introduction to computing using python csc 242-501 winter 2013 week 8: www and search world wide...
TRANSCRIPT

Introduction to Computing Using Python
CSC 242-501 Winter 2013Week 8: WWW and Search
World Wide Web Python Modules for WWW Web Crawling Thursday: String Pattern Matching

Introduction to Computing Using Python
The World Wide Web (WWW)
The Internet is a global network that connects computers around the world
• It allows two programs running on two computers to communicate• The programs communicate using a client/server protocol: one program (the
client) requests a resource from another (the server). For example, a browser requests a web page from a web server.
• The computer hosting the server program is often referred to as a server too
The World Wide Web (WWW or, simply, the web) is a distributed system of resources linked through hyperlinks and hosted on servers across the Internet
• Resources can be web pages, documents, multimedia, etc.• Web pages are a critical resource as they contain hyperlinks to other resources• Servers hosting WWW resources are called web servers• A program that requests a resource from a web server is called a web client
The technology required to do the above includes:
• Uniform Resource Locator (URL)• HyperText Transfer Protocol (HTTP)
• HyperText Markup Language (HTML)
Introduction to Computing Using Python
WWW plumbing
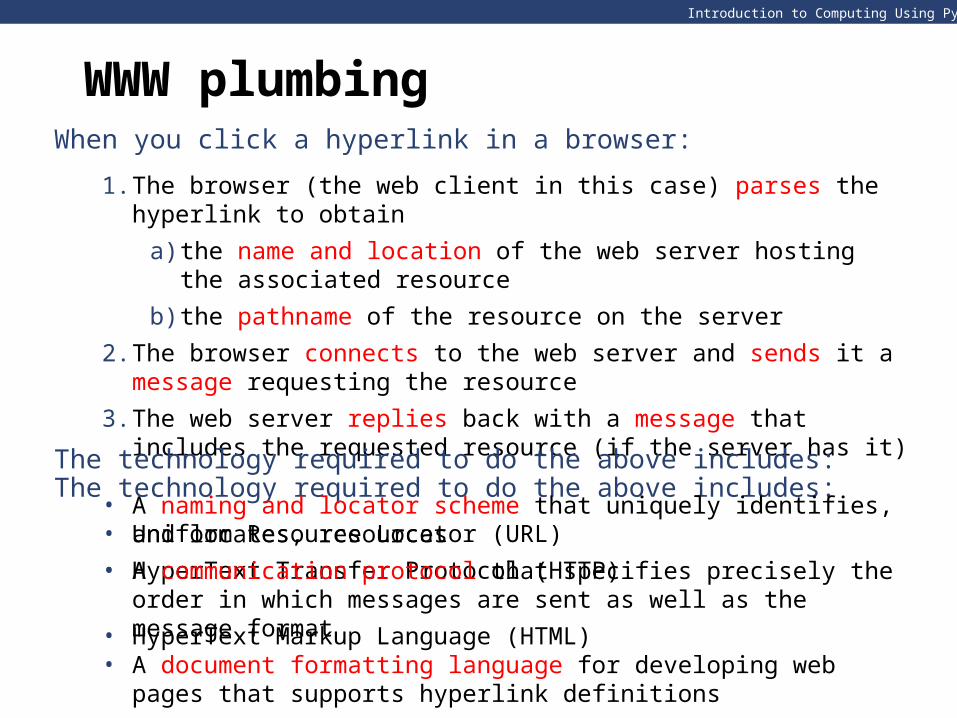
When you click a hyperlink in a browser:
1. The browser (the web client in this case) parses the hyperlink to obtain
a) the name and location of the web server hosting the associated resource
b) the pathname of the resource on the server
2. The browser connects to the web server and sends it a message requesting the resource
3. The web server replies back with a message that includes the requested resource (if the server has it)
The technology required to do the above includes:
• A naming and locator scheme that uniquely identifies, and locates, resources• A communication protocol that specifies precisely the order in which messages
are sent as well as the message format• A document formatting language for developing web pages that supports
hyperlink definitions

Introduction to Computing Using Python
WWW plumbing
The technology required to do the above includes:
• A naming and locator scheme that uniquely identifies, and locates, resources• Called Uniform Resource Locator (URL)
• A communication protocol that specifies precisely the order in which messages are sent as well as the message format
• Called HTTP (Hypertext Transfer Protocol)• A document formatting language for developing web pages that supports
hyperlink definitions• Caled HyperText Markup Languge (HTML)
Introduction to Computing Using Python
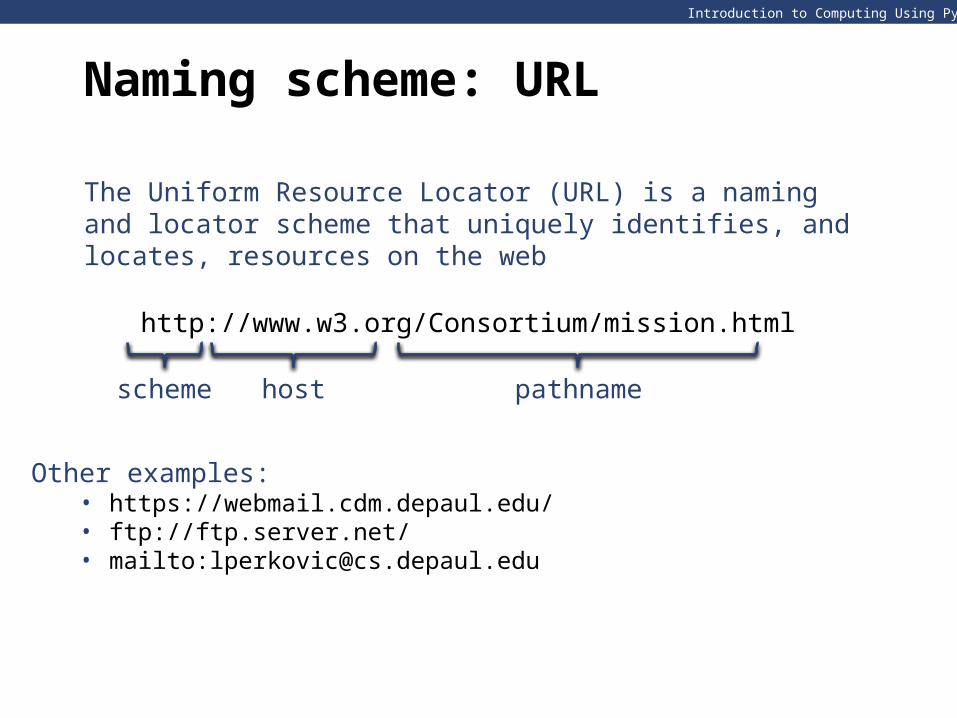
Naming scheme: URL
http://www.w3.org/Consortium/mission.html
scheme host pathname
The Uniform Resource Locator (URL) is a naming and locator scheme that uniquely identifies, and locates, resources on the web
Other examples:• https://webmail.cdm.depaul.edu/ • ftp://ftp.server.net/• mailto:[email protected]
Introduction to Computing Using Python
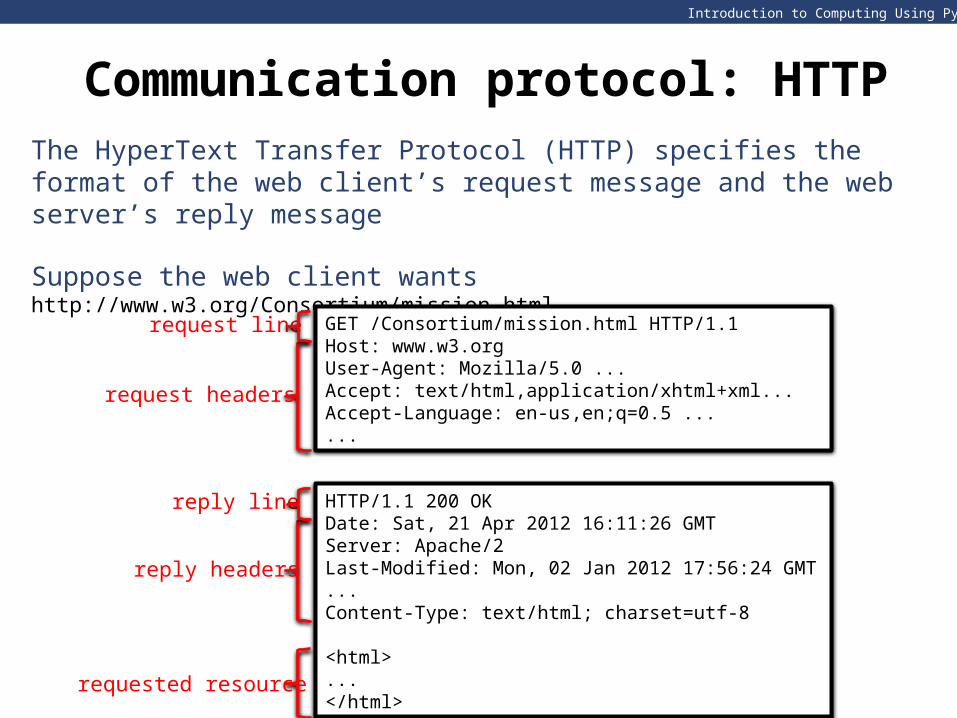
Communication protocol: HTTP
The HyperText Transfer Protocol (HTTP) specifies the format of the web client’s request message and the web server’s reply message
Suppose the web client wants http://www.w3.org/Consortium/mission.html
HTTP/1.1 200 OKDate: Sat, 21 Apr 2012 16:11:26 GMTServer: Apache/2Last-Modified: Mon, 02 Jan 2012 17:56:24 GMT...Content-Type: text/html; charset=utf-8
<html>...</html>
GET /Consortium/mission.html HTTP/1.1Host: www.w3.org User-Agent: Mozilla/5.0 ... Accept: text/html,application/xhtml+xml... Accept-Language: en-us,en;q=0.5 ......
request headers
request line
reply headers
reply line
requested resource
<html><head><title>W3C Mission Summary</title></head><body><h1>W3C Mission</h1><p>The W3C mission is to lead the World Wide Web to its full potential<br>by developing protocols and guidelines that ensure the long-term growth of the Web.</p><h2>Principles</h2><ul><li>Web for All</li><li>Web on Everything</li></ul>See the complete <a href="http://www.w3.org/Consortium/mission.html">W3C Mission document</a>.</body></html>
Introduction to Computing Using Python
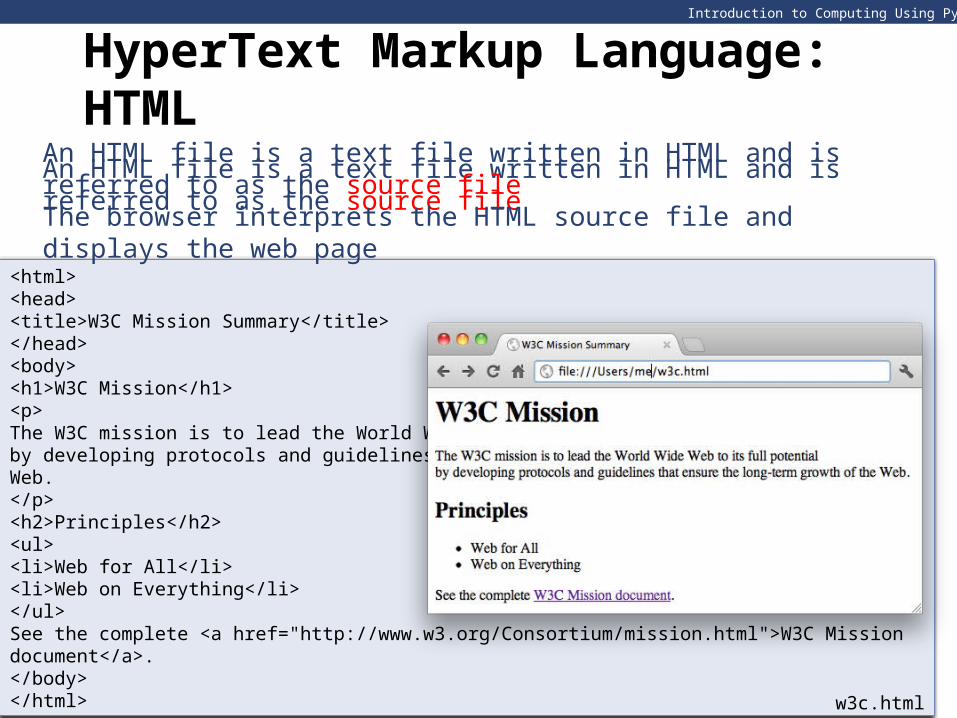
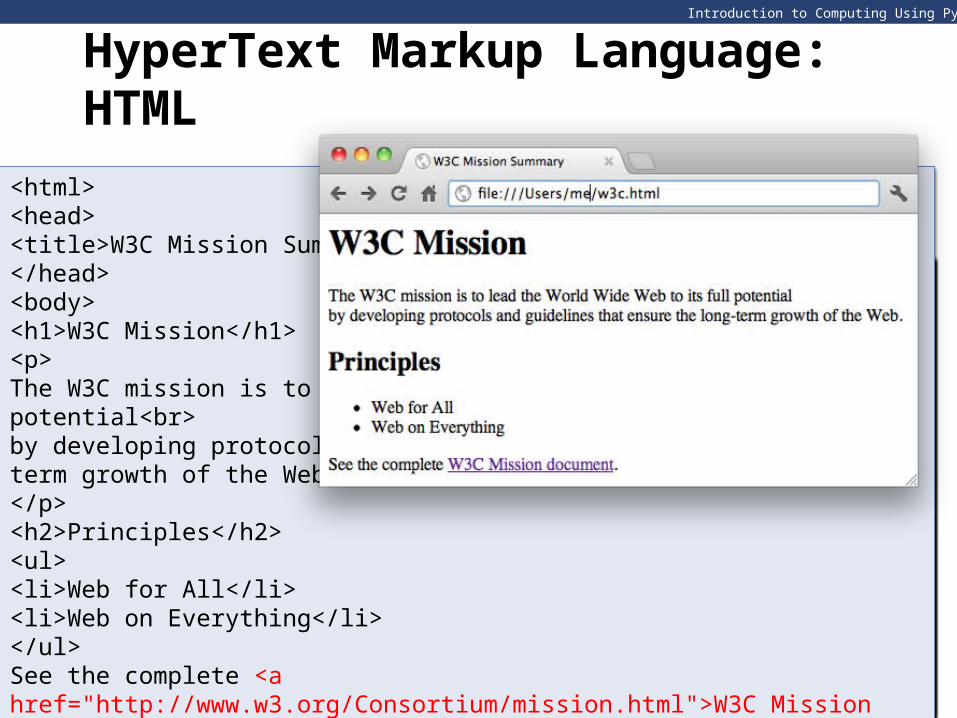
HyperText Markup Language: HTML
An HTML file is a text file written in HTML and is referred to as the source fileAn HTML file is a text file written in HTML and is referred to as the source fileThe browser interprets the HTML source file and displays the web page
w3c.html

In the source file, an HTML element is described using:• A pair of tags, the start tag and the end tag• Optional attributes within the start tag• Other elements or data between the start and end tag
Introduction to Computing Using Python
HyperText Markup Language: HTML
An HTML source file is composed of HTML elements• Each element defines a component of the
associated web page
<html>
</html>
Introduction to Computing Using Python
HyperText Markup Language: HTML
<html><head>
</head><body>
</body></html>
<html><head><title>W3C Mission Summary</title></head><body>
</body></html>
<html><head><title>W3C Mission Summary</title></head><body><h1>W3C Mission</h1>
</body></html>
<html><head><title>W3C Mission Summary</title></head><body><h1>W3C Mission</h1><p>The W3C mission is to lead the World Wide Web to its full potential<br>by developing protocols and guidelines that ensure the long-term growth of the Web.</p>
</body></html>
<html><head><title>W3C Mission Summary</title></head><body><h1>W3C Mission</h1><p>The W3C mission is to lead the World Wide Web to its full potential<br>by developing protocols and guidelines that ensure the long-term growth of the Web.</p><h2>Principles</h2>
</body></html>
<html><head><title>W3C Mission Summary</title></head><body><h1>W3C Mission</h1><p>The W3C mission is to lead the World Wide Web to its full potential<br>by developing protocols and guidelines that ensure the long-term growth of the Web.</p><h2>Principles</h2><ul>
</ul>
</body></html>
<html><head><title>W3C Mission Summary</title></head><body><h1>W3C Mission</h1><p>The W3C mission is to lead the World Wide Web to its full potential<br>by developing protocols and guidelines that ensure the long-term growth of the Web.</p><h2>Principles</h2><ul><li>Web for All</li><li>Web on Everything</li></ul>
</body></html>
<html><head><title>W3C Mission Summary</title></head><body><h1>W3C Mission</h1><p>The W3C mission is to lead the World Wide Web to its full potential<br>by developing protocols and guidelines that ensure the long-term growth of the Web.</p><h2>Principles</h2><ul><li>Web for All</li><li>Web on Everything</li></ul>See the complete .</body></html>
<html><head><title>W3C Mission Summary</title></head><body><h1>W3C Mission</h1><p>The W3C mission is to lead the World Wide Web to its full potential<br>by developing protocols and guidelines that ensure the long-term growth of the Web.</p><h2>Principles</h2><ul><li>Web for All</li><li>Web on Everything</li></ul>See the complete <a href="http://www.w3.org/Consortium/mission.html">W3C Mission document</a>.</body></html>
Introduction to Computing Using Python
<a href="http://www.w3.org/Consortium/mission.html">W3C Mission document</a>.
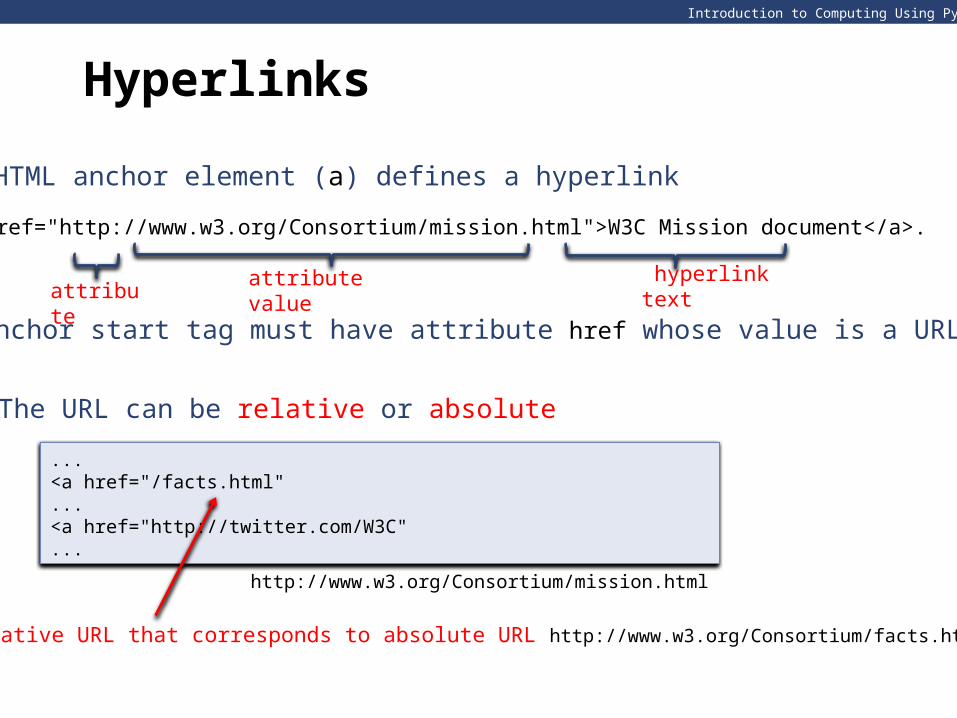
HTML anchor element (a) defines a hyperlink
attribute attribute value
The anchor start tag must have attribute href whose value is a URL
Hyperlinks
...<a href="/Consortium/facts.html"...<a href="http://twitter.com/W3C"...
The URL can be relative or absolute
http://www.w3.org/Consortium/mission.html
...<a href="/facts.html"...<a href="http://twitter.com/W3C"...
hyperlink text
relative URL that corresponds to absolute URL http://www.w3.org/Consortium/facts.html

Murach’s Java Servlets/JSP (2nd Ed.), C4 © 2008, Mike Murach & Associates, Inc.
Slide 11
An HTML document that contains comments <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <!-- begin the Head section of the HTML document --> <head> <title>Murach's Java Servlets and JSP</title> </head> <!-- begin the Body section of the HTML document --> <body> <h1>Email List applications</h1> <p>To run the following applications, click on the appropriate link:</p> <!-- <p>Links to come.</p> --> </body> </html>

Murach’s Java Servlets/JSP (2nd Ed.), C4 © 2008, Mike Murach & Associates, Inc.
Slide 12
Basic HTML tags
Tag Description
<!doctype ... > Identifies the type of HTML document. This tag is often inserted automatically by the HTML editor.
<html> </html> Marks the beginning and end of an HTML document.
<head> </head> Marks the beginning and end of the Head section of the HTML document.
<title> </title> Marks the title that is displayed in the title bar of the browser.
<body> </body> Marks the beginning and end of the Body section of the HTML document.

Murach’s Java Servlets/JSP (2nd Ed.), C4 © 2008, Mike Murach & Associates, Inc.
Slide 13
Basic HTML tags (cont.)
Tag Description
<h1> </h1> Tells the browser to use the default format for a heading-1 paragraph.
<h2> </h2> Tells the browser to use the default format for a heading-2 paragraph.
<p> </p> Tells the browser to use the default format for a standard paragraph.
<br> Inserts a line break.
<b> </b> Marks text as bold.
<i> </i> Marks text as italic.
<u> </u> Marks text as underlined.
<!-- --> Defines a comment that is ignored by the browser.
Murach’s Java Servlets/JSP (2nd Ed.), C4 © 2008, Mike Murach & Associates, Inc.
Slide 14
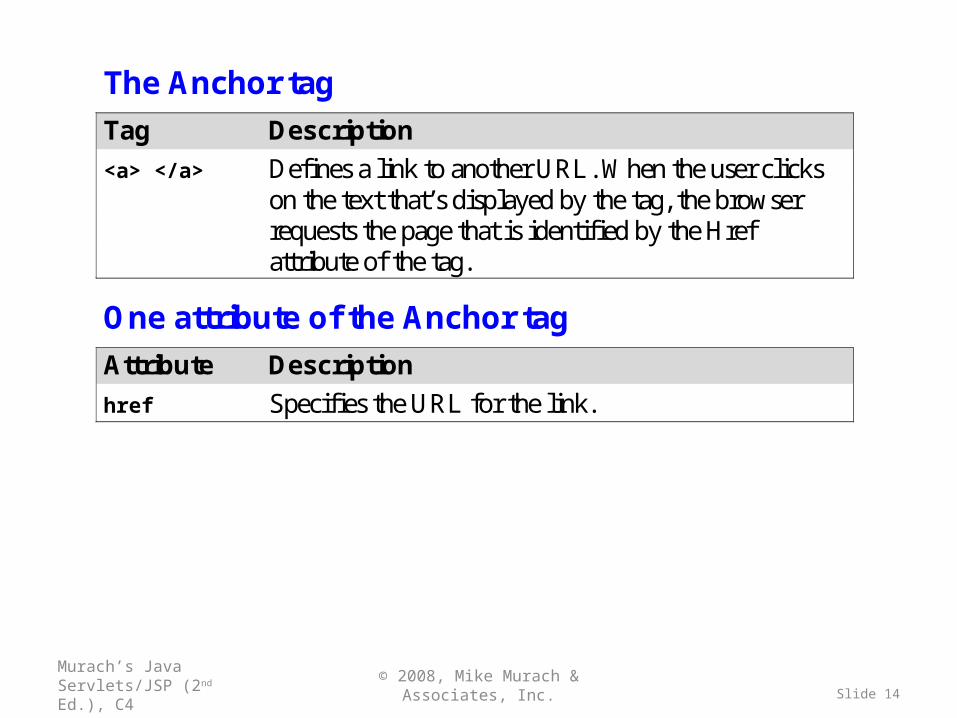
The Anchor tag
Tag Description
<a> </a> Defines a link to another URL. When the user clicks on the text that’s displayed by the tag, the browser requests the page that is identified by the Href attribute of the tag.
One attribute of the Anchor tag
Attribute Description
href Specifies the URL for the link.

Murach’s Java Servlets/JSP (2nd Ed.), C4 © 2008, Mike Murach & Associates, Inc.
Slide 15
Two Anchor tags viewed in a browser

Murach’s Java Servlets/JSP (2nd Ed.), C4 © 2008, Mike Murach & Associates, Inc.
Slide 16
Anchor tags… With URLs that are relative to the current directory <a href="join.html">The Email List application 1</a><br> <a href="email/join.html"> The Email List application 2</a><br>
With relative URLs that navigate up the directory structure <a href="../">Go back one directory level</a><br> <a href="../../">Go back two directory levels</a><br>
With URLs that are relative to the webapps directory <a href="/">Go to the default root directory for the web server</a><br> <a href="/musicStore">Go to the root directory of the musicStore app</a>
With absolute URLs <a href= "http://www.murach.com/email">An Internet address</a> <a href="http://64.71.179.86/email">An IP address</a>
Murach’s Java Servlets/JSP (2nd Ed.), C4 © 2008, Mike Murach & Associates, Inc.
Slide 17
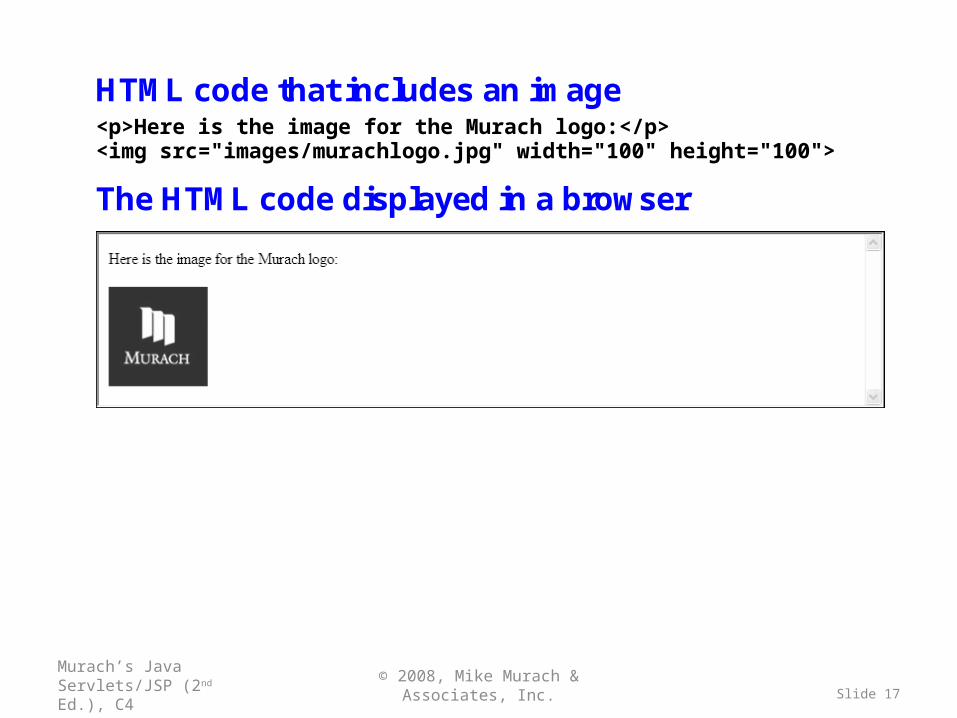
HTML code that includes an image <p>Here is the image for the Murach logo:</p> <img src="images/murachlogo.jpg" width="100" height="100">
The HTML code displayed in a browser

Murach’s Java Servlets/JSP (2nd Ed.), C4 © 2008, Mike Murach & Associates, Inc.
Slide 18
The Image tag
Tag Description
<img> Specifies how to place a GIF or JPEG image within an HTML page.

Murach’s Java Servlets/JSP (2nd Ed.), C4 © 2008, Mike Murach & Associates, Inc.
Slide 19
Common attributes of the Image tag
Attribute Description
src Specifies the relative or absolute URL for the GIF or JPEG file.
height Specifies the height of the image in pixels.
width Specifies the width of the image in pixels.
alt Specifies the text that’s displayed when the image can’t be displayed.
border Specifies the width of the border in pixels with 0 specifying no border at all.
hspace Specifies the horizontal space in pixels. This space is added to the left and right of the image.
vspace Specifies the vertical space in pixels. This space is added to the top and bottom of the image.

Murach’s Java Servlets/JSP (2nd Ed.), C4 © 2008, Mike Murach & Associates, Inc.
Slide 20
Common attributes of the Image tag (cont.)
Attribute Description
align Specifies the alignment of the image on the page. Acceptable values include Left, Right, Top, Bottom, and Middle.

Murach’s Java Servlets/JSP (2nd Ed.), C4 © 2008, Mike Murach & Associates, Inc.
Slide 21
Other image examples <img src="java.gif" width="175" height="243"> <img src="../../images/murachlogo.jpg" width="100" height="100"> <img src="http://www.murach.com/images/ murachlogo.jpg" width="100" height="100">
How to include images in an HTML page The two types of image formats that are supported by most web
browsers are the Graphic Interchange Format (GIF) and the Joint Photographic Experts Group (JPEG). JPEG files, which have a JPEG or JPG extension, are typically used for photographs and scans, while GIF files are typically used for other types of images.

Hypertext Transfer Protocol (HTTP)
A protocol is a set of rules that a client and server useto communicate with each other
Hypertext Transfer Protocol is used by Web clients andWeb servers

At the highest level, HTTP is very simple:
• The client (typically, a Web browser) sends the serverAn HTTP request
• The server sends back an HTTP response
• HTTP request specifies the resource the client wants• A web page, a multimedia file, etc.
• If the resource is available, the HTTP responsecontains the contents of that resource
Although we discussed some of the details of HTTP earlier, it is not necessary to know them for CSC 242
Hypertext Transfer Protocol (HTTP)

• The urllib.request module contains a method called urlopen
Example: urlopen(‘http://condor.depaul.edu/slytinen’)
• The urlopen function generates an HTTP request that issent to the specified Web server
In the above example, the server’s name iscondor.depaul.edu
• urlopen returns a Python HttpResponse object
• The HttpResponse class has a read() method, which returnsthe body of the response
HTTP and Python

• The read() method returns an object whose type is binary (not str)
• This is because not all resources on the Web are textual – for example, multimedia files
• If a resource is text (for example a Web page), then the decode() method must be called to convert from binary to str
HTTP and Python
Introduction to Computing Using Python
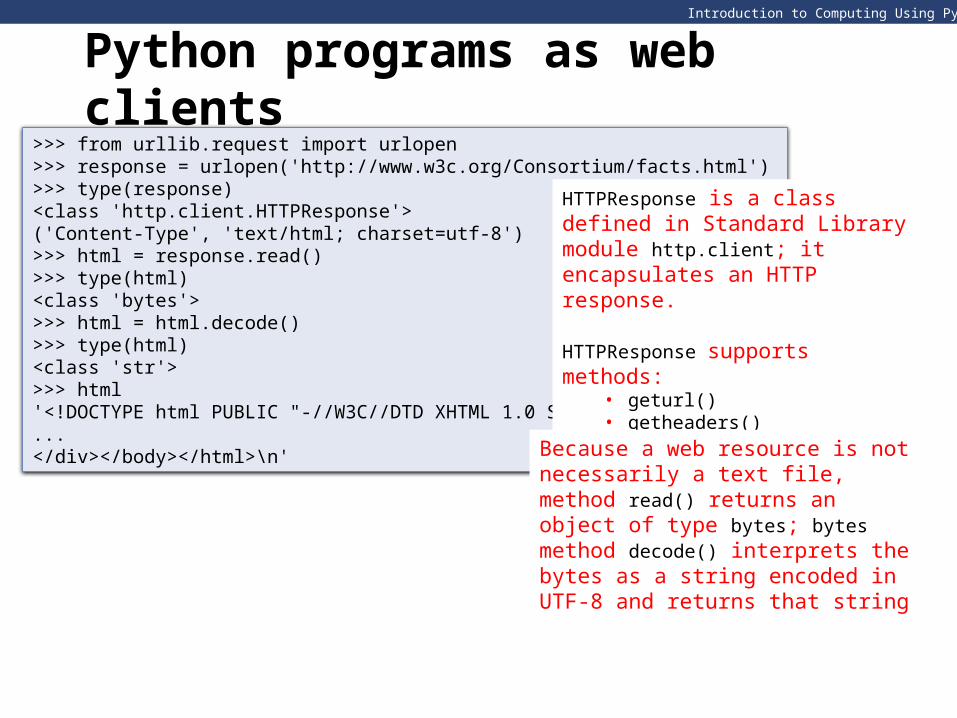
Python programs as web clients>>> from urllib.request import urlopen>>> response = urlopen('http://www.w3c.org/Consortium/facts.html')>>> type(response)<class 'http.client.HTTPResponse'>('Content-Type', 'text/html; charset=utf-8')>>> html = response.read()>>> type(html)<class 'bytes'>>>> html = html.decode()>>> type(html)<class 'str'>>>> html'<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN”...</div></body></html>\n'
HTTPResponse is a class defined in Standard Library module http.client; it encapsulates an HTTP response.
HTTPResponse supports methods:• geturl()• getheaders()• read(), etc
Because a web resource is not necessarily a text file, method read() returns an object of type bytes; bytes method decode() interprets the bytes as a string encoded in UTF-8 and returns that string

Introduction to Computing Using Python
Exercise
from urllib.request import urlopendef news(url, topics): '''counts in resource with URL url the frequency of each topic in list topics'''
response = urlopen(url) html = response.read() content = html.decode().lower() for topic in topics: n = content.count(topic) print('{} appears {} times.'.format(topic,n))
Write method news() that takes a URL of a news web site and a list of news topics (i.e., strings) and computes the number of occurrences of each topic in the news.
>>> news('http://bbc.co.uk',['economy','climate','education']) economy appears 3 timesclimate appears 3 times education appears 1 times
Introduction to Computing Using Python
Parsing a web page
When an HTMLParser object is fed a string containing HTML, it processes it
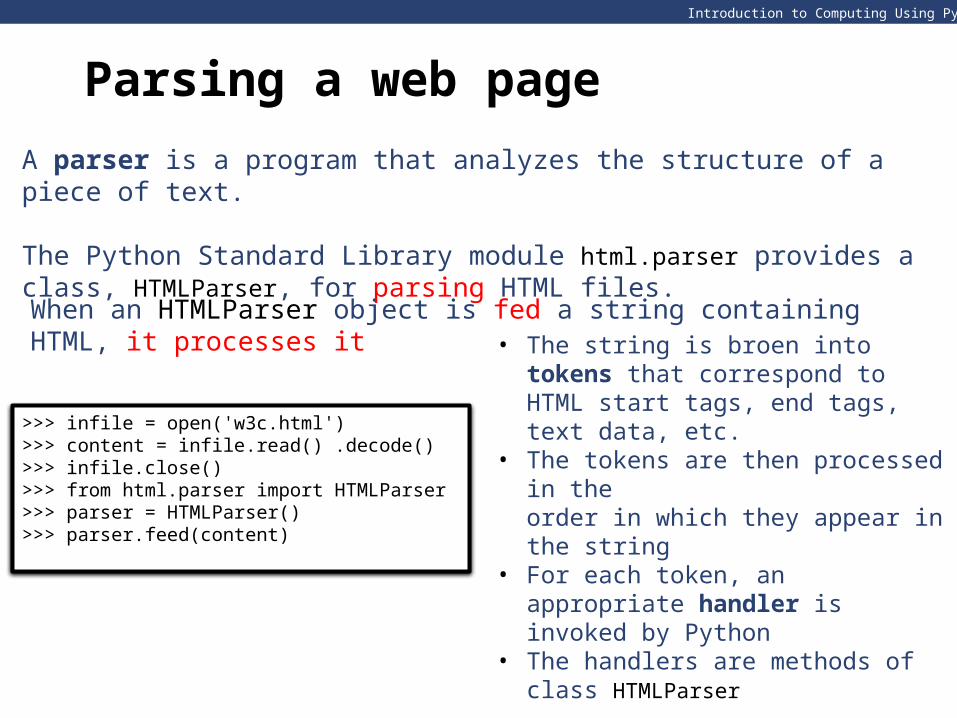
A parser is a program that analyzes the structure of a piece of text.
The Python Standard Library module html.parser provides a class, HTMLParser, for parsing HTML files.
• The string is broen into tokens that correspond to HTML start tags, end tags, text data, etc.
• The tokens are then processed in theorder in which they appear in the string
• For each token, an appropriate handler is invoked by Python
• The handlers are methods of class HTMLParser
>>> infile = open('w3c.html') >>> content = infile.read() .decode()>>> infile.close() >>> from html.parser import HTMLParser >>> parser = HTMLParser()>>> parser.feed(content)
Introduction to Computing Using Python
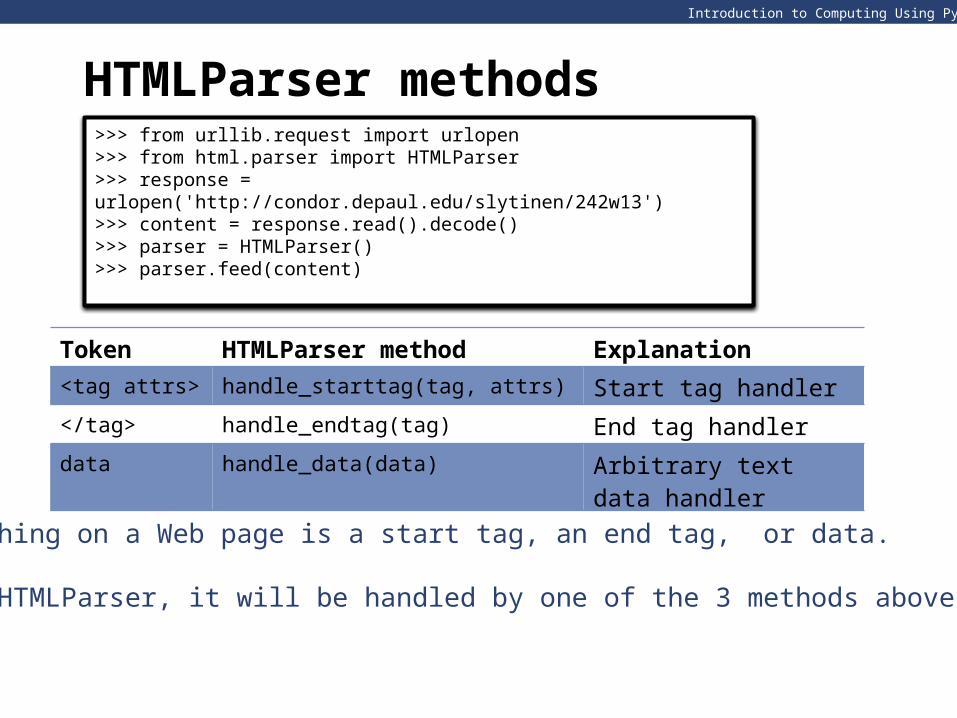
HTMLParser methods>>> from urllib.request import urlopen>>> from html.parser import HTMLParser >>> response = urlopen('http://condor.depaul.edu/slytinen/242w13')>>> content = response.read().decode()>>> parser = HTMLParser()>>> parser.feed(content)
Token HTMLParser method Explanation
<tag attrs> handle_starttag(tag, attrs) Start tag handler
</tag> handle_endtag(tag) End tag handler
data handle_data(data) Arbitrary text data handler
Everything on a Web page is a start tag, an end tag, or data.
Using HTMLParser, it will be handled by one of the 3 methods above.
Introduction to Computing Using Python
Parsing a web page
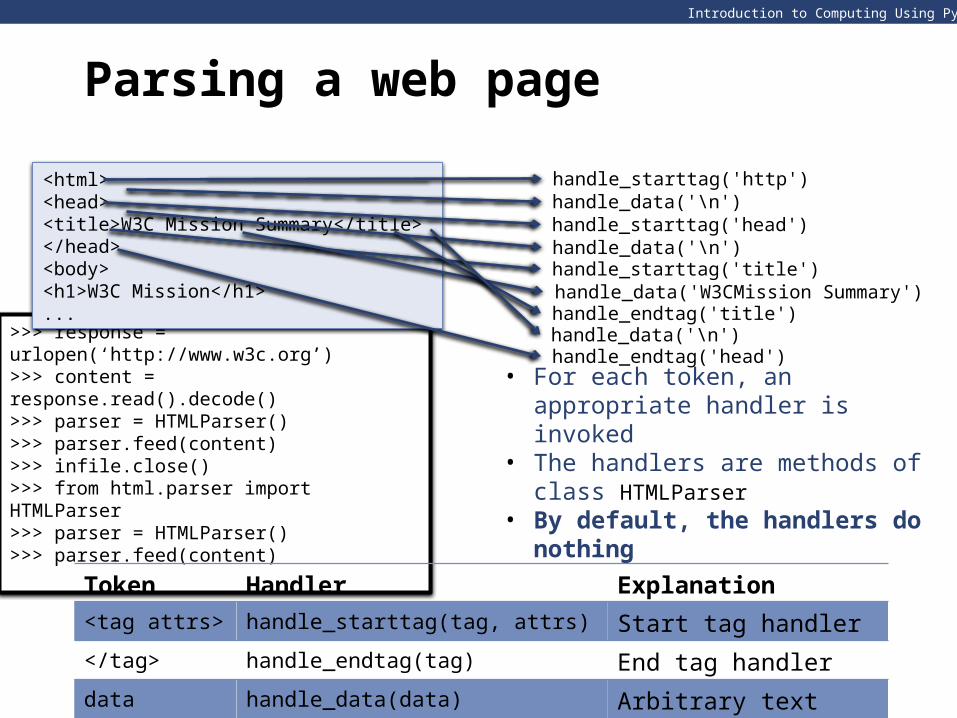
>>> response = urlopen(‘http://www.w3c.org’) >>> content = response.read().decode()>>> parser = HTMLParser()>>> parser.feed(content)>>> infile.close() >>> from html.parser import HTMLParser >>> parser = HTMLParser()>>> parser.feed(content)
Token Handler Explanation
<tag attrs> handle_starttag(tag, attrs) Start tag handler
</tag> handle_endtag(tag) End tag handler
data handle_data(data) Arbitrary text data handler
<html><head><title>W3C Mission Summary</title></head><body><h1>W3C Mission</h1>...
handle_starttag('http')handle_data('\n')handle_starttag('head')handle_data('\n')handle_starttag('title')handle_data('W3CMission Summary')handle_endtag('title')handle_data('\n')handle_endtag('head')
• For each token, an appropriate handler is invoked
• The handlers are methods of class HTMLParser
• By default, the handlers do nothing
Introduction to Computing Using Python
Parsing a web page
ch11.html
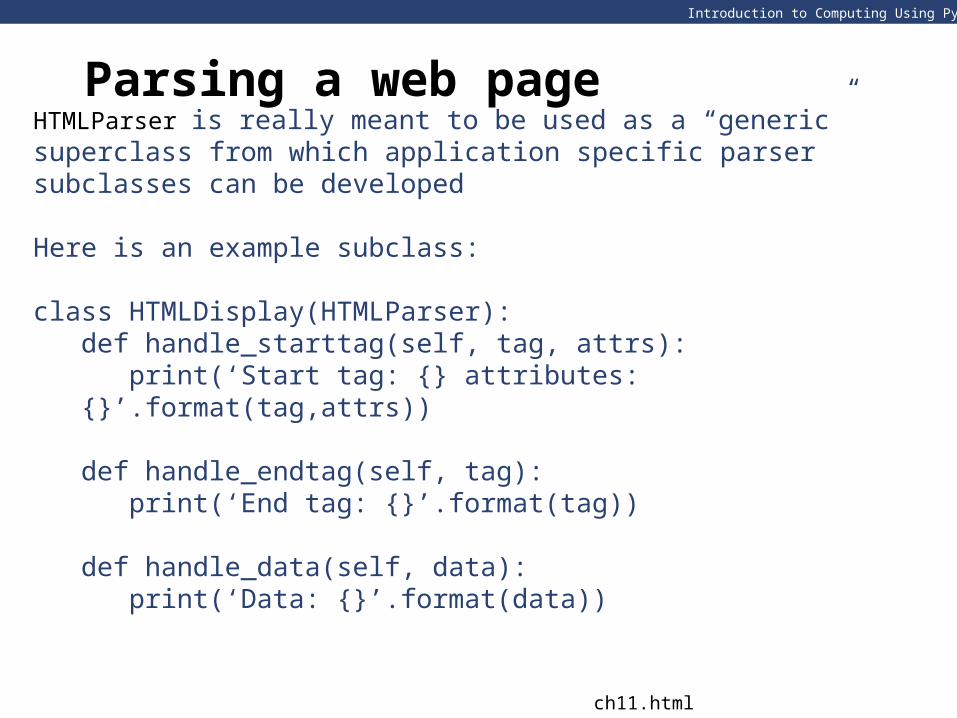
HTMLParser is really meant to be used as a “generic” superclass from which application specific parser subclasses can be developed
Here is an example subclass:
class HTMLDisplay(HTMLParser):def handle_starttag(self, tag, attrs):
print(‘Start tag: {} attributes: {}’.format(tag,attrs))
def handle_endtag(self, tag):print(‘End tag: {}’.format(tag))
def handle_data(self, data):print(‘Data: {}’.format(data))

Start tag: html attributes: []Start tag: title attributes: []Data: CSC 242-501 simple Web pageEnd tag: titleStart tag: body attributes: []Start tag: center attributes: []Start tag: h3 attributes: []Data: CSC 242 Section 501Start tag: br attributes: []Data: A simple Web pageEnd tag: h3Start tag: p attributes: []Data: Hello world!Start tag: p attributes: []Start tag: a attributes: [('href', 'http://condor.depaul.edu/slytinen/242w13/’)]Data: CSC 242-501 home pageEnd tag: aEnd tag: pEnd tag: bodyEnd tag: html
<html><title>CSC 242-501 simple Web page</title><body><center><h3>CSC 242 Section 501<br>A simple Web page</h3><p>Hello world!</p></body></html>
Web page PrintParser output
Introduction to Computing Using Python
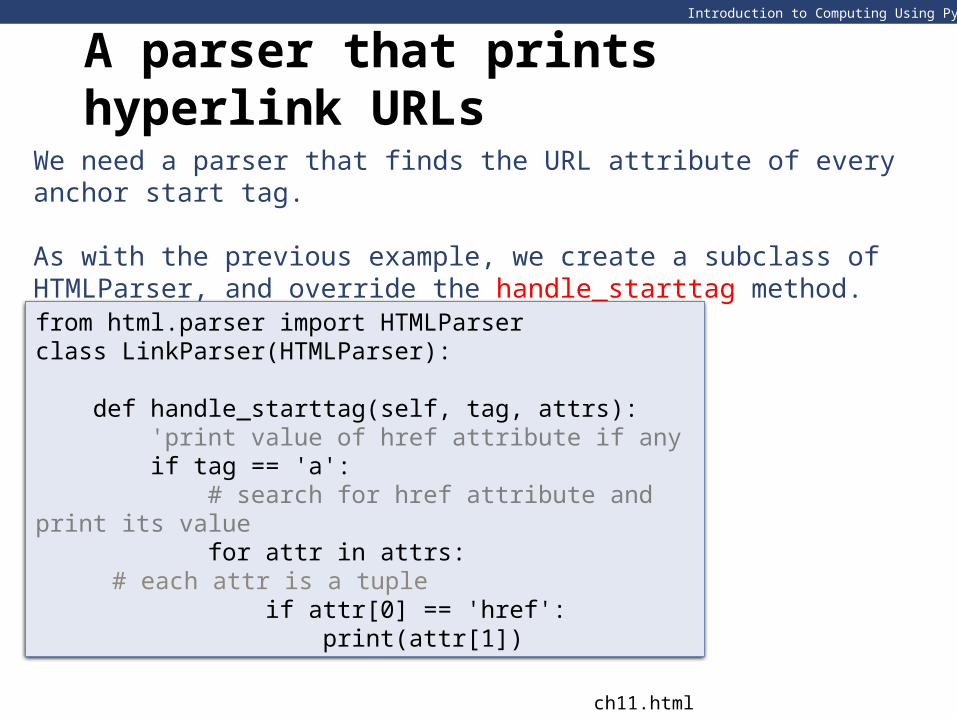
A parser that prints hyperlink URLs
We need a parser that finds the URL attribute of every anchor start tag.
As with the previous example, we create a subclass of HTMLParser, and override the handle_starttag method.
from html.parser import HTMLParserclass LinkParser(HTMLParser):
def handle_starttag(self, tag, attrs): 'print value of href attribute if any if tag == 'a': # search for href attribute and print its value for attr in attrs:
# each attr is a tuple if attr[0] == 'href': print(attr[1])
ch11.html
Introduction to Computing Using Python
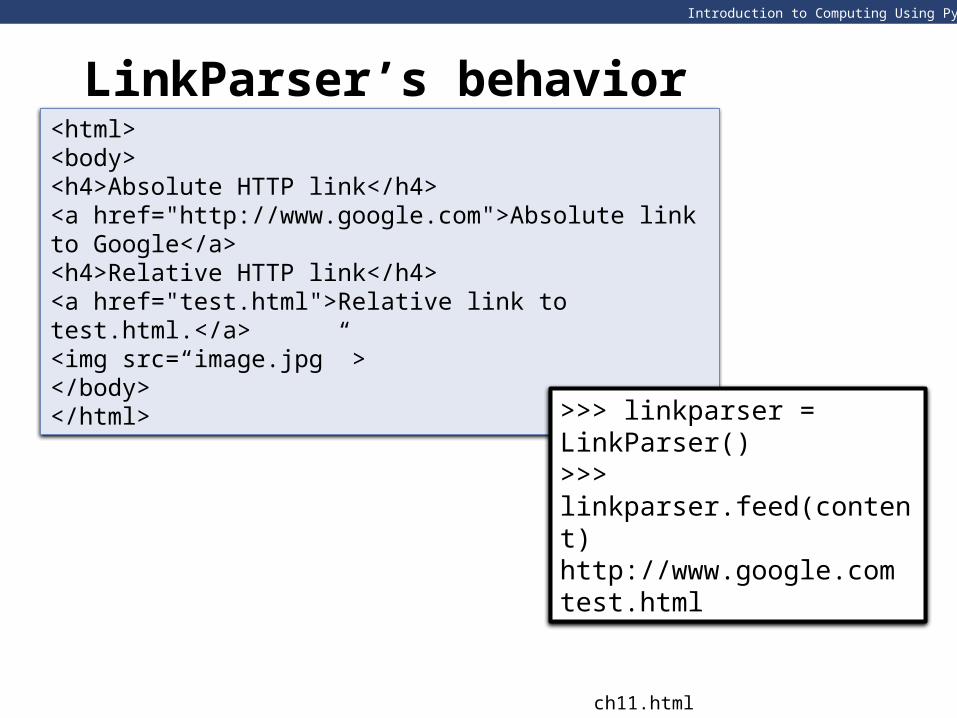
LinkParser’s behavior<html><body><h4>Absolute HTTP link</h4><a href="http://www.google.com">Absolute link to Google</a><h4>Relative HTTP link</h4><a href="test.html">Relative link to test.html.</a><img src=“image.jpg” ></body></html>
ch11.html
>>> linkparser = LinkParser() >>> linkparser.feed(content) http://www.google.comtest.html
Introduction to Computing Using Python
Collecting hyperlinks (as absolute URLs)
links.html
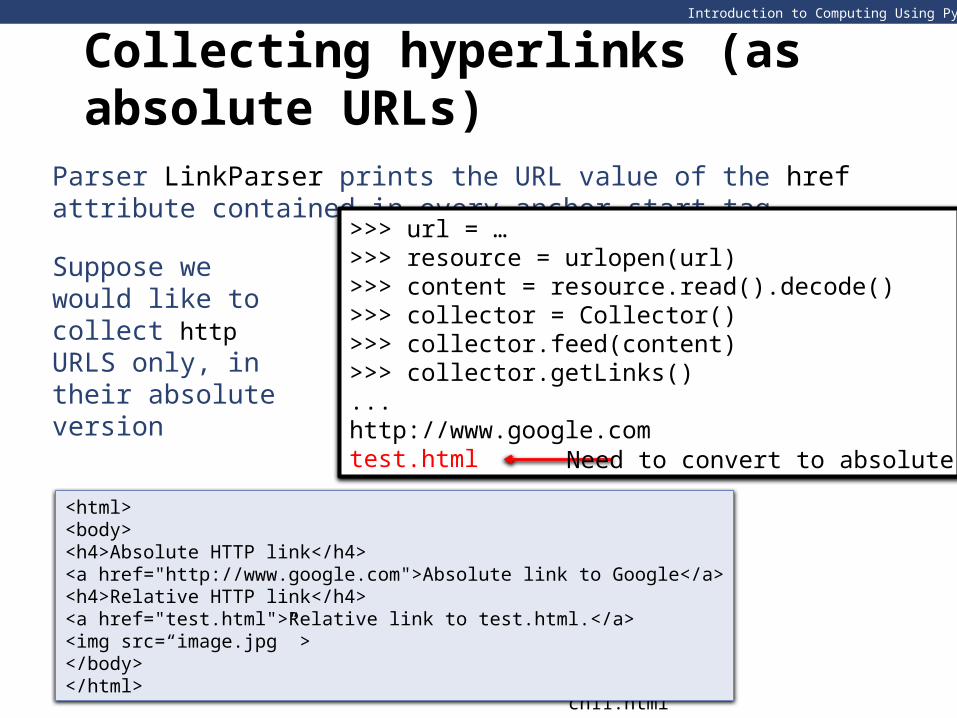
Parser LinkParser prints the URL value of the href attribute contained in every anchor start tag
Suppose we would like to collect http URLS only, in their absolute version
>>> url = …>>> resource = urlopen(url)>>> content = resource.read().decode()>>> collector = Collector()>>> collector.feed(content)>>> collector.getLinks()...http://www.google.comtest.html
ch11.html
<html><body><h4>Absolute HTTP link</h4><a href="http://www.google.com">Absolute link to Google</a><h4>Relative HTTP link</h4><a href="test.html">Relative link to test.html.</a><img src=“image.jpg” ></body></html>
Need to convert to absolute URL
>>> url = 'http://www.w3.org/Consortium/mission.html'>>> resource = urlopen(url)>>> content = resource.read().decode()>>> collector = Collector()>>> collector.feed(content)...http://www.w3.org/Consortium/suphttp://www.w3.org/Consortium/siteindexhttp://lists.w3.org/Archives/Public/site-comments/http://twitter.com/W3C
...
>>> url = 'http://www.w3.org/Consortium/mission.html'>>> resource = urlopen(url)>>> content = resource.read().decode()>>> linkparser = LinkParser()>>> linkparser.feed(content).../Consortium/sup/Consortium/siteindexmailto:[email protected]://lists.w3.org/Archives/Public/site-comments/http://twitter.com/W3C...
Introduction to Computing Using Python
Collecting hyperlinks (as absolute URLs)
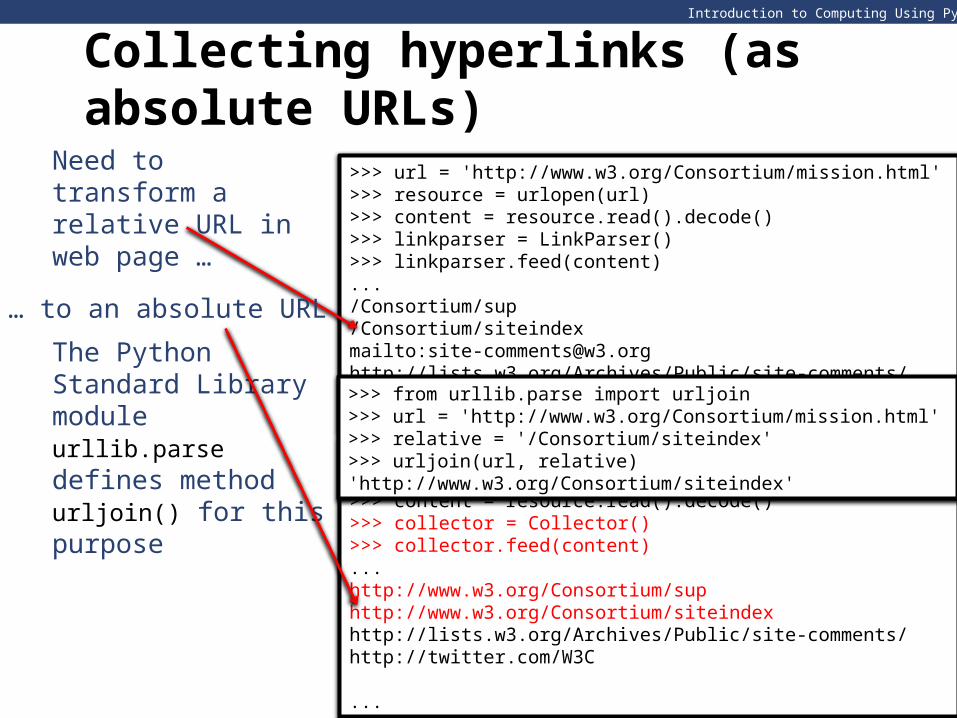
Need to transform a relative URL in web page …
The Python Standard Library module urllib.parse defines method urljoin() for this purpose
… to an absolute URL
>>> from urllib.parse import urljoin >>> url = 'http://www.w3.org/Consortium/mission.html' >>> relative = '/Consortium/siteindex' >>> urljoin(url, relative) 'http://www.w3.org/Consortium/siteindex'
Introduction to Computing Using Python
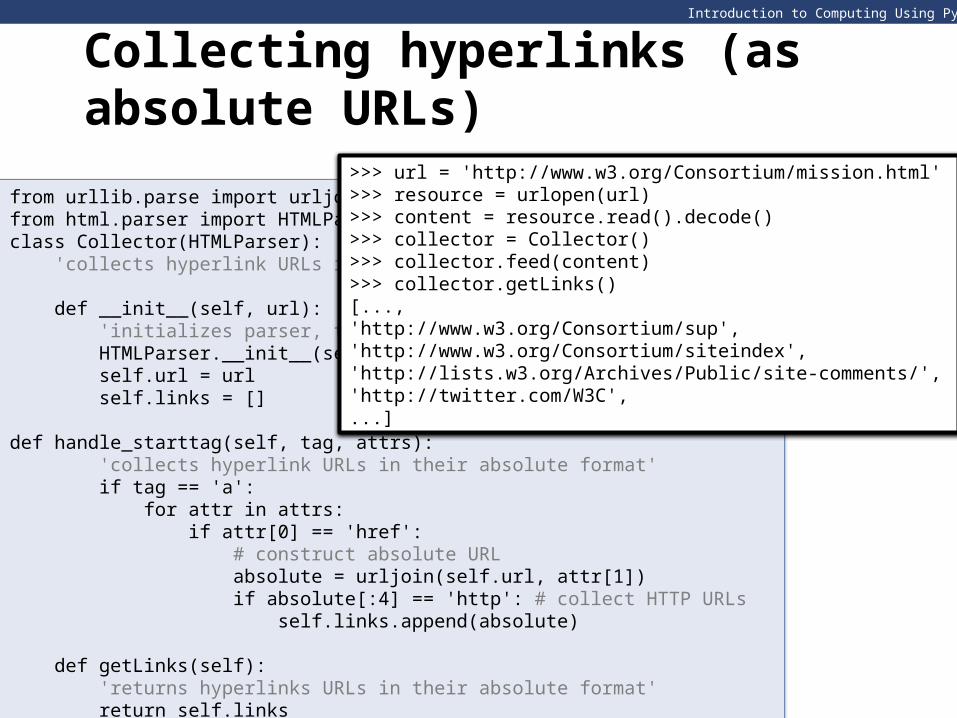
Collecting hyperlinks (as absolute URLs)
from urllib.parse import urljoinfrom html.parser import HTMLParserclass Collector(HTMLParser): 'collects hyperlink URLs into a list'
def __init__(self, url): 'initializes parser, the url, and a list' HTMLParser.__init__(self) self.url = url self.links = []
def handle_starttag(self, tag, attrs): 'collects hyperlink URLs in their absolute format' if tag == 'a': for attr in attrs: if attr[0] == 'href': # construct absolute URL absolute = urljoin(self.url, attr[1]) if absolute[:4] == 'http': # collect HTTP URLs self.links.append(absolute) def getLinks(self): 'returns hyperlinks URLs in their absolute format' return self.links
>>> url = 'http://www.w3.org/Consortium/mission.html'>>> resource = urlopen(url)>>> content = resource.read().decode()>>> collector = Collector()>>> collector.feed(content)>>> collector.getLinks()[...,'http://www.w3.org/Consortium/sup','http://www.w3.org/Consortium/siteindex','http://lists.w3.org/Archives/Public/site-comments/','http://twitter.com/W3C',...]
Exercise: Change Collector so that itcollects img URLs
Collecting image links (as absolute URLs)