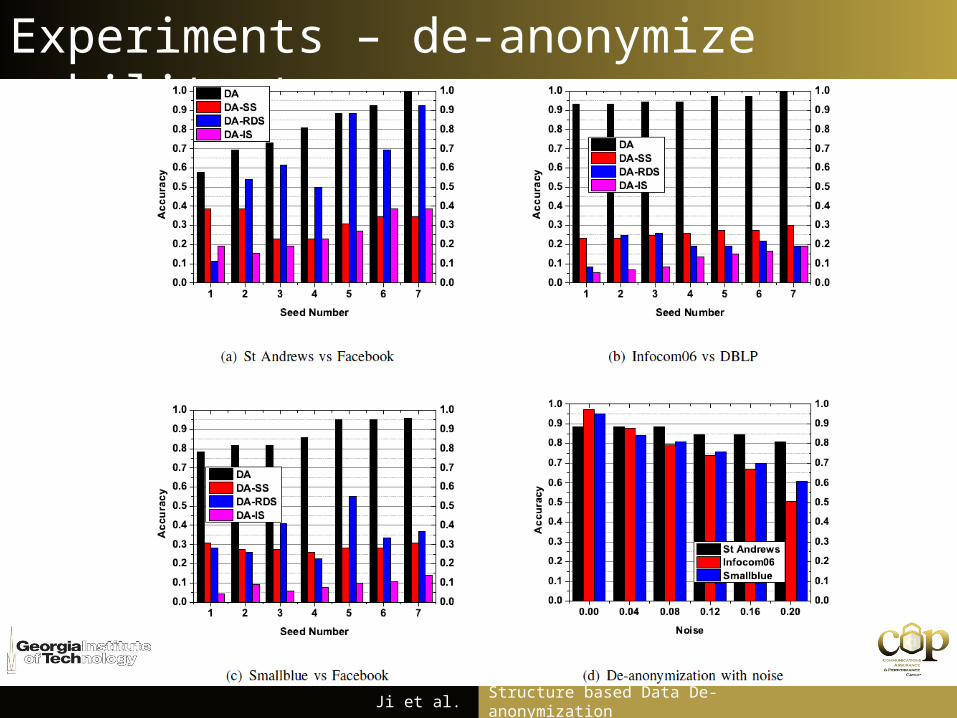
Experiments – de-anonymize mobility traces

Ji et al. Structure based Data De-anonymization
Experiments – de-anonymize ArnetMiner
Ji et al. Structure based Data De-anonymization
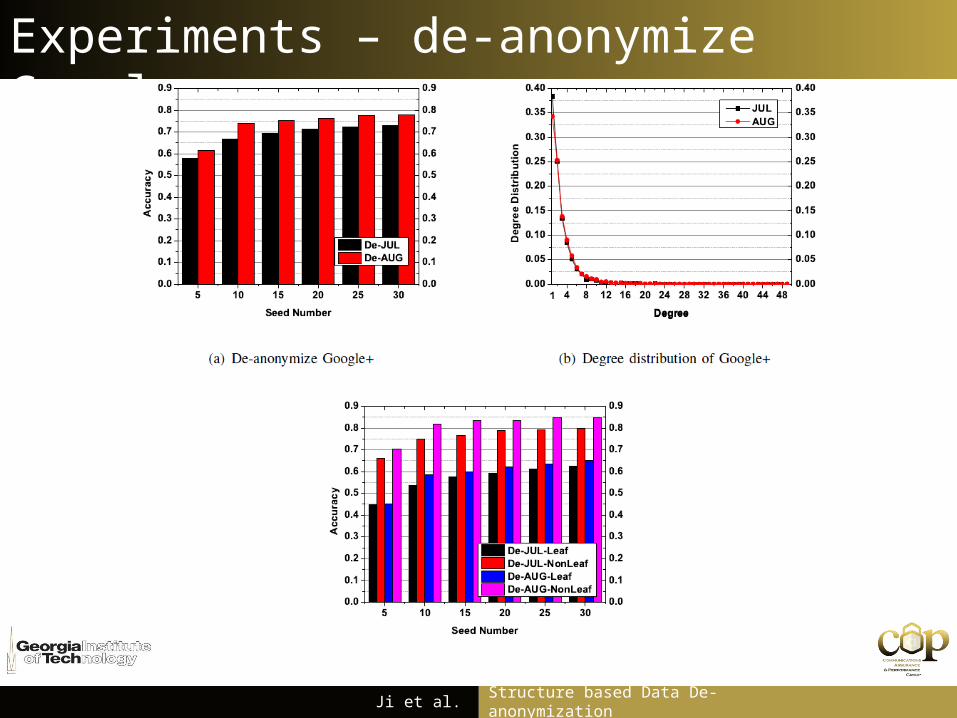
Experiments – de-anonymize Google+

Ji et al. Structure based Data De-anonymization
Experiments – de-anonymize Facebook

Ji et al. Structure based Data De-anonymization
Conclusion and Future Work
• Conclusion– Proposed and examined several structural similarity metrics– Designed a new scalable structural de-anonymization framework for
mobility traces and social networks– Validated the proposed de-anonymization framework on multiple
mobility traces and social networks
• Future work– More experiments on large-scale datasets– De-anonymizablity quantification (partially done in our ACM CCS 2014
paper)– Secure data publishing system

Ji et al. Structure based Data De-anonymization
Thank you and the presenter Qin Liu!Shouling Ji
http://users.ece.gatech.edu/sji/